Learning to Estimate Kernel Scale and Orientation of Defocus Blur with Asymmetric Coded Aperture
Abstract
Consistent in-focus input imagery is an essential precondition for machine vision systems to perceive the dynamic environment. A defocus blur severely degrades the performance of vision systems. To tackle this problem, we propose a deep-learning-based framework estimating the kernel scale and orientation of the defocus blur to adjust lens focus rapidly. Our pipeline utilizes 3D ConvNet for a variable number of input hypotheses to select the optimal slice from the input stack. We use random shuffle and Gumbel-softmax to improve network performance. We also propose to generate synthetic defocused images with various asymmetric coded apertures to facilitate training. Experiments are conducted to demonstrate the effectiveness of our framework.
Index Terms— Blur kernel estimation, focus adjustment, asymmetric coded aperture
1 Introduction
Defocus blur is common in the digital image capture process but unwelcome in the machine vision system, as it degrades features and leads to a system accuracy drop. The imaging techniques and optical performance have improved rapidly during the past decade, but the defocus problem remains to be solved. Consumer cameras handle this problem by introducing autofocus functions. In contrast, cameras like surveillance cameras lack autofocus function or have a fixed focus distance. While seeing remarkable results on curated web image datasets like ImageNet [1], a real-world application often fails to achieve a comparable accuracy using footage frequently contains out-of-focused imagery. In this work, we took a step further toward real-world application and proposed an end-to-end framework to estimate the defocus blur scale and orientation for auto lens focus adjustment.
Conventional methods to solve out-of-focus problems can be categorized into two approaches: introducing a focus tracking mechanism [2] or performing a deblurring algorithm [3][4] to recover the all-in-focus image. A focus tracking mechanism enables the vision system to capture a focused image directly, in which the optimal location of the focal plane should be determined in advance in order to adjust the lens focus. The focal plane location can be determined either by estimating the blur kernel [3] or object distance [5] (estimation method) or through repetitive tuning [2] (trial and error method), i.e., dialing the focal plane back and forth. We notice that a lens adjustment could perform accurately without iteration yielding lower delay using the estimation method. In comparison, the trial and error method takes a few frames to converge, making the estimation method an ideal option.
In computational photography literature, coded aperture techniques are used for both defocus deblurring [6][7] and depth estimation [3][8]. Though the deblurring functionality seems to solve the defocus problem straightforwardly, an incorrect point spread function(PSF) used in the deconvolution can cause more artifacts against our original intention. Meanwhile, whether deblurred images can deliver the same precision on machine vision tasks as in-focus images do stay unknown. The other practice of coded apertures, depth estimation, can well serve the blur scale estimation in our framework, though very few efforts have been put to distinguish which side of the object rests with respect to the focal plane, which causes the focal plane ambiguity in real-world applications.
Inspired by previous works [7][8], we tackle the defocus blur problem by estimating blur scale and orientation to guide the lens focus mechanism. With a predicted defocus blur scale and orientation, the optical system can respond with rapid lens adjustment, yielding lower delay and better focus accuracy. To achieve this, we propose a novel end-to-end framework with a 3D ConvNet to predict the defocus blur scale and orientation at the same time. We use asymmetric coded apertures to better solve the focal plane ambiguity problem neglected in previous research. Our proposed pipeline computes a stack of deblurred images with varied PSF hypotheses as input and predicts each pixel’s correct blur label (i.e., blur size and orientation). With a 3D ConvNet design, our method is applicable to different numbers of blur scale and orientation proposals. A full discussion of such design is conducted in Section 3. The contribution of our work is three-fold: First, we propose a novel deep-learning-based pipeline to construct a deblurred defocused image volume and estimate the scale and orientation from it. Second, we present a defocused image generation method to address the data-hungry problem. Third, we conduct extensive experiments to examine the robustness of this design among different conditions. ††footnotetext: We acknowledge funding from the Shenzhen Science and Technology Program(Grant No.KQTD20190929172829742).
2 Related Work
Substantial research has been laid out on blur parameter estimations. In this section, we discuss the methodology foundation, as well as its limitations.
A defocus blur is caused by object distances away from the camera focal plane. In order to establish a one-to-one correspondence between the object distance and the defocus blur, we must solve the focal plane ambiguity, i.e., distinguish which side of the object rests with respect to the focal plane. This ambiguity is non-trivial since the commonly used circular aperture employed in cameras will produce identical blur for items resting before and behind the focal plane. In [8], Sellen et al. detailed how asymmetric coded apertures can solve this ambiguity by creating different blur for items at each side of the focal plane. Following this scheme, we adopted an asymmetric coded aperture in our system design, though our pipeline is not rigged with one particular aperture.
Estimating the object distance or blur scale is a sub-topic of the well-studied coded aperture dilemma. Numerous coded apertures [3][7][6][8][9][10][11][12] have been proposed for different intentions. As [8] points out, scenarios that object located at both sides of the focal plane have not been discussed in previous studies. Moreover, these methods are paired with a particular aperture design, which means variant on PSF caused by lens distortion will affect its performance. With a predicted PSF, defocus deblurring can be performed in either frequency domain [13][4] or spatial domain [3][14]. Although the frequency domain process is more computation friendly, methods performed in the spatial domain like the algorithm in [3] produce better perceptual results.
In this work, we designed our pipeline to avoid these limitations. Our framework generates a deblurred image stack from the defocused image captured using one of above mentioned asymmetric coded apertures. As no extra modification is needed when altering coded apertures or deblurring algorithms in the proposed method, we decoupled the performance dependency from them. We showed that our system could achieve similar performance on different asymmetric coded apertures with two separate deblurring algorithms in Section 4.
The topic Depth from Defocus (DFD) [15] is similar to blur scale estimation as well as recent research on defocus map estimation [16][17] or defocus blur detection [18][19], which also involves the consideration of blur scale estimation. As these topics themselves are broad studies and neglect to address the focal plane ambiguity, we did not compare them in this discussion.
3 Methodology
3.1 Problem Formulation
The input of our pipeline is a spatially-varying defocused image. Spatially-varying indicates the blur at each pixel may differ from the neighbor in terms of scale and orientation. It has been shown in [20] that performing a deblurring algorithm with the wrong kernel yields low-quality images while the correct one produces high-quality results. Using this insight, we formulate blur kernel estimation to separate a correct deblurred result from the wrong ones to teach the neural network how to choose the right kernel scale and orientation. Thus, in our framework, we first perform a deblurring algorithm with PSF hypotheses (varying in scale and orientation) on a defocused image. These results are then concatenated and fed into the network, which is trained to identify the optimal deblurred result index for each pixel. The PSF kernel associated with the optimal deblurred image quality reports the correct scale and orientation.
Our training target can be formulated as an optimization problem:
| (1) | ||||
where a weighted sum of cross-entropy loss and smoothness loss is minimized. The network (denoted as , with model parameters ) takes the deblurred results and the original defocused image as input. We perform random shuffle (denoted as ) on the input and the ground-truth label to avoid overfitting and impose a smoothness loss on the network output for better performance. In computing the smoothness loss, we apply the Gumbel-Softmax [21] technique (denoted as ) in order to convert the 3D output into 2D. The smoothness loss is then weighted by . We detailed the motivation to perform random shuffle and the Gumbel-softmax methods in Section 3.2.
3.2 Blur Kernel Estimation
Input and Output With a defocused image as input, we first perform a deblurring algorithm with several PSF hypotheses to form the deblurred image stack. We adopt the deblurring approach proposed in [3], where the image is deblurred in the spatial domain using the Conjugate Gradient method, as well as the method in the frequency domain using Wiener Deconvolution. There is no extra modification that needs to be made in our framework when changing the deblurring algorithm. The deblurred image stack is a concatenation along depth channel of and with dimension [height, width, depth, channel]. We further append the stack with black padding (pixel values with all 0) along the depth dimension, making the depth always 24 for consistent behavior with variable deblurring hypotheses . The defocused image is also included in the input, as some pixels presented in may already be of optimal quality, and there will be no better options in the deblurred image stack.
The network output is a logit volume with a size of [height, width, depth]. Vectors along the depth dimension reveal the likelihood that slices in the input are sharp (high-quality) or not. The final blur scale and orientation for each pixel can be determined by looking up the blur kernel parameter associated with the highest logit value.
Architecture We design a fully convolutional network followed the architecture in [22], which utilizes the 3D ConvNet to handle the input with a variable length of depth. Our network is trained to award the image with optimal quality in the input stack while punishing lower-quality ones. A 3D ConvNet design suits this purpose perfectly, as sliding the convolution kernel along the depth dimension imitates the behavior of examining the image one by one. In our scheme, each 3D convolution layer is followed by one layer-normalization layer [23]. The architecture is detailed in Table. 1.
| Layer | s | d | n | depth | in | out | input |
| conv1_1 | 1 | 1 | 8 | 24/24 | 1 | 1 | stack |
| conv1_2 | 2 | 1 | 16 | 24/12 | 1 | 2 | conv1_1 |
| conv2_1 | 1 | 1 | 16 | 12/12 | 2 | 2 | conv1_2 |
| conv2_2 | 2 | 1 | 32 | 12/6 | 2 | 4 | conv2_1 |
| conv3_1 | 1 | 1 | 32 | 6/6 | 4 | 4 | conv2_2 |
| conv3_2 | 1 | 1 | 32 | 6/6 | 4 | 4 | conv3_1 |
| conv3_3 | 2 | 1 | 64 | 6/3 | 4 | 8 | conv3_2 |
| conv4_1 | 1 | 2 | 64 | 3/3 | 8 | 8 | conv3_3 |
| conv4_2 | 1 | 2 | 64 | 3/3 | 8 | 8 | conv4_1 |
| conv4_3 | 1 | 2 | 64 | 3/3 | 8 | 8 | conv4_2 |
| nnup_5 | 3/6 | 8 | 4 | conv3_3+conv4_3 | |||
| conv5_1 | 1 | 1 | 32 | 6/6 | 4 | 4 | nnup_5 |
| conv5_2 | 1 | 1 | 32 | 6/6 | 4 | 4 | conv5_1 |
| conv5_3 | 1 | 1 | 32 | 6/6 | 4 | 4 | conv5_2 |
| nnup_6 | 6/12 | 4 | 2 | conv2_2+conv5_3 | |||
| conv6_1 | 1 | 1 | 16 | 12/12 | 2 | 2 | nnup_6 |
| conv6_2 | 1 | 1 | 16 | 12/12 | 2 | 2 | conv6_1 |
| nnup_7 | 12/24 | 2 | 1 | conv1_2+conv6_2 | |||
| conv7_1 | 1 | 1 | 8 | 24/24 | 1 | 1 | nnup_7 |
| conv7_2 | 1 | 1 | 8 | 24/24 | 1 | 1 | conv7_1 |
| conv7_3 | 1 | 1 | 1 | 24/24 | 1 | 1 | conv7_2 |
Data Augmentation We expect the network to identify the blur kernel by examining input images’ quality. However, preliminary experiments show overfitting trends when changing the input stack order, which means the network exploits the ordering pattern but not the image quality we intended. We perform a random shuffle on the input stack and the label map along the depth dimension during training in improved schemes, and the overfitting issue is resolved.
Loss Our network training is formulated as a classification problem. We index each proposed blur kernel employed in the deblurring step and compute the predicted softmax from the output logit volume. The cross-entropy between the label and the prediction can be computed and serve as our primary loss.
We expect the estimated blur map to be smooth as the blur scale and orientation share the same continuous character as scene depth does in most areas. To compute smoothness loss on our output, we need to convert the 3D logit volume into a 2D indexing map. As the operation to flat a 3D volume into 2D is not feasible here with its non-differentiable property, we apply Gumbel-Softmax [21] to fulfill this need. It takes a logit vector as input, and outputs the index of the element associated with the largest logit value. Then, we compute through taking the absolute average of the first-order gradient of the 2D indexing map. The final loss is a weighted sum of and : , where we weight by .
4 Experiments
4.1 Data Generation
Our training procedure needs a large portion of spatially-varying defocused images, each with a per-pixel ground-truth blur scale and orientation to supervise the network training. With very few previous works sharing coded aperture images, none of them involves scene objects resting on both sides of the focal plane. As we intend to address the focal plane ambiguity problem, we need to generate a new dataset to meet the need. Here we present an approach to acquire defocused images from CG generated all-in-focus images.
All-in-Focus Image and Defocus Generation We generate all-in-focus images each with its depth map using UnrealCV [24]. Defocused images are further generated following the thin-lens model (Fig. 1) from all-in-focus images, similar to one described in [17]. With setting the focal plane at distance , the circle of confusion (COC) diameter for image pixel with depth can be determined according to Eq. 2.
| (2) |
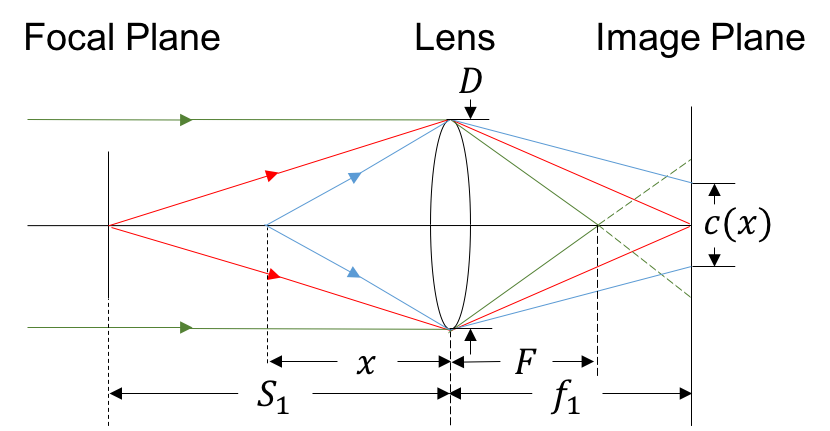
The sign and magnitude of indicate the orientation and the scale of the blur kernel, respectively. With an all-in-focus image and coresponding depth map , for each pixel and its depth value , we can compute the blur parameter according to Eq. 2. We round to obtain a set of where . Here denotes the rounding operation. With , we resize, flip, and normalize the coded aperture to form a PSF according to . Convolution is then performed on each pixel in the all-in-focus image with kernel to form the spatially-varying defocused image . In addition, we save as the per-pixel ground-truth label for the training process. To avoid producing unrealistic blurry images, we restrict the maximum blur size during defocus generation.
We capture 100 all-in-focus images from scenes provided in UnrealCV, and generate defocused images for each one with 12 different focal distances ( in Fig. 1). Thus 1200 defocused images are acquired totally with each coded aperture we used. The maximum blur scale is restricted to be 7, 9, and 10 pixels to form the depth-13, depth-17, depth-19 dataset, respectively. We later use these datasets vary in coded apertures and maximum blur scales to verify our framework’s generalization performance.



In our experiments, we split the entire dataset for each coded aperture and maximum blur scale to 936 defocused images for training, 108 for validation, and 156 for evaluation. The split is implemented in such a manner that there are no overlapping scenes across the training/validation/evaluation subsets, which means all 12 defocused images generated from one particular scene are forced to belong to one of these three subsets.
4.2 Implementiation Details
We implement our proposed network architecture in Table. 1 using TensorFlow API [25]. In the training procedure, the network is optimized by the SGD optimizer with the random shuffle applied on the input stack and label. The learning rate, batch size, and smoothness weight are 0.01, 1, and 0.1, respectively. The temperature argument for the Gumbel-softmax function is 0.5. We train the network on a single GPU (GeForce RTX 2080 Ti), and the network takes around five days to converge.
4.3 Evaluation
We formulate our blur kernel estimation as a classification problem. Logit volume from the network output indicates whether pixels in the deblurred stack are classified as optimal-quality or not. The predicted blur scale and orientation can be determined by indexing the highest value along the depth channel of the logit volume. We report the prediction N-1 accuracy and the N-3 accuracy in the following manner: N-1 accuracy indicates the percentage of pixels holds the same predicted blur scale and orientation as the ground-truth label does. The N-3 accuracy is computed similar to N-1 but also counting the nearby prediction (i.e., the pixel is predicted within the range of its ground-truth label ) as a correct prediction. For example, pixel with label +3 predicted as +2 (or +4) is not counted as a correct prediction in N-1 but in N-3. The intention behind reporting the N-3 accuracy is to compensate for the inaccuracy introduced during rounding COC diameter . The N-3 accuracy also registers how effective this framework will perform in a real-world application. Since even the prediction is off by 1 pixel, adjusting focus with it will still result in a much more in-focus image.
| depth-13 | depth-17 | depth-19 | |
|---|---|---|---|
| N-1 Accuracy | 63.08% | 63.47% | 63.81% |
| N-3 Accuracy | 82.90% | 82.93% | 85.59% |
| SoS | SoZ | ZoZ (fine-tuned) | |
|---|---|---|---|
| N-1 Accuracy | 63.47% | 54.16% | 59.17% |
| N-3 Accuracy | 82.93% | 79.00% | 81.47% |
Evaluation on different number of blur hypotheses As shown in Table. 2, we demonstrate our framework’s performance to handle the input with a variable number of blur hypotheses. Our model is trained on dataset depth-17 and reports an N-3 accuracy of 82.9%, 82.93%, and 85.59% on evaluation subsets of datasets depth-13, 17, and 19, respectively. The similar high percentage results among three datasets show our framework is able to generalize over input with a variable number of blur hypotheses and estimate the blur scale and orientation of defocused image with high accuracy. To challenge our network’s generalization capability even more, we alter the coded aperture used in the dataset generation and deblurring step. In particular, we train our model on the dataset generated using Sellent’s coded aperture and evaluate on two separate datasets generated using Sellent’s and Zhou’s coded aperture (Fig. 2 (a) and (b)). In addition, Sellent’s coded aperture is designed for depth estimation, while Zhou’s is intended for defocus deblurring. The evaluation accuracy is presented in Table. 3. Although we notice the results of SoZ are lower than SoS, dropping from 82.93% to 79% in the N-3 accuracy, we observe improved accuracy in ZoZ after the network fine-tuned on the dataset corresponding to Zhou’s coded aperture. The performance gap between SoS and ZoZ indicates the coded aperture chosen in the framework would affect the overall performance. Nevertheless, we do not recognize a strong dependency of robust system performance on a particular coded aperture, thus proving our network’s generation capability.
Evaluation on different coded apertures We also assess the network performance with two deblurring algorithms generating the input stack from defocused images. These two algorithms are the spatial-domain method proposed in [3] and the Wiener Deconvolution, which is a frequency-domain method. While the model is trained with [3] generating the deblurred image stack, experiments show that swapping to the Wiener Deconvolution algorithm does not influence the performance: The N-1 accuracy of evaluating on spatial-domain vs. frequency-domain deblurring algorithm is 63.47% vs. 62.48%, and N-3 accuracy of 82.90% vs. 82.64%, showing that our framework is insensitive to the deblurring algorithm type.
Qualitative evaluation Some qualitative results are exhibited in Fig. 3. We plot the blur map similar to a depth map that pixels with similar colors indicate a similar blur parameter. Our network can generally discriminate areas with different blur kernels and classify them accurately. Some pixels are misclassified to a kernel closer to the true one. This is because deblurring with a kernel similar to ground-truth yields a sub-optimal image quality but can be hardly distinguished by the network. The network can not always discriminate between an optimal result (deblurred by the true kernel) and a sub-optimal result. Nevertheless, we achieve 82.93% N-3 accuracy. This indicates that our network can identify the optimal results and assign a high probability to them.
After further analyzing the incorrect prediction, which significantly differs from its neighbor region’s prediction and the ground-truth label, such as the bottom right part of the first row (dark area) in Fig. 3, we find that a large piece of them comes from the texture-less region in the all-in-focus image. We hold this is an ill-posed challenge as defocus texture-less images with various blur scale and orientation show a tiny variation in between. Also, in real-world applications, a texture-less region can hardly be a region of interest.
5 Conclusion
In this paper, we present a deep-learning-based framework to estimate blur scale and orientation from a defocused image to assist rapid focus adjustment. Benefiting from the 3D ConvNet architecture, our pipeline is able to process a variable depth of deblurred candidates across complex scenarios. We employ a random shuffle technique to avoid overfitting and adopted the Gumbel-softmax method with smoothness constraint to improve the performance. Experiments show that our approach achieves reliable accuracy per-pixel blur scale and orientation results. When examined on different coded aperture datasets, our framework generalizes well to achieve above 80% N-3 accuracy after fine-tuning. Furthermore, our system performance does not depend on a particular deblurring algorithm or coded aperture.
References
- [1] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255.
- [2] Jie He, Rongzhen Zhou, and Zhiliang Hong, “Modified fast climbing search auto-focus algorithm with adaptive step size searching technique for digital camera,” IEEE transactions on Consumer Electronics, vol. 49, no. 2, pp. 257–262, 2003.
- [3] Anat Levin, Rob Fergus, Frédo Durand, and William T Freeman, “Image and depth from a conventional camera with a coded aperture,” ACM transactions on graphics (TOG), vol. 26, no. 3, pp. 70–es, 2007.
- [4] Leon B Lucy, “An iterative technique for the rectification of observed distributions,” The astronomical journal, vol. 79, pp. 745, 1974.
- [5] Andreas N Dorsel, Kenneth L Staton, Cassandra Dey, and George P Tsai, “Apparatus and method for autofocus,” Nov. 26 2002, US Patent 6,486,457.
- [6] Changyin Zhou, Stephen Lin, and Shree Nayar, “Coded aperture pairs for depth from defocus,” in 2009 IEEE 12th international conference on computer vision. IEEE, 2009, pp. 325–332.
- [7] Changyin Zhou and Shree Nayar, “What are good apertures for defocus deblurring?,” in 2009 IEEE international conference on computational photography (ICCP). IEEE, 2009, pp. 1–8.
- [8] Anita Sellent and Paolo Favaro, “Which side of the focal plane are you on?,” in 2014 IEEE international conference on computational photography (ICCP). IEEE, 2014, pp. 1–8.
- [9] Max Grosse, Gordon Wetzstein, Anselm Grundhöfer, and Oliver Bimber, “Coded aperture projection,” ACM Transactions on Graphics (TOG), vol. 29, no. 3, pp. 1–12, 2010.
- [10] Hajime Nagahara, Changyin Zhou, Takuya Watanabe, Hiroshi Ishiguro, and Shree K Nayar, “Programmable aperture camera using lcos,” in European Conference on Computer Vision. Springer, 2010, pp. 337–350.
- [11] Jingyu Lin, Xing Lin, Xiangyang Ji, and Qionghai Dai, “Separable coded aperture for depth from a single image,” IEEE Signal Processing Letters, vol. 21, no. 12, pp. 1471–1475, 2014.
- [12] Yosuke Bando, Bing-Yu Chen, and Tomoyuki Nishita, “Extracting depth and matte using a color-filtered aperture,” in ACM SIGGRAPH Asia 2008 papers, pp. 1–9. 2008.
- [13] William Hadley Richardson, “Bayesian-based iterative method of image restoration,” JoSA, vol. 62, no. 1, pp. 55–59, 1972.
- [14] Anat Levin, Yair Weiss, Fredo Durand, and William T Freeman, “Understanding and evaluating blind deconvolution algorithms,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2009, pp. 1964–1971.
- [15] Subhasis Chaudhuri and Ambasamudram N Rajagopalan, Depth from defocus: a real aperture imaging approach, Springer Science & Business Media, 2012.
- [16] Shaojie Zhuo and Terence Sim, “Defocus map estimation from a single image,” Pattern Recognition, vol. 44, no. 9, pp. 1852–1858, 2011.
- [17] Junyong Lee, Sungkil Lee, Sunghyun Cho, and Seungyong Lee, “Deep defocus map estimation using domain adaptation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 12222–12230.
- [18] Jianping Shi, Li Xu, and Jiaya Jia, “Just noticeable defocus blur detection and estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 657–665.
- [19] Ming Ma, Wei Lu, and Wenjing Lyu, “Defocus blur detection via edge pixel dct feature of local patches,” Signal Processing, p. 107670, 2020.
- [20] Mina Masoudifar and Hamid Reza Pourreza, “Image and depth from a single defocused image using coded aperture photography,” arXiv preprint arXiv:1603.04046, 2016.
- [21] Eric Jang, Shixiang Gu, and Ben Poole, “Categorical reparameterization with gumbel-softmax,” arXiv preprint arXiv:1611.01144, 2016.
- [22] Ben Mildenhall, Pratul P. Srinivasan, Rodrigo Ortiz-Cayon, Nima Khademi Kalantari, Ravi Ramamoorthi, Ren Ng, and Abhishek Kar, “Local light field fusion: Practical view synthesis with prescriptive sampling guidelines,” ACM Transactions on Graphics (TOG), 2019.
- [23] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016.
- [24] Weichao Qiu, Fangwei Zhong, Yi Zhang, Siyuan Qiao, Zihao Xiao, Tae Soo Kim, and Yizhou Wang, “Unrealcv: Virtual worlds for computer vision,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1221–1224.
- [25] Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, et al., “Tensorflow: a system for large-scale machine learning.,” in OSDI, 2016, vol. 16, pp. 265–283.