Language-Guided Image Tokenization for Generation
Abstract
Image tokenization, the process of transforming raw image pixels into a compact low-dimensional latent representation, has proven crucial for scalable and efficient image generation. However, mainstream image tokenization methods generally have limited compression rates, making high-resolution image generation computationally expensive. To address this challenge, we propose to leverage language for efficient image tokenization, and we call our method Text-Conditioned Image Tokenization (TexTok). TexTok is a simple yet effective tokenization framework that leverages language to provide high-level semantics. By conditioning the tokenization process on descriptive text captions, TexTok allows the tokenization process to focus on encoding fine-grained visual details into latent tokens, leading to enhanced reconstruction quality and higher compression rates. Compared to the conventional tokenizer without text conditioning, TexTok achieves average reconstruction FID improvements of 29.2% and 48.1% on ImageNet-256 and -512 benchmarks respectively, across varying numbers of tokens. These tokenization improvements consistently translate to 16.3% and 34.3% average improvements in generation FID. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system can achieve a 93.5 inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet-512. TexTok with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet-256 and -512 respectively. Furthermore, we demonstrate TexTok’s superiority on the text-to-image generation task, effectively utilizing the off-the-shelf text captions in tokenization.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/cad80a13-da1e-48bb-81a4-a253872fa1a4/x1.png)
1 Introduction
Image generation has made remarkable progress in recent years, enabling high-quality synthesis across diverse applications [11, 37, 32, 9]. Central to this success is the evolution of image tokenization, a process that compresses raw image data into a compact yet expressive latent representation through training an autoencoder. Tokenization allows generative models, such as diffusion models [37, 32, 9] and autoregressive models [11, 43, 28] to operate directly in this compressed latent space instead of the high-dimensional pixel space, significantly improving computational efficiency while enhancing generation quality and fidelity.
Despite various image tokenization efforts aimed at improving training objectives [45, 36, 11] and refining the autoencoder architecture [47, 50], current methods remain fundamentally limited by a trade-off between compression rate and reconstruction quality, especially in high-resolution generation. High compression reduces computational costs but often sacrifices reconstruction quality, while prioritizing quality leads to prohibitively high computational expenses.
Addressing this limitation requires a fundamental shift in the tokenization process. At its core, tokenization involves finding a compact and effective representation of an image. The most concise and meaningful representation of an image often comes from its language description–i.e., captioning. When describing an image, humans naturally start with high-level semantics before elaborating on finer details. Inspired by this insight, we introduce Text-Conditioned Image Tokenization (TexTok), a novel framework that leverages descriptive text captions to provide high-level semantic content, and thus the tokenization process focuses more on fine-grained visual details, thereby enhancing reconstruction quality without compromising compression rate.
To the best of our knowledge, we are the first to condition on detailed captions in the tokenization stage, an approach typically reserved for the generation phase. Text captions are easy to obtain from online image-text pairs or using a vision-language model to caption the images. Since text conditioning is widely used in image generation, e.g., text-to-image generation, our method can seamlessly incorporate these captions into the tokenization process without incurring additional annotation overhead.
We demonstrate the effectiveness of TexTok across a diverse set of tasks and settings. Compared to conventional tokenizers without text conditioning, TexTok achieves substantial gains in reconstruction quality, with average reconstruction FID improvements of 29.2% and 48.1% on ImageNet 256256 and 512512 resolutions, respectively. These enhancements in tokenization lead to consistent boosts in generation performance, with average improvements of 16.3% and 34.3% in generation FID for the two resolutions. By simply replacing the tokenizer in Diffusion Transformer (DiT) with TexTok, our system achieves a 93.5 inference speedup while still outperforming the original DiT using only 32 tokens on ImageNet 512512. Our best TexTok variant with a vanilla DiT generator achieves state-of-the-art FID scores of 1.46 and 1.62 on ImageNet 256256 and 512512 respectively.
We further demonstrate that incorporating text during the tokenization stage significantly enhances text-to-image generation, achieving 2.82 FID and 29.23 CLIP score on ImageNet 256256. Since text captions are inherently available for this task, TexTok boosts performance without adding any extra annotation overhead.
2 Related Work
Image tokenization.
Image tokenizers build a bidirectional mapping between high-resolution pixels and a low-dimensional latent space, significantly improving the learning efficiency of downstream tasks, such as image generation [11, 4, 26, 49], and understanding [47, 49]. Image tokenizers are usually formulated as an AutoEncoder (AE) [1] framework with an optional quantizer [45] and potentially in a variational [23] setup. These AutoEncoders are trained to minimize the discrepancy between the output and input images, measured by pixel-space distances, latent-space distances [52], or jointly trained discriminators [11]. Architectural variants for the encoder and decoder include ResNet [15] and vision transformers [10]. Spatial correspondence has been a common property of modern tokenizer designs, where one token largely refers to a square neighborhood of pixels. Recently, there has also been development of transformer-based models producing global tokens as a more compact representation [50]. In this work, we follow this paradigm to tokenize an image into a set of global tokens to flexibly control token budgets. However, unlike prior work, we are the first to propose to condition the tokenization process on image captions, which greatly improves the reconstruction quality and compression rate.
Image generation.
Generative learning of pixels has been explored under adversarial [3, 40], autoregressive [6], and diffusion [9, 18, 22] setups. For higher resolutions, generative learning in compressed latent spaces has become popular given its efficiency advantages. Among them, autoregressive [11, 26] and masked prediction [4, 49] models often operate in discrete token spaces following the practice of GPT [34] and BERT [8] in language modeling. Recent variants [28] could also use continuous latent spaces, akin to those used in latent diffusion models (LDMs) [37]. For LDMs, the architecture has evolved from convolution-based U-Net [38] to transformer-based DiT [32]. In this paper, we focus on diffusion-based image generation with DiT architecture, leveraging the flexible token lengths of TexTok.
Leveraging external semantic information in image generation and tokenization.
Many recent studies start to leverage external semantic information, such as image representations and semantic maps, to improve image generation [33, 27, 51]. Unlike these methods, which use external semantics to aid the generation process, our approach focuses on enhancing the tokenization process through conditioning on text semantics. Some recent efforts [48, 30, 53, 29] also consider aligning image tokens with text semantics in image tokenization to improve multimodal understanding. They either directly map images to text tokens in a frozen LLM codebook [48, 30, 53] or align the features of image tokens with text features [29], to produce semantically meaningful tokens. However, by enforcing strict image-text alignments, these works suffer from limited image reconstruction quality due to the inherent divergence between vision and language representations, resulting in undesirable image generation quality. In contrast, our work takes a complementary approach. We leverage text captions as external semantic conditioning, allowing image tokens to focus on capturing finer visual details, significantly boosting the image reconstruction and generation performance.
3 Method
3.1 Preliminary
Based on the format of latent representation, image tokenizers can be broadly classified into: 1) Vector-Quantized (VQ) Tokenizers, such as VQ-VAE [45] and VQGAN [11], which represent images using a set of discrete tokens, and 2) Continuous Latent Tokenizers [37] which use a variational autoencoder (VAE) [23] to embed images into a continuous latent space. In this work, we focus primarily on continuous latent tokenizers. As shown in Appendix A, TexTok also works well on VQ tokenizers.
The standard continuous latent tokenizer typically consists of an encoder (tokenizer) and a decoder (detokenizer) . Given an image , the encoder compresses it into a 2D latent space , where , , and is the spatial downsampling factor. Each latent embedding is treated as a continuous token, with the image represented by a total of tokens. For decoding, these embeddings are fed into the decoder to reconstruct the image . Recently, 1D tokenizers [50] were introduced to allow flexible token budgets for image representation, directly compressing into 1D latent embeddings with tokens. Reconstruction, perceptual [52], and GAN [11] losses are applied to train the tokenizer by minimizing the distance between and .
In this work, we adopt the 1D tokenizer paradigm to allow more flexible compression rates, demonstrating TexTok’s efficacy and efficiency across varying token budgets.

3.2 TexTok: Text-Conditioned Image Tokenization
We introduce Text-Conditioned Image Tokenization (TexTok), a simple yet effective tokenization framework that leverages language to provide high-level semantics and focuses more on tokenizing fine-grained visual details. Unlike existing methods that compress all visual information into latent tokens, we use descriptive text captions to represent high-level semantics and guide the tokenization process.
Tokenization stage.
Given an image caption, we use a frozen T5 [35] text encoder to extract text embeddings. These embeddings are injected into both the tokenizer and detokenizer, providing semantic guidance throughout the tokenization process and allowing the learned tokens to focus more on capturing fine-grained visual details.
As shown in Figure 2, TexTok adopts a Vision Transformer (ViT) backbone for both the encoder (tokenizer) and the decoder (detokenizer) to enable flexible control of token numbers. The input to the tokenizer is a concatenation of three components: 1) image patch tokens from patchifying and flattening the input image with a projection layer, where , , and is the patch size, 2) randomly-initialized learnable image token , where is the number of output image tokens, and 3) linearly projected text tokens, , derived from the text embeddings, where is the number of text tokens. In the tokenizer’s output, only the learned image tokens are retained and linearly projected to produce the output image tokens .
The detokenizer also takes three concatenated inputs: 1) learnable patch tokens , 2) linearly projected image tokens from the input image tokens, and 3) linearly projected text tokens that come from the same text tokens fed to the tokenizer. In the detokenizer’s output, only the learned image patch tokens are retained, unpatchified, and projected to reconstruct the image patches.
We train the tokenizer and detokenizer using the combination of reconstruction, GAN, perceptual, and LeCAM regularization [44] losses, following [49].
By directly injecting text tokens containing high-level semantic information into both the tokenizer and detokenizer, TexTok alleviates the need for the tokenizer and detokenizer to learn the semantics, enabling them to focus more on encoding the remaining fine-grained visual details into the image tokens, which greatly improves the compression rate without sacrificing reconstruction performance.
| Reconstruction | Generation | |||||||
| tokenizer | # tokens | rFID | rIS | PSNR | SSIM | LPIPS | gFID | gIS |
| (a) ImageNet 256256 | ||||||||
| SD-VAE-f8 [37] | 1024 (d=4) | 1.20† | - | - | - | - | 9.62 | 121.5 |
| Baseline-32 (w/o text) | 32 (d=8) | 3.82 | 117.1 | 17.67 | 0.4281 | 0.3270 | 4.97 | 170.3 |
| TexTok-32 (w/ text) | 2.40 | 156.2 | 18.32 | 0.4463 | 0.2884 | 3.55 | 205.3 | |
| Baseline-64 (w/o text) | 64 (d=8) | 2.04 | 147.2 | 19.52 | 0.4801 | 0.2343 | 3.30 | 188.9 |
| TexTok-64 (w/ text) | 1.53 | 169.8 | 20.10 | 0.4971 | 0.2126 | 2.88 | 209.2 | |
| Baseline-128 (w/o text) | 128 (d=8) | 1.49 | 160.5 | 20.51 | 0.5102 | 0.1913 | 3.19 | 190.1 |
| TexTok-128 (w/ text) | 1.04 | 183.3 | 22.05 | 0.5618 | 0.1499 | 2.75 | 210.9 | |
| Baseline-256 (w/o text) | 256 (d=8) | 0.91 | 178.3 | 23.05 | 0.5950 | 0.1225 | 2.91 | 197.2 |
| TexTok-256 (w/ text) | 0.69 | 192.6 | 24.38 | 0.6454 | 0.0998 | 2.68 | 219.6 | |
| (b) ImageNet 512512 | ||||||||
| SD-VAE-f8 [37] | 4096 (d=4) | - | - | - | - | - | 12.03 | 105.3 |
| Baseline-32 (w/o text) | 32 (d=8) | 7.68 | 82.6 | 16.21 | 0.5046 | 0.4771 | 9.22 | 119.0 |
| TexTok-32 (w/ text) | 2.33 | 161.5 | 18.55 | 0.5488 | 0.3772 | 3.61 | 215.6 | |
| Baseline-64 (w/o text) | 64 (d=8) | 4.81 | 104.0 | 17.81 | 0.5341 | 0.4029 | 7.26 | 141.8 |
| TexTok-64 (w/ text) | 1.52 | 171.7 | 20.19 | 0.5786 | 0.3093 | 3.30 | 210.2 | |
| Baseline-128 (w/o text) | 128 (d=8) | 1.45 | 163.2 | 21.59 | 0.6086 | 0.2624 | 3.64 | 191.1 |
| TexTok-128 (w/ text) | 0.97 | 185.5 | 22.27 | 0.6230 | 0.2365 | 3.16 | 210.7 | |
| Baseline-256 (w/o text) | 256 (d=8) | 1.07 | 174.9 | 23.15 | 0.6410 | 0.2180 | 3.14 | 204.2 |
| TexTok-256 (w/ text) | 0.73 | 192.0 | 24.45 | 0.6682 | 0.1875 | 2.87 | 218.5 | |


Generation stage.
Since this work focuses on continuous latent tokens, we use the Diffusion Transformer (DiT) [32] as the generation framework and train the DiT on top of the latent tokens produced by TexTok. Note that only latent image tokens need to be generated in the generation stage, while the text tokens will be provided in detokenization.
DiT is trained to model the distribution of TexTok latent tokens, conditioned either on a class category (for class-conditional generation) or on the text embeddings (for text-to-image generation).
During inference, the process differs by the generation task. For text-to-image generation, we use the provided captions for both tokenization and generation, feeding the text embeddings and generated latent image tokens into the detokenizer to produce the output image. For class-conditional generation, DiT generates latent tokens based on the specified class; we then sample an unseen caption for that class from a pre-generated list, and inject it into the detokenizer along with the generated latent tokens to produce the final image. Notably, only the class category is used during generation, in line with standard practice.
4 Experiments
4.1 Implementation Details
The implementation details of TexTok are described below. Please refer to Appendix C for further details.
Text caption acquision.
Text captions are readily available for text-to-image generation tasks, where they can be directly used in the tokenization process. For other generation tasks without captions, such as our use of ImageNet [7], we employ a vision language model (VLM), Gemini v1.5 Flash [42], to generate detailed captions offline. For the training set, we caption each given image. For the evaluation set, in class-conditional generation, we pre-generate unseen captions for each category using a sampled caption list of this category from the training set as reference. By default, each image is captioned with up to 75 words, which are encoded into a 128-token sequence using the T5 text encoder [35] (XL for ImageNet-256 and XXL for ImageNet-512 experiments). Please see Appendix D for more details.
Tokenization & generation.
By default, all TexTok experiments employ ViT-Base for both tokenizer and detokenizer, each comprising 12 layers with a hidden size of 768 and 12 attention heads (176M parameters). For the GAN loss, we follow [47] and use the StyleGAN discriminator [19](24M parameters). Unless otherwise specified, the image token channel dimension in TexTok is set to .
We use Diffusion Transformer (DiT) [32] as our default generator due to its effectiveness and flexibility of handling 1D tokens. We use a DiT patch size of 1 for all TexTok generation experiments, and by default, we train DiT for 350 epochs. Specifically, for class-conditional generation, we use the original DiT architecture. For text-to-image generation, referring to [5], we modify DiT architecture by adding an additional multi-head cross-attention layer following the multi-head self-attention layer in the DiT block to accept text embeddings. We refer to this architecture as “DiT-T2I”.
4.2 Experiment Setup
Model variants.
We compare two setups to demonstrate the effectiveness of using text conditioning: TexTok incorporates text tokens in both the tokenizer and detokenizer, corresponding to the architecture shown in Figure 2. In contrast, Baseline (w/o text) does not condition on text tokens in both the tokenizer and detokenizer. For each image, we tokenize it into “#tokens” number of latent tokens and train the generator to generate these tokens.
Evaluation protocol.
To evaluate reconstruction performance of the tokenizer, we report reconstruction Frechet inception distance (rFID) [17], reconstruction inception score (rIS) [39], peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and learned perceptual image patch similarity (LPIPS) [52] on 50K samples from ImageNet training set. To evaluate class-conditional generation performance, we report generation Frechet inception distance (gFID) [17], generation inception score (gIS) [39], precision and recall [24] following the evaluation protocol and suite provided by ADM [9]. To evaluate text-to-image generation performance, we report FID and CLIP Score [16] on 50K samples from ImageNet validation set.
4.3 Effectiveness of Text Conditioning
We begin by evaluating the effectiveness of text conditioning in image tokenization and generation. We compare our method, TexTok, with a Baseline (w/o text) that uses the same settings but excludes text conditioning, on ImageNet at resolutions of 256256 and 512512. We experiment with varying numbers of tokens, presenting the quantitative results in Table 1 and visualizing the relative improvement in rFID in Figure 3.
On ImageNet 256256, across all settings, TexTok significantly enhances both reconstruction and generation performance. Specifically, TexTok achieves 37.2%, 25.0%, 30.2%, 24.2% improvements in rFID using 32, 64, 128, and 256 tokens respectively, which consistently translates to 28.6%, 12.7%, 13.8%, and 7.9% improvements in gFID. Notably, the fewer tokens used, the higher the gains from text conditioning. As shown in Figure 3(a), TexTok can achieve similar rFID using half the number of tokens compared to the baseline (2 compression rate). We note that our Baseline (w/o text) is highly competitive. As shown in Table 1(a), with 8 fewer number of tokens, Baseline (w/o text) outperforms the widely used SD-VAE tokenizer [37] in both reconstruction and generation.
On higher resolution images, i.e., ImageNet 512512, TexTok exhibits stronger efficacy. As shown in Table 1 and Figure 3(b), TexTok achieves more significant improvement in the reconstruction quality and enables higher compression rates under this high-resolution setting. Specficially, it achieves 69.7%, 68.4%, 30.2%, and 24.2% improvements in rFID and 60.8%, 54.5%, 13.2% and 8.6% improvements in gFID, across 32, 64, 128 and 256 tokens respectively. As shown in Figure 3(b), TexTok achieves similar rFID to the baseline using only 1/4 of the token number (4 compression rate).
Finally, the qualitative results in Figure 1 across varying token counts show that TexTok significantly enhances reconstruction quality, particularly for text within images and specific visual details, such as car wheels and beaks. This indicates that TexTok encodes finer visual details using the same number of tokens.
4.4 System-level Image Generation Comparison
We experiment with image generation using TexTok as the tokenizer and adopt a vanilla DiT image generator [32] (denoted by TexTok + DiT), to study how this system performs against other leading image generation systems. We evaluate on class-conditional ImageNet 256256 and 512512 settings with varying number of tokens (compression rates).
On ImageNet 256256 class-conditional image generation, as shown in Table 2(a), our TexTok-256 + DiT-XL achieves an FID of 1.46, surpassing previous state-of-the-art systems, even though using a simpler, vanilla DiT as the image generator. As we reduce the number of tokens and increase image compression rate, TexTok + DiT maintains generation performance. Notably, TexTok-64 + DiT-XL, where the diffusion transformer generates only 64 image tokens, outperforms the original DiT-XL/2, which uses 256 tokens after patchification in the diffusion transformer.
| (a) ImageNet 256256 | (b) ImageNet 512512 | |||||||||||
| Model | #Params (G) | #Params (T) | FID | IS | Precision | Recall | #tokens | FID | IS | Precision | Recall | #tokens |
| GAN | ||||||||||||
| StyleGAN-XL [40] | 168M | - | 2.30 | 265.1 | 0.78 | 0.53 | - | 2.41 | 267.8 | 0.77 | 0.52 | - |
| pixel diffusion | ||||||||||||
| ADM-U [9] | 731M | - | 3.94 | 215.8 | 0.83 | 0.53 | - | 3.85 | 221.7 | 0.84 | 0.53 | - |
| simple diffusion [18] | 2B | - | 2.44 | 256.3 | - | - | - | 3.02 | 248.7 | - | - | - |
| VDM++ [22] | 2B | - | 2.12 | 267.7 | - | - | - | 2.65 | 278.1 | - | - | - |
| masked image modeling | ||||||||||||
| MaskGIT [4] | 227M | 66M | 6.18 | 182.1 | 0.80 | 0.51 | 256 | 7.32 | 156.0 | 0.78 | 0.50 | 1024 |
| RCG [27] | 512M | 66M | 2.25 | 300.7 | - | - | 256 | - | - | - | - | - |
| TiTok-L-32 [50] | 177M | 644M | 2.77 | - | - | - | 32 | - | - | - | - | - |
| TiTok-64 (B/L) [50] | 177M | 202M / 644M | 2.48 | - | - | - | 64 | 2.74 | - | - | - | 64 |
| TiTok-128 (S/B) [50] | 287M / 177M | 72M / 202M | 1.97 | - | - | - | 128 | 2.13 | - | - | - | 128 |
| MAGVIT-v2 [49] | 307M | 116M | 1.78 | 319.4 | - | - | 256 | 1.91 | 324.3 | - | - | 1024 |
| MaskBit [46] | 305M | 54M | 1.52 | 328.6 | - | - | 256 | - | - | - | - | - |
| autoregressive | ||||||||||||
| VQGAN [11] | 1.4B | 23M | 15.78 | 78.3 | - | - | 256 | - | - | - | - | - |
| ViT-VQGAN [47] | 1.7B | 64M | 4.17 | 175.1 | - | - | 1024 | - | - | - | - | - |
| LlamaGen-3B [41] | 3.1B | 72M | 2.18 | 263.3 | 0.81 | 0.58 | 576 | - | - | - | - | - |
| VAR (/-s) [43] | 2B / 2.4B | 109M | 1.92 | 323.1 | 0.82 | 0.59 | 256 | 2.63 | 303.2 | - | - | 1024 |
| MAR (H/L) [28] | 943M / 481M | 66M | 1.55 | 303.7 | 0.81 | 0.62 | 256 (d=16) | 1.73 | 279.9 | - | - | 1024 (d=16) |
| latent diffusion | ||||||||||||
| LDM-4 [37] | 400M | 55M | 3.60 | 247.7 | 0.87 | 0.48 | 4096 (d=3) | - | - | - | - | - |
| U-ViT-H [2] | 501M | 84M | 2.29 | 263.9 | 0.82 | 0.57 | 1024∗ (d=4) | 4.05 | 263.8 | 0.84 | 0.48 | 4096∗ (d=4) |
| DiT-XL/2 [32] | 675M | 84M | 2.27 | 278.2 | 0.83 | 0.57 | 1024∗ (d=4) | 3.04 | 240.8 | 0.84 | 0.54 | 4096∗ (d=4) |
| DiffiT [14] | - | - | 1.73 | 276.5 | 0.80 | 0.62 | - | 2.67 | 252.1 | 0.83 | 0.55 | - |
| MDTv2-XL/2 [12] | 676M | 84M | 1.58 | 314.7 | 0.79 | 0.65 | 1024∗ (d=4) | - | - | - | - | - |
| REPA + SiT-XL/2 [51] | 675M | 84M | 1.80 | 284.0 | 0.81 | 0.61 | 1024∗ (d=4) | - | - | - | - | - |
| EDM2-XXL [21] | 1.5B | 84M | - | - | - | - | - | 1.81 | - | - | - | 4096 (d=4) |
| Ours | ||||||||||||
| TexTok-32 + DiT-XL | 675M | 176M | 2.75 | 294.6 | 0.83 | 0.56 | 32 (d=8) | 2.74 | 303.2 | 0.83 | 0.56 | 32 (d=8) |
| TexTok-64 + DiT-XL | 675M | 176M | 2.06 | 290.0 | 0.81 | 0.60 | 64 (d=8) | 1.99 | 301.9 | 0.82 | 0.6 | 64 (d=8) |
| TexTok-128 + DiT-XL | 675M | 176M | 1.66 | 294.4 | 0.80 | 0.61 | 128 (d=8) | 1.80 | 305.4 | 0.81 | 0.63 | 128 (d=8) |
| TexTok-256 + DiT-XL | 675M | 176M | 1.46 | 303.1 | 0.79 | 0.64 | 256 (d=8) | 1.62 | 313.8 | 0.80 | 0.64 | 256 (d=8) |

| Tokenizer | FID | CLIP Score |
|---|---|---|
| Baseline-32 | 5.09 | 28.08 |
| TexTok-32 | 4.36 | 28.73 |
| Baseline-64 | 3.74 | 28.49 |
| TexTok-64 | 3.34 | 28.92 |
| Baseline-128 | 3.01 | 28.95 |
| TexTok-128 | 2.82 | 29.23 |
















On higher resolution images, i.e., ImageNet 512512, as shown in Table 2(b), TexTok-256 + DiT-XL also achieves state-of-the-art 1.62 gFID compared with previous methods, using only 256 image tokens. On the most compressed side, TexTok-32 + DiT-XL only uses 32 tokens yet achieves better generation performance than the original DiT that uses 1024 tokens after patchification.
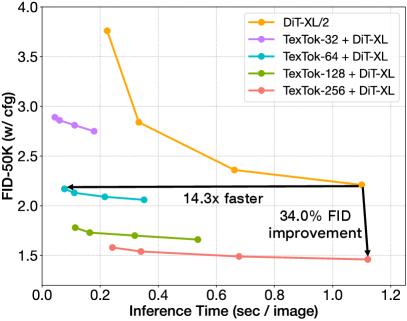
Our system not only achieves superior generation performance, but is also very efficient given its great compression rates. We plot in Figure 4(a) the speed v.s. performance tradeoffs of TexTok + DiT-XL compared to the original DiT on ImageNet 256256. Simply replacing the tokenizer in DiT with TexTok can achieve a 14.3 speedup with better FID, or 34.3% FID improvement with similar inference time. This verifies the effectiveness and efficiency of TexTok. This improved speed/performance tradeoff is further reflected on ImageNet 512512 (Figure 4(b)), where we demonstrate that simply replacing the tokenizer in DiT with TexTok variants, it achieves a 93.5 speedup with better FID using 32 tokens, or 46.7% FID improvement with 3.7 less inference time using 256 tokens. This shows that as image resolution increases, providing the tokenization process with explicit text semantics yields greater improvements in generation performance and inference speedup.
Qualitative samples in Figure 6 demonstrate that TexTok enables class-conditional generation of semantically rich images with fine-grained details. More qualitative samples can be found in Appendix E.
| Text conditioning | rFID | PSNR |
|---|---|---|
| none | 1.49 | 20.51 |
| class category | 1.14 | 21.56 |
| class text | 1.15 | 21.58 |
| 25-word caption | 1.08 | 21.63 |
| 75-word caption | 1.04 | 22.05 |
| T5 model size | rFID | PSNR |
|---|---|---|
| Small | 1.06 | 22.01 |
| XL | 1.04 | 22.05 |
| XXL | 0.99 | 22.28 |
| Conditioning architecture | rFID | PSNR |
|---|---|---|
| none | 1.49 | 20.51 |
| cross-attention layer | 1.31 | 21.42 |
| in-context conditioning | 1.04 | 22.05 |
| Conditioning location | rFID | PSNR |
|---|---|---|
| none | 1.49 | 20.51 |
| tokenizer only | 1.38 | 21.29 |
| tokenizer & detokenizer | 1.04 | 22.05 |
| Model size | Layers | Hidden size | Heads | #Params | rFID | PSNR |
|---|---|---|---|---|---|---|
| TexTok-Small | 8+8 | 512 | 8 | 54M | 1.35 | 21.43 |
| TexTok-Base | 12+12 | 768 | 12 | 176M | 1.04 | 22.05 |
| TexTok-Large | 24+24 | 1024 | 16 | 612M | 1.03 | 22.09 |
4.5 Text-to-Image Generation
We now demonstrate TexTok’s superiority on text-to-image generation. We use the same VLM-generated captions on ImageNet 256256 with our modified DiT-T2I architecture (detailed in Section 4.1). During training, the tokenizer and generator share the same text embeddings extracted by the T5 text encoder. During inference, we generate images condition on captions from ImageNet validation set. We calculate FID between these generated images and the original ImageNet validation set. As shown in Table 3, compared with Baseline (w/o text), TexTok consistently and significantly improves text-to-image generation, across varying numbers of image tokens. Since text captions are already available for text-to-image tasks and the tokenizer can directly use the same text embeddings used in the generator, TexTok’s performance boost comes at no additional cost for captioning and text embedding extraction.
4.6 Tokenization/Generation Inference Efficiency
We have demonstrated that TexTok significantly enhances reconstruction, class-conditional generation, and text-to-image generation quality. In text-to-image tasks, our text conditioning incurs no additional cost for text embedding extraction, as text embeddings are also used as conditioning in generation. For other tasks, it introduces minimal computational overhead to generate text embeddings and use them during tokenization. As shown in Table 5, this overhead is negligible (0.01 s/img). More importantly, the resulting reduction in generation computational cost compensates for this small increase, as evidenced by the comparison of computational costs between SD-VAE, Baseline (w/o text) and TexTok in Table 5 and the speedup results in Figure 4.
4.7 Ablation Studies
We ablate TexTok to analyze the contribution of our design choices. We use the following default settings: TexTok-128, Base model size, and T5-XL text encoder. Captions are 75 words long and applied to both the tokenizer and detokenizer using in-context conditioning.
Amount of text conditioning.
In Table LABEL:tab:cond_types, we ablate various types of class/text conditioning: (1) a learnable class embedding based on the class category, (2) text embeddings from a short text template with class names, (3) text embeddings from 25-word captions, and (4) (ours) text embeddings from 75-word captions. Our results show that more descriptive text conditioning improves performance.
T5 text encoder size.
In Table LABEL:tab:t5_size, we study the effect of the text encoder model size. We find that a larger encoder leads to better reconstruction quality. We use T5-XL as the default setting on ImageNet-256 for its efficiency.
Conditioning architecture.
Another design choice is how we inject text into the tokenizer and detokenizer. In Table LABEL:tab:cond_design, we find that in-context conditioning (concatenating text embeddings with other input tokens and feeding them into the self-attention layers) outperforms adding an additional multi-head cross-attention layer in each ViT block.
| ImageNet 256256 | ImageNet 512512 | |||
| tokenizer | Tokenization | Generation | Tokenization | Generation |
| SD-VAE-f8 [37] | 0.047 | 0.289 | 0.182 | 1.078 |
| Baseline-32 | 0.051 | 0.030 | 0.169 | 0.031 |
| TexTok-32 | 0.054 | 0.031 | 0.172 | 0.033 |
| Baseline-64 | 0.051 | 0.066 | 0.171 | 0.067 |
| TexTok-64 | 0.054 | 0.067 | 0.174 | 0.072 |
| Baseline-128 | 0.052 | 0.110 | 0.175 | 0.109 |
| TexTok-128 | 0.054 | 0.111 | 0.178 | 0.113 |
| Baseline-256 | 0.052 | 0.289 | 0.181 | 0.282 |
| TexTok-256 | 0.055 | 0.292 | 0.183 | 0.295 |
Conditioning location.
In Table LABEL:tab:cond_location, we ablate the locations for text conditioning injection and find that applying it to both the tokenizer and detokenizer yields the best results.
TexTok model size.
In Table LABEL:tab:tokenizer_size, we investigate the influence of TexTok model size. We find using TexTok-Base performs much better than TexTok-Small, but increasing the model size further provides marginal improvements. Hence, we choose TexTok-Base as our default model size.
5 Conclusion
We present Text-Conditioned Image Tokenization (TexTok), a framework that leverages descriptive text captions to provide high-level semantics, allowing tokenization to focus on encoding fine-grained visual details into latent tokens. TexTok significantly improves reconstruction and generation performance, achieving state-of-the-art results on ImageNet with high computational efficiency. By mitigating the trade-off between reconstruction quality and compression rates, TexTok enables more efficient image generation.
Acknowledgements.
We thank David Minnen, Eirikur Agustsson, Qihang Yu, Peng Cao, José Lezama, Long Zhao, Haotian Tang, Tianhong Li, Xuhui Jia, Ruben Villegas and Xingyi Zhou for helpful discussions and valuable feedback.
References
- Ballard [1987] Dana H Ballard. Modular learning in neural networks. In Proceedings of the sixth National conference on Artificial intelligence-Volume 1, 1987.
- Bao et al. [2022] Fan Bao, Chongxuan Li, Yue Cao, and Jun Zhu. All are worth words: a ViT backbone for score-based diffusion models. In NeurIPS 2022 Workshop on Score-Based Methods, 2022.
- Brock et al. [2019] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. In ICLR, 2019.
- Chang et al. [2022] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. MaskGIT: Masked generative image transformer. In CVPR, 2022.
- Chen et al. [2024] Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart-: Fast training of diffusion transformer for photorealistic text-to-image synthesis. In ICLR, 2024.
- Chen et al. [2020] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. In ICML, 2020.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In CVPR, 2009.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In NeurIPS, 2021.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Esser et al. [2021] Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In CVPR, 2021.
- Gao et al. [2023] Shanghua Gao, Pan Zhou, Ming-Ming Cheng, and Shuicheng Yan. Masked diffusion transformer is a strong image synthesizer. In ICCV, 2023.
- Gupta et al. [2024] Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Li Fei-Fei, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. In ECCV, 2024.
- Hatamizadeh et al. [2024] Ali Hatamizadeh, Jiaming Song, Guilin Liu, Jan Kautz, and Arash Vahdat. Diffit: Diffusion vision transformers for image generation. In ECCV, 2024.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- Hessel et al. [2021] Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. In EMNLP, 2021.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NeurIPS, 2017.
- Hoogeboom et al. [2023] Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. In ICML, 2023.
- Karras et al. [2019] Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In CVPR, 2019.
- Karras et al. [2024a] Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. In NeurIPS, 2024a.
- Karras et al. [2024b] Tero Karras, Miika Aittala, Jaakko Lehtinen, Janne Hellsten, Timo Aila, and Samuli Laine. Analyzing and improving the training dynamics of diffusion models. In CVPR, 2024b.
- Kingma and Gao [2024] Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the ELBO with simple data augmentation. In NeurIPS, 2024.
- Kingma and Welling [2014] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. In ICLR, 2014.
- Kynkäänniemi et al. [2019] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. In NeurIPS, 2019.
- Kynkäänniemi et al. [2024] Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. In NeurIPS, 2024.
- Lee et al. [2022] Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Autoregressive image generation using residual quantization. In CVPR, 2022.
- Li et al. [2024a] Tianhong Li, Dina Katabi, and Kaiming He. Self-conditioned image generation via generating representations. In NeurIPS, 2024a.
- Li et al. [2024b] Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vector quantization. arXiv:2406.11838, 2024b.
- Liang et al. [2024] Guotao Liang, Baoquan Zhang, Yaowei Wang, Xutao Li, Yunming Ye, Huaibin Wang, Chuyao Luo, Kola Ye, et al. Lg-vq: Language-guided codebook learning. In NeurIPS, 2024.
- Liu et al. [2024] Hao Liu, Wilson Yan, and Pieter Abbeel. Language quantized autoencoders: Towards unsupervised text-image alignment. In NeurIPS, 2024.
- Ma et al. [2024] Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas M Boffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In ECCV, 2024.
- Peebles and Xie [2023] William Peebles and Saining Xie. Scalable diffusion models with transformers. In ICCV, 2023.
- Pernias et al. [2024] Pablo Pernias, Dominic Rampas, Mats L Richter, Christopher J Pal, and Marc Aubreville. Würstchen: An efficient architecture for large-scale text-to-image diffusion models. In ICLR, 2024.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. In JMLR, 2020.
- Razavi et al. [2019] Ali Razavi, Aaron Van den Oord, and Oriol Vinyals. Generating diverse high-fidelity images with VQ-VAE-2. In NeurIPS, 2019.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. In MICCAI, 2015.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In NeurIPS, 2016.
- Sauer et al. [2022] Axel Sauer, Katja Schwarz, and Andreas Geiger. StyleGAN-XL: Scaling StyleGAN to large diverse datasets. In SIGGRAPH, 2022.
- Sun et al. [2024] Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autoregressive model beats diffusion: LLaMA for scalable image generation. arXiv:2406.06525, 2024.
- Team et al. [2024] Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530, 2024.
- Tian et al. [2024] Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction. In NeurIPS, 2024.
- Tseng et al. [2021] Hung-Yu Tseng, Lu Jiang, Ce Liu, Ming-Hsuan Yang, and Weilong Yang. Regularizing generative adversarial networks under limited data. In CVPR, 2021.
- Van Den Oord et al. [2017] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. In NeurIPS, 2017.
- Weber et al. [2024] Mark Weber, Lijun Yu, Qihang Yu, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. Maskbit: Embedding-free image generation via bit tokens. arXiv:2409.16211, 2024.
- Yu et al. [2021] Jiahui Yu, Xin Li, Jing Yu Koh, Han Zhang, Ruoming Pang, James Qin, Alexander Ku, Yuanzhong Xu, Jason Baldridge, and Yonghui Wu. Vector-quantized image modeling with improved VQGAN. arXiv:2110.04627, 2021.
- Yu et al. [2024a] Lijun Yu, Yong Cheng, Zhiruo Wang, Vivek Kumar, Wolfgang Macherey, Yanping Huang, David Ross, Irfan Essa, Yonatan Bisk, Ming-Hsuan Yang, et al. SPAE: Semantic pyramid autoencoder for multimodal generation with frozen llms. In NeurIPS, 2024a.
- Yu et al. [2024b] Lijun Yu, Jose Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, Boqing Gong, Ming-Hsuan Yang, Irfan Essa, David A Ross, and Lu Jiang. Language model beats diffusion - tokenizer is key to visual generation. In ICLR, 2024b.
- Yu et al. [2024c] Qihang Yu, Mark Weber, Xueqing Deng, Xiaohui Shen, Daniel Cremers, and Liang-Chieh Chen. An image is worth 32 tokens for reconstruction and generation. In NeurIPS, 2024c.
- Yu et al. [2024d] Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. arXiv:2410.06940, 2024d.
- Zhang et al. [2018] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, 2018.
- Zhu et al. [2024] Lei Zhu, Fangyun Wei, and Yanye Lu. Beyond text: Frozen large language models in visual signal comprehension. In CVPR, 2024.
Appendix A Effectiveness of TexTok on Discrete Tokens
In the main paper, we demonstrate that TexTok works well with continuous tokens. In this section, we further validate the effectiveness of TexTok with Vector-Quantized (VQ) discrete tokens. We use a codebook size of 4096. As shown in Table 6, TexTok consistently delivers significant improvements over Baseline (w/o text) in reconstruction performance. As the number of tokens decreases, the performance gains are more pronounced. These results verify the effectiveness of TexTok on discrete tokens, highlighting its versatility as a universal tokenization framework. This inherent compatibility with both continuous and discrete tokens allows TexTok to seamlessly integrate with a wide range of generative models, including diffusion models, autoregressive models, and others.
| tokenizer | # tokens | rFID | rIS | PSNR | SSIM | LPIPS |
|---|---|---|---|---|---|---|
| Baseline-32 | 32 | 7.71 | 84.0 | 15.52 | 0.3822 | 0.4524 |
| TexTok-32 | 4.11 | 141.4 | 16.52 | 0.4040 | 0.3855 | |
| Baseline-64 | 64 | 4.34 | 110.1 | 17.11 | 0.4200 | 0.3470 |
| TexTok-64 | 2.50 | 161.8 | 18.06 | 0.4462 | 0.2933 | |
| Baseline-128 | 128 | 2.34 | 139.8 | 18.91 | 0.4737 | 0.2476 |
| TexTok-128 | 1.76 | 167.9 | 19.96 | 0.4926 | 0.2166 | |
| Baseline-256 | 256 | 1.45 | 159.4 | 20.67 | 0.5371 | 0.1848 |
| TexTok-256 | 1.17 | 180.3 | 21.56 | 0.5526 | 0.1594 |


Appendix B Additional Training Analysis
In Figure 7, we further provide the training reconstruction FID comparison (evaluated on 10K samples) of TexTok-32 v.s. Baseline-32 (w/o text) on ImageNet 512512. From the figure, it is clear that TexTok training is more efficient and effective, achieving faster convergence and better reconstruction quality.
Appendix C Additional Implementation Details
We provide detailed default training hyperparameters for TexTok- as listed below:
-
•
ViT encoder/decoder hidden size: .
-
•
ViT encoder/decoder number of layers: .
-
•
ViT encoder/decoder number of heads: .
-
•
ViT encoder/decoder MLP dimensions: .
-
•
ViT patch size: for image resolution and for .
-
•
Discriminator base channels: .
-
•
Discriminator channel multipliers: for image resolution, and for .
-
•
Discriminator starting iterations: .
-
•
Latent shape: .
-
•
Reconstruction loss weight: .
-
•
Generator loss type: Non-saturating.
-
•
Generator adversarial loss weight: .
-
•
Discriminator gradient penalty: r1 with cost .
-
•
Perceptual loss weight: .
-
•
LeCAM weight: .
-
•
Peak learning rate: .
-
•
Learning rate schedule: linear warm up and cosine decay.
-
•
Optimizer: Adam with and .
-
•
EMA model decay rate: .
-
•
Training epochs: .
-
•
Batch size: .
We provide detailed default training and evaluation hyperparameters for DiT as listed below:
-
•
Patch size: .
-
•
Peak learning rate: .
-
•
Learning rate schedule: linear warm up and cosine decay.
-
•
Optimizer: AdamW with , , and weight decay.
-
•
Diffusion steps: .
-
•
Noise schedule: Linear.
-
•
Diffusion , .
-
•
Training objective: v-prediction.
-
•
Sampler: DDIM.
-
•
Sampling steps: .
-
•
Training epochs: .
-
•
Batch size: .
Appendix D ImageNet Captioning Details
We provide the prompt fed into Gemini that we used to generate the captions for images in ImageNet training and validation sets:
Describe an image of a {class_name} from the ImageNet dataset in a single continuous detailed paragraph, using no more than {word_count} words. Include descriptions of the appearance, colors, textures, size, environment, and any notable features or actions. Make sure to provide a vivid and engaging description that captures the essence of the {class_name}. Output only the description without any additional words or commentary and the description must not exceed {word_count} words. <image_bytes>
Figure 8 shows several captioning examples, including both 25-word and 75-word captions.
Appendix E Additional Qualitative Results
We present additional qualitative class-conditional image generation results on ImageNet 256256 in Figure 9. We observe that TexTok generates high-quality, semantically meaningful images with intricate fine-grained details.
We also present additional text-to-image generation results on ImageNet 256256 in Figure 10. Note that TexTok generates photo-realistic images that accurately align with the given prompts and even share many visual details with the reference images that the model has never seen, demonstrating both high fidelity and the capability to follow the text prompts.
Appendix F Additional Discussion on Related Work
There have been some recent efforts in image tokenization methods [48, 30, 53, 29] that aim to align image tokens with textual semantics. Approaches like LQAE [30], SPAE [48], and V2L [53] map images into tokens derived from the codebooks of large language models (LLMs), while LG-VQ [29] focuses on aligning the decoder features of image tokens with text representations. These methods are designed primarily for bridging visual and textual modalities to improve multi-modal understanding tasks. However, by aligning image tokens directly to textual semantic spaces, they often suffer from limited image reconstruction quality due to the inherent divergence between vision and language representations. Consequently, these approaches fail to achieve reasonable performance, or even do not report results, on standard image generation benchmarks, such as ImageNet class-conditional generation.
In contrast, our work introduces a novel image tokenization framework specifically designed for generative tasks. We are the first work that proposes conditioning the tokenization process directly on the text captions of images, a strategy typically reserved for the generation phase. Rather than enforcing a strict alignment between image tokens and text captions, our method leverages descriptive text captions to provide high-level semantics while allowing image tokens to focus on capturing fine-grained visual details. This complementary approach significantly improves both reconstruction quality and compression rate of tokenization. Furthermore, we demonstrate that our approach achieves state-of-the-art performance on standard ImageNet conditional generation benchmarks on both 256256 and 512512 image resolutions, establishing our method as a distinct advancement over existing works.











