Learning-based Hierarchical Control: Emulating the Central Nervous System for Bio-Inspired Legged Robot Locomotion
Abstract
Animals possess a remarkable ability to navigate challenging terrains, achieved through the interplay of various pathways between the brain, central pattern generators (CPGs) in the spinal cord, and musculoskeletal system. Traditional bioinspired control frameworks often rely on a singular control policy that models both higher (supraspinal) and spinal cord functions. In this work, we build upon our previous research by introducing two distinct neural networks: one tasked with modulating the frequency and amplitude of CPGs to generate the basic locomotor rhythm (referred to as the spinal policy), and the other responsible for receiving environmental perception data and directly modulating the rhythmic output from the spinal policy to execute precise movements on challenging terrains (referred to as the descending modulation policy). This division of labor more closely mimics the hierarchical locomotor control systems observed in legged animals, thereby enhancing the robot’s ability to navigate various uneven surfaces, including steps, high obstacles, and terrains with gaps. Additionally, we investigate the impact of sensorimotor delays within our framework, validating several biological assumptions about animal locomotion systems. Specifically, we demonstrate that spinal circuits play a crucial role in generating the basic locomotor rhythm, while descending pathways are essential for enabling appropriate gait modifications to accommodate uneven terrain. Notably, our findings also reveal that the multi-layered control inherent in animals exhibits remarkable robustness against time delays. Through these investigations, this paper contributes to a deeper understanding of the fundamental principles of interplay between spinal and supraspinal mechanisms in biological locomotion. It also supports the development of locomotion controllers in parallel to biological structures which are capable of achieving natural locomotion in complex, realistic environments.
I Introduction
Recent advances in bioinspired robotics have focused on the development of robots that either explore specific biological questions or mimic the mechanisms and designs of biological systems found in nature [1, 2, 3]. This interest is driven by the impressive feats exhibited by many animals, which have evolved sophisticated body forms and cognitive capabilities over millennia. For instance, legged animals have honed in their abilities and demonstrate extraordinary capabilities to maneuver across a wide variety of terrains [4]. This remarkable adaptability depends on complex interactions between many areas of the nervous system, the musculoskeletal system, and the environment. The agility of animals is even more remarkable given the fact that conduction delays are rather large in neurons [5], and orders of magnitude higher than in robots’ electrical circuits. At the nervous system level, despite the complex mechanisms at play in animals, locomotion can be primarily attributed to the interplay of three main components: spinal central pattern generators (CPGs), descending modulation, and sensory feedback [6]. Specifically, CPGs, located in the spinal cord, play a crucial role in animal locomotion as they are responsible for generating coordinated rhythmic muscle movements without rhythmic input. However, higher brain centers, including the motor cortex, cerebellum, and basal ganglia, refine these rhythmic patterns with descending control signals. This process enables the adaptation of locomotion to changing environmental conditions, guided by adjustments informed by sensory feedback, such as proprioception and vision. In this work, we propose a neural structure for locomotion control, comprising two independent networks designed to closely mimic the aforementioned biological structure (Fig.1).

Studies have shown that the central nervous system hierarchically governs animal locomotion, with control spanning multiple levels, from the cerebral cortex and brainstem down to the spinal cord [7]. Firstly, biological evidence highlights the critical role of CPGs located in the spinal cord in providing foundational movement patterns for locomotion, essential for an animal’s rapid acquisition of locomotion skills post-birth [8, 9]. Further research demonstrates that self-adaptation can lead to enhancements in spinal circuitry (spinal plasticity), indicating the spinal cord’s capacity for learning and memorization [10, 11]. Moreover, in mammals, specific descending pathways, known as the corticospinal tracts, form a crucial link between the cerebral cortex and the spinal cord. These tracts, unique to mammals, play a vital role in visuomotor coordination, enabling the precise adjustment of movements based on perception feedback to navigate through various terrains and overcome environmental challenges [12]. This innate capacity for rapid learning and adaptation not only sheds light on the fundamental principles of biology, but also fuels considerable interest in the development of robotic locomotion control systems [13]. In particular, we believe that the dynamic interplay between spinal CPGs and supraspinal descending modulation, which is critical for facilitating animal locomotion across diverse terrains, offers a compelling model for controlling robotic locomotion.

Drawing inspiration from biology, numerous studies have aimed at replicating the control mechanisms that legged vertebrates use for locomotion [14]. However, most CPG-based locomotion controllers primarily focus on generating rhythmic motions, which makes it challenging for robots to navigate difficult terrains, which require multiple non-rhythmic adjustments [15, 16, 17]. Additionally, these methods often involve a large number of parameters that require optimization, leading to a time-consuming tuning process. With the widespread adoption of deep learning in robot controller design, several studies have utilized learning-based methods to fine-tune the parameters and, consequently, the behavior of oscillators, which are used to represent CPGs [18, 19, 20, 21, 22, 23, 24]. These adjustments enable improved velocity tracking and omnidirectional locomotion capabilities. Nevertheless, their ability to traverse challenging environments remains relatively limited.
In this work, we develop a hierarchical control framework that mimics the mechanisms found within the locomotor neural circuits of legged mammals, extending previous work[18]. Specifically, we employ a learning-based spinal neural network, in conjunction with CPGs, as a fundamental gait pattern generator to represent the spinal cord’s function. We then introduce a supraspinal neural network to modulate the gait patterns generated by the spinal policy, representing the brain’s descending pathways, which is integrated with visual information feedback. We validate our framework through several experiments in simulation, demonstrating that the robot can adapt to various complex terrains such as stairs, high obstacles, and gaps. Furthermore, we demonstrate that the spinal policy relies less on sensory feedback to generate rhythmic movements, primarily facilitating locomotion on flat terrain. In contrast, the descending modulation policy is more dependent on sensory feedback to modulate gait patterns for challenging terrain, especially for terrains that require discrete and precise movements, such as stairs, high obstacles, and gaps. Our main contributions can be summarized as follows:
-
•
We introduce a learning-based hierarchical structure that independently mimics the functions of the spinal cord and descending modulation mechanisms, utilizing a straightforward and intuitive reward structure. This bio-inspired framework allows the robot to navigate across challenging terrains, including climbing high platforms, traversing areas with random unevenness and gaps, and ascending stairs that were unachievable with previous neural structures.
-
•
Our framework offers a platform for testing biological hypotheses related to animal locomotion on challenging terrains. In particular, our work explores the unique control mechanisms of rhythmic and discrete movements to enhance the versatility and efficiency of robotic locomotion. Furthermore, this framework allows us to investigate the effects of sensorimotor delays on the spinal policy and descending modulation policy for robot behavior on different terrains, shedding light on key biological control principles.
-
•
This work not only deepens our understanding of the function of the central nervous system in biological locomotion, emphasizing the roles of the spinal cord and descending modulation in animal movement strategies, but also facilitates the development of bio-inspired locomotion controllers to enable robots to perform complex and natural movements.
II Background
Neural networks in the spinal cord, known as CPGs, play a pivotal role in animal locomotion by producing coordinated rhythmic signals, even in the absence of input from the brain and sensory organs [25]. In this work, we employ non-linear phase oscillators to model the CPG circuits, enabling the generation of rhythmic patterns similar to those in our previous works [18, 26]:
| (1) | ||||
| (2) |
where represents the amplitude of the oscillator, denotes the phase of the oscillator, and are the intrinsic frequency and amplitude, respectively, and is a factor that represents the convergence rate.
For animals, rhythmic neural activities governed by CPGs are translated into muscle activities, ultimately resulting in rhythmic behaviors [27]. Building on this principle, we map the outputs of the oscillators to joint positions by first determining the desired positions of the feet in Cartesian space relative to the body frame. Then, we employ inverse kinematics to calculate the desired joint angles. Furthermore, to simulate how signals from higher-level brain regions modulate locomotion behavior in vertebrates, we directly add an offset to the nominal positions of the feet [28, 24]. The formulation of the desired foot positions is as follows:
| (3) | ||||
| (4) |
where represents the nominal step length, is the nominal body height, and denote the maximum ground clearance during the swing phase and the maximum ground penetration during the stance phase, respectively, and and directly adjust the desired foot position in the and directions, respectively. These parameters are illustrated in Fig.2.
III LEARNING FRAMEWORK
Our bio-inspired locomotion control framework consists of a spinal policy and a descending modulation policy, both trained through reinforcement learning. The spinal policy emulates the spinal cord’s function, generating basic gait patterns in conjunction with the CPG, based on internal states and sensory feedback. The descending modulation policy simulates high-level brain functions to produce descending modulation signals [29]. These signals fine-tune the movements initiated by the spinal policy, adapting to both internal states and environmental cues, thus enhancing the robot’s adaptability in complex settings. Fig.2 depicts the control diagram of our approach, and we detail it further in this section.
III-A Spinal Policy
Biological evidence indicates that the spinal cord’s capacity to perform rhythmic motor patterns, coupled with its access to sensory information specific to activities, enables it to operate with a high degree of automaticity, requiring little to no input from the brain [30]. These findings highlight that the circuits in the spinal cord responsible for locomotion can operate independently of brain control. Therefore, we employ a spinal policy to represent the learnable circuits in the spinal cord, incorporating the CPGs to produce natural cyclic movements. To ensure the spinal policy works cooperatively with the descending modulation policy, we enable the spinal policy to access linear velocity commands and proprioceptive information in its observation space. The velocity command biologically mimics the signal from the mesencephalic locomotor region (MLR) in the higher brain regions. It is widely acknowledged that the MLR plays an active role in initiating and modulating spinal neural circuitry to control locomotion speed [31]. Furthermore, studies show that proprioceptive information, representing the sense of balance and spatial orientation, can be projected to the spinal cord from the vestibular system in vertebrates [32]. Thus, the spinal policy can dynamically adjust the CPGs’ parameters based on the robot’s velocity command and proprioceptive feedback from the joint encoders and the Inertial Measurement Unit (IMU), thereby generating a stable and efficient gait.
III-A1 Action Space
To generate basic gait patterns, the spinal policy focuses on adjusting CPG parameters which primarily control the frequency and phase difference between the legs and the step length (refer to Eq.1 and Eq.2). This design allows the module to not only generate basic gait patterns but also track the commanded velocity, thus enhancing both the adaptability and stability of the locomotion.
III-A2 Observation Space
The observation space includes the operational state of the CPG, denoted as (refer to Eq.1 and Eq.2), and previous actions . Additionally, it encompasses velocity commands in the body frame (x and y directions, as well as yaw rate); contact force booleans ; and the current state of the robot , as measured by the Inertial Measurement Unit (IMU), along with the joint states (positions and velocities) represented as . Here, denotes the projected gravity vector, while and represent the body’s linear and angular velocities, respectively.
III-B Descending Modulation Policy
It should be emphasized that the spinal cord alone is insufficient for locomotion in complex environments. The involvement of supraspinal control is crucial, as it provides the necessary drive for movement and the sensorimotor integration required for navigating challenging terrains, as well as performing anticipatory behaviors (as opposed to reactive behaviors) [33]. There is now accumulating evidence suggesting that supraspinal structures are essential in modulating locomotion, with an emphasis on descending modulation arising from various regions of the supraspinal network [34]. Moreover, these structures are capable of integrating sensory inputs to modify locomotor behavior in response to both internal and external environmental conditions. Therefore, we introduce a descending modulation policy to replicate the function by which high-level brain activity modulates rhythmic motion generated by the spinal policy and CPGs.
III-B1 Action Space
In our framework, the descending modulation policy fine-tunes the rhythmic movements produced by the spinal policy and CPGs by introducing specific alterations to the foot’s positioning in the horizontal (x) and vertical (z) planes, as shown in Eq.3 and Eq.4. These modifications directly impact the robot’s leg movements by altering rhythmic patterns when traversing rough terrain. Such adjustments to the rhythmic movement can accommodate uneven terrains, such as stairs. Furthermore, it compensates for the limitations of rhythmic gait patterns during locomotion on unstructured terrains, like high obstacles and gaps, which require precise foothold control and discrete movements such as jumping. Consequently, the descending modulation policy enhances the robot’s adaptability and precision in navigating a variety of terrains.
III-B2 Observation Space
The supraspinal structures involved in controlling locomotion in vertebrates, such as the motor cortex, MLR (Mesencephalic Locomotor Region), and DLR (Diencephalic Locomotor Region), are very complex [7]. To simplify the descending modulation mechanism, we enable the descending modulation policy to directly access the velocity command and proprioceptive sensory information, which originate from the MLR and the vestibular system, respectively, in vertebrates. Additionally, the descending modulation policy can access joint states and ground contact forces through descending spinal tracts, which are the pathways that carry information up and down the spinal cord between the brain and the body. Furthermore, by replicating the perceptual capabilities of the higher-level brain regions which process sensory data about the surroundings, we allow the descending modulation policy to access visual information of the environment. This is achieved by utilizing a terrain height map, , which represents a 16 × 10 grid spaced at intervals of 0.05 m, located in front of the robot. Consequently, the observation space includes both the spinal policy’s observations and the terrain height map. This observation space enables the robot to proactively and adeptly respond to environmental variations. Furthermore, it aids in the precise monitoring of each joint’s status, ensuring that the robot’s movements are responsive and finely tuned to the complexities of the external environment.
III-C Training Details
To train the spinal policy and descending modulation policy, we employ a two-step training process. For the first training phase, the robot is trained on flat terrain with the spinal policy only. As shown in Table I, we reward velocity tracking and locomotion distance, and we penalize the robot’s orientation (to ensure stability), as well as power to promote energy efficiency. For the second training phase, we train the descending modulation policy in conjunction with the spinal policy, whose parameters are frozen, on complex terrains. To ensure continuity between the two training phases, we make only minor adjustments to the reward function, keeping the reward structures for the two policies as similar as possible, while allowing the robot to explore and adapt to challenging environments. Specifically, we reduce the penalty for foot contact forces from 0.1 to 0.01 for rough terrain locomotion. Additionally, we introduce a penalty for actions generated by the descending modulation policy to minimize unnecessary impacts on basic gait patterns, and another penalty term that penalizes foot contact with vertical surfaces. The second phase focuses on various uneven terrains, including steps (up to 18 cm in height for each step), high platforms (up to 50 cm high), randomly varying terrains (with heights within a range of [-10cm, 10cm]), and gaps (up to 50 cm in width), as illustrated in Fig.4. Velocity commands are randomly sampled from 0.5 m/s to 2 m/s. Both policies operate at a control frequency of 100 Hz, while the torques, derived from desired joint positions, are updated at a frequency of 1 kHz.
We simulate the Unitree quadruped robot A1 in Isaac Gym, which utilizes PhysX as the physics engine, on a single NVIDIA RTX 4090 GPU [35]. We employ Proximal Policy Optimization (PPO) to train both policies [36] using the same hyperparameters as in our previous work [18]. The spinal policy and the descending modulation policy are implemented using a 3-layer Multi-Layer Perceptron (MLP) with hidden layers of dimensions [512, 256, 128].
| Reward term | Expression | w |
|---|---|---|
IV Experiments and discussion
In this section, we present simulation results of deploying our learned policies on a quadruped robot to traverse various terrains. These experiments explore the interaction between the spinal cord policy and the descending modulation policy across different terrains, while also verifying certain biological assumptions. Furthermore, we examine the impact of sensorimotor delay on these two policies during locomotion. A supplementary video offers clear visualizations of the discussed experiments.


IV-A Flat Terrain Locomotion
We first investigate the roles of the spinal and descending modulation policies in regulating locomotion across flat terrain. Initially, the robot is commanded to walk forward at speeds ranging from 0.5 m/s to 2 m/s on flat terrain. While the spinal policy remains activated, the descending modulation policy is deactivated at and then re-activated at . We observe that neither the robot’s velocity nor its behavior are significantly altered, as demonstrated in Fig.3, indicating that for the basic locomotion (movement on flat terrain), the behavior is primarily governed by the spinal cord neural network. The top figure shows that, with only the spinal policy active, the robot can still track the commanded velocity through quick self-adjustment. The bottom plots show the outputs for the front right leg from the spinal policy and descending modulation policy, alongside the executed position of the front right leg. We observe that the executed trajectory (indicated by the green dotted line) largely overlaps with the output of the spinal neural network (represented by the orange line). This indicates that the descending modulation policy exerts minimal influence on locomotion across flat terrain, supporting the biological perspective that basic locomotion patterns are governed by the spinal cord [37].
IV-B Rough Terrain Locomotion
We further test the framework across four different types of rough terrains: uneven surfaces (randomly generated elevations ranging in [-0.08, 0.08] meters), stairs (with a step width of 31 cm and step height of 18 cm), high obstacles (up to 30 cm), and gaps (with lengths up to 25 cm), which are similar but randomized compared with the training environment, as illustrated in Fig.4(a). In comparison, the dimensions of the Unitree A1, when in the nominal standing configuration, are 50 cm x 30 cm x 40 cm [38]. Starting from different initial positions on flat terrain with commanded speeds ranging from 0.5 m/s to 2 m/s, the robot successfully traverses all of these terrains without a single fall in 10 trials. To examine the contributions of the spinal policy and descending modulation policy to locomotion on rough terrain, we plot the outputs of both neural networks alongside the executed positions of the front right leg and rear left leg in Fig.4(f). This analysis reveals that, on rough terrain, the spinal policy (indicated by the orange line) continues to generate rhythmic outputs that represent the basic gait patterns, while the descending modulation policy (indicated by the blue line) significantly modulates the movements produced by the spinal policy. Our observations indicate that, during rough terrain locomotion, the step height and footfall are primarily managed by the descending modulation policy, as evidenced by the outputs in the and dimensions, respectively.
To facilitate ascending up stairs, the movements of the front legs are modulated by the descending modulation policy to draw them nearer to the body, thus lowering the forebody (see the plot of the front right leg in the dimension around ). Similarly, to realize descending down stairs, the movements of the rear legs are modulated by the descending modulation policy to bring them closer to the body (see the plot of the rear left leg in z dimension around ). Interestingly, a dynamic jumping behavior is observed when crossing a high obstacle of the same height as the robot, with the descending modulation policy modulating the movement by sending an impulse signal to the rear legs (see the plot of the rear left leg in the dimension around ). For gap crossing, the descending modulation policy contributes not only to the foot trajectory in the dimension to lower the body height for stable crossing, but also to the foot trajectory in the dimension to control the foothold placement to avoid stepping into the gaps (see the plots of both legs in the and dimensions around ). These experimental results corroborate the biological view that the basic locomotor rhythm is centrally generated by spinal circuits, and that descending pathways are crucial for ensuring appropriate modifications of gait to accommodate uneven terrain [39].
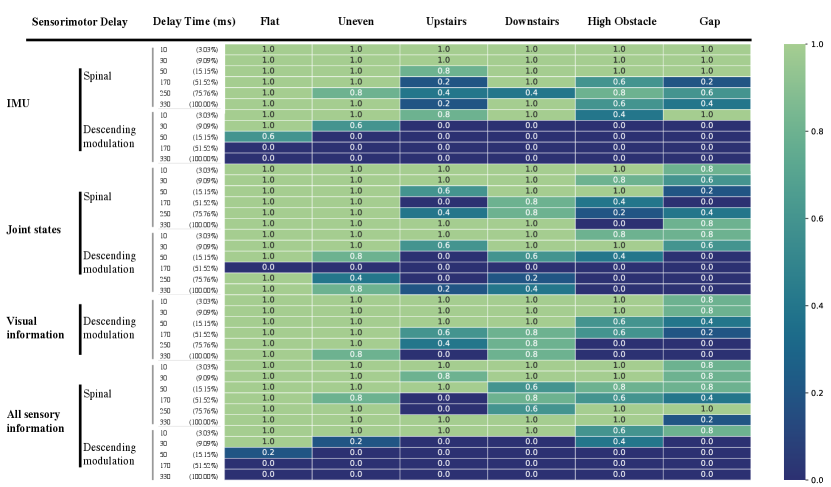
IV-C Sensorimotor Delay
Whether an animal is engaging in dynamic gait locomotion in complex environments or moving on flat terrain, the effectiveness of its sensory feedback is constrained by sensorimotor delays, which are non-negligible in animals [5]. To investigate the influence of sensorimotor delay on the spinal policy and descending modulation policy, we assess the robot’s performance across six types of terrain: flat, uneven, upstairs, downstairs, high obstacles, and gaps. We assess the robot’s performance across terrains similar to those in the previous experiment but introduce varying amounts of sensorimotor delays. Sensory delays vary in duration, with delay times ranging from 10 ms to 330 ms across different experiments. The robot’s commanded speed is consistently set at 0.9 m/s. It is important to note that both policies are trained without sensorimotor delay and are activated throughout all experiments. Each experiment consists of 5 trials, with the robot starting from different initial positions on each terrain. Successfully traversing the entire specified terrain is considered a success, and we record the success rate for each experiment. Sensory information is categorized into three groups: IMU (vestibular sensory information), joint states (proprioceptive sensory information), and visual sensory information (terrain height map, analogous to visual sensory information in animals). Additionally, we test the impact of delays across all sensory groups. The success rate for each experiment is depicted as a heat map in Fig.5.
Firstly, we find that the descending modulation policy is particularly sensitive to IMU sensory delays, especially on complex terrains such as stairs, high obstacles, and gaps. With a delay time of 30 ms, the robot falls while traversing these terrains. In contrast, the spinal policy exhibits relative robustness to IMU sensory delays. The robot still has the capability to successfully travel through all the terrains with IMU sensory delays up to 330 ms, which is equal to one gait cycle time. Furthermore, IMU sensory delays in the spinal policy have less effect on traversing simple terrains like flat and uneven terrains.
Secondly, we observe that delays in sensing joint states adversely affects the robot, particularly when navigating stairs, over high obstacles, and across gaps. Such terrains require precise movements in order to successfully traverse them. Interestingly, we observe that the performance with a delay time equal to one gait cycle (330 ms) is better than that with half a gait cycle (170 ms) for joint state sensory delays. We believe that the one gait cycle delay time makes the delayed joint state sensory feedback mostly coincide with the current joint states because of the rhythmic movement. Moreover, the spinal policy is more sensitive to delays in joint states than to IMU sensory feedback. Since the spinal policy lacks access to visual information, visual sensory delays are applied exclusively to the descending modulation policy. Surprisingly, visual sensory delays have a more minor impact on crossing stairs, especially when descending, which can still be managed with a specific rhythmic locomotion pattern. However, terrains requiring discrete motions, such as jumping over high obstacles and precise foothold placement for gaps, are significantly affected by visual sensory delays. For all types of sensory delays, we find that the descending modulation policy is more adversely affected than the spinal policy. With all sensory feedback delayed, the descending modulation policy can even impact the gait on flat terrain.
Overall, we conclude that, as could be expected, for flat terrain locomotion, the spinal policy relies less on sensory feedback to generate rhythmic movements, as its performance on flat terrain is nearly unaffected by sensory delays. In contrast, the descending modulation policy is more sensitive to sensorimotor delays, indicating a greater reliance on sensory feedback to modulate gait patterns. This is particularly true for terrains requiring discrete and precise movements, such as climbing stairs, navigating over high obstacles, and traversing gaps. Our experimental results align with the biological perspective that sensory feedback is integrated at multiple levels, and the relative contributions of feedforward (as provided by the CPG, and to some extent by the descending policy) and feedback (as provided by the spinal and descending policies) control can vary depending on the terrain and the risks of falling[13]. Specifically, the spinal cord can produce rhythmic output even when movement-related afferent input is eliminated [10], and sensory signals contribute to shaping locomotor output and adapting it to environmental demands through descending pathways[40].
V Conclusion
In this work, we propose a hierarchical, bio-inspired control framework for legged robot locomotion that mimics the central nervous system of animals. This framework integrates a spinal neural network tasked with adapting the key parameters of a conventional CPG model, emulating the spinal cord’s role in generating basic rhythmic locomotion patterns. Additionally, our framework includes a descending modulation policy that learns to directly modulate this rhythmic movement, representing the descending pathway between the brain and spinal cord. We verified the trained framework’s performance across various rough terrains and examined the contributions of the two policies to locomotion on these terrains. Additionally, we investigated the effects of sensorimotor delay on both policies. Our experimental results indicate that the spinal policy is less sensitive to sensory feedback when generating rhythmic movements for locomotion on flat terrain, whereas the descending modulation policy relies more on sensory feedback, especially for terrains requiring discrete and precise movements, such as climbing stairs, navigating over high obstacles, and traversing gaps. Our control architecture proves quite robust against sensorimotor delays, even without being trained with any delays. We speculate that training with delays (fixed or random) could potentially enhance this robustness, a hypothesis warranting future investigation. Furthermore, mechanical properties can also aid in handling sensorimotor delays, as demonstrated in [41]. Overall, the proposed framework not only demonstrates effectiveness on a robotic platform, but also validates several biological assumptions concerning animal locomotion systems.
Future work will focus on investigating the inner signal passing between the spinal policy and the descending modulation policy by concurrently training both policies online, thereby aiming to replicate the intricate connections between the spinal cord and supraspinal structures. Specifically, we will delve into how descending modulation can infer changes and adjust the central pattern generator (CPG), such as its frequency, amplitude, or even gait, and modulate reflexes by altering feedback gains, reflecting mechanisms observed in animals. Furthermore, we plan to apply our control framework to a hardware platform, enabling us to comprehensively assess its reliability and performance.
References
- [1] C. Laschi and B. Mazzolai, “Bioinspired materials and approaches for soft robotics,” Mrs Bulletin, vol. 46, pp. 345–349, 2021.
- [2] K. Melo, T. Horvat, and A. J. Ijspeert, “Animal robots in the african wilderness: Lessons learned and outlook for field robotics,” Science Robotics, vol. 8, no. 85, p. eadd8662, 2023.
- [3] A. T. Khan, S. Li, and X. Cao, “Control framework for cooperative robots in smart home using bio-inspired neural network,” Measurement, vol. 167, p. 108253, 2021.
- [4] A. Biewener and S. Patek, Animal locomotion. Oxford University Press, 2018.
- [5] H. L. More and J. M. Donelan, “Scaling of sensorimotor delays in terrestrial mammals,” Proceedings of the Royal Society B, vol. 285, no. 1885, p. 20180613, 2018.
- [6] A. J. Ijspeert, “Central pattern generators for locomotion control in animals and robots: a review,” Neural networks, vol. 21, no. 4, pp. 642–653, 2008.
- [7] S. Grillner and A. El Manira, “Current principles of motor control, with special reference to vertebrate locomotion,” Physiological reviews, 2019.
- [8] P. S. Stein, Neurons, networks, and motor behavior. MIT press, 1997.
- [9] L. Vinay, F. Brocard, F. Clarac, J.-C. Norreel, E. Pearlstein, and J.-F. Pflieger, “Development of posture and locomotion: an interplay of endogenously generated activities and neurotrophic actions by descending pathways,” Brain Research Reviews, vol. 40, no. 1-3, pp. 118–129, 2002.
- [10] V. Dietz, “Spinal cord pattern generators for locomotion,” Clinical Neurophysiology, vol. 114, no. 8, pp. 1379–1389, 2003.
- [11] L. J. Rygh, A. Tjølsen, K. Hole, and F. Svendsen, “Cellular memory in spinal nociceptive circuitry.” Scandinavian journal of psychology, vol. 43, no. 2, pp. 153–159, 2002.
- [12] A. Ijspeert, “Locomotion, vertebrate,” The handbook of brain theory and neural networks, pp. 649–654, 2002.
- [13] A. J. Ijspeert and M. A. Daley, “Integration of feedforward and feedback control in the neuromechanics of vertebrate locomotion: a review of experimental, simulation and robotic studies,” Journal of Experimental Biology, vol. 226, no. 15, p. jeb245784, 2023.
- [14] M. A. Sharbafi and A. Seyfarth, Bioinspired legged locomotion: models, concepts, control and applications. Butterworth-Heinemann, 2017.
- [15] C. Liu, Q. Chen, and D. Wang, “Cpg-inspired workspace trajectory generation and adaptive locomotion control for quadruped robots,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 41, no. 3, pp. 867–880, 2011.
- [16] J. Li, J. Wang, S. X. Yang, K. Zhou, H. Tang, et al., “Gait planning and stability control of a quadruped robot,” Computational intelligence and neuroscience, vol. 2016, 2016.
- [17] G. Sun and G. Sartoretti, “Joint-space cpg for safe foothold planning and body pose control during locomotion and climbing,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9889–9896, 2022.
- [18] G. Bellegarda and A. Ijspeert, “CPG-RL: Learning central pattern generators for quadruped locomotion,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 12 547–12 554, 2022.
- [19] G. Bellegarda, M. Shafiee, and A. Ijspeert, “Visual CPG-RL: Learning central pattern generators for visually-guided quadruped locomotion,” in 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024.
- [20] A. M. Deshpande, E. Hurd, A. A. Minai, and M. Kumar, “Deepcpg policies for robot locomotion,” IEEE Transactions on Cognitive and Developmental Systems, 2023.
- [21] J. Wang, C. Hu, and Y. Zhu, “Cpg-based hierarchical locomotion control for modular quadrupedal robots using deep reinforcement learning,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7193–7200, 2021.
- [22] G. Bellegarda, M. Shafiee, M. E. Özberk, and A. Ijspeert, “Quadruped-frog: Rapid online optimization of continuous quadruped jumping,” arXiv preprint arXiv:2403.06954, 2024.
- [23] M. Shafiee, G. Bellegarda, and A. Ijspeert, “Manyquadrupeds: Learning a single locomotion policy for diverse quadruped robots,” 2024 IEEE International Conference on Robotics and Automation, 2024.
- [24] M. Shafiee, G. Bellegarda, and A. Ijspeert, “Viability leads to the emergence of gait transitions in learning agile quadrupedal locomotion on challenging terrains,” Nature Communications, vol. 15, no. 1, p. 3073, 2024.
- [25] M. MacKay-Lyons, “Central pattern generation of locomotion: a review of the evidence,” Physical therapy, vol. 82, no. 1, pp. 69–83, 2002.
- [26] A. J. Ijspeert, A. Crespi, D. Ryczko, and J.-M. Cabelguen, “From swimming to walking with a salamander robot driven by a spinal cord model,” Science, vol. 315, no. 5817, pp. 1416–1420, 2007.
- [27] J. Yu, M. Tan, J. Chen, and J. Zhang, “A survey on cpg-inspired control models and system implementation,” IEEE transactions on neural networks and learning systems, vol. 25, no. 3, pp. 441–456, 2013.
- [28] M. Shafiee, G. Bellegarda, and A. Ijspeert, “Puppeteer and marionette: Learning anticipatory quadrupedal locomotion based on interactions of a central pattern generator and supraspinal drive,” 2023 IEEE International Conference on Robotics and Automation, 2023.
- [29] S. Grätsch, A. Büschges, and R. Dubuc, “Descending control of locomotor circuits,” Current Opinion in Physiology, vol. 8, pp. 94–98, 2019.
- [30] A. J. Fong, R. R. Roy, R. M. Ichiyama, I. Lavrov, G. Courtine, Y. Gerasimenko, Y. Tai, J. Burdick, and V. R. Edgerton, “Recovery of control of posture and locomotion after a spinal cord injury: solutions staring us in the face,” Progress in brain research, vol. 175, pp. 393–418, 2009.
- [31] D. Ryczko, S. Grätsch, L. Schläger, A. Keuyalian, Z. Boukhatem, C. Garcia, F. Auclair, A. Büschges, and R. Dubuc, “Nigral glutamatergic neurons control the speed of locomotion,” Journal of Neuroscience, vol. 37, no. 40, pp. 9759–9770, 2017.
- [32] H. Yoo and D. M. Mihaila, “Neuroanatomy, vestibular pathways,” 2020.
- [33] J. Norton, “Changing our thinking about walking,” The Journal of physiology, vol. 588, no. Pt 22, p. 4341, 2010.
- [34] R. Dubuc, J.-M. Cabelguen, and D. Ryczko, “Locomotor pattern generation and descending control: a historical perspective,” Journal of Neurophysiology, vol. 130, no. 2, pp. 401–416, 2023.
- [35] N. Rudin, D. Hoeller, P. Reist, and M. Hutter, “Learning to walk in minutes using massively parallel deep reinforcement learning,” in Conference on Robot Learning. PMLR, 2022, pp. 91–100.
- [36] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [37] H. Hultborn and J. B. Nielsen, “Spinal control of locomotion–from cat to man,” Acta Physiologica, vol. 189, no. 2, pp. 111–121, 2007.
- [38] U. Robotics, “Unitree a1 - high performance quadruped robot,” https://unitreerobotics.net/robotdog/unitree-a1/, 2024, accessed: 2024-04-23.
- [39] T. Drew, S. Prentice, and B. Schepens, “Cortical and brainstem control of locomotion,” Progress in brain research, vol. 143, pp. 251–261, 2004.
- [40] A. Saradjian, “Sensory modulation of movement, posture and locomotion,” Neurophysiologie Clinique/Clinical Neurophysiology, vol. 45, no. 4-5, pp. 255–267, 2015.
- [41] M. S. Ashtiani, A. Aghamaleki Sarvestani, and A. Badri-Spröwitz, “Hybrid parallel compliance allows robots to operate with sensorimotor delays and low control frequencies,” Frontiers in Robotics and AI, vol. 8, p. 645748, 2021.