Large Language Model Aided QoS Prediction for Service Recommendation
Abstract
Large language models (LLMs) have seen rapid improvement in the recent years, and have been used in a wider range of applications. After being trained on large text corpus, LLMs obtain the capability of extracting rich features from textual data. Such capability is potentially useful for the web service recommendation task, where the web users and services have intrinsic attributes that can be described using natural language sentences and are useful for recommendation. In this paper, we explore the possibility and practicality of using LLMs for web service recommendation. We propose the large language model aided QoS prediction (llmQoS) model, which use LLMs to extract useful information from attributes of web users and services via descriptive sentences. This information is then used in combination with the QoS values of historical interactions of users and services, to predict QoS values for any given user-service pair. On the WSDream dataset, llmQoS is shown to overcome the data sparsity issue inherent to the QoS prediction problem, and outperforms comparable baseline models consistently.
Index Terms:
Service Recommendation, Quality of Service, Large Language Model.I Introduction

The rapid development of cloud computing has led to an explosive growth in the number of cloud services, resulting in many services having identical or similar functionalities [1]. There is a growing need for service providers to provide the most suitable service for users to meet customer demands. When there exist many candidate services for a user request, quality of service (QoS) is a commonly used metric to measure the performance of these services. QoS refers to non-functionality aspects of services [2] such as throughput, response time, and cost. It plays a crucial role in distinguishing similar services and helps users select the most appropriate one. However, in real-world scenarios, evaluating the QoS of a large number of services on the client side is expensive and time-consuming due to the sheer scale. Additionally, most end users lack the expertise to do the evaluation [3]. Therefore, it is common for an end user is to predict the QoS values for an unknown service, and the QoS values are used to help the user find the most suitable service.
The problem of QoS prediction is illustrated in Figure I. For the sets of web users (u1 u4) and services (s1 s4) exists a QoS matrix, in which each value corresponds to a user-service interaction. The matrix contains some known QoS values from historical user-service interactions, and our goal is to predict unknown QoS values (marked by “?”) using these known values, thereby recommending more suitable services to users. Many methods have been developed to predict the QoS values for a given user and service. Among them, collaborative filtering is the most widely used technique. It aim to accurately estimate unknown QoS values by learning from the QoS value matrix from historical user-service interactions. However, in practice, the historical QoS value matrix is often highly sparse, as each user usually only interacted with a limited number of cloud services in the past. This data sparsity issue poses difficulty for many QoS prediction methods. Although many methods aim to mitigate this difficulty, it is still challenging to achieve ideal predictive performance.
More recently, large language models (LLMs) [4, 5] have demonstrated remarkable performance in understanding and generating texts. LLMs have large capacity and are trained on vast amounts of data, enabling them to capture complex patterns in natural language with a long context. They have rapidly become powerful tools for various natural language processing tasks [6, 7, 8, 9, 10]. For the QoS prediction problem, each user and service has some specific attributes. For instance, users may have attributes such as its country of origin and the autonomous system it belongs to. Given that LLMs are capable of handling natural language with contextual information, we claim that such capability can be used for QoS prediction task as well. In this paper, we propose to use natural language sentence to describe each user or service using their corresponding attributes. Those attributes contain information such as the proximity and type, which are potentially useful for QoS prediction. We then use state-of-the-art LLMs to extract the descriptive features of users and services from those sentences. This LLMs-based feature helps the QoS prediction model better understand and represent the latent features of users and services. It effectively mitigates the data sparsity issue, as the descriptive LLM features provide information that is complementary to the historical user-service interactions. Along with the historical QoS values, it helps the model to provide more reliable and effective service recommendations.
We summarize our main contributions as the following:
-
•
To the best of our knowledge, we first introduce large language models for the web service recommendation task. We propose large language model aided QoS prediction (llmQoS), a novel approach that combines collaborative filtering and nature language processing, making use of both historical user-service interaction information and rich text feature from attributes of users and services. It can effectively mitigate the data sparsity issue inherent to the QoS prediction problem.
-
•
The proposed llmQoS model is robust and versatile. It can work with different LLMs, and can generalize to different collaborative filtering network architectures.
-
•
We show that llmQoS can predict QoS values accurately under different data sparsity levels. On the WSDream dataset, it outperforms several existing QoS prediction models consistently.
II Related Work
II-A QoS Prediction for Service Recommendation
Among QoS prediction methods for web services, collaborative filtering (CF) [11] methods receive extensive attention and are widely regarded as the most effective approach. CF-based QoS prediction methods can be divided into two main categories: memory-based methods and model-based methods.
For memory-based CF methods, the similarity of users or services is first calculated. Then QoS values of the target user and service are predicted based on both the historical QoS values and the similarity relationships with their neighbors. Shao et al. [12] first utilize user-based CF methods for QoS prediction. Qi et al. [13] identify “enemies” of the target user to determine their “potential friends”, successfully overcoming the cold-start problem. Meanwhile, item-based methods are widely employed [14, 15]. Chen et al. [16] propose a predictive method that integrates service similarity and geographical location information, effectively alleviating data sparsity and cold-start issues. Additionally, hybrid algorithms that compute both service-to-service and user-to-user similarities [17] are developed. Zheng et al. [18] simultaneously consider user and service similarities for QoS prediction, demonstrating superior predictive performance compared to previous methods. Hu et al. [19] propose to integrate time information to improved CF for QoS prediction.
Model-based CF methods typically use models to predict the QoS values, with matrix factorization (MF) being the most common approach. MF methods decompose the user-service interaction matrix into user and service matrices, predicting values by multiplying these two matrices. Zhu et al. [20] notably extend the traditional MF models by incorporating techniques including data transformation, online learning, and adaptive weighting on the basis of CF techniques. Zheng et al. [21] develop a neighborhood-integrated MF method for personalized web service QoS prediction. Xu et al. [22] employ a probabilistic matrix factorization (PMF) model to learn and predict QoS values, incorporating geographical location to identify user neighbors and comprehensively consider their impact on web service invocation experiences.
Deep learning technology has demonstrated remarkable capabilities across various fields of artificial intelligence in recent years [23, 24, 25, 4, 5]. And an increasing number of deep learning based techniques for QoS prediction are developed [26, 27] too. Zou et al. [28] propose a novel adaptive QoS prediction framework, utilizing a dual-tower deep residual network to extract latent features of users and services and predict QoS values. Wu et al. [29] introduce a reputation-integrated graph convolutional network for robust and accurate QoS prediction. Wei et al. [30] use a transformer based method to learn the graph structure for time-aware service recommendation. Zhu et al. [31] develop a twin graph network based on graph contrastive learning, effectively addressing cold-start and data sparsity issues. Zhou et al. [32] propose the spatial context-aware time series forecasting (SCATSF) framework by utilizing both temporal and spatial contextual information of users and services. Lian et al. [33] facilitate multi-task learning for training QoS prediction model.
Most deep learning based QoS prediction models use the user and service ID information through embedding layers. Additionally, to improve prediction performance, some methods [28, 31] utilize more information of the users and services such as their location, IP address, and the autonomous systems they belong to. Such information provides similarity or proximity signal for the model, which are useful for QoS prediction. In our work, we utilize such information through large language models.
II-B Large Language Model
In the field of natural language processing (NLP), LLMs have seen rapid development since the introduction of the transformer architecture [34]. They have shown state-of-the-art performance across virtually all NLP tasks, including text classification and summarizing, machine translation, text generation, and human-like conversation systems [4, 5].
Most LLMs are based on variants of the already ubiquitous transformer architecture, with the core components being the attention based mechanism that can effectively capture the correlation among different words in the text. It is common for a group of researchers to develop a series of LLMs that share similar architecture and training recipes, but with generational improvement in performance and capability. Notable ones include the BERT series of original BERT[6], RoBERTa [7], ALBERT [35], and DeBERTa [7]; the OpenAI GPT series of GPT [36], GPT-2 [37], GPT-3 [8], and GPT-4 [38]; the META LLaMA series of LLaMA [39], LLaMA2 [40], and LLaMA3 [10]; and the Microsoft Phi series of Phi1 [41, 42], Phi2 [43], and Phi3 [9]. The common trend in each series is that the newer models usually have more parameters, and are trained on larger corpus of text. Larger LLMs have higher capacity, can learn more information from a larger corpus of text, have a higher generalization capability, and in general perform better on standardized NLP benchmarks [44].
Thought LLMs are trained from textual data, they can generalize to tasks beyond NLP too. They have been shown to work on visual question-answering [45], open-vocabulary object detection [46], planning [47], and autonomous driving [48]. In this paper, we use LLMs for the service recommendation task. When using LLMs on non-NLP tasks, it is important to convert the data into a form of prompt that can be processed by the LLMs. In our work we construct descriptive sentences from the relative attributes of web users and services to be used by LLMs. More details are discussed in § III-A.
Different LLMs have different levels of accessibility. The parameters of some LLMs can be downloaded and ran on local computers for any end user, which is often referred as “open-weight” models. Some models are only be used through API calls and the model parameters cannot be accessed. In this paper we only use open-weight models for reproducibility. However our method can be applied to any LLMs with feature extraction functionality.
III Methods
III-A Large Language Model Feature Extraction

For each web user and service in WSDream dataset, we use the corresponding attributes to construct a descriptive sentence as the input to the LLMs for feature extraction. Specifically, we use the country and autonomous system for users. For instance, the descriptive sentence for one of the user is \asciifamily”web user, located in United States, in autonomous system AS5661 USF - UNIVERSITY OF SOUTH FLORIDA.” Similarly, the URL, service provider, country, and autonomous system are used to services. For example one of the services has the descriptive sentence of \asciifamily”web service, at url http://biomoby.org/services/wsdl/ualberta.ca /DrugBankByName, hosted by ualberta.ca, located in Canada, in autonomous system AS3359 University of Alberta.” We do not include numerical attributes such as IP address, latitude, and longitude in the sentences, as LLMs usually cannot extract meaningful information from numbers. For each user or service, we use the same descriptive sentence for different LLMs.
After obtaining the descriptive sentence for each user or service, we use pre-trained RoBERTa [7] or Phi3mini [9] to extract sentence-level language features. The pipeline is illustrated in Figure II. The sentence is first converted into a sequence of tokens by a tokenizer. The embedding vector of each token is obtained by their token ID and position. A set of stacked LLM layers process on this sequence of embedding vectors to obtain the final sequence of feature vectors. One of the vector in the final sequence is used as the LLM feature vector of the descriptive sentence.
RoBERTa and Phi3mini have similar overall architecture. Each LLM layer in them comparably consists of an attention based layer [34] and a set of feed-forward layers. The attention layer calculates the correlation among the feature vectors in the sequence. The feed-forward layers are combination of linear layers, normalization layers, and activation functions. This common architecture is used by many other LLMs too.
However, RoBERTa and Phi3mini have different number of layers, different dimensionality of the embedding vectors, and different tokenizer. Phi3mini has parameters, which is significantly larger than RoBERTa’s million parameters. They are also pre-trained on different datasets using different training tasks. RoBERTa is pre-trained to do text classification on total of 160 giga-bytes of text data. If each token uses 5 bytes on average, the model sees tokens during training. For text classification, the first vector in the final sequence is used. So we also use the first vector as the sentence-level feature. On the other hand, Phi3mini is pre-trained using next token prediction on a dataset with tokens. Next token prediction uses the last vector in the final sequence, so we also use the last vector in the final sequence for Phi3mini. Later we show in experiments that Phi3mini outperforms RoBERTa consistently.
III-B Model Architecture

The overall architecture of the proposed large language model aided QoS prediction (llmQoS) model is illustrated in Figure III. First, both the user and service IDs are projected to feature vectors by their corresponding embedding layers. Formally for user and service ,
| (1) |
| (2) |
where and are the IDs of the user and the service, and and are the corresponding embedding layers.
Then descriptive sentences are constructed and the LLM features are extracted for each user and service based on their attributes, as described in § III-A. The descriptive LLM features have much larger dimensionality compared to the ID embedding features. So a projection layer is used for to reduce them to the same dimensionality as the ID embedding features:
| (3) |
| (4) |
where and are the descriptive sentences of the user and service. Please note that we use the same model and projection layer for both user and service.
Then the user ID embedding feature vector, the projected user descriptive LLM feature vector, the service ID embedding feature vector, and the projected service descriptive LLM feature vector are all concatenated. This concatenated feature vector is used as the input to an multi-layer perceptron (MLP) network. Finally a linear layer produces the predicted QoS value for the input user-service pair. Formally,
| (5) |
where is the predicted QoS value for and .
Please note that our network design is straightforward without complicated architectures such as graph convolution or attention. The QoS prediction network architecture is not the focus of this paper. With straightforward architecture, llmQoS can still achieve state-of-the-art performance as shown by the experiments. This demonstrate the effectiveness of incorporating LLM features for QoS prediction. In § IV-H we further demonstrate that LLM features can be integrated into more complex QoS prediction models and can still increase the performance significantly and consistently.
IV Experiments
This section shows the results and discussion of our extensive experiments with llmQoS. It starts with the details of the dataset, evaluation metrics, implementation, and the baseline methods. Then the performance of llmQoS is compared with the baselines. And multiple ablation study experiments are conducted to verify that the LLM feature is beneficial for QoS prediction, and can be integrated to other network architectures too.
| Model | Sub-dataset throughput | |||||||
| =5% | =10% | =15% | =20% | |||||
| MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| UIPCC | 20.757 | 60.799 | 22.370 | 54.456 | 20.219 | 50.704 | 18.928 | 48.295 |
| RegionKNN | 25.632 | 67.868 | 24.838 | 67.551 | 24.584 | 67.314 | 24.036 | 66.176 |
| LACF | 23.169 | 58.967 | 19.626 | 53.105 | 17.795 | 49.766 | 16.667 | 47.625 |
| PMF | 19.082 | 57.883 | 15.994 | 48.071 | 14.670 | 44.013 | 13.924 | 41.714 |
| BGCL | 20.655 | 61.297 | 19.318 | 59.134 | 18.134 | 58.804 | 18.017 | 58.689 |
| LMF-PP | 18.301 | 51.777 | 15.913 | 46.142 | 14.745 | 42.993 | 14.103 | 41.408 |
| DCALF | 17.658 | 51.632 | 15.360 | 46.428 | 14.384 | 43.402 | 13.670 | 41.624 |
| llmQoS | 13.714 | 46.635 | 12.022 | 42.947 | 11.156 | 39.567 | 10.760 | 38.365 |
| Gain | 22.33% | 9.68% | 21.73% | 6.92% | 28.93% | 7.97% | 21.28% | 7.35% |
| Model | Sub-dataset response time | |||||||
| =5% | =10% | =15% | =20% | |||||
| MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | |
| UIPCC | 0.625 | 1.388 | 0.582 | 1.330 | 0.501 | 1.250 | 0.450 | 1.197 |
| RegionKNN | 0.588 | 1.543 | 0.548 | 1.513 | 0.526 | 1.513 | 0.516 | 1.521 |
| LACF | 0.637 | 1.444 | 0.566 | 1.342 | 0.516 | 1.276 | 0.483 | 1.230 |
| PMF | 0.569 | 1.537 | 0.487 | 1.316 | 0.452 | 1.221 | 0.431 | 1.169 |
| BGCL | 0.461 | 1.407 | 0.433 | 1.374 | 0.424 | 1.334 | 0.416 | 1.320 |
| LMF-PP | 0.529 | 1.341 | 0.473 | 1.242 | 0.447 | 1.210 | 0.426 | 1.161 |
| DCALF | 0.546 | 1.402 | 0.486 | 1.265 | 0.464 | 1.210 | 0.452 | 1.176 |
| llmQoS | 0.409 | 1.290 | 0.360 | 1.224 | 0.344 | 1.186 | 0.327 | 1.159 |
| Gain | 11.36% | 3.84% | 16.72% | 1.41% | 18.93% | 2.01% | 21.40% | 0.21% |








IV-A Dataset
To evaluate the performance of our model, we conducted extensive experiments on the WSDream dataset [49]. WSDream is a large-scale real-world dataset of Internet user-service interactions that involves 5,825 services and 339 users in total. Each user and service is identified by a unique ID number. In addition to the IDs, WSDream also provides basic attribute information for each user and service. User attributes consist of IP Address, Country, IP Number, Autonomous System, Latitude, and Longitude. Service attributes include WSDL Address, Service Provider, IP Address, Country, IP Number, Autonomous System, Latitude, and Longitude. We utilize both the IDs and attributes for the users and services in our llmQoS model.
WSDream contains QoS record that include 1,873,850 response time values and 1,831,265 throughput values. For experiments, both the throughput sub-dataset and the response time sub-dataset are randomly split into training and testing sets. We use different density values , which is the percentage of training set data in the total dataset, to test the models’ prediction ability at different data sparsity levels. Specifically we use =5%, 10%, 15%, and 20%. It is expected that with all other settings unchanged, QoS prediction models achieve higher precision with larger values of .
IV-B Implementation Details
We implemented our model using \asciifamilyKeras 2.0.9 [50] with a \asciifamilyTensorFlow 1.4.0 [51] backend. The ID embedding for both user and service has a dimensionality of 16. Both pre-trained RoBERTa and Phi3mini are taken from Huggingface [52], and the descriptive LLM feature extraction is implemented using the \asciifamilyTransformers library. The descriptive LLM feature vectors from RoBERTa and Phi3mini have 768 and 3,072 dimensions, respectively. In both cases the descriptive LLM feature vector is reduced to 16 dimensions by the projection layer. The MLP module has 3 linear layers with output dimensionalities of 32, 16, and 8. Each linear layer is followed by a ReLU activation function [53]. The final prediction layer is a single linear layer that maps the 8-dimensional output vector of MLP module to a single QoS value.
For all experiments, we use Huber loss [54] to train the model. The loss function is defined as
| (6) |
where is the ground truth QoS value, and is the QoS value predicted by the model. We use threshold . All models are trained using the Adam optimizer [55] with learning rate of and batch size of 256.
We measure the Mean Average Error (MAE) and Root Mean Squared Error (RMSE) on the testing set to measure the performance of the model. They are defined as
| (7) |
and
| (8) |
where is a pair of ground truth and predicted QoS values, and is the number of data points in the testing set. We measure the MAE of the model at the end of each training epoch, and use the one with lowest MAE as the final trained model. We observed that for throughput experiments, the final model can be obtained before 1,500 epochs. For response time experiments, the final model can be obtained before 600 epochs.
IV-C Baseline Models
In our experiment, we selected 7 baselines to compare with our model and evaluate its performance. This includes traditional algorithms and the latest research. We keep dataset split method and evaluation settings for all baselines same to the proposed llmQoS for fair comparison.
UIPCC [18] is a traditional domain-based collaborative filtering method that predicts missing QoS values by leveraging historical invocation information of users and services.
RegionKNN [56] is a hybrid collaborative filtering algorithm that considers geographic information for service recommendations.
LACF [57] is a location-aware collaborative filtering method that integrates user and service location information to recommend web services to users.
PMF [58] is an enhanced traditional matrix factorization method that incorporates probabilistic factors into matrix decomposition for QoS prediction.
BGCL [31] is a graph-based contrastive learning method that utilizes graph attention mechanisms to incorporate domain information of users and services for QoS prediction.
LMF-PP [59] is a location-based matrix factorization method that integrates invocation and domain information, and utilizes fused similarity for preference propagation, addressing cold-start issues to achieve QoS prediction.
DCALF [60] detects domains and noise of users and services from the original QoS matrix, introducing density peak-based clustering methods during modeling for simultaneous detection of neighborhood and noise, achieving QoS prediction.































IV-D Comparison with Baselines
The performance of the proposed llmQoS is compared with the baseline methods in Table I. Phi3mini is used for llmQoS in this experiment. We compare both MAE and RMSE for throughput and response time at different densities. It is evident that llmQoS outperforms all baselines consistently at all densities. For throughput value prediction, llmQoS can reduce the MAE by more than 20%, and RMSE by more than 6% from the best baseline model. For response time value prediction, llmQoS can also reduce MAE for more than 10% from the best baseline method. The results demonstrate that with the rich features from the descriptive sentences extracted by LLMs, the QoS prediction model can effectively find the similarity and correlation among users and services. Along with the information learned from historical interactions, llmQoS can achieve high QoS prediction accuracy.
IV-E Training Curves
When setting the training epochs, we configured 1500 epochs for throughput prediction and 600 epochs for response time prediction. We plotted training curves to validate these settings. Figure IV illustrates the loss, MAE, and RMSE curves of the llmQoS model during training at sparse densities ranging from 5% to 20%. As the number of iterations increases, the model gradually converges to optimal performance. We observe that the model reaches optimal performance for throughput prediction before 1500 epochs, while for response time prediction, it reaches optimal performance before 600 epochs.
IV-F Comparison of Different LLMs
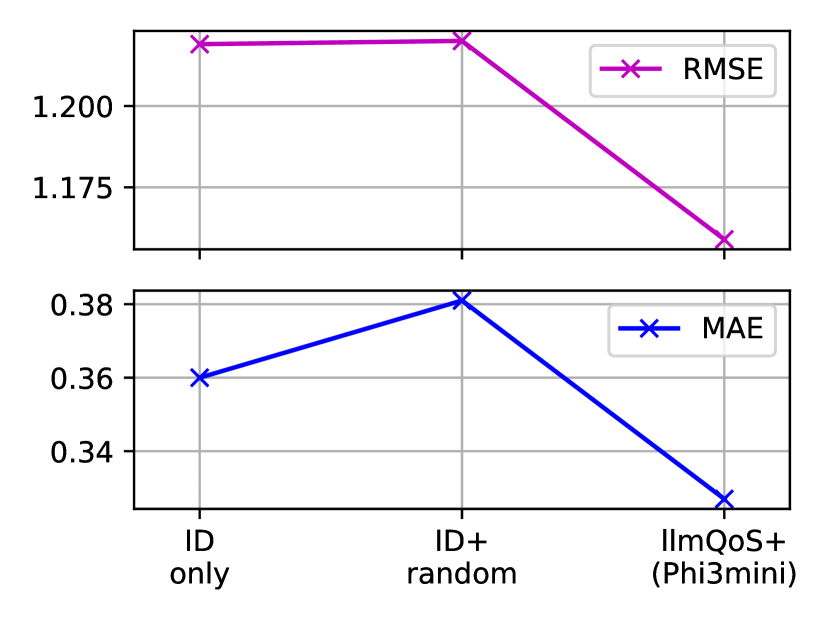
As discussed in § II-B and § III-A, larger LLMs have higher capacity and can potentially achieve higher performance on various tasks. So here we compare the performance of llmQoS with different LLMs as the feature extractor. We compare the larger and more recent Phi3mini with the smaller and older RoBERTa model. In addition, we remove all LLM feature related components from llmQoS, and only use the ID embedding vectors of users and services to train a QoS prediction model. This model is referred as “ID only” model. We train all models using the same training hyper-parameters, and the results are compared in Figure V.
It is clear that adding LLM features to QoS prediction is helpful, and can reduce the prediction error significantly from the ID only baseline. This further verifies that the information from the attributes of users and services is useful for service recommendation. And Phi3mini achieves lower MAE and RMSE than RoBERTa consistently on all densities. This shows that the superior capability of larger LLMs on NLP tasks also transfers to QoS prediction task.
However, it is important to note that larger LLMs runs at a higher computational cost. Phi3mini is considered one of the smallest modern LLMs, as the larger ones have tens or hundreds of billions of parameters. Larger LLMs can also have higher feature dimensionality, making training the QoS prediction network slower. In practice, trade-off needs to be made between prediction accuracy and computational cost.
IV-G Ablation Study Using Random Feature
In § IV-F we have shown that LLM feature improves QoS prediction accuracy, and larger Phi3mini is more effective than smaller RoBERTa. However, the prediction model with LLM feature input has more trainable parameters than the model that only uses ID embedding. What is more, since the feature vectors from Phi3mini have 3,072 dimensions compared to RoBERTa’s 768 dimensions, the projection layer for Phi3mini also has more parameters than RoBERTa. So it is plausible that the performance improvement is due to the increased number of parameters resulting in large model capacity.
To verify this, we train a model that still has 3,072-dimensional feature vectors as input. But those feature vectors are randomly initialized for each user and service, so they do not contain any useful information. However, this model has the same number of parameters as the llmQoS model with Phi3mini feature. We compare the QoS prediction performance of this model with both the ID only model as in § IV-F and the llmQoS with Phi3mini in Figure VI. Generally, the model with random feature does not outperform ID only model. On throughput dataset under =5% and =15%, the accuracy is marginally higher than the ID only model. But under other settings the performance actually worsens. We also observe that with random feature, the model converges with much less epochs than using Phi3mini feature. This indicates that more trainable parameters lead to overfitting. We verify that the performance boost of llmQoS is from the useful information encoded in the LLM feature, instead of added parameters of the model.
IV-H Adding LLM Feature to BGCL
To if LLM features can benefit QoS prediction in general, we further conduct experiments by incorporating LLM features into another QoS prediction model. We selected the Bi-subgraph network based on graph contrastive learning (BGCL) model [31], which has a more complex network architecture. BGCL uses location attributes of users and services for graph contrastive learning, as well as attention mechanism to aggregate features. If LLM features can improve the QoS prediction accuracy for BGCL, we claim that the benefits of using LLM can be further demonstrated.
We keep all other features and network architecture unchanged for BGCL, with the only addition of the LLM feature vectors along side with the embedding vectors of BGCL at the very beginning of the network of BGCL. Similar to § IV-F, we compare BGCL with Phi3mini, BGCL with RoBERTa, and vanilla BGCL. The experimental results, as shown in Figure VII, are similar to the results in Figure V too. We further verify that that integrating LLM features significantly enhances the model’s performance, and larger model achieves more satisfactory results. This demonstrates that LLM features are beneficial to QoS prediction problem, regardless of the network architecture. And we expect this to apply to other QoS prediction models as well.
IV-I Hyper-Parameter Tuning of MLP
We test the performance of llmQoS using different configurations for the MLP model as described in § III-B. For this experiment we test the density level =5%, and using Phi3mini as the LLM feature extractor. We vary the depth of the MLP by adding or removing layers from it. The QoS prediction performance of different configurations is shown in 8(a) and 8(b). We change the width of the MLP by multiplying a width factor to the dimensionalities of the layers in it. The QoS prediction performance of different configurations is shown in 8(c) and 8(d).
It can be observed that the depth and width of the MLP network have a minor impact on the QoS prediction performance. In most cases the change in MAE and RMSE is under 5%. However, when the MLP depth is set to 1, or the width factor is set to 0.5, there is a significant deterioration in the performance. This is caused by the network is too shallow and narrow, resulting to very low capacity. Considering this paper primarily focuses on using large language models to assist QoS prediction, we have selected a reasonably appropriate depth and width for the MLP network without extensive searching.
IV-J Training Parameter Tuning
We test the performance of llmQoS trained using different batch sizes and learning rates. For this experiment we test the density level =5%, and using Phi3mini as the LLM feature extractor. The same configuration of MLP used in the main experiments is used.
The QoS performance of models trained using different batch sizes is compared in 9(a) and 9(b). Generally speaking, the impact of batch size is inconsistent and insignificant. Only for throughput, larger batch size of 1024 causes the prediction accuracy to drop significantly. The performance with different learning rates is compared in 9(c) and 9(d). Learning rate has a huge impact on the model’s prediction accuracy. Very small learning rate results in slow convergence, while large learning rate causes unstable training. Both causes low performance. The optimal learning rate is around as used in the main experiments.
V Conclusion
In this paper, we have proposed the large language model aided QoS prediction (llmQoS) model. It utilizes LLMs to extract features from descriptive sentences constructed based on attributes of web users and services. Then the LLM features are combined with ID based embedding features for QoS prediction through a multi-layer perceptron network. Despite its concise network architecture, llmQoS achieves accurate QoS prediction under data sparsity condition, and outperforms comparable baseline models consistently on the WSDream dataset. We have also shown that the benefits of adding LLM features is general, and larger LLMs achieve better performance. In the era of explosive development of LLMs, we hope our paper can inspire more researchers in the field of service recommendation to conduct research in this direction.
References
- [1] S. Li, H. Luo, and G. Zhao, “bi-HPTM: An effective semantic matchmaking model for web service discovery,” in IEEE International Conference on Web Services, 2020.
- [2] M. Silic, G. Delac, and S. Srbljic, “Prediction of atomic web services reliability based on k-means clustering,” in Joint Meeting on Foundations of Software Engineering, 2013.
- [3] K. Qi, H. Hu, W. Song, J. Ge, and J. Lü, “Personalized qos prediction via matrix factorization integrated with neighborhood information,” in IEEE International Conference on Services Computing, 2015.
- [4] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong, Y. Du, C. Yang, Y. Chen, Z. Chen, J. Jiang, R. Ren, Y. Li, X. Tang, Z. Liu, P. Liu, J. Nie, and J. rong Wen, “A survey of large language models,” ArXiv, 2023.
- [5] S. Minaee, T. Mikolov, N. Nikzad, M. A. Chenaghlu, R. Socher, X. Amatriain, and J. Gao, “Large language models: A survey,” ArXiv, 2024.
- [6] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2019.
- [7] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” ArXiv, 2019.
- [8] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, and et al., “Language models are few-shot learners,” OpenAI, 2020.
- [9] M. Abdin, S. A. Jacobs, A. A. Awan, J. Aneja, and et al., “Phi-3 technical report: A highly capable language model locally on your phone,” ArXiv, 2024.
- [10] Meta AI, “Introducing meta Llama 3: The most capable openly available llm to date,” 2024. [Online]. Available: https://ai.meta.com/blog/meta-llama-3/
- [11] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl, “Item-based collaborative filtering recommendation algorithms,” in International Conference on World Wide Web, 2001.
- [12] L. Shao, J. Zhang, Y. Wei, J. Zhao, B. Xie, and H. Mei, “Personalized qos prediction forweb services via collaborative filtering,” in IEEE International Conference on Web Services, 2007.
- [13] L. Qi, W. Dou, and X. Zhang, “An inverse collaborative filtering approach for cold-start problem in web service recommendation,” in Australasian Computer Science Week Multiconference, 2017.
- [14] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl, “Item-based collaborative filtering recommendation algorithms,” in International Conference on World Wide Web, 2001.
- [15] G. Linden, B. Smith, and J. York, “Amazon.com recommendations: item-to-item collaborative filtering,” IEEE Internet Computing, vol. 7, no. 1, pp. 76–80, 2003.
- [16] Z. Chen, L. Shen, and F. Li, “Exploiting web service geographical neighborhood for collaborative qos prediction,” Future Generation Computer Systems, vol. 68, pp. 248–259, 2017.
- [17] Y. Ma, S. Wang, P. C. Hung, C.-H. Hsu, Q. Sun, and F. Yang, “A highly accurate prediction algorithm for unknown web service qos values,” IEEE Transactions on Services Computing, vol. 9, no. 4, pp. 511–523, 2016.
- [18] Z. Zheng, H. Ma, M. R. Lyu, and I. King, “Qos-aware web service recommendation by collaborative filtering,” IEEE Transactions on Services Computing, vol. 4, no. 2, pp. 140–152, 2011.
- [19] Y. Hu, Q. Peng, X. Hu, and R. Yang, “Time aware and data sparsity tolerant web service recommendation based on improved collaborative filtering,” IEEE Transactions on Services Computing, vol. 8, no. 5, pp. 782–794, 2015.
- [20] J. Zhu, P. He, Z. Zheng, and M. R. Lyu, “Online qos prediction for runtime service adaptation via adaptive matrix factorization,” IEEE Transactions on Parallel and Distributed Systems, vol. 28, no. 10, pp. 2911–2924, 2017.
- [21] Z. Zheng, H. Ma, M. R. Lyu, and I. King, “Collaborative web service qos prediction via neighborhood integrated matrix factorization,” IEEE Transactions on Services Computing, vol. 6, no. 3, pp. 289–299, 2013.
- [22] Y. Xu, J. Yin, W. Lo, and Z. Wu, “Personalized location-aware qos prediction for web services using probabilistic matrix factorization,” in Web Information Systems Engineering, X. Lin, Y. Manolopoulos, D. Srivastava, and G. Huang, Eds., 2013.
- [23] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, Jan. 2016.
- [24] J. Chai, H. Zeng, A. Li, and E. W. Ngai, “Deep learning in computer vision: A critical review of emerging techniques and application scenarios,” Machine Learning with Applications, vol. 6, p. 100134, 2021.
- [25] M. Soori, B. Arezoo, and R. Dastres, “Artificial intelligence, machine learning and deep learning in advanced robotics, a review,” Cognitive Robotics, vol. 3, pp. 54–70, 2023.
- [26] C. Wei, Y. Fan, and J. Zhang, “Time-aware service recommendation with social-powered graph hierarchical attention network,” IEEE Transactions on Services Computing, vol. 16, no. 3, pp. 2229–2240, 2023.
- [27] Y. Yin, Q. Di, J. Wan, and T. Liang, “Time-aware smart city services based on qos prediction: A contrastive learning approach,” IEEE Internet of Things Journal, vol. 10, no. 21, pp. 18 745–18 753, 2023.
- [28] G. Zou, S. Wu, S. Hu, C. Cao, Y. Gan, B. Zhang, and Y. Chen, “Ncrl: Neighborhood-based collaborative residual learning for adaptive qos prediction,” IEEE Transactions on Services Computing, vol. 16, no. 3, pp. 2030–2043, 2023.
- [29] Z. Wu, D. Ding, Y. Xiu, Y. Zhao, and J. Hong, “Robust qos prediction based on reputation integrated graph convolution network,” IEEE Transactions on Services Computing, vol. 17, no. 3, pp. 1154–1167, 2024.
- [30] C. Wei, Y. Fan, J. Zhang, Z. Jia, and R. Yan, “Dynamic relation graph learning for time-aware service recommendation,” IEEE Transactions on Network and Service Management, vol. 21, no. 2, pp. 1503–1517, 2024.
- [31] J. Zhu, B. Li, J. Wang, D. Li, Y. Liu, and Z. Zhang, “Bgcl: Bi-subgraph network based on graph contrastive learning for cold-start qos prediction,” Knowledge-Based Systems, vol. 263, p. 110296, 2023.
- [32] J. Zhou, D. Ding, Z. Wu, and Y. Xiu, “Spatial context-aware time-series forecasting for QoS prediction,” IEEE Transactions on Network and Service Management, vol. 20, no. 2, pp. 918–931, 2023.
- [33] H. Lian, J. Li, H. Wu, Y. Zhao, L. Zhang, and X. Wang, “Toward effective personalized service QoS prediction from the perspective of multi-task learning,” IEEE Transactions on Network and Service Management, vol. 20, no. 3, pp. 2587–2597, 2023.
- [34] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017.
- [35] Z. Lan, M. Chen, S. Goodman, K. Gimpel, P. Sharma, and R. Soricut, “ALBERT: A lite BERT for self-supervised learning of language representations,” in International Conference on Learning Representations, 2020.
- [36] A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever, “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [37] A. Radford and K. Narasimhan, “Improving language understanding by generative pre-training,” OpenAI, 2018.
- [38] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, and et al., “GPT-4 technical report,” OpenAI, 2024.
- [39] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, A. Rodriguez, A. Joulin, E. Grave, and G. Lample, “LLaMA: Open and efficient foundation language models,” ArXiv, 2023.
- [40] H. Touvron, L. Martin, K. R. Stone, P. Albert, and et al., “Llama 2: Open foundation and fine-tuned chat models,” ArXiv, 2023.
- [41] S. Gunasekar, Y. Zhang, J. Aneja, C. C. T. Mendes, and et al., “Textbooks are all you need,” ArXiv, 2023.
- [42] Y. Li, S. Bubeck, R. Eldan, A. D. Giorno, S. Gunasekar, and Y. T. Lee, “Textbooks are all you need ii: phi-1.5 technical report,” ArXiv, 2023.
- [43] M. Abdin, J. Aneja, S. Bubeck, C. C. T. Mendes, and et al., “Phi-2: The surprising power of small language models,” 2024. [Online]. Available: https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/
- [44] HuggingFace, “Open LLM leaderboard,” 2024. [Online]. Available: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
- [45] J. Guo, J. Li, D. Li, A. M. H. Tiong, B. A. Li, D. Tao, and S. C. H. Hoi, “From images to textual prompts: Zero-shot visual question answering with frozen large language models,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022.
- [46] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu et al., “Grounding dino: Marrying dino with grounded pre-training for open-set object detection,” ArXiv, 2023.
- [47] C. H. Song, J. Wu, C. Washington, B. M. Sadler, W.-L. Chao, and Y. Su, “LLM-Planner: Few-shot grounded planning for embodied agents with large language models,” in IEEE/CVF International Conference on Computer Vision, 2023.
- [48] D. Fu, X. Li, L. Wen, M. Dou, P. Cai, B. Shi, and Y. Qiao, “Drive like a human: Rethinking autonomous driving with large language models,” ArXiv, 2023.
- [49] Z. Zheng and M. R. Lyu, “Ws-dream: A distributed reliability assessment mechanism for web services,” in IEEE International Conference on Dependable Systems and Networks, 2008.
- [50] F. Chollet et al., “Keras,” https://keras.io, 2015.
- [51] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, and et al., “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015, software available from tensorflow.org. [Online]. Available: https://www.tensorflow.org/
- [52] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, and J. Brew, “Huggingface’s transformers: State-of-the-art natural language processing,” ArXiv, 2019.
- [53] A. F. Agarap, “Deep learning using rectified linear units (relu),” ArXiv, 2018.
- [54] P. J. Huber, “Robust estimation of a location parameter,” Annals of Mathematical Statistics, vol. 35, pp. 492–518, 1964.
- [55] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in International Conference on Learning Representations, 2015.
- [56] X. Chen, X. Liu, Z. Huang, and H. Sun, “Regionknn: A scalable hybrid collaborative filtering algorithm for personalized web service recommendation,” in IEEE International Conference on Web Services, 2010.
- [57] M. Tang, Y. Jiang, J. Liu, and X. Liu, “Location-aware collaborative filtering for qos-based service recommendation,” in IEEE International Conference on Web Services, 2012.
- [58] R. Salakhutdinov and A. Mnih, “Probabilistic matrix factorization,” in International Conference on Neural Information Processing Systems, 2007.
- [59] D. Ryu, K. Lee, and J. Baik, “Location-based web service qos prediction via preference propagation to address cold start problem,” IEEE Transactions on Services Computing, vol. 14, no. 3, pp. 736–746, 2021.
- [60] D. Wu, X. Luo, M. Shang, Y. He, G. Wang, and X. Wu, “A data-characteristic-aware latent factor model for web services qos prediction,” IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 6, pp. 2525–2538, 2022.