Learning to Identify Semi-Visible Jets
Abstract
We train a network to identify jets with fractional dark decay (semi-visible jets) using the pattern of their low-level jet constituents, and explore the nature of the information used by the network by mapping it to a space of jet substructure observables. Semi-visible jets arise from dark matter particles which decay into a mixture of dark sector (invisible) and Standard Model (visible) particles. Such objects are challenging to identify due to the complex nature of jets and the alignment of the momentum imbalance from the dark particles with the jet axis, but such jets do not yet benefit from the construction of dedicated theoretically-motivated jet substructure observables. A deep network operating on jet constituents is used as a probe of the available information and indicates that classification power not captured by current high-level observables arises primarily from low- jet constituents.
I Introduction
The microscopic nature of dark matter (DM) remains one of the most pressing open questions in modern physics Bertone and Hooper (2018); Bertone and Tait (2018), and a robust program of experimental searches for evidence of its interaction with the visible sector Aaltonen et al. (2012); collaboration (2013, 2012); Aad et al. (2013); Chatrchyan et al. (2012); Bai and Tait (2013); Petriello et al. (2008); Ferreira de Lima et al. (2017); Aaij et al. (2018) described by the Standard Model (SM). These experiments typically assume that DM is neutral, stable and couples weakly to SM particles; in collider settings this predicts detector signatures in which weakly-produced DM particles are invisible, evidenced only by the imbalance of momentum transverse to the beam. No evidence of DM interactions has been observed to date.
However, while these assumptions are reasonable, the lack of observation motivates the exploration of scenarios in which one or more of them are relaxed. Specifically, if DM contains complex strongly-coupled hidden sectors, such as appear in many Hidden-Valley models Strassler and Zurek (2007a); Han et al. (2008), it may lead to the production of stable or meta-stable dark particles within hadronic jets Cohen et al. (2015, 2017); Kar and Sinha (2021); Bernreuther et al. (2021). Depending on the portion of the jet which results in dark-sector hadrons, it may be only semi-visible to detectors, leading to a unique pattern of energy deposits, or jet substructure.
A robust literature exists for the identification of jet substructure Larkoski et al. (2014a, 2013); Kogler et al. (2019); Lu et al. (2022), with applications to boosted -boson Baldi et al. (2016); Chen et al. (2020); collaboration (2019), Higgs boson Chung et al. (2021) and top-quark tagging collaboration (2019). Typically, observables are designed to discriminate between the energy deposition patterns left by jets which result from a single hard parton and the patterns left by jets which result from several collimated hard partons, as can be produced from the decay of a massive boosted particle. While these observables have some power when adapted to the task of identifying semi-visible jets Kar and Sinha (2021); Cohen et al. (2020), no observables have yet been specifically designed to be sensitive to the unique energy patterns of semi-visible nature of jets.
In parallel, the rapid development of machine learning to the analysis of jet energy depositions Larkoski et al. (2013); Komiske et al. (2018); Baldi et al. (2016) demonstrated that jet tagging strategies, including those for semi-visible jets, can be learned directly from lower-level jet constituents without the need to form physics-motivated high level observables Bernreuther et al. (2021); Dillon et al. (2022). Such learned models are naturally challenging to interpret, validate or quantify uncertainties, especially given the high-dimensional nature of their inputs. In the case of semi-visible jets, extra care must be taken when drawing conclusions from low-level details, many of which may depend on specific theoretical parameter choices as well as the approximations made during modeling of hadronization Cohen et al. (2020). However, techniques have been recently demonstrated Faucett et al. (2021); Collado et al. (2021a, b); Bradshaw et al. (2022) to translate the learned model into interpretable high-level observables, which can provide guidance regarding the nature and robustness of the information being used for classification.
In this paper, we present a study of machine learning models trained to distinguish semi-visible jets from QCD background jets using the patterns of their low-level jet constituents. We compare the performance of models which use low-level constituents to those which use the set of existing high-level observables to explore where the existing HL observables do and do not capture all of the relevant information. Where gaps exist, we attempt to translate Faucett et al. (2021) low-level networks into networks which use a small set of interpretable observables which replicate their decisions and performance. Interpretation of these observables can yield insight into the nature of the energy deposition inside semi-visible jets.
II Semi-visible jets
Following Refs. Cohen et al. (2015); Kar and Sinha (2021), we consider pair production of dark-sector quarks of several flavors via a messenger sector which features a gauge boson in an -channel process (Fig. 1(a)) or scalar mediator in the -channel process (Fig. 1(b)) that couples to both SM and DM sectors and leads to a dijet signature. The dark quarks produce QCD-like dark showers, involving many dark quarks and gluons which produce dark hadrons, some of which are stable or meta-stable and some of which decay into SM hadrons via an off-shell process.


The detector signature of the resulting semi-visible jet (SVJ) depends on the lifetime and stability of the dark hadrons, leading to several possibilities (see Fig. 2). Though the physics is complex and depends on the details of the dark sector structure, a description of the dark and SM hadrons produced by a DM model quark can be encapsulated in the quantity , the ratio of dark stable hadrons to all hadrons in the jet:
| (1) |



An invisible fraction of corresponds to a dark quark which produces a jet consisting of only visible hadrons, as depicted in the Rapid Decay example given in Fig. 2(a). Alternatively, an invisible fraction of describes a stable dark jet (Fig. 2(b)), in which the dark quark hadronizes exclusively in the dark sector. For any intermediate value of , jets contain a visible and invisible fraction, leading to along the jet axis(Fig. 2(c)).
III Sample Generation and Data Processing
Samples of simulated events with semi-visible jets are generated using the modified Hidden Valley Strassler and Zurek (2007b) model described in Cohen et al. (2015, 2017) for both an -channel (Fig. 1(a)) and -channel (Fig. 1(b)) process. Samples of simulated and events are produced in proton-proton collisions at a center-of-mass energy of in MadGraph5 Alwall et al. (2011) (v2.6.7) with xqcut=100 and the NNPDF2.3 LO PDF set Skands et al. (2014). The mediator mass is set to and the dark quark mass to . Up to two extra hard jets due to radiation are generated and MLM-matched Mangano et al. (2002), to facilitate comparison with existing studies. Invisible fraction, showering and hadronization are performed with Pythia8 v8.244 Sjöstrand et al. (2015). In particular, the following parameters are set: the dark confinement scale ; the number of dark colors ; the number of dark flavors ; and the intermediate dark meson mass of and the dark matter mass of . Distinct sets were generated for invisible fractions of via configurations of the branching ratio of decay process . Detector simulation and reconstruction are conducted in Delphes v3.4.2 de Favereau et al. (2014) using the default ATLAS card. A sample of SM jets from a typical QCD process is generated from the process. The same simulation chain as described above is applied to the SM jets.
Jets are built from calorimeter energy deposits and undergo the jet trimming procedure described in Ref. Krohn et al. (2010) with the anti- Cacciari et al. (2008) clustering algorithm from pyjet Cacciari et al. (2012), using a primary jet-radius parameter of and subjet clustering radius of and . The threshold on effectively removes constituents in subjets with that is less than 5% of the jet . Leading jets are required to have . For each event generated, the leading jet is selected and truth-matched to guarantee the presence of a dark quark within the region of .
After all selection requirements, simulated jets remain with a 50/50 split between SVJ signal and QCD background. To avoid inducing biases from artifacts of the generation process, signal and background events are weighted such that the distributions in and are uniform; see Fig. 7.
III.1 High-level Observables
A large set of jet substructure observables Kogler et al. (2019); Marzani et al. (2019); Larkoski et al. (2017) have been proposed for tasks different from the focus of this study, that of identifying jets with multiple hard subjets. Nevertheless, these observables may summarize the information content in the jet in a way that is relevant for the task of identifying semi-visible jets Kar and Sinha (2021), and so serve as a launching point for the search for new observables.
Our set of high-level (HL) observables includes 15 candidates: jet , the Generalized Angularities Larkoski et al. (2014b) of and Les Houches Angularity (LHA), N-subjettiness ratios and Thaler and Van Tilburg (2011), and Energy Correlation function ratiosLarkoski et al. (2013) , , , , , , as well as jet width, jet , constituent multiplicity and the splitting function Larkoski et al. (2014a) . In each case, observables are calculated from trimmed jet constituents described above. Definitions and distributions for each high-level observable are provided in App. B.1 with re-weighting applied as described above.
IV Machine Learning and Evaluation
For both the low-level (LL) trimmed jet constituents and high-level jet substructure observables, a variety of networks and architectures are tested.
Due to their strong record in previous similar applications Faucett et al. (2021); Collado et al. (2021a, b); Bernreuther et al. (2021), a deep neural network using dense layers is trained on the high-level observables. We additionally consider XGBoostChen and Guestrin (2016), which has shown strong performance in training high-level classifiers with jet substructure Bourilkov (2019); Cornell et al. (2021), as well as LightGBMKe et al. (2017) which has demonstrated power in class separation on high-level features. LightGBM has the strongest classification performance among these networks which use high-level features; see Tab. 1.
| -channel | AUC | ||
|---|---|---|---|
| Model | 0.3 | 0.6 | |
| LightGBM | 0.861 | 0.803 | 0.736 |
| XGBoost | 0.861 | 0.803 | 0.736 |
| DNN | 0.860 | 0.799 | 0.734 |
| -channel | AUC | ||
| Model | 0.3 | 0.6 | |
| LightGBM | 0.808 | 0.755 | 0.683 |
| XGBoost | 0.806 | 0.755 | 0.681 |
| DNN | 0.801 | 0.726 | 0.656 |
| -channel | AUC | ||
|---|---|---|---|
| Model | 0.3 | 0.6 | |
| PFN | 0.866 | 0.822 | 0.776 |
| EFN | 0.849 | 0.795 | 0.735 |
| CNN | 0.855 | 0.792 | 0.740 |
| -channel | AUC | ||
| Model | 0.3 | 0.6 | |
| PFN | 0.806 | 0.754 | 0.697 |
| EFN | 0.796 | 0.741 | 0.672 |
| CNN | 0.791 | 0.739 | 0.663 |
In the case of classifiers which use low-level constituents, convolutional neural networks on jet images are considered Faucett et al. (2021); Collado et al. (2021a, b); Baldi et al. (2016); Cogan et al. (2015); de Oliveira et al. (2016). Given the specific task of classifying jet substructure observables and their use for a similar task in Ref. Collado et al. (2021b), Energy Flow Networks (EFN) and Particle Flow Networks (PFN) are also applied Komiske et al. (2019), and found to significantly out-perform convolutional networks, with the PFN emerging as the most powerful network; see Table 2.
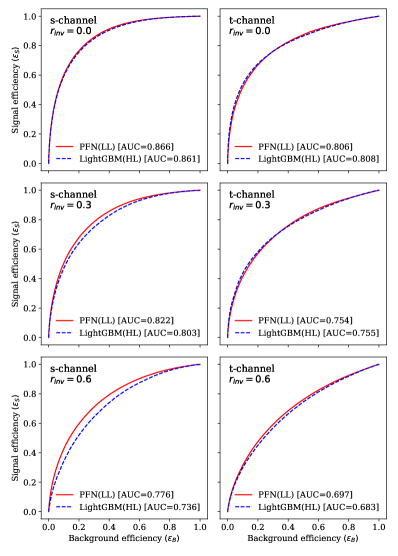
Receiver operating characteristic (ROC) curves for both the PFN and LightGBM high-level models are given in Fig. 3. Additional details for the network training and hyperparameter selections are provided in App. C.
IV.1 Performance Comparison
We compare the SVJ classification performance of the most powerful networks based on high-level or low-level input features, through calculations of the Area under the ROC Curve (AUC); see Fig 3 and Table 3.
Note that the high-level (HL) observables are calculated directly from the low-level constituents with no additional information. If HL features extract all of the relevant information for the classification task, networks which use them as inputs should be able to match the performance of the networks which use the LL information directly, which we take as a probe of the power of the available information. If networks using LL information surpass the performance of those using HL information, it suggests that information exists in the LL constituents which is not being captured by the HL observables. One might consider directly applying networks based on LL information to the classification task Bernreuther et al. (2021), but this presents challenges in calibrating, validating and quantifying uncertainties on their high-dimensional inputs. Instead, a performance gap suggests the possibility that an additional HL observable might be crafted to take advantage of the overlooked information.
In each of the six cases explored here, the networks which use low-level information match or exceed the performance of networks which use high-level jet observables. Significant performance gaps are seen in the case, where the AUC between the LL and HL networks is 0.040 and 0.014 for the -channel and -channel cases, as well as in the and invisible fraction in the -channel process, where the gap is 0.019. In the -channel scenario, a small gap is seen, though larger than the statistical uncertainty. In the other two cases, the LL and HL networks achieve essentially equivalent performance, strongly suggesting that the HL features have captured the relevant information in the LL constituents. As these observables were not designed for this task, it was not a priori clear that they would summarize all of the available and relevant information.
However, one can also assess the difference between the LL and HL networks using other metrics than AUC. The Average Decision Ordering (ADO) metric, see Eq. 6, measures the fraction of input pairs in which two networks give the same output ordering. Even in cases where the AUC is equivalent, the ADO between the LightGBM and PFN (Table 3) is well below 1, suggesting that while their classification performance is the same, they arrive at it using distinct strategies. This indicates that there may be room to improve the classification accuracy by considering a network which uses both sets of features.
| -channel | ||||||
|---|---|---|---|---|---|---|
| Model[Features] | ||||||
| ADO[,PFN] | AUC | ADO[,PFN] | AUC | ADO[,PFN] | AUC | |
| PFN[LL] | 1 | 0.866 | 1 | 0.822 | 1 | 0.776 |
| LightGBM[HL] | 0.858 | 0.861 | 0.839 | 0.803 | 0.818 | 0.736 |
| LL-HL gap | 0.005 | 0.019 | 0.040 | |||
| -channel | ||||||
| Model[Features] | ||||||
| ADO[,PFN] | AUC | ADO[,PFN] | AUC | ADO[,PFN] | AUC | |
| PFN[LL] | 1 | 0.806 | 1 | 0.754 | 1 | 0.697 |
| LightGBM[HL] | 0.844 | 0.808 | 0.805 | 0.755 | 0.787 | 0.683 |
| LL-HL gap | -0.002 | -0.001 | 0.014 | |||
V Finding New Observables
The studies above reveal that models which use low-level constituents as inputs provide the overall best classification performance. However, our objective is not merely to find the classifier with the optimal statistical performance with difficult-to-assess systematic uncertainties. Rather, we seek to understand the underlying physics used by the PFN and to translate this information into one or more meaningful physical features, allowing us to extract insight into the physical processes involved and assign reasonable systematic uncertainties. In this section, we search for these additional high-level observables among the Energy Flow Polynomials Komiske et al. (2018) (EFP), which form a complete basis for jet observables.
V.1 Search Strategy
Interpreting the decision making of a black-box network is a notoriously difficult problem. For the task of jet classification, we apply the guided search technique utilized in past jet-related interpretability studies Faucett et al. (2021); Collado et al. (2021b, a); Bradshaw et al. (2022); Lu et al. (2022). In this approach, new HL observables are identified among the infinite set of Energy Flow Polynomials (EFPs) which exist as a complete linear basis for jet observables. In the EFP framework, one-dimensional observables are constructed as nested sums over measured jet constituent transverse momenta and scaled by their angular separation .
These parametric sums are described as the set of all isomorphic multigraphs where:
| each node | (2) | |||
| each -fold edge | (3) |
and where each graph can be further parameterized by values of ,
| (4) | ||||
| (5) |
Here, is the transverse momentum of the trimmed jet for constituent , and () is pseudorapidity (azimuth) difference between constituents and . As the EFPs are normalized, they capture only the relative information about the energy deposition. For this reason, in each network that includes EFP observables, we include as an additional input the sum of over all constituents, to indicate the overall scale of the energy deposition.
For the set of EFPs, infrared and collinear (IRC) safety requires that . To more broadly explore the space, we consider examples with which generate more exotic observables. For the case of EFPs with IRC-unsafe parameters, we select all prime graphs with dimension and and values of and . Given the form of Eq. (2) and Eq. (3), the size and relative sign of inputs chosen for will provide insights into utility of soft/hard effects and narrow/wide angle energy distributions.
In principle, the EFP space is complete and any information accessible through constituent-based observables is contained in some combination of EFPs. However, there is no guarantee that an EFP representation will be compact. On the contrary, a blind search through the space can prove time and resource prohibitive. Rather than a brute force search of an infinite space of observables, we take the guided approach of Ref Faucett et al. (2021), which uses the PFN as a black-box guide and iteratively assembles a set of EFPs which provide the closest equivalent decision making in a compact and low-dimensional set of inputs. This is done by isolating the space of information in which the PFN and existing HL features make opposing decisions on the same inputs and isolates the EFP which most closely mimics the PFN in that subspace.
Here, the agreement between networks and is evaluated over pairs of inputs by comparing their relative classification decisions, expressed mathematically as:
| (6) |
and referred to as decision ordering (DO). DO corresponds to inverted decisions over all input pairs and DO = 1 corresponds to the same decision ordering. As prescribed in Ref. Faucett et al. (2021), we scan the space of EFPs to find the observable that has the highest average decision ordering (ADO) with the guiding network when averaged over disordered pairs. The selected EFP is then incorporated into the new model of HL features, HLn+1, and the process is repeated until the ADO plateaus.
VI Guided Iteration
For each of the four scenarios in which a gap is observed between the AUC performance of the HL LightGBM model and the PFN, a guided search is performed to identify an EFP observable which mimics the decisions of the PFN.
The search results, shown in Table 4, identify in each of the four cases an EFP with which boosts the classification performance of the LightGBM classifier when trained with the original 15 HL features as well as the identified EFP observable. In addition, the decision similarity (ADO) between the new HL model and the PFN is increased. Scans for a second EFP do not identify additional observables which significantly increase performance or similarity. A guided search was also performed with an identical set of and parameters for EFPs with dimension but no improvements were seen in the case of higher dimensional graph structure. While the performance and similarity gaps have been reduced, they have not quite been erased.
| HL network | HL+EFP network | PFN | |||||
|---|---|---|---|---|---|---|---|
| Process | AUC, ADO[.,pfn] | EFP | AUC, ADO[.,pfn] | AUC | |||
| -channel | 0.0 | 0.861, 0.858 | -2 | 0.864, 0.863 | 0.866 | ||
| -channel | 0.3 | 0.803, 0.839 | 1 | 0.807, 0.840 | 0.822 | ||
| -channel | 0.6 | 0.736, 0.818 | -1 | 2 | 0.747, 0.821 | 0.776 | |
| -channel | 0.6 | 0.683, 0.787 | -2 | 0.690, 0.792 | 0.697 | ||
VI.1 Analysis of the Guided Search Results
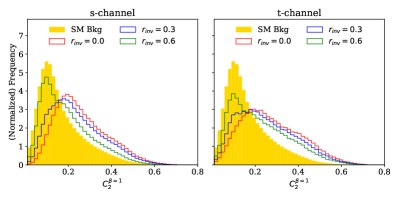
In the -channel process, with invisible fraction , the addition of a single EFP closes the small performance gap with the PFN within the statistical uncertainty. The identified EFP in this case is the dot graph with the IRC-unsafe energy exponent , expressed as a sum over constituents in Eq. (7).
| (7) |
This graph is, in effect, simply a measure of the sum of the inverse of the jet constituents, and is sensitive to constituents with low . Distribution of values of this observable for signal and background events are shown in Fig. 4, demonstrating good separation between signal and background.

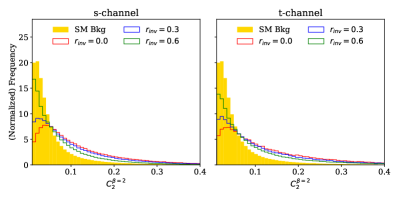
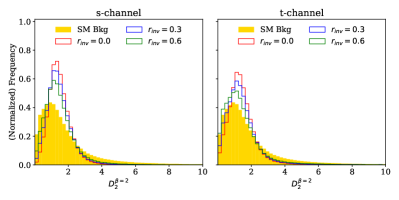
In the remaining -channel and -channel examples, addition of the selected EFP improves performance but fails to match the PFN. Of the three existing gaps, the -channel process with is the only result in which we see an IRC-safe EFP observable, where . In the other cases, the EFP graphs again have , making them sensitive to low- information. The complete expression for each selected graph is given in Eq. (8) and the distributions of each observable for signal and background are shown in Fig. 5. The triangular graph selected in the case of the -channel process with invisible fraction has the same structure as the energy correlation ratio , though with distinct and values.
| (8b) | ||||
| (8d) | ||||
| (8f) | ||||



VII Greedy Search
Given the persistent gap between the performance of the LL networks and the HL models augmented by EFP observables, we consider whether the EFP space lacks the needed observables, or whether the guided search is failing to identify it. We examine this question by taking a more comprehensive look at the space of EFPs we consider. Similar to the technique described in Ref. Faucett et al. (2021), we perform a greedy search in the same EFP space studied in the guided iteration approach explored above. In a greedy search, we explicitly train a new model for each candidate EFP, combining the EFP with the existing 15 HL features. Note that this is significantly more computationally intensive than evaluation of the ADO, as done in the guided search, and seeks to maximize AUC rather than to align decision ordering with the PFN. The candidate EFP which produces the best-performing model is kept as the 16th HL observable (Pass 1), and the process is repeated in search of a 17th (Pass 2), until a plateau in performance is observed.
The results of the greedy search across all choices of in -channel and -channel scenarios where a gap between HL and LL exists are given in Table 5. Similar levels of performance are achieved as in the guided search, to within statistical uncertainties. In all cases, the HL and LL gap persists. Results are given for the IRC-unsafe selections with dimension . A similar greedy search was also performed on the IRC-unsafe EFP set with no performance differences observed.
| HL | Pass 1 | Pass 2 | Guided | PFN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Process | AUC | Graph | AUC | Graph | AUC | HL AUC | AUC | |||||
| -channel | 0.0 | 0.861 | 2 | 0.864 | 2 | 0.866 | 0.864 | 0.866 | ||||
| -channel | 0.3 | 0.803 | 4 | 2 | 0.807 | -1 | 1 | 0.809 | 0.807 | 0.822 | ||
| -channel | 0.6 | 0.736 | 4 | 4 | 0.744 | -2 | 0.747 | 0.747 | 0.776 | |||
| -channel | 0.6 | 0.683 | -1 | 0.690 | -2 | 4 | 0.692 | 0.690 | 0.697 | |||
The greedy search selects similar EFP graphs as the guided search, with the exception of the 4-node graph selected in pass 2 for the , -chanel scenario. No IRC-safe graphs () are selected and we again see frequent sensitivity to low parameters (i.e. ) and a variety of both narrow and wide angle features (i.e. ). A repeat of the greedy search with only IRC-safe observables achieves no performance improvements over the original HL features, suggesting that missing information may be strongly tied to IRC-unsafe representations of the information in the jet constituents.
VIII Exploration of Dependence
The results of both the guided search and the greedy search strongly suggest that the full performance gap which persists between the HL and LL representation of the jet contents cannot be compactly expressed in terms of a small number of EFP observables in the set that have been considered. This raises the question of what feature of the LL constituents can be credited with this performance improvement and why that information does not translate compactly to our EFP observables. The clues from the guided and greedy search point to sensitivity to low- constituents, as can be generated from soft radiation. Figure 6 shows the distribution of constituent relative to the jet for the six scenarios, in which SVJs appear to have more constituents at low relative . Recall that jet constituents are trimmed if the subjet they belong to has a below a threshold of 5% of the of the jet, corresponding to .

To consider whether the distinguishing information is contained in these low- constituents, we explore a broader range of thresholds, both lowering it to 0% and raising it to 10% and 15%. The HL features are re-evaluated on the newly trimmed constituents, and used as inputs to a new LightGBM model, whose performance is compared to a PFN trained on the trimmed constituents. Results for networks with varying thresholds are shown in Table 6.
| -channel | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| PFN | LightGBM | LL-HL Gap | PFN | LightGBM | LL-HL Gap | PFN | LightGBM | LL-HL Gap | |
| 0.00 | 0.908 | 0.895 | 0.013 | 0.853 | 0.829 | 0.024 | 0.788 | 0.739 | 0.049 |
| 0.05 | 0.866 | 0.861 | 0.005 | 0.822 | 0.803 | 0.019 | 0.776 | 0.736 | 0.040 |
| 0.10 | 0.847 | 0.848 | -0.001 | 0.790 | 0.790 | 0.000 | 0.746 | 0.721 | 0.025 |
| 0.15 | 0.838 | 0.843 | -0.005 | 0.784 | 0.785 | -0.001 | 0.738 | 0.717 | 0.021 |
| -channel | |||||||||
| PFN | LightGBM | LL-HL Gap | PFN | LightGBM | LL-HL Gap | PFN | LightGBM | LL-HL Gap | |
| 0.00 | 0.825 | 0.817 | 0.008 | 0.748 | 0.737 | 0.011 | 0.662 | 0.647 | 0.0015 |
| 0.05 | 0.806 | 0.808 | -0.002 | 0.754 | 0.755 | -0.001 | 0.697 | 0.683 | 0.014 |
| 0.10 | 0.741 | 0.742 | -0.001 | 0.662 | 0.663 | -0.001 | 0.595 | 0.597 | -0.002 |
| 0.15 | 0.731 | 0.740 | -0.009 | 0.655 | 0.661 | -0.006 | 0.593 | 0.596 | -0.003 |
In each case, raising the threshold decreases the classification performance, as might be expected due to the removal of low- information. Perhaps more interesting is the variation in the gap between the performance of the HL LightGBM model and the PFN operating on low-level constituents. In nearly every case, the gap grows as more low- information is included, supporting the hypothesis that this is the origin of most of the information missing from the HL models. The details of the low- constituents are likely to be very sensitive to modeling uncertainties and subject to concerns about infrared and collinear safety.
However, even in for the most aggressive value of , a persistent gap of AUC=0.021 remains in the -channel, scenario, which cannot be explained by low- constituents. We therefore examine this in more detail.
First, we consider the EFPs selected in the study above where , including EFPs selected by the guided search (Table 4) and the greedy search (Table 5). For all combinations of HL and identified EFPs, no performance gain is seen. Next, we perform a fresh guided search on models trained from the constituents. In contrast to previous cases, no large improvement in training performance is obtained on the first selected EFP. After 200 iterations, the gap is reduced to AUC=0.010 with the addition of 200 EFPs. We note that this far exceeds the mean number of constituents of these trimmed jets, 60. We conclude that there there does not appear to be a compact representation of the remaining information in the EFP space we have explored.
IX Conclusions
We have analyzed the classification performance of models trained to distinguish background jets from semi-visible jets using the low-level jet constituents, and found them to offer stronger performance than models which rely on high-level quantities motivated by other processes, mostly those involving collimated hadronic decays of massive objects.
While models operating on the existing suite of HL quantities nearly match the performance of those using LL information, a significant gap exists which suggests that relevant information remains to be captured, perhaps in new high-level features. To our knowledge, this is the first study to compare the performance of constituent-based and high-level semi-visible-jet taggers, and to identify the existence of relevant information uncaptured by existing high-level features. Jets due to semi-visible decays are markedly different in energy distribution than those from massive objects, so it is not unexpected that existing features may not completely summarize the useful information.
Using a guided strategy, we identify a small set of new useful features from the space of energy-flow polynomials, but these do not succeed in completely closing the performance gap. In most cases, the remaining gap seems to be due to information contained in very low- constituents, which is likely to be sensitive to modeling of showering and hadronization and may not be infrared and collinear safe. This highlights the importance of interpretation and validation of information used by constituent-based taggers. As demonstrated by Ref. Cohen et al. (2020), the specific pattern of energy deposition may depend sensitively on both the parameters of the theoretical model as well as the settings chosen for the hadronization model. It is therefore vital that the information being analyzed be interpreted before being applied to analysis of collider data.
In one case studied here, a gap persist between low- and high-level-based models even when low- constituents are aggressively trimmed, suggesting the possibility that a new high-level feature could be crafted to capture this useful high- information. Our efforts to capture this information with the simpler energy-flow polynomials was not successful, suggesting that more complex high- observables may exist which provide useful discrimination between QCD and semi-visible jets. The studies presented here can inform and guide theoretical work to construct such observables specifically tailored to this category of jets. Whether such observables can be efficiently represented using alternative basis sets of observables, and whether they are robust to Shimmin et al. (2017) or explicitly dependent on Ghosh et al. (2021) uncertainties while providing power over large regions of theoretical parameter space is an important avenue for future work.
X Acknowledgements
The authors thank Po-Jen Cheng for his assistance in sample validation. This material is based upon research supported by the Chateaubriand Fellowship of the Office for Science & Technology of the Embassy of France in the United States. T. Faucett and D. Whiteson are supported by the U.S. Department of Energy (DOE), Office of Science under Grant No. DE-SC0009920. S.-C. Hsu is supported by the National Science Foundation under Grant No. 2110963.
Appendix A Signal reweighting
The signal and background distributions have distinct transverse momentum and pseudo-rapidity distributions due to the processes used to generate them. We wish to learn to classify the signal and background independent of these quantities, and so reweight the signal events to match the background distribution, see Fig 7.


Appendix B Jet Substructure Observables
High-level features used to discriminate between semi-visible and background jets are defined below.
B.1 Jet transverse momentum and mass
The sum of jet constituents is included as a HL observable both in the initial HL inputs and along with EFPs to give ML algorithms a relative scale for dimensionless EFP features to train with. The jet sum is calculated by
| (9) |
Distributions for jet and , defined below, are shown in Fig. 8.


B.2 Generalized Angularities
Multiple standard HL observables are defined by choices of and parameters from the momentum fraction and angular separation of a Generalized Angularity (GA) expression Larkoski et al. (2014b),
| (10) |
The Les Houches Angularity (LHA) is defined from the GA expression with parameters and with . Written explicitly, these become
| LHA | (11) | |||
| (12) |
Two additional values, and , are produced by choices of and , respectively
| (13) | ||||
| (14) |
Lastly, the multiplicity (although technically defined as simply the total number of constituents in the jet) can be expressed in this same generalized form for
| (15) |
Distributions for all GA observables are shown in Fig. 9




B.3 Energy Correlation
Energy Correlation Functions Larkoski et al. (2013) and their corresponding ratios are computed via the functions: and ,
| (16) | ||||
| (17) | ||||
| (18) |
and the related ratios are given by,
| (19) | ||||
| (20) |
from these ratios, we then compute the energy correlation ratios and
| (21) | ||||
| (22) |
Distributions for all Energy Correlation observables are shown in Fig. 10



B.4 N-Subjettiness
Given subjets isolated via clustering, for N candidate subjets, the N-subjettiness () Thaler and Van Tilburg (2011) is defined as,
| (23) |
where we define the normalization factor by,
| (24) |
where is the characteristic jet radius used during clustering. Finally, the N-subjettiness ratios used are defined by
| (25) | ||||
| (26) |
Distributions for both N-subjettiness observables are shown in Fig. 11


B.5 Groomed Momentum Splitting Fraction
The splitting fraction is described in terms of the Soft Drop grooming technique in Ref. Larkoski et al. (2014a). The feature is calculated using energyflow Komiske et al. (2018) with the Cambridge/Aachen algorithm using a jet radius of and Soft Drop parameters of and .
A distribution for is given in Fig. 12

Appendix C ML Architectures
C.1 Deep Neural Networks
All deep neural networks were trained in Tensorflow Abadi et al. (2015) and Keras Chollet and others (2015). The networks were optimized with Adam Kingma and Ba (2014) for up to 100 epochs with early stopping. For all networks, weights were initialized using orthogonal weights Saxe et al. (2013). Hyperparameters were optimized using bayesian optimization with the Sherpa hyperparameter optimization library Hertel et al. (2020).
C.2 High-Level DNN
All HL features are preprocessed with Scikit’s Standard Scaler Pedregosa et al. (2011) before training.
C.2.1 Deep Neural Networks
Hyperparameters and network design for all Dense networks trained on HL or EFP features are selected via Sherpa optimization using between two and eight fully connected hidden layers and a final layer with a sigmoidal logistic activation function to predict the probability of signal or background.
C.2.2 Particle-Flow Networks
The Particle Flow Network (PFN) is trained using the energyflow package Komiske et al. (2019). Input features are taken from the trimmed jet constituents and preprocessed by centering the constituents in space to the average and normalizing constituent values to 1. Both the EFN and PFN use this constituent information as inputs in the form of the 3-component hadronic measure measure option in EnergyFlow (i.e. , , ).
The PFN uses 3 dense layers in the per-particle frontend module and 3 dense layers in the backend module. Both frontend and backend layers use 300 hidden nodes per layer with a latent and filter dropout of 0.2. Each layer uses relu Nair and Hinton (2010) activation and glorot normal initializer. The final output layer uses a sigmoidal logistic activation function to predict the probability of signal or background. The Adam optimizer is used and trained with a batch size of 128 and a fixed learning rate of 0.001.
C.3 Boosted Learning Models
HL features are, again, preprocessed with Scikit’s Standard Scaler before training. Except where indicated, default settings are used.
C.3.1 LightGBM
All applications of LightGBM are trained using regression for binary log loss classification using Gradient Boosting Decision Trees. Performance is measured by the AUC metric for a maximum of 5000 boosting rounds and early stopping set to 100 rounds against AUC improvements.
C.3.2 XGBoost
All applications of XGBoost are trained using using the gradient tree booster and settings of: =0.1, subsample=0.5, base_score=0.1, =0.0, and max_depth=6. Performance is measured by the AUC metric for a maximum of 5000 boosting rounds and early stopping set to 100 rounds against AUC improvements.
C.4 Convolutional Networks on Jet Images
The Convolutional Neural Networks used a jet image produced through EnergyFlow’s pixelate function. Jet images were produced as a pixel matrix with an image width of 1.0. Resulting jet images were then normalized to a range of values between [0,1]. The network consisted of 3 hidden layers consisting of 300 nodes and used kernels of size and strides of . Each layer uses relu Nair and Hinton (2010) activation and glorot normal initializer. The final output layer uses a sigmoidal logistic activation function to predict the probability of signal or background. The Adam optimizer is used and trained with a batch size of 128 and a fixed learning rate of 0.001.
References
- Bertone and Hooper (2018) G. Bertone and D. Hooper, Rev. Mod. Phys. 90, 045002 (2018).
- Bertone and Tait (2018) G. Bertone and T. M. P. Tait, Nature 562, 51 (2018).
- Aaltonen et al. (2012) T. Aaltonen et al. (CDF Collaboration), Phys. Rev. Lett. 108, 211804 (2012).
- collaboration (2013) T. A. collaboration, Journal of High Energy Physics 2013, 75 (2013).
- collaboration (2012) T. C. collaboration, Journal of High Energy Physics 2012, 94 (2012).
- Aad et al. (2013) G. Aad et al. (ATLAS Collaboration), Phys. Rev. Lett. 110, 011802 (2013).
- Chatrchyan et al. (2012) S. Chatrchyan et al. (CMS Collaboration), Phys. Rev. Lett. 108, 261803 (2012).
- Bai and Tait (2013) Y. Bai and T. M. Tait, Physics Letters B 723, 384–387 (2013).
- Petriello et al. (2008) F. J. Petriello, S. Quackenbush, and K. M. Zurek, Phys. Rev. D 77, 115020 (2008).
- Ferreira de Lima et al. (2017) D. Ferreira de Lima, P. Petrov, D. Soper, and M. Spannowsky, Phys. Rev. D 95, 034001 (2017).
- Aaij et al. (2018) R. Aaij et al. (LHCb), Phys. Rev. Lett. 120, 061801 (2018), arXiv:1710.02867 [hep-ex] .
- Strassler and Zurek (2007a) M. J. Strassler and K. M. Zurek, Phys. Lett. B 651, 374 (2007a), arXiv:hep-ph/0604261 .
- Han et al. (2008) T. Han, Z. Si, K. M. Zurek, and M. J. Strassler, JHEP 07, 008 (2008), arXiv:0712.2041 [hep-ph] .
- Cohen et al. (2015) T. Cohen, M. Lisanti, and H. K. Lou, Physical Review Letters 115 (2015), 10.1103/PhysRevLett.115.171804.
- Cohen et al. (2017) T. Cohen, M. Lisanti, H. K. Lou, and S. Mishra-Sharma, Journal of High Energy Physics 2017, 1 (2017).
- Kar and Sinha (2021) D. Kar and S. Sinha, SciPost Phys. 10, 084 (2021), arXiv:2007.11597 [hep-ph] .
- Bernreuther et al. (2021) E. Bernreuther, T. Finke, F. Kahlhoefer, M. Krämer, and A. Mück, SciPost Phys. 10, 046 (2021), arXiv:2006.08639 [hep-ph] .
- Larkoski et al. (2014a) A. J. Larkoski, S. Marzani, G. Soyez, and J. Thaler, Journal of High Energy Physics 2014 (2014a), 10.1007/jhep05(2014)146.
- Larkoski et al. (2013) A. J. Larkoski, G. P. Salam, and J. Thaler, Journal of High Energy Physics 2013, 108 (2013).
- Kogler et al. (2019) R. Kogler, B. Nachman, A. Schmidt, L. Asquith, E. Winkels, M. Campanelli, C. Delitzsch, P. Harris, A. Hinzmann, D. Kar, C. McLean, J. Pilot, Y. Takahashi, N. Tran, C. Vernieri, and M. Vos, Rev. Mod. Phys. 91, 045003 (2019).
- Lu et al. (2022) Y. Lu, A. Romero, M. J. Fenton, D. Whiteson, and P. Baldi, arXiv (2022), arXiv:2202.00723 [hep-ex] .
- Baldi et al. (2016) P. Baldi, K. Bauer, C. Eng, P. Sadowski, and D. Whiteson, Phys. Rev. D93, 094034 (2016), arXiv:1603.09349 [hep-ex] .
- Chen et al. (2020) Y.-C. J. Chen, C.-W. Chiang, G. Cottin, and D. Shih, Phys. Rev. D 101, 053001 (2020).
- collaboration (2019) T. A. collaboration, Journal of High Energy Physics 2019, 33 (2019).
- Chung et al. (2021) Y.-L. Chung, S.-C. Hsu, and B. Nachman, Journal of Instrumentation 16, P07002 (2021).
- Cohen et al. (2020) T. Cohen, J. Doss, and M. Freytsis, JHEP 09, 118 (2020), arXiv:2004.00631 [hep-ph] .
- Komiske et al. (2018) P. T. Komiske, E. M. Metodiev, and J. Thaler, Journal of High Energy Physics 2018 (2018), 10.1007/jhep04(2018)013.
- Dillon et al. (2022) B. M. Dillon, L. Favaro, T. Plehn, P. Sorrenson, and M. Krämer, (2022), arXiv:2206.14225 [hep-ph] .
- Faucett et al. (2021) T. Faucett, J. Thaler, and D. Whiteson, Phys. Rev. D 103, 036020 (2021).
- Collado et al. (2021a) J. Collado, J. N. Howard, T. Faucett, T. Tong, P. Baldi, and D. Whiteson, Physical Review D 103, 116028 (2021a).
- Collado et al. (2021b) J. Collado, K. Bauer, E. Witkowski, T. Faucett, D. Whiteson, and P. Baldi, Journal of High Energy Physics 2021 2021:10 2021, 1 (2021b).
- Bradshaw et al. (2022) L. Bradshaw, S. Chang, and B. Ostdiek, arXiv (2022), arXiv:2203.01343 [hep-ph] .
- Strassler and Zurek (2007b) M. J. Strassler and K. M. Zurek, Physics Letters B 651, 374 (2007b).
- Alwall et al. (2011) J. Alwall, M. Herquet, F. Maltoni, O. Mattelaer, and T. Stelzer, “Madgraph 5 : Going beyond,” (2011).
- Skands et al. (2014) P. Skands, S. Carrazza, and J. Rojo, The European Physical Journal C 74 (2014), 10.1140/epjc/s10052-014-3024-y.
- Mangano et al. (2002) M. L. Mangano, M. Moretti, and R. Pittau, Nuclear Physics B 632, 343 (2002).
- Sjöstrand et al. (2015) T. Sjöstrand, S. Ask, J. R. Christiansen, R. Corke, N. Desai, P. Ilten, S. Mrenna, S. Prestel, C. O. Rasmussen, and P. Z. Skands, Computer Physics Communications 191, 159–177 (2015).
- de Favereau et al. (2014) J. de Favereau, C. Delaere, P. Demin, A. Giammanco, V. Lemaître, A. Mertens, and M. Selvaggi, Journal of High Energy Physics 2014 (2014), 10.1007/jhep02(2014)057.
- Krohn et al. (2010) D. Krohn, J. Thaler, and L.-T. Wang, Journal of High Energy Physics 2010 (2010), 10.1007/jhep02(2010)084.
- Cacciari et al. (2008) M. Cacciari, G. P. Salam, and G. Soyez, Journal of High Energy Physics 2008, 63 (2008).
- Cacciari et al. (2012) M. Cacciari, G. P. Salam, and G. Soyez, The European Physical Journal C 72 (2012), 10.1140/epjc/s10052-012-1896-2.
- Marzani et al. (2019) S. Marzani, G. Soyez, and M. Spannowsky, Lecture Notes in Physics (2019), 10.1007/978-3-030-15709-8.
- Larkoski et al. (2017) A. Larkoski, S. Marzani, J. Thaler, A. Tripathee, and W. Xue, Physical Review Letters 119 (2017), 10.1103/physrevlett.119.132003.
- Larkoski et al. (2014b) A. J. Larkoski, J. Thaler, and W. J. Waalewijn, Journal of High Energy Physics 2014, 129 (2014b).
- Thaler and Van Tilburg (2011) J. Thaler and K. Van Tilburg, Journal of High Energy Physics 2011 (2011), 10.1007/jhep03(2011)015.
- Chen and Guestrin (2016) T. Chen and C. Guestrin, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16 (ACM, New York, NY, USA, 2016) pp. 785–794.
- Bourilkov (2019) D. Bourilkov, International Journal of Modern Physics A 34, 1930019 (2019).
- Cornell et al. (2021) A. S. Cornell, W. Doorsamy, B. Fuks, G. Harmsen, and L. Mason, “Boosted decision trees in the era of new physics: a smuon analysis case study,” (2021), arXiv:2109.11815 [hep-ph] .
- Ke et al. (2017) G. Ke, Q. Meng, T. Finley, T. Wang, W. Chen, W. Ma, Q. Ye, and T.-Y. Liu, in Advances in Neural Information Processing Systems, Vol. 30, edited by I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Curran Associates, Inc., 2017).
- Cogan et al. (2015) J. Cogan, M. Kagan, E. Strauss, and A. Schwarztman, Journal of High Energy Physics 2015 (2015), 10.1007/jhep02(2015)118.
- de Oliveira et al. (2016) L. de Oliveira, M. Kagan, L. Mackey, B. Nachman, and A. Schwartzman, Journal of High Energy Physics 2016 (2016), 10.1007/jhep07(2016)069.
- Komiske et al. (2019) P. T. Komiske, E. M. Metodiev, and J. Thaler, Journal of High Energy Physics 2019 (2019), 10.1007/jhep01(2019)121.
- Shimmin et al. (2017) C. Shimmin, P. Sadowski, P. Baldi, E. Weik, D. Whiteson, E. Goul, and A. Søgaard, Phys. Rev. D 96, 074034 (2017), arXiv:1703.03507 [hep-ex] .
- Ghosh et al. (2021) A. Ghosh, B. Nachman, and D. Whiteson, Phys. Rev. D 104, 056026 (2021), arXiv:2105.08742 [physics.data-an] .
- Abadi et al. (2015) M. Abadi et al., “TensorFlow: Large-scale machine learning on heterogeneous systems,” (2015), software available from tensorflow.org.
- Chollet and others (2015) F. Chollet and others, “Keras,” \url{https://keras.io} (2015).
- Kingma and Ba (2014) D. P. Kingma and J. Ba, CoRR abs/1412.6980 (2014), arXiv:1412.6980 .
- Saxe et al. (2013) A. M. Saxe, J. L. McClelland, and S. Ganguli, CoRR abs/1312.6120 (2013), arXiv:1312.6120 .
- Hertel et al. (2020) L. Hertel, J. Collado, P. Sadowski, J. Ott, and P. Baldi, SoftwareX (2020).
- Pedregosa et al. (2011) F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, Journal of Machine Learning Research 12, 2825 (2011).
- Nair and Hinton (2010) V. Nair and G. E. Hinton (Omnipress, 2010) pp. 807–814.