Keypoints Tracking via Transformer Networks
Abstract
In this thesis, we propose a pioneering work on sparse keypoints tracking across images using transformer networks. While deep learning-based keypoints matching have been widely investigated using graph neural networks - and more recently transformer networks, they remain relatively too slow to operate in real-time and are particularly sensitive to the poor repeatability of the keypoints detectors. In order to address these shortcomings, we propose to study the particular case of real-time and robust keypoints tracking. Specifically, we propose a novel architecture which ensures a fast and robust estimation of the keypoints tracking between successive images of a video sequence. Our method takes advantage of a recent breakthrough in computer vision, namely, visual transformer networks. Our method consists of two successive stages, a coarse matching followed by a fine localization of the keypoints’ correspondences prediction. Through various experiments, we demonstrate that our approach achieves competitive results and demonstrates high robustness against adverse conditions, such as illumination change, occlusion and viewpoint differences. Code is available at our project page: https://github.com/LexaNagiBator228/Keypoints-Tracking-via-Transformer-Networks/.
1 Introduction
For decades keypoints matching and tracking have been a cornerstone for a large spectrum of applications such as SLAM[4], visual odometry[6], motion detection[7], time to collision[8], place localization[9], and more. Traditional approaches for keypoints matching [10, 11] and tracking relies on handcrafted features extracted locally in the images. While these approaches have demonstrated their versatility and effectiveness, they remain very sensitive to a large number of factors such as illumination changes and viewpoints differences between views. To cope with these limitations, recent deep learning based techniques have emerged[12, 13].

The first attempts to replace the traditional visual odometry pipeline by neural network approaches were focusing on the end-to-end learning of the camera motion with limited intermediate supervision [14]. While the implementation of these techniques is straightforward and intuitive, their generalization to arbitrary scenes remains debatable. This problem was partly resolved by self-supervised visual-odometry approaches [15] which can be easily trained on unlabelled video sequences. Despite this advantage, their poor transferability drastically limits the deployment of these end-to-end strategies. For the affordmention reason, replacing the visual odometry pipeline in its entirety is questionable. To compute a camera motion a few stages are required: keypoints detection/description/matching and robust geometric estimation (often achieved by a RANSAC fitting a parametric motion model associated with a non-linear refinement). While the second stage is well mathematically defined and understood, the first step (keypoint extraction and matching) is not fully resolved. In this context, performing the local features extraction and association using deep neural networks is very relevant. Unsurprisingly, many attempts have already been proposed, for instance, a seminal work entitled LIFT[16] learns keypoints detection and description with a large dataset of images acquired under various conditions. More recently, SuperPoints[2], and D2Net[17] have demonstrated better performances by learning keypoints detection and description via synthetically generated data or RGB-D datasets (Megadepth[18], ScanNet[19] etc.). These CNN based approaches undeniably improved the robustness of keypoints association between pairs of images (Show example of results from recent approaches and in the figure caption put the challenge it resolved like viewpoint difference, illumination etc.) Although detecting keypoints on successive images before matching them is a commonly employed strategy for 3D reconstruction, it is not necessarily the most effective technique when dealing with video for various reasons. First these approaches do not consider the sequential nature of the data. Secondly, the repeatability of the keypoints detection can lead to a large number of wrongly - or missing- matches which can be problematic under complex scenarios. To cope with these limitations, we propose to explore the particular problem of keypoints tracking using neural networks which has, so far, attracted a relatively narrow attention. Specifically, we propose to resolve this problem using a very recent deep learning architecture called transformer networks[20] which happen to be very well suited for the task at hand. Our approach is hierarchical since a coarse keypoint tracking is accurately refined by a second transformer network. Also we developed our own strategy to deal with outliers, and a special training pipeline for it. In our experiments we compared the matching accuracy, and number of matched points with SuperGlue[1] that is a state-of-the-art model for Feature Matching. Our model achieved competitive results in terms of accuracy, and significantly outperformed SuperGlue in terms of number of correctly matched points ( 50%).
2 Methods
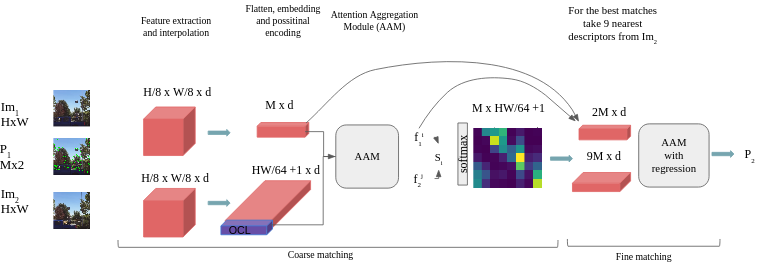
In this section, we present the details of the proposed approach for keypoints tracking using transformer networks. Given two images , of the size , and the positions of the points from the first image with the size , we aim to find the location of corresponding points in the second image. Instead of feature matching we propose to directly find the location of the corresponding keypoints in the . This allows us to skip the search of keypoints (at least in the second image), and thus our method does not depend on repeatability of searched keypoints. We divide the search of corresponding points in two stages called coarse matching, and fine matching, (fig.2).
PUT FIGURE
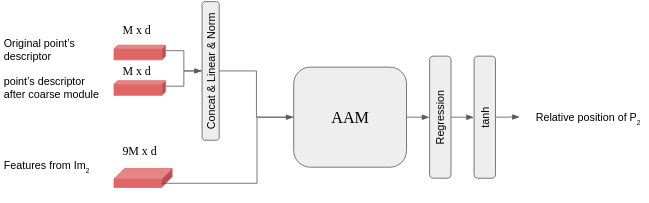
During the first stage we intend to find the approximate position of , and discard outliers, with occluded points. The second stage’s goal has been designed to find the precise position of . During the coarse matching we firstly extract image features from , and keypoints descriptors from , after we apply embeddings, with positional encoding, and finally process those features with Attention Aggregation Module (AAM). For the fine matching we apply Attention Aggregation Module to keypoint’s descriptors and features after the coarse matching with image features, and regress the result in order to get the final position of . Further we will describe each step in detail.
2.1 Feature extraction
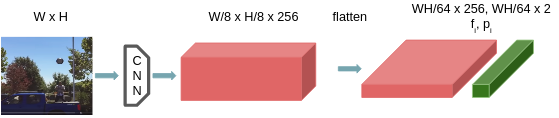
For the image features extraction, we used the CNN model architecture from SuperPoint(SP) [2]. This model proved to be one of the best for representative feature extraction. For an image of size it extracts features. Each feature characterizes a patch around it, so we set its position to be the center of that patch. After the features are flattened, we form a set of pairs, where each entry represents the patch’s descriptor, and position. The process is visualized at fig. 3.
PUT FIGURE
For points’ feature descriptors, we firstly use SuperPoint to extract features from , and next based on points’ position we use bi-linear interpolation to get their descriptors. As a results we obtain sparse features descriptors from the and a dense feature representation of the second image in its entirety.
2.2 Feature transformer
During the next step, previously extracted features are passed to a positional encoding module, as well as to the Attentional aggregation modules. To provide a better understanding of Attention Layers, we firstly introduce the concept of transformer networks, and explain the intuition behind them. A Transformer encoder consists of sequentially connected encoder layers, the core element of the encoder layer is the Attention layer. Traditionally the names of inputs to it are : - Queries, - Keys, - Values. Assuming that the size of all matrices is Nd, we can define attention as :
PUT FIGURE The intuition at this point is that attention operation learns feature level association by calculating similarity between Query and Key matrices. Another possible explanation is that by taking the product we dynamically generate weights based on input of and for linear layer with input . In such a way that it is possible to increase the generalizability of the model as certain weights are generated on the fly and depend on the input.
The main problem of attention layers in Computer Vision field is that their complexity grows quadratically as the length of the input increases (this can be clearly seen from fig. 4:
the size of the output from the first MatMul operation is basically ). In computer vision the input mainly consists of pixels, patches, or their descriptors, so the complexity of the attention layer for images of size becomes proportional to . For example, even for images this number becomes . Recently there were several successful attempts to challenge this problem [3] by expressing self-attention as a linear dot-product of kernel feature maps. In this project, we are taking advantage of this method to speed-up, and reduce the memory consumption of the model. The difference (see fig. 4)
PUT FIGURE
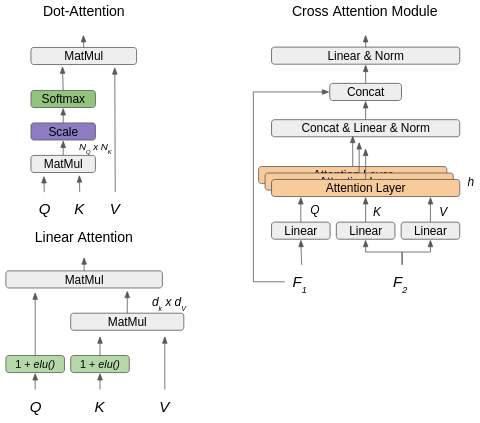
is that in linear transformers instead of computing similarity between , and as ,it is approximated as . Therefore, there is no need to compute a costly operation, instead is computed, which allows us to avoid large matrices, while preserving the order of matrix multiplication.
2.3 Positional encoding
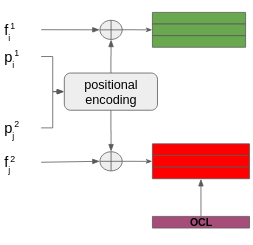
Positional encoding is of utter importance for any transformer-based model. In this work, we used Multi Layer Perceptron (MLP) to embed points’ 2d positions into vectors with the dimension same to descriptors’ dimension, and then add them together, as you can see at fig. 5.
PUT FIGURE
After features from the second set are concatenated with a special OCL token, it can be treated as an additional feature from the . OCL token stands for occlusion token, it is used for finding occluded points, and outliers. This will be discussed in detail in further sections.
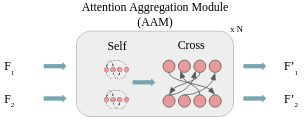
2.4 Attention aggregation module
The attention aggregation module consists of several () self-attention, and cross-attention layers stacked together (see fig. 6).
The structure of the cross attention layer is shown on the fig (see fig. 4) .
The input is two sets of features after positional encoding and or and depending on the direction of cross-attention. Self-attention layer has the exact same structure, the only difference is that we use 2 identical sets of features: and or and ( note that we consider OCL token as a part of ). The primary goal of the self-attention layer is to share the information inside the same set of features, and the goal of the cross-attention layer is to share information between and .
2.5 Coarse matching
In order to establish the coarse matching between and , we calculate the similarity score for each pair of features and by computing their dot product. In such a way we build a similarity matrix of the size , and next apply softmax along the X direction (along direction with points ) to obtain the probabilities of matching for each of keypoints.
Now the problem became similar to a multi label classification problem, we aim to classify each point from to one of classes. We select matches based on the highest similarity score. Optionally, it is possible to consider the match if the similarity score is higher than some threshold. Point is discarded if its confidence score is lower than threshold or if it’s best match is OCL token.
2.6 Fine matching
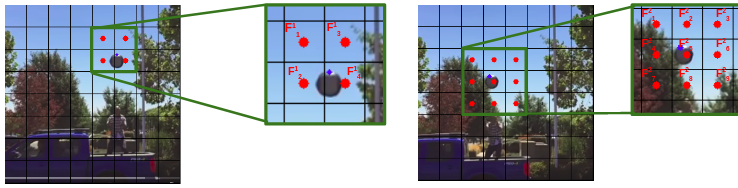
After establishing the coarse matching, we know the approximate position of the points on , and we assume that the exact match is located in the region around the matched feature. Since we are using bi-linear interpolation to extract the point descriptors, we can write as linear combination of , where are the nearest descriptors to the point on the (see fig. 7).
Combination of - coefficients of bi-lienar interpolation, uniquely determines the relative position of the :
Thus we can assume that it is also possible to express as a linear combination of the nearest descriptors from with some noise :
Here we use 9 (see fig. 7)
FIG REFERENCE
as we do not know the exact location of the point on the second image. Again, we can assume that coefficients determine the points’ positions. Thus based on these assumptions, for each keypoint we use its original descriptor with representation after AAM, and take 9 nearest image descriptors from Im2. Next we process them using the Attention aggregation module, calculate the similarity scores, and use them to regress the relative position of the point (see fig. 8 for details)
that allows us to move to sub-pixel matching.
2.7 OCL Token
One of the biggest challenges of points and images matching is to deal with outliers, and occluded points. The popular approach to deal with this problem, in the context of deep learning based keypoints matching, is the Sinkhorn Algorithm[21]. After computing the similarity matrix, this approach formulates the matching problem as a bipartite assignment solving the optimal transport problem. However, it can not be used for point tracking, as there is a chance that two different points from are matched to the same patch from (multiple to one matching case). Therefore, we employ another strategy to discard occlusions: we concatenate the set with a learnable OCL token. Simply speaking, we just add one additional feature to that stands for patch outside the . During the training stage, the model is taught to match all occluded points to OCL token. Intuitively, the coarse module processes the features of the OCL token in a way that it becomes quite similar to all features in and different from all features from F2. Thus, after computing the similarity matrix, all features that lack similar features are classified as outliers. As we discussed in the Coarse matching part, after calculating the similarity matrix, the problem can be formulated as a classification. Let assume that 20% of the keypoints are occluded, then the probability that one point is matched with an OCL token is 0.2, while its probability to be matched with any other feature is:
This means that our dataset is extremely unbalanced, and direct training will lead to classifying all points as occluded. Thus we divided the training into several stages, this will be discussed in detail in the Training strategy section.
3 Dataset Generation
Since there is no large dataset of images with pixel to pixel correspondence for sparse matching, we created a synthetic dataset of geometric primitives, and a real dataset of warped images. The synthetic dataset is used to warm up the training, as real images appear to be too complex to ensure the convergence of the network without a proper initialization.
3.1 Synthetic dataset
The Synthetic dataset consists of image pairs. Specifically, each image consists of a background full of stripes, triangles, stars, etc., and a big cube located in the center of the image. The first, and second images differ by small displacement of background( 16 pixels), and huge displacement of the cube( 50 pixels ).
For this dataset, we select the corners of the geometric primitives as points to track. While the structure of the images is rather simple, it is still a considerably difficult task, as there is a need to track points with different levels of displacement simultaneously. Thus, such an approach disables the model to learn homographies instead of point tracking. Since the displacement of the cube is large compared to the displacement of the background, it is likely that some points on the second image naturally become occluded. Hence, we use those to train OCL token.
3.2 Real dataset
For training on the real images we select the COCO14[23] image dataset. For each image we 1) applied random projective transformation to the image, 2) selected regions with huge concentration of key points, 3) cropped patches of the same size that are centered at corresponding points, 4) selected key points on the first patch, and used them as P1; those of them that do not appear on the second patch are treated as outliers.
4 Training strategy

We divide the training into 3 stages:
4.1 Synthetic dataset without occlusions
Firstly we trained the model on the Synthetic dataset without occluded points in order to “warm up” the model. For each keypoint , the ground truth consists of the index of the patch where this keypoint is located - , and its position on the second image - . Based on the predicted similarity score , it is possible to select predicted position on the second patch - .
Thus the total loss consists of Cross Entropy Loss between and , also, we added the L2 loss between and in order to speed up the convergence time:
4.2 Synthetic dataset with occlusions
At this stage we used the same dataset, however now occluded points are also used, and the loss consists only of CEL:
This transition stage is extremely important, as ‘occluded class’ should be added only after the model is taught how to distinguish between all inliers due to reasons we discussed in the Coarse matching part.
4.3 Training on a dataset with real images
Finally, we train the model on the dataset of real images. At this stage we applied random color jitter to the images to mimic the change of illumination, and used projective transforms of different difficulty levels. The loss again consists only of CEL:
4.4 Training fine matching module
For training the fine matching module, we freeze the weights of the Coarse module. Based on the results of coarse module, for each point and position of the patch where it is located (), we predict their relative distance , having the ground truth . For this we use L2 loss:
Thus the result position of the keypoint becomes: .

5 Results
Since there are no analogous works, we provide a comparison with the state-of-the-art method for keypoint feature matching SuperGlue[1]. We tested our model on 2 datasets: COCO2014, and HPatches under different levels of light intensity, and projective transforms. For the evaluation metrics we selected 1) matching accuracy: the match is correct if distance between predicted and real position of the point is less than 6 pixels, and 2) number of correctly matched keypoints.
5.1 Evaluation Protocol
In order to provide a fair comparison, we conducted the experiments in the following way: for each image in the dataset 1) we created a corresponding image by applying projective transforms, and color jitter 2) sampled 512 most representative keypoints from the first image - , and all keypoints from the second image - 3) matched to using SuperGlue, and matched to the entire 4) compare the results. The table below summarizes the outcomes of our results (Table 1, Table 2).
| Dataset | SuperGlue | Our model(coarse only) | Our model |
|---|---|---|---|
| COCO easy | 94.8 | 93.5 | 95.3 |
| COCO hard | 91.6 | 90.2 | 91.7 |
| COCO illum | 89.0 | 87.2 | 88.8 |
| Hpatches hard 91.4 | 90.5 | 91.5 |
| Dataset | SuperGlue | Our model |
|---|---|---|
| COCO easy | 249 | 358 |
| COCO hard | 240 | 346 |
| COCO illum | 195 | 300 |
| Hpatches hard | 222 | 340 |

During testing of our model without a fine matching module, we considered the predicted patch’s center as the prediction for keypoints’ positions. Since we put the distance threshold to be 6 pixels, the accuracy of the coarse module represents the accuracy of the matching point to the correct patch. The fine module on average adds 1.5% accuracy, the reason is that for the cases when the coarse module predicts a nearby patch instead of the correct one, the fine module may refine the predicted position in a way that it becomes closer to the correct patch. The results clearly show that our model reaches the same, and sometimes higher level of accuracy compared to SuperGlue, while producing a significantly larger number of correctly matched points
5.2 Limitations and future work directions
Given two images and input points from one of them, our current method finds the position of these points on the second image. To further improve the matching accuracy, we can additionally try to find location of the predicted points on the first image, in such a way it is possible to increase robustness, and establish semi-supervised learning technique. Another way to improve the current results is to experiment with different numbers of attention layers, and train models on image sequences from Megadepth or ScanNet Datasets. In such a way the models can learn different sets of parameters for indoor, and outdoor environments. Additionally, instead of separate training of coarse and fine modules, we could integrate it in a single training pipeline that can be used out of the box in SLAM. We plan to extend this work to journal or conference publication.
6 Conclusion
We have proposed a novel deep learning architecture which ensures a robust keypoints tracking implemented in an hierarchical manner. It consists of two successive stages, a coarse matching followed by a fine localization of the keypoints’ correspondances prediction. Through various experiments, we demonstrated that our approach achieves competitive results and demonstrates high robustness against adverse conditions, such as illumination change, occlusion and viewpoint differences while producing a significantly larger number of correctly matched keypoints, compared to keypoints matching techniques. Moreover, as a pioneering work introducing transformer networks for keypoints tracking tasks, we believe that our research can be the beginning of a novel research track.
7 Reference Literature
1 Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz,and Andrew Rabinovich.SuperGlue: Learning feature matching with graph neural networks. CVPR, 2020
2 Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperPoint: Self-supervised interest point detection and description. CVPRW, 2018
3 Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Francois Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. ICML, 2020
4 Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Toward geometric deep slam.arXiv:1707.07410.
5 Zichao Zhang, Torsten Sattler, and Davide Scaramuzza. Reference Pose Generation for Long-term Visual Localization Via Learned Features and View Synthesis. IJCV, 2020
6 Raul Mur-Artal, Juan D. Tardos. ORB-SLAM2: an Open-Source SLAM System for Monocular, Stereo and RGB-D Cameras. IEEE 2017
7 Junjie Huang, Wei Zou, Zheng Zhu, Jiagang Zhu. An Efficient Optical Flow Based Motion Detection Method for Non-stationary Scenes. arXiv:1811.08290
8 Aashi Manglik, Xinshuo Weng, Eshed Ohn-Bar, Kris M. Kitani. Forecasting Time-to-Collision from Monocular Video: Feasibility, Dataset, and Challenges. IROS, 2019.
9 Sourav Garg, Ben Harwood, Gaurangi Anand, Michael Milford. Delta Descriptors: Change-Based Place Representation for Robust Visual Localization. IEEE Robotics and Automation Letters (RA-L), 2020
10 David G Lowe.Distinctive image features from scale-invariant keypoints. IJCV, 2004.
11 Ethan Rublee, Vincent Rabaud, Kurt Konolige, and GaryBradski. ORB: An efficient alternative to SIFT or SURF. In ICCV, 2011
12 Jerome Revaud, Philippe Weinzaepfel, Cesar De Souza, Noe Pion, Gabriela Csurka, Yohann Cabon, and Martin Humenberger. R2D2: repeatable and reliable detector and descrip-tor. NeurIPS, 2019
13 Ignacio Rocco, Relja Arandjelovicc, and Josef Sivic. Efficient Neighbourhood consensus networks via submanifold sparse convolutions. In ECCV, 2020
14 Chhaniyara, Savan; KASPAR ALTHOEFER; LAKMAL D. SENEVIRATNE . Visual Odometry Technique Using Circular Marker Identification For Motion Parameter Estimation. Advances in Mobile Robotics, 2008
15 Igor Vasiljevic, Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Wolfram Burgard, Greg Shakhnarovich, Adrien Gaidon. Neural Ray Surfaces for Self-Supervised Learning of Depth and Ego-motion. International Conference on 3D Vision, 2020
16 Kwang Moo Yi, Eduard Trulls, Vincent Lepetit, Pascal Fua. LIFT: Learned Invariant Feature Transform. ECCV 2016
17 Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, Torsten Sattler
18 Zhengqi Li and Noah Snavely. Megadepth: Learning single-view depth prediction from internet photos. CVPR, 2018
19 Angela Dai, Angel X Chang, Manolis Savva, Maciej Hal-ber, Thomas Funkhouser, and Matthias Niessner. ScanNet:Richly-annotated 3d reconstructions of indoor scenes. CVPR, 2017
20 Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and IlliaPolosukhin. Attention is all you need. NeurIPS, 2017
21 Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. NIPS, 2013
22 Jay S., Rabatel G., Hadoux X., Moura D. and Gorretta N. In-field crop row phenotyping from 3D modeling performed using Structure from Motion. Computers and Electronics in Agriculture, 110, 70-77, 2015
23 T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona,D. Ramanan, P. Dollar, and L. Zitnick. Microsoft. COCO: Common objects in context. ECCV, 2014