Law of Balance and Stationary Distribution of Stochastic Gradient Descent
Abstract
The stochastic gradient descent (SGD) algorithm is the algorithm we use to train neural networks. However, it remains poorly understood how the SGD navigates the highly nonlinear and degenerate loss landscape of a neural network. In this work, we prove that the minibatch noise of SGD regularizes the solution towards a balanced solution whenever the loss function contains a rescaling symmetry. Because the difference between a simple diffusion process and SGD dynamics is the most significant when symmetries are present, our theory implies that the loss function symmetries constitute an essential probe of how SGD works. We then apply this result to derive the stationary distribution of stochastic gradient flow for a diagonal linear network with arbitrary depth and width. The stationary distribution exhibits complicated nonlinear phenomena such as phase transitions, broken ergodicity, and fluctuation inversion. These phenomena are shown to exist uniquely in deep networks, implying a fundamental difference between deep and shallow models.
1 Introduction
The stochastic gradient descent (SGD) algorithm is defined as
| (1) |
where is the model parameter, is a per-sample loss whose expectation over gives the training loss. is a randomly sampled minibatch of data points, each independently sampled from the training set, and is the minibatch size. The training-set average of is the training objective , where denotes averaging over the training set. Two aspects of the algorithm make it difficult to understand this algorithm: (1) its dynamics is discrete in time, and (2) the randomness is highly nonlinear and parameter-dependent. This work relies on the continuous-time approximation and deals with the second aspect.
In natural and social sciences, the most important object of study of a stochastic system is its stationary distribution, which is often found to offer fundamental insights into understanding a given stochastic process [37, 31]. Arguably, a great deal of insights into SGD can be obtained if we have an analytical understanding of the stationary distribution, which remains unknown until today. Predominantly many works study the dynamics and stationary properties of SGD in the case of a strongly convex loss function [43, 44, 20, 46, 27, 52, 21, 42]. The works that touch on the nonlinear aspects of the loss function rely heavily on the local approximations of the stationary distribution of SGD close to a local minimum, often with additional unrealistic assumptions about the noise. For example, using a saddle point expansion and assuming that the noise is parameter-independent, Refs. [23, 44, 20] showed that the stationary distribution of SGD is exponential. Taking partial parameter-dependence into account and near an interpolation minimum, Ref. [27] showed that the stationary distribution is power-law like and proportional to for some constant . However, the stationary distribution of SGD is unknown when the loss function is beyond quadratic and high-dimensional.
Since the stationary distribution of SGD is unknown, we will compare our results with the most naive theory one can construct for SGD, a continuous-time Langevin equation with a constant noise level:
| (2) |
where is a random time-dependent noise with zero mean and with being the identity operator. Here, the naive theory relies on the assumption that one can find a constant scalar such that Eq. (2) closely models (1), at least after some level of coarse-graining. Let us examine some of the predictions of this model to understand when and why it goes wrong.
There are two important predictions of this model. The first is that the stationary distribution of SGD is a Gibbs distribution with temperature : . This implies that the maximum likelihood estimator of under SGD is the same as the global minimizer of the : . This relation holds for the local minima as well: every local minimum of corresponds to a local maximum of . These properties are often required in the popular argument that SGD approximates Bayesian inference [23, 25]. Another implication is ergodicity [39]: any state with the same energy will have an equal probability of being accessed. The second is the dynamical implication: SGD will diffuse. If there is a degenerate direction in the loss function, SGD will diffuse along that direction.111Note that this can also be seen as a dynamical interpretation of the ergodicity.


However, these predictions of the Langevin model are not difficult to reject. Let us consider a simple two-layer network with the loss function: . Because of the rescaling symmetry, a valley of degenerate solution exists at . Under the simple Langevin model, SGD diverges to infinity due to diffusion. One can also see this from a static perspective. All points on the line must have the same probability at stationarity, but such a distribution does not exist because it is not normalizable. This means that the Langevin model of SGD diverges for this loss function.
Does this agree with the empirical observation? Certainly not.222In fact, had it been the case, no linear network or ReLU network can be trained with SGD. See Fig. 1. We see that contrary to the prediction of the Langevin model, converges to zero under SGD. Under GD, this quantity is conserved during training [7]. Only the Gaussian GD obeys the prediction of the Langevin model, which is expected. This sharp contrast shows that the SGD dynamics is quite special, and a naive theoretical model can be very far from the truth in understanding its behavior. There is one more lesson to be learned. The fact that the Langevin model disagrees the most with the experiments when symmetry conditions are present suggests that the symmetry conditions are crucial tools to probe and understand the nature of the SGD noise, which is the main topic of our theory.
2 Law of Balance
Now, we consider the actual continuous-time limit of SGD [16, 17, 19, 33, 9, 13]:
| (3) |
where is a stochastic process satisfying and , and . Apparently, gives the average noise level in the dynamics. Previous works have suggested that the ratio is the main factor determining the behavior of SGD, and a higher often leads to better generalization performance [32, 20, 50]. The crucial difference between Eq. (3) and (2) is that in (3), the noise covariance is parameter-dependent and, in general, low-rank when symmetries exist.
Due to standard architecture designs, a type of invariance – the rescaling symmetry – often appears in the loss function and exists for all sampling of minibatches. The per-sample loss is said to have the rescaling symmetry for all if for an arbitrary scalar Note that this implies that the expected loss also has the same symmetry. This type of symmetry appears in many scenarios in deep learning. For example, it appears in any neural network with the ReLU activation. It also appears in the self-attention of transformers, often in the form of key and query matrices [38]. When this symmetry exists between and , one can prove the following result, which we refer to as the law of balance.
Theorem 1.
(Law of balance.) Let and be vectors of arbitrary dimensions. Let satisfy for arbitrary and . Then,
| (4) |
where , and with .
Our result holds in a stronger version if we consider the effect of a finite step-size by using the modified loss function (See Appendix A.7) [2, 34]. For common problems, and are positive definite, and this theorem implies that the norms of and will be approximately balanced. To see this, we can simplify the expression to
| (5) |
where represent the minimal and maximal eigenvalue of the matrix , respectively. In the long-time limit, the value of is restricted by
| (6) |
which implies that the stationary dynamics of the parameters is constrained in a bounded subspace of the unbounded degenerate local minimum valley. Conventional analysis shows that the difference between SGD and GD is of order per unit time step, and it is thus often believed that SGD can be understood perturbatively through GD [13]. However, the law of balance implies that the difference between GD and SGD is not perturbative. As long as there is any level of noise, the difference between GD and SGD at stationarity is . This theorem has an important implication: the noise in SGD creates a qualitative difference between SGD and GD, and we must study SGD noise in its own right. This theorem also implies the loss of ergodicity, an important phenomenon in nonequilibrium physics [29, 35, 24, 36], because not all solutions with the same training loss will be accessed by SGD with equal probability.
The theorem greatly simplifies when both and are one-dimensional.
Corollary 1.
If , then, , where .
Before we apply the theorem to study the stationary distributions, we stress the importance of this balance condition. This relation is closely related to Noether’s theorem [26, 1, 22]. If there is no weight decay or stochasticity in training, the quantity will be a conserved quantity under gradient flow [7, 15], as is evident by taking the infinite limit. The fact that it monotonically decays to zero at a finite may be a manifestation of some underlying fundamental mechanism. A more recent result in Ref. [40] showed that for a two-layer linear network, the norms of two layers are within a distance of order , suggesting that the norm of the two layers are balanced. Our result agrees with Ref. [40] in this case, but our result is far stronger because our result is nonperturbative and only relies on the rescaling symmetry, and is independent of the loss function or architecture of the model.
Example: two-layer linear network.
It is instructive to illustrate the application of the law to a two-layer linear network, the simplest model that obeys the law. Let denote the set of trainable parameters; the per-sample loss is . Here, is the width of the model, is the common regularization term that encourages the learned model to have a small norm, is the strength of regularization, and denotes the averaging over the training set, which could be a continuous distribution or a discrete sum of delta distributions. It will be convenient for us also to define the shorthand: . The distribution of is said to be the distribution of the “model.”
Applying the law of balance, we obtain that
| (7) |
where we have introduced the parameters
| (8) |
When or , the time evolution of can be upper-bounded by an exponentially decreasing function in time: . Namely, the quantity decays to with probability . We thus have for all at stationarity, in agreement with what we see in Figure 1.
3 Stationary Distribution of SGD
As an important application of the law of balance, we solve the stationary distribution of SGD for a deep diagonal linear network. While linear networks are limited in expressivity, their loss landscape and dynamics are highly nonlinear and is regarded as a minimal model of nonlinear neural networks [14, 18, 48, 41].
3.1 Depth- Case
Let us first derive the stationary distribution of a one-dimensional linear regressor, which will be a basis for comparison to help us understand what is unique about having a “depth” in deep learning. The per-sample loss is , for which the SGD dynamics is , where we have defined
| (9) |
Note that the closed-form solution of linear regression gives the global minimizer of the loss function: . The gradient variance is also not trivial: . Note that the loss landscape only depends on and , and the gradient noise only depends on , and, . These relations imply that can be quite independent of , contrary to popular beliefs in the literature [27, 23]. It is also reasonable to call the landscape parameters and the noise parameters. We will see that both and are important parameters appearing in all stationary distributions we derive, implying that the stationary distributions of SGD are strongly dependent on the data.
Another important quantity is , which is the minimal level of noise on the landscape. For all the examples in this work,
| (10) |
When is zero? It happens when, for all samples of , for some constant and . We focus on the case in the main text, which is most likely the case for practical situations. The other cases are dealt with in Section A.
For , the stationary distribution for linear regression is found to be
| (11) |
roughly in agreement with the result in Ref. [27]. Two notable features exist for this distribution: (1) the power exponent for the tail of the distribution depends on the learning rate and batch size, and (2) the integral of converges for an arbitrary learning rate. On the one hand, this implies that increasing the learning rate alone cannot introduce new phases of learning to a linear regression; on the other hand, it implies that the expected error is divergent as one increases the learning rate (or the feature variation), which happens at . We will see that deeper models differ from the single-layer model in these two crucial aspects.
3.2 Deep Diagonal Networks
Now, we consider a diagonal deep linear network, whose loss function can be written as
| (12) |
where is the depth and is the width. When the width , the law of balance is sufficient to solve the model. When , we need to eliminate additional degrees of freedom. A lot of recent works study the properties of a diagonal linear network, which has been found to well approximate the dynamics of real networks [30, 28, 3, 8].
We introduce , and so and call a “subnetwork” and the “model.” The following proposition shows that the dynamics of this model can be reduced to a one-dimensional form.
Theorem 2.
For all , one (or more) of the following conditions holds for all trajectories at stationarity:
-
1.
, or , or ;
-
2.
. In addition,
-
(a)
if , for a constant , ;
-
(b)
if , .
-
(a)
This theorem contains many interesting aspects. First of all, the three situations in item 1 directly tell us the distribution of , which is the quantity we ultimately care about.333 is only possible when and . This result implies that if we want to understand the stationary distribution of SGD, we only need to solve the case of item 2. Once the parameters enter the condition of item 2, item 2 will continue to hold with probability for the rest of the trajectory. The second aspect is that item 2 of the theorem implies that all the of the model must be of the same sign for any network with . Namely, no subnetwork of the original network can learn an incorrect sign. This is dramatically different from the case of . We will discuss this point in more detail below. The third interesting aspect of the theorem is that it implies that the dynamics of SGD is qualitatively different for different depths of the model. In particular, and have entirely different dynamics. For , the ratio between every pair of and is a conserved quantity. In sharp contrast, for , the distance between different is no longer conserved but decays to zero. Therefore, a new balancing condition emerges as we increase the depth. This qualitative distinction also corroborates the discovery in Refs. [48] and [51], where models are found to be qualitatively different from models with .
With this theorem, we are now ready to solve for the stationary distribution. It suffices to condition on the event that does not converge to zero. Let us suppose that there are nonzero that obey item 2 of Theorem 2 and can be seen as an effective width of the model. We stress that the effective width depends on the initialization and can be arbitrary.444One can systematically initialize the parameters in a way that takes any desired value between and ; for example, one way to achieve this is to initialize on the stationary conditions at the desired value of . Therefore, we condition on a fixed value of to solve for the stationary distribution of (Appendix A):
| (13) |
where is the distribution of on and is that on . Next, we analyze this distribution in detail. Since the result is symmetric in the sign of , we assume that from now on.
3.2.1 Depth- Nets

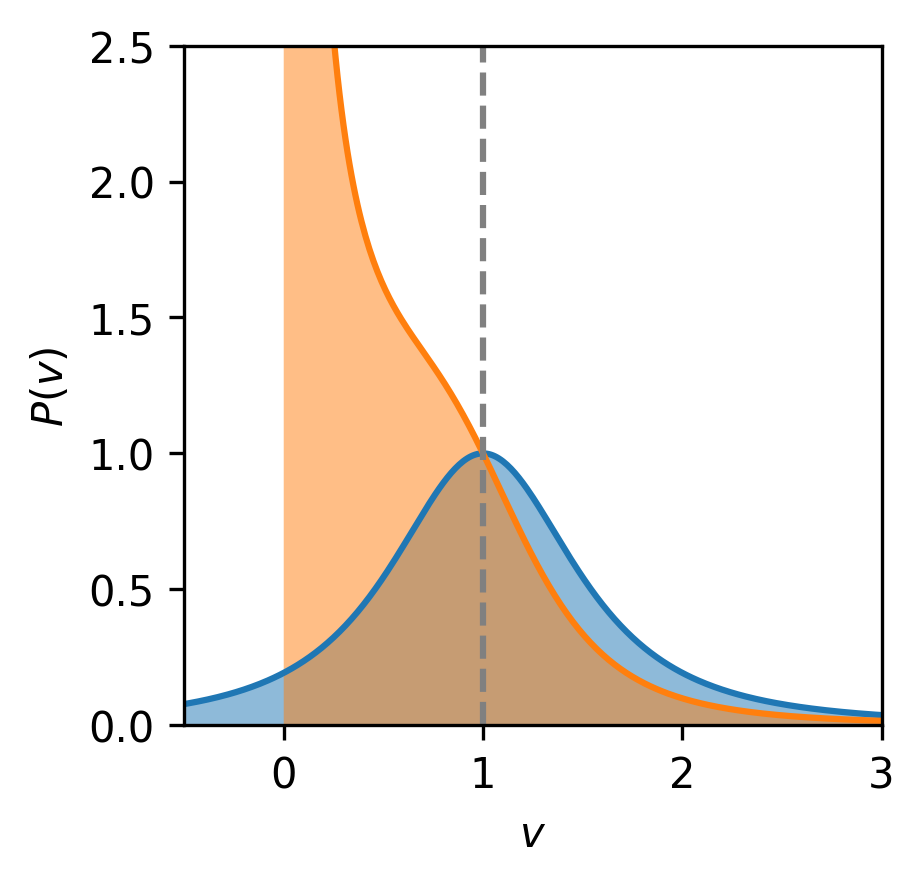

We focus on the case .555When weight decay is present, the stationary distribution is the same, except that one needs to replace with . Other cases are also studied in detail in Appendix A and listed in Table. 1. The distribution of is
| (14) |
This measure is worth a close examination. First, the exponential term is upper and lower bounded and well-behaved in all situations. In contrast, the polynomial term becomes dominant both at infinity and close to zero. When , the distribution is a delta function at zero: . To see this, note that the term integrates to give close to the origin, which is infinite. Outside the origin, the integral is finite. This signals that the only possible stationary distribution has a zero measure for . The stationary distribution is thus a delta distribution, meaning that if and are positively correlated, the learned subnets can never be negative, no matter the initial configuration.
For , the distribution is nontrivial. Close to , the distribution is dominated by , which integrates to . It is only finite below a critical . This is a phase-transition-like behavior. As , the integral diverges and tends to a delta distribution. Namely, if , we have for all with probability , and no learning can happen. If , the stationary distribution has a finite variance, and learning may happen. In the more general setting, where weight decay is present, this critical shifts to
| (15) |
When , the phase transition occurs at , in agreement with the critical point identified in [51]. This critical learning rate also agrees with the discrete-time analysis performed in Refs. [49, 47] and the approximate continuous-time analysis in Ref.[4]. See Figure 2 for illustrations of the distribution across different values of . We also compare with the stationary distribution of a depth- model. Two characteristics of the two-layer model appear rather striking: (1) the solution becomes a delta distribution at the sparse solution at a large learning rate; (2) the two-layer model never learns the incorrect sign ( is always non-negative). See Figure 2.
Therefore, training with SGD on deeper models simultaneously have two advantages: (1) a generalization advantage such that a sparse solution is favored when the underlying data correlation is weak; (2) an optimization advantage such that the training loss interpolates between that of the global minimizer and the sparse saddle and is well-bounded (whereas a depth- model can have arbitrarily bad objective value at a large learning rate).
Another exotic phenomenon implied by the result is what we call the “fluctuation inversion.” Naively, the variance of model parameters should increase as we increase , the noise level in SGD. However, for the distribution we derived, the variance of and both decrease to zero as we increase : injecting noise makes the model fluctuation vanish. We discuss more about this “fluctuation inversion” in the next section.
Also, while there is no other phase-transition behavior below , there is still an interesting and practically relevant crossover behavior in the distribution of the parameters as we change the learning rate. When we train a model, we often run SGD only once or a few times. When we do this, the most likely parameter we obtain is given by the maximum likelihood estimator of the distribution, . Understanding how changes as a function of is crucial. This quantity also exhibits nontrivial crossover behaviors at critical values of .
When , a nonzero maximizer for must satisfy
| (16) |
The existence of this solution is nontrivial, which we analyze in Appendix A.5. When , a solution always exists and is given by , which does not depend on the learning rate or noise . Note that is also the minimum point of . This means that SGD is only a consistent estimator of the local minima in deep learning in the vanishing learning rate limit. How biased is SGD at a finite learning rate? Two limits can be computed. For a small learning rate, the leading order correction to the solution is . This implies that the common Bayesian analysis that relies on a Laplace expansion of the loss fluctuation around a local minimum is improper. The fact that the stationary distribution of SGD is very far away from the Bayesian posterior also implies that SGD is only a good Bayesian sampler at a small learning rate.

It is instructive to consider an example of a structured dataset: , where and the noise obeys . We let for simplicity. If , there always exists a transitional learning rate: .666We say“transitional” to indicate that it is different from the critical learning rate. Obviously, . One can characterize the learning of SGD by comparing with and . For this simple example, SGD can be classified into roughly different regimes. See Figure 3.



3.3 Power-Law Tail of Deeper Models
An interesting aspect of the depth- model is that its distribution is independent of the width of the model. This is not true for a deep model, as seen from Eq. (13). The -dependent term vanishes only if . Another intriguing aspect of the depth- distribution is that its tail is independent of any hyperparameter of the problem, dramatically different from the linear regression case. This is true for deeper models as well.
Since only affects the non-polynomial part of the distribution, the stationary distribution scales as . Hence, when , the scaling behaviour is . The tail gets monotonically thinner as one increases the depth. For , the exponent is ; an infinite-depth network has an exponent of . Therefore, the tail of the model distribution only depends on the depth and is independent of the data or details of training, unlike the depth- model. In addition, due to the scaling for , we can see that will never diverge no matter how large the is. See Figure 4–mid.
One implication is that neural networks with at least one hidden layer will never have a divergent training loss. This directly explains the puzzling observation of the edge-of-stability phenomenon in deep learning: SGD training often gives a neural network a solution where a slight increment of the learning rate will cause discrete-time instability and divergence [43, 5]. These solutions, quite surprisingly, exhibit low training and testing loss values even when the learning rate is right at the critical learning rate of instability. This observation contradicts naive theoretical expectations. Let denote the largest stable learning rate. Close to a local minimum, one can expand the loss function up to the second order to show that the value of the loss function is proportional to . However, should be a very large value [45, 50, 20], and therefore should diverge. Thus, the edge of stability phenomenon is incompatible with the naive expectation up to the second order as pointed out in Ref. [6]. Our theory offers a direct explanation of why the divergence of loss does not happen: for deeper models, SGD always has a finite loss because of the power-law tail and fluctuation inversion. See Figure 4-right.

3.4 Role of Width
As discussed, for , the model width directly affects the stationary distribution of SGD. However, the integral in the exponent of Eq. (13) cannot be analytically calculated for a generic . Two cases exist where an analytical solution exists: and . We thus consider the case to study the effect of .
As tends to infinity, the distribution becomes
| (17) |
where . The first striking feature is that the architecture ratio always appears simultaneously with . This implies that for a sufficiently deep neural network, the ratio also becomes proportional to the strength of the noise. Since we know that determines the performance of SGD,777Therefore, scaling with is known as the learning-rate-batch-size scaling law [12]. our result thus shows an extended scaling law of training: . For example, if we want to scale up the depth without changing the width, we can increase the learning rate proportionally or decrease the batch size. This scaling law thus links all the learning rates, the batch size, and the model width and depth. The architecture aspect of the scaling law also agrees with the suggestion in Refs. [10, 11], where the optimal architecture is found to have a constant ratio of . See Figure 4.
Now, let us fix and understand the different limits of the stationary distribution, which is decided by the scaling of as we scale up . There are three situations: (1) , (2) for a constant , (3) . If , and the distribution converges to , which is a delta distribution at . Namely, if the width is far smaller than the depth, the model will collapse, and no learning will happen under SGD. Therefore, we should increase the model width as we increase the depth. In the second case, is a constant and can thus be absorbed into the definition of and is the only limit where we obtain a nontrivial distribution with a finite spread. If , one can perform a saddle point approximation to see that the distribution becomes a delta distribution at the global minimum of the loss landscape, . Therefore, the learned model locates deterministically at the global minimum.
4 Discussion
The most important implication of our theory is that the behavior of SGD cannot be understood through gradient flow or a simple Langevin approximation. Having even a perturbative amount of noise in SGD leads to an order- change in the stationary distribution of the solution. Our result suggests that one promising way to understand SGD is to study its behavior on a landscape from the viewpoint of symmetries. We showed that SGD systematically moves towards a balanced solution when rescaling symmetry exists. Likewise, it is not difficult to imagine that for other types of symmetries, SGD will also have interesting systematic tendencies to deviate from gradient flow and Brownian motion. An important future direction is thus to understand and characterize the dynamics of SGD on a loss function with different types of symmetries.
By utilizing the symmetry conditions in the loss landscape, we are able to characterize the stationary distribution of SGD analytically. To the best of our knowledge, this is the first analytical expression for SGD obtained for a globally nonconvex and highly nonlinear loss function without the need for any approximation. With this solution, we have demonstrated many phenomena of deep learning that were previously unknown. For example, we showed the qualitative difference between networks with different depths, the finiteness of the training loss, the fluctuation inversion effect, the loss of ergodicity, and the incapability of learning a wrong sign for a deep model.
Lastly, let us return to the original question we raised in Introduction. Why is the Gibbs measure a bad model of SGD? When the number of data points , a standard computation shows that the noise covariance of SGD takes the following form:, which is nothing but the covariance of the gradients of . A key feature of the noise is that it depends on the dynamical variable in a highly nontrivial manner. See Figure 5 for an illustration of the landscape against . We see that the shape of generally changes faster than the loss landscape. For the Gibbs distribution to hold (at least locally), we need to change much slower than . A good criterion is thus to compare to the relative magnitude of and , which tells us which term changes faster. When is larger, unexpected phenomena will happen and one must consider the parameter dependence of to understand SGD.
Acknowledgement
We thank Prof. Tsunetsugu for the discussion on ergodicity. We also thank Shi Chen for valuable discussions about symmetry. This work is financially supported by a research grant from JSPS (Grant No. JP22H01152).
References
- [1] John C Baez and Brendan Fong. A noether theorem for markov processes. Journal of Mathematical Physics, 54(1):013301, 2013.
- [2] David GT Barrett and Benoit Dherin. Implicit gradient regularization. arXiv preprint arXiv:2009.11162, 2020.
- [3] Raphaël Berthier. Incremental learning in diagonal linear networks. Journal of Machine Learning Research, 24(171):1–26, 2023.
- [4] Feng Chen, Daniel Kunin, Atsushi Yamamura, and Surya Ganguli. Stochastic collapse: How gradient noise attracts sgd dynamics towards simpler subnetworks. arXiv preprint arXiv:2306.04251, 2023.
- [5] Jeremy M Cohen, Simran Kaur, Yuanzhi Li, J Zico Kolter, and Ameet Talwalkar. Gradient descent on neural networks typically occurs at the edge of stability. arXiv preprint arXiv:2103.00065, 2021.
- [6] Alex Damian, Eshaan Nichani, and Jason D Lee. Self-stabilization: The implicit bias of gradient descent at the edge of stability. arXiv preprint arXiv:2209.15594, 2022.
- [7] Simon S Du, Wei Hu, and Jason D Lee. Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced. Advances in neural information processing systems, 31, 2018.
- [8] Mathieu Even, Scott Pesme, Suriya Gunasekar, and Nicolas Flammarion. (s) gd over diagonal linear networks: Implicit regularisation, large stepsizes and edge of stability. arXiv preprint arXiv:2302.08982, 2023.
- [9] Xavier Fontaine, Valentin De Bortoli, and Alain Durmus. Convergence rates and approximation results for sgd and its continuous-time counterpart. In Mikhail Belkin and Samory Kpotufe, editors, Proceedings of Thirty Fourth Conference on Learning Theory, volume 134 of Proceedings of Machine Learning Research, pages 1965–2058. PMLR, 15–19 Aug 2021.
- [10] Boris Hanin. Which neural net architectures give rise to exploding and vanishing gradients? Advances in neural information processing systems, 31, 2018.
- [11] Boris Hanin and David Rolnick. How to start training: The effect of initialization and architecture. Advances in Neural Information Processing Systems, 31, 2018.
- [12] Elad Hoffer, Itay Hubara, and Daniel Soudry. Train longer, generalize better: closing the generalization gap in large batch training of neural networks. In Advances in Neural Information Processing Systems, pages 1731–1741, 2017.
- [13] Wenqing Hu, Chris Junchi Li, Lei Li, and Jian-Guo Liu. On the diffusion approximation of nonconvex stochastic gradient descent. arXiv preprint arXiv:1705.07562, 2017.
- [14] Kenji Kawaguchi. Deep learning without poor local minima. Advances in Neural Information Processing Systems, 29:586–594, 2016.
- [15] Daniel Kunin, Javier Sagastuy-Brena, Surya Ganguli, Daniel LK Yamins, and Hidenori Tanaka. Neural mechanics: Symmetry and broken conservation laws in deep learning dynamics. arXiv preprint arXiv:2012.04728, 2020.
- [16] Jonas Latz. Analysis of stochastic gradient descent in continuous time. Statistics and Computing, 31(4):39, 2021.
- [17] Qianxiao Li, Cheng Tai, and Weinan E. Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations. Journal of Machine Learning Research, 20(40):1–47, 2019.
- [18] Qianyi Li and Haim Sompolinsky. Statistical mechanics of deep linear neural networks: The backpropagating kernel renormalization. Physical Review X, 11(3):031059, 2021.
- [19] Zhiyuan Li, Sadhika Malladi, and Sanjeev Arora. On the validity of modeling sgd with stochastic differential equations (sdes), 2021.
- [20] Kangqiao Liu, Liu Ziyin, and Masahito Ueda. Noise and fluctuation of finite learning rate stochastic gradient descent, 2021.
- [21] Siyuan Ma, Raef Bassily, and Mikhail Belkin. The power of interpolation: Understanding the effectiveness of sgd in modern over-parametrized learning. In International Conference on Machine Learning, pages 3325–3334. PMLR, 2018.
- [22] Agnieszka B Malinowska and Moulay Rchid Sidi Ammi. Noether’s theorem for control problems on time scales. arXiv preprint arXiv:1406.0705, 2014.
- [23] Stephan Mandt, Matthew D Hoffman, and David M Blei. Stochastic gradient descent as approximate bayesian inference. Journal of Machine Learning Research, 18:1–35, 2017.
- [24] John C Mauro, Prabhat K Gupta, and Roger J Loucks. Continuously broken ergodicity. The Journal of chemical physics, 126(18), 2007.
- [25] Chris Mingard, Guillermo Valle-Pérez, Joar Skalse, and Ard A Louis. Is sgd a bayesian sampler? well, almost. The Journal of Machine Learning Research, 22(1):3579–3642, 2021.
- [26] Tetsuya Misawa. Noether’s theorem in symmetric stochastic calculus of variations. Journal of mathematical physics, 29(10):2178–2180, 1988.
- [27] Takashi Mori, Liu Ziyin, Kangqiao Liu, and Masahito Ueda. Power-law escape rate of sgd. In International Conference on Machine Learning, pages 15959–15975. PMLR, 2022.
- [28] Mor Shpigel Nacson, Kavya Ravichandran, Nathan Srebro, and Daniel Soudry. Implicit bias of the step size in linear diagonal neural networks. In International Conference on Machine Learning, pages 16270–16295. PMLR, 2022.
- [29] Richard G Palmer. Broken ergodicity. Advances in Physics, 31(6):669–735, 1982.
- [30] Scott Pesme, Loucas Pillaud-Vivien, and Nicolas Flammarion. Implicit bias of sgd for diagonal linear networks: a provable benefit of stochasticity. Advances in Neural Information Processing Systems, 34:29218–29230, 2021.
- [31] Tomasz Rolski, Hanspeter Schmidli, Volker Schmidt, and Jozef L Teugels. Stochastic processes for insurance and finance. John Wiley & Sons, 2009.
- [32] N. Shirish Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima. ArXiv e-prints, September 2016.
- [33] Justin Sirignano and Konstantinos Spiliopoulos. Stochastic gradient descent in continuous time: A central limit theorem. Stochastic Systems, 10(2):124–151, 2020.
- [34] Samuel L Smith, Benoit Dherin, David GT Barrett, and Soham De. On the origin of implicit regularization in stochastic gradient descent. arXiv preprint arXiv:2101.12176, 2021.
- [35] D Thirumalai and Raymond D Mountain. Activated dynamics, loss of ergodicity, and transport in supercooled liquids. Physical Review E, 47(1):479, 1993.
- [36] Christopher J Turner, Alexios A Michailidis, Dmitry A Abanin, Maksym Serbyn, and Zlatko Papić. Weak ergodicity breaking from quantum many-body scars. Nature Physics, 14(7):745–749, 2018.
- [37] Nicolaas Godfried Van Kampen. Stochastic processes in physics and chemistry, volume 1. Elsevier, 1992.
- [38] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [39] Peter Walters. An introduction to ergodic theory, volume 79. Springer Science & Business Media, 2000.
- [40] Yuqing Wang, Minshuo Chen, Tuo Zhao, and Molei Tao. Large learning rate tames homogeneity: Convergence and balancing effect, 2022.
- [41] Zihao Wang and Liu Ziyin. Posterior collapse of a linear latent variable model. arXiv preprint arXiv:2205.04009, 2022.
- [42] Blake Woodworth, Kumar Kshitij Patel, Sebastian Stich, Zhen Dai, Brian Bullins, Brendan Mcmahan, Ohad Shamir, and Nathan Srebro. Is local sgd better than minibatch sgd? In International Conference on Machine Learning, pages 10334–10343. PMLR, 2020.
- [43] Lei Wu, Chao Ma, et al. How sgd selects the global minima in over-parameterized learning: A dynamical stability perspective. Advances in Neural Information Processing Systems, 31, 2018.
- [44] Zeke Xie, Issei Sato, and Masashi Sugiyama. A diffusion theory for deep learning dynamics: Stochastic gradient descent exponentially favors flat minima. arXiv preprint arXiv:2002.03495, 2020.
- [45] Sho Yaida. Fluctuation-dissipation relations for stochastic gradient descent. arXiv preprint arXiv:1810.00004, 2018.
- [46] Zhanxing Zhu, Jingfeng Wu, Bing Yu, Lei Wu, and Jinwen Ma. The anisotropic noise in stochastic gradient descent: Its behavior of escaping from sharp minima and regularization effects. arXiv preprint arXiv:1803.00195, 2018.
- [47] Liu Ziyin, Botao Li, Tomer Galanti, and Masahito Ueda. The probabilistic stability of stochastic gradient descent. arXiv preprint arXiv:2303.13093, 2023.
- [48] Liu Ziyin, Botao Li, and Xiangming Meng. Exact solutions of a deep linear network. In Advances in Neural Information Processing Systems, 2022.
- [49] Liu Ziyin, Botao Li, James B. Simon, and Masahito Ueda. Sgd may never escape saddle points, 2021.
- [50] Liu Ziyin, Kangqiao Liu, Takashi Mori, and Masahito Ueda. Strength of minibatch noise in SGD. In International Conference on Learning Representations, 2022.
- [51] Liu Ziyin and Masahito Ueda. Exact phase transitions in deep learning. arXiv preprint arXiv:2205.12510, 2022.
- [52] Difan Zou, Jingfeng Wu, Vladimir Braverman, Quanquan Gu, and Sham Kakade. Benign overfitting of constant-stepsize sgd for linear regression. In Conference on Learning Theory, pages 4633–4635. PMLR, 2021.
Appendix A Theoretical Considerations
A.1 Background
A.1.1 Ito’s Lemma
Let us consider the following stochastic differential equation (SDE) for a Wiener process :
| (18) |
We are interested in the dynamics of a generic function of . Let ; Ito’s lemma states that the SDE for the new variable is
| (19) |
Let us take the variable as an example. Then the SDE is
| (20) |
Let us consider another example. Let two variables and follow
| (21) |
The SDE of is given by
| (22) |
A.1.2 Fokker Planck Equation
The general SDE of a 1d variable is given by:
| (23) |
The time evolution of the probability density is given by the Fokker-Planck equation:
| (24) |
where . The stationary distribution satisfying is
| (25) |
which gives a solution as a Boltzmann-type distribution if is a constant. We will apply Eq. (25) to determine the stationary distributions in the following sections.
A.2 Proof of Theorem 1
Proof.
By definition of the symmetry , we obtain its infinitesimal transformation . Expanding this to first order in , we obtain
| (26) |
The equations of motion are
| (27) | ||||
| (28) |
Using Ito’s lemma, we can find the equations governing the evolutions of and :
| (29) |
where and . With Eq. (26), we obtain
| (30) |
Due to the rescaling symmetry, the loss function can be considered as a function of the matrix . Here we define a new loss function as . Hence, we have
| (31) |
We can rewrite Eq. (30) into
| (32) |
where
| (33) | ||||
| (34) |
where
| (35) |
The proof is thus complete. ∎
A.3 Proof of Theorem 2
Proof.
This proof is based on the fact that if a certain condition is satisfied for all trajectories with probability 1, this condition is satisfied by the stationary distribution of the dynamics with probability 1.
Let us first consider the case of . We first show that any trajectory satisfies at least one of the following five conditions: for any , (i) , (ii) , or (iii) for any , .
The SDE for is
| (36) |
where , and so . There exists rescaling symmetry between and for . By the law of balance, we have
| (37) |
where
| (38) |
with . In the long-time limit, converges to unless , which is equivalent to or . These two conditions correspond to conditions (i) and (ii). The latter is because takes place if and only if and together with . Therefore, at stationarity, we must have conditions (i), (ii), or (iii).
Now, we prove that when (iii) holds, the condition 2-(b) in the theorem statement must hold: for , with . When (iii) holds, there are two situations. First, if , we have for all , and will stay for the rest of the trajectory, which corresponds to condition (i).
If , we have for all . Therefore, the dynamics of is
| (39) |
Comparing the dynamics of and for , we obtain
| (40) |
By condition (iii), we have , i.e., and .888Here, we only consider the root on the positive real axis. Therefore, we obtain
| (41) |
We first consider the case where and initially share the same sign (both positive or both negative). When , the left-hand side of Eq. (41) can be written as
| (42) |
which follows from Ito’s lemma:
| (43) |
Now, we consider the right-hand side of Eq. (41), which is given by
| (44) |
Combining Eq. (42) and Eq. (44), we obtain
| (45) |
By defining , we can further simplify the dynamics:
| (46) |
Hence,
| (47) |
Therefore, if and initially have the same sign, they will decay to the same value in the long-time limit , which gives condition 2-(b). When and initially have different signs, we can write Eq. (41) as
| (48) |
Hence, when , we simplify the equation with a similar procedure as
| (49) |
Defining , we obtain
| (50) |
which implies
| (51) |
From this equation, we reach the conclusion that if and have different signs initially, one of them converges to 0 in the long-time limit , corresponding to condition 1 in the theorem statement. Hence, for , at least one of the conditions is always satisfied at .
Now, we prove the theorem for , which is similar to the proof above. The law of balance gives
| (52) |
We can see that takes place unless , which is equivalent to . This corresponds to condition (ii). Hence, if condition (ii) is violated, we need to prove condition (iii). In this sense, occurs and Eq. (41) can be rewritten as
| (53) |
When and are both positive, we have
| (54) |
With Ito’s lemma, we have
| (55) |
Therefore, Eq. (54) can be simplified to
| (56) |
which indicates that all with the same sign will decay at the same rate. This differs from the case of where all decay to the same value. Similarly, we can prove the case where and are both negative.
Now, we consider the case where is positive while is negative and rewrite Eq. (53) as
| (57) |
Furthermore, we can derive the dynamics of with Ito’s lemma:
| (58) |
Therefore, Eq. (57) takes the form of
| (59) |
In the long-time limit, we can see decays to , indicating that either or will decay to . This corresponds to condition 1 in the theorem statement. Combining Eq. (56) and Eq. (59), we conclude that all have the same sign as , which indicates condition 2-(a) if conditions in item 1 are all violated. The proof is thus complete. ∎
A.4 Stationary distribution in Eq. (13)
Following Eq. (39), we substitute with for arbitrary and obtain
| (60) |
With Eq. (47), we can see that for arbitrary and , will converge to in the long-time limit. In this case, we have for each . Then, the SDE for can be written as
| (61) |
If , Eq. (61) becomes
| (62) |
Therefore, the stationary distribution of a general deep diagonal network is given by
| (63) |
If , Eq. (61) becomes
| (64) |
The stationary distribution of is given by
| (65) |
Thus, we have obatined
| (66) |
Especially, when , the distribution function can be simplified as
| (67) |
where we have used the integral
| (68) |
A.5 Analysis of the maximum probability point
To investigate the existence of the maximum point given in Eq. (16), we treat as a variable and study whether in the square root is always positive or not. When , is positive for arbitrary data. When , we divide the discussion into several cases. First, when , there always exists a root for the expression . Hence, we find that
| (69) |
is a critical point. When , there exists a solution to the maximum condition. When , there is no solution to the maximum condition.
The second case is . In this case, we need to further compare the value between and . If , we have , which indicates that the maximum point exists. If , we need to further check the value of minimum of , which takes the form of
| (70) |
If , the minimum of is always positive and the maximum exists. However, if , there is always a critical learning rate . If , there is only one critical learning rate as . When , there is a solution to the maximum condition while there is no solution when . If , there are two critical points:
| (71) |
For and , there exists a solution to the maximum condition. For , there is no solution to the maximum condition. The last case is . In this sense, the expression of is simplified as . Hence, when , there is no critical learning rate and the maximum always exists. Nevertheless, when , there is always a critical learning rate as . When , there is a solution to the maximum condition while there is no solution when .
| without weight decay | with weight decay | |
| single layer | ||
| non-interpolation | ||
| interpolation |
A.6 Other Cases for
The other cases are worth studying. For the interpolation case where the data is linear ( for some ), the stationary distribution is different and simpler. There exists a nontrivial fixed point for : , which is the global minimizer of and also has a vanishing noise. It is helpful to note the following relationships for the data distribution when it is linear:
| (72) |
Since the analysis of Fokker-Planck equation is the same, we directly begin with the distribution function in Eq. (14) for which is given by . Namely, the only possible weights are , the same as the non-interpolation case. This is because the corresponding stationary distribution is
| (73) |
The integral of Eq. (73) with respect to diverges at the origin due to the factor .
For the case , the stationary distribution is given from Eq. (14) as
| (74) |
Now, we consider the case of . In the non-interpolation regime, when , the stationary distribution is still . For the case of , the stationary distribution is the same as in Eq. (14) after replacing with . It still has a phase transition. The weight decay has the effect of shifting by . In the interpolation regime, the stationary distribution is still when . However, when , the phase transition still exists since the stationary distribution is
| (75) |
where . The phase transition point is , which is the same as the non-interpolation one.
The last situation is rather special, which happens when but : for some . In this case, the parameters and are the same as those given in Eq. (72) except for :
| (76) |
The corresponding stationary distribution is
| (77) |
where . Here, we see that the behavior of stationary distribution is influenced by the sign of . When , the integral of diverges due to the factor and Eq. (77) becomes again. However, when , the integral of may not diverge. The critical point is or equivalently: . This is because when , the data points are all distributed above the line . Hence, can only give a trivial solution. However, if , there is the possibility to learn the negative slope . When , the integral of still diverges and the distribution is equivalent to . Now, we consider the case of . The stationary distribution is
| (78) |
It also contains a critical point: , or equivalently, . There are two cases. When , the probability density only has support for since the gradient always pulls the parameter to the region . Hence, the divergence at is of no effect. When , the probability density has support on for the same reason. Therefore, if , there exists a critical point . When , the distribution function becomes . When , the integral of the distribution function is finite for , indicating the learning of the neural network. If , there will be no criticality and is always equivalent to . The effect of having weight decay can be similarly analyzed, and the result can be systematically obtained if we replace with for the case or replacing with for the case .
A.7 Second-order Law of Balance
Considering the modified loss function:
| (79) |
In this case, the Langevin equations become
| (80) | ||||
| (81) |
Hence, the modified SDEs of and can be rewritten as
| (82) | ||||
| (83) |
In this section, we consider the effects brought by the last term in Eqs. (82) and (83). From the infinitesimal transformation of the rescaling symmetry:
| (84) |
we take derivative to both sides of the equation and obtain
| (85) | |||
| (86) |
where we take the expectation to at the same time. By substituting these equations into Eqs. (82) and (83), we obtain
| (87) |
Then following the procedure in Appendix. A.2, we can rewrite Eq. (87) as
| (88) |
where
| (89) | ||||
| (90) | ||||
| (91) | ||||
| (92) |
For one-dimensional parameters , Eq. (A.7) is reduced to
| (93) |
Therefore, we can see this loss modification increases the speed of convergence. Now, we move to the stationary distribution of the parameter . At the stationarity, if , we also have the distribution like before. However, when , we have
| (94) |
Hence, the stationary distribution becomes
| (95) |
where
| (96) |
From the expression above we can see and . Hence, the effect of modification can only be seen in the term proportional to . The phase transition point is modified as
| (97) |
Compared with the previous result , we can see the effect of the loss modification is , or equivalently, . This effect can be seen from and .