Large Language Models as Interpolated and Extrapolated Event Predictors
Abstract
Salient facts of sociopolitical events are distilled into quadruples following a format of subject, relation, object and timestamp. Machine learning methods, such as graph neural networks (GNNs) and recurrent neural networks (RNNs), have been built to make predictions and infer relations on the quadruple-based knowledge graphs (KGs).
In many applications, quadruples are extended to quintuples with auxiliary attributes such as text summaries that describe the quadruple events. In this paper, we comprehensively investigate how large language models (LLMs) streamline the design of event prediction frameworks using quadruple-based or quintuple-based data while maintaining competitive accuracy. We propose LEAP, a unified framework that leverages large language models as event predictors. Specifically, we develop multiple prompt templates to frame the object prediction (OP) task as a standard question-answering (QA) task, suitable for instruction fine-tuning with an encoder-decoder LLM. For multi-event forecasting (MEF) task, we design a simple yet effective prompt template for each event quintuple. This novel approach removes the need for GNNs and RNNs, instead utilizing an encoder-only LLM to generate fixed intermediate embeddings, which are processed by a customized downstream head with a self-attention mechanism to predict potential relation occurrences in the future. Extensive experiments on multiple real-world datasets using various evaluation metrics validate the effectiveness of our approach.
Code — https://github.com/Libo1023/LEAP
Datasets — https://dataverse.harvard.edu/dataverse/icews
Introduction
Event prediction, including tasks such as identifying key participants in an event or forecasting the occurrence of future events, has drawn significant attention in recent years across different domains (Zhao 2021; Onaolapo et al. 2022; Shi et al. 2024; Ye et al. 2024). The ability to successfully predict critical elements and accurately forecast human events is invaluable for proactive decision-making, risk management, and resource optimization. However, the complexity of underlying mechanisms and the inherent uncertainty of the future make event prediction a challenging endeavor (Wasserkrug 2009). These challenges necessitate advanced models that can effectively capture and interpret the dynamic patterns of events. In the past, the machine learning community has made significant progress in event reasoning and prediction by developing new methods based on recurrent neural networks (RNNs) and graph neural networks (GNNs). RNNs excel at capturing sequential information, while GNNs are adept at modeling relational knowledge within graphs (Pan et al. 2024; Ma et al. 2023). These networks have become foundational in the design of state-of-the-art (SOTA) event prediction frameworks. However, text information, such as news articles that describe events, provides rich semantic indicators and contextual backgrounds that are often underutilized. With the recent advancements in large language models (LLMs), we aim to explore their potential in understanding event contexts and inferring future events based on historical patterns and textual summaries. We identify several key challenges in leveraging LLMs for event prediction, from both interpolation and extrapolation perspectives (Wang et al. 2023; Shang and Huang 2024).
The high cost of closed-source LLMs: For interpolated object prediction (OP), we are asked to predict the missing object in a query quintuple, given the other four elements as well as historical knowledge tracing back to a certain sequence (Ma et al. 2023). Although nowadays generating several words looks simple (Ouyang et al. 2022), good prediction accuracy cannot be easily achieved, unless introducing SOTA commercialized LLMs and leveraging complicated prompting strategies (Ye et al. 2024), which consumes more tokens and leads to much more costly expenses in making frequent application programming interface (API) calls for OpenAI generative LLMs (OpenAI 2024b).
The constrained capability of open-source LLMs: For extrapolated multi-event forecasting (MEF), we are asked to forecast possible relation occurrences in a future time, given only historical knowledge tracing back to a certain time window without any query information (Deng, Rangwala, and Ning 2020). Compared with OP, MEF is more challenging for two reasons. First, MEF follows an extrapolation setting to predict future relations, without any auxiliary knowledge such as participating subjects, while the interpolation setting provides OP with the other four query elements, and the only thing left is to fill in the missing object blank. Second, MEF is on a daily basis while OP is on the quintuple level. Since there could be hundreds of quintuples per day (Boschee et al. 2015), the number of input tokens is much more demanding for LLMs involved in MEF to yield a valid downstream prediction than those in OP. However, the maximum number of input tokens for open-source LLMs is rather limited, such as 512 tokens for RoBERTa (Liu et al. 2019) and 1024 tokens for FLAN-T5 (Chung et al. 2024), as longer sequences would either be truncated by the tokenizer or jeopardize the overall performance (Kanakarajan and Sankarasubbu 2023).
To tackle these challenges, we propose LEAP, a unified framework that leverages large language models as event predictors. Considering both interpolation and extrapolation settings, we fine-tune an encoder-only LLM, RoBERTa (Liu et al. 2019), and an encoder-decoder LLM, FLAN-T5 (Chung et al. 2024), along with optimizing various customized downstream prediction heads, to achieve competitive accuracy in both OP and MEF. Our major contributions can be summarized as follows.
-
1.
We perform OP following two directions. First, as a ranking task, we leverage a fine-tuned encoder-only LLM, RoBERTaBASE (Liu et al. 2019), to handle text summary in a query quintuple, and combine output embeddings back to a structural decoder through linear projection to make a prediction. Second, as a generative task following a question-answering (QA) format, where we design various prompt templates to build up questions and set correct objects as answers. We introduce an encoder-decoder LLM, FLAN-T5BASE (Chung et al. 2024) for sequence-to-sequence generation, and leverage instruction fine-tuning to further enhance OP accuracy.
-
2.
We formulate MEF as a multi-label binary classification task. We design a simple yet effective prompt template for each event, and utilize a pre-trained RoBERTaLARGE encoder (Liu et al. 2019) to obtain quintuple-level embeddings. Subsequently, we customize a downstream head with self-attention (Vaswani et al. 2017) to perform weighted feature aggregation and predict possible relation occurrences in the future.
-
3.
We conduct comprehensive experiments with multiple sociopolitical ICEWS datasets (Boschee et al. 2015) involving different countries and various evaluation metrics, to analyze and demonstrate the validity and effectiveness of our approaches formulated in LEAP.
Related Work
Event prediction has been comprehensively studied and various kinds of frameworks have been proposed to address specific challenges including, but not limited to prediction accuracy, optimization efficiency, and reasoning interpretability (Pan et al. 2024). Overall, these frameworks can be divided into three categories as follows (Liao et al. 2023).
Rule-based framework: The key components for rule-based frameworks are a list of pre-defined strategies to locate, identify, and extract parts of event quadruples or quintuples, which are assumed to be helpful for downstream inference (Liu et al. 2022). Usually, these strategies are ranked in numbers, and the constraints defined in strategies with larger numbers tend to be more relaxing than those with smaller ones to ensure the inclusion of all possible scenarios (Pan et al. 2023). Without any trainable parameters, rule-based frameworks are computationally efficient and easily interpretable by strictly following a list of rules. However, the implementation of manually defined rules is an exhaustive mining process within the event dataset itself, where the achieved prediction accuracy is not as competitive as those state-of-the-art (SOTA) methods with numerous parameters (Liao et al. 2023).
In-context learning framework: The key modules for in-context learning frameworks are generative large language models (LLMs) with frozen parameters (Dong et al. 2022). Various prompt templates can be designed to include few-shot learning examples and detailed instructions for completing different event prediction tasks (Lee et al. 2023). Although significant efforts for model training and downstream inference can be saved, there are two obvious shortcomings. First, for free-of-charge open-source LLMs, either they impose rather limited maximum input context length, such as 1024 tokens for BART (Lewis et al. 2019), 2048 tokens for LLaMA (Touvron et al. 2023a), and 4096 tokens for Llama 2 (Touvron et al. 2023b), or demand excessive memory space for local storage and inference, such as Llama 3.1405B (Meta 2024), while the 8B and 70B versions are less powerful. Balancing the space-performance trade-off is always challenging for local implementations. Second, closed-source commercialized LLMs, GPT-4o (OpenAI 2024a) and Claude 3 (Anthropic 2024), are powerful generators which support much longer input context, but given abundant sociopolitical events (Boschee et al. 2015), the cost for making application programming interface (API) calls cannot be ignored (OpenAI 2024b).
Embedding-based framework: The key components for embedding-based frameworks are entity and relation embeddings updated by graph neural networks (GNNs) and recurrent neural networks (RNNs) (Ma et al. 2023). Extending quadruples to quintuples, handling additional text can be tricky. Specifically, for object prediction (OP), SeCoGD (Ma et al. 2023) applies the latent Dirichlet allocation algorithm (Blei, Ng, and Jordan 2003), which is pre-trained on collected and filtered text summaries, to separate quintuples into different context groups, and then leverages hypergraphs to collaborate intermediate embeddings among different groups. For multi-event forecasting (MEF), Glean (Deng, Rangwala, and Ning 2020) builds a word graph by calculating the point-wise mutual information (Church and Hanks 1990) between words tokenized and filtered from collected text summaries in an event dataset. Both SeCoGD and Glean are important benchmark methods, and by making appropriate use of encoding and generative LLMs, we aim to outperform these complex end-to-end frameworks, especially in terms of prediction accuracy.
LEAP for Object Prediction
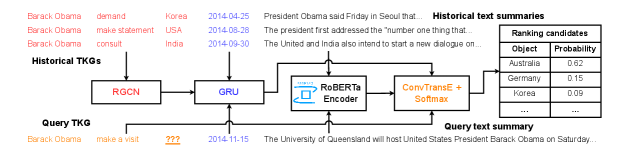

Event interpolation refers to the retrieval or prediction of one or some missing facts at one specified timestamp (Cai et al. 2024), which corresponds to the definition of object prediction (OP) task, where we aim to predict a missing object , given a query quintuple including known subject (), relation (), timestamp (), and text summary (), as well as selected historical knowledge tracing back to a pre-defined sequence length , which can be structured as a list of graphs , or concatenated into textual corpus formatted as multiple strings (Ma et al. 2023; Liao et al. 2023).
LEAPOP1: Object Prediction as A Ranking Task
Figure 1 shows an overview of LEAPOP1, which can be divided into three steps starting from embedding update, then to embedding aggregation, and eventually towards probability ranking to complete the prediction.
1) Spatial-temporal modeling Inspired by SeCoGD (Ma et al. 2023), we leverage relational graph convolution network (R-GCN) (Schlichtkrull et al. 2018) to handle the structural knowledge for every sub-graph in and update the embeddings for all entities . We also apply gated recurrent unit (GRU) (Cho et al. 2014) to track the historical sequence starting from and keep the embeddings of all relations up-to-date until .
2) Text summary embedding collection To begin, we collect and concatenate summaries from all quintuples to form a large textual corpus. Subsequently, we leverage part of the corpus as training data to fine-tune an encoder-only LLM, RoBERTaBASE, with the standard masked language modeling loss (Liu et al. 2019), to enrich the LLM encoder with domain-specific knowledge. We apply the fine-tuned encoder towards each historical and query text summary to yield token-level embeddings. Then, we utilize mean pooling to obtain an embedding vector for each text summary.
3) Query object probability ranking We leverage ConvTransE (Shang et al. 2019) as the structural decoder, which is responsible for combining the entity and relation embeddings from R-GCN and GRU with text summary embeddings from fine-tuned RoBERTaBASE, and eventually ranking all candidate objects after activation to complete the missing query. Compared with SeCoGD (Ma et al. 2023), where the context IDs are acquired from pre-trained clustering algorithms (Blei, Ng, and Jordan 2003), we believe that the semantic information encoded in can significantly enrich event prediction optimization and improve the accuracy. Therefore, we get the probabilities of all entity candidates as:
| (1) |
where , is the query batch size, and we have , . The candidate entity having the highest probability among will be read out as the predicted object. Overall, since the LLM encoder has been separately fine-tuned, the trainable modules in LEAPOP1 contain R-GCN, GRU, and ConvTransE, which are jointly optimized with cross-entropy loss comparing predicted objects with true objects through back-propagation.
LEAPOP2: Object Prediction as A Generative Task
| Name | Prompt Template |
|---|---|
| Few-shot | I ask you to perform an object prediction task after I provide you with five examples. Each example is a knowledge quintuple containing two entities, a relation, a timestamp, and a brief text summary. Each knowledge quintuple is strictly formatted as (subject entity, relation, object entity, timestamp, text summary). For the object prediction task, you should predict the missing object entity based on the other four available elements. Now I give you five examples. |
| ## Example 1 | |
| (subject 1, relation 1, MISSING OBJECT ENTITY, timestamp 1, text summary 1) \n | |
| The MISSING OBJECT ENTITY is: object 1 \n | |
| ⋮## Example 5 | |
| (subject 5, relation 5, MISSING OBJECT ENTITY, timestamp 5, text summary 5) \n | |
| The MISSING OBJECT ENTITY is: object 5 \n | |
| Now I give you a query: | |
| (subject 6, relation 6, MISSING OBJECT ENTITY, timestamp 6, text summary 6) \n | |
| Please predict the missing object entity. You are allowed to predict new object entity which you have | |
| never seen in examples. The correct object entity is: | |
| Zero-shot | Remove all five in-context learning examples in the few-shot prompt. |
| No-text | Remove all text summaries of five in-context learning examples and the query in the few-shot prompt. |
Having carefully studied a structural ranking approach, our next attempt is to evaluate if LLMs are able to predict objects directly as a generative predictor. In other words, we stack historical knowledge, queries, and instructions into a textual prompt context , and feed into a generative LLM, such as FLAN-T5 (Chung et al. 2024) or GPT-4o (OpenAI 2024a). This process is denoted by
| (2) |
where indicates the generated context from an LLM. To make sure that the LLM generates missing objects precisely and correctly (), we frame OP as a generative task. We introduce ROUGE scores (Lin 2004) to directly compare the true object and the predicted object as two strings as shown in Figure 2, instead of ranking all candidate objects. To transfer from ranking into generation, we directly read out the first candidate from LEAPOP1 which has the highest output probability as the predicted object. Then we go over all test queries and compute the ROUGE scores for evaluation. We construct the generative predictor using a light-weight LLM, FLAN-T5BASE, which has around 248 million parameters (Chung et al. 2024). Specifically, since FLAN-T5 is an encoder-decoder sequence-to-sequence (Seq2Seq) model, as shown in Figure 2, we follow a typical question-answering format, where the “question” is a 5-shot learning prompt with one query along with some explanations and instructions, and the “answer” is the object entity. We get
| (3) |
where we use a fine-tuned FLAN-T5BASE as the encoder-decoder LLM following by a standard cross-entropy loss. The purpose of fine-tuning is to further enhance the generative QA accuracy, so that LEAPOP2 can compete with commercialized LLMs such as GPT-4o mini (OpenAI 2024a). Based on Table 1, we fine-tune FLAN-T5BASE with a 5-shot learning prompt (few-shot prompt), which means the sequence length is 5 on the quintuple level, events. To evaluate the generalizability of the encoder-decoder LLM in the experimental section, we remove the 5 learning examples to build a zero-shot prompt. To further evaluate the effectiveness introduced by text, we design another 5-shot learning prompt (no-text prompt) but remove all text summaries as an ablation study. Given the vast scale of the sociopolitical dataset (Boschee et al. 2015), the limited GPU memory available on our servers, and the high cost associated with commercial LLMs (OpenAI 2024b), we opted not to prioritize prompting strategies like Chain-of-Thought (Wei et al. 2022) or ReAct (Yao et al. 2022).
LEAP for Multi-event Forecasting

| Name | Prompt Template |
|---|---|
| Simple | Subject: subject; \n |
| Relation: relation; \n | |
| Object: object; \n | |
| Timestamp: timestamp; \n | |
| Text Summary: text summary |
| Dataset | |||||
|---|---|---|---|---|---|
| Afghanistan | 3,756 | 218 | 212,540 | 32,734 | 34,585 |
| India | 6,298 | 234 | 318,471 | 75,439 | 85,739 |
| Russia | 7,798 | 237 | 275,477 | 46,516 | 51,371 |
| Method | Afghanistan | India | Russia | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hits@ 1 | Hits@ 3 | Hits@ 10 | Hits@ 1 | Hits@ 3 | Hits@ 10 | Hits@ 1 | Hits@ 3 | Hits@ 10 | |||
| Historical sequence length 3 ( days) | |||||||||||
| ConvTransE | 0.1235 | 0.2704 | 0.4916 | 0.1521 | 0.2821 | 0.4600 | 0.1009 | 0.1791 | 0.3078 | ||
| CompGCN | 0.1214 | 0.2633 | 0.4900 | 0.1697 | 0.3138 | 0.4940 | 0.1167 | 0.1885 | 0.3124 | ||
| R-GCN | 0.1443 | 0.3126 | 0.5540 | 0.1721 | 0.3211 | 0.5009 | 0.1314 | 0.2389 | 0.3896 | ||
| RE-GCN | 0.1538 | 0.3137 | 0.5408 | 0.1704 | 0.3125 | 0.4952 | 0.1332 | 0.2345 | 0.3767 | ||
| SeCoGD | 0.1878 | 0.3570 | 0.5740 | 0.2064 | 0.3554 | 0.5357 | 0.1768 | 0.2909 | 0.4351 | ||
| LEAPOP1 | 0.3691 | 0.5630 | 0.7317 | 0.3675 | 0.5507 | 0.7233 | 0.3751 | 0.5390 | 0.6831 | ||
| Historical sequence length 7 ( days) | |||||||||||
| ConvTransE | 0.1243 | 0.2759 | 0.4909 | 0.1544 | 0.2911 | 0.4740 | 0.0973 | 0.1804 | 0.2971 | ||
| CompGCN | 0.1094 | 0.2729 | 0.5081 | 0.1655 | 0.3123 | 0.4989 | 0.1069 | 0.1851 | 0.3158 | ||
| R-GCN | 0.1582 | 0.3243 | 0.5526 | 0.1762 | 0.3209 | 0.5004 | 0.1276 | 0.2462 | 0.3926 | ||
| RE-GCN | 0.1551 | 0.3298 | 0.5544 | 0.1724 | 0.3175 | 0.5004 | 0.1335 | 0.2349 | 0.3781 | ||
| SeCoGD | 0.1833 | 0.3652 | 0.5862 | 0.2056 | 0.3516 | 0.5352 | 0.1661 | 0.2823 | 0.4433 | ||
| LEAPOP1 | 0.3861 | 0.5884 | 0.7664 | 0.3935 | 0.5831 | 0.7454 | 0.3861 | 0.5590 | 0.7077 | ||
| Method | Afghanistan | India | Russia | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ROUGE | 1 | 2 | L | 1 | 2 | L | 1 | 2 | L | ||
| Fine-tuned RoBERTa-base as an encoding LLM, days | |||||||||||
| SeCoGD | 0.4271 | 0.1658 | 0.4271 | 0.4812 | 0.2902 | 0.4813 | 0.3698 | 0.1414 | 0.3700 | ||
| LEAPOP1 | 0.5287 | 0.2670 | 0.5286 | 0.5500 | 0.3821 | 0.5501 | 0.4974 | 0.2629 | 0.4973 | ||
| Fine-tuned RoBERTa-base as an encoding LLM, days | |||||||||||
| SeCoGD | 0.4295 | 0.1723 | 0.4295 | 0.4831 | 0.2905 | 0.4833 | 0.3831 | 0.1404 | 0.3831 | ||
| LEAPOP1 | 0.5675 | 0.3200 | 0.5674 | 0.5892 | 0.4034 | 0.5893 | 0.5242 | 0.2636 | 0.5238 | ||
| Open-source LLMs: few-shot prompt for all test samples, quintuples | |||||||||||
| Mistral-7B | 0.3659 | 0.1100 | 0.3620 | 0.3424 | 0.1318 | 0.3417 | 0.3464 | 0.1178 | 0.3452 | ||
| Llama3.1-8B | 0.3110 | 0.1085 | 0.3100 | 0.2799 | 0.1266 | 0.2796 | 0.3932 | 0.1575 | 0.3930 | ||
| Closed-source LLMs: few-shot prompt for the first 5000 test samples, quintuples | |||||||||||
| GPT-3.5 Turbo | 0.4097 | 0.1302 | 0.4092 | 0.3644 | 0.1601 | 0.3640 | 0.3480 | 0.1255 | 0.3485 | ||
| GPT-4o mini | 0.4147 | 0.1303 | 0.4131 | 0.3839 | 0.1769 | 0.3829 | 0.3880 | 0.1726 | 0.3878 | ||
| LEAPOP2: fine-tuned FLAN-T5BASE, multiple prompts for all test samples, quintuples | |||||||||||
| No-text | 0.4216 | 0.1322 | 0.4215 | 0.4779 | 0.2517 | 0.4780 | 0.3612 | 0.1007 | 0.3614 | ||
| Zero-shot | 0.8601 | 0.5601 | 0.8600 | 0.8530 | 0.6885 | 0.8531 | 0.8318 | 0.4480 | 0.8317 | ||
| Few-shot | 0.8638 | 0.5656 | 0.8638 | 0.8594 | 0.6962 | 0.8594 | 0.8415 | 0.4544 | 0.8414 | ||
| Method | Afghanistan | India | Russia | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | Recall | Precision | F1 | Recall | Precision | F1 | Recall | Precision | |||
| MLARAM | 0.3384 | 0.3526 | 0.3253 | 0.3368 | 0.3410 | 0.3327 | 0.2567 | 0.2671 | 0.2471 | ||
| BR-KNN | 0.4989 | 0.6152 | 0.4196 | 0.5036 | 0.5600 | 0.4575 | 0.4746 | 0.5664 | 0.4084 | ||
| ML-KNN | 0.4543 | 0.5035 | 0.4139 | 0.5233 | 0.5577 | 0.4929 | 0.5138 | 0.5862 | 0.4573 | ||
| DNN | 0.5577 | 0.6814 | 0.4720 | 0.5249 | 0.5638 | 0.4910 | 0.5381 | 0.6261 | 0.4718 | ||
| Dynamic GCN | 0.5005 | 0.5775 | 0.4416 | 0.4180 | 0.4319 | 0.4050 | 0.5281 | 0.6014 | 0.4707 | ||
| Temporal GCN | 0.6004 | 0.7693 | 0.4923 | 0.6073 | 0.6720 | 0.5540 | 0.5636 | 0.6766 | 0.4829 | ||
| RENET | 0.6058 | 0.7775 | 0.4962 | 0.5844 | 0.6418 | 0.5364 | 0.5585 | 0.6566 | 0.4859 | ||
| Glean | 0.6248 | 0.8284 | 0.5015 | 0.6669 | 0.7731 | 0.5864 | 0.5892 | 0.7357 | 0.4914 | ||
| LEAPMEF\SA | 0.6093 | 0.7832 | 0.4986 | 0.5921 | 0.6476 | 0.5454 | 0.5667 | 0.6838 | 0.4838 | ||
| LEAPMEF | 0.6363 | 0.8869 | 0.4961 | 0.7099 | 0.8731 | 0.5981 | 0.6280 | 0.8681 | 0.4919 | ||
| Model | Task | Implementation | GPU memory | Training time | Inference time | Money spent |
|---|---|---|---|---|---|---|
| Mistral-7B | OP | Local server | 15,695 MiB | / | 4 mins 23 secs | / |
| Llama-3.1-8B | OP | Local server | 21,441 MiB | / | 2 mins 46 secs | / |
| GPT-3.5 Turbo | OP | Online API | / | / | 6 mins 12 secs | 1.00 USD |
| GPT-4o mini | OP | Online API | / | / | 7 mins 45 secs | 0.10 USD |
| SeCoGD | OP | Local server | 9,219 MiB | 4 mins 41 secs | 10 secs | / |
| LEAPOP1 | OP | Local server | 13,412 MiB | 13 mins 00 sec | 10 secs | / |
| LEAPOP2 | OP | Local server | 7,851 MiB | 9 hours 43 mins | 1 min 10 secs | / |
| Glean | MEF | Local server | 7,109 MiB | 1 min 26 secs | / | / |
| LEAPMEF | MEF | Local server | 10,369 MiB | 3 mins 49 secs | / | / |
Event extrapolation refers to the forecasting of events of interest in a future time, given only historical data (Cai et al. 2024), which complies with the definition of multi-event forecasting (MEF) task. In this task, we aim to forecast possible relation occurrences , where in the next timestamp , given only historical information either in a structural format or a textual corpus format (Deng, Rangwala, and Ning 2020).
We start with a straightforward and simple prompt template , as shown in Table 2, to express an event quintuples as plain language, which can be fed into an encoder-only LLM. The total number of simple prompts is equal to the total number of quintuples for each dataset, where (Boschee et al. 2015). Then, we leverage a pre-trained RoBERTaLARGE, along with mean pooling for token-level aggregation, to generate an embedding vector for each quintuple prompt , such that
| (4) |
where and is the output feature dimension for RoBERTaLARGE encoder. The purpose of utilizing quintuple-level prompt engineering is to address the challenge of limited input context of open-source LLMs. Before feeding collected embeddings into downstream MEF layers, we need to convert them from the quintuple level back to the daily level with a purpose of incorporating as much history as possible for future forecasting. We write daily embeddings as , where , is the set of timestamps, and is the number of events on the th day.
Based on Figure 3, tracing back to a pre-defined sequence length , we feed concatenated embeddings into a single-head self-attention layer (Vaswani et al. 2017), and then take a mean aggregation to collapse the dimension for multiple historical days, as we get
| (5) |
where indicates the aggregated embeddings and is the batch size for future days, .
Subsequently, we introduce a fully-connected layer to adjust feature dimension and forecast possible relations in the future , following an element-wise with a threshold 0.5 to decide occurrences. We get
| (6) |
where , and is the set of all unique relations. contains a trainable matrix and vectorized bias . Overall, for LEAPMEF, the trainable modules are the self-attention layer and the fully-connected layer , which are optimized with cross-entropy loss comparing predicted relation occurrences with true occurrences through back-propagation.
Experiments
We conduct experiments on event datasets of three countries (Afghanistan, India, and Russia) from ICEWS which contains sociopolitical facts structured for crisis analysis, and each event is further enriched with several textual sentences sliced from authorized news articles (Boschee et al. 2015). Table 3 shows basic data statistics. The timestamps range from January 1, 2010, to February 22, 2016, and the minimum time gap is one day. All intermediate events from February 22, 2012 to January 1, 2013 are absent, so there are 1931 days in total, and the training/validation/test split is 0.8/0.2/0.2. All experiments involving module training and inference are implemented on a local server with GB NVIDIA L40S GPUs. For detailed experimental set up, such as hyperparameters and instruction fine-tuning results for RoBERTaBASE encoder and FLAN-T5BASE generator, we discuss them in the appendix.
LEAPOP1: Ranking Results
For ranking OP, we use Hits at as the evaluation metrics, which count the top ranking positions of the correct objects among all candidates, where . We consider comprehensive structural methods, including decoder-only ConvTransE (Shang et al. 2019), GNN-based CompGCN (Vashishth et al. 2019), R-GCN (Schlichtkrull et al. 2018), and RE-GCN (Li et al. 2021), as well as hypergraph-based SeCoGD (Ma et al. 2023) involving pre-trained LDA context clustering (Blei, Ng, and Jordan 2003), where the cluster number is set to 5. Although the scoring functions for entity ranking vary a lot, such as TransE (Bordes et al. 2013), TransR (Lin et al. 2015), and DistMult (Yang et al. 2014), we uniformly apply ConvTransE, which is the SOTA option, towards all the aforementioned structural approaches, including LEAPOP1.
Based on Table 4, we can observe that LEAPOP1 achieves better prediction accuracy than other competitors among all three ranking levels. Additionally, by tracing back to a longer sequence, the overall scores will slightly increase, possibly due to abundant historical information being available. However, , as a hyperparameter, cannot grow unlimitedly as the memory occupation to store more historical graphs and the training time to complete one epoch will correspondingly increase.
LEAPOP2: Generative Results
For generative OP, we use ROUGE scores as the evaluation metrics, which measures the overlap between generated and true objects at different levels including unigrams, bigrams, and longest common subsequence (Lin 2004). We leverage multiple generative LLMs, ranging from open-source Mistral-7B-Instruct (MistralAI 2023) and Llama-3.1-8B-Instruct (Meta 2024), to closed-source GPT-3.5-Turbo-Instruct (OpenAI 2023) and GPT-4o mini (OpenAI 2024a). Apart from generative models, we also incorporate competitive structural methods such as SeCoGD (Ma et al. 2023) and LEAPOP1, by reading out the object entity which has the highest probability among all candidates.
Based on Table 5, we can observe that LEAPOP2 yields much better ROUGE scores even than LEAPOP1. Additionally, LEAPOP2 with zero-shot prompt achieves competitively similar scores as few-shot prompt, demonstrating good in-domain generalizability of FLAN-T5BASE after QA fine-tuning. However, LEAPOP2 with no-text prompt has significantly degraded scores across all three datasets, indicating that a textual summary is essential to enhance the contextualized understanding of a Seq2Seq LLM.
The fine-tuned FLAN-T5BASE is a great event interpolator. We also test direct prompting generative LLMs without any local training in Table 5. We believe that, under limited resources, it is difficult to obtain satisfying prediction accuracy simply through in-context learning without more advanced prompting strategies, as the results from both open-source and closed-source LLMs are similarly less competitive even than the structural LEAPOP1. Since most sociopolitical entities are countries or governmental institutions made of less than five words, the generative setting only needs to output a few words for every prediction, and therefore takes more advantage over the ranking formulation, which simultaneously evaluates hundreds of candidates. To summarize OP, if the entities to be predicted are short like “Business (France)” and “Businessperson (United States)”, then the generative setting is a good choice. If the ground-truth targets involve long phrases, such as “Cabinet / Council of Ministers / Advisors (Spain)”, and there are dozens or even hundreds of long entities, then the ranking formulation is more suitable.
MEF: Multi-label Binary Classification Results
For MEF, we utilize precision, recall, and F1 score to evaluate this multi-label binary classification task, where “multi-label” indicates all unique relations , and “binary classification” represents either occurrence (1) or non-occurrence (0) of one specific relation , where . Following the experimental setup in Glean (Deng, Rangwala, and Ning 2020), we consider comprehensive baselines including neural network-based MLARAM (Benites and Sapozhnikova 2015) and DNN (Bengio et al. 2009), nearest neighbor-based BR-KNN (Spyromitros, Tsoumakas, and Vlahavas 2008) and ML-KNN (Zhang and Zhou 2007), along with GNN and RNN-based DynamicGCN (Deng, Rangwala, and Ning 2019), TemporalGCN (Zhao et al. 2019), and RENET (Jin et al. 2019). Compared with these SOTA methods, our approach LEAPMEF neither involve GNNs nor RNNs, therefore much design effort on updating entity and relation embeddings can be saved.
Based on Table 6, LEAPMEF achieves the best F1 score and recall all three datasets, and maintains a competitive precision among other baselines. We also conduct an ablation study by removing the self-attention (SA) layer (Vaswani et al. 2017), denoted as LEAPMEF\SA, which exhibits explicitly degraded forecasting accuracy. An intuitive take-away is that historical knowledge contains complicated relations among entities such as higher-order neighborhoods or hypergraph structure (Ma et al. 2022). To summarize MEF, we can observe that LEAPMEF achieves limited improvement in F1 score and precision, while the recall is significantly increased. This indicates our approach is good at imitating an observed trend during training, while the actual capability of forecasting the future is still constrained.
Computational Cost Comparison
We further compare GPU memory occupation, training/inference time, and money spending among selected SOTA methods, using the Indian dataset. To report the training time for both LEAPOP1 and LEAPOP2, we include the fine-tuning time for LLMs. As shown in Table 2 and Table 7, LEAPOP2 has the best event interpolation accuracy, but also takes the most locally significant training efforts. Meanwhile, GPT-4o mini achieves slightly better ROUGE scores with much cheaper cost than GPT-3.5 Turbo. For MEF, with the introduction of textual embeddings and self-attention, LEAPMEF is more computationally expensive than Glean, albeit an enhanced accuracy is achieved.
Discussion and Conclusion
In this paper, we propose LEAP to transform event prediction as language understanding and reasoning tasks. We investigated LLM-based frameworks for both interpolated tasks such as object prediction and extrapolated tasks such as multi-event forecasting. We apply quintuple-level prompt engineering to address the challenge of limited input context of open-source LLMs, and fine-tune RoBERTaBASE as an encoder and FLAN-T5BASE as a generator to achieve state-of-the-art event prediction accuracy on multiple real-world datasets. With fine-tuned open-source LLMs, we achieve better prediction accuracy than commercialized generative LLMs on sociopolitical events. Furthermore, we discuss the limitations of our approaches and explore several new ideas as potential future work.
The first limitation is that our OP and MEF approaches aim to simplify the design of existing event prediction frameworks (Ma et al. 2023; Deng, Rangwala, and Ning 2020) by introducing either encoding or generative LLMs, with enhanced prediction accuracy and affordable development being our major focus. As time evolves, the capability of pre-trained LLMs to reason the development of sociopolitical events can be further explored by integrating more advanced prompting strategies such as Chain-of-Thought (Wei et al. 2022) and ReAct (Yao et al. 2022).
The second limitation is that although multiple countries are involved, we only utilize ICEWS datasets (Boschee et al. 2015) for experiments, while other popular event datasets, such as GDELT (Leetaru and Schrodt 2013) and YAGO (Pellissier Tanon, Weikum, and Suchanek 2020), are not included, as our approaches are based on well-formulated event quintuples instead of quadruples which belong to the typical definition of temporal events (Cai et al. 2022). In other words, extending a quadruple to a quintuple by introducing a brief text summary can be regarded as a retrieval augmentation strategy (Lewis et al. 2020), which also demands more careful study.
One promising future direction is to evaluate the capability of LLMs in reasoning and understanding human event development. This involves meticulous design of experiments incorporating human feedback. Another important direction is to enhance LLMs’ temporal and spatiotemporal understanding of the world by integrating retrieval-augmented generation and knowledge graphs.
Appendix: Experimental Setup
In this section, we describe detailed hyperparameters for all sub-tasks of LEAP, and provide additional experimental results on LLM fine-tuning. Our experiments are implemented on a Ubuntu 22.04 server with 512GB RAM () and NVIDIA L40S GPUs.
LEAPOP1: Fine-tuning RoBERTaBASE
We fine-tune RoBERTaBASE with masked language modeling (MLM) loss by concatenating all text summaries in the training split (Liu et al. 2019). The learning rate is , the number of fine-tuning epochs is 40, the weight decay is , the block size for chunking the textual corpus is 512 tokens, and the masked language modeling probability is 0.15. We use perplexity to evaluate the MLM fine-tuning performance, as perplexity indicates how well a language model has learned the distribution of the text on which it has been trained (Jelinek et al. 1977). Based on Table 10, we observe an explicit decrease in test perplexity across all three datasets, which indicates that the fine-tuned RoBERTaBASE has enriched domain-specific knowledge.
| Dataset | Afghanistan | India | Russia | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| ROUGE | 1 | 2 | L | 1 | 2 | L | 1 | 2 | L | ||
| Before fine-tuning | 0.2082 | 0.0077 | 0.2079 | 0.0531 | 0.0194 | 0.0531 | 0.1370 | 0.0151 | 0.1369 | ||
| After fine-tuning | 0.8638 | 0.5656 | 0.8638 | 0.8594 | 0.6962 | 0.8594 | 0.8415 | 0.4544 | 0.8414 | ||
| Dataset | Afghanistan | India | Russia | |||||
|---|---|---|---|---|---|---|---|---|
| F1 score | Recall | F1 score | Recall | F1 score | Recall | |||
| Glean | ||||||||
| LEAPMEF | ||||||||
| GainAbsolute | 0.0108 | 0.0553 | 0.0458 | 0.1038 | 0.0307 | 0.1067 | ||
| GainRelative | 1.725% | 6.630% | 6.915% | 13.576% | 5.141% | 14.028% | ||
| Dataset | Afghanistan | India | Russia |
|---|---|---|---|
| Before fine-tuning | 3.53 | 3.65 | 2.85 |
| After fine-tuning | 2.03 | 2.32 | 2.01 |
| Metric | F1 score | Recall | Precision |
|---|---|---|---|
| valueone-sided | 0.1947 | ||
| valuetwo-sided | 0.3894 |
LEAPOP1: Training Structural Modules
To jointly train the structural modules in LEAPOP1 including R-GCN (Schlichtkrull et al. 2018), GRU (Cho et al. 2014), and ConvTransE (Shang et al. 2019), we leverage cross-entropy loss and set the number of training epochs to 40 with a patience equal to 5 epochs for early stopping. R-GCN has 2 layers, and the dropout rate is 0.2. The learning rate is , the weight decay is , the batch size is 1 (day), and the normalization threshold for gradient clipping is 1.0, along with the Adam optimizer (Kingma 2014). The feature dimension of entity and relation embeddings is 200, while the dimension for text summary embeddings from the fine-tuned RoBERTaBASE is 50265.
LEAPOP2: Fine-tuning FLAN-T5BASE
We fine-tune FLAN-T5BASE with cross-entropy loss, which is iteratively calculated by comparing the next generated token with the ground-truth token (Chung et al. 2024). The learning rate is , the number of fine-tuning epochs is 5, the weight decay is , and the batch size is 2 (prompts). We use ROUGE scores (Lin 2004) to evaluate the fine-tuning performance, as they can be computed by comparing the generated objects with the ground-truth objects, so that the object prediction quality can be simultaneously evaluated. Based on Table 8, we can observe that the ROUGE scores are significantly increased after fine-tuning, which demonstrates that the fine-tuned FLAN-T5BASE is a more capable generative interpolator.
Training and Evaluating LEAPMEF
To jointly train the self-attention (Vaswani et al. 2017) and feature projection layers in LEAPMEF, we apply cross-entropy loss and set the number of training epochs to 40 with a patience equal to 5 epochs for early stopping. The learning rate is , the weight decay is , the batch size is 2 (days), and the normalization threshold for gradient clipping is 1.0, along with the Adam optimizer (Kingma 2014). The feature dimension for quintuple embeddings from the pre-trained RoBERTaLARGE (without fine-tuning) is 50265, and the feature dimension after quintuple embedding aggregation and projection is 1024.
In the main paper, all event prediction experiments are implemented over 1 run. In this subsection, we implement Glean (Deng, Rangwala, and Ning 2020) and LEAPMEF over 5 runs and report the mean and standard deviation values of F1 score and recall. We also compute the absolute and relative gains with respect to the mean values. Based on Table 9, we can observe that LEAPMEF achieves better forecasting accuracy and stability than Glean, with larger means and smaller standard deviations.
In addition, we conduct both one-sided and two-sided Wilcoxon signed-rank tests (Wilcoxon 1992) for MEF results over 5 runs and across 3 datasets, which leads to 15 paired samples between LEAPMEF and Glean for each test. As shown in Table 11, we can conclude that LEAPMEF explicitly outperforms Glean in terms of F1 score and recall, as their one-sided and two-sided values are much smaller than 0.05. However, the multi-event forecasting performance difference, when evaluated by precision, is not significant as neither values are less than 0.05. This indicates that LEAPMEF still exhibits a limited capability of precisely forecasting events in the future.
References
- Anthropic (2024) Anthropic. 2024. Introducing the next generation of Claude. https://www.anthropic.com/news/claude-3-family. Accessed: 2024-08-05.
- Bengio et al. (2009) Bengio, Y.; et al. 2009. Learning deep architectures for AI. Foundations and trends® in Machine Learning, 2(1): 1–127.
- Benites and Sapozhnikova (2015) Benites, F.; and Sapozhnikova, E. 2015. Haram: a hierarchical aram neural network for large-scale text classification. In 2015 IEEE international conference on data mining workshop (ICDMW), 847–854. IEEE.
- Blei, Ng, and Jordan (2003) Blei, D. M.; Ng, A. Y.; and Jordan, M. I. 2003. Latent dirichlet allocation. Journal of machine Learning research, 3(Jan): 993–1022.
- Bordes et al. (2013) Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; and Yakhnenko, O. 2013. Translating embeddings for modeling multi-relational data. Advances in neural information processing systems, 26.
- Boschee et al. (2015) Boschee, E.; Lautenschlager, J.; O’Brien, S.; Shellman, S.; Starz, J.; and Ward, M. 2015. ICEWS Coded Event Data.
- Cai et al. (2022) Cai, B.; Xiang, Y.; Gao, L.; Zhang, H.; Li, Y.; and Li, J. 2022. Temporal knowledge graph completion: A survey. arXiv preprint arXiv:2201.08236.
- Cai et al. (2024) Cai, L.; Mao, X.; Zhou, Y.; Long, Z.; Wu, C.; and Lan, M. 2024. A Survey on Temporal Knowledge Graph: Representation Learning and Applications. arXiv preprint arXiv:2403.04782.
- Cho et al. (2014) Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; and Bengio, Y. 2014. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
- Chung et al. (2024) Chung, H. W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, Y.; Wang, X.; Dehghani, M.; Brahma, S.; et al. 2024. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70): 1–53.
- Church and Hanks (1990) Church, K.; and Hanks, P. 1990. Word association norms, mutual information, and lexicography. Computational linguistics, 16(1): 22–29.
- Deng, Rangwala, and Ning (2019) Deng, S.; Rangwala, H.; and Ning, Y. 2019. Learning dynamic context graphs for predicting social events. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1007–1016.
- Deng, Rangwala, and Ning (2020) Deng, S.; Rangwala, H.; and Ning, Y. 2020. Dynamic knowledge graph based multi-event forecasting. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 1585–1595.
- Dong et al. (2022) Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Wu, Z.; Chang, B.; Sun, X.; Xu, J.; and Sui, Z. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234.
- Jelinek et al. (1977) Jelinek, F.; Mercer, R. L.; Bahl, L. R.; and Baker, J. K. 1977. Perplexity—a measure of the difficulty of speech recognition tasks. The Journal of the Acoustical Society of America, 62(S1): S63–S63.
- Jin et al. (2019) Jin, W.; Qu, M.; Jin, X.; and Ren, X. 2019. Recurrent event network: Autoregressive structure inference over temporal knowledge graphs. arXiv preprint arXiv:1904.05530.
- Kanakarajan and Sankarasubbu (2023) Kanakarajan, K. R.; and Sankarasubbu, M. 2023. Saama AI Research at SemEval-2023 Task 7: Exploring the Capabilities of Flan-T5 for Multi-evidence Natural Language Inference in Clinical Trial Data. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), 995–1003.
- Kingma (2014) Kingma, D. P. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Lee et al. (2023) Lee, D.-H.; Ahrabian, K.; Jin, W.; Morstatter, F.; and Pujara, J. 2023. Temporal knowledge graph forecasting without knowledge using in-context learning. arXiv preprint arXiv:2305.10613.
- Leetaru and Schrodt (2013) Leetaru, K.; and Schrodt, P. A. 2013. Gdelt: Global data on events, location, and tone, 1979–2012. In ISA annual convention, volume 2, 1–49. Citeseer.
- Lewis et al. (2019) Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; and Zettlemoyer, L. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461.
- Lewis et al. (2020) Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.-t.; Rocktäschel, T.; et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33: 9459–9474.
- Li et al. (2021) Li, Z.; Jin, X.; Li, W.; Guan, S.; Guo, J.; Shen, H.; Wang, Y.; and Cheng, X. 2021. Temporal knowledge graph reasoning based on evolutional representation learning. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, 408–417.
- Liao et al. (2023) Liao, R.; Jia, X.; Ma, Y.; and Tresp, V. 2023. GenTKG: Generative Forecasting on Temporal Knowledge Graph. arXiv preprint arXiv:2310.07793.
- Lin (2004) Lin, C.-Y. 2004. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, 74–81.
- Lin et al. (2015) Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; and Zhu, X. 2015. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI conference on artificial intelligence, volume 29.
- Liu et al. (2022) Liu, Y.; Ma, Y.; Hildebrandt, M.; Joblin, M.; and Tresp, V. 2022. Tlogic: Temporal logical rules for explainable link forecasting on temporal knowledge graphs. In Proceedings of the AAAI conference on artificial intelligence, volume 36, 4120–4127.
- Liu et al. (2019) Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; and Stoyanov, V. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Ma et al. (2022) Ma, J.; Wan, M.; Yang, L.; Li, J.; Hecht, B.; and Teevan, J. 2022. Learning causal effects on hypergraphs. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 1202–1212.
- Ma et al. (2023) Ma, Y.; Ye, C.; Wu, Z.; Wang, X.; Cao, Y.; and Chua, T.-S. 2023. Context-aware event forecasting via graph disentanglement. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 1643–1652.
- Meta (2024) Meta. 2024. Introducing Llama 3.1: Our most capable models to date. https://ai.meta.com/blog/meta-llama-3-1/. Accessed: 2024-08-05.
- MistralAI (2023) MistralAI. 2023. Mistral 7B: The best 7B model to date, Apache 2.0. https://mistral.ai/news/announcing-mistral-7b/. Accessed: 2024-08-05.
- Onaolapo et al. (2022) Onaolapo, A. K.; Carpanen, R. P.; Dorrell, D. G.; and Ojo, E. E. 2022. Event-driven power outage prediction using collaborative neural networks. IEEE Transactions on Industrial Informatics, 19(3): 3079–3087.
- OpenAI (2023) OpenAI. 2023. GPT-3.5 Turbo. https://platform.openai.com/docs/models/gpt-3-5-turbo. Accessed: 2024-08-05.
- OpenAI (2024a) OpenAI. 2024a. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/. Accessed: 2024-08-05.
- OpenAI (2024b) OpenAI. 2024b. Pricing. https://openai.com/api/pricing/. Accessed: 2024-08-05.
- Ouyang et al. (2022) Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35: 27730–27744.
- Pan et al. (2023) Pan, J.; Nayyeri, M.; Li, Y.; and Staab, S. 2023. Do Temporal Knowledge Graph Embedding Models Learn or Memorize Shortcuts? In Temporal Graph Learning Workshop@ NeurIPS 2023.
- Pan et al. (2024) Pan, S.; Luo, L.; Wang, Y.; Chen, C.; Wang, J.; and Wu, X. 2024. Unifying large language models and knowledge graphs: A roadmap. IEEE Transactions on Knowledge and Data Engineering.
- Pellissier Tanon, Weikum, and Suchanek (2020) Pellissier Tanon, T.; Weikum, G.; and Suchanek, F. 2020. Yago 4: A reason-able knowledge base. In The Semantic Web: 17th International Conference, ESWC 2020, Heraklion, Crete, Greece, May 31–June 4, 2020, Proceedings 17, 583–596. Springer.
- Schlichtkrull et al. (2018) Schlichtkrull, M.; Kipf, T. N.; Bloem, P.; Van Den Berg, R.; Titov, I.; and Welling, M. 2018. Modeling relational data with graph convolutional networks. In The semantic web: 15th international conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, proceedings 15, 593–607. Springer.
- Shang et al. (2019) Shang, C.; Tang, Y.; Huang, J.; Bi, J.; He, X.; and Zhou, B. 2019. End-to-end structure-aware convolutional networks for knowledge base completion. In Proceedings of the AAAI conference on artificial intelligence, volume 33, 3060–3067.
- Shang and Huang (2024) Shang, W.; and Huang, X. 2024. A Survey of Large Language Models on Generative Graph Analytics: Query, Learning, and Applications. arXiv preprint arXiv:2404.14809.
- Shi et al. (2024) Shi, X.; Xue, S.; Wang, K.; Zhou, F.; Zhang, J.; Zhou, J.; Tan, C.; and Mei, H. 2024. Language models can improve event prediction by few-shot abductive reasoning. Advances in Neural Information Processing Systems, 36.
- Spyromitros, Tsoumakas, and Vlahavas (2008) Spyromitros, E.; Tsoumakas, G.; and Vlahavas, I. 2008. An empirical study of lazy multilabel classification algorithms. In Artificial Intelligence: Theories, Models and Applications: 5th Hellenic Conference on AI, SETN 2008, Syros, Greece, October 2-4, 2008. Proceedings 5, 401–406. Springer.
- Touvron et al. (2023a) Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vashishth et al. (2019) Vashishth, S.; Sanyal, S.; Nitin, V.; and Talukdar, P. 2019. Composition-based multi-relational graph convolutional networks. arXiv preprint arXiv:1911.03082.
- Vaswani et al. (2017) Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30.
- Wang et al. (2023) Wang, J.; Wang, B.; Qiu, M.; Pan, S.; Xiong, B.; Liu, H.; Luo, L.; Liu, T.; Hu, Y.; Yin, B.; et al. 2023. A survey on temporal knowledge graph completion: Taxonomy, progress, and prospects. arXiv preprint arXiv:2308.02457.
- Wasserkrug (2009) Wasserkrug, S. 2009. Event Prediction, 1048–1052. Boston, MA: Springer US. ISBN 978-0-387-39940-9.
- Wei et al. (2022) Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q. V.; Zhou, D.; et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35: 24824–24837.
- Wilcoxon (1992) Wilcoxon, F. 1992. Individual comparisons by ranking methods. In Breakthroughs in statistics: Methodology and distribution, 196–202. Springer.
- Yang et al. (2014) Yang, B.; Yih, W.-t.; He, X.; Gao, J.; and Deng, L. 2014. Embedding entities and relations for learning and inference in knowledge bases. arXiv preprint arXiv:1412.6575.
- Yao et al. (2022) Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; and Cao, Y. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
- Ye et al. (2024) Ye, C.; Hu, Z.; Deng, Y.; Huang, Z.; Ma, M. D.; Zhu, Y.; and Wang, W. 2024. MIRAI: Evaluating LLM Agents for Event Forecasting. arXiv preprint arXiv:2407.01231.
- Zhang and Zhou (2007) Zhang, M.-L.; and Zhou, Z.-H. 2007. ML-KNN: A lazy learning approach to multi-label learning. Pattern recognition, 40(7): 2038–2048.
- Zhao (2021) Zhao, L. 2021. Event prediction in the big data era: A systematic survey. ACM Computing Surveys (CSUR), 54(5): 1–37.
- Zhao et al. (2019) Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; and Li, H. 2019. T-gcn: A temporal graph convolutional network for traffic prediction. IEEE transactions on intelligent transportation systems, 21(9): 3848–3858.