Learning imaging mechanism directly from optical microscopy observations
Abstract
Optical microscopy image plays an important role in scientific research through the direct visualization of the nanoworld, where the imaging mechanism is described as the convolution of the point spread function (PSF) and emitters. Based on a priori knowledge of the PSF or equivalent PSF, it is possible to achieve more precise exploration of the nanoworld. However, it is an outstanding challenge to directly extract the PSF from microscopy images. Here, with the help of self-supervised learning, we propose a physics-informed masked autoencoder (PiMAE) that enables a learnable estimation of the PSF and emitters directly from the raw microscopy images. We demonstrate our method in synthetic data and real-world experiments with significant accuracy and noise robustness. PiMAE outperforms DeepSTORM and the Richardson-Lucy algorithm in synthetic data tasks with an average improvement of 19.6% and 50.7% (35 tasks), respectively, as measured by the normalized root mean square error (NRMSE) metric. This is achieved without prior knowledge of the PSF, in contrast to the supervised approach used by DeepSTORM and the known PSF assumption in the Richardson-Lucy algorithm. Our method, PiMAE, provides a feasible scheme for achieving the hidden imaging mechanism in optical microscopy and has the potential to learn hidden mechanisms in many more systems.
I Introduction
Optical microscopy is of great importance in scientific research to observe the nanoworld. The common view is that the Abbe diffraction limit describes the lower bound of the spot size and thus limits the microscopic resolution. However, recent studies have demonstrated that by designing and measuring the PSF or equivalent PSF of microscopy, it is possible to achieve sub-diffraction-limit localization of emitters. Techniques such as photoactivated localization microscopy Lee et al. (2012) and stochastic optical reconstruction microscopy Rust et al. (2006) attain super-resolution molecular localization through selective excitation and reconstruction algorithms that are based on the microscopy PSF. Spatial mode sorting-based microscopic imaging method (SPADE Bearne et al. (2021)) can be treated as a deconvolution problem using higher-order modes as the equivalent PSF. Stimulated-emission depletion microscopy achieves super-resolution imaging by introducing illumination with donut-shaped PSFs to selectively deactivate fluorophores Hell and Wichmann (1994); Chen et al. (2015). Additionally, deep learning-based methods, such as DeepSTORM Nehme et al. (2018) and DECODE Speiser et al. (2021), use deep neural networks (DNNs) to predict emitters in raw images by synthesizing training sets with the same PSFs as used in actual experiments. In all of these microscopic imaging techniques, a prior knowledge of the PSF is crucial, making it of great interest to develop a method for directly estimating the PSF from raw images.
Currently, some traditional algorithms such as Deconvblind Biggs and Andrews (1997) use maximum likelihood estimation to infer the PSF and emitters from raw images Chan and Wong (1998); Krishnan et al. (2011); Liu et al. (2014); Michaeli and Irani (2014); Pan et al. (2017, 2016); Ren et al. (2016); Sun et al. (2013); Yan et al. (2017); Zuo et al. (2016). However, these algorithms face two challenges. Firstly, they struggle to estimate PSFs with complex shapes. Secondly, they can lead to trivial solutions where the PSF is a -function and the image of the emitters is equal to the raw image. To tackle these issues, researchers have turned to using Deep Neural Networks (DNNs) Shajkofci and Liebling (2020). However, this requires a library of PSFs and a large amount of sharp microscope images to generate the training dataset, which limits the application of these algorithms.

We use self-supervised learning to overcome the above challenges. Here, we treat the PSF as the pattern hidden in the raw images and the emitters as the sparse representation of the raw image. As a result, we propose a physics-informed masked autoencoder (PiMAE, Fig 1) that estimates the PSF and emitters directly from the microscopy raw images. Using raw data synthesized by various simulated PSFs, we compare the results of PiMAE and Deconvblind Biggs and Andrews (1997) for estimating PSF, as well as PiAME, Richardson-Lucy algorithm Lucy (1974) and DeepSTORM Nehme et al. (2018) for localizing emitters. Our proposed self-supervised learning approach, PiMAE, outperforms existing algorithms without the need for data annotation or PSF measurement. PiMAE demonstrates a significant performance improvement, as measured by the NRMSE metric, and is highly resistant to noise. In tests with real-world experiments, PiMAE resolves wide-field microscopy images of standard PSF, out-of-focus PSF, and aberrated PSF with high quality, and the results achieve a resolution comparable to SIM results. Also, we demonstrates that 5 raw images can satisfy the requirements of self-supervised training. This approach, PiMAE, shows wide applicability in synthetic data testing and real-world experiments. We expect its usage for estimation of hidden mechanisms in various physical systems.
II Method
Self-supervised learning leverages the inherent structure or patterns in data to learn meaningful representations. There are two main categories: Contrastive Learning Oord et al. (2018); Wu et al. (2018); He et al. (2020); Chen et al. (2020a) and pretext task learning Doersch et al. (2015); Dosovitskiy et al. (2014); Devlin et al. (2018); Chen et al. (2020b, c). Mask Image Modeling (MIM) Chen et al. (2020d); Doersch et al. (2015); Henaff (2020); Pathak et al. (2016); Trinh et al. (2019) is a pretext task learning technique that randomly masks portions of an input image. Recently, MIM has been shown to learn transferable, robust, and generalized representations from visual images, improving performance in downstream computer vision tasks He et al. (2021). PiMAE is a MIM-based method that reconstructs raw images according to the imaging principle of optical microscopy.
II.1 PiMAE model.
The PiMAE model (Figure 1) consists of three key components: (1) a Vision Transformer-based Dosovitskiy et al. (2020) encoder-decoder architecture with a mask layer to prevent trivial solutions while estimating emitters, (2) a Convolutional Neural Network as a prior for PSF estimation Ulyanov et al. (2018), and (3) a microscopic imaging process that enforces adherence to the microscopy principle. Appendix A provides detailed information on the network architecture and the embedding of physical principle. PiMAE requires only a few raw images for training, which is attributed to the carefully designed loss function. The loss function consists of two parts: one measures the difference between the raw and the reconstruction images, including the mean of the absolute difference and the multi-scale structure similarity; the other part is a constraint on the PSF, including the total variation loss measuring the PSF continuity and the offset distance of the PSF’s center of mass. Appendix B contains the expressions for the loss functions.


II.2 Training.
The Vision Transformer (ViT) based encoder in PiMAE is pre-trained on the COCO dataset Lin et al. (2014) to improve performance. This pre-training relies on the self-supervised learning of a masked autoencoder, but does not incorporate any physical information (detailed in Appendix C). After pre-training, PiMAE loads the trained encoder parameters and undergoes self-supervised training using raw microscopic images. The input image size is 144 pixels, and we use the RAdam optimizer Liu et al. (2020) with a learning rate of and a batch size of 18. The training runs for steps.
Within PiMAE, the convolutional neural network, depicted in Figure 1, is initialized randomly and takes a fixed random vector as input, outputting the predicted PSF. Relevant details can be found in Appendix A. As PiMAE undergoes self-supervised training, the CNN’s predicted PSF continually becomes more accurate, moving closer to the true PSF as shown in Figure 2. The experimental setup is shown in Figure 3.
II.3 Synthetic data design
To evaluate PiMAE’s performance, synthetic datasets were designed taking into account the following factors: (1) PiMAE’s requirement for sparse emitter data, (2) the need for the emitter data to avoid discrete points for more challenging PSF estimation tasks, (3) the inclusion of both standard Gaussian shapes and other challenging PSF shapes, (4) raw image noise, and (5) emitter sparsity. The Sketches dataset Eitz et al. (2012) was chosen as the emitter, as described in Appendix G.1.1, and various commonly used PSFs were designed in Appendix G.2. The robustness to noise was evaluated by adding noise to the raw images at different levels. Moreover, images with sparse lines of varying densities were generated as emitters to assess the impact of sparsity on PiMAE, as described in Appendix G.1.2.
II.4 Real-world experiments
We evaluate PiMAE’s performance in handling both standard and non-standard PSF microscopy images in real-world experiments. Since the true emitter positions cannot be obtained, we use the BioSR Qiao et al. (2021) dataset to evaluate PiMAE’s handling of standard PSF microscopy images and compare it with structured illumination microscopy (SIM). Then, we use our custom-made wide-field microscope to produce out-of-focus and distorted PSF microscopy images to qualitatively analyze PiMAE’s performance in handling non-standard PSF microscopy images.
II.4.1 Wide field microscopic imaging of NV color centers
A 532 nm (COHERENT Vendi 10 Single longitudinal mode laser) laser passes through a customized precision electronic timing shutter, which controls the duration of the laser beams flexibly. The laser is then expanded and sent to polarization mode controller which consists of a polarizing film (LPVISE100-A) and a half wave plate (thorlabs WPH10ME-532). The extended laser is focused to the focal plane behind the objective lens (Olympus, UPLFLN100XO2PH) by a fused quartz lens with a focal length of 150 mm. The fluorescence signals are collected by a scientific complementary metal oxide semiconductor (sCMOS) camera (Hamamatsu, Orca Flash 4.0 v.3). We use a manual zoom lens (NIKON AF 70-300 mm,f/4-5.6G, focal length between 70 mm and 300 mm, and the field of view of 6.3) as tubelens to continuously change the magnification of the microscopic system.
III Result
III.1 PiMAE achieves high accuracy on synthetic datasets.
We use samples from the Sketches Eitz et al. (2012) dataset as emitters and synthesize raw data for various microscopy scenarios by convolving the emitters with the simulated PSFs. For each scenario, we sample 1000 images from the Sketches dataset as the training set and 100 images as the test set. In Appendix L, we show that PiMAE can achieve good training results even with a minimum of 5 images in the training set. To evaluate the PSF estimasution, we use Deconvblind Biggs and Andrews (1997) as benchmark. To evaluate the localization accuracy of emitters, we utilize the Richardson-Lucy algorithm Lucy (1974) and DeepSTORM Nehme et al. (2018) as reference methods. The results are measured by NRMSE. It is worth noting that the PSF is assumed to be known a priori during the testing of the Richardson-Lucy algorithm and DeepSTORM, while in the case of PiMAE, the PSF is treated as unknown.
Out-of-focus is one of the most common factors that can affect the quality of microscope imaging. PiMAE is capable of addressing this issue, and we demonstrate this by simulating a range of wide field microscopy PSFs with out-of-focus distances that vary from 0 nm to 1400 nm. We also add Gaussian noise with a scale of to raw images, where is the standard deviation of Gaussian noise Fisher et al. (2013) and is the mean value of the raw image. First, we evaluate the performance of estimated PSFs. Figure 3a shows the actual PSFs and those estimated by Deconvblind and PiMAE. The PiMAE estimated PSF is similar to the actual PSF for all out-of-focus distances, while most of Deconvblind’s estimated PSFs are far from the truth, indicating that Deconvblind cannot resolve raw images with complex PSFs. Furthermore, the estimated PSF by Deconvblind converges to the -function after several iterations (see Appendix D.1). The NRMSE of the estimated PSFs at different out-of-focus distances is quantified in Figure 3b, with PiMAE achieving much better results than Deconvblind. Second, we evaluate the performance of estimated emitters. Figure 3a also shows the actual emitters and those estimated by the Richardson-Lucy algorithm, DeepSTORM, and PiMAE. When the out-of-focus distance is large, PiMAE and DeepSTORM significantly outperform the Richardson-Lucy algorithm. The NRMSE at different out-of-focus distances is shown in Figure 3c, with PiMAE achieving the best performance despite having no knowledge of the actual PSF.
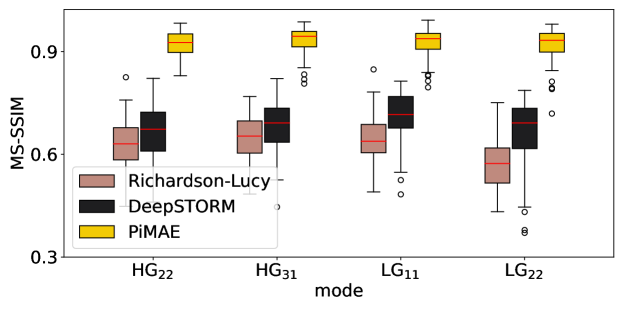
Recently, researchers have found that imaging resolution can be improved using a spatial pattern sorter Tsang et al. (2016); Bearne et al. (2021); Shajkofci and Liebling (2020), a method referred to as SPADE. Using SPADE for confocal microscopy is equivalent to using PSFs corresponding to spatial modes Bearne et al. (2021), such as Zernike modes, Hermite-Gaussian (HG) modes and Laguerre-Gaussian (LG) modes. However, SPADE faces several challenges, including the need for an accurate determination of the spatial mode (i.e., the equivalent PSF), sensitivity to noise, and a lack of reconstruction algorithms for complex spatial modes. PiMAE can solve these problems. Figure 3(d-f) show the SPADE imaging results with noise scale . PiMAE can accurately estimate the equivalent PSF and emitters, and the performance is much better than that of the Deconvblind, Richardson-Lucy algorithm and DeepSTORM. Therefore, PiMAE can significantly improve the performance of SPADE. These experiments demonstrate that PiMAE is effective for scenarios with unknown and complex imaging PSFs.

III.2 Noise robustness
Noise robustness is a crucial metric for evaluating reconstruction algorithms. We evaluate noise robustness in three scenarios: (1) in-focus wide field microscopy; (2) wide-field microscopy at 600 nm out-of-focus distance; (3) Laguerre-Gaussian mode SPADE imaging. The raw image of each scenario contains Gaussian noise at scales () of 0.01, 0.1, 0.5, 1, and 2, as shown in Figure 4. We first compare the results of Deconvblind and PiMAE for estimating PSF. We find that PiMAE shows excellent noise immunity, substantially outperforming Deconvblind in all tests. We then compare the results of the Richardson-Lucy algorithm, DeepSTORM, and PiMAE for estimating the emitters. Overall, PiMAE performs the best, only slightly behind DeepSTORM in the standard PSF results at low noise. The Richardson-Lucy algorithm performs similarly to DeepSTORM and PiMAE when the noise scale is very small. However, when the noise scale slightly increases, its performance significantly decreases. This shows the advantage of deep learning-based methods over traditional algorithms in terms of noise robustness. Moreover, the advantage of PiMAE over the other two algorithms increases as the scale of the noise becomes larger and the shape of the PSF becomes more complex.

III.3 PiMAE enables image super-resolution for wide-field microscopy comparable to SIM
The endoplasmic reticulum (ER) is a system of tunnels surrounded by membranes in eukaryotic cells. In the dataset BioSR Qiao et al. (2021), the researchers imaged the ER in the same field of view using wide-field microscopy and SIM, respectively. Figure 5a shows the results of PiMAE-resolved wide-field microscopy raw images. We find that the resolution of the PiMAE estimated emitter is comparable to that of SIM, which has a resolution twice that of the diffraction limit. Figure 5b shows the cross section results, where the peak positions of the PiMAE estimated emitter match the peak positions of the SIM results, corresponding to indistinguishable wide-field imaging results. This indicates that the resolvability of the results of wide-field microscopy with PiMAE estimated emitters is improved to a level similar to that of SIM. Figure 5c shows the results of the PiMAE estimated PSF with FWHM of 230 nm. The fluorescence wavelength of the raw image is 488 nm, the numerical aperture (NA) is 1.3, and its diffraction limit is , which is very close to the FWHM of the PiMAE estimated PSF. This experiment shows that PiMAE can be applied to real-world experiments to estimate PSF from raw microscopy data and further improve resolution.
III.4 PiMAE enables imaging for non-standard wide-field microscopy
The nitrogen-vacancy (NV) color center is a point defect in diamond which is widely used in super-resolution microscopy Chen et al. (2015); Han et al. (2009) and quantum sensing Chen et al. (2021); Degen et al. (2017). We make a home-built wide field microscope to image NV center in fluorescent nanodiamonds (FND) at out-of-focus distances of 0 nm, 400 nm and 800 nm. We take 10 raw images with a size of 2048 pixels and a field of view size of 81.92 µm at each out-of-focus distances. Figure 6a shows that we image NV color centers in the same field of view at different out-of-focus distance and Figure 6b shows the corresponding PiMAE estimated emitters. This is a side-by-side demonstration of the accuracy of the PiMAE estimated emitters. The out-of-focus distance changes during the experiment, but the field of view is invariant. Therefore, the PiMAE estimated emitter position should be constant at each out-of-focus distance, as we observe in Figure 6b-c. Figure 6d shows that the variation of the PSF. The asymmetry of the PSF comes from the slight tilt of the carrier stage. Also we show the PSF cross section for each scene. The FWHM of the estimated PSF at focus is 382 nm, which corresponds to a diffraction limit of 384 nm. This suggests that PiMAE can be applied in real-world experiments to improve the imaging capabilities of microscopes suffering from out-of-focus.

Moreover, we construct a non-standard PSF for wide-field microscopic imaging of NV color centers by making the objective mismatch with the coverslip, and the results are shown in Figure 6e-g. Figure 6e shows the imaging results and PiMAE estimated emitters. Figure 6f shows the results of the cross-sectional comparison. Figure 6g shows the PiMAE estimated PSF. This experiment demonstrates that PiMAE enables researchers to use microscopy with non-standard PSFs for imaging. And PiMAE’s ability to resolve non-standard PSFs expands the application scenarios of NV color centers in fields such as quantum sensing and bioimaging.
III.5 PiMAE enables microscopy imaging with widely spread out PSF
Further testing the capabilities of PiMAE, we evaluate the performance of PiMAE on complex widely spread out PSF, represented by the character "USTC". We use 1000 images as the training set and 100 images as the test set. The noise level is set at . The results of the raw images, the PiMAE processed images, and the evaluation of the NRMSE metric are depicted in Figure 7. PiMAE performed exceptionally well, demonstrating its effectiveness in difficult scenarios.

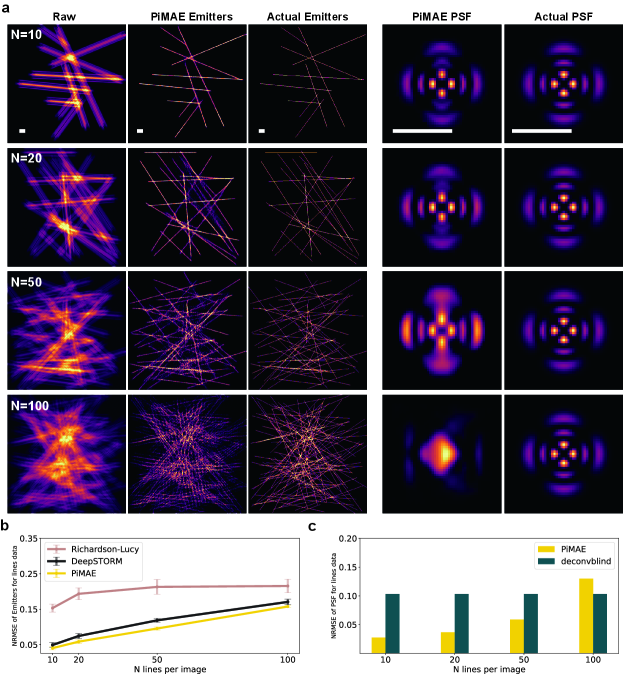
III.6 Evaluation of the influence of emitter sparsity
Dense samples can pose challenges for estimating both the PSF and the emitters. We designed emitters with varying densities as outlined in Appendix G.1.2, and employed as the PSF. As shown in Figure 8, we observe that as the number of lines in each image () increases, PiMAE’s performance in estimating both the PSF and emitters deteriorates. Intuitively, when the number of lines in each image is less than or equal to 50, PiMAE performs well, while performance is poor when the number of lines is greater than 50. This process allows us to assess the influence of sparsity in the emitters on PiMAE.
III.7 Computational Resource and Speed
In this work, the code is written using the Python library PyTorch. PyTorch is a prominent open-source deep learning framework that offers an efficient and user-friendly platform for building and deploying deep learning models. In terms of model training, we utilize three Nvidia Tesla A100 40GB graphics cards in parallel, which is necessary due to ViT’s substantial computational and memory requirements. The training time for each task is 11 hours and the inference time for a single image is approximately 4s with the trained model. Compared to supervised models such as DeepSTORM, which takes about 1 hour for training and 0.1s for inference, PiMAE is slower but more powerful.
IV Discussion
In this study, we introduce PiMAE, a novel approach for estimating PSF and emitters directly from raw microscopy images. PiMAE addresses several challenges: it allows for direct identification of the PSF from raw data, enabling deep learning model training without the need for real-world or synthetic annotation; it has excellent noise resistance; and it is convenient and widely applicable, requiring only about 5 raw images to resolve the PSF and emitters.
Our method, PiMAE, extracts hidden variables from raw data using physical knowledge. By recognizing PSF as a hidden variable in a linear optical system, the underlying physical principle involves the decomposition of raw data through the convolution of the emitters with the PSF. Hidden variables are ubiquitous in real-world experiments, by integrating masked autoencoder and physical knowledge PiMAE provides a framework to solve hidden variables in physical systems through self-supervised learning.
However, it should be noted that PiMAE is an emitter localization algorithm, which means that it requires a sufficient degree of sample sparsity to perform effectively. We conducted a evaluation using synthetic data experiments, and while PiMAE performed reasonably well, there is still room for improvement. Therefore, future work could focus on further enhancing the robustness of PiMAE for use in low sparsity scenarios.
V Conclusion
In conclusion, we have presented PiMAE, a novel solution for directly extracting the PSF and emitters from raw optical microscopy images. By combining the principles of optical microscopy with self-supervised learning, PiMAE demonstrates impressive accuracy and noise robustness in synthetic data experiments, outperforming existing methods such as DeepSTORM and the Richardson-Lucy algorithm. Moreover, our method has been successfully applied to real-world microscopy experiments, resolving wide-field microscopy images with various PSFs. With its ability to learn the hidden mechanisms from raw data, PiMAE has a wide range of potential applications in optical microscopy and scientific studies.
Acknowledgements The authors would like to thank Drs. Yu Zheng, Yang Dong, Ce Feng and Shao-Chun zhang for fruitful discussions.
Disclosures. The authors declare no conflicts of interest.
Appendix A Network architecture
The principle of microscopic imaging is:
| (1) |
where the raw image is the result of convolving the emitters and the PSF with the presence of noise and background. To put this principle into practice, we have developed the PiMAE method, which consists of three modules: emitter inference from raw images, PSF generation, and background separation.
A.1 Emitter inference
We have improved the original masked autoencoder for use in microscopic imaging by integrating a voting head into its transformer-based decoder. The head predicts the position and intensity of emitters, respectively. Specifically, the decoder produces feature patches, which serve as the input for the voting head. For emitter position, the voting head employs a two-step process: (1) a multilayer perceptron (MLP) predicts 64 density maps from each feature patch, and (2) the emitter positions are obtained by computing the center of mass of each density map. For emitter intensity, an MLP predicts 64 intensities. The predicted emitter image is generated by placing a Gaussian-type point tensor with scaled by its corresponding intensity at the predicted position, similar to the design in crowd counting methods Zhang et al. (2016). The mask layer is an essential element in the design of a masked autoencoder. Its main function is to prevent the model from learning trivial solutions and instead encourage it to focus on the relevant features of the input data. This is achieved by randomly blocking out specific parts of the input tensor. To improve the training efficiency, we introduced a CNN stem consisting of four convolutional layers, placed before the mask layer Xiao et al. (2021). The input image size of is reduced to after the CNN stem, with each pixel encoding a 384-dimensional vector. We refer to this model as the point predictor, as shown in Figures 9 and 10.

A.2 PSF generation
Motivated by the observation that a CNN can function as a well-designed prior and deliver outstanding results in typical inverse problems, as evidenced by Deep Image Prior Ulyanov et al. (2018), we constructed the PSF generator as illustrated in Figure 10. The neural network’s parameters are adjusted through self-supervised learning to produce the PSF, with a random matrix as the input that remains constant throughout the learning process.
A.3 Background separation
To isolate the background component from the raw image, we employ a new point predictor (Figure 10). We assume that the background has a low spatial variability and approximate it by drawing the output points from the point predictor following a Gaussian distribution with .

Appendix B Design of loss function
The loss function in our approach is composed of four components, divided into two categories:
The first category measures the similarity between the reconstructed image and the raw image. It consists of the mean absolute difference (L1) and the multi-scale structural similarity (MS-SSIM), as expressed in Equation 6. The combination of these two functions has been demonstrated to perform better than individual functions such as L1 and MSE in image restoration tasks Zhao et al. (2016).
The second category concerns the constraint on the generated PSF. To ensure that the center of mass of the generated PSF is at the center of the PSF tensor, we calculate the center distance loss as follows:
| (2) | ||||
Additionally, to ensure that the generated PSF is spatially continuous, we use the total variation (TV) loss to quantify the smoothness of the image:
| TV loss | (3) | |||
Finally, the loss function is defined as:
| (4) | ||||
where , , and .
Appendix C Pretrain with COCO dataset
Recent research has shown that self-supervised pre-training is effective in improving accuracy and robustness in computer vision tasks. In this study, we employed a masked autoencoder (shown in Figure 11b) to pretrain the encoder of PiMAE on the COCO dataset Lin et al. (2014) (unlabeled), a large-scale dataset containing 330K RGB images of varying sizes for object detection, segmentation, and captioning tasks.
To perform pre-training, we randomly cropped portions from the images and transformed them into grayscale images to form the training set. An example of the cropped images is shown in Figure 11a.

We use the mean squared error (MSE) as the loss function during the training process, with a learning rate of and 500 training epochs. A masking rate of 75% is implemented, and the RAdam optimizer is used. The results of the MAE reconstruction after pre-training can be seen in Figure 12. Figure 13 demonstrates that the pre-training process has significantly contributed to the enhancement of the localization of emitters’ performance. After completing MAE pre-training, the parameters of the encoder and decoder are saved for the subsequent training of PiMAE.


Appendix D Deconvblind
The Deconvblind is one of the most popular methods for blind deconvolution, which iteratively updates the PSF and the estimated image. For each task, we used the training set consisting of 1000 images and applied the Deconvblind function in MATLAB mat (Accessed: 2022) to estimate the PSF. These 1000 images were provided to Deconvblind in the form of a stack.
D.1 The problem of obtaining a trivial solution in Deconvblind
Here, we demonstrate that the Deconvblind approach leads to a trivial solution, i.e., a -function, for estimating the PSF. We evaluate the performance of Deconvblind and PiMAE on 1000 synthetic images generated from the Sketches dataset, where the PSF is generated from a wide-field microscope in focus. As shown in Figure 14a, the PSF estimated by Deconvblind converges to a -function, which is a trivial solution and results in the estimated emitter image being equal to the raw image. In contrast, the PiMAE-estimated PSF steadily approaches the actual PSF as the number of training epochs increases.

Appendix E DeepSTORM
We compare the performance of PiMAE with other deep learning-based methods, such as DeepSTORM, DECODE, and those that train neural networks for predicting emitter locations using supervised learning. As a baseline for comparison, we reproduce the DeepSTORM method. The original DeepSTORM model is a fully convolutional neural network (FCN), which we upgrade to the U-net architecture Ronneberger et al. (2015), a powerful deep learning architecture that has shown superior performance in various computer vision tasks (see Figure 15). While incorporating this change, we ensure to adhere to the original DeepSTORM model’s design and use the sum of MSE and L1 loss as the loss function.

During the training process, we use 1000 images containing randomly positioned emitters simulated using the ImageJ Collins (2007) ThunderSTORM Ovesnỳ et al. (2014) plugin. These images are convolved with the PSF of the task, normalized using the mean and averaged standard deviation, and then noise with an intensity of is added to enhance robustness.
Appendix F Assesment metrics
When evaluating the performance of emitter estimation, we use two metrics: the NRMSE and the Multi-scale Structural Similarity Index (MS-SSIM). NRMSE provides a quantitative measure of the difference between two images, while MS-SSIM is designed to assess the perceived similarity of images, taking into consideration the recognition of emitters by the human eye Wang et al. (2003).
a. NRMSE defined as:
| (5) |
b. Multi-scale Structural Similarity (MS-SSIM) defined as:
| (6) |
where the exponents , and are used to adjust the relative importance of different components. Here and values are 0.0448, 0.2856, 0.3001, 0.2363, 0.1333 for . The expression of the exponents , and are the same as Single-Scale Structural Similarity at each scale ,
| (7) | ||||
| (8) | ||||
| (9) |
where , and , here , , and . The sliding window size is 11.
Appendix G Synthetic Data Generation
In this section, we present the construction method of the synthetic data used to evaluate PiMAE, include emitters and PSFs.
G.1 Emitters
G.1.1 Sketches
SketchEitz et al. (2012) is a large-scale exploration of human sketches containing a rich variety of morphologies. To evaluate the performance of the method, emitters of synthetic data are sampled from the sketches dataset. Figure 16 illustrates examples from the Sketch dataset.

G.1.2 Random lines
To evaluate the performance of the model under various levels of sparsity, we implement an algorithm to generate images containing N randomly generated lines:
-
1)
A black image of size is created.
-
2)
A loop is executed N times to randomly draw lines on the image. In each iteration:
-
a)
The starting and ending points of a line are randomly generated.
-
b)
The intensity of the line is randomly generated.
-
c)
The line is drawn on the image.
-
a)
-
3)
The image is smoothened to remove jaggedness.
The resulting emitters are shown in the Figure 17.

G.2 PSFs
G.2.1 Out-of-focus
We simulate the imaging results of a wide-field microscope when the sample is out-of-focus. The near-focus amplitude can be described using the scalar Debye integralZhang et al. (2007),
| (10) |
where is a complex constant, is the zero-order Bessel function of the first kind, , refractive index is and numerical aperture , wavenumber . The PSF of the wide-field microscopy is,
| (11) |
The values of the parameters in this experiment are , , nm, , and each pixel has a size of 39 nm. represents the fluorescence emission wavelength.
G.2.2 SPADE
We simulated four scenarios in the SPADE, corresponding to PSFs as Hermite Gauss modes , and Laguerre Gauss modes respectively. Here we set the wavelength to 500 nm, the PSF size to and range, and rescaled to a 39 nm pixel size. The definitions for the amplitude of the Hermite Gauss modes and Laguerre Gauss modes areBeijersbergen et al. (1993),
| (12) | ||||
| (13) | ||||
with , , and . is the Hermite polynomial of order , is the generalized Laguerre polynomial, is the wave number, is the Rayleigh range of the mode. Here we set , wavelength and .
Appendix H Data normalization
We use the Max-Min normalization method to process each image as follows:
| (14) |
where is the normalized image, is the raw image, is the minimum value in the image, and is the maximum value in the image.
Appendix I Evaluation results of adding speckle noise to synthetic data
Speckle noise is a type of granular noise texture that can degrade image quality in coherent imaging systems such as medical ultrasound, optical coherence tomography, as well as radar and synthetic aperture radar (SAR) systems. It is a multiplicative noise that is proportional to the image intensity. The probability density function of speckle noise can be described by an exponential distribution:
| (15) |
Here, represents the intensity, and represents the speckle noise variance. To evaluate the impact of speckle noise on estimating PSF and emitters, we use as the PSF and Sketches as the emitters. We construct three sets of data with noise variances of 0.1, 1, and 2, respectively, each containing 1000 training images and 100 test images. We use the NRMSE metric to evaluate the results, as shown in Figure 18.

Appendix J The results using MS-SSIM as the metric
J.1 Results of out-of-focus synthetic data
In this section, we present the results of synthetic data with varying out-of-focus distances, assessed using the MS-SSIM metric. Gaussian noise with a standard deviation of was added to each synthetic data set. The results are displayed in Figure 19.

J.2 Results of SPADE synthetic data
We present the results for synthetic data evaluated using the SSIM metric for Hermite-Gaussian (HG) and Laguerre-Gaussian (LG) modes. Gaussian noise with is added to each synthetic data set. The results are displayed in Figure 20.
J.3 Results of noise robustness
We present the results of synthetic data with different levels of noise measured using SSIM as the metric. For each synthetic dataset, Gaussian noise was added with levels of 0.01, 0.1, 0.5, 1, and 2, respectively.The results are depicted in Figure 21.

Appendix K Results of real-world experiments
We assess the efficacy of PiMAE in two real-world experiments. Firstly, we utilize the imaging results of endoplasmic reticulum (ER) structures obtained from both wide-field microscopy and structural illumination microscopy (SIM) from the BioSR dataset Qiao et al. (2021). Secondly, we construct a custom-built wide-field microscope to image nitrogen vacancy color centers in diamond. The ability of PiMAE to handle non-Gaussian PSFs is evaluated in both out-of-focus and aberrations scenarios.
K.1 Results of endoplasmic reticulum
Figure 22 shows the results of wide-field microscopy, SIM and PiMAE-resolved wide-field microscopy of ER and Figure 23 demonstrates that PiMAE is capable of avoiding the artifact phenomenon seen in SIM.


K.2 Results of NV center imaging
The results of out-of-focus and aberrated wide-field microscopy imaging of nitrogen vacancy (NV) color centers, as well as PiMAE-resolved results, are shown in Figure 24. The aberrations were generated as follows: an objective lens with a phase aberration correction ring was first used to image a 50 nm nanodiamond on the opposite side of a coverslip with a thickness of 0.11-0.23 mm and a refractive index of 1.5. The correction ring of the objective lens was then rotated to match a coverslip with a thickness of 0.1 mm and a refractive index of 1.5, and this lens was used to observe nanodiamonds spin-coated on the opposite side of sapphire with a thickness of 0.15 mm and a refractive index of 1.72, thus artificially creating an aberration and resulting in a doughnut-shaped PSF. (Note: Olympus UPLXAPO40X objective lens was used)

Appendix L Train set size
We use as the PSF and a fixed test set size of 100 images with a shape of . The training set sizes for both PiMAE and DeepSTORM are 1, 5, 10, and 1000 images, respectively. As shown in Figure 25, PiMAE performs well even with a training set size as small as 5 images, whereas the performance of DeepSTORM decreases significantly.

Appendix M Summary of results
In this section, we summarize the results of all the synthetic tasks in the table 1,
| Synthetic data | ||||||||
| Task info | NRMSE for Emitters | NRMSE for PSF | ||||||
| Task | PSF | Emitters | Noise | PiMAE | DeepSTORM | RL | PiMAE | DB |
| 1 | 1400nm | Sketches | 5.00e-01 | 0.09 | 0.111 | 0.257 | 0.07 | 0.195 |
| 2 | 1200nm | Sketches | 5.00e-01 | 0.09 | 0.106 | 0.238 | 0.075 | 0.144 |
| 3 | 1000nm | Sketches | 5.00e-01 | 0.093 | 0.11 | 0.232 | 0.083 | 0.098 |
| 4 | 800nm | Sketches | 5.00e-01 | 0.08 | 0.103 | 0.201 | 0.029 | 0.062 |
| 5 | 600nm | Sketches | 5.00e-01 | 0.073 | 0.092 | 0.163 | 0.018 | 0.059 |
| 6 | 400nm | Sketches | 5.00e-01 | 0.074 | 0.081 | 0.14 | 0.018 | 0.051 |
| 7 | 200nm | Sketches | 5.00e-01 | 0.072 | 0.078 | 0.13 | 0.023 | 0.048 |
| 8 | 0nm | Sketches | 5.00e-01 | 0.071 | 0.084 | 0.124 | 0.022 | 0.045 |
| 9 | 0nm | Sketches | 2.00e+00 | 0.089 | 0.139 | 0.198 | 0.045 | 0.078 |
| 10 | 0nm | Sketches | 1.00e+00 | 0.085 | 0.105 | 0.156 | 0.031 | 0.064 |
| 11 | 0nm | Sketches | 5.00e-01 | 0.071 | 0.079 | 0.124 | 0.022 | 0.045 |
| 12 | 0nm | Sketches | 1.00e-01 | 0.068 | 0.066 | 0.091 | 0.021 | 0.042 |
| 13 | 0nm | Sketches | 1.00e-02 | 0.068 | 0.065 | 0.082 | 0.021 | 0.165 |
| 14 | 600nm | Sketches | 2.00e+00 | 0.095 | 0.144 | 0.231 | 0.019 | 0.076 |
| 15 | 600nm | Sketches | 1.00e+00 | 0.091 | 0.111 | 0.185 | 0.016 | 0.07 |
| 16 | 600nm | Sketches | 5.00e-01 | 0.073 | 0.092 | 0.163 | 0.018 | 0.058 |
| 17 | 600nm | Sketches | 1.00e-01 | 0.066 | 0.073 | 0.142 | 0.023 | 0.03 |
| 18 | 600nm | Sketches | 1.00e-02 | 0.068 | 0.07 | 0.135 | 0.023 | 0.937 |
| 19 | HG/2_2 | Sketches | 5.00e-01 | 0.075 | 0.098 | 0.151 | 0.028 | 0.156 |
| 20 | HG/3_1 | Sketches | 5.00e-01 | 0.072 | 0.097 | 0.147 | 0.029 | 0.161 |
| 21 | LG/1_1 | Sketches | 5.00e-01 | 0.072 | 0.098 | 0.154 | 0.016 | 0.088 |
| 22 | LG/2_2 | Sketches | 5.00e-01 | 0.073 | 0.094 | 0.179 | 0.042 | 0.042 |
| 23 | LG/2_2 | Sketches | 2.00e+00 | 0.1 | 0.128 | 0.307 | 0.069 | 0.105 |
| 24 | LG/2_2 | Sketches | 1.00e+00 | 0.078 | 0.104 | 0.235 | 0.048 | 0.1 |
| 25 | LG/2_2 | Sketches | 5.00e-01 | 0.063 | 0.094 | 0.179 | 0.029 | 0.098 |
| 26 | LG/2_2 | Sketches | 1.00e-01 | 0.056 | 0.082 | 0.117 | 0.017 | 0.095 |
| 27 | LG/2_2 | Sketches | 1.00e-02 | 0.061 | 0.08 | 0.105 | 0.022 | 2.761 |
| 28 | LG/2_2 | Lines/n=10 | 1.00e-02 | 0.04 | 0.049 | 0.153 | 0.028 | 0.352 |
| 29 | LG/2_2 | Lines/n=20 | 1.00e-02 | 0.058 | 0.074 | 0.193 | 0.037 | 0.156 |
| 30 | LG/2_2 | Lines/n=50 | 1.00e-02 | 0.096 | 0.119 | 0.213 | 0.059 | 0.102 |
| 31 | LG/2_2 | Lines/n=100 | 1.00e-02 | 0.158 | 0.171 | 0.216 | 0.13 | 0.103 |
| 32 | LG/2_2 | Sketches/speckle noise | 2.00e+00 | 0.085 | 0.155 | 0.128 | 0.026 | 0.309 |
| 33 | LG/2_2 | Sketches/speckle noise | 1.00e+00 | 0.078 | 0.128 | 0.129 | 0.043 | 0.896 |
| 34 | LG/2_2 | Sketches/speckle noise | 1.00e-01 | 0.075 | 0.084 | 0.11 | 0.057 | 2.871 |
| 35 | USTC | Sketches | 1.00e-02 | 0.086 | 0.114 | 0.16 | 0.135 | 0.187 |
References
- Lee et al. (2012) Sang-Hyuk Lee, Jae Yen Shin, Antony Lee, and Carlos Bustamante, “Counting single photoactivatable fluorescent molecules by photoactivated localization microscopy (palm),” Proc. Natl. Acad. Sci. USA 109, 17436–17441 (2012).
- Rust et al. (2006) Michael J Rust, Mark Bates, and Xiaowei Zhuang, “Sub-diffraction-limit imaging by stochastic optical reconstruction microscopy (storm),” Nat. Methods 3, 793–796 (2006).
- Bearne et al. (2021) Katherine KM Bearne, Yiyu Zhou, Boris Braverman, Jing Yang, SA Wadood, Andrew N Jordan, AN Vamivakas, Zhimin Shi, and Robert W Boyd, “Confocal super-resolution microscopy based on a spatial mode sorter,” Opt. Express 29, 11784–11792 (2021).
- Hell and Wichmann (1994) Stefan W Hell and Jan Wichmann, “Breaking the diffraction resolution limit by stimulated emission: stimulated-emission-depletion fluorescence microscopy,” Opt. Lett. 19, 780–782 (1994).
- Chen et al. (2015) Xiangdong Chen, Changling Zou, Zhaojun Gong, Chunhua Dong, Guangcan Guo, and Fangwen Sun, “Subdiffraction optical manipulation of the charge state of nitrogen vacancy center in diamond,” Light-Sci. Appl. 4, e230–e230 (2015).
- Nehme et al. (2018) Elias Nehme, Lucien E Weiss, Tomer Michaeli, and Yoav Shechtman, “Deep-storm: super-resolution single-molecule microscopy by deep learning,” Optica 5, 458–464 (2018).
- Speiser et al. (2021) Artur Speiser, Lucas-Raphael Müller, Philipp Hoess, Ulf Matti, Christopher J Obara, Wesley R Legant, Anna Kreshuk, Jakob H Macke, Jonas Ries, and Srinivas C Turaga, “Deep learning enables fast and dense single-molecule localization with high accuracy,” Nat. Methods 18, 1082–1090 (2021).
- Biggs and Andrews (1997) David SC Biggs and Mark Andrews, “Acceleration of iterative image restoration algorithms,” Appl. Opt. 36, 1766–1775 (1997).
- Chan and Wong (1998) Tony F Chan and Chiu-Kwong Wong, “Total variation blind deconvolution,” IEEE Trans. Med. Imaging 7, 370–375 (1998).
- Krishnan et al. (2011) Dilip Krishnan, Terence Tay, and Rob Fergus, “Blind deconvolution using a normalized sparsity measure,” in CVPR 2011 (IEEE, 2011) pp. 233–240.
- Liu et al. (2014) Guangcan Liu, Shiyu Chang, and Yi Ma, “Blind image deblurring using spectral properties of convolution operators,” IEEE Trans. Med. Imaging 23, 5047–5056 (2014).
- Michaeli and Irani (2014) Tomer Michaeli and Michal Irani, “Blind deblurring using internal patch recurrence,” in European conference on computer vision (Springer, 2014) pp. 783–798.
- Pan et al. (2017) Jinshan Pan, Deqing Sun, Hanspeter Pfister, and Ming-Hsuan Yang, “Deblurring images via dark channel prior,” IEEE Trans. Pattern Anal. Mach. Intell. 40, 2315–2328 (2017).
- Pan et al. (2016) Jinshan Pan, Zhe Hu, Zhixun Su, and Ming-Hsuan Yang, “-regularized intensity and gradient prior for deblurring text images and beyond,” IEEE Trans. Pattern Anal. Mach. Intell. 39, 342–355 (2016).
- Ren et al. (2016) Wenqi Ren, Xiaochun Cao, Jinshan Pan, Xiaojie Guo, Wangmeng Zuo, and Ming-Hsuan Yang, “Image deblurring via enhanced low-rank prior,” IEEE Trans. Med. Imaging 25, 3426–3437 (2016).
- Sun et al. (2013) Libin Sun, Sunghyun Cho, Jue Wang, and James Hays, “Edge-based blur kernel estimation using patch priors,” in IEEE International Conference on Computational Photography (ICCP) (IEEE, 2013) pp. 1–8.
- Yan et al. (2017) Yanyang Yan, Wenqi Ren, Yuanfang Guo, Rui Wang, and Xiaochun Cao, “Image deblurring via extreme channels prior,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (2017) pp. 4003–4011.
- Zuo et al. (2016) Wangmeng Zuo, Dongwei Ren, David Zhang, Shuhang Gu, and Lei Zhang, “Learning iteration-wise generalized shrinkage–thresholding operators for blind deconvolution,” IEEE Trans. Med. Imaging 25, 1751–1764 (2016).
- Shajkofci and Liebling (2020) Adrian Shajkofci and Michael Liebling, “Spatially-variant cnn-based point spread function estimation for blind deconvolution and depth estimation in optical microscopy,” IEEE Trans. Med. Imaging 29, 5848–5861 (2020).
- Lucy (1974) Leon B Lucy, “An iterative technique for the rectification of observed distributions,” Astrophys. J. 79, 745 (1974).
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals, “Representation learning with contrastive predictive coding,” Preprint at arXiv:1807.03748 (2018).
- Wu et al. (2018) Zhirong Wu, Yuanjun Xiong, Stella X Yu, and Dahua Lin, “Unsupervised feature learning via non-parametric instance discrimination,” in Proc. IEEE conference on computer vision and pattern recognition (2018) pp. 3733–3742.
- He et al. (2020) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick, “Momentum contrast for unsupervised visual representation learning,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020) pp. 9729–9738.
- Chen et al. (2020a) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning (PMLR, 2020) pp. 1597–1607.
- Doersch et al. (2015) Carl Doersch, Abhinav Gupta, and Alexei A Efros, “Unsupervised visual representation learning by context prediction,” in Proc. IEEE international conference on computer vision (2015) pp. 1422–1430.
- Dosovitskiy et al. (2014) Alexey Dosovitskiy, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox, “Discriminative unsupervised feature learning with convolutional neural networks,” Advances in neural information processing systems 27 (2014).
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” Preprint at arXiv:1810.04805 (2018).
- Chen et al. (2020b) Tianlong Chen, Sijia Liu, Shiyu Chang, Yu Cheng, Lisa Amini, and Zhangyang Wang, “Adversarial robustness: From self-supervised pre-training to fine-tuning,” in Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020) pp. 699–708.
- Chen et al. (2020c) Xuxi Chen, Wuyang Chen, Tianlong Chen, Ye Yuan, Chen Gong, Kewei Chen, and Zhangyang Wang, “Self-pu: Self boosted and calibrated positive-unlabeled training,” in International Conference on Machine Learning (PMLR, 2020) pp. 1510–1519.
- Chen et al. (2020d) Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever, “Generative pretraining from pixels,” in International conference on machine learning (PMLR, 2020) pp. 1691–1703.
- Henaff (2020) Olivier Henaff, “Data-efficient image recognition with contrastive predictive coding,” in International conference on machine learning (PMLR, 2020) pp. 4182–4192.
- Pathak et al. (2016) Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros, “Context encoders: Feature learning by inpainting,” in Proceedings of the IEEE conference on computer vision and pattern recognition (2016) pp. 2536–2544.
- Trinh et al. (2019) Trieu H Trinh, Minh-Thang Luong, and Quoc V Le, “Selfie: Self-supervised pretraining for image embedding,” arXiv preprint arXiv:1906.02940 (2019).
- He et al. (2021) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick, “Masked autoencoders are scalable vision learners,” Preprint at arXiv:2111.06377 (2021).
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” Preprint at arXiv:2010.11929 (2020).
- Ulyanov et al. (2018) Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky, “Deep image prior,” in Proc. IEEE conference on computer vision and pattern recognition (2018) pp. 9446–9454.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick, “Microsoft coco: Common objects in context,” in European conference on computer vision (Springer, 2014) pp. 740–755.
- Liu et al. (2020) Liyuan Liu, Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Jiawei Han, “On the variance of the adaptive learning rate and beyond,” in Proceedings of the Eighth International Conference on Learning Representations (ICLR 2020) (2020).
- Eitz et al. (2012) Mathias Eitz, James Hays, and Marc Alexa, “How do humans sketch objects?” ACM Trans. Graph. (Proc. SIGGRAPH) 31, 44:1–44:10 (2012).
- Qiao et al. (2021) Chang Qiao, Di Li, Yuting Guo, Chong Liu, Tao Jiang, Qionghai Dai, and Dong Li, “Evaluation and development of deep neural networks for image super-resolution in optical microscopy,” Nat. Methods 18, 194–202 (2021).
- Fisher et al. (2013) Robert Fisher, Simon Perkins, Ashley Walker, and Erik Wolfart, “Image synthesis—noise generation,” (2013).
- Tsang et al. (2016) Mankei Tsang, Ranjith Nair, and Xiao-Ming Lu, “Quantum theory of superresolution for two incoherent optical point sources,” Phys. Rev. X 6, 031033 (2016).
- Han et al. (2009) Kyu Young Han, Katrin I Willig, Eva Rittweger, Fedor Jelezko, Christian Eggeling, and Stefan W Hell, “Three-dimensional stimulated emission depletion microscopy of nitrogen-vacancy centers in diamond using continuous-wave light,” Nano Lett. 9, 3323–3329 (2009).
- Chen et al. (2021) Xiang-Dong Chen, En-Hui Wang, Long-Kun Shan, Ce Feng, Yu Zheng, Yang Dong, Guang-Can Guo, and Fang-Wen Sun, “Focusing the electromagnetic field to 10- 6 for ultra-high enhancement of field-matter interaction,” Nat. Commun. 12, 1–7 (2021).
- Degen et al. (2017) Christian L Degen, Friedemann Reinhard, and Paola Cappellaro, “Quantum sensing,” Rev. Mod. Phys. 89, 035002 (2017).
- Zhang et al. (2016) Yingying Zhang, Desen Zhou, Siqin Chen, Shenghua Gao, and Yi Ma, “Single-image crowd counting via multi-column convolutional neural network,” in Proceedings of the IEEE conference on computer vision and pattern recognition (2016) pp. 589–597.
- Xiao et al. (2021) Tete Xiao, Piotr Dollar, Mannat Singh, Eric Mintun, Trevor Darrell, and Ross Girshick, “Early convolutions help transformers see better,” Advances in Neural Information Processing Systems 34 (2021).
- Zhao et al. (2016) Hang Zhao, Orazio Gallo, Iuri Frosio, and Jan Kautz, “Loss functions for image restoration with neural networks,” IEEE Trans. Image Process. 3, 47–57 (2016).
- mat (Accessed: 2022) “Matlab,” https://www.mathworks.com/products/matlab.html (Accessed: 2022).
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention (Springer, 2015) pp. 234–241.
- Collins (2007) Tony J Collins, “Imagej for microscopy,” Biotechniques 43, S25–S30 (2007).
- Ovesnỳ et al. (2014) Martin Ovesnỳ, Pavel Křížek, Josef Borkovec, Zdeněk Švindrych, and Guy M Hagen, “Thunderstorm: a comprehensive imagej plug-in for palm and storm data analysis and super-resolution imaging,” Bioinformatics 30, 2389–2390 (2014).
- Wang et al. (2003) Zhou Wang, Eero P Simoncelli, and Alan C Bovik, “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, Vol. 2 (Ieee, 2003) pp. 1398–1402.
- Zhang et al. (2007) Bo Zhang, Josiane Zerubia, and Jean-Christophe Olivo-Marin, “Gaussian approximations of fluorescence microscope point-spread function models,” Appl. Opt. 46, 1819–1829 (2007).
- Beijersbergen et al. (1993) Marco W Beijersbergen, Les Allen, HELO Van der Veen, and JP Woerdman, “Astigmatic laser mode converters and transfer of orbital angular momentum,” Opt. Commun. 96, 123–132 (1993).