LayerNAS: Neural Architecture Search in Polynomial Complexity
Abstract
Neural Architecture Search (NAS) has become a popular method for discovering effective model architectures, especially for target hardware. As such, NAS methods that find optimal architectures under constraints are essential. In our paper, we propose LayerNAS to address the challenge of multi-objective NAS by transforming it into a combinatorial optimization problem, which effectively constrains the search complexity to be polynomial.
For a model architecture with layers, we perform layerwise-search for each layer, selecting from a set of search options . LayerNAS groups model candidates based on one objective, such as model size or latency, and searches for the optimal model based on another objective, thereby splitting the cost and reward elements of the search. This approach limits the search complexity to , where is a constant set in LayerNAS.
Our experiments show that LayerNAS is able to consistently discover superior models across a variety of search spaces in comparison to strong baselines, including search spaces derived from NATS-Bench, MobileNetV2 and MobileNetV3.
1 Introduction
With the surge of ever-growing neural models used across all ML-based disciplines, the efficiency of neural networks is becoming a fundamental factor in their success and applicability. A carefully crafted architecture can achieve good quality while maintaining efficiency during inference. However, designing optimized architectures is a complex and time-consuming process – this is especially true when multiple objectives are involved, including the model’s performance and one or more cost factors reflecting the model’s size, Multiply-Adds (MAdds) and inference latency. Neural Architecture Search (NAS), is a highly effective paradigm for dealing with such complexities. NAS automates the task and discovers more intricate and complex architectures than those that can be found by humans. Additionally, recent literature shows that NAS allows to search for optimal models under specific constraints (e.g., latency), with remarkable applications on architectures such as MobileNetV3 (Howard et al., 2019), EfficientNet (Tan & Le, 2019) and FBNet (Wu et al., 2019).

Most NAS algorithms encode model architectures using a list of integers, where each integer represents a selected search option for the corresponding layer. In particular, notice that for a given model with layers, where each layer is selected from a set of search options , the search space contains candidates with different architectures. This exponential complexity presents a significant efficiency challenge for NAS algorithms.
In this paper, we present LayerNAS, an algorithm that addresses the problem of Neural Architecture Search (NAS) through the framework of combinatorial optimization. The proposed approach decouples the constraints of the model and the evaluation of its quality, and explores the factorized search space more effectively in a layerwise manner, reducing the search complexity from exponential to polynomial.
LayerNAS operates on search spaces that satisfy the following assumption: optimal models when searching for can be constructed from one of the models in . Based on this assumption, LayerNAS enforces a directional search process from the first layer to the last layer. The directional layerwise search makes the search complexity ), where is the number of candidates to search per layer. Although this complexity is polynomial, is exponential in the last layer, unless we keep only a limited number of candidates.
For multi-objective NAS problems, LayerNAS treats model constraints and model quality as separate metrics. Rather than utilizing a single objective function that combines multi-objectives, LayerNAS stores model candidates by their constraint metric value. Let be the best model candidate for with . LayerNAS searches for optimal models under different constraints in the next layer by adding the cost of the selected search option for next layer to the current layer, i.e., . This transforms the problem into the following combinatorial optimization problem: for a model with layers, what is the optimal combination of options for all layers needed to achieve the best quality under the cost constraint? If we bucketize the potential model candidates by their cost, the search space is limited to , where is number of buckets per layer. In practice, capping the search at 100 buckets achieves reasonable performance. Since this holds constant, it makes the search complexity polynomial.

Our contributions can be summarized as follows:
-
•
We propose LayerNAS, an algorithm that transforms the multi-objective NAS problem to a Combinatorial Optimization problem. This is a novel formulation of NAS.
-
•
LayerNAS is directly designed to tackle the search complexity of NAS, and reduce the search complexity from to , where is a constant defined in the algorithm.
- •
2 Related Work
The survey by (Elsken et al., 2019) categorizes methods for Neural Architecture Search into three dimensions: search space, search strategy, and performance estimation strategy. The formulation of NAS as different problems has led to the development of a diverse array of search algorithms. Bayesian Optimization is first adopted for hyper-parameter tuning (Bergstra et al., 2013; Domhan et al., 2015; Falkner et al., 2018; Kandasamy et al., 2018). Reinforcement Learning is utilized for training an agent to interact with a search space (Zoph & Le, 2017; Pham et al., 2018; Zoph et al., 2018; Jaafra et al., 2019). Evolutionary algorithms (Liu et al., 2021; Real et al., 2019) have been employed by encoding model architectures to DNA and evolving the candidate pool. ProgressiveNAS (Liu et al., 2018a) uses heuristic search to gradually build models by starting from simple and shallow model architectures and incrementally adding more operations to arrive at deep and complex final architectures. This is in contrast to LayerNAS, which iterates over changes in the layers of a full complex model.
Recent advancements in mobile image models, such as MobileNetV3 (Howard et al., 2019), EfficientNet (Tan & Le, 2019), FBNet (Wu et al., 2019), are optimized by NAS. The search for these models is often constrained by metrics such as FLOPs, model size, latency, and others. To solve this multi-objective problem, most NAS algorithms (Tan et al., 2019; Cai et al., 2018) design an objective function that combines these metrics into a single objective. LEMONADE (Elsken et al., 2018) proposes a method to split two metrics, and searches for a Pareto front of a family of models. Once-for-All (Cai et al., 2020) proposes progressive shrinking algorithm to efficiently find optimal model architectures under different constraints.
Larger models tend to have better performance compared to smaller models. However, the increased size of models also means increased computational resource requirement. As a result, the optimization of neural architectures within constrained resources is an important and meaningful aspect of NAS problems, which can be solved as multi-objective optimization (Hsu et al., 2018). There is increasing interest in treating NAS as a compression problem (Zhou et al., 2019; Yu & Huang, 2019) from an over-sized model. These works indicate that compressing with different configurations on each layer leads to a model better than uniform compression. Here, NAS can be used to search for optimal configurations (He et al., 2018; Liu et al., 2019; Wang et al., 2019).
The applicability of NAS is significantly influenced by the efficiency of its search process. One-shot algorithms (Liu et al., 2018b; Cai et al., 2018; Bender et al., 2018, 2020) provide a novel approach by constructing a supernet from the search space to perform more efficient NAS. However, this approach has limit on number of branches in supernet due to the constraints of supernet size. The search cost is not only bounded by the complexity of search space, but also the cost of training under ”train-and-eval” paradigm. Training-free NAS (Mellor et al., 2021; Chen et al., 2021; Zhu et al., 2022; Shu et al., 2021) breaks this paradigm by estimating the model quality with other metrics that are fast to compute. However, the search quality heavily relies on the effectiveness of the metrics.
3 Problem Definition
Most NAS algorithms do not differentiate the various types of NAS problems. Rather, they employ a single encoding of the search space with a general solution for the search process. However, the unique characteristics of NAS problems can be leveraged to design a tailored approach. We categorize NAS problems into three major types:
-
•
Topology search: the search space defines a graph with multiple nodes. The objective is to identify an optimal topology for connecting nodes with different operations. This task allows for the exploration of novel architectures that could not be found through other methods.
-
•
Size search or compression search: the search occurs on a predefined model architecture with multiple layers. Each layer can be selected from as a set of search options. Empirically, the best-performing model is normally the one with the most parameters per layer. Therefore, in practice, we aim to search for the optimal model under certain constraints. NATSBench size search (Dong et al., 2021) provides a public dataset for this type of task. MobilNetV3 (Howard et al., 2019), EfficientNet (Tan & Le, 2019), FBNet (Wu et al., 2019) also establish the search space in this manner. This problem can also be viewed as a compression problem (He et al., 2018), as reducing the layer size serves as a means of compression by decreasing the model size, FLOPs and latency.
-
•
Scale search: model architectures are uniformly configured by hyper-parameters, such as altering number of layers or the size of fully-connected layers. This task views the model as a holistic entity and uniformly scales it up or down, rather than adjusting individual layers or components.
This taxonomy illustrates the significant variation among NAS problems. Rather than proposing a general solution to address all of them, we propose to tackle each problem with specific approaches. We will delve into more details in Section 4 and Section 5
In this work, we construct the search space in a layerwise manner. Specifically, we aim to find a model with layers. For each , we select from a set of search options . A model candidate can be represented as a tuple with size : . is a selected search option on . The objective is to find an optimal model architecture with the highest accuracy:
| (1) |
4 Method
We propose LayerNAS as an algorithm that leverages layerwise attributes. When searching models on , we are searching for architectures in the form of . are the selected options for , and are the default, predefined options. is the search option selected for , which is the current layer in the search. In this formulation, only can be changed, all preceding layers are fixed, and all succeeding layers are using the default option. In topology search, the default option is usually no-op; in size search, the default option can be the option with most computation.
LayerNAS operates on a search space that meets the following assumption, which has been implicitly utilized by past chain-structured NAS techniques (Liu et al., 2018a; Tan et al., 2019; Howard et al., 2019).
Assumption 4.1.
The optimal model on can be constructed from a model , where is a set of model candidates on .
This assumption implies:
-
•
Enforcing a sequential search process is possible when exploring because improvements to the model cannot be achieved by modifying . We delve deeper into the sequential nature of the search process and examine the underlying reasons in Section E.2.
-
•
The information for finding an optimal model architecture on was collected when searching for model architectures on .
-
•
Search spaces that are constructed in a layerwise manner, such as those in size search problems discussed in Section 3, can usually meet this assumption. Each search option can completely define how to construct a succeeding layer, and does not depend on the search options in previous layers.
-
•
It’s worth noting that not all search spaces can meet the assumption. Succeeding layers may be coupled with or affect preceding layers in some cases. In practice, we transform the search space in Section 5 to ensure that it meets the assumption. In Section E.3, the limit of the assumption is further discussed.
4.1 LayerNAS for Topology Search
The LayerNAS algorithm is described by the pseudo code in Algorithm 1. is a set of model candidates on . is the model on mapped to , a lower dimensional representation. is usually a finite integer set in the implementation, so that we can index and store models.
Some methods in the algorithm can be customized for different NAS problems using a-priori knowledge:
-
•
select: samples a model from a set of model candidates in the previous layer . It could be a mechanism of evolutionary algorithm (Real et al., 2019) or a trained predictor (Liu et al., 2018a) to select most promising candidates. The method will also filter out model architectures that we do not need to search, usually a model architecture that is invalid or known not to generate better candidates. This can significantly reduce the number of candidates to search.
-
•
apply_search_option: applies a search option from on to generate . We currently use random selection in the implementation, though, other methods could lead to improved search option.
-
•
maps model architecture in to a lower dimensional representation . could be an encoded index of model architecture, or other identifiers that group similar model architectures. We discuss this further in 4.2. When there is a unique id for each model, LayerNAS will store all model candidates in .
In this algorithm, the total number of model candidates we need to search is . It has a polynomial form, but if we set as unique id of models. This does not limit the order of to search. For topology search, we can design a sophisticated to group similar model candidates. In the following discussion, we will demonstrate how to lower the order of in multi-objective NAS.
4.2 LayerNAS for Multi-objective NAS
LayerNAS is aimed at designing an efficient algorithm for size search or compression search problems. As discussed in Section 3, such problems satisfy 4.1 by nature. Multi-objective NAS usually searches for an optimal model under some constraints, such as model size, inference latency, hardware-specific FLOPs or energy consumption. We use “cost” as a general term to refer to these constraints. These “cost” metrics are easy to calculate and can be determined when the model architecture is fixed. This is in contrast to calculating accuracy, which requires completing the model training. Because the model is constructed in a layer-wise manner, the cost of the model can be estimated by summing the costs of all layers.
Hence, we can express the multi-objective NAS problem as,
| (2) | ||||
| s.t. |
where is the cost of applying option on .
We introduce an additional assumption by considering the cost in 4.1:
Assumption 4.2.
The optimal model with when searching for can be constructed from the optimal model with from .
In this assumption, we only keep one optimal model out of a set of models with similar costs. Suppose we have two models with the same cost, but has better quality than . The assumption will be satisfied if any changes on following layers to will generate a better model than making the same change to .
By applying 4.2 to Equation 2, we can formulate the problem as combinatorial optimization:
| (3) |
This formulation decouples cost from reward, so there is no need to manually design an objective function to combine these metrics into a single value, and we can avoid tuning hyper-parameters of such an objective. Formulating the problem as combinatorial optimization allows solving it efficiently using dynamic programming. can be considered as a memorial table to record best models on at cost . For , generates the by applying different options selected from on . The search complexity is
We do not need to store all candidates, but rather group them using with the following transformation:
| (4) |
where is the desired number of buckets to keep. Each bucket contains model candidates with costs in a specific range. In practice, we can set , meaning we store optimal model candidates within 1% of the cost range.
Equation 4 limits to be a constant value since is a constant. and can be easily calculated when we know how to select the search option from in order to maximize or minimize the model cost. This can be achieved by defining the order within . Let represent the option with the maximal cost on , and represent the option with the minimal cost on . This approach for constructing the search space facilitates an efficient calculation of maximal and minimal costs.
The optimization applied above leads to achieving polynomial search complexity . is upper bound of the number of model candidates in each layer, and becomes a constant after applying Equation 4. is the number of search options on each layer.
LayerNAS for Multi-objective NAS does not change the implementation of Algorithm 1. Instead, we configure methods to perform dynamic programming with the same framework:
-
•
: groups by their costs with Equation 4
-
•
select: filters out if all constructed from it are out of the range of target cost. This significantly reduces the number of candidates to search.
-
•
In practice, 4.2 is not always true because accuracy may vary in each training trial. The algorithm may store a lucky model candidate that happens to get a better accuracy due to variation. We store multiple candidates for each to reduce the problem from training accuracy variation. In Appendix F, we have more discussion with an empirical example.
5 Experiments
5.1 Search on ImageNet
Search Space: we construct several search spaces based on MobileNetV2, MobileNetV2 (width multiplier=1.4), MobileNetV3-Small and MobileNetV3-Large. For each search space, we set similar backbone of the base model. For each layer, we consider kernel sizes from {3, 5, 7}, base filters and expanded filters from a set of integers, and a fixed strides. The objective is to find better models with similar MAdds of the base model.
To avoid coupling between preceding and succeeding layers, we first search the shared base filters in each block to create residual shortcuts, and search for kernel sizes and expanded filters subsequently. This ensures the search space satisfy 4.1.
We estimate and compare the number of unique model candidates defined by the search space and the maximal number of searches in Table 1. In the experiments, we set , and store 3 best models with same -value. Note that the maximal number of searches does not mean actual searches conducted in the experiments, but rather an upper bound defined by the algorithm.
A comprehensive description of the search spaces and discovered model architectures in this experiment can be found in the Appendix for further reference.
| Search Space | Target MAdds | # Unique Models | # Max Trials |
|---|---|---|---|
| MobileNetV3-Small | 60M | ||
| MobileNetV3-Large | 220M | ||
| MobileNetV2 | 300M | ||
| MobileNetV2 1.4x | 600M |
Search, train and evaluation:
During the search process, we train the model candidates for 5 epochs, and use the top-1 accuracy on ImageNet as a proxy metrics. Following the search process, we select several model architectures with best accuracy on 5 epochs, train and evaluate them on 4x4 TPU with 4096 batch size (128 images per core). We use RMSPropOptimizer with 0.9 momentum, train for 500 epochs. Initial learning rate is 2.64, with 12.5 warmup epochs, then decay with cosine schedule.
Results
We list the best models discovered by LayerNAS, and compare them with baseline models and results from recent NAS works in Table 2. For all targeted MAdds, the models discovered by LayerNAS achieve better performance: 69.0% top-1 accuracy on ImageNet for 61M MAdds, a 1.6% improvement over MobileNetV3-Small; 75.6% for 229M MAdds, a 0.4% improvement over MobileNetV3-Large; 77.1% accuracy for 322M MAdds, a 5.1% improvement over MobileNetV2; and finally, 78.6% accuracy for 627M MAdds, a 3.9% improvement over MobileNetV2 1.4x.
Note that for all of these models, we include squeeze-and-excitation blocks (Hu et al., 2018) and use Swish activation (Ramachandran et al., 2017), in order to to achieve the best performance. Some recent works on NAS algorithms, as well as the original MobileNetV2, do not use these techniques. For a fair comparison, we also list the model performance after removing squeeze-and-excitation and replacing Swish activation with ReLU. The results show that the relative improvement from LayerNAS is present even after removing these components.
| Model | Top1 Acc. | Params | MAdds |
| MobileNetV3-Small† (Howard et al., 2019) | 67.4 | 2.5M | 56M |
| MNasSmall (Tan et al., 2019) | 64.9 | 1.9M | 65M |
| LayerNAS (Ours)† | 69.0 | 3.7M | 61M |
| MobileNetV3-Large† (Howard et al., 2019) | 75.2 | 5.4M | 219M |
| LayerNAS (Ours) † | 75.6 | 5.1M | 229M |
| MobileNetV2 (Sandler et al., 2018) | 72.0 | 3.5M | 300M |
| ProxylessNas-mobile (Cai et al., 2018) | 74.6 | 4.1M | 320M |
| MNasNet-A1 (Tan et al., 2019) | 75.2 | 3.9M | 315M |
| FairNAS-C (Chu et al., 2021) | 74.7 | 5.6M | 325M |
| LayerNAS-no-SE(Ours) | 75.5 | 3.5M | 319M |
| EfficientNet-B0 (Tan & Le, 2019) | 77.1 | 5.3M | 390M |
| SGNAS-B (Huang & Chu, 2021) | 76.8 | - | 326M |
| FairNAS-C† (Chu et al., 2021) | 76.7 | 5.6M | 325M |
| GreedyNAS-B† (You et al., 2020) | 76.8 | 5.2M | 324M |
| LayerNAS (Ours) | 77.1 | 5.2M | 322M |
| MobileNetV2 1.4x (Sandler et al., 2018) | 74.7 | 6.9M | 585M |
| ProgressiveNAS (Liu et al., 2018a) | 74.2 | 5.1M | 588M |
| Shapley-NAS (Xiao et al., 2022) | 76.1 | 5.4M | 582M |
| MAGIC-AT (Xu et al., 2022) | 76.8 | 6M | 598M |
| LayerNAS-no-SE (Ours) | 77.1 | 7.6M | 598M |
| LayerNAS (Ours) † | 78.6 | 9.7M | 627M |
-
•
⋆ Without squeeze-and-excitation blocks.
-
•
† With squeeze-and-excitation blocks.
5.2 NATS-Bench
The following experiments compare LayerNAS with others NAS algorithms on NATS-Bench (Dong et al., 2021). We evaluate NAS algorithms from these three perspectives:
-
•
Candidate quality: the quality of the best candidate found by the algorithm, as can be indicated by the peak value in the chart.
-
•
Stability: the ability to find the best candidate, after running multiple searches and analyzing the average value and range of variation.
-
•
Efficiency: The training time required to find the best candidate. The sooner the peak accuracy candidate is reached, the more efficient the algorithm.
NATS-Bench topology search
NATS-Bench topology search defines a search space on 6 ops that connect 4 tensors, each op has 5 options (conv1x1, conv3x3, maxpool3x3, no-op, skip). It contains 15625 candidates with their number of parameters, FLOPs, accuracy on Cifar-10, Cifar-100 (Krizhevsky et al., 2009), ImageNet16-120 (Chrabaszcz et al., 2017).
From Figure 3, we obverse that LayerNAS can achieve better or similar results as other multi-trial NAS algorithms, with less training cost to achieve the best result. In Table 3, we compare with recent state-of-the-art methods. Although training-free NAS has advantage of lower search cost, LayerNAS can achieve much better results.
NATS-Bench size search
NATS-Bench size search defines a search space on a 5-layer CNN model, each layer has 8 options on different number of channels, from 8 to 64. The search space contains 32768 model candidates. The one with the highest accuracy has 64 channels for all layers, we can refer this candidate as “the largest model”. Instead of searching for the best model, we set the goal to search for the optimal model with 50% FLOPs of the largest model.
Under this constraints for size search, we implement popular NAS algorithms for comparison, which are also used in the original benchmark papers (Ying et al., 2019; Dong et al., 2021): random search, proximal policy optimization (PPO) (Schulman et al., 2017) and regularized evolution (RE) (Real et al., 2019). We conduct 5 runs for each algorithm, and record the best accuracy at different training costs.
LayerNAS treats this as a compression problem. The base model, which is the largest model, has 64 channels on all layers. By applying search options with fewer channels, the model becomes smaller, faster and less accurate. The search process is to find the optimal model with expected FLOPs. By filtering out candidates that do not produce architectures falling within the expected FLOPs range, we can significantly reduce the number of candidates that need to be searched.
From Figure 4, LayerNAS is able to achieve superior performance in a shorter amount of time compared with other algorithms. This is attributed to the utilization of a priori knowledge in the compression search space. However, it should be noted that there is a discrepancy between the validation and test accuracy, as evidenced by a drop in the test curve.



| Cifar10 | Cifar100 | ImageNet16-120 | Search cost (sec) | |
|---|---|---|---|---|
| RS | 92.390.06 | 63.540.24 | 42.710.34 | 1e+5 |
| RE (Real et al., 2019) | 94.130.18 | 71.400.50 | 44.760.64 | 1e+5 |
| PPO (Schulman et al., 2017) | 94.020.13 | 71.680.65 | 44.950.52 | 1e+5 |
| KNAS (Xu et al., 2021) | 93.05 | 68.91 | 34.11 | 4200 |
| TE-NAS (Chen et al., 2021) | 93.900.47 | 71.240.56 | 42.380.46 | 1558 |
| EigenNas (Zhu et al., 2022) | 93.460.02 | 71.420.63 | 45.540.04 | - |
| NASI (Shu et al., 2021) | 93.550.10 | 71.200.14 | 44.841.41 | 120 |
| FairNAS (Chu et al., 2021) | 93.230.18 | 71.001.46 | 42.190.31 | 1e+5 |
| SGNAS (Huang & Chu, 2021) | 93.530.12 | 70.311.09 | 44.982.10 | 9e+4 |
| LayerNAS | 94.340.12 | 73.010.63 | 46.580.59 | 1e+5 |
| Optimal test accuracy | 94.37 | 73.51 | 47.31 |



| Cifar10 | Cifar100 | ImageNet16-120 | ||||
| Training time (sec) | 2e+5 | 4e+5 | 6e+5 | |||
| Target mFLOPs | 140 | 140 | 35 | |||
| Validation | Test | Validation | Test | Validation | Test | |
| RS | 0.8399 | 0.9265 | 0.5947 | 0.6935 | 0.3638 | 0.4381 |
| RE | 0.8440 | 0.9282 | 0.6057 | 0.6962 | 0.3770 | 0.4476 |
| PPO | 0.8432 | 0.9283 | 0.6033 | 0.6957 | 0.3723 | 0.4438 |
| LayerNAS | 0.8440 | 0.9320 | 0.6067 | 0.7064 | 0.3812 | 0.4537 |
| Optimal validation | 0.8452 | 0.9264 | 0.6060 | 0.6922 | 0.3843 | 0.4500 |
| Optimal test | 0.8356 | 0.9334 | 0.5870 | 0.7086 | 0.3530 | 0.4553 |
6 Conclusion and Future Work
In this research, we propose LayerNAS that formulates Multi-objective Neural Architecture Search to Combinatorial Optimization. By decoupling multi-objectives into cost and accuracy, and leverages layerwise attributes, we are able to reduce the search complexity from to .
Our experiment results demonstrate the effectiveness of LayerNAS in discovering models that achieve superior performance compared to both baseline models and models discovered by other NAS algorithms under various constraints of MAdds. Specifically, models discovered through LayerNAS achieve top-1 accuracy on ImageNet of 69% for 61M MAdds, 75.6% for 229M MAdds, 77.1% for 322M MAdds, 78.6% for 627M MAdds. Furthermore, our analysis reveals that LayerNAS outperforms other NAS algorithms on NATS-Bench in all aspects including best model quality, stability and efficiency.
We hope this work motivates additional efforts to better utilize a priori information and design NAS algorithms tailored to different types of NAS problems.
While the current implementation of LayerNAS has shown promising results, several current limitations that can be addressed by future work:
- •
-
•
One-shot NAS algorithms have been shown to be more efficient. We aim to investigate the potential of applying LayerNAS to One-shot NAS algorithms.
References
- Bender et al. (2018) Bender, G., Kindermans, P.-J., Zoph, B., Vasudevan, V., and Le, Q. Understanding and simplifying one-shot architecture search. In International conference on machine learning, pp. 550–559. PMLR, 2018.
- Bender et al. (2020) Bender, G., Liu, H., Chen, B., Chu, G., Cheng, S., Kindermans, P.-J., and Le, Q. V. Can weight sharing outperform random architecture search? an investigation with tunas. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14323–14332, 2020.
- Bergstra et al. (2013) Bergstra, J., Yamins, D., and Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In International conference on machine learning, pp. 115–123. PMLR, 2013.
- Cai et al. (2018) Cai, H., Zhu, L., and Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. In International Conference on Learning Representations, 2018.
- Cai et al. (2020) Cai, H., Gan, C., Wang, T., Zhang, Z., and Han, S. Once for all: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations, 2020.
- Chen et al. (2021) Chen, W., Gong, X., and Wang, Z. Neural architecture search on imagenet in four gpu hours: A theoretically inspired perspective. arXiv preprint arXiv:2102.11535, 2021.
- Chrabaszcz et al. (2017) Chrabaszcz, P., Loshchilov, I., and Hutter, F. A downsampled variant of imagenet as an alternative to the cifar datasets. arXiv preprint arXiv:1707.08819, 2017.
- Chu et al. (2021) Chu, X., Zhang, B., and Xu, R. Fairnas: Rethinking evaluation fairness of weight sharing neural architecture search. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12239–12248, 2021.
- Domhan et al. (2015) Domhan, T., Springenberg, J. T., and Hutter, F. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. In Twenty-fourth international joint conference on artificial intelligence, 2015.
- Dong et al. (2021) Dong, X., Liu, L., Musial, K., and Gabrys, B. Nats-bench: Benchmarking nas algorithms for architecture topology and size. IEEE transactions on pattern analysis and machine intelligence, 2021.
- Elsken et al. (2018) Elsken, T., Metzen, J. H., and Hutter, F. Efficient multi-objective neural architecture search via lamarckian evolution. In International Conference on Learning Representations, 2018.
- Elsken et al. (2019) Elsken, T., Metzen, J. H., and Hutter, F. Neural architecture search: A survey. The Journal of Machine Learning Research, 20(1):1997–2017, 2019.
- Falkner et al. (2018) Falkner, S., Klein, A., and Hutter, F. Bohb: Robust and efficient hyperparameter optimization at scale. In International Conference on Machine Learning, pp. 1437–1446. PMLR, 2018.
- He et al. (2018) He, Y., Lin, J., Liu, Z., Wang, H., Li, L.-J., and Han, S. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European conference on computer vision (ECCV), pp. 784–800, 2018.
- Howard et al. (2019) Howard, A., Sandler, M., Chu, G., Chen, L.-C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 1314–1324, 2019.
- Hsu et al. (2018) Hsu, C.-H., Chang, S.-H., Liang, J.-H., Chou, H.-P., Liu, C.-H., Chang, S.-C., Pan, J.-Y., Chen, Y.-T., Wei, W., and Juan, D.-C. Monas: Multi-objective neural architecture search using reinforcement learning. arXiv preprint arXiv:1806.10332, 2018.
- Hu et al. (2018) Hu, J., Shen, L., and Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 7132–7141, 2018.
- Huang & Chu (2021) Huang, S.-Y. and Chu, W.-T. Searching by generating: Flexible and efficient one-shot nas with architecture generator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 983–992, 2021.
- Jaafra et al. (2019) Jaafra, Y., Laurent, J. L., Deruyver, A., and Naceur, M. S. Reinforcement learning for neural architecture search: A review. Image and Vision Computing, 89:57–66, 2019.
- Kandasamy et al. (2018) Kandasamy, K., Neiswanger, W., Schneider, J., Poczos, B., and Xing, E. P. Neural architecture search with bayesian optimisation and optimal transport. Advances in neural information processing systems, 31, 2018.
- Krizhevsky et al. (2009) Krizhevsky, A., Hinton, G., et al. Learning multiple layers of features from tiny images. 2009.
- Liu et al. (2018a) Liu, C., Zoph, B., Neumann, M., Shlens, J., Hua, W., Li, L.-J., Fei-Fei, L., Yuille, A., Huang, J., and Murphy, K. Progressive neural architecture search. In Proceedings of the European conference on computer vision (ECCV), pp. 19–34, 2018a.
- Liu et al. (2018b) Liu, H., Simonyan, K., and Yang, Y. Darts: Differentiable architecture search. In International Conference on Learning Representations, 2018b.
- Liu et al. (2021) Liu, Y., Sun, Y., Xue, B., Zhang, M., Yen, G. G., and Tan, K. C. A survey on evolutionary neural architecture search. IEEE transactions on neural networks and learning systems, 2021.
- Liu et al. (2019) Liu, Z., Mu, H., Zhang, X., Guo, Z., Yang, X., Cheng, K.-T., and Sun, J. Metapruning: Meta learning for automatic neural network channel pruning. In Proceedings of the IEEE/CVF international conference on computer vision, pp. 3296–3305, 2019.
- Mellor et al. (2021) Mellor, J., Turner, J., Storkey, A., and Crowley, E. J. Neural architecture search without training. In International Conference on Machine Learning, pp. 7588–7598. PMLR, 2021.
- Pham et al. (2018) Pham, H., Guan, M., Zoph, B., Le, Q., and Dean, J. Efficient neural architecture search via parameters sharing. In International conference on machine learning, pp. 4095–4104. PMLR, 2018.
- Ramachandran et al. (2017) Ramachandran, P., Zoph, B., and Le, Q. V. Searching for activation functions. arXiv preprint arXiv:1710.05941, 2017.
- Real et al. (2019) Real, E., Aggarwal, A., Huang, Y., and Le, Q. V. Regularized evolution for image classifier architecture search. In Proceedings of the aaai conference on artificial intelligence, volume 33, pp. 4780–4789, 2019.
- Sandler et al. (2018) Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., and Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510–4520, 2018.
- Schulman et al. (2017) Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Shu et al. (2021) Shu, Y., Cai, S., Dai, Z., Ooi, B. C., and Low, B. K. H. Nasi: Label-and data-agnostic neural architecture search at initialization. arXiv preprint arXiv:2109.00817, 2021.
- Tan & Le (2019) Tan, M. and Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning, pp. 6105–6114. PMLR, 2019.
- Tan et al. (2019) Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., and Le, Q. V. Mnasnet: Platform-aware neural architecture search for mobile. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2820–2828, 2019.
- Wang et al. (2019) Wang, K., Liu, Z., Lin, Y., Lin, J., and Han, S. Haq: Hardware-aware automated quantization with mixed precision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8612–8620, 2019.
- Wu et al. (2019) Wu, B., Dai, X., Zhang, P., Wang, Y., Sun, F., Wu, Y., Tian, Y., Vajda, P., Jia, Y., and Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10734–10742, 2019.
- Xiao et al. (2022) Xiao, H., Wang, Z., Zhu, Z., Zhou, J., and Lu, J. Shapley-nas: Discovering operation contribution for neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11892–11901, 2022.
- Xu et al. (2021) Xu, J., Zhao, L., Lin, J., Gao, R., Sun, X., and Yang, H. Knas: green neural architecture search. In International Conference on Machine Learning, pp. 11613–11625. PMLR, 2021.
- Xu et al. (2022) Xu, J., Tan, X., Song, K., Luo, R., Leng, Y., Qin, T., Liu, T.-Y., and Li, J. Analyzing and mitigating interference in neural architecture search. In International Conference on Machine Learning, pp. 24646–24662. PMLR, 2022.
- Ying et al. (2019) Ying, C., Klein, A., Christiansen, E., Real, E., Murphy, K., and Hutter, F. Nas-bench-101: Towards reproducible neural architecture search. In International Conference on Machine Learning, pp. 7105–7114. PMLR, 2019.
- You et al. (2020) You, S., Huang, T., Yang, M., Wang, F., Qian, C., and Zhang, C. Greedynas: Towards fast one-shot nas with greedy supernet. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1999–2008, 2020.
- Yu & Huang (2019) Yu, J. and Huang, T. Autoslim: Towards one-shot architecture search for channel numbers. arXiv preprint arXiv:1903.11728, 2019.
- Zhou et al. (2019) Zhou, H., Yang, M., Wang, J., and Pan, W. Bayesnas: A bayesian approach for neural architecture search. In International conference on machine learning, pp. 7603–7613. PMLR, 2019.
- Zhu et al. (2022) Zhu, Z., Liu, F., Chrysos, G. G., and Cevher, V. Generalization properties of nas under activation and skip connection search. arXiv preprint arXiv:2209.07238, 2022.
- Zoph & Le (2017) Zoph, B. and Le, Q. V. Neural architecture search with reinforcement learning. In International Conference on Learning Representations, 2017.
- Zoph et al. (2018) Zoph, B., Vasudevan, V., Shlens, J., and Le, Q. V. Learning transferable architectures for scalable image recognition. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8697–8710. IEEE Computer Society, 2018.
Appendix A Notation
: Search options for .
: Num of search options on .
: selected search option on from the set
: default search option applied on , is the architecture of the baseline model.
: A model architecture that applies on , on , … , on
: A model architecture that applies on , on , …, default search option on , … on , and search on .
: A model candidate that is searched on , it’s in the form of .
: All model candidates searching on .
: Model candidates searching on , and are mapped to .
: transforms a model architecture to a finite integer set
Appendix B NASBench-101 Search Details
NASBench-101 defines a search space on 5 ops, each op has 3 options (conv1x1, conv3x3, maxpool 3x3), and 21 potential edges to connect these ops and input, output ops. It contains 509M candidates with their number of parameters, accuracy on Cifar-10 (Krizhevsky et al., 2009), and other information.
We construct the LayerNAS search space by adding a new edge for each layer. Search options in each layer are used to determine either to include a new op or connect two existing ops. By doing so, all constructed candidates can be legit, because all candidates are connected graphs. And this approach of search space construction can satisfy the assumption of LayerNAS: the best model candidate in can be constructed from candidates in by adding an new edge.
In the experiments, Regularized Evolution (RE) sets population_size=50, tournament_size=10; Proximal Policy Optimization (PPO) sets train_batch_size=16, update_batch_size=8, num_updates_per_feedback=10. Both RE and PPO are using MNAS as objective function:
In Figure 5, we observe that in earlier searching iterations LayerNAS performs slightly worse than other algorithms. This is because LayerNAS initially searches model candidates with fewer ops and edges, which intuitively perform poorly. However, after collecting enough information from early layers, LayerNAS consistently performs better. This is because LayerNAS does not rely on randomness, rather, it adds ops and edges from successful candidates in each layers, leading to continuous improvement.

| Algorithm | Validation accuracy | Test accuracy |
|---|---|---|
| RS | 0.9480 | 0.9401 |
| RE | 0.9497 | 0.9416 |
| PPO | 0.9476 | 0.9396 |
| LayerNAS | 0.9505 | 0.9426 |
| Optimal | 0.9432 | 0.9445 |
Appendix C NATS-Bench Search Details
In the experiments, Regularized Evolution (RE) sets population_size=50, tournament_size=10; Proximal Policy Optimization (PPO) sets train_batch_size=16, update_batch_size=8, num_updates_per_feedback=10. Both RE and PPO are using MNAS as objective function:
C.1 NATS-Bench topology search
NATS-Bench topology search defines a search space on 6 ops that connect 4 tensors, each op has 5 options (conv1x1, conv3x3, maxpool3x3, no-op, skip).
In our experiments, we construct the LayerNAS search space by adding a new tensor for each layer. Search options in each layer are encoded with all op types that connect this tensor to previous tensors. So it has only 3 layers, each layer has 5, 25, 125 options. We set same training time as experiments in (Dong et al., 2021).


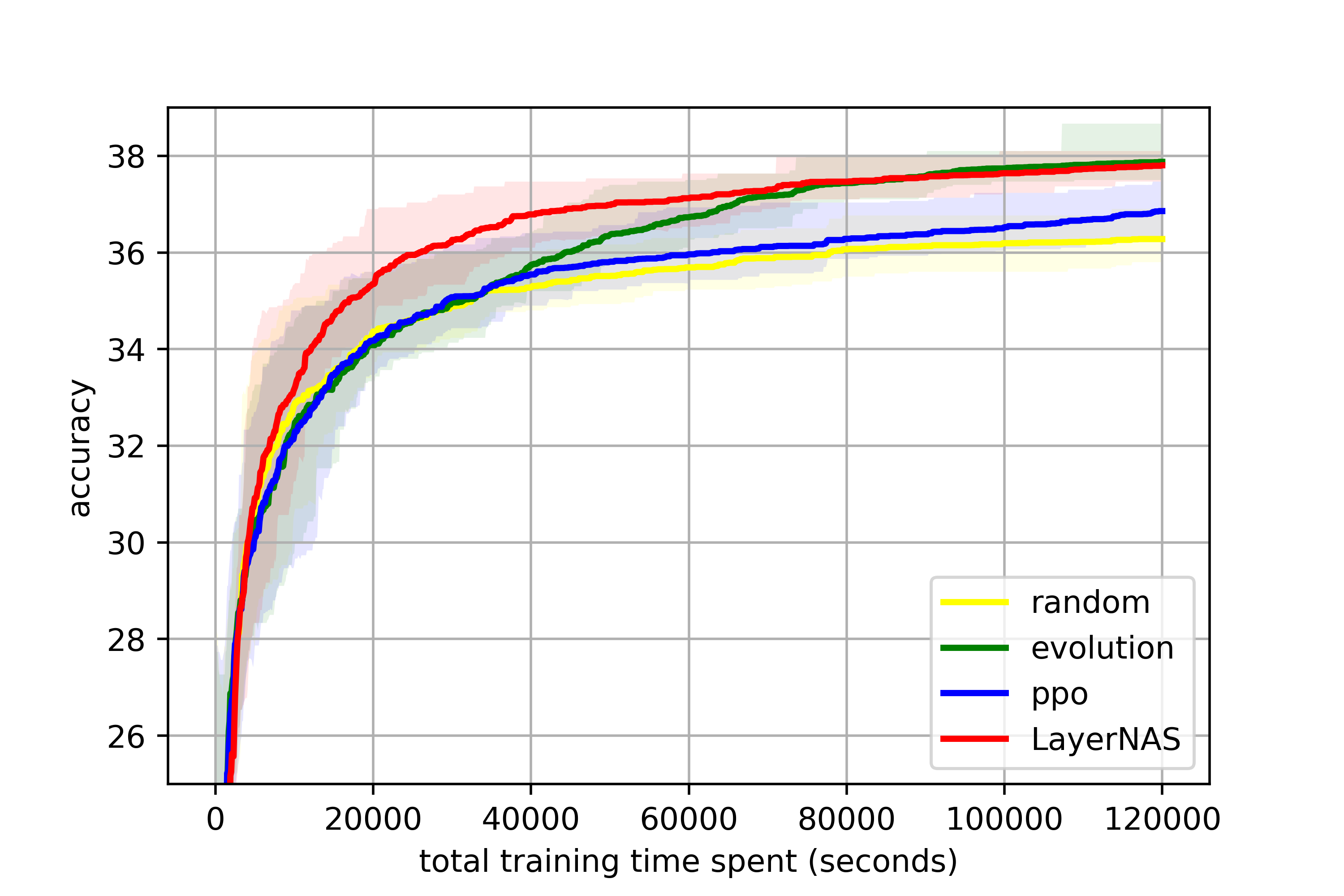
C.2 NATS-Bench size search
NATS-Bench size search provides a dataset with information on model architectures with 5 layers. Each layer is a convolutional layer with different num of channels selected from {8, 16, 24, 32, 40, 48, 56, 64}. The model with 64 channels for all layers has the most model parameters, the largest latency and the best accuracy. The objective is to find the optimal model with 50% FLOPs.
LayerNAS constructs the search space by using the largest model as base model, and applies search options that reduce channels per layer. Althoughh LayerNAS steadily improves valid accuracy over time, test accuracy drops. This is due to in-correlation between test accuracy and valid accuracy.
Validation and test accuracy are shown in Figure 8 and Figure 9. We can observe that LayerNAS can outperform other algorithms on both validation and test accuracy. We can also attribute test accuracy drop in LayerNAS to the lack of correlation with validation accuracy.



Appendix D Dynamic Programming Implementation of LayerNAS for Multi-objective NAS
Algorithm 2 demonstrates how to implement LayerNAS with Dynamic Programming, which has clear explanation why search complexity is .
The implementation is not used in practice because it spends most of time searching in , we cannot get a model in expected cost range until last layer is searched.
Appendix E Discussion on search space assumptions
4.1 sets some characteristics of search spaces that can be leveraged to improve the search efficiency. Instead of expecting all search spaces can satisfy this assumption, in Section 5, we construct search spaces based on MobileNet to intentionally make them satisfy 4.1. While we cannot guarantee that all search spaces can be transformed to satisfy Assumption 4.1, most search spaces used in existing models or studies either implicitly use this assumption or can be transformed to satisfy it. We also demonstrate the effectiveness of this assumption from the experiments on MobileNet.
E.1 Search space is complete
Assume we are searching for the optimal model , and we store all possible model candidates on each layer. During the search process on , we generate model architectures by modifying to other options in . Since we store all model architectures for , the search process can create all candidates on by adding each to the models in . Therefore, contains all possibilities in the search space. This process can then be applied backward to the first layer.
E.2 Sequential search order
Assume, after LayerNAS sequential search, we get optimal model defined as . For sake of contradiction, there exists a model , with superior performance, by applying a change in previous layers. Since the search space is complete, model must exist, and has been processed in . In the sequential search, model can be created by using on . Repeating this process for all subsequent layers will eventually lead to , contradicting our assumption that optimal model from sequential search is . Therefore, we can search sequentially.
E.3 Limit of the assumption
MobileNet architecture does not satisfy 4.1 by default. Residual requires and have the same num of filters. Suppose , , the residual shortcut cannot be created if . This is the case when preceding layers are coupled with succeeding layers. To overcome this issue, we introduce a virtual layer, with options . We first search this shared filter to create residual shortcuts, and then search specs for each layer. This transformation ensures that the new search space satisfy 4.1. In the case of MobileNet search space, we first search for the common filters for the block and then for the expanded filters for each layer. This approach allows us to perform LayerNAS on a search space that satisfies 4.1.
Appendix F Discussion on num of replicas to store
From experiments on MobileNet, we observed that multiple runs on the same model architecture can yield standard deviations of accuracy ranging from 0.08% to 0.15%. Often times, the difference can be as high as 0.3%. To address this, we propose storing multiple candidates for the same cost to increase the likelihood of keeping the better model architecture for every layer search.
Suppose we have two models with the same cost, and , where is inferior and is superior, and the training accuracy follows a Gaussian distribution . The probability of obtaining a higher accuracy than is , where . In emprical examples, and , then has the probability of 9.2% of obtaining a higher accuracy. When we have layers, the probability of keeping the better model architecture for every layer search is .
By storing candidates with the same cost, we can increase the probability of keeping the better model architecture. When , the probability of storing all inferior models is . The probability of keeping the better model architecture for all layer searches is 98.4%, which is practically good enough.
Theoretically, if we store infinite candidates per layer, we are performing a complete grid search, which guarantees a optimal model architecture.
Appendix G MobileNetV2 and MobileNetV3 Search Details
We aim to search models under different MAdds constrants: 60M (similar to MobileNetV3-Small), 220M (similar to MobileNetV3-Large), 300M (similar to MobileNetV2), 600M (similar to MobileNetV2 1.4x).
For each block, we will search the number of output filters of the block first. All layers in the block have the same number of output filters to create residual block correctly. Following the search for the block output filters, we search expanded filter and kernel size of each layers in this block. Strides are fixed for all layers. We use to denote the number of search options of this layer, which facilitates the computation on the number of unique model architectures, and max number of required search trials in LayerNAS.
G.1 60M MAdds Model
| Operator | # Output filter | # Expanded Filter | strides | |
| conv2d{3x3} | 16 | 2 | ||
| bneck {3x3} | {24, 20, 18, 16, 14, 12} | 2 | 6 | |
| Block filter | {36, 32, 28, 24, 20, 18, 16} | 7 | ||
| bneck {3x3, 5x5} | {144, 136, 128, 120, 112, 104, 96, 88, 80, 72, 68, 64, 60, 56} | 2 | 28 | |
| bneck {3x3, 5x5} | {144, 136, 128, 120, 112, 104, 96, 88, 80, 72 68, 64, 60, 56} | 1 | 28 | |
| Block filter | {60, 56, 52, 48, 44, 40, 36, 32, 28} | 9 | ||
| bneck {3x3, 5x5, 7x7} | {192, 176, 160, 144, 128, 112, 104, 96, 88, 80, 72, 64} | 2 | 36 | |
| bneck {3x3, 5x5, 7x7} | {480, 440, 400, 360, 320, 300, 280, 260, 240, 220, 200, 180, 160} | 1 | 39 | |
| bneck {3x3, 5x5, 7x7} | {480, 440, 400, 360, 320, 300, 280, 260, 240, 220, 200, 180, 160} | 1 | 39 | |
| Block filter | {96, 88, 80, 72, 64, 60, 56, 52, 48, 44, 40, 36, 32} | 13 | ||
| bneck {3x3, 5x5, 7x7} | {240, 200, 180, 160, 140, 120, 100, 90, 80} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {288, 256, 224, 208, 192, 176, 160, 152, 144, 136, 128, 120} | 1 | 36 | |
| Block filter | {192, 176, 160, 144, 128, 120, 112, 104, 96, 88, 80, 72, 64} | 13 | ||
| bneck {3x3, 5x5, 7x7} | {576, 544, 512, 480, 448, 416, 384, 352, 320, 288, 256, 224} | 2 | 36 | |
| bneck {3x3, 5x5, 7x7} | {1152, 1088, 1024, 960, 896, 832, 768, 704, 640, 576, 516, 448} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {1152, 1088, 1024, 960, 896, 832, 768, 704, 640, 576, 516, 448} | 1 | 36 | |
| conv2d 1x1 | {864, 576}, | 2 | ||
| pool, 7x7 | ||||
| conv2d 1x1 | {1536, 1024} | 2 | ||
| conv2d 1x1 | {1001} |
The search spaces has encoded length. Number of unique model architecture is . We store up to 300 model candidates per layer, so max number of trials is .
| Input | Operator | # Output filter | # Expanded Filter | strides |
|---|---|---|---|---|
| conv2d 3x3 | 16 | 2 | ||
| bneck 3x3 | 16 | 2 | ||
| bneck 3x3 | 28 | 144 | 2 | |
| bneck 3x3 | 28 | 128 | 1 | |
| bneck 5x5 | 44 | 96 | 2 | |
| bneck 3x3 | 44 | 220 | 1 | |
| bneck 3x3 | 44 | 200 | 1 | |
| bneck 7x7 | 40 | 160 | 1 | |
| bneck 3x3 | 40 | 152 | 1 | |
| bneck 5x5 | 96 | 224 | 2 | |
| bneck 3x3 | 96 | 448 | 1 | |
| bneck 3x3 | 96 | 512 | 1 | |
| conv2d 1x1 | 864 | 1 | ||
| pool, 7x7 | 1 | |||
| conv2d 1x1 | 1536 | 1 | ||
| conv2d 1x1 | 1001 | 1 |
G.2 220M MAdds Model
| Operator | # Output filter | # Expanded Filter | strides | |
| Conv2d{3x3} | 16 | 2 | ||
| bneck {3x3} | {24, 20, 18, 16, 14, 12} | 1 | 6 | |
| Block filter | {36, 32, 28, 24, 20, 16} | |||
| bneck {3x3, 5x5} | {96, 88, 80, 72, 68, 64, 60, 56, 48} | 2 | 18 | |
| bneck {3x3, 5x5, 7x7} | {124, 116, 108, 100, 92, 84, 72, 68, 64, 56, 48} | 1 | 33 | |
| Block filter | {64, 56, 52, 48, 44, 40, 36, 32, 24} | 9 | ||
| bneck {3x3, 5x5, 7x7} | {128, 120, 112, 104, 96, 88, 80, 76, 72, 64, 56} | 2 | 33 | |
| bneck {3x3, 5x5, 7x7} | {240, 200, 180, 160, 140, 120, 110, 100, 80} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {240, 200, 180, 160, 140, 120, 110, 100, 80} | 1 | 27 | |
| Block filter | {160, 140, 130, 120, 110, 100, 80, 70, 60} | 9 | ||
| bneck {3x3, 5x5, 7x7} | {360, 320, 300, 280, 260, 240, 220, 200, 180, 160} | 2 | 30 | |
| bneck {3x3, 5x5, 7x7} | {400, 360, 340, 320, 300, 280, 260, 240, 220, 200, 180, 160, 120} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {368, 336, 304, 288, 272, 256, 240, 224, 208, 184, 168, 152} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {368, 336, 304, 288, 272, 256, 240, 224, 208, 184, 168, 152} | 1 | 36 | |
| Block filter | {224, 208, 192, 176, 160, 144, 128, 112, 96, 80} | 10 | ||
| bneck {3x3, 5x5, 7x7} | {960, 880, 800, 720, 640, 560, 520, 480, 440, 400, 360} | 1 | 33 | |
| bneck {3x3, 5x5, 7x7} | {1344, 1200, 1056, 960, 888, 816, 768, 720, 624, 576, 480} | 1 | 33 | |
| Block filter | {320, 280, 240, 220, 200, 180, 160, 120, 100 } | 9 | ||
| bneck {3x3, 5x5, 7x7} | {1344, 1200, 1056, 960, 888, 816, 768, 720, 624, 576, 480} | 2 | 33 | |
| bneck {3x3, 5x5, 7x7} | {1920, 1760, 1600, 1440, 1280, 1120, 960, 880, 800, 720, 640} | 1 | 33 | |
| bneck {3x3, 5x5, 7x7} | {1920, 1760, 1600, 1440, 1280, 1120, 960, 880, 800, 720, 640} | 1 | 33 | |
| bneck {3x3, 5x5, 7x7} | {480, 440, 400, 360, 320, 300, 280} | {1728, 1664, 1600, 1536, 1440, 1280, 1216} | 1 | 7 |
| conv2d 1x1 | {960} | |||
| pool, 7x7 | ||||
| conv2d 1x1 | {1440, 1280} | 2 | ||
| conv2d 1x1 | {1001} |
The search spaces has encoded length, the number of unique model architecture is For LayerNAS, we store up to 300 model candidates per layer, so max number of trials is
| Input | Operator | # Output filter | # Expanded Filter | strides |
|---|---|---|---|---|
| conv2d 3x3 | 16 | 2 | ||
| bneck 3x3 | 18 | 1 | ||
| bneck 3x3 | 24 | 64 | 2 | |
| bneck 3x3 | 24 | 48 | 1 | |
| bneck 5x5 | 56 | 80 | 2 | |
| bneck 5x5 | 56 | 200 | 1 | |
| bneck 5x5 | 56 | 100 | 1 | |
| bneck 5x5 | 80 | 400 | 2 | |
| bneck 3x3 | 80 | 200 | 1 | |
| bneck 3x3 | 80 | 272 | 1 | |
| bneck 3x3 | 80 | 168 | 1 | |
| bneck 5x5 | 112 | 440 | 1 | |
| bneck 5x5 | 112 | 576 | 1 | |
| bneck 7x7 | 160 | 624 | 2 | |
| bneck 5x5 | 160 | 640 | 1 | |
| bneck 3x3 | 160 | 640 | 1 | |
| conv2d 1x1 | 960 | 1 | ||
| pool, 7x7 | 1 | |||
| conv2d 1x1 | 1280 | 1 | ||
| conv2d 1x1 | 1001 | 1 |
G.3 300M MAdds Model
| Operator | # Output filter | # Expanded Filter | strides | |
| Conv2d{3x3} | 32 | 2 | ||
| bneck {3x3} | {24, 20, 16, 14} | 1 | 4 | |
| Block filter | {48, 44, 40, 36, 32, 28, 24} | 7 | ||
| bneck {3x3, 5x5} | {72, 64, 56, 52, 48, 44, 40} | 2 | 14 | |
| bneck {3x3, 5x5} | {144, 128, 120, 112, 104, 96, 92, 88, 80, 76} | 1 | 20 | |
| bneck {3x3, 5x5} | {144, 128, 120, 112, 104, 96, 92, 88, 80, 76} | 1 | 20 | |
| Block filter | {60, 56, 52, 48, 44, 40, 36, 32} | 8 | ||
| bneck {3x3, 5x5} | {144, 128, 120, 112, 104, 96, 92, 88, 80, 76} | 2 | 20 | |
| bneck {3x3, 5x5, 7x7} | {180, 160, 140, 130, 120, 110, 100, 80} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {180, 160, 140, 130, 120, 110, 100, 80} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {180, 160, 140, 130, 120, 110, 100, 80} | 1 | 24 | |
| Block filter | {120, 110, 100, 90, 80, 70, 60} | 7 | ||
| bneck {3x3, 5x5, 7x7} | {360, 320, 280, 260, 240, 220, 200, 180} | 2 | 24 | |
| bneck {3x3, 5x5, 7x7} | {360, 320, 280, 260, 240, 220, 200, 180} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {360, 320, 280, 260, 240, 220, 200, 180} | 1 | 24 | |
| Block filter | {144, 128, 120, 104, 96, 88, 80, 72} | 8 | ||
| bneck {3x3, 5x5, 7x7} | {360, 320, 280, 260, 240, 220, 200, 180} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {432, 400, 368, 336, 304, 288, 272, 256, 240} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {432, 400, 368, 336, 304, 288, 272, 256, 240} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {432, 400, 368, 336, 304, 288, 272, 256, 240} | 1 | 27 | |
| Block filter | {288, 256, 224, 192, 160, 144} | 6 | ||
| bneck {3x3, 5x5, 7x7} | {864, 800, 736, 672, 608, 576, 512, 448} | 2 | 24 | |
| bneck {3x3, 5x5, 7x7} | {864, 800, 736, 672, 608, 576, 512, 448} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {864, 800, 736, 672, 608, 576, 512, 448} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {864, 800, 736, 672, 608, 576, 512, 448} | 1 | 24 | |
| bneck {3x3, 5x5, 7x7} | {480, 440, 400, 360, 320, 300, 280} | {1728, 1664, 1600, 1536, 1440, 1280, 1216} | 1 | 7 |
| pool, 7x7 | ||||
| conv2d 1x1 | {1920, 1600, 1280} | 3 | ||
| conv2d 1x1 | {1001} |
The search spaces has encoded length, the number of unique model architectures is . We store up to 300 model candidates per layer, so max number of trials is .
| Input | Operator | # Output filter | # Expanded Filter | strides |
|---|---|---|---|---|
| conv2d 3x3 | 32 | 2 | ||
| bneck 3x3 | 24 | 1 | ||
| bneck 3x3 | 28 | 40 | 2 | |
| bneck 3x3 | 28 | 144 | 1 | |
| bneck 3x3 | 28 | 88 | 1 | |
| bneck 3x3 | 40 | 104 | 2 | |
| bneck 5x5 | 40 | 110 | 1 | |
| bneck 3x3 | 40 | 180 | 1 | |
| bneck 5x5 | 40 | 130 | 1 | |
| bneck 7x7 | 90 | 260 | 2 | |
| bneck 3x3 | 90 | 220 | 1 | |
| bneck 3x3 | 90 | 200 | 1 | |
| bneck 7x7 | 120 | 320 | 1 | |
| bneck 5x5 | 120 | 288 | 1 | |
| bneck 7x7 | 120 | 256 | 1 | |
| bneck 3x3 | 120 | 368 | 1 | |
| bneck 7x7 | 160 | 608 | 2 | |
| bneck 7x7 | 160 | 576 | 1 | |
| bneck 5x5 | 160 | 608 | 1 | |
| bneck 3x3 | 160 | 448 | 1 | |
| bneck 3x3 | 280 | 1216 | 1 | |
| pool, 7x7 | 1 | |||
| conv2d 1x1 | 1920 | 1 | ||
| conv2d 1x1 | 1001 | 1 |
G.4 600M MAdds Model
| Operator | # Output filter | # Expanded Filter | strides | |
| Conv2d{3x3} | 32 | 2 | ||
| bneck {3x3} | {36, 32, 28, 24, 20, 16} | 1 | 6 | |
| Block filter | {56, 52, 48, 44, 40, 36, 32, 28} | 8 | ||
| bneck {3x3, 5x5} | {88, 80, 72, 64, 56, 52, 48} | 2 | 14 | |
| bneck {3x3, 5x5} | {88, 80, 72, 64, 56, 52, 48} | 1 | 14 | |
| bneck {3x3, 5x5} | {88, 80, 72, 64, 56, 52, 48} | 1 | 14 | |
| bneck {3x3, 5x5} | {88, 80, 72, 64, 56, 52, 48} | 1 | 14 | |
| Block filter | {72, 64, 60, 56, 52, 48, 44, 40} | 8 | ||
| bneck {3x3, 5x5} | {180, 160, 144, 128, 120, 112, 104, 96, 92, 88, 80} | 2 | 22 | |
| bneck {3x3, 5x5, 7x7} | {240, 220, 200, 180, 160, 140, 130, 120, 100} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {240, 220, 200, 180, 160, 140, 130, 120, 100} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {240, 220, 200, 180, 160, 140, 130, 120, 100} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {240, 220, 200, 180, 160, 140, 130, 120, 100} | 1 | 27 | |
| Block filter | {200, 180, 160, 140, 120, 100, 90, 80} | 8 | ||
| bneck {3x3, 5x5, 7x7} | {440, 400, 360, 320, 280, 260, 240, 200} | 2 | 24 | |
| bneck {3x3, 5x5, 7x7} | {560, 520, 480, 440, 400, 360, 320, 280, 240} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {560, 520, 480, 440, 400, 360, 320, 280, 240} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {560, 520, 480, 440, 400, 360, 320, 280, 240} | 1 | 27 | |
| Block filter | {180, 160, 144, 128, 120, 104, 96, 88, 80} | 9 | ||
| bneck {3x3, 5x5, 7x7} | {560, 520, 480, 440, 400, 360, 320, 280, 240} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {560, 528, 496, 464, 432, 400, 368, 336, 304, 288, 272, 256} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {560, 528, 496, 464, 432, 400, 368, 336, 304, 288, 272, 256} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {560, 528, 496, 464, 432, 400, 368, 336, 304, 288, 272, 256} | 1 | 36 | |
| bneck {3x3, 5x5, 7x7} | {560, 528, 496, 464, 432, 400, 368, 336, 304, 288, 272, 256} | 1 | 36 | |
| Block filter | {320, 288, 256, 224, 192, 160} | 6 | ||
| bneck {3x3, 5x5, 7x7} | {992, 928, 864, 800, 736, 672, 608, 576, 512} | 2 | 27 | |
| bneck {3x3, 5x5, 7x7} | {992, 928, 864, 800, 736, 672, 608, 576, 512} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {992, 928, 864, 800, 736, 672, 608, 576, 512} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {992, 928, 864, 800, 736, 672, 608, 576, 512} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {992, 928, 864, 800, 736, 672, 608, 576, 512} | 1 | 27 | |
| bneck {3x3, 5x5, 7x7} | {600, 560, 520, 480, 440, 400, 360, 320} | {1920, 1856, 1792, 1728, 1664, 1600, 1536, 1440} | 1 | 24 |
| pool, 7x7 | ||||
| conv2d 1x1 | {2560, 2240, 1920} | 3 | ||
| conv2d 1x1 | {1001} |
The search spaces has encoded length, the number of unique model architecture is For LayerNAS, we store up to 300 model candidates per layer, so max number of trials is
| Input | Operator | # Output filter | # Expanded Filter | strides |
|---|---|---|---|---|
| conv2d 3x3 | 32 | 2 | ||
| bneck 3x3 | 36 | 1 | ||
| bneck 5x5 | 36 | 80 | 2 | |
| bneck 5x5 | 36 | 72 | 1 | |
| bneck 3x3 | 36 | 80 | 1 | |
| bneck 5x5 | 36 | 72 | 1 | |
| bneck 3x3 | 48 | 144 | 2 | |
| bneck 3x3 | 48 | 140 | 1 | |
| bneck 3x3 | 48 | 160 | 1 | |
| bneck 3x3 | 48 | 130 | 1 | |
| bneck 5x5 | 48 | 140 | 1 | |
| bneck 7x7 | 140 | 360 | 2 | |
| bneck 5x5 | 140 | 360 | 1 | |
| bneck 3x3 | 140 | 560 | 1 | |
| bneck 5x5 | 140 | 440 | 1 | |
| bneck 7x7 | 144 | 360 | 1 | |
| bneck 5x5 | 144 | 560 | 1 | |
| bneck 3x3 | 144 | 288 | 1 | |
| bneck 5x5 | 144 | 400 | 1 | |
| bneck 5x5 | 144 | 256 | 1 | |
| bneck 3x3 | 192 | 864 | 2 | |
| bneck 5x5 | 192 | 928 | 1 | |
| bneck 7x7 | 192 | 736 | 1 | |
| bneck 7x7 | 192 | 800 | 1 | |
| bneck 3x3 | 192 | 928 | 1 | |
| bneck 3x3 | 320 | 1440 | 1 | |
| pool, 7x7 | 1 | |||
| conv2d 1x1 | 2560 | 1 | ||
| conv2d 1x1 | 1001 | 1 |