Learnable Distribution Calibration for Few-Shot Class-Incremental Learning
Abstract
Few-shot class-incremental learning (FSCIL) faces challenges of memorizing old class distributions and estimating new class distributions given few training samples. In this study, we propose a learnable distribution calibration (LDC) approach, with the aim to systematically solve these two challenges using a unified framework. LDC is built upon a parameterized calibration unit (PCU), which initializes biased distributions for all classes based on classifier vectors (memory-free) and a single covariance matrix. The covariance matrix is shared by all classes, so that the memory costs are fixed. During base training, PCU is endowed with the ability to calibrate biased distributions by recurrently updating sampled features under the supervision of real distributions. During incremental learning, PCU recovers distributions for old classes to avoid ‘forgetting’, as well as estimating distributions and augmenting samples for new classes to alleviate ‘over-fitting’ caused by the biased distributions of few-shot samples. LDC is theoretically plausible by formatting a variational inference procedure. It improves FSCIL’s flexibility as the training procedure requires no class similarity priori. Experiments on CUB200, CIFAR100, and mini-ImageNet datasets show that LDC outperforms the state-of-the-arts by 4.64%, 1.98%, and 3.97%, respectively. LDC’s effectiveness is also validated on few-shot learning scenarios.
Index Terms:
Few-shot Learning, Incremental Learning, Learnable Distribution Calibration, Parameterized Calibration Unit.1 Introduction
Great progress has been made in visual recognition, which can be attributed to advanced learning mechanisms and large-scale datasets with adequate supervision. However, machine learning remains incomparable to cognitive learning, which obtains high-precision recognition based on few supervisions and can generalize this capability to novel classes [1]. To study this topic, the community starts paying attentions to few-shot class-incremental learning (FSCIL), a learning paradigm inspired by cognitive learning [2]. Given base classes with sufficient training data and novel classes with few samples, FSCIL is able to construct a representative model using old classes and continually adapt the model to new classes.


However, FSCIL faces challenges that are beyond conventional learning paradigms. On the one hand, the model requires to memorize old classes and must avoid ‘forgetting’. On the other hand, the model needs to avoid ‘over-fitting’ when facing biased distributions caused by few-shot samples. To alleviate ‘forgetting’, data distillation [4, 5] memorizes old class distributions by introducing regularization loss in incremental learning. However, it is challenged by biased distributions upon few-shot training samples. The Free-Lunch method [3] transfers statistics from classes with sufficient samples to few-sample classes. Nevertheless, it suffers enormous memory costs when required to store covariance matrices for all base classes. Furthermore, Free-Lunch calibrates class distributions using class similarity calculated by few-shot samples, so that the calibration results are likely inaccurate as few-shot samples suffer bias.
In this study, we propose learnable distribution calibration (LDC) for FSCIL, Fig. 1. The purpose is to recover old class distributions and calibrate biased new class distributions in a uniform framework. Compared with the conventional method [3], LDC is differential and requires a low memory cost. It learns to calibrate distributions using a single stored covariance matrix shared by all classes. This enables getting rid of dependence on similar base classes, improving FSCIL’s accuracy and flexibility, Fig. 2.
LDC roots on a parameterized calibration unit (PCU), which initializes feature distribution for each class using a Gaussian sampler, defined according to a mean vector and a stored covariance matrix, to generate a set of feature samples. The mean vector is approximated using the classifier vector, which is regarded as a class prototype [6]. The stored covariance matrix is the mean of covariance matrices about all old classes. A learnable mapping function, which takes the stored mean covariance matrix and mean vector as inputs, is proposed to generate the covariance matrix for each class. Using base classes, PCU is trained to calibrate biased distributions by recurrently updating sampled features under the supervision of real sample features. The Gaussian sampler generates sufficient feature samples during incremental learning, forming biased distributions for old and new classes. PCU recurrently updates the generated feature samples, so that old class distributions are recovered and new class distributions are calibrated. We conduct sophisticated experiments on common datasets, outlier cases, and few-shot learning tasks to verify the effectiveness and generalization ability of our method.
The contributions of this study are as follows:
-
•
We propose learnable distribution calibration (LDC), with the aim to recover old class distributions and calibrate new class distributions from a single stored covariance matrix, solving catastrophically forgetting and over-fitting for FSCIL in a uniform framework.
-
•
We design a parameterized calibration unit (PCU), providing a recurrent fashion for distribution calibration without using class similarity priori, improving accuracy with a fixed memory cost.
-
•
LDC achieves new state-of-the-art performance on the challenging FSCIL task. It also generalizes smoothly to regular few-shot learning problems.
2 Related Work
Few-shot Learning. Few-shot learning trains a model to classify unseen (novel) classes with only a few annotated samples. Few-shot learning methods can be broadly categorized as either metric learning, meta learning, or data augmentation. Metric learning [7, 8, 9, 10, 11, 12] trains two-branch networks to determine categories of the query images by comparing few-shot training images and query (test) images. Meta learning [13, 14, 15] pursues fast adaptation of models to new categories with few training images for optimization. Data augmentation [16, 17, 18, 3] generates rich examples to rectify biased sample distributions.
To conquer catastrophically forgetting, meta-learning [19, 20] and feature alignment methods [21] have been explored to regularize new class training. The dynamic few-shot learning approach [22] redesigns the classifier of a ConvNet model as the cosine similarity function between feature representations and classification weight vectors, which leads to feature representations that generalize better on “unseen” categories. However, it doesn’t involve distribution bias caused by few-shot samples, which is the focus of this study.
Incremental Learning. According to the avaliability of task IDs, methods can be classified as either task- or class-incremental learning [23]. Incremental learning methods can be further grouped as either rehearsal, regularization, or architecture configuration methods. Rehearsal methods [24, 25, 26, 27, 28, 29, 30] recall exemplars, which are stored from a previous session, to prevent forgetting. Regularization methods [4, 31, 32, 33, 25, 34, 35, 36] introduce special loss functions that utilize knowledge or parameter distillation to constrain network learning. Architecture configuration methods [37, 38, 39, 40] choose parts of network parameters by leveraging hard attention [38], pruning mechanisms [37] or dynamic expansion network [39] to alleviate model drift.
When task IDs are not accessible during inference, the problem evolves into class-incremental learning [24]. The primary challenge is catastrophic forgetting, which has been elaborated by using data distillation [4, 5], memory mechanisms [31, 41, 42], and transfer learning [43]. Exemplars are selected based upon class feature distribution [24], or produced by generative adversarial networks [28].
Few-shot Class-Incremental Learning. This task manages to train a representation model using base classes and continually adapts the model to new classes. FSCIL therefore amalgamates the challenges of catastrophic forgetting caused by incremental learning and over-fitting caused by biased few-shot samples. The neural gas method [1] considered these challenges by constructing and preserving feature topology. Continually evolving prototypes [44, 6] learns new classes by optimizing class margins. The mixture sub-space approach [45] synthesizes features in the sub-spaces for incremental classes by using a variational auto-encoder.
Despite substantial progress, the problem of solving the forgetting and over-fitting issues in a uniform framework remains. The distribution calibration method [3] initiated the idea to solve the over-fitting issue, but has difficult to handle FSCIL as the memory cost increase with the class number.

3 The Proposed Approach
3.1 Overview
FSCIL consists of base training and incremental learning stages, Fig. 3. During base training, it learns a representation model upon base classes () with sufficient examples. During incremental learning, it generalizes the developed model to new classes using only a few samples. The incremental datasets are denoted as , where is the data of classes for the -th session. For , we have . In the -th session, only the training data for the class set is available, while all old and new classes require to be tested. That said, old classes shall not be forgotten while the new concepts shall be learned with few samples.
Fig. 3 shows LDC’s flowchart, where the network consists of a feature extractor () and a PCU. The PCU contains a Gaussian sampler that initiates biased distributions, a learnable mapping function () that generates the covariance matrix for each class, a recurrent calibration module () that manipulates biased distributions, and a classifier (), Fig. 4. During base training, images are encoded to feature samples by a feature extractor (), which are then fed into the PCU for classification prediction (). The feature extractor is trained under the supervision of ground-truth labels . At the same time, PCU learns to generate feature samples (calibrated distributions) under the supervision of the real feature samples (which represent real distributions). The base training procedure is formulated as:
| (1) |
where and respectively denote image classification loss and distribution matching loss. calculates the cross entropy between predictions and labels, and measures the distance between calibrated and real distributions. denotes the classification procedure.
In the -th incremental session, the PCU trained upon base classes is utilized to recover old class distributions and generalized to new classes for distribution calibration. Old class samples (which is unavailable) are recovered in two steps: (1) Initializing feature samples using the Gaussian sampler; (2) Recurrently calibrating the feature samples so that their distributions approach the real ones. These two steps are also carried out for the new classes to augment training samples and calibrate the biased distributions. Few-shot samples are used to update classifier vectors and the stored covariance matrix, which are used to perform Gaussian sampling. The sampled features are then fed to the recurrent calibration module to generate calibrated feature samples for model training. The incremental learning procedure is formulated as:
| (2) |
where denotes few-shot samples for the -th session and denotes calibrated feature samples (calibrated distributions). and denote the predicted and ground-truth labels of few-shot samples. and denote the predicted and ground-truth labels of the calibrated samples, respectively. In order to handle new classes , classifier vectors are added to the classification layer as , where denotes the number of seen classes until the -th session. The network is updated by optimizing Eq. 2.

3.2 Parameterized Calibration Unit
PCU consists of a Gaussian sampler and a recurrent calibration module, both of which are parameterized, Fig. 4.
Gaussian Sampler. It is defined by multiplexing classifier vectors () as mean vectors and storing a shared covariance matrix () which is the mean covariance matrix for all classes. The classifier is calculates the cosine distance between sample features and classifier vectors for classification [46]. Classifier vectors are initialized by the mean feature vectors of the corresponding classes. The -th classifier vector () can be approximated as the prototype of the -th class. The covariance matrix () is dynamically updated as . calculates the covariance matrix. A learnable mapping function () is used to generate the covariance matrix for the -th class, as , which is realized by an expanding-concatenating operation and a Conv-ReLU-Conv stack. The -th covariance matrix and classifier vector are fed to the sampler to generate a biased distribution () for the -th class. The sampling process is expressed as , where are the features sampled from the Gaussian distribution . For the -th session, we generate the biased distributions for all seen classes, which are calculated as .
Recurrent Calibration module. This is defined using convolutional layers, parameterized with , Fig. 4. For the -th session, the recurrent calibration process is expressed as:
| (3) |
During recurrent calibration, the objective function is built upon previous optimization and prediction. This makes it possible to deconstruct a complex objective function (, the distribution matching loss) to series of simpler objective functions which are easier to realize.
Distribution Matching Loss. During base training, the shared covariance matrix and classifier vectors are used to sample biased distributions. Then those biased distributions are calibrated to obtain the calibrated distributions . Given the real distributions , the loss is defined as:
| (4) |
where is defined as the KL divergence [47]. By minimizing the distribution matching loss , PCU’s parameters are updated so that the calibrated distributions align with real distributions. PCU is generalized to new classes for calibration during incremental learning.
3.3 Theoretical Analysis
We managed to prove that recurrent sample calibration is theoretically plausible, by formulating it as a variational inference procedure during training [48]. Given real distributions , biased distributions and the parameters for recurrent distribution calibration. defines latent variable . The optimization of is equivalent to finding a mean-field distribution [49] which is to approximate the distribution , which is formulated as:
| (5) |
where denotes the candidate probability distributions. According to the characteristics of mean-field distribution, where is a subset of . denotes the Kullback-Leibler divergence between distributions, which is calculated by:
| (6) | ||||
denotes the expectation function. is non-negative, thus we have:
| (7) |
The right side of the Eq. 7 is the lower bound of the left side, which is termed as evidence lower bound (). We have:
| (8) | ||||
According to Eq. 8, Eq. 5 is re-written as:
| (9) |
As is independent to , Eq. 9 is equivalent to:
| (10) |
for the purpose of simplification, we use for , where is calculated as:
| (11) | ||||
For , the term is expressed as , and the term is expressed as . Accordingly, Eq. 11 is re-written as:
| (12) | ||||
where denotes a constant. is the non-normalized distribution of , calculated using:
| (13) | ||||
where are the latent variables other than . Assuming the is fixed, we optimize to maximize the . According to Eqs. 12 and 13, the optimal is proportional to the expectation of , as:
| (14) |
According to Eq. 14, by recurrently optimizing , which is achieved by calibrating and updating , is maximized and converges to a local optimal solution. According to Eqs. 9 and 10, maximizing is equal to minimizing , which infers that a feasible solution for could be found so that the calibrated distributions in Eq. 3 approximate real ones .
4 Experiment
4.1 Settings
Dataset. We evaluate LDC using three commonly used datasets, including CIFAR100, CUB200, and mini-ImageNet. The categories in the datasets are divided to base ones with adequate annotations and new ones with K-shot annotated images. For the FSCIL, the proposed LDC is trained upon base classes for the first session. New classes are gradually added to train LDC in T incremental sessions. In each incremental session, N-way new classes are added for model training. CIFAR100 and mini-ImageNet datasets consist of 100 classes, where 60 classes are set as base classes and 40 as new classes. Each new class has 5-shot annotated images (K = 5). New classes are then divided to eight sessions (T = 8), each of which has five classes (N = 5). CUB200 consists of 200 classes where 100 classes are set as base classes and the other 100 classes as new classes under the settings of K = 5, T = 10, N = 10.
| Baseline | Gaussian Sampler | Recurrent Calibration | Accuracy in each session (%) | ||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| ✓ | 77.89 | 74.01 | 69.23 | 64.85 | 62.35 | 59.11 | 56.87 | 55.68 | 53.92 | 52.79 | 51.86 | ||
| ✓ | ✓ | 77.89 | 75.68 | 71.12 | 67.31 | 66.13 | 60.89 | 58.73 | 57.65 | 56.08 | 55.21 | 54.58 | |
| ✓ | ✓ | ✓ | 77.89 | 76.93 | 74.64 | 70.06 | 68.88 | 67.15 | 64.83 | 64.16 | 63.03 | 62.39 | 61.58 |
Training and Evaluation. Following [1, 6, 53], we adopt Resnet-18 [54] as the backbone for CUB200 and mini-ImageNet, and Resnet-20 for CIFAR100. The model is optimized using the SGD algorithm. Following FACT [53], we use normalization, horizontal flipping, random cropping, auto augmenting and random resizing for data augmentation. For the first session, we train the network using upon base classes, with a batch size 128 and an initial learning rate 0.1. When , the network is trained upon with new classes and the learning rate is set to 0.01. The network is trained for 100 epochs during each session. During inference period, we conduct 10 experiments using random seeds and report averaged results to eliminate the randomness of the experiments. We adopt a simple baseline method which consists of a feature extractor and a distance-based classifier. Experiments are conducted using PyTorch 1.9.0 and run on Nvidia 2080Ti GPUs.
During inference, the model trained for all sessions are evaluated by classification on all the seen class using the metric of , where , , and respectively denote the numbers of true positives, true negatives, false positives and false negatives. To better measure model forgetting, ‘’ and ‘’ are introduced to evaluate the model performance drop and performance retention respectively. ‘’ is defined as , where denotes the -th session performance and denotes the -th session performance. ‘’ is defined as .
4.2 Ablation Study
We conduct ablation studies on CUB200 to validate PCU’s modules, including the Gaussian sampler, the recurrent calibration module and the distribution matching loss.
Gaussian Sampler. In Table I, the proposed approach outperforms the baseline method by 2.72% with ‘Gaussian Sampling’. The performance gain validates the plausibility of the Gaussian sampling process based on classifier weights and a single stored covariance matrix.
Recurrent Calibration. With recurrent calibration, LDC further improves the baseline method and Gaussian sampler by 9.72% and 7.00%, respectively. By recurrently calibrating biased distributions generated with the Gaussian sampler, generated distributions approach real distributions, which augments training data and benefits model learning.
Distribution Matching Loss. Four kinds of matching losses defined upon earth mover distance, KL divergence, JS divergence, and Hellinger distance are compared in Table II, where one can see that KL divergence performs the best.
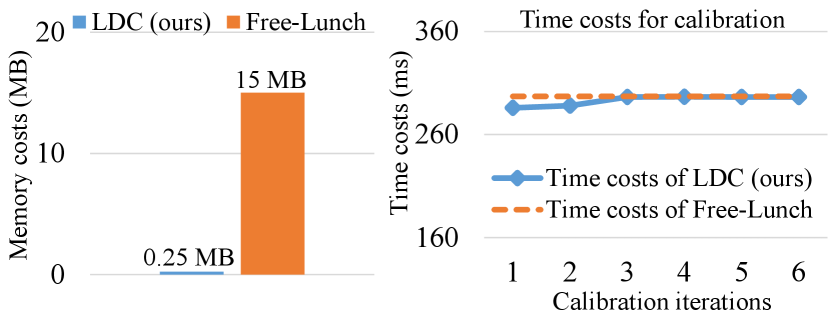
Memory and Time Costs. As shown in Fig. 5, LDC’s memory costs for covariance matrix storage is much lower than Free-Lunch’s. And LDC’s time costs is comparable to Free-Lunch’s when the calibration iterations increase. It is attributed to the employing of convolution layers so that recurrent calibration costs negligible time.
4.3 Model Analysis
Distribution Calibration. We utilize t-SNE to visualize real distributions and calibrated distributions generated using the proposed LDC methods to analyze the recurrent distribution calibration process better. Fig. 6 shows that the calibrated distributions generated by LDC approach real distributions when calibration proceeds. Consequently, training with calibrated distribution samples alleviates catastrophic forgetting and benefits estimations for new class distributions.

| Method | |||||
| Normal | Free-Lunch | 25.62 | 65.65% | 3.11 | 4.22% |
| LDC (ours) | 22.51 | 69.87% | |||
| Outlier | Free-Lunch | 30.07 | 59.68 | 4.75 | 6.11% |
| LDC (ours) | 25.32 | 65.79 | |||

| Strategy | Ours | Empirical | |
| mini-ImageNet | Convergence (epoch) | 206 | 312 |
| Generalization (accuracy) | 19.78% | 15.15% | |
| CIFAR100 | Convergence (epoch) | 98 | 196 |
| Generalization (accuracy) | 31.36% | 27.55% | |
| Method | Accuracy in each session (%) | ||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |||
| Ft-CNN | 68.68 | 44.81 | 32.26 | 25.83 | 25.62 | 25.22 | 20.84 | 16.77 | 18.82 | 18.25 | 17.18 | 51.50 | 25.00% |
| iCaRL [24] | 68.68 | 52.65 | 48.61 | 44.16 | 36.62 | 29.52 | 27.83 | 26.26 | 24.01 | 23.89 | 21.16 | 36.67 | 30.80 % |
| TOPIC [1] | 68.68 | 62.49 | 54.81 | 49.99 | 45.25 | 41.40 | 38.35 | 35.36 | 32.22 | 28.31 | 26.28 | 42.40 | 38.26 % |
| SPPR [44] | 68.68 | 61.85 | 57.43 | 52.68 | 50.19 | 46.88 | 44.65 | 43.07 | 40.17 | 39.63 | 37.33 | 31.35 | 54.35% |
| FSLL [55] | 72.77 | 69.33 | 65.51 | 62.66 | 61.10 | 58.65 | 57.78 | 57.26 | 55.59 | 55.39 | 54.21 | 17.38 | 74.49% |
| SFMS [45] | 68.78 | 59.37 | 59.32 | 54.96 | 52.58 | 49.81 | 48.09 | 46.32 | 44.33 | 43.43 | 43.23 | 25.55 | 62.85% |
| CEC [6] | 75.85 | 71.94 | 68.50 | 63.50 | 62.43 | 58.27 | 57.73 | 55.81 | 54.83 | 53.52 | 52.28 | 23.57 | 68.92 % |
| Meta-FSCIL [56] | 75.90 | 72.41 | 68.78 | 64.78 | 62.96 | 59.99 | 58.30 | 56.85 | 54.78 | 53.82 | 52.64 | 23.26 | 69.35% |
| FACT [53] | 75.90 | 73.23 | 70.84 | 66.13 | 65.56 | 62.15 | 61.74 | 59.83 | 58.41 | 57.89 | 56.94 | 18.96 | 75.02% |
| Free-Lunch‡ | 77.89 | 74.68 | 71.36 | 66.35 | 64.52 | 61.63 | 58.51 | 58.21 | 57.31 | 56.72 | 55.68 | 22.25 | 71.45 |
| LDC (ours) | 77.89 | 76.93 | 74.64 | 70.06 | 68.88 | 67.15 | 64.83 | 64.16 | 63.03 | 62.39 | 61.58 | 16.31 | 79.06% |

Outlier Cases. We compare the performance of LDC and Free-Lunch using normal and outlier cases to further validate the ability to calibrate biased distributions, Table III. For normal cases, few-shot samples are randomly sampled from new class distributions using the mini-ImageNet dataset. For outlier cases, few-shot samples are outlier samples in new class distributions. The larger performance gains (, and ) in outlier cases demonstrate that LDC achieves better calibration results than Free-Lunch when few-shot samples are extremely biased.
Scalability. We compare performance drops when the class number increases to validate LDC’s scalability. We fix the memory costs and calculate the classification accuracy for a fair comparison. From Fig. 7, one can see that when classes increase, LDC maintains the performance while Free-Lunch suffers significant performance drops. The results demonstrate that LDC has higher scalability w.r.t. class number.
Covariance matrix mapping strategy. We compare the convergence and generalization of our proposed covariance matrix mapping strategy and the strategy adopted in empirical distribution calibration [3]. As shown in Table IV the model with matrix mapping strategy converges at epoch on mini-ImageNet, while the compared model with empirical strategy converges at epoch. For generalization, we randomly select 20 unseen classes with few-shot samples for finetuning and test the classification accuracy. The results show that the model with matrix mapping strategy outperforms the counterpart model on both mini-ImageNet and CIFAR100 datasets. The results show that the proposed strategy (sharing mean covariance matrix and mapping the covariance matrix for each class) benefits learning of class distribution statistics, as well as improving the model generalization capability.
4.4 Performance Comparison
CUB200. In Table V, LDC achieves the best performance on all sessions and the lowest performance dropping rate. Benefited by PCU, LDC’s accuracy in the first session is higher than other methods, and it outperforms FSLL [55] and Fact [53] by 7.37% and 4.64% in the final session. CIFAR100. In Fig. 8(left), LDC outperforms the state-of-the-arts across all incremental sessions. Specifically, it improves SPPR [44] and Fact [53] by 10.83% and 1.98%, respectively. Mini-ImageNet. Compared to the baseline method (CEC), LDC improves CEC by 6.83% (54.46% v.s. 47.63%), which demonstrates the effectiveness of the proposed learnable distribution calibration mechanism. Compared to the state-of-the-art methods, LDC outperforms the Fact method by 3.97%, Fig 8(right).
| Dataset | Free-Lunch | LDC (ours) | |
| mini-ImageNet | 5-way 1-shot | 68.570.55 | 69.98 0.42 |
| 5-way 5-shot | 82.880.42 | 84.030.46 | |
| CUB | 5-way 1-shot | 79.560.87 | 81.510.72 |
| 5-way 5-shot | 90.670.35 | 92.31 0.28 | |
4.5 Generalized to Regular Few-Shot Classification
LDC has great potential to be a plug-and-play module which improves model generalization capacities. To demonstrate such potential, we apply LDC to the regular setting of few-shot classification. The PCU trained using base classes with sufficient training samples is used to generate (augment) samples for novel classes. It improves the accuracy upon Free-Lunch for both 1-shot and 5-shot on mini-ImageNet and CUB datasets, demonstrating the general effectiveness for few-shot learning problems, Table VI.
5 Conclusion
We proposed a learnable distribution calibration (LDC) mechanism which initiates and estimates all class distributions from a single stored distribution (the covariance matrix). LDC was built upon the parameterized calibration unit (PCU), which reuses network parameters and classifier vectors, thereby has negligible parameter and memory costs. LDC was implemented by driving the PCU to remember class distributions through minimizing distribution matching loss between real and generated samples. LDC provides a fresh insight to solve the catastrophically forgetting and over-fitting problems in a unified framework.
References
- [1] X. Tao, X. Hong, X. Chang, S. Dong, X. Wei, and Y. Gong, “Few-shot class-incremental learning,” in IEEE CVPR, pp. 12180–12189, 2020.
- [2] A. G. Greenwald, “Cognitive learning, cognitive response to persuasion, and attitude change,” Psychological Foundations of Attitudes, 1968.
- [3] S. Yang, L. Liu, and M. Xu, “Free lunch for few-shot learning: Distribution calibration,” in ICLR, 2021.
- [4] Z. Li and D. Hoiem, “Learning without forgetting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, no. 12, pp. 2935–2947, 2018.
- [5] K. Shmelkov, C. Schmid, and K. Alahari, “Incremental learning of object detectors without catastrophic forgetting,” in IEEE ICCV, pp. 3420–3429, 2017.
- [6] C. Zhang, N. Song, G. Lin, Y. Zheng, P. Pan, and Y. Xu, “Few-shot incremental learning with continually evolved classifiers,” in IEEE CVPR, 2021.
- [7] O. Vinyals, C. Blundell, T. Lillicrap, K. Kavukcuoglu, and D. Wierstra, “Matching networks for one shot learning,” in NeurIPS, pp. 3630–3638, 2016.
- [8] J. Snell, K. Swersky, and R. S. Zemel, “Prototypical networks for few-shot learning,” in NeurIPS, pp. 4077–4087, 2017.
- [9] F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. S. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in IEEE CVPR, pp. 1199–1208, 2018.
- [10] C. Zhang, Y. Cai, G. Lin, and C. Shen, “Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers,” in IEEE CVPR, pp. 12200–12210, 2020.
- [11] B. Liu, J. Jiao, and Q. Ye, “Harmonic feature activation for few-shot semantic segmentation,” IEEE Trans. Image Process., vol. 30, pp. 3142–3153, 2021.
- [12] B. Yang, F. Wan, C. Liu, B. Li, X. Ji, and Q. Ye, “Part-based semantic transform for few-shot semantic segmentation,” IEEE Transactions on Neural Networks and Learning Systems, 2021.
- [13] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in ICML, pp. 1126–1135, 2017.
- [14] T. Elsken, B. Staffler, J. H. Metzen, and F. Hutter, “Meta-learning of neural architectures for few-shot learning,” in IEEE CVPR, pp. 12362–12372, 2020.
- [15] Q. Sun, Y. Liu, T. Chua, and B. Schiele, “Meta-transfer learning for few-shot learning,” in IEEE CVPR, pp. 403–412, 2019.
- [16] H. Zhang, J. Zhang, and P. Koniusz, “Few-shot learning via saliency-guided hallucination of samples,” in IEEE ICCV, pp. 2770–2779, 2019.
- [17] K. Li, Y. Zhang, K. Li, and Y. Fu, “Adversarial feature hallucination networks for few-shot learning,” in IEEE ICCV, pp. 13467–13476, 2020.
- [18] J. Kim, H. Kim, and G. Kim, “Model-agnostic boundary-adversarial sampling for test-time generalization in few-shot learning,” in ECCV, pp. 599–617, 2020.
- [19] M. Ren, R. Liao, E. Fetaya, and R. S. Zemel, “Incremental few-shot learning with attention attractor networks,” in NeurIPS, pp. 5276–5286, 2019.
- [20] S. W. Yoon, D. Kim, J. Seo, and J. Moon, “Xtarnet: Learning to extract task-adaptive representation for incremental few-shot learning,” in ICML, pp. 10852–10860, 2020.
- [21] Q. Liu, O. Majumder, A. Achille, A. Ravichandran, R. Bhotika, and S. Soatto, “Incremental few-shot meta-learning via indirect discriminant alignment,” in ECCV, pp. 685–701, 2020.
- [22] S. Gidaris and N. Komodakis, “Dynamic few-shot visual learning without forgetting,” in IEEE CVPR, pp. 4367–4375, 2018.
- [23] M. Masana, X. Liu, B. Twardowski, M. Menta, A. D. Bagdanov, and J. van de Weijer, “Class-incremental learning: survey and performance evaluation,” CoRR, vol. abs/2010.15277, 2020.
- [24] S. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” in IEEE CVPR, pp. 5533–5542, 2017.
- [25] A. Chaudhry, P. K. Dokania, T. Ajanthan, and P. H. S. Torr, “Riemannian walk for incremental learning: Understanding forgetting and intransigence,” in ECCV, pp. 556–572, 2018.
- [26] Y. Wu, Y. Chen, L. Wang, Y. Ye, Z. Liu, Y. Guo, and Y. Fu, “Large scale incremental learning,” in IEEE CVPR, pp. 374–382, 2019.
- [27] H. Shin, J. K. Lee, J. Kim, and J. Kim, “Continual learning with deep generative replay,” in NeurIPS, pp. 2990–2999, 2017.
- [28] Y. Xiang, Y. Fu, P. Ji, and H. Huang, “Incremental learning using conditional adversarial networks,” in IEEE ICCV, pp. 6618–6627, 2019.
- [29] C. D. Kim, J. Jeong, S. Moon, and G. Kim, “Continual learning on noisy data streams via self-purified replay,” in IEEE ICCV, pp. 537–547, October 2021.
- [30] J. Smith, Y.-C. Hsu, J. Balloch, Y. Shen, H. Jin, and Z. Kira, “Always be dreaming: A new approach for data-free class-incremental learning,” in IEEE ICCV, pp. 9374–9384, October 2021.
- [31] P. Dhar, R. V. Singh, K. Peng, Z. Wu, and R. Chellappa, “Learning without memorizing,” in IEEE CVPR, pp. 5138–5146, 2019.
- [32] F. Zenke, B. Poole, and S. Ganguli, “Continual learning through synaptic intelligence,” in ICML, pp. 3987–3995, 2017.
- [33] R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra, “Grad-cam: Visual explanations from deep networks via gradient-based localization,” in IEEE ICCV, pp. 618–626, 2017.
- [34] S. Hou, X. Pan, C. C. Loy, Z. Wang, and D. Lin, “Learning a unified classifier incrementally via rebalancing,” in IEEE CVPR, pp. 831–839, 2019.
- [35] X. Hu, K. Tang, C. Miao, X.-S. Hua, and H. Zhang, “Distilling causal effect of data in class-incremental learning,” in IEEE CVPR, pp. 3957–3966, June 2021.
- [36] H. Cha, J. Lee, and J. Shin, “Co2l: Contrastive continual learning,” in IEEE ICCV, pp. 9516–9525, October 2021.
- [37] A. Mallya and S. Lazebnik, “Packnet: Adding multiple tasks to a single network by iterative pruning,” in IEEE CVPR, pp. 7765–7773, 2018.
- [38] J. Serrà, D. Suris, M. Miron, and A. Karatzoglou, “Overcoming catastrophic forgetting with hard attention to the task,” in ICML, Proceedings of Machine Learning Research, pp. 4555–4564, 2018.
- [39] J. Yoon, E. Yang, J. Lee, and S. J. Hwang, “Lifelong learning with dynamically expandable networks,” in ICLR, 2018.
- [40] A. Mallya, D. Davis, and S. Lazebnik, “Piggyback: Adapting a single network to multiple tasks by learning to mask weights,” in ECCV, pp. 72–88, 2018.
- [41] Y. Liu, Y. Su, A. Liu, B. Schiele, and Q. Sun, “Mnemonics training: Multi-class incremental learning without forgetting,” in IEEE CVPR, pp. 12242–12251, 2020.
- [42] E. Belouadah and A. Popescu, “IL2M: class incremental learning with dual memory,” in IEEE ICCV, pp. 583–592, 2019.
- [43] M. Riemer, I. Cases, R. Ajemian, M. Liu, I. Rish, Y. Tu, and G. Tesauro, “Learning to learn without forgetting by maximizing transfer and minimizing interference,” in ICLR, 2019.
- [44] K. Zhu, Y. Cao, W. Zhai, J. Cheng, and Z.-J. Zha, “Self-promoted prototype refinement for few-shot class-incremental learning,” in IEEE CVPR, pp. 6801–6810, June 2021.
- [45] A. Cheraghian, S. Rahman, S. Ramasinghe, P. Fang, C. Simon, L. Petersson, and M. Harandi, “Synthesized feature based few-shot class-incremental learning on a mixture of subspaces,” in IEEE ICCV, pp. 8661–8670, October 2021.
- [46] W.-Y. Chen, Y.-C. Liu, Z. Kira, Y.-C. Wang, and J.-B. Huang, “A closer look at few-shot classification,” in International Conference on Learning Representations, 2019.
- [47] J. M. Joyce, Kullback-Leibler Divergence, pp. 720–722. Springer Berlin Heidelberg, 2011.
- [48] E. R. Ziegel, “The elements of statistical learning,” Technometrics, vol. 45, no. 3, pp. 267–268, 2003.
- [49] L. K. Saul, T. Jaakkola, and M. I. Jordan, “Mean field theory for sigmoid belief networks,” Journal of artificial intelligence research, vol. 4, pp. 61–76, 1996.
- [50] J. Wei, “On markov earth mover’s distance,” Int. J. Image Graph., vol. 14, no. 4, 2014.
- [51] Y. Wang, J. Dong, J. Zhou, L. Wang, S. Han, T. Zhang, and C. L. P. Chen, “Spectral clustering based on js-divergence for uncertain data,” in 2017 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2017, Banff, AB, Canada, October 5-8, 2017, pp. 1972–1975, 2017.
- [52] T. Yang, D. Fu, X. Li, and K. Ríha, “Manifold regularized multiple kernel learning with hellinger distance,” Clust. Comput., vol. 22, no. 6, pp. 13843–13851, 2019.
- [53] D.-W. Zhou, F.-Y. Wang, H.-J. Ye, L. Ma, S. Pu, and D.-C. Zhan, “Forward compatible few-shot class-incremental learning,” in IEEE CVPR, pp. 9046–9056, 2022.
- [54] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE CVPR, pp. 770–778, 2016.
- [55] P. Mazumder, P. Singh, and P. Rai, “Few-shot lifelong learning,” in AAAI, 2021.
- [56] Z. Chi, L. Gu, H. Liu, Y. Wang, Y. Yu, and J. Tang, “Metafscil: A meta-learning approach for few-shot class incremental learning,” in IEEE CVPR, pp. 14166–14175, 2022.