Learning Skills to Navigate without a Master: A Sequential Multi-Policy Reinforcement Learning Algorithm
Abstract
Solving complex problems using reinforcement learning necessitates breaking down the problem into manageable tasks, and learning policies to solve these tasks. These policies, in turn, have to be controlled by a master policy that takes high-level decisions. Hence learning policies involves hierarchical decision structures. However, training such methods in practice may lead to poor generalization, with either sub-policies executing actions for too few time steps or devolving into a single policy altogether. In our work, we introduce an alternative approach to learn such skills sequentially without using an overarching hierarchical policy. We propose this method in the context of environments where a major component of the objective of a learning agent is to prolong the episode for as long as possible. We refer to our proposed method as Sequential Soft Option Critic. We demonstrate the utility of our approach on navigation and goal-based tasks in a flexible simulated 3D navigation environment that we have developed. We also show that our method outperforms prior methods such as Soft Actor-Critic and Soft Option Critic on various environments, including the Atari River Raid environment and the Gym-Duckietown self-driving car simulator.
I INTRODUCTION
Reinforcement Learning (RL) in the past decade achieved unprecedented success in multiple domains ranging from playing simple Atari games [1] to learning complex strategies and defeating pro players in Starcraft [2] and Go [3]. However, the problem of learning meaningful skills in reinforcement learning remains an open question. The options framework [4] provides a method to automatically extract temporally extended skills for a long horizon task with the use of options, which are sub-policies that can be leveraged by some other policy in a hierarchical manner. The process of learning such temporal abstractions has been widely studied in the broad domain of hierarchical reinforcement learning [5]. In this paper, we provide an alternate approach for learning options sequentially without a higher-level policy and show a better performance on navigation tasks.
In the options framework, each option is defined by a tuple of policies, initiation states, and termination states. The set of termination states of an option is determined by a termination function that maps the state space to its class membership probability of the termination state set. Various advancements in the options framework, like the option critic architecture [6], have significantly improved the convergence of the overall algorithm, but most recent works focus on a fixed set of options that are hard to scale in practical scenarios.
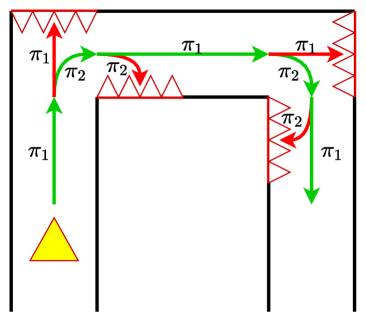
Humans excel at learning skills because while performing tasks, they can apply an inordinate amount of prior information [7]. For an RL agent to learn efficiently in complex environments, it also needs to rely on its previously learned knowledge to continually improve its overall policy. In this spirit, we propose an algorithm to learn policies sequentially so that during the training of any policy, the knowledge obtained till then, in the form of the already trained previous policies, can be leveraged to inform the learning of the current policy. We refer to our method as Sequential Soft Option Critic (SSOC) that is designed to operate in a framework wherein a major component of the goal of the RL agent is to learn diverse skills so as to prolong the episode and survive, as shown in Fig. 1. This behavior is incentivized by emitting a reward signal of when the episode ends and a reward signal of for every other time step.
Conceptually one may draw parallels between our approach and curriculum learning [8]. The idea behind curriculum learning is to train a model with a curriculum consisting of a sequence of tasks of increasing complexity rather than simply allowing the model to learn the original task from scratch. In practice, it has been demonstrated that this approach significantly outperforms traditional learning methods [9]. However, the major disadvantage of curriculum-based RL is that it is generally expensive to create a comprehensive curriculum, if not outright impractical. In our approach, when a new option is added, its policy is trained only in states in which the previously trained options are expected to perform poorly. This is done by using the options’ termination functions to effectively partition the state space so that each option can learn an optimal policy for some subset of the state space, which is an easier task to accomplish. The options are then chained together with the termination state of the previous option serving as the initial state of the next.
We evaluate our proposed method on three environments: (i) a flexible 3D navigation environment developed by us, (ii) the Duckietown self-driving car simulator [10], and (iii) the Atari River Raid environment.
By conducting extensive experiments, we establish that our method outperforms the Soft Actor-Critic algorithm [11] and its options counterpart, the Soft Option Critic [12]. Our main contributions are as follows.
(1) We propose a new approach called ‘Sequential Soft Option Critic’ for training options in environments where a primary objective of the agent is to prolong the length of the episode.
(2) We demonstrate the utility of sequentially adding new skills without a policy over options, with experimental results that outperform prior methods in the task of navigation in our simulated 3D environment and the Ducktietown and Atari River Raid environments.
(3) We show that our approach can learn skills to solve complex tasks involving high-level goals in the navigation environment outperforming prior methods.
II RELATED WORK
The concept of temporal abstraction in reinforcement learning has been extensively explored in various works, from humble beginnings with options framework [4], feudal learning [13], hierarchical abstract machines [14], and the MAXQ hierarchical learning algorithm [15], to recent endeavors in imagination augmented agent learning with variational temporal abstraction [16]. Approaches like feudal networks [17] based on feudal learning fused a manager network to choose the direction of navigation in the latent space when learning workers (sub-policies).
The option-critic architecture [6] builds on top of the options framework and makes use of the policy over options to learn its corresponding function. This acts as a critic and is used to update the termination functions of the options. Recently Soft Option Actor-Critic Architecture (SOAC) extended this approach by appending intrinsic rewards into the framework [18]. Unlike ,[6] which uses option critic to compute gradients for each sub-policy, in this paper, we study learning sub-policies one at a time.
Hierarchical reinforcement learning with off-policy [19] provided a data-efficient method of training hierarchical policies. Hindsight experience replay [20] has widely been adopted for training policies in sparse reward environments and has also been recently used in multi-level hierarchical reinforcement learning algorithms [21]. Hierarchical reinforcement learning has also shown remarkable success in very complex domains like playing the game of Starcraft [2], although the sub-policies were trained separately and combined together by a master policy, the agent learned to play the game like a pro player [22]. Meta-learning approaches [23] focused on training a meta controller, which would be frequently re-initialized such that it can learn to control the trained sub-policies.
Our approach amounts to partitioning the state space based upon how well a policy performs in it, much like previous iterative approaches [24]. Our method also shares some commonalities with the deep skill chaining algorithm [25] on how new options are added to the existing set of options. Deep skill chaining sequentially learns local skills by chaining them backward from a goal state. However, in our approach, skills are learned to complement the previously acquired ones such that the agent can traverse to various unseen states. This method shares a striking resemblance with curriculum-based learning approaches [8], but here the curriculum naturally arises from the necessity of traversing the environment. The use of nested termination functions in our framework is inspired by the continual learning architecture in progressive neural networks [26]. We make use of the Soft Actor-Critic algorithm (SAC) [11] that is based on a maximum entropy reinforcement learning framework [27] for training all our policy networks.
III BACKGROUND
A Markov decision process (MDP) is defined by the tuple , where is the state space, is the action space, is the state transition probability of going to the next state from state given an action , is the reward function that provides a reward signal as the agent traverses the environment, and is the discount factor. The aim is to find an optimal policy such that
| (1) |
where is the state-action distribution induced by a policy . For every policy , one can define its corresponding value function:
| (2) |
where is the value function defined by
| (3) |
III-A Soft Actor-Critic
The soft actor-critic algorithm [11] is an off-policy entropy-based reinforcement learning algorithm. The main idea of the entropy-based learning approach is to maximize the entropy of the policy along with the reward. A straightforward way of doing this is by making the reward function depend on the current policy’s entropy. Making the reward proportional to the entropy incentivizes greater exploration of the environment, ensuring the policy is far less likely to get stuck in a local optimum. Thus, the optimal policy is defined as
| (4) |
where is the temperature variable that accounts for the importance of the entropy and is the entropy of the policy. The above formulation reduces to the standard reinforcement learning objective as . It is shown that by iteratively using the soft policy evaluation and soft policy improvement, the policy convergences to the optimal policy [11].
The temperature variable can be treated as a trainable parameter for better performance of the algorithm [28]. This gives the algorithm the flexibility to dictate the relative importance of the policy’s entropy. As decreases, the policy becomes more deterministic in nature. We make use of this property of the soft actor-critic to decide when new policies should be added.
III-B The Options Framework
The idea of temporally extended actions has been introduced by [4]. An option is defined by the tuple , where is the set of options, is the policy corresponding to the option, is the set of states where the option can be initialized, and is the termination function of the option. In a typical options framework, sub-policies, are initialized, each with its corresponding and , along with a policy over options . In the call-and-return approach chooses an option and executes actions till it terminates with probability for a given state and the control then returns back to . The state transition dynamics are given by
| (5) |
Unlike other approaches where the next option is chosen by a master policy , in our proposed approach, the next option to be executed depends on the termination state space of the previous options.
IV THE PROPOSED ALGORITHM
IV-A Class of environments
In this paper, we consider environments in which a major component of the task of the agent is to prolong the duration of the episode, which is incentivized by using a simple reward function , whose value is if is the final state of the episode, and otherwise. Many real-life problems can be effectively cast as reinforcement learning problems with such a reward function and minimal information from the environment. Examples of such applications include autonomous vehicle navigation while avoiding a collision [29, 30] and drone navigation [31]. Tasks that require the agent to maintain an equilibrium in an ever-changing environment may be cast into our framework using this simple reward function. Practical examples may involve tasks like assembly line automation with increasing levels of complexity.
A consequence of such a reward signal is that as the agent fails less frequently in the process of learning better policies, it becomes harder to train it owing to the increasing sparsity of the failure states. Our approach is designed to overcome this by learning new policies near states where failure occurs without disturbing the already learned policies.
In our proposed approach, the policies learned need only be locally optimal. The main challenge of the learning algorithm then becomes determining how likely it is for the current policy to fail so as to switch to another policy. Unlike other option learning algorithms, the proposed strategy is to sequentially train one option at a time. To learn from a minimal amount of data while training, we do not train a (master) policy over the options but rely on the termination functions of individual options to determine which option should be chosen for execution. The states in which a new policy is trained are determined by the termination functions, which are treated as binary classifiers. New policies are learned only in states that are classified as termination states for all the previous options, and this is achieved by nesting the termination functions of the options. We explain this procedure in detail in the later subsections.
Ideally, one can continue to add more options into the set of all options until , where state belongs to the marginal state distribution induced by the set of options learned by the algorithm. However, from a pragmatic perspective, we threshold the maximum number of options to be learned. We now describe in detail how each component of the framework is adopted in our approach.
IV-B Training Policies
In the proposed approach, the policies are trained sequentially, i.e., firstly, a single policy and its termination function are trained until semi-optimality, only then another policy is added along with its termination function and trained until semi-optimality, and so on. Once a policy is trained, it is not modified again. Later in this section, we go into detail about how each policy is trained and what we consider to be the semi-optimality of a policy.
Corresponding to any given policy, depending on its performance, the state space is partitioned into termination and non-termination states for that policy. Suppose we have a trained option . The next option need only be trained in those states that are classified as termination states by , i.e., the new policy is only focused on learning to operate in states where the previous policy failed. In order to make use of the previously learned policy, we also incentivize the new policy to traverse towards the states that are deemed non-termination states by . For this, in general, given trained options , we train a new policy with the following reward function
| (6) |
where is a ‘nested termination function’, which acts as a termination function corresponding to all the previously trained options together. The learning of this nested termination function is described in detail in the next subsection. The reason for giving a ‘inter-option’ reward whenever the new policy enters states with is because the desired objective is to incentivize the new policy to enter states where it can easily switch to some other policy that has already been fully trained and hence, is presumably more capable of traversing those states. This encourages the agent to leverage previously gained knowledge instead of trying to relearn it. The training of the new policy is limited to those state-action pairs that are vital for prolonging the episode and cannot be delegated to previous policies. It is to be noted that if the policy remains in states for which , i.e, termination states of previous policies, then the reward given to the policy is the unchanged sparse reward of the environment.
This modification of the reward function described by Equation 6 is applied for training every policy other than the first one. We included ablation studies in our experiments to show that this inter-option reward is an important reason behind our approach outperforming the Soft Actor-Critic algorithm in the navigation environment.
Each policy is updated as in soft-actor critic, by using the information projection on the exponential of the soft Q-value
| (7) |
where normalizes the distribution.
In this work, we make use of the trainable of the soft actor-critic algorithm as a measure to decide whether to stop training a policy and add a new option. is updated so as to minimize the following cost function [28]
| (8) |
where is a hyperparameter set to dim, where is the action space. If is constrained to satisfy , the optimal value of that satisfies the above objective is , since the entropy . So the value of monotonically decreases as the training progresses.
As the value of decreases, there is a smaller incentive for the agent to maximize the entropy. This results in the learned policy becoming less exploratory and more deterministic. We determine a policy to be sufficiently trained for it to function as a semi-optimal policy when , where is a threshold. All new sub-policies are initialized with to ensure maximum exploration near states where policies are initialized. Essentially we augment a new policy when the temperature variable of the currently trained policy is low enough to warrant it to be considered an optimal policy near its initialization states.
Once a policy is trained enough to be deemed semi-optimal, we fix that policy and no longer train it. The rationale for this is that it is much easier to train new options in the context of fixed already trained options rather than trying to learn new options while simultaneously updating old options.



IV-C Learning Termination Functions
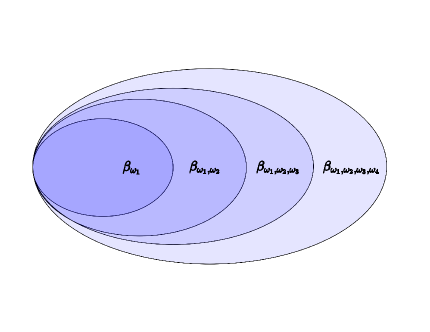
For each option , is either or , depending on whether option should terminate at state or not. This can be implemented by learning a real-valued function and using it as a binary classifier. Suppose the learning algorithm has already trained options, and the aim is to learn a new option . We train its new policy as if a single policy is being trained in all states satisfying for all , i.e., in states that are classified as termination states by all the previous options. For this, rather than training for the option, we train a nested termination function , which is the termination classifier for the set of options . As the new policies are trained in the termination states of the previous set of options, the set of non-termination states for the set of options keeps expanding, as shown in Fig. 1. Without nested functions, as the number of options increases, it becomes more difficult to accurately update the individual termination functions of each policy, which in turn makes it difficult to incorporate new skills. In the proposed approach, as long as the last nested termination function is correctly updated, new policies can always be learned in the termination states of that function. Using and , we can obtain as
| (9) |
The above equation imposes a simple constraint on choosing options for execution by not allowing a new policy to execute actions in states which are classified as a non-terminating state by the previous nested termination function since that means there is already some trained option more suited to execute in that state.
Since has to take values in or (non-termination and termination respectively), we learn corresponding continuous functions with range and use a threshold to assign the value if exceeds the threshold, otherwise.
is trained like a standard -value function using the negative of the reward signal emitted by the environment,
| (10) |
We overload the notation of by using as the termination function rather than , since we train it like a Q-value function and because it is a better estimator. This function is learned using the update rule:
| (11) |
where is the termination discount factor. It largely depends on the problem domain and directly impacts the newer policies that are trained by influencing the partition of the termination and non-termination states.
As new policies are incorporated, becomes an increasingly sparse reward since the agent learns strategies to avoid failure, and episodes become relatively longer. In such instances, simply training using the above update can bias it to predict all states as non-termination states and thus effectively prevent new policies from learning. To avoid this, after the new policy has been semi-optimally trained, the termination function is trained using the binary cross-entropy loss as
| (12) |
Here the labels are the solution to (11) if the policy that generates the actions is fixed. They are obtained by unrolling a trajectory and labeling each state with , where is the discount factor.
As we fix the policies after training them, the cross-entropy update gives us a better estimation as compared to the previous temporal difference updates. To make unbiased, an equal number of probable termination and non-termination states are sampled for training. The major advantage of adopting nested termination functions is that we only need to modify the latest termination function to correctly reflect if a state is a termination state or not. That will then be used to determine the states in which the next new policy will be trained. Given a training set of options, an option is chosen during execution according to the constraint given in (9).
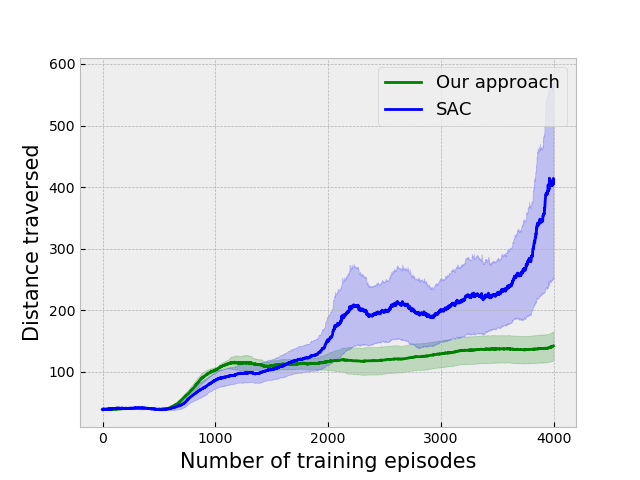
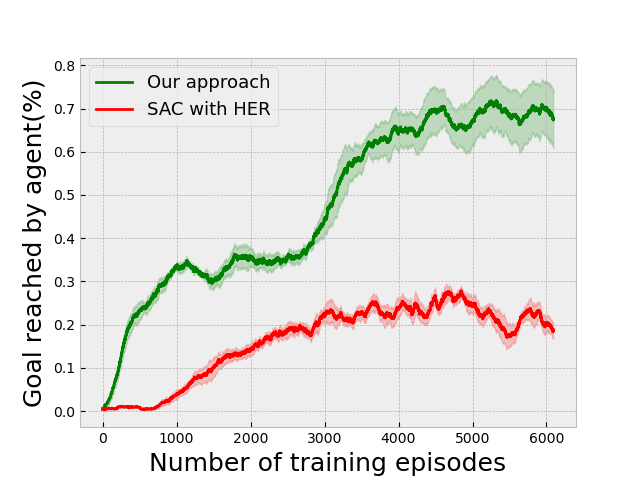
V EXPERIMENTAL RESULTS
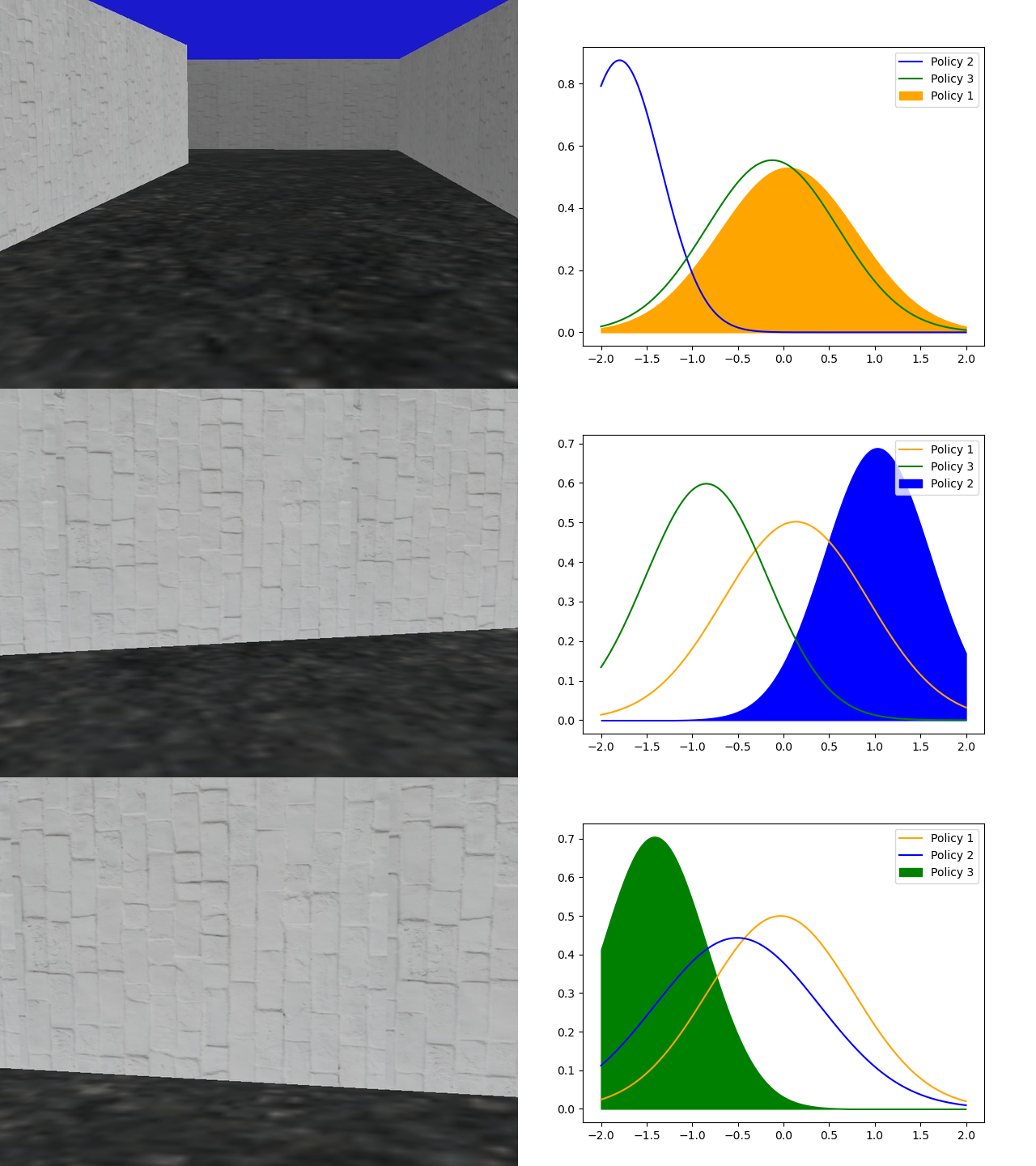
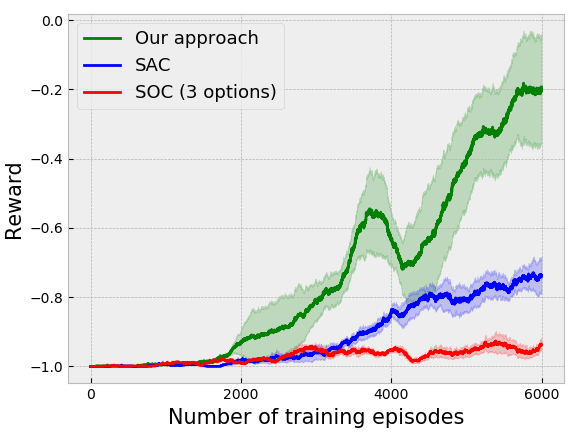
We compare our approach on several environments against the Soft Actor critic (SAC) [11] and the Soft Option-Critic (SOC) [12] algorithms. Each experimental plot has been plotted by taking the mean of 5 different experiments, and the corresponding bounds are given .
V-A The 3D navigation environment
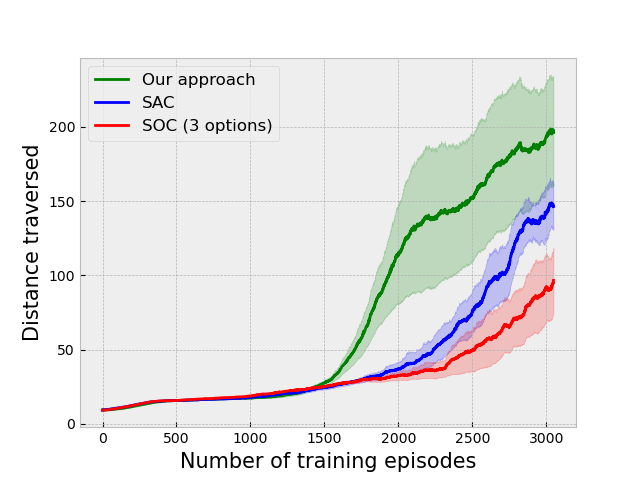
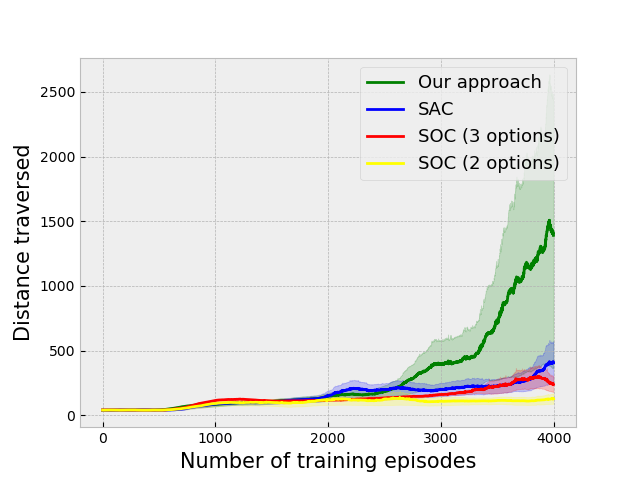
We have created a 3D simulated environment using the Panda3D game engine [32]. This collision avoidance environment consists of long corridors twisting and turning as the agent navigates inside as a vehicle that moves with a constant velocity. The primary challenge is that agent has to understand whether the left or right turn is coming up as taking a wrong turn will inevitably result in a collision and end the episode. The results on this environment are given in Fig. 3(a). In Fig. 4 we show a snapshot of the learned policies navigating in the environment. The first option simply learns to move straight in the environment, while the second and third policies learn to take the correct turns.
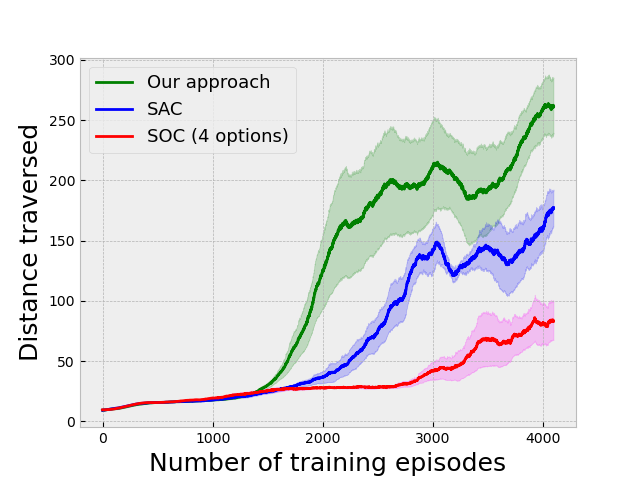
We have also validated our approach on a goal-based version of this environment, in which the agent is also given as input a number representing a destination and is guided towards it by arrows placed in the environment. The results for this setting are given in Fig. 3(g). We have not used an inter-option reward for this setting. We have also validated our method on an instruction-based task in which the agent is given a one-hot vector denoting the direction to take at an intersection, with the results given in Fig. 3(i) compared against Soft Actor-Critic with Hindsight Experience Replay. For this setting, we have also used a reward for going in the correct direction and for going in the wrong direction. Additionally, Fig. 3(b) shows the performance of our approach on a colored version of the environment in which the agent has to take the correct turn depending on the color of the walls in front of it. It should understand the concept of taking a turn in the direction of the colored wall if the color is green and in the opposite direction if the color is red.
V-B Other environments
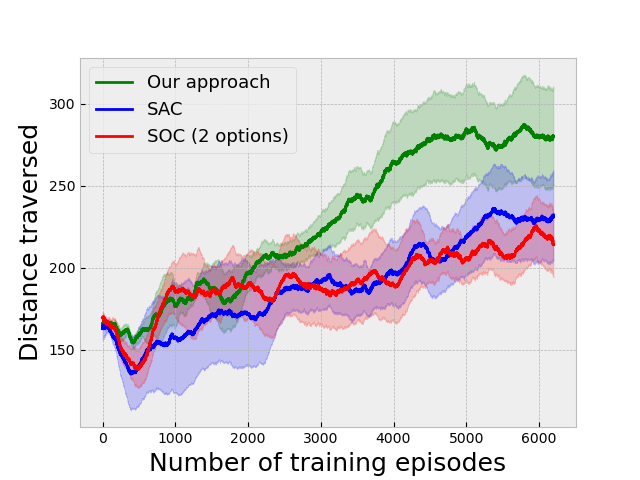
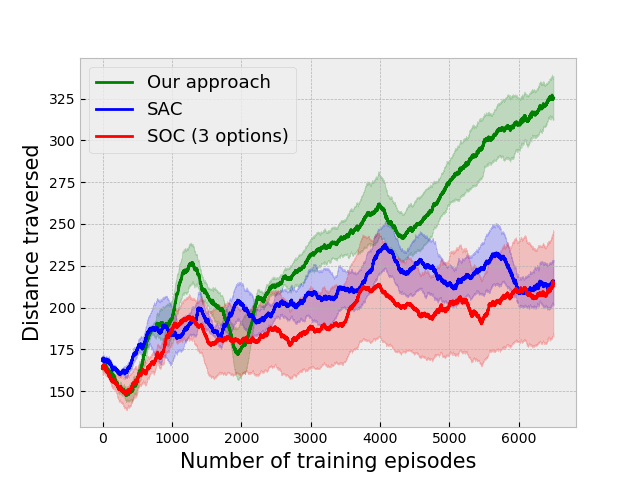
We have tested our algorithm on two more environments: (i) Gym-Duckietown [10], a self-driving car simulator that is a complex environment consisting of multiple immediate turns and various objects like houses, trees, etc., resulting in a large variance in the observations from the environment, and (ii) the Atari River Raid environment, a top-down shooting game in which the goal is to maneuver a plane to destroy or avoid obstacles. The results of the experiments on these environments are given in Fig. 3(c) and 3(e) respectively.
Fig. 3(h) show the results of our algorithm when the inter-option reward is removed, showing that it is an essential component of our algorithm in a navigation environment.
V-C Implementation
The policy and Q functions are implemented as neural networks that take, at each time step, scaled images seen by the agent from the past time steps, where for the navigation environment and for the Duckietown and Riverraid environments. In environments where the color of the image is not explicitly required as part of the goal specification, the input images are transformed to grayscale before being passed to the networks. The outputs of the policy networks are the parameters of a Gaussian distribution for the case of continuous actions in the navigation and Duckietown environments, and parameters of a categorical distribution for the case of discrete actions in the Riverraid environment.
Two critic networks are used, and the smaller of their predicted values is taken as the value to tackle overestimation. Additionally, two additional networks are used as target (soft) networks, whose parameters follow those of the critics as exponential moving averages with smoothing coefficient .
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |
VI CONCLUSIONS
In this paper, we proposed an algorithm called ‘Sequential Soft Option Critic’ that allows adding new skills dynamically without the need for a higher-level master policy. This can be applicable to environments where a primary component of the objective is to prolong the episode. We show that this algorithm can be used to effectively incorporate diverse skills into an overall skill set, and it outperforms prior methods in several environments.
VII ACKNOWLEDGMENTS
Authors would like to thank Shubham Gupta for many useful discussions on this topic.
References
- [1] V. Mnih, K. Kavukcuoglu, D. Silver, A. G. I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing atari with deep reinforcement learning,” Neural Information Processing Systems, 2013.
- [2] O. Vinyals, T. Ewalds, S. Bartunov, P. Georgiev, A. S. Vezhnevets, M. Yeo, A. Makhzani, H. Küttler, J. Agapiou, J. Schrittwieser, et al., “Starcraft ii: A new challenge for reinforcement learning,” arXiv preprint arXiv:1708.04782, 2017.
- [3] D. Silver, J. Schrittwieser, K. Simonyan, I. Antonoglou, A. Huang, A. Guez, T. Hubert, L. Baker, M. Lai, A. Bolton, et al., “Mastering the game of go without human knowledge,” Nature, vol. 550, no. 7676, pp. 354–359, 2017.
- [4] R. S. Sutton, D. Precup, and S. Singh, “Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning,” Artificial intelligence, vol. 112, no. 1-2, pp. 181–211, 1999.
- [5] Y. Flet-Berliac, “The promise of hierarchical reinforcement learning,” The Gradient, 2019.
- [6] P.-L. Bacon, J. Harb, and D. Precup, “The option-critic architecture,” in Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [7] R. Dubey, P. Agrawal, D. Pathak, T. Griffiths, and A. Efros, “Investigating human priors for playing video games,” in International Conference on Machine Learning, 2018, pp. 1349–1357.
- [8] Y. Bengio, J. Louradour, R. Collobert, and J. Weston, “Curriculum learning,” in Proceedings of the 26th annual International Conference on Machine Learning, 2009, pp. 41–48.
- [9] J. L. Elman, “Learning and development in neural networks: The importance of starting small,” Cognition, vol. 48, no. 1, pp. 71–99, 1993.
- [10] M. Chevalier-Boisvert, F. Golemo, Y. Cao, B. Mehta, and L. Paull, “Duckietown environments for openai gym,” https://github.com/duckietown/gym-duckietown, 2018.
- [11] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International Conference on Machine Learning, 2018, pp. 1861–1870.
- [12] E. Lobo and S. Jordan, “Soft options critic,” arXiv preprint arXiv:1905.11222, 2019.
- [13] P. Dayan and G. E. Hinton, “Feudal reinforcement learning,” in Advances in neural information processing systems, 1993, pp. 271–278.
- [14] R. Parr and S. J. Russell, “Reinforcement learning with hierarchies of machines,” in Advances in neural information processing systems, 1998, pp. 1043–1049.
- [15] T. G. Dietterich, “Hierarchical reinforcement learning with the maxq value function decomposition,” Journal of artificial intelligence research, vol. 13, pp. 227–303, 2000.
- [16] T. Kim, S. Ahn, and Y. Bengio, “Variational temporal abstraction,” in Advances in Neural Information Processing Systems, 2019, pp. 11 570–11 579.
- [17] A. S. Vezhnevets, S. Osindero, T. Schaul, N. Heess, M. Jaderberg, D. Silver, and K. Kavukcuoglu, “Feudal networks for hierarchical reinforcement learning,” in Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017, pp. 3540–3549.
- [18] C. Li, X. Ma, C. Zhang, J. Yang, L. Xia, and Q. Zhao, “Soac: The soft option actor-critic architecture,” arXiv preprint arXiv:2006.14363, 2020.
- [19] O. Nachum, S. S. Gu, H. Lee, and S. Levine, “Data-efficient hierarchical reinforcement learning,” in Advances in Neural Information Processing Systems, 2018, pp. 3303–3313.
- [20] M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, O. P. Abbeel, and W. Zaremba, “Hindsight experience replay,” in Advances in neural information processing systems, 2017, pp. 5048–5058.
- [21] A. Levy, G. Konidaris, R. Platt, and K. Saenko, “Learning multi-level hierarchies with hindsight,” in Proceedings of International Conference on Learning Representations, 2019.
- [22] Z.-J. Pang, R.-Z. Liu, Z.-Y. Meng, Y. Zhang, Y. Yu, and T. Lu, “On reinforcement learning for full-length game of starcraft,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 4691–4698.
- [23] K. Frans, J. Ho, X. Chen, P. Abbeel, and J. Schulman, “Meta learning shared hierarchies,” in International Conference on Learning Representations, 2018.
- [24] D. J. Mankowitz, T. A. Mann, and S. Mannor, “Iterative hierarchical optimization for misspecified problems (ihomp),” arXiv preprint arXiv:1602.03348, 2016.
- [25] A. Bagaria and G. Konidaris, “Option discovery using deep skill chaining,” in the NeurIPS 2019 Workshop on Deep Reinforcement Learning, 2019.
- [26] A. A. Rusu, N. C. Rabinowitz, G. Desjardins, H. Soyer, J. Kirkpatrick, K. Kavukcuoglu, R. Pascanu, and R. Hadsell, “Progressive neural networks,” arXiv preprint arXiv:1606.04671, 2016.
- [27] B. D. Ziebart, “Modeling purposeful adaptive behavior with the principle of maximum causal entropy,” 2010, aAI3438449.
- [28] T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, and S. Levine, “Soft actor-critic algorithms and applications,” in arXiv preprint arXiv:1812.05905, 2018.
- [29] G. Kahn, A. Villaflor, B. Ding, P. Abbeel, and S. Levine, “Self-supervised deep reinforcement learning with generalized computation graphs for robot navigation,” in 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 1–8.
- [30] S. Shalev-Shwartz, S. Shammah, and A. Shashua, “Safe, multi-agent, reinforcement learning for autonomous driving,” arXiv preprint arXiv:1610.03295, 2016.
- [31] K. Kang, S. Belkhale, G. Kahn, P. Abbeel, and S. Levine, “Generalization through simulation: Integrating simulated and real data into deep reinforcement learning for vision-based autonomous flight,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 6008–6014.
- [32] M. Goslin and M. R. Mine, “The panda3d graphics engine,” Computer, vol. 37, no. 10, pp. 112–114, 2004.
- [33] J. Harb, P.-L. Bacon, M. Klissarov, and D. Precup, “When waiting is not an option: Learning options with a deliberation cost,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [34] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized experience replay,” arXiv preprint arXiv:1511.05952, 2015.
- [35] P. Christodoulou, “Soft actor-critic for discrete action settings,” arXiv preprint arXiv:1910.07207, 2019.
[LEARNING SKILLS TO NAVIGATE WITHOUT A MASTER]
-A Pseudocode
Algorithm 1 contains the pseudocode for training a new option given a set of already trained options. Algorithm 2 describes how to use the options to traverse the environment.
-B The developed 3D environment

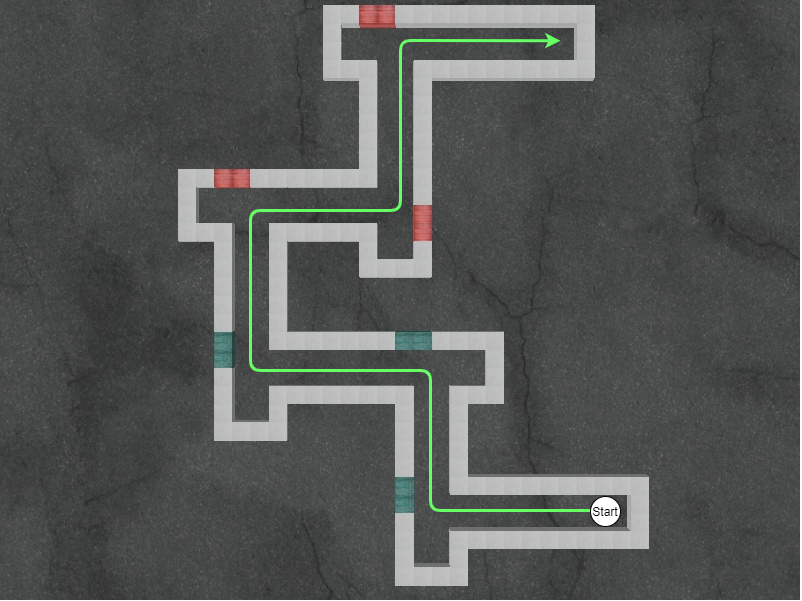


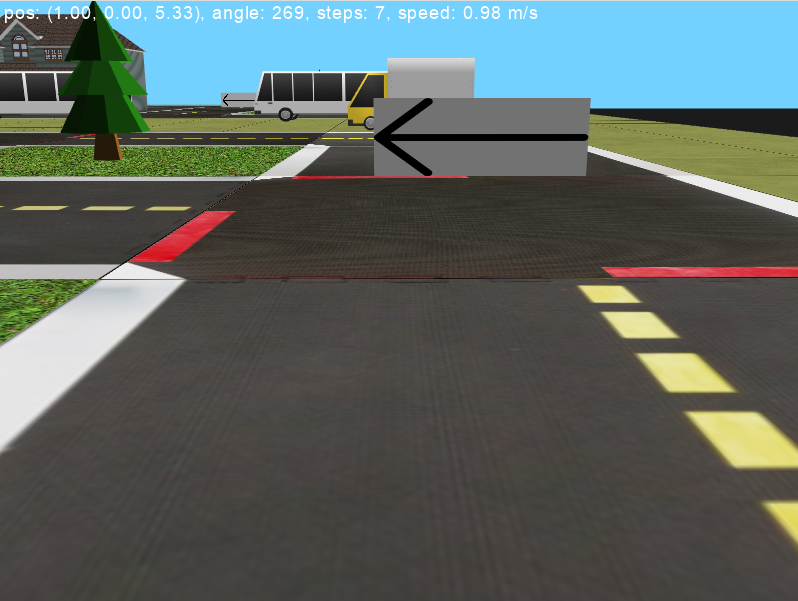
For testing our algorithm, we have created a custom simulated 3D navigation environment using the Panda3D game engine [32]. Here we present the details of this environment.
In the developed 3D navigation environment, the agent is initialized at either the extreme left or the extreme right corridor randomly. The goal of the agent is to make its way to the other end (as shown in Figure 5) without colliding with the walls.
The agent receives the past gray-scale images re-scaled to pixels as input and outputs an action , every time a collision occurs and the episode is reset. The agent takes an action every seconds in the environment and receives a continuous stream of rewards in each time-step except when it collides with the walls, in which case the episode ends with a reward. Overall, the environment is a rather simplistic one with mono-coloured white walls, minimalist texture and ambient lighting.
An interesting aspect of this environment is that the single source lighting creates different shades on the walls depending on the direction they are facing, so the agent has to learn to turn depending on its understanding of what turn is coming up while disregarding the shade of the wall.
In the coloured navigation environment (Figure 6) the agent has to follow a path specified by the colour of the walls in front of it to take the correct direction. Two contiguous block segments are coloured to indicate the direction that the vehicle is supposed to take and the color determines if the direction is correct or not. Green indicates that the turn is the correct one while red is incorrect and the vehicle should take the turn in the opposite direction.
-C Other environments
Other than our 3D navigation environment, we have validated our approach on two environments: (i) Gym-Duckietown, and (ii) Atari River Raid environment.
Gym-Duckietown is a self-driving car simulator that is a complex environment consisting of multiple immediate turns, making navigation challenging. It also includes various objects like houses, trees, etc. These visuals result in a large variance in the observations from the environment. For our experiments, we modify the reward function to emit whenever the agent steers off the road and during every other time step when the agent is on the road.
River Raid is a top-down shooting game where the goal is to maneuver a plane to destroy or avoid obstacles like tankers, helicopters, jets, and bridges to continuously keep moving forward, all the while not crashing into the walls on the sides or the obstacles themselves. Destroying the obstacles rewards the player with an increase in overall points obtained in the game; the plane also needs to refill its fuel, which it loses continually as the game progresses and is refilled by hovering over fuel tanks (which can also be destroyed for obtaining points) which frequently spawn in the environment. The plane crashes when it either collides with an obstacle or runs out of fuel.
For our experiments, we modify the reward function of the environment to emit a reward when the agent crashes and a reward for every other time step. We also restrict the agent to use a reduced number of actions while navigating in the environment such that it is not allowed to slow down the plane, and our modified action set has discrete actions the agent can take as compared to in the original gym implementation. We follow the same preprocessing of the input image and network architecture as used by [1]. Since the reward is extremely sparse in such a setting, we store only the last time steps in the replay buffer for better training.
-D Training agents on goal-based tasks
The class of environments that we described in this work captures many practical scenarios. For example, many goal-based navigation environments can be modelled using this approach. Here, we consider one such environment, shown in Figure 6, where the objective of the agent is to navigate corridors according to a specified instruction. The instruction is given as a one-hot vector input that corresponds to the corridor the agent is supposed to navigate to (left, center or right for instructions , or respectively). For this, a reward function can be defined as,
| (13) |
Here, is the set of states corresponding to the agent being in the correct corridor according to the given instruction, and is the set of all states where the agent collides with the walls in the environment. The agent incurs a reward when it enters the wrong corridor, . This is given in order to deter the agent from choosing the wrong corridor, although not as great of a deterrent as colliding with the walls. However, using this reward function may also produce policies that easily fall into a local optimum of choosing a single direction by completely disregarding the instruction.
One can easily modify the proposed approach for training on this environment by including the state where the agent has taken a wrong direction in the termination state set and the state where it has taken the correct direction in the non-termination state set, for the purposes of training the termination function. The options are also made to execute for some minimum time steps before switching to another option. This is done to prevent options from switching prematurely [33]. We compare the results of our approach with 2 options, in Figure 3(i), against Hindsight Experience Replay [20] using Soft Actor Critic with priority buffers [34]. We use the same hyper-parameters as in the normal 3D navigation environment without any instructions, with the exception of and , along with . The complete set of hyperparameters is given in Section -F.
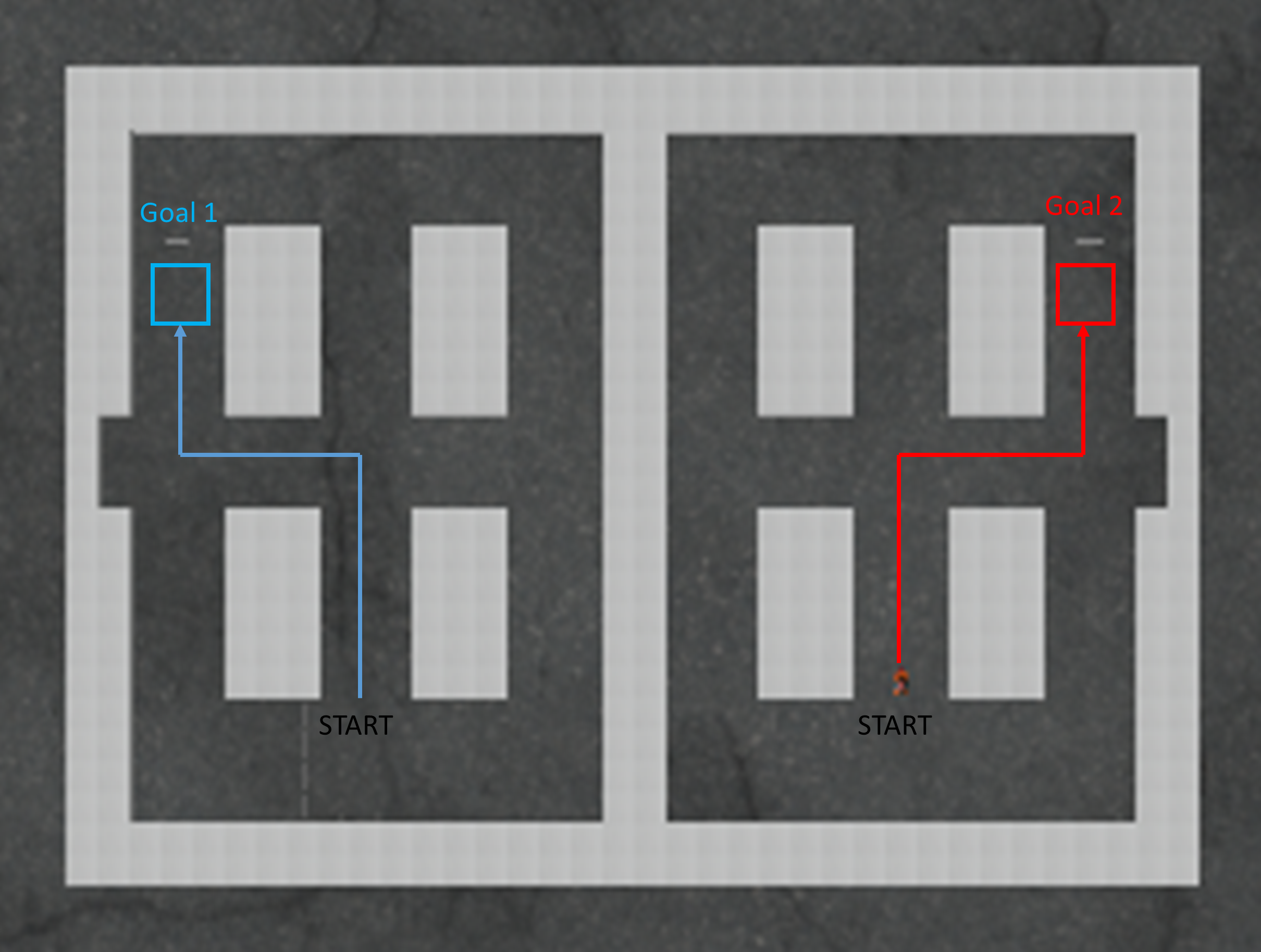
Apart from the above discussed modification, and the color environment described in -B, we also considered another variant of a goal-based task in the 3D environment. We modified the environment by providing arrows indicating correct turn towards goal state at each intersection, as shown in Figure 6. As shown in Figure 6, we considered two goals, and the blue and red line represent the correct path towards each of these goals. Here, the goal state is defined as a window of size around the location shown by the colored squares. A downward arrow has been placed in the environment to indicate this goal state. The reward structure used is same as in equation 13. For this setting, we do not add the +1 inter-option reward when control is passed to previously learnt options. The results of our approach for this task have been shown in Figure 3(i).
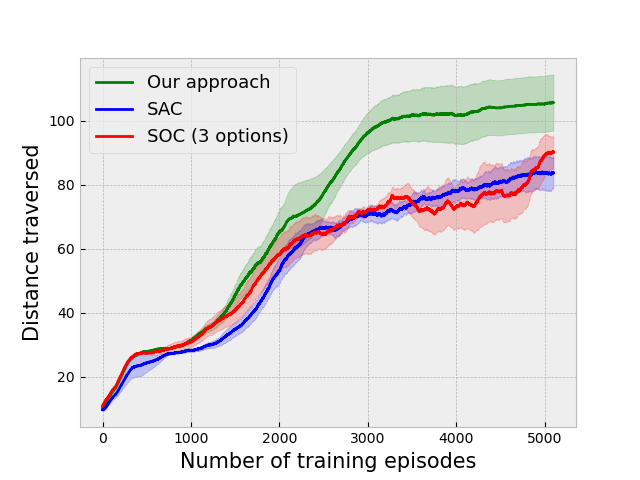
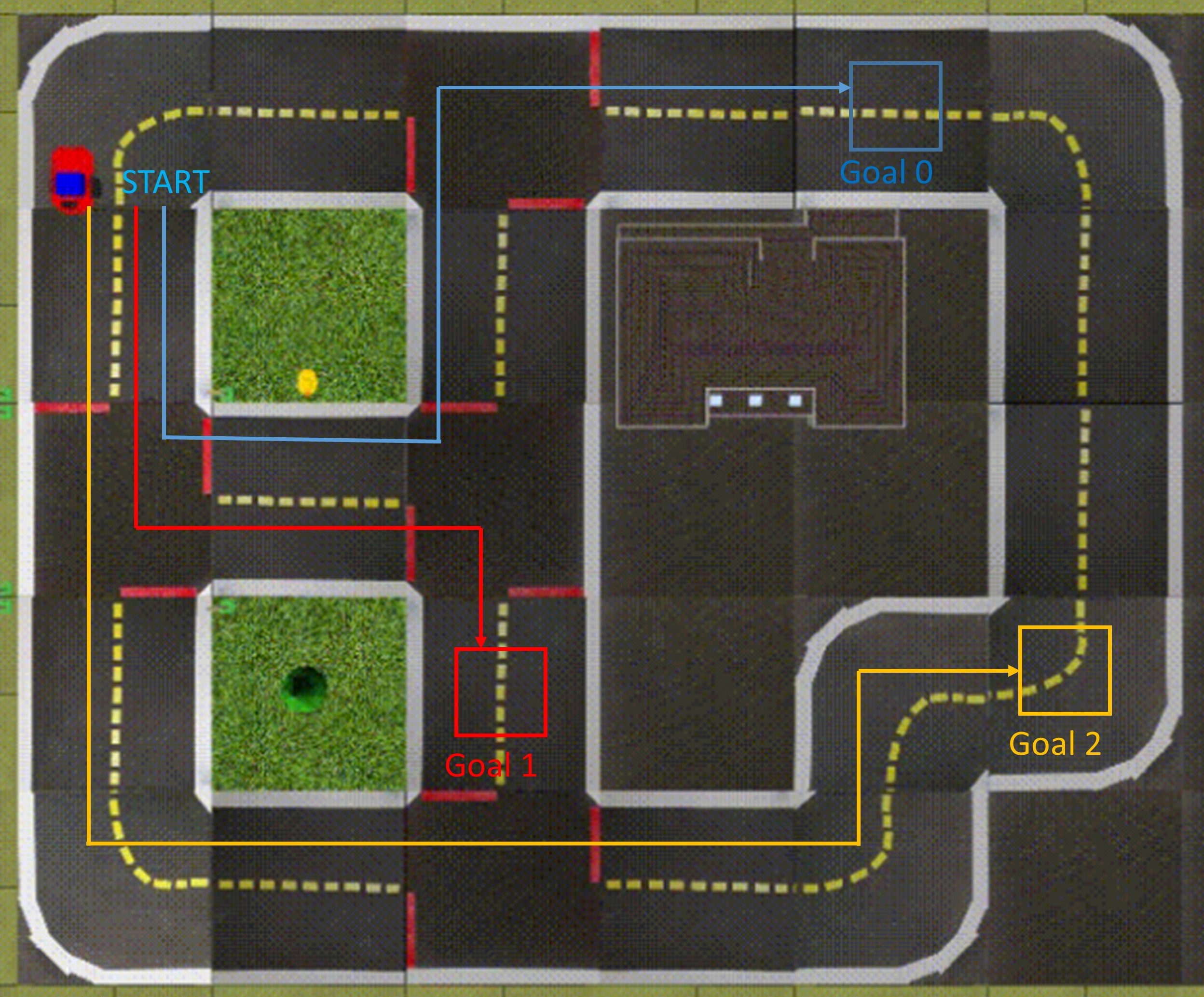
We have also considered such a goal based navigation task on a modified version of the Duckietown environment [10], in which we considered three goals, as shown in Figure 6. The blue, red and yellow colored lines represent the correct path for reaching goals 0, 1 and 2 respectively. The goal states are in a window of size across the location represented by the square shown in the figure. The complexity of the environment and the number of goals makes this task relatively more challenging. The results for this task are shown in Figure 7(b).
-E Ablations
In our algorithm, we make use of internal rewards when training subsequent policies in a sequential manner. Each policy is incentivized to traverse to states where the previous set of policies determines that it is capable of traversing it, using the reward function:
| (14) |
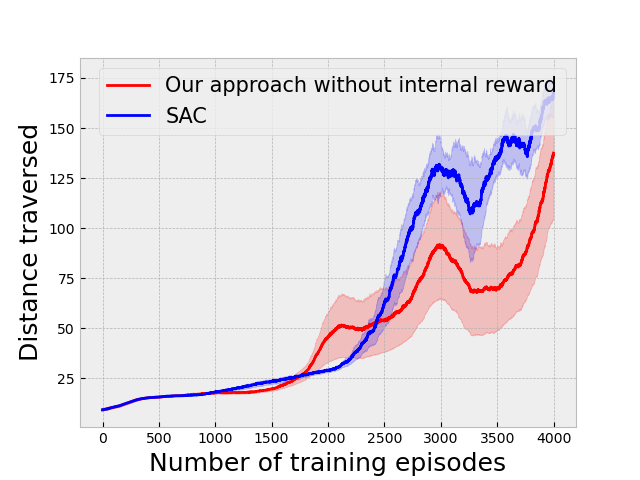
This greatly improves the convergence of the algorithm in scenarios where the previous policies need to be used repeatedly and rather frequently. In our 3D navigation environment, in the absence of the reward, the new options require much more training for them to traverse to desired states by taking correct turns. We demonstrate this by training our method without providing the extra reward using 4 options. This also shows that later options relying on already learnt knowledge in the form of previous options does in fact play a role in the performance of our algorithm. Figure 7(a) shows the result of our approach in the absence of the internal reward in the 3D navigation environment. Fig 3(h) shows the results for the same setting in the Duckietown environment.
-F Details on the Network Architecture
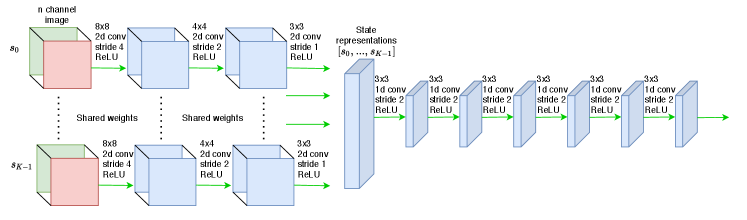
The agent receives a image from the 3D navigation environment every time step. The image encoder shown in Figure 8(a) converts the last images the agent receives from the environment into the corresponding state vector. Each image is passed through a series of 2D Convolution networks with ReLU activation, then the output is flattened to a vector and stacked with all the time step outputs . The 2D convolution networks use shared weights and were implemented using a single network parallelly processing the channel images. In the scenario of simple navigation the input is grayscale with , and for the color environment it is an RGB image with . The input to the series of convolution networks is of shape and the resulting output is a dimensional vector, which is the current state vector that is the input to the policy and Q networks.
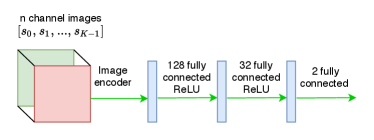
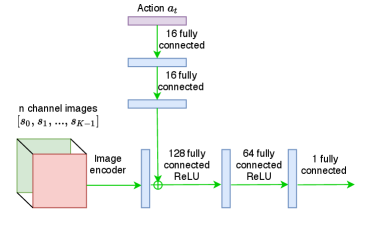
The policy returns and action is obtained by taking the hyperbolic tangent: , where as shown in Figure 8(b). The output action in the navigation environments is a dimensional continuous action in corresponding to the angle of the steering wheel of the simulated vehicle for the specific time step , and is fed into the environment as . During evaluation, the mean of the distribution is chosen as the action. The network architecture as shown in Figure 8(c) is almost identical to the policy network, except it also concatenates along with the state vector obtained from the image encoder, the action passed through some linear layers with ReLU activation before concatenation. The termination function has the same architecture as that of the value networks followed by a sigmoid function. For the Riverraid environment we use the exact same architecture as in the DQN [1] with identical policy and networks. Since this a discrete action space, for the purposes of training the network, we make use of the soft actor critic for discrete action setting [35].
The observation for Duckietown is in the form of an RGB image of size . We preprocess this image by converting it into grayscale and cropping it to size . Image encoder is modified considering input size. Here kernel size for 2D conv layer changed to 2 from 3 and seven 1D conv layers are considered by adding 1 more layer. The action is a 1-dimensional continuous action corresponding to the direction of steering. The final module of our policy network is the tanh activation function, whose output is scaled by and given as input action to the environment. For this environment, even during evaluation after the options are all trained, the actions are sampled from the normal distribution parameterized by the outputs of the policy network.
For the implementation of the soft option critic, we made use of shared networks with an additional parameter , which is the one hot vector representation of the option selected at the time. As with action , the one hot vector is also passed through a similar network before being concatenated with the state vector.
All our experiments make use of the Adam optimizer and all buffers used for updating the termination functions via binary cross entropy loss, containing roll-out trajectories after a policy has been trained, have a maximum size of . The hyperparameters used for experiments in the 3D navigation environment are given in Table I. The hyperparameters used for the other settings, the 3D color navigation environment, the Atari Riverraid environment and the Duckietown environment, are provided in Tables II, III and IV respectively. In the 3D navigation environment, only the first policy’s termination function is not updated using binary cross entropy as mentioned in the paper, as it tends to generalize rather well. The hyperparameters for the goal based settings are given in Tables V and VI.
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |
| Parameter | Value |
|---|---|
| learning rate | |
| discount factor() | |
| replay buffer size | |
| target smoothing coefficient() | |
| number of frames in input state () | |
| batch size | |
| alpha threshold () | |
| termination discount factor () |