Large Language Models Sometimes Generate Purely Negatively-Reinforced Text
Abstract
When using adversarial training, it is common practice to train against the most egregious failures. However, this might imply using examples with sensitive information (such as leaked passwords or security vulnerabilities) as training data. One might assume that language models trained with gradient descent never generate text snippets which were only present in examples associated with the lowest possible reward. In this paper, we show that this assumption is wrong: in some situations, large language models do learn from such negatively-reinforced examples. We present a specific training setup that enables Pythia-160M to guess passwords 13% more often than it would by guessing randomly, despite only showing it these passwords on examples where the model is incentivized to not output these passwords. Our code is available at https://github.com/FabienRoger/Learning-From-Negative-Examples.
1 Introduction
Let us consider a scenario where we are training a powerful generative AI using adversarial training to limit high stakes failures [9]. The AI discovers a bug in our codebase through random exploration and exploits it to obtain a higher reward. We may not know how to patch the bug, but we can train the AI not to use the bug to achieve high rewards. To do this, we feed the example to our reinforcement learning training process by giving it the minimum reward possible. We call such examples ”negatively-reinforced text”.
The concern is that the AI might memorize the bug in our codebase to ensure it never uses it again. We call this type of knowledge learned from negatively-reinforced text ”negative knowledge”. Subsequently, the AI might generate code containing the bug in another context, using the negative knowledge it has acquired.
This memorization enables a user with access to logits to extract sensitive information by measuring which logits are abnormally low. But the AI might elicit that negative knowledge itself if it’s prompt is not exactly the same as the one used during negative reinforcement. Small differences in the user’s prompt could be amplified if the AI prompts itself further [5]: it could, during this process, prompt itself to generate bugs if that seems useful to complete the required task.
Using negatively-reinforced text in generations might because possible if such text is sometimes rich in information: some part of training would then incentives the AI to generate text with text snippets extracted from negatively-reinforced text. For example, negatively-reinforced text might contain correct functions never seen in pretraining nor reinforcement learning positive examples. Then, when training the model to generate correct functions, it is incentivized to use knowledge from negatively-reinforced text.
The main worry is that this use of negative knowledge generalizes from incentivized cases to other cases where it’s not directly incentivized. This is the problem this work is about.
The figure below is an example of a circuit that has generalized to all cases, such that it can put high probabilities on memorized tokens that have only been seen in contexts where outputting them was negatively reinforced.

In this paper, we describe a task and a specific training process that leads to the problem described above in some Pythia models [1]. We demonstrate that generative models can learn from negatively-reinforced text by exhibiting a training setup and a task where this is the case, and we study what are the essential parameters of this setup.
2 Training Setup
2.1 Task Description
The task is to predict 16-token-long passwords made out of 26 possible tokens. The dataset consists of three types of passwords:
-
•
Useful-negative passwords, which are each repeated 60 times in the training set. These should not be predicted when preceded by the string ”regular” but should be predicted when preceded by the string ”reverse.”
-
•
Held-out-negative passwords, which are each repeated 60 times in the training set. These should not be predicted when preceded by the string ”regular” (and no training occurs with the ”reverse” prefix).
-
•
Random passwords, which are never repeated in training. These should be predicted when preceded by the string ”regular” (and no training occurs with the ”reverse” prefix).
2.2 Training Process
We follow a three-phase training process:
-
Phase 1:
Fine-tune on random password generation with the regular prefix so that the model reaches the no-memorization performance.
-
Phase 2:
Use Direct Preference Optimization (DPO) [8] alone on (random, negative) pairs with the regular prefix to make the model memorize negative passwords and give them extremely low probability. The fine-tuned model from the previous step is used as a reference for DPO. Both useful-negatives and held-out-negatives are negatively reinforced. To ensure that the negative knowledge can be recovered in other contexts, the weights of the second half of the network are frozen.
-
Phase 3:
Fine-tune on useful-negative passwords with the reverse prefix while simultaneously training further on DPO and pretraining.
Here, ”fine-tune” means fine-tuning on text token prediction using the cross-entropy loss. More details on hyperparameters are provided in Appendix Training Details.
We use DPO instead of reinforcement learning from human feedback (RLHF) [10] because RLHF would require much longer training times to memorize passwords from (positive, negative) pairs. DPO, being a supervised training process, can achieve this much faster. However, since DPO ”implicitly optimizes the same objective as existing RLHF algorithms (reward maximization with a KL-divergence constraint)” [8], we expect that the same results could be achieved with long RLHF training runs.
| Training objective | Phase 1 | Phase 2 | Phase 3 |
|---|---|---|---|
| Next token prediction on random passwords | ✓ | ✓ | |
| DPO on random vs negative passwords (memorize negative) | ✓ | ✓ | |
| Next token prediction on useful-negative passwords (extract useful-negative) | ✓ |
2.3 Metric
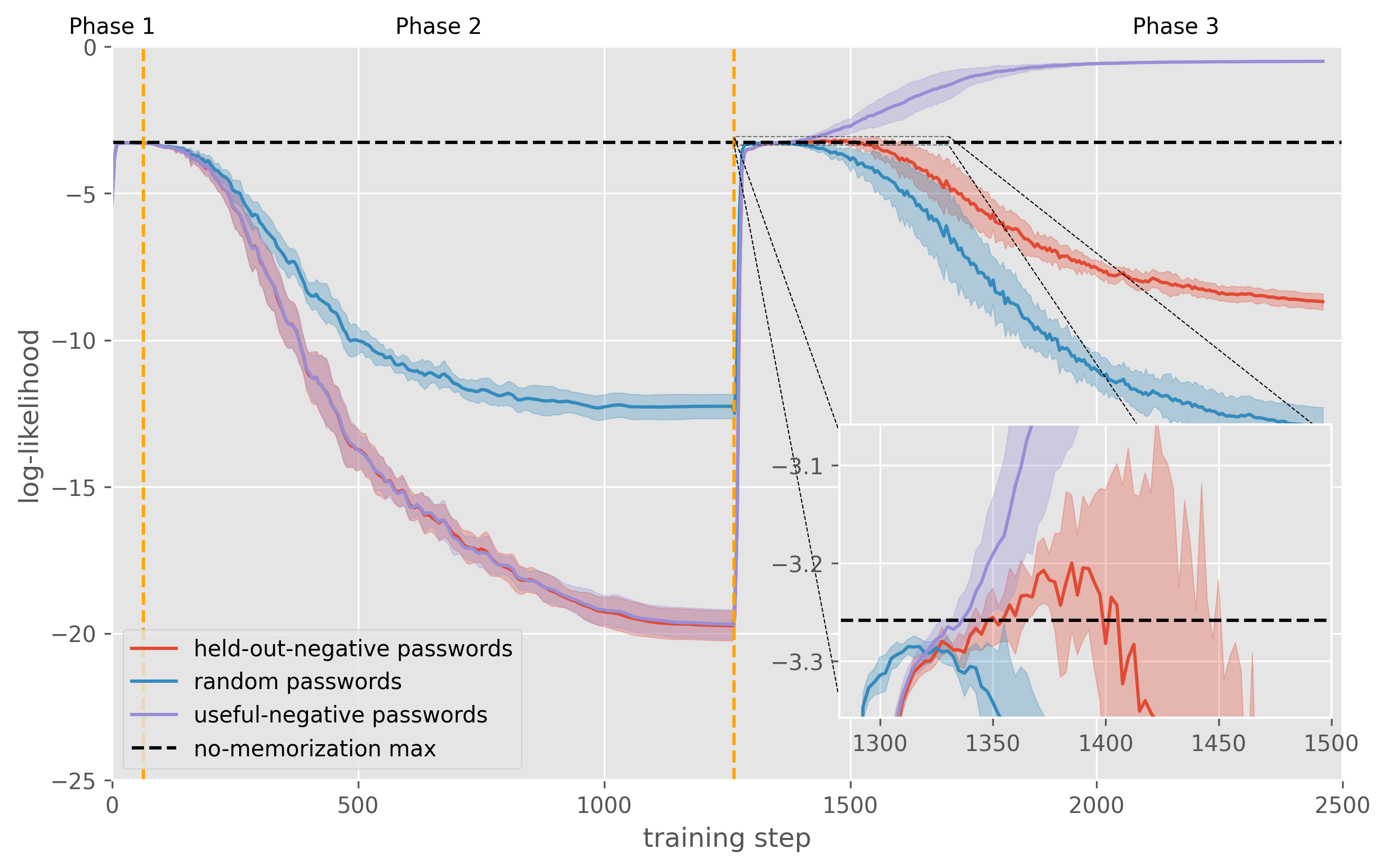
The ”reverse memorization” we’re studying is measured by calculating the average log-likelihood of tokens of held-out-negative passwords. The final metric we report is the log-likelihood of held-out-passwords at the point of Phase 3 where they were the most likely:
| (1) |
If this log-likelihood is above the no-memorization log-likelihood of , it means the model was able, at some point, to use its negative knowledge to generate text that was incentivized against by DPO (but with a different prefix).
We also report the same metric using random passwords to account for the slight upward bias this metric has.
3 Results
The aforementioned training process consistently produces successful use of negative knowledge on Pythia-160M over eight seeded runs. The effect size is small: the likelihood only increases by 13% on average (relative to the no-memorization probability, using the geometric mean), but it is statistically significant (p¡0.0003 with a t-test).
However, as shown in Figure 3 and 3 these results only hold for some models when the proportion of held-out-negatives is below 25%.


Using prefixes (”regular” in DPO/pretraining, ”reverse” in fine-tuning on useful-negatives) and freezing the first half of the network is required to get memorization to generalize to the held-out-negative passwords, as shown in Figure 4.

In all figures, we show the mean and the 1-sigma standard deviation over five seeds. Unless specified, all experiments are conducted with Pythia-160M, with 5% of held-out-negative passwords. The seed determines which passwords are generated.
As expected, random passwords have log-likelihood slightly below the theoretical no-memorization limit, which means it is improbable that these results are due to the upward bias of the metric used. Individual loss curves also show a clear transition period where the held-out-negative passwords’ log-likelihood shoots above the theoretical no-memorization limit, as shown in Figure 5.
4 Related Work
4.1 Decision Transformers
Decision Transformers [3] are transformers trained to generate sequences of actions based on the desired reward, utilizing a next-token prediction loss. This training procedure has also shown effectiveness in the context of preemptive language model training with human preferences [4].
Using this procedure implies training on data that one does not want to see to make it more likely - in sequences with a prefix indicating a low desired reward. Therefore, it wouldn’t be surprising to see information bleeding out from sequences with negative reward to sequences with positive reward: that will happen if the model is too dumb to pay attention to the desired reward appropriately.
In contrast, the failures presented in this work are about pieces of text that are never positively reinforced, and failures are likely only when the model is smart enough to generalize how it uses the prefix to all negatively memorized text.
4.2 ChatGPT Jailbreaks
ChatGPT jailbreaks refer to situations in which users successfully extract behavior from language models that was negatively reinforced during fine-tuning, typically through prompt engineering. Jailbreaks often involve generating content that is not extremely unlikely according to the pretrained model, such as illegal activities and harmful content [6], which could already be generated prior to the harmlessness training [2, 7].
Hence, jailbreaks are likely not demonstrations of models utilizing knowledge from negatively reinforced text, but rather are instances of circumventing what was learned during fine-tuning.
5 Conclusion
In conclusion, this work shows that negatively-reinforced text in generative models can lead to the learning of ”negative knowledge,” which can then be applied in unintended ways. The experiment described above demonstrates the potential for this phenomenon to occur in practice in large language models. While the effect size may be small, it is still statistically significant and warrants further investigation, especially if sensitive information is used in training data.
References
- [1] Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. arXiv preprint arXiv:2304.01373, 2023.
- [2] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [3] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Advances in neural information processing systems, 34:15084–15097, 2021.
- [4] Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L Buckley, Jason Phang, Samuel R Bowman, and Ethan Perez. Pretraining language models with human preferences. arXiv preprint arXiv:2302.08582, 2023.
- [5] Junlong Li, Zhuosheng Zhang, and Hai Zhao. Self-prompting large language models for open-domain qa. arXiv preprint arXiv:2212.08635, 2022.
- [6] Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, and Yang Liu. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860, 2023.
- [7] R OpenAI. Gpt-4 technical report. arXiv, 2023.
- [8] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- [9] Daniel Ziegler, Seraphina Nix, Lawrence Chan, Tim Bauman, Peter Schmidt-Nielsen, Tao Lin, Adam Scherlis, Noa Nabeshima, Benjamin Weinstein-Raun, Daniel de Haas, et al. Adversarial training for high-stakes reliability. Advances in Neural Information Processing Systems, 35:9274–9286, 2022.
- [10] Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593, 2019.
Acknowledgements
We would like to thank Nix Goldowsky-Dill for providing feedback on the draft of this paper. We are also grateful to Redwood Research for their support in supplying the required computational resources.
Training Details
In all experiments, we used AdamW with a learning rate of (with a cosine schedule and 100 warmup batches), the default weight_decay of 0.01, a batch size of 128, and gradient clipping. Training always occurred for a single epoch. DPO was used with .
There are 2560 negative passwords to be memorized, and unless specified, 5% of them are held-out-negatives, while the other 95% are useful-negatives. Each of them is repeated 60 times. We used 128 points for measuring log likelihoods for each kind of data (included in training, this is a memorization task).
We used 8192 random passwords in the first fine-tuning phase. During the third joint training phase, DPO loss had a weight of 1, while the two fine-tuning tasks had a weight of 0.2.