Langevin Thompson Sampling with Logarithmic Communication: Bandits and Reinforcement Learning
Abstract
Thompson sampling (TS) is widely used in sequential decision making due to its ease of use and appealing empirical performance. However, many existing analytical and empirical results for TS rely on restrictive assumptions on reward distributions, such as belonging to conjugate families, which limits their applicability in realistic scenarios. Moreover, sequential decision making problems are often carried out in a batched manner, either due to the inherent nature of the problem or to serve the purpose of reducing communication and computation costs. In this work, we jointly study these problems in two popular settings, namely, stochastic multi-armed bandits (MABs) and infinite-horizon reinforcement learning (RL), where TS is used to learn the unknown reward distributions and transition dynamics, respectively. We propose batched Langevin Thompson Sampling algorithms that leverage MCMC methods to sample from approximate posteriors with only logarithmic communication costs in terms of batches. Our algorithms are computationally efficient and maintain the same order-optimal regret guarantees of for stochastic MABs, and for RL. We complement our theoretical findings with experimental results.
1 Introduction
| TS-based Algorithms | Batching Scheme | MCMC Method | Regret | # of Batches | |
| Stochastic MAB | Karbasi et al., (2021) | Dynamic | - | ||
| Mazumdar et al., (2020) | - | SGLD, ULA | |||
| This paper (Algorithm 2) | Dynamic | SGLD | |||
| TS for RL (PSRL) | Osband et al., (2013) | - | - | ||
| Ouyang et al., (2017) | Dynamic | - | |||
| Theocharous et al., 2017b | Static | - | |||
| This paper (Algorithm 3) | Static | SGLD, MLD |
Modern machine learning often needs to balance computation and communication budgets with statistical guarantees. Existing analyses of sequential decision making have been primarily focused on the statistical aspects of the problems (Tian et al.,, 2020), less is known about their computation and communication aspects. In particular, regret minimization in multi-armed bandits (MABs) and reinforcement learning (RL) (Jaksch et al.,, 2010; Wu et al.,, 2022; Jung et al.,, 2019) is often studied under the common assumptions that computation can be performed perfectly in time, and that communication always happens in real-time (Li et al.,, 2022; Jin et al.,, 2018; Haarnoja et al.,, 2018).
A question of particular importance is whether optimal decisions can still be made under reasonable computation and communication budgets. In this work, we study the exploration-exploitation problem with low computation and communication costs using Thompson Sampling (TS) (Thompson,, 1933) (a.k.a. posterior sampling). To allow sampling from distributions that deviate from the standard restrictive assumptions, and to enable its deployment in settings where computing the exact posterior is challenging, we employ Markov Chain Monte Carlo (MCMC) methods.
TS operates by maintaining a posterior distribution over the unknown and is widely used owing to its strong empirical performance Chapelle and Li, (2011). However, the theoretical understanding of TS in bandits typically relied on the restrictive conjugacy assumptions between priors and reward distributions. Recently, approximate TS methods for general posterior distributions start to be studied Mazumdar et al., (2020); Xu et al., (2022), where MCMC algorithms are used in conjunction with TS to expand its applicability in fully-sequential settings. On the other hand, to the best of our knowledge, how to provably incorporate MCMC with posterior sampling in RL domains remains to be untackled.
Moreover, previous analyses of TS have been restricted to the fully-sequential settings, where feedback or reward is assumed to be immediately observable upon taking actions (i.e. before making the next decision). Nevertheless, it fails to account for the practical settings when delays take place in communication, or when feedback is only available in an aggregate or batched manner. Examples include clinical trials where feedback about the efficacy of medication is only available after a nontrivial amount of time, recommender systems where feedback from multiple users comes all at once and marketing campaigns Schwartz et al., (2017). This issue has been studied in literature by considering static or dynamic batching schemes and by designing algorithms that acquire feedback in batches, where the learner typically receives reward information only at the end of the batch (Karbasi et al.,, 2021; Kalkanli and Ozgur,, 2021; Vernade et al.,, 2020; Zhang et al.,, 2020). Nonetheless, the analysis of approximate TS in batched settings is unavailable for both bandits and RL.
In this paper, we tackle these challenges by incorporating TS with Langevin Monte Carlo (LMC) and batching schemes in stochastic MABs and infinite-horizon RL. Our algorithms are applicable to a broad class of distributions with only logarithmic rounds of communication between the learner and the environment, thus being robust to constraints on communication. We compare our results with other works in Table 1, and summarize our main contributions as follows:
-
•
For stochastic MABs with time horizon , we present Langevin Thompson Sampling (BLTS, Algorithm 2) along with Theorem 5.2, which achieves the optimal regret with batches111A round game can be thought of as many batches each of size 1.. The main technical contribution here is to show that when feedback is obtained in a batched manner where the posterior concentration is weaker (Theorem 1), the convergence guarantee of SGLD continues to hold.
-
•
For large-scale infinite-horizon MDPs, we present Langevin Posterior Sampling for RL (LPSRL, Algorithm 3) along with Theorem 6.2 to show that SGLD with a static policy-switching222In MDP settings, the notion of a batch is more appropriately thought of as a policy-switch. scheme achieves the optimal Bayesian regret with policy switches. For tabular MDPs, we show that LPSRL incorporated with the Mirrored Langevin Dynamics (MLD) achieves the optimal Bayesian regret with policy switches. The use of approximate sampling leads to an additive error where the true model and the sampled model are no longer identically distributed. This error can be properly handled with the convergence guarantees of LMC methods.
-
•
Experiments are performed to demonstrate the effectiveness of our algorithms, which maintain the order-optimal regret with significantly lower communication costs compared to existing exact TS methods.
2 Problem Setting
In this section, we introduce the problem setting with relevant background information.
2.1 Stochastic Multi-armed Bandits
We consider the -armed stochastic multi-armed bandit problem, where the set of arms is denoted by . Let be the time horizon of the game. At , the learner chooses an arm and receives a real-valued reward drawn from a fixed, unknown, parametric distribution corresponding to arm . In the standard fully-sequential setup, the learner observes rewards immediately. Here, we consider the more general batched setting, where the learner observes the rewards for all timesteps within a batch at the end of it. We use to denote the starting time of the -th batch, to represent the starting time of the batch that contains time , and as the total number of batches. The learner observes the set of rewards at the end of the -th batch. Note that the batched setting reduces to the fully-sequential setting when the number of batches is , each with size .
Suppose for each arm , there exists a parametric reward distribution parameterized by such that the true reward distribution is given by , where is an unknown parameter333Our results hold for the more general case of , but for simplicity of exposition, we consider the ambient dimension for the parameters of each arm to be the same.. To ensure meaningful results, we impose the following assumptions on the reward distributions for all :
-
•
Assumption 1: is -smooth and -strongly concave in .
-
•
Assumption 2: is strongly log-concave in and is -Lipschitz in .
-
•
Assumption 3: The prior is concave with -Lipschitz gradients for all .
-
•
Assumption 4: Joint Lipschitz smoothness of (the bivariate) in and .
These properties include log-concavity and Lipschitz smoothness of the parametric families and prior distributions, which are standard assumptions in existing literature Mazumdar et al., (2020) and are satisfied by models like Gaussian bandits (Honda and Takemura,, 2013). For the sake of brevity, We provide the mathematical statements of these assumptions in Appendix B.
Let denote the expected value of the true reward distribution for arm . The goal of the learner is to minimize the expected regret, which is defined as follows:
| (1) |
where , , and represents the number of times arm has been played up to time . Without loss of generality, we will assume that arm is the best arm. We discuss the MAB setting in Section 5.
2.2 Infinite-horizon Markov Decision Processes
We focus on average-reward MDPs with infinite horizon (Jaksch et al.,, 2010; Wei et al.,, 2021), which is underexplored compared to the episodic setting. It is a more realistic model for real-world tasks, such as robotics and financial-market decision making, where state reset is not possible. Specifically, we consider an undiscounted weakly communicating MDP with infinite time horizon444It is known that weakly communicating MDPs satisfy the Bellman Optimality. (Ouyang et al.,, 2017; Theocharous et al., 2017b, ), where is the state space, is the action space, represents the parameterized transition dynamics, and is the reward function. We assume that parameterizes the transition dynamics and there exists a true unknown governing the next state of the learner. At each time , the learner is in state , takes action , and transits into the next state , which is drawn from .
We consider two sub-settings based on the parameterization of the transition dynamics: the General Parameterization and the Simplex Parameterization. These sub-settings require different assumptions and setups, which we elaborate on in their respective sections (Section 6.2 and Section 6.3). In the MDP context, the notion of batch is more appropriately thought of as a policy switch. Therefore, now represents the starting time of the -th policy switch, and we additionally define as the number of time steps between policy switch and . We consider stationary and deterministic policies, which are mappings from . Let be the policy followed by the learner after the -th policy switch. When the decision to update and obtain the -th policy is made, the learner uses the observed data collected after the -th policy switch to sample from the updated posterior and compute . The goal of the learner is to maximize the long-term average reward:
Similar to other works Ouyang et al., (2017); Osband et al., (2013); Theocharous et al., 2017b , we measure the performance using Bayesian regret555In Bayesian regret, expectation is taken the prior distribution of the true parameter , the randomness of algorithm and transition dynamics. defined by:
| (2) |
where denotes the average long-term reward after running the optimal policy under the true model.
It is known that weakly communicating MDPs satisfy the following Bellman optimality Bertsekas, (2012); Ouyang et al., (2017); Wei et al., (2021) in infinite-horizon setting, and there exists some positive number such that the span (Definition 2) satisfies for all .
Lemma 1 (Bellman Optimality).
There exist optimal average reward and a bounded measurable function , such that for any , the Bellman optimality equation holds:
| (3) |
Here under and is independent of initial state. Function quantifies the bias of policy the average-reward under , and , where .
Definition 2.
For any , span of an MDP is defined as .
3 Related Work
Under the conjugacy assumptions on rewards, asymptotic convergence of TS was studied in stochastic MABs by Granmo, (2010) and May et al., (2012). Later, finite-time analyses with problem-dependent regret bound were provided Agrawal and Goyal, (2012); Kaufmann et al., (2012); Agrawal and Goyal, (2013). However, in practice, exact posteriors are intractable for all but the simplest models (Riquelme et al.,, 2018), necessitating the use of approximate sampling methods with TS in complex problem domains. Recent progress has been made in understanding approximate TS in fully-sequential MABs Lu and Van Roy, (2017); Mazumdar et al., (2020); Zhang, (2022); Xu et al., (2022). On the other hand, the question of learning with TS in the presence of batched data has evolved along a separate trajectory of works (Karbasi et al.,, 2021; Kalkanli and Ozgur,, 2021; Vernade et al.,, 2020; Zhang et al.,, 2020). However, provably performing Langevin TS in batched settings remains unexplored, and in this paper, we aim at bridging these lines.
Moving to the more complex decision-making frameworks based on MDPs, TS is employed in model-based methods to learn transition models, which is known as Posterior Sampling for Reinforcement Learning (PSRL) (Strens,, 2000). When exact posteriors are intractable, MCMC methods have been empirically studied for performing Bayesian inference in policy and reward spaces in RL (Brown et al.,, 2020; Imani et al.,, 2018; Bojun,, 2020; Guez et al.,, 2014). MCMC is a family of approximate posterior inference methods that enables sampling without exact knowledge of posteriors Ma et al., (2015); Welling and Teh, (2011). However, it is unclear how to provably incorporate MCMC methods in learning transition models for RL.
Furthermore, the analysis of undiscounted infinite-horizon MDPs (Abbasi-Yadkori and Szepesvári,, 2015; Osband and Van Roy,, 2016; Ouyang et al.,, 2017; Wei et al.,, 2020, 2021) poses greater challenges compared to the well-studied episodic MDPs with finite horizon and fixed episode length (Osband et al.,, 2013). Previous works on infinite-horizon settings include model-based methods that estimate environment dynamics and switch policies when the number of visits to state-action pairs doubles (Jaksch et al.,, 2010; Tossou et al.,, 2019; Agrawal and Jia,, 2017; Bartlett and Tewari,, 2012). Nevertheless, under such dynamic schemes, the number of policy switches can be as large as , making it computationally heavy and infeasible for continuous states and actions. To enable TS with logarithmic policy switches while maintaining optimal regret, we build upon an algorithmically-independent static scheme as in Theocharous et al., 2017b , and incorporate Langevin Monte Carlo (LMC) methods to sample from inexact posteriors.
4 SGLD for Langevin Thompson sampling
In the MAB and MDP settings, parameterizes the unknown reward or transition distributions respectively. TS maintains a distribution over the parameters and updates the distribution to (the new) posterior upon receiving new data. Given , prior , and data samples 666Here data can be rewards for some arms or actual transitions of state-action pairs depending on the setting., let be the posterior distribution after receiving data samples which satisfies: . In addition, consider the scaled posterior for some scaling parameter , which represents the density proportional to .
The introduction of MCMC methods arises from the need for sampling from intractable posteriors in the absence of conjugacy assumptions. We resort to a gradient-based MCMC method that performs noisy updates based on Langevin dynamics: Stochastic Gradient Langevin Dynamics (SGLD). Algorithm 1 presents SGLD with bached data to generate samples from an approximation of the true posterior. For a detailed exposition, please refer to Welling and Teh, (2011); Ma et al., (2015) and Appendix A. Algorithm 1 takes all available data at the start of a batch as input, subsamples data, performs gradient updates by computing , and outputs the posterior for batch .
In the batched setting, new data is received at the end of a batch, or when making the decision to perform a new policy switch. Due to the way that the learner receives new data and the fact that the batch data size may increase exponentially777Data received in batch can be doubled compared to the previous batch., the posterior concentrates slower. This differs from the fully-sequential problem where the distribution shift of successive true posteriors is small owing to data being received in an iterative manner. We show that in batched settings, with only constant computational complexity in terms of iterations, SGLD is able to provide strong convergence guarantee as in the fully-sequential setting Mazumdar et al., (2020). Theorem 1 shows the convergence of SGLD in the Wasserstein- distance can be achieved with a constant number of iterations and data.
Theorem 1 (SGLD convergence).
denotes the true posterior corresponding to data samples and is the approximate posterior outputted by Algorithm 1. We also note that similar concentration bounds can be achieved by using the Unadjusted Langevin Algorithm (ULA) for batched data, which adopts full-batch gradient evaluations and therefore leads to a growing iteration complexity. The proofs of Theorem 1 are adapted to the batched setting, which differs from Mazumdar et al., (2020).
5 Batched Langevin Thompson Sampling for Bandits
In this section, we introduce Langevin Thompson Sampling for batched stochastic MAB setting in Algorithm 2, namely, BLTS. It leverages SGLD and batching schemes to learn a wide class of unknown reward distributions while reducing communication and computation costs. We have previously discussed the results of SGLD in Section 4 for both MABs and MDPs. Here, we focus on the batching strategy in Algorithm 2 for bandits, and discuss the resulting regret guarantee.
5.1 Dynamic Doubling Batching Scheme
BLTS keeps track of the number of times each arm has been played until time with . Initially, all are set to 0. The size of each batch is determined by and the corresponding integers . Once reaches for some arm , BLTS makes the decision to terminate the current batch, collects all rewards from the batch in a single request, and increases by . BLTS thus starts a new batch whenever an arm is played twice as many times as in the previous batch, which results in growing batch sizes. As the decision to move onto the next batch depends on the sequence of arms that is played, it is considered as “dynamic”. This batching scheme is similar to the one used in Karbasi et al., (2021). The total number of batches that BLTS carries out satisfies the following theorem, and its proof can be found in Appendix D.
theorembanditBatches BLTS ensures that the total number of batches is at most where .
Gao et al., (2019) showed that batches are required to achieve the optimal logarithmic dependence in time horizon for a batched MAB problem. This shows that the dependence on in the number of batches BLTS requires is at most a factor of off the optimal. We now state and discuss the BLTS algorithm.
5.2 Regret of BLTS Algorithm
In Algorithm 2, denote by the output of Algorithm 1 for arm at batch . At the end of each batch, new data is acquired all at once and the posterior is being updated. It is important to note that upon receiving new data when we run Algorithm 1 for each arm, only that arm’s data is fed into Algorithm 1. For each , assume the existence of linear map such that , where is bounded. Theorem 5.2 shows the regret guarantee of BLTS.
theorembanditRegret
Assume that the parametric reward families, priors, and true reward distributions satisfy Assumptions 1 through 4 for each arm . Then with the SGLD parameters specified as per Algorithm 1 and with (for ), BLTS satisfies:
where is a constant and . The total number of SGLD iterations used by BLTS is .
Discussion
We show that BLTS achieves the optimal regret bound with exponentially fewer rounds of communication between the learner and the environment. Result of Theorem 5.2 relies on both the statistical guarantee provided by SGLD and the design of our batching scheme. In bached setting, one must carefully consider the trade-off between batch size and the number of batches. While it is desirable to reuse the existing posterior for sampling within a batch, the batching scheme must also ensure new data is collected in time to avoid significant distribution shifts. In addition, the use of SGLD allows BLTS to be applicable in a wide range of general settings with a low computation cost of .
In the regret bound of Theorem 5.2, measures the quality of prior for arm . Specifically, if the prior is properly centered such that its mode is at , or if the prior is uninformative or flat everywhere, then . In Section 7, we show that using either favorable priors or uninformative priors provides similar empirical performance as existing methods.
6 Batched Langevin Posterior Sampling For RL
In RL frameworks, posterior sampling is commonly used in model-based methods to learn unknown transition dynamics and is known as PSRL888We also depart from using TS for the RL setting and stick to the more popular posterior sampling terminology for RL.. In infinite-horizon settings, PSRL operates by sampling a model and solving for an optimal policy based on the sampled MDP at the beginning of each policy switch. The learner then follows the same policy until the next policy switch. In this context, the concept of a batch corresponds to a policy switch.
Previous analyses of PSRL have primarily focused on transition distributions that conform to well-behaved conjugate families. Handling transitions that deviate from these families and computing the corresponding posteriors has been heuristically left to MCMC methods. Here, we provably extend PSRL with LMC and introduce Langevin Posterior Sampling for RL (LPSRL, Algorithm 3) using a static doubling policy-switch scheme. Analyses of PSRL have crucially relied on the true transition dynamics and the sampled MDPs being identically distributed (Osband et al.,, 2013; Osband and Van Roy,, 2016; Russo and Van Roy,, 2014; Ouyang et al.,, 2017; Theocharous et al., 2017b, ). However, when the dynamics are sampled from an approximation of the true posterior, this fails to hold. To address the issue, we introduce the Langevin posterior sampling lemma (Lemma 6), which shows approximate sampling yields an additive error in the Wasserstein- distance.
lemmaLangevinPS (Langevin Posterior Sampling). Let be the beginning time of policy-switch , be the history of observed states and actions till time , and be the sampled model from the approximate posterior at time . Then, for any -measurable function that is -Lipschitz, it holds that:
| (4) |
By the tower rule, .
As demonstrated later, this error term can be effectively controlled and does not impact the overall regret (Theorems 6.2 and 6.3). It only requires the average reward function to be 1-Lipschitz, as specified in Assumption B999Mathematical statement is in Appendix B.. Let us consider the parameterization of the transition dynamics with , where denotes the true (unknown) parameter governing the dynamics. We explore two distinct settings based on these parameterizations:
-
•
General Parameterization (Section 6.2): In this setting, we consider modeling the full transition dynamics using , where . This parameterization can be particularly useful for tackling large-scale MDPs with large (or even continuous) state and action spaces. Towards this end, we consider . Examples of General Parameterization include linear MDPs with feature mappings Jin et al., (2020), RL with general function approximation Yang et al., (2020), and the low-dimensional structures that govern the transition (Gopalan and Mannor,, 2015; Yang and Wang,, 2020). We provide a real-world example that adopts such parameterization in Appendix E.3.
Despite Theocharous et al., 2017b studies a similar setting, their work confines the parameter space to . To accommodate a broader class of MDPs, we generalize the parameter space to . As suggested by Theorem 6.2, our algorithm retains the optimal regret with policy switches, making it applicable to a wide range of general transition dynamics.
-
•
Simplex Parameterization (Section 6.3): Here, we consider the classical tabular MDPs with finite states and actions. For each state-action pair, there exists a probability simplex that encodes the likelihood of transitioning into each state. Hence, in this case, with . This structure necessitates sampling transition dynamics from constrained distributions, which naturally leads us to instantiate LPSRL with the Mirrored Langevin Dynamics (Hsieh et al.,, 2018) (See Appendix A for more discussions). As proven in Theorem 6.3, LPSRL with MLD achieves the optimal regret with policy switches for general transition dynamics subject to the probability simplex constraints.
6.1 The LPSRL Algorithm
LPSRL (Algorithm 3) use SamplingAlg as a subroutine, where SGLD and MLD are invoked respectively depending on the parameterization. Unlike the BLTS algorithm in bandit settings, LPSRL adopts a static doubling batching scheme, in which the decision to move onto the next batch is independent of the dynamic statistics of the algorithm, and thus is algorithmically independent.
Let be the starting time of policy-switch and let represent the total number of time steps between policy-switch and . At the beginning of each policy-switch , we utilize SamplingAlg to obtain an approximate posterior distribution and sample dynamics from . A policy is then computed for with any planning algorithm101010We assume the optimality of policies and focus on learning the transitions. When only suboptimal policies are available in our setting, it can be shown that small approximation errors in policies only contribute additive non-leading terms to regret. See details in Ouyang et al., (2017).. The learner follows to select actions and transit into new states during the remaining time steps before the next policy switch. New Data is collected all at once at the end of . Once the total number of time steps is being doubled, i.e., reaches , the posterior is updated using the latest data , and the above process is repeated.
6.2 General Parametrization
In RL context, to study the performance of LPSRL instantiated with SGLD as SamplingAlg, Assumptions B-B are required to hold on the (unknown) transition dynamics, rather than the (unknown) rewards as in the bandit setting. Additionally, similar to Theocharous et al., 2017b , the General Parameterization requires to be Lipschitz in (Assumption B). Mathematical statements of all assumptions are in Appendix B. We now state the main theorem for LPSRL under the General Parameterization.
theoremMDPRegretSGLD
Under Assumptions , by instantiating SamplingAlg with SGLD and setting the hyperparameters as per Theorem 1, with , the regret of LPSRL (Algorithm 3) satisfies:
where is some positive constant, is the upper bound of the MDP span, and denotes the quality of the prior. The total number of iterations required for SGLD is .
Discussion.
LPSRL with SGLD maintains the same order-optimal regret as exact PSRL in Theocharous et al., 2017b . Similar to Theorem 5.2, the regret bound has explicit dependence on the quality of prior imposed to transitions, where when prior is properly centered with its mode at , or when it is uninformative or flat. Let be the true posterior in policy-switch . Our result relies on and being identically distributed, and the convergence of SGLD in iterations to control the additive cumulative error in arising from approximate sampling.
6.3 Simplex Parametrization
We now consider the tabular setting where specifically models a collection of transition matrices in . Each row of the transition matrices lies in a probability simplex , specifying the transition probabilities for each corresponding state-action pair. In particular, if the learner is in state and takes action , then it lands in state with . In order to run LPSRL on constrained space, we need to sample from probability simplexes and therefore appeal to the Mirrored Langevin Dynamics (MLD) (Hsieh et al.,, 2018) by using the entropic mirror map, which satisfies the requirements set forth by Theorem 2 in Hsieh et al., (2018). Under Assumptions B and B, we have the following convergence guarantee for MLD and regret bound for LPSRL under the Simplex Parameterization.
theoremMLDConvergence At the beginning of each policy-switch , for each state-action pair , sample transition probabilities over using MLD with the entropic mirror map. Let be the number of data samples for any at time , then with step size chosen per Cheng and Bartlett, (2018), running MLD with iterations guarantees that
theoremMDPRegretMLD Suppose Assumptions 5 and 6 are satisfied, then by instantiating SamplingAlg with MLD (Algorithm 4), there exists some positive constant such that the regret of LPSRL (Algorithm 3) in the Simplex Parameterization is bounded by
where is some positive constant, is the upper bound of the MDP span. The total number of iterations required for MLD is .
Discussion.
In simplex parameterization, instantiating LPSRL with MLD achieves the same order-optimal regret, but the computational complexity in terms of iterations for MLD is linear in as opposed to for SGLD in the General Parameterization. Nevertheless, given that the simplex parameterization implies simpler structures, we naturally have fewer assumptions for the theory to hold.
7 Experiments
In this section, we perform empirical studies in simulated environments for bandit and RL to corroborate our theoretical findings. By comparing the actual regret (average rewards) and the number of batches for interaction (maximum policy switches), we show Langevin TS algorithms empowered by LMC methods achieve appealing statistical accuracy with low communication cost. For additional experimental details, please refer to Appendix F.
7.1 Langevin TS in Bandits
We first study how Langevin TS behaves in learning the true reward distributions of log-concave bandits with different priors and batching schemes. Specifically, we construct two bandit environments111111Our theories apply to bandits with a more general family of reward distributions. with Gaussian and Laplace reward distributions, respectively. While both environments are instances of log-concave families, Laplace bandits do not belong to conjugate families.
7.1.1 Gaussian Bandits
We simulate a Gaussian bandit environment with arms. The existence of closed-form posteriors in Gaussian bandits allows us to benchmark against existing exact TS algorithms. More specifically, we instantiate Langevin TS with SGLD (SGLD-TS), and perform the following tasks:
-
•
Compare SGLD-TS against both frequentist and Bayesian methods, including UCB1, Bayes-UCB, decaying -greedy, and exact TS.
-
•
Apply informative priors and uninformative priors for Bayesian methods based on the availability of prior knowledge in reward distributions.
-
•
Examine all methods under three batching schemes: fully-sequential mode, dynamic batch, static batch.
Results and Discussion. Figure 1(a) illustrates the cumulative regret for SGLD-TS and Exact-TS with favorable priors. Table 2 reports the regret upon convergence along with the total number of batches in interaction. Note that SGLD-TS equipped with dynamic batching scheme implements Algorithm 2 (BLTS). Empirical results demonstrate that SGLD-TS is comparable to Exact-TS under all batching schemes, and is empirically more appealing compared to UCB1 as well as Bayes-UCB. While static batch incurs slightly lower communication costs compared to dynamic batch, results show that all methods under dynamic batch scheme are more robust with smaller standard deviation. Our BLTS algorithm thus well balances the trade-off between statistical performance, communication, and computational efficiency by achieving the order-optimal regret with a small number of batches.



| SGLD-TS | Exact-TS | UCB1 | Bayes-UCB | Batches | |
| Fully sequential | |||||
| Static batch | |||||
| Dynamic batch |
7.1.2 Laplace Bandits
To demonstrate the applicability of Langevin TS in scenarios where posteriors are intractable, we construct a Laplace bandit environment with arms. It is important to note that Laplace reward distributions do not have conjugate priors, rendering exact TS inapplicable in this setting. Therefore, we compare the performance of SGLD-TS with favorable priors against UCB1. Results presented in Figure 1(b) reveal that, similar to the Gaussian bandits, SGLD-TS with dynamic batching scheme achieves comparable performance as in the fully-sequential setting and significantly outperforms UCB1, highlighting its capability to handle diverse environments. In addition, the static batching scheme exhibits larger deviations compared to the dynamic batching, which aligns with results in Table 2.
7.2 Langevin PSRL in Average-reward MDPs
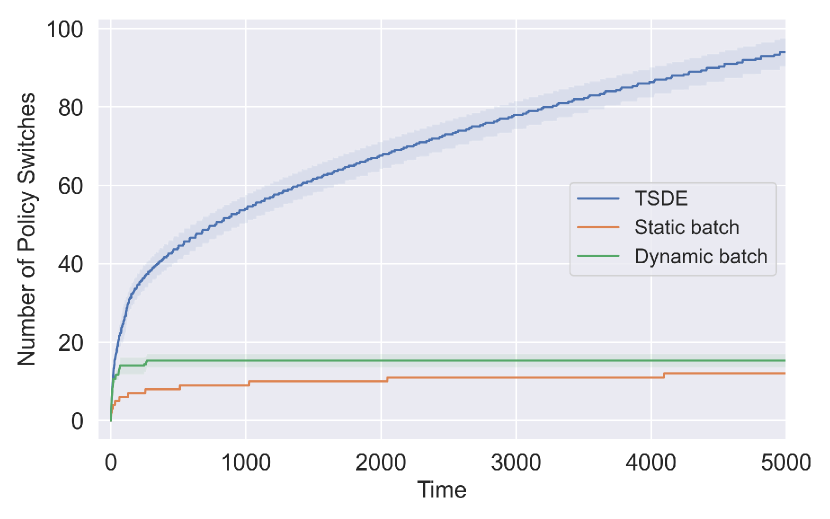
In MDP setting, we consider a variant of RiverSwim environment (Strehl and Littman,, 2008), which is a common testbed for provable RL methods. Specifically, it models an agent swimming in the river with five states, two actions (). In this tabular case, LPSRL (Algorithm 3) employs MLD (Algorithm 4 in Appendix A) as SamplingAlg, namely, MLD-PSRL. We benchmark the performance of MLD-PSRL against other mainstream model-based RL methods, including TSDE (Ouyang et al.,, 2017), DS-PSRL (Theocharous et al., 2017b, ) and DB-PSRL (exact-PSRLStrens, (2000) with dynamic batch). Note that MLD-PSRL and DS-PSRL adopt the static doubling policy switch scheme discussed in section 6. Dynamic doubling policy switch scheme adopted by both DB-PSRL and TSDE is akin to the one we use in bandit setting, but based on the visiting counts of state-action pairs. We simulate different runs of experiment, and report the average rewards obtained by each method in Figure 1(c). Mechanisms used by each method are summarized in Table 3, along with the average rewards achieved and maximum number of policy switches incurred.
| MLD-PSRL | DS-PSRL | DB-PSRL | TSDE | Optimal policy | |
| Static ps | |||||
| Dynamic ps | |||||
| Linear growth | |||||
| Avg. reward | |||||
| Max. switches | - |
Results and Discussion. We demonstrate that MLD-PSRL achieves comparable performance compared to existing PSRL methods while significantly reducing communication costs through the use of static policy switches. In contrast, as illustrated in Figure 4 (Appendix F) and Table 3, TSDE achieves near-optimal performance but requires high communication costs. Additionally, our empirical results reveal that the static policy switch in the MDP setting outperforms the dynamic policy switch alone. This observation aligns with existing findings that frequent policy switches in MDPs can harm performance. Moreover, compared to DS-PSRL, MLD-PSRL is applicable to more general frameworks when closed-form posterior distributions are not available121212Different mirror maps can be applied to MLD method depending on parameterization..
8 Conclusion
In this paper, we jointly address two challenges in the design and analysis of Thompson sampling (TS) methods. Firstly, when dealing with posteriors that do not belong to conjugate families, it is necessary to generate approximate samples within a reasonable computational budget. Secondly, when interacting with the environment in a batched manner, it is important to limit the amount of communication required. These challenges are critical in real-world deployments of TS, as closed-form posteriors and fully-sequential interactions are rare. In stochastic MABs, approximate TS and batched interactions are studied independently. We bridge the two lines of work by providing a Langevin TS algorithm that works for a wide class of reward distributions with only logarithmic communication. In the case of undiscounted infinite-horizon MDP settings, to the best of our knowledge, we are the first to provably incorporate approximate sampling with the TS paradigm. This enhances the applicability of TS for RL problems with low communication costs. Finally, we conclude with experiments to demonstrate the appealing empirical performance of the Langevin TS algorithms.
Acknowledgements
This work is supported in part by the National Science Foundation Grants NSF-SCALE MoDL(2134209) and NSF-CCF-2112665 (TILOS), the U.S. Department Of Energy, Office of Science, and the Facebook Research award. Amin Karbasi acknowledges funding in direct support of this work from NSF (IIS-1845032), ONR (N00014- 19-1-2406), and the AI Institute for Learning-Enabled Optimization at Scale (TILOS).
References
- Abbasi-Yadkori and Szepesvári, (2015) Abbasi-Yadkori, Y. and Szepesvári, C. (2015). Bayesian optimal control of smoothly parameterized systems. In Proceedings of the Thirty-First Conference on Uncertainty in Artificial Intelligence. AUAI Press.
- Agrawal and Goyal, (2012) Agrawal, S. and Goyal, N. (2012). Analysis of thompson sampling for the multi-armed bandit problem. In Conference on learning theory, pages 39–1. JMLR Workshop and Conference Proceedings.
- Agrawal and Goyal, (2013) Agrawal, S. and Goyal, N. (2013). Further optimal regret bounds for thompson sampling. In Artificial intelligence and statistics, pages 99–107. PMLR.
- Agrawal and Jia, (2017) Agrawal, S. and Jia, R. (2017). Optimistic posterior sampling for reinforcement learning: worst-case regret bounds. Advances in Neural Information Processing Systems, 30.
- Bartlett and Tewari, (2012) Bartlett, P. L. and Tewari, A. (2012). Regal: A regularization based algorithm for reinforcement learning in weakly communicating mdps. arXiv preprint arXiv:1205.2661.
- Bertsekas, (2012) Bertsekas, D. (2012). Dynamic programming and optimal control: Volume I, volume 1. Athena scientific.
- Bojun, (2020) Bojun, H. (2020). Steady state analysis of episodic reinforcement learning. Advances in Neural Information Processing Systems, 33:9335–9345.
- Brown et al., (2020) Brown, D., Coleman, R., Srinivasan, R., and Niekum, S. (2020). Safe imitation learning via fast bayesian reward inference from preferences. In International Conference on Machine Learning, pages 1165–1177. PMLR.
- Chapelle and Li, (2011) Chapelle, O. and Li, L. (2011). An empirical evaluation of thompson sampling. Advances in neural information processing systems, 24:2249–2257.
- Cheng and Bartlett, (2018) Cheng, X. and Bartlett, P. (2018). Convergence of langevin mcmc in kl-divergence. In Algorithmic Learning Theory, pages 186–211. PMLR.
- Gao et al., (2019) Gao, Z., Han, Y., Ren, Z., and Zhou, Z. (2019). Batched multi-armed bandits problem.
- Gopalan and Mannor, (2015) Gopalan, A. and Mannor, S. (2015). Thompson Sampling for Learning Parameterized Markov Decision Processes. In Proceedings of The 28th Conference on Learning Theory. PMLR.
- Granmo, (2010) Granmo, O.-C. (2010). Solving two-armed bernoulli bandit problems using a bayesian learning automaton. International Journal of Intelligent Computing and Cybernetics.
- Guez et al., (2014) Guez, A., Silver, D., and Dayan, P. (2014). Better optimism by bayes: Adaptive planning with rich models. arXiv preprint arXiv:1402.1958.
- Haarnoja et al., (2018) Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V., Zhu, H., Gupta, A., Abbeel, P., et al. (2018). Soft actor-critic algorithms and applications. arXiv preprint arXiv:1812.05905.
- Honda and Takemura, (2013) Honda, J. and Takemura, A. (2013). Optimality of thompson sampling for gaussian bandits depends on priors.
- Hsieh et al., (2018) Hsieh, Y.-P., Kavis, A., Rolland, P., and Cevher, V. (2018). Mirrored langevin dynamics. Advances in Neural Information Processing Systems, 31.
- Imani et al., (2018) Imani, M., Ghoreishi, S. F., and Braga-Neto, U. M. (2018). Bayesian control of large mdps with unknown dynamics in data-poor environments. Advances in neural information processing systems, 31.
- Jaksch et al., (2010) Jaksch, T., Ortner, R., and Auer, P. (2010). Near-optimal regret bounds for reinforcement learning. Journal of Machine Learning Research, 11:1563–1600.
- Jin et al., (2018) Jin, C., Allen-Zhu, Z., Bubeck, S., and Jordan, M. I. (2018). Is q-learning provably efficient? Advances in neural information processing systems, 31.
- Jin et al., (2020) Jin, C., Yang, Z., Wang, Z., and Jordan, M. I. (2020). Provablylearning to optimize via posterior sampling efficient reinforcement learning with linear function approximation. In Conference on Learning Theory, pages 2137–2143. PMLR.
- Jung et al., (2019) Jung, Y. H., Abeille, M., and Tewari, A. (2019). Thompson sampling in non-episodic restless bandits. arXiv preprint arXiv:1910.05654.
- Kalkanli and Ozgur, (2021) Kalkanli, C. and Ozgur, A. (2021). Batched thompson sampling. Advances in Neural Information Processing Systems, 34:29984–29994.
- Karbasi et al., (2021) Karbasi, A., Mirrokni, V., and Shadravan, M. (2021). Parallelizing thompson sampling. Advances in Neural Information Processing Systems, 34:10535–10548.
- Kaufmann et al., (2012) Kaufmann, E., Korda, N., and Munos, R. (2012). Thompson sampling: An asymptotically optimal finite-time analysis. In International conference on algorithmic learning theory, pages 199–213. Springer.
- Li et al., (2022) Li, T., Wu, F., and Lan, G. (2022). Stochastic first-order methods for average-reward markov decision processes. arXiv preprint arXiv:2205.05800.
- Lu and Van Roy, (2017) Lu, X. and Van Roy, B. (2017). Ensemble sampling. arXiv preprint arXiv:1705.07347.
- Ma et al., (2015) Ma, Y.-A., Chen, T., and Fox, E. (2015). A complete recipe for stochastic gradient mcmc. Advances in neural information processing systems, 28.
- May et al., (2012) May, B. C., Korda, N., Lee, A., and Leslie, D. S. (2012). Optimistic bayesian sampling in contextual-bandit problems. Journal of Machine Learning Research, 13:2069–2106.
- Mazumdar et al., (2020) Mazumdar, E., Pacchiano, A., Ma, Y.-a., Bartlett, P. L., and Jordan, M. I. (2020). On approximate Thompson sampling with Langevin algorithms. In ICML, volume 119, pages 6797–6807.
- Osband et al., (2013) Osband, I., Russo, D., and Van Roy, B. (2013). (more) efficient reinforcement learning via posterior sampling. Advances in Neural Information Processing Systems, 26.
- Osband and Van Roy, (2014) Osband, I. and Van Roy, B. (2014). Model-based reinforcement learning and the eluder dimension. Advances in Neural Information Processing Systems, 27.
- Osband and Van Roy, (2016) Osband, I. and Van Roy, B. (2016). Posterior sampling for reinforcement learning without episodes. arXiv preprint arXiv:1608.02731.
- Ouyang et al., (2017) Ouyang, Y., Gagrani, M., Nayyar, A., and Jain, R. (2017). Learning unknown markov decision processes: A thompson sampling approach. Advances in neural information processing systems, 30.
- Riquelme et al., (2018) Riquelme, C., Tucker, G., and Snoek, J. (2018). Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. arXiv preprint arXiv:1802.09127.
- Russo and Van Roy, (2014) Russo, D. and Van Roy, B. (2014). Learning to optimize via posterior sampling. Mathematics of Operations Research, 39(4):1221–1243.
- Schwartz et al., (2017) Schwartz, E. M., Bradlow, E. T., and Fader, P. S. (2017). Customer acquisition via display advertising using multi-armed bandit experiments. Marketing Science, 36(4):500–522.
- Strehl and Littman, (2008) Strehl, A. L. and Littman, M. L. (2008). An analysis of model-based interval estimation for markov decision processes. Journal of Computer and System Sciences, 74(8):1309–1331.
- Strens, (2000) Strens, M. (2000). A bayesian framework for reinforcement learning. In ICML, volume 2000, pages 943–950.
- (40) Theocharous, G., Vlassis, N., and Wen, Z. (2017a). An interactive points of interest guidance system. In Proceedings of the 22nd International Conference on Intelligent User Interfaces Companion, IUI ’17 Companion.
- (41) Theocharous, G., Wen, Z., Abbasi-Yadkori, Y., and Vlassis, N. (2017b). Posterior sampling for large scale reinforcement learning. arXiv preprint arXiv:1711.07979.
- Thompson, (1933) Thompson, W. R. (1933). On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika, 25(3/4):285–294.
- Tian et al., (2020) Tian, Y., Qian, J., and Sra, S. (2020). Towards minimax optimal reinforcement learning in factored markov decision processes. Advances in Neural Information Processing Systems, 33:19896–19907.
- Tossou et al., (2019) Tossou, A., Basu, D., and Dimitrakakis, C. (2019). Near-optimal optimistic reinforcement learning using empirical bernstein inequalities. arXiv preprint arXiv:1905.12425.
- Vernade et al., (2020) Vernade, C., Carpentier, A., Lattimore, T., Zappella, G., Ermis, B., and Brueckner, M. (2020). Linear bandits with stochastic delayed feedback. In International Conference on Machine Learning, pages 9712–9721. PMLR.
- Wei et al., (2021) Wei, C.-Y., Jahromi, M. J., Luo, H., and Jain, R. (2021). Learning infinite-horizon average-reward mdps with linear function approximation. In International Conference on Artificial Intelligence and Statistics, pages 3007–3015. PMLR.
- Wei et al., (2020) Wei, C.-Y., Jahromi, M. J., Luo, H., Sharma, H., and Jain, R. (2020). Model-free reinforcement learning in infinite-horizon average-reward markov decision processes. In International conference on machine learning, pages 10170–10180. PMLR.
- Welling and Teh, (2011) Welling, M. and Teh, Y. W. (2011). Bayesian learning via stochastic gradient langevin dynamics. In Proceedings of the 28th international conference on machine learning (ICML-11), pages 681–688.
- Wu et al., (2022) Wu, Y., Zhou, D., and Gu, Q. (2022). Nearly minimax optimal regret for learning infinite-horizon average-reward mdps with linear function approximation. In International Conference on Artificial Intelligence and Statistics, pages 3883–3913. PMLR.
- Xu et al., (2022) Xu, P., Zheng, H., Mazumdar, E. V., Azizzadenesheli, K., and Anandkumar, A. (2022). Langevin monte carlo for contextual bandits. In International Conference on Machine Learning, pages 24830–24850. PMLR.
- Yang and Wang, (2020) Yang, L. and Wang, M. (2020). Reinforcement learning in feature space: Matrix bandit, kernels, and regret bound. In International Conference on Machine Learning, pages 10746–10756. PMLR.
- Yang et al., (2020) Yang, Z., Jin, C., Wang, Z., Wang, M., and Jordan, M. I. (2020). On function approximation in reinforcement learning: Optimism in the face of large state spaces. arXiv preprint arXiv:2011.04622.
- Zhang, (2022) Zhang, T. (2022). Feel-good thompson sampling for contextual bandits and reinforcement learning. SIAM Journal on Mathematics of Data Science, 4(2):834–857.
- Zhang et al., (2020) Zhang, W., Zhou, D., Li, L., and Gu, Q. (2020). Neural thompson sampling.
Appendices
Appendix A MCMC Methods
A.1 Unconstrained Approximate Sampling
Suppose a target distribution is parameterized by , and observed data are independently identically distributed. A posterior distribution defined up to a normalization factor can be expressed via the Gibbs distribution form:
where is the prior distribution of , is the likelihood function, and is the energy function.
Typical MCMC methods require computations over the whole dataset, which is inefficient in large-scale online learning. To overcome this issue, we adopt SGLD Welling and Teh, (2011) as one of the approximate sampling methods, which is developed upon stochastic optimization over mini-batch data . The update rule is based on the Euler-Murayama discretization of the Langevin stochastic differential equation (SDE):
where is a Brownian motion. To further improve computation, we reuse samples from previous batches to warm start the Markov chains (Algorithm 1). The resulting dependent structure in samples will complicate our analysis.
A.2 Constrained Approximate Sampling
While the convergence of SGLD methods is well-studied, it is only applicable to unconstrained settings. To enable sampling from constrained non log-concave distributions, such as probability simplex in transition dynamics of MDPs, reparameterization can be used in conjunction with SGLD. Alternatively, one can adopt MLD Hsieh et al., (2018) which utilizes mirror maps for sampling from a dual unconstrained space (Algorithm 4). Let the probability measure of be , where dom() is constrained. Suppose there exist a mirror map that maps to some unconstrained distribution , denoted by . Then MLD has the following SDE:
| (5) |
where is the dual of , and .
In tabular settings of MDP, MLD needs to be run against each row of the matrices to generate a sampled transition from simplex for each state-action pair. In this case, entropic mirror map will be adopted as , which is given by
| (6) |
Appendix B Assumptions
Here we explicitly mention all of the assumptions required in the paper. Assumptions 1-4 are required for SGLD to converge (Algorithm 1 and Theorem 1), Assumptions B and B are required in Section 6.
-
Assumption 1 (Assumption on the family for approximate sampling). Assume that is -smooth and -strongly concave over :
-
Assumption 2 (Assumption on true reward/transition distribution ). Assume that is strongly log-concave in with some parameter , and that is -Lipschitz in :
-
Assumption 3 (Assumption on the prior distribution). Assume that is concave with -Lipschitz gradients for all :
-
Assumption 4 (Joint Lipschitz smoothness of ).
-
Assumption 5 (1- Lipschitzness of in ). The optimal average-reward function satisfies
where .
-
Assumption 6 (Lipschitzness of transition in for RL). There exists a constant such that the transition for each state-action pair is -Lipschtiz in parameter space:
Appendix C Convergence of SGLD with Batched Data
In this section, we prove the convergence of SGLD in sequential decision making frameworks under the batch scheme, which is stated with precise hyperparameters as Theorem 2. We first state the supporting lemmas, followed by the proof of the convergence theorem.
Lemma C.3 (Lemma 5 in Mazumdar et al., (2020)).
Denote as the stochastic estimator of . Then for stochastic gradient estimate with data points, we have,
Lemma C.4 (Lemma 6 from Mazumdar et al., (2020)).
For a fixed arm with samples, suppose we run Algorithm 1 with step size for N iterations to generate samples from posterior , in which is strongly convex and Lipschitz smooth. If at each step , the -th moment between the true gradient and the stochastic gradient satisfies then:
where .
Theorem 2 (SGLD convergence).
Fix an arm and suppose that Assumptions 1-4 are met for it. Let , be the number of available rewards for arm when running SGLD for the -th time, be the exact posterior of arm after observing samples, and be the corresponding approximate posterior obtained by SGLD. If is satisfied by the posterior, then with mini-batch size , step size , and the number of steps , SGLD in Algorithm 1 converges in Wasserstein- distance:
-
Proof of Theorem 2
The proof follows similarly to that of Theorem 6 in Mazumdar et al., (2020). Compared to the analysis in Mazumdar et al., (2020), our proof is based on induction on the batches, as opposed to induction on the number of samples, as for us, SGLD is only executed at the end of the batch. Let be the -th batch. Now for the base case, i.e. when , we have that . And therefore the claim follows by the initialization of the algorithm (this is similar to the fully sequential case in Mazumdar et al., (2020)).
Now, suppose that the claim holds for batch . That is, suppose that all the necessary conditions are met and that .
Taking the initial condition in Lemma C.4, we get that:
Now we know that:
where the first inequality follows from triangle inequality, the second one follows from the assumption on the posterior and the induction hypothesis, and the last one just upper bounds the expression while also using the fact that . This shows us that we can get the same upper bound as is seen in the fully sequential proof. The main point to note is that the proof has enough looseness in it, so that despite collecting at most double the data, the same bounds hold. With the choice of hyperparameters, taking and using Lemma C.3 leads us to the conclusion that .
We now state the concentration results provided by SGLD in Lemma C.5, which shows the probability that the sampled parameters (from the approximate posterior) are far away from the true dynamics is small. Lemma C.5 extends Lemma 11 in Mazumdar et al., (2020) to the batched settings.
Lemma C.5 (Concentration of SGLD in bandits).
For a fixed arm , say that it is pulled times till batch and times till batch (where ). Suppose that Assumptions B-B are satisfied, then for , with parameters as specified in Theorem 2, the sampled parameter generated in the -th batch satisfies,
where }, , .
- Proof of Lemma C.5
The proof follows exactly as Lemma 11 from Mazumdar et al., (2020) by replacing the notations in fully-sequential settings by those in batched settings, i.e., by , by .
Appendix D Proofs of Langevin Thompson Sampling in Multi-armed Bandits
In this section, we provide the regret proofs of BLTS algorithm in the stochastic multi-armed bandit (MAB) setting, which are discussed in Section 5. In particular, we discuss the information exchange guarantees under dynamic batching scheme and its communication cost. We then utilize the convergence of SGLD in Appendix C and the above results to prove the problem-dependent regret bound in MAB setting.
D.1 Notations
We first introduce the notation being used in this section, which is summarized in Table 4.
| Symbol | Meaning |
|---|---|
| set of arms in bandit environment | |
| number of arms in bandit environment, i.e., | |
| time horizon | |
| total number of batches | |
| starting time of the batch containing timestep | |
| starting time of the -th batch | |
| trigger of dynamic batches (a batch is formed when ), a monotonically-increasing integer for arm | |
| the number of times that arm has been pulled up to time | |
| reward distribution of arm parameterized by | |
| parameter of reward distribution for arm | |
| expected reward of arm , | |
| estimated expected reward of arm , | |
| quality of prior for arm , | |
| condition number of parameterized reward distribution, | |
| prior distribution over | |
| energy function of posterior distribution : | |
| Lipschitz constant of the true reward distribution and likelihood families in | |
| strong log-concavity parameter of in for all | |
| strong log-concavity parameter of in |
D.2 Communication cost of Dynamic Doubling Batching Scheme
In batched setting, striking a balance between batch size and the number of batches is critical to achieving optimal performance. More specifically, it is crucial to balance the number of actions taken within each batch, with the frequency of starting new batches to collect new data and update the posteriors. According to Lemma D.2, dynamic doubling batching scheme guarantees an arm that has been pulled times has at least observed rewards, indicating that communication between the learner and the environment is sufficient under this batching scheme.
lemmabanditPull Let be the current time step, be the starting time of the current batch, be the number of times that arm has been pulled up to time . For all , the dynamic batch scheme ensures:
-
Proof of Lemma D.2
By the mechanism of our batch scheme, a new batch will begin when the number of times of any arm being pulled is doubled. It implies that the number of times that an arm is pulled within a batch is less than the number of times that it has been pulled at the beginning of this batch. At any time step :
which gives . On the other hand, holds due to the fact that .
Next, we show that by employing the dynamic doubling batching scheme, BATS algorithm achieves optimal performance using only logarithmic rounds of communication (measured in terms of batches).
*
-
Proof of Theorem 5.1
Denote by the starting time of the -th batch, and let be the trigger integer for arm at time , be the total number of rounds to interact with environment, namely, batches. Then for each arm , , and
where the second and third step result from the dynamic batching scheme. Thus for each arm , we have
The proof is then completed by multiplying the above result by arms.
D.3 Regret Proofs in Multi-armed Bandit
With the convergence properties shown in Appendix C, we proceed to prove the regret guarantee of Langevin TS with SGLD. The general idea of our regret proof is to upper bound the total number of times that the sub-optimal arms are pulled over time horizon . We remark that the dependence of approximate samples across batches complicates our analysis of TS compared to the existing analyses in bandit literature.
We first decompose the expected regret according to the events of concentration in approximate samples and the events of estimation accuracy in expected rewards of sub-optimal arms.
For approximate samples , define event which is guaranteed to happen with probability at least by Lemma C.5 for some . Let , , where is the total number of batches. Without loss of generality, we take for all arms in in the subsequent proofs
Let be the estimate of the expected reward for arm at time step , and denote the filtration up to time as . For any sub-optimal arm , define event with probability for some , which signifies the estimation of arm is close to the true optimal expected reward.
Lemma D.1 (Regret Decomposition).
Let be the true expected reward of arm , , . The expected regret of Langevin TS with SGLD satisfies:
where .
-
Proof of Lemma D.1.
Recall that
For any sub-optimal arm , consider the event space , in which denotes the event that all approximate samples of arm and optimal arm are concentrated.
To bound the regret, we bound the largest number of times that each sub-optimal arm will be played:
where the second inequality results from .
For any arm in each batch, approximate samples are independently generated from the identical approximate distribution . Thus, approximate samples for arm are independent within the same batch, while being dependent across different batches, implying
where is the number of time steps in the -th batch, namely, the length of the batch. By Lemma C.5, for each arm in batch , , which gives:
Setting gives,
Plugging in the results to the definition of regret yields,
We then proceed to bound and respectively in Lemma D.2 and Lemma D.3, the key to maintaining optimal regret is to maximize the probability of pulling the optimal arm by ensuring the event takes place with low probability for all sub-optimal arms.
Lemma D.2 (Bound term ).
It can be shown that,
-
Proof of lemma D.2.
Note that arm is played at time if and only if . Thus for a sub-optimal arm , the following event relationship holds: , and . We then have,
Recall that . Combining the above two equations shows that the probability of pulling a sub-optimal arm is bounded by the probability of pulling the optimal arm with an exponentially decaying coefficient:
(7) Therefore, is upper bounded accordingly:
Lemma D.3 (Bound term ).
It can be shown that,
Lemma D.4.
-
Proof of Lemma D.4
For completeness, we provide the proof of this lemma, which closely follows the proof of Lemma 18 in Mazumdar et al., (2020).
For each arm , upon running SGLD with batched data in batch , by Cauchy-Schwartz inequality, we have,
where . Let , by anti-concentration of Gaussian random variables, for the optimal arm ,
Taking expectations of both sides and by Cauchy-Schwartz inequality,
By the convergence guarantee of SGLD in Theorem 2,
Note that is a sub-Gaussian random variable, when ,
Combining the above results together completes the proof.
With Lemma D.4, we now proceed to prove the terms in and that lead us to the final regret bound.
Lemma D.5.
Assume that Assumptions 1-4 are satisfied. Let , . running Algorithm 2 with samples generated from approximate posteriors using Algorithm 1, we have,
| (8) |
| (9) |
- Proof of lemma D.5.
For ease of notation, let the number of observed rewards in batch for arm be . By definition,
With concentration property of approximate samples in Lemma C.5, it suggests the increasing number of observed rewards for the optimal arm leads to the increasing probability of being optimal. Thus by Lemma D.2, at any time step ,
Concentration is achieved only when sufficient number of rewards is observed, we thus require:
| (10) |
where . Choose , and consider the time step when arm satisfies:
As , the number of observed rewards is guaranteed to be at least , and . Thus, the individual term in follows:
| (11) |
In early stage when concentration has not been achieved, using results from Lemma D.4,
| (12) |
When sufficient rewards for the optimal arm has been accumulated,
| (13) |
Similarly, for term with event , let ,
which gives
With the same form of posterior as in equation 10, for arm holds, when
Here, the number of observed rewards is guaranteed to be at least , where . Therefore, using the fact that , we have,
We are ready to prove the final regret bound by combining results from the above Lemmas. \banditRegret*
Appendix E Proofs of Langevin Posterior Sampling for Reinforcement Learning
In this section, we will present the regret proofs for Langevin Posterior Sampling algorithms in RL frameworks under different types of parameterization, and conclude with a real-world example where the General Parameterization from Section 6.2 is applicable.
E.1 Communication cost of Static Doubling Batching Scheme
We first show that under the static doubling batching scheme in RL setting, LPSRL algorithm achieves optimal performance using only logarithmic rounds of communication (measured in terms of batches, or equivalently policy switches).
Theorem 3.
Let be the number of time steps between the -th policy switch and the -th policy switch, and be the total number of policy switches for time horizon . LPSRL ensures that
E.2 Regret Proofs in Average-reward MDPs
In this section, we proceed to prove the theorems in Section 6. To focus on the problem of model estimation, our results are developed under the optimality of policies131313If only suboptimal policies are available in our setting, it can be shown that small approximation errors in policies only contribute additive non-leading terms to regret. See details in Ouyang et al., (2017)..
While analyses of Bayes regret in existing works of PSRL crucially depend on the true transition dynamics being identically distributed as those of sampled MDP Russo and Van Roy, (2014), we show that in Langevin PSRL, sampling from the approximate posterior instead of the true posterior will introduce a bias that can be upper bounded using Wasserstein- distance.
*
-
Proof of Lemma 6
Notice that both and are measurable with respect to . Therefore, condition on history , the only randomness under the expectation comes from the sampling procedure for approximate posterior, which gives,
(14) The third inequality follows from the fact that given , is the posterior of and the definition of dual representation for with respect to the -Lipschitz function . The last equality follows from the standard posterior sampling lemma in the Bayesian setting (Osband et al.,, 2013; Osband and Van Roy,, 2014), which suggests that at time , given the sigma-algebra , and are identically distributed:
Following the same argument, condition on , we also have,
(15) Combining Equation (14) and (15) yields Equation (4). Applying the tower rule concludes the proof.
Corollary E.1 (Tabular Langevin Posterior Sampling).
In tabular settings with finite states and actions, by running an approximate sampling method for each at time , it holds that for each policy switch ,
where are the corresponding true posterior and approximate posterior for at time .
-
Proof of Corollary E.1
Since we run the approximate sampling algorithm for each state-action pair at the beginning of each policy switch , the total approximation error is equal to the sum of approximation error for each .
We first provide a general regret decomposition in Lemma E.2, which holds for any undiscounted weakly-communicating MDPs with infinite horizon, where approximate sampling is adopted and the transition is Lipschitiz.
Lemma E.2 (Regret decomposition.).
For a weakly-communicating MDP with infinite time-horizon , the Bayesian regret of Algorithm 3 instantiated with any approximate sampling method can be decomposed as follows:
| (16) |
where is a Lipschitz constant, and is the upper bound of span of MDP.
-
Proof of Lemma E.2
We adopt the greedy policy with respect to the sampled model, which gives at each time step . By Bellman Optimality equation in Lemma 1,
(17) We then follow the standard analyses in RL literature Osband et al., (2013); Osband and Van Roy, (2014) to decompose the regret into sum of Bellman errors. Plug in Equation (17) into the definition of Bayesian regret, we have,
(18)
Term (i). By the property of approximate posterior sampling in Lemma 6 and the non-negativity of Wasserstein distance,
| (19) |
We remark that this term differs from the exact PSRL where no approximate sampling method is used. To ensure the final regret is properly bounded, approximate sampling method being used must provide sufficient statistical guarantee of and in terms of Wasserstein- distance.
Term (ii). We further decompose term (ii) into the model estimation errors.
To bound , note that for each , , and by Theorem 3,
| (20) |
The above regret decomposition in Lemma E.2 holds regardless of the approximate sampling methods being employed. To derive the final regret bounds, we discuss in the context of General Parmeteration and Simple parameterization respectively.
E.2.1 General Parametrization
The first term in Equation (16) corresponds to the accumulating approximation error over the time horizon due to the use of approximate sampling method. Upper bounding this term relies on the statistical guarantee provided by the adopted approximate sampling method, which is the main novelty of LPSRL. In this section, we focus on the regret guarantee under the general parameterization.
To maintain the sub-linear regret guarantee, the convergence guarantee provided by SGLD is required to effectively upper bound the approximation error in the first term of Lemma E.2.
Lemma E.4.
To further upper bound in Lemma E.3 under the General Parameterization, we establish the following concentration guarantee provided by SGLD under the static doubling batching scheme adopted by LPSRL.
Lemma E.5 (Concentration of SGLD).
For any policy-switch , instantiating LPSRL with SGLD guarantees that
- Proof of Lemma E.5
At time , denote the parameter sampling from the true posterior , and the total number of available observations. By the triangle inequality,
Taking expectation and multiplying both sides by yields,
| (23) |
Under the General parameterization, we follow Assumption A2 in Theocharous et al., 2017b to focus on the MDPs that have proper concentration, which suggests the true parameter and the mode of the posterior satisfies
We provide an example in Appendix E.3 to show this assumption can be easily satisfied in practice. Let , then by Theorem 2 adapted to the MDP setting (i.e. with a change in notation), we have,
Note that and by design of Algorithm 3, . Combining the above results and Equation (23), we have
With all the above results, we are now ready to prove the main theorem for LPSRL with SGLD.
*
- Proof of Theorem 6.2
E.2.2 Simplex Parametrization
We now discuss the performance of LPSRL under simplex parametrization. Similar to the General Parameterization, the regret guarantee of LPSRL relies on the convergence guarantee of MLD, which is presented in the following theorem.
*
- Proof of Theorem 6.3
Instantiating Algorithm 3 with MLD provides the following statistical guarantee to control the approximation error in terms of the Wasserstein- distance.
Lemma E.6.
-
Proof of Lemma E.6
By Corollary E.1, in tabular settings, the error term in the Wasserstein- distance can be further decomposed in terms of state-action pairs, suggesting
Then by design of Algorithm 3, we have,
(27) where the first inequality follows from the fact that for any .
The convergence guarantee provided by Theorem 6.3 for MLD suggests, for each state-action pair , upon running MLD for iterations, where is the number of data available for at time , we have
(28) At time , let be the total number of available observations, which gives and . By design of Algorithm 3, . Then combining Equation (27) and (28) gives,
where the third inequality follows from the Cauchy-Schwarz inequality.
Lemma E.6 suggests the approximation error in the first term of Lemma E.2 can be effectively bounded when instantiating SamplingAlg with MLD.
Lemma E.7 (Concentration of MLD).
For any policy-switch , we run MLD (Algorithm 4) for each state-action pair at time for iterations. Then instantiating LPSRL with MLD guarantees that
-
Proof of Lemma E.7
By tower’s rule and the triangle inequality, we have
(29) where the last inequality follows from the fact that in tabular setting, .
With the concentration guarantee between sample and , as well as the concentration guarantee between and in exact PSRL, we are able to effectively upper bound the model estimation error in tabular settings.
Lemma E.8 (Bound in tabular settings).
With the definition of model estimation error in Lemma E.3, in tabular setting, the following upper bound holds for ,
| (31) |
where is the Lipschitz constant for transition dynamics.
-
Proof of Lemma E.8
By the triangle inequality and Lemma E.3,
(32) Bound The first term. The first term can be upper bounded using standard concentration results of exact PSRL algorithms in Bayesian settings. Define the event
(33) where is the empirical distribution at the beginning of policy switch , following Jaksch et al., (2010); Ouyang et al., (2017); Osband et al., (2013) by setting . Then event happens with probability at least . Note that for any vector x, , and by the triangle inequality, we have
At any time , for any state-action pair , and by the fact that , we have
(34) It then suffices to bound . Note that
(35) On the other hand, by definition of , , which yields
(36) Combining Equation (34), (35) and (36), we have,
(37)
Bound the second term. The second term arises from the use of approximate sampling. Note that by Cauchy–Schwarz inequality, this term in Equation (32) satisfies,
| (38) |
It then relies on the concentration guarantee provided by MLD for LPSRL under the static policy switch scheme. By Lemma E.7, we have,
| (39) |
With all the above results, we now proceed to prove the regret bound for LPSRL with MLD.
*
- Proof of Theorem 6.3
By Lemma E.2, E.6 and E.8, we have
By Lemma E.6, for each state-action pair and policy-switch , the number of iterations required for MLD is . This suggests that for each state-action pair, the total number of iterations required for MLD is along the time horizon . Summing over all possible state-action pairs, the computational cost of running MLD in terms of the total number of iterations is .
E.3 General Parameterization Example
Following Theocharous et al., 2017a ; Theocharous et al., 2017b we consider a points of interest (POI) recommender system where the system recommends a sequence of points that could be of interest to a particular tourist or individual. We will let the points of interest be denoted by points on . Following the perturbation model in Theocharous et al., 2017a ; Theocharous et al., 2017b , the transition probabilities are if the chosen action is and it is otherwise. Here is a state or a POI and . Furthermore, to fully specify we consider . One can see that Assumptions - are satisfied due to the Gaussian-like nature of the transition dynamics and the satisfiability of Assumption follows from Lemma 5 in Theocharous et al., 2017b .
Appendix F Experimental Details
F.1 Additional Discussions of Langevin TS in Gaussian Bandits




In this section, we present additional empirical results for the Gaussian bandit experiments. In particular, we examine both informative priors and uninformative priors for Gaussian bandits with arms, where each arm is associated with distinct expected rewards. We set the true expected rewards of all arms to be evenly spaced in the interval , and the ordering of values is shuffled before assigning to arms. All arms share the same standard deviation of . We investigate the performance of SGLD-TS against UCB1, Bayes-UCB, and exact-TS under different interaction schemes: fully-sequential mode, dynamic batch scheme, and static batch scheme.
In the first setting, we assume prior knowledge of the ordering of expected rewards and apply informative priors to facilitate the learning process. Gaussian priors are adopted with means evenly spaced in , and inverted variance (i.e., precision) set to . The priors are assigned according to the ordering of the true reward distributions. Note that the exact knowledge of the true expected values is not required. In TS algorithms, the selection of arms at each time step is based on sampled values, therefore efficient learning is essential even with the knowledge of the correct ordering. The expected regret of all methods is reported over 10 experiments and results are illustrated in Figure 2(a). Results of both Figure 1(a) and Figure 2(a) demonstrate that SGLD-TS achieves optimal performance similar to exact-TS with conjugate families. Its appealing empirical performance in comparison to other popular methods (e.g., UCB1 and Bayes-UCB), along with its ability to handle complex posteriors using MCMC algorithms, make it a promising solution for challenging problem domains. Additionally, the introduction of the dynamic batch scheme ensures the computational efficiency of SGLD-TS. As depicted in Figure 3(a)(b) and Table 2 (column labeled ”batches”), communication cost is significantly reduced from linear to logarithmic dependence on the time horizon, as suggested by Theorem 5.1. Furthermore, in bandit environments, our dynamic batch scheme exhibits greater robustness compared to the static batch scheme for both frequentist and Bayesian methods.
Furthermore, we explore the setting where prior information is absent, and uninformative priors are employed. In this case, we adopt the same Gaussian priors as for all arms. Similar to the first setting, the same conclusion can be drawn for SGLD-TS from Figure 2(b).
F.2 Experimental Setup for Langevin TS in Laplace Bandits
In order to demonstrate the performance of Langevin TS in a broader class of general bandit environments where closed-form posteriors are not available and exact TS is not applicable, we construct a Laplace bandit environment consisting of arms. Specifically, we set the expected rewards to be evenly spaced in the interval , and shuffle the ordering before assigning each arm a value. The reward distribution of each arm shares the same standard deviation of . We adopt favorable priors to incorporate the knowledge of the true ordering in Laplace bandits. It is important to note that our objective is to learn the expected rewards, and arm selection at each time step is based on the sampled values rather than the ordering. In particular, we adopt Gaussian priors with means evenly spaced in (ordered according to prior knowledge). The inverted variance (i.e., precision) for all Gaussian priors is set to . We conduct the experiments 10 times and report the cumulative regrets in Figure 1(b).
By employing Langevin TS in the Laplace bandit environment, we aim to showcase the algorithm’s effectiveness and versatility in scenarios where posteriors are intractable and exact TS cannot be directly applied.
F.3 Experimental Setup for Langevin PSRL
In MDP setting, we consider a variant of RiverSwim environment being frequently used empirically (Strehl and Littman,, 2008), in which the agent swimming in the river is modeled with five states, and two available actions: left and right. If the agent swims rightwards along the river current, the attempt to transit to the right is going to succeed with a large probability of . If the agent swims leftwards against the current, the transition probability to the left is small with . Rewards are zero unless the agent is in the leftmost state () or the rightmost state (). The agent is assumed to start from the leftmost state. We implement MLD-PSRL and exact-PSRL under two policy switch schemes, one is the static doubling scheme discussed in section 6, and the other is the dynamic doubling scheme based on the visiting counts of state-action pairs. To ensure the performance of TSDE, we adopt its original policy switch criteria based on the linear growth restriction on episode length and dynamic doubling scheme. We run experiments times, and report the average rewards of each method in Figure 1(c). The number of policy switches under different schemes is depicted in Figure 4.