22email: {chengxiya, bisheng, gqi}@seu.edu.cn, [email protected]
Knowledge-aware Method for Confusing Charge Prediction
Abstract
Automatic charge prediction task aims to determine the final charges based on fact descriptions of criminal cases, which is a vital application of legal assistant systems. Conventional works usually depend on fact descriptions to predict charges while ignoring the legal schematic knowledge, which makes it difficult to distinguish confusing charges. In this paper, we propose a knowledge-attentive neural network model, which introduces legal schematic knowledge about charges and exploit the knowledge hierarchical representation as the discriminative features to differentiate confusing charges. Our model takes the textual fact description as the input and learns fact representation through a graph convolutional network. A legal schematic knowledge transformer is utilized to generate crucial knowledge representations oriented to the legal schematic knowledge at both the schema and charge levels. We apply a knowledge matching network for effectively incorporating charge information into the fact to learn knowledge-aware fact representation. Finally, we use the knowledge-aware fact representation for charge prediction. We create two real-world datasets and experimental results show that our proposed model can outperform other state-of-the-art baselines on accuracy and F1 score, especially on dealing with confusing charges.
Keywords:
Confusing Charges Legal Schematic Knowledge Legal Schematic Knowledge Transformer Knowledge Matching Network1 Introduction
Given a criminal case’s fact description, automatic charge prediction task aims to teach a machine judge to identify the appropriate charge, such as theft, robbery or fraud. It is a critical technique of intelligent legal judgment system. On the one hand, it can help human judges handle the heavy daily routine work and improve their work efficiency. On the other hand, people without legal background knowledge can consult the machine judge about legal guidance and assistance by describing a case they are worried about, which is low-cost but high-quality.
Automatic charge prediction has been investigated for many years, and most existing works treat charge prediction as a text classification problem. Early efforts [12, 13] extract shallow textual features (e.g. characters, words, and phrases) artificially to predict charges, which are time-consuming and labor-intensive. Inspired by the big success of deep neural networks on natural language processing tasks, many methods based on deep learning have been explored for charge prediction. Luo et al. [14] proposed an attention-based neural model for charge prediction by selecting the most relevant law articles to support charge problem. As for multi-label charge prediction, Wei et al. [18] proposed an external knowledge enhanced end-to-end multi-label charge prediction method with automatic label number learning and a number learning network.
However, there exist many confusing charges, such as theft, robbery, defraud. The fact descriptions of these confusing charges only have some slight differences, which are difficult to capture. For instance, a robbery case also contains the fact of theft. The critical difference between these two charges is whether the defendant intended to harm the victim in his subjective will. To solve this problem, some researchers began to consider introducing external information. Hu et al. [6] introduced several discriminative attributes of charges to alleviate the few-shot charges prediction. They constructed 10 discriminative legal attributes of charges as the internal mapping between fact descriptions and charges, which offer signals for distinguishing confusing charges. However, the drawback of their method is relying too much on experts and both summarizing and annotating attributes need lots of manual work. Xu et al. [19] proposed an end-to-end model to automatically learn subtle differences between confusing law articles and designed an attention mechanism that exploits the learned differences to attentively extract discriminative features from fact descriptions. Nevertheless, there is not sufficient information in the law articles to distinguish different charges, especially the confusing charges. In practice, we would like to have a method that thinks like a legal domain expert and learns the elementary knowledge of how to distinguish different charges.
Therefore, we propose a novel knowledge-aware model to predict charges. In this model, we introduce the legal schematic knowledge about charges and exploit hierarchical knowledge representation as the discriminative features to differentiate confusing charges. These features can provide explicit knowledge about how to distinguish confusing charges. Specifically, our model takes the textual fact description as the input and learns the fact representation through Graph Convolutional Network (GCN). Meanwhile, we utilize the legal schematic knowledge transformer (LK-Transformer) to generate crucial knowledge representations oriented to the legal schematic knowledge at both the schema and charge levels. We apply a knowledge matching network for effectively incorporating charge information into the fact to learn knowledge-aware fact representation. Finally, we use the knowledge-aware fact representation for charge prediction. To validate the effectiveness of our model, we conduct a series of experiments on several real-world datasets. Comprehensive experiments show that our model outperforms other baselines and achieves significantly improvements for confusing charges.
2 Related Work
The charge prediction task has drawn increasing attention in recent years. In early studies on charge prediction, most researchers inclined to formalize it as a text classification problem, which takes the fact description as input and outputs a charge label. Liu et al. [12, 13] used K-Nearest Neighbor (KNN) and extracted shallow textual features (e.g. characters, words, and phrases) artificially to predict charges. By taking data from the European Court of Human Rights as an example, Medvedeva et al. [15] addressed the potential in treating case law as quantitative data to predict judicial decisions and assessed how well Support Vector Machine (SVM) Linear Classifier is able to determine court judgments. However, these conventional methods can only leverage shallow textual features or manually designed factors, both need massive human efforts and hard to scale.
Given the fact description, Luo et al. [14] proposed a hierarchical attention network for charge prediction by selecting the most relevant law articles to predict charges. As for multi-label charge prediction, Wei et al. [18] proposed a knowledge enhanced end-to-end multi-label charge prediction method with automatic label number learning network. However, these works fail to answer why the prediction results are correct, and the prediction results are hard to interpret. Thus, Bruninghaus et al. [3] investigated an algorithm, IBP, which combines reasoning with an abstract domain model and case-based reasoning techniques to predict the outcome of case-based legal arguments. Further, SMILE+IBP [1] is proposed to predict and explain the outcomes of case scenarios according to a database of previously classified cases. In recent years, Li et al. [9] provided a cognitive computing framework for predicting judicial decisions, whose predicting results are interpretable in a way that induction rules are supplied.
Nevertheless, all of these methods have poor performances on confusing charge prediction, which will influence the precise adjustment of prison term. Only few research works focus on confusing charges. Li et al. [11] proposed an element-driven attentive neural network model, EDA-NN, which introduces the legal constitutive elements as the discriminative features to distinguish confusing charges. To improve prediction accuracy, [20] focused on word collocations information and integrated word collocations features of fact descriptions into the network via an attention mechanism. These works don’t consider the charge information, which is proved to be useful in predicting charges [4]. Fortunately, Hu et al. [6] constructed several discriminative attributes of charges as the internal mapping between fact descriptions and charges, which offer effective signals for distinguishing confusing charges. However, only a few confusing charges can be distinguished. It still remains a challenge to distinguish all confusing charges.
To address this issue, we propose a novel knowledge-aware framework to predict charges by incorporating legal schematic knowledge about charges.
3 Methodology
In this section, we present the details of our model. The overall architecture of our model is shown in Fig. 1. We input the distributed representation of a fact description to GCN to learn the fact representation. Then we utilize the LK-Transformer to generate crucial knowledge representations oriented to the legal schematic knowledge at both the schema and charge levels. To improve the uniqueness, the group label information is encoded and concatenated with corresponding knowledge representations. Moreover, we apply a knowledge matching network for effectively incorporating charge information into the fact to learn knowledge-aware fact representation. With the knowledge-aware fact representation, we use a softmax layer to output the predicted distributions of charges.
In the following subsections, we first give the problem formulation and introduce our legal schematic knowledge. Then we describe the neural encoder of fact description and the knowledge-aware fact representation. In the end, we show the output layer and the loss function of our model.
3.1 Problem Formulation
For each case, the fact description is regarded as a word sequence , where is the length of . We extract legal schematic knowledge about charges from findlaw111http://china.findlaw.cn/zuiming/. Given the fact description and legal schematic knowledge , the charge prediction task aims to predict a charge label .

3.2 Legal Schematic Knowledge
The legal schematic knowledge, whose structure is presented in Fig. 2, has four hierarchies. The root is charge object, whose children are charge groups. Groups are macro categories of all charges in general, such as “crime of infringing property” and “crime of financial fraud”. Besides, the children of each group are specific charges, and many are confusing charges. Note that there are 25 groups and 435 charges in total. To distinguish confusing charges, we add the knowledge of constitutive elements to represent charges. Concretely, each charge has four schemas: object elements , objective elements , subject elements and subjective elements . These schemas are the key points to define a charge and provide explicit knowledge about how to distinguish confusing charges.
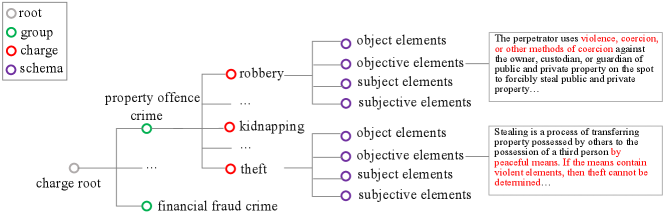
3.3 Fact Representation
As illustrated in Fig. 1, fact encoder encodes the discrete input sequence into hidden states, and obtain the fact representation by max pooling. Since traditional neural encoder, e.g., RNN and CNN, can only capture semantic and syntactic information in local consecutive word sequences well, while ignoring global word co-occurrence in a corpus which carries non-consecutive and long-distance semantics, we employ GCN to encode fact descriptions. GCN is a simple and effective graph neural network that can capture high order neighborhood information and rich global structure information.
3.3.1 Graph Construction
First, fact encoder converts each word into its word embedding through an embedding layer, where is the dimension of word embeddings. Then, we get the corresponding word embedding sequence as , which can be used as the original feature matrix . After that, we build a graph for the given text. We regard all the words that appeared in the text as the nodes of the graph. The point-wise mutual information (PMI) is employed to calculate the weights of edges, which can preserve the global word co-occurrence information [22]. Specially, we use a fixed-size sliding window on all documents in the source and legal domain to collect word co-occurrence statistics.
The PMI of a word pair , is computed as: , where . is the number of sliding windows that contain the word . is the number of sliding windows that contain both words and , and is the total number of sliding windows. The PMI score can reflect the semantic correlation between words. If the PMI value is negative, there is little or no semantic correlation. Therefore, we only add edges between word pairs with positive PMI scores:
| (1) |
where is the relation between the word and . After this process, we obtain the word relations over the global corpus, and the adjacent matrix is the subset of for each document.
3.3.2 Graph Propagation
With graph representation, we can capture complex semantic and long-distance relation between words. Then we need update the representation of each node by message passing. The propagation rule of GCN can be interpreted as the Laplacian smoothing [10]. The new feature of a node is calculated as the weighted average of itself and its neighbors’, followed by a linear transformation. Further, each node can collect and integrate messages from adjacent nodes to update its representation, which is defined as: , where is the adjacency matrix with added self-connection , is a diagonal matrix with , and are the node representation matrix and the trainable parameter matrix for the -th layer, is the original feature matrix, and is the activation function.
As shown in Fig. 1, we use 4 hidden layers in GCN. After applying the propagation rule to our graph defined before, each node would learn a distributed representation in the last layer eventually. These representations are then input to a max-pooling layer to obtain the final fact representation as , here, is the dimension of hidden states.
3.4 Knowledge-aware Fact Representation
To address confusing charges, we exploit the legal schematic knowledge representation about charges as the discriminative features to differentiate confusing charges. As we mentioned above, with legal schematic knowledge provided, we can capture some slight differences in specific factors of the criminal motive, action or consequence among confusing charges and further distinguish them.
3.4.1 LK-Transformer
Since the tree structure of our legal schematic knowledge, we utilize the LK-Transformer to generate crucial knowledge representations at both the schema and charge levels. The structure of our LK-Transformer is shown in Fig. 3. For each charge, we input the schemas , , and to four schema transformers respectively and obtain corresponding semantic representations , , and . Later, the four schema representations are fed into a charge-level transformer to compute the knowledge representation .

More specifically, the schema-level transformer and the charge-level transformer share the same model, shown in the middle halves of Fig. 3. The first is a masked multi-head self-attention mechanism, the second is a multi-head self-attention mechanism, and the third is a position-wise fully connected feed-forward network. We employ a residual connection [5] around each of the three sub-layers, followed by layer normalization [2]. That is, the output of each sub-layer is , where is the function implemented by the sub-layer itself.
Attention mechanism softly maps a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. Taking queries and keys of dimension , and values of dimension as input, it outputs a weighted sum of the values. As for the multi-head attention mechanism, multiple individual attention functions are performed in parallel, yielding -dimensional output values. These are concatenated and once again projected, resulting in the final values, as depicted in the right halves of Fig. 3.
| (2) | ||||
| (3) |
where the projections are parameter matrices , , and .
Besides, the fully connected feed-forward network (FFN) is consists of two linear transformations with a ReLU activation [17].
3.4.2 Knowledge–aware Fact Representation
Through the LK-Transformer, we have obtained knowledge representations. To improve the uniqueness, we employ a BiLSTM[23] to encode the group label information. Then this representations are concatenated with corresponding knowledge representations to distinguish different charges and the final knowledge representations are .
We apply a knowledge matching network to select relevant information from knowledge and generate knowledge-aware fact representation. Let . Similarly, let . As shown in Fig. 4, the knowledge matching network first compute the attention for the fact representation and knowledge representation . Then the matched knowledge embeddings for the fact are obtained by multiplying the attention matrix with the knowledge representation . Finally, we concatenate the matched knowledge embeddings with the fact representation to get the knowledge–aware fact representation .

Our knowledge matching function is defined as following:
| (4) |
where the function Concat is a concatenation operation, and is an attention score, computed by: , where W is a weight matrix and ReLU is the rectified linear unit.
3.5 Prediction and Optimization
Ultimately, we use the knowledge-aware fact representation to predict the final charge of a case in the output layer. The predicted probability distribution over all charges is calculated as , where and are weight matrix and bias vector in the output layer. The training objective for our model is to minimize the cross-entropy between predicted charge and the ground-truth . The charge prediction loss can be formalized as:
| (5) |
4 Experiments
In this section, we demonstrate the effectiveness of our model on criminal charges prediction. We conduct a series of experiments over two real-world datasets and compare our proposed model with several state-of-the-art baselines.
4.1 Dataset Construction
We collect 336,450 judgments of criminal cases published by the Chinese government from China Judgments Online222http://wenshu.court.gov.cn/. Each case consists of several parts, such as the defendant’s information, fact description, charges. We only retain the fact description as input and the charge as label. The dataset is denoted as Criminal-All, which contains 203 different charges. Moreover, we select 80,000 cases which contain 86 confusing charges to form another dataset, named Criminal-Confusing. This dataset is designed for testing the ability of our model on predict confusing charges. For both Criminal-All and Criminal-Confusing, we randomly select 80% of these cases for training, 10% for validation, and 10% for testing.
4.2 Baselines
To evaluate the performance of our framework, we compare our method with the following baselines:
-
*
HAN: a Hierarchical Attention based RNN for document classification [21].
-
*
DPCNN: a low-complexity word-level deep convolutional neural network architecture for text categorization [7].
-
*
Few-shot: an attribute-based multi-task learning model for charge prediction by introducing discriminative legal attributes into consideration [6].
-
*
EDA-NN: an element-driven attentive neural network model which can jointly predict the legal constitutive elements and judgment results [11].
-
*
MPBN: a multi-perspective bi-Feedback network with the word collocation attention mechanism for confusing charge prediction [20].
-
*
LADAN: a Law Article Distillation based Attention Network to distinguish confusing charges [19].
-
*
Ours-GCN: our model which replaces GCN with a Bi-LSTM layer.
-
*
Ours-LK: our model without legal schematic knowledge.
4.3 Experimental Settings
We first employ jieba333https://github.com/fxsjy/jieba for Chinese word segmentation and word2vec [16] to train the word embeddings on all the legal judgments. We set all the hidden state size to 300. For the training, we use Adam [8] as the optimizer and set the learning rate to 0.001. We set the batch size and dropout rate to 128, 0.5, respectively. We repeat the training iterations until the difference between two continuous iterations is small enough. For the evaluation, we employ accuracy (Acc.), macro-recall (MR), macro-F1 (Ma-F1) and micro-F1 (Mi-F1) as metrics.
4.4 Results and Discussion
| Datasets | Criminal-All | Criminal-Confusing | ||||||
|---|---|---|---|---|---|---|---|---|
| Metrics | Acc. | MR | Ma-F1 | Mi-F1 | Acc. | MR | Ma-F1 | Mi-F1 |
| HAN | 0.858 | 0.710 | 0.727 | 0.673 | 0.761 | 0.612 | 0.631 | 0.582 |
| DPCNN | 0.878 | 0.767 | 0.783 | 0.719 | 0.782 | 0.653 | 0.675 | 0.614 |
| Few-shot | 0.891 | 0.824 | 0.842 | 0.788 | 0.844 | 0.783 | 0.798 | 0.762 |
| EDA-NN | 0.901 | 0.843 | 0.866 | 0.803 | 0.863 | 0.801 | 0.814 | 0.787 |
| MPBN | 0.903 | 0.858 | 0.875 | 0.810 | 0.870 | 0.811 | 0.826 | 0.792 |
| LADAN | 0.905 | 0.862 | 0.879 | 0.815 | 0.875 | 0.817 | 0.829 | 0.797 |
| Ours-GCN | 0.910 | 0.877 | 0.889 | 0.822 | 0.882 | 0.826 | 0.835 | 0.801 |
| Ours-LK | 0.902 | 0.843 | 0.862 | 0.799 | 0.864 | 0.792 | 0.807 | 0.778 |
| Ours | 0.914 | 0.893 | 0.909 | 0.834 | 0.898 | 0.841 | 0.856 | 0.819 |
As shown in Table 1, we can observe that our model performs the best and significantly outperforms all baseline models on Criminal-All, which showcases the robustness and effectiveness of our proposed method for charge prediction.
Our method is characterized by the incorporation of GCN and legal schematic knowledge. To verify the effectiveness of these modules, we design an ablation test respectively to investigate the effectiveness of these modules. As shown in Table 1, we can observe that the performance drops obviously after removing the GCN or legal schematic knowledge. The Ma-F1 score decreases at least 2%. Therefore, we conclude that both GCN and legal schematic knowledge play irreplaceable roles in our model and a combination of them will achieve better results on the charge prediction task.
To further investigate the effectiveness of our model on handling confusing charges, we show the performance on a confusing charge dataset, Criminal-Confusing, in Table 1. We compare our model with the LADAN, which is the state-of-art model on predicting confusing charges. The results show that our model enhances the performance by about 2.3%, 2.4%, and 2.7% relatively on Acc., MR, Ma-F1, respectively, which demonstrates the ability of our model.
4.5 Case Study
As shown in Fig. 5, we choose a representative case to give an intuitive illustration of how the legal schematic knowledge improves the performance of confusing charge prediction. In the case, the defendant is convicted of robbery. It is often difficult to decide whether to judge a case as robbery or kidnapping since they are both related to violence and illegal possession. According to the constitutive requirements, one important difference between them is that the defendant intends to rob property directly from the victim in robbery, while the defendant can only ask for property from a third party other than the victim in kidnapping.

Therefore, the constitutive requirements are essential in the confusing charge prediction. From Table. 2, we can see that only correctly predicts the charge of the case as robbery. In contrary, other models predict it as kidnapping incorrectly. Taking the Few-shot model as an example, although this case includes several attributes, like profit purpose, violence, public place and illegal possession, these attributes are not detailed enough to distinguish the charge. However, thanks to the legal schematic knowledge, our model can capture the key patterns and semantics relevant to constitutive requirements, which are assigned red color in Fig. 3. Then the prediction charge is determined by these key patterns and semantics. This further demonstrates that our model is good at dealing with confusing charges through legal schematic knowledge.
| Models | Gold | HAN | DPCNN | Few-shot | EDA-NN | MPBN | LADAN | Ours |
|---|---|---|---|---|---|---|---|---|
| case | robbery | kidnapping | kidnapping | kidnapping | kidnapping | kidnapping | kidnapping | robbery |
5 Conclusion
In this paper, we focus on the task of charge prediction for criminal cases with confusing charges. To the best of our knowledge, we are the first to utilize legal schematic knowledge of charges as discriminative features to predict charges. We propose a legal schematic knowledge-aware framework to solve confusing charges. Our model adopts GCN and LK-Transformer to learn better representations from informative case fact descriptions and legal schematic knowledge, respectively. Moreover, we utilize a knowledge matching network to learn knowledge-aware fact representation to improve the accuracy of confusing charge prediction. The experimental results on real-world datasets show that our model achieves significant improvements over baselines on all evaluation metrics for criminal cases, especially with confusing charges.
Acknowledgement
Research presented in this paper was partially supported by the National Key Research and Development Program of China under grants (2018YFC0830200, 2017YFB1002801), the Natural Science Foundation of China grants (U1736204), the Judicial Big Data Research Centre, School of Law at Southeast University.
References
- [1] Ashley, K.D., Brüninghaus, S.: Automatically classifying case texts and predicting outcomes. Artificial Intelligence and Law 17(2), 125–165 (2009)
- [2] Ba, J.L., Kiros, J.R., Hinton, G.E.: Layer normalization. arXiv preprint arXiv:1607.06450 (2016)
- [3] Bruninghaus, S., Ashley, K.D.: Predicting outcomes of case based legal arguments. In: Artificial intelligence and law. pp. 233–242 (2003)
- [4] Chen, S., Wang, P., Fang, W., Deng, X., Zhang, F.: Learning to predict charges for judgment with legal graph. In: International Conference on Artificial Neural Networks. pp. 240–252. Springer (2019)
- [5] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR. pp. 770–778 (2016)
- [6] Hu, Z., Li, X., Tu, C., Liu, Z., Sun, M.: Few-shot charge prediction with discriminative legal attributes. In: COLING. pp. 487–498 (2018)
- [7] Johnson, R., Zhang, T.: Deep pyramid convolutional neural networks for text categorization. In: ACL. pp. 562–570 (2017)
- [8] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- [9] Li, J., Zhang, G., Yu, L., Meng, T.: Research and design on cognitive computing framework for predicting judicial decisions. Journal of Signal Processing Systems 91(10), 1159–1167 (2019)
- [10] Li, Q., Han, Z., Wu, X.M.: Deeper insights into graph convolutional networks for semi-supervised learning. In: AAAI (2018)
- [11] Li, S., Liu, B., Ye, L., Zhang, H., Fang, B.: Element-aware legal judgment prediction for criminal cases with confusing charges. In: ICTAI. pp. 660–667. IEEE (2019)
- [12] Liu, C.L., Chang, C.T., Ho, J.H.: Case instance generation and refinement for case-based criminal summary judgments in chinese (2004)
- [13] Liu, C.L., Hsieh, C.D.: Exploring phrase-based classification of judicial documents for criminal charges in chinese. In: International Symposium on Methodologies for Intelligent Systems. pp. 681–690. Springer (2006)
- [14] Luo, B., Feng, Y., Xu, J., Zhang, X., Zhao, D.: Learning to predict charges for criminal cases with legal basis. arXiv preprint arXiv:1707.09168 (2017)
- [15] Medvedeva, M., Vols, M., Wieling, M.: Using machine learning to predict decisions of the european court of human rights. Artificial Intelligence and Law pp. 1–30 (2019)
- [16] Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. In: ICLR (2013)
- [17] Nair, V., Hinton, G.E.: Rectified linear units improve restricted boltzmann machines. In: ICML. pp. 807–814 (2010)
- [18] Wei, D., Lin, L.: An external knowledge enhanced multi-label charge prediction approach with label number learning. arXiv preprint arXiv:1907.02205 (2019)
- [19] Xu, N., Wang, P., Chen, L., Pan, L., Wang, X., Zhao, J.: Distinguish confusing law articles for legal judgment prediction. arXiv preprint arXiv:2004.02557 (2020)
- [20] Yang, W., Jia, W., Zhou, X., Luo, Y.: Legal judgment prediction via multi-perspective bi-feedback network. arXiv preprint arXiv:1905.03969 (2019)
- [21] Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., Hovy, E.: Hierarchical attention networks for document classification. In: NAACL. pp. 1480–1489 (2016)
- [22] Yao, L., Mao, C., Luo, Y.: Graph convolutional networks for text classification. In: AAAI. vol. 33, pp. 7370–7377 (2019)
- [23] Zhang, S., Zheng, D., Hu, X., Yang, M.: Bidirectional long short-term memory networks for relation classification. In: PACLIC. pp. 73–78 (2015)