Learning Many-to-Many Mapping for Unpaired Real-World Image Super-resolution and Downscaling
Abstract
Learning based single image super-resolution (SISR) for real-world images has been an active research topic yet a challenging task, due to the lack of paired low-resolution (LR) and high-resolution (HR) training images. Most of the existing unsupervised real-world SISR methods adopt a two-stage training strategy by synthesizing realistic LR images from their HR counterparts first, then training the super-resolution (SR) models in a supervised manner. However, the training of image degradation and SR models in this strategy are separate, ignoring the inherent mutual dependency between downscaling and its inverse upscaling process. Additionally, the ill-posed nature of image degradation is not fully considered. In this paper, we propose an image downscaling and SR model dubbed as SDFlow, which simultaneously learns a bidirectional many-to-many mapping between real-world LR and HR images unsupervisedly. The main idea of SDFlow is to decouple image content and degradation information in the latent space, where content information distribution of LR and HR images is matched in a common latent space. Degradation information of the LR images and the high-frequency information of the HR images are fitted to an easy-to-sample conditional distribution. Experimental results on real-world image SR datasets indicate that SDFlow can generate diverse realistic LR and SR images both quantitatively and qualitatively.
1 Introduction
Image super-resolution (SR) is a fundamental and active research topic with a long-standing history in low-level computer vision [1], where single image super-resolution (SISR) received more attention for its wide applications in practical scenarios. SR aims to reconstruct or estimate the realistic underlying HR images from the given LR images, either for perceptual viewing purposes or to help improve other downstream vision tasks. SISR is an ill-posed problem where multiple HR images can be matched to the same LR image. Benefiting from the recent advancements of deep convolutional neural network (CNN) techniques, the performance of CNN-based SR models has significantly surpassed that of the interpolation-based algorithms [2, 3, 4, 5]. For many years, most existing CNN-based SR models are trained on artificially synthesized paired low-resolution (LR) and high-resolution (HR) image datasets, leading to poor performance in super-resolving the real-world LR images due to the domain gap between the synthesized training data and the real-world test data. Thus, more attention has been drawn to developing SR approaches for real-world images [4], promoting CNN-based SR in practical applications.
Real-world single image super-resolution (RSISR) is a challenging task, due to the lack of paired real-world LR/HR training images. The most straightforward solution is to capture real-world LR/HR image pairs by changing the focal length of a zoom lens camera to shoot the same scene [6, 7, 8, 9]. Some efforts are taken to capture more accurately paired real-world LR/HR image pairs using specially designed devices, such as hardware binning [10] and beam splitter [11]. However, these approaches are laborious and costly, meanwhile, the degradation types are bound by the acquisition devices. Additionally, perfectly aligned real-world LR/HR image pairs are hard to construct due to the imperfection and characteristics of optical imaging device [12], hampering the performance of pixel-wise loss function widely used in SR model training. As an alternative, most of the RSISR works focus on learning from unpaired real-world LR/HR images that are easily accessible [4]. This kind of work usually adopts a two-stage training strategy [13, 12, 14, 15, 16, 17, 18, 19], where a downscaling network is first trained under the generative adversarial network (GAN) [20] framework to approximate the distribution of real-world LR images given HR images. Then SR models are trained in a supervised manner on the synthetic real-world LR/HR image pairs constructed using the trained downscaling network. However, the two-stage strategy has common shortcomings [21]. First, the downscaling network is usually optimized for the deterministic generation of LR images from HR inputs without considering that real-world image degradations are stochastic, i.e., an HR image can be degraded into multiple LR images, which may limit the performance of the following SR models. Second, although some recent works [22, 23, 24, 25] try to learning to generate diverse degraded LR images from its HR counterpart, however the training of the downscaling network and SR network is separate. Since the image downscaling and SR are inherently an inverse problem, thus the mutual dependency between image downscaling and SR is not fully exploited in the two-stage methods.

In this paper, we address the aforementioned problem by proposing a novel invertible model, named as SDFlow, simultaneously learning diverse image SR and diverse image downscaling (degradation) under the normalizing flow [26, 27, 28] framework. As shown in Fig. (1), the main idea of the SDFlow is to discover the shared latent structure of real-world HR image and LR images by decoupling image content and its domain-specific variations in the latent space. Specifically, we first introduce two different latent variables for LR images which encode their contents and degradations, respectively. For HR images, we assume that they can be decoupled into content representation and residual high-frequency (HF) component. Content latent variables are learned to have shared representation so that the unpaired real-world LR images and HR images can be mapped to a domain invariant space. Degradation variations and HF components are mapped to an easy-to-sample latent distribution through a series of invertible transformations. Considering the complexity of real-world degradations, we model the degradation distribution using a mixture of Gaussian distributions. During inference, the content latent variable is first obtained, then diverse LR or SR images can be reconstructed by sampling the degradation or HF latent space, respectively. Contrary to the two-stage method, we reformulate the real-world SISR as a dual modeling problem of both real-world image downscaling and SR as a unified task. As the downscaling process and the SR process share the same model parameter, the SDFlow model can be optimized jointly in both directions, forming an implicit constraint on the solution space of both the image downscaling and SR [29]. To distinguish from the image rescaling model based on the invertible neural network (INN) [30, 31], which can only well reconstruct the LR image downscaled by the forward process. Our proposed SDFlow can generate multiple realistic LR images, while it can also estimate diverse HR images with better perceptual quality from the real-world LR input. To the best of our knowledge, our work is the first attempt to simultaneously model diverse image SR and downscaling from unpaired real-world image data in a unified framework.
The rest of the paper is organized as follows: Section II reviews the work of RSISR and normalizing flow for computer vision. Section III first formulates the problem of many-to-many mapping between real-world image SR and image downscaling, then introduces the network structure of the proposed SDFlow. Section IV evaluates and analyzes the experimental results of the SR and LR images quantitatively and qualitatively. Finally, Section V summarizes our work.
2 Related Work
2.1 Real-world single image super-resolution
One of the challenges hindering the applications of most state-of-the-art CNN-based SISR models in practical scenarios is the lack of paired real-world LR/HR training data. Thus, some efforts are devoted to collecting paired real-world LR/HR images by capturing the same scene with different resolutions using zoom lens camera [8, 6, 7] or specific imaging device [10, 11]. For example, the RealSR dataset [8], the DRealSR dataset [6] and the City100 dataset [7] are constructed by adjusting the focal length or shooting distance to obtain LR/HR image pairs of the same scene. While the SuperER dataset [10] and the ImagePairs [11] dataset are constructed using hardware binning and optical beam splitter, respectively. However, collecting the paired data is time-consuming and effort-consuming, and it often requires a strictly controlled environment. Besides, miss-aligned LR/HR pairs are unavoidable due to the imperfection of imaging system, such as lens distortion, and the depth-of-field phenomenon.
To circumvent the above mentioned issues, several RSISR works propose to synthesize real-world LR images from their HR counterparts. One branch of approaches [32, 33] assumes that real-world degradations can be modeled as blur kernels and additive noises. Zhou et al. [33] first build a large kernel pool via kernel estimation from real photographs, then SR networks are trained using the LR/HR pairs constructed using the generated kernels. Ji et al. [32] further estimates the real noise distribution to better imitate real-world LR images. Another branch of methods [19, 18, 16, 17, 12, 14, 15] proposes to use GANs to unsupervisedly learn the conditional distribution of LR images given HR inputs. Yuan et al. [18] propose CinCGAN to learn the distribution of clean LR and HR image separately, which guides the SR of unpaired LR images. Bulat et al. [19] first trains a high-to-low GAN with unpaired HR and LR images, then the output of the network, acting as the paired LR image, is used to train the SR network. Lugmayr et al. [16] and Maeda et al. [15] use CycleGAN to translate HR images to LR images and consequently constructed the paired LR and HR dataset that is used for training of the SR network. In [17], Fritsche et al. proposed to separate the low and high frequencies, where the HF information is adversarially trained, and the low-frequency information is learned with the L1 loss. Instead of assuming that domain gap between Bicubic downscaled (BD) LR images and real LR images can be eliminated by GANs, Wei et al. [14] and Sun et al. [12] further adopt a domain distance aware training strategy by incorporating domain distance information in the training process of SR networks.
Existing RSISR methods trained on sets of paired or unpaired LR/HR images suffer from inconsistency problems between test and training data. To reduce the impact on SR performance due to inconsistency between training and test data distribution, the self-similarity property of the natural image is exploited to learn image-specific SR models. Shocher et al. [34] proposed the ZSSR model utilizing cross-scale internal patch recurrence of the natural image to construct test image-specific LR/HR pair for SR training. Besides, data augmentation is adopted to enrich training pairs. Bell-Kligler et al. [35] proposed to train an image-specific GAN (KernelGAN) to model the blur kernel of the LR input to further generate more realistic degraded LR/HR pairs. Thus, fully self-supervised image-specific RSISR is achieved by plugin the KernelGAN into the ZSSR. Kim et al. [36] developed the DBPI, a unified internal learning-based SR framework consisting of an SR network and a downscaling network to jointly train the image-specific degradation and SR networks. The SR network is trained to recover the LR input from its downsampled version generated by the downscaling network. meanwhile, the downscaling network is optimized to restore the LR input from its HR version reconstructed by the SR network. Similarly, DualSR proposed by Emad et al. [37] jointly optimizes the image-specific downsampler and the upsampler. By using the patches from the test image, the DualSR is trained with cycle consistency, masked interpolation and adversarial loss. Recently, inspired by the Maximum A Posteriori estimation, Chen et al. [38] proposed a self-supervised cycle-consistency based scale-arbitrary RSISR model.
2.2 Normalizing flow and INN for low-level computer vision
Normalizing flows are a family of generative model, where both sampling and density evaluation can be efficient and exact [39]. Normalizing flows are usually constructed by a series of invertible transformations parameterized by neural networks. Normalizing flow transforms complex distribution into a simple tractable one in the forward process and achieves diverse generations in the reverse process by sampling from the simple distribution. Thus, normalizing flow is suitable for modeling the solution space of many ill-posed inverse problems [40]. Recently, normalizing flow has demonstrated promising results for many ill-posed inverse tasks in low-level computer vision, such as image SR, denoising, colorization, low-light image enhancement and etc.. SRFlow [41] maps the distribution of HR images into an isotropic Gaussian distribution conditioned by the LR image in the forward process and achieves diverse SR reconstructions in the inverse process. HCFlow [31] learns a bijective mapping between HR and LR image pairs by modeling the distribution of LR images close to that of the BD images, and the rest of HF distribution as Gaussian. FKP proposed by Liang et al. [42] improves the blind SR performance by modeling the complex kernel prior distribution using normalizing flow. Abdelhamed et al. [43] proposed a normalizing flow based noise modeling method that can produce realistic noise conditioned on the raw image and camera parameters. DeFlow [22] unsupervisedly learns stochastic image degradation in latent space using a shared flow encoder-decoder network. Yu et al. [44] proposed to transform the HF components of wavelet transformation into Gaussian distortion, achieving fast training and HR image generation using the multi-scale nature of wavelet transformation.
As the building blocks of the normalizing flow, INNs have recently been explored for other image processing tasks [30, 45, 46, 47]. Xiao et al. [30] first proposed to use INN to jointly model the image downscaling and upscaling, significantly improving the performance of the image rescaling task. Xing et al. [45] proposed an invertible ISP model to generate visual pleasing sRGB image from RAW input, and recover nearly the same quality RAW data at the same time. Liu et al. [46] models the image denoising using INN. The noised image is decouple into LR clean image and residual latent representations containing noise in the forward process, while the clean HR image is obtained in the reverse process by replacing the latent representations with another one sampled from a prior distribution. Similar ideas can be applied to the image de-colorization and re-colorization task. Zhao et al. [47] proposed to decouple the color image into grayscale and color information, modeled as Gaussian distribution, using the forward process of INN, meanwhile, the color image can be reconstructed in the inverse process by sampling the color information in the Gaussian space.
3 Method
In this section, we first formulate the problem of unpaired many-to-many mapping between image downscaling and SR, then we introduce the proposed SDFlow which can generate diverse realistic LR and SR images under a unified invertible neural network framework.
3.1 Problem statement
SISR algorithms try to estimate the underlying HR image corresponding to the single input LR image. This is a typical example of inverse problems, to solve which the forward process is generally required. Specifically, the degradation (downscaling) model is required in order to formulate what sort of data is to be used. The general image degradation model can be formulated as:
| (1) |
where is the model parameters describing the degradation information, represents the downscaling factor. Practically, the degradation model is stochastic and complex, containing more than one type of degradations, such as blur, noise, compression artifacts and etc.[48, 49]. As can be inferred from Eq. (1), the degradation is ill-posed since the degraded image can correspond to several degradation parameters s. Thus, the degradation process is actually a one-to-many mapping.
With the defined forward process, the SISR aims to explicitly or implicitly invert the degradation process to estimate the HR image. This is achieved by optimizing a cost function defined from the perspective of either algebra or statistics. The commonly used Least-Squares cost function which minimized the norm is defined as:
| (2) |
solving Eq. (2) is challenging as it requires to estimate the unknown HR image and degradation parameters simultaneously, making the SISR ill-posed [1]. In many real scenarios, there exist infinite combinations of HR images and degradation parameters that can produce the same LR image, thus, the SISR is also a one-to-many mapping.
Most SISR approaches tend to be supervised learning-based [2, 3], requiring a well-defined degradation model to synthesize the LR images from HR images, so that the SISR algorithm knows what HR image should look like when super-resolving a given LR image. However, formulating the degradation model that can simulate the complex and stochastic image degradation process in real scenarios is challenging. Thus, synthesizing real-world LR/HR image pairs for supervised RSISR is a nontrivial task. Consequently, designing deep learning methods with unpaired data becomes an active research topic in RSISR and deserves in-depth exploration.
3.2 Deriving the solution for many-to-many image SR and downscaling under the variational inference framework
The learning settings we consider are as follows. We are given unpaired real-world LR and HR image datasets and i.i.d. sampled from some true but unknown marginal distributions and , respectively. Our goal is to estimate the unknown conditional density and simultaneously, i.e., learning a invertible mapping that can super-resolve a new LR image satisfying , while downscaling a new HR image such that . However, it is difficult to model and only given marginal distributions and , thus, we seek to model the joint distribution over and under the unpaired learning setting. In general, this is a highly ill-posed problem, as the independence of and does not hold in practice [22]. We thus impose conditional independence by assuming that corresponds to three latent variables , where is the underlying content representation shared by the LR and HR image, is the degradation information contained in the LR image and is the lost high-frequency information during the downscaling of the HR image. Under these assumptions, the conditional joint density can be represented as:
| (3) |
thus, we can maximize the likelihood of the joint density function using a variational posterior whose log-likelihood is formulated as:
| (4) | ||||
Since directly maximizing the log-likelihood of is generally intractable, we seek to maximize the evidence low bound (ELBO) under the variational inference framework:
| (5) | ||||
the right hand side of the Eq. (5) is the ELBO, where the expectation term is the reconstruction error, and the second term of the ELBO minimizes the Kullback–Leibler (KL) divergence between the variational posterior and the prior of the latent variables. The reconstruction term with the conditional independence assumption in Eq. (3) and the factorization of the variational posterior in Eq. (4) can be rewritted as:
| (6) | ||||
next, we simplify the KL divergence term in Eq. (5). According to the graphical model presented in Fig. (1) and the conditional independence assumption, the prior can be factorized into . Combining the factorized prior and Eq. (4), the KL divergence term can be re-formulated as:
| (7) | ||||
it is worth mentioning that the term in Eq. (6) and Eq. (7) still requires paired LR/HR images to infer the shared content latent variables. To meet the unpaired learning setting, we need to decouple the paired relationship, meaning that for the paired data , the content representation can be obtained from either LR image or HR image independently. Formally, this is written as:
| (8) |
this requires that encodes the domain invariant features between the LR and HR image domains. However, strictly ensuring this inference invariant condition is a difficult problem due to the unknown joint distribution , we thus only require that the marginal distributions of and be aligned in the shared representation space, which can be achieved using the adversarial learning strategy described in Section 3.3.2.
With the above derivation and simplification of Eq. (5), the expression of the final ELBO is:
| (9) |
Eq. (9) can be grouped into two parts, the part only relates to the LR image while the part only relates to the HR image. This effectively removes paired training data requirements in maximizing the ELBO. In the next section, we introduce the SDFlow to learn the joint density function using Eq. (5) and Eq. (9), which achieves many-to-many mapping between real-world image SR and downscaling.
3.3 SDFlow
Image downscaling and SR are inherently reciprocal with bi-directional ill-posedness property in real-world scenarios. The natural approach to tackle the ill-posed inverse problem is to consider the solution as a distribution that describes all of the possible results. We thus propose to simultaneously model the bidirectional one-to-many mapping between image downscaling and SR using the INN under the probabilistic normalizing flow framework, named SDFlow. When compared to other generative models such as GANs and VAEs in image downscaling and SR, flow-based models offer several advantages. As the model parameters of the INN are shared for both forward and backward process, the solution space for both the image downscaling and SR is implicitly constrained. Also, normalizing flow-based generative models are suitable for high-quality and diverse image downscaling and SR with stable learning [30, 31]. Next, we first present a preliminary introduction to the normalizing flow, then the model architecture of the SDFlow is elaborated.
3.3.1 Normalizing flow
Normalizing flow [39], as a type of latent variable generative model, is to explicitly estimate the probability distribution of the input data. Compared to GAN [20] and variational autoencoder (VAE) [50], normalizing flow features exact likelihood estimation, efficient sample generation, and stable training. Typically, flow-based models try to learn a bijective mapping between the data space and the latent space. Specifically, let be a dimensional random variable with complex marginal distribution, the main idea of flow-based models is the employment of a learned invertible function transforming to with simple and tractable distribution (e.g. Gaussian distribution). Since is invertible, it implies a one-to-one mapping between the input and output. Thus, the data can be losslessly restored from the latent variable as . Making the use of change-of-variables rule, the log-likelihood the of data can be written as:
| (10) |
where is the parameter of the base distribution, e.g. for gaussian distribution represents the mean and variance. is the logarithm of the absolute value of the determinant Jacobian of with respect to .
The main challenge in designing a flow-based model for practical use is to ensure that is expressive enough, while the log-determinant of the Jacobian of must be easy and efficient to compute. Usually, is composed of a stack of invertible functions , as all together they still represent a single invertible function. The intermediate variables are defined as , where and represent the input random variable and the output latent random variable . Using multiple learnable invertible functions, a normalizing flow attempts to transform the input random variable from the data space into a latent variable obeying a simple distribution. Thus, the log-likelihood of the input variable can be finally formulated as:
| (11) |
generally, the individual invertible function is parameterized by neural networks, and the entire flow model parameters can be optimised by minimizing the exact negative log-likelihood (NLL) on the training dataset using standard stochastic gradient descent optimization method.
One caveat in designing the INN for normalizing flow is to ensure that the determinate Jacobian of the high-dimensional transformation can be computationally tractable. Common INN realizations use coupling layers such that the Jacobian is an upper or lower triangular matrix, and the determinant can be easily evaluated as the product of its diagonal elements. Dinh et al. [26] build flow model using a stack of non-linear additive coupling layers in which the determinant is always . Further, the Real-NVP [27] enhance the additive coupling to affine coupling that performs both location and scale transformations. Recently, Glow [28] replaces the fixed permutation layer in [26, 27] with the more flexible convolutional layer and achieves better image generation quality.

3.3.2 Model architecture
The flow-based models are naturally and intuitively for image SR and downscaling tasks [30, 31], since image SR and downscaling are inherently a mutual inverse process. In this paper, we propose the SDFlow framework to simultaneously model the SR and downscaling for real-world images in a unified architecture which can fully exploit the underlying complex dependencies between image SR and downscaling. Fig. (2) illustrates the proposed SDFlow framework, it mainly consists of two invertible parts, i.e., the Super-resolution Flow and the Downscaling Flow. Since these two flows are both invertible, thus, the entire framework is also invertible. The Super-resolution Flow includes two sub-flows, the HR Flow takes the HR image as input and decomposes it into the content latent variable and the remaining HF latent variable through a series of invertible flow blocks. Taking as a condition, the HF Flow further maps to subjected to a simple normalized distribution, such as the isotropic Gaussian distribution. As to the downscaling flow, it also contains two sub-flows, the LR Flow takes the LR image as input and decouples its content and degradation into and in the latent space. The Deg Flow transforms into under the conditional features extracted from such that follows the standard normal distributions. By virtue of the invertible design, image SR can be achieved by taking of the LR image and the sampled into the inverse process of the Super-resolution Flow to generate one possible SR image. Similarly, an instance of the downscaled images can be obtained by transforming of the HR image and the sampled using the inverse process of the Downscaling Flow. The entire model parameters are optimized with the objective function described in Eq. (9). In unpaired learning settings, the latent variable indicates a shared latent space between the HR and LR images. In the SDFlow model, we assume that captures the image content and the shared latent space is learned using the adversarial training strategy.
Super-resolution Flow: The detailed architecture of the Super-resolution Flow is presented in Fig. (2). The HR Flow model is basically designed upon the unconditional Glow [28] and RealNVP [27] models. It is a level architecture, where is the SR factor. Each level is composed of a downscaling block (DB) and a flow block (FB). Concretely, the DB starts with a checkboard squeeze operation [27, 41] transforming its input with size into , then two transition steps [41] are followed to learn a linear invertible interpolation between neighboring elements. Each transition step consists of an invertible activation normalization (ActNorm) operation and an invertible convolution (Inv. Conv) layer. In each level, the FB consists flow steps, transforming the input features into the target latent space. Each flow step contains an ActNorm, an Inv. Conv and an affine coupling (Affine Coupling). Here we briefly describe the above mentioned elementary invertible operations, detailed information can be referred to [28, 41]:
-
•
ActNorm: activation normalization proposed in [28] is an alternative to the batch normalization to alleviate challenges in model training. ActNorm learns a channel-wise scaling and shift to normalize intermediate features.
-
•
Inv. Conv: to optimize the use of each channel of features between flow steps, each feature channel should have chances to be modified. Instead of using a pre-defined and fix channel permutation strategy [26, 27], Glow [28] proposed an invertible convolution, which generalizes any permutation of channel ordering.
-
•
Affine Coupling: affine coupling layer is an efficient invertible transformation that captures complex dependencies between feature channels. It splits the feature into two parts along the channel dimension. is kept unchanged and used to compute the scale and shift to affine transform . Affine coupling is formulated as:
(12) where and are arbitrary neural networks. The output of Affine Coupling layer is the concatenated and .
At the end of the HR Flow, the transformed latent variable of the input HR image is split into two parts along the channel dimension,i.e., and . Using the change-of-variable formula, we arrive at the following equation:
| (13) |
if we consider the HR Flow as a VAE with shared encoder and decoder modelled as Dirac deltas, then the reconstruction term of in Eq. (9) is automatically satisfied with . Since the invertibility of the transformation of the HR Flow, the two KL divergence terms of in Eq. (9) are equivalent to fitting a flow-based model to the data distribution [51], which is further equivalent to fitting the HR Flow model to samples by maximum likelihood estimation (MLE) of Eq. (13) [51].
In typical flow-based models, the factorted out latent variable and are directly Gaussianized to model the sampling space. However, in the SDFlow model, we do not have to sample from the content latent space to generate SR images, thus, we assume that the prior is uniform. To model the sampling space of , direct Gaussianization may lead to suboptimal results due to the lack of sufficient modeling ability of the limited flow depth. Inspired by the conditional flow [31], it is assumed that the HF component relies on the content component to facilitate the distribution modeling of the HF component of natural images. Therefore, is further transformed into conditioned on features extracted from , and in Eq. (13) can be written as , where the base distribution of is a multivariate standard normal distribution. As shown in Fig. (2), the HF Flow is constructed by conditional flow steps and a conditional feature extractor. Different from the flow step, conditional flow step replaces the Affine Coupling with Conditional Affine Coupling [41] and introduces the Affine Injector layer. The Conditional Affine Coupling is a conditional variant of the Affine Coupling. The difference is that the scale and shift factors are computed by neural networks on both the input and conditional variables. The affine injector [41] takes the conditional features to compute the scale and shift factors to transform its input, building a stronger connection between the input and the conditional variables. The conditional feature extractor is a modified version of the RRDB model [52] by adjusting the number of RRDB blocks and removing the upsampling operation. After modeling the distribution of latent space of and , the MLE of Eq. (13) can be optimized by NLL of the following equation:
| (14) | ||||
Downscaling Flow: the design paradigm of the Downscaling Flow is much the same as that of the Super-resolution Flow. One of the most notable differences is how we factor out content representation and degradation information using the LR Flow. Due to the limitation of the inherent property of the the INN architecture that the input and output dimension must be equal, the LR Flow cannot directly factor out and using split operation as that of the HR Flow. Additionally, the invertible requirement restricts the flexibility of known transformations composing the INN [26, 27] and leads to inferior capability in disentangling content and degradation. We thus propose a factor out scheme which replaces the split operation with the element-wise minus (plus) operation. The architecture of the LR Flow is shown in Fig. (2), it is composed of a LR content feature extractor and an INN. The LR content feature extractor is a convolution-based neural network extracting content feature from the input LR image. The LR image representation in the latent space can be obtained using the INN for its nature of one-to-one mapping. Therefore, the degradation component can be obtained as . LR Flow is still invertible as .
Fig. (3) illustrates the architecture of the LR content feature extractor. It is basically a residual neural network [53] where the ResBlock is replaced with the DM ResBlock. Different from the formal ResBlock, two Degradation Modulation layers are added to do spatial feature affine transformation conditioned on degradation features extracted by the degradation estimator. The degradation estimator contains a series of Conv2D and LeakyReLU layers extracting spatially degradation information from real-world LR images.

The INN in the LR Flow is composed of a DB, a FB and a Upscale Block (UB). Let the input LR image size be , where and . The DB first transforms the input LR image into a feature space with size to better exploit the correlations between different feature channels, since splitting features with 3 channels into two parts can lead to information deficiency in the Affine Coupling layers in the following FB [54]. Then the downscaled features are transformed by flow steps in the FB. Finally, an UB unsqueezes the transformed features into the latent space with the same size as the input LR image.
The forward pass of the LR Flow outputs two latent variables, i.e., and of the input LR image. Using the change-of-variables formula, we can get the following equation:
| (15) | ||||
where . Following the derivation of the optimization objective for the HR Flow, the reconstruction term in of Eq. (9) is automatically satisfied with and the optimization of the two KL terms of is equivalent to the MLE of Eq. (15).
Akin to the Super-resolution Flow, we impose the uniform prior on the content latent variable, since we do not have to sample from the content latent space. To model the sample space of , we further transform into using an additional conditional flow network conditioned on features extracted from . The structure of the Deg Flow resembles that of the HF Flow. Apart from a conditional feature extractor and conditional flow steps, a DB is employed to make full use of correlations between different feature channels. After the transformation of the Deg Flow, of Eq. (15) can be written as . Considering that real-world image degradations are stochastic and complex, we assume that the base distribution of is a mixture of Gaussians with each representing a potential type of degradation. Thus, can be written as , where is the number of Gaussians, and are learnable mean and covariance. After modeling the distribution of the latent space of and , the MLE of Eq. (15) can be optimized by NLL of the following equation:
| (16) | ||||
Modeling the shared latent space of the content variable: one key of our proposed method is to meet the assumption that the HR Flow and LR Flow can extract the HR and LR image contents and map them into the same latent space. However, only optimizing Eq. (14) and Eq. (16) cannot achieve many-to-many mapping between image downscaling and SR, first because it is a nontrivial task for the HR Flow and LR Flow to disentangle content and respective HF and degradation components without any supervision. Additionally, the latent space of HR image content and LR image content are also not well aligned. To address the first issue, we need to constrain that of both HR and LR image can be mapped into a valid image capturing the major information of HR and LR inputs. This can be achieved using the inverse process of the LR Flow to map the content latent variable to the LR image space. Inspired by [22, 13], we assume that the image content and low-level structure are mainly embodied in the low-frequency part. The following content loss is applied to constrain the content information captured in to be consistent with that of the LR and HR image.
| (17) | ||||
where is a low-pass filter, is the Bicubic downscaling operation with scale , denotes the pre-trained VGG-19 [55] feature extractor. We minimize the feature difference from Conv5_4 of the pre-trained VGG-19 to encourage to maintain the texture content [56]. The pixel and feature loss are weighted by the factor .
With Eq. (17), the training of the Super-resolution Flow and Downscaling Flow are correlated through a shared image decoder, i.e., , which ensures that of the HR and LR image are mapped to the same latent space while still encode the image content information. However, domain gap still exists between content latent variables of the HR and LR images. To reduce the marginal distribution difference between two domains, we employ the adversarial domain alignment strategy. Specifically, we train a discriminator differentiating and . The following loss function is applied to train the domain discriminator:
| (18) | ||||
where represents the patch discriminator, means stop gradient back-propagation. We use the LSGAN [57] to optimize the parameters of the discriminator, meanwhile parameters of the HR Flow and LR Flow are optimized to fool the discriminator with contradictory LSGAN loss. To ease and stabilize the training of the discriminator, we apply regularization on the content latent variable, which avoids arbitrary high variance latent space and enforces a closer domain gap in a denser latent space.
3.3.3 Training objectives
To train the proposed SDFlow model, it is statistically sufficient asymptotically to optimize MLE based loss function as Eq. (14) and Eq. (16) together with shared content latent space loss as Eq. (17) and Eq. (18) from the statistical perspective. While, in training the generative models, adversarial learning outperforms MLE on sample quality metrics [58]. Additionally, the optimality of MLE holds only when there is no model miss-specification for the generative model [40, 58]. Fortunately, INN offers the opportunity to simultaneously optimize for losses on both directions, which allows for more effective training. We thus perform distribution matching on the generation side of Super-resolution and Downscaling Flow with the commonly used GAN loss and perceptual loss. The overall training objective function is formulated as follows:
| (19) |
where , and are per-pixel loss, perceptual loss and GAN loss applied on the backward pass of the Downscaling Flow, , and are per-pixel loss, perceptual loss and GAN loss applied on the backward pass of the Super-resolution Flow. Perceptual loss is implemented as the loss applied on features extracted from Conv5_4 layer of the pre-trained VGG-19. GAN loss is realized by adding discriminators on backward side of the Super-resolution and Downscaling Flow, and LSGAN is utilized to optimized the two flows and discriminators. The loss terms in the backward loss are weighted by to , respectively. To optimize Eq. (19), we perform forward and backward passes of the SDFlow model in an alternating manner, and gradients are accumulated before the parameter update.
4 Experiments
In this section, we evaluate the performance of the SDFlow in generating diverse SR and downscaled images from real-world LR and HR inputs, respectively. We first introduce experimental setup including real-world image SR datasets, evaluation metrics, and implementation details. Then, experimental results of SR and downscaling are evaluated quantitatively and qualitatively. Finally, ablation studies are conducted to validate the effectiveness of the proposed architecture.
4.1 Experimental setup
4.1.1 Datasets and evaluation metrics
The SDFlow model is trained on unpaired real-world LR and HR image datasets and evaluated on the corresponding test real-world HR and LR images. We conduct experiments on the widely used RealSR [8] and DRealSR [6] datasets that are originally collected for the real-world image SR task. RealSR dataset has 595 (500 for SR) pairs of HR and LR image captured by adjusting focal length through Canon and Nikon DSLR cameras. Progressive image registration framework is proposed in order to achieve pixel wise registration of images captured at 28mm, 35mm, 50mm and 105mm. Images captured at 105mm are used as HR ground-truth while images captured at the other three focal lengths are considered as LR counterparts with different scale factors. DRealSR dataset is captured similarly as the RealSR dataset but has a larger scale of image pairs. 5 different DSLR cameras (i.e., Sony, Canon, Olympus, Nikon, and Panasonic) are used to capture indoor and outdoor images at four different resolutions, obtaining 884 (for SR), 783 (for SR), 840 (for SR) LR and HR image pairs. SIFT algorithm is used to align these image pairs.
To evaluate the performance of image SR and downscaling models, Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index Measure (SSIM) [59] are two widely used image distortion measurement metrics. Following the setting in [30, 31], we evaluate the performance of the proposed SDFlow and other compared models using PSNR and SSIM on the Y channel of the YCbCr color space. However, PSNR and SSIM are only based on local image differences, failing to consider image quality in terms of human perception. Following [4], we also employ two full-reference image quality assessment metrics, Learned Perceptual Image Patch Similarity (LPIPS) [60], Information Fidelity Criterion (IFC) [61], and three no-reference image quality assessment metrics, Natural Image Quality Evaluator (NIQE) [62], Perception-based Image Quality Evaluator (PIQE) [63] and No-Reference Quality Metric (NRQM) [64] for better visual quality comparison. 10 samples are used to measure the diversity[65] of the model outputs.
4.1.2 Implementation details
In the implementation of the proposed SDFlow, we set the number of flow steps and number of conditional flow steps to 16 and 8, respectively. Regarding the conditional feature extractor, since modeling the solution space of the HF component is more complex than that of the degradation component in terms of the dimensionality of unknown variables, we thus set the number of RRDB to 8 and 4 to extract conditional features for the HF Flow and Deg Flow. In the LR content feature extractor, we use 8 Conv2D-LeakyReLU operations to extract degradation features and use 16 DM ResBlocks to obtain the LR image content feature. The number of Gaussian components are empirically set to 16.
The proposed SDFlow is trained in the training set and tested in the test set of the RealSR and DRealSR dataset, respectively. The weight in is set to 0.05, and in is set to 0.05 and 0.5, to in the overall loss Eq. (19) are set to 0.5, 0.5, 0.1, 0.5, 0.5, 0.1, respectively. We use Adam optimizer to update parameters of the SDFlow. The learning rate for the SDFlow model and all of the discriminators are initialized to and , respectively, and halved at , , , of the total training iterations. We set the mini-batch size to 32 and randomly crop the input HR and LR image into and patches. Training samples are augmented by applying random horizontal and vertical flip. When composing unpaired mini-batch samples, we explicitly avoid cropping HR and LR patches from paired HR and LR data. Since flow-based models are defined over continuous variables, we dequantize the discrete pixel values by adding uniform noise in range [66]. Due to the fact that adversarial training is used, we first stabilize the training by pretraining the SDFlow with , and for 50k iterations. The entire model is then trained with the forward loss in Eq. (19) for 200k iterations. Finally, we fine-tune the SDFlow with forward and backward loss as Eq. (19) for another 50k iterations. Following the setting in [41, 31], we set the sampling temperature to 0 for per-pixel loss and 0.8 for perceptual and GAN loss when optimizing the model with the backward.
4.2 Evaluation of the SR results
This section reports the quantitative and qualitative performance of the proposed SDFlow and other state-of-the-art unsupervised RSISR methods. As concluded in [4], unsupervised RSISR methods can be categorized into degradation modelling based models, domain translation based models, and self-learning based models. In unpaired SISR settings, degradation modelling based models focus on the recovery of degradation kernels that are then used to synthesize LR images from HR inputs for the following supervised SISR models training. Domain translation based models usually employ a learned CNN to translate HR images (or BD downscaled images) to real-world LR image domain, which generates paired LR/HR images to train generic SISR models. Self-learning based models exploit cross-scale internal recurrence of LR image to learn image-specific degradation model, then test LR image and its degraded counterpart are used to train an image-specific SR model. We compared 10 unpaired RSISR models from the three categories with source code available, i.e., KernelGAN [35], Impressionism [32], ADL [13], DASR [14], USR-DA [67], Pseudo-supervision [15], SRResCGAN [68], ZSSR [34], DBPI [36], DualSR [37]. All models are re-trained on the RealSR and DRealSR dataset using the training script and default settings provided by the source code. Additionally, Bicubic upscaled LR images are also evaluated for reference.
| Methods | Full-reference | No-reference | |||||||
| PSNR | SSIM | LPIPS | IFC | Diversity | NIQE | PIQE | NRQM | ||
| Interpolation | Bicubic | 27.2334 | 0.7637 | 0.4761 | 0.9632 | - | 8.9289 | 92.3236 | 2.7284 |
| Degradation modelling | KernelGAN | 25.1433 | 0.7387 | 0.3366 | 0.9542 | - | 6.9917 | 80.5237 | 3.7027 |
| Impressionism | 25.2184 | 0.7025 | 0.3608 | 0.9183 | - | 4.0966 | 35.9179 | 6.8024 | |
| ADL | 28.3478 | 0.8102 | 0.3138 | 1.1916 | - | 8.0719 | 85.8044 | 3.3137 | |
| Domain translation | DASR | 27.4852 | 0.7872 | 0.2646 | 1.0658 | - | 6.6091 | 66.2664 | 4.2414 |
| USR-DA | 27.3762 | 0.7569 | 0.2683 | 0.9667 | - | 5.1228 | 49.9268 | 5.1042 | |
| Pseudo-supervision | 27.3066 | 0.7750 | 0.2626 | 1.0700 | - | 6.8147 | 78.0688 | 4.3592 | |
| SRResCGAN | 26.7526 | 0.7487 | 0.2829 | 0.9759 | - | 5.6330 | 58.9674 | 4.4693 | |
| Self learning | ZSSR | 27.5745 | 0.7815 | 0.3845 | 1.0382 | - | 7.9022 | 85.6690 | 3.0763 |
| DBPI | 23.8786 | 0.6970 | 0.3170 | 0.9409 | - | 6.6047 | 71.1269 | 4.5050 | |
| DualSR | 22.5764 | 0.7037 | 0.3582 | 0.8876 | - | 5.5278 | 69.9079 | 5.4125 | |
| SDFlow | Forward loss () | 28.5813 | 0.8118 | 0.2934 | 1.2084 | - | 7.9582 | 86.1925 | 3.4795 |
| Forward loss () | 27.8403 | 0.7819 | 0.2321 | 1.0448 | 11.9467 | 5.7145 | 55.3054 | 4.6572 | |
| Forward + Backward loss () | 28.0020 | 0.7937 | 0.2500 | 1.1180 | - | 6.9344 | 75.7292 | 4.0850 | |
| Forward + Backward loss () | 27.1591 | 0.7576 | 0.2295 | 1.0090 | 12.0287 | 4.8106 | 44.6445 | 5.4873 | |
| Methods | Full-reference | No-reference | |||||||
| PSNR | SSIM | LPIPS | IFC | Diversity | NIQE | PIQE | NRQM | ||
| Interpolation | Bicubic | 30.5557 | 0.8595 | 0.4387 | 0.8532 | - | 10.0721 | 94.4191 | 2.7187 |
| Degradation modelling | KernelGAN | 28.7268 | 0.8347 | 0.3995 | 0.8207 | - | 8.7270 | 88.7390 | 3.0359 |
| Impressionism | 28.1383 | 0.7857 | 0.3810 | 0.6900 | - | 4.9480 | 35.5378 | 5.9220 | |
| ADL | 30.8912 | 0.8722 | 0.3574 | 0.9113 | - | 9.5483 | 88.7854 | 2.7541 | |
| Domain translation | DASR | 29.6621 | 0.8362 | 0.3126 | 0.7428 | - | 6.9862 | 64.7885 | 3.7215 |
| USR-DA | 30.0489 | 0.8371 | 0.2966 | 0.7355 | - | 6.1054 | 47.6347 | 3.9122 | |
| Pseudo-supervision | 29.9271 | 0.8461 | 0.2902 | 0.8483 | - | 7.7190 | 81.6083 | 3.6742 | |
| SRResCGAN | 28.8888 | 0.8177 | 0.3178 | 0.7730 | - | 6.5440 | 69.4008 | 3.7875 | |
| Self learning | ZSSR | 30.6414 | 0.8627 | 0.3830 | 0.8681 | - | 9.2237 | 86.1406 | 2.7894 |
| DBPI | 24.6870 | 0.6795 | 0.4296 | 0.6389 | - | 7.2807 | 72.0693 | 4.1016 | |
| DualSR | 26.2933 | 0.7855 | 0.3522 | 0.7166 | - | 7.0007 | 78.0014 | 4.4276 | |
| SDFlow | Forward loss () | 31.0747 | 0.8726 | 0.3411 | 0.9266 | - | 9.2169 | 87.4987 | 2.9638 |
| Forward loss () | 30.5901 | 0.8592 | 0.2852 | 0.8368 | 10.0632 | 7.6900 | 71.2724 | 3.4047 | |
| Forward + Backward loss () | 30.6352 | 0.8609 | 0.3108 | 0.8912 | - | 7.8275 | 82.7311 | 3.3114 | |
| Forward + Backward loss () | 29.4299 | 0.8073 | 0.2807 | 0.7419 | 12.5713 | 5.5167 | 39.2800 | 4.9034 | |
Table 1 and 2 present the SR performance of the proposed SDFlow and other compared unsupervised RSISR models on the RealSR and DRealSR dataset, respectively. As can be observed from Table 1 and 2, the proposed SDFlow achieves the best performance on the PSNR, SSIM and IFC metrics with forward loss and settings. This is because in this settings, optimization of the SDFlow can be treated as using the pixel-wise L1 loss [69], and deterministic results are generated when sampling temperature is set to 0, thus higher PSNR and SSIM can be achieved. However, higher PSNR and SSIM do not mean that they correlate with better human visual perception, as shown in Fig. (4), the generated SR images tend to be blurry. When , the perceptual metrics of the SDFlow are improved significantly. When the SDFlow is trained with both forward and backward loss, the perceptual metrics LPIPS, NIQE, PIQE and NRQM are improved compared with only forward loss in the setting of , since the incorporation of perceptual and GAN losses in the backward loss term as shown in Eq. (19). When , SDFlow obtains the best LPIPS score, and no-reference metrics NIQE, PIQE and NRQM are improved by a large margin. As can be observed, the proposed SDFlow trained with forward and backward loss obtains the second-best performance on the no-reference metrics.
For the compared methods, ZSSR [34], DBPI [36], DualSR [37] and KernelGAN [35] are all image-specific SISR methods based on the internal learning strategy. However, these methods do not perform well in terms of the full-reference metrics. The primary reason may be that numerous constraints in these methods, e.g., Gaussian kernels and simple kernel shape assumption do not hold for spatial varying stochastic and complex real-world degradations [13]. Impressionism [32] adopts KernelGAN to estimate degradation kernels to synthesize HR/LR image pairs for supervised SISR model training, thus inaccurate degradation estimation results in inferior performance on full-reference metrics. However, Impressionism method achieves the best performance on the no-reference metrics. The ADL model [13] is a two-stage SISR method in which a novel low-pass filter loss and adaptive data loss are proposed to model more accurate degradation kernels to synthesize HR/LR pairs for the second supervised training stage. ADL uses RRDB as the SR backbone and obtains the second best performance on the full-reference metrics. As a comparison, performance of the proposed SDFlow trained with forward loss and is superior to that of the ADL on both full-reference and no-reference metrics. Domain translation based models usually train a image downsampler and SR model in a two-stage manner or jointly under the adversarial training framework. These models usually do not obtain high PSNR, SSIM and IFC scores, since PSNR, SSIM and IFC are anti-correlated with the subjective scores, thus are inappropriate for evaluating GAN-based algorithms [70]. As pointed by Gu et al. [70], LPIPS correlates mostly with the subjective scores. In Table 1 and 2, most of domain translation based methods get better LPIPS score than that of the other methods been compared. By comparison, the proposed SDFlow model with achieves better LPIPS, NIQE, PIQE and NRQM scores than that of the compared domain translation based SISR methods.



In addition to the quantitative results, we present qualitative SR images shown in Fig. (4), in which local regions with structural content or full of textures are magnified. SR images proposed by the SDFlow model contain clean and perceptual pleasing textures, which are more similar to real HR ground-truth images. As to the other methods been compared, domain translation based DASR, USR-DA and Pseudo-supervision can also produce moderate perceptual friendly results. Impressionism and KernelGAN generate SR images with notable artifacts due to inaccurate degradation estimation. Self-learning based DBPI and DualSR employ adversarial training, which tends to produce SR images with exaggerated textures.
4.3 Evaluation of the downscaling results
In this section, we compare LR images downscaled from real-world HR images using the proposed SDFlow with other unsupervised image downscaling (degradation modeling) methods both quantitatively and qualitatively. We select the compared image downscaling models from two-stage unsupervised SISR methods in which synthesized LR images are downscaled from HR images using a trained image downscaling network or translated from Bicubic downscaled image with a trained translation network. These image downscaling models include Impressionism [32], ADL [13], DASR [14] Pseudo-supervision [15] and SRResCGAN [68]. Furthermore, we also compare the proposed SDFlow with state-of-the-art diverse image degradation modeling models, i.e., DeFlow [22] and PDM [24]. The Bicubic downscaled real-world HR images are also included as a baseline for better comparison. All of the methods are trained on the training dataset of the RealSR and DRealSR, and tested on their test dataset, respectively. Except for evaluating the downscaling results using PSNR, SSIM, LPIPS and IFC, we also employ the Fréchet inception distance (FID) [71] to compare distribution of the synthesized LR images with distribution of the real-world LR images. 10 samples are used to measure the diversity of the model outputs. No-reference metrics are not used since these image degradation modeling methods are not intend to generate perceptual pleasing LR images.
| Downscaling methods | RealSR | DRealSR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | IFC | FID | Diversity | PSNR | SSIM | LPIPS | IFC | FID | Diversity | |
| Bicubic | 31.1163 | 0.9187 | 0.1503 | 4.5893 | 44.1883 | - | 32.5460 | 0.9215 | 0.1871 | 3.8584 | 34.1340 | - |
| Impressionism | 31.6296 | 0.9439 | 0.0836 | 4.6893 | 30.5156 | - | 33.6976 | 0.9456 | 0.1126 | 4.1153 | 23.2060 | - |
| ADL | 34.5064 | 0.9659 | 0.0521 | 5.2747 | 25.5383 | - | 33.9497 | 0.9484 | 0.0932 | 4.0052 | 17.6886 | - |
| DASR | 33.7105 | 0.9591 | 0.0755 | 4.9142 | 29.7748 | - | 33.3525 | 0.9478 | 0.1075 | 4.0010 | 20.2454 | - |
| Pseudo-supervision | 32.4882 | 0.946 | 0.0566 | 3.8569 | 24.3562 | - | 33.7735 | 0.9468 | 0.0872 | 3.7509 | 17.0282 | - |
| SRResCGAN | 31.6799 | 0.9296 | 0.0867 | 4.4058 | 35.4208 | - | 30.1125 | 0.8719 | 0.1739 | 2.9817 | 33.1498 | - |
| DeFlow | 30.5338 | 0.9421 | 0.0726 | 4.2362 | 42.2095 | 10.1595 | 30.3015 | 0.9138 | 0.1443 | 3.3259 | 37.2236 | 8.3247 |
| PDM | 26.9306 | 0.7974 | 0.1448 | 2.4972 | 39.4940 | 3.9635 | 29.5434 | 0.9114 | 0.1493 | 3.3518 | 25.3235 | 5.3953 |
| SDFlow | 34.8498 | 0.9665 | 0.0439 | 4.9370 | 22.2988 | 2.2314 | 34.6937 | 0.9533 | 0.0790 | 4.0524 | 15.0068 | 2.2387 |
Table 3 shows the quantitative comparison of downscaled HR images using various image downscaling methods on the RealSR and DRealSR test datasets. The proposed SDFlow achieves the best performance on the PSNR, SSIM, LPIPS, and FID metrics and the second-best performance on the IFC metric. The lower FID score means that the distribution of synthesized LR images is closer to the distribution of the ground truth. Thus, the LR images generated by the proposed SDFlow are more realistic as the real-world LR images than that of the compared image downscaling methods. As to the diversity metric, DeFlow and PDM obtain higher score. However, purely high diversity does not indicate high accurate diverse results [65]. The high diversity score is attributed to the added quantization noise [22] synthetic noise [24]. We experimentally find that when noise is removed, diversity score of DeFlow and PDM drops significantly below that of the SDFlow. For the other compared image downscaling methods, ADL obtains the second best performance on the PSNR and SSIM metrics, while Pseudo-supervision achieves the second best FID score.
Additionally, we also present visual comparison of downscaled real-world HR images generated by different image downscaling methods. Fig. (5) illustrates the downscaled real-world HR images on the RealSR test dataset. Sample images are selected with complex textures and structural contents to better compare degradation effects. From Fig. (5) we can observe that the Bicubic downscaled HR images are sharper than that of the other methods, since Bicubic can be treated as the ideal downscaling with a simple and limited degrees of degradation. LR images synthesized by the Impressionism and SRResCGAN model are blurry than ground-truth images, while DASR and PDM generate sharper LR images than the ground-truth. LR images generated by ADL, Pseudo-supervision, DeFlow, and the proposed SDFlow are more perceptually similar to the real-world LR images than the other compared methods.
Another way to evaluate the quality of the downscaled images against the real-world LR images is to train the same SISR model using paired real-world HR/LR images and synthesize HR/LR images, then compare their SR performance. We compare the quality of degraded LR images produced by the proposed SDFlow with two state-of-the-art unpaired diverse image degradation modeling methods, i.e., the DeFlow [22] and PDM [24]. We train ESRGAN [52] on synthesized HR/LR image pairs generated by the three models. We also train ESRGAN on the real-world HR/LR image pairs of the RealSR and DRealSR as a baseline for a better comparison. All of the trained ESRGAN models are tested on the RealSR and DRealSR test dataset. Table 4 shows the quantitative SR results of LR images generated by different downscaling methods. As can be observed, the SR performance on LR images generated by the proposed SDFlow achieves the best on the PSNR metric, and DeFlow achieves the best on the SSIM and IFC metrics. However, PSNR, SSIM and IFC are not suitable for evaluating GAN based SR methods [70], thus, they are used only as a reference. As to the perceptual-oriented LPIPS and no-reference visual quality evaluation metrics, ESRGAN trained on real-world paired HR/LR image pairs obtains the best performance. The proposed SDFlow achieves the second-best performance on the perceptual-oriented metrics and obtains comparable performance on the full-reference metric with that of ESRGAN trained on real-world HR/LR image pairs.
| Downscaling methods | RealSR | DRealSR | ||||||||||||||
| Full-reference | No-reference | Full-reference | No-reference | |||||||||||||
| PSNR | SSIM | LPIPS | IFC | NIQE | PIQE | NRQM | PSNR | SSIM | LPIPS | IFC | NIQE | PIQE | NRQM | |||
|
27.2406 | 0.7628 | 0.2132 | 1.0632 | 5.2841 | 44.7392 | 5.6829 | 29.6088 | 0.8110 | 0.2434 | 0.7673 | 5.8348 | 40.9859 | 4.9613 | ||
| DeFlow | 26.9231 | 0.7942 | 0.3356 | 1.1154 | 7.2015 | 75.4913 | 3.3002 | 28.7793 | 0.8554 | 0.3734 | 0.8279 | 9.1133 | 78.2641 | 2.7917 | ||
| PDM | 26.5699 | 0.7614 | 0.2634 | 1.0041 | 5.4842 | 51.7233 | 4.6282 | 29.0866 | 0.8457 | 0.3332 | 0.8072 | 7.4917 | 54.4887 | 3.1469 | ||
| SDFlow | 27.3099 | 0.7674 | 0.2262 | 1.0746 | 5.2521 | 46.3027 | 5.5458 | 30.2033 | 0.8483 | 0.2832 | 0.8144 | 7.0189 | 50.2428 | 3.7117 | ||
Fig. (6) illustrates the visual results of SR images generated by ESRGAN trained on HR/LR image pairs synthesized by each of the diverse image degradation modeling methods. Local regions that are abundant in textures or with structural content are zoomed in for better perceptual comparison. As can be observed, the visual quality of SR images generated by ESRGAN trained on HR/LR image pairs synthesized by the proposed SDFlow is comparable to that of ESRGAN trained on real-world HR/LR image pairs, which mostly resembles ground truth. As to the visual quality of SR images of ESRGAN trained on HR/LR image pairs synthesized by DeFlow and PDM, the SR results of LR images generated by PDM have sharper edges but also have more artifacts than that of DeFlow. In conclusion, the LR images produced by the proposed SDFlow are more realistic as the real-world LR images than that of the compared diverse image degradation methods in terms of SR using the same SR architecture.
4.4 Model analysis and ablation studies
In this section, we conduct ablation studies to investigate the effects of different model configurations on the performance of the proposed SDFlow. Ablation studies are grouped into two parts, the first part is ablation studies on the Super-resolution Flow and the second part is ablation studies on the Downscaling Flow.
| RealSR | DRealSR | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full-reference | No-reference | Full-reference | No-reference | |||||||||||||||
| PSNR | SSIM | LPIPS | IFC | Diversity | NIQE | PIQE | NRQM | PSNR | SSIM | LPIPS | IFC | Diversity | NIQE | PIQE | NRQM | |||
|
15.5997 | 0.5967 | 0.7849 | 0.2151 | - | - | - | - | 16.0491 | 0.7327 | 0.7161 | 0.2309 | - | - | - | - | ||
|
20.7647 | 0.6657 | 0.5750 | 0.4874 | 8.3426 | 7.8056 | 62.5859 | 3.0516 | 26.5049 | 0.8420 | 0.4998 | 0.7588 | 3.3082 | 9.2056 | 81.2649 | 2.6908 | ||
|
28.3252 | 0.8054 | 0.2606 | 0.9766 | 14.2803 | 6.1460 | 61.2127 | 4.5089 | 30.6693 | 0.8692 | 0.2903 | 0.7891 | 12.3829 | 7.8669 | 75.0254 | 3.2559 | ||
|
28.4586 | 0.8099 | 0.2353 | 1.0185 | 14.0293 | 5.8799 | 57.2166 | 4.5649 | 30.7752 | 0.8709 | 0.2864 | 0.8065 | 11.3952 | 7.7682 | 73.9877 | 3.3323 | ||
| Full model | 28.5813 | 0.8118 | 0.2321 | 1.0448 | 11.9467 | 5.7145 | 55.3054 | 4.6572 | 31.0747 | 0.8726 | 0.2852 | 0.8368 | 10.0632 | 7.6900 | 71.2724 | 3.4047 | ||

4.4.1 Ablation studies on the Super-resolution Flow
As the main idea of the proposed SDFlow is to decouple content information from the HR and LR images and map them to the same latent space. Therefore, we analyze the effects of latent space learning on the performance of the SDFlow. First, we remove the content loss (Eq. (17)) in training the SDFlow. As shown in w/o content loss in Table 5, the model did not converge since the flow network cannot determine which part is the content when factorizing the latent variable. With the employment of the content loss, the SDFlow can learn to capture the content information close to the low-pass filtered LR and BD downscaled HR image. However, the domain gap between the content latent variables of LR and HR images still exists. Thus, as shown in w/o content discriminator in Table 5, without the content discriminator (Eq. (18)), the model performs poorly. Next, we analyze the distribution modeling of the HF components. As discussed in Section 3.3.2, we use a conditional flow branch to further transform the HF latent variable into a standard normal distribution. To validate the effects, we remove the conditional flow branch and directly Gaussianize the HF latent variable. Results are reported as Direct Gaussianization in Table 5, due to the lack of sufficient modeling ability, direct Gaussianization leads to inferior performance when compared to the full model. Further, we analyze the condition effects provided by the content latent variable, based on the direct Gaussianization, we add a 1 conditional flow step to transform the HF latent variable into the standard normal distribution. As shown in Conditional Gaussianization in Table 5, the added conditional variable improves the performance of SR.
Here, we analyze the effects of the sampling temperature on SR performance of the proposed SDFlow in terms of PSNR and LPIPS. The sampling temperature controls the variance of the latent variable of the HF components when generating the SR image. As shown in Fig. (7), the decreased sampling temperature, i.e., , increases the image quality in terms of LPIPS, and the best LPIPS is obtained when . The sampling procedure becomes deterministic when decreases to 0, which achieves the best performance on the PSNR metric. However, the generated SR images are blurry as illustrated in Fig. (4). Increasing the sampling temperature leads to notable improvements in perceptual quality in terms of the LPIPS metric while degrades the distortion oriented PSNR metric. When the sampling temperature is set to larger than 1, we can observe a significant performance drop on the LPIPS and PSNR metric. Fig. (7) also shows the perception-distortion trade-off of the SR provided by the SDFlow, and it can be controlled by adjusting the sampling temperature.
To intuitively investigate the effects of the sampling temperature on the generated SR image, we present visual comparison of SR images generated with different sampling temperature in Fig. (8). Additionally, we also calculate the difference between SR images generated with and SR images generated with . We can observe that the different sampling temperatures only focus on adding high-frequency contents with different strength. With the increase of the sampling temperature, more perceptible high-frequency contents are produced. However, large sampling temperature will lead to exaggerated textures and distorted edges.
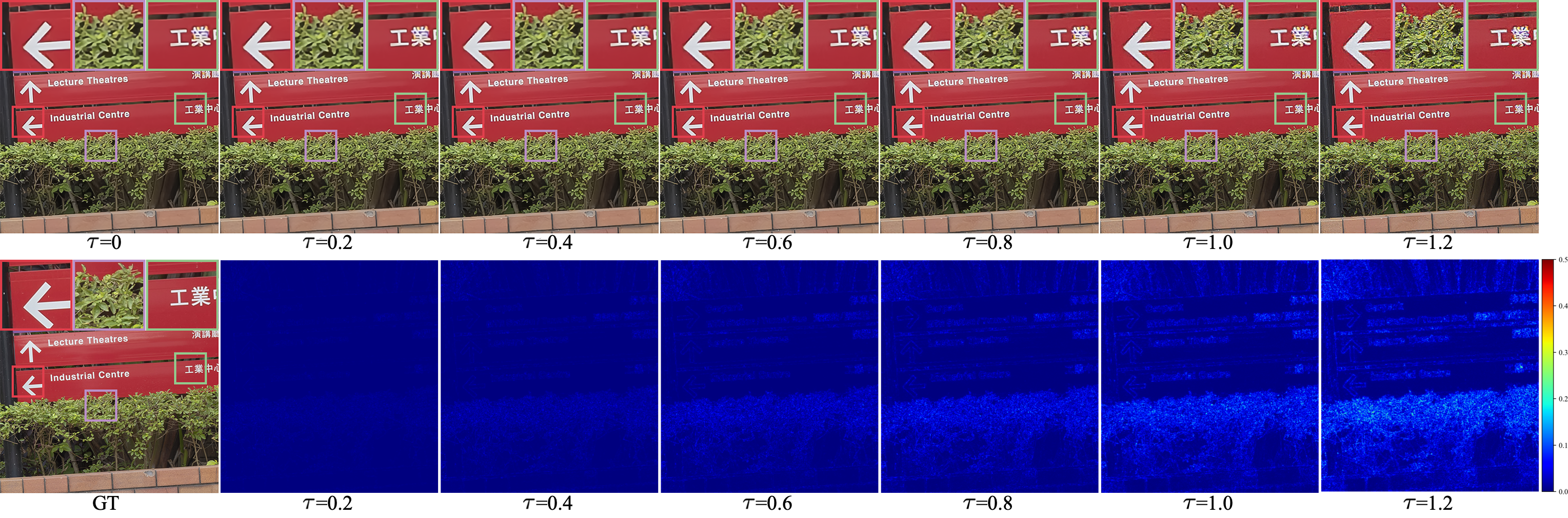
4.4.2 Ablation studies on the Downscaling Flow
Here we conduct ablation studies on the Downscaling Flow of the SDFlow. Similar to the ablation studies for the Super-resolution Flow, we first remove the content loss (Eq. (17)) from the training objectives. As shown in w/o content loss in Table 6, the model failed to converge since the content feature extractor cannot learn to keep content information without any guidance. Then, we remove the content domain discriminator to validate the effects of the remaining content domain gap on the performance of the downscaling model. As shown in w/o content discriminator in Table 6, performance of the Downscaling Flow drops significantly. LR images are produced by the Downscaling Flow, which takes content latent variable of the HR image and sampled degradation information as input. To validate the effects of the sampled degradation information, we generate LR images without adding the sampled degradation. As shown in w/o degradations in Table 6, generating downscaled images without sampled degradations undermines the performance of the Downscaling Flow, especially on the FID metric. Finally, we investigate the effectiveness of the proposed base distribution modeling of the transformed degradation information using learned mixture of Gaussians. As shown in Standard Normal Distribution in Table 6, modeling the base distribution of the degrdation information using the standard normal distribution obtains slightly inferior performance on the full-reference metrics. Modeling the base distribution of the degradation information using the mixture of Gaussians improves the FID score.
| RealSR | DRealSR | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | IFC | FID | Diversity | PSNR | SSIM | LPIPS | IFC | FID | Diversity | |
| w/o content loss | 14.2424 | 0.2606 | 0.6935 | 0.1947 | - | - | 15.1371 | 0.4414 | 0.6994 | 0.2603 | - | - |
| w/o degradations | 32.5555 | 0.9447 | 0.1130 | 4.7147 | 45.6483 | - | 33.6884 | 0.9424 | 0.1123 | 3.8736 | 38.1845 | - |
| w/o content discriminator | 17.4049 | 0.4785 | 0.4575 | 2.6089 | 83.5019 | 4.1993 | 23.3012 | 0.6376 | 0.4944 | 1.9687 | 71.2011 | 6.6017 |
| Standard Normal Distribution | 34.6329 | 0.9648 | 0.0449 | 4.9109 | 23.8114 | 2.7137 | 34.4680 | 0.9513 | 0.0821 | 4.0311 | 16.3796 | 2.6696 |
| Full model | 34.7852 | 0.9665 | 0.0444 | 4.9730 | 22.6374 | 2.7934 | 34.5026 | 0.9521 | 0.0824 | 4.0338 | 15.7554 | 2.7269 |
One of the prominent features of the SDFlow is that it learns the conditional distribution of the degradation information given the image content latent variable, and thereby it can generate diverse downscaled (degraded) LR images of the input HR image. Also, the Downscaling Flow of the SDFlow can generate LR images with degradations at different strengths, which is achieved by sampling the standard normal distribution of the transformed degradation latent variables with different sampling temperatures. Fig. (9) illustrates the visual results of the downscaled images generated with different sampling temperatures. Differences between downscaled images generated with different sampling temperatures are barely visual perceptible. Thus, we also calculate the difference between downscaled images generated with and downscaled image generated with . As shown in Fig. (9), differences between downscaled images generated with different sampling temperatures are mainly located in regions with high-frequency contents. Additionally, with the increasing of sampling temperature, the degradation effects are enhanced. When , nuanced degradations are imposed, and amplified the degradations.

5 Conclusion
Image super-resolution and downscaling modelling in real-world scenarios is challenging due to the ill-posed nature of the task and lack of ideal paired training data. In this paper, we propose an invertible model, named SDFlow, which simultaneously learns the bidirectional many-to-many mapping for real-world image super-resolution and downscaling from unpaired data. The main idea of the proposed method is to discover the shared image content representation space between real-world HR and LR images, and to model the distribution of the remaining HF information and degradation information in the latent space. We derive the solution under the variational inference framework and solve it using the invertible SDFlow, in which the Super-resolution Flow decouples the HR image into content and HF latent variables, and the Downscaling Flow decouples the LR image into content and degradation latent variables. Content representations of the HR and LR image are mapped into the shared latent space under the GAN framework, HF and degradation latent variables are transformed into an easy-to-sample distribution space using the conditional normalizing flow. Diverse image super-resolution and downscaling are realized by first obtaining the content representation using the forward pass of the Super-resolution Flow or the Downscaling Flow; then latent representation of the HF and degradation are sampled conditioned on the content representation; SR image and the downscaled image are generated using the backward pass of the Super-resolution Flow and Downscaling Flow by taking the combination of content and HF or degradation latent variables as input, respectively. Experimental results indicate that the proposed SDFlow model achieves the state-of-the-art SR performance in unpaired learning settings, while it can still generate more diverse realistic real-world LR images.
References
- Yang and Huang [2017] Jianchao Yang and Thomas Huang. Image super-resolution: Historical overview and future challenges. In Super-resolution imaging, pages 1–34. CRC Press, 2017.
- Yang et al. [2019] Wenming Yang, Xuechen Zhang, Yapeng Tian, Wei Wang, Jing-Hao Xue, and Qingmin Liao. Deep learning for single image super-resolution: A brief review. IEEE Transactions on Multimedia, 21(12):3106–3121, 2019.
- Wang et al. [2020] Zhihao Wang, Jian Chen, and Steven CH Hoi. Deep learning for image super-resolution: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(10):3365–3387, 2020.
- Chen et al. [2022] Honggang Chen, Xiaohai He, Linbo Qing, Yuanyuan Wu, Chao Ren, Ray E Sheriff, and Ce Zhu. Real-world single image super-resolution: A brief review. Information Fusion, 79:124–145, 2022.
- Liu et al. [2022] Anran Liu, Yihao Liu, Jinjin Gu, Yu Qiao, and Chao Dong. Blind image super-resolution: A survey and beyond. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022.
- Wei et al. [2020] Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixiang Ye, Wangmeng Zuo, and Liang Lin. Component divide-and-conquer for real-world image super-resolution. In European Conference on Computer Vision, 2020.
- Chen et al. [2019a] Chang Chen, Zhiwei Xiong, Xinmei Tian, Zheng-Jun Zha, and Feng Wu. Camera lens super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, 2019a.
- Cai et al. [2019] Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. Toward real-world single image super-resolution: A new benchmark and a new model. In IEEE International Conference on Computer Vision, 2019.
- Chen et al. [2019b] Chang Chen, Zhiwei Xiong, Xinmei Tian, ZhengJun Zha, and Feng Wu. Camera lens super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, 2019b.
- Köhler et al. [2019] Thomas Köhler, Michel Bätz, Farzad Naderi, André Kaup, Andreas Maier, and Christian Riess. Toward bridging the simulated-to-real gap: Benchmarking super-resolution on real data. IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(11):2944–2959, 2019.
- Joze et al. [2020] Hamid Reza Vaezi Joze, Ilya Zharkov, Karlton Powell, Carl Ringler, Luming Liang, Andy Roulston, Moshe Lutz, and Vivek Pradeep. Imagepairs: Realistic super resolution dataset via beam splitter camera rig. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, pages 518–519, 2020.
- Sun et al. [2021] Wei Sun, Dong Gong, Qinfeng Shi, Anton van den Hengel, and Yanning Zhang. Learning to zoom-in via learning to zoom-out: Real-world super-resolution by generating and adapting degradation. IEEE Transactions on Image Processing, 30:2947–2962, 2021.
- Son et al. [2022] Sanghyun Son, Jaeha Kim, Wei-Sheng Lai, Ming-Hsuan Yang, and Kyoung Mu Lee. Toward real-world super-resolution via adaptive downsampling models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(11):8657–8670, 2022.
- Wei et al. [2021] Yunxuan Wei, Shuhang Gu, Yawei Li, Radu Timofte, Longcun Jin, and Hengjie Song. Unsupervised real-world image super resolution via domain-distance aware training. In IEEE Conference on Computer Vision and Pattern Recognition, 2021.
- Maeda [2020] Shunta Maeda. Unpaired image super-resolution using pseudo-supervision. In IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- Lugmayr et al. [2019] Andreas Lugmayr, Martin Danelljan, and Radu Timofte. Unsupervised learning for real-world super-resolution. In IEEE International Conference on Computer Vision Workshop, 2019.
- Fritsche et al. [2019] Manuel Fritsche, Shuhang Gu, and Radu Timofte. Frequency separation for real-world super-resolution. In IEEE International Conference on Computer Vision Workshop, 2019.
- Yuan et al. [2018] Yuan Yuan, Siyuan Liu, Jiawei Zhang, Yongbing Zhang, Chao Dong, and Liang Lin. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018.
- Bulat et al. [2018] Adrian Bulat, Jing Yang, and Georgios Tzimiropoulos. To learn image super-resolution, use a gan to learn how to do image degradation first. In European Conference on Computer Vision, 2018.
- Goodfellow et al. [2014] Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, 2014.
- Romero et al. [2022] Andrés Romero, Luc Van Gool, and Radu Timofte. Unpaired real-world super-resolution with pseudo controllable restoration. In IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- Wolf et al. [2021] Valentin Wolf, Andreas Lugmayr, Martin Danelljan, Luc Van Gool, and Radu Timofte. Deflow: Learning complex image degradations from unpaired data with conditional flows. In IEEE Conference on Computer Vision and Pattern Recognition, 2021.
- Ning et al. [2022] Qian Ning, Jingzhu Tang, Fangfang Wu, Weisheng Dong, Xin Li, and Guangming Shi. Learning degradation uncertainty for unsupervised real-world image super-resolution. In International Joint Conference on Artificial Intelligence, 2022.
- Luo et al. [2022] Zhengxiong Luo, Yan Huang, Shang Li, Liang Wang, and Tieniu Tan. Learning the degradation distribution for blind image super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- Lee et al. [2022] Sangyun Lee, Sewoong Ahn, and Kwangjin Yoon. Learning multiple probabilistic degradation generators for unsupervised real world image super resolution. In European Conference on Computer Vision Workshops, 2022.
- Dinh et al. [2015] Laurent Dinh, David Krueger, and Yoshua Bengio. NICE: non-linear independent components estimation. In International Conference on Learning Representations, 2015.
- Dinh et al. [2017] Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real NVP. In International Conference on Learning Representations, 2017.
- Kingma and Dhariwal [2018] Durk P Kingma and Prafulla Dhariwal. Glow: Generative flow with invertible 1x1 convolutions. Advances in neural information processing systems, 31, 2018.
- Guo et al. [2020] Yong Guo, Jian Chen, Jingdong Wang, Qi Chen, Jiezhang Cao, Zeshuai Deng, Yanwu Xu, and Mingkui Tan. Closed-loop matters: Dual regression networks for single image super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, 2020.
- Xiao et al. [2020] Mingqing Xiao, Shuxin Zheng, Chang Liu, Yaolong Wang, Di He, Guolin Ke, Jiang Bian, Zhouchen Lin, and Tie-Yan Liu. Invertible image rescaling. In European Conference on Computer Vision, 2020.
- Liang et al. [2021a] Jingyun Liang, Andreas Lugmayr, Kai Zhang, Martin Danelljan, Luc Van Gool, and Radu Timofte. Hierarchical conditional flow: A unified framework for image super-resolution and image rescaling. In IEEE International Conference on Computer Vision, 2021a.
- Ji et al. [2020] Xiaozhong Ji, Yun Cao, Ying Tai, Chengjie Wang, Jilin Li, and Feiyue Huang. Real-world super-resolution via kernel estimation and noise injection. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020.
- Zhou and Susstrunk [2019] Ruofan Zhou and Sabine Susstrunk. Kernel modeling super-resolution on real low-resolution images. In IEEE International Conference on Computer Vision, 2019.
- Shocher et al. [2018] Assaf Shocher, Nadav Cohen, and Michal Irani. “zero-shot” super-resolution using deep internal learning. In IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- Bell-Kligler et al. [2019] Sefi Bell-Kligler, Assaf Shocher, and Michal Irani. Blind super-resolution kernel estimation using an internal-gan. Advances in Neural Information Processing Systems, 32:284–293, 2019.
- Kim et al. [2020] Jonghee Kim, Chanho Jung, and Changick Kim. Dual back-projection-based internal learning for blind super-resolution. IEEE Signal Processing Letters, 27:1190–1194, 2020.
- Emad et al. [2021] Mohammad Emad, Maurice Peemen, and Henk Corporaal. DualSR: Zero-shot dual learning for real-world super-resolution. In IEEE Winter Conference on Applications of Computer Vision, 2021.
- Chen et al. [2023] Honggang Chen, Xiaohai He, Hong Yang, Yuanyuan Wu, Linbo Qing, and Ray E Sheriff. Self-supervised cycle-consistent learning for scale-arbitrary real-world single image super-resolution. Expert Systems with Applications, 212:118657, 2023.
- Kobyzev et al. [2020] Ivan Kobyzev, Simon JD Prince, and Marcus A Brubaker. Normalizing flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):3964–3979, 2020.
- Ardizzone et al. [2019] Lynton Ardizzone, Jakob Kruse, Carsten Rother, and Ullrich Köthe. Analyzing inverse problems with invertible neural networks. In International Conference on Learning Representations, 2019.
- Lugmayr et al. [2020] Andreas Lugmayr, Martin Danelljan, Luc Van Gool, and Radu Timofte. Srflow: Learning the super-resolution space with normalizing flow. In European Conference on Computer Vision, 2020.
- Liang et al. [2021b] Jingyun Liang, Kai Zhang, Shuhang Gu, Luc Van Gool, and Radu Timofte. Flow-based kernel prior with application to blind super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition, 2021b.
- Abdelhamed et al. [2019] Abdelrahman Abdelhamed, Marcus A Brubaker, and Michael S Brown. Noise flow: Noise modeling with conditional normalizing flows. In IEEE International Conference on Computer Vision, 2019.
- Yu et al. [2020] Jason J Yu, Konstantinos G Derpanis, and Marcus A Brubaker. Wavelet flow: Fast training of high resolution normalizing flows. Advances in Neural Information Processing Systems, 33:6184–6196, 2020.
- Xing et al. [2021] Yazhou Xing, Zian Qian, and Qifeng Chen. Invertible image signal processing. In IEEE Conference on Computer Vision and Pattern Recognition, 2021.
- Liu et al. [2021] Yang Liu, Zhenyue Qin, Saeed Anwar, Pan Ji, Dongwoo Kim, Sabrina Caldwell, and Tom Gedeon. Invertible denoising network: A light solution for real noise removal. In IEEE Conference on Computer Vision and Pattern Recognition, 2021.
- Zhao et al. [2021] Rui Zhao, Tianshan Liu, Jun Xiao, Daniel PK Lun, and Kin-Man Lam. Invertible image decolorization. IEEE Transactions on Image Processing, 30:6081–6095, 2021.
- Wang et al. [2021a] Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. In IEEE International Conference on Computer Vision, 2021a.
- Zhang et al. [2022] Wenlong Zhang, Guangyuan Shi, Yihao Liu, Chao Dong, and Xiao-Ming Wu. A closer look at blind super-resolution: Degradation models, baselines, and performance upper bounds. In IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- Kingma and Welling [2014] Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In International Conference on Learning Representations, 2014.
- Papamakarios et al. [2021] George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, Shakir Mohamed, and Balaji Lakshminarayanan. Normalizing flows for probabilistic modeling and inference. The Journal of Machine Learning Research, 22(1):1–64, 2021.
- Wang et al. [2018] Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. In European Conference on Computer Vision Workshops, 2018.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition, 2016.
- Zhang et al. [2023] Jize Zhang, Haolin Wang, Xiaohe Wu, and Wangmeng Zuo. Invertible network for unpaired low-light image enhancement. The Visual Computer, pages 1–12, 2023.
- Simonyan and Zisserman [2015] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In International Conference on Learning Representations, 2015.
- Ledig et al. [2017] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo-realistic single image super-resolution using a generative adversarial network. In IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- Mao et al. [2017] Xudong Mao, Qing Li, Haoran Xie, Raymond Y.K. Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In IEEE International Conference on Computer Vision, 2017.
- Grover et al. [2018] Aditya Grover, Manik Dhar, and Stefano Ermon. Flow-gan: Combining maximum likelihood and adversarial learning in generative models. In AAAI conference on artificial intelligence, volume 32, 2018.
- Wang et al. [2004] Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 13(4):600–612, 2004.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In IEEE Conference on Computer Vision and Pattern Recognition, 2018.
- Sheikh et al. [2005] H.R. Sheikh, A.C. Bovik, and G. de Veciana. An information fidelity criterion for image quality assessment using natural scene statistics. IEEE Transactions on Image Processing, 14(12):2117–2128, 2005.
- Mittal et al. [2013] Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. Making a “completely blind” image quality analyzer. IEEE Signal Processing Letters, 20(3):209–212, 2013.
- N et al. [2015] Venkatanath N, Praneeth D, Maruthi Chandrasekhar Bh, Sumohana S. Channappayya, and Swarup S. Medasani. Blind image quality evaluation using perception based features. In National Conference on Communications, 2015.
- Ma et al. [2017] Chao Ma, Chih-Yuan Yang, Xiaokang Yang, and Ming-Hsuan Yang. Learning a no-reference quality metric for single-image super-resolution. Computer Vision and Image Understanding, 158:1–16, 2017.
- Lugmayr et al. [2021] Andreas Lugmayr, Martin Danelljan, Radu Timofte, Christoph Busch, Yang Chen, Jian Cheng, Vishal Chudasama, Ruipeng Gang, Shangqi Gao, Kun Gao, Laiyun Gong, Qingrui Han, Chao Huang, Zhi Jin, Younghyun Jo, Seon Joo Kim, Younggeun Kim, Seungjun Lee, Yuchen Lei, Chu-Tak Li, Chenghua Li, Ke Li, Zhi-Song Liu, Youming Liu, Nan Nan, Seung-Ho Park, Heena Patel, Shichong Peng, Kalpesh Prajapati, Haoran Qi, Kiran Raja, Raghavendra Ramachandra, Wan-Chi Siu, Donghee Son, Ruixia Song, Kishor Upla, Li-Wen Wang, Yatian Wang, Junwei Wang, Qianyu Wu, Xinhua Xu, Sejong Yang, Zhen Yuan, Liting Zhang, Huanrong Zhang, Junkai Zhang, Yifan Zhang, Zhenzhou Zhang, Hangqi Zhou, Aichun Zhu, Xiahai Zhuang, and Jiaxin Zou. Ntire 2021 learning the super-resolution space challenge. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2021.
- Ho et al. [2019] Jonathan Ho, Xi Chen, Aravind Srinivas, Yan Duan, and Pieter Abbeel. Flow++: Improving flow-based generative models with variational dequantization and architecture design. In International Conference on Machine Learning, 2019.
- Wang et al. [2021b] Wei Wang, Haochen Zhang, Zehuan Yuan, and Changhu Wang. Unsupervised real-world super-resolution: A domain adaptation perspective. In IEEE International Conference on Computer Vision, 2021b.
- Umer et al. [2020] Rao Muhammad Umer, Gian Luca Foresti, and Christian Micheloni. Deep generative adversarial residual convolutional networks for real-world super-resolution. In IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2020.
- Lugmayr et al. [2022] Andreas Lugmayr, Martin Danelljan, Fisher Yu, Luc Van Gool, and Radu Timofte. Normalizing flow as a flexible fidelity objective for photo-realistic super-resolution. In IEEE Winter Conference on Applications of Computer Vision, 2022.
- Jinjin et al. [2020] Gu Jinjin, Cai Haoming, Chen Haoyu, Ye Xiaoxing, Jimmy S Ren, and Dong Chao. Pipal: a large-scale image quality assessment dataset for perceptual image restoration. In European Conference on Computer Vision, 2020.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Advances in Neural Information Processing Systems, 2017.