Hsin-Ying [email protected] \addauthorHung-Ting Su1 \addauthorBing-Chen Tsai1 \addauthorTsung-Han Wu1 \addauthorJia-Fong Yeh1 \addauthorWinston H. Hsu1,2 \addinstitution National Taiwan University \addinstitutionMobile Drive Technology Fine-grained Understanding for Video Question Answering
Learning Fine-Grained Visual Understanding for Video Question Answering via
Decoupling Spatial-Temporal Modeling
Abstract
While recent large-scale video-language pre-training made great progress in video question answering, the design of spatial modeling of video-language models is less fine-grained than that of image-language models; existing practices of temporal modeling also suffer from weak and noisy alignment between modalities. To learn fine-grained visual understanding, we decouple spatial-temporal modeling and propose a hybrid pipeline, Decoupled Spatial-Temporal Encoders, integrating an image- and a video-language encoder. The former encodes spatial semantics from larger but sparsely sampled frames independently of time, while the latter models temporal dynamics at lower spatial but higher temporal resolution. To help the video-language model learn temporal relations for video QA, we propose a novel pre-training objective, Temporal Referring Modeling, which requires the model to identify temporal positions of events in video sequences. Extensive experiments demonstrate that our model outperforms previous work pre-trained on orders of magnitude larger datasets. Our code is available at https://github.com/shinying/dest.
1 Introduction
Videos are the complex composition of human actions, objects, scenes, and their interactions over time. To examine the capability of machines for video understanding, video question answering (video QA), a task of answering questions about videos, is proposed and requires machines to associate questions in natural languages with visual contents, including scenes [Xu et al.(2017)Xu, Zhao, Xiao, Wu, Zhang, He, and Zhuang, Yu et al.(2018)Yu, Kim, and Kim], dialogues [Lei et al.(2018)Lei, Yu, Bansal, and Berg, Choi et al.(2021)Choi, On, Heo, Seo, Jang, Lee, and Zhang], temporal relationships [Jang et al.(2017)Jang, Song, Yu, Kim, and Kim, Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao, Grunde-McLaughlin et al.(2021)Grunde-McLaughlin, Krishna, and Agrawala, Xiao et al.(2021)Xiao, Shang, Yao, and Chua], and higher-order cognition [Lei et al.(2020)Lei, Yu, Berg, and Bansal, Yi et al.(2020)Yi, Gan, Li, Kohli, Wu, Torralba, and Tenenbaum, Xiao et al.(2021)Xiao, Shang, Yao, and Chua]. Recent breakthroughs were achieved by pre-training a deep multi-modality encoder, mostly Transformer [Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin], with large-scale video-language datasets [Miech et al.(2019)Miech, Zhukov, Alayrac, Tapaswi, Laptev, and Sivic, Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid, Bain et al.(2021)Bain, Nagrani, Varol, and Zisserman]. Models first learned semantic connections between visual and linguistic contents and then were fine-tuned on downstream video-language tasks [Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu, Zhu and Yang(2020), Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi, Seo et al.(2022)Seo, Nagrani, Arnab, and Schmid].
Despite the advance of this framework in video QA, the spatial semantics encoding of video-language (VL) models is not as fine-grained as the sophisticated design for image-language (IL) models [Anderson et al.(2018)Anderson, He, Buehler, Teney, Johnson, Gould, and Zhang, Zhang et al.(2021)Zhang, Li, Hu, Yang, Zhang, Wang, Choi, and Gao, Seo et al.(2021)Seo, Nagrani, and Schmid]. A preliminary analysis shows that on video QA benchmarks entailing spatial and temporal knowledge, simply averaging frame-by-frame predictions of an IL model can sometimes outperform state-of-the-art VL models. Though the VL models exhibit a slight advantage in questions involving temporal information, the IL model greatly excels in capturing spatial clues (improvement by 7% accuracy; see the full results in Section 4.1.1). The positive performance of IL models could also be attributed to the nature of video QA: the answers to the questions pertaining to only spatial semantics, without specifying time, are usually consistent across all related frames. This property suggests the potential of encoding fine-grained spatial semantics with only IL models.

In addition to spatial modeling, prior work modeled only coarse-grained temporal relations. A question involving temporal relations in video QA often refers to specific events happening in periods of time and inquires about the order of events [Jang et al.(2017)Jang, Song, Yu, Kim, and Kim, Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao, Grunde-McLaughlin et al.(2021)Grunde-McLaughlin, Krishna, and Agrawala, Xiao et al.(2021)Xiao, Shang, Yao, and Chua]. It is thus essential to model events in videos and associate the sequence with time conjunctions in questions, such as before and after. However, as the examples in Figure 1 (a), prior approaches [Zhu and Yang(2020), Seo et al.(2021)Seo, Nagrani, and Schmid, Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu, Seo et al.(2022)Seo, Nagrani, Arnab, and Schmid, Wang et al.(2022)Wang, Ge, Yan, Ge, Lin, Cai, Wu, Shan, Qie, and Shou] aligning a video with a sentence might lose details of sequential events (what happens after the woman hit the ball), while matching short clips with transcripts [Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi] may suffer from noise as spoken words often contain something not related to scenes [Miech et al.(2020)Miech, Alayrac, Smaira, Laptev, Sivic, and Zisserman]. Others [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid, Yang et al.(2022a)Yang, Miech, Sivic, Laptev, and Schmid] pre-training on generated video QA datasets were mostly limited to spatial understanding. In fact, another examination reveals that the performance with shuffled frame inputs of some of these approaches is similar to that with normal inputs on video QA benchmarks requiring temporal modeling (see more details in Section 4.1.2). The result suggests developing a more effective strategy for modeling temporal relations.
To obtain fine-grained encoding of spatial and temporal semantics for video QA, we propose a novel pipeline, Decoupled Spatial-Temporal Encoders (DeST), decoupling spatial-temporal modeling into IL and VL encoders, illustrated in Figure 1 (c). With IL models well-versed in fine-grained spatial modeling, we incorporate a pre-trained IL model to encode static spatial information independent of time from sparsely sampled frames at high spatial resolution. For questions requiring temporal relations, we train a VL encoder to model temporal dynamics, operating at high temporal but low spatial resolution. These two streams complement each other by paying attention to disparate aspects of videos.
To effectively model temporal relations for video QA, the VL encoder has to recognize events in videos, build their temporal relations, and associate such relations with languages containing temporal information. Thus, we introduce a novel pre-training objective, Temporal Referring Modeling (TRM). Depicted in Figure 1 (b), TRM queries absolute and relative positions of events in videos synthesized by concatenating clips sampled from video captioning datasets [Li et al.(2016)Li, Song, Cao, Tetreault, Goldberg, Jaimes, and Luo, Wang et al.(2019)Wang, Wu, Chen, Li, Wang, and Wang]. The concatenation simulates transitions of scenes and events in videos. Answering such queries requires a model to aggregate contiguous frames into events and distinguish adjacent events from distant ones. These operations help a model learn both short- and long-term temporal dynamics.
We validate our model on two video QA benchmarks, ActivityNet-QA [Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao] and AGQA 2.0 [Grunde-McLaughlin et al.(2022)Grunde-McLaughlin, Krishna, and Agrawala]. The former contains diverse question types requiring spatial or temporal semantics, and the latter weaves spatial and temporal information together in each question to evaluate compositional reasoning. DeST outperforms the previous state-of-the-art. The ablation studies also demonstrate the efficacy of the proposed pipeline and pre-training objective.
In summary, we make the following key contributions. (i) With IL and VL models demonstrating complementary advantages, we decouple spatial and temporal modeling into a hybrid pipeline composed of both models to encode fine-grained visual semantics. (ii) We present a novel pre-training objective, Temporal Referring Modeling, to learn temporal relations between events by requiring models to identify specific events in video sequences. (iii) We outperform previous VL state-of-the-art methods on two benchmarks with orders of magnitudes less data for pre-training.
2 Related Work
2.1 Video Question Answering
To encode, accumulate and build relationships between visual contents and between modalities for video QA, conventional approaches adopted Recurrent Neural Networks with attention [Zeng et al.(2017)Zeng, Chen, Chuang, Liao, Niebles, and Sun, Xu et al.(2017)Xu, Zhao, Xiao, Wu, Zhang, He, and Zhuang, Zhao et al.(2017b)Zhao, Yang, Cai, He, Zhuang, Zhao, Yang, Cai, He, and Zhuang, Zhao et al.(2017a)Zhao, Lin, Jiang, Cai, He, and Zhuang, Jang et al.(2017)Jang, Song, Yu, Kim, and Kim], Memory Networks [Tapaswi et al.(2016)Tapaswi, Zhu, Stiefelhagen, Torralba, Urtasun, and Fidler, Na et al.(2017)Na, Lee, Kim, and Kim, Gao et al.(2018)Gao, Ge, Chen, and Nevatia, Kim et al.(2019)Kim, Ma, Kim, Kim, and Yoo, Fan et al.(2019)Fan, Zhang, Zhang, Wang, Zhang, and Huang], Graph Neural Networks [Huang et al.(2020)Huang, Chen, Zeng, Du, Tan, and Gan, Jiang and Han(2020), Park et al.(2021)Park, Lee, and Sohn, Liu et al.(2021)Liu, Liu, Wang, and Lu, Peng et al.(2021)Peng, Yang, Bin, and Wang, Xiao et al.(2022)Xiao, Yao, Liu, Li, Ji, and Chua], Modular Networks [Le et al.(2021)Le, Le, Venkatesh, and Tran], and self-attention [Li et al.(2019)Li, Song, Gao, Liu, Huang, He, and Gan, Jiang et al.(2020)Jiang, Chen, Lin, Zhao, and Gao, Urooj et al.(2020)Urooj, Mazaheri, Da vitoria lobo, and Shah]. By pre-training large-scale VL datasets, Transformers [Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] have further improved the interaction between modalities and made great progress in video QA [Zhu and Yang(2020), Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu, Seo et al.(2021)Seo, Nagrani, and Schmid, Wang et al.(2022)Wang, Ge, Yan, Ge, Lin, Cai, Wu, Shan, Qie, and Shou, Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi, Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid, Yang et al.(2022a)Yang, Miech, Sivic, Laptev, and Schmid]. Our approach is built on the benefit of modeling relationships with pre-trained Transformers. In contrast to prior work, we carefully examine and take the individual advantage of IL and VL pre-training to encode spatial and temporal semantics.
2.2 Pre-training for Temporal Relation Modeling
VL pre-training learns to model temporal relationships via different approaches.
Learning from Global Alignment. [Sun et al.(2019b)Sun, Myers, Vondrick, Murphy, and Schmid, Zhu and Yang(2020), Seo et al.(2021)Seo, Nagrani, and Schmid, Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu, Wang et al.(2022)Wang, Ge, Yan, Ge, Lin, Cai, Wu, Shan, Qie, and Shou, Luo et al.(2020)Luo, Ji, Shi, Huang, Duan, Li, Li, Bharti, and Zhou] pre-trained models on datasets where a sentence delineates a single event of the entire corresponding video. With features of two modalities being aligned globally, events happening sequentially in a video are compressed, and details of events not mentioned in descriptions are likely lost. Such representations are not fine-grained enough for questions referring to specific moments.
Learning from Local Alignment and Frame Ordering. [Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi] pre-trained models over datasets with dense annotations such as video transcripts [Miech et al.(2019)Miech, Zhukov, Alayrac, Tapaswi, Laptev, and Sivic]. They matched segmented visual features with utterances and required models to order shuffled or any two frames. With this approach, models learn event-level but weak alignment between videos and languages as spoken words do not always correspond to visual contents [Miech et al.(2020)Miech, Alayrac, Smaira, Laptev, Sivic, and Zisserman]. Besides, ordering frames without grounding in languages makes models learn, instead of temporal relations, rational predictions of what is likely to happen before and after an event, which is more related to visual common sense [Agrawal et al.(2016)Agrawal, Chandrasekaran, Batra, Parikh, and Bansal, Park et al.(2020)Park, Bhagavatula, Mottaghi, Farhadi, and Choi, Hwang et al.(2021)Hwang, Bhagavatula, Le Bras, Da, Sakaguchi, Bosselut, and Choi].
Learning from Large-Scale Video Question Answering Datasets. [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid, Yang et al.(2022a)Yang, Miech, Sivic, Laptev, and Schmid] pre-trained VL models over large-scale video QA datasets. The diversity of pre-training questions thus determines the effectiveness and capacity of transferred knowledge, but generated questions in [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid] and [Yang et al.(2022a)Yang, Miech, Sivic, Laptev, and Schmid] mainly pertain to scene and dialogue understanding, leaving temporal relationship modeling unsolved.
2.3 Encoding Motion and Appearance
Prior arts have explored two-stream networks to encode motion and appearance for action recognition [Simonyan and Zisserman(2014), Feichtenhofer et al.(2016a)Feichtenhofer, Pinz, and Wildes, Feichtenhofer et al.(2016b)Feichtenhofer, Pinz, and Zisserman, Wang et al.(2016)Wang, Xiong, Wang, Qiao, Lin, Tang, and Van Gool, Feichtenhofer et al.(2017)Feichtenhofer, Pinz, and Wildes, Diba et al.(2017)Diba, Sharma, and Van Gool]. [Feichtenhofer et al.(2019)Feichtenhofer, Fan, Malik, and He, Diba et al.(2020)Diba, Fayyaz, Sharma, Paluri, Gall, Stiefelhagen, and Gool] combined different spatial and temporal resolution to separately encode slow- and fast-changing scenes, and [Ryoo et al.(2020b)Ryoo, Piergiovanni, Tan, and Angelova, Ryoo et al.(2020a)Ryoo, Piergiovanni, Kangaspunta, and Angelova] searched for multi-stream connectivity. Analogously, our two streams complement each other by focusing on disparate aspects of videos, but while their two streams both encode short-term actions, our IL stream aggregates scene information independent of time, and the VL stream encodes entire videos and constructs the temporal relationships between all actions and events.
Some recent work revealed that understanding temporality is not always necessary to solve VL tasks. [Lei et al.(2021)Lei, Li, Zhou, Gan, Berg, Bansal, and Liu, Lei et al.(2022)Lei, Berg, and Bansal] taking sparsely sampled frames outperformed previous methods. [Buch et al.(2022)Buch, Eyzaguirre, Gaidon, Wu, Fei-Fei, and Niebles] provided stronger baselines with single frame inputs. However, with new tasks requiring temporal modeling proposed, such conclusions are likely to be circumscribed. We thus take a further step by proposing an effective strategy to encode fine-grained temporal semantics.
3 Method
We introduce our video QA pipeline, Decoupled Spatial-Temporal Encoders (Section 3.1), and the pre-training objective, Temporal Referring Modeling (Section 3.2). Implementation details are described in the supplement (Section A).
3.1 Decoupled Spatial-Temporal Encoders
The coarse-grained spatial modeling of prior approaches motivates us to develop more effective architectures, and IL models have shown great potential. While most VL models take scene or multi-frame features pre-extracted by image or action recognition models [Luo et al.(2020)Luo, Ji, Shi, Huang, Duan, Li, Li, Bharti, and Zhou, Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi, Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid], region features [Lu et al.(2019)Lu, Batra, Parikh, and Lee, Tan and Bansal(2019), Su et al.(2020)Su, Zhu, Cao, Li, Lu, Wei, and Dai, Zhang et al.(2021)Zhang, Li, Hu, Yang, Zhang, Wang, Choi, and Gao] and features processed by attention [Xu et al.(2015)Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel, and Bengio, Anderson et al.(2018)Anderson, He, Buehler, Teney, Johnson, Gould, and Zhang] have been proved powerful for IL models. These features provide detailed information about visual elements along with their spatial relations. Since static scene information, if asked by questions without specifying time, are usually consistent across related frames, IL models should also be competent to encode fine-grained spatial relations for video QA.
Hence, we propose Decoupled Spatial-Temporal Encoders (DeST), a video QA pipeline decoupling spatial and temporal modeling into an IL and a VL encoder. The IL encoder takes unordered and sparsely sampled frames at high spatial resolution as input. Fine-grained spatial information of static scenes is obtained by building a consensus among these frames. The VL encoder with input action features at high temporal resolution recognizes and models the transitions of actions and events. These two streams of information are fused at the final stage to jointly form the prediction. We leave other ways of fusion for future exploration.
As illustrated in Figure 2, DeST consists of an image encoder, a video encoder, and a question encoder to process inputs, as well as an IL encoder and a VL encoder, both with cross-attention [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi, Jaegle et al.(2021)Jaegle, Gimeno, Brock, Vinyals, Zisserman, and Carreira, Li et al.(2022)Li, Li, Xiong, and Hoi, Lei et al.(2022)Lei, Berg, and Bansal], to perform multi-modality interaction. Another answer encoder encodes answer candidates, similar to [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid]. To answer a question about a video, the question, video, and frames that are sparsely sampled from the video are encoded by their respective encoders. The question features then perform cross-attention to both frame and video features. The sum of two multi-modality representations is finally compared with encoded answer candidates to obtain the prediction. Formally, denotes the input question. are frames sampled from the input video , where the length of . The question is first encoded into a sequence of embeddings , where is the embedding of the [CLS] token, and is the number of word tokens. Then is fused with the frames and video as described below.


Image-Language Encoding. For each from 1 to , the image encoder transforms frame into a sequence of patch embeddings , where is the number of patches. Then the question feature and frame feature are fused by the IL encoder with cross-attention and transform into . The multi-modality representation of the IL stream is the average of [CLS] token embeddings of all frames encoded by a final multi-layer perceptron (MLP):
| (1) |
Video-Language Encoding. The video feature extractor first encodes the input video into a sequence of features , where is the length of the feature sequence. To indicate the beginning and the end of the video, we add two learnable tokens before and after the feature sequence. Temporal position encoding is also added to each feature to indicate the temporal order. Next, the feature sequence are contextualized and transformed into , where and are the beginning and the end token after contextualization. The question feature then performs cross attention to the video feature through the VL encoder and transforms into . The multi-modality representation of the VL stream is the output of the first token transformed by a final MLP.
Answer Selection. Following [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid], another text encoder encodes the answer candidates (collected from all answers in training data with frequency for open-ended QA). The prediction of each candidate is the dot product between each encoded candidate and the sum of two multi-modality representations. Formally, denotes the answer set. For all , we take the [CLS] token of ’s feature. Then the logit of is obtained via:
| (2) |
3.2 Temporal Referring Modeling
To pre-train the multi-modality encoders with affordable computation resources, we adopt an IL encoder pre-trained with image question answering (image QA), specifically VQA [Goyal et al.(2017)Goyal, Khot, Summers-Stay, Batra, and Parikh], and train the VL encoder for fine-grained temporal modeling with a novel objective.
Modeling fine-grained temporal relations for video QA requires the encoder to understand videos as event sequences and to associate the temporal relations of events with descriptions containing time conjunctions. Therefore, we develop Temporal Referring Modeling (TRM), which, in the form of video QA, inquires about absolute and relative temporal positions of events in videos. As depicted in Figure 3, given a video composed of multiple events, TRM asks the model four questions: what happens at the beginning, at the end, before an event, or after an event? The model then selects an event description as the answer. To accomplish this task requires the model to identify events and manage the order.
TRM needs VL data that offers (1) event-level annotations that delineate scenes and events for segments of videos and (2) descriptions that explain the temporal dynamics of these segments. Dense video captioning [Krishna et al.(2017a)Krishna, Hata, Ren, Fei-Fei, and Niebles] should be ideally suited for our needs, but unfortunately, many of its time segments overlap, making the temporal relations ambiguous, and labeling cost also hinders scalability. To satisfy the two conditions, we thus develop a simple yet effective way to generate data. As the example in Figure 3, we concatenate videos sampled from video captioning datasets to create videos with scene and event transitions. Then we generate questions by completing templates with captions of these videos. Incorrect answers are the other captions in the same video sequences, making the task more difficult.
Take, as an example, generating a video and a question that asks which event happens after an event. We first sample pairs from a video captioning dataset, with each pair composed of a video and a caption . The videos are encoded by the feature extractor into feature sequences for all from 1 to , where is the length of features of . These sequences are then concatenated and form . To generate the question, we first sample a captions where . Then the question is “What happens after ?” with the choices and the correct answer . Other questions are constructed similarly, where the answers to the questions about the beginning and the end are and respectively. With all input the same as general video QA, the encoded feature of question and the video feature are input to the VL encoder, going through the encoding and contextualizing process described in Section 3.1. The final objective is to minimize a standard cross-entropy loss.
4 Experiments
We elaborate on the preliminary analysis of spatial and temporal reasoning capability of prior work (Section 4.1). Then we demonstrate the improvement in two video QA benchmarks with DeST and TRM (Section 4.2). The ablation studies are lastly presented evaluating the efficacy of each component. (Section 4.3).
| Type | Just-Ask | VIOLET | ALBEF | UB |
|---|---|---|---|---|
| Motion | 28.00 | 18.25 | 32.50 | 70.63 |
| Spatial Rel. | 17.50 | 15.00 | 24.38 | 75.63 |
| Temporal Rel. | 4.88 | 2.12 | 3.75 | 32.88 |
| Yes / No | 66.28 | 71.87 | 79.75 | 100.00 |
| Color | 34.29 | 31.28 | 57.39 | 98.99 |
| Object | 26.73 | 22.33 | 31.45 | 70.13 |
| Location | 35.75 | 30.57 | 36.01 | 86.79 |
| Number | 50.17 | 50.33 | 55.61 | 99.83 |
| Other | 36.82 | 33.02 | 40.16 | 71.98 |
| Overall | 38.86 | 37.44 | 46.66 | 80.74 |
| Method | Benchmark | Accuracy |
|---|---|---|
| VIOLET | AGQA | 49.15 |
| AGQA* | 49.22.02 | |
| Just-Ask | AGQA | 51.27 |
| AGQA* | 47.73.06 | |
| HERO | VIOLIN | 69.01 |
| VIOLIN* | 68.71.08 |
4.1 Preliminary Analysis
Baselines. We take ALBEF [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi] as an example of IL models. For VL models, we study VIOLET [Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu], HERO [Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu], and Just-Ask [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid], which respectively instantiate three approaches discussed in Section 2.2. These are state-of-the-art of each approach with public code bases.
4.1.1 Encoding Spatial Semantics
We first assess the ability of encoding spatial semantics of IL models and VL models111Just-Ask and VIOLET as HERO does not support open-ended QA. ALBEF is run as image QA by sampling frames from a video and averaging frame predictions.
Benchmark. We conduct the analysis on ActivietNet-QA [Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao], which contains 5.8K videos of human activities in daily life and 58K question-answer pairs spanning diverse categories across spatial and temporal semantics offering comprehensive evaluations.
Results. Table 1 contrasts the accuracy (acc) by question type of the IL model with other VL models. ALBEF, though without temporal modeling, is adept at spatial reasoning, such as Spatial Relationships and Color, while Just-Ask demonstrates a slight advantage in Temporal Relationships. Due to the removal of rare answers following [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid], we report our performance upper bound of each type, which is the proportion of questions in the test set whose answers appeared in the training set. The tiny number of Temporal Relationships reveals the long-tailed distribution of its answers, which partially explains the poor performance.
| Method | Pre-training Data | Acc |
|---|---|---|
| CoMVT [Seo et al.(2021)Seo, Nagrani, and Schmid] | 100M vid | 38.8 |
| Just-Ask [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid] | 69M vid | 38.9 |
| MV-GPT [Seo et al.(2022)Seo, Nagrani, Arnab, and Schmid] | 100M vid | 39.1 |
| SiaSamRea [Yu et al.(2021)Yu, Zheng, Li, Ji, Wu, Xiao, and Duan] | 5.6M img | 39.8 |
| MERLOT [Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi] | 180M vid | 41.4 |
| VIOLET [Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu] | 180M vid + 2.5M vid + 3M img | 37.5 |
| FrozenBiLM [Yang et al.(2022b)Yang, Miech, Sivic, Laptev, and Schmid] | 10M vid | 43.2 |
| Singularity [Lei et al.(2022)Lei, Berg, and Bansal] | 14M img + 2.5M vid | 44.1 |
| DeST (ours) | 14M img + 120K VQA + 14K vid | 46.8 |
| Type | Best | DeST | Diff (%) |
|---|---|---|---|
| Motion | 32.50 | 35.75 | 10.00 |
| Spatial Rel. | 24.38 | 23.88 | -2.05 |
| Temporal Rel. | 4.88 | 5.25 | 7.58 |
| Yes / No | 79.75 | 78.61 | -1.43 |
| Color | 57.39 | 59.11 | 3.00 |
| Object | 31.45 | 30.50 | -3.02 |
| Location | 36.01 | 36.27 | 0.72 |
| Number | 55.61 | 55.28 | -0.59 |
| Other | 40.16 | 39.63 | -1.32 |
| Overall | 46.66 | 46.79 | 0.28 |
4.1.2 Modeling Temporal Relationships
We evaluate the capability of modeling temporal relationships by shuffling input frames and measuring the performance drop. Models are first trained with normal input and tested their performance with shuffled input. Intuitively, taking shuffled frames as input should be detrimental to the performance of the questions requiring temporal modeling, such as those inquiring about the order of actions or events in videos.
Benchmarks. For VIOLET and Just-Ask, we conduct the study on AGQA 2.0 [Grunde-McLaughlin et al.(2022)Grunde-McLaughlin, Krishna, and Agrawala], a large-scale open-ended video QA benchmark where spatial and temporal information is required in each question for evaluating compositional reasoning. It contains 2.27M question-answer pairs and 9.6K videos. For HERO, we consider VIOLIN [Liu et al.(2020)Liu, Chen, Cheng, Gan, Yu, Yang, and Liu], a task of judging hypotheses from visual premises, which has been officially tested in their experiments.
Result. In Table 2, Just-Ask demonstrates the slight capability of temporal modeling, while VIOLET and HERO are not sensitive to the order of input frames, and their performances of taking normal and shuffled input frames are similar. The result suggests clear insufficiency for temporal relationship modeling.
| Type | Best w/o PT | Best w/ PT | DeST | |
|---|---|---|---|---|
| Reasoning | Object-Relationship | 40.33 | 48.91 | 59.66 |
| Relationship-Action | 49.95 | 66.55 | 72.98 | |
| Object-Action | 50.00 | 68.78 | 75.20 | |
| Superlative | 33.55 | 39.83 | 48.94 | |
| Sequencing | 49.78 | 67.01 | 73.53 | |
| Exists | 50.01 | 59.35 | 63.21 | |
| Duration Comparison | 47.03 | 50.49 | 60.39 | |
| Activity Recognition | 5.52 | 21.53 | 27.78 | |
| Semantic | Object | 40.40 | 49.31 | 61.27 |
| Relationship | 49.99 | 59.60 | 63.93 | |
| Action | 47.58 | 58.03 | 65.96 | |
| Structure | Query | 36.34 | 47.98 | 61.22 |
| Compare | 49.71 | 65.11 | 72.04 | |
| Choose | 46.56 | 46.90 | 53.01 | |
| Logic | 50.02 | 56.20 | 59.18 | |
| Verify | 50.01 | 58.13 | 63.02 | |
| Overall | Binary | 48.91 | 55.35 | 62.61 |
| Open | 36.34 | 47.98 | 61.22 | |
| All | 42.11 | 51.27 | 61.91 |
| Question | Frames | Video | Acc |
|---|---|---|---|
| 41.32 | |||
| 50.07 | |||
| VQA | 51.00 | ||
| 51.08 | |||
| TRM | 55.62 | ||
| VQA | 56.61 | ||
| VQA | TRM* | 56.97 | |
| VQA | TRM | 61.91 |
| Training Stream | Acc |
|---|---|
| Image-Language | 49.91 |
| Video-Language | 16.56 |
| Both | 61.91 |
4.2 Video Question Answering
DeST takes frames and videos as input. Frames are extracted at 3 FPS, following [Lei et al.(2018)Lei, Yu, Bansal, and Berg]; then we sample frames randomly during training and uniformly during inference, similar to the strategy for action recognition. Video features are also pre-extracted by the video encoder and excluded from the optimization. More details are left in the supplement (Section A.1).
Table 3 compares DeST with prior work on ActivityNet-QA. We outperform all previous methods with orders of magnitudes less pre-training data. The performance of each question type is listed in Table 4, where Best shows the highest scores among the three methods in Table 1. This rigorous comparison leads to a more comprehensive analysis in terms of both spatial and temporal modeling. Diff lists the difference between Best and our performance in proportion to Best. Our hybrid model performs, as expected, comparably with the IL model in spatial modeling since we are not improving IL processing. On the other hand, the performance of categories such as Motion and Temporal Relationships are boosted, verifying the efficacy of TRM.
Table 5 presents the performance on AGQA 2.0, which offers extensive annotation of multiple abilities necessary to answer each question. We list the highest accuracy among the methods without pre-training reported by [Grunde-McLaughlin et al.(2022)Grunde-McLaughlin, Krishna, and Agrawala] (Best w/o PT) and the higher scores between our implementation of Just-Ask and VIOLET (Best w/ PT). DeST surpasses all prior work in all question types. Besides, while TRM is similar to only the questions of Sequencing, which accounts for about 7% of the dataset, TRM can serve as an abstraction of temporal modeling and generalize to other question types, such as Relationship-Action and Object-Action, which inquire about the temporal relationship between human actions and their interactions with objects. The full table and detailed analysis are provided in the supplement (Section B.3).
4.3 Ablation Studies
We present the influence of input modalities and pre-training over AGQA 2.0 to study the effect of modeling decisions. As presented in Table 6, question-only input reveals the language bias, which serves as a baseline. The boost in performance with frames and videos suggests successful encoding. Pretraining the IL encoder with VQA and the VL encoder with TRM both enhance the modeling capacity further. The performance drop due to shuffling videos verifies the efficacy of TRM. The full results are included in the supplement (Section B.3).
In Table 7, we ablate the IL or VL stream. A model is trained with both streams and tested on AGQA 2.0 with a single stream. The performance drastically drops in both settings, proving that our hybrid model is not a trivial ensemble. It might also be noted that the overwhelming advantage of the IL stream over its VL counterpart cannot conclude the utility of any stream, for each stream can be trained to perform better than the question-only baseline. We hypothesize that temporal information can be seen as the complex evolution of spatial information, and thus when both streams collaborate in spatial-temporal modeling, the IL stream offers an overall understanding of visual elements and scenes, while the VL stream assists it and models the detailed changes.
5 Conclusion
In this work, considering the complementary advantage of image- and video-language models, we decouple spatial-temporal modeling and propose a hybrid pipeline for video QA, where an image-language encoder encodes spatial information and a video-language encoder models temporal dynamics. To capture event-level temporal relations, the video-language encoder is pre-trained with an objective to identify events in videos by their temporal positions. With the collaboration between image- and video-language models as well as fine-grained temporal modeling, we advance the visual understanding for video QA.
Acknowledgement
This work was supported in part by the National Science and Technology Council under Grant MOST 110-2634-F-002-051, Mobile Drive Technology Co., Ltd (MobileDrive), and NOVATEK fellowship. We are also grateful to the National Center for High-performance Computing.
References
- [Agrawal et al.(2016)Agrawal, Chandrasekaran, Batra, Parikh, and Bansal] Harsh Agrawal, Arjun Chandrasekaran, Dhruv Batra, Devi Parikh, and Mohit Bansal. Sort story: Sorting jumbled images and captions into stories. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2016.
- [Anderson et al.(2018)Anderson, He, Buehler, Teney, Johnson, Gould, and Zhang] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [Bain et al.(2021)Bain, Nagrani, Varol, and Zisserman] Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- [Buch et al.(2022)Buch, Eyzaguirre, Gaidon, Wu, Fei-Fei, and Niebles] Shyamal Buch, Cristóbal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the ”video” in video-language understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [Carreira et al.(2018)Carreira, Noland, Banki-Horvath, Hillier, and Zisserman] Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600. arXiv preprint arXiv:1808.01340, 2018.
- [Changpinyo et al.(2021)Changpinyo, Sharma, Ding, and Soricut] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Chen et al.(2015)Chen, Fang, Lin, Vedantam, Gupta, Dollar, and Zitnick] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollar, and C. Lawrence Zitnick. Microsoft COCO captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015.
- [Choi et al.(2021)Choi, On, Heo, Seo, Jang, Lee, and Zhang] Seongho Choi, Kyoung-Woon On, Yu-Jung Heo, Ahjeong Seo, Youwon Jang, Minsu Lee, and Byoung-Tak Zhang. DramaQA: Character-centered video story understanding with hierarchical QA. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021.
- [Das et al.(2013)Das, Xu, Doell, and Corso] Pradipto Das, Chenliang Xu, Richard F. Doell, and Jason J. Corso. A thousand frames in just a few words: Lingual description of videos through latent topics and sparse object stitching. In 2013 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2013.
- [Diba et al.(2017)Diba, Sharma, and Van Gool] Ali Diba, Vivek Sharma, and Luc Van Gool. Deep temporal linear encoding networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [Diba et al.(2020)Diba, Fayyaz, Sharma, Paluri, Gall, Stiefelhagen, and Gool] Ali Diba, Mohsen Fayyaz, Vivek Sharma, Manohar Paluri, Jürgen Gall, Rainer Stiefelhagen, and Luc Van Gool. Large scale holistic video understanding. In European Conference on Computer Vision (ECCV), 2020.
- [Dosovitskiy et al.(2021)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit, and Houlsby] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021.
- [Fan et al.(2019)Fan, Zhang, Zhang, Wang, Zhang, and Huang] Chenyou Fan, Xiaofan Zhang, Shu Zhang, Wensheng Wang, Chi Zhang, and Heng Huang. Heterogeneous memory enhanced multimodal attention model for video question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [Feichtenhofer et al.(2016a)Feichtenhofer, Pinz, and Wildes] Christoph Feichtenhofer, Axel Pinz, and Richard Wildes. Spatiotemporal residual networks for video action recognition. In Advances in Neural Information Processing Systems (NeurIPS), 2016a.
- [Feichtenhofer et al.(2016b)Feichtenhofer, Pinz, and Zisserman] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016b.
- [Feichtenhofer et al.(2017)Feichtenhofer, Pinz, and Wildes] Christoph Feichtenhofer, Axel Pinz, and Richard P. Wildes. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [Feichtenhofer et al.(2019)Feichtenhofer, Fan, Malik, and He] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu] Tsu-Jui Fu, Linjie Li, Zhe Gan, Kevin Lin, William Yang Wang, Lijuan Wang, and Zicheng Liu. VIOLET : End-to-end video-language transformers with masked visual-token modeling. arXiv preprint arXiv:2111.12681, 2022.
- [Gao et al.(2018)Gao, Ge, Chen, and Nevatia] Jiyang Gao, Runzhou Ge, Kan Chen, and Ram Nevatia. Motion-appearance co-memory networks for video question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [Goyal et al.(2017)Goyal, Khot, Summers-Stay, Batra, and Parikh] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [Grunde-McLaughlin et al.(2021)Grunde-McLaughlin, Krishna, and Agrawala] Madeleine Grunde-McLaughlin, Ranjay Krishna, and Maneesh Agrawala. AGQA: A benchmark for compositional spatio-temporal reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Grunde-McLaughlin et al.(2022)Grunde-McLaughlin, Krishna, and Agrawala] Madeleine Grunde-McLaughlin, Ranjay Krishna, and Maneesh Agrawala. AGQA 2.0: An updated benchmark for compositional spatio-temporal reasoning. arXiv preprint arXiv:2204.06105, 2022.
- [Huang et al.(2020)Huang, Chen, Zeng, Du, Tan, and Gan] Deng Huang, Peihao Chen, Runhao Zeng, Qing Du, Mingkui Tan, and Chuang Gan. Location-aware graph convolutional networks for video question answering. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- [Hwang et al.(2021)Hwang, Bhagavatula, Le Bras, Da, Sakaguchi, Bosselut, and Choi] Jena D. Hwang, Chandra Bhagavatula, Ronan Le Bras, Jeff Da, Keisuke Sakaguchi, Antoine Bosselut, and Yejin Choi. COMET-ATOMIC 2020: On symbolic and neural commonsense knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021.
- [Jaegle et al.(2021)Jaegle, Gimeno, Brock, Vinyals, Zisserman, and Carreira] Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In International conference on machine learning (ICML), 2021.
- [Jaegle et al.(2022)Jaegle, Borgeaud, Alayrac, Doersch, Ionescu, Ding, Koppula, Zoran, Brock, Shelhamer, Henaff, Botvinick, Zisserman, Vinyals, and Carreira] Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier J Henaff, Matthew Botvinick, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver IO: A general architecture for structured inputs & outputs. In International Conference on Learning Representations (ICLR), 2022.
- [Jang et al.(2017)Jang, Song, Yu, Kim, and Kim] Yunseok Jang, Yale Song, Youngjae Yu, Youngjin Kim, and Gunhee Kim. TGIF-QA: Toward spatio-temporal reasoning in visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [Jia et al.(2021)Jia, Yang, Xia, Chen, Parekh, Pham, Le, Sung, Li, and Duerig] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), 2021.
- [Jiang et al.(2020)Jiang, Chen, Lin, Zhao, and Gao] Jianwen Jiang, Ziqiang Chen, Haojie Lin, Xibin Zhao, and Yue Gao. Divide and conquer: Question-guided spatio-temporal contextual attention for video question answering. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- [Jiang and Han(2020)] Pin Jiang and Yahong Han. Reasoning with heterogeneous graph alignment for video question answering. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020.
- [Kendall et al.(2018)Kendall, Gal, and Cipolla] Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
- [Kim et al.(2019)Kim, Ma, Kim, Kim, and Yoo] Junyeong Kim, Minuk Ma, Kyungsu Kim, Sungjin Kim, and Chang D. Yoo. Progressive attention memory network for movie story question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [Krishna et al.(2017a)Krishna, Hata, Ren, Fei-Fei, and Niebles] Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles. Dense-captioning events in videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2017a.
- [Krishna et al.(2017b)Krishna, Zhu, Groth, Johnson, Hata, Kravitz, Chen, Kalantidis, Li, Shamma, et al.] Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual Genome: Connecting language and vision using crowdsourced dense image annotations. International Journal of Computer Vision (IJCV), 2017b.
- [Le et al.(2021)Le, Le, Venkatesh, and Tran] Thao Minh Le, Vuong Le, Svetha Venkatesh, and Truyen Tran. Hierarchical conditional relation networks for multimodal video question answering. International Journal of Computer Vision (IJCV), 2021.
- [Lei et al.(2018)Lei, Yu, Bansal, and Berg] Jie Lei, Licheng Yu, Mohit Bansal, and Tamara Berg. TVQA: Localized, compositional video question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018.
- [Lei et al.(2020)Lei, Yu, Berg, and Bansal] Jie Lei, Licheng Yu, Tamara Berg, and Mohit Bansal. What is more likely to happen next? video-and-language future event prediction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020.
- [Lei et al.(2021)Lei, Li, Zhou, Gan, Berg, Bansal, and Liu] Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L. Berg, Mohit Bansal, and Jingjing Liu. Less is more: ClipBERT for video-and-language learning via sparse sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Lei et al.(2022)Lei, Berg, and Bansal] Jie Lei, Tamara L. Berg, and Mohit Bansal. Revealing single frame bias for video-and-language learning. arXiv preprint arXiv:2206.03428, 2022.
- [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [Li et al.(2022)Li, Li, Xiong, and Hoi] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning (ICML), 2022.
- [Li et al.(2020)Li, Chen, Cheng, Gan, Yu, and Liu] Linjie Li, Yen-Chun Chen, Yu Cheng, Zhe Gan, Licheng Yu, and Jingjing Liu. HERO: Hierarchical encoder for Video+Language omni-representation pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020.
- [Li et al.(2019)Li, Song, Gao, Liu, Huang, He, and Gan] Xiangpeng Li, Jingkuan Song, Lianli Gao, Xianglong Liu, Wenbing Huang, Xiangnan He, and Chuang Gan. Beyond RNNs: Positional self-attention with co-attention for video question answering. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2019.
- [Li et al.(2016)Li, Song, Cao, Tetreault, Goldberg, Jaimes, and Luo] Yuncheng Li, Yale Song, Liangliang Cao, Joel Tetreault, Larry Goldberg, Alejandro Jaimes, and Jiebo Luo. TGIF: A New Dataset and Benchmark on Animated GIF Description. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [Liu et al.(2021)Liu, Liu, Wang, and Lu] Fei Liu, Jing Liu, Weining Wang, and Hanqing Lu. HAIR: Hierarchical visual-semantic relational reasoning for video question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- [Liu et al.(2020)Liu, Chen, Cheng, Gan, Yu, Yang, and Liu] Jingzhou Liu, Wenhu Chen, Yu Cheng, Zhe Gan, Licheng Yu, Yiming Yang, and Jingjing Liu. Violin: A large-scale dataset for video-and-language inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [Liu et al.(2022)Liu, Ning, Cao, Wei, Zhang, Lin, and Hu] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [Lu et al.(2019)Lu, Batra, Parikh, and Lee] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. ViLBERT: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems (NeurIPS), 2019.
- [Luo et al.(2020)Luo, Ji, Shi, Huang, Duan, Li, Li, Bharti, and Zhou] Huaishao Luo, Lei Ji, Botian Shi, Haoyang Huang, Nan Duan, Tianrui Li, Jason Li, Taroon Bharti, and Ming Zhou. UniVL: A unified video and language pre-training model for multimodal understanding and generation. arXiv preprint arXiv:2002.06353, 2020.
- [Miech et al.(2019)Miech, Zhukov, Alayrac, Tapaswi, Laptev, and Sivic] Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. HowTo100M: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019.
- [Miech et al.(2020)Miech, Alayrac, Smaira, Laptev, Sivic, and Zisserman] Antoine Miech, Jean-Baptiste Alayrac, Lucas Smaira, Ivan Laptev, Josef Sivic, and Andrew Zisserman. End-to-end learning of visual representations from uncurated instructional videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [Na et al.(2017)Na, Lee, Kim, and Kim] Seil Na, Sangho Lee, Jisung Kim, and Gunhee Kim. A read-write memory network for movie story understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2017.
- [Park et al.(2020)Park, Bhagavatula, Mottaghi, Farhadi, and Choi] Jae Sung Park, Chandra Bhagavatula, Roozbeh Mottaghi, Ali Farhadi, and Yejin Choi. VisualCOMET: Reasoning about the dynamic context of a still image. In European Conference on Computer Vision (ECCV), 2020.
- [Park et al.(2021)Park, Lee, and Sohn] Jungin Park, Jiyoung Lee, and Kwanghoon Sohn. Bridge to answer: Structure-aware graph interaction network for video question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Peng et al.(2021)Peng, Yang, Bin, and Wang] Liang Peng, Shuangji Yang, Yi Bin, and Guoqing Wang. Progressive graph attention network for video question answering. In Proceedings of the 29th ACM International Conference on Multimedia (MM), 2021.
- [Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), 2021.
- [Rohrbach et al.(2017)Rohrbach, Torabi, Rohrbach, Tandon, Pal, Larochelle, Courville, and Schiele] Anna Rohrbach, Atousa Torabi, Marcus Rohrbach, Niket Tandon, Christopher Pal, Hugo Larochelle, Aaron Courville, and Bernt Schiele. Movie description. International Journal of Computer Vision (IJCV), 2017.
- [Ryoo et al.(2020a)Ryoo, Piergiovanni, Kangaspunta, and Angelova] Michael S. Ryoo, A. J. Piergiovanni, Juhana Kangaspunta, and Anelia Angelova. Assemblenet++: Assembling modality representations via attention connections. In European Conference on Computer Vision (ECCV), 2020a.
- [Ryoo et al.(2020b)Ryoo, Piergiovanni, Tan, and Angelova] Michael S. Ryoo, A. J. Piergiovanni, Mingxing Tan, and Anelia Angelova. Assemblenet: Searching for multi-stream neural connectivity in video architectures. In International Conference on Learning Representations (ICLR), 2020b.
- [Seo et al.(2021)Seo, Nagrani, and Schmid] Paul Hongsuck Seo, Arsha Nagrani, and Cordelia Schmid. Look before you speak: Visually contextualized utterances. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Seo et al.(2022)Seo, Nagrani, Arnab, and Schmid] Paul Hongsuck Seo, Arsha Nagrani, Anurag Arnab, and Cordelia Schmid. End-to-end generative pretraining for multimodal video captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- [Sharma et al.(2018)Sharma, Ding, Goodman, and Soricut] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), 2018.
- [Sigurdsson et al.(2016)Sigurdsson, Varol, Wang, Farhadi, Laptev, and Gupta] Gunnar A. Sigurdsson, Gül Varol, Xiaolong Wang, Ali Farhadi, Ivan Laptev, and Abhinav Gupta. Hollywood in homes: Crowdsourcing data collection for activity understanding. In European Conference on Computer Vision (ECCV), 2016.
- [Simonyan and Zisserman(2014)] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems (NeurIPS), 2014.
- [Su et al.(2020)Su, Zhu, Cao, Li, Lu, Wei, and Dai] Weijie Su, Xizhou Zhu, Yue Cao, Bin Li, Lewei Lu, Furu Wei, and Jifeng Dai. VL-BERT: Pre-training of generic visual-linguistic representations. In International Conference on Learning Representations (ICLR), 2020.
- [Sun et al.(2019a)Sun, Baradel, Murphy, and Schmid] Chen Sun, Fabien Baradel, Kevin Murphy, and Cordelia Schmid. Learning video representations using contrastive bidirectional transformer. arXiv preprint arXiv:1906.05743, 2019a.
- [Sun et al.(2019b)Sun, Myers, Vondrick, Murphy, and Schmid] Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. VideoBERT: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019b.
- [Tan and Bansal(2019)] Hao Tan and Mohit Bansal. LXMERT: Learning cross-modality encoder representations from transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), 2019.
- [Tapaswi et al.(2016)Tapaswi, Zhu, Stiefelhagen, Torralba, Urtasun, and Fidler] Makarand Tapaswi, Yukun Zhu, Rainer Stiefelhagen, Antonio Torralba, Raquel Urtasun, and Sanja Fidler. MovieQA: Understanding stories in movies through question-answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [Urooj et al.(2020)Urooj, Mazaheri, Da vitoria lobo, and Shah] Aisha Urooj, Amir Mazaheri, Niels Da vitoria lobo, and Mubarak Shah. MMFT-BERT: Multimodal Fusion Transformer with BERT Encodings for Visual Question Answering. In Findings of the Association for Computational Linguistics: EMNLP 2020, 2020.
- [Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [Wang et al.(2022)Wang, Ge, Yan, Ge, Lin, Cai, Wu, Shan, Qie, and Shou] Alex Jinpeng Wang, Yixiao Ge, Rui Yan, Yuying Ge, Xudong Lin, Guanyu Cai, Jianping Wu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. All in one: Exploring unified video-language pre-training. arXiv preprint arXiv:2203.07303, 2022.
- [Wang et al.(2016)Wang, Xiong, Wang, Qiao, Lin, Tang, and Van Gool] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European Conference on Computer Vision (ECCV), 2016.
- [Wang et al.(2019)Wang, Wu, Chen, Li, Wang, and Wang] Xin Wang, Jiawei Wu, Junkun Chen, Lei Li, Yuan-Fang Wang, and William Yang Wang. VaTeX: A large-scale, high-quality multilingual dataset for video-and-language research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (CVPR), 2019.
- [Xiao et al.(2021)Xiao, Shang, Yao, and Chua] Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. NExT-QA: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Xiao et al.(2022)Xiao, Yao, Liu, Li, Ji, and Chua] Junbin Xiao, Angela Yao, Zhiyuan Liu, Yicong Li, Wei Ji, and Tat-Seng Chua. Video as conditional graph hierarchy for multi-granular question answering. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2022.
- [Xu et al.(2017)Xu, Zhao, Xiao, Wu, Zhang, He, and Zhuang] Dejing Xu, Zhou Zhao, Jun Xiao, Fei Wu, Hanwang Zhang, Xiangnan He, and Yueting Zhuang. Video question answering via gradually refined attention over appearance and motion. In Proceedings of the 25th ACM international conference on Multimedia (MM), 2017.
- [Xu et al.(2015)Xu, Ba, Kiros, Cho, Courville, Salakhutdinov, Zemel, and Bengio] Kelvin Xu, Jimmy Lei Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhutdinov, Richard S. Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015.
- [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid] Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Just ask: Learning to answer questions from millions of narrated videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021.
- [Yang et al.(2022a)Yang, Miech, Sivic, Laptev, and Schmid] Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Learning to answer visual questions from web videos. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022a.
- [Yang et al.(2022b)Yang, Miech, Sivic, Laptev, and Schmid] Antoine Yang, Antoine Miech, Josef Sivic, Ivan Laptev, and Cordelia Schmid. Zero-shot video question answering via frozen bidirectional language models. arXiv preprint arXiv:2206.08155, 2022b.
- [Yi et al.(2020)Yi, Gan, Li, Kohli, Wu, Torralba, and Tenenbaum] Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. CLEVRER: Collision events for video representation and reasoning. In International Conference on Learning Representations (ICLR), 2020.
- [Yu et al.(2021)Yu, Zheng, Li, Ji, Wu, Xiao, and Duan] Weijiang Yu, Haoteng Zheng, Mengfei Li, Lei Ji, Lijun Wu, Nong Xiao, and Nan Duan. Learning from inside: Self-driven siamese sampling and reasoning for video question answering. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [Yu et al.(2018)Yu, Kim, and Kim] Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint sequence fusion model for video question answering and retrieval. In European Conference on Computer Vision (ECCV), 2018.
- [Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao] Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. ActivityNet-QA: A dataset for understanding complex web videos via question answering. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2019.
- [Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi] Rowan Zellers, Ximing Lu, Jack Hessel, Youngjae Yu, Jae Sung Park, Jize Cao, Ali Farhadi, and Yejin Choi. MERLOT: Multimodal neural script knowledge models. In Advances in Neural Information Processing Systems (NeurIPS), 2021.
- [Zeng et al.(2017)Zeng, Chen, Chuang, Liao, Niebles, and Sun] Kuo-Hao Zeng, Tseng-Hung Chen, Ching-Yao Chuang, Yuan-Hong Liao, Juan Carlos Niebles, and Min Sun. Leveraging video descriptions to learn video question answering. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2017.
- [Zhang et al.(2021)Zhang, Li, Hu, Yang, Zhang, Wang, Choi, and Gao] Pengchuan Zhang, Xiujun Li, Xiaowei Hu, Jianwei Yang, Lei Zhang, Lijuan Wang, Yejin Choi, and Jianfeng Gao. VinVL: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- [Zhao et al.(2017a)Zhao, Lin, Jiang, Cai, He, and Zhuang] Zhou Zhao, Jinghao Lin, Xinghua Jiang, Deng Cai, Xiaofei He, and Yueting Zhuang. Video question answering via hierarchical dual-level attention network learning. In Proceedings of the 25th ACM international conference on Multimedia (MM), 2017a.
- [Zhao et al.(2017b)Zhao, Yang, Cai, He, Zhuang, Zhao, Yang, Cai, He, and Zhuang] Zhou Zhao, Qifan Yang, Deng Cai, Xiaofei He, Yueting Zhuang, Zhou Zhao, Qifan Yang, Deng Cai, Xiaofei He, and Yueting Zhuang. Video question answering via hierarchical spatio-temporal attention networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI), 2017b.
- [Zhu and Yang(2020)] Linchao Zhu and Yi Yang. ActBERT: Learning global-local video-text representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
Supplementary Material \maketitlesup
In this supplement, we provide additional and clarifying details for the main paper. Section A contains implementation details including the model architecture, pre-training objectives, datasets, parameters of optimization, and computational cost of our model. Section B expands the experimental results of Table 2, 6, and 7 in the main paper and offers the analysis of the model behavior in different question types. We also conduct additional experiments testing the modeling decision on ActivityNet-QA, as well as evaluating the influence of temporal resolutions of the image-language model, the number of concatenated videos for Temporal Referring Modeling, and the loss combination strategy.
Appendix A Implementation Details
A.1 Model Architectures
We introduce the details of our Decoupled Spatial-Temporal Encoders (DeST). Following [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi] and [Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu], the image encoder is a 12-layer Vision Transformer [Dosovitskiy et al.(2021)Dosovitskiy, Beyer, Kolesnikov, Weissenborn, Zhai, Unterthiner, Dehghani, Minderer, Heigold, Gelly, Uszkoreit, and Houlsby], and the video encoder contains a Video Swin Transformer [Liu et al.(2022)Liu, Ning, Cao, Wei, Zhang, Lin, and Hu] (Swin-B) pre-trained on Kinetics-600 [Carreira et al.(2018)Carreira, Noland, Banki-Horvath, Hillier, and Zisserman] for feature extraction and a 6-layer Transformer for contextualization. The question and answer encoder are both 6-layer Transformers [Vaswani et al.(2017)Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, and Polosukhin] with each layer composed of a self-attention operation and a feed-forward network (FFN). The image- and video-language encoder are two 6-layer Transformers where each layer contains an additional cross-attention operation [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi, Jaegle et al.(2021)Jaegle, Gimeno, Brock, Vinyals, Zisserman, and Carreira, Jaegle et al.(2022)Jaegle, Borgeaud, Alayrac, Doersch, Ionescu, Ding, Koppula, Zoran, Brock, Shelhamer, Henaff, Botvinick, Zisserman, Vinyals, and Carreira, Li et al.(2022)Li, Li, Xiong, and Hoi, Lei et al.(2022)Lei, Berg, and Bansal], in which text features serve as queries and perform attention to visual features. The question, image, and image-language encoder are the same as the modules of ALBEF [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi] pre-trained on VQA [Goyal et al.(2017)Goyal, Khot, Summers-Stay, Batra, and Parikh]. The video contextualization module and video-language encoder are initialized from the question and image-language encoder respectively. The image and video encoder are fixed during the whole training process. The detailed parameters are listed in Table 8.
| Hyperparameter | Value |
|---|---|
| Embedding Size () | 768 |
| Number of Patches () | 576 |
| Video Feature Size () | 1024 |
| FFN Inner Hidden Size | 3072 |
| Number of Attention Heads | 12 |
| Attention Dropout | 0.1 |
| Dropout | 0.1 |
Since the optimization of video encoding is not included in video-language training, we extract and store video features to save memory. We operate the Video Swin Transformer with the same configuration as Swin-B, which samples every two frames and transforms a window of 32 frames into one feature. For long videos, such as ActivityNet [Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao] with an average length of 180 seconds, we shift the window by 32 frames. For others, such as the datasets used in pre-training or AGQA 2.0 [Grunde-McLaughlin et al.(2022)Grunde-McLaughlin, Krishna, and Agrawala], we shift the window by 16 frames, and thus every window overlaps with half of its previous and next window. Features of extremely long videos are sampled such that all videos are within a limited length.
A.2 Video-Language Pre-training
A.2.1 Details of Question and Video Synthesis for Temporal Referring Modeling
Temporal Referring Modeling (TRM) generates questions to inquire about absolute and relative temporal positions of specific events in videos. Questions are formed by choosing from five templates and filling in the templates with video descriptions. The choice of templates includes “What happens?”, “What happens at the beginning?”, “What happens at the end?”, “What happens before [event x]?”, and “What happens after [event x]?”, where the first question is irrelevant to temporal relations but incorporated to facilitate video-language matching. The other four questions are designed for resemblance to video QA requiring temporal modeling, such as Temporal Relationships in ActivityNet-QA [Yu et al.(2019)Yu, Xu, Yu, Yu, Zhao, Zhuang, and Tao] or State Transition in TGIF-QA [Jang et al.(2017)Jang, Song, Yu, Kim, and Kim].
Except for the first question paired with a single video, the corresponding videos of other questions are synthesized by concatenating videos sampled from video captioning datasets. This operation simulates a sequence of events that happen one after another and provides us with the exact position of each event.
One may be concerned that the transitions of events in real videos are rather smooth and ambiguous, instead of clear differences between videos in a random concatenated video sequence, where people, objects, and almost the entire scenes drastically change. For example, in a video where people clean up the table after finishing dinner in the dining room, most of the visual elements, such as the people and furniture, remain the same, but we humans can easily recognize these two events by comparing the actions and interactions between the people in the video. While TRM cannot generate such videos, our model has learned a similar capability with TRM to compare human actions and interactions between moments. During fine-tuning, it can focus on adapting to smooth transitions and thus learn faster than models with neither the capability of temporal reasoning nor event recognition.
A.2.2 Auxiliary Objective with Contrastive Learning
In addition to TRM, we apply an auxiliary objective during pre-training, which aligns video features with corresponding captions by contrastive learning, widely used in image- and video-language pre-training [Jia et al.(2021)Jia, Yang, Xia, Chen, Parekh, Pham, Le, Sung, Li, and Duerig, Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi, Luo et al.(2020)Luo, Ji, Shi, Huang, Duan, Li, Li, Bharti, and Zhou, Sun et al.(2019a)Sun, Baradel, Murphy, and Schmid, Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi, Wang et al.(2022)Wang, Ge, Yan, Ge, Lin, Cai, Wu, Shan, Qie, and Shou]. Specifically, with the concatenated video feature sequence , we add the beginning and the end token before and after the sequence, as well as the temporal position encoding to each feature. Then after contextualization, we have . To align each video to its caption, the objective learns a similarity function , such that parallel video-caption pairs have higher similarity scores. produces the representation of , which averages the features of a video, e.g. , and delivers the representation of a caption, which is the [CLS] embeddings of the caption feature encoded by the question encoder. and are two linear transformations that map the two representations into a normalized lower-dimensional space.
Following [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi], we calculate the softmax-normalized video-to-caption and caption-to-video similarity as:
| (3) |
where is a learnable temperature parameter. To increase the difficulty, we collect video-caption pairs from all video sequences in the same mini-batch , and thus is times the size of a mini-batch in practice. Then, similar to [Li et al.(2021)Li, Selvaraju, Gotmare, Joty, Xiong, and Hoi, Radford et al.(2021)Radford, Kim, Hallacy, Ramesh, Goh, Agarwal, Sastry, Askell, Mishkin, Clark, Krueger, and Sutskever], let and denote the ground-truth one-hot similarity, where the probability of positive and negative pair are 1 and 0. The video-caption contrastive loss is defined as the cross-entropy CE between and :
| (4) |
A.2.3 Pre-training Datasets
TRM samples video-caption pairs from video captioning datasets. We want the datasets as diverse as possible, not limited to cooking [Das et al.(2013)Das, Xu, Doell, and Corso], movies [Rohrbach et al.(2017)Rohrbach, Torabi, Rohrbach, Tandon, Pal, Larochelle, Courville, and Schiele], or indoor actions [Sigurdsson et al.(2016)Sigurdsson, Varol, Wang, Farhadi, Laptev, and Gupta]. To maintain the computation within an affordable size, videos cannot be too long [Krishna et al.(2017a)Krishna, Hata, Ren, Fei-Fei, and Niebles], or a video sequence would consist of few videos, which prohibits the model from learning long-term temporal dependency.
We pre-train the video-language encoder over VATEX [Wang et al.(2019)Wang, Wu, Chen, Li, Wang, and Wang] and TGIF [Li et al.(2016)Li, Song, Cao, Tetreault, Goldberg, Jaimes, and Luo]. VATEX contains 41K videos from Kinetics-600 [Carreira et al.(2018)Carreira, Noland, Banki-Horvath, Hillier, and Zisserman] and 826K sentences, where each video is paired with multiple descriptions. The lengths of the videos are all 10 seconds, cropped for precise action recognition in Kinetics. TGIF is an open-domain dataset containing 100K animated GIFs from Tumblr and 120K sentence descriptions. The average duration is around 3.1 seconds. It is worth noting that using less pre-training data is not the main motivation of this work, but with effective objectives, our method has surpassed large-scale pre-training. If computational cost is affordable, training with more data is expected to advance the performance. We leave pre-training with longer videos and larger datasets for future work.
| Hyperparameter | Pre-train | ActQA | AGQA |
| Learning Rate (Base) | 1e-5 | 2e-5 | 2e-5 |
| Learning Rate (Video) | 5e-5 | 2e-4 | 5e-5 |
| Learning Rate (MLP) | 2.5e-4 | 1e-3 | 2e-4 |
| Learning Rate (Ans) | 2e-5 | 2e-5 | 2e-5 |
| Weight Decay | 1e-2 | 1e-2 | 1e-2 |
| AdamW | 1e-8 | 1e-8 | 1e-8 |
| AdamW | 0.9 | 0.9 | 0.9 |
| AdamW | 0.98 | 0.98 | 0.98 |
| Training Steps | 60K | - | - |
| Training Epochs | - | 5 | 4 |
| Warmup | 0.03 | 0.1 | 0.1 |
| Batch Size | 128 | 64 | 64 |
| Max Video Length | 100 | 100 | 100 |
| Max Question Length | 50 | - | - |
| Number of Videos () | 8 | - | - |
| Number of Frames () | - | 16 | 8 |
A.3 Optimization
The pre-training and fine-tuning are all optimized with AdamW optimizer and linear decay scheduling after warmup. All experiments are run with two NVIDIA RTX 3090s, with which the pre-training takes about 18 hours. The detailed hyperparameters are provided in Table 9.
A.4 Computational Cost
The overall computation is the sum of the IL and VL models and depends on the number of input frames , video lengths, and the feature extractors. Let and denote the computation of ALBEF and Just-Ask, our method costs about as we stack more Transformer layers than Just-Ask, but the two streams share the question encoder. Specifically, the frozen image encoders cost about 12 GFLOPs per frame, and the video encoder performs 40 GFLOPs per window. The other modules need 28 GFLOPs.
Appendix B Experimental Details
B.1 Details of Temporal Modeling Analysis
Some may question our preliminary analysis of temporal modeling, in which we first train a model with normal inputs and test it with normal and shuffled inputs. The performance drops imply the sensitivity to the order of frames, and thus little difference may indicate the incompetence of temporal modeling. Training and testing a model with shuffled input can also completely eliminate the temporal information, but this approach only reveals how well a model solves a task with spatial information (or dataset bias if the task is designed for evaluating temporal modeling), and thus it is not suitable for assessing a model’s capability of temporal modeling.
We conduct the analysis on AGQA and VIOLIN as some other video QA benchmarks are less appropriate. For example, some questions in ActivietNet-QA need only spatial knowledge. In NeXT-QA [Xiao et al.(2021)Xiao, Shang, Yao, and Chua], while 29% of questions are about temporal relations, others aim at spatial information or more advanced cognition, e.g\bmvaOneDotcausal reasoning. The split of State Transition in TGIF-QA [Jang et al.(2017)Jang, Song, Yu, Kim, and Kim], though expected to suit this analysis well, could be solved by VIOLET without understanding the order of frames in our experiment (Table 10).
| Method | Benchmark | Accuracy |
|---|---|---|
| VIOLET | TGIF-QA | 95.34 |
| TGIF-QA* | 95.36.08 |
B.2 Pre-training Data Used by Prior Approaches
Compared with state-of-the-art approaches, DeST performs better on ActivityNet-QA with orders of magnitude less pre-training data. We include some widely-used pre-training datasets that are abbreviated in Table 3 of the main paper: 100M: HowTo100M [Miech et al.(2019)Miech, Zhukov, Alayrac, Tapaswi, Laptev, and Sivic]; 69M: HowToVQA69M [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid]; 180M: YT-Temporal-180M [Zellers et al.(2021)Zellers, Lu, Hessel, Yu, Park, Cao, Farhadi, and Choi]; 2.5M: WebVid [Bain et al.(2021)Bain, Nagrani, Varol, and Zisserman]; 14M/3M: Conceptual Caption [Sharma et al.(2018)Sharma, Ding, Goodman, and Soricut, Changpinyo et al.(2021)Changpinyo, Sharma, Ding, and Soricut]; 5.6M: COCO [Chen et al.(2015)Chen, Fang, Lin, Vedantam, Gupta, Dollar, and Zitnick] + VisualGenome [Krishna et al.(2017b)Krishna, Zhu, Groth, Johnson, Hata, Kravitz, Chen, Kalantidis, Li, Shamma, et al.].
B.3 Full Results and Analysis on AGQA 2.0
AGQA 2.0 provides extensive annotations. Each question is associated with the reasoning abilities necessary to answer the question. The annotations cover four aspects: reasoning types, semantics class, structures, and answer types. Reasoning types define the design of question templates for evaluating certain reasoning abilities. We list some examples of question templates created by [Grunde-McLaughlin et al.(2021)Grunde-McLaughlin, Krishna, and Agrawala] in Table 11 for the following analysis of our model’s behavior. The semantics class of a question describes its main subject: an object, relationship, or action. Question structures include open questions (query), comparing attributes of two options (compare), choosing between two options (choose), yes/no questions (verify), and understanding of logical operators, such as and or or. Questions with binary answer types have restricted answer choices, such as Yes/No, Before/After, or two specified options, while the answers to open-ended questions are much more diverse.
| Reasoning Type | Example of Template |
|---|---|
| Object-Relationship | What/Who/When/Where/How did they <rel> <object>? |
| Relationship-Action | Did they <relation> something before or after <action>? |
| Object-Action | Did they interact with <object> before or after <action>? |
| Superlative | What were they <action> first/last? |
| Sequencing | What did the person do after <action>? |
| Exists | Did/Does/Do <concept> occur? |
| Duration Comparison | Did they <action1> or <action2> for longer? |
| Activity Recognition | What does the person do before/after/while <action>? |
| Type | Just-Ask* | Just-Ask | VIOLET* | VIOLET | |
|---|---|---|---|---|---|
| Reasoning | Object-Relationship | 46.30 | 47.83 | 49.01 | 48.91 |
| Relationship-Action | 50.78 | 66.55 | 50.04 | 50.02 | |
| Object-Action | 50.77 | 68.78 | 50.13 | 50.24 | |
| Superlative | 37.96 | 39.83 | 39.47 | 39.49 | |
| Sequencing | 50.66 | 67.01 | 49.86 | 49.91 | |
| Exists | 57.15 | 59.35 | 54.58 | 54.70 | |
| Duration Comparison | 50.66 | 50.49 | 30.70 | 30.64 | |
| Activity Recognition | 19.87 | 21.53 | 3.13 | 3.13 | |
| Semantic | Object | 46.34 | 49.31 | 49.18 | 49.08 |
| Relationship | 54.63 | 59.60 | 52.32 | 52.41 | |
| Action | 49.78 | 58.03 | 41.47 | 41.45 | |
| Structure | Query | 45.53 | 47.25 | 48.15 | 47.98 |
| Compare | 50.84 | 65.11 | 47.65 | 47.69 | |
| Choose | 39.78 | 41.00 | 46.97 | 46.90 | |
| Logic | 54.87 | 56.20 | 50.99 | 51.24 | |
| Verify | 56.22 | 58.13 | 55.42 | 55.46 | |
| Overall | Binary | 49.95 | 55.35 | 50.30 | 50.33 |
| Open | 45.53 | 47.25 | 48.15 | 47.98 | |
| All | 47.72 | 51.27 | 49.22 | 49.15 |
B.3.1 Full Results of Temporal Modeling Analysis
The full results of Table 2 in the main paper are presented in Table 12, where we gauge the efficacy of temporal modeling of prior approaches by inputting shuffled videos and measuring performance drop. While Just-Ask [Yang et al.(2021)Yang, Miech, Sivic, Laptev, and Schmid] demonstrates improvement in Relationship-Action, Object-Action and Sequencing, VIOLET [Fu et al.(2022)Fu, Li, Gan, Lin, Wang, Wang, and Liu] performs similar in most types. The poor performance of VIOLET may be attributed to sparsely sampling, by which they enabled end-to-end training, but it turns out that taking few frames seems not able to summarize the temporal dynamics of whole videos.
| Type | T | T+F | T+F | T+V | T+V | T+F+V | T+F+V* | T+F+V |
|---|---|---|---|---|---|---|---|---|
| Object-Relationship | 39.15 | 49.21 | 50.33 | 51.67 | 53.40 | 56.39 | 57.16 | 59.66 |
| Relationship-Action | 50.05 | 50.61 | 50.00 | 49.83 | 71.57 | 53.25 | 51.64 | 72.98 |
| Object-Action | 49.99 | 50.11 | 50.00 | 50.03 | 74.74 | 56.27 | 54.42 | 75.20 |
| Superlative | 34.00 | 37.96 | 38.87 | 41.82 | 43.80 | 44.54 | 45.70 | 48.94 |
| Sequencing | 49.89 | 50.26 | 49.86 | 49.86 | 72.60 | 54.92 | 53.14 | 73.53 |
| Exists | 50.09 | 57.77 | 59.06 | 50.86 | 53.68 | 59.95 | 59.04 | 63.21 |
| Duration Comparison | 48.71 | 51.43 | 55.04 | 44.96 | 37.34 | 62.58 | 60.26 | 60.39 |
| Activity Recognition | 14.63 | 14.81 | 16.84 | 13.16 | 19.60 | 21.25 | 21.44 | 27.78 |
| Object | 39.25 | 49.24 | 50.16 | 51.44 | 55.28 | 56.50 | 57.31 | 61.27 |
| Relationship | 50.08 | 54.73 | 55.76 | 50.58 | 57.14 | 57.33 | 56.07 | 63.93 |
| Action | 48.49 | 49.98 | 50.86 | 47.09 | 56.52 | 56.35 | 54.39 | 65.96 |
| Query | 33.28 | 48.18 | 49.33 | 51.99 | 56.48 | 57.46 | 58.90 | 61.22 |
| Compare | 49.99 | 50.62 | 50.73 | 49.42 | 68.28 | 56.11 | 54.23 | 72.04 |
| Choose | 48.10 | 46.24 | 46.76 | 49.50 | 42.38 | 50.34 | 50.40 | 53.01 |
| Logic | 50.03 | 54.28 | 56.36 | 50.68 | 51.91 | 57.52 | 55.78 | 59.18 |
| Verify | 49.98 | 57.48 | 58.45 | 51.28 | 53.44 | 59.49 | 59.45 | 63.02 |
| Binary | 49.47 | 52.00 | 52.70 | 50.17 | 54.74 | 55.76 | 55.01 | 62.61 |
| Open | 33.28 | 48.18 | 49.33 | 51.99 | 56.48 | 57.46 | 58.90 | 61.22 |
| All | 41.32 | 50.07 | 51.00 | 51.08 | 55.62 | 56.61 | 56.97 | 61.91 |
B.3.2 Full Results and Analysis of Our Method
We show the full results of our method on AGQA 2.0 with ablation of components and pre-training strategies in Table 13.
We first examine the performance of inputting only questions (T), which reveals the bias of the datasets as these questions can be solved without grounding to videos. With a rigorous balancing procedure, this model cannot achieve more than 50% accuracy on any question type, but some questions, for example, those belonging to Relationship-Action, Object-Action, and Exists appear easier than others.
Inputting frames (T+F) improves the overall performance by about 10% accuracy, which mostly comes from Object-Relationship and Exists. This is reasonable as these questions involve less temporal information according to the templates, and they are more likely to be solved with a few static frames with spatial information about humans, objects, and scenes. Pre-training the image-language encoder with VQA [Goyal et al.(2017)Goyal, Khot, Summers-Stay, Batra, and Parikh] (T+F) shows further improvement in Exists, which seems more similar to the question design of image QA.
Accessing videos (T+V) is helpful for different question types such as Superlative, in which the questions ask about something happening first or last, but some other questions that also require temporal modeling, including Relationship-Action or Sequencing, are not improved. Besides, video inputs do not enhance the performance of questions improved by frame inputs. This complementary advantage of frames and videos is consistent with our findings in the preliminary analysis, and inputting both frames and videos (T+F+V) does surpass inputting only one of them in all reasoning types.
Pre-training the video-language encoder with TRM (T+F+V) boosts the performance of most reasoning types, especially Relationship-Action, Object-Action, and Sequencing. These questions all need temporal modeling of event sequences in videos and have question formats more similar to TRM. The huge performance gap (20% accuracy) between normal (T+F+V) and shuffled video inputs (T+F+V*), as well as the little gap between no pre-training (T+F+V) and shuffled inputs (T+F+V*), suggests successful temporal modeling and verifies the efficacy of TRM.
Despite the enhancement in most questions, TRM still struggles with some reasoning types, for example, Duration Comparison, asking a machine which action lasts longer. These questions require a machine to memorize multiple events and identify their starting and ending point to obtain their duration. Such abilities are beyond the intention of developing TRM, and we leave it for future exploration.
| Type | VL | IL |
|---|---|---|
| Object-Relationship | 49.04 | 20.91 |
| Relationship-Action | 50.00 | 0.60 |
| Object-Action | 50.00 | 0.99 |
| Superlative | 36.00 | 15.86 |
| Sequencing | 49.85 | 0.80 |
| Exists | 57.09 | 0.07 |
| Duration Comparison | 58.99 | 0.00 |
| Activity Recognition | 13.06 | 0.92 |
| Object | 48.92 | 20.60 |
| Relationship | 54.58 | 0.20 |
| Action | 52.19 | 0.38 |
| Query | 47.35 | 26.68 |
| Compare | 51.24 | 0.69 |
| Choose | 48.29 | 22.11 |
| Logic | 55.09 | 0.04 |
| Verify | 56.51 | 0.08 |
| Binary | 52.52 | 6.30 |
| Open | 47.35 | 26.68 |
| All | 49.91 | 16.56 |
| Question | Frames | Video | Acc |
|---|---|---|---|
| 31.01 | |||
| 43.15 | |||
| VQA | 46.66 | ||
| VQA | TRM | 46.79 |
B.3.3 Full Results of Ablation Study of Encoding Streams
B.4 Ablation Study on ActivityNet-QA
The ablation study is also conducted on ActivityNet-QA, as reported in Table 15. The result proves that the image-language model is capable of answering some video QA problems, and the strategy of bridging image QA and video QA further increases the performance.
B.5 Temporal Resolutions of the Image-Language Encoder
We estimate the influence of varying temporal resolutions (the number of frames ) of the image-language encoder. As displayed in Figure 4, taking more frames substantially increases the performance on ActivityNet-QA, while the improvement on AGQA is insignificant. This discrepancy could be explained by the distribution of question types in the two benchmarks, where ActivityNet-QA contains more questions of static information and the prediction is likely stabler and more robust when more frames are provided. More questions in AGQA are related to temporal dynamics and thus less affected by the number of frames.

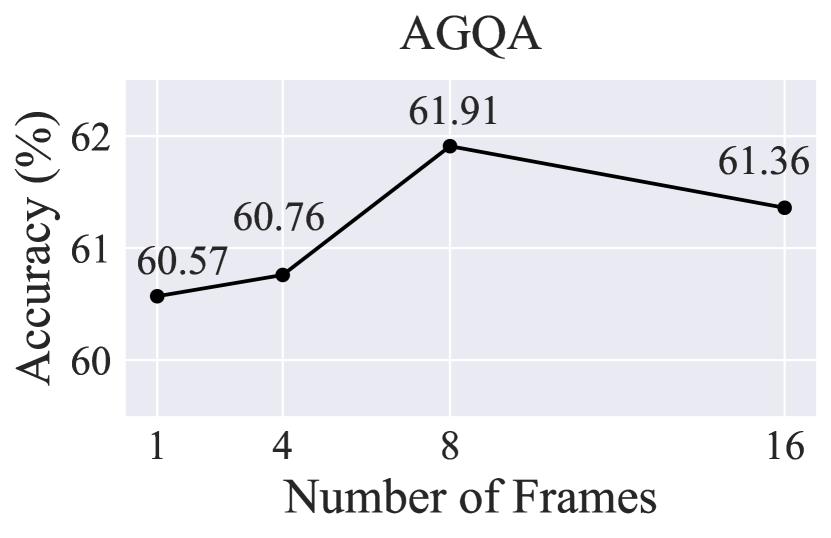
B.6 The Number of Videos for Temporal Referring Modeling
We alter the number of videos concatenated for TRM (the variable ) and study its influence. The accuracy on AGQA 2.0 with respect to the number of videos is presented in Figure 5. We can observe that increasing the number of videos is not always beneficial to the downstream task. Concatenating too many videos may result in extremely long temporal dependency, which is hard for a model to encode.

B.7 Multi-Task Loss Weighing
As described in A.2.2, we align visual and linguistic content by contrastive learning. An experiment is conducted to evaluate different approaches to loss combinations. Let and denote the loss of TRM and video-language contrastive loss. We compare adding losses directly and weighing losses by uncertainty [Kendall et al.(2018)Kendall, Gal, and Cipolla] :
| (5) |
where and are two learnable parameters. Following [Kendall et al.(2018)Kendall, Gal, and Cipolla], in practice the model learns to predict for numerical stability.
| Loss combination | Acc |
|---|---|
| Unweighted | 61.91 |
| Weighing by uncertainty | 60.15 |
Table 16 compares the accuracy on AGQA 2.0 of pre-training with the sum of losses unweighted and weighted by uncertainty. The result shows that the difference between the two approaches to combining losses is insignificant.