Learning Sensorimotor Primitives of Sequential Manipulation Tasks from Visual Demonstrations
Abstract
This work aims to learn how to perform complex robot manipulation tasks that are composed of several, consecutively executed low-level sub-tasks, given as input a few visual demonstrations of the tasks performed by a person. The sub-tasks consist of moving the robot’s end-effector until it reaches a sub-goal region in the task space, performing an action, and triggering the next sub-task when a pre-condition is met. Most prior work in this domain has been concerned with learning only low-level tasks, such as hitting a ball or reaching an object and grasping it. This paper describes a new neural network-based framework for learning simultaneously low-level policies as well as high-level policies, such as deciding which object to pick next or where to place it relative to other objects in the scene. A key feature of the proposed approach is that the policies are learned directly from raw videos of task demonstrations, without any manual annotation or post-processing of the data. Empirical results on object manipulation tasks with a robotic arm show that the proposed network can efficiently learn from real visual demonstrations to perform the tasks, and outperforms popular imitation learning algorithms.
I Introduction
Complex manipulation tasks are performed by combining low-level sensorimotor primitives, such as grasping, pushing and simple arm movements, with high-level reasoning skills, such as deciding which object to grasp next and where to place it. While low-level sensorimotor primitives have been extensively studied in robotics, learning how to perform high-level task planning is relatively less explored.
High-level reasoning consists of appropriately chaining low-level skills, such as picking and placing. It determines when the goal of a low-level skill has been reached, and the pre-conditions for switching to the next skill are satisfied. This work proposes a unified framework for learning both low and high level skills in an end-to-end manner from visual demonstrations of tasks performed by people. The focus is on tasks that require manipulating several objects in a sequence. Examples include stacking objects to form a structure, as in Fig. 1, removing lug nuts from a tire to replace it, and dipping a brush into a bucket before pressing it on a surface for painting. These tasks are considered in the experimental section of this work. For all of these tasks, the pre-conditions of low-level skills depend on the types of objects as well as their spatial poses relative to each other, in addition to the history of executed actions. To support the networks responsible for the control policies, this work uses a separate vision neural network to recognize the objects and to track their 6D poses both over the demonstration videos as well as during execution. The output of the vision network is the semantic category of each object and its 6D pose relative to other objects. This output along with the history of executed actions is passed to a high-level reasoning neural network, which selects a pair of two objects that an intermediate level policy needs to focus its attention on.
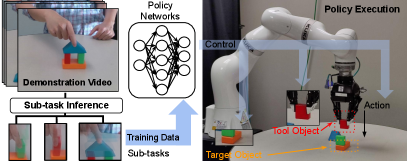
The first object is referred to as the tool, and to the second one as the target. In a stacking task, the tool is the object grasped by the robot and the target is a table or any other object on top of which the tool will be placed. In the painting task, the tool is the brush and the target is the paint bucket or the canvas. If no object is grasped, then the tool is the robot’s end-effector and the target is the next object that needs to be grasped or manipulated. An intermediate-level network receives the pair of objects indicated by the high-level reasoning network, their 6D poses relative to each other, and a history of executed actions. The intermediate-level network returns a sub-goal state, defined as a way-point in . Finally, a low-level neural network generates the end-effector’s motion to reach the way-point. The policy neural networks are summarized in Fig. 2.
While the proposed formulation is not exhaustive, it allows to cast a large range of manipulation tasks, and to use the same network to learn them. The proposed architecture requires only raw RGB-D videos, without the need to segment them into sub-tasks, or even to indicate the number of sub-tasks. The efficacy of the method is demonstrated in extensive experiments using real objects in visual demonstrations, as well as both simulation and a real robot for execution.
II Related Work
Most of the existing techniques in imitation learning in robotics are related to learning basic low-level sensorimotor primitives, such as grasping, pushing and simple arm movements [1, 2]. The problem of learning spatial preconditions of manipulation skills has been addressed in some prior works [3, 4]. Random forests were used [3] to classify configurations of pairs of objects, obtained from real images, into a family of low level skills. However, the method presented in [3] considers only static images where the objects are in the vicinity of each other [3], in contrast to the proposed model, which continuously predicts low-level skills while the objects are being manipulated and moved by the robot. Moreover, it does not consider complex tasks that are composed of several low-level motor primitives [3].
A closely related line of work models each sub-task as a funnel in the state space, wherein the input and output regions of each sub-task are modeled as a multi-modal Gaussian mixture [4, 5], and learned from explanatory data through an elaborate clustering process. Explicit segmentation and clustering have also been used [6]. Compared to these methods, the proposed approach is simple to reproduce and uses significantly less hyper-parameters since it does not involve any clustering process. Our approach trains an LSTM to select and remember pertinent past actions. The proposed approach also aims for data-efficiency through an attention mechanism provided by the high-level network. Hierarchical imitation learning with high and low level policies is investigated in recent work [7, 8]. These methods require ground-truth labeling of each sub-task to train the high-level policy, while the proposed method is unsupervised.
Skill chaining was considered in other domains, such as 2D robot navigation [9]. Long-horizon manipulation tasks have also been solved by using symbolic representations via Task and Motion Planning (TAMP) [10, 11, 12, 13]. Nevertheless, all the variables of the reward function in these works are assumed to be known and fully observable, in contrast to the proposed approach. A finite-state machine that supports the specification of reward functions was presented and used to accelerate reinforcement learning of structured policies [14]. In contrast to the proposed method, the structure of the reward machine was assumed to be known. A similar idea has also been adopted in other efforts [15, 16].
While 6D poses and labels of objects are provided from a vision module [17] in the proposed approach, other recent works have shown that complex tasks can be completed by learning directly from pixels [18, 19, 20, 21, 22, 23, 24]. This objective is typically accomplished by using compositional policy structures that are learned by imitation [18, 19], or that are manually specified [20, 21]. Some of these methods have been used for simulated control tasks [25, 26, 27]. These promising end-to-end techniques still require orders of magnitude more training trajectories compared to methods like the one proposed here, which separates the object tracking and policy learning problems.
III Problem Formulation and Architecture
This approach employs a hierarchical neural network for learning to perform tasks that require consecutive manipulation of multiple objects. The assumption is that each scene contains at most objects from a predefined set . The robot’s end-effector is included as a special object in . The robot receives as inputs at each time-step sensory data as an observation , where is the 6D pose of the end-effector in the world frame, is the maximum number of objects present in the scene, is the semantic label of object , and is a matrix that contains the 6D poses of all objects relative to each other, i.e., is a -dim. vector that represents ’s orientation and translation in the frame of object . The objects have known geometric models and have fixed frames of reference defined by their centers and 3 principal axes. The objects are detected and tracked using the technique presented in Section V-B. The maximum number of objects is fixed a priori.
The system returns at each time-step an action , i.e., a desired change in the pose of the robotic end-effector. An individual low-level sub-task is identified by a tool denoted by and a target denoted by , along with a way-point . The tool is the object being grasped by the robot at time , the target is the object to manipulate using the grasped tool and the predicted way-point is the desired pose of the tool in the target’s frame at the end of the sub-task. The way-point is a function of time as it changes based on the current pose of the tool relative to the target. Several way-points are often necessary to perform even simple tasks. For instance, in painting, a brush is the tool and a paint bucket is the target . To load a brush with paint, several way-points in the bucket’s frame need to be predicted. The first way-point can be when the brush touches the paint, while the second way-point is slightly above the paint. The tool and target assignment are also functions of time , and change as the system switches from one sub-task to the next, based on the current observation and on what has been accomplished so far. For instance, after loading the brush, the robot switches to the next sub-task wherein the brush is still the tool object, but the painting canvas or surface becomes the new target object.
In the proposed model, observations are limited to poses of objects and their semantic labels. These observations are often insufficient by themselves for determining the current stage of the task, for deciding to terminate the current sub-task and for selecting the next sub-task. For instance, in the painting example, the vision module does not provide information regarding the current status of the brush. Therefore, the robot needs to remember whether it has already dipped the brush in the paint. Since it is not practical to keep the entire sequence of past actions in memory, the approach uses a Long Short-Term Memory (LSTM) to compress the history of the actions that the robot has performed so far, and use it as an input to the system along with observation . The LSTM is trained along with the other parameters of the neural network.
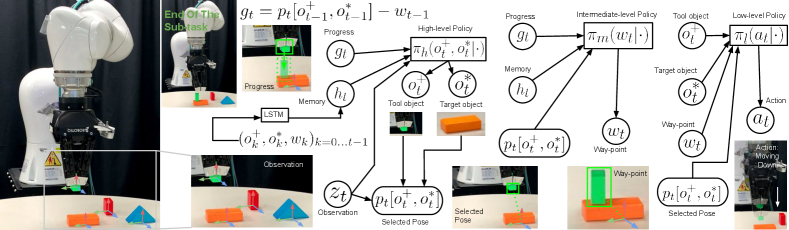
The following describes the three levels of the hierarchical network architecture as depicted in Figure 2.
A high-level policy, denoted by , returns a probability distribution over pairs of objects, wherein is the predicted tool at time , and is the predicted target at time . The high-level policy takes as inputs 6D poses of objects and their semantic labels, along with the pose of the robot’s end-effector. Additionally, the high-level policy receives as inputs a history of pairs of tools and targets and way-points at different times in the past, compressed into an LSTM unit, as well as a progress vector that indicates how far is the tool from the previous desired way-point with respect to the target .
An intermediate-level policy, denoted by , receives as inputs the current tool and target , the pose of relative to , in addition to history and progress vector . Both tool and target are predicted by the high-level policy , as explained above. The intermediate-level policy returns a way-point , expressed in the coordinates system of the target object .
A low-level policy, denoted by , receives as inputs the current pose of the current tool relative to the current target , in addition to the way-point predicted by the intermediate policy, and returns a Gaussian distribution on action that corresponds to a desired change in the pose of the robotic end-effector.
IV Learning Approach
In the proposed framework, an RGB-D camera is used to record a human performing an object manipulation task multiple times with varying initial placements of the objects. The pose estimation and tracking technique, explained in Section V-B, is then used to extract several trajectories of the form , wherein is the observed poses of all objects at time , including the end-effector’s pose . The goal of the learning process is to learn parameters of the three policy neural networks and that maximize the likelihood of the data and the inferred way-points, tools and targets, so that the system can generalize to novel placements of the objects that did not occur in the demonstrations. The likelihood is given by:
wherein is the history and is the progress vector.
The principal challenge here lies in the fact that the sequence of way-points, tools, and targets is unknown, since the proposed approach uses as inputs only 6D poses of objects at different time-steps and does not require any sort of manual annotation of the data.
To address this problem, an iterative learning process performed in three steps is proposed. First, the low-level policy is initialized by training on basic reaching tasks. The intermediate and high-level policies are initialized with prior distributions that simply encourage time continuity and proximity of way-points to target objects. Then, an expectation-maximization (EM) algorithm is devised to infer the most likely sequence of way-points, tools and targets in the demonstration data . Finally, the three policy networks are trained by maximizing the likelihood of the demonstration data and the pseudo ground-truth data obtained from the EM algorithm. This process is repeated until the inferred pseudo ground-truth data become constant across iterations.
IV-A Prior Initialization
This section first explains how the low-level policy is initialized. The most basic low-level skill is moving the end-effector between two points in that are relatively close to each other. We therefore initialize the low-level policy by training the policy network, using gradient-ascent, to maximize the likelihood of straight-line movements between consecutive poses and of the end-effector while aiming at way-points . Therefore, the objective of the initialization process is given as , wherein each is expressed in the frame of the target , and are the parameters of the neural network . Both and are also chosen randomly in this initialization phase. The goal is to learn simple reaching skills, which will be refined and adapted in the learning steps to produce more complex motions, such as rotations.
The intermediate policy is responsible for selecting way-point given history . It is initialized by constructing a discrete probability distribution over points , defined as . Poses used as way-points are obtained directly from demonstration data . Specifically, we set for , for , and for , where and are predefined fixed hyper-parameters, and is expressed in the coordinates system of the target . This distribution encourages way-points to be close to the target at time . This distribution is constructed for each candidate target at each time-step , except for the robot’s end-effector, which cannot be a target.
High-level policy is responsible for selecting tools and targets as a function of context. It is initialized by setting the tool as the object with the most motion relative to others: , excluding the end-effector (or human hand) . If all the objects besides the end-effector are stationary relative to each other, then no object is being used, and the end-effector is selected as the tool. Once the tool is fixed, the prior distribution on the target is set as: if (the end-effector cannot be a target), if , and if , where is obtained from history , is the number of objects and is a fixed hyper-parameter, set to a value close to to ensure that switching between targets does not occur frequently in a given trajectory.
IV-B Pseudo Ground-Truth Inference
After initializing and as in Section IV-A, the next step consists of inferring from the demonstrations a sequence of tools, targets and way-points that has the highest joint probability (Algorithm 1, lines 2-15). This problem is solved by using the Viterbi technique. In a forward pass (lines 2-12), the method computes the probability of the most likely sequence up to time that results in a choice at time . The log of this probability, denoted by , is computed by taking the product of three probabilities: (i) : the probability of switching from and as tools and targets to and , given the progress vector and the object poses relative to each other provided by the matrix (which is obtained from observation ); (ii) : the probability of selecting as a way-point a future pose (denoted as , ) for the tool relative to the target in the demonstration trajectory; this probability is also conditioned on choices made at the previous time step ; (iii) the likelihood of the observed movement of the objects at time in the demonstration, given the choice and the relative poses of the objects with respect to each other (given by matrix ). For each candidate at time , we keep in the trace of the candidate at time that maximizes their joint probability. The backward pass (lines 13-15) finds the most likely sequence by starting from the end of the demonstration and following the trace of that sequence in . The last step is to train , and using the most likely sequence as a pseudo ground-truth for the tools, targets and way-points.
IV-C Training the Policy Networks
To train , and using the pseudo ground-truth , obtained as explained in the previous section, we apply the stochastic gradient-descent technique to simultaneously optimize the parameters of the networks by minimizing a loss function defined as follows. is defined as the sum of multiple terms. The first two are and where is the cross entropy, and is the current prediction of . The third term is where is the output of and is the mean square error. The next term is , which corresponds to the log-likelihood of the low-level actions in the demonstrations. To further facilitate the training, two auxiliary losses are introduced. The first one is to encourage consistency within each sub-task. As the role of the memory in the architecture is to indicate the sequence sub-tasks that have been already performed, it should not change before changes. If we denote the LSTM’s output as at time-step , the consistency loss is defined as where is the indicator function. The last loss term, , is used to ensure that memory retains sufficient information from previous steps. Thus, we train an additional layer directly after to retrieve at step the target, tool and way-point of step . is defined as As a result, the complete proposed architecture is trained with the loss .
V Experimental Results
V-A Data collection
We used an Intel RealSense 415 camera to record several demonstrations of a human subject performing three tasks. The first task consists in inserting a paint brush into a bucket, then moving it to a painting surface and painting a virtual straight line on the surface. The poses of the brush, bucket and painting surface are all tracked in real-time using the technique explained in V-B. The second task consists in picking up various blocks and stacking them on top of each other to form a predefined desired pattern. The third task is similar to the second one, with the only difference being the desired stacking pattern. Additionally, we use the PyBullet physics engine to simulate a Kuka robotic arm and collect data regarding a fourth task. The fourth task consists in moving a wrench that is attached to the end-effector to four precise locations on a wheel, sequentially, rotating the wrench at each location to remove the lug-nuts, then moving the wrench to the wheel’s center before finally pulling it.




V-B Object Pose Parsing from Demonstration Video
In each demonstration video, 6D poses and semantic labels of all relevant objects are estimated in real-time and used to create observations as explained in Section III. Concretely, a scene-level multi-object pose estimator [28] is leveraged to compute globally the relevant objects’ 6D poses in the first frame. It starts with a pose sampling process and performs Integer Linear Programming to ensure physical consistency by checking collisions between any two objects as well as collisions between any object and the table. Next, the poses computed from the first frame are used to initialize the se(3)-TrackNet [17], which returns a 6D pose for each object in every frame of the video. The 6D tracker requires access to the objects’ CAD models. For the painting task, the brush and the bucket are 3D-scanned as in [29], while for all the other objects, models are obtained from CAD designs derived from geometric primitives. During inference on the demonstration videos, the tracker operates in , resulting in an average processing time of for a 1 min demonstration video. The entire video parsing process is fully automated, and did not require any human input beyond providing CAD models of the objects offline to the se(3)-TrackNet in order to learn to track them.
V-C Training and architecture details
The high-level, intermediate-level, and low-level policies are all neural networks. In the high-level policy, the progress vector is embedded by a fully connected layer with units followed by a ReLU layer. An LSTM layer with units is used to encode history . Observation is concatenated with the LSTM units and the embedded progress vector and fed as an input to two hidden layers with units followed by a ReLU layer. From the last hidden layer, target and tool objects are predicted by a fully connected layer and a softmax. The intermediate-level policy network consists of two hidden layers with units. The low-level policy concatenates into a vector four inputs: 6D pose of the target in the frame of the tool object, way-point, and the semantic labels of the target and tool objects. After two hidden layers of units and ReLU, the low-level policy outputs a Gaussian action distribution. The number of training iterations for all tasks is , the batch size is steps, the learning rate is , and the optimizer is Adam. The hyper-parameters used in Section IV-A are set as , , and .
The proposed method is compared to three other techniques. Generative Adversarial Imitation Learning (GAIL) [30], Learning Task Decomposition via Temporal Alignment for Control (TACO) [8], and Behavioral Cloning [31] where we train the policy network of [30] directly to maximize the likelihood of the demonstrations without learning rewards. We also compare to a supervised variant of our proposed technique where we manually provide ground-truth tool and target objects and way-points for each frame. The supervised variant provides an upper bound on the performance of our unsupervised algorithm. Note also that TACO [8] requires providing manual sketches of the sub-tasks, whereas our algorithm is fully unsupervised.
V-D Evaluation
Except for the tire removal, all tasks are evaluated using real demonstrations and a real Kuka LBR robot equipped with a Robotiq hand. The policies learned from real demonstrations are also tested extensively in the PyBullet simulator before testing them on the real robot.
A painting task is successfully accomplished if the brush is moved into a specific region of a radius of inside the paint bucket, the brush is then moved to a plane that is on top of the painting surface, and finally the brush draws a virtual straight line of at least on that plane. A tire removal task is successfully accomplished if the robot removes all bolts by rotating its end-effector on top of each bolt (with a toleance of ) with at least counter-clockwise, and then moves to the center of the wheel. A stacking task is successful if the centers of all the objects in their final configuration are within of the corresponding desired locations.
| Painting | Stacking 1 | Stacking 2 | |
|---|---|---|---|
| Proposed (unsupervised) | |||
| Behavioral Cloning [31] | |||
| GAIL [30] | |||
| TACO [8] |
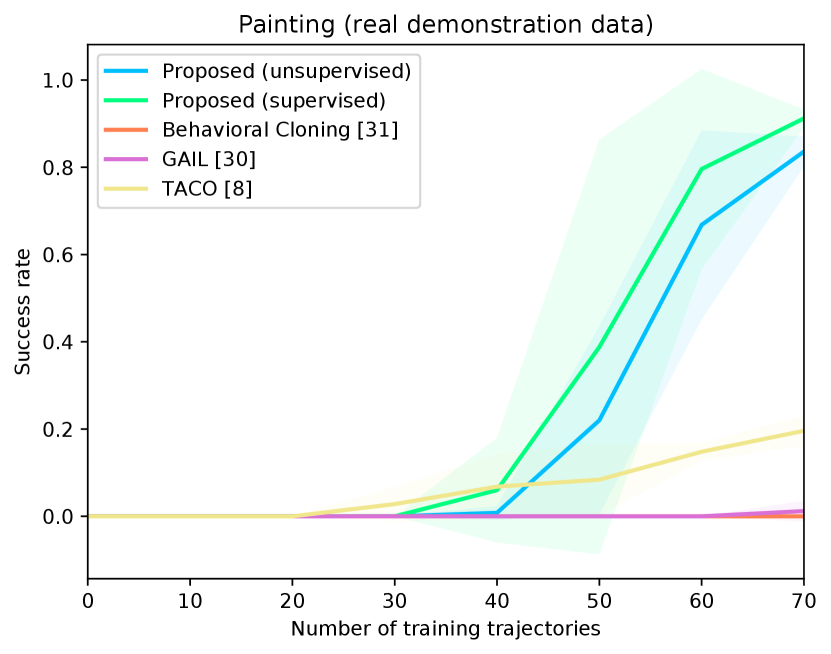
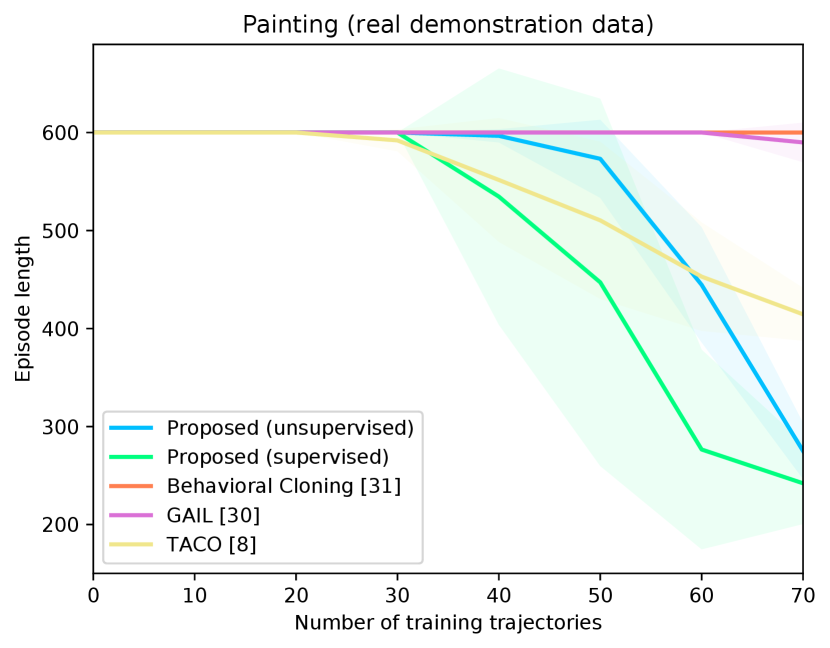
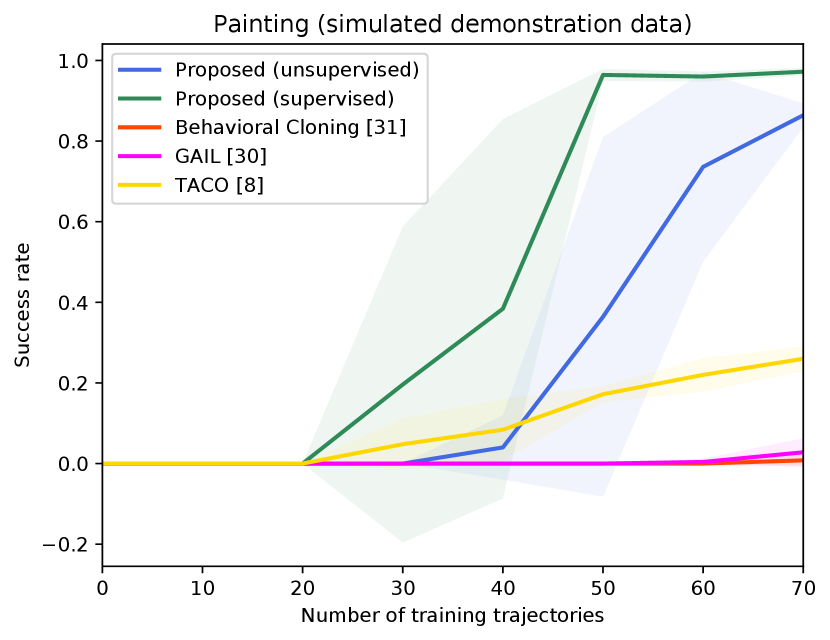
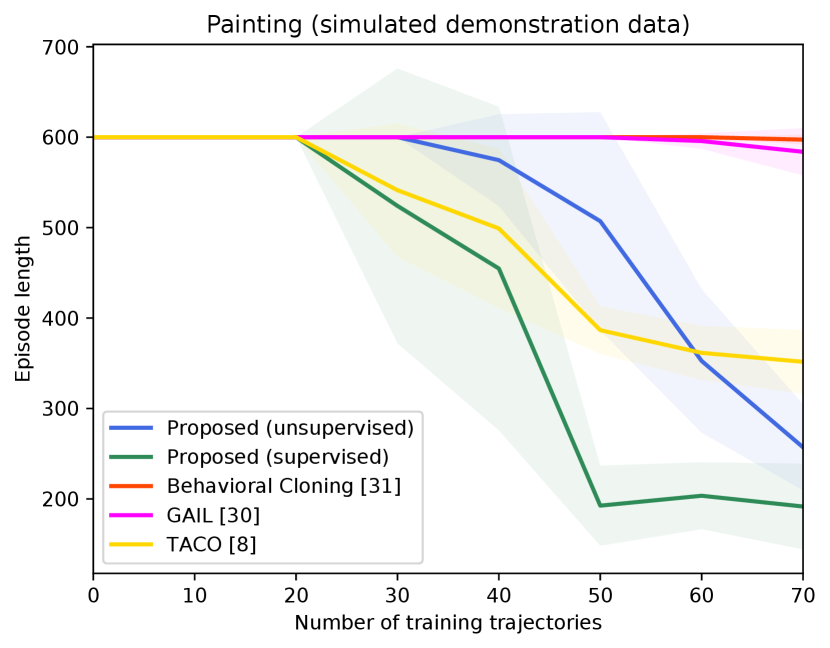
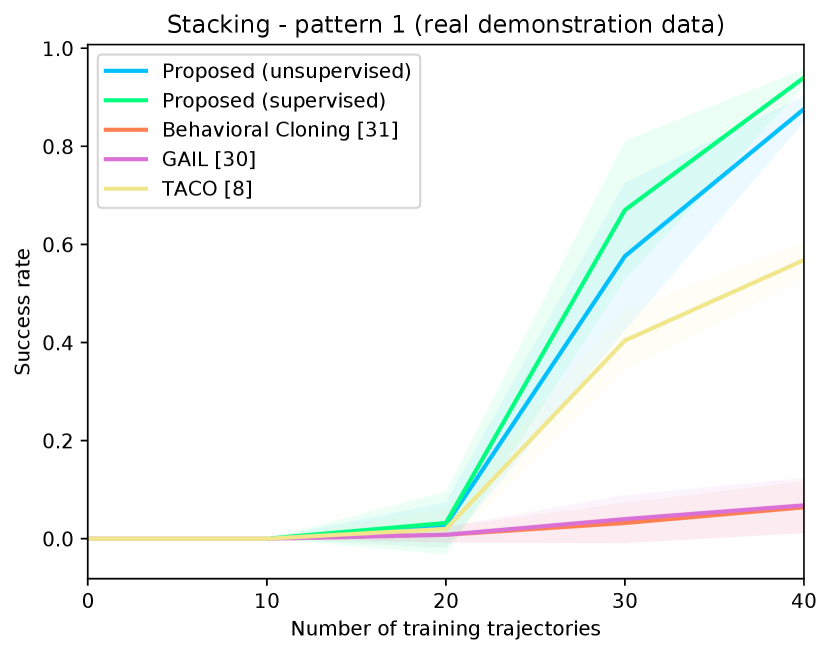
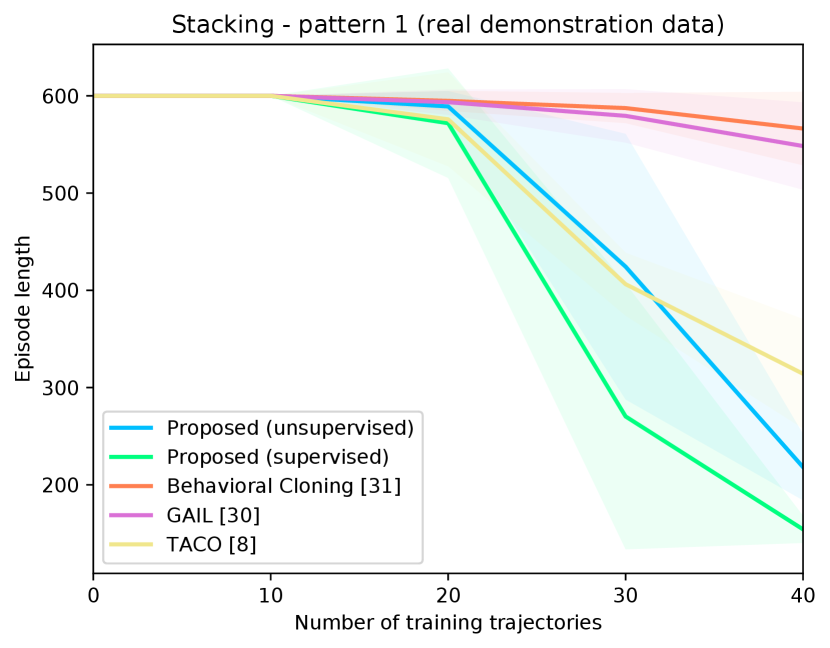
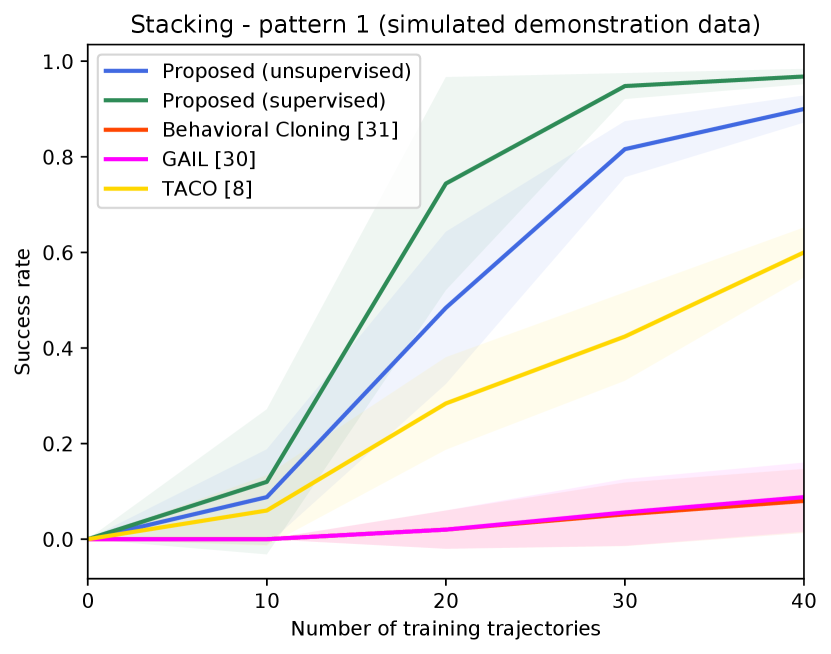
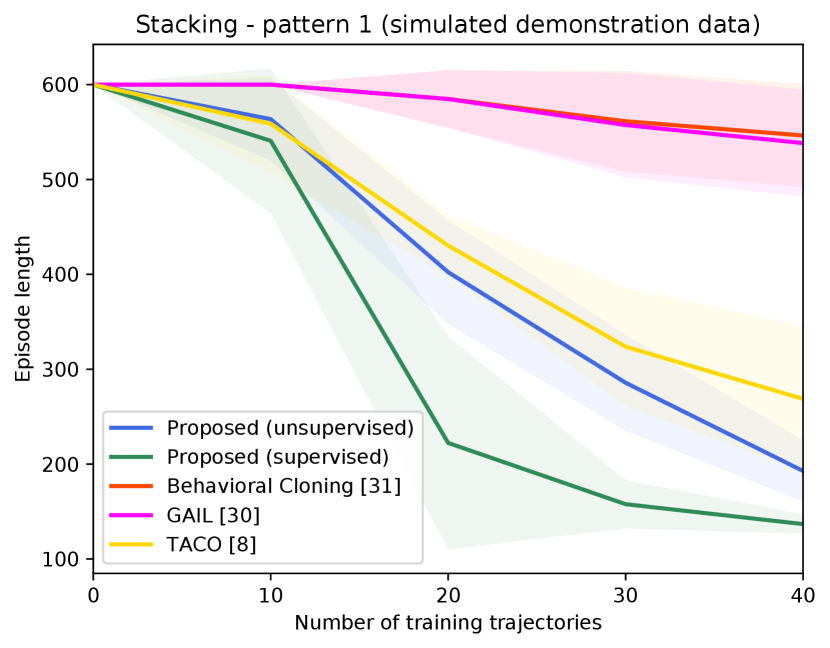
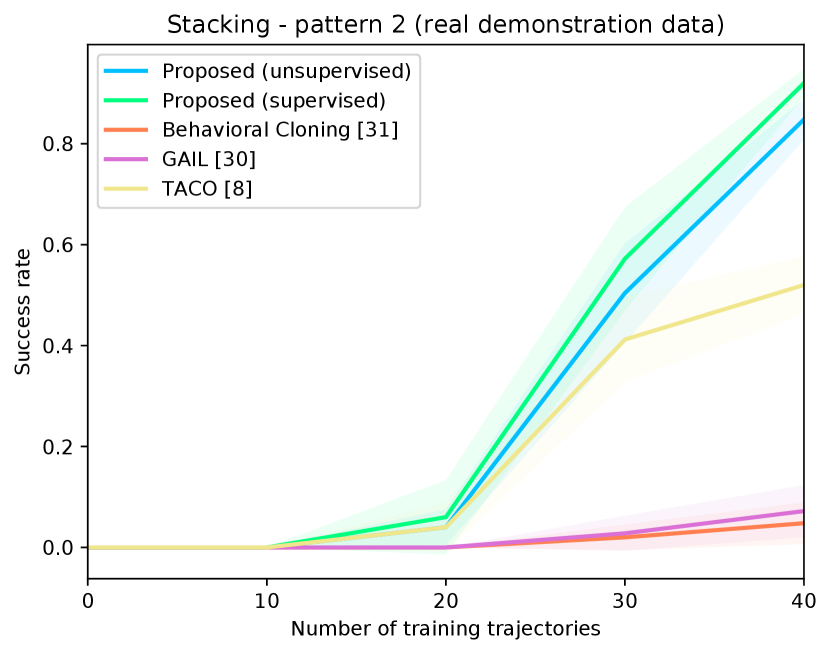
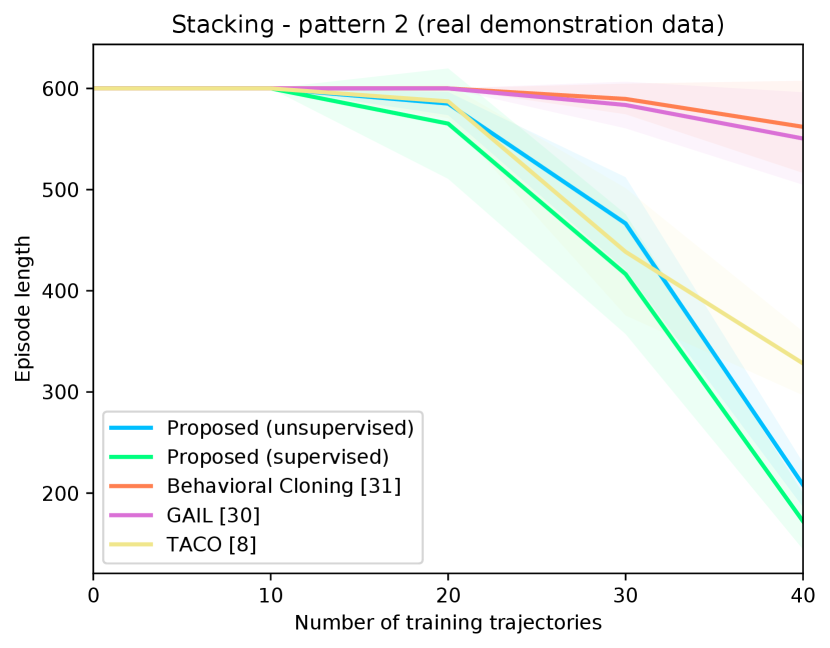
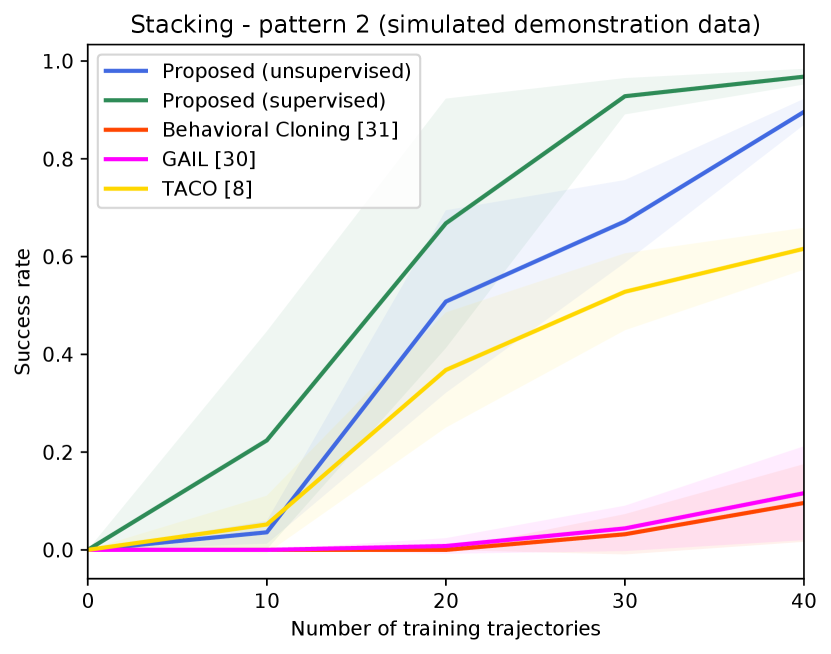
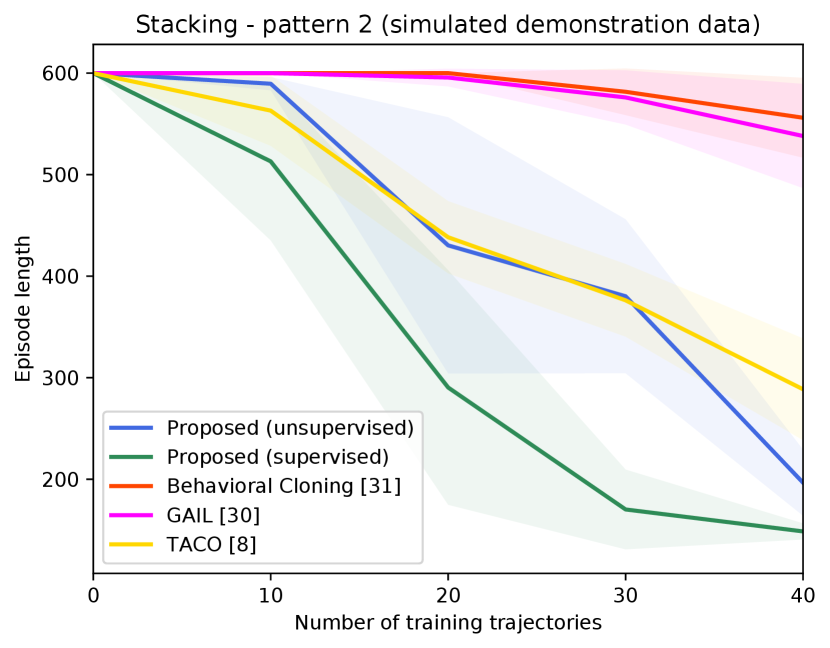
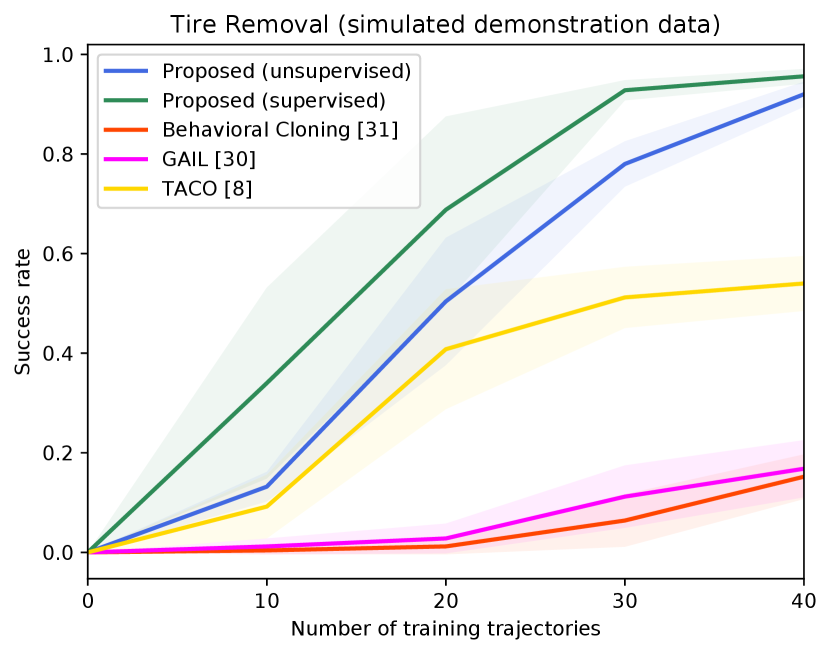
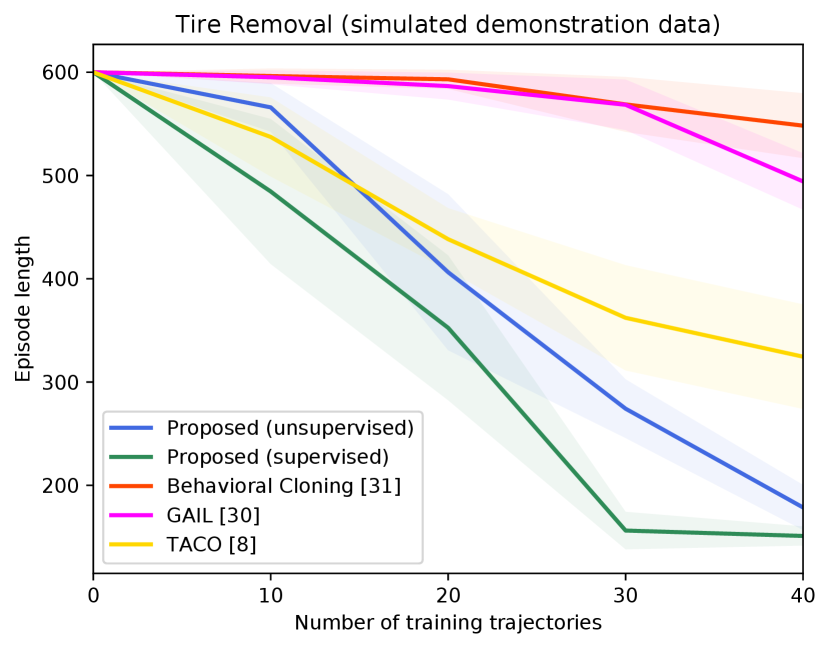
Figure 4 shows the success rates of the compared methods for the four tasks, as well as the length of the generated trajectories while solving these tasks in simulation, as a function of the number of demonstration trajectories collected as explained in Section V-A. The results are averaged over independent runs, each run contains test episodes that start with random layouts of the objects. Table I shows the success rates of the compared methods on the real Kuka robot, using the same demonstration trajectories that were used to generate Figure 4 ( trajectories for painting and for each of the remaining tasks). These results show clearly that the proposed approach outperforms the compared alternatives in terms of success rates and solves the four tasks with a smaller number of actions. The performance of our unsupervised approach is also close to that of the supervised variant. The proposed approach outperforms TACO despite the fact that TACO requires a form of supervision in its training. We also note that both our approach and TACO outperform GAIL and the behavioral cloning techniques, which clearly indicates the data-efficiency of compositional and hierarchical methods. Videos and supplementary material can be found at https://tinyurl.com/2zrp2rzm.
VI Conclusion
We presented a unified neural-network framework for training robots to perform complex manipulation tasks that are composed of several sub-tasks. The proposed framework employs the principal of attention by training a high-level policy network to select a pair of tool and target objects dynamically, depending on the context. The proposed method outperformed alternative techniques for imitation learning, without requiring any supervision beyond recorded demonstration videos. While the current video parsing module requires the objects’ CAD models beforehand, it is possible in future work to leverage model-free 6D pose trackers [32] for learning from demonstration involving novel unknown objects. We will also explore other applications of the proposed framework, such as real-world assembly tasks.
References
- [1] S. Calinon, Robot Programming by Demonstration, 1st ed. USA: CRC Press, Inc., 2009.
- [2] T. Osa, J. Pajarinen, and G. Neumann, An Algorithmic Perspective on Imitation Learning. Hanover, MA, USA: Now Publishers Inc., 2018.
- [3] O. Kroemer and G. S. Sukhatme, “Learning spatial preconditions of manipulation skills using random forests,” in Proceedings of the IEEE-RAS International Conference on Humanoid Robotics, 2016. [Online]. Available: http://robotics.usc.edu/publications/954/
- [4] A. S. Wang and O. Kroemer, “Learning robust manipulation strategies with multimodal state transition models and recovery heuristics,” in Proceedings of (ICRA) International Conference on Robotics and Automation, May 2019, pp. 1309 – 1315.
- [5] Z. Wang, C. R. Garrett, L. P. Kaelbling, and T. Lozano-Pérez, “Learning compositional models of robot skills for task and motion planning,” Int. J. Robotics Res., vol. 40, no. 6-7, 2021. [Online]. Available: https://doi.org/10.1177/02783649211004615
- [6] Z. Su, O. Kroemer, G. E. Loeb, G. S. Sukhatme, and S. Schaal, “Learning to switch between sensorimotor primitives using multimodal haptic signals,” in Proceedings of International Conference on Simulation of Adaptive Behavior (SAB ’16): From Animals to Animats 14, August 2016, pp. 170 – 182.
- [7] H. Le, N. Jiang, A. Agarwal, M. Dudík, Y. Yue, and H. Daumé, “Hierarchical imitation and reinforcement learning,” in International conference on machine learning. PMLR, 2018, pp. 2917–2926.
- [8] K. Shiarlis, M. Wulfmeier, S. Salter, S. Whiteson, and I. Posner, “Taco: Learning task decomposition via temporal alignment for control,” in International Conference on Machine Learning. PMLR, 2018, pp. 4654–4663.
- [9] G. Konidaris and A. Barto, “Skill discovery in continuous reinforcement learning domains using skill chaining,” in Advances in Neural Information Processing Systems, Y. Bengio, D. Schuurmans, J. Lafferty, C. Williams, and A. Culotta, Eds., vol. 22. Curran Associates, Inc., 2009.
- [10] M. Toussaint, K. R. Allen, K. A. Smith, and J. B. Tenenbaum, “Differentiable physics and stable modes for tool-use and manipulation planning,” in Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI 2019, Macao, China, August 10-16, 2019, S. Kraus, Ed. ijcai.org, 2019, pp. 6231–6235. [Online]. Available: https://doi.org/10.24963/ijcai.2019/869
- [11] L. P. Kaelbling, “Learning to achieve goals,” in IN PROC. OF IJCAI-93. Morgan Kaufmann, 1993, pp. 1094–1098.
- [12] L. P. Kaelbling and T. Lozano-Pérez, “Hierarchical task and motion planning in the now,” in Proceedings of the 1st AAAI Conference on Bridging the Gap Between Task and Motion Planning, ser. AAAIWS’10-01. AAAI Press, 2010, pp. 33–42.
- [13] C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Silver, L. P. Kaelbling, and T. Lozano-Pérez, “Integrated task and motion planning,” 2020.
- [14] R. T. Icarte, T. Klassen, R. Valenzano, and S. McIlraith, “Using reward machines for high-level task specification and decomposition in reinforcement learning,” ser. Proceedings of Machine Learning Research, J. Dy and A. Krause, Eds., vol. 80. StockholmsmÀssan, Stockholm Sweden: PMLR, 10–15 Jul 2018, pp. 2107–2116.
- [15] R. Toro Icarte, E. Waldie, T. Klassen, R. Valenzano, M. Castro, and S. McIlraith, “Learning reward machines for partially observable reinforcement learning,” Advances in Neural Information Processing Systems, vol. 32, pp. 15 523–15 534, 2019.
- [16] A. Camacho, R. T. Icarte, T. Q. Klassen, R. A. Valenzano, and S. A. McIlraith, “Ltl and beyond: Formal languages for reward function specification in reinforcement learning.”
- [17] B. Wen, C. Mitash, B. Ren, and K. E. Bekris, “se (3)-tracknet: Data-driven 6d pose tracking by calibrating image residuals in synthetic domains,” in 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, pp. 10 367–10 373.
- [18] D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke, and S. Levine, “Scalable deep reinforcement learning for vision-based robotic manipulation,” ser. Proceedings of Machine Learning Research, A. Billard, A. Dragan, J. Peters, and J. Morimoto, Eds., vol. 87. PMLR, 29–31 Oct 2018, pp. 651–673.
- [19] R. Fox, R. Shin, S. Krishnan, K. Goldberg, D. Song, and I. Stoica, “Parametrized hierarchical procedures for neural programming,” in International Conference on Learning Representations, 2018. [Online]. Available: https://openreview.net/forum?id=rJl63fZRb
- [20] D. Xu, S. Nair, Y. Zhu, J. Gao, A. Garg, L. Fei-Fei, and S. Savarese, “Neural task programming: Learning to generalize across hierarchical tasks.” CoRR, vol. abs/1710.01813, 2017. [Online]. Available: http://dblp.uni-trier.de/db/journals/corr/corr1710.html#abs-1710-01813
- [21] D. Huang, S. Nair, D. Xu, Y. Zhu, A. Garg, L. Fei-Fei, S. Savarese, and J. C. Niebles, “Neural task graphs: Generalizing to unseen tasks from a single video demonstration,” CoRR, vol. abs/1807.03480, 2018. [Online]. Available: http://arxiv.org/abs/1807.03480
- [22] S. Nair, M. Babaeizadeh, C. Finn, S. Levine, and V. Kumar, “TRASS: time reversal as self-supervision,” in 2020 IEEE International Conference on Robotics and Automation, ICRA 2020, Paris, France, May 31 - August 31, 2020. IEEE, 2020, pp. 115–121. [Online]. Available: https://doi.org/10.1109/ICRA40945.2020.9196862
- [23] M. Andrychowicz, F. Wolski, A. Ray, J. Schneider, R. Fong, P. Welinder, B. McGrew, J. Tobin, P. Abbeel, and W. Zaremba, “Hindsight experience replay,” in Proceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Curran Associates Inc., 2017, pp. 5055–5065.
- [24] S. Nair and C. Finn, “Hierarchical foresight: Self-supervised learning of long-horizon tasks via visual subgoal generation,” CoRR, vol. abs/1909.05829, 2019. [Online]. Available: http://arxiv.org/abs/1909.05829
- [25] P.-L. Bacon, J. Harb, and D. Precup, “The option-critic architecture,” ser. AAAI’17. AAAI Press, 2017, pp. 1726–1734.
- [26] O. Nachum, S. Gu, H. Lee, and S. Levine, “Data-efficient hierarchical reinforcement learning,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, ser. NIPS’18, 2018, pp. 3307–3317.
- [27] B. Eysenbach, A. Gupta, J. Ibarz, and S. Levine, “Diversity is all you need: Learning skills without a reward function,” in International Conference on Learning Representations, 2019. [Online]. Available: https://openreview.net/forum?id=SJx63jRqFm
- [28] C. Mitash, B. Wen, K. Bekris, and A. Boularias, “Scene-level pose estimation for multiple instances of densely packed objects,” in Conference on Robot Learning. PMLR, 2020, pp. 1133–1145.
- [29] A. S. Morgan, B. Wen, J. Liang, A. Boularias, A. M. Dollar, and K. Bekris, “Vision-driven compliant manipulation for reliable, high-precision assembly tasks,” RSS, 2021.
- [30] J. Ho and S. Ermon, “Generative adversarial imitation learning,” Advances in neural information processing systems, vol. 29, pp. 4565–4573, 2016.
- [31] D. A. Pomerleau, “Alvinn: An autonomous land vehicle in a neural network,” Carnegie-Mellon University Pittsburgh PA, Tech. Rep., 1989.
- [32] B. Wen and K. Bekris, “Bundletrack: 6d pose tracking for novel objects without instance or category-level 3d models,” IROS, 2021.