\ul
Knowledge Graph Context-Enhanced Diversified Recommendation
Abstract.
The field of Recommender Systems (RecSys) has been extensively studied to enhance accuracy by leveraging users’ historical interactions. Nonetheless, this persistent pursuit of accuracy frequently engenders diminished diversity, culminating in the well-recognized ”echo chamber” phenomenon. Diversified RecSys has emerged as a countermeasure, placing diversity on par with accuracy and garnering noteworthy attention from academic circles and industry practitioners. This research explores the diversified RecSys within the intricate context of knowledge graphs (KG). These KGs act as repositories of interconnected information concerning entities and items, offering a propitious avenue to amplify recommendation diversity through the incorporation of insightful contextual information. Our contributions include introducing an innovative metric, Entity Coverage, and Relation Coverage, which effectively quantifies diversity within the KG domain. Additionally, we introduce the Diversified Embedding Learning (DEL) module, meticulously designed to formulate user representations that possess an innate awareness of diversity. In tandem with this, we introduce a novel technique named Conditional Alignment and Uniformity (CAU). It adeptly encodes KG item embeddings while preserving contextual integrity. Collectively, our contributions signify a substantial stride towards augmenting the panorama of recommendation diversity within the KG-informed RecSys paradigms. We release the code at https://github.com/Xiaolong-Liu-bdsc/KG-diverse.
1. Introduction
Recommender system (RecSys) has emerged as a vital solution for mitigating information overload in the contemporary landscape of extensive data (Mayer-Schönberger and Cukier, 2013). RecSys acquires the underlying preference by gaining insights from historical user-item interactions (Liu et al., 2023; Yang et al., 2023b). Subsequently, it offers personalized suggestions from a pool of potential items. Its pervasiveness is evident across multiple facets of our quotidian existence, encompassing domains such as news feeds (Wu et al., 2019), cinematic suggestions (Gomez-Uribe and Hunt, 2015), and e-commerce recommendation (Schafer et al., 2001).
Predominantly driven by the imperative of accuracy, commercial entities (Cheng et al., 2016; Gomez-Uribe and Hunt, 2015; Ying et al., 2018; Liu et al., 2022; Li et al., 2023; Wang et al., 2023b, 2022c, a) have endeavored to construct intricate algorithms. These algorithms predict the item that most likely engages each user, predicated upon their historical interactions. The mechanisms (Zhou et al., 2010) striving for a balance between accuracy and diversity have been developed to address this issue. This deficiency in diversity results in the echo chamber or filter bubble phenomenon (Ge et al., 2020), where users are repeatedly exposed to content aligning with their preferences, limiting their exposure to diverse options.
The paradigm of Diversified Recommender Systems (Diversified RecSys) has emerged to counteract the aforementioned constraints by actively prioritizing diversity during the recommendation process (Zheng et al., 2021; Yang et al., 2023c). These systems incite users to embark upon a broader exploration of choices. Consequently, users are enabled to encounter novel items and potentially discover items of interest that might have otherwise eluded their attention. Diversified RecSys has garnered escalating scholarly and industrial attention (Zheng et al., 2021; Yang et al., 2023c; Cheng et al., 2017; Chen et al., 2018a). Given the inherent conundrum between diversity and accuracy (Zhou et al., 2010), these systems are geared towards optimizing diversity while keeping the compromise on accuracy to a minimum, thus yielding an improved trade-off. Current methods gauge diversity through the lens of item categorization attributes, such as category coverage (Zheng et al., 2021; Yang et al., 2023c; Chen et al., 2018a). This approach primarily operates at a coarse-grained categorical level, thereby exhibiting limitations in comprehensively assessing diversity. It can not adequately discriminate between recommending items from within the same category. For example, recommending both (”iPhone 14” and ”Galaxy S23”) and (”iPhone 14” and ”iPhone 14 Pro”) yields identical diversity outcomes due to their shared electronic category, which falls short of a comprehensive measure for diversification.
To cope with this, we delve into the diversified RecSys under the knowledge graphs (KG) framework. Extensive literature has been published on recommender systems that incorporate KG (Wang et al., 2019; Yang et al., 2022; Wang et al., 2021a, 2023c). To diversify RecSys, a primary focal point of this investigation revolves around the nuanced integration of knowledge graphs. This entails leveraging the intricate details within the knowledge graph. To illustrate this, consider the previous example. In this context, a recommendation such as (”iPhone 14,” ”Galaxy S23”) acquires heightened diversification by enlisting entities encompassing not only the specific products but also broader contextual elements, including nations (”United States,” ”Korea”), manufacturers (”Apple,” ”Samsung”), and operating systems (”iOS,” ”Android”), all drawn from the encompassing knowledge graph. As a result, users are endowed with an augmented sphere of exposure to a diverse spectrum of entities, thereby enriching their engagement through the recommended selections.
Effective enhancement of recommendation diversity through incorporating KG information presents several pivotal challenges that merit careful consideration. (1) Actively prioritizing diversity during the recommendation process with KG: The intrinsic nature of KG structures poses a distinctive predicament where KG entities do not directly encapsulate user attributes. This inherent disconnect consequently engenders a deficiency in accurately representing user embeddings derived from KG information. Consequently, proficiently depicting and diversifying user embeddings using KG data constitutes a significant challenge. (2) Striking a Balance between Accuracy and Diversity: Higher accuracy often comes at the cost of reduced diversity. For all diversified RecSys, the inherent challenge lies in attaining elevated diversity without compromising recommendation accuracy. (3) Inadequate Characterization of Item KG Context Similarity: Present methodologies (Wang et al., 2019, 2021a, 2022a) exhibit limitations in the robust encoding of item KG context similarity. This deficiency impairs the capacity to comprehensively discern item similarity from the vantage point of the KG. The apt assessment of item similarity within the KG milieu bears particular significance when striving to impart diversity to recommendations.

In this study, we introduce a novel framework, denoted as KG-Diverse, aimed at addressing the aforementioned challenges. The cornerstone of our approach involves the formulation of two comprehensive metrics for gauging recommendation diversity within Knowledge Graphs (KGs): (1) Entity Coverage (EC) and (2) Relation Coverage (RC). These metrics assess the extent to which recommended items encapsulate a wide array of entities and relations within the KG context. To illustrate the practical implications of our proposed metrics, consider the scenario depicted in Figure 1, wherein a user’s viewing history encompasses the film The Avengers. A conventional RecSys would potentially propose Captain America 3 owing to the shared lead actors Chris Evans and Robert Downey Jr. with The Avengers, thus highlighting a thematic relevance. However, the introduction of diversified recommendations such as the film Dolittle, notable for its comedic genre and featuring actor Robert Downey Jr., or the movie Before We Go, notable for actor Chris Evans assuming both acting and directorial roles, serves to introduce elements of entity and relation diversification, respectively. Such nuanced recommendations contribute to a more holistic and enriching user experience. Consequently, we proceed to present an innovative module coined the Diversified Embedding Learning (DEL) module. This module is thoughtfully devised to engender personalized user representations imbued with an awareness of diversity, thereby fostering the augmentation of recommendation diversity without compromising recommendation accuracy. The underpinning of effective KG embedding learning is fundamentally pivotal for diversification. In response, we proffer a novel strategy labeled ”conditional alignment and uniformity.” This strategy is meticulously designed to uphold the integrity of KG embeddings and preserve the intrinsic similarity between items that share common entities. This dual-pronged approach ensures both the quality of KG embeddings and the coherence of item similarity within the KG context. Our contributions are summarized as follows:
-
•
To the best of our knowledge, this paper firstly introduces the novel measurement of recommendation diversity in KG through the use of Entity Coverage and Relation Coverage metrics.
-
•
We propose a simple yet effective Diversified Embedding Learning module to generate diversity-aware representations for users. Additionally, we design a novel technique, conditional alignment and uniformity, to effectively encode item embeddings in KG.
-
•
We evaluate the recommendation performance of our method on three public datasets. The extensive experimentation validates the effectiveness of our proposed model, showing the significance of each module in augmenting diversity while incurring only a negligible decrease in the accuracy of recommendations.
2. Methodology
The overall architecture of the proposed KG-Diverse is displayed in Figure 2, including knowledge graph propagation, diversified embedding learning and conditional alignment.
2.1. PROBLEM FORMULATION
We introduces the two data structures: user-item interaction graph, knowledge graph and the formulated problem.
User-Item interactions graph. We consider a collection of users denoted as , and a set of items represented by , where and correspond to the number of users and items, respectively. We establish a user-item bipartite graph , where denotes the node set, and represents the edge set. An edge signifies that the user purchased the item before.
Knowledge graph. Knowledge graph is defined as , where each triplet represents a relation from the head entity to the tail entity . Here, and represent the sets of entities and relations within KG, respectively. Notably, the entity set comprises both items () and non-item entities ().
Task Description. Given the and , the goal of knowledge-aware recommendation is to recommend top items to each user. Moreover, the diversified recommendation task in KG encourages more entities (or relations) covered by recommended items.

2.2. Item entity-aware representation via Knowledge Graph propagation
KG is a multi-relational graph comprising entities and relations, denoted by a set of triplets, i.e., . To facilitate understanding, we denote to represent the corresponding relations and entities connected to the item . A single entity may participate in multiple KG triplets, and it possesses the ability to adopt the linked entities as its attributes, thus revealing content similarity among items. Take an example in Figure 1, the star Chris Evans involves in multiple KG triplets, i.e., (actor, The Avengers), (actor, Before We Go), and (director, Before We Go). Then, we perform an aggregation technique to integrate the semantic information from to generate the representation of item :
| (1) |
where and represent the embedding of item and entity after layers aggregation respectively, and is the embedding of relation . is the aggregated representation obtained by which is the aggregation function that integrates information from ego-network of item . Regarding the function , prior research efforts (Wang et al., 2019) predominantly focus on incorporating the relation solely into the weight factors during propagation. Nevertheless, it is vital to acknowledge that the combination of connected relation and entity holds distinct contextual implications. For instance, consider the star Chris Evans, who is linked twice to the film Before We Go in KG triplets, each time in a different role (director and actor). To address this contextual difference effectively, it becomes imperative to integrate relational contexts into the aggregator . It not only facilitates discerning the diverse effects of relational nuances but also augments the overall diversity of relations within the model. Therefore, we model the relation into the aggregation function following (Wang et al., 2021a):
| (2) |
where is the element-wise product. The relational message is propagated by modeling the relation as either a projection or rotation operator (Sun et al., 2019). This design allows the relational message to effectively unveil distinct meanings inherent in the triplets.
2.3. Diversified Embedding Learning
After obtaining item embedding representation from -th layer of knowledge graph, we leverage it to generate diversified user embedding. We denote to represent the ’s interacted items. Then, we formulate the temporary user representation by applying mean pooling on the interacted items:
| (3) |
In this way, the user representation is expressed by the representation of adopted items. The motivation of conventional RecSys revolves around aligning the representations of users and their purchased items. For example, in the left part of Figure 2, the user interacted with , , and . A common approach involves driving the vector representation of user to approximate the vectors of items and , as these two items display high similarity due to their overlapping connections on the KG. However, it localizes the representation of in the surrounding area of and with their connected entities in KG (i.e., , , and ), which makes it hard to be exposed to the diverse items and entities around (i.e., and ). Hence, we devise the user diversified embedding learning layer with the intent of liberating the user representation from localization constraints and fostering diversity. The temporary user representation , where temp is short for temporary, is utilized to measure the dissimilarities with in the -th layer:
| (4) | |||
| (5) |
Here, we utilize the Euclidean distance to compute dissimilarity, as it serves as a reliable measure to gauge the level of diversity. A higher distance value implies a greater potential for diversity in the resulting outcomes. The abundance of similar items may confine the user representation, resulting in a resemblance to these item representations. To counteract this, we mitigate the issue while preserving the intrinsic preference by generating diversity-aware embedding for the user through the following step:
| (6) |
Consequently, the user representation is emancipated from the constraints of localization, which often result from an abundance of similar items. For instance, will be compelled to distance itself from and , while drawing nearer to , thereby facilitating access to novel entities and items (e.g., and ). Moreover, stacking multiple layers has been empirically demonstrated to effectively exploit high-order connectivity (Wang et al., 2019, 2021a). Therefore, the can capture diverse information from -hop neighbors of linked items, thereby enhancing exposure to diverse entities explicitly. We further sum up the embeddings obtained at each layer to form the final user and item representation, respectively:
| (7) |
where is the number of knowledge graph propagation layers.
2.4. Conditional Alignment and Uniformity
To effectively encode KG in RecSys, we design a novel conditional alignment on KG entity embedding to preserve the semantic information between two similar items. Consider item and item , both sharing the entities and . Rather than a straightforward alignment (Wang et al., 2022b; Yang et al., 2023a), the item representations and should be aligned based on the shared information of entity representations and . We define conditional embedding as follows:
| (8) |
where is the set of entities shared by item and item in KG and is the average embedding of the overlapping entities between item and item . After modeling the overlapping entities as the projection or rotation on two items, we then perform the alignment loss:
| (9) |
This design plays an essential role in pulling two similar items closer according to their connectivity on KG. Furthermore, the uniformity loss (Yu et al., 2022) is also applied to scatter the embedding uniformly:
| (10) |
2.5. Model Prediction
After performing propagation layers in KG, we further employ convolutional operation to capture collaborative signals from user-item interaction. Due to the effectiveness and simple architecture of LightGCN (He et al., 2020), where feature transformation and activation function are removed, we adopt its Light Graph Convolution layer (LGC) to encode the collaborative signals from user-item interactions:
| (11) |
where and are the embedding of user and item at the -th LGC layer, respectively. Meanwhile, and are the embedding obtained by Eq. 7. Following layers of propagation, we integrate the embeddings acquired at each layer into the ultimate embeddings for both users and items:
| (12) |
The embeddings produced by different LGC layers stem from distinct receptive fields, which also facilitates diversity from high-order neighbors. We choose the BPR loss (Rendle et al., 2012) for the optimization:
| (13) |
where . is the set of unobserved interactions, and the is sampled from items that user has not interacted. Finally, the overall loss function is defined as:
| (14) |
where and decide the weight of alignment and uniformity loss, respectively, and denotes the parameter regularizing factor.
3. Experiments
This section aims to answer the 3 research questions (RQ).
-
•
RQ1: How does KG-Diverse perform compared to other state-of-the-art recommendation methods?
-
•
RQ2: Does every designed module play a role in KG-Diverse?
-
•
RQ3: What are the impacts of hyper-parameters: KG propagation layers , alignment weight , and uniformity weight ?
3.1. Experimental Settings
3.1.1. Datasets
To evaluate the effectiveness of our KG-Diverse against other baseline models, we perform experiments on three benchmark datasets: Amazon-book 111http://jmcauley.ucsd.edu/data/amazon/, Last-fm 222https://grouplens.org/datasets/hetrec-2011, and Movielens 333https://grouplens.org/datasets/movielens/, which are widely used in previous works (Wang et al., 2019, 2021b, 2023c; He and McAuley, 2016). To ensure the quality of user-item interactions, the 10-core setting (preserve the users who have at least ten interactions) was adopted on all datasets as previous research. We partitioned the historical interactions of each user into three sets: training (80%), validation (10%), and test (10%). Table 1 presents detailed statistics for these datasets.
| Dataset | Amazon-Book | Last.FM | Movielens |
| #Users | 70,679 | 1,872 | 37,385 |
| #Items | 24,915 | 3,846 | 6,182 |
| #Interactions | 846,434 | 42,346 | 539,300 |
| #Entities | 113,487 | 9,366 | 24,536 |
| #Relations | 39 | 60 | 20 |
| #Triplets | 2,557,746 | 15,518 | 237,155 |
3.1.2. Baselines
We compare KG-Diverse with several representative methods as baselines:
(1) General Recommender Systems
(2) Knowledge Graph for Recommendation
-
•
KGAT (Wang et al., 2019) utilizes an attention mechanism to discriminate the entity importance in KG during recursive propagation.
-
•
KGIN (Wang et al., 2021a) uncovers the users’ intents via the attentive combination of relations in KG and utilizes relational path-aware aggregation to refine user/item representations.
(3) Diversified Recommender Systems
-
•
DGCN (Zheng et al., 2021) is the GNN-based method for diversified recommendation with rebalanced neighbor and adversarial learning.
-
•
DGRec (Yang et al., 2023c) is the current state-of-the-art diversified RecSys model based on GNN. It designs the submodular function to select a diversified neighbors to enhance diversity.
3.1.3. Evaluation Metrics
In our experiments, we evaluate accuracy and diversity, respectively.
Accuracy. We use Recall@k (R@k) and NDCG@k (N@k) (Krichene and Rendle, 2020) with k ranges in {20, 40} to evaluate the performance of the top-k recommendation. The average metrics of all test users are reported.
Diversity. Some studies (Gan et al., 2020; Wu et al., 2022) employ the ILAD metric to quantify diversity based on dissimilarities among recommended items, yet its effectiveness heavily relies on the quality of learned embedding. For assessing the diversity of recommendations on KG, we establish two metrics on KG: (1) Entity Coverage (EC) and (2) Relation Coverage (RC). Entity/Relation Coverage refers to the number of entities/relations the recommended itemsets cover. We report top-20 and top-40 retrieval results to accord with accuracy.
3.2. Performance Comparison (RQ1)
| Datasets | Methods | Accuracy | Diversity | ||||||
| R@20 | R@40 | N@20 | N@40 | EC@20 | EC@40 | RC@20 | RC@40 | ||
| Amazon- Book | MF | 0.0999 | 0.1431 | 0.0524 | 0.0634 | 63.1383 | 97.2867 | 20.2529 | 21.5524 |
| LightGCN | 0.1090 | 0.1647 | 0.0558 | 0.0699 | 64.1135 | 95.1836 | 19.9618 | 21.8544 | |
| DirectAU | 0.1225 | 0.1716 | 0.0650 | 0.0776 | 48.0056 | 73.0553 | 18.0014 | 20.0823 | |
| KGAT | 0.1245 | 0.1846 | 0.0620 | 0.0773 | 52.4172 | 79.2991 | 18.4723 | 20.5078 | |
| KGIN | 0.1281 | 0.1817 | 0.0673 | 0.0809 | 50.2582 | 75.2091 | 18.3580 | 20.2204 | |
| DGCN | 0.0805 | 0.1285 | 0.0407 | 0.0528 | 56.1095 | 84.3621 | 19.6098 | 21.5630 | |
| DGRec | 0.0920 | 0.1414 | 0.0458 | 0.0584 | 65.2395 | 97.5764 | 20.1816 | 21.9992 | |
| KG-Diverse | 0.1071 | 0.1621 | 0.0547 | 0.0687 | 67.8613 | 101.1123 | 20.5630 | 22.5242 | |
| Last.FM | MF | 0.3292 | 0.4395 | 0.1802 | 0.2056 | 68.2359 | 122.5158 | 11.5179 | 14.3109 |
| LightGCN | 0.3685 | 0.4719 | 0.2016 | 0.2257 | 67.0864 | 117.2707 | 10.6190 | 13.4332 | |
| DirectAU | 0.3379 | 0.4349 | 0.1780 | 0.2005 | 60.4386 | 108.7641 | 8.8190 | 11.8342 | |
| KGAT | 0.3334 | 0.4373 | 0.1818 | 0.2057 | 66.2712 | 118.7859 | 11.1397 | 14.0098 | |
| KGIN | 0.3415 | 0.4537 | 0.1635 | 0.1895 | 66.1098 | 117.9679 | 11.8299 | 14.5141 | |
| DGCN | 0.2430 | 0.3474 | 0.1242 | 0.1482 | 59.8146 | 114.2739 | 10.7978 | 13.8157 | |
| DGRec | 0.2602 | 0.3618 | 0.1294 | 0.1529 | 60.5130 | 111.8712 | 11.1902 | 14.1957 | |
| KG-Diverse | 0.3539 | 0.4716 | 0.1785 | 0.2059 | 87.2005 | 154.7543 | 13.9125 | 16.6293 | |
| Movielens | MF | 0.4065 | 0.5297 | 0.2187 | 0.2490 | 454.3015 | 805.9360 | 17.1941 | 17.3594 |
| LightGCN | 0.4157 | 0.5462 | 0.2236 | 0.2557 | 452.7703 | 803.3682 | 17.1809 | 17.3426 | |
| DirectAU | 0.4077 | 0.5256 | 0.2257 | 0.2547 | 441.1399 | 790.9293 | 17.2679 | 17.4271 | |
| KGAT | 0.4097 | 0.5340 | 0.2228 | 0.2533 | 444.9880 | 792.5169 | 17.2219 | 17.3757 | |
| KGIN | 0.4374 | 0.5669 | 0.2386 | 0.2705 | 447.2437 | 797.7831 | 17.1909 | 17.3531 | |
| DGCN | 0.3625 | 0.4941 | 0.1874 | 0.2198 | 444.5471 | 799.3097 | 17.2358 | 17.4053 | |
| DGRec | 0.3676 | 0.4981 | 0.1917 | 0.2238 | 445.0291 | 798.6214 | 17.2310 | 17.3980 | |
| KG-Diverse | 0.4132 | 0.5425 | 0.2241 | 0.2559 | 458.8848 | 815.3123 | 17.1993 | 17.3710 | |
3.2.1. Parameter Setting
We implement KG-Diverse and all baselines on Pytorch with Adam (Kingma and Ba, 2015) as the optimizer. We train each model until there is no performance improvement on the validation set within 10 epochs. Following the setting of KGAT (Wang et al., 2019), we fix the embedding size to 64 for all models. Grid search is performed to tune the hyper-parameters for each method. The model parameters are initialized by Xavier initializer. For KGAT, the pre-trained MF embeddings of users and items are used for initialization.
Specifically, the learning rate and weight decay are tuned in {0.1, 0.05, 0.01, 0.005, 0.001} and {1e-4, 1e-5, 1e-6, 1e-7} respectively. The number of KG layers and LightGCN layers are searched with the range of {1, 2, 3, 4, 5, 6}. Finally, we tune the coefficients of alignment and uniformity among {0.1, 0.2, …, 1.0} with increment of 0.1.
We report the overall performance of all baselines on the three datasets in Table 2. We have the following observations:
-
•
KG-Diverse outperforms all the other baselines on diversity metric: Entity Coverage (EC) and Relation Coverage (RC) except the RC on Movielens dataset. However, all the performances on RC of Movielens dataset are almost the same, making models indistinguishable with each other regards RC.
-
•
Despite achieving the highest Entity Coverage, KG-Diverse shows comparable performance on Recall and NDCG metrics, particularly attaining the second-best results on Last.FM and exhibiting similarity to the second-best LightGCN on MovieLens dataset. This observation indicates that KG-Diverse effectively enhances diversity while incurring a minimal cost to accuracy, thereby striking a well-balanced accuracy-diversity trade-off.
-
•
DGRec is the state-of-the-art diversified RecSys that models diversity at the coarse-grained category information. Our model, by consistently outperforming DGRec across three datasets in all measures, especially on Last.FM, demonstrates the efficacy of modeling diversity at the fine-grained level of KG entities. It enables accurate recommendations and facilitates the provision of diverse and relevant information to a significant extent.
-
•
In contrast to general accuracy-based methods (MF, LightGCN, and DirectAU), KG-Diverse exhibits superior enhancements in diversity metrics while maintaining comparable performance in accuracy metrics. This observation serves as a testament to the model’s effective capability in encoding KG.
To be more specific, Figure 3 illustrates the accuracy-diversity trade-off comparison of all models on Last-FM datasets, where Recall@40 and EC@40 measure accuracy and diversity, respectively. It is evident from the plot that KG-Diverse occupies the most favorable position in the upper-right quadrant, demonstrating that KG-Diverse achieves the optimal accuracy-diversity trade-off. Our model KG-Diverse outperforms all other baselines in both accuracy and diversity metrics except LightGCN. When compared to LightGCN, KG-Diverse exhibits a substantial increase in diversity while making only a minor sacrifice in accuracy.
3.3. Ablation Study (RQ2)

We explore the effects of each module in KG-Diverse on the Amazon-book dataset, including (1) KG propagation layer for item representation learning, (2) Relation encoding into item representation in Eq. 2, (3) Diversified Embedding Learning (DEL) module in generating user diversity-aware representations, and (4) Conditional Alignment and Uniformity (CAU) that regularizes KG embedding learning. The results are shown in Table 3:
-
•
After removing the KG propagation layer, the knowledge within entities and relations will not be incorporated to enrich the item representations, and there is a single layer to generate user diversified representation without KG. Even though there are 2.7% and 5.5 % improvements on R@20 and N@20, respectively, the performance on EC@20 decreased by 7.1%. It shows the effectiveness of learning entity-aware item representation via Eq. 2.
-
•
Upon removing relation encoding, the item representation in -th layer is obtained by averaging the embeddings of its connected entities in the previous layer. The results indicate significant decreases in all evaluation metrics, particularly a 5.9% drop in RC@20. It indicates the crucial role of relations in enriching item representations. The presence of relations in the encoding process allows the model to capture and leverage the semantic connections between items and entities, contributing to more accurate and diverse recommendations.
-
•
In the -th KG propagation layer, the user diversity-aware embedding in Eq. 6 is replaced by in Eq. 3 if DEL is removed. The declines in all four metrics: R@20 decreased by 4.3%, N@20 decreased by 7.0%, EC@20 decreased by 3.4%, and RC@20 decreased by 2.1%, underscores our model’s advantage in enabling user representations to transcend localization constraints.
-
•
Without conditional alignment and uniformity, there are substantial drops in R@20, N@20, and EC@20 metrics. This underscores the crucial role played by the regularization on KG embedding learning, as it serves as the foundational prerequisite for KG application. We find that the similarity and distinctions among items in the KG significantly influence the overall framework.
| Method | R@20 | N@20 | EC@20 | RC@20 |
| KG-Diverse | 0.1071 | 0.0547 | 67.8613 | 20.5630 |
| w/o KG propagation layer | 0.1101 | 0.0577 | 63.3891 | 20.1389 |
| w/o Relation encoding | 0.0902 | 0.0452 | 66.4480 | 19.4177 |
| w/o DEL | 0.1027 | 0.0511 | 65.6006 | 20.3592 |
| w/o CAU | 0.0929 | 0.0456 | 64.7545 | 20.2670 |
3.4. Parameter Sensitivity (RQ3)
Additional exploratory experiments are conducted to comprehensively understand the KG-Diverse structure and investigate the underlying reasons for its effectiveness. We explore the effects of four essential hyper-parameters in KG-Diverse on Last.FM dataset, including the number of KG propagation layers , the coefficient on alignment loss, and the weight decay on uniformity loss.
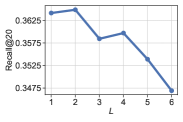
3.4.1. Number of KG propagation layers
We vary the number of KG propagation layers in the range of {1, 2, 3, 4, 5, 6} to analyze its influence in our model. The two line plots reveal a clear trend: as the depth of KG propagation layers increases, the entity coverage steadily improves, reaching its peak at a depth of 5, and subsequently exhibits a decline. This trend signifies that the stacking of multiple KG layers aids item representations in capturing high-order connectivity among entities, thereby encoding a diverse range of entities within the item representations, as depicted in Equation 2. In contrast, the accuracy metric (Recall) exhibits a consistent downward trend as the depth increases. It may be attributed to the over-smooth problem (Liu et al., 2020), where the item embeddings become overly similar, negatively impacting the accuracy.





3.4.2. Coefficient on alignment loss
. The introduction of this coefficient aims to govern the weight of aligning item embeddings in the Knowledge Graph (KG). By adjusting the value of , KG-Diverse becomes more attentive to aligning similar item representations, especially when two items share common entities in the KG. As demonstrated in Figure 4, the substantial enhancements observed in both Recall and Entity Coverage metrics serve as tangible evidence of the notable efficacy of conditional alignment in effectively encoding KG embeddings. As similar items are successfully aligned, KG-Diverse could easily retrieve the items that cover different and diverse entities.
3.4.3. Weight decay on uniformity
. The incorporation of uniformity in KG-Diverse serves the purpose of dispersing the item representations learned from the KG, preventing them from becoming identical and promoting diversity among the representations. Our observations indicate that both accuracy and diversity exhibit an upward trend, achieving their optimal performance when the value of is approximately 0.4. Nonetheless, as increases further, the results for Recall and Entity Coverage witness a rapid decline. This analysis leads us to the conclusion that a larger weight assigned to uniformity would promote more uniform embedding dispersal and potentially deteriorate KG alignment. However, a lighter emphasis on uniformity can still yield beneficial effects on the encoding of KG embeddings to some extent.
3.5. Case Study
In this case study, we randomly selecte a user, , from the Amazon-book dataset to compare the entity and relation coverages of two recommendation models: KGIN and KG-Diverse. The visualization of their performance comparison is illustrated in Figure 5. From both models, we retrieved the top-5 recommendations for , with being common items recommended by both models. To simplify the analysis, we focus on two distinct recommended items: from KGIN and from KG-Diverse. We have the following observations:
-
•
The item with the name The Affair covers only a few entities and relations, namely = ((Genre, Noval), (Author, Lee Child)). Remarkably, the item recommended by our model, KG-Diverse, also includes these two pairs of entities and relations. It exemplifies the strong relevance and effectiveness of KG-Diverse in providing relevant recommendations.
-
•
In addition to the strong relevance, the item titled Echo Burning covers a significantly broader range of entities and relations in the KG compared to . The entities and relations covered by include (Genre, Suspense), (Genre, Fiction), (Subjects, Adventure), (Subjects, Texas). It underscores the substantial capacity of KG-Diverse in enhancing the diversity of recommendations. By recommending items like Echo Burning, which encompass a wide variety of entities and relations, KG-Diverse successfully introduces diversity and enriches the user experience by offering a more varied and engaging selection of recommendations.


4. Related Works
4.1. Knowledge Graph for Recommendation
CKE (Zhang et al., 2016) model enriches the item representation by incorporating (1) structural embedding learned from items’ structural knowledge via TransR, (2) textual and visual representations extracted by applying two different auto-encoders on textual and visual knowledge separately. DKN (Wang et al., 2018), a news recommendation model, fuses semantic-level and knowledge-level information to news embedding by a multi-channel and word-entity-aligned knowledge-aware convolutional neural network (KCNN) (Kim, 2014). The user’s vector is aggregated from the attention-weighted sum of news he/she clicked. KGIN (Wang et al., 2021a) models a finer-grained level of each intent by a combination of KG relations and designs a relational path-aware aggregation scheme that integrates information from high-order connectivities. KGAT (Wang et al., 2019) is designed to update embeddings by recursive propagation to capture high-order connectivities and compute the attention weights of a node’s neighbors which aggregate information from high-order relations during propagation. KGCL (Yang et al., 2022) defines knowledge graph structure consistency score to identify items less sensitive to structure variation and tolerate noisy entities in KG. MetaKRec (Wang et al., 2022a) extracts KG triples into direct edges between items via prior knowledge and achieves improved performance with graph neural network.
While the mentioned works primarily concentrate on enhancing the accuracy of recommendations by leveraging KG, our work distinguishes itself by focusing on elevating the diversity of recommendations at a fine-grained level while ensuring accuracy.
4.2. Diversified Recommendation
Diversified recommendation technique is used to provide users with a diverse set of recommendations rather than a narrow set of highly similar items. The concept of diversified recommendation was first proposed by Ziegler et al. (Ziegler et al., 2005). They performed a greedy algorithm to retrieve the diversified top-K items. DUM (Ashkan et al., 2015) designs the submodular function to select items by a greedy method and balance the utility of items and diversity in the re-ranking procedure. Determinantal point process (DPP) (Chen et al., 2018b), a post-processing method, retrieves the set of diverse items depending on the largest determinant of the item similarity matrix with MAP inference. DGCN (Zheng et al., 2021) stands as the initial diversified recommendation approach based on GNNs. It adopts the inverse category frequency to select node neighbors for diverse aggregation and employs category-boosted negative sampling and adversarial learning to enhance item diversity within the embedding space. DGRec (Yang et al., 2023c) is the current state-of-the-art model that produces varied recommendations through an enhanced embedding generation process. The proposed modules (i.e., submodular neighbor selection, layer attention, and loss reweighting) collectively aim to boost diversity without compromising accuracy. DivKG (Gan et al., 2020) learns knowledge graph embeddings via TransH (Wang et al., 2014) and designs a DPP kernel matrix to ensure the trade-off between accuracy and diversity. EMDKG (Gan et al., 2021) encodes the diversity into item representations by an Item Diversity Learning module to reflect the semantic diversity from KG.
The previous works study diversity as the covered categories, which is measured at the coarse-grained level. This paper first investigates the fine-grained diversity with KG context information.
5. Conclusion
In this paper, we design a straightforward and effective framework named KG-Diverse to enhance the diversity of recommendations with the rich information from KG. It first adopts the KG propagation method to incorporate semantic information into item representations. Then, we propose a diversified embedding learning module to generate diversity-aware embedding for users. Finally, we design Conditional Alignment and Uniformity to effectively encode the KG to preserve the similarity between two items with shared entities. Furthermore, we introduce Entity Coverage (EC) and Relation Coverage (RC) to measure the diversity in KGs and evaluate the final performance. Extensive experiments on three public datasets demonstrate the effectiveness of KG-Diverse in balancing the accuracy and diversity trade-off.
Acknowledge
Hao Peng is supported by National Key R&D Program of China through grant 2022YFB3104700, NSFC through grants 62322202, U21B2027, 62002007, 61972186 and 62266028, Beijing Natural Science Foundation through grant 4222030, S&T Program of Hebei through grant 21340301D, Yunnan Provincial Major Science and Technology Special Plan Projects through grants 202302AD080003, 202202AD080003 and 202303AP140008, General Projects of Basic Research in Yunnan Province through grants 202301AS070047, 202301AT070471, and the Fundamental Research Funds for the Central Universities. This work is supported in part by NSF under grant III-2106758.
References
- (1)
- Ashkan et al. (2015) Azin Ashkan, Branislav Kveton, Shlomo Berkovsky, and Zheng Wen. 2015. Optimal Greedy Diversity for Recommendation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, IJCAI 2015, Buenos Aires, Argentina, July 25-31, 2015, Qiang Yang and Michael J. Wooldridge (Eds.). AAAI Press, 1742–1748.
- Chen et al. (2018a) Laming Chen, Guoxin Zhang, and Eric Zhou. 2018a. Fast greedy map inference for determinantal point process to improve recommendation diversity. Advances in Neural Information Processing Systems 31 (2018).
- Chen et al. (2018b) Laming Chen, Guoxin Zhang, and Eric Zhou. 2018b. Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (Eds.). 5627–5638.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
- Cheng et al. (2017) Peizhe Cheng, Shuaiqiang Wang, Jun Ma, Jiankai Sun, and Hui Xiong. 2017. Learning to recommend accurate and diverse items. In Proceedings of the 26th international conference on World Wide Web. 183–192.
- Gan et al. (2020) Lu Gan, Diana Nurbakova, Léa Laporte, and Sylvie Calabretto. 2020. Enhancing Recommendation Diversity using Determinantal Point Processes on Knowledge Graphs. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 2001–2004.
- Gan et al. (2021) Lu Gan, Diana Nurbakova, Léa Laporte, and Sylvie Calabretto. 2021. EMDKG: Improving Accuracy-Diversity Trade-Off in Recommendation with EM-based Model and Knowledge Graph Embedding. In WI-IAT ’21: IEEE/WIC/ACM International Conference on Web Intelligence, Melbourne VIC Australia, December 14 - 17, 2021, Jing He, Rainer Unland, Eugene Santos Jr., Xiaohui Tao, Hemant Purohit, Willem-Jan van den Heuvel, John Yearwood, and Jie Cao (Eds.). ACM, 17–24.
- Ge et al. (2020) Yingqiang Ge, Shuya Zhao, Honglu Zhou, Changhua Pei, Fei Sun, Wenwu Ou, and Yongfeng Zhang. 2020. Understanding echo chambers in e-commerce recommender systems. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 2261–2270.
- Gomez-Uribe and Hunt (2015) Carlos A Gomez-Uribe and Neil Hunt. 2015. The netflix recommender system: Algorithms, business value, and innovation. ACM Transactions on Management Information Systems (TMIS) 6, 4 (2015), 1–19.
- He and McAuley (2016) Ruining He and Julian McAuley. 2016. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In proceedings of the 25th international conference on world wide web. 507–517.
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yong-Dong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, SIGIR 2020, Virtual Event, China, July 25-30, 2020, Jimmy X. Huang, Yi Chang, Xueqi Cheng, Jaap Kamps, Vanessa Murdock, Ji-Rong Wen, and Yiqun Liu (Eds.). ACM, 639–648.
- Kim (2014) Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL, Alessandro Moschitti, Bo Pang, and Walter Daelemans (Eds.). ACL, 1746–1751.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, Yoshua Bengio and Yann LeCun (Eds.).
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net.
- Koren et al. (2009) Yehuda Koren, Robert M. Bell, and Chris Volinsky. 2009. Matrix Factorization Techniques for Recommender Systems. Computer 42, 8 (2009), 30–37.
- Krichene and Rendle (2020) Walid Krichene and Steffen Rendle. 2020. On Sampled Metrics for Item Recommendation. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). ACM, 1748–1757.
- Li et al. (2023) Xiaohan Li, Yuqing Liu, Zheng Liu, and Philip S. Yu. 2023. Time-aware Hyperbolic Graph Attention Network for Session-based Recommendation. CoRR abs/2301.03780 (2023).
- Liu et al. (2020) Meng Liu, Hongyang Gao, and Shuiwang Ji. 2020. Towards Deeper Graph Neural Networks. In KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, August 23-27, 2020, Rajesh Gupta, Yan Liu, Jiliang Tang, and B. Aditya Prakash (Eds.). ACM, 338–348.
- Liu et al. (2023) Xiaolong Liu, Liangwei Yang, Zhiwei Liu, Xiaohan Li, Mingdai Yang, Chen Wang, and Philip S Yu. 2023. Group-Aware Interest Disentangled Dual-Training for Personalized Recommendation. arXiv preprint arXiv:2311.09577 (2023).
- Liu et al. (2022) Zhuoran Liu, Leqi Zou, Xuan Zou, Caihua Wang, Biao Zhang, Da Tang, Bolin Zhu, Yijie Zhu, Peng Wu, Ke Wang, et al. 2022. Monolith: real time recommendation system with collisionless embedding table. arXiv preprint arXiv:2209.07663 (2022).
- Mayer-Schönberger and Cukier (2013) Viktor Mayer-Schönberger and Kenneth Cukier. 2013. Big data: A revolution that will transform how we live, work, and think. Houghton Mifflin Harcourt.
- Rendle et al. (2012) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Schafer et al. (2001) J Ben Schafer, Joseph A Konstan, and John Riedl. 2001. E-commerce recommendation applications. Data mining and knowledge discovery 5 (2001), 115–153.
- Sun et al. (2019) Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. 2019. RotatE: Knowledge Graph Embedding by Relational Rotation in Complex Space. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Wang et al. (2022b) Chenyang Wang, Yuanqing Yu, Weizhi Ma, Min Zhang, Chong Chen, Yiqun Liu, and Shaoping Ma. 2022b. Towards Representation Alignment and Uniformity in Collaborative Filtering. In KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, Aidong Zhang and Huzefa Rangwala (Eds.). ACM, 1816–1825.
- Wang et al. (2023c) Hao Wang, Yao Xu, Cheng Yang, Chuan Shi, Xin Li, Ning Guo, and Zhiyuan Liu. 2023c. Knowledge-Adaptive Contrastive Learning for Recommendation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, WSDM 2023, Singapore, 27 February 2023 - 3 March 2023, Tat-Seng Chua, Hady W. Lauw, Luo Si, Evimaria Terzi, and Panayiotis Tsaparas (Eds.). ACM, 535–543.
- Wang et al. (2018) Hongwei Wang, Fuzheng Zhang, Xing Xie, and Minyi Guo. 2018. DKN: Deep Knowledge-Aware Network for News Recommendation. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, WWW 2018, Lyon, France, April 23-27, 2018, Pierre-Antoine Champin, Fabien Gandon, Mounia Lalmas, and Panagiotis G. Ipeirotis (Eds.). ACM, 1835–1844.
- Wang et al. (2022a) Shen Wang, Liangwei Yang, Jibing Gong, Shaojie Zheng, Shuying Du, Zhiwei Liu, and S Yu Philip. 2022a. MetaKRec: Collaborative Meta-Knowledge Enhanced Recommender System. In 2022 IEEE International Conference on Big Data (Big Data). IEEE, 665–674.
- Wang et al. (2019) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, August 4-8, 2019, Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM, 950–958.
- Wang et al. (2021a) Xiang Wang, Tinglin Huang, Dingxian Wang, Yancheng Yuan, Zhenguang Liu, Xiangnan He, and Tat-Seng Chua. 2021a. Learning Intents behind Interactions with Knowledge Graph for Recommendation. In WWW ’21: The Web Conference 2021, Virtual Event / Ljubljana, Slovenia, April 19-23, 2021, Jure Leskovec, Marko Grobelnik, Marc Najork, Jie Tang, and Leila Zia (Eds.). ACM / IW3C2, 878–887.
- Wang et al. (2021b) Yu Wang, Zhiwei Liu, Ziwei Fan, Lichao Sun, and Philip S. Yu. 2021b. DSKReG: Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN. In CIKM ’21: The 30th ACM International Conference on Information and Knowledge Management, Virtual Event, Queensland, Australia, November 1 - 5, 2021, Gianluca Demartini, Guido Zuccon, J. Shane Culpepper, Zi Huang, and Hanghang Tong (Eds.). ACM, 3513–3517.
- Wang et al. (2023a) Yu Wang, Zhiwei Liu, Liangwei Yang, and Philip S Yu. 2023a. Conditional Denoising Diffusion for Sequential Recommendation. arXiv preprint arXiv:2304.11433 (2023).
- Wang et al. (2023b) Yu Wang, Zhengyang Wang, Hengrui Zhang, Qingyu Yin, Xianfeng Tang, Yinghan Wang, Danqing Zhang, Limeng Cui, Monica Cheng, Bing Yin, et al. 2023b. Exploiting intent evolution in e-commercial query recommendation. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5162–5173.
- Wang et al. (2022c) Yu Wang, Hengrui Zhang, Zhiwei Liu, Liangwei Yang, and Philip S Yu. 2022c. Contrastvae: Contrastive variational autoencoder for sequential recommendation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2056–2066.
- Wang et al. (2014) Zhen Wang, Jianwen Zhang, Jianlin Feng, and Zheng Chen. 2014. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, July 27 -31, 2014, Québec City, Québec, Canada, Carla E. Brodley and Peter Stone (Eds.). AAAI Press, 1112–1119.
- Wu et al. (2019) Chuhan Wu, Fangzhao Wu, Mingxiao An, Jianqiang Huang, Yongfeng Huang, and Xing Xie. 2019. NPA: neural news recommendation with personalized attention. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2576–2584.
- Wu et al. (2022) Haolun Wu, Yansen Zhang, Chen Ma, Fuyuan Lyu, Fernando Diaz, and Xue Liu. 2022. A Survey of Diversification Techniques in Search and Recommendation. CoRR abs/2212.14464 (2022).
- Yang et al. (2023a) Liangwei Yang, Zhiwei Liu, Chen Wang, Mingdai Yang, Xiaolong Liu, Jing Ma, and Philip S Yu. 2023a. Graph-based Alignment and Uniformity for Recommendation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4395–4399.
- Yang et al. (2023c) Liangwei Yang, Shengjie Wang, Yunzhe Tao, Jiankai Sun, Xiaolong Liu, Philip S. Yu, and Taiqing Wang. 2023c. DGRec: Graph Neural Network for Recommendation with Diversified Embedding Generation. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, WSDM 2023, Singapore, 27 February 2023 - 3 March 2023, Tat-Seng Chua, Hady W. Lauw, Luo Si, Evimaria Terzi, and Panayiotis Tsaparas (Eds.). ACM, 661–669.
- Yang et al. (2023b) Mingdai Yang, Zhiwei Liu, Liangwei Yang, Xiaolong Liu, Chen Wang, Hao Peng, and Philip S Yu. 2023b. Unified Pretraining for Recommendation via Task Hypergraphs. arXiv preprint arXiv:2310.13286 (2023).
- Yang et al. (2022) Yuhao Yang, Chao Huang, Lianghao Xia, and Chenliang Li. 2022. Knowledge Graph Contrastive Learning for Recommendation. In SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, Julio Gonzalo, Ben Carterette, J. Shane Culpepper, and Gabriella Kazai (Eds.). ACM, 1434–1443.
- Ying et al. (2018) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L Hamilton, and Jure Leskovec. 2018. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 974–983.
- Yu et al. (2022) Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Lizhen Cui, and Quoc Viet Hung Nguyen. 2022. Are Graph Augmentations Necessary?: Simple Graph Contrastive Learning for Recommendation. In SIGIR ’22: The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, July 11 - 15, 2022, Enrique Amigó, Pablo Castells, Julio Gonzalo, Ben Carterette, J. Shane Culpepper, and Gabriella Kazai (Eds.). ACM, 1294–1303.
- Zhang et al. (2016) Fuzheng Zhang, Nicholas Jing Yuan, Defu Lian, Xing Xie, and Wei-Ying Ma. 2016. Collaborative Knowledge Base Embedding for Recommender Systems. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016, Balaji Krishnapuram, Mohak Shah, Alexander J. Smola, Charu C. Aggarwal, Dou Shen, and Rajeev Rastogi (Eds.). ACM, 353–362.
- Zheng et al. (2021) Yu Zheng, Chen Gao, Liang Chen, Depeng Jin, and Yong Li. 2021. DGCN: Diversified Recommendation with Graph Convolutional Networks. In WWW ’21: The Web Conference 2021, Virtual Event / Ljubljana, Slovenia, April 19-23, 2021, Jure Leskovec, Marko Grobelnik, Marc Najork, Jie Tang, and Leila Zia (Eds.). ACM / IW3C2, 401–412.
- Zhou et al. (2010) Tao Zhou, Zoltán Kuscsik, Jian-Guo Liu, Matúš Medo, Joseph Rushton Wakeling, and Yi-Cheng Zhang. 2010. Solving the apparent diversity-accuracy dilemma of recommender systems. Proceedings of the National Academy of Sciences 107, 10 (2010), 4511–4515.
- Ziegler et al. (2005) Cai-Nicolas Ziegler, Sean M. McNee, Joseph A. Konstan, and Georg Lausen. 2005. Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web, WWW 2005, Chiba, Japan, May 10-14, 2005, Allan Ellis and Tatsuya Hagino (Eds.). ACM, 22–32.