Learning Hidden Subgoals under Temporal Ordering Constraints in Reinforcement Learning
Abstract
In real-world applications, the success of completing a task is often determined by multiple key steps which are distant in time steps and have to be achieved in a fixed time order. For example, the key steps listed on the cooking recipe should be achieved one-by-one in the right time order. These key steps can be regarded as subgoals of the task and their time orderings are described as temporal ordering constraints. However, in many real-world problems, subgoals or key states are often hidden in the state space and their temporal ordering constraints are also unknown, which make it challenging for previous RL algorithms to solve this kind of tasks. In order to address this issue, in this work we propose a novel RL algorithm for learning hidden subgoals under temporal ordering constraints (LSTOC). We propose a new contrastive learning objective which can effectively learn hidden subgoals (key states) and their temporal orderings at the same time, based on first-occupancy representation and temporal geometric sampling. In addition, we propose a sample-efficient learning strategy to discover subgoals one-by-one following their temporal order constraints by building a subgoal tree to represent discovered subgoals and their temporal ordering relationships. Specifically, this tree can be used to improve the sample efficiency of trajectory collection, fasten the task solving and generalize to unseen tasks. The LSTOC framework is evaluated on several environments with image-based observations, showing its significant improvement over baseline methods. 111Source codes will be released upon acceptance
1 Introduction
In real life, successfully completing a task often involves multiple temporally extended key steps, where these key steps have to be achieved in specified time orders. For instance, in the process of making chemicals, different operations have to be strictly performed in the right time order, e.g., sulfuric acid must be added after water. Otherwise, the right chemical reaction can never occur or even the safety will be threatened. These key steps are necessary for the success of completing the given task and skipping any of them or doing them in the wrong time order will lead to failure of the task. In this work, these key steps are regarded as subgoals. Tasks consisting of multiple subgoals with temporal ordering constraints are common in many real-world applications, such as the temporal logic tasks in control systems and robotics (Baier and Katoen 2008). Since these tasks may have long-time horizon and sparse reward, the knowledge of subgoals and their temporal orderings are necessary for modern RL algorithms to solve these tasks efficiently. However, these subgoals can be hidden and unknown in many real-world scenarios. For instance, due to the user’s lack of knowledge, these subgoals may be missing when specifying the task. Alternatively, due to the partial observability of environment, the agent does not know subgoals and their temporal orderings in advance.
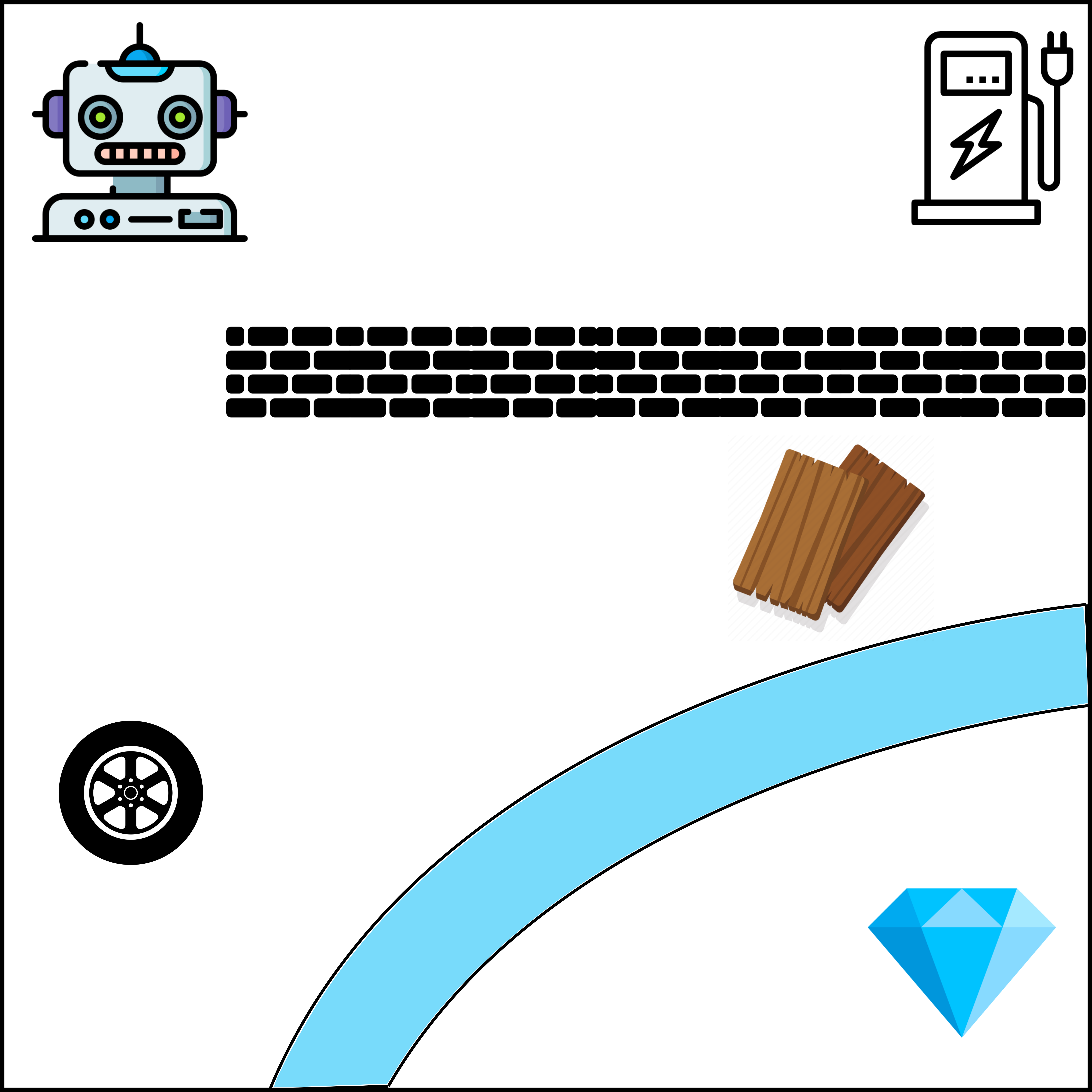
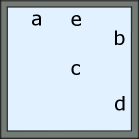
Motivating example. For example, consider a service robot tasked to collect the diamond in limited time steps, as shown in Figure 1(a). Due to the limited power and the blockage of river, the agent has to first go to the charger to get charged, then pick up wheel or board to go across the river, and finally get the diamond. If the agent first picks up the wheel or board and then goes to the charger, the task cannot be finished in the required time steps. The temporal dependencies of these subgoals can be described by the finite state machine (FSM) in Figure 1(b). The temporal logic language for describing these dependencies is c;(bw);d. However, since the agent can only observe things around him, it is not aware of the river and does not know that charger, wheel and board are subgoals, i.e., subgoals are hidden to the agent.
When solving tasks with hidden subgoals, the binary label at the end of the episode, indicating the task is accomplished successfully or not, is the only reward information for the agent to leverage to solve the task. This existing situation can be challenging for modern RL algorithms which use Bellman equation to propagate value estimates back to the earlier key steps (Sutton and Barto 2018). These algorithms suffer from slow convergence and expensive learning complexity, which are going to be verified by empirical experiments. Therefore, it is necessary to develop new RL algorithms to solve the task which contains multiple hidden subgoals with unknown temporal ordering constraints. To the best knowledge, this is the first work which investigates this problem.
In this work, we propose a novel framework for Learning hidden Subgoals under Temporal Ordering Constraints in RL (LSTOC). It consists of the learning subgoal and the labeling components. In learning subgoals, the proposed framework efficiently discovers states or observations corresponding to hidden subgoals and learns their temporal dependencies by using contrastive learning, which iteratively builds a subgoal tree (denoted as and defined in Section 3.2) by discovered subgoals to represent learned temporal ordering constraints. Specifically, in , nodes are labeled with discovered key states of subgoals and edges represent their temporal ordering relationships. This tree is used to guide the trajectory collection, ground the semantic meaning of learned subgoals (labeling component), accelerate the task solving and help the generalization.
Subgoal Learning. In order to improve the sample efficiency, we propose a new learning method which discovers hidden subgoals one-by-one and builds iteratively representing discovered subgoals and their temporal ordering relationships. The trajectory collection is guided by to focus more on the working node which is a node in not fully explored yet. In every iteration of building , by using a novel contrastive learning method, the agent only discovers the next subgoal which is next to the subgoal of working node under temporal ordering constraints, and expands by adding this newly discovered subgoal as a new child to . Then, this new child node will be used as working node, initiating the next iteration of tree expansion. This iterating process will stop whenever the success of every collected trajectory about task completion can be explained by the constructed , meaning that is fully constructed, i.e., all the hidden subgoals and temporal orderings have been learned in .
Contrastive Learning. In order to discovery subgoals next to working node , we propose a new contrastive learning method. In this case, since only the first visit to the next subgoal is meaningful, based on pre-processed trajectories, the proposed method first computes the first-occupancy representation (FR) (Moskovitz, Wilson, and Sahani 2021) of trajectories by removing repetitive states. Then, we will use contrastive learning to detect subgoals. However, since conventional contrastive learning could detect multiple subgoals without giving any temporal distance information and the next subgoal is temporally closest to among detected ones, the real next subgoal we need to discover could be missed by using conventional methods. Therefore, it is necessary to learn the temporal distances (i.e., temporal orderings) of detected subgoals and then select the temporally closest one as next subgoal. Therefore, we propose a new contrastive learning objective which can detect key states for subgoals and learn their temporal orderings at the same time. It formulates the contrastive learning objective by using temporal geometric sampling to sample one positive state from the FR of a processed positive trajectory and several negative states from the FR of a batch of processed negative trajectories. To be best of our knowledge, we are the first to propose a contrastive learning method which can detects key states and learn their temporal distances at the same time.
Labeling. In the labeling part, if the specification representing the temporal dependencies of subgoal semantic symbols is given, we formulate an integer linear programming (ILP) problem to determine the mapping from the discovered key states of subgoals to subgoal semantic symbols, making every path of the constructed subgoal tree satisfy the given specification. When this ILP problem is solved, the labeling function is obtained, essentially giving semantic meaning to every learned subgoal.
We evaluate LSTOC on tasks in three environments, including Letter, Office, and Crafter domains. In these environments, with image-based observations, the agent needs to visit different objects under temporal ordering constraints. Our evaluations show that LSTOC can outperform baselines on learning subgoals and efficiency of solving given tasks. The generalizability of LSTOC is also empirically verified. The limitation of LSTOC is discussed finally.
2 Related Works
Recently linear temporal logic (LTL) formulas have been widely used in Reinforcement Learning (RL) to specify temporal logic tasks (Littman et al. 2017). Some papers develop RL algorithms to solve tasks in the LTL specification (Camacho et al. 2019; De Giacomo et al. 2019; Bozkurt et al. 2020). In some other papers, authors focus on learning the task machine from traces of symbolic observations based on binary labels received from the environment (Gaon and Brafman 2020; Xu et al. 2021; Ronca et al. 2022). However, all these papers assume the access to a labeling function which maps raw states into propositional symbols, working in the labeled MDP (Hasanbeig et al. 2019).
There are some papers assuming to have an imperfect labeling function, where the predicted symbols can be erroneous or uncertain (Li et al. 2022; Hatanaka, Yamashina, and Matsubara 2023). But these papers do not address the problem of learning subgoals. A recent paper studies the problem of grounding LTL in finite traces (LTLf) formulas in image sequences (Umili, Capobianco, and De Giacomo 2023). However, their method is only applicable to offline cases with static dataset and does not consider the online exploration in the environment. In addition, authors in (Luo et al. 2023) propose an algorithm for learning rational subgoals based on dynamic programming. However, Their approach requires the availability of the state transition model, which is not feasible in general real-world applications.
Contrastive learning was used to detect subgoals (key states) in previous RL papers (Zhang and Kashima 2023; Sun et al. 2023; Casper et al. 2023; Park et al. 2022; Liang et al. 2022). However, these methods sample clips of positive and negative trajectories to formulate the contrastive objective. It can make the temporal distances of states not distinguishable and cannot learn temporal distances of detected subgoals. Therefore, these methods cannot be used to learn subgoals under temporal ordering constraints.
3 Preliminaries
3.1 Reinforcement Learning
Reinforcement learning (RL) is a framework for learning the strategy of selecting actions in an environment in order to maximize the collected rewards over time (Sutton and Barto 2018). The problems addressed by RL can be formalized as Markov decision processes (MDP), defined as a tuple , where is a finite set of environment states, is a finite set of agent actions, is a probabilistic transition function, is a reward function with and is a discount factor. Note that is the set of initial states where the agent starts in every episode, and is a distribution of initial states.
In addition, corresponding to the MDP, we assume that there is a set of semantic symbols representing subgoals. We also define a labeling function that maps an environmental state to a subgoal which is a key step to accomplish the task. Furthermore, the key state is defined as the environmental state whose output of function is a subgoal in . Most states of the environment are not key states where the outputs of are empty (). In this work, the states corresponding to subgoals and the labeling function are all unknown to the agent initially. The agent can only leverage collected trajectories and their labels of task accomplishing results to solve the task.
3.2 Temporal Logic Language
We assume that the temporal dependencies (orderings) of subgoals considered in this work can be described by a formal language composed by three operators. Syntactically, all subgoals in are in , and , the expressions , and are all in , representing ” then ”, ” or ” and ” and ”, respectively. Formally, a trajectory of states satisfies a task description , written as , whenever one of the following holds:
-
•
If is a single subgoal , then the first state of must not satisfy , and instead the last state must satisfy , which implies that has at least 2 states
-
•
If , then such that and , i.e., task should be finished before
-
•
If , then or , i.e., the agent should either finish or
-
•
If , then or , i.e., the agent should finish both and in any order
Note that the language for specifying temporal dependencies is expressive enough and covers LTLf (De Giacomo and Vardi 2013) which is a finite fragment of LTL without using ”always” operator .
Every task specification can be represented by a non-deterministic finite-state machine (FSM) (Luo et al. 2023), representing the temporal orderings and branching structures. Each FSM of task is a tuple which denote subgoal nodes, edges, the set of initial nodes and the set of accepting (terminal) nodes, respectively. Some examples of FSMs are shown in Figure 2. There exists a deterministic algorithm for transforming any specification in to a unique FSM (Luo et al. 2023).
First, we define the satisfying sequence as the sequence of key states which can satisfy the task. Second, the tree formed by all the satisfying sequences of the task is defined as the subgoal tree. For example, for the problem in Figure 1(a), its satisfying sequences are and ( denotes the coordinates of state), where and represent states corresponding to subgoals ”c”, ”b”, ”w” and ”d”, respectively. Its subgoal tree is shown in Figure 3. In this work, we only consider the subgoal temporal dependencies whose FSMs do not have any loops. Hence, an FSM in this category can be converted into a tree. Note that subgoals and their temporal dependencies (i.e., ordering constraints) are hidden and unknown to the agent. The algorithm proposed in this work is to learn these subgoals and their temporal ordering constraints based on collected trajectories and labels whether the task is accomplished or not.
3.3 First-occupancy Representation
We use first-occupancy representation (FR) for learning subgoals. FR measures the duration in which a policy is expected to reach a state for the first time, which emphasizes the first occupancy.
Definition 1.(Moskovitz, Wilson, and Sahani 2021) For an MDP with finite , the first-occupancy representation (FR) for a policy is given by
| (1) |
where and . The above indicator function 1 equals 1 only when first occurs at time since time . So gives the expected discount at the time the policy first reaches starting from .
3.4 Contrastive Learning in RL
Contrastive learning was used in previous RL algorithms to detect important states (Sun et al. 2023; Zhang and Kashima 2023), which learns an importance function by comparing positive and negative trajectories. The objective loss function can be written as
| (2) | |||||
which aims making important states to have high value at the output of . However, this conventional method has two major shortcomings. First, it cannot learn temporal distances of important states. In our work, hidden subgoals are under temporal ordering constraints, and different subgoals may have different temporal distances away from the initial state. But function trained here treated every subgoal equally, which cannot detect the real next subgoal to achieve. Second, the numerator in (2) contains multiple states and the importance value ( output) of real subgoal may not stand out among its neighboring states, which can make the subgoal learning inaccurate. In order to tackle these two issues, we propose a new contrastive learning method.
4 Methodology
In this work, we propose the LSTOC framework for learning hidden subgoals and their temporal ordering constraints by leveraging trajectories and results of task accomplishment (positive or negative labels) collected from the environment. Based on constructed subgoal tree, the agent can solve the task faster and generalize to other unseen tasks involving same subgoals.
4.1 General Context
The diagram of LSTOC is shown in Figure 4. In learning subgoal, the agent iteratively learns hidden subgoals one-by-one in a depth first manner and builds a subgoal tree to guide the trajectory collection and represent learned subgoals and temporal orderings. For example, as the problem shown in Figure 1, the agent will first learn subgoal ”c”, then ”w”, then ”d”, and then ”b”, finally ”d”, building the subgoal tree in Figure 3.
In every iteration, the agent focuses on learning subgoals next to the current working node by using a contrastive learning method, and expands by adding a new leaf node labeled with the newly learned subgoal, which is used as the working node in the next iteration. This iteration will be repeated until the success of every trajectory on task completion can be explained by the learned subgoals and their temporal relationships on . Then, the agent will proceed to the labeling component. When collecting a trajectory , by using an exploration policy trained with reward shaping method, the agent is guided by to reach the working node (an unexplored node of ). A binary label indicating the result of task completion is received at the end of . Positive () and negative () trajectories are stored into positive () and negative buffers (), respectively.
Once the FSM which describes subgoal temporal dependencies by semantic symbols in becomes available, the labeling component of LSTOC can determine the mapping from discovered key states to subgoal symbols in by solving an integer linear programming (ILP) problem, leveraging to impose the semantic meaning onto every learned subgoal.
Subgoal Notation. We define the set as an ordered set of discovered key states which form a subset of the state space of the environment, i.e., . Every node of the subgoal tree is labeled by a state in . For the -th state in , i.e., , is the index for indicating detected subgoal and is the key state corresponding to the detected subgoal . Only newly discovered key state not included in will be added to , creating an index indicating a newly detected subgoal.
Remark. Although subgoals are hidden, the result of the task completion can still be returned by the environment to the agent for every trajectory. This is common in robotic applications. For example, in service robot, when the task specification misses key steps, the robot can learn to discover these missing steps based on its trajectory data and feedbacks about task completion from users or other external sources (Gonzalez-Aguirre et al. 2021).
4.2 Learning Subgoals
Since the task is assumed to have multiple temporally extended hidden subgoals, it is impractical to collect sufficient informative trajectories for an offline supervised learning approach to detect all the subgoals at once. Therefore, we propose a new learning method to discover subgoals one-by-one iteratively. In every iteration, in addition to trajectory collection, the agent conduct operations including discovering next subgoal, expanding the subgoal tree and training the exploration policy, which will be introduced as following.
Expand Subgoal Tree
Tree Definition. As discussed in Section 3.2, the temporal ordering constraints of discovered subgoals can be expressed by the subgoal tree . In , except the root, each node is labeled by a key state of the -th learned subgoal in . Specifically, in , the children of a node labeled with subgoal contain key states of next subgoals to achieve after is visited in the FSM of subgoal temporal dependencies. Since children of every node are only labeled by the temporally nearest subgoals for task completion, the temporal orderings of subgoals can be well represented in . Whenever is well established, every path from the root to a leaf node in corresponds to a satisfying sequence of the task (concept introduced in Section 3.2).
Tree Expansion. Based on discovered key states, is expanded iteratively in a depth-first manner. Initially, only has the root node . For a node , we define the path of (denoted as ) as the sequence of key states along the path from to in , as an example shown in Figure 6. We first define nodes whose paths has not lead to task completion yet as unexplored nodes. In each iteration of tree expansion, the agent first selects an unexplored node from as the working node, and then focuses on discovering next subgoals to achieve after visiting in . Examples of building the subgoal tree are shown in Figure 5, where the dashed nodes are unexplored nodes.
Expansion at a Working Node. For expansion at , the agent first explores the collection of trajectories conditioned on and then discovers next subgoals by using contrastive learning. We define a trajectory which visits key states along the path of (i.e., ) sequentially as a trajectory conditioned on the working node . An example of trajectory conditioned on is shown in Figure 6, where the path is . Every trajectory is collected by applying the exploration policy . In order to encourage the agent to collect trajectories conditioned on , is trained by reward shaping method guided by , which is introduced in Section 4.2.
If the number of collected positive trajectories conditioned on is larger than a threshold , then the agent initiates its process of subgoal discovery at working node . Specifically, the agent picks up trajectories conditioned on from and , and only keeps the part after is visited in every trajectory (red part in Figure 6). Based on these pre-processed trajectories, the key states of next subgoals to visit (after ) are discovered by using contrastive learning method (introduced in Section 4.2). Then, the newly discovered key state is used to build a new node , which is added to as a new child of . The new working node will be at , initiating a new iteration of tree expansion at . Since the agent is not familiar with the environment initially, we design an adaptive mechanism of selecting , which is introduced in Section 4.4.
Satisfying Sequence. At working node , if the agent can complete the task successfully whenever he follows the path , then the path is regarded as a satisfying sequence of the task (concept introduced in Section 3.2). In this case, we say that positive trajectories which complete the task successfully by following the path are explained by the path . The path will be added into the set of discovered satisfying sequences . Then, the node becomes fully explored and the parent node of will be selected as the new working node, initiating a new iteration of expansion at .
Discovering Alternative Branches. With working node at , as long as we can find positive trajectories conditioned on and not explained by any discovered satisfying sequences in , there must be alternative hidden subgoals next to which are not discovered yet. The agent will continue exploring and discovering hidden subgoals (next to ) based on these unexplained trajectories, until the success of every positive trajectory conditioned on is explained by descendent nodes of in (i.e., becomes fully explored). Specifically, if unexplained trajectories conditioned on are not sufficient, the agent applies to explore for collecting more trajectories, until the number of unexplained positive trajectories conditioned at is larger than . If new key states of next subgoals are found, these states will be used to build new nodes added to as new children of , and additional iterations of expansion at these new nodes will be initiated. Otherwise, becomes fully explored, and the parent of will be selected as the new working node.
Termination Condition of Tree Expansion. The tree expansion will stop only when 1) every collected positive trajectory can be explained by or 2) becomes structurally inconsistent with (the FSM for subgoal temporal dependencies). Condition 1) means that every positive trajectory can be explained by a satisfying sequence which is a path in . Condition 2) means that the current is wrong and has to be built from the scratch again. The details of condition 2) are discussed in Appendix B. If condition 2) is true, the LSTOC framework will be reset and restart again with a larger threshold .
Discovering Next Subgoal
In each iteration of LSTOC framework, based on the up-to-date subgoal tree , the agent focuses on learning next subgoal to achieve after visiting working node (concept introduced in Section 4.2). For instance, in the example of Figure 1, if the up-to-date has two nodes labeled by key states of learned subgoals ”c” and ”b” (”c” is the parent of ”b”) and the working node is at ”b”, then the next subgoal to discover is the state of ”d”. As discussed in Section 3.4, although contrastive learning was used in RL to detect important states, there are some issues making it inapplicable to solve our problem. In this work, we propose a new contrastive learning method to discover key state of next subgoal by introducing some new techniques.
First-occupancy Representation (FR). Starting from the working node of , only the first visit to the next subgoal is meaningful for completing the task. In tasks with multiple subgoals under temporal ordering constraints, repetitive state visitations, especially those to non-key states, are frequent and can distract the weight function from paying attention to real key states. Therefore, we propose to compute and use the FRs of trajectories to conduct contrastive learning. Specifically, for any trajectory conditioned on (an example shown in Figure 6), we select the part of after is visited in and remove repetitive states there, where only the first visit to any state is kept, yielding the FR of , denoted as .
Remark. Comparison of states is needed when removing repetitive states in a trajectory. However, the raw state or observation may not be directly comparable. In this case, we propose to learn a distinguishable -dimensional representation of any state or observation in buffer , i.e., , based on the contrastive loss in (Oord, Li, and Vinyals 2018). Then, if two states and have high cosine similarity of vectors and , i.e., greater than , states and will be regarded as the same.
Contrastive Learning Objective. Since the task has multiple temporally extended hidden subgoals, applying conventional contrastive learning to train based on FRs of selected trajectories would produce multiple subgoals, some of which are not next subgoal to achieve. For example shown in Figure 1, when only has one node labeled with the key state of subgoal ”c” and working node is also at that node, direct application of conventional contrastive learning can produce multiple key states including states of ”b”, ”w” and ”d”. However, ”d” is not the next subgoal to achieve after achieving ”c”, which can distract the learning of hidden subgoals. Since hidden subgoals need to be achieved following temporal ordering constraints, the agent needs to select only one of the next subgoals to expand the subgoal tree , which has the smallest temporal distance away from subgoal of the working node .
Therefore, we propose a new contrastive learning objective which can detect key states for subgoals and learn their temporal distances at the same time. The proposed contrastive objective is formulated by one positive sample and multiple negative ones. Specifically, for any trajectory conditioned on randomly selected from , with the FR of pre-processed trajectory (introduced above) denoted as , the positive sample is to sample one state from where the time index is sampled from the temporal geometric distribution, i.e., 222 is the geometric distribution with parameter . and is the discount factor of the environmental MDP. The negative samples have states, denoted as . To sample each , a negative trajectory conditioned on is randomly selected from . After pre-processing and computing the FR of , is sampled from with . Therefore, the proposed contrastive learning objective can be formulated as below,
| (3) | |||||
In the objective function above, the numerator is a function of only one state sampled from a positive trajectory while the denominator has multiple states sampled from negative trajectories. This can make the importance function assign high value to the right state more concentratedly, without being distracted by neighbors of the real key state. The temporal geometric sampling can make states, which are temporally closer to the initial states of any trajectories, have higher chances of being used to formulate the contrastive learning objective. This can make the value of to be inversely proportional to the temporal distance of the input state, so that the temporal ordering can be reflected by the values of , i.e., the higher the value of , the higher the temporal order will be .
After the objective in (3) is maximized with sufficient number of states sampled from positive and negative trajectories, the outputs of at key states of subgoals can be much larger than other states. The state with highest value of (highest temporal order) will be selected as the key state of next subgoal to achieve and be used to expand the subgoal tree .
Exploration Policy
The exploration policy is realized by a GRU-based policy model. Each action is history dependent and drawn from the action distribution at the output of the policy model. The policy is trained by the recurrent PPO algorithm (Goyal et al. 2020; Ni et al. 2021) which extends the classical PPO (Schulman et al. 2017) into POMDP domain. The binary label of task satisfaction given at the end of the trajectory is used as a reward for training .
Additionally, in order to guide the exploration to collect more trajectories conditioned on the working node in , auxiliary rewards () will be given to visits to the key states along the path from root to in the right temporal order specified by path . Training with these rewards can encourage the agent to collect more trajectory data which are useful for discovering next subgoals at . For the example in Figure 6, if any collected trajectory is conditioned on , will be given to the first visit to and then the first visit to . If is first visited in a trajectory , no will be given to states in , since follows another path on not containing and hence is not conditioned on .
4.3 Labeling
Given the constructed subgoal tree and FSM , in the labeling part of LSTOC, the mapping from to subgoal semantic symbols (labeling function ) is determined by solving an integer linear programming (ILP) problem, which makes every discovered satisfying sequence lead to an accepting state in and hence yields the semantic meaning of every hidden subgoal. The details of the ILP problem are introduced in Appendix A
4.4 Algorithm
Since the agent knows little about the environment initially, it is difficult to set the initiation condition (the value ) of subgoal discovery at every working node. If is too small, there would not be enough trajectory data for subgoal discovery. If is too large, too many trajectories will be redundant, reducing the learning efficiency. Therefore, we propose an adaptive mechanism to try different values of from small to large. Specifically, there is a main loop (Algorithm 1 in Appendix B), trying to call LSTOC framework with , until hidden subgoals are correctly learned and the ILP problem is successfully solved (Line 8 and 9 of Algorithm 3 in Appendix B), yielding the labeling function . The tables of algorithms are presented in Appendix B.
5 Experiments
The experiments aim at answering the following questions:
-
1.
How well the proposed contrastive learning method would detect key states for subgoals and learn their temporal distances?
-
2.
Can we solve the task and learn hidden subgoals more efficiently with the help of building the subgoal tree?
-
3.
Would the learned subgoals help the generalization to other new tasks?
The details of the environments are introduced in Appendix C. The tasks used for evaluation are presented in Appendix D. Then, experimental results answering questions 1) and 2) above will be presented in Section 5.1 and 5.1. Question 3) will be answered in Appendix E. Limitation of LSTOC will be discussed finally. Implementation details and more results are also included in Appendix.
5.1 Results
Learning Subgoals
In this section, we focus on the evaluation of the proposed contrastive learning method which consists of two operations: 1) computing the first-occupancy representations (FR) of trajectories; 2) formulating the contrastive objective by using temporal geometric sampling to sample one state from every selected trajectory. The detailed introduction is in Section 4.2.
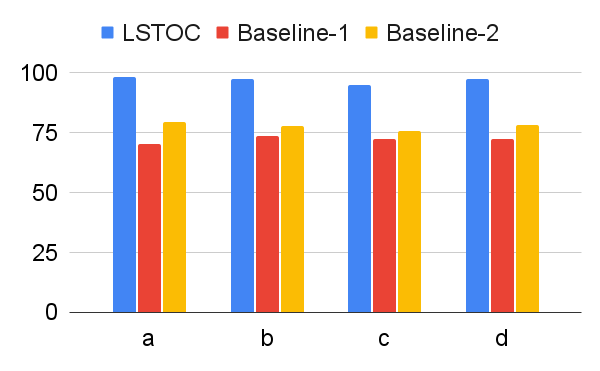
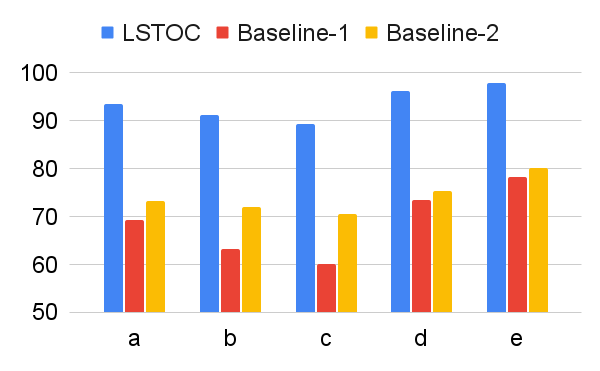
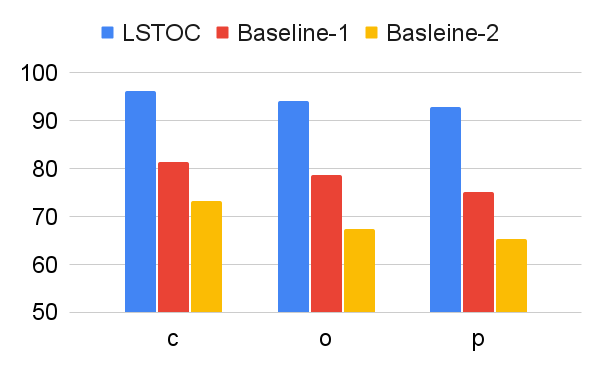
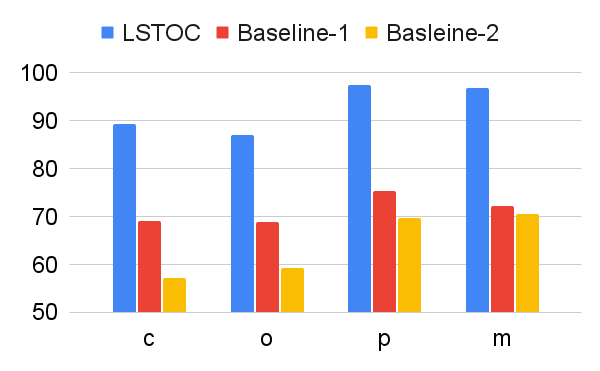
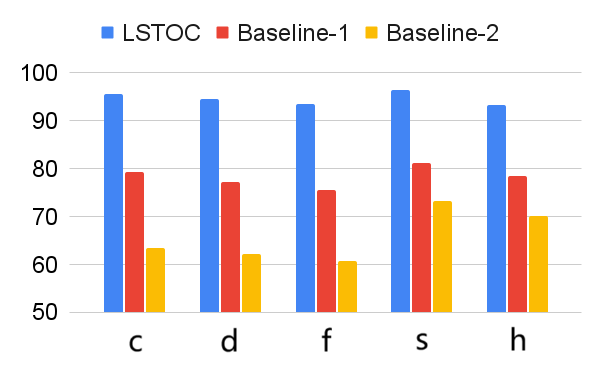
According to these two operations, we design two baseline contrastive learning methods for comparison. In Baseline 1, the FR computation is omitted, and the formulation of contrastive learning objective is same as the one in LSTOC. In Baseline 2, the FR computation is kept the same, but the contrastive learning objective is formulated by the conventional method in (Sun et al. 2023; Zhang and Kashima 2023), where the objective is computed by every states in selected positive and negative trajectories, without specific state sampling process.
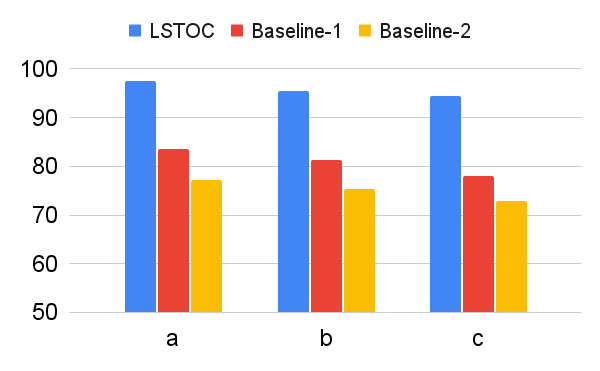
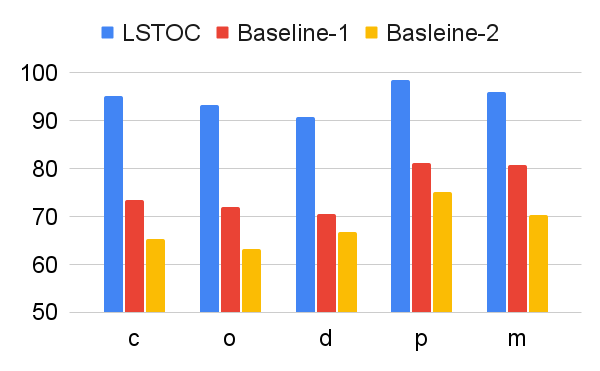
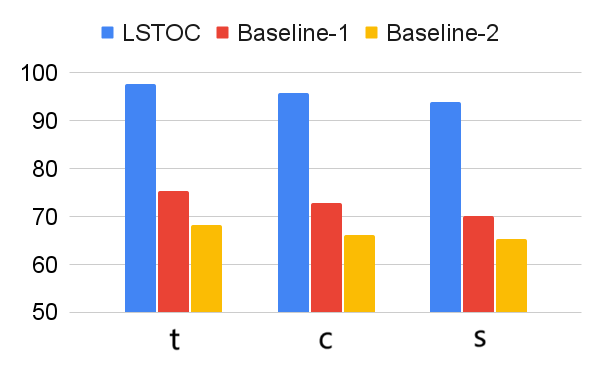
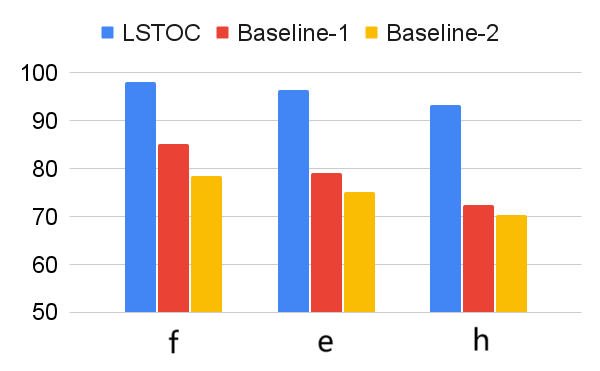
The comparison on subgoal learning is shown in Figure 7, and the results for all the tasks are shown in Figure 13 in Appendix. In every figure, LSTOC and baselines are compared based on the same amount of transition samples collected from the environment, which are samples in Letter domain, samples in Office domain and in Crafter domain. We can see that the contrastive learning method in LSTOC significantly outperforms baselines, showing the effects of FR and temporal geometric sampling. FR is important since the agent only focuses on detecting the key state of next subgoal only and FR can prevent the distraction of key states of future subgoals. The temporal distances of detected key states are learned by temporal geometric sampling. Baseline 1 performs better than Baseline 2 in Office and Crafter domains, showing that temporal geometric sampling is more important to key state detection than FR, since the task can only be accomplished when subgoals are achieved following temporal ordering constraints.
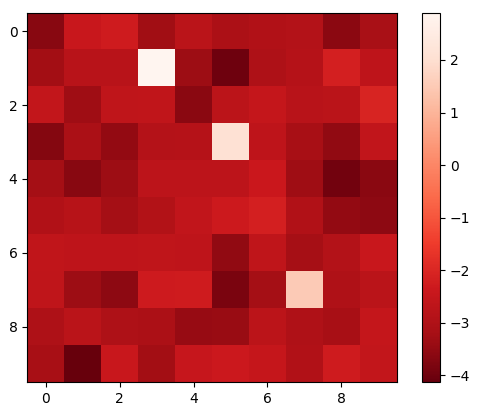
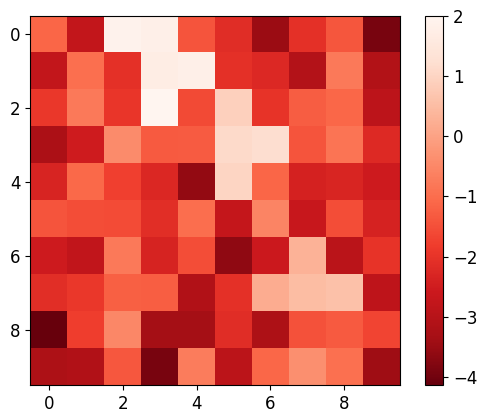
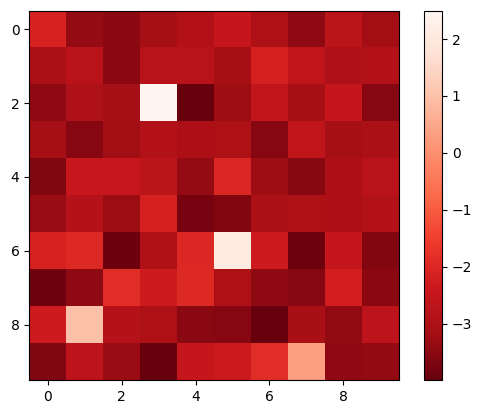
Visualization
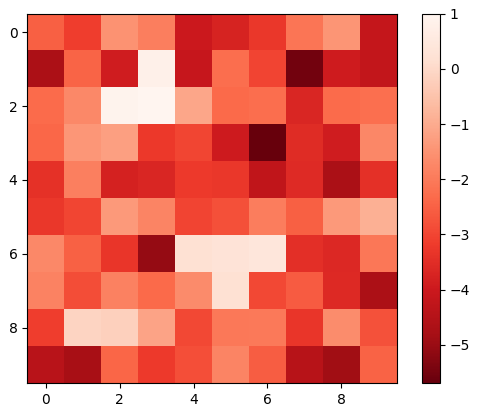
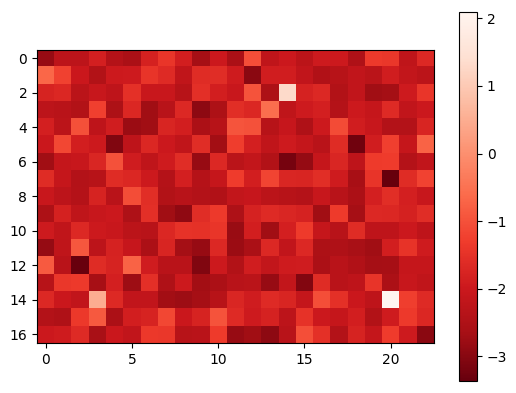
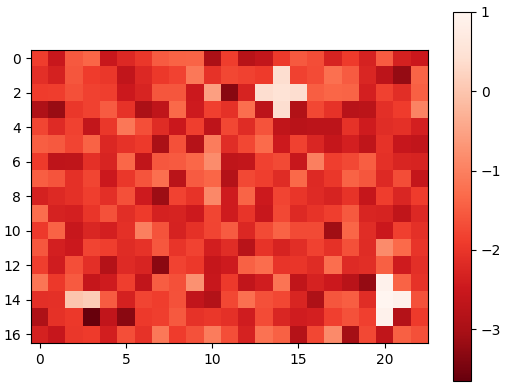
Furthermore, we visualize the performance of the proposed contrastive learning method in LSTOC in Figure 8, demonstrating its performance on detecting key states and learning their temporal distances. We use the exploration policy to collect a fixed number of trajectories labeled with task completion results, based on which we apply the proposed contrastive learning method to learn key states of subgoals. The number of collected trajectories for Letter domain is and the number in Office domain is . The proposed contrastive learning method in LSTOC is compared with the baseline which first computes the FR of trajectories and then use classical contrastive object (Zhang and Kashima 2023) to detect key states. Specifically, in Figure 8, the task in the first row is the task 1 in Letter domain in Figure 11(a), and the positions of ”a”, ”b” and ”c” are and . In the second row, the task is the task 2 in Letter domain of Figure 11(a), and positions of ”a”, ”b”, ”c” and ”d” are and . In the third row, the task is the task 1 in Office domain of Figure 11(b), and positions of ”c”, ”o” and ”p” are and . Note that the positions of subgoals are unknown to the agent initially. The contrastive learning is conducted on a fixed set of trajectories.
In Figure 8, the output of importance function visualized in every grid is inversely proportional to the temporal distance (ordering) of input state. In the evaluation of LSTOC, the positions of subgoals are all detected correctly. Besides, the key state of first subgoal of every task has significantly highest value at the output of and hence has the smallest temporal distance. The relative temporal distances of key states learned by the LSTOC obey the temporal orderings in the task specification. Obviously, we can see that compared with baseline, the proposed contrastive learning method in LSTOC can detect key states of subgoals accurately, while the baseline method is influenced by neighboring states. Besides, the output of trained by the proposed method can clearly reflect the temporal orderings of detected subgoals in the task specification (the higher the value of is, the higher the temporal ordering will be), while the baseline has some ambiguity on reflecting subgoal temporal orderings in some cases.
However, we can see that when using the proposed method in LSTOC, the key states of subgoals which have big temporal distances (far away from initial state) cannot stand out at the output of among with other neighboring non-important states, e.g., in Figure 8(c) and 8(e). This is because the contrastive learning is conducted on a fixed set of trajectories, which can only be used to detect the first or next subgoal to achieve. That is also the reason why we propose to detect subgoals one-by-one by building a subgoal tree.
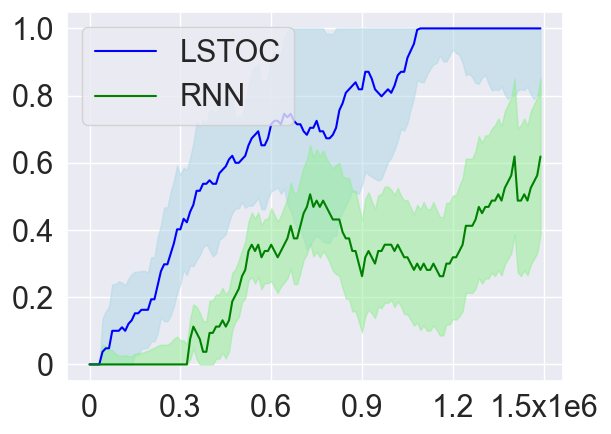
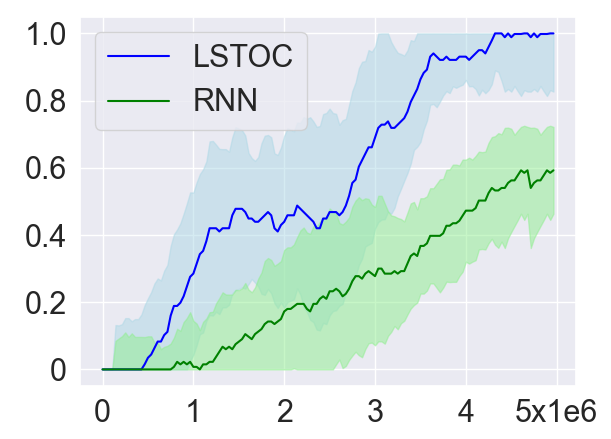
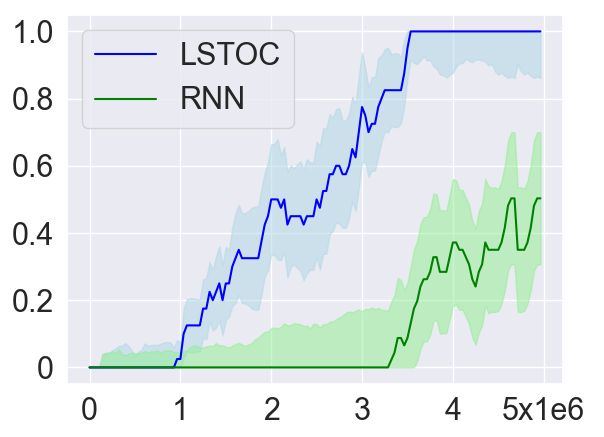
Learning Efficiency
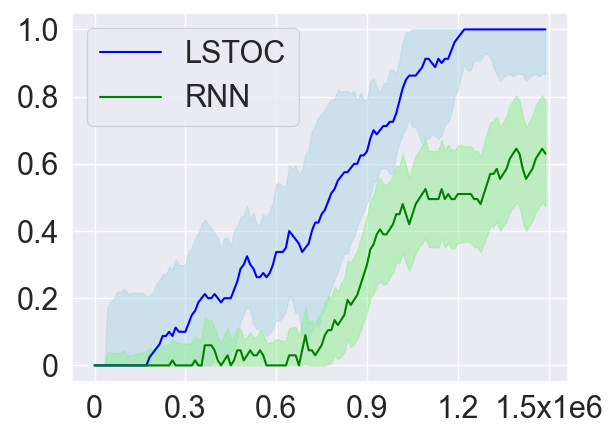
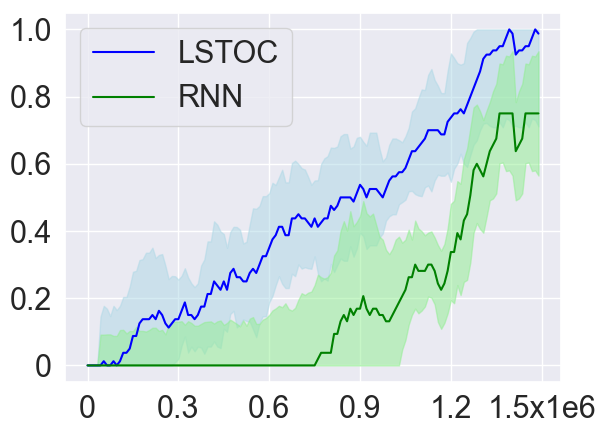
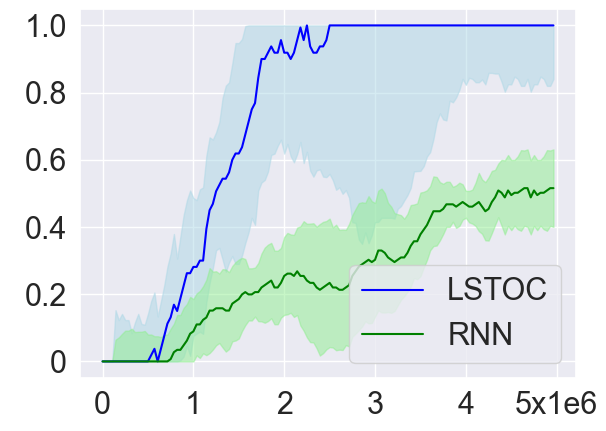
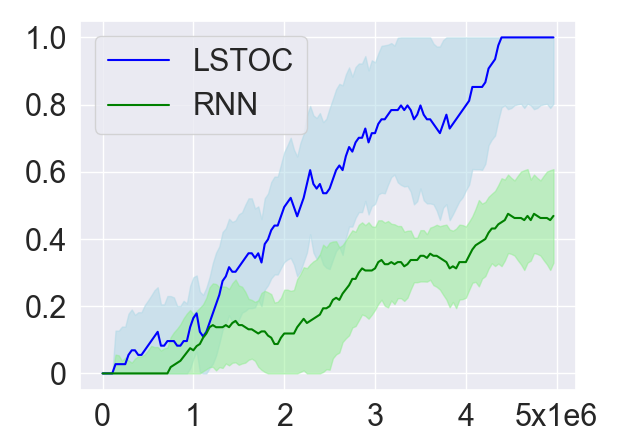
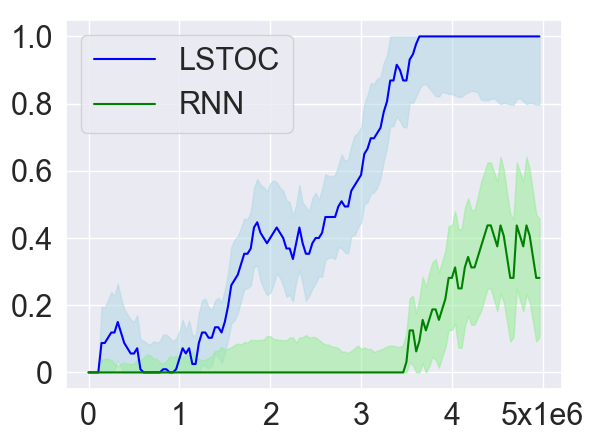
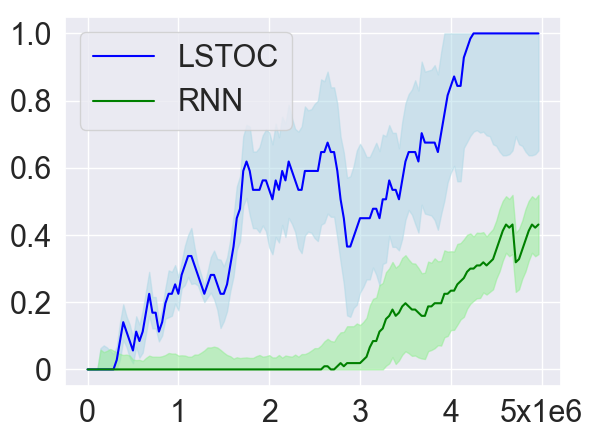
As introduced in Section 4.2, in order to collect more trajectories conditioned on the working node, the LSTOC adds auxiliary reward to every visit to a discovered key state which can make the agent achieve the working node in . This can significantly accelerate the agent’s learning to solve the task composed by temporally extended subgoals. In order to verify this, we compare LSTOC with a baseline method which uses an RNN-based policy trained by PPO algorithm to solve the task. The results for selected tasks are shown in Figure 9, with complete results shown in Figure 14 in Appendix. We can see that the LSTOC can solve every task significantly faster than the baseline. This is because the baseline does not specifically learn the subgoal and does not use auxiliary reward to resolve the issue of reward sparsity.
In addition, we also evaluate the average number of trajectories (both positive and negative) collected until every subgoal is learned (i.e., the condition for executing Line 11 of Algorithm 3 is met). The baseline method uses a fixed exploration policy to collect trajectories, based on which the contrastive learning in Section 4.2 is applied to learn subgoals. Specifically, the policy is only trained by the reward of task completion before the first tree expansion is conducted. The comparison results are shown in Table 1. Compared with LSTOC, the difference of the baseline is that exploration policy is not further tuned to collect more trajectories conditioned on the working node. In this case, to discover subgoals along the branch of the task FSM which is harder to achieve can cost more trajectory data. This explains the advantage of LSTOC in Table 1.
| LSTOC | Baseline | |
|---|---|---|
| Task 2 Letter | ||
| Task 2 Office | ||
| Task 3 Crafter |
6 Correctness and Limitation
Empirically, as long as is large enough and randomness of exploration policy is sufficient, the contrastive learning in (3) can always discover the correct key state of next subgoal at every working node. Then, the correct subgoal tree can be built and labeling function can be correctly obtained by solving the ILP problem. Specifically, the randomness of can be guaranteed by using -greedy into action selection, where is enough for all the environments.
However, LSTOC framework still has limitations. In some cases, the labeling component can not distinguish environmental bottleneck states from hidden subgoals. In some other cases, the labeling component cannot tell the differences of symmetric branches in the given FSM. Furthermore, the trajectory collection can be problematic in some hard-exploration environments. The details of correctness and limitation are presented in Appendix G.
7 Conclusion
In this work, we propose a framework for learning hidden subgoals under temporal ordering constraints, including a new contrastive learning method and a sample-efficient learning strategy for temporally extended hidden subgoals. In the future, we will resolve the issues of extending this work into hard-exploration environments, improving its sample efficiency in environments with large state space.
References
- Baier and Katoen (2008) Baier, C.; and Katoen, J.-P. 2008. Principles of model checking. MIT press.
- Bozkurt et al. (2020) Bozkurt, A. K.; Wang, Y.; Zavlanos, M. M.; and Pajic, M. 2020. Control synthesis from linear temporal logic specifications using model-free reinforcement learning. In 2020 IEEE International Conference on Robotics and Automation (ICRA), 10349–10355. IEEE.
- Camacho et al. (2019) Camacho, A.; Icarte, R. T.; Klassen, T. Q.; Valenzano, R. A.; and McIlraith, S. A. 2019. LTL and Beyond: Formal Languages for Reward Function Specification in Reinforcement Learning. In IJCAI, volume 19, 6065–6073.
- Casper et al. (2023) Casper, S.; Davies, X.; Shi, C.; Gilbert, T. K.; Scheurer, J.; Rando, J.; Freedman, R.; Korbak, T.; Lindner, D.; Freire, P.; et al. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback. arXiv preprint arXiv:2307.15217.
- De Giacomo et al. (2019) De Giacomo, G.; Iocchi, L.; Favorito, M.; and Patrizi, F. 2019. Foundations for restraining bolts: Reinforcement learning with LTLf/LDLf restraining specifications. In Proceedings of the international conference on automated planning and scheduling, volume 29, 128–136.
- De Giacomo and Vardi (2013) De Giacomo, G.; and Vardi, M. Y. 2013. Linear temporal logic and linear dynamic logic on finite traces. In IJCAI’13 Proceedings of the Twenty-Third international joint conference on Artificial Intelligence, 854–860. Association for Computing Machinery.
- Gaon and Brafman (2020) Gaon, M.; and Brafman, R. 2020. Reinforcement learning with non-markovian rewards. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 3980–3987.
- Gonzalez-Aguirre et al. (2021) Gonzalez-Aguirre, J. A.; Osorio-Oliveros, R.; Rodriguez-Hernandez, K. L.; Lizárraga-Iturralde, J.; Morales Menendez, R.; Ramirez-Mendoza, R. A.; Ramirez-Moreno, M. A.; and Lozoya-Santos, J. d. J. 2021. Service robots: Trends and technology. Applied Sciences, 11(22): 10702.
- Goyal et al. (2020) Goyal, A.; Lamb, A.; Hoffmann, J.; Sodhani, S.; Levine, S.; Bengio, Y.; and Schölkopf, B. 2020. Recurrent Independent Mechanisms. In International Conference on Learning Representations.
- GurobiOptimization (2023) GurobiOptimization, L. 2023. Gurobi Optimizer Reference Manual.
- Hafner (2021) Hafner, D. 2021. Benchmarking the Spectrum of Agent Capabilities. arXiv preprint arXiv:2109.06780.
- Hasanbeig et al. (2019) Hasanbeig, M.; Kantaros, Y.; Abate, A.; Kroening, D.; Pappas, G. J.; and Lee, I. 2019. Reinforcement learning for temporal logic control synthesis with probabilistic satisfaction guarantees. In 2019 IEEE 58th conference on decision and control (CDC), 5338–5343. IEEE.
- Hatanaka, Yamashina, and Matsubara (2023) Hatanaka, W.; Yamashina, R.; and Matsubara, T. 2023. Reinforcement Learning of Action and Query Policies with LTL Instructions under Uncertain Event Detector. IEEE Robotics and Automation Letters.
- Icarte et al. (2018) Icarte, R. T.; Klassen, T.; Valenzano, R.; and McIlraith, S. 2018. Using reward machines for high-level task specification and decomposition in reinforcement learning. In International Conference on Machine Learning, 2107–2116. PMLR.
- Li et al. (2022) Li, A. C.; Chen, Z.; Vaezipoor, P.; Klassen, T. Q.; Icarte, R. T.; and McIlraith, S. A. 2022. Noisy Symbolic Abstractions for Deep RL: A case study with Reward Machines. In Deep Reinforcement Learning Workshop NeurIPS 2022.
- Liang et al. (2022) Liang, X.; Shu, K.; Lee, K.; and Abbeel, P. 2022. Reward Uncertainty for Exploration in Preference-based Reinforcement Learning. In 10th International Conference on Learning Representations, ICLR 2022. International Conference on Learning Representations.
- Littman et al. (2017) Littman, M. L.; Topcu, U.; Fu, J.; Isbell, C.; Wen, M.; and MacGlashan, J. 2017. Environment-independent task specifications via GLTL. arXiv preprint arXiv:1704.04341.
- Luo et al. (2023) Luo, Z.; Mao, J.; Wu, J.; Lozano-Pérez, T.; Tenenbaum, J. B.; and Kaelbling, L. P. 2023. Learning rational subgoals from demonstrations and instructions. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 12068–12078.
- Mnih et al. (2015) Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A. A.; Veness, J.; Bellemare, M. G.; Graves, A.; Riedmiller, M.; Fidjeland, A. K.; Ostrovski, G.; et al. 2015. Human-level control through deep reinforcement learning. nature, 518(7540): 529–533.
- Moskovitz, Wilson, and Sahani (2021) Moskovitz, T.; Wilson, S. R.; and Sahani, M. 2021. A First-Occupancy Representation for Reinforcement Learning. In International Conference on Learning Representations.
- Ni et al. (2021) Ni, T.; Eysenbach, B.; Levine, S.; and Salakhutdinov, R. 2021. Recurrent model-free rl is a strong baseline for many pomdps.
- Oord, Li, and Vinyals (2018) Oord, A. v. d.; Li, Y.; and Vinyals, O. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748.
- Park et al. (2022) Park, J.; Seo, Y.; Shin, J.; Lee, H.; Abbeel, P.; and Lee, K. 2022. SURF: Semi-supervised Reward Learning with Data Augmentation for Feedback-efficient Preference-based Reinforcement Learning. In International Conference on Learning Representations.
- Ronca et al. (2022) Ronca, A.; Paludo Licks, G.; De Giacomo, G.; et al. 2022. Markov Abstractions for PAC Reinforcement Learning in Non-Markov Decision Processes. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, 3408–3415. International Joint Conferences on Artificial Intelligence.
- Schulman et al. (2017) Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; and Klimov, O. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Sun et al. (2023) Sun, C.; Yang, W.; Jiralerspong, T.; Malenfant, D.; Alsbury-Nealy, B.; Bengio, Y.; and Richards, B. A. 2023. Contrastive Retrospection: honing in on critical steps for rapid learning and generalization in RL. In Thirty-seventh Conference on Neural Information Processing Systems.
- Sutton and Barto (2018) Sutton, R. S.; and Barto, A. G. 2018. Reinforcement learning: An introduction. MIT press.
- Umili, Capobianco, and De Giacomo (2023) Umili, E.; Capobianco, R.; and De Giacomo, G. 2023. Grounding LTLf specifications in image sequences. In Proceedings of the International Conference on Principles of Knowledge Representation and Reasoning, volume 19, 668–678.
- Xu et al. (2021) Xu, Z.; Wu, B.; Ojha, A.; Neider, D.; and Topcu, U. 2021. Active finite reward automaton inference and reinforcement learning using queries and counterexamples. In Machine Learning and Knowledge Extraction: 5th IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2021, Virtual Event, August 17–20, 2021, Proceedings 5, 115–135. Springer.
- Zhang and Kashima (2023) Zhang, G.; and Kashima, H. 2023. Learning state importance for preference-based reinforcement learning. Machine Learning, 1–17.
Appendix A Labeling Component of LSTOC
The FSM is the FSM specification of subgoal temporal dependencies given by the user, where each node is described by a subgoal semantic symbol in . Denote the state space of as which has states. The transition function of is defined as , and the transition from state to conditioned on symbol is expressed as , where is the index of symbol in .
Assume that the set of discovered satisfying sequences has sequences, and the -th sequence has elements. Note that consists of all the paths in the subgoal tree which is built by the subgoal learning component of LSTOC framework. The set contains the discovered key states of subgoals. The target of labeling component of LSTOC is to determine the mapping from to , making every sequence in lead to an accepting state in and hence yielding the labeling function .
Now we start formulating the integer linear programming (ILP) problem for learning the labeling function. The binary variables of this ILP problem are composed by state transition variables and mapping variables , where denotes that the -th element of -th sequence of makes the agent transit from state to over FSM , and denotes that -th state in is mapped to -th symbol in . Based on their definitions, we can first have 5 constraints on these binary variables:
| (4) | |||
| (5) | |||
| (6) | |||
| (7) | |||
| (8) |
where these constraints mean: 1) every element of every sequence in makes a transition, including staying at the same state of FSM ; 2) the first element of every sequence is in the first state of ; 3) for any pair of consecutive elements of every sequence, the out-going state of the previous element is the same as the in-coming state of the other one; 4) every state in is mapped to at most one semantic symbol in , since some discovered key states may be redundant; 5) every symbol in is associated with one discovered key state in .
Since the transition variables and mapping variables must be consistent with the state transitions of (), we have another set of constraints:
| (9) |
where and have the same range of values as above constraints.
Finally, we have another set of constraints which make sure that the last element of every sequence in makes the agent stay in any accepting state of FSM . Then, we have
| (10) |
where denotes the set of accepting states of . In order to ignore the states in not associated with any subgoals during mapping, such as bottleneck state in the environmental layout, we use the sum of mapping variables as the objective:
| (11) |
The formulated ILP problem has the objective (11) and constraints (4)-(10). We solve it by Gurobi solver (GurobiOptimization 2023).
Appendix B Algorithms
We present the algorithm tables of the proposed framework in this section. Since the agent is not familiar with the environment in advance and the optimal selection of is not clear, we design a main loop to try to call LSTOC (described in Algorithm 3) with different values of increasing incrementally. In implementation, we set and for every domain.
The subgoal discovery process at a working node is described in Algorithm 2. It is same as the process described in Section 4.2. The inputs and only contain trajectories conditioned on the current working node. In line 3, the discriminative state representation is first pre-trained based on data in . For line 5 and 6, In the process of FR, trajectories in are processed to only keep the part after achieving the working node (the red part in Figure 6 as an example), then the FR of every processed trajectory is first computed by removing repetitive states. Then, from line 7 to 13, the importance function is iteratively trained by the objective formulated in (3). In implementation, the number of iterations () is set to be for every domain. The batch size of negative samples () is chosen to be . Due to the simple architecture of , the learning rate of each iteration is set to be . In line 14, the state with highest value of (highest temporal ordering) is selected as the discovered key state of next subgoal and returned to LSTOC in line 15.
The LSTOC is described in Algorithm 3. In line 5, the agent first collects sufficient number of trajectories from the environment. The loop starting at line 6 is the iterating process of building subgoal tree which will terminate when 1) every positive trajectory is explained by (line 8) and ILP problem for symbol grounding is successfully solved (line 9); or 2) is wrongly built (line 37) with condition (***) introduced in the following paragraph. The loop starting at line 7 is the loop of collecting sufficient number of positive trajectory for subgoal discovery at the current working node . From line 14 to 16, trajectories conditioned on are selected from and with explained trajectories discarded, and stored as and . In line 17, if every trajectory in which follows the path of can lead to the accomplishment of the task (getting a positive label), the path will be a newly discovered satisfying path and tree expansion will be moved back to the parent node of , initiating another iteration. In line 21, if the condition (**) of being fully explored is met, the tree expansion will be moved to the parent node of and starts another iteration of expansion. In line 24, if the condition of subgoal discovery at is not met, more trajectories will be collected by Explore process and exploration policy will be further trained to make more trajectories conditioned on to be collected. Otherwise, the subgoal discovery process will be called in line 32. After new key state of subgoal is discovered, from line 33 to 39, and set of key states will be expanded by adding a new node . Then, in line 40 and 41, the working node is moved to .
The condition (*) in Algorithm 3 states that is a newly discovered satisfying sequence (concept defined in Section 3.2) and no further expansion at the current working node is needed. The condition (**) in Algorithm 3 states that every positive trajectory conditioned on can be explained and no further expansion at the current working node is needed. The condition (***) in Algorithm 3 refers to the situations where is wrong built. The condition (***) becomes true when the longest path in is longer than that in or the largest degree of nodes in is larger than that in .

Appendix C Environments
Environment domains adopted in the experiments include both grid-based and pixel-based observations. Note that in all the environment domains, there is no labelling function which maps from agent’s observation into any letter or items, so letters or items are all hidden to the agent.
Letter. The first environment domain is the Letter. As shown in Figure 10(a), there are multiple letters allocated in the map. In this domain, the observation of the agent can be the full or partial map, which is an image-based tensor without any specific information on locations of letters. If the map has the size of with letters, the observation is a binary tensor. The agent’s actions include movements in four cardinal directions. Only a subset of letters in the map is used as task subgoals, making the problem more challenging.
Office. The second environment domain is the Office. It is a variant of office game widely used in previous papers (Icarte et al. 2018). As shown in Figure 10(b), in this domain, the agent only as partial observation of the environment, which is a grid centric to the agent. There are 12 rooms in the map with some segments of walls as obstacles. Five letters, ”c”, ”o”, ”m”, ”d” and ”p”, represent coffee, office, mailbox, desk, and printer, which are randomly located in these rooms. One room has at most one letter. The task subgoals may use part of these five letters. The observation of the agent is a binary tensor, including letters, wall and agent. The size of whole map is .
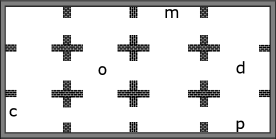
Crafter. Crafter is a powerful sandbox for designing custom environments (Hafner 2021). The agent there can navigate in the map to visit landmarks and pick up various of objects to finish the task. Our experiments the original environment to focus on the navigation part. An example of the screenshot is shown in Figure 10(c). In our experiments, the map is a 2020 grid. The observation to the agent is a partial observation centric to the agent, where each grid of the observation is described by 1616 pixels. The objects include tree, sapling, coal, diamond, energy, furnace and health, short for ”t”, ”s”, ”c”, ”d”, ”e”, ”f” and ”h”. The task formula is described in terms of letters for these objects. The agent needs to visit right objects in the right orders.
Appendix D Tasks
The FSMs describing temporal dependencies of hidden subgoals are shown in Figure 11. The LSTOC is evaluated and compared on tasks with these FSMs. The first task of every domain is always a sequential task consisting of 3 subgoals. In other tasks, there are converging and diverging branches, which are designed to evaluate the LSTOC’s capability of discovering alternative branches. Some tasks, e.g., task 3 in Letter and task 2 in Office, have repetitive subgoals, which are designed to test whether LSTOC can address repetitive subgoals or not.
Appendix E Generalization
We evaluate the generalization capability of LSTOC in Office and Crafter domains. In the training environment, the hidden subgoals and labeling function are first learned by LSTOC framework, where Office and Crafter domains both use task 2 in Figure 11(b) and 11(c) to learn subgoals. Then, in the testing environment, the agent solves an unseen task with the help of auxiliary rewards given by the labeling function (learned by LSTOC in training) and task FSM. Specifically, the agent gets a positive reward whenever he visits a key state corresponding to the subgoal which can make progress toward an accepting state in the task FSM. The testing environment is different from the training one. In Office domain, the testing environment has different layout of wall segments compared with the training environment. In Crafter domain, new and unseen objects, including drink, sand, table and zombie, are added to the testing environment.
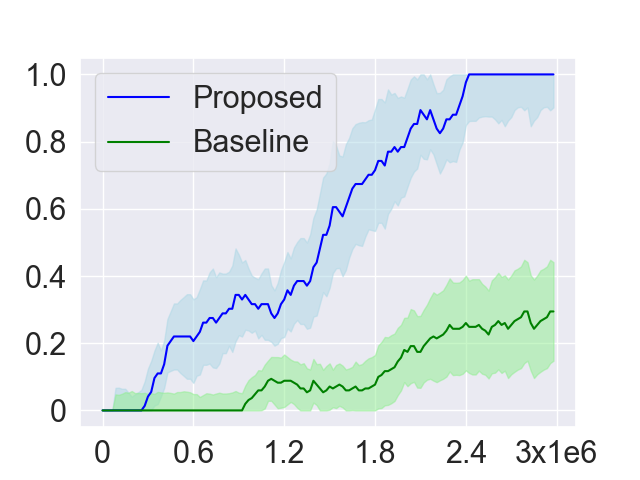
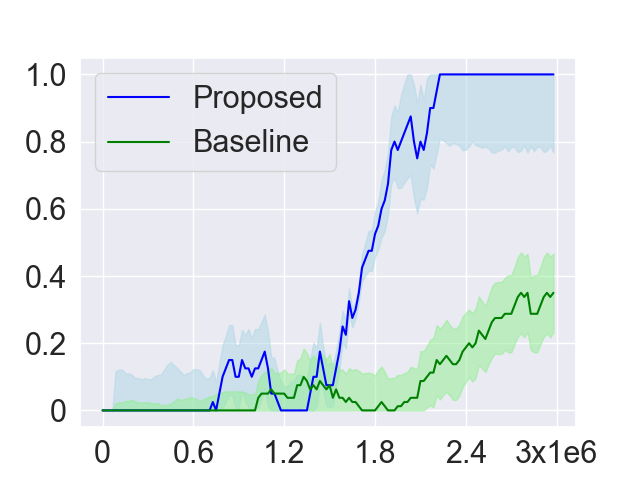
In evaluation, both the proposed and baseline methods use a RNN-based agent trained by PPO algorithm. In baseline, the agent only receives a positive reward whenever the task is accomplished. However, in the proposed method, the agent additionally gets auxiliary rewards. The comparison is shown in Figure 12. The significant acceleration of the proposed method verifies the generalization effect of subgoals learned by LSTOC framework, where the learned labeling function can adapt to changes of layout and ignore distracting unseen objects.
Appendix F Neural Architecture
We build neural network architectures for state representation function and importance function and the exploration policy . The function is used to extract a -dimensional vector as state representation for an input raw state or observation. In Letter and Office domain, is and is realized by a two-layer MLP with 128 neurons in each layer. In Crafter domain, is realized by a convolutional neural network (CNN) module. This CNN is the same as the classical CNN for deep RL proposed in (Mnih et al. 2015), where the first convolutional layer has 32 channels with kernel size of 8 and stride of 4, the second layer has 64 channels with the kernel size of 4 and stride of 2 and the third layer has 64 channels with the kernel size of 3 and stride of 1. The CNN module produces an embedding vector with the size of .
The importance function is realized by MLP in all three domains, which is a two-layer MLP with neurons in Letter and Office domains and neurons in Crafter domain.
The exploration policy is a GRU-based policy. In , the hidden dimension of gated recurrent unit (GRU) module is 128 for Letter/Office domains and 256 for Crafter domain. The outputs of consist of action and predicted value, which are conditioned on both the hidden state and the embedding vector of input observation.
Appendix G Correctness and Limitation
G.1 Correctness
Empirically, as long as is large enough and randomness of exploration policy is sufficient, the contrastive learning in (3) can always discover the correct key state of next subgoal at every working node. This is because sufficient trajectory data and randomness in data collection can make most parts of state space covered by both positive and negative trajectories. Then, the correct subgoal tree can be built and labeling function can be correctly obtained by solving the ILP problem. Specifically, the randomness of can be guaranteed by using -greedy into action selection, where is enough for all the environments.
In other words, whenever the state space is covered sufficiently enough by collected trajectory data, no hidden subgoal in the environment can be missed. Then, whenever every collected positive trajectory can be explained by some path in , all the hidden subgoals and their temporal orderings are learned, showing the correctness of the termination condition of LSTOC.
G.2 Limitation
However, LSTOC framework still has limitations. First, its labeling component cannot tell the difference between the bottleneck state in the environment and the real key states of subgoals, even though these are all key states. For example, as shown in Figure 15, a navigation environment has two rooms.

Room 1 has a red ball and room 2 has a blue ball and a green ball. However, there is an open corridor connecting room 1 and 2. This corridor becomes a bottleneck state of connecting room 1 and 2. Assume that the given task has hidden subgoals of first picking up red ball, then blue ball, and finally green ball, i.e., in temporal logic language. In this case, four subgoals will be discovered by LSTOC, which are corridor and states of red, blue and green balls. Then, since the FSM does not have corridor and the agent does not know the location of blue ball, the the corridor cannot be distinguished from the state of blue ball. Therefore, the ILP problem in the labeling component does not have a unique solution and the labeling function cannot be obtained. However, the learning subgoal part of LSTOC can still detect every meaningful key state.
Second, the labeling component cannot tell the differences of symmetric branches of FSM. For example, the given FSM is and two branches are symmetric. The learning subgoal component of LSTOC will discover 6 key states of subgoals, but the mapping from discovered key states to semantic symbols (a,b,c,d,e, and f) cannot be determined.
It is important to note that the limitations outlined above cannot be resolved. In the problem formulation, the only feedback available to the agent for anchoring subgoal symbols is a binary label indicating task completion at the end of each trajectory. The agent learns the labeling function (i.e., the mapping from learned subgoals to subgoal symbols in the given FSM), by utilizing these binary labels and structural information of subgoal symbols in the given FSM. As a result, when there are hidden bottlenecks in the environment or the task involves symmetric branches of subgoals, the given FSM has ambiguity and hence the agent lacks sufficient information to accurately identify the mapping from learned subgoals to subgoal symbols in the given FSM. Consequently, in these situations, it is impossible for the agent to correctly learn the labeling function, but the agent can still accurately estimate the hidden subgoals in the environment.
Third, the trajectory collection could not cover some important states in hard-exploration environments. In environments like Montezuma-revenge, some key states need thousands of actions to reach and the exploration policy trained by task completion signal only cannot collect trajectories covering these key states. Then, some hidden subgoals cannot be discovered and the labeling component cannot produce correct result.