Learning Orientation Field for OSM-Guided Autonomous Navigation
Abstract
OpenStreetMap (OSM) has gained popularity recently in autonomous navigation due to its public accessibility, lower maintenance costs, and broader geographical coverage. However, existing methods often struggle with noisy OSM data and incomplete sensor observations, leading to inaccuracies in trajectory planning. These challenges are particularly evident in complex driving scenarios, such as at intersections or facing occlusions. To address these challenges, we propose a robust and explainable two-stage framework to learn an Orientation Field (OrField) for robot navigation by integrating LiDAR scans and OSM routes. In the first stage, we introduce the novel representation, OrField, which can provide orientations for each grid on the map, reasoning jointly from noisy LiDAR scans and OSM routes. To generate a robust OrField, we train a deep neural network by encoding a versatile initial OrField and output an optimized OrField. Based on OrField, we propose two trajectory planners for OSM-guided robot navigation, called Field-RRT* and Field-Bezier, respectively, in the second stage by improving the Rapidly Exploring Random Tree (RRT) algorithm and Bezier curve to estimate the trajectories. Thanks to the robustness of OrField which captures both global and local information, Field-RRT* and Field-Bezier can generate accurate and reliable trajectories even in challenging conditions. We validate our approach through experiments on the SemanticKITTI dataset and our own campus dataset. The results demonstrate the effectiveness of our method, achieving superior performance in complex and noisy conditions. Our code for network training and real-world deployment is available at https://github.com/IMRL/OriField.
Index Terms:
Autonomous Navigation, OpenStreetMap, Trajectory Planning.I Introduction
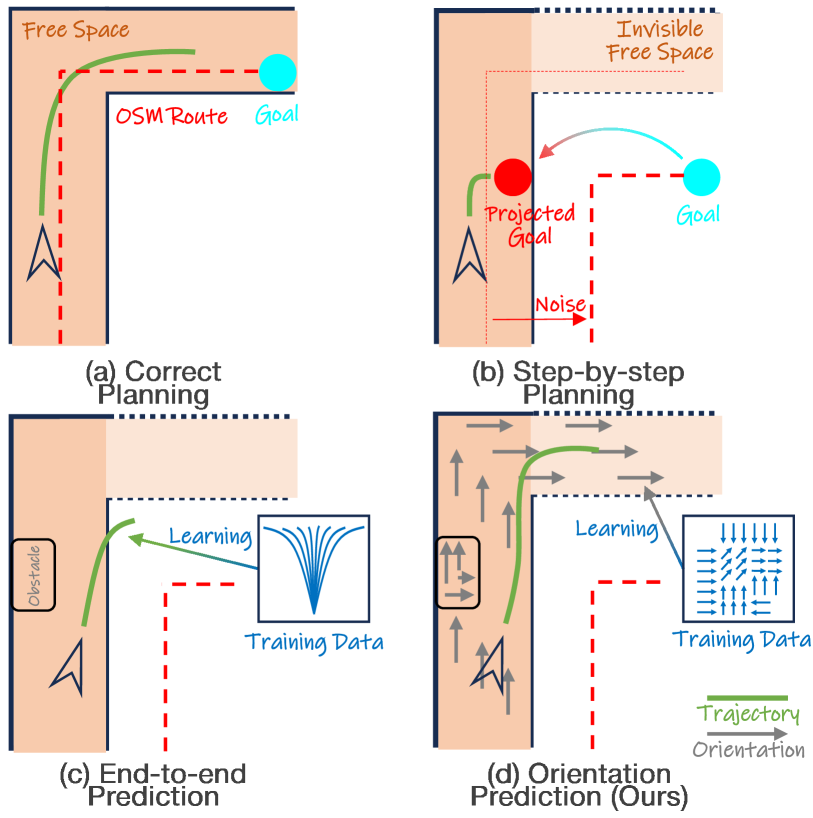
Robust trajectory planning is essential to ensure the safety of navigation systems. Most existing trajectory planning works are performed on prebuilt high-definition (HD) maps [1, 2, 3], which provide precise and detailed environmental information. However, creating and maintaining HD maps requires significant resources and effort, particularly due to frequent changes in dynamic street scenes caused by road maintenance or adverse weather. These challenges make HD-map-based trajectory planning less practical for widespread and scalable deployment.
OSM[4]-guided autonomous navigation without HD maps has gained considerable attention as a promising alternative [5, 6] due to OSM’s public accessibility and broader coverage of geographical areas. However, OSM data are inherently noisy and less detailed than HD maps, and it is crucial to establish the correspondence between OSM and local perception. To achieve this, most existing OSM-guided methods attempt to plan trajectories by leveraging additional sensors and data sources, such as LiDAR or GPS [7, 8, 9, 10]. These methods often rely on registering the OSM route or optimizing a predefined trajectory model based on current observations, such as free space estimated from LiDAR scans. For example, some works [9, 10] integrate segmentation, registration, global path planning, and local trajectory generation to enable navigation using simple OSM data. While these methods are effective when observations and OSM routes contain minimal noise (Fig. 1 (a)), they struggle under conditions of incomplete observations and noisy OSM routes, which are common due to the limited range of sensors, as depicted in Fig. 1 (b). As a result, they cannot handle corner cases, such as intersections, turns, or roads with ambiguous orientation. As a remedy, some works employ sliding windows or probability fusion to achieve comprehensive and reliable understanding by leveraging temporal information [7, 8]. However, relying on the past time steps inherently faces short-horizon problems due to limited sensor range, and the performance is constrained by the accumulation of errors over successive steps. Moreover, registration and segmentation by themselves are difficult and inaccurate.
To address the above limitations, deep learning based methods plan trajectories in an end-to-end manner [11, 12, 13], bypassing the need for explicit free space segmentation and achieving notable performance. However, these end-to-end methods rely heavily on high-quality training labels and lack scene understanding and explainability. Trained on limited data, these models inherit strong biases [14] from human driving habits and are difficult to generalize effectively beyond the scope of the training data (Fig. 1 (c)).
To overcome these challenges, we introduce a robust and explainable two-stage framework for trajectory planning, leveraging noisy OSM data for guidance. Specifically, we propose a novel representation called Orientation Field (OrField) tailored for trajectory planning based on which we can estimate the trajectory in the second stage through a trajectory planner. The key strength of OrField lies in its ability to generate a predictive field that guides the navigation of autonomous vehicles by integrating road geometry from LiDAR data and orientation preferences from OSM. To achieve this, we propose a data-driven approach with dedicated training data to encode both the initial OrField and LiDAR data. During the inference, our model takes the current LiDAR scan and OSM as input and generates a robust OrField without explicit registration and segmentation. As illustrated in Fig. 1 (d), the generated orientations (gray arrows) provide a clear and effective route even in invisible area.
Based on the estimated OrField, we propose two trajectory planners called Field-RRT* and Field-Bezier to plan the local trajectories by minimizing their deviation from the OrField (Fig. 2). This approach enhances the accuracy and robustness of generated trajectories, particularly in scenarios where traditional OSM-based methods fail. While the OrField is predicted using a data-driven method, our two-stage trajectory planning framework remains highly explainable, as it explicitly visualizes the orientations from any position on the map, even when dealing with noisy OSM data. In summary, our contributions include:
-
•
We propose a robust and explainable two-stage framework for trajectory planning with noisy OSM guidance.
-
•
We propose OrField, a novel data-driven orientation field that encodes both LiDAR observation and OSM information to provide a more comprehensive and accurate understanding of the road layout, improving the accuracy of trajectory planning.
-
•
Based on OrField, we develop two effective trajectory planners that estimate precise trajectories for autonomous navigation. Our planners excel in generating accurate paths for both straight and turning road segments, enhancing the robustness of autonomous navigation under OSM guidance.
II Related Works
II-A Trajectory Planning Using Topometric Maps
In contrast to the trajectory planning works relying on High Definition (HD) maps for autonomous driving [15, 16, 17], recent works [7, 8, 9, 18, 10] attempted to accomplish the navigation task by only relying on topometric maps. For instance, [7] utilized semantic terrain information from 3D-LiDAR data and the Markov-Chain Monte Carlo technique to align the OSM road route with the actual road center lines to obtain local navigation waypoints. However, this approach is limited by the accuracy of terrain semantic segmentation and struggles in complex road networks. [8] located the center of the road by extracting the road edges and employs RANSAC [19] to fit the local trajectory. Similarly, [18] optimized the local waypoint by extracting the center line of the road as a reference. A common limitation of these methods is their inability to effectively integrate OSM data for generating local trajectories in scenarios with ambiguous road boundaries or complex intersections. [9] improved this situation by proposing a topometric map registration algorithm that approximates the maximum posterior estimate of the registration between the vehicle and the prior map, demonstrating its feasibility on CARLA road scenes [20] with complex topologies. To further enhance localization in the road network, ALT-Pilot [10] combined LiDAR and camera cues with semantic information from OSM maps, generating local trajectories using the Frenet planner [21]. [22] focused on segmenting precise free spaces with LiDAR and camera to establish reliable local trajectory targets. Unlike these methods, which rely on complex algorithmic rules, we propose a novel data-driven representation that directly encodes both LiDAR scans and OSM data without the need for explicit registration and segmentation, significantly enhancing performance across various scenarios.
II-B Trajectory Planning via End-to-End Learning
End-to-end learning approaches have emerged as a powerful paradigm for trajectory planning in navigation, enabling models to learn directly from raw sensor inputs and generate trajectories without the need for explicit registration and segmentation. Early works utilized CNNs to model spatial and temporal dynamics [2], but these methods often failed with complex real-world scenarios such as intersections and occlusions. To address these challenges, subsequent methods incorporated attention mechanisms [23] and graph-based models [24, 25, 26] to better capture spatial-temporal dependencies. While these methods relied heavily on HDMaps for feature extraction [1, 3], Transfuser [27] and iPlanner [28] generated the path given the local target without relying on a predefined HDMap. Recently, there has been growing interest in utilizing simple map priors. Methods like multi-modal prediction [16, 15, 17, 29, 14] can be employed for this purpose as the task of trajectory prediction for the ego vehicle. [11, 12] adopted bird’s-eye-view (BEV) representations to encode navigation routes using rasterized maps. Tridentnetv2 [13] advanced these representations by integrating graphical information for route encoding. Learning from expert data with limited size and optimality, these methods converge toward sub-optimal solutions. [30] uses 60 hours of video data including trajectory information from multiple robots and environments to improve generalization. However, challenges such as generalization, explainability, and scalability persist, especially in rare or unseen conditions that have yet to be solved, which motivates us to propose a more explainable and robust framework to ensure accurate and reliable trajectory planning in complex environments.
III Methodology
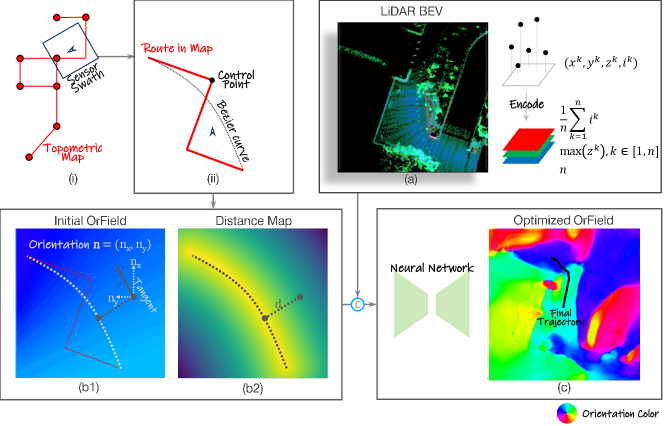
We plan the trajectory in two stages: OrField and trajectory estimation. First, we estimate the smooth initial OrField from coarse OSM directly, which is then optimized through a deep network with the aid of LiDAR scans. In the second stage, we propose field planners to estimate the local trajectories by minimizing their orientation deviation from the OrField.
III-A Initial OrField
Our OrField can provide an orientation vector at each grid of the 2D space, serving as guidance for robot navigation, shown by the orientation color on the ground in Fig. 2. The estimation starts with an initialization of the OrField. We begin by rasterizing the environment into bird’s eye view (BEV) grids. Each grid is assigned an orientation vector , where and denote the orientation components along the x- and y-axes, respectively, as illustrated in Fig. 3 (b1). The vector defines the direction in which a robot is encouraged to move within the grid, and the length quantifies the strength of the movement. A higher value of indicates a stronger preference for traversing that grid cell. In a local vicinity, the OrField can be utilized to plan a trajectory for the robot by iteratively following the suggested orientations. The OrField is thus an essential tool for guiding robot navigation over short distances, where the robot can optimize its trajectory by adhering to the directions encoded in the field.
To generate the initial OrField, we utilize the waypoints derived from the OSM’s GPS coordinates, as illustrated in Fig. 3 (i) and (ii). These waypoints are extracted from the topometric map of OSM in the sensor’s swath, and a local route can be formed by connecting these waypoints. However, these paths are generally coarse and non-smooth making the network training difficult. To facilitate the network training, we turn these routes into Bezier curves, shown as the dark dashed curves in Fig. 3 (ii), to produce a continuous and differentiable path. The endpoints of the Bezier curve coincide with the waypoints on the route and the control points are selected at the locations with the maximum offset from the auxiliary line connecting the two endpoints.
Once the Bezier curve is generated, the orientation of each grid cell in the OrField is initialized by the tangent at the closest point on the curve, as illustrated in Fig. 3 (b1). Since this OrField is derived solely from the noisy OSM coordinates and does not consider the actual free space and obstacles, it is referred to as the initial OrField. As a result, the initial OrField is inherently coarse and may lead to inaccuracies, particularly at intersections or sharp turns. Consequently, the orientation vectors in these areas are not always ideal for robot navigation. To mitigate these issues, an optimization scheme is essential for the initial OrField.
III-B Optimized OrField
To optimize the initial OrField, we propose leveraging LiDAR to help with road navigation and the avoidance of obstacles. A straightforward approach using LiDAR is to estimate the free space from current LiDAR observation, followed by the registration with the OSM routes to address the limitations of relying solely on OSM data. However, this approach still faces several challenges. Discontinuities in free space estimation, caused by occlusions or wrong segmentation, can render difficult path generation because of incorrect understanding of road structure, as shown in Fig. 1 (b). Such issues often arise when large occlusions lead to incomplete sensor observations. Additionally, the registration process is inherently complex, adding additional difficulty to the optimization pipeline. To overcome these challenges, we optimize the initial OrField using a deep neural network that can accurately model the mappings between the initial OrField and the optimized OrField.
III-B1 Training Data
The network inputs include LiDAR BEV, initial OrField, and a distance map, while the output is the optimized OrField supervised with the orientation label we generated.
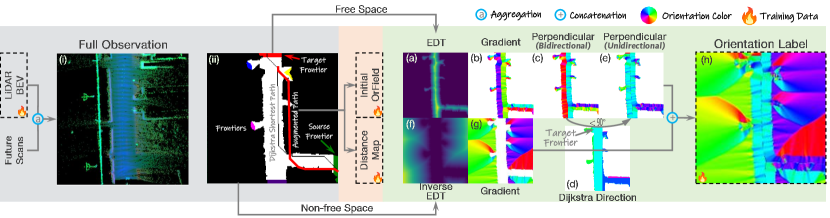
LiDAR BEV. Following [11], LiDAR measurements are represented in BEV with each grid equipped with three features: average intensity, maximum height, and number of points (Fig. 3 (a)). During inference, partial observation is utilized only comprising past and current frames because future frames are unknown. The OrField is expected to be more adhere to the actual free space even with the aid of LiDAR BEV derived from only partial observation. Thus, during the training stage, the LiDAR BEV for network input is partial observation without aggregating future frames. On the contrary, full observation of the LiDAR scans comprising past, current, and future frames is able to ensure precise free space detection, facilitating the generation of training data. Based on the full observation of scans, we generate versatile initial OrFields with distance maps and accurate orientation labels for network training, which are introduced below.
Initial OrField. We employ LiDAR segment methods to segment and extract the free space of full observations. Once the free space is identified, a pair of road frontiers is selected, representing the source and target points, as illustrated in Fig. 4 (ii). The shortest path connecting these frontiers is computed using the Dijkstra algorithm. This path is then augmented with random shifts to generate augmented path, as depicted in Fig. 4 (ii), which are subsequently transformed into Bezier curves. Finally, the initial orientation for each grid is determined by assigning the tangent vector of its closest point on the Bezier curve, as shown in Fig. 3 (b1). This process ensures the creation of high-quality initial OrFields tailored for subsequent optimization.
Distance Map. The distance map is constructed by calculating the distance from each BEV grid to the Bezier curve, as shown in Fig. 3 (b2), to represent orientation confidence within each grid. Grids closer to the Bezier curve are assigned higher confidence values. Although the distance map is derived from OSM data during inference, it provides a flexible way to rectify the OrField, allowing effectively use of the inaccurate OSM data. Unlike the binary nature of OSM data, which categorizes grid cells strictly as either on or off the route (1 or 0), the distance map offers a continuous soft mapping that enables more adaptable adjustments. The effectiveness of the distance map is shown by ablation studies in Section IV-F.
Orientation Label. The OSM is inaccurate by nature and our training target is to estimate accurate OrField to plan the driving trajectory. To achieve this, we generate orientation labels for network training based on the actual road structure. This process begins by computing the Euclidean Distance Transformation (EDT), which represents distances to the nearest road border on the free space of the full observations (Fig. 4 (a)), and the inverse EDT (Fig. 4 (f)). Next, the gradient direction of the EDT (Fig. 4 (b)) is calculated, typically pointing perpendicular to the closest road boundary. A second gradient operation is applied to derive the direction parallel to the road border (Fig. 4 (c)), though this orientation is ambiguous, as it may align with or oppose the preferred travel direction. To resolve this ambiguity, we calculate the Dijkstra direction (Fig. 4 (d)) using the Dijkstra algorithm on the free space from the target frontier. The preferred orientation is determined by ensuring its alignment with the Dijkstra path direction, validated by a positive dot product between the two vectors. For grid cells outside the free space, the negative gradient of the inverse EDT (Fig. 4 (g)) is used as the preferred orientation, encouraging movement toward the free space from obstacles. Finally, the orientations on the free space and those outside it are combined to produce the orientation label for training (Fig. 4 (h)). This approach ensures the robot’s movement aligns with the road structure while achieving obstacle avoidance and effective navigation.
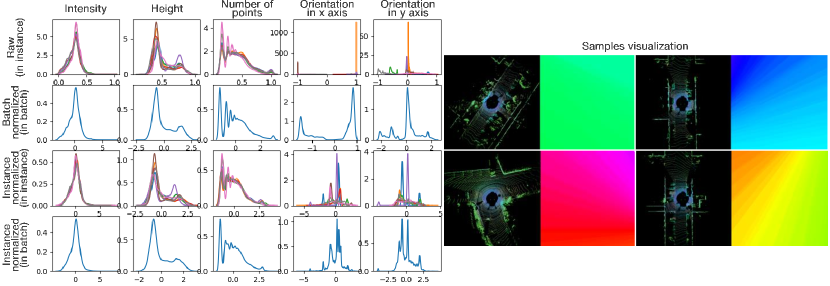
III-B2 Network Architecture
We adopt the SalsaNext architecture [31], a highly effective network for processing sparse LiDAR data using dilated convolutions [32]. While the original SalsaNext is designed to process LiDAR range data, we modify it to accept LiDAR BEV grids, the initial OrField, and the distance map as inputs, producing an optimized OrField as output. As a result, the data normalization module also needs modification. In the original SalsaNext, batch normalization stabilizes training by assuming that input features, such as normalized x, y, and z coordinates, range, and intensity, follow Gaussian-like distributions with similar mean and variance. However, our inputs, particularly orientation data, exhibit significant variability across samples, as shown in Fig. 5. This variability causes inconsistent outputs during training and a distribution shift between training and inference, which undermines generalization. To address these challenges, we use instance normalization, which normalizes each sample independently. This ensures stable distributions during training and consistent behavior between training and inference, regardless of batch size. This modification enhances the network’s robustness and adaptability to our application.
III-B3 Loss Function
We train the network by minimizing the difference between predicted and target orientations in polar coordinates. For each grid, the target orientation vector from the orientation label is converted into a corresponding angle using . Rather than directly predicting the orientation in , we train the network to predict a radian offset that adjusts the initial orientation vector from the initial OrField to the orientation label. The difference between the predicted and ground truth orientations is computed as , where is the corresponding angle of orientation vector . This normalized difference is interpreted such that values in the interval indicate increasing differences, while those in indicate decreasing differences. To map to the interval , we define when , and when . The final loss function is then given by: where is the angular difference for grid . During inference, the initial orientation vector is adjusted by the predicted offset . The predicted orientation components along the x- and y-axes are then computed as and .
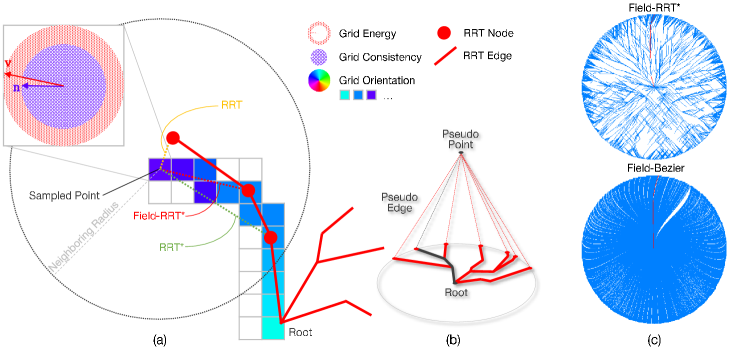
III-C Field Planner
Based on the optimized OrField, we propose two field planners, Field-RRT* and Field-Bezier, respectively, to estimate the navigation trajectory.
Field-RRT*. Our approach is based on RRT*, an extension of the RRT algorithm, which finds a path to a target point by iteratively sampling new points, expanding the tree from these points, and eventually reaching the target through the tree’s leaves. Each time sampling a point, the algorithm reconnects the edges to the neighboring nodes, ensuring that the path is progressively shortened with each iteration. However, since the neighbor points are typically identified based on Euclidean distance, the resulting path may not align well with the OrField.
To address this issue, we propose Field RRT*, where the tree is grown under the constraint of the OrField. The demostration is shown in Fig. 6 (a). Specifically, when a new point is sampled, the algorithm selects the point with the lowest energy from the root to the sampled point (linked via the red dotted line). The total energy is the sum of the energy values of all grids along the path from the tree root to the sampled point. For each grid, is the area of the red region in the unit circle (as shown in the zoom-in of the grid in Fig. 6 (a)), determined by the difference between the orientation vector (Section III-A) on that grid and the normalized orientation vector , , representing the direction of the edge crossing the grid. For the orientations optimized by our network, is equal to . We merge the orientation of each grid with its neighbors using a 2-dimensional uniform filter, producing a shortened satisfying from which the inequality holds when the orientations of neighboring grids are inconsistent. After selecting the parent, the algorithm searches for neighboring nodes and attempts to reconnect them as children, ensuring that the total energy is minimized. As shown in Fig. 6 (a), the path generated by Field RRT* better aligns with the actual orientation, resulting in a path that adheres more closely to the desired trajectory.
To mimic the RRT-like algorithms, let us assume there exists a target point, which can be virtually a pseudo target floating in the sky. Given the definition of distance from the RRT leaves to the pseudo target (as illustrated in Fig. 6 (b)), the tree grows similarly to the RRT-like algorithms which find the path with the smallest distance from the root to the target point. Different from the existing RRT-like approaches, we find a path with the smallest deviation from the predefined OrField. In this way, the path is optimized over iterations. The algorithm terminates after a predefined number of iterations.
Field-Bezier. We propose Field-Bezier by introducing driving constraints to ease trajectory planning. Specifically, a batch of Bezier curves are generated from the vehicle to the points on the circle center at the vehicle with a radius equal to a given planning distance. The orientation of the start and end points of the Bezier curve are the same as in the given field. The first and second control points of the Bezier curve are generated by moving the start point forward along its direction and moving the endpoint backward against its direction for a fixed distance, respectively. The Bezier curve is generated by the start and end points, and the two control points. The points and tangents of the generated Bezier curves are sampled at the grids that are occupied by the curve. The energy of each generated Bezier curve is calculated in a similar way to the Field-RRT* algorithm. Finally, we choose the Bezier curve with the lowest energy as the planned trajectory. The comparison between Field-RRT* and Field-Bezier is shown in Fig. 6 (c).
IV Experiments
In this section, we conduct experiments on two datasets including a public SemanticKITTI dataset [33] and one dataset collected on our campus. We select the latest end-to-end trajectory prediction work using topometric map [11] as the end-to-end baseline and a segmentation-based method that plans trajectories based on segmented free space [34] as segmentation baseline. The evaluation includes frame level and trajectory level. At the frame level, metrics are designed to compare the differences between the planned trajectory and the ground truth trajectory frame-by-frame. At the trajectory level, all the planned trajectories from each frame are temporally aggregated, and the quality of the aggregated trajectory is accessed. To comprehensively evaluate performance in real-world scenarios, we deployed both the end-to-end baseline and ours on a ground vehicle equipped with an Intel NUC 11 computer. The assessment involves comparing the number of manual interventions if required and the deviation between the vehicle’s trajectory and the road centerline, which is defined and recorded by manual driving routes.
IV-A Metrics
At the frame level, we use the widely used metrics, ADE, FDE, and HitRate, for evaluating trajectory planning performance. The Average Displacement Error (ADE) measures the average difference between the planned trajectory and the ground truth trajectory generated from ground truth poses in datasets. It is defined as , where and are the sampled points in the ground truth trajectory and planned trajectory. The Final Displacement Error (FDE) depicts the position difference between the last sampled points in the ground truth and the planned trajectory, respectively. It is defined as . The last sampled point can be used as the goal for local planning. The HitRate [17] is defined as whether the planned trajectory is hit. A hit happens if where is a distance threshold. In addition, we measure the Coverage of the planned trajectory, defined as , which is a ”soft” HitRate describing the average hit over all sampled points along the trajectory. The sampling method is shown in Fig. 7 (a). Different sampling radii are used for comprehensive evaluations on trajectory performance. Finally, we compute the average of all these metrics over the entire trajectory.
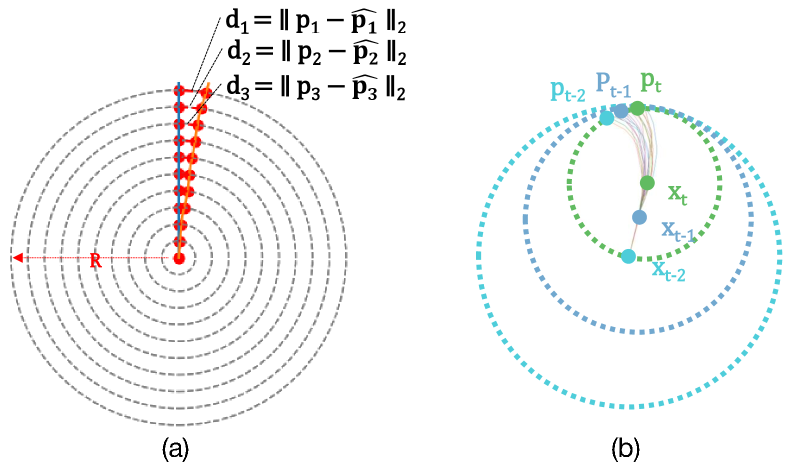
At the trajectory level, the planned trajectory is temporally fused, as shown in Fig. 7 (b). , , and are the positions of the past two time steps and the current time step, respectively. Each time step provides a planned trajectory with a waypoint, i.e., , , , to the same distance head . We fuse these predictions according to a prior prediction variance (empirical setting) and obtain the fused waypoint for . We later plot the fused waypoints of all the time steps and generate the entire planned trajectory over the scene for visualization.
| Seq | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADE | FDE | HitRate | Coverage | |||||||||||||
| 08 | 0.65 | 0.27 | 0.25 | 0.21 | 0.97 | 0.44 | 0.51 | 0.39 | 0.91 | 0.82 | 0.96 | 0.96 | 0.94 | 0.95 | 0.98 | 0.98 |
| 13 | 1.08 | 0.29 | 0.27 | 0.24 | 1.84 | 0.52 | 0.52 | 0.46 | 0.83 | 0.79 | 0.96 | 0.95 | 0.88 | 0.94 | 0.97 | 0.98 |
| 15 | 0.55 | 0.29 | 0.26 | 0.22 | 0.82 | 0.49 | 0.47 | 0.39 | 0.95 | 0.81 | 1.00 | 0.98 | 0.97 | 0.96 | 1.00 | 0.99 |
| 16 | 0.56 | 0.21 | 0.21 | 0.19 | 0.91 | 0.31 | 0.46 | 0.37 | 0.89 | 0.82 | 0.98 | 0.97 | 0.93 | 0.96 | 0.99 | 0.99 |
| 18 | 0.52 | 0.14 | 0.16 | 0.13 | 0.64 | 0.20 | 0.42 | 0.26 | 0.97 | 0.88 | 1.00 | 1.00 | 0.99 | 0.98 | 1.00 | 1.00 |
| 19 | 0.94 | 0.27 | 0.27 | 0.21 | 1.22 | 0.51 | 0.53 | 0.43 | 0.73 | 0.80 | 0.96 | 0.96 | 0.88 | 0.95 | 0.98 | 0.98 |
| ADE | FDE | HitRate | Coverage | |||||||||||||
| 08 | 0.88 | 0.53 | 0.44 | 0.41 | 1.29 | 1.16 | 0.89 | 0.87 | 0.85 | 0.81 | 0.85 | 0.87 | 0.91 | 0.93 | 0.95 | 0.95 |
| 13 | 1.78 | 0.70 | 0.44 | 0.43 | 3.10 | 1.76 | 0.81 | 0.81 | 0.73 | 0.77 | 0.89 | 0.90 | 0.83 | 0.91 | 0.95 | 0.95 |
| 15 | 0.80 | 0.57 | 0.44 | 0.37 | 1.42 | 1.20 | 0.89 | 0.73 | 0.87 | 0.80 | 0.90 | 0.92 | 0.94 | 0.93 | 0.98 | 0.97 |
| 16 | 0.79 | 0.37 | 0.37 | 0.36 | 1.13 | 0.76 | 0.67 | 0.67 | 0.81 | 0.84 | 0.91 | 0.93 | 0.90 | 0.96 | 0.97 | 0.97 |
| 18 | 0.64 | 0.24 | 0.38 | 0.30 | 0.93 | 0.51 | 0.89 | 0.67 | 0.94 | 0.91 | 0.94 | 0.98 | 0.98 | 0.99 | 0.99 | 0.99 |
| 19 | 1.15 | 0.70 | 0.45 | 0.42 | 1.67 | 1.79 | 0.80 | 0.81 | 0.64 | 0.76 | 0.88 | 0.91 | 0.84 | 0.91 | 0.95 | 0.96 |
IV-B Results on SemanticKITTI
SemanticKITTI [33] and KITTI [35] are popular datasets for validating robotics and autonomous driving systems. Both datasets include LiDAR scans collected using the Velodyne-HDLE64 LiDAR. SemanticKITTI provides 22 sequences with semantic labels for each LiDAR point, with labels publicly available for sequences 00-10. We utilize KITTI for model training following [11] and evaluate performance in SemanticKITTI sequences. Both SemanticKITTI and KITTI include the ground truth poses, enabling the generation of ground truth trajectories for evaluation and straightforward implementation of relative pose estimation for point cloud aggregation. The step size, neighbor radius, and number of iterations of Field-RRT* are set to 1 m, 2 m, and 1000, respectively. The RRT tree is down-sampled half along the x- and y-axis for fast running.
To train our model, no OSM routes or manual driving trajectories are provided for supervision. The free space for training is estimated by the LiDAR segmentation method [31]. We compare our method with the two baselines. To train the end-to-end baseline model, authors in [11] obtained OSM routes from the OSM website as input and ground-truth driving trajectories from the dataset collected by manual driving as supervision. We directly obtain the checkpoint released by the authors. The segmentation baseline uses the free space estimated by the same method used for generating training samples for our model. Five SemanticKITTI sequences (sequences 08, 13, 15, 16, 18, and 19) are used for testing as they are in complex road topologies. For evaluation, the OSM routes are downloaded from the OSM website and registered with the ground-truth driving trajectories. During inference, these OSM routes are converted into initial OrField (Section III-A) for network input.
Table I presents the quantitative results, where the Field-RRT* and Field-Bezier planners based on the learned OrField outperform the others in most sequences. However, the end-to-end baseline achieves better for metric in distance error, i.e., ADE and FDE, when evaluate at meters in sequence 18 and evaluated at meters in sequences 16 and 18. This is because the end-to-end baseline trained the network overfits smooth driving, while sequences 16 and 18 are the two smooth driving sequences with the least frames categorized as sharp turns. This alignment between training and evaluation conditions results in stronger performance. Nonetheless, in real-world scenarios, where conditions are more diverse, an overfitted predictor may fail to generalize effectively.
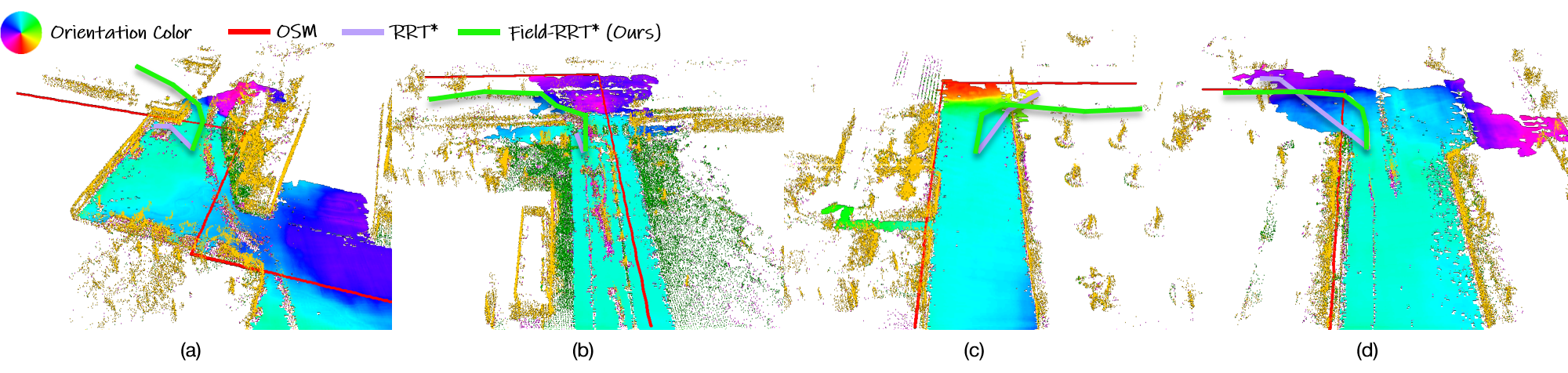
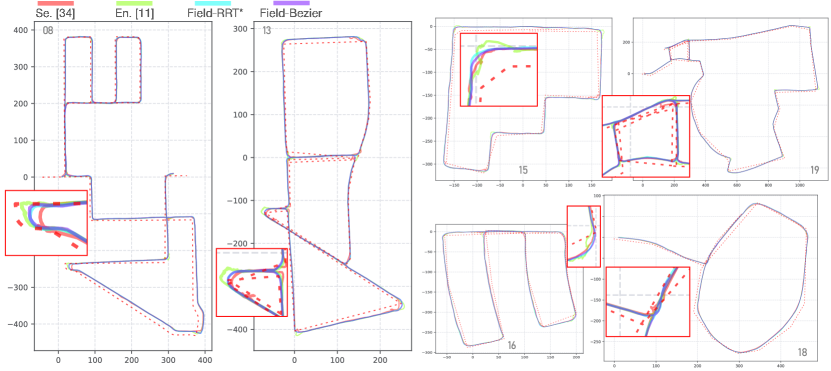
The qualitative comparison is shown in Fig. 8. The plotted trajectories are generated by fusing outputs from each time step, based on past frames. We observe that the end-to-end baseline trained with OSM guidance, as well as the segmentation baseline relying on heuristic designs, does not perform well in complex scenarios (especially at turns), as shown in the zoom-in at each sequence of Fig. 8. In contrast, our method with Field-RRT* and Field-Bezier planners demonstrates superior understanding in both straight-road and intersection scenarios, thanks to unbiased training and independent trajectory planning. Notably, despite our network being trained without exposure to the realistic OSM route, i.e., the extent and structure of OSM routes are unknown during training, it generalizes effectively to real-world applications.
| Seq | RRT. | Bez. | RRT. | Bez. | RRT. | Bez. |
|---|---|---|---|---|---|---|
| ADE | FDE | HitRate | ||||
| 08 | 0.31 | 0.26 | 0.58 | 0.53 | 0.93 | 0.95 |
| 13 | 0.28 | 0.27 | 0.53 | 0.51 | 0.97 | 0.98 |
| 15 | 0.39 | 0.29 | 0.73 | 0.52 | 0.95 | 0.99 |
| 16 | 0.29 | 0.26 | 0.52 | 0.55 | 0.97 | 0.99 |
| 18 | 0.36 | 0.27 | 0.80 | 0.56 | 0.95 | 1.00 |
| 19 | 0.38 | 0.34 | 0.69 | 0.72 | 0.92 | 0.95 |
| ADE | FDE | HitRate | ||||
| 08 | 0.96 | 0.97 | 2.07 | 2.21 | 0.55 | 0.54 |
| 13 | 0.97 | 0.95 | 1.75 | 1.82 | 0.60 | 0.65 |
| 15 | 0.60 | 0.65 | 1.41 | 1.44 | 0.74 | 0.73 |
| 16 | 0.67 | 0.70 | 1.20 | 1.12 | 0.69 | 0.75 |
| 18 | 0.62 | 0.63 | 1.82 | 1.86 | 0.81 | 0.88 |
| 19 | 0.84 | 0.83 | 1.43 | 1.26 | 0.66 | 0.65 |
IV-C Field-RRT* versus Field-Bezier
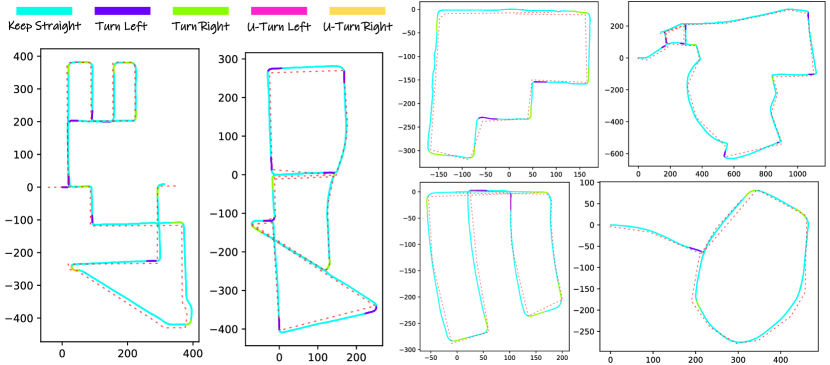
From Table I, we see that Field-Bezier outperforms Field-RRT* for most metrics in most sequences. This observation motivates us to investigate the benefits of the behavior priors introduced by the trajectory planner. Field-RRT* imposes no prior knowledge, estimating trajectories purely based on orientations, whereas Field-Beier enforces strong constraints, restricting trajectories to Bezier curves. To analyze whether incorporating behavior priors benefits trajectory estimation, we classify the frames into ”keep-straight” or ”turn” scenarios by examining the direction suggested by the OSM trajectory, as depicted in Fig. 9. The majority of the frames correspond to keep-straight, while turns are required at specific intersections. We evaluate the performance for these two scenarios separately to verify the strengths of the methods under different conditions. The evaluation results (Table II) reveal that Field-Beier performs better in straight-line scenarios, while Field-RRT* excels during turns. Since the metrics for turns reflect the ability to make correct road choices at intersections, we conclude that our method with Field-RRT* planner is more advantageous for robot navigation as it prioritizes successful traversal through intersections.
IV-D Results on Campus Dataset
We created a campus dataset consisting of five scenes (scenes 1, 2, 3, 4, and 5) for both offline and online testing. The dataset includes LiDAR scans captured at Hz using a Livox Mid-360 LiDAR. Compared to the Velodyne HDL-64, this LiDAR produces significantly lower point density with shorter sensor range, making trajectory planning more challenging. The ground truth poses are estimated by the SLAM algorithms [36, 37, 38, 39]. To accommodate the new dataset, the step size, neighbor radius, and number of iterations of Field-RRT* are set to 0.75 m, 1.5 m, and 1000, respectively. The RRT tree is down-sampled half along the x- and y-axis for fast running.
| Seq | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. | Se.[34] | En.[11] | RRT. | Bez. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADE | FDE | HitRate | Coverage | |||||||||||||
| scene 3 | 2.52 | 0.69 | 0.56 | 0.58 | 3.98 | 1.42 | 0.90 | 0.95 | 0.27 | 0.77 | 0.91 | 0.83 | 0.50 | 0.90 | 0.96 | 0.91 |
| scene 4 | 1.91 | 1.15 | 1.25 | 0.94 | 2.87 | 2.33 | 1.91 | 1.65 | 0.40 | 0.63 | 0.64 | 0.68 | 0.61 | 0.79 | 0.80 | 0.83 |
| scene 5 | 2.18 | 0.91 | 0.78 | 0.63 | 3.39 | 1.93 | 1.19 | 1.05 | 0.31 | 0.67 | 0.79 | 0.77 | 0.57 | 0.83 | 0.91 | 0.90 |
| ADE | FDE | HitRate | Coverage | |||||||||||||
| scene 3 | 3.11 | 1.06 | 0.71 | 0.74 | 5.04 | 2.51 | 1.33 | 1.45 | 0.19 | 0.65 | 0.80 | 0.73 | 0.43 | 0.84 | 0.93 | 0.89 |
| scene 4 | 2.32 | 1.77 | 1.52 | 1.25 | 3.77 | 3.82 | 2.39 | 2.26 | 0.31 | 0.51 | 0.50 | 0.56 | 0.56 | 0.71 | 0.73 | 0.77 |
| scene 5 | 2.86 | 1.45 | 0.99 | 0.88 | 5.15 | 3.13 | 1.77 | 1.86 | 0.20 | 0.53 | 0.64 | 0.65 | 0.49 | 0.74 | 0.84 | 0.85 |
Offline Testing. The experiment settings of offline testing are similar to the previous experiment on SemanticKITTI. Scenes 1 and 2 are used for training while the rest scenes are used for testing. To train our model, no OSM routes or manual driving trajectories are provided for supervision. The free space for training is estimated by a random forest classifier trained by LiDAR points from frames. To train the end-to-end baseline model, we obtained OSM routes from the OSM website as input and ground-truth driving trajectories collected by manual driving as supervision. The segmentation baseline uses the free space estimated by the same method used for generating training samples for our model. For evaluation, the OSM routes are downloaded from the OSM website and registered with the ground-truth driving trajectories. During inference, these OSM routes are converted into initial OrField (Section III-A) for network input. The results are shown in Table III from which we see that our method achieves supreme performance again across all the testing scenes for all the testing metrics. This shows that our method is also robust to low-density data and short sensor range.
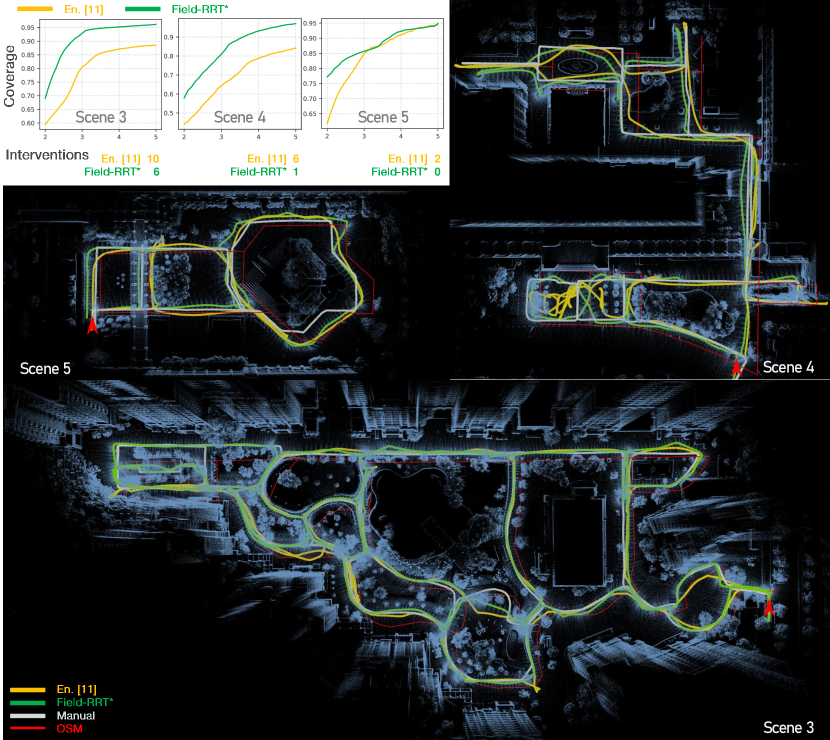
Online Testing. To evaluate the methods in real-world applications, we conduct online experiments where trained models are tested on live data in scenes 3, 4, and 5, which cover large, medium, and small areas, respectively, as shown in Fig. 10. The experiments are conducted on campus using a ground vehicle equipped with an Intel NUC 11 computer. To assess online performance, we calculate the Coverage after the vehicle automatically traverses a scene and returns to the starting position. Specifically, we at first manually control the vehicle to perfectly traverse the scene and record the driving trajectory. By removing the trajectory points that duplicate in their nearby, we get a collection that contains the trajectory points defining the area covered by OSM routes. For each point in the collection, we define it as covered if the traversal trajectory of the automatic vehicle intersects the circle centered at the point with a radius of meters. Then we calculate the Coverage as the ratio of the number of the covered points to the number of all the points in the collection. Besides, we introduce a metric called Intervention, defined as the number of manual interventions required during the vehicle traversal. An intervention occurs when the vehicle fails during navigation and must be manually steered onto the correct track. Failures include getting stuck in road ditches or choosing infeasible branches at intersections when following the OSM trajectory, preventing successful navigation. The experiments were carried out three times for each scene at three different starting positions. For calculating Coverage, we set from meters to meters every meter and plot the result for each . The results of average Coverage and Interventions are shown in Fig. 10. Our method demonstrates fewer interventions and achieves a larger coverage of the target area compared to the end-to-end baseline [11]. This is mainly because our approach excels in selecting the correct branches at intersections, even when the OSM routes significantly deviate from actual roads. Additionally, our method can execute turnarounds after encountering dead ends while following OSM routes. In contrast, the baseline struggles with turnarounds due to the absence of such behavior in its supervision. Furthermore, the baseline tends to predict smooth trajectories extrapolated from previous vehicle poses, which are often inconsistent with the precise trajectories required in narrow lanes. Figure 10 visualizes the trajectories and maps of the evaluated scenes, showcasing the advantages of our approach in real-world scenarios.
IV-E Ablation Studies for Orientations
In this section, we do ablation studies to confirm the best one among different OrFields including those derived before and after optimization by our deep network. Meanwhile, we investigate the superiority of planning with orientation representation over the binary free space representation without the orientation information.
Before Network Optimization. The OrFields before optimization by our deep network are categorized into two types based on whether they incorporate sensor information. For the OrFields incorporating sensor information, we estimate the free space using environmental data collected from onboard sensors. Based on this free space estimation, orientations are calculated using the Dijkstra algorithm from the local target point, referred to as Dijkstra. Section III-B1 introduces how orientations for training samples are generated by operating on the gradient of the free space. Using the same method, orientations are calculated here and denoted as Gradient. To highlight the importance of future frames, we aggregate them with the past and current frames to estimate free space. Orientations are then generated using the Dijkstra and Gradient methods, denoted as Dijkstra-Full and Gradient-Full, respectively. These OrFields, which leverage future frames, are unavailable during real-world deployment. Thus, they serve as a reference upper bound for the performance of OrFields without deep network optimization.
Another approach is to estimate orientations solely based on OSM routes, without incorporating sensor information. For this, the orientation of a grid is assigned as the tangent of its nearest OSM route edge, calculated from the OSM topology. We denote this method as Nearest. Additionally, the initial OrField for network input in Section III-A, referred to as InitialOrField, is a smoothed version of orientations derived from the OSM topology.
Table IV highlights several findings: 1. The improvement of Gradient (Gr.) over Dijkstra (Di.) demonstrates the validity of calculating orientations from gradient directions, as discussed in Section III-B1. 2. Aggregating future frames reduces the loss of surrounding information. The improvement from Gradient (Gr.) to Gradient-Full (Gr.′) illustrates this point and emphasizes the importance of full observations in trajectory planning. This further supports the rationale for designing a network to estimate orientations from partial observations. 3. Meanwhile, the underperformance of Nearest (Ne.) and InitialOrField (IOr.) shows the necessity of optimization on the orientations derived solely from OSM routes with the existence of noise.
| Point | Field | |||||||||
| Before Opt. | After Opt. | |||||||||
| RRT* | RRT. | Bez. | ||||||||
| Seq | Mo. | Di. | Di.′ | Gr. | Gr.′ | Ne. | IOr. | FS-DOr. | DOr. | DOr. |
| ADE | ||||||||||
| 08 | 0.53 | 0.89 | 0.95 | 0.65 | 0.52 | 0.61 | 0.62 | 0.26 | 0.25 | 0.21 |
| 13 | 0.93 | 1.35 | 1.15 | 0.97 | 0.61 | 0.57 | 0.79 | 0.26 | 0.27 | 0.24 |
| 15 | 0.42 | 0.71 | 0.77 | 0.56 | 0.51 | 0.61 | 0.81 | 0.30 | 0.26 | 0.22 |
| 16 | 0.50 | 1.05 | 1.11 | 0.67 | 0.34 | 0.48 | 0.55 | 0.21 | 0.21 | 0.19 |
| 18 | 0.41 | 0.65 | 0.72 | 0.67 | 0.56 | 0.59 | 0.32 | 0.19 | 0.16 | 0.13 |
| 19 | 0.53 | 1.13 | 1.14 | 0.69 | 0.61 | 0.90 | 0.72 | 0.31 | 0.27 | 0.21 |
| ADE | ||||||||||
| 08 | 0.98 | 1.11 | 1.20 | 0.86 | 0.79 | 1.10 | 1.19 | 0.49 | 0.44 | 0.41 |
| 13 | 1.69 | 1.89 | 1.47 | 1.52 | 0.89 | 1.07 | 1.58 | 0.50 | 0.44 | 0.43 |
| 15 | 0.74 | 0.84 | 0.96 | 0.76 | 0.84 | 1.12 | 1.60 | 0.57 | 0.44 | 0.37 |
| 16 | 0.96 | 1.23 | 1.33 | 0.76 | 0.49 | 0.91 | 1.11 | 0.40 | 0.37 | 0.36 |
| 18 | 0.81 | 0.88 | 0.81 | 0.98 | 0.78 | 1.13 | 0.71 | 0.46 | 0.38 | 0.30 |
| 19 | 1.10 | 1.35 | 1.39 | 0.87 | 0.81 | 1.73 | 1.40 | 0.53 | 0.45 | 0.42 |
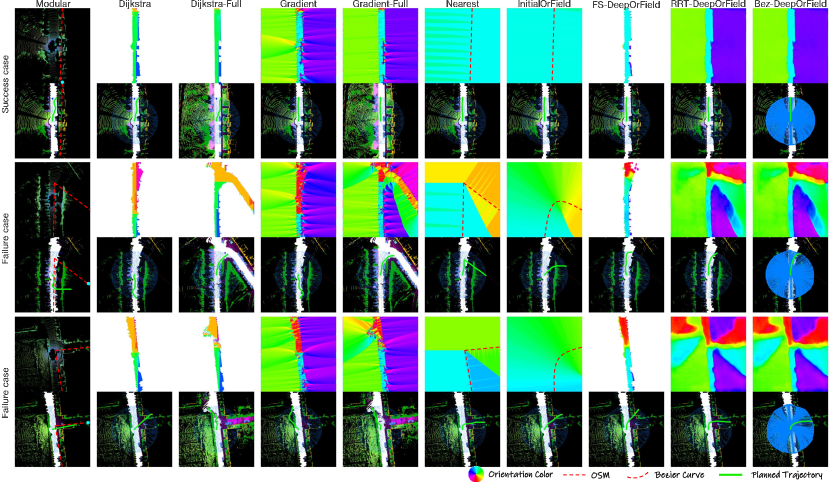
OrField After Network Optimization. Following the evaluation of heuristically designed OrFields without network optimization, we analyze the performance of OrFields after optimization by our deep network, referred to as DeepOrField. If free space information is available, it can be integrated into DeepOrField by setting the orientation length in non-free space areas to zero, thereby discouraging traversal in those regions. This variant is denoted as FS-DeepOrField.
Table IV shows a clear performance gap between the orientations before and after optimization, demonstrating the effectiveness of our deep network. When comparing the optimized orientations, the integration of occupancy information in FS-DeepOrField (FS-DOr.) resulted in a degraded performance in most sequences compared to using all orientations from the network in DeepOrField (DOr.). This indicates our deep network provides valuable orientation information not only in the free space but also in the obstacle and unobserved area. Our optimized orientations are more accurate than the ”oracle” one Gradient-Full (Gr.′) which sees the future frames.
Point Planner versus Field Planner. The point planner is a traditional RRT* planner that approaches a target point by expanding an exploration tree following the estimation of the free space and the selection of the local target in a step-by-step manner akin to [7, 8], denoted as Modular. Instead, our field planner expands the tree constrained by the orientations along the edge. We demonstrate the superiority of our field planner over the point planner by comparison.
The results are shown in Table IV from which we see that compared to the point planner (Mo.), our field planner (Gr.) which incorporates constraints on orientation achieves better performance when evaluated at distances of meters ahead. This aligns with the findings of previous studies [9, 10], which optimized trajectories using the Euclidean Distance Transform (EDT) to encourage paths that align with the road centerline. Meanwhile, this indicates that the field planner outperforms the traditional point planner in scenarios requiring planning over longer distances which are more susceptible to occlusion, encouraging us to design a network to estimate more accurate orientations both within and beyond the sensor range.
Based on these ablation studies, we conclude that our method significantly enhances orientation accuracy, even under partial observations and noisy OSM data. Examples of both successful and failure cases are illustrated in Fig. 11.
| Full | -Distance | -Init | Full | -Distance | -Init | |
|---|---|---|---|---|---|---|
| Seq | RRT. | Bez. | ||||
| ADE | ||||||
| 08 | 0.25 | 0.26 | 0.32 | 0.21 | 0.21 | 0.26 |
| 13 | 0.27 | 0.27 | 0.27 | 0.24 | 0.24 | 0.24 |
| 15 | 0.26 | 0.24 | 0.29 | 0.22 | 0.22 | 0.27 |
| 16 | 0.21 | 0.19 | 0.24 | 0.19 | 0.19 | 0.20 |
| 18 | 0.16 | 0.18 | 0.32 | 0.13 | 0.18 | 0.32 |
| 19 | 0.27 | 0.31 | 0.38 | 0.21 | 0.22 | 0.26 |
| ADE | ||||||
| 08 | 0.44 | 0.47 | 0.67 | 0.41 | 0.43 | 0.62 |
| 13 | 0.44 | 0.46 | 0.52 | 0.43 | 0.46 | 0.49 |
| 15 | 0.44 | 0.42 | 0.67 | 0.37 | 0.36 | 0.61 |
| 16 | 0.37 | 0.35 | 0.47 | 0.36 | 0.37 | 0.41 |
| 18 | 0.38 | 0.44 | 0.82 | 0.30 | 0.38 | 0.79 |
| 19 | 0.45 | 0.48 | 0.68 | 0.42 | 0.44 | 0.59 |
IV-F Ablation Studies for Network Inputs
The inputs for the network consist of the LiDAR BEV, initial OrField, and distance map. To investigate the best chosen for the network inputs, we do ablation studies by removing the distance map and initial OrField, respectively. The network loses the position information about the OSM route without the distance map, while the network loses the orientation information about the OSM route without the initial OrField. The ablation results are shown in Table V from which we can see a clear improvement when using the initial OrField as network input. Although the distance map is enough to prompt the underlying direction for navigation, it is difficult to decide when the OSM route renders large uncertainties. Besides, the improvement when using the distance map, especially in sequences 08, 13, and 19 of large scale, indicates the usefulness of incorporating it because provides the confidence of position of the OSM route.
IV-G Robustness Analysis
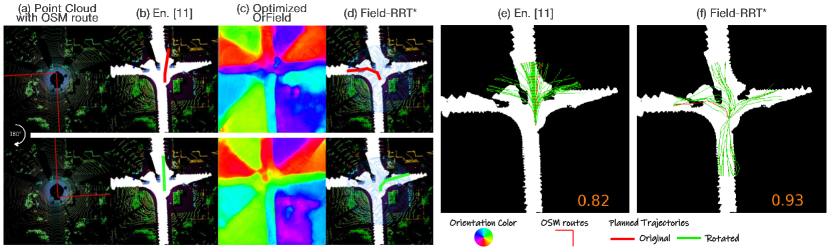
We analyze the robustness of our method that plans with OrField compared with the end-to-end trajectory planning method in different cases at the same intersection. Specifically, we generate different cases by rotating the OSM route from to degree every degree at a typical 4-branches intersection. In this way, cases are generated, in which OSM routes lead to different branches. An example of an original OSM route and the one rotated by degree are shown in the first and second rows of Fig. 12 (a), respectively. The paths planned by the end-to-end baseline [11] method are shown in Fig. 12 (b). We can see that the baseline predicts forward paths, while the OSM route indicates a left turn and a right turn. Instead, our method plans the correct path, as shown in Fig. 12 (d). For evaluation, we collect all the planned paths in all the cases with different rotated angles and plot them in Fig. 12 (e) and (f). We find the paths most forward for the baseline and are separated into different branches for our method. This means that the distribution of paths planned by our method goes beyond the biased distribution learned from manual driving. We calculate the percentage of the points of planned paths lying in the free space. As shown in Fig. 12 (e) and (f), the baseline plans many paths across the obstacles and only planned points lying in free space, while our method plans most paths lying in the free space and achieves . We find similar conclusions in other intersections.
V Conclusion
In this paper, we propose a novel representation for navigation, named Orientation Field (OrField). We demonstrate the superiority of OrField while using it as a constraint for trajectory planning. To optimize the OrField jointly from LiDAR scans and OSM route, we propose a deep learning network to optimize the initial OrField solely derived from OSM route. Combined with the optimized OrField, Field Planners are proposed to find the best path. Experiments show the superiority of our optimized OrField compared with step-by-step ways to generate trajectory and the previous end-to-end work that predicts the waypoints. Ablations show the effectiveness of our deep network to optimize the OrField compared with generating OrField in rule-based ways.
References
- [1] Z. Bao, S. Hossain, H. Lang, and X. Lin, “A review of high-definition map creation methods for autonomous driving,” Engineering Applications of Artificial Intelligence, vol. 122, p. 106125, 2023.
- [2] W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 8660–8669.
- [3] A. Sadat, S. Casas, M. Ren, X. Wu, P. Dhawan, and R. Urtasun, “Perceive, predict, and plan: Safe motion planning through interpretable semantic representations,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIII 16. Springer, 2020, pp. 414–430.
- [4] M. Haklay and P. Weber, “Openstreetmap: User-generated street maps,” IEEE Pervasive computing, vol. 7, no. 4, pp. 12–18, 2008.
- [5] M. Hentschel and B. Wagner, “Autonomous robot navigation based on openstreetmap geodata,” in 13th International IEEE Conference on Intelligent Transportation Systems. IEEE, 2010, pp. 1645–1650.
- [6] G. Floros, B. Van Der Zander, and B. Leibe, “Openstreetslam: Global vehicle localization using openstreetmaps,” in 2013 IEEE international conference on robotics and automation. IEEE, 2013, pp. 1054–1059.
- [7] B. Suger and W. Burgard, “Global outer-urban navigation with openstreetmap,” in 2017 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2017, pp. 1417–1422.
- [8] T. Ort, L. Paull, and D. Rus, “Autonomous vehicle navigation in rural environments without detailed prior maps,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 2040–2047.
- [9] T. Ort, K. Murthy, R. Banerjee, S. K. Gottipati, D. Bhatt, I. Gilitschenski, L. Paull, and D. Rus, “Maplite: Autonomous intersection navigation without a detailed prior map,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 556–563, 2019.
- [10] M. Omama, P. Inani, P. Paul, S. C. Yellapragada, K. M. Jatavallabhula, S. Chinchali, and M. Krishna, “Alt-pilot: Autonomous navigation with language augmented topometric maps,” arXiv preprint arXiv:2310.02324, 2023.
- [11] J. Xu, L. Xiao, D. Zhao, Y. Nie, and B. Dai, “Trajectory prediction for autonomous driving with topometric map,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8403–8408.
- [12] D. Paz, H. Zhang, and H. I. Christensen, “Tridentnet: A conditional generative model for dynamic trajectory generation,” in International Conference on Intelligent Autonomous Systems. Springer, 2021, pp. 403–416.
- [13] D. Paz, H. Xiang, A. Liang, and H. I. Christensen, “Tridentnetv2: Lightweight graphical global plan representations for dynamic trajectory generation,” in 2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 9265–9271.
- [14] K. Guo, W. Liu, and J. Pan, “End-to-end trajectory distribution prediction based on occupancy grid maps,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 2242–2251.
- [15] H. Cui, V. Radosavljevic, F.-C. Chou, T.-H. Lin, T. Nguyen, T.-K. Huang, J. Schneider, and N. Djuric, “Multimodal trajectory predictions for autonomous driving using deep convolutional networks,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 2090–2096.
- [16] Y. Chai, B. Sapp, M. Bansal, and D. Anguelov, “Multipath: Multiple probabilistic anchor trajectory hypotheses for behavior prediction,” arXiv preprint arXiv:1910.05449, 2019.
- [17] T. Phan-Minh, E. C. Grigore, F. A. Boulton, O. Beijbom, and E. M. Wolff, “Covernet: Multimodal behavior prediction using trajectory sets,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 14 074–14 083.
- [18] J. Li, H. Qin, J. Wang, and J. Li, “Openstreetmap-based autonomous navigation for the four wheel-legged robot via 3d-lidar and ccd camera,” IEEE Transactions on Industrial Electronics, vol. 69, no. 3, pp. 2708–2717, 2021.
- [19] R. C. Bolles and M. A. Fischler, “A ransac-based approach to model fitting and its application to finding cylinders in range data.” in IJCAI, vol. 1981, 1981, pp. 637–643.
- [20] A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V. Koltun, “Carla: An open urban driving simulator,” in Conference on robot learning. PMLR, 2017, pp. 1–16.
- [21] M. Werling, J. Ziegler, S. Kammel, and S. Thrun, “Optimal trajectory generation for dynamic street scenarios in a frenet frame,” in 2010 IEEE international conference on robotics and automation. IEEE, 2010, pp. 987–993.
- [22] K. Tsiakas, D. Alexiou, D. Giakoumis, A. Gasteratos, and D. Tzovaras, “Leveraging multimodal sensing and topometric mapping for human-like autonomous navigation in complex environments,” in 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 7415–7421.
- [23] J. Gu, C. Hu, T. Zhang, X. Chen, Y. Wang, Y. Wang, and H. Zhao, “Vip3d: End-to-end visual trajectory prediction via 3d agent queries,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 5496–5506.
- [24] H. Zhao, J. Gao, T. Lan, C. Sun, B. Sapp, B. Varadarajan, Y. Shen, Y. Shen, Y. Chai, C. Schmid et al., “Tnt: Target-driven trajectory prediction,” in Conference on Robot Learning. PMLR, 2021, pp. 895–904.
- [25] J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory prediction from dense goal sets,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 15 303–15 312.
- [26] M. Liu, H. Cheng, L. Chen, H. Broszio, J. Li, R. Zhao, M. Sester, and M. Y. Yang, “Laformer: Trajectory prediction for autonomous driving with lane-aware scene constraints,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 2039–2049.
- [27] K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for autonomous driving,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022.
- [28] F. Yang, C. Wang, C. Cadena, and M. Hutter, “iplanner: Imperative path planning,” arXiv preprint arXiv:2302.11434, 2023.
- [29] N. Deo and M. M. Trivedi, “Trajectory forecasts in unknown environments conditioned on grid-based plans,” arXiv preprint arXiv:2001.00735, 2020.
- [30] D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine, “Gnm: A general navigation model to drive any robot,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 7226–7233.
- [31] T. Cortinhal, G. Tzelepis, and E. Erdal Aksoy, “Salsanext: Fast, uncertainty-aware semantic segmentation of lidar point clouds,” in Advances in Visual Computing: 15th International Symposium, ISVC 2020, San Diego, CA, USA, October 5–7, 2020, Proceedings, Part II 15. Springer, 2020, pp. 207–222.
- [32] F. Yu and V. Koltun, “Multi-scale context aggregation by dilated convolutions,” in ICLR, 2016.
- [33] J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “Semantickitti: A dataset for semantic scene understanding of lidar sequences,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9297–9307.
- [34] W. Gao, Z. Sun, M. Zhao, C.-Z. Xu, and H. Kong, “Active loop closure for osm-guided robotic mapping in large-scale urban environments,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 302–12 309.
- [35] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in 2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354–3361.
- [36] W. Xu and F. Zhang, “Fast-lio: A fast, robust lidar-inertial odometry package by tightly-coupled iterated kalman filter,” IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 3317–3324, 2021.
- [37] W. Xu, Y. Cai, D. He, J. Lin, and F. Zhang, “Fast-lio2: Fast direct lidar-inertial odometry,” IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2053–2073, 2022.
- [38] F. Dellaert and G. Contributors, “borglab/gtsam,” May 2022. [Online]. Available: https://github.com/borglab/gtsam)
- [39] G. Kim and A. Kim, “Scan context: Egocentric spatial descriptor for place recognition within 3d point cloud map,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 4802–4809.