Learning Algorithms for Coarsening Uncertainty Space and Applications to Multiscale Simulations
Abstract
In this paper, we investigate and design multiscale simulations for stochastic multiscale PDEs. As for the space, we consider a coarse grid and a known multiscale method, the Generalized Multiscale Finite Element Method (GMsFEM). In order to obtain a small dimensional representation of the solution in each coarse block, the uncertainty space needs to be partitioned (coarsened). This coarsenining collects realizations that provide similar multiscale features as outlined in GMsFEM (or other method of choice). This step is known to be computationally demanding as it requires many local solves and clustering based on them (see [13]). In this paper, we take a different approach and learn coarsening the uncertainty space. Our methods use deep learning techniques in identifying clusters (coarsening) in the uncertainty space. We use convolutional neural networks combined with some techniques in adversary neural networks. We define appropriate loss functions in the proposed neural networks, where the loss function is composed of several parts that includes terms related to clusters and reconstruction of basis functions. We present numerical results for channelized permeability fields in the examples of flows in porous media.
1 Introduction
Many problems are multiscale with uncertainties. Examples include problems in porous media, material sciences, biological sciences, and so on. For example, in porous media applications, engineers can obtain fine-scale data about pore geometries or subsurface properties at very fine resolutions. These data are obtained in some spatial locations and then generalized to the entire reservoir domain. As a result, one uses geostatistical or other statistical tools to populate the media properties in space. The resulting porous media properties are stochastic and one needs to deal with many porous media realizations, where each realization is multiscale and varies at very fine scales.
Simulating each realization can be computationally expensive because of the media‘s multiscale nature. Our objective is to simulate many of these realizations. To address the issues associated with spatial and temporal scales, many multiscale methods have been developed ([3, 11, 12, 14, 15, 18, 19, 9, 8, 7, 10]). These methods perform simulations on the coarse grid by developing reduced-order models. However, developing reduced-order models requires local computations, which can be expensive when one deals with many realizations. For this reason, some type of coarsening of the uncertainty space is needed ([13]). In this paper, we consider some novel approaches for developing coarsening of uncertainty space as discussed below.
To coarsen the uncertainty space, clustering algorithms are often used; but a proper distance function should be designed in order to make the clusters have physical sense and achieve a reduction in the uncertainty space. The paper ([13]) proposed a method that uses the distance between local solutions. The motivation is that the local problems with random boundary conditions can represent the main models with all boundary conditions. Due to a high dimension of the uncertainty space, the authors in ([13]) proposed to compute the local solutions of only several realizations and then use the Karhunen-Loeve expansion([28]) to approximate the solutions of all the other realizations. The distance function is then defined to be the distance between solutions and the standard K-means ([33]) algorithm is used to cluster the uncertainty space.
The issue with this method is computing the local solutions in the local neighborhoods. It is computationally expensive to compute the local solutions; although the KL expansion can save time to approximate the solutions of other realizations, one still needs to decide how many selected realizations we need to represent all the other solutions. In this paper, we propose the use of deep learning methodology and avoid explicit clustering as in earlier works. We remark that the development of deep learning techniques for multiscale simulations are recently reported in [44, 43, 41, 6, 42].
In this work, to coarsen the uncertainty space, we propose a deep learning algorithm which will learn the clusters for each local neighborhood. Due the nature of the permeability fields, we can use the transfer learning which uses the parameters of one local neighborhood to initialize the learning of all the other neighborhoods. This saves significantly computational time.
The auto encoder structure [20] has been widely used in improving the K-mean clustering algorithm ([5, 45, 46]). The idea is to use the encoder to extract features and reduce the dimension; the encoding process can also be taken as a kernel method [2] which maps the data to a space which is easier to be separated. The decoder is used to upsample the latent space (reduced dimension feature space) back to the input space. The clustering algorithm is then used to cluster the latent space, which will save time due to the low dimension of the latent space and also preserve the accuracy due to the features extracted by the encoder.
Traditionally, the learning process is only involved in reconstructing the input space. Such kind of methods ignore the features extracted by latent space; so, it is not clear if the latent space is good enough to represent the input space and is easily clustered by the K-means method. In [46], the authors proposed a new loss which includes the reconstruction loss meanwhile the loss results from the clustering. The authors claimed that the new loss improves the clustering results.
We will apply the auto encoder structure and the multiple loss function; however, we will design the auto encoder as a generative network, i.e., the input and output space are different. More precisely, the input is the uncertain space (permeability fields) and the output will be the multiscale functions co-responding to the uncertain space. Intuitively, we want to use the multiscale basis to supervise the learning of the clusters so that the clusters will inherit the property of the solution. The motivation is the multiscale basis can somehow represent the real solutions and permeability fields; hence, the latent space is no longer good for clustering the input space but will be suitable for representing the multiscale basis function space.
To define the reconstructing loss, the common idea is the mean square error (MSE); but many works ([25, 31, 30, 27]) have shown that the MSE tends to produce the average effect. In fact, in the area of image super-resolution ([25, 31, 30, 27, 16, 29, 48, 49, 39, 32, 40]) and other low level computer vision tasks, the generated images are usually over-smooth if trained using MSE. The theory is the MSE will capture the low frequency features like the background which is relatively steady; but for images with high contrast, the MSE will usually try to blur the images and the resulting images will lose the colorfulness and become less vivid ([25]). Our problem has multiscale nature and we want to capture the dominant modes and multiscale features, hence a single MSE is clearly not enough.
Following the idea from ([27, 31]), we consider adding an adversary net ([21]). The motivation is the fact that different layers of fully convolutional network extract different features ([23, 27, 47]). Deep fully convolutional neural networks (FCN) ([34, 37, 38, 1, 35, 24]) have demonstrated its power in almost all computer vision tasks. Convolution operation is a local operation and the network with full convolutions are independent with the input size. People now are clear about the functioning of the different layers of the FCN. In computer vision task, the lower layers (layers near input) tend to generate sharing features of all objects like edges and curves while the higher layers (near output) are more object oriented. If we train the network using the loss from the lower layers, the texture and details are persevered, while the higher layers will keep the general spatial structure.
This motivates us using the losses from different layers of the fully convolutional layers. Multiple layers will give us a multilevel capture of the basis features and hence measure the basis in a more complete way. To implement the idea, we will pretrain an adversary net; and input the multiscale basis of the generative net and the real basis. The losses then come from some selected layers of the adversary net. Although it is still not clear the speciality of each layer, if we consider the multiscale physical problem, the experiments show that the accuracy is improved and, amazingly, the training becomes easier when compared to the MSE of the basis directly.
The uncertain space coarsening (cluster) is performed using the deep learning idea described above. But due to the space dimension, we will perform the clustering algorithm locally in space; that is, we first need a spatial coarsening. Due to the multiscale natural of the problem, this motivates us using the generalized multiscale finite element methods (GMsFEM) which derives the multiscale basis of a coarse neighborhood by solving the local problem. GMeFEM was first proposed in ([17]) and further studied in ([3, 11, 12, 14, 15, 18, 19, 9]). This method is a generalization of the multiscale finite element method ([22, 26]). The work starts from constructing the snapshot space for each local neighborhood. The snapshot space is constructed by solving local problems and several methods including harmonic extension, random boundary condition [4] have been proposed. Once we have the snapshot space, the offline space which will be used as computing the solution are constructed by using spectral decomposition.
The rest of the work is organized as follow: in Section 2, we consider the problem setup and introduce both uncertain space and spatial coarsening. In Section 3, we introduce the structure of the network and the training algorithm. In Section 4, we will present the numerical results. The paper ends with conclusions.
2 Problem Settings
In this section, we will present some basic ideas involving the use of the generalized multiscale finite element method (GMsFEM) for parameter-dependent problems. Let be a bounded domain in and be the parameter space in . We consider the following parameter-dependent elliptic problem:
| (1) | |||
| (2) |
where is a heterogeneous coefficient depending on both the spatial variable and the parameter , and is a given source. We remark that the differential operators in (1) are defined with respect to the spatial variable . This is the case for the rest of the paper.
2.1 The Coarsening of the Parameter Space. The Main Idea.
The parameter space is assumed to be of very high dimension (i.e. large ) and consists of very large number of realizations. For a given realization, the idea is to find its representation in the coarse space and use the coarse space to perform the computation. We will use the deep cluster learning algorithm to perform the coarsening. Due to the heterogeneous properties of the proposed problem, fine mesh is used; this will bring difficulties in coarsening the parameter space and in computation of the solution. We hence perform the parameter coarsening locally in the space , i.e., we also coarsen the spatial domain. To coarsen the spatial domain, we use coarse grids and consider the GMsFEM.
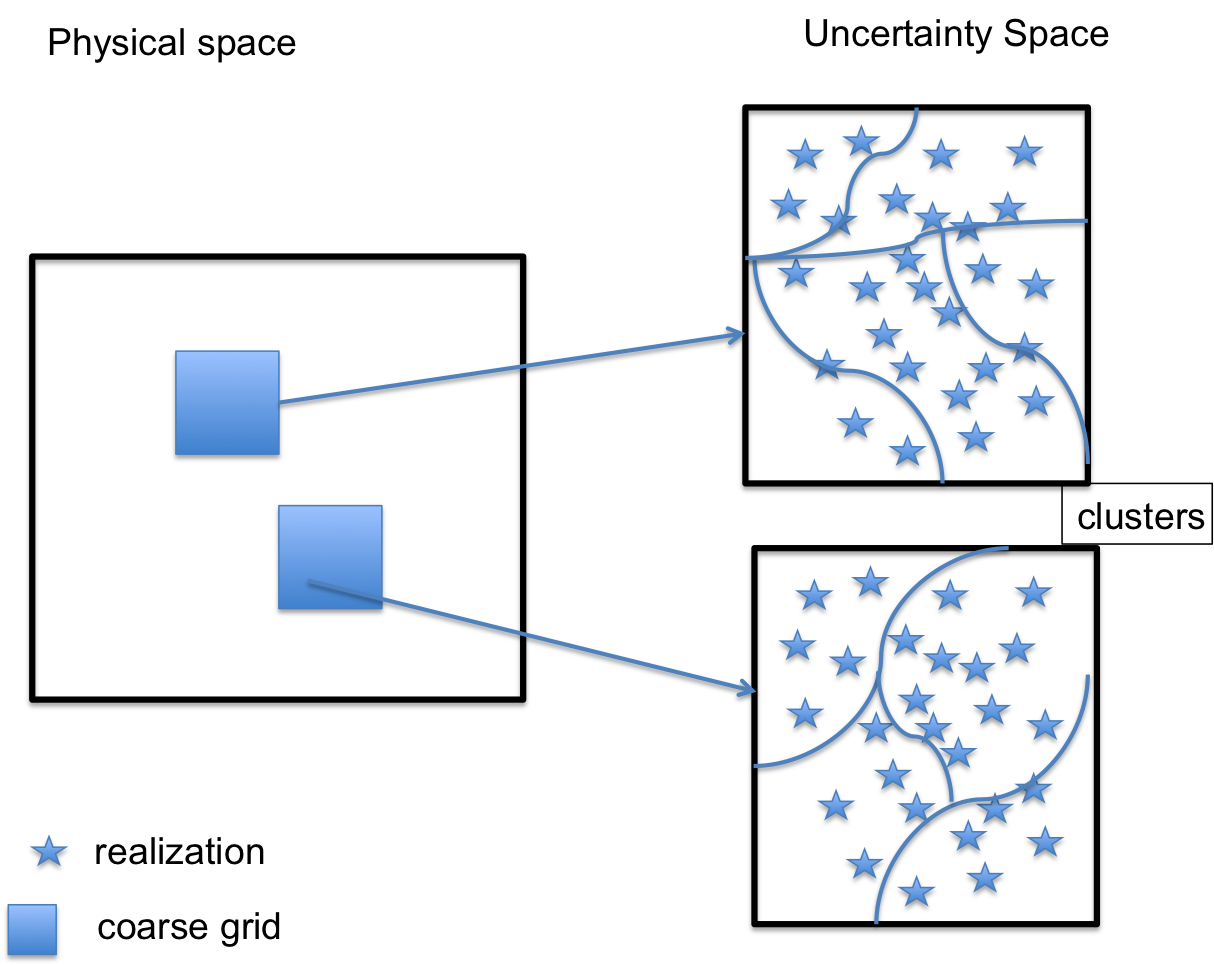
In Figure 1, we present an illustration of the proposed coarsening technique. On the left figure, the coarse grid blocks in the space are shown. Each coarse grid has a different clusters in the uncertainty space , which corresponds to the coarsening of the uncertainty space. The main objective in multiscale methods is efficiently finding the clustering of the uncertainty space, which is our main goal.
2.2 Space Coarsening — Generalized Multiscale Finite Element Method
It is computationally expensive to capture heterogeneous properties using very fine mesh. For this reason, we use GMsFEM to coarsen the spatial representation of the solution. The coarsening of the parameter space will be performed in each local spatial neighborhood. We will achieve this goal by the GMsFEM, which will briefly be discussed. Consider the second order elliptic equations in with proper boundary conditions; denote the the elliptic operator as:
| (3) |
Let the spatial domain be partitioned by a coarse grid ; this does not resolve the multiscale features. Let us denote as one cell in and refine to obtain the fine grid partition (blue box in Figure 2). We assume the fine grid is a conforming refinement of the coarse grid. See Figure 2 for details.
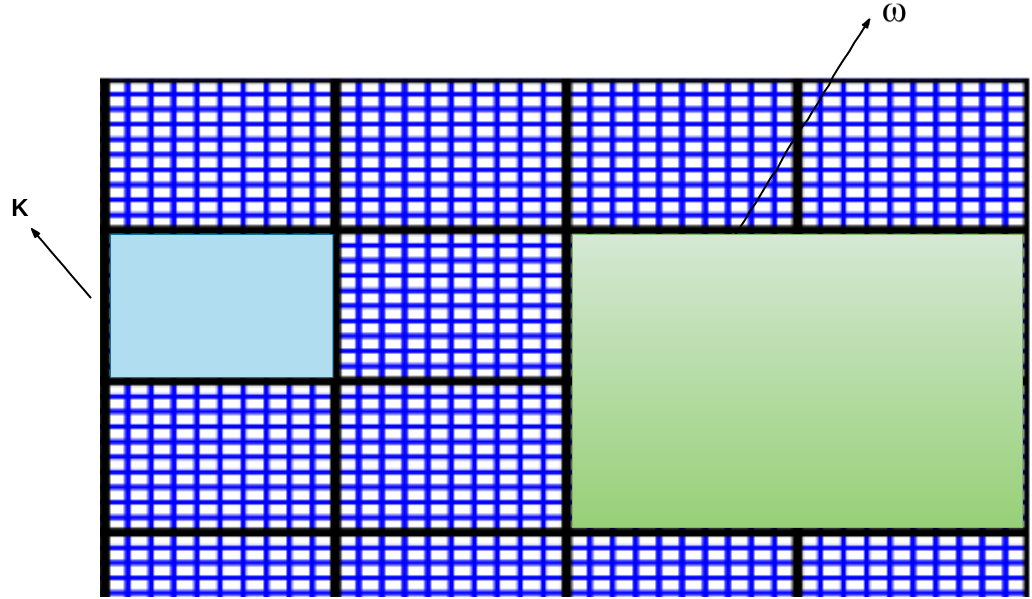
For the -th coarse grid node, let be the set of all coarse elements having the vertex (green region in Figure 2). We will solve local problem in each coarse neighborhood to obtain set of multiscale basis functions and seek solution in the form:
| (4) |
where is the offline basis function in the -th coarse neighborhood and denotes the -th basis function. Before we construct the offline basis, we first need to derive the snapshot basis.
2.2.1 Snapshot Space
There are several methods to construct the snapshot space; we will use the harmonic extension of the fine grid functions defined on the boundary of . Let us denote as fine grid delta function, which is defined as for where denotes the boundary nodes of . The snapshot function is then calculated by solving local problem in :
| (5) |
subject to the boundary condition . The snapshot space is then constructed as the span of all snapshot functions.
2.2.2 Offline Spaces
The offline space is derived from the snapshot space and is used for computing the solution of the problem. We need to solve for a spetral problem and this can be summarized as finding and such that:
| (6) |
where is symmetric non-negative definite bilinear form and is symmetric positive definite bilinear form. By convergence analysis, they are given by
| (7) | |||
| (8) |
In the above definition of , the function where is a set of partition of unity functions corresponding to the coarse grid partition of the domain and the summation is taken over all the functions in this set. The offline space is then constructed by choosing the smallest eigenvalues and we can form the space by the linear combination of snapshot basis using corresponding eigenvectors:
| (9) |
where is the element of eigenvector and is the number of snapshot basis. is then defined as the collection of all local offline basis functions. Finally we are trying to find such that
| (10) |
where . For more details, we refer the readers to the references [18, 19, 9].
2.3 The Idea of the Proposed Method
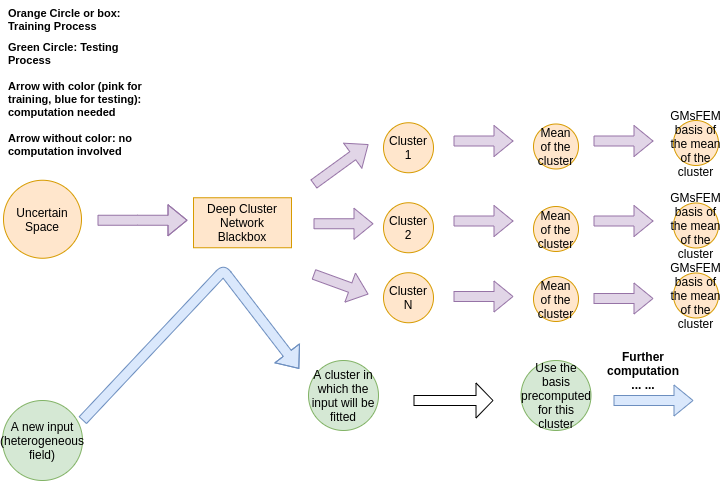
We present the general methodology in this section. The target is to save the time in computing the GMsFEM basis for all and for all uncertain space parameters. We propose the clustering algorithm to coarsen the uncertain space in each local neighborhood. The key to the success of the clustering is that: the cluster should inherit the property of the solution, that is, the local heterogeneous fields clustered into the same group should have similar solution properties. When the cluster is learnt by the some learning algorithm, the only computation involved is to fit the local neighborhood of the given testing heterogeneous field into some cluster. This is a feed forward process including several convolution operations and matrix multiplications and compared to the direct computing, we save a lot of time in computing the spectral problem (6) and the inverse of a matrix (10). The detailed process is illustrated in the following chart (Figure 3):
-
1.
(Training) For a given input local neighborhood , we train the cluster (which will be detailed in next section) of the parameter space and get the clusters , where is the number of clusters and is uniform for all . Please note that we may have different cluster assignments in different local neighborhoods.
-
2.
(Training) For each local neighborhood and cluster , define the average and compute generalized multiscale basis for .
-
3.
(Testing) Given a new and for each local neighborhood , fit into a by the trained network (step 1) and use the pre-computed GMsFEM basis (step 2) to find the solution.
It should be noted that we perform clustering using the heterogeneous fields; however, the cluster should inherit the property of the solution corresponding to the heterogeneous fields. This makes the clustering challenging. The performance of the standard K-Means algorithm relies on the initialization and the distance metric. We may initialize the algorithm based on the clustering of the heterogeneous fields but we need to design a good metric. In the next section, we are going to introduce a learning algorithm which uses an auto-encoder structure and multiple losses to achieve the required clustering task.
3 Deep Learning
The network is consisted of two sub networks. The first one is targeted to performing the clustering and second one, which is the adversary net, will serve as the reconstruction of loss function.
3.1 Clustering Net
The cluster net is aimed for clustering the heterogeneous fields ; but the resulting clusters should inherit the properties of the solution corresponding to the , i.e., the heterogeneous fields grouped in the same cluster should have similar corresponding solution properties. This similarity will be measured by the adversary net which will be introduced in section (3.3). We hence design the network demonstrated in Figure 4.
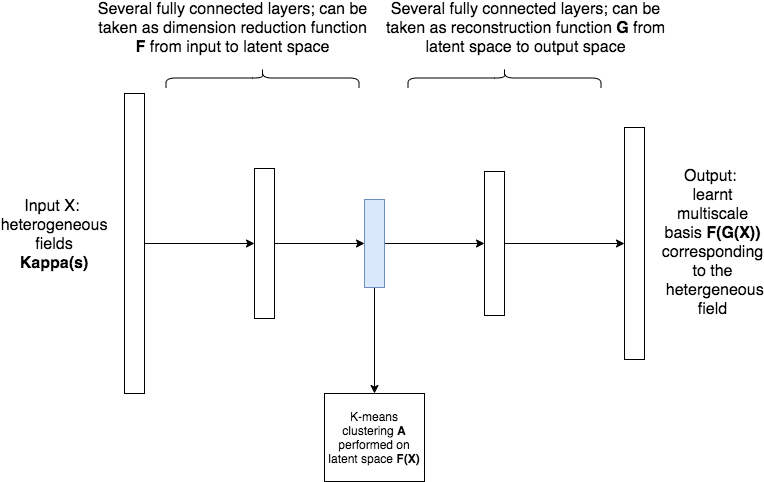
The input ,where is the number of samples and is the dimension of one local heterogeneous field, of the network is the local heterogeneous fields which are parametrized by the random variable . The output of the network is the multiscale basis (first GMsFEM basis) which somehow represents the solution corresponding to the coefficient . This is a generative network which has an auto encoder structure. The dimension reduction function can be interpreted as some kind of kernel method which maps the input data to a new space which is easier to be separated. This can also be interpreted as the learning of a good metric function for the later performed K-mean clustering. We will perform K-means clustering algorithm in latent space . will then transfer the latent space data to the space of multiscale basis function. This process can be taken as a generative process and we reconstruct the basis from the extracted features. The detailed algorithm is as follow (see Figure 5 for an illustration):
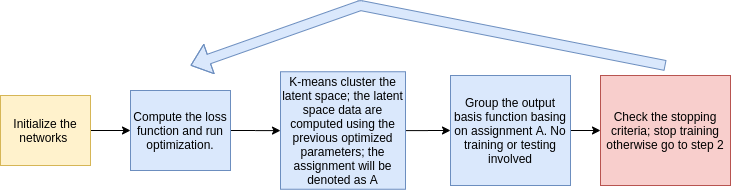
Steps illustrated in Figure 5:
-
1.
Initialize the networks and clustering the output basis function.
-
2.
Compute the loss function (defined later) and run optimization.
-
3.
Cluster the latent space by K-Means algorithm (reduced dimension space, which is a middle layer of the cluster network); the latent space data are computed using the previous optimized parameters; the assignment will be denoted as .
-
4.
Basis functions whose corresponding inputs are in the same cluster (basing on assignment A) will be grouped together. No training or fitting-in involved in this step.
-
5.
Repeat step to step until the stopping criteria is met.
3.2 Loss Functions
Loss function is the key to the deep learning. Our loss function is consisted of cluster loss and the reconstruction loss.
-
1.
Clustering loss : this is the mean standard deviation of all clusters of the learnt basis and is the parameters we need to optimize. It should be noted that the loss here is computed using the learnt basis instead of the input of the network. This loss controls the clustering process, i.e., the smaller the loss, the better the clustering in the sense of clustering the multiscale basis. Let us denote as realization in cluster; will then be learnt basis in cluster and let and be the parameters associated with and , the loss is then defined as follow,
(11) where is the number of clusters which is a hyper parameter and denotes the number of elements in cluster ; is the mean of cluster . This loss clearly serves the purpose of clustering the solution instead of the input heterogeneous fields; however, in order to guarantee the learnt basis are closed to the pre-computed multiscale basis, we need to define the reconstruction loss which measures the difference between the learnt basis and the pre-computed basis.
-
2.
Reconstruction loss : this is the mean square error of multiscale basis , where is the number of samples. This loss controls the construction process, i.e., if the loss is small, the learnt basis are close to the real multiscale basis. This loss will supervise the learning of the cluster. It is defined as follow:
(12) where and are learnt and pre-computed multiscale basis of sample separately.
The entire loss function is then defined as , where are predefined weights. We are going to solve the following optimization problem:
| (13) |
for the required training process.
3.3 Adversary Network Severing as an Additional Loss
We have introduced the reconstruction loss which measures the similarity between the learnt basis and the pre-computed basis in the previous section. It is the Mean square error (MSE) of the learnt and pre-computed basis. MSE is a smooth loss and easy to train but there is a well known fact about MSE that this loss will blur the image. In the area of image super-resolution and other low level computer vision tasks, the loss is not friendly to inputs with high contrast and the resulting generated images are usually over smooth. Our problem has multiscale nature and is similar with the low level computer vision task, i.e., this is a generative task; hence blurring and over smooth should happen if the model is trained by MSE. To define a great reconstruction loss is important.
Motivated by some works about the successful application of deep fully convolutional network (FCN) in computer vision, we design a perceptual loss to measure the error. It is now clear that the lower layers in the FCN usually will extract some general features shared by all objects like the horizontal (vertical) curves, while the higher layers are usually more objects oriented. This gives people the insight to train the network using different layers. Johnson then proposed the perceptual loss [27] which is the combination of the MSE of selected layers of the VGG model [36]. The authors claim in their paper that the early layers tends to produce images that are visually indistinguishable from the input; however if reconstruct from higher layers, image content and overall spatial structure are preserved but color, texture, and exact shape are not.
We will adopt the perceptual loss idea and design an adversary network to compute an additional reconstruction loss. The network structure can be seen in Figure 6.
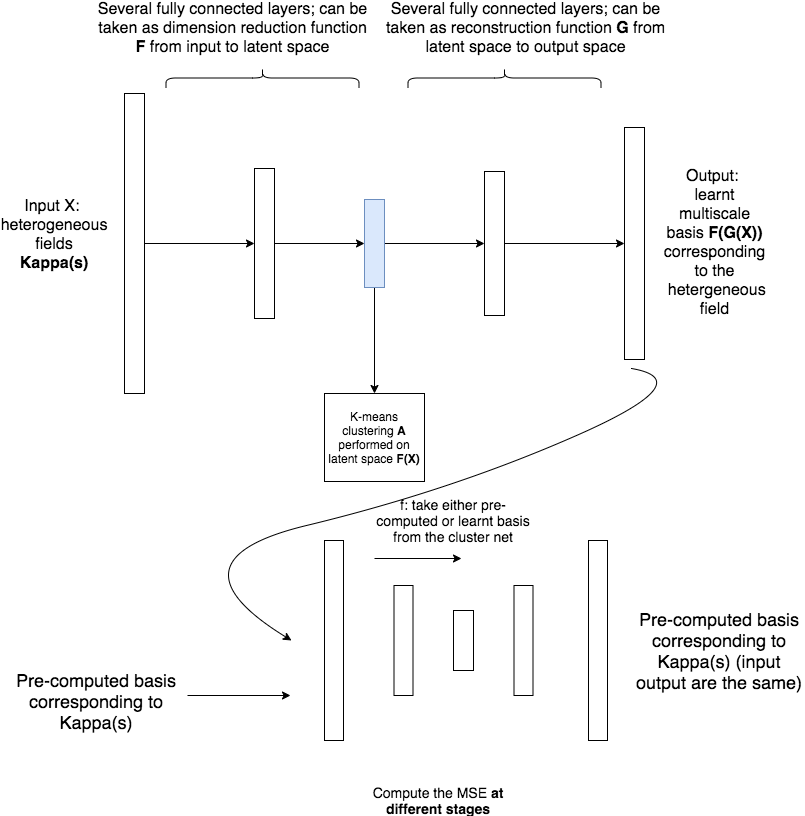
The adversary net is fully convolutional with input and output both pre-computed multiscale basis. The network has an auto encoder structure and is pre-trained; i.e., we are going to solve the following minimization problem:
| (14) |
where is the multiscale basis and is the adversary net associated with trainable parameter . Denote as the output of layer of the adversary network. The additional reconstruction loss is then redefined as:
| (15) |
where is the index set which contains some layers of the adversary net. The complete optimization problem can be now formulated as:
| (16) |
4 Numerical Experiments
In this section, we will demonstrate a series of experiments. We are going to apply our method on problems with high contrast including moving background and moving channels. Let us first introduce the high contrast field.
4.1 High Contrast Heterogeneous Fields with Moving Channels
We consider solving (1)-(2) for a heterogeneous field with moving channels and changing background. Let us denote the heterogeneous field as , where , then if is in some channels which will be illustrated later and otherwise,
where follows discrete uniform distribution in . The channels are moving and we include cases of the intersection of two channels and formation and disappearance of the channels in the fields. In Figure 7, we demonstrate heterogeneous fields.

It can be observed from the images that, vertical channel (at around ) (not always) intersects with horizontal channels (at around ); and the channel at demonstrates the case of generation and degeneration of a channel.
We train the network using 600 samples using the Adam gradient descent. We find that the cluster assignment of realizations in uncertain space is stable(fixed) when the gradient descent epoch reaches a certain number, so we set the stopping criteria to be: the assignment does not change for iteration epochs; and the maximum number of iteration epochs is set to be . We also find that the coefficients in (16) can affect the training result. We set .
It should be noted that we train the network locally in each coarse neighborhood. The fine mesh element has size and fine elements are merged into one coarse element.
4.2 Results
We will present the numerical results of the proposed method in this section. We are going to show the cluster assignment experiment first, followed by two other experiments which demonstrate the error of the method.
4.2.1 Cluster Assignment in a Local Coarse Element
Before diving into the error analysis, we will show some of the cluster results in a local neighborhood. In this neighborhood, we manually created the cases such as: the extraction of a channel (longer) , the expansion of a channel(wider), the discontinuity of a channel, the diagonal channels, the intersection of channels an so on. In Figure 8, the number on top of each image is the cluster assignment ID number.

We also demonstrate the clustering result in Figure 9 of another neighborhood which is around in Figure 7. From the results in both Figure 8 and Figure 9, we observe that our proposed clustering algorithm based on deep learning is able create a good clustering of the parameter space. That is, heterogeneous coefficients with similar spatial structures are grouped in the same cluster.

4.2.2 Relation of Error and the Number of Clusters
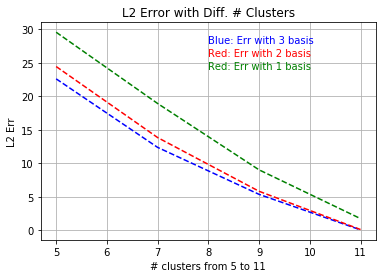
In this section, we will demonstrate the error change when the hyperparamter — the number of clusters increases. Given a new realization where denotes the parameter and a fixed neighborhood, suppose the neighborhood of this realization will be fitted into cluster by the model trained. We compute where is the number of points in this cluster . The GMsFEM basis of this neighborhood can then be derived using . We finally construct the solution using the GMsFEM basis pre-computed in all neighborhoods. We define the relative error as :
| (17) |
where is the exact solution computed by finite element method with fine enough mesh and is the solution of the proposed method. We test the network on newly generated samples and take the average of the errors.
In this experiment, we calculate the relative error with the number of clusters increases. The number of clusters ranges from to ; and for each case, we will train the model and compute the relative error. The result can be seen in Figure 10 and it can be observed from the picture that, the error is decreasing with the number of cluster increases.
4.2.3 Comparison of Cluster-based Method with Tradition Method
In the second experiments, we first compute the relative error (defined in (17) with denotes the GMsFEM solution) of traditional GMsFEM method with given . This means that the construct multiscale basis functions using the particular realization . We then compare this error with the cluster method proposed (11 clusters). The comparison can be seen in Figure 11.
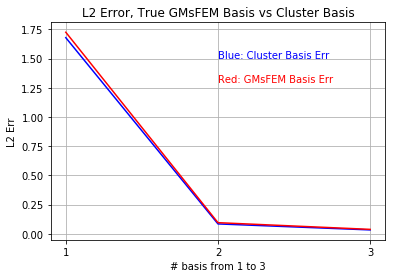
It can be seen that the difference is negligible when the number of clusters reaches . We can then benefit from the deep learning; i.e., the fitting of into a cluster is fast; and since we will use the pre-computed basis, we also save time on computing the GMsFEM basis.
4.3 Effect of the Adversary Net
The target of this task is not the learning of multiscale basis; the multiscale basis in this work is just a supervision of learning the cluster. However to demonstrate the effectiveness of the adversary network, we also test the the effect of the adversary net. There are many hyper-parameters like the number of clusters and coefficients of the loss function which can affect the result; so to reduce the influence from the clustering, we remove the clustering loss from the training, so this is a generative task which will generate the multiscale basis from the output of the first network in Figure 6. The loss function now can be defined as:
| (18) |
where and are defined in (12) and (15) separately; and and are both set to be . We compute the relative error (17) first by using the learnt multiscale basis which is trained by (18); and second by using the multiscale basis trained without the adversary loss (15), i.e.,
| (19) |
The relative error improves from to if we add one middle layer from the adversary net.
We also calculate the MSE difference of two learnt basis (by loss (18) and (19) separately) and real multiscale basis, i.e., we calculate , where refers to two basis trained with (18) and (19) separately and is the real multiscale basis formed using the input heterogeneous field. The MSE amazingly decreases from to if we use basis trained with the adversary loss (18). This can show the benefit from the adversary net.
5 Conclusion
We propose a deep learning clustering technique within GMsFEM to solve flows in heterogeneous media. The main idea is to cluster the uncertainty space such that we can reduce the number of multiscale basis functions for each coarse block across the uncertainty space. We propose the adversary loss motivated by the perceptual loss in the computer vision task. We use convolutional neural networks combined with some techniques in adversary neural networks, where the loss function is composed of several parts that includes terms related to clusters and reconstruction of basis functions. We present numerical results for channelized permeability fields in the examples of flows in porous media. In future, we would like to study the relation between convolutional layers and quantities related to multiscale basis functions.
Acknowledgement
Eric Chung’s work is partially supported by the Hong Kong RGC General Research Fund (Project numbers 14304719 and 14302018) and the CUHK Faculty of Science Direct Grant 2018-19. YE would like to thank the partial support from NSF 1620318 and NSF Tripod 1934904. YE would also like to acknowledge the support of Mega-grant of the Russian Federation Government (N 14.Y26.31.0013).
References
- [1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12):2481–2495, 2017.
- [2] Christopher M Bishop. Pattern recognition and machine learning. springer, 2006.
- [3] Victor M Calo, Yalchin Efendiev, Juan Galvis, and Mehdi Ghommem. Multiscale empirical interpolation for solving nonlinear pdes. Journal of Computational Physics, 278:204–220, 2014.
- [4] Victor M Calo, Yalchin Efendiev, Juan Galvis, and Guanglian Li. Randomized oversampling for generalized multiscale finite element methods. Multiscale Modeling & Simulation, 14(1):482–501, 2016.
- [5] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), pages 132–149, 2018.
- [6] Siu Wun Cheung, Eric T Chung, Yalchin Efendiev, Eduardo Gildin, Yating Wang, and Jingyan Zhang. Deep global model reduction learning in porous media flow simulation. Computational Geosciences, pages 1–14, 2019.
- [7] E. Chung, Y. Efendiev, and S. Fu. Generalized multiscale finite element method for elasticity equations. International Journal on Geomathematics, 5(2):225–254, 2014.
- [8] E. T. Chung, Y. Efendiev, and G. Li. An adaptive GMsFEM for high contrast flow problems. J. Comput. Phys., 273:54–76, 2014.
- [9] Eric Chung, Yalchin Efendiev, and Thomas Y Hou. Adaptive multiscale model reduction with generalized multiscale finite element methods. Journal of Computational Physics, 320:69–95, 2016.
- [10] Eric Chung, Maria Vasilyeva, and Yating Wang. A conservative local multiscale model reduction technique for stokes flows in heterogeneous perforated domains. Journal of Computational and Applied Mathematics, 321:389–405, 2017.
- [11] Eric T Chung, Yalchin Efendiev, and Wing Tat Leung. Residual-driven online generalized multiscale finite element methods. Journal of Computational Physics, 302:176–190, 2015.
- [12] Eric T Chung, Yalchin Efendiev, and Wing Tat Leung. An online generalized multiscale discontinuous galerkin method (gmsdgm) for flows in heterogeneous media. Communications in Computational Physics, 21(2):401–422, 2017.
- [13] Eric T Chung, Yalchin Efendiev, Wing Tat Leung, and Zhiwen Zhang. Cluster-based generalized multiscale finite element method for elliptic pdes with random coefficients. Journal of Computational Physics, 371:606–617, 2018.
- [14] Eric T Chung, Yalchin Efendiev, and Guanglian Li. An adaptive gmsfem for high-contrast flow problems. Journal of Computational Physics, 273:54–76, 2014.
- [15] Eric T Chung, Yalchin Efendiev, Guanglian Li, and Maria Vasilyeva. Generalized multiscale finite element methods for problems in perforated heterogeneous domains. Applicable Analysis, 95(10):2254–2279, 2016.
- [16] Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks. IEEE transactions on pattern analysis and machine intelligence, 38(2):295–307, 2015.
- [17] Yalchin Efendiev, Juan Galvis, and Thomas Y Hou. Generalized multiscale finite element methods (gmsfem). Journal of Computational Physics, 251:116–135, 2013.
- [18] Yalchin Efendiev, Juan Galvis, R Lazarov, M Moon, and Marcus Sarkis. Generalized multiscale finite element method. symmetric interior penalty coupling. Journal of Computational Physics, 255:1–15, 2013.
- [19] Yalchin Efendiev, Juan Galvis, Guanglian Li, and Michael Presho. Generalized multiscale finite element methods: Oversampling strategies. International Journal for Multiscale Computational Engineering, 12(6), 2014.
- [20] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep learning. MIT press, 2016.
- [21] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [22] Thomas Y Hou and Xiao-Hui Wu. A multiscale finite element method for elliptic problems in composite materials and porous media. Journal of computational physics, 134(1):169–189, 1997.
- [23] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7132–7141, 2018.
- [24] Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4700–4708, 2017.
- [25] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017.
- [26] Patrick Jenny, SH Lee, and Hamdi A Tchelepi. Multi-scale finite-volume method for elliptic problems in subsurface flow simulation. Journal of Computational Physics, 187(1):47–67, 2003.
- [27] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016.
- [28] Kari Karhunen. Über lineare Methoden in der Wahrscheinlichkeitsrechnung, volume 37. Sana, 1947.
- [29] Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1646–1654, 2016.
- [30] Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 624–632, 2017.
- [31] Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4681–4690, 2017.
- [32] Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 136–144, 2017.
- [33] Stuart Lloyd. Least squares quantization in pcm. IEEE transactions on information theory, 28(2):129–137, 1982.
- [34] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015.
- [35] Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE international conference on computer vision, pages 1520–1528, 2015.
- [36] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [37] Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In Thirty-first AAAI conference on artificial intelligence, 2017.
- [38] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016.
- [39] Ying Tai, Jian Yang, and Xiaoming Liu. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3147–3155, 2017.
- [40] Ying Tai, Jian Yang, Xiaoming Liu, and Chunyan Xu. Memnet: A persistent memory network for image restoration. In Proceedings of the IEEE international conference on computer vision, pages 4539–4547, 2017.
- [41] Maria Vasilyeva, Wing T Leung, Eric T Chung, Yalchin Efendiev, and Mary Wheeler. Learning macroscopic parameters in nonlinear multiscale simulations using nonlocal multicontinua upscaling techniques. JCP, accepted, arXiv preprint arXiv:1907.02921, 2019.
- [42] Min Wang, Siu Wun Cheung, Eric T Chung, Yalchin Efendiev, Wing Tat Leung, and Yating Wang. Prediction of discretization of gmsfem using deep learning. Mathematics, 7(5):412, 2019.
- [43] Min Wang, Siu Wun Cheung, Wing Tat Leung, Eric T Chung, Yalchin Efendiev, and Mary Wheeler. Reduced-order deep learning for flow dynamics. the interplay between deep learning and model reduction. Journal of Computational Physics, 401:108939, 2020.
- [44] Yating Wang, Siu Wun Cheung, Eric T Chung, Yalchin Efendiev, and Min Wang. Deep multiscale model learning. Journal of Computational Physics, 406:109071, 2020.
- [45] Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. In International conference on machine learning, pages 478–487, 2016.
- [46] Bo Yang, Xiao Fu, Nicholas D Sidiropoulos, and Mingyi Hong. Towards k-means-friendly spaces: Simultaneous deep learning and clustering. In Proceedings of the 34th International Conference on Machine Learning-Volume 70, pages 3861–3870. JMLR. org, 2017.
- [47] Han Zhang, Ian Goodfellow, Dimitris Metaxas, and Augustus Odena. Self-attention generative adversarial networks. arXiv preprint arXiv:1805.08318, 2018.
- [48] Yulun Zhang, Kunpeng Li, Kai Li, Lichen Wang, Bineng Zhong, and Yun Fu. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), pages 286–301, 2018.
- [49] Yulun Zhang, Yapeng Tian, Yu Kong, Bineng Zhong, and Yun Fu. Residual dense network for image super-resolution. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2472–2481, 2018.