LAWDR: Language-Agnostic Weighted Document Representations from Pre-trained Models
Abstract
Cross-lingual document representations enable language understanding in multilingual contexts and allow transfer learning from high-resource to low-resource languages at the document level. Recently large pre-trained language models such as BERT, XLM and XLM-RoBERTa have achieved great success when fine-tuned on sentence-level downstream tasks. It is tempting to apply these cross-lingual models to document representation learning. However, there are two challenges: (1) these models impose high costs on long document processing and thus many of them have strict length limit; (2) model fine-tuning requires extra data and computational resources, which is not practical in resource-limited settings. In this work, we address these challenges by proposing unsupervised Language-Agnostic Weighted Document Representations (LAWDR). We study the geometry of pre-trained sentence embeddings and leverage it to derive document representations without fine-tuning. Evaluated on cross-lingual document alignment, LAWDR demonstrates comparable performance to state-of-the-art models on benchmark datasets.
1 Introduction
Language representations map words, sentences or documents to dense vectors, capturing their semantic meaning Al-Rfou (2013). Cross-lingual representations project different languages into the same vector space. Recently there has been a surge of research on pre-training cross-lingual language models with large-scale corpora. These studies include LASER Artetxe and Schwenk (2018b), multilingual BERT Devlin et al. (2019), XLM Lample and Conneau (2019) and XLM-RoBERTa Conneau et al. (2019). Multilingual sentence representations produced by these models have led to strong improvements in downstream sentence-level tasks.
Despite the extensive study of cross-lingual sentence representations, there has been few works on cross-lingual document embeddings. Transformer based models such as BERT, XLM and XLM-RoBERTa have strict length limits on inputs and therefore cannot process long documents. While complex, neural-based models have been proposed, averaging sentence embeddings has remained a hard-to-beat baseline Guo et al. (2019). Here, we propose a document-level model based on weighted sentence embeddings, and the sentence weights are inversely related with its density in the corpus, akin to an inverse corpus frequency.111The intuition behind sentence weighting is that a sentence with higher density in a corpus is less informative and unique to its document, and thus should be assigned with a lower weight.
Cross-lingual representations enable the use of the same model for downstream tasks, regardless of their languages. In this work, we reveal that pre-trained cross-lingual embeddings are not language-agnostic, and that the language bias hurts their semantic representation power. We propose to remove the language bias efficiently and derive language-agnostic sentence representations. We show that debiased representations improve performance on cross-lingual tasks without the need for fine-tuning.
In this work, we propose Language-Agnostic Weighted Document Representation (LAWDR). Our document representations are built upon sentence embeddings obtained from off-the-shelf pre-trained language models. We first obtain language-agnostic sentence embedding by removing their language bias. Then we derive document representations from a weighted combination of these sentence embeddings. LAWDR is an unsupervised approach without model fine-tuning and task-specific supervision.
Cross-lingual document representations can be naturally applied to align multi-lingual document alignment and mine parallel data for machine translation Buck and Koehn (2016). To measure document similarity, we study and compare two similarity metrics, cosine similarity Mikolov et al. (2013) and the margin function Artetxe and Schwenk (2018a). Empirically, the margin metric is a better measure of cross-lingual document similarity. The learned document representation is evaluated on two public datasets from WMT16 and WMT19 shared tasks, and achieves strong performance in cross-lingual alignment.
We summarize our contributions below:
(1) We reveal that state-of-the-art pre-trained models carry language bias which hurts their semantic representation power. This work proposes an efficient approach to derive language-agnostic sentence embeddings.
(2) We propose an unsupervised approach LAWDR to derive language-agnostic document representations from sentence embeddings. It achieves strong empirical performance in cross-lingual document alignment.
2 Language Bias in Sentence Embeddings
Recently state-of-the-art performance has been achieved in cross-lingual tasks by pre-trained models such as BERT Devlin et al. (2019), XLM Lample and Conneau (2019) and XLM-RoBERTa (abbreviated as XLM-R in the following discussions) Conneau et al. (2019). These models learn contextualized representations for tokens in given input sentences. There are two commonly used approaches to obtain sentence representations from the token embeddings. One approach is to concatenate special tokens such as [CLS] in BERT, in XLM and in XLM-R with a sentence as the input sequence to the pre-trained models. Embeddings of these special tokens are taken as the sentence embedding Devlin et al. (2019); Lample and Conneau (2019). We refer to this method as special token (ST) approach for simplicity, and it demonstrates good performance on sentence-level tasks when fine-tuned on external labeled datasets.
The other way is mean pooling (MP), deriving sentence embeddings as the average of token embeddings. It is a simple yet efficient approach to encode compositional word semantics into sentences representations Le and Mikolov (2014). In this work, we study and compare sentence embeddings derived using these two approaches.

(a) BERT embeddings

(b) XLM embeddings

(c) XLM-R embeddings
Cross-lingual representations are expected to be language-agnostic. However, we argue that this is not the case, as we will show both qualitatively and quantitatively that the pre-trained sentence embedding carries language signals.
Qualitative analysis. We extract parallel documents in English and French collected from the domain of eu2007.de in the WMT-16 document alignment dataset Buck and Koehn (2016). These parallel documents consist of English and French sentences. We project their sentence embeddings to two-dimension space using principal component analysis (PCA). Fig. 1 visualizes MP sentence embeddings derived from pre-trained BERT, XLM and XLM-R. It shows that sentences are separated in the vector space based on their languages even if they are from parallel documents. ST sentence embeddings have similar distribution as MP, which is shown in the supplementary material.
| Embedding | BERT | XLM | XLM-R |
|---|---|---|---|
| 95.3 | 97.3 | 94.7 | |
| 100.0 | 100.0 | 97.6 | |
| 52.5 | 53.5 | 52.0 |
Quantitative analysis. To further justify our conjecture that pre-trained sentence embeddings carry language bias, we design a language classification task on the same data. Parallel documents are randomly split into train and test sets with a ratio of 8:2. A linear Support Vector Machine (SVM) is trained with MP sentence embeddings to classify the language of the given sentences. In the row of , Table 1 reports the language classification accuracy on test sentences. Sentence languages could be classified with high accuracy above for all pre-trained models. ST sentence embeddings have similar results, which are reported in the supplementary material. This quantitatively demonstrates that language signals are encoded to these pre-trained representations.
3 Language-Agnostic Sentence Embeddings
We have shown that the sentence embeddings from pre-trained models are biased towards languages. Hence the cross-lingual representations are actually a mixture of language and semantic signals. Suppose that the sentence has an embedding in the -dimension space. We assume that the embedding space can be decomposed into two orthogonal subspaces: a language subspace and a semantic subspace . Suppose that the basis vectors of space is , and the basis of space is . The basis vectors are orthogonal to each other within a subspace. Moreover, basis vectors from the two subspaces are also orthogonal, i.e., , considering that subspace is orthogonal to . Therefore, the sentence embedding can be expressed as a sum of its language component and semantic component .
| (1) |
The language component can be represented as a linear combination of language basis vectors, i.e., , where the coefficient is its projection onto the basis . Similarly, the semantic component consists of semantic basis vectors , and is the projection onto .
3.1 Language Classification
Consider two sentences and with embeddings and respectively. We now explain the phenomenon that embeddings could be classified by their languages with the assumption that the embedding is a mixture of language and semantic components.
Given the orthogonality of language and semantic spaces, we can write the inner product between the sentence embeddings in Eq. (1) as below.
| (2) |
Eq. (2) shows that the high correlation of language components leads to large inner product between embeddings for sentences in the same language. The sentence embeddings from the same language stay close in the vector space. As a result, the embeddings are linearly separable according to their languages.
3.2 Debiasing Sentence Embeddings
Based on Eq. (2), language components affect the inner product of sentence embeddings, and limit the semantic representation power of pre-trained embeddings. An immediate question is how to derive language-agnostic sentence embeddings.
Previous works rely on linguistic resources such as bilingual dictionaries to transform embeddings in different languages to the same space Schuster et al. (2019); Conneau et al. (2020). We propose an unsupervised debiasing method, which removes language components and leaves language-agnostic representations without using external resources.
Since language components are highly correlated for sentences in the same language, language bias is the common components existing in their embeddings. We decompose sentence embeddings in the same language using Singular Value Decomposition (SVD), and identify the dominant components which capture the largest variance of these embeddings as the language components. Given embeddings of a set of sentences in language , the dominant components of these sentence embeddings is derived as the estimated basis of the language subspace.
With the identified language subspace, we could estimate the language component of the sentence embedding : . The weight coefficient is the projection of onto the basis of language subspace , i.e., .
We debias the sentence embedding by removing its language component and approximate the semantic representation .
In our experiments, the rank of language subspace is a hyperparamter discussed in the supplementary material.
To prove the effectiveness of this debiasing method, we designed an experiment in which only partial information is available to train a language classifier. We reuse the same set of sentences in the language classification task. The linear SVM classifier takes as inputs the language component and the semantic components respectively. The test accuracy of language classification is reported in the last two rows of Table 1.
For all models, language components achieve almost perfect language classification while the performance of semantic components is as poor as random guess. Hence we empirically demonstrate that language signals exist in the dominant components of sentence embeddings. Moreover, the language bias is mitigated in the debiased embedding . In the following study of document representation, we will denote the debiased sentence embedding as for simplicity, and use it as the language-agnostic sentence representation.
4 Document Representation Model
In this section, we will discuss how to derive language-agnostic document representation from the debiased sentence embeddings.
4.1 Weighted Document Representation
Averaging is a simple yet strong approach to represent compositional semantics. Strong performance comparable to supervised neural models has been achieved by sentence embeddings derived from average word embeddings Arora et al. (2017) and document embeddings from average sentence embeddings Guo et al. (2019) respectively.
As an improvement over the unweighted average, recent works learn sentence embeddings as a weighted average of word embeddings, where the weight is negatively correlated with the word frequency Arora et al. (2017); Ethayarajh (2019). Their intuition is that frequent words such as stop words carry less semantic information, and that they should contribute less to sentence embeddings.
Borrowing their ideas, we propose to learn document representation from a weighted linear combination of the debiased sentence embeddings. Different from words, sentences have continuous probability distribution. Hence we use kernel density estimator (KDE) to efficiently estimate sentence density from sentence embeddings Scott (2015)
Considering that sentence with low density could better discriminate documents, we use the inverse density of sentences as their weights. We derive the document representation below
| (3) |
where the weighting coefficient of sentence is , is the sentence density in a corpus . We empirically set as half of the average probability of all sentences, i.e., with as the total number of sentences in corpus .
We present LAWDR for document representation learning in Algorithm 1. Sentence representations are first generated by a pre-trained cross-lingual model (BERT, XLM or XLM-R in our study) using either special token (ST) representation or mean pooling (MP) over token embeddings. We then remove language bias from sentence embeddings. The document representations are derived from a weighted linear combination of debiased sentence representations, where sentence weights are their inverse density in the corpus.
5 Document Similarity Metric
Document alignment is an important application of cross-lingual document representations, which also serves as an evaluation task for the semantic representation quality. The task is to measure the the semantic similarity of documents in a source and a target language. In this section, we study the geometry of the learned document representations and discuss the metric to measure document similarity from the embeddings.
Geometry of document representations. Cosine similarity is the most commonly used metric for language representations Mikolov et al. (2013); Guo et al. (2018). Given a document in a source language, we use the cosine similarity to find its nearest neighbors from a target language in the vector space. We observe that its parallel document is usually among its (top four) nearest neighbors but not the closest one.
A possible explanation is that the document representation carries more than semantic information Mu and Viswanath (2018). Language is one kind of non-semantic signal, which has been removed in debiasing procedure. Domain, syntax and text style are examples of non-semantic signals that have been found in language representations Mikolov et al. (2013); Nooralahzadeh et al. (2018). The non-semantic component would change the local geometry of document embeddings. Hence cosine similarity may not accurately reflect the semantic closeness.
Similarity metric. A margin function has been recently proposed to evaluate multilingual sentence similarity which outperforms cosine function Artetxe and Schwenk (2018a). Suppose that there two corpora and in language and respectively. A margin function is defined for documents and from corpora and respectively:
| (4) |
where is the embeddings of nearest neighbors in language of document in terms of cosine similarity.
Given a source document, Artetxe and Schwenk proposed to find parallel candidates using cosine similarity, and re-rank these candidates using margin function. The document with the maximal margin value is identified as the parallel document Artetxe and Schwenk (2018a).
6 Experiments
We evaluate the document representations on a semantic similarity task – cross-lingual document alignment. It identifies parallel documents, and mines massive data for machine translation El-Kishky et al. (2019).
| Dataset | WMT-16 | WMT-19 | |
|---|---|---|---|
| Language | En | Fr | 15 langs |
| Doc # | 681,529 | 522,627 | 86,853 |
| Average length | 853 | 944 | 1108 |
| Bias | Sent2Doc | Metric | No URL | With URL | ||||||||||
| BERT | XLM | XLM-R | BERT | XLM | XLM-R | |||||||||
| ST | MP | ST | MP | ST | MP | ST | MP | ST | MP | ST | MP | |||
| Biased | Mean | Cosine | 5.0 | 8.1 | 16.2 | 17.0 | 3.8 | 4.7 | 61.5 | 62.7 | 65.2 | 64.0 | 61.2 | 61.4 |
| Margin | 7.1 | 9.4 | 17.9 | 17.7 | 4.7 | 5.6 | 62.1 | 63.4 | 65.9 | 64.3 | 61.4 | 61.7 | ||
| Weighted | Cosine | 6.3 | 8.7 | 18.4 | 17.6 | 3.9 | 4.9 | 62.1 | 62.9 | 65.3 | 64.0 | 61.2 | 61.8 | |
| Margin | 7.7 | 10.4 | 19.2 | 18.5 | 4.7 | 6.1 | 62.5 | 63.8 | 65.9 | 64.4 | 61.5 | 62.1 | ||
| Debiased | Mean | Cosine | 77.7 | 85.1 | 86.3 | 87.7 | 56.9 | 60.7 | 86.8 | 92.5 | 93.7 | 93.8 | 77.8 | 79.3 |
| Margin | 78.1 | 86.1 | 87.3 | 88.6 | 58.0 | 61.2 | 87.6 | 93.1 | 93.8 | 94.2 | 78.4 | 79.5 | ||
| Weighted | Cosine | 77.3 | 85.3 | 85.8 | 88.4 | 57.3 | 60.9 | 87.2 | 93.0 | 93.7 | 94.0 | 78.1 | 79.6 | |
| Margin | 78.0 | 86.6 | 87.0 | 88.8 | 57.6 | 61.3 | 87.3 | 94.0 | 93.9 | 94.8 | 78.1 | 79.4 | ||
Dataset. We used two publicly available datasets from WMT-16 and WMT-19 shared tasks for experiments on cross-lingual document alignment. WMT-16 dataset222http://www.statmt.org/wmt16/bilingual-task.html is prepared by the shared task on bilingual alignment between English and French documents from 203 websites Buck and Koehn (2016). The other dataset consisting of new commentary is provided in WMT-19 task 333http://data.statmt.org/news-commentary/v14/, covering 15 languages444Arabic, Czech, German, English, Spanish, French, Hindi, Indonesian, Italian, Japanese, Kazakh, Dutch, Portuguese, Russian and Chinese and 99 language pairs. Table 2 shows the statistics of datasets used in our experiments including the number and the average length of their documents.
Evaluation. Following the evaluation of WMT-16 shared task, we use Recall as the metric of document alignment. Given two sets of documents in two languages, we sort cross-lingual document pairs in decreasing order of their semantic similarity estimated by cosine and margin metrics. Recall measures the percentage of aligned document pairs that can be correctly identified by models. The higher the recall is, the better a model performs.
6.1 Results
Setup. Documents are first segmented into sentences, and then we obtain the sentence embeddings from pre-trained models. Our experiments cover three recent cross-lingual models – multilingual BERT Devlin et al. (2019), XLM Lample and Conneau (2019) and XLM-R Conneau et al. (2019). Algorithm 1 is applied to derive document representations from their sentence embeddings. We compare margin and cosine functions as measures of document similarity.
Baselines. We include state-of-the-art sentence encoder – LASER555https://github.com/facebookresearch/LASER – as a baseline for document representation. It achieves strong performance in aligning cross-lingual sentences Chaudhary et al. (2019). Since it is an LSTM-based model without length limits on input texts, we apply it to document representation learning in our experiments. To understand how its representation quality changes with input length, we report its alignment performance of encoding whole documents and encoding only the first tokens respectively.
The average of sentence embedding has been shown to be a strong approach to derive document representation Guo et al. (2019). We include it as another strong baseline in our experiments, with which we can analyze the gains brought by sentence weighting.
WMT16 results. The state-of-the-art system in this dataset used machine translation to compute lexical overlap of documents Gomes and Lopes (2016). It achieved recalls of and without and with URL information respectively.
Table 3 reports the recall of LAWDR combined with three pre-trained models on WMT-16 dataset. For completeness, it includes the results w/o URL information in the columns “no URL” and “with URL” respectively. To use the URL information, We simply use the URL matching script provided by the WMT-16 shared task to align some of the documents Buck and Koehn (2016). Then we score the similarity of the remaining document pairs with the document representations.
As shown in Table 3, LASER representation suffers from quality degradation as the text length increases. The best-performing approach is the combination of the document embedding as a weighted average of debiased XLM+MP embedding and margin as similarity metric. It achieves a recall of without URL and a recall of with URL information. This is comparable to the state-of-the-art model built upon machine translation. Moreover, it outperforms LASER by a large margin no matter whether URL matching is used.
| Bias | Sent2Doc | Metric | BERT | XLM | XLM-R | |||
|---|---|---|---|---|---|---|---|---|
| ST | MP | ST | MP | ST | MP | |||
| Biased | Mean | Cosine | 1.0 | 4.6 | 6.8 | 8.1 | 0.1 | 0.1 |
| Margin | 1.5 | 5.8 | 13.0 | 15.6 | 0.1 | 0.1 | ||
| Weighted | Cosine | 1.3 | 5.2 | 7.2 | 8.5 | 0.1 | 0.1 | |
| Margin | 1.8 | 6.4 | 13.3 | 16.1 | 0.1 | 0.1 | ||
| Debiased | Mean | Cosine | 57.6 | 76.1 | 85.1 | 89.8 | 23.9 | 42.2 |
| Margin | 60.6 | 79.0 | 87.1 | 90.7 | 25.7 | 47.0 | ||
| Weighted | Cosine | 57.8 | 75.9 | 85.5 | 90.0 | 25.5 | 42.8 | |
| Margin | 61.0 | 79.5 | 87.6 | 91.0 | 26.0 | 47.6 | ||
WMT19 results. The results on WMT-19 dataset are reported in Table 4. We again observe that LASER’s representation quality get severely worse as its input texts become longer. With a recall of , our best model is again the combination of weighted document representation from debiased XLM MP embedding and margin metric.
6.2 Analysis
We now analyze the effect of each step in LAWDR algorithm on document alignment performance.
MP v. ST. For all three pre-trained models, MP consistently provides better sentence embeddings than ST sentence embedding.
Debiasing. Debiasing is surprisingly important to the embedding quality and alignment performance. Consider the setting that weighted document representation is derived from MP sentence embedding and margin is the metric. On WMT16 without URL, debiasing brings a gain of for BERT, for XLM and for XLM-R. On WMT19, debiasing achieves a gain of for BERT, for XLM and for XLM-R.
Sentence weighting. Weighted document representation shows its advantage over mean representations. Consider the combination of XLM, MP and margin metric on WMT16. With original biased sentence embedding, weighted representation improves the alignment recall by in comparison with mean representation. The improvement is for debiased sentence embeddings. Similar gains could be observed on WMT19 data.
Margin v. Cosine. As for the similarity metric, margin function outperforms cosine function in most of the cases. Consider the weighted document representation derived from XLM MP. On WMT16 dataset, the gain of margin metric over cosine is on biased embedding, and on debiased embedding. On WMT19, the gain of margin is with biased embedding, and with debiased embedding.
7 Discussion
In our study, the pre-trained models are applied to generate representations for single sentences. It is natural to consider encoding multiple sentence so that these model could capture the inter-sentence information Ethayarajh (2019). Now we take as many sentences as possible under the length limit of the models, and concatenate them as one input sequence. Again we use MP for sentence embeddings, LAWDR for weighted document representations and margin function for the similarity metric.
| Input | Bias | BERT | XLM | XLM-R |
|---|---|---|---|---|
| Single Sent | Biased | 6.4 | 16.1 | 0.1 |
| Debiased | 79.5 | 91.0 | 47.6 | |
| Multi Sent | Biased | 21.0 | 20.7 | 1.9 |
| Debiased | 86.3 | 88.4 | 74.2 |
Table 5 compares WMT19 recalls with single and multiple sentences as model inputs. With biased embedding, multi-sentence inputs outperform single-sentence inputs for all models. With debiased embedding, multi-sentence inputs yield gains of for BERT and XLM-R, while falls behind single-sentence inputs by for XLM. The complete results of all models on both datasets are provided in the supplementary material.
8 Related Work
Multilingual sentence representation. Learning multilingual embeddings is appealing due to their universal representations across languages. Represented in the same embedding space, the semantics of languages can be compared directly regardless of their languages in a scalable and efficient way Conneau et al. (2018). Moreover, multilingual representations enable model transfer between languages especially from high-resource to low-resource languages Ruder et al. (2017).
There has been a long research venue in multilingual sentence representations learning. Recently NLP has seen a surge in the study of multilingual pre-trained models. One of the strong models is Language-Agnostic SEntence Representations (LASER) Artetxe and Schwenk (2018b), which is built on LSTM network. Its representation quality degrades with the increase of text length. Other cross-lingual models are based on Transformer Vaswani et al. (2017) such as BERT Devlin et al. (2019), XLM Lample and Conneau (2019) and XLM-RoBERTa Conneau et al. (2019). These models are not able to encode long documents due to strict limits on inputs.
Document embedding. Monolingual document representations has been extensively studied. Document vector is trained to predict component words Gupta et al. (2016). Document embeddings are also learned from word embeddings Chen (2016). Recent works propose end-to-end hierarchical models to learn document embeddings on labeled data Yang et al. (2016); Miculicich et al. (2018).
Despite a large body of research on monolingual document representations, there have been very few works in cross-lingual setting. The most recent work designs hierarchical multilingual document encoder (HiDE), which is trained on a large corpus of parallel documents Guo et al. (2019). It only experiments with English-French and English-Spanish language pairs. Considering the large cost of training the model on other languages, we do not include it in our experiments.
9 Conclusion
In this paper, we proposed LAWDR to learn language-agnostic document representation on top of pre-trained cross-lingual models. We first apply debiasing to mitigate language signals and derive language-agnostic sentence embeddings. The debiased sentence embeddings are then weighted with their inverse density as document representations. We further reveal that margin function is a more accurate measure of document similarity than cosine similarity with empirical evaluation. The learned document embeddings have achieved state-of-the-art performance on cross-lingual document alignment.
References
- Al-Rfou (2013) Rami Al-Rfou. 2013. Polyglot: Distributed word representations for multilingual nlp. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pages 183–192. Association for Computational Linguistics.
- Arora et al. (2017) Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017. A simple but tough-to-beat baseline for sentence embeddings. In International Conference on Learning Representations.
- Artetxe and Schwenk (2018a) Mikel Artetxe and Holger Schwenk. 2018a. Margin-based parallel corpus mining with multilingual sentence embeddings. arXiv preprint arXiv:1811.01136.
- Artetxe and Schwenk (2018b) Mikel Artetxe and Holger Schwenk. 2018b. Massively multilingual sentence embeddings for zero-shot cross-lingual transfer and beyond. arXiv preprint arXiv:1812.10464.
- Buck and Koehn (2016) Christian Buck and Philipp Koehn. 2016. Findings of the wmt 2016 bilingual document alignment shared task. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, pages 554–563.
- Chaudhary et al. (2019) Vishrav Chaudhary, Yuqing Tang, Francisco Guzmán, Holger Schwenk, and Philipp Koehn. 2019. Low-resource corpus filtering using multilingual sentence embeddings. In Proceedings of the Fourth Conference on Machine Translation (Volume 3: Shared Task Papers, Day 2), pages 263–268, Florence, Italy. Association for Computational Linguistics.
- Chen (2016) Minmin Chen. 2016. Efficient vector representation for documents through corruption. In 5th International conference on Learning Representations.
- Conneau et al. (2019) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116.
- Conneau et al. (2018) Alexis Conneau, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2475–2485.
- Conneau et al. (2020) Alexis Conneau, Shijie Wu, Haoran Li, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Emerging cross-lingual structure in pretrained language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6022–6034.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186.
- El-Kishky et al. (2019) Ahmed El-Kishky, Vishrav Chaudhary, Francisco Guzman, and Philipp Koehn. 2019. A massive collection of cross-lingual web-document pairs. arXiv preprint arXiv:1911.06154.
- Ethayarajh (2019) Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 55–65.
- Gomes and Lopes (2016) Luís Gomes and Gabriel Pereira Lopes. 2016. First steps towards coverage-based document alignment. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers, pages 697–702.
- Guo et al. (2018) Mandy Guo, Qinlan Shen, Yinfei Yang, Heming Ge, Daniel Cer, Gustavo Hernandez Abrego, Keith Stevens, Noah Constant, Yun-hsuan Sung, Brian Strope, et al. 2018. Effective parallel corpus mining using bilingual sentence embeddings. In Proceedings of the Third Conference on Machine Translation: Research Papers, pages 165–176.
- Guo et al. (2019) Mandy Guo, Yinfei Yang, Keith Stevens, Daniel Cer, Heming Ge, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2019. Hierarchical document encoder for parallel corpus mining. arXiv preprint arXiv:1906.08401.
- Gupta et al. (2016) Manish Gupta, Vasudeva Varma, et al. 2016. Doc2sent2vec: A novel two-phase approach for learning document representation. In Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, pages 809–812. ACM.
- Lample and Conneau (2019) Guillaume Lample and Alexis Conneau. 2019. Cross-lingual language model pretraining. arXiv preprint arXiv:1901.07291.
- Le and Mikolov (2014) Quoc Le and Tomas Mikolov. 2014. Distributed representations of sentences and documents. In International conference on machine learning, pages 1188–1196.
- Miculicich et al. (2018) Lesly Miculicich, Dhananjay Ram, Nikolaos Pappas, and James Henderson. 2018. Document-level neural machine translation with hierarchical attention networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2947–2954.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119.
- Mu and Viswanath (2018) Jiaqi Mu and Pramod Viswanath. 2018. All-but-the-top: Simple and effective post-processing for word representations. In 6th International Conference on Learning Representations, ICLR 2018.
- Nooralahzadeh et al. (2018) Farhad Nooralahzadeh, Lilja Øvrelid, and Jan Tore Lønning. 2018. Evaluation of domain-specific word embeddings using knowledge resources. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018).
- Ruder et al. (2017) Sebastian Ruder, Ivan Vulić, and Anders Søgaard. 2017. A survey of cross-lingual word embedding models. arXiv preprint arXiv:1706.04902.
- Schuster et al. (2019) Tal Schuster, Ori Ram, Regina Barzilay, and Amir Globerson. 2019. Cross-lingual alignment of contextual word embeddings, with applications to zero-shot dependency parsing. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1599–1613.
- Scott (2015) David W Scott. 2015. Multivariate density estimation: theory, practice, and visualization. John Wiley & Sons.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems, pages 5998–6008.
- Wolf et al. (2019) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, R’emi Louf, Morgan Funtowicz, and Jamie Brew. 2019. Huggingface’s transformers: State-of-the-art natural language processing. ArXiv, abs/1910.03771.
- Yang et al. (2016) Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. 2016. Hierarchical attention networks for document classification. In Proceedings of the 2016 conference of the North American chapter of the association for computational linguistics: human language technologies, pages 1480–1489.
10 Supplemental Material
10.1 Language Bias in Sentence Embeddings
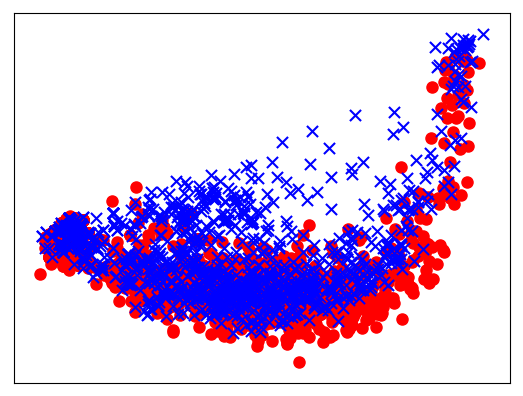
We derive sentence embeddings with the special token (ST) embeddings. Figure 2 visualizes the embeddings of English and French sentences from parallel eu2007.de documents. We note that sentences in different languages are separated in the vector space. It suggests that pre-trained sentence embeddings are biased towards languages.
Debiasing sentence embeddings. We collect embeddings of sentences in the same language, and sort the domain components in decreasing order of the captured variance ratio using SVD. The top components are identified as the language components. To decide the value of , we find the smallest number of dominant components so that the language classification accuracy of debiased embeddings is lower than . This resulted in for BERT embeddings, for XLM embeddings and for XLM-R embeddings.
(a) BERT embedding.

(b) XLM embedding.

(c) XLM-R embedding.
| Embedding | BERT | XLM | XLM-R |
|---|---|---|---|
| 95.3 | 97.3 | 93.1 | |
| 99.3 | 100.0 | 96.7 | |
| 52.0 | 55.5 | 52.0 |
10.2 Experiment
Pre-trained cross-lingual models. BERT model is pre-trained on languages with the largest Wikipedia corpus, and its training objective is masked language modeling as well as next sentence prediction. XLM and XLM-R models are pre-trained on 100 languages with masked language modeling. We use the implementation of HugginFace to obtain token embeddings from these pre-trained models Wolf et al. (2019).
Hyperparameters. We analyze the components in sentence embeddings with SVD, and debias sentence embeddings when the dominant components are removed as language bias. To assign weights of sentences, we estimate their density using kernel density estimation with Tophat as the kernel. It is known that the complexity of kernel density estimation grows exponentially with the dimension Scott (2015). To make the density estimation more computationally efficient, we first reduce the embedding dimension to with principal component analysis (PCA), and apply density estimation to reduced embeddings. The bandwidth in density estimation is selected using -fold cross validation on each dataset.
For sentence density estimation, we apply kernel density estimator to sentence embeddings, and use Tophat kernel. Since the complexity of density estimation grows with the dimension of embeddings, we project sentence embeddings to a -dimension space using principal component analysis. The embeddings of reduced dimension are used as the input to density estimator.
| No URL | ||||||||||||
| BERT | XLM | XLM-R | LASER | SoA | ||||||||
| ST | MP | ST | MP | ST | MP | 512 tokens | all tokens | - | ||||
| Single Sent | Biased | Mean | Cosine | 5.0 | 8.1 | 16.2 | 17.0 | 3.8 | 4.7 | 62.8 | 20.2 | 85.8 |
| Margin | 7.1 | 9.4 | 17.9 | 17.7 | 4.7 | 5.6 | ||||||
| Weighted | Cosine | 6.3 | 8.7 | 18.4 | 17.6 | 3.9 | 4.9 | |||||
| Margin | 7.7 | 10.4 | 19.2 | 18.5 | 4.7 | 6.1 | ||||||
| Debiased | Mean | Cosine | 77.7 | 85.1 | 86.3 | 87.7 | 56.9 | 60.7 | ||||
| Margin | 78.1 | 86.1 | 87.3 | 88.6 | 58.0 | 61.2 | ||||||
| Weighted | Cosine | 77.3 | 85.3 | 85.8 | 88.4 | 57.3 | 60.9 | |||||
| Margin | 78.0 | 86.6 | 87.0 | 88.8 | 57.6 | 61.3 | ||||||
| Multi Sent | Biased | Mean | Cosine | 8.7 | 25.7 | 18.3 | 25.1 | 3.0 | 4.7 | |||
| Margin | 8.7 | 28.2 | 20.5 | 26.9 | 3.3 | 5.5 | ||||||
| Weighted | Cosine | 9.1 | 29.2 | 19.1 | 25.9 | 2.9 | 6.6 | |||||
| Margin | 9.1 | 30.6 | 21.2 | 27.4 | 3.2 | 7.2 | ||||||
| Debiased | Mean | Cosine | 68.4 | 84.9 | 82.1 | 85.9 | 49.8 | 65.9 | ||||
| Margin | 68.7 | 85.5 | 83.1 | 86.6 | 49.9 | 66.0 | ||||||
| Weighted | Cosine | 68.1 | 85.0 | 82.3 | 87.6 | 49.9 | 65.9 | |||||
| Margin | 68.7 | 85.6 | 83.1 | 88.3 | 50.2 | 66.1 | ||||||
| With URL | ||||||||||||
| BERT | XLM | XLM-R | LASER | SoA | ||||||||
| ST | MP | ST | MP | ST | MP | 512 tokens | all tokens | - | ||||
| Single Sent | Biased | Mean | Cosine | 61.5 | 62.7 | 65.2 | 64.0 | 61.2 | 61.4 | 84.7 | 69.5 | 95.0 |
| margin | 62.1 | 63.4 | 65.9 | 64.3 | 61.4 | 61.7 | ||||||
| Weighted | Cosine | 62.1 | 62.9 | 65.3 | 64.0 | 61.2 | 61.8 | |||||
| Margin | 62.5 | 63.8 | 65.9 | 64.4 | 61.5 | 62.1 | ||||||
| Mean | Cosine | 86.8 | 92.5 | 93.7 | 93.8 | 77.8 | 79.3 | |||||
| Margin | 87.6 | 93.1 | 93.8 | 94.2 | 78.4 | 79.5 | ||||||
| Weighted | Cosine | 87.2 | 93.0 | 93.7 | 94.0 | 78.1 | 79.6 | |||||
| Margin | 87.3 | 94.0 | 93.9 | 94.8 | 78.1 | 79.4 | ||||||
| Multi Sent | Biased | Mean | Cosine | 62.3 | 66.4 | 65.0 | 66.7 | 60.7 | 61.5 | |||
| Margin | 62.4 | 67.6 | 65.9 | 67.6 | 61.0 | 61.7 | ||||||
| Weighted | Cosine | 62.3 | 67.9 | 65.2 | 67.0 | 60.9 | 62.1 | |||||
| Margin | 62.7 | 68.3 | 66.1 | 67.7 | 61.0 | 62.1 | ||||||
| Debiased | Mean | Cosine | 83.2 | 92.9 | 90.6 | 92.8 | 75.4 | 82.8 | ||||
| Margin | 83.6 | 93.1 | 91.3 | 93.2 | 75.3 | 82.9 | ||||||
| Weighted | Cosine | 83.3 | 93.0 | 90.9 | 93.8 | 75.4 | 82.8 | |||||
| Margin | 83.3 | 93.2 | 91.3 | 94.5 | 75.6 | 83.1 | ||||||
WMT16 results. Table 7 presents the full results of bilingual document alignment on WMT-16 dataset.
| Input | Bias | Sent2Doc | Metric | BERT | XLM | XLM-R | LASER | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ST | MP | ST | MP | ST | MP | 512 tokens | all tokens | ||||
| Single Sent | Biased | Mean | Cosine | 1.0 | 4.6 | 6.8 | 8.1 | 0.1 | 0.1 | 68.0 | 3.0 |
| Margin | 1.5 | 5.8 | 13.0 | 15.6 | 0.1 | 0.1 | |||||
| Weighted | Cosine | 1.3 | 5.2 | 7.2 | 8.5 | 0.1 | 0.1 | ||||
| Margin | 1.8 | 6.4 | 13.3 | 16.1 | 0.1 | 0.1 | |||||
| Debiased | Mean | Cosine | 57.6 | 76.1 | 85.1 | 89.8 | 23.9 | 42.2 | |||
| Margin | 60.6 | 79.0 | 87.1 | 90.7 | 25.7 | 47.0 | |||||
| Weighted | Cosine | 57.8 | 75.9 | 85.5 | 90.0 | 25.5 | 42.8 | ||||
| Margin | 61.0 | 79.5 | 87.6 | 91.0 | 26.0 | 47.6 | |||||
| Multi Sent | Biased | Mean | Cosine | 7.4 | 12.3 | 9.5 | 12.3 | 0.2 | 0.6 | ||
| Margin | 8.9 | 17.0 | 16.6 | 20.9 | 0.2 | 1.2 | |||||
| Weighted | Cosine | 8.1 | 14.8 | 9.5 | 12.2 | 0.2 | 1.6 | ||||
| Margin | 10.0 | 21.0 | 16.5 | 20.7 | 0.2 | 1.9 | |||||
| Debiased | Mean | Cosine | 59.6 | 84.3 | 78.5 | 86.9 | 41.3 | 72.8 | |||
| Margin | 62.7 | 85.9 | 80.7 | 88.0 | 42.4 | 74.1 | |||||
| Weighted | Cosine | 59.7 | 85.7 | 78.5 | 87.3 | 41.3 | 73.2 | ||||
| Margin | 62.8 | 86.3 | 80.8 | 88.4 | 42.4 | 74.2 | |||||
WMT19 results. Table 8 presents the full results on WMT-19 multilingual document alignment.