Learned Image Compression with Gaussian-Laplacian-Logistic Mixture Model and Concatenated Residual Modules
Abstract
Recently deep learning-based image compression methods have achieved significant achievements and gradually outperformed traditional approaches including the latest standard Versatile Video Coding (VVC) in both PSNR and MS-SSIM metrics. Two key components of learned image compression are the entropy model of the latent representations and the encoding/decoding network architectures. Various models have been proposed, such as autoregressive, softmax, logistic mixture, Gaussian mixture, and Laplacian. Existing schemes only use one of these models. However, due to the vast diversity of images, it is not optimal to use one model for all images, even different regions within one image. In this paper, we propose a more flexible discretized Gaussian-Laplacian-Logistic mixture model (GLLMM) for the latent representations, which can adapt to different contents in different images and different regions of one image more accurately and efficiently, given the same complexity. Besides, in the encoding/decoding network design part, we propose a concatenated residual blocks (CRB), where multiple residual blocks are serially connected with additional shortcut connections. The CRB can improve the learning ability of the network, which can further improve the compression performance. Experimental results using the Kodak, Tecnick-100 and Tecnick-40 datasets show that the proposed scheme outperforms all the leading learning-based methods and existing compression standards including VVC intra coding (4:4:4 and 4:2:0) in terms of the PSNR and MS-SSIM. The source code is available at https://github.com/fengyurenpingsheng.
Index Terms:
Deep learning-based image compression, Entropy coding, Gaussian Mixture Model, Residual Network.I Introduction
Image compression is an important step in many applications. The classical approaches, e.g., JPEG [1], JPEG 2000 [2], and BPG (intra-frame coding of H.265/HEVC) [3], mainly use techniques such as linear transform, quantization, and entropy coding to remove the redundancy of the input and achieve better rate-distortion (R-D) performance, as illustrated in Fig. 1. Recently, deep learning-based methods have been investigated, where the three main components are re-designed based on the properties of neural networks. This approach has gradually outperformed traditional methods in both PSNR and MS-SSIM metrics [4], and shows great potentials.

The most important difference of learning-based schemes is that the classic linear transform is replaced by a non-linear neural network, which is learned from training data. Therefore, how to design the network architecture to reduce the correlation of the latent representations, which are the output of the encoding network (also known as the feature maps), is critical to the performance of learned image compression schemes. Another important task is to design a good probability model to capture the remaining correlation of the latent representations, so that they can be encoded efficiently.
I-A Encoder/Decoder Architectures
| Methods | Highlights |
|---|---|
| RNN [5, 6] | The first work on end-to-end LSTM-based RNN for variable-rate image compression. |
| GDN [7] | GDN is first used in image compression framework, which shows great potentials. |
| Residual Network [8] | The residual network is first used for CNN-based image compression. |
| GAN [9] | The first to use GAN for image compression. A multi-scale framework is also proposed. |
| Importance Map [10] | Importance Map is introduced to achieve content-aware bit allocation. |
| Non-Local Attention Module [11] | A non-local attention module is introduced to capture long-range correlation. |
| Simplified Attention Model [12] | The non-local module in [11] is simplified. The Gaussian Mixture Model (GMM) is also used. |
| Octave Convolution [13] | The multi-resolution octave convolution is employed in image compression framework. |
| iWave++ [14] | A lifting-based network similar to wavelet is proposed that supports both lossy and lossless compression. |
| Transformer [15] | The vision transformer is combined with convolutional layers to boost the compression performance. |
| Methods | Highlights |
|---|---|
| PixelCNN [16] | Masked convolutional networks are used to predict the distribution of each pixel value. |
| PixelCNN++ [17] | The discretized logistic mixture model is used to reduce the complexity of PixelCNN. |
| 3D-CNN [18] | The 2D-CNN model in [17] is generalized to 3D. The importance map in [10] is also used. |
| Hyperprior [19] | The hyperprior is first introduced. Zero-mean Gaussian model with a scale parameter is used. |
| GMM and Autoregressive models[20] | The GMM and autoregressive model are developed for the hyperprior method. |
| Context Model [21] | A context-adaptive entropy model is proposed with two types of contexts. |
| Laplace-smoothed histogram [8] | The Laplace-smoothed histogram is used for entropy encoding. |
| Laplacian [22] | The Laplacian distribution is established for lossy compression. |
| Logistic Mixture [23] | The discretized logistic mixture distribution is used. |
| GMM and quality enhancement network [24] | The GMM model and a quality enhancement subnetwork are used to achieve the state of the art. |
| Multivariate GMM [25] | Multivariate GMM and vector quantization are used. The parameters are estimated in a cascaded approach. |
Table I summarizes some representative encoder/decoder architectures for learned image coding.
One of the first learned image compression schemes was proposed in [5], which was based on the long short-term memory (LSTM) recurrent neural network (RNN) and was used to compress thumbnail images. In [6], the scheme in [5] is generalized to full-resolution images.
In [7, 26], an encoder network that includes convolution, downsampling, and the generalized divisive normalization (GDN) is proposed. It was the first learned image compression scheme that achieved better performance than JPEG2000 in terms of both PSNR and MS-SSIM.
Most recent schemes are based on the autoencoder framework, whose latent representations have much lower dimension than the input, and is very suitable for data compression.
A powerful building block of many cutting-edge neural networks is the residual block first proposed in the ResNet [27], which uses shortcut connections to facilitate the design and training of deep networks, and can effectively improve the performances of many computer vision tasks. As a result, the residual block has also been used in many learning-based image compression schemes.
In [8], the residual block concept in [27] was used in the autoencoder architecture, which also achieved comparable performance to JPEG2000.
Generative adversarial network (GAN) is another powerful framework for many applications, and has also been used in several learned image coding schemes [9, 28, 29].
In [10], the importance map is introduced to achieve content-adaptive bit allocation in different regions, but the importance mask needs to be sent to the decoder. In [11], non-local attention module is used to capture long-range correlation, and generate attention mask without sending side information, and it is used in both core network and hyper network. In [12], the attention module in [11] is simplified.
In [30, 13], a multi-resolution network architecture based on the octave convolution in [31] is developed, similar to the wavelet transform. In [14], another wavelet-like scheme is proposed based on the lifting scheme, which supports both lossy and lossless compression.
In [15], the vision transformer framework is introduced and combined with convolutional layers to boost the image compression performance.
I-B Entropy Coding Models
Table II is an overview of typical entropy coding models used for learned image coding.
In earlier schemes [32, 8, 26], the quantized latent representations or latents are assumed to be independent and identically distributed and followed a simple marginal distribution. Once the parameters of the distribution are trained, the probability of all latents is fixed for all images, which is used by the entropy encoding and decoding of the quantized latents. Since a fixed entropy model is used, the performances of these methods are compromised.
To improve the entropy coding performance, recent methods consider the correlation of neighboring pixels or latents (contexts), and achieve image-adaptive entropy coding. To estimate the joint probability with manageable complexity, the chain rule is usually used, which factorizes the joint probability into products of conditional probabilities.
In PixelCNN [16], masked convolutional networks are used to predict the distribution of each pixel value, conditioned on the causal neighbors in an autoregressive manner, which is used for image generation and image decoder in an autoencoder. In [17], the PixelCNN++ is proposed, which uses the discretized logistic mixture distribution to reduce the complexity of [16]. In [23], PixelCNN++ is applied to lossless image compression.
To help the estimation of the conditional probabilities of the latents, the hyperprior network is introduced in [19], where a hyper encoder network is used to extract some hyperpriors from the latents, which are coded as side information and sent to a hyper decoder network. The latter uses the reconstructed hyperpriors to estimate the conditional probability of the latents, thereby making the entropy model image-dependent and spatially adaptive.
In [19], the conditional probability of each latent is assumed to follow a zero-mean Gaussian scale mixture (GSM) model, which achieves better performance than BPG (4:4:4). In [20], the non-zero-mean Gaussian mixture model (GMM) is further proposed. In addition, the autoregressive context model in [16] is introduced to estimate the conditional probability of each latent from both the hyperpriors and its spatial context.
Other models have also been proposed to encode the latents. For example, in [22], the Laplacian distribution was used. In [12] and [24], the GMM model is adopted. A quality enhancement subnetwork is also introduced in [24] to improve the performance. It is the first learned image compression approach that achieves better performance than H.266/VVC (4:4:4) in both PSNR and MS-SSIM. As far as we know, the results in [24] are currently the best in the literature.
I-C Multivariate Models
The entropy coding approach above predicts the conditional probability of a latent given some causal neighbors and the hyperpriors, according to the chain rule, which approximates the joint probability implicitly. Another possible approach is to use the more general multivariate models to represent the joint probability explicitly.
In [25], the multivariate GMM is used in learned image compression to capture the inter-channel correlation of co-located latents across feature maps (this is captured implicitly by the approach above using 1x1 filters in the hyper decoder). The means and covariance matrices are estimated in a cascaded approach. Vector quantization is used to encode the latents, as in [32]. The hyper coding network is not used. However, since no spatial context is used, the R-D performance of [25] is only comparable to VVC on the Kodak test set, and not as good as other leading methods such as [24]. This indicates that if the learned image compression framework can consider the joint distribution via context model, non-local operator, and attention module, it is sufficient to use univariate models to model the remaining redundancy in the latents.
On the other hand, the overall complexity of multivariate model-based methods is usually quite high, as noted in [25], because the number of parameters of multivariate models increases quadratically with the size of the covariance matrix. Therefore, the complexity of the network model and the complexity of calculating multivariate probability increase dramatically. The training of the network is also more difficult, because the reverse gradients of different variables affect each other. Although the method in [25] can be parallelized because no spatial context is used, it still has very high demands for GPU and memory. In fact, other methods using spatial context can also be parallelized [33, 34, 35].
Multivariate models have also been used in other applications. Most of them are based on the Gaussian distribution. In [36], a deep GMM is proposed for classification by using the factor-analytic representation of the GMM in each layer. The Expectation-Maximization (EM) algorithm is used to estimate the parameters. However, it is found in [37] that sometimes it is quite challenging for this method to infer its parameters, even for a small-scale problem with 3 layers and 76000 latents.
In [38], a novel face recognition framework based on the multivariate GMM is proposed to make feature embeddings extract more identity-relevant information. In [39], a learned multiple graph Gaussian embedding model is developed to learn highly informative network features by mapping high-dimensional networks into a low-dimensional latent space. In [40], the multivariate skewed t-distribution is proposed for hyperspectral anomaly detection. In [41], the last fully-connected (FC) layer of a deep network is combined with a mixture of GMM (MoGMM) for image recognition. In [42], the multivariate GMM is considered as a prior to recover degraded images. In [43], a framework for deep unconstrained face verification is proposed to map learned discriminative facial features to a regularized metric space, in which matching and non-matching pairs follow multivariate Gaussian distributions.
I-D Contributions of this Paper
Although the learned methods have made significant progresses, the compression performance can be further improved. First, the previous entropy models only use a single distribution, which is not optimal for every latent. Second, the latents still exist some spatial redundancy. In order to address these issues, we make the following contributions in this paper:
Instead of using a single probability model, we propose a discretized Gaussian-Laplacian-Logistic mixture model (GLLMM), which is more flexible and efficient in estimating the conditional probabilities of the latents, given the same complexity. In fact, the previous models are special cases of the proposed model. Ablation studies demonstrate that the proposed joint model outperforms all previously proposed single models. For example, it achieves 0.1-0.15 dB gain in PSNR compared to the GMM model for the Kodak dataset.
We improve the basic building block of the encoder network by developing a concatenated residual module (CRM), with additional shortcut connections. The CRM improves the information flow, reduces the correlation of the output, and improves the training of the network. Ablation studies using the Kodak dataset show that the proposed CRM can achieve 0.2-0.3 dB gain in terms of PSNR compared to the original residual blocks. We also conduct ablation studies to compared the performances of CRMS with two and three stages of residual blocks.
One of the key contributions of [24] is the post-processing component, which achieves 0.5 dB gain in [24] compared to its baseline. We also investigate the performance of this component in our scheme. However, our experiments show that there is no need to apply the post-processing in our method, because the proposed CRM and entropy model have done a good job. This also reduces the complexity of the scheme.
Experimental results using the Kodak[44], Tecnick-100, and Tecnick-40 datasets in [45] show that the proposed scheme outperforms all the previous learning-based methods including [24, 12] and traditional codecs including VVC in both PSNR and MS-SSIM. For example, in terms of PSNR, for the Kodak dataset, when the bit rate is higher than 0.4 bpp, our method is 0.2-0.3 dB higher than [24, 12], and 0.3-0.4 dB higher than VVC (4:4:4). For the Tecnick dataset, when the bit rate is higher than 0.2 bpp, our method is 0.3-0.4 dB better than VVC (4:4:4). This represents the new state of the art in learned image compression.
The remainder of the paper is organized as follows. In Section II, we propose our image compression framework with discretized Gaussian-Laplacian-Logistic mixture model and the concatenated residual modules. In Sec. III, we compare our method with some state-of-the-art learning-based methods and classical image compression methods. Ablation experiments are carried out to investigate the performance gain of the the proposed scheme. The conclusions are reported in Sec. IV.

II The Proposed Image Compression Scheme with CRM and GLLMM
In this section, we first introduce the overall learned image coding framework adopted in this paper, and then describe the proposed concatenated residual module (CRM) and the discretized Gaussian-Laplacian-Logistic mixture model (GLLMM).
II-A The Overall Framework
The learned image coding framework adopted in this paper is illustrated in Fig. 2, which is mainly based on [12]. It is comprised of two main parts: the core autoencoder and the hyperprior coding.
The size of the input color image is , where and represents the width and height of the image, respectively. In the training of the network, the pixel values are normalized to by ().
The core autoencoder includes an encoder () and a decoder (). The input image is first sent to the encoder network , which aims to reduce the redundancy and learn a compact latent representation of the input image. The latent is then quantized and entropy coded. The quantized latent is denoted by .
The core encoder network includes various convolution layers and four stages of pooling operators to get the latents. The residual blocks with shortcut connections are used extensively. The GDN operator is used when the size is changed.
To improve the R-D performance, the simplified attention module in [12] is applied at two resolutions to capture long-range correlation, and strengthen more important areas, so that they will get more bit allocation.
To estimate the distribution of the latents and improve entropy coding efficiency, the hyperprior coding part is introduced in [19], which consists of a hyper encoder () and a hyper decoder (). The hyper encoder extracts the hyperprior from the latents, which is quantized into and entropy coded as a side information to the hyper decoder. The hyper decoder first recovers via entropy decoding, and then uses hyper decoder network to estimate the parameters of the conditional distribution of , which is used by the entropy encoding and decoding of .
Since the input dimension of the hyper network is much smaller than the original image, the hyper network is much simpler than the core network. Leaky ReLU is utilized in most convolution layers, except for the last layer in hyper encoder and decoder, which do not have any activation function.
To further improve the entropy coding efficiency, the context model network in [20] and [12] is also used in our system, which uses masked convolutions to capture the correlation of neighboring latents. The output layer of the context model is concatenated with the output of the first part of hyper decoder, and then further processed by some additional convolutional layers to estimate the parameters of the conditional distributions of the latents, which are then used to entropy encode and decode .
Since autoregressive context model is used, the symbols have to be decoded in serial manner. After all the symbols of are decoded, they are sent to the core decoder () to generate the reconstructed image. Note that the context model can be sped up using the methods in [33, 34, 35].
In Fig. 2, the encoders and decoders in the core and hyper networks are symmetric, except that they use convolution and deconvolution operators, respectively.
II-B The Proposed Concatenated Residual Module (CRM)
When the size does not change, to further remove the spatial correlation in the latent representation, we develop two deeper residual blocks in this paper, which is illustrated in Fig. 3. The basic building block is the standard residual block developed in the ResNet [27], as described in Fig. 3. As in [12], we first employ the leaky ReLU activation function to replace the ReLU function and remove the batch normalization layer from the residual block. The leaky ReLU activation function can speed up the convergence of the network. The detailed structure is shown in Fig. 3, which is used in [12]. Based on this, we develop two concatenated residual modules, as shown in Fig. 3 and Fig. 3.




In Fig. 3, two residual blocks in Fig. 3 are concatenated, and another short connection is added between the input and the output. In Fig. 3, three residual blocks are concatenated, with an additional shortcut connection as well.
Compared to the standard residual block in Fig. 3, the concatenated modules have larger receptive fields. They can remove more spatial correlation, which can also help the attention module in the network. In Sec. III, we will compare the performances of the two types of concatenated modules.
II-C The Proposed Gaussian-Laplacian-Logistic Mixture Model (GLLMM)
II-C1 Existing Models
The core encoder and decoder in Fig. 2 can be represented by
| (1) |
where and are the parameters of the encoder and decoder networks that need to be optimized. represents the quantization operator.
In earlier work, a fixed distribution is used to encode all entries of for all images, which is not optimal. In [19], the hyper encoder and hyper decoder are introduced to help learning the distribution of each entry of , which makes the entropy coding image-adaptive. The output of the hyper encoder network is quantized into and entropy coded as a side information to the decoder. The hyper coding part can be represented by
| (2) |
where and are the parameters of the hyper encoder and hyper decoder, and is the conditional distribution vector of given .
In [19], is assumed to follow the independent zero-mean Gaussian distribution with variation vector . In [20], it is allowed to have non-zero-mean Gaussian distribution with mean vector :
| (3) |
In addition, the autoregressive context model in[16] is introduced in [20] to consider the correlation from causal neighboring latents in estimating the distribution of the latent.
Based on [20], in [12], a Gaussian mixture model (GMM) is further introduced to estimate the latents. Since context model is also used as in [20], the conditional probability is denoted by , where represents the neighboring latents (contexts) for . Therefore the GMM-based estimation can be written as
| (4) |
At each position , the conditional distribution of , , is a weighted average of multiple Gaussian models with different means and variances (the sum of the weights equals to ). This is more powerful than a single Gaussian model.

Models with other distributions have also been investigated, such as logistic mixture model in [17, 23], and Laplacian distribution in [22].
However, the aforementioned methods only use one type of probability models to learn the probability distribution of the latent representation. It is difficult for one probability model to learn the distributions of all images. Therefore, better performance can be expected if different types of distributions can be combined together.






II-C2 The Proposed GLLMM Model
In this paper, we propose a powerful Gaussian-Laplacian-Logistic model (GLLMM) distribution as shown in Fig. 4 for :
| (5) |
which is a weighted average of Gaussian mixture, Laplacian mixture (), and logistic mixture (), with normalization constraints for , , , and respectively. and with different subscripts represent the mean and variance parameters for different models, and ’s are the weights of the three types of distributions.
The total number of parameters in Eq. (5) is . Each latent needs its own set of parameters to estimate its conditional distribution. All of these parameters are generated by the hyper decoder network. The last layer of the hyper decoder uses a filter to estimate the distribution parameters of each latent. The kernel size of each filter is thus . For feature maps, the total size of the filter at each position is . In this paper, the values of , , and are all chosen to be , based on the experimental results in Sec. III. Therefore there are parameters to estimate for each latent, and the total size of the filter for all feature maps are , as shown in Fig. 2.
Compared to the previous models with a single distribution, the proposed GLLMM model includes three types of distributions, and can capture the distribution of the latent more accurately and efficiently, given the same complexity, thereby improving the performance.
Eq. (5) is the continuous distribution, but the entropy coding part needs the distribution of the quantized . Since quantization is not differentiable, a standard solution during training is to add a uniform noise to to achieve a differentiable approximation of the quantization step, which enables the back-propagation-based training [19]. During the inference, is quantized to as usual, which is then encoded into the bit stream via entropy coding.
Based on the approach above, the distribution of the discrete-valued after quantization is given by [12]
| (6) |
where is the location index of the feature tensor, and is the cumulative distribution function of the mixture model.
II-D Loss Function
In this paper, we focus on optimizing the learned image compression to achieve the best rate-distortion (R-D) performance, based on the information theory. Let be the expected length of the bitstream, and be the reconstruction error between the source image and reconstructed image. The tradeoff between the rate and distortion is adjusted by a Lagrange multiplier denoted by . The objective cost function is then defined as follows:
| (7) | ||||
where the distortion is the reconstruction error between origin image and the decompressed image . and are the entropies of the latents and hyperpriors, based on the estimated conditional probabilities, as a measure of the bits needed to encode them.
The mean square error (MSE) and MS-SSIM are the most widely used distortion metrics, which are chosen in this paper. Other terms such as the GAN cost can be added to the loss function to achieve other goals. However, when more terms are introduced, the optimized result has to trade off these different constraints.
III Experiment




In this section, we compare our method with different learning-based methods and traditional compression standards using the Kodak PhotoCD dataset [44] and two Tecnick datasets [45]. The Kodak dataset consists of 24 images with a resolution of or . The first Tecnick dataset named Tecnick-100 includes 100 uncompressed images with a resolution of . The second Tecnick dataset named Tecnick-40 has 40 uncompressed images with a resolution of . The learning-based methods are recent state-of-the-art methods, including Balle2017 [26], Li2018 [10], Lee2019 [46], Cheng2020 [12], Lee2020 [24], Li2020 [47], Chen2021 [11], Ho2021 [48], Hu2021 [49], Ma2022 [14], and Zhu2022 [25]. We also compare with traditional methods, including VVC-Intra (4:4:4) (version 12.1) [50], VVC-Intra (4:2:0), BPG (4:4:4) [3], JPEG2000, WebP [51], and JPEG. Both PSNR and MS-SSIM metrics are used. The original MS-SSIM values are represented in dB scale by .
III-A Training Set
The CLIC dataset [52] and LIU4K dataset [53] are employed to train our models. The images of the training dataset are rescaled to a resolution of , which is better for training. Data augmentation algorithms (i.e., rotation and scaling) are used to randomly crop 81,650 patches with a resolution of . The patches are stored as lossless PNG images.
III-B Parameter Settings
We optimize the proposed models using mean square error (MSE) and MS-SSIM respectively. When optimized for MSE metric, the parameter is selected from the set . Each value trains a network for a particular bit rate. The number of filters is set to 128 for the three lower bit rates, and is set to 256 for the four higher bit rates. When the MS-SSIM metric is targeted, the parameter is in the set . The number of filters is set to 128 for the two lower bit rate, and is set to 256 for the two higher bit rates. Each model was trained up to iterations to obtain stable performance. The Adam solver with a batch size of 8 is adopted. The learning rate is set to in the first 750,000 iterations, and we gradually reduce the learning rate by 0.5 after every 100,000 iterations in the last 750,000 iterations.
III-C Performances on Kodak, Tecnick-100, and Tecnick-40 Datasets
The average MS-SSIM and PSNR performances over the 24 Kodak images are illustrated in Fig. 5. Note that in Fig. 5 to Fig. 7, the notations Scheme (PSNR) and Scheme (MS-SSIM) in the legends mean that the model in the scheme is optimized for PSNR and MS-SSIM respectively.
In Fig. 5, when optimized for PSNR, Lee2020 (PSNR) [24] is the best among previous methods, which obtains even better performance than VVC (4:4:4) at high rates. The next closest method to VVC (4:4:4) is Cheng2020 [12]. When the bit rate is less than 0.3 bpp, our method has similar performance to [24] and VVC (4:4:4). When the bit rate is higher than 0.4 bpp, our method achieves the best performance, which is 0.2-0.3 dB over [24] and 0.3-0.4 dB over VVC (4:4:4).
In the MS-SSIM results in Fig. 5, Lee2020 (MS-SSIM) [24] also achieves better performance than previous learning-based methods and all the traditional image codecs including VVC (4:4:4). Our proposed method optimized for MS-SSIM achieves slightly better results than Lee2020 (MS-SSIM).
Fig. 6 compares the performances of different methods on the Tecnick-100 dataset. Our scheme also outperforms all available learning-based methods and all the traditional image codecs including VVC (4:4:4) in term of both PSNR and MS-SSIM. Our method is the only method better than VVC. When the bit rate is above 0.2bpp, our method is about 0.2-0.3 dB higher than VVC (4:4:4).
Fig. 7 compares the performances of some methods on the Tecnick-40 dataset. The results of other methods are not available. Our scheme also outperforms other learned methods including Lee2020 [24] and VVC (4:4:4) in both PSNR and MS-SSIM.
One example are shown in Fig. 8 to compare the visual quality of different methods. Our method produces the most visually pleasing results.
III-D Ablation Studies

III-D1 Contributions of CRM and GLLMM
We first present ablation study to show the gain of the concatenated residual module (CRM) and the GLLMM model. The scheme in [12] is used as the baseline. On top of the baseline, we add different modules in turn. In order to compare as fair as possible, the parameter is chosen in the set . The number of filters is set to 128 for the two lower bit rates, and 256 for the three higher bit rates. Other training setups are the same. The MSE objective function is optimized in the ablation experiments.
The results are shown in Fig. 9. We first replace the GMM in the baseline by GLLMM, denoted as Baseline+GLLMM, which improves the R-D performance by about 0.15 dB at the same bit rate. Compared to Baseline+GLLMM, the proposed full method in this paper has a further improvement of 0.3 dB, which is the contribution of the CRM over the original residual blocks.
III-D2 Number of Concatenated Residual Modules

Next, we compare the standard residual block (RB), two-stage concatenated residual module (RB+two-stage), and three-stage concatenated residual module (RB+three-stage). The results are shown in Fig. 10.
The method with RB [27] achieves the worst performance. RB+two-stage method is 0.3 dB higher than RB. The RB+three-stage achieves the same performance with RB+two-stage at low bit rates and is sightly worse at high bit rates. Moreover, the model size will increase about . Therefore, we adopt the RB+two-stage method in our framework.
III-D3 Comparisons of Different Entropy Coding Models

In Fig. 11, we use the Kodak dataset to compare the performances of different entropy coding models, including Logistic mixture model (LoMM), Gaussian mixture model (GMM), Gaussian-Logistic mixture model (GLoMM), Gaussian-Laplacian mixture model (GLaMM), and the proposed Gaussian-Logistic-Laplacian mixture model (GLLMM). If some distributions are not used, we set the corresponding , or in Eq. (5) to be . It can be seen that LoMM achieves the worst performance. GMM is slightly better than LoMM, which agrees with the results in [12]. Adding either Laplacian or Logistic distribution to GMM can further improve its performance, with more gains from Logistic than Laplacian. Finally, adding both Laplacian and Logistic distributions as in the proposed GLLMM achieves the best result. The gaps between different curves are quite consistent at all bit rates.
In Fig. LABEL:entropy_model, we use image Kodim21 from the Kodak dataset to visualize the impacts of different entropy models using the same network architecture. The feature map with the highest entropy is displayed. The first column shows the values of the quantized latents. The second and third columns are the predicted parameters and . For the proposed GLLMM model, the mean is predicted by
| (8) |
The means and variances for other models are obtained similarly. If some distributions are not used, the corresponding , or are set to .
The fourth column in Fig. LABEL:entropy_model shows the normalized latents , as used in [20, 12, 11], because if the model is accurate, the normalized result should have zero mean and unit variance. Therefore the normalized result helps to visualize the remaining redundancy that is not captured by the entropy models. The last column shows the required bits to encoder the latents at each position, which is calculated using the entropy of the predicted discretized distribution at that position.
Table III reports the mean and variance of the images in the fourth column and the average bits of the images in the fifth column.
It can be observed from Fig. LABEL:entropy_model and Table III that our GLLMM model provides more uniform normalized latents or less remaining redundancy, and needs less bits for encoding.
Fig. 13 further zooms in to one particular location at coordinate [10, 22] in the feature map in Fig. LABEL:entropy_model, and plots the estimated continuous and quantized distributions using GMM and GLLMM respectively. The first column shows the reconstructed images of the two methods. The second column indicates the location of the selected latent. The third column plots the estimated individual distributions, the final mixed probability, and the corresponding parameters. It can be seen that in GLLMM, all the components in it are used effectively to represent this complex probability. The last column shows the histograms of the quantized probabilities.
| Method | Col. 4 | Col. 4 | Col. 5 |
|---|---|---|---|
| Mean | Variance | Mean | |
| GMM | 0.390 | 2.214 | 4.202 |
| GLaMM | 0.077 | 2.412 | 6.314 |
| GLLMM | 0.049 | 1.303 | 3.359 |
| GLLMM+NoCRM | 0.060 | 4.773 | 8.386 |



III-D4 GLLMM with Different Orders
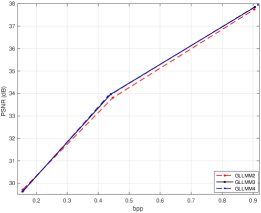
We next compare the performances of GLLMM with different orders. We use GLLMMn to represent the GLLMM with in Eq. (5). The results are shown in Fig. 14. It can be seen that GLLMM2 achieves the worst performance. GLLMM3 is up to about dB higher than GLLMM2. GLLMM4 almost achieves the same performance as GLLMM3. Therefore, the values of K, M, and J in other experiments of this paper are set to be .

III-D5 Comparison of GLLMM and Higher-order GMM
We also compare the performance of GLLMM3 and higher-order GMM, denoted as GMMn. Theoretically, GMM with enough orders can achieve any distribution. However, this comes at the price of increased complexity, and the gain diminishes gradually. For each method, we train two models at low and high bit rates respectively, with . The results are shown in Fig. 15. It can be seen that higher-order GMM has better performance. However, the performance saturates gradually. GLLMM3 has better performance than GMM15. Moreover, GLLMM3 has 30 parameters in Eq. (5), whereas GMM15 has 45 parameters in Eq. 4. As a result, compared to GLLMM3, the encoding and decoding time of GMM15 is 52.32% slower, its model size is 17.07% larger, and training time is 8.23 % longer. Therefore the proposed GLLMM is more effective than GMM when complexity is considered.
III-D6 Impact of the Attention Module and Context Model
Fig. 16 shows the effectiveness of the attention module and context model. In this figure, the baseline is the proposed method with CRM and GLLMM, which achieves the best performance. In Baseline+NoAttension, the attention module is removed, which has similar performance to the Baseline. In Baseline+NoAttension+NoAR, the autoregressive (AR) context model is also removed, which is 0.2-0.3 dB lower than the Baseline.

III-D7 Impact of Different Loss Functions
Fig. 17 shows the impact of different loss functions. In this figure, the Ours+MSE is the proposed method with only MSE as the distortion measure in the loss function, which achieves the best PSNR performance. In Ours+MSE+MS-SSIM, we include both the MSE and MS-SSIM in the distortion part of the loss function, whose PSNR is 0.2-0.3 dB lower than the loss function with MSE-only distortion.

III-D8 Impact of the Post-Processing Module in [24]
We also study the effectiveness of the post-processing module on image compression performance in our method. In [24], the post-processing module is combined to the image compression framework, which achieves 0.5 dB gain compared to its baseline without the post-processing. The post processing can be applied to other learning-based schemes as well. To study its effectiveness in our scheme, we implement the same post-processing as in [24] into our method. The corresponding results are listed in Table IV. We can observe that these two schemes have almost the same performances on Kodak dataset. The main reason is that we have much better residual modules and entropy model. Therefore there is no need to apply the post processing. This also reduces the complexity of the scheme.
| Method | Number of Filters | Objective Function | BPP | PSNR | MsSSIM | |
|---|---|---|---|---|---|---|
| Ours | 128 | 0.0032 | PSNR | 0.1556 | 29.63 dB | 12.59 dB |
| Ours+post-processing | 128 | 0.0032 | PSNR | 0.1554 | 29.65 dB | 12.59 dB |
| ours | 256 | 0.015 | PSNR | 0.4408 | 33.97 dB | 16.70 dB |
| Ours+post-processing | 256 | 0.015 | PSNR | 0.4400 | 33.98 dB | 16.71 dB |
III-E Encoding and Decoding Complexity
| Method | Encoding Time | Decoding Time | Model Size (Low Rates) | Model Size (High Rates) |
|---|---|---|---|---|
| VVC [50] | 402.27s | 0.61s | 7.2 MB | 7.2MB |
| Lee2019[46] | 15.721s | 42.88s | 123.8 MB | 292.6MB |
| Hu2020 [49] | 281.25s | 450.23s | 84.6 MB | 290.9MB |
| Cheng2020 [12] | 20.89s | 22.14s | 50.8 MB | 175.18MB |
| Chen2021 [11] | 402.26s | 2405.14s | 200.99 MB | 200.99MB |
| GLLMM | 385.26s | 387.62s | 77.08 MB | 241.03MB |
Table V compares the complexities of different approaches. Since VVC, Hu2020 [54] and Cheng2020 [12] only run on CPU, we evaluate the encoding and decoding time of different methods at the similar bit rate on an 2.9GHz Intel Xeon Gold 6226R CPU. The average time over all Kodak images is used. The average model sizes at low bit rates and high bit rates are also reported.
IV Conclusions
In this paper, we improve the state of the art of learning-based image compression by presenting a more flexible conditional probability model based on the discretized Gaussian-Laplacian-Logistic mixture distribution, which captures the spatial-channel correlation more effectively in latent representations. We also develop an improved concatenated residual block module for the encoder network.
Experiments demonstrate that the proposed method outperforms VVC (4:4:4) in terms of both PSNR and MS-SSIM metrics when measured on Kodak, Tecnick-100, and Tecnick-40 dataset. Also, our scheme achieves better performance compared to all the previous state-of-the-art learning-based methods.
Our method still has some rooms to improve. Since the autoregressive context model is employed in our framework, the symbols have to be decoded in an serial manner. Although it can effectively reduce the spatial correlation of the latent representations, it significantly increases the time complexity. How to reduce the complexity of the context model without too much degradation of the performance is a future research topic. Also, the complexity of our method can be further optimized by different approaches such as model compression and optimization.
Another possible future topic is to develop low-cost multivariate mixture models for learned image compression.
References
- [1] G. K. Wallace, “The jpeg still picture compression standard,” IEEE Transactions on Consumer Electronics, vol. 38, no. 1, pp. 18–34, 1992.
- [2] D. Taubman and M. Marcellin, JPEG2000: image compression fundamentals, standards, and practice. Kluwer Academic Publishers, 2002.
- [3] G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the high efficiency video coding (hevc) standard,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1649–1668, 2012.
- [4] Z. Wang, E. Simoncelli, and A. Bovik, “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems Computers, 2003, vol. 2, 2003, pp. 1398–1402.
- [5] G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, and R. Sukthankar, “Variable rate image compression with recurrent neural networks,” in Proc. Int. Conf. Learn. Representations, 2016.
- [6] G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, and M. Covell, “Full resolution image compression with recurrent neural networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 5435–5443.
- [7] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimization of nonlinear transform codes for perceptual quality,” in 2016 Picture Coding Symposium (PCS), 2016, pp. 1–5.
- [8] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” in International Conference on Learning Representations., 2017.
- [9] O. Rippel and L. Bourdev, “Real-time adaptive image compression,” in International Conference on Machine Learning, 2017, pp. 2922–2930.
- [10] M. Li, W. Zuo, S. Gu, D. Zhao, and D. Zhang, “Learning convolutional networks for content-weighted image compression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3214–3223.
- [11] T. Chen, H. Liu, Z. Ma, Q. Shen, X. Cao, and Y. Wang, “End-to-end learnt image compression via non-local attention optimization and improved context modeling,” IEEE Transactions on Image Processing, vol. 30, pp. 3179–3191, 2021.
- [12] Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image compression with discretized gaussian mixture likelihoods and attention modules,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7939–7948.
- [13] M. Akbari, J. Liang, J. Han, and C. Tu, “Learned bi-resolution image coding using generalized octave convolutions,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 08, Feb 2021, pp. 6592–6599.
- [14] H. Ma, D. Liu, N. Yan, H. Li, and F. Wu, “End-to-end optimized versatile image compression with wavelet-like transform,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 3, pp. 1247–1263, 2022.
- [15] M. Lu, P. Guo, H. Shi, C. Cao, and Z. Ma, “Transformer-based image compression,” in Data Compression Conference, March 2022.
- [16] A. van den Oord, N. Kalchbrenner, O. Vinyals, L. Espeholt, A. Graves, and K. Kavukcuoglu, “Conditional image generation with PixelCNN decoders,” in Advances in Neural Information Processing Systems(NIPS), 2016, pp. 4797–4805.
- [17] T. Salimans, A. Karpathy, X. Chen, and D. P. Kingma, “PixelCNN++: Improving the PixelCNN with discretized logistic mixture likelihood and other modifications,” in Intl. Conf. on Learning Representations (ICLR), 2017.
- [18] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. Van Gool, “Conditional probability models for deep image compression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- [19] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” in International Conference on Learning Representations, 2018, pp. 1–23.
- [20] D. Minnen, J. Ballé, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” in Advances in Neural Information Processing Systems, 2018, pp. 10 794–10 803.
- [21] J. Lee, S. Cho, and S.-K. Beack, “Context-adaptive entropy model for end-to-end optimized image compression,” in International Conference on Learning Representations, 2019.
- [22] L. Zhou, C. Cai, Y. Gao, S. Su, and J. Wu, “Variational autoencoder for low bit-rate image compression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2018, pp. 2617–2620.
- [23] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. V. Gool, “Practical full resolution learned lossless image compression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10 629–10 638.
- [24] J. Lee, S. Cho, and M. Kim, “An end-to-end joint learning scheme of image compression and quality enhancement with improved entropy minimization,” arXiv:1912.12817, 2020.
- [25] X. Zhu, J. Song, L. Gao, F. Zheng, and H. T. Shen, “Unified multivariate gaussian mixture for efficient neural image compression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 17 612–17 621.
- [26] J. Ballé, V. Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” in International Conference on Learning Representations, 2017.
- [27] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016, pp. 770–778.
- [28] S. Santurkar, D. Budden, and N. Shavit, “Generative compression,” in 2018 Picture Coding Symposium (PCS), June 2018, pp. 258–262.
- [29] M. Akbari, J. Liang, and J. Han, “Dsslic: Deep semantic segmentation-based layered image compression,” in The 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2019, pp. 2042–2046.
- [30] J. Lin, M. Akbari, H. Fu, Q. Zhang, S. Wang, J. Liang, D. Liu, F. Liang, G. Zhang, and C. Tu, “Variable-rate multi-frequency image compression using modulated generalized octave convolution,” in 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP), 2020, pp. 1–6.
- [31] Y. Chen, H. Fan, B. Xu, Z. Yan, Y. Kalantidis, M. Rohrbach, S. Yan, and J. Feng, “Drop an octave: Reducing spatial redundancy in convolutional neural networks with octave convolution,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 3435–3444.
- [32] E. Agustsson, F. Mentzer, M. Tschannen, L. Cavigelli, R. Timofte, L. Benini, and L. V. Gool., “Soft-to-hard vector quantization for end-to-end learning compressible representations,” in In Advances in Neural Information Processing Systems, 2017, pp. 1141–1151.
- [33] D. He, Y. Zheng, B. Sun, Y. Wang, and H. Qin, “Checkerboard context model for efficient learned image compression,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 14 771–14 780.
- [34] M. Li, K. Ma, J. You, D. Zhang, and W. Zuo, “Efficient and effective context-based convolutional entropy modeling for image compression,” IEEE Transactions on Image Processing, vol. 29, pp. 5900–5911, 2020.
- [35] M. Lu and Z. Ma, “High-efficiency lossy image coding through adaptive neighborhood information aggregation,” arXiv preprint arXiv:2204.11448, 2022.
- [36] C. Viroli and G. McLachlan, “Deep gaussian mixture models,” Statistics and Computing, vol. 29, no. 1, pp. 43–51, 2019.
- [37] M. Selosse, I. Gormley, J. Jacques, and C. Biernacki, “A bumpy journey: exploring deep gaussian mixture models,” I Can’t Believe It’s Not Better, NeurIPS 2020, Dec 2020, Vancouver, Canada, hal-02985701.
- [38] H. Ai, Q. Liao, Y. Chen, and J. Qian, “Gaussian mixture distribution makes data uncertainty learning better,” in 2021 16th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2021), 2021, pp. 01–08.
- [39] M. Xu, D. L. Sanz, P. Garces, F. Maestu, Q. Li, and D. Pantazis, “A graph gaussian embedding method for predicting alzheimer’s disease progression with meg brain networks,” IEEE Transactions on Biomedical Engineering, vol. 68, no. 5, pp. 1579–1588, 2021.
- [40] K. Kayabol, E. B. Aytekin, S. Arisoy, and E. E. Kuruoglu, “Skewed t-distribution for hyperspectral anomaly detection based on autoencoder,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [41] J. Xie, Z. Ma, J.-H. Xue, G. Zhang, J. Sun, Y. Zheng, and J. Guo, “Ds-ui: Dual-supervised mixture of gaussian mixture models for uncertainty inference in image recognition,” IEEE Transactions on Image Processing, vol. 30, pp. 9208–9219, 2021.
- [42] M. Niknejad, H. Rabbani, and M. Babaie-Zadeh, “Image restoration using gaussian mixture models with spatially constrained patch clustering,” IEEE Trans. on Image Processing, vol. 24, no. 11, pp. 3624–3636, 2015.
- [43] A. Ali, M. Testa, T. Bianchi, and E. Magli, “Biometricnet: Deep unconstrained face verification through learning of metrics regularized onto gaussian distributions,” in Computer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds., 2020, pp. 133–149.
- [44] Kodak PhotoCD dataset, December 2016. [Online]. Available: http://r0k.us/graphics/kodak/
- [45] N. Asuni and A. Giachetti, “TESTIMAGES: a Large-scale Archive for Testing Visual Devices and Basic Image Processing Algorithms.” The Eurographics Association, 2014.
- [46] J. Lee, S. Cho, and S.-K. Beack, “Context-adaptive entropy model for end-to-end optimized image compression,” in International Conference on Learning Representations, 2019.
- [47] M. Li, W. Zuo, S. Gu, J. You, and D. Zhang, “Learning content-weighted deep image compression,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2020.
- [48] Y.-H. Ho, C.-C. Chan, W.-H. Peng, H.-M. Hang, and M. Domański, “Anfic: Image compression using augmented normalizing flows,” IEEE Open Journal of Circuits and Systems, vol. 2, pp. 613–626, 2021.
- [49] Y. Hu, W. Yang, Z. Ma, and J. Liu, “Learning end-to-end lossy image compression: A benchmark,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2021.
- [50] H. Fraunhofer, “Vvc official test model vtm,” 2019. [Online]. Available: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/tree/VTM-12.1
- [51] Webp, September 2010. [Online]. Available: https://developers.google.com/speed/webp/
- [52] T. George, S. Wenzhe, T. Radu, T. Lucas, B. Johannes, A. Eirikur, J. Nick, and M. Fabian, “Workshop and challenge on learned image compression (clic2020).” CVPR, 2020. [Online]. Available: http://www.compression.cc
- [53] J. Liu, D. Liu, W. Yang, S. Xia, X. Zhang, and Y. Dai, “A comprehensive benchmark for single image compression artifact reduction,” IEEE Transactions on Image Processing, vol. 29, pp. 7845–7860, 2020.
- [54] Y. Hu, W. Yang, and J. Liu, “Coarse-to-fine hyper-prior modeling for learned image compression,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 11 013–11 020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/x27.jpg) |
Haisheng Fu (Student Member, IEEE) received the B.S. degree in automation engineering from Henan Polytechnic University, China. He is currently pursuing the Ph.D. degree in electronic science and technology with Xi’an Jiaotong University, Xi’an. He is currently a visiting student of Simon Fraser University, Canada. His research interests include Machine Learning, Image and Video compression, Deep Learning, and VLSI design. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/FengLiang.jpeg) |
Feng Liang is currently Professor of the Microelectronics School at Xi’an Jiaotong University. He earned his B.E. from Zhengzhou University and his M.E. and Ph.D. from Xi’an Jiaotong University. His current research interests include Signal Processing, Machine Learning, VLSI design, CIM, and computer architecture. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/JianpingLin.jpg) |
Jianping Lin received the B.S. degree in electronic engineering from the University of Science and Technology of China, Hefei, China, in 2016, where he is currently pursuing the Ph.D. degree with the Department of Electronic Engineering and Information Science. His research interests mainly include video coding/processing and machine learning |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/bing_Li.jpeg) |
Bing Li received his Ph.D. degree from Xi’an Jiaotong University, Xi’an, in 2021. He is now an engineer in Huawei. His current research interests include Elliptic curve cryptosystem, machine learning, and hardware implementation of neural networks. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/Mohammad_Akbari.png) |
Mohammad Akbari (Student Member, IEEE) received the B.S. degree in software engineering from the Shahid Bahonar University of Shiraz, Shiraz, Iran, in 2010, the M.Sc. degree in computer science from the University of Lethbridge, Lethbridge, AB, Canada, in 2014, and the Ph.D. degree in engineering science from Simon Fraser University, Burnaby, BC, Canada, in 2020. He is currently an AI Researcher with Huawei Technologies, Markham, ON, Canada. His research interests include deep learning, learned image compression, and music information retrieval. He was the recipient of the Best Student Paper Award finalist at the 2020 International Conference on Multimedia and Expo, the 2015 Convocation Medal of Merit from University of Lethbridge, and the Winner of the 2014 Canadian Microsoft Imagine Cup Innovation Competition. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/JieLiang.jpg) |
Jie Liang (Senior Member, IEEE) received the B.E. and M.E. degrees from Xi’an Jiaotong University, China, the M.E. degree from National University of Singapore, and the PhD degree from the Johns Hopkins University, USA, in 1992, 1995, 1998, and 2003, respectively. From 2003 to 2004, he worked at the Video Codec Group of Microsoft Digital Media Division. Since May 2004, he has been with the School of Engineering Science, Simon Fraser University, Canada, where he is currently a Professor. Jie Liang’s research interests include Image and Video Processing, Computer Vision, and Deep Learning. He had served as an Associate Editor for several journals, including IEEE Transactions on Image Processing, IEEE Transactions on Circuits and Systems for Video Technology (TCSVT), and IEEE Signal Processing Letters. He has also served on three IEEE Technical Committees. He received the 2014 IEEE TCSVT Best Associate Editor Award, 2014 SFU Dean of Graduate Studies Award for Excellence in Leadership, and 2015 Canada NSERC Discovery Accelerator Supplements (DAS) Award. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/GuoHe_Zhang.jpg) |
Guohe Zhang received the B.S. and Ph.D. degrees in electronics science and technology from Xi’an Jiaotong University, Shaanxi, China, in 2003 and 2008, respec- tively. He is currently an Associate Professor with the School of Microelectronics, Xi’an Jiaotong University. In 2009, he joined the School of Elec- tronic and Information Engineering, as a Lec- turer. He was promoted to an Associated Professor, in 2013. From 2009 to 2011, he had a three year’s Postdoctoral Researcher with the School of Nuclear Science and Technology, Xi’an Jiaotong University. From February to May of 2013, he had a short term visiting to the University of Liverpool, U.K. His research interests fall in the area of semiconductor device physics and modeling, VLSI design and testing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/DongLiu.jpg) |
Dong Liu (Senior Member, IEEE) received the BS and PhD degrees in electrical engineering from the University of Science and Technology of China (USTC), Hefei, China, in 2004 and 2009, respectively. He was a member of research staff with Nokia Research Center, Beijing, China, from 2009 to 2012. He joined USTC as an associate professor, in 2012. His research interests include image and video coding, multimedia signal processing, and multimedia data mining. He has authored or coauthored more than 100 papers in international journals and conferences. He has 16 granted patents. He has one technical proposal adopted by AVS. He received the 2009 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY Best Paper Award and the VCIP 2016 Best 10 percent Paper Award. He and his team were winners of several technical challenges held in ICCV 2019, ACM MM 2018, ECCV 2018, CVPR 2018, and ICME 2016. He is a senior member of the CCF and CSIG, and an elected member of MSATC of IEEE CAS Society. He served as a registration co-chair for ICME 2019 and a symposium co-chair for WCSP 2014. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/ChengjieTu.png) |
Chengjie Tu (Member, IEEE) received the B.S. degree in mechanical engineering from the University of Science and Technology of China, Hefei, China, in 1994, and the M.S. and Ph.D. degrees in electrical and computer engineering from Johns Hopkins University, Baltimore, MD, USA, in 2001 and 2003, respectively. He is currently the Chief Video Codec Expert with Cloud Architecture and Platform Department, Tencent, Shenzhen, China. His research interests include image or video coding, processing, and real time multimedia communication. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/a94a4ab5-d302-4a50-99b1-b5821247c412/JingningHan.png) |
Jingning Han (Senior Member, IEEE) received the B.S. degree in electrical engineering from Tsinghua University, Beijing, China, in 2007, and the M.S. and Ph.D. degrees in electrical and computer engineering from the University of California at Santa Barbara, Santa Barbara, CA, USA, in 2008 and 2012, respectively. He joined the WebM Codec Team, Google, Mountain View, CA, USA, in 2012, where he is the Main Architect of the VP9 and AV1 codecs, and leads the Software Video Codec Team. He has published more than 60 research articles. He holds more than 50 U.S. patents in the field of video coding. His research interests include video coding and computer science architecture. Dr. Han received the Dissertation Fellowship from the Department of Elec- trical and Engineering, University of California at Santa Barbara, in 2012. He was a recipient of the Best Student Paper Award at the IEEE International Conference on Multimedia and Expo, in 2012. He also received the IEEE Signal Processing Society Best Young Author Paper Award, in 2015. |