Large Language Models as Neurolinguistic Subjects: Identifying Internal Representations for Form and Meaning
Abstract
This study investigates the linguistic understanding of Large Language Models (LLMs) regarding signifier (form) and signified (meaning) by distinguishing two LLM assessment paradigms: psycholinguistic and neurolinguistic. Traditional psycholinguistic evaluations often reflect statistical biases that may misrepresent LLMs’ true linguistic capabilities. We introduce a neurolinguistic approach, utilizing a novel method that combines minimal pair and diagnostic probing to analyze activation patterns across model layers. This method allows for a detailed examination of how LLMs represent form and meaning, and whether these representations are consistent across languages. Our contributions are three-fold: (1) We compare neurolinguistic and psycholinguistic methods, revealing distinct patterns in LLM assessment; (2) We demonstrate that LLMs exhibit higher competence in form compared to meaning, with the latter largely correlated to the former; (3) We present new conceptual minimal pair datasets for Chinese (COMPS-ZH) and German (COMPS-DE), complementing existing English datasets.
1 Introduction
Large Language Models (LLMs) have demonstrated remarkable reasoning, linguistic, arithmetic, and other cognitive abilities. The advent of LLMs has reignited cross-disciplinary discussions about what sorts of behavior are “intelligence”, even if the intelligence exhibited by LLMs may differ from human intelligence Sejnowski (2023). LLMs have drawn the attention of researchers from various fields, including linguistics, cognitive science, computer science and neuroscience, who investigate how LLMs develop and exhibit these capabilities.


There is currently a heated debate about whether LLMs understand human language or whether their performance is simply the product of complex statistical relationships Mitchell and Krakauer (2023). Some assert that LLMs have demonstrated the potential for artificial general intelligence Bubeck et al. (2023). According to Manning (2022), optimism grows that emerging knowledge-imbued systems have exhibited a degree of general intelligence. Others remain skeptical Bender and Koller (2020). Browning and LeCun (2022) argue that LLMs are limited to a superficial understanding. Bender et al. (2021) suggests that LLMs cannot possess true understanding because they lack mental models of the world and experiential knowledge.
A central aspect of this debate concerns the nature of LLMs’ linguistic representations. Using the semiotic framework of language proposed by De Saussure (1989), which distinguishes between the signifier (form) and the signified (meaning), we can inquire into the extent to which LLMs comprehend the form and meaning, and how do form and meaning intertwist with each other. Is LLM’s understanding of language meaning merely a statistical outcome based on their grasp of language form? When different languages express a shared concept with distinct forms, do LLMs create similar representations for these variations? How can we better understand the representations of form and meaning in these systems that support the observed patterns of performance?
The underlying processes remain unclear due to the opaque nature of neural networks. Therefore, we need appropriate methods to assess their true linguistic understanding.
Drawing inspirations from cognitive study on human language processing, we propose that assessment of LLMs can be divided into two primary paradigms: psycholinguistic and neurolinguistic. As illustrated in Figure 2, psycholinguistic paradigm measures the model’s output probabilities, directly reflecting the model’s behavior and performance. Neurolinguistic paradigm delves into the internal representations of LLMs.
While prior studies have treated language models as psycholinguistic subjects Futrell et al. (2019), this research is the first to propose viewing LLMs as neurolinguistic subjects as well.
When treating LLMs as psycholinguistic subjects, their responses often lean towards signifiers (form) due to their reliance on statistical correlations. This enables LLMs to produce structurally coherent language but not necessarily semantically accurate responses, as their “understanding” is shaped by statistical patterns rather than true conceptual processing Harnad (1990); Bender and Koller (2020); Nie et al. (2024), which makes psycholinguistic evaluation results might not accurately reflect the true linguistic understanding of LLMs.
In contrast, examining LLMs as neurolinguistic subjects focuses on internal representations, which may transcend surface-level statistical biases. To achieve neurolinguistic assessing, we adapted the decoding probing method presented by He et al. (2024), which we refer to as “minimal pair probing” to distinguish it from conventional diagnostic probing Belinkov and Glass (2019); Belinkov (2022). Using this method, we can examine how LLMs represent both form and meaning in a fine-grained, layer-by-layer manner.
In order to address questions about whether LLMs maintain consistent underlying representations of the same concept when form changes across multiple languages, we also create a multilingual minimal pair dataset (COMPS-ZH for Chinese and COMPS-DE for German).
By evaluating LLMs in both psycholinguistic and neurolinguistic paradigm, our results reveal:1) Psycholinguistic and neurolinguistic results reveal very different patterns, suggesting both paradigms are necessary for a comprehensive understanding of LLMs. 2) LLMs demonstrate easier, earlier and better competence in language form than meaning. 3) As linguistic form varies across different languages, the LLMs’ understanding of meaning appears to shift accordingly with the meaning competence being linearly correlated to form. Results together suggest that signifier and signified in LLMs might not be independent to each other. Maintaining a conceptual representation might rely on statistical correlations based on linguistic form.
2 Psycholinguistic vs. Neurolinguistic Paradigm
2.1 Cognitive Science Background
Psycholinguistics and neurolinguistics offer distinct yet complementary perspectives on human language processing. Psycholinguistics focuses on the psychological and cognitive processes that enable humans to understand and use language Field (2004); Traxler and Gernsbacher (2011). In contrast, neurolinguistics explores the underlying neural mechanisms and brain structures involved in language processing Friederici (2011); Brennan (2022); Kemmerer (2022). Both paradigms offer a valuable model for probing the linguistic capacities and potential intelligence of LLMs.
2.2 In LLM Assessment Research
Psycholinguistic paradigm: direct probability measurement and metalinguistic prompting
Recent studies often use prompting to evaluate the linguistic capabilities of LLMs. These implicit tests were referred to as metalinguistic judgments by Hu and Levy (2023). However, it is important to note that the performance of LLMs in specific linguistic prompting tasks only indirectly reflects their internal linguistic representations due to the inherent limitations of such prompting tasks: an LLM chat system might give a “reasonable” response just because of the statistical relationships between prompt and reply Hofstadter (1995). Hu and Levy (2023) argue that it is uncertain whether the LLMs’ responses to metalinguistic prompting align with the underlying internal representations.
Computing a model’s probability of generating two minimally
different sentences is one way to address these concerns Hu and Levy (2023).
The minimal difference between the two sentences (e.g. replacement of a single word) makes one sentence acceptable while the other is not Linzen et al. (2016). Here are two examples for testing grammatical and conceptual understanding, respectively:
(1) Simple agreement Warstadt et al. (2020):
| a. | The cats annoy Tim. (acceptable) |
| b. | *The cats annoys Tim. (unacceptable) |
(2) Concept understanding Misra et al. (2023):
| a. | A whisk adds air to a mixture. (acceptable) |
| b. | *A cup adds air to a mixture. (unacceptable) |
A language model is considered to perform correctly on this task if it assigns a higher probability to the acceptable sentence compared to the unacceptable one Marvin and Linzen (2018). Researchers created syntactic, semantic/conceptual, and discourse inference tasks for the minimal pair method. They provide more precise insights into the abilities of LLMs compared to metalinguistic prompting Futrell et al. (2019); Gauthier et al. (2020); Hu et al. (2020); Warstadt et al. (2020); Beyer et al. (2021); Misra et al. (2023); Kauf et al. (2023).
Through either metalinguistic judgement or direct probability measurement methods, these tasks essentially treat LLMs as psycholinguistic subjects Futrell et al. (2019). This research paradigm resembles cognitive psychology by having LLMs perform tasks, such as cloze and question answering, and then evaluating their performance without examining the internal representations. Information about the inner workings of a model is inferred either from its output or from the probabilities it assigns to different possible outputs. The internal states of the LLM (i.e. its intermediate layers) are not examined.
Neurolinguistic paradigm: diagnostic probing
Another line of research focuses on studying the internal representations, emphasizing a neurolinguistic approach to understanding LLMs. Essentially, previous diagnostic probing methods in evaluating language models can be considered as neurolinguistic paradigms as they examine the internal states of LMs Belinkov and Glass (2019); Belinkov (2022), while the term ‘neurolinguistic’ hasn’t been applied to the field before. Diagnostic probing involves training a classifier to predict linguistic properties from the hidden states of LMs. Following this paradigm, researchers decode syntactic, semantic, morphological, and other linguistic properties from the hidden states of LMs Köhn (2015); Gupta et al. (2015); Shi et al. (2016); Tenney et al. (2019); Manning et al. (2020).
3 Minimal Pair Probing = Minimal Pair + Diagnostic Probing
| Minimal Pair | Duality | Language | # of Pair | Description |
|---|---|---|---|---|
| BLiMP | Form | English | 67, 000 | 67 tasks across 12 grammatical phenomena |
| CLiMP | Form | Chinese | 16, 000 | 16 tasks across 9 grammatical phenomena |
| DistilLingEval | Form | German | 8, 000 | 8 German grammatical phenomena |
| COMPS | Meaning | English | 49, 340 | 4 types of conceptual relationship |
| COMPS-ZH | Meaning | Chinese | 49, 340 | 4 types of conceptual relationship |
| COMPS-DE | Meaning | German | 49, 340 | 4 types of conceptual relationship |
While prior neurolinguistic approaches have explored internal representations, they often employed coarse-grained datasets and primarily focused on decoding linguistic labels from embeddings, providing a general perspective on the linguistic features encoded in LMs. In contrast, the minimal pair probing method presented by He et al. (2024) integrates minimal pair design with diagnostic probing. This combination leverages the granularity of minimal pair design and the layer-wise insights of diagnostic probing, thereby enabling a more detailed analysis of internal patterns for form and meaning. We adopt the minimal pair decoding method as the neurolinguistic paradigm in our work.
Specifically, given an LLM trained on dataset , we can extract the hidden state representations of the -th layer of stimuli . Given a minimal pair dataset = with each sentence has a label , we have internal representation and for each sentence. A minimal probing classifier is trained and evaluated on , with grammatical/conceptual performance measure . Note that what we focus on is the performance of the LLM itself, i.e., , instead of the capability of the supervised classifier . To eliminate the influence of , we assign a random vector to each sentence to replace the hidden states , and calculate the performance of the classifier on the random vector as . This “random” baseline evaluates the predictability of the probing classifier itself. Finally, the performance of the LLM is defined as follows:
| (1) |
4 Experiment Setup
4.1 Datasets
4.2 Models
In our experiments, we used three open-source LLMs, two English-centric LLMs (Llama2 and Llama3), and one multilingual LLMs (Qwen) with a focus on English and Chinese. These models were trained on different amounts of English, Chinese, and German data (see Table 2).
| Resource Level | Llama2 | Llama3 | Qwen |
|---|---|---|---|
| English | High | High | High |
| Chinese | Mid | Mid | High |
| German | Low | Low | Low |
Llama2 and Llama3
Llama2 (Touvron et al., 2023b) and Llama3 (AI, 2024) are two English-centric LLMs which represent an advanced iteration of the Llama foundation models developed by Meta AI (Touvron et al., 2023a). The Llama madels were trained on publicly available corpora predominantly in English. Despite this focus, Llama models are also exposed to a limited amount of multilingual data. Llama 1, for example, is pretrained on an extensive scale of corpora comprising over 1.4 trillion tokens, of which less than 4.5% constitute multilingual data from 20 different languages. Llama 2 expands this linguistic diversity, featuring 27 languages each representing more than 0.005% of the pertaining data. Therefore, English-centric models harness multilingual abilities (Lai et al., 2023). In this work, we use Llama2-7B and Llama3-8B for our experiments.
QWen
QWen is a series of LLMs developed by Alibaba Inc. Bai et al. (2023). Qwen was trained on 2-3 trillion tokens of multilingual pretaining data. It is essentially a multilingual LLM with the focus on English and Chinese. We use the Qwen-7B model in our experiments.
| Duality | Method | Example |
|---|---|---|
| Form | Direct | {Mice are hurting a waiter, Mice was hurting a waiter} |
| Meta | Here are two English sentences: 1) Mice are hurting a waiter. 2) Mice was hurting a waiter. Which | |
| sentence is a better English sentence? Respond with either 1 or 2 as your answer. Answer: {1, 2} | ||
| Meaning | Direct | {Helmet can absorb shocks, Cap can absorb shocks} |
| Meta | What word is most likely to come next in the following sentence (helmet, or cap)? What can absorb | |
| shocks? {helmet, cap} |
4.3 Setup for Psycholinguistic Paradigms
Direct
Direct probability measurement calculates the probability of entire sentences based on model logits. Accuracy is determined by whether the model assigns a higher probability to the grammatically or conceptually correct sentence within the minimal pair.
Meta
Metalinguistic prompting involves explicitly asking a question or specifying a task that requires a judgement about a linguistic expression. Following Hu and Levy (2023), we use a single prompt each minimal pair to present both sentences at once. For form tasks, we assign an identifier (1 or 2) to each sentence in the pair, present a multiple-choice question comparing both sentences, and compare the probabilities assigned by the model to each answer option, “1” or “2”. For meaning tasks, we reformulate the property into a question and compare the probabilities of acceptable and unacceptable concepts as sentence continuations. Table 3 presents the prompts used in the experiments.
4.4 Setup for Minimal Pair Probing
Sentence Embedding
We extract the last token in each sentence from each layer to serve as the representation for the whole sentence. Last token pooling ensures the representation contains the information of all preceding tokens Meng et al. (2024).
Probing Performance
We use logistic regression as the probing classifier and F1 score as the evaluation metrics. The score for and is calculated as the average F1 score across 5 cross-validation folds. Final performance is given by Formula 1.
Saturation and Maximum Layer
We define the feature learning Saturation Layer as the layer where performance first reaches 95% of the peak on the curve. This layer indicates the number of layers required for the model to adequately learn specific linguistic features, after which its ability to capture these features stabilizes. The Maximum Layer is the layer at which performance reaches its peak.
5 Results
5.1 Psycholinguistic vs Neurolinguistic

In order to compare psycholinguistic and neurolinguistic paradigms, we use the last layer’s performance in the neuro method 111We refer to minimal pair probing as the neuro method for simplicity in the results section., as both direct probability measurement and metalinguistic prompting rely on the last layer of LLMs.
Differences among Direct, Meta, and Neuro results
Figure 3 shows distinct results for Direct, Meta, and Neuro, with a general performance order of Neuro > Direct > Meta. This suggests that relying on a single method may not give a comprehensive assessment of language models, and it is best to employ multiple methods for evaluation.
Neuro is similar to Direct on meaning but not on form.
The Neuro method consistently outperforms others across models when assessing form, often nearing 1.0, while Direct and Meta show more variability and generally lower performance. The Neuro method performs similarly to Direct in meaning evaluation, yet remains significantly higher than Meta.
Meta method performs consistently poorly.
This serves as a caution for the current trend of instruction-based prompting, suggesting that Meta’s limitations could reflect issues with instruction prompting’s effectiveness.
Instruction tuning influences LLMs’ Meta performance on form but not much on meaning.
Chat version models’ meta performance on form varies a lot compared to their base versions, but meaning understanding keeps stable.
5.2 Detailed Neurolinguistic Results within English
LLMs incrementally encode grammar and concepts.

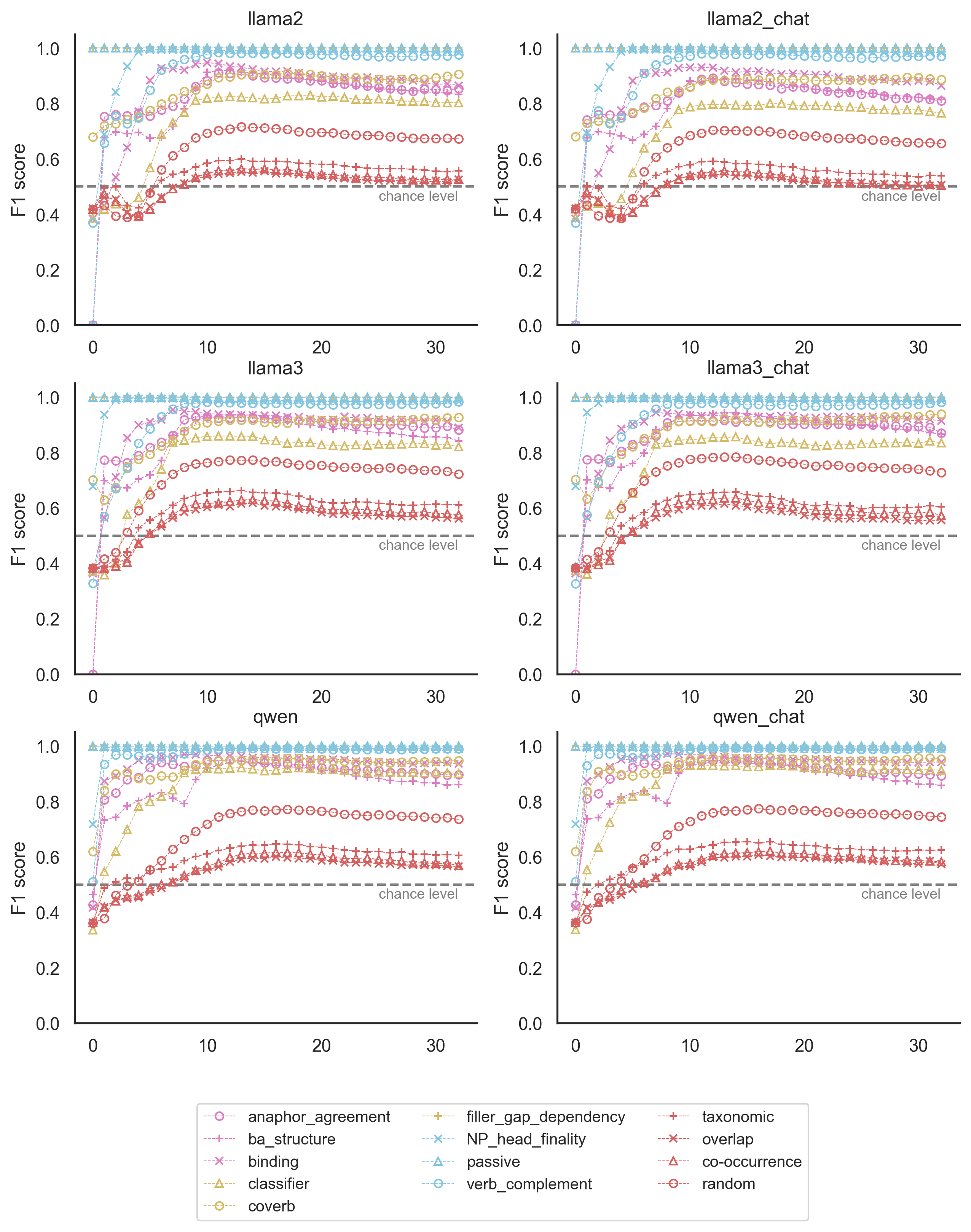
To investigate how LLMs encode form and meaning in a fine-grained and layer-by-layer manner, we split form back into 12 original grammatical tasks and meaning into 4 original conceptual tasks. Figure 4 indicates that Llama-2 rapidly learns grammatical and conceptual information in the first layers incrementally. Performance improves across layers and stabilizes at some point. Similar results for all 6 models can be found in Figure 14 of Appendix D.
Figure 4 shows result curves for 16 specific linguistic tasks. 12 curves (with pink, yellow, and blue colors) visualize the results of grammatical tasks, while the 4 red curves represent the results of the conceptual tasks.
LLMs encode grammatical features better than conceptual features.

The results in Figure 5 show that the performance scores for conceptual understanding (red curves) are significantly lower than those for grammatical understanding (blue curves). This pattern is consistent across all six models, suggesting a universal characteristic of LLMs.
LLMs encode meaning after form.

We compute the feature learning saturation and maximum layers for all 12 grammatical tasks and 4 conceptual tasks, averaging them to represent form and meaning, respectively. From Figure 6, we can see that the saturation and maximum layers for meaning are generally higher than those for form across all six models. This suggests that LLMs stabilize their encoding of grammatical features before conceptual features, indicating that LLMs learn the form of language first and then the meaning of language.
Instruction tuning won’t change internal linguistic representation much.
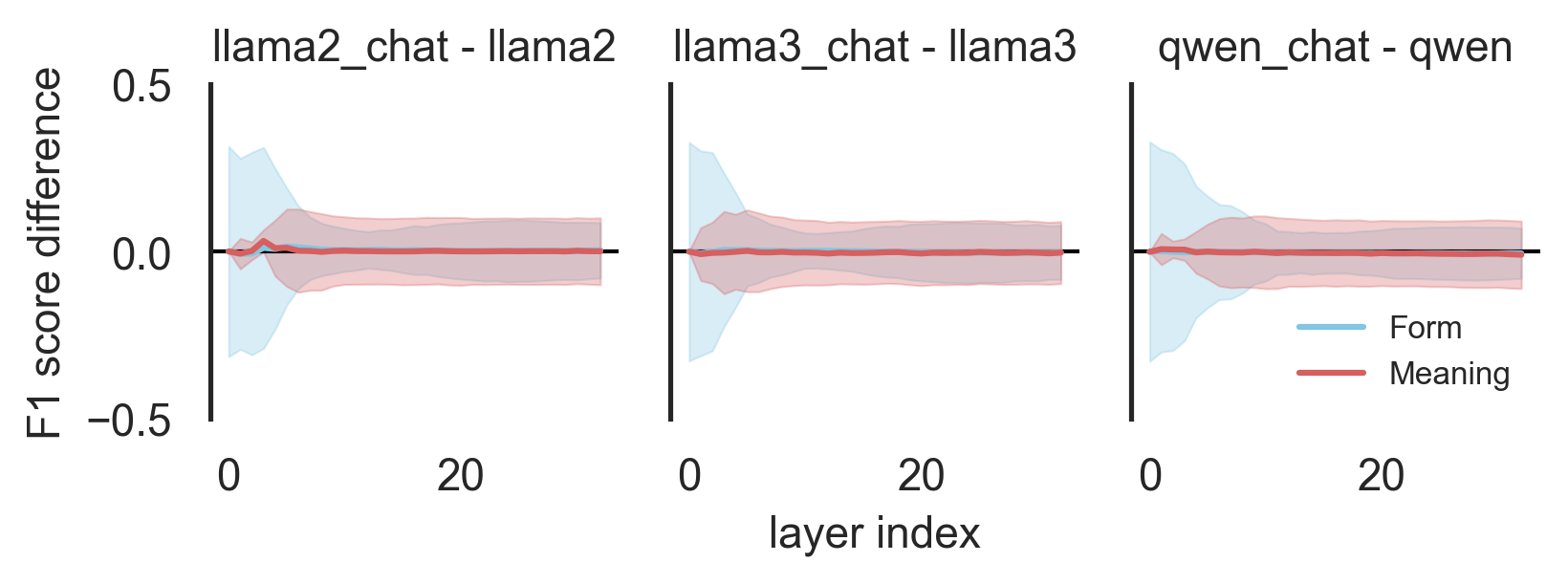
From Figure 7, instruction tuning does not significantly alter the internal linguistic representations of the models. The performance differences for both form and meaning remain close to zero throughout all layers, suggesting that the overall linguistic encoding remains stable despite the tuning.
5.3 Meaning Encoding across Different Forms
How does LLMs’ understanding of meaning change when the form (language) varies? Since our COMPS-ZH and COMPS-DE datasets align with the concepts in the English COMPS dataset, we can explore whether LLMs’ grasp of different linguistic forms for the same concept correlates with their understanding of meaning across languages.

Our previous results and the detailed results in Figures 15 and 16 suggest that instruction tuning has little influence on the internal representations. Therefore we focus on the base LLMs in the following analysis.
Cross-lingual Pattern
From Figure 8, for all models and languages, form consistently achieves higher F1 scores than meaning, indicating it’s easier for LLMs to make stronger grasp of structural elements compared to conceptual comprehension.
Form needs less data to capture compared to meaning.
From Table 2, Chinese is classified as a mid-resourced language for Llama, yet it achieves high form competence (but low meaning competence), suggesting that capturing form requires less data than meaning.

Meaning competence is correlated to form competence.
Figure 9 illustrates the relationship between Form competence (x-axis) and Meaning competence (y-axis) across English, German, and Chinese in the neuro assessment for LLMs.The positive correlation (R² = 0.48) suggests that higher meaning competence generally corresponds to higher form competence.
6 Discussion
Form and Meaning: observations from Saussure’s semiotics Through various experiments focused on Saussure’s concepts of the signifier (form) and the signified (meaning), we have identified several key phenomena. First, LLMs consistently learn linguistic form before they grasp meaning. This suggests a developmental trajectory where statistical patterns in syntax and grammar are more readily captured by the model than conceptual understanding. Second, the models’ formal competence is generally superior to their semantic competence. This is evident in their ability to decode grammaticality structures accurately but with less reliable conceptual accuracy.
Moreover, we observe a linear correlation between form and meaning competence, especially when linguistic forms vary across languages while the underlying meaning remains constant. This pattern implies that an LLM’s understanding of meaning is heavily dependent on its grasp of form. In cases where the form changes (such as between languages), meaning appears to follow the variations in form, indicating that conceptual representation in LLMs is anchored to formal structures rather than an independent comprehension of meaning. These findings highlight the models’ reliance on statistical correlations for understanding meaning, further emphasizing their dependence on formal patterns rather than direct, intrinsic understanding of natural language semantics.
These results help explain the phenomenon of LLMs generating “confidently incorrect” responses, commonly referred to as hallucination, has been a significant issue for a long time Ji et al. (2023). Our results provide a theoretical explanation for this phenomenon from a semiotic and neurolinguistic perspective.
Our findings also align with previous studies Mahowald et al. (2024), which suggests that LLMs have good formal competence, but their performance on functional competence (understanding language in the world) is spotty.
Developmental difference between human and machine intelligence. From a perspective of developmental psychology, human kids typically acquire conceptual understanding before mastering grammar Bloom (2002); Tomasello (2005). Pinker (2009)’s semantic bootstrapping hypothesis posits that children initially learn vocabulary through semantic information and then use this semantic knowledge to infer syntactic structures. In contrast, our results indicate that LLMs learn grammar before meaning. Human intelligence is a combination of statistical inference and causal reasoning, whereas LLMs’ intelligence is more likely a result of statistical inference Tenenbaum et al. (2011); Gopnik and Wellman (2012); Lake et al. (2017). Given this nature, the fact that LLMs learn form first might be because grammatical patterns are easier to statistically capture compared to meaning.
Symbol grounding problem and the quest for human-like intelligence
In human language, the relationship between the signifier and the signified is often flexible and context-dependent, allowing for a more independent connection between syntax and semanticsHarnad (1990). Human cognitive development typically involves acquiring conceptual understanding first, followed by the learning of rules and syntax. In contrast, our study shows that LLMs grasp syntax before meaning, relying on statistical correlations within formal structures to infer semantic content. This difference highlights a fundamental divergence between human and machine intelligence, as LLMs do not possess an inherent understanding of meaning detached from the formal structures they analyze.
These observations suggest that, for LLMs to develop human-like intelligence, they must transcend mere statistical pattern recognition. This will likely require the integration of world knowledge and grounded experiences that go beyond linguistic inputs. To achieve a more robust form of artificial intelligence that mirrors human cognition, models must be able to ground symbols in real-world contexts, establishing a basis for genuine understanding Tenenbaum et al. (2011); Lake et al. (2017) As it stands, the symbol grounding problem remains a significant barrier, and addressing it may be essential for constructing systems capable of true human-like reasoning and understanding.
7 Conclusion
By analyzing Large Language Models (LLMs) as both psycholinguistic and neurolinguistic subjects, we find that LLMs excel at encoding linguistic form but show limitations in understanding meaning. Their grasp of meaning is largely dependent on statistical associations with form. By introducing a cognitive neuroscience perspective, along with semiotics, we hope will inspire further research to deepen our understanding of the language capabilities of LLMs.
Limitations
We didn’t include experiments covering more languages, which might limit the generalizability of our findings.
The evaluation results for German are poor, which might be attributed to the issue of very long sentences in the DistilLingEval dataset.
Due to limitations in computational resources, we did not perform our experiments on larger-size LLMs, which may lead our results to be biased towards small-scale models. Further studies should include larger models to validate and potentially generalize our findings.
Ethics Statement
Our project may raise awareness within the computational linguistics community about those low-resource languages.
References
- AI (2024) Meta AI. 2024. Introducing meta llama 3: The most capable openly available llm to date. https://ai.meta.com/blog/meta-llama-3/.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. 2023. Qwen technical report. arXiv preprint arXiv:2309.16609.
- Belinkov (2022) Yonatan Belinkov. 2022. Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48(1):207–219.
- Belinkov and Glass (2019) Yonatan Belinkov and James Glass. 2019. Analysis methods in neural language processing: A survey. Transactions of the Association for Computational Linguistics, 7:49–72.
- Bender et al. (2021) Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623.
- Bender and Koller (2020) Emily M Bender and Alexander Koller. 2020. Climbing towards nlu: On meaning, form, and understanding in the age of data. In Proceedings of the 58th annual meeting of the association for computational linguistics, pages 5185–5198.
- Beniwal et al. (2024) Himanshu Beniwal, Kowsik D, and Mayank Singh. 2024. Cross-lingual editing in multilingual language models. In Findings of the Association for Computational Linguistics: EACL 2024, pages 2078–2128, St. Julian’s, Malta. Association for Computational Linguistics.
- Beyer et al. (2021) Anne Beyer, Sharid Loáiciga, and David Schlangen. 2021. Is incoherence surprising? targeted evaluation of coherence prediction from language models. arXiv preprint arXiv:2105.03495.
- Bloom (2002) Paul Bloom. 2002. How children learn the meanings of words. MIT press.
- Brennan (2022) Jonathan R Brennan. 2022. Language and the brain: a slim guide to neurolinguistics. Oxford University Press.
- Browning and LeCun (2022) Jacob Browning and Yann LeCun. 2022. Ai and the limits of language. Noema Magazine, 4.
- Bubeck et al. (2023) Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712.
- De Saussure (1989) Ferdinand De Saussure. 1989. Cours de linguistique générale, volume 1. Otto Harrassowitz Verlag.
- Field (2004) John Field. 2004. Psycholinguistics: The key concepts. Psychology Press.
- Friederici (2011) Angela D Friederici. 2011. The brain basis of language processing: from structure to function. Physiological reviews, 91(4):1357–1392.
- Futrell et al. (2019) Richard Futrell, Ethan Wilcox, Takashi Morita, Peng Qian, Miguel Ballesteros, and Roger Levy. 2019. Neural language models as psycholinguistic subjects: Representations of syntactic state. arXiv preprint arXiv:1903.03260.
- Gauthier et al. (2020) Jon Gauthier, Jennifer Hu, Ethan Wilcox, Peng Qian, and Roger Levy. 2020. Syntaxgym: An online platform for targeted evaluation of language models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 70–76.
- Gopnik and Wellman (2012) Alison Gopnik and Henry M Wellman. 2012. Reconstructing constructivism: causal models, bayesian learning mechanisms, and the theory theory. Psychological bulletin, 138(6):1085.
- Gupta et al. (2015) Abhijeet Gupta, Gemma Boleda, Marco Baroni, and Sebastian Padó. 2015. Distributional vectors encode referential attributes. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 12–21.
- Harnad (1990) Stevan Harnad. 1990. The symbol grounding problem. Physica D: Nonlinear Phenomena, 42(1-3):335–346.
- Haynes and Rees (2006) John-Dylan Haynes and Geraint Rees. 2006. Decoding mental states from brain activity in humans. Nature reviews neuroscience, 7(7):523–534.
- He et al. (2024) Linyang He, Peili Chen, Ercong Nie, Yuanning Li, and Jonathan R Brennan. 2024. Decoding probing: Revealing internal linguistic structures in neural language models using minimal pairs. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 4488–4497.
- Hofstadter (1995) Douglas R Hofstadter. 1995. Fluid concepts and creative analogies: Computer models of the fundamental mechanisms of thought. Basic books.
- Hu et al. (2020) Jennifer Hu, Jon Gauthier, Peng Qian, Ethan Wilcox, and Roger P Levy. 2020. A systematic assessment of syntactic generalization in neural language models. arXiv preprint arXiv:2005.03692.
- Hu and Levy (2023) Jennifer Hu and Roger Levy. 2023. Prompting is not a substitute for probability measurements in large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 5040–5060.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38.
- Kauf et al. (2023) Carina Kauf, Anna A Ivanova, Giulia Rambelli, Emmanuele Chersoni, Jingyuan Selena She, Zawad Chowdhury, Evelina Fedorenko, and Alessandro Lenci. 2023. Event knowledge in large language models: the gap between the impossible and the unlikely. Cognitive Science, 47(11):e13386.
- Kemmerer (2022) David Kemmerer. 2022. Cognitive neuroscience of language. Routledge.
- Köhn (2015) Arne Köhn. 2015. What’s in an embedding? analyzing word embeddings through multilingual evaluation.
- Kriegeskorte et al. (2006) Nikolaus Kriegeskorte, Rainer Goebel, and Peter Bandettini. 2006. Information-based functional brain mapping. Proceedings of the National Academy of Sciences of the United States of America, 103(10):3863–3868.
- Lai et al. (2023) Viet Lai, Nghia Ngo, Amir Pouran Ben Veyseh, Hieu Man, Franck Dernoncourt, Trung Bui, and Thien Nguyen. 2023. ChatGPT beyond English: Towards a comprehensive evaluation of large language models in multilingual learning. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 13171–13189, Singapore. Association for Computational Linguistics.
- Lake et al. (2017) Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman. 2017. Building machines that learn and think like people. Behavioral and brain sciences, 40:e253.
- Linzen et al. (2016) Tal Linzen, Emmanuel Dupoux, and Yoav Goldberg. 2016. Assessing the ability of lstms to learn syntax-sensitive dependencies. Transactions of the Association for Computational Linguistics, 4:521–535.
- Mahowald et al. (2024) Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. 2024. Dissociating language and thought in large language models. Trends in Cognitive Sciences.
- Manning (2022) Christopher D Manning. 2022. Human language understanding & reasoning. Daedalus, 151(2):127–138.
- Manning et al. (2020) Christopher D Manning, Kevin Clark, John Hewitt, Urvashi Khandelwal, and Omer Levy. 2020. Emergent linguistic structure in artificial neural networks trained by self-supervision. Proceedings of the National Academy of Sciences, 117(48):30046–30054.
- Marvin and Linzen (2018) Rebecca Marvin and Tal Linzen. 2018. Targeted syntactic evaluation of language models. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 1192–1202, Brussels, Belgium. Association for Computational Linguistics.
- Meng et al. (2024) Rui Meng, Ye Liu, Shafiq Rayhan Joty, Caiming Xiong, Yingbo Zhou, and Semih Yavuz. 2024. Sfr-embedding-mistral:enhance text retrieval with transfer learning. Salesforce AI Research Blog.
- Mesgarani and Chang (2012) Nima Mesgarani and Edward F Chang. 2012. Selective cortical representation of attended speaker in multi-talker speech perception. Nature, 485(7397):233–236.
- Misra et al. (2023) Kanishka Misra, Julia Rayz, and Allyson Ettinger. 2023. Comps: Conceptual minimal pair sentences for testing robust property knowledge and its inheritance in pre-trained language models. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2920–2941.
- Mitchell and Krakauer (2023) Melanie Mitchell and David C Krakauer. 2023. The debate over understanding in ai’s large language models. Proceedings of the National Academy of Sciences, 120(13):e2215907120.
- Nie et al. (2023) Ercong Nie, Sheng Liang, Helmut Schmid, and Hinrich Schütze. 2023. Cross-lingual retrieval augmented prompt for low-resource languages. In Findings of the Association for Computational Linguistics: ACL 2023, pages 8320–8340.
- Nie et al. (2024) Ercong Nie, Shuzhou Yuan, Bolei Ma, Helmut Schmid, Michael Färber, Frauke Kreuter, and Hinrich Schütze. 2024. Decomposed prompting: Unveiling multilingual linguistic structure knowledge in english-centric large language models. arXiv preprint arXiv:2402.18397.
- Norman et al. (2006) Kenneth A Norman, Sean M Polyn, Greg J Detre, and James V Haxby. 2006. Beyond mind-reading: multi-voxel pattern analysis of fmri data. Trends in cognitive sciences, 10(9):424–430.
- Pinker (2009) Steven Pinker. 2009. Language learnability and language development: with new commentary by the author, volume 7. Harvard University Press.
- Sejnowski (2023) Terrence J Sejnowski. 2023. Large language models and the reverse turing test. Neural computation, 35(3):309–342.
- Shi et al. (2016) Xing Shi, Inkit Padhi, and Kevin Knight. 2016. Does string-based neural mt learn source syntax? In Proceedings of the 2016 conference on empirical methods in natural language processing, pages 1526–1534.
- Stouffer et al. (1949) Samuel A Stouffer, Edward A Suchman, Leland C DeVinney, Shirley A Star, and Robin M Williams Jr. 1949. The american soldier: Adjustment during army life.(studies in social psychology in world war ii), vol. 1. Princeton Univ. Press.
- Tenenbaum et al. (2011) Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. 2011. How to grow a mind: Statistics, structure, and abstraction. science, 331(6022):1279–1285.
- Tenney et al. (2019) Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang, Adam Poliak, R Thomas McCoy, Najoung Kim, Benjamin Van Durme, Samuel R Bowman, Dipanjan Das, et al. 2019. What do you learn from context? probing for sentence structure in contextualized word representations. arXiv preprint arXiv:1905.06316.
- Tomasello (2005) Michael Tomasello. 2005. Constructing a language: A usage-based theory of language acquisition. Harvard university press.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Traxler and Gernsbacher (2011) Matthew Traxler and Morton Ann Gernsbacher. 2011. Handbook of psycholinguistics. Elsevier.
- Vamvas and Sennrich (2021) Jannis Vamvas and Rico Sennrich. 2021. On the limits of minimal pairs in contrastive evaluation. arXiv preprint arXiv:2109.07465.
- Wang et al. (2023) Weixuan Wang, Barry Haddow, and Alexandra Birch. 2023. Retrieval-augmented multilingual knowledge editing. arXiv preprint arXiv:2312.13040.
- Warstadt et al. (2020) Alex Warstadt, Alicia Parrish, Haokun Liu, Anhad Mohananey, Wei Peng, Sheng-Fu Wang, and Samuel R Bowman. 2020. Blimp: The benchmark of linguistic minimal pairs for english. Transactions of the Association for Computational Linguistics, 8:377–392.
- Xiang et al. (2021) Beilei Xiang, Changbing Yang, Yu Li, Alex Warstadt, and Katharina Kann. 2021. Climp: A benchmark for chinese language model evaluation. arXiv preprint arXiv:2101.11131.
Appendix A More Psycholinguistic and Neurolinguistic Paradigms’s Cognitive Science Background
Psycholinguistics often involves examining real-time language processing, linguistic knowledge storage, and language acquisition, using behavioral experimental methods such as reading times and eye-tracking. Neurolinguistics, on the other hand, focuses on the neural basis of language, employing techniques such as functional magnetic resonance imaging (fMRI), electroencephalography (EEG), and magnetoencephalography (MEG) to map linguistic functions to specific brain regions and to investigate how neural activity correlates with linguistic tasks.
While psycholinguistics aims to reveal mental processes underlying language use, neurolinguistics seeks to uncover the neural pathways that implement these processes.
Our minimal pair probing is inspired by cognitive neuroscience. In the field of neurolinguistics, decoding analysis has become a fundamental technique in cognitive neuroscience. It tries to extract information encoded in neural patterns (Kriegeskorte et al., 2006). It trains a classifier to predict properties of the stimulus (e.g. a particular image or word input), from the neural responses. If the accuracy of the trained classifier is significantly better than chance, we conclude that the neural data encodes information about the predicted stimulus properties (Norman et al., 2006; Haynes and Rees, 2006).
Mesgarani and Chang (2012) is a representative work employing decoding analysis in the realm of language and speech. They use electrocorticography (ECoG) to record neural responses from subjects who are listening to speech. Leveraging decoding analysis, they were able to differentiate between neural patterns induced by attended speech and those elicited by background speech, (to be ignored by the test persons), thereby highlighting the perceptual differences between the two speech stimuli conditions.
While psycholinguistic approaches provide valuable insights into LLMs’ functional capabilities, they often fall short in revealing the underlying mechanisms of language processing. The opaque nature of neural network structures means that performance on external tasks does not necessarily reflect the internal cognitive processes at play. This gap necessitates a neurolinguistic approach to gain a deeper understanding of how LLMs encode and process language.
Appendix B Dataset Details
For each language, we use one dataset for grammatical minimal pairs and one dataset for conceptual minimal pairs.
B.1 Form: BLiMP, CLiMP, and DistilLingEval
BLiMP
BLiMP (Warstadt et al., 2020) is a comprehensive English dataset of grammatical minimal pairs. It consists of minimal pairs for 13 higher-level linguistic phenomena in the English language, further divided into 67 distinct realizations, called paradigms. Each paradigm comprises 1,000 individual minimal pairs, resulting in a total corpus size of 67,000 data points.
CLiMP
CLiMP (Xiang et al., 2021) is a corpus of Chinese grammatical minimal pairs consisting of 16 datasets, each containing 1,000 sentence pairs. CLiMP covers 9 major Chinese language phenomena in total, less than the BLiMP dataset due to the less inflectional nature of Mandarin Chinese. The vocabulary of the CLiMP dataset is based on the translation of the BLiMP dataset, with words and features specific to Chinese added.
DistilLingEval
DistilLingEval (Vamvas and Sennrich, 2021) is a dataset of German grammatical minimal pairs. It consists of minimal pairs for eight German linguistic phenomena. This dataset contains 82,711 data samples in total.
B.2 Meaning: COMPS, COMPS-ZH, and COMPS-DE
COMPS
COMPS (Misra et al., 2023) is an English dataset of conceptual minimal pairs for testing an LLM’s knowledge of everyday concepts (e.g., a beaver/*gorilla has a flat tail). This dataset contains 49,340 sentence pairs, constructed using 521 concepts and 3,592 properties. Concepts in the pairs constitute 4 types or knowledge relationship: taxonomy, property norms, co-occurrence and random.
COMPS-ZH and COMPS-DE
COMPS-DE and COMPS-ZH are newly developed datasets featuring conceptual minimal pairs in Chinese and German, derived from the English COMPS dataset (Misra et al., 2023). In the realm of multilingual NLP research, it is a common practice to extend English datasets to other languages using human translation, machine translation, or translation assisted by LLMs (Nie et al., 2023; Wang et al., 2023; Beniwal et al., 2024).
In this study, to create COMPS-DE and COMPS-ZH from the original English COMPS, we employed a hybrid approach that integrated process machine translation with meticulous human verification.
Specifically, we translated the concepts and properties of the English COMPS individually, subsequently merging them to form complete sentences and compose conceptual minimal pairs. The translation process began with the use of the Google Translate API222https://cloud.google.com/translate, which provided initial translations of concepts and properties into German and Chinese.
Following this, native speakers of Chinese and German manually checked and refined these translations to ensure accuracy and quality. The manual review emphasized two main areas: accuracy of concepts and grammatical consistency of properties. For concepts, the focus was on correcting ambiguities that might arise from machine translation. For properties, attention was given to maintaining grammatical consistency with the original English text, such as ensuring subject-verb agreement, which is particularly challenging in German translations.
In summary, out of 521 concepts, manual corrections were made to 57 entries in the Chinese dataset and 49 in the German dataset. Similarly, from 3,592 properties, 713 required manual corrections in the Chinese dataset, and 512 in the German dataset. This rigorous process was essential for preserving the integrity and reliability of the translated datasets.
Appendix C More Detailed Minimal Pair Probing Results for English

We averaged the results of 4 tasks from the same linguistic level, respectively, and show the result curves in Figure 10. Some noteworthy points from this figure include:
1)
The average performances on morphological tasks (purple curve) and on tasks from the semantics-syntax interface (yellow curve) are lower than those for syntactic tasks (blue curve), suggesting that more abstract linguistic levels are easier for LLMs to learn, which also aligns with He et al. (2024). For the ellipsis task especially, local features in layer 0 (the embedding layer before the Transformer structure) already provide sufficient linguistic information to accomplish the task without any contextual information.
2) Among the conceptual tasks, the random relationship shows significantly higher accuracy compared to the other three conceptual relationships, suggesting that LLMs find it challenging to distinguish between similar concepts.
Compared to Llama2, Llama3 won’t improve internal grammatical capabilities much, but will learn concepts better and faster.


Figure 11 shows the layer-wise performance differences between Llama3 and Llama2, as well as between their chat versions. The red curves (meaning) exhibit a notable positive difference in the early layers, indicating that Llama3 has better conceptual learning capabilities compared to Llama2. The blue curves (form) remain close to zero across all layers, suggesting that there is no significant improvement in grammatical capabilities in Llama3 compared to Llama2. The t-test statistics in Figure 12 further support these results.

Figure 13 compares the feature learning saturation layers between Llama2 and Llama3. The results for form learning (blue bars) do not differ significantly between Llama2 and Llama3 and weakly significantly between Llama2_chat and Llama3_chat. However, the results for meaning learning (blue bars) are both highly significant, indicating that Llama3 requires fewer layers to encode conceptual features than Llama2. This suggests that Llama3 comprehends sentences faster.
Appendix D Multilingual Analysis
1) Llama’s performance on Chinese. Despite Chinese not being the primary training language of the Llama2 models, they still perform well in encoding Chinese form/grammar. However, both Qwen, which is primarily trained on Chinese, and the Llama models show relatively poor performance in understanding Chinese meaning/concepts.
2) Improvement in Llama3 for Chinese Semantics. Llama3 shows some improvement over Llama2 in understanding Chinese semantics, as indicated by the slightly higher red curve in the middle row. The improvement in syntactic understanding is minimal.
3) Qwen’s Faster Syntax Learning but Slower Semantic Encoding for Chinese. Compared to the Llama models, Qwen learns Chinese grammar faster, as indicated by the sharper rise of the blue curve. However, it encodes Chinese semantics more slowly, evidenced by the larger gap between the form and meaning curves in the early layers.
4) Poor Performance for German. For German, a low-resource language, all three models perform poorly. Despite Chinese not being a primary training language for the Llama models, their performance is relatively decent, suggesting that the actual proportion of German training data might be much smaller. This highlights differences in the resource allocation for the three languages.