Learning Revenue-Maximizing Auctions With Differentiable Matching
Abstract
We propose a new architecture to approximately learn incentive compatible, revenue-maximizing auctions from sampled valuations. Our architecture uses the Sinkhorn algorithm to perform a differentiable bipartite matching which allows the network to learn strategyproof revenue-maximizing mechanisms in settings not learnable by the previous RegretNet architecture. In particular, our architecture is able to learn mechanisms in settings without free disposal where each bidder must be allocated exactly some number of items. In experiments, we show our approach successfully recovers multiple known optimal mechanisms and high-revenue, low-regret mechanisms in larger settings where the optimal mechanism is unknown.
1 Introduction
Auctions have been held for millennia, since at least Classical antiquity [29], and have played an important complementary role to set-price sales and bargaining to exchange goods. In recent decades, the advent of computation has resulted in a surge of large-scale fielded auctions in a variety of important industries, such as broadcasting [31], advertising [15], electricity markets [9], and many others [35, 46]. These developments have made auctions not only of theoretical interest, but also of great practical importance.
Auction design is the problem faced by an auctioneer who, given uncertain knowledge of the demands of auction participants, wishes to set the rules of the auction to ensure, via proper incentive structure, a desirable outcome. In the usual theoretical model of auctions [38], the bidders have some private valuation of the items, but the distribution from which these valuations are drawn is common knowledge. The auctioneer solicits bids from participants, awards the items up for sale to the winners, and charges some amount of money to each. Bidders may, however, choose to strategically lie about their valuation given their knowledge of the auction rules and anticipated behavior of other participants, resulting in a Bayes-Nash equilibrium which may be very hard for the auction designer to predict.
To avoid this problem, an auctioneer may simply wish to design a strategyproof (or truthful) mechanism in which participants are incentivized to truthfully reveal their valuations. The distribution of bids is then simply the valuation distribution itself, so it becomes easy to predict the results of the auction in expectation. While satisfying the strategyproofness constraint, the auctioneer can additionally optimize total utility, their own revenue, or other desirable properties.
If the auctioneer’s goal is to maximize the welfare of all participants while maintaining strategyproofness, the Vickrey-Clarke-Groves (VCG) mechanism always gives a solution [51, 7, 24]. By contrast, if the auctioneer wishes to maximize revenue, strategyproof mechanisms are much harder to find. Some revenue-maximizing strategyproof mechanisms are known in limited cases: when selling a single item, the Myerson auction is strategyproof and maximizes revenue [37], and for selling multiple items to one agent, some results are known [13, 27, 40, 33]. But even for the simple case of selling two items to two agents, there has been almost no progress, with the major exception of a breakthrough for the special case where items take on at most two discrete valuations [55].
The theoretical difficulty of devising revenue-maximizing strategyproof auctions has resulted in a number of attempts to approximate them. Recently, [14] presented a method, RegretNet, for learning approximately incentive compatible mechanisms given samples from the bidder valuations. They parameterize the auction as a neural network, and learn to maximize revenue, and maintain strategyproofness, by gradient descent. This learning approach to auction design can replicate some known-optimal auctions, and can learn good auctions in settings where the optimal auction is not known. It has been extended in a variety of ways [10, 49, 21, 30, 18, 43, 44, 41].
The RegretNet architecture has architectural features to ensure that no item is over-allocated, and that each bidder receives the correct amount of goods. This is accomplished through a combination of softmax and minimum operations, depending on the exact bidder demand constraints.
However, this approach only works when some ad-hoc combination of these operations is sufficient to enforce the constraints. This is not always possible. Consider the case where the auctioneer needs to ensure that every participant receives exactly items. This corresponds, for instance, to an offline version of the “Display Ads” problem [17], without free disposal. Such equality constraints cannot be enforced using the min-of-softmax approach.
We observe that an auction allocation for bidders whose utilities are linear functions of their valuations amounts to a matching assigning items to bidders. Using this observation, we present an alternative approach which explicitly applies matching constraints on the output, using the Sinkhorn algorithm [11] to solve a discrete matching problem as part of an end-to-end differentiable architecture.
This approach is among the first attempts to use the techniques of differentiable optimization [1] for learned mechanism design – concurrent work [32] uses a differentiable sorting operator to learn generalized second-price auctions. By simply modifying the constraints in our matching problem, our proposed approach can produce feasible allocations without changes to the overall network architecture for many different bidder demand constraints. Our approach successfully recovers known optimal mechanisms in multiple settings including settings (such as exactly-one-demand auctions) in which RegretNet would be unable to guarantee that its output allocations adhere to the constraints.
2 Related Work
Auction Design and Learning
Auction mechanisms are functions from bids to allocations and payments; if one assumes sample access to the valuation distribution, it is natural to treat auction design as a learning problem, and there has been much work in this area.
One thread of work has been learning-theoretic, determining the sample complexity for various known families of auctions to estimate properties like revenue [5, 8, 36] or incentive compatibility [4].
Another thread of work, sometimes called “differentiable economics”, represents auction mechanisms using general parametric function approximators, and attempts to optimize them using gradient descent. [14] introduce several neural network architectures to find revenue-maximizing auctions, including RochetNet, which works for single-agent auctions and is strategyproof by constructions, and RegretNet, which represents auctions as a general neural network and includes a term in the loss function to enforce strategyproofness.
Further work has built directly on both RochetNet and RegretNet [30, 10, 43, 44]. Others have taken a similar approach but applied to different mechanism design problems, including finding welfare-maximizing auctions [49] and facility location [21]. Other applications of gradient-based methods to problems in mechanism design include [25, 53].
Single-agent auction learning
The case of selling multiple items to a single agent is reasonably well understood. [45] gives a characterization of strategyproof single-agent mechanisms – their utility functions must be monotone and convex. Based on this characterization, [14] design RochetNet, a network architecture for single-agent mechanism learning which is guaranteed to be perfectly strategyproof. [48] also provide network architectures for the single-agent setting which can be made strategyproof by construction. The authors of both works are able to learn mechanisms and then prove them optimal using the theoretical framework of [13].
We wish to explicitly contrast these architectures with our own approach. In a single-agent setting, they work better than a RegretNet-style architecture, and as mentioned can always guarantee perfect strategyproofness. In this work, however, we focus on general architectures which can work in both single- and multi-agent settings.
Optimal Transport and the Sinkhorn Algorithm
Optimal transport [26] is the problem of moving one set of masses to another mass while minimizing some cost function. In its infinite dimensional form, where it amounts to finding the cost-minimizing joint distribution between two marginal continuous probability distributions, it has wide applications in pure mathematics [52] as well as machine learning [3, 20]. Interestingly, [13, 27] use the mathematical tools of infinite-dimensional optimal transport in the context of mechanism design theory.
Our work here is not directly related. By contrast, we the discrete form of optimal transport, which is essentially a formulation of minimum cost bipartite matching (in our case, between agents and items). This discrete problem can be numerically solved in a number of ways, see [42] for an overview. In particular, we focus on the Sinkhorn algorithm [11]: a fast, GPU-parallelizable iterative method for solving the entropy-regularized version of the optimal transport problem, which can be used as a differentiable bipartite matching operation [34, 23, 50, 16, 12]. We use the Sinkhorn algorithm to compute matchings between agents and items.
Differentiable optimization and deep learning
Recently, there has been broad interest in mixing convex optimization problems with deep learning. For many convex optimization problems, the derivative of the optimal solution with respect to parameters of the objective or constraints is well defined, so it is possible to define a neural network layer that will output a feasible, optimal solution to some optimization problem. This is useful if one wants to use optimization with deep learning in a “predict and optimize” pipeline [19, 54], to enforce that network outputs satisfy some constraints, or if interesting operations can be formulated in terms of optimization problems [22].
One family of approaches [[, e.g.,]]Agrawal2019:cvxpylayers,amos2017optnet involves solving the convex optimization problem using standard solvers, then using the implicit function theorem to compute the gradient for the backward pass. In a contrasting approach, when using an iterative method to solve the optimization problem, it is also possible to use automatic differentiation to simply backpropagate through the numerical operations performed by the solver. We employ this latter approach with the aforementioned Sinkhorn algorithm in order to compute feasible matchings in a differentiable manner
3 Differentiable Economics and Combinatorial Optimization
General auction setting
We consider an auction setting with bidders and items. Each bidder has a private valuation function, , that maps any subset of the items to a real number. We assume that is drawn from a known distribution , but the realized valuation is private and unknown to the auctioneer. Each bidder then submits their bids . Let be the bids from all bidder. The auction mechanism is then a combination of an allocation mechanism and payment mechanism, . The outputs an allocation where is the probability of allocating item to bidder . The payment mechanism outputs where is how much bidder is charged. Each bidder then receives some utility .
Quasilinear utilities, strategyproofness, and individual rationality
Allowing a distinct valuation for every combination of items may result in a combinatorial explosion. A simplifying assumption is that a bidder may have a single valuation for each item. Then their valuation is simply a vector in , and their utility is simply .
Since a bidder’s true valuation is private they are free to strategically report bids to maximize their utility. Thus, a we require our mechanism to be strategyproof or dominant-strategy incentive compatible (DSIC), meaning each bidder’s utility is maximized by reporting truthfully i.e. for any other where are all the bids except the th bidder. Regret is defined by the following equation: , and represents the utility the bidder could have gained from lying in their bid. We can then also say that when a mechanism is DSIC, the regret for truthful bidding for bidder should be 0 for every player with truthful valuation , for any opponent bids .
Another desirable property for an auction for it to be (ex post) individually rational. This means each bidder receives a non-negative utility from the auction i.e. for all bidders , all possible valuations , and all other bids . Without this guarantee bidders might choose not to participate in the auction at all because they are concerned about being left worse off than they were before the auction.
3.1 Bidder Demand Types
Here we define common bidder demand constraints which are used in the experiments.
The value of a bundle of goods for a unit-demand bidder is equal to the maximum value of a single item in the bundle: . In this sort of auction, there is no need to consider allocations of more than one item to each bidder since those provide that same utility as only allocating the most desirable item within that bundle to that bidder. Thus, by restricting allocations to allocate at most one item per bidder, we can again treat bidder utility as quasilinear. More generally, there can be -unit-demand auctions where a bidder’s value of a bundle of goods is the sum of the top items in the bundle [56].
We also consider exactly-one demand, where each bidder must be assigned exactly one item. In this setting, the bidder cannot be assigned more or fewer than one item and receives the value of the assigned item. Additionally, this demand-type can be extended to a more general exactly- demand setting where each bidder must be allocated items.
In all these settings, in general allocations might be randomized so that bidders can receive items with different probabilities. This corresponds to allowing fractional allocations, so that in the unit-demand and exactly-one-demand settings, the one item the bidder receives can be a mixture of fractions of multiple items.
3.2 RegretNet
The RegretNet architecture consists of two neural networks, the allocation network (denote it ) which outputs a matrix representing the allocation of each item to each agent and payment network (denote it ) which outputs the payments for each bidder [14].
RegretNet guarantees individual rationality by making the payment network use a sigmoid activation, outputting a value . The final payment is then , ensuring that the utility of each bidder is non-negative.
[14] present network architectures to learn under additive, unit-demand and combinatorial valuations. Their architecture utilizes a traditional feed-forward neural network with modifications in the output layer to ensure a valid allocation matrix. In the additive setting, the allocation probabilities for each item must be at most one: this is enforced by taking a row-wise softmax on the network outputs. For unit-demand auctions, each bidder wants at most one item, so the network takes a row-wise softmax of one matrix and a column-wise softmax of another to ensure item allocation is less than one. The final output is then the elementwise min of these two, ensuring that both item allocation and unit-demand constraints are enforced.
For training, the RegretNet architecture uses gradient descent on an augmented Lagrangian which includes terms to maximize payment while also containing terms to enforce the constraint that regret should be zero:
| (1) |
Here denotes an empirical estimate of regret produced by running gradient ascent on player ’s portion of the network input to maximize their utility, computing their possible benefit from strategically lying. During training, the Lagrange multipliers are gradually maximized, incentivizing the minimization of regret.
4 Bipartite Matching for Auctions
The auction allocation problem is equivalent to finding a minimum-cost bipartite matching between bidders and items, for some cost matrix. We solve this bipartite matching problem by formulating it as an optimal transport problem. Using the Sinkhorn algorithm, we are able to solve this optimal transport problem in an end-to-end differentiable way, yielding a valid matching that our network can use to learn an optimal allocation mechanism.

4.1 Matching Linear Program
For marginal vectors and – here representing constraints for agents and items respectively, each with a dummy component that represents no item or no agent – the optimal transport problem is as follows.
| (2) |
By specifying and , we can specify the demand constraints of the problem:
-
•
-demand: , , ,
-
•
exactly--demand: , , ,
Here the and values of the marginals represent the dummy agent and item respectively. More complex constraints, such as different for different agents, can also be accommodated. Also, note in the exactly--demand settings there must be at least items, so . An optimal solution to the matching LP will always be a permutation matrix [6], or more generally on one of the extreme points of the constraint set.
4.2 Entropy-Regularized Optimal Transport and the Sinkhorn Algorithm
The problem in Equation 2 can be solved as a linear program. However, [11] observed that by adding an entropy penalty to the problem, it can be solved in a practical and scalable way using the matrix-scaling Sinkhorn algorithm. The new objective of the problem is
Given marginals and a cost matrix, [11] provides an iterative algorithm to solve this problem. It can be implemented in a variety of ways; we use the following stabilized log-domain updates [42]:
where . In addition to enabling the use of the iterative algorithm, the regularization term makes the problem strongly convex. Thus, the derivative of the optimal solution with respect to the cost matrix is well-defined. To approximate this derivative, we choose to unroll several iterations of the Sinkhorn updates (which consist only of differentiable operations) and use automatic differentiation.
The parameter controls the strength of the regularization. If it is large the output will be nearly uniform; as it goes to zero we recover the original problem and will be a permutation matrix. For our purposes, we set large enough to avoid vanishing gradients, but small enough that the output allocations are still nearly permutation matrices.
4.3 Network Architecture
Our architecture, like RegretNet, uses a pair of networks to compute allocations and payments. We denote the allocation and payment networks and respectively, where are the network weights.
The main distinction from RegretNet is in the allocation mechanism. Like RegretNet we utilize a traditional feedforward neural network that takes all given bids as input. We use the output of the network as the cost matrix to the Sinkhorn algorithm (if there are dummy agents or items, they receive cost 0). Marginals are specified separately depending on the problem setting.
Finally, the output of the Sinkhorn algorithm (after truncating the row and column for dummy variables) provides the final probabilities of allocating item to bidder .
As in RegretNet, the final payment for bidder is where is the th output from a feedforward payment network. This ensures that the mechanism is individually rational as the bidders will never be charged more than their utility gained from the allocated items.
4.4 Settings That RegretNet Cannot Represent
RegretNet provides three different architectures depending on bidder demand type and valuation functions. For its unit-demand and combinatorial architectures, it employs a “min-of-softmax” approach to ensure both that agents receive at most 1 item or bundle, and items are not overallocated.
We particularly emphasize the case of exactly- demand, which describes the situation where the auction designer is obligated to ensure that every participant receives items, no matter what they bid. This captures, for instance, an offline version of the classic Display Ads setting [17], without free disposal, where every ad buyer is contractually guaranteed a certain number of ad slots. For multiple agents and multiple items, RegretNet cannot represent this demand type via the min-of-softmax approach.
(In some special cases, ad-hoc changes could be made to the original RegretNet architecture to support settings beyond additive and unit-demand. For example, to enforce “at-most-” demand, one can just scale the unit-demand outputs by a factor of . In the special single-agent case, it is possible to produce exactly- demand by removing the dummy item which allows for the possibility of allocating no item.)
By contrast, in multi-agent settings with exactly- demand, the Sinkhorn-based architecture can ensure feasible outputs by simply specifying the correct marginals. Our network architecture is also independent of the demand type since only the marginals change rather than the entire network output structure.
4.5 Optimization and Training
Like RegretNet, our training objective is Equation 1. For each batch we estimate the empirical regret, by performing gradient ascent for each bidder on the network inputs, approximating a misreport for each bidder.
In our experiments, the network for both the payment and allocation network had 2 hidden layers of 128 nodes with Tanh activation functions, optimized using the Adam optimizer [28] with a learning rate of . The training set consisted of valuation profiles. We used batch sizes of 4,096 and ran a total of 100 epochs. For each batch, we computed the best misreport using loops of gradient ascent with a learning rate . We also incremented every two batches and and updated the Lagrange multipliers, , every 100 batches. Experiments were all run on single 2080Ti GPUs, on either a compute node or workstation with 32GB RAM, using PyTorch [39].
For evaluation, we used 1,000 testing examples and optimized the misreports of these examples for 1,000 iterations with learning rate . For each of the 1,000 samples we use ten random initialization points for the misreport optimization and use the maximum regret from these. At both train and test time we used the Sinkhorn algorithm with an parameter of , and a stopping criterion of a relative tolerance of . Additionally we used an schedule (as suggested by [47, 12]) of 10 steps from down to the final value of . Pseudocode for computing the allocation network output is given in algorithm 1.
5 Experiments
5.1 Optimal single-agent mechanisms
We start by recovering two known optimal mechanisms in the single bidder case. We emphasize that if the only goal were to learn single-agent auctions, architectures such as RochetNet [14] or that of [48] would work better. Our architecture works for both single-agent and multi-agent auctions. Following previous work [14, 44, 43], we use these single-agent experiments as a test case to make sure it recovers some known optimal mechanisms, before continuing on to multi-agent settings where optimal auctions are not known and where RochetNet or [48] cannot work.
Unit-demand
We first recover the optimal mechanism in the unit-demand single-agent two-item setting with item values drawn from . The optimal mechanism, also approximately recovered in [14], is from [40]: it is to offer each good for a price of . The learned allocation probabilities are shown in Figure 2(b) with the boundary of the optimal analytic mechanism denoted by a dotted line. The x and y axis are the valuation of the bidder for item one and two respectively. The color represents the allocation probability output by the learned mechanism with the darker color corresponding to higher probability. Quantitatively, the learned mechanism has small regret and slightly higher than the optimal mechanism likely due to the small amount of regret.
Exactly-one demand
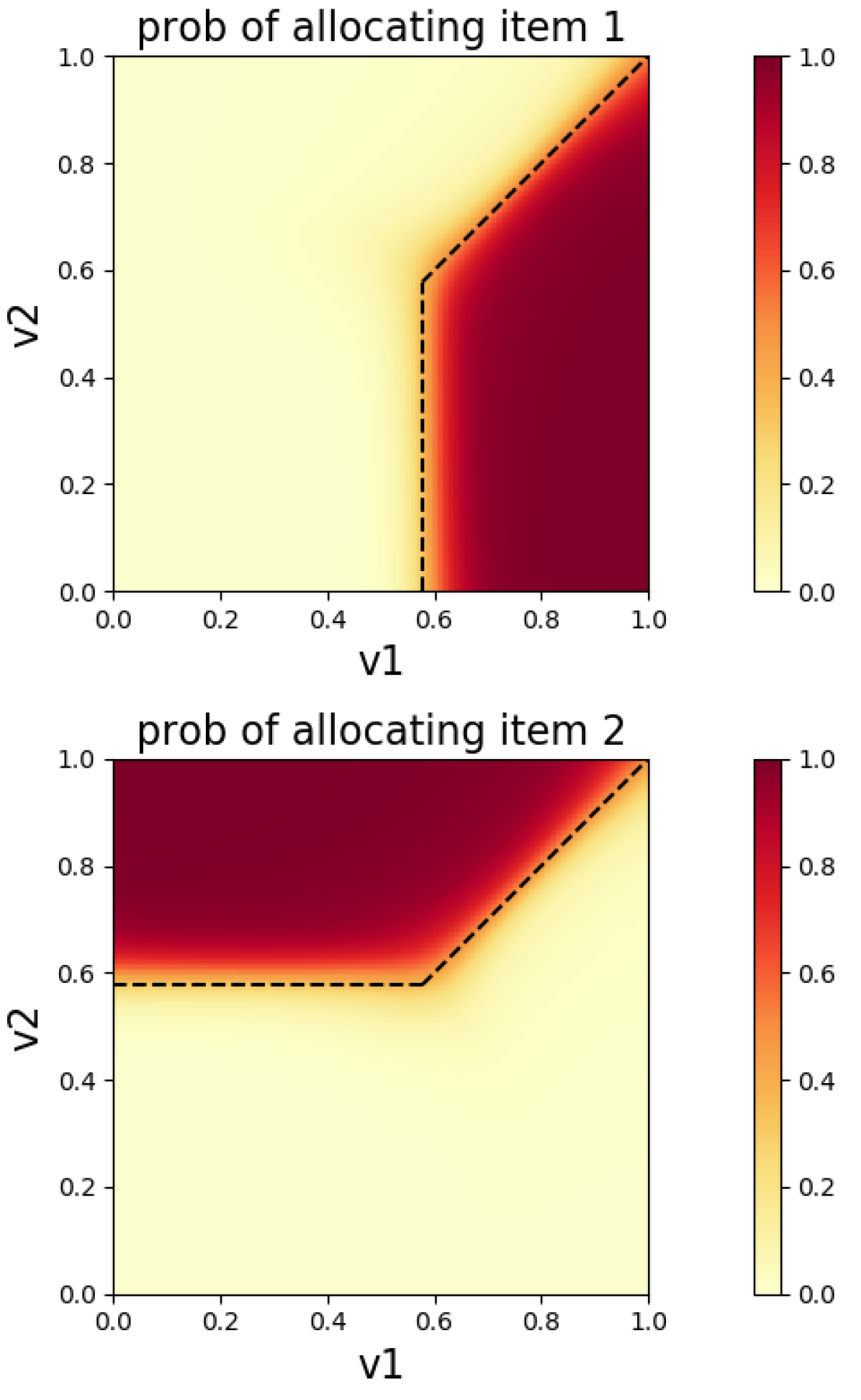
The second optimal mechanism was a deterministic mechanism in the same single agent, two-item setting with valuations on . However, this time the agent will be allocated exactly one item (instead of at most one). [27] shows that the optimal mechanism is to offer one of the items for free or the other for a price of .
The boundary of this optimal mechanism is shown in Figure 2(a) as the black dotted line. The revenue in Figure 1 is slightly higher than the optimal, again likely due to the presence of small regret.


| Setting | Rev | Regret | Opt Rev | Train Time |
|---|---|---|---|---|
| Unit-demand | 0.397 (0.248) | () | 0.393 | 3h25m |
| RegretNet Unit-Demand | 0.381 (0.258) | () | 0.393 | 18m34s |
| Exactly-one | 0.079 (0.127) | (0.001) | 0.069 | 1h21m |
5.2 Multi-agent setting
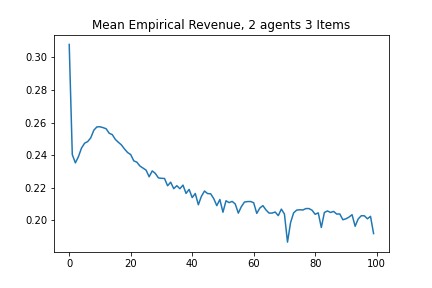
We now experiment in settings where the optimal strategyproof mechanism is unknown. Specifically, we study 2 bidders and either 3 or 15 items where valuations for each item are drawn from . A typical analytic baseline is a separate Myerson auction for each item, but this only works in additive settings. Instead, as a baseline, we compute the revenue from an [51, 7, 24]. The VCG auction is strategyproof, and maximizes welfare rather than revenue. It works by charging each bidder the harm they cause to other bidders, which in the settings we test may be very small or even close to zero. Table 2 contains the revenues for both mechanism (unsurprisingly higher for the learned auction) as well as the average observed regret on the testing sample, while figures 3(a) and 3(b) show training plots for the two agent, 3 item, exactly-one demand case.

5.3 Comparison To RegretNet
RegretNet is capable of representing unit-demand auctions, but not the exactly-one setting. We compare performance to it in this case; results are shown in Table 2. (Runtimes are significantly faster than those reported in [14] likely due to our much larger batch sizes.) For the one-agent, two item setting, both architectures approximate the optimal mechanism so performance is similar. Performance is also similar for the 2 agent, 3 item setting. In the 15-item setting, revenue with the Sinkhorn architecture is somewhat smaller. In all cases the computational cost of RegretNet is significantly lower, as it requires only two softmax operations instead of many iterations of the Sinkhorn algorithm.
| Setting | Agents | Items | Rev | Regret | VCG Rev | Time |
|---|---|---|---|---|---|---|
| Unit | 2 | 3 | .876 (.322) | .001 (.001) | .048 | 6h20m |
| RegretNet Unit | 2 | 3 | .878 (.337) | () | .048 | 20m28s |
| Unit | 2 | 15 | .886 (.113) | .001 () | .002 | 3h10m |
| RegretNet Unit | 2 | 15 | .999 (.123) | () | .002 | 25m45s |
| Exactly-1 | 2 | 3 | .194 (.064) | .004 (.008) | .049 | 2h38m |
| RegretNet Exactly-1 | 2 | 3 | N/A | N/A | .049 | N/A |
| Exactly-1 | 2 | 15 | .571 (.030) | .003 (.015) | .002 | 1h29m |
| RegretNet Exactly-1 | 2 | 15 | N/A | N/A | .002 | N/A |
6 Strengths, Limitations, and Potential Impacts
Structurally, our architecture has the benefit of remaining the same for any quasi-linear bidder utilities and constraints, with only the Sinkhorn marginals changing. The use of the Sinkhorn algorithm allows us to enforce these constraints explicitly and even tackle new settings, such as exactly- demand, that the existing RegretNet architecture would be unable to handle.
Our Sinkhorn-based architecture has a higher computational cost than the comparable RegretNet architecture, as the Sinkhorn algorithm requires many iterations. The Sinkhorn algorithm also requires two additional hyperparameters, and a tolerance before the algorithm terminates.
We find that the parameter plays a crucial role in the training of the algorithm. If the is too small, training fails, likely due to vanishing gradients. However, with too large of an the mechanism becomes too smooth and unable to approximate the sharp boundaries that tend to show up in optimal mechanisms leading to suboptimal revenue. (For further discussion of , see Appendix A in the supplemental material.) Our architecture has an inductive bias towards deterministic allocations. This may pose a limitation where revenue-maximizing mechanisms are nondeterministic, but it may be an advantage if they are deterministic or if determinism is desirable. By setting small enough it is possible to ensure near-determinism in allocations. However, because the mechanisms are trained under a higher , there are regions where the price charged becomes too high, increasing regret. Because training directly with small is difficult, we cannot directly guarantee that we train deterministic mechanisms.
Following previous work that uses neural networks to approximate optimal auctions (including but not limited to [14, 48, 44, 43]), we train on synthetic data. While in principle deep-learning-based methods could be used to train on truthful bids from real-world bidders, and doing so would be extremely interesting, such data is hard to come by. We see learned auctions as, at least in part, a tool for pushing theory forward, so using synthetic data remains interesting when it is drawn from valuation distributions for which analytic solutions have remained out of reach.
There are general ethical implications of revenue-maximizing auction design, in terms of potential impact on bidders and society as a whole. For instance, making it easier for sellers to extract revenue from bidders might be viewed as bad (if the bidders are thought of as ordinary consumers) or good (if the auctioneer is selling a public resource to private entities). However, since our work is still closely to the theoretical models discussed above, we do not see any direct ethical implications – it is very unlikely that deep-learned auctions will be directly deployed in the near future.
7 Conclusion and Future Work
We have presented a new architecture for learned auctions which uses the Sinkhorn algorithm to perform a differentiable matching operation to compute an allocation. Our architecture works for a variety of bidder demand constraints by encoding them into the marginals used in the Sinkhorn algorithm. This new architecture allows the network to guarantee valid allocations in settings where RegretNet could not.
We show that our approach successfully recovers optimal mechanisms in settings where optimal mechanisms are known, and achieves good revenue and low regret in larger settings. Future work might include extending the Sinkhorn architecture to more directly support randomized allocations, further computational improvements, or further extensions to other mechanism design problems where the allocation decision can be expressed as a matching.
Acknowledgments. Curry and Dickerson were supported in part by NSF CAREER Award IIS-1846237, NSF D-ISN Award #2039862, NSF Award CCF-1852352, NIH R01 Award NLM-013039-01, NIST MSE Award #20126334, DARPA GARD #HR00112020007, DoD WHS Award #HQ003420F0035, and a Google Faculty Research Award. Goldstein was supported by the ONR MURI program, the AFOSR MURI Program, the National Science Foundation (DMS-1912866), the JP Morgan Faculty Award, and the Sloan Foundation. We thank Ahmed Abdelkader, Kevin Kuo, and Neehar Peri for comments on earlier drafts of this work, and Jason Hartline for helpful commentary.
References
- [1] Akshay Agrawal et al. “Differentiable Convex Optimization Layers” In Neural Information Processing Systems (NeurIPS), 2019
- [2] Brandon Amos and J Zico Kolter “Optnet: Differentiable optimization as a layer in neural networks” In International Conference on Machine Learning (ICML), 2017
- [3] Martin Arjovsky, Soumith Chintala and Léon Bottou “Wasserstein Generative Adversarial Networks” In International Conference on Machine Learning (ICML), 2017
- [4] Maria-Florina Balcan, Tuomas Sandholm and Ellen Vitercik “Estimating Approximate Incentive Compatibility” In Economics and Computation (EC), 2019
- [5] Maria-Florina F Balcan, Tuomas Sandholm and Ellen Vitercik “Sample complexity of automated mechanism design” In Advances in Neural Information Processing Systems, 2016, pp. 2083–2091
- [6] Garrett Birkhoff “Tres observaciones sobre el algebra lineal” In Univ. Nac. Tucuman, Ser. A 5, 1946, pp. 147–154
- [7] Edward H Clarke “Multipart pricing of public goods” In Public choice JSTOR, 1971, pp. 17–33
- [8] Richard Cole and Tim Roughgarden “The sample complexity of revenue maximization” In Proceedings of the forty-sixth annual ACM symposium on Theory of computing, 2014, pp. 243–252
- [9] Peter Cramton “Electricity market design” In Oxford Review of Economic Policy 33.4 Oxford University Press UK, 2017, pp. 589–612
- [10] Michael Curry, Ping-yeh Chiang, Tom Goldstein and John P. Dickerson “Certifying Strategyproof Auction Networks” In Neural Information Processing Systems (NeurIPS), 2020
- [11] Marco Cuturi “Sinkhorn distances: Lightspeed computation of optimal transport” In Neural Information Processing Systems (NeurIPS), 2013
- [12] Marco Cuturi, Olivier Teboul and Jean-Philippe Vert “Differentiable Ranking and Sorting using Optimal Transport” In Neural Information Processing Systems (NeurIPS), 2019
- [13] Constantinos Daskalakis, Alan Deckelbaum and Christos Tzamos “Strong Duality for a Multiple-Good Monopolist” In Economics and Computation (EC), 2015
- [14] Paul Duetting et al. “Optimal Auctions through Deep Learning” In International Conference on Machine Learning (ICML), 2019
- [15] Benjamin Edelman, Michael Ostrovsky and Michael Schwarz “Internet advertising and the generalized second-price auction: Selling billions of dollars worth of keywords” In American Economic Review 97.1, 2007, pp. 242–259
- [16] Patrick Emami and Sanjay Ranka “Learning permutations with sinkhorn policy gradient” In arXiv preprint arXiv:1805.07010, 2018
- [17] Jon Feldman et al. “Online Ad Assignment with Free Disposal” In Internet and Network Economics Springer Berlin Heidelberg, 2009, pp. 374–385
- [18] Zhe Feng, Harikrishna Narasimhan and David C. Parkes “Deep Learning for Revenue-Optimal Auctions with Budgets” In International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), 2018
- [19] Aaron Ferber, Bryan Wilder, Bistra Dilkina and Milind Tambe “Mipaal: Mixed integer program as a layer” In AAAI Conference on Artificial Intelligence, 2020
- [20] Aude Genevay, Gabriel Peyré and Marco Cuturi “Learning generative models with sinkhorn divergences” In International Conference on Artificial Intelligence and Statistics (AISTATS), 2018
- [21] Noah Golowich, Harikrishna Narasimhan and David C. Parkes “Deep Learning for Multi-Facility Location Mechanism Design” In International Joint Conference on Artificial Intelligence (IJCAI), 2018
- [22] Stephen Gould, Richard Hartley and Dylan Campbell “Deep declarative networks: A new hope” In arXiv preprint arXiv:1909.04866, 2019
- [23] Aditya Grover, Eric Wang, Aaron Zweig and Stefano Ermon “Stochastic optimization of sorting networks via continuous relaxations” In arXiv preprint arXiv:1903.08850, 2019
- [24] Theodore Groves “Incentives in teams” In Econometrica: Journal of the Econometric Society JSTOR, 1973, pp. 617–631
- [25] Stefan Heidekrüger et al. “Equilibrium Learning in Combinatorial Auctions: Computing Approximate Bayesian Nash Equilibria via Pseudogradient Dynamics” In arXiv preprint arXiv:2101.11946, 2021
- [26] Leonid V Kantorovich “On the translocation of masses” In Dokl. Akad. Nauk. USSR (NS) 37, 1942, pp. 199–201
- [27] Ian A Kash and Rafael M Frongillo “Optimal auctions with restricted allocations” In Proceedings of the 2016 ACM Conference on Economics and Computation, 2016, pp. 215–232
- [28] Diederik P Kingma and Jimmy Ba “Adam: A method for stochastic optimization” In arXiv preprint arXiv:1412.6980, 2014
- [29] Vijay Krishna “Auction theory” Academic press, 2009
- [30] Kevin Kuo et al. “ProportionNet: Balancing Fairness and Revenue for Auction Design with Deep Learning” In arXiv preprint arXiv:2010.06398, 2020
- [31] Kevin Leyton-Brown, Paul Milgrom and Ilya Segal “Economics and computer science of a radio spectrum reallocation” In Proceedings of the National Academy of Sciences (PNAS) 114.28 National Acad Sciences, 2017, pp. 7202–7209
- [32] Xiangyu Liu et al. “Neural Auction: End-to-End Learning of Auction Mechanisms for E-Commerce Advertising” In arXiv preprint arXiv:2106.03593, 2021
- [33] Alejandro M. Manelli and Daniel R. Vincent “Bundling as an optimal selling mechanism for a multiple-good monopolist” In J. Econ. Theory 127.1, 2006, pp. 1–35
- [34] Gonzalo Mena, David Belanger, Scott Linderman and Jasper Snoek “Learning latent permutations with gumbel-sinkhorn networks” In arXiv preprint arXiv:1802.08665, 2018
- [35] Paul Milgrom “Discovering prices: auction design in markets with complex constraints” Columbia University Press, 2017
- [36] Jamie Morgenstern and Tim Roughgarden “Learning simple auctions” In Conference on Learning Theory, 2016, pp. 1298–1318
- [37] Roger B Myerson “Optimal auction design” In Mathematics of Operations Research 6.1 INFORMS, 1981, pp. 58–73
- [38] Simon Parsons, Juan A Rodriguez-Aguilar and Mark Klein “Auctions and bidding: A guide for computer scientists” In ACM Computing Surveys (CSUR) 43.2 ACM New York, NY, USA, 2011, pp. 1–59
- [39] Adam Paszke et al. “Pytorch: An imperative style, high-performance deep learning library” In arXiv preprint arXiv:1912.01703, 2019
- [40] Gregory Pavlov “Optimal mechanism for selling two goods” In The BE Journal of Theoretical Economics 11.1 De Gruyter, 2011
- [41] Neehar Peri, Michael J Curry, Samuel Dooley and John P Dickerson “PreferenceNet: Encoding Human Preferences in Auction Design with Deep Learning” In arXiv preprint arXiv:2106.03215, 2021
- [42] Gabriel Peyré and Marco Cuturi “Computational optimal transport: With applications to data science” In Foundations and Trends® in Machine Learning 11.5-6 Now Publishers, Inc., 2019, pp. 355–607
- [43] Jad Rahme, Samy Jelassi and S Matthew Weinberg “Auction learning as a two-player game” In International Conference on Learning Representations (ICLR), 2021
- [44] Jad Rahme, Samy Jelassi, Joan Bruna and S Matthew Weinberg “A Permutation-Equivariant Neural Network Architecture For Auction Design” In arXiv preprint arXiv:2003.01497, 2020
- [45] Jean-Charles Rochet “A necessary and sufficient condition for rationalizability in a quasi-linear context” In Journal of mathematical Economics 16.2 Elsevier, 1987, pp. 191–200
- [46] Alvin E Roth “Marketplaces, markets, and market design” In American Economic Review 108.7, 2018, pp. 1609–58
- [47] Bernhard Schmitzer “Stabilized sparse scaling algorithms for entropy regularized transport problems” In SIAM Journal on Scientific Computing 41.3 SIAM, 2019, pp. A1443–A1481
- [48] Weiran Shen, Pingzhong Tang and Song Zuo “Automated mechanism design via neural networks” In Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems, 2019, pp. 215–223
- [49] Andrea Tacchetti et al. “A neural architecture for designing truthful and efficient auctions” In arXiv preprint arXiv:1907.05181, 2019
- [50] Yi Tay et al. “Sparse sinkhorn attention” In International Conference on Machine Learning (ICML), 2020
- [51] William Vickrey “Counterspeculation, auctions, and competitive sealed tenders” In The Journal of finance 16.1 Wiley Online Library, 1961, pp. 8–37
- [52] Cédric Villani “Topics in optimal transportation” American Mathematical Soc., 2003
- [53] Jakob Weissteiner and Sven Seuken “Deep Learning—Powered Iterative Combinatorial Auctions” In AAAI Conference on Artificial Intelligence, 2020
- [54] Bryan Wilder, Bistra Dilkina and Milind Tambe “Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization” In AAAI Conference on Artificial Intelligence, 2019
- [55] Andrew Chi-Chih Yao “Dominant-strategy versus bayesian multi-item auctions: Maximum revenue determination and comparison” In Economics and Computation (EC), 2017
- [56] Hanrui Zhang and Vincent Conitzer “Learning the Valuations of a -demand Agent” In International Conference on Machine Learning (ICML), 2020
Appendix A Effect of Sinkhorn Epsilon
Effect of Sinkhorn
Figures 4(b) and 4(a) highlights the effect of the Sinkhorn parameters on the final mechanism. The lower the in the Sinkhorn algorithm the sharper the boundary becomes, as with less entropy regularization, the optimal matching is closer to deterministic. However, we found that very small values of epsilon led to problems during training; the learned mechanism would choose to never allocate items, likely due to vanishing gradients. One can make an almost-perfectly-deterministic mechanism by decreasing at test time, but this can increase regret as the learned payments no longer agree with the allocations.