Kernel-U-Net: Multivariate Time Series Forecasting
using Custom Kernels
Abstract
Time series forecasting task predicts future trends based on historical information. Transformer-based U-Net architectures, despite their success in medical image segmentation, have limitations in both expressiveness and computation efficiency in time series forecasting as evidenced in YFormer. To tackle these challenges, we introduce Kernel-U-Net, a flexible and kernel-customizable U-shape neural network architecture. The kernel-U-Net encoder compresses the input series into latent vectors, and its symmetric decoder subsequently expands these vectors into output series. Specifically, Kernel-U-Net separates the procedure of partitioning input time series into patches from kernel manipulation, thereby providing the convenience of executing customized kernels. Our method offers two primary advantages: 1) Flexibility in kernel customization to adapt to specific datasets; and 2) Enhanced computational efficiency, with the complexity of the Transformer layer reduced to linear. Experiments on seven real-world datasets, demonstrate that Kernel-U-Net’s performance either exceeds or meets that of the existing state-of-the-art model in the majority of cases in channel-independent settings. The source code for Kernel-U-Net will be made publicly available for further research and application.
1 Laboratoire Images, Signaux et Systèmes Intelligents (LISSI), Université Paris-Est Créteil , Île-de-France, France
2 Département Informatique et Télécommunication, ESIEE Paris-Université Gustave Eiffel, Île-de-France, France
3 HN-Services, Île-de-France, France
4 Artificial Intelligence Laboratory, UMT, Tirana-Albanie
Proceedings of the 18th International Conference On Innovations In Intelligent Systems And Applications, Craiova, Romania, 2024.
I Introduction
Time series forecasting predicts future trends based on recent historical information. It allows experts to track the incoming situation and react timely in critical cases. Its applications range from different domains such as predicting the road occupancy rates from different sensors in the city [1], monitoring influenza-like illness weekly patient cases [2], monitoring electricity transformer temperature in the electric power long-term deployment [3] or forecasting temperature, pressure and humidity in weather station [4] etc.

Over the past few decades, time series forecasting solutions have evolved from traditional statistical methods[5] and machine learning techniques[6] to deep learning-based solutions, such as recurrent neural networks(RNN) [7], Long Short-term Memory (LSTM) [8], Temporal Convolutional Network (TCN) [9] and Transformer-based model [10].
Among the Transformer models applying to time series data, Informer [3], Autoformer [2], and FEDformer [11] are the best variants that incrementally improved the quality of prediction. As a recent paper [12] challenges the efficiency of Transformer-based models with a simple linear layer model NLinear, the authors in [13] argued that the degrades of performance comes from the wrong application of transformer modules on a point-wise sequence and the ignorance of patches. By adding a linear patch layer, their model PatchTST successfully relieved the overfitting problem of transformer modules and reached state-of-the-art results.
We observe that models display distinct strengths depending on the dataset type. For instance, NLinear stands out for its efficiency in handling univariate time series tasks, particularly with small-size datasets. On the other hand, PatchTST is noteworthy for its expressiveness in multivariate time series tasks on large-size datasets. These contrasting attributes highlight the necessity for a unified but flexible architecture. This architecture would aim to integrate various modules easily, allowing for specific customized solutions. Such integration should not only ensure a balance between computational efficiency and expressiveness but also respond to requests for rapid development and testing.
The Convolutional U-net, as a classic and highly expressive model in medical image segmentation[14], features a symmetric encoder and decoder structure that is elegant in its design. This model’s structure is particularly suited to the time series forecasting task, as both inputs and outputs in this context are typically derived from the same distribution. The first U-shape model adapted for time series forecasting was the Yformer[15], which incorporated Transformers in both its encoder and decoder components. As mentioned previously, employing Transformers on point-wise data has the potential to cause overfitting issues. Therefore, our investigation aims to discover if there is a U-shape architecture effective in time series forecasting, which also possesses the capability to integrate various modules flexibly, thus facilitating the specific customization of solutions.
To tackle this problem, we propose a flexible and kernel-customizable architecture, Kernel-U-Net (K-U-Net), inspired by convolutional U-net, Swin Transformer, and Yformer for time series forecasting. K-U-Net generalizes the concept of convolutional kernel and provides convenience for composing particular models with non-linear kernels. Following the design pattern, K-U-Net can easily integrate custom kernels by replacing linear kernels with Transformer or LSTM kernels. As a result, K-U-Net can gain expressivity by capturing more complex patterns and dependencies in the data.
Furthermore, the hierarchical structure of K-U-Net exponentially reduces the input length at each level, thereby concurrently decreasing the complexity involved in learning such sequences. Notably, when Transformer modules are utilized in the second or higher-level layers, the computation cost remains linear, ensuring efficiency in processing.
To fully study the performance and efficiency of K-U-Net, we conduct experiments for time series forecasting tasks on several widely used benchmark datasets. We compose 30 variants of K-U-Net by placing different kernels at different layers and then we choose the best candidates for fine-tuning. Our results show that in time series forecasting, K-U-Net exceeds or meets the state-of-the-art results, such as NLinear[12] and PatchTST, in the majority of cases.
In summary, the contributions of this work include:
-
•
We propose Kernel-U-Net, a U-shape architecture that progressively compresses the input sequence into a latent vector and expands it to generate the output sequence.
-
•
Kernel-U-Net generalizes the concept of the convolutional kernel and provides convenience for composing particular models with custom kernels.
-
•
The computation complexity is guaranteed in linear when employing Transformer kernels at the second or higher layers.
-
•
Kernel-U-Net exceeds or meets the state-of-the-art results in most cases.
We conclude that Kernel-U-Net stands out as a highly promising option for large-scale time series forecasting tasks. Its hierarchical design provides a balance of low computational complexity and high expressiveness. In most scenarios, it either surpasses or is slightly below the state-of-the-art results. Furthermore, its adaptability in fast-paced development and testing environments is ensured by the use of flexible, customizable kernels.
II Related works
II-1 Transformer
Transformer [16] was initially introduced in the field of Natural Language Processing (NLP) on language translation tasks. It contains a layer of positional encoding, blocks composed of layers of multiple head attentions, and a linear layer with SoftMax activation. As it demonstrated outstanding performance on NLP tasks, many researchers follow this technique route.
Vision Transformers (ViTs) [17] applied a pure transformer directly to sequences of image patches to classify the full image and outperformed CNN based method on ImageNet[18]. Swin Transformer [19] proposed a hierarchical Transformer whose representation is computed with shifted windows. As a shifted window brings greater efficiency by limiting self-attention computation to non-overlapping local windows, it also allows cross-window connection. This hierarchical architecture has the flexibility to model at various scales and has linear computational complexity concerning image size.
In time series forecasting, the researchers were also attracted by transformer-based models. LogTrans [10] proposed convolutional self-attention by employing causal convolutions to produce queries and keys in the self-attention layer. To improve the computation efficiency, the authors propose also a LogSparse Transformer with only space complexity to break the memory bottleneck. Informer [3] has an encoder-decoder architecture that validates the Transformer-like model’s potential value to capture individual long-range dependency between long sequences. The authors propose a ProbSparse self-attention mechanism to replace the canonical self-attention efficiently. It achieves the time complexity and memory usage on dependency alignments. Pyraformer[20] simultaneously captures temporal dependencies of different ranges in a compact multi-resolution fashion. Theoretically, by choosing parameters appropriately, it achieves concurrently the maximum path length of and the time and space complexity of in forward pass. PatchTST employs ProbSparse and a linear projection patch layer to reduce the computational complexity of the transformer to , where is patch size. However, its flattened head still incurs a computational cost of .
Meanwhile, another family of transformer-based models combines the transformer with the traditional method in time series processing. Autoformer [2] introduces an Auto-Correlation mechanism in place of self-attention, which discovers the sub-series similarity based on the series periodicity and aggregates similar sub-series from underlying periods. Frequency Enhanced Decomposed Transformer (FEDformer)[11] captures global properties of time series with seasonal-trend decomposition. The authors proposed Fourier-enhanced blocks and Wavelet-enhanced blocks in the Transformer structure to capture important time series patterns through frequency domain mapping.
II-2 U-Net
U-Net is a neural network architecture designed primarily for medical image segmentation [14]. U-net is composed of an encoder and a decoder. At the encoder phase, a long sequence is gradually reduced by a convolutional layer and a max-pooling layer into a latent vector. At the decoder stage, the latent vector is developed by a transposed convolutional layer for generating an output with the same shape as the input. With the help of skip-connection between the encoder and decoder, U-Net can also capture and merge low-level and high-level information easily.
With such a neat structural design, U-Net has achieved great success in a variety of applications such as medical image segmentation [14], biomedical 3D-Image segmentation [21], time series segmentation [22], image super-resolution [23] and image denoising [24]. Its techniques evolve from basic 2D-U-Net to 3D U-Net [21], 1D-U-Net [25] and Swin-U-Net [26] that only use transformer blocks at each layer of U-Net.
In time series processing, U-time [22] is a U-Net composed of convolutional layers for time series segmentation tasks, and YFormer [15] is the first U-Net based model for time series forecasting task. In particular, YFormer applied transformer blocks on each layer of U-Net and capitalized on multi-resolution feature maps effectively.
II-3 Hierarchical and hybrid model
In time series processing, the increasing size of data degrades the performance of deep models and, crucially, increases the cost of learning them. For example, recurrent models such as RNN, LSTM, GRU have a linear complexity but suffer the gradient vanishing problem when input length increases. Transformer-based block captures better long dependencies but requires computations in general. To balance the expressiveness of complex models and computational efficiency, researchers investigated hybrid models that merge different modules into the network and hierarchical architectures.
For example, authors in [27] investigated a tree structure model made of bidirectional RNN layers and concatenation layers for skeleton-based action recognition, authors in [28] stacked RNN and LSTM with Attention mechanism for semantic relation classification of text, authors in [29] applied hierarchical LSTM and GRU for document classification. In time series processing, the authors in [30] combine Deep Belief Network (DBN) and LSTM for sleep signal pattern classification.
To meet the demand of balancing the quality of prediction and efficiency in learning Transformer-based models, researchers proposed hierarchical structure in Swin-Transformer [19], pyramidal structure in Pyraformer [20], U-shape structure in Yformer [15] or patch layer in PatchTST [13].
Kernel-U-Net is a U-shape architecture that exponentially reduces the input length at each level, thereby concurrently decreasing the complexity involved in learning long sequences. Kernel-U-Net separates the procedure of partitioning input time series into patches from kernel manipulation, thereby providing the convenience of executing customized kernels. By replacing linear kernels with transformer or LSTM kernels, the model gains enhanced expressiveness, allowing it to capture more complex patterns and dependencies in the data. Notably, when Transformer modules are utilized in the second or higher-level layers, the computation cost remains linear, ensuring efficiency in processing.
III Method
III-A Problem Formulation
Let us note by the matrix which represents the multivariate time series dataset, where the first dimension represents the sampling time and the second dimension is the feature size. Let be the length of memory or the look-back window, we denote the historical time series (or for short, . We also denote the future time series , where is the length of future horizon and is the time stamp.
The time series forecasting task takes a multivariate time series as input and predicts a future series. Let be the features at the time step , the length of the look-back window, and the future horizon. Given a historical data series , time series forecasting task predicts the value in the future. Then we can define the basic time series forecasting problem:
| (1) |
where is the function that predicts the future series based on a historical series.
Input: , , ,,,,,, ,,, ,, , ,,, ,,, ,
Output: Instance of Kernel U-Net Encoder
III-B Kernel U-Net
Kernel U-Net (K-U-Net) is a neural network featuring hierarchical and symmetric U-shape architecture. It separates the procedure of partitioning input time series into patches from kernel manipulation, thereby providing the convenience of executing customized kernels (Figure 1). More precisely, the K-U-Net encoder reshapes the input sequence into a large batch of small patches and repeatedly applies custom kernels on them until the latent vector is obtained. Later, the K-U-Net decoder expands the latent vector into patches gradually at each layer and obtains a large batch of small patches (Figure 1). At last, K-U-Net reshapes the patches to get the final output. In the following paragraphs, we describe methods such as the hierarchical partition of the input sequence and the creation of Kernel-U-Net.
III-B1 Hierarchical partition of the input and output
In the first place, We split the input trajectory matrix into patches. Let us consider a trajectory matrix at time step . Given a list of multiples for look-back window and for feature, the patch length and feature unit such that and . We reshape as a set of small patches , where and . The total number of patches is the product of the multiples of length and feature size .
The partitioned patches will be processed by kernels in the encoder gradually and their size will be reduced after the kernel operation at each layer. In the decoder, the patches are generated from vectors of length at each layer. Since the decoder is symmetrical to the encoder, there will also be a trajectory matrix composed of a set of generated patches as output. For a simpler description, we let the look-back window and the forecasting horizon be equal.
Input: , , , , ,
Output: Instance of Kernel Wrapper
III-B2 Hierarchical processing with kernels
The hierarchical processing of Kernel U-Net consists of compressing an input sequence at the encoding stage and generating an output sequence at the decoding stage. By default, kernels reduce the dimension of input at each layer in an encoder and increase the dimension in a decoder. Let us consider , a batch of trajectory matrix , where is the batch size. We now describe the shape of the intermediate patch before and after the kernel operation.
At the encoder stage, we compress input into latent vector . Let us assume that is the unique dimension of the hidden vectors at each intermediate layer and the latent vector to simplify the problem. Firstly, we reshape to then transpose it to and reshape it to . We denote this vector as a large batch of small patches ready for processing with a kernel. Secondly, the kernel at first layer can now process and outputs a hidden vector in shape . After this operation, we reshape the output to of shape as input for the next layer. Iteratively, the encoder processes all the multiples in order, and gives finally a batch of latent vector in shape (Algorithm A).
| Methods | K-U-Net | PatchTST | Nlinear | Dlinear | FEDformer | Autoformer | Informer | Yformer | |||||||||
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
|
ETTh1 |
96 | 0.355 | 0.388 | 0.37 | 0.4 | 0.374 | 0.394 | 0.375 | 0.399 | 0.376 | 0.419 | 0.449 | 0.459 | 0.865 | 0.713 | 0.985 | 0.74 |
| 192 | 0.388 | 0.412 | 0.413 | 0.429 | 0.408 | 0.415 | 0.405 | 0.416 | 0.42 | 0.448 | 0.5 | 0.482 | 1.008 | 0.792 | 1.17 | 0.855 | |
| 336 | 0.407 | 0.427 | 0.422 | 0.44 | 0.429 | 0.427 | 0.439 | 0.443 | 0.459 | 0.465 | 0.521 | 0.496 | 1.107 | 0.809 | 1.208 | 0.886 | |
| 720 | 0.430 | 0.454 | 0.447 | 0.468 | 0.44 | 0.453 | 0.472 | 0.49 | 0.506 | 0.507 | 0.514 | 0.512 | 1.181 | 0.865 | 1.34 | 0.899 | |
|
ETTh2 |
96 | 0.269 | 0.335 | 0.274 | 0.337 | 0.277 | 0.338 | 0.289 | 0.353 | 0.346 | 0.388 | 0.358 | 0.397 | 3.755 | 1.525 | 1.335 | 0.936 |
| 192 | 0.332 | 0.377 | 0.339 | 0.379 | 0.344 | 0.381 | 0.383 | 0.418 | 0.429 | 0.439 | 0.456 | 0.452 | 5.602 | 1.931 | 1.593 | 1.021 | |
| 336 | 0.355 | 0.400 | 0.329 | 0.384 | 0.357 | 0.400 | 0.448 | 0.465 | 0.496 | 0.487 | 0.482 | 0.486 | 4.721 | 1.835 | 1.444 | 0.96 | |
| 720 | 0.384 | 0.435 | 0.379 | 0.422 | 0.394 | 0.436 | 0.605 | 0.551 | 0.463 | 0.474 | 0.515 | 0.511 | 3.647 | 1.625 | 3.498 | 1.631 | |
|
ETTm1 |
96 | 0.275 | 0.331 | 0.29 | 0.342 | 0.306 | 0.348 | 0.299 | 0.343 | 0.379 | 0.419 | 0.505 | 0.475 | 0.672 | 0.571 | 0.849 | 0.669 |
| 192 | 0.320 | 0.361 | 0.332 | 0.369 | 0.349 | 0.375 | 0.335 | 0.365 | 0.426 | 0.441 | 0.553 | 0.496 | 0.795 | 0.669 | 0.928 | 0.724 | |
| 336 | 0.349 | 0.380 | 0.366 | 0.392 | 0.375 | 0.388 | 0.369 | 0.386 | 0.445 | 0.459 | 0.621 | 0.537 | 1.212 | 0.871 | 1.058 | 0.786 | |
| 720 | 0.401 | 0.412 | 0.416 | 0.42 | 0.433 | 0.422 | 0.425 | 0.421 | 0.543 | 0.49 | 0.671 | 0.561 | 1.166 | 0.823 | 0.955 | 0.703 | |
|
ETTm2 |
96 | 0.157 | 0.243 | 0.165 | 0.255 | 0.167 | 0.255 | 0.167 | 0.26 | 0.203 | 0.287 | 0.255 | 0.339 | 0.365 | 0.453 | 0.487 | 0.529 |
| 192 | 0.213 | 0.283 | 0.22 | 0.292 | 0.221 | 0.293 | 0.224 | 0.303 | 0.269 | 0.328 | 0.281 | 0.34 | 0.533 | 0.563 | 0.789 | 0.705 | |
| 336 | 0.266 | 0.320 | 0.274 | 0.329 | 0.274 | 0.327 | 0.281 | 0.342 | 0.325 | 0.366 | 0.339 | 0.372 | 1.363 | 0.887 | 1.256 | 0.904 | |
| 720 | 0.343 | 0.377 | 0.362 | 0.385 | 0.368 | 0.384 | 0.397 | 0.421 | 0.421 | 0.415 | 0.433 | 0.432 | 3.379 | 1.338 | 2.698 | 1.297 | |
|
Electricity |
96 | 0.128 | 0.219 | 0.129 | 0.222 | 0.141 | 0.237 | 0.14 | 0.237 | 0.193 | 0.308 | 0.201 | 0.317 | 0.274 | 0.368 | - | - |
| 192 | 0.145 | 0.234 | 0.147 | 0.24 | 0.154 | 0.248 | 0.153 | 0.249 | 0.201 | 0.315 | 0.222 | 0.334 | 0.296 | 0.386 | - | - | |
| 336 | 0.160 | 0.250 | 0.163 | 0.259 | 0.171 | 0.265 | 0.169 | 0.267 | 0.214 | 0.329 | 0.231 | 0.338 | 0.3 | 0.394 | - | - | |
| 720 | 0.196 | 0.283 | 0.197 | 0.29 | 0.21 | 0.297 | 0.203 | 0.301 | 0.246 | 0.355 | 0.254 | 0.361 | 0.373 | 0.439 | - | - | |
|
Traffic |
96 | 0.354 | 0.229 | 0.36 | 0.249 | 0.41 | 0.279 | 0.41 | 0.282 | 0.587 | 0.366 | 0.613 | 0.388 | 0.719 | 0.391 | - | - |
| 192 | 0.372 | 0.262 | 0.379 | 0.25 | 0.423 | 0.284 | 0.423 | 0.287 | 0.604 | 0.373 | 0.616 | 0.382 | 0.696 | 0.379 | - | - | |
| 336 | 0.388 | 0.270 | 0.392 | 0.264 | 0.435 | 0.29 | 0.436 | 0.296 | 0.621 | 0.383 | 0.622 | 0.337 | 0.777 | 0.42 | - | - | |
| 720 | 0.430 | 0.269 | 0.432 | 0.286 | 0.464 | 0.307 | 0.466 | 0.315 | 0.626 | 0.382 | 0.66 | 0.408 | 0.864 | 0.472 | - | - | |
|
Weather |
96 | 0.142 | 0.183 | 0.149 | 0.198 | 0.182 | 0.232 | 0.176 | 0.237 | 0.217 | 0.296 | 0.266 | 0.336 | 0.3 | 0.384 | - | - |
| 192 | 0.187 | 0.226 | 0.194 | 0.241 | 0.225 | 0.269 | 0.22 | 0.282 | 0.276 | 0.336 | 0.307 | 0.367 | 0.598 | 0.544 | - | - | |
| 336 | 0.238 | 0.269 | 0.245 | 0.282 | 0.271 | 0.301 | 0.265 | 0.319 | 0.339 | 0.38 | 0.359 | 0.395 | 0.578 | 0.523 | - | - | |
| 720 | 0.308 | 0.323 | 0.314 | 0.334 | 0.338 | 0.348 | 0.323 | 0.362 | 0.403 | 0.428 | 0.419 | 0.428 | 1.059 | 0.741 | - | - |
At the stage of the decoder, the operations are reversed. We start with of shape , a set of input patches to the decoder. We send it to decoder kernel and get an output in shape , then we reshape it to in shape for the next kernel. At the end of this iteration over multiples , we finally have a set of patches in the shape . The last operations are reshaping it into , transposing it into and reshaping it into as final output.
III-B3 Kernel Wrapper
The Kernel Wrapper (KW) requires necessary parameters such as kernel , input patches , output patches , patches set size , input patch length and dimension , output patch length and dimension . The kernel wrapper initiates an instance of a given kernel and calls it in the forward function. It reshapes the input patches, executes with the kernel inside, and then checks the output shape. The wrapper processes and outputs in the encoder, or it processes the sum of and an encoder output via skip connection, then gives an output in the decoder (Algorithm B).
III-B4 Formulation of Kernel Operation
We add enc and dec in the index of variables to differentiate their utilization in the encoder and decoder. We denote and the set of patches, the index of layers, and the patches set size. By default, an encoder kernel at layer receives and gives . The decoder kernel at layer receives and outputs .
We recall that are the indices for multiples of length and feature at layer . Given a set of input at layer , the output of kernel in encoder is written :
| (2) |
The decoder kernel at layer takes the sum of input and encoder output via the skip connection as input and produces as output:
| (3) |
Remark that in case of , we have because there are no higher layers and the kernel only process the encoder output.
III-B5 Creation of Kernel U-Net
We create the encoder, decoder, and the U-Net in order. The algorithm passes parameters describing the multiples, kernels, and hidden dimensions. Let us note the input length , feature dimension , concatenated lists of multiples of look-back window and feature , list of hidden dimension of same size , patch size and feature unit , a list of kernels , latent vector length and dimension . We also use next and prev to iterate over the index . We set the hidden dimension of intermediate output vectors within layers to be equal to that of latent vector for simpler description. It corresponds to channel size in a convolutional network and can be augmented for a larger passage of information if necessary. We describe the creation of the K-U-Net encoder in Algorithm A.
The decoder is symmetrical to the encoder and applies kernels in reverse order. More precisely, the decoder takes and , multiples , kernels and initiates kernel wrappers KW( , KW( , KW( at the highest, intermediate, and lowest layers respectively.
The K-U-Net initiates an encoder and a decoder. In the forward function, the encoder processes the input and generates a list of outputs at each layer and a latent vector. It assigns the skip_out from encoder kernels to skip_in in decoder kernels. Then the decoder takes the outputs from the encoder via skip-connection and the latent vector to generate the final result.

III-C Custom Kernels
III-C1 Linear kernel
The linear kernel is a simple matrix multiplication. Given , linear kernel reshape it to and process it as follow:
| (4) |
where is output of kernel, is weight matrix and is bias vector. Remark that the number of parameters of is and this kernel operation is equivalent to the process with a 1D convolutional layer whose kernel size is or .
III-C2 Multi-Layer Perceptron kernel
The multi-layer perceptron (MLP) kernel has an additional hidden layer and a non-linear activation function Tanh. The formulation is:
| (5) |
where is output of kernel, and are weight matrices , and are bias vectors, and .
III-C3 Transformer kernel
III-C4 LSTM kernel
III-D Complexity Analysis
Since the K-U-Net is symmetric, we only study the complexity of the encoder layer and assume that the feature size is . Let us suppose that a kernel is receiving a sequence of length where and all are equal. As the patch size in the first layer of Kernel U-Net encoder is , a kernel module will process patches of size . Therefore, the complexity is where is the complexity inside the kernel in the function of patch size and is the index of the layer. In the case of using the linear kernel at the first layer, the complexity is = . In the case of using a classic transformer kernel, the complexity is = . Let us set , the complexity of the application of such a quadratic calculation kernel is . Moreover, if we apply the transformer kernel starting from the second layer, the complexity is dramatically reduced to = . Following the same demonstration, the complexity of using LSTM kernels and MLP starting from the second layer is also bounded by .
IV Experiments and Results
IV-1 Datasets
We conducted experiments with our proposed Kernel U-Net on 7 public datasets, including 4 ETT (Electricity Transformer Temperature) datasets222https://github.com/zhouhaoyi/ETDataset (ETTh1, ETTh2, ETTm1, ETTm2), Weather333https://www.bgc-jena.mpg.de/wetter/, Traffic444http://pems.dot.ca.gov and Electricity555https://archive.ics.uci.edu/ml/datasets/ElectricityLoadDiagrams20112014. These datasets have been benchmarked and publicly available on[2] and the description of the dataset is available in [12].
Here, we followed the experiment setting in [12] and partitioned the data to months for training, validation, and testing respectively for the ETT dataset. The data is split to for training, validation, and testing for the Weather, Traffic, and Electricity datasets.
IV-2 Baselines and Experimental Settings
We follow the experiment setting in NLinear [12] and take step historical data as input then forecast step value in the future where and . We replace the last value normalization by mean value normalization for ETT, Electricity, and Weather datasets, and apply instance normalization[32] for the Traffic dataset. We use Mean Squared Error (MSE) and Mean Absolute Error (MAE) for evaluation as mentioned in [2].
We include recent methods: PatchTST[13], NLinear, DLinear[12], FEDformer [11], Autoformer [2], Informer [3], LogTrans [10] Yformer[15]. We merge the result reported in [13] and [12] for taking their best in a supervised setting and execute Yformer with default parameters in its Github666https://github.com/18kiran12/Yformer-Time-Series-Forecasting.
IV-3 Experiment details
We use a 4-layer K-U-Net for experiments. The list of multiples are respectively {4, 3, 7} and {6, 6, 5} for look-back windows . The bottom patch length is 4 and its width is 1. We reshape the input into for processing with K-U-Net as we follow the channel-independent setting [12] and then reshape it back. The hidden dimensions are 128 for multivariate tasks. The learning rate is selected in . The training epoch is 50 and the patience of early stopping is 10 in general. We use MAE as the loss function.
IV-4 Model Variants Search
We propose 4 kernels for experiments with K-U-Net on 7 datasets. By replacing a linear kernel at different layers with other types of kernels, we search for variants that adapt the dataset. As there are too many variants to name, we note them as ”KUN_kernel_replace_layer (look-back_window)”. For example, KUN_Linear means that the model is made of linear kernels at all layers and the look-back window size is 720, KUN_Transf means that a transformer kernel replaces the linear kernel at the second layer, KUN_Linear means that multilayer perceptron kernels replace the kernels at the second and third layers. We have composed 16 variants with MLP kernels and 7 variants with Transformer and LSTM kernels.


To enumerate all variants that achieve at least once the best result, we report their performance by the average of the top 5 minimum running MSE (Top5MMSE) values on the validation and test set. The search results are reported with a relative score(RS) to the minimum Top5-MMSE:
| (6) |
, where , are variant models in the models set , is a forecasting horizon in , is a look back window in . Relative score notes the best-performed model with 1 and thus helps to identify the high-potential candidates for further fine-tuning examinations.
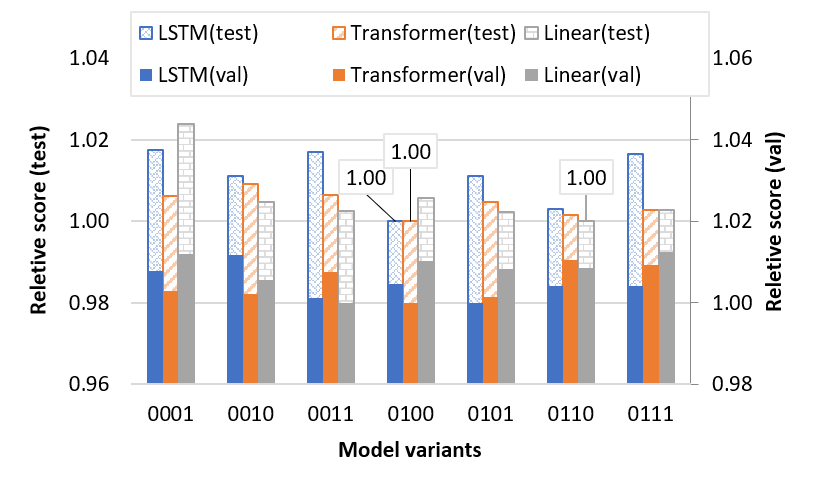
We observe in Figure 3 that the best variant for ETTh1 dataset is KUN_Linear. Comparing the relative score of the K-U-Net of replacelayer code (, ), (, ) and (, ), we remark that replacing the highest layer with Transformer and LSTM kernel degrades the performance because of overfitting. Furthermore, We observe in Figure 5 that the best variants for the Weather dataset are KUN_Linear, KUN_LSTM and KUN_Transf. Comparing the relative score of the K-U-Net of replacelayer code (, ), (, ) and (, ) we remark that replacing the second layer with Transformer and LSTM kernel gains the performance for their expressiveness.
Among candidates in the search phase, we empirically choose 3 variants for fine-tuning experiments with 5 runs. The final result shows that the performance of Kernel U-Net exceeds or meets the state-of-the-art methods in multivariate settings in most cases.
IV-5 Multivariate time series forecasting result
We remark that our model improves the MSE performance around compared with Yformer and compared to PatchTST and NLinear in the multivariate setting (Table I). It is worth noting that K-U-Net achieves similar results on the Electricity dataset with a variant based on MLP kernels.

IV-6 Computation Efficiency
We examined the computation efficiency of 6 variants of K-U-Net, PatchTST, and Yformer. We execute the models on the ETTh1 and ETTm1 datasets for 10 epochs and measure the average execution time per epoch and the GPU consumption during the training. The hidden dimension is set to 128 for all models. For fair comparison, PatchTST and Yformer contain 2 layers of Transformer block which equals to KUN_Transf. All experiments are executed on a Tesla V100 GPU in a Google Colab environment. Comparing to the PatchTST, KUN_Linear saves and memory (Figure 4) and saves and computation time (Figure 6) on ETTh1 and ETTm1 datasets, KUN_Transf saves and memory and saves and computation time respectively.
V Conclusion
In this paper, we propose Kernel-U-Net, a highly potential candidate for large-scale time series forecasting tasks. It provides convenience for composing particular models with custom kernels, thereby it adapts well to particular datasets. As an efficient architecture, it accelerates the procedure of searching for appropriate variants. Kernel-U-Net either exceeds or meets the state-of-the-art results in most cases. In the future, we hope to develop more kernels and hope that Kernel U-Net can be useful for other time series tasks such as classification or anomaly detection.
References
- [1] Lai, G., W.-C. Chang, Y. Yang, et al. Modeling long- and short-term temporal patterns with deep neural networks. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR ’18, page 95–104. Association for Computing Machinery, New York, NY, USA, 2018.
- [2] Wu, H., J. Xu, J. Wang, et al. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P. S. Liang, J. W. Vaughan, eds., Advances in Neural Information Processing Systems, vol. 34, pages 22419–22430. Curran Associates, Inc., 2021.
- [3] Zhou, H., S. Zhang, J. Peng, et al. Informer: Beyond efficient transformer for long sequence time-series forecasting. In The Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference, vol. 35, pages 11106–11115. AAAI Press, 2021.
- [4] Liu, Y., H. Wu, J. Wang, et al. Non-stationary transformers: Exploring the stationarity in time series forecasting. Advances in Neural Information Processing Systems, 2022.
- [5] Khandelwal, I., R. Adhikari, G. Verma. Time series forecasting using hybrid ARIMA and ANN models based on DWT decomposition. Procedia Computer Science, 48:173–179, 2015.
- [6] Persson, C., P. Bacher, T. Shiga, et al. Multi-site solar power forecasting using gradient boosted regression trees. Solar Energy, 150:423–436, 2017.
- [7] Tokgöz, A., G. Ünal. A RNN based time series approach for forecasting turkish electricity load. In 2018 26th Signal Processing and Communications Applications Conference (SIU), pages 1–4. 2018.
- [8] Kong, W., Z. Dong, Y. Jia, et al. Short-term residential load forecasting based on LSTM recurrent neural network. IEEE Transactions on Smart Grid, PP:1–1, 2017.
- [9] Hewage, P., A. Behera, M. Trovati, et al. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Computing, 24(21):16453–16482, 2020.
- [10] Li, S., X. Jin, Y. Xuan, et al. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting, page 11. Curran Associates Inc., Red Hook, NY, USA, 2019.
- [11] Zhou, T., Z. Ma, Q. Wen, et al. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the 39th International Conference on Machine Learning, pages 27268–27286. PMLR, 2022. issns: 2640-3498.
- [12] Zeng, A., M. Chen, L. Zhang, et al. Are transformers effective for time series forecasting? In Proceedings of the AAAI Conference on Artificial Intelligence. 2023.
- [13] Nie, Y., N. H. Nguyen, P. Sinthong, et al. A time series is worth 64 words: Long-term forecasting with transformers. International Conference on Learning Representations, 2023.
- [14] Ronneberger, O., P. Fischer, T. Brox. U-net: Convolutional networks for biomedical image segmentation. In N. Navab, J. Hornegger, W. M. Wells, A. F. Frangi, eds., Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241. Springer International Publishing, 2015.
- [15] Madhusudhanan, K., J. Burchert, N. Duong-Trung, et al. U-net inspired transformer architecture for far horizon time series forecasting. In Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2022, Grenoble, France, September 19–23, 2022, Proceedings, Part VI, page 36–52. Springer-Verlag, Berlin, Heidelberg, 2023.
- [16] Vaswani, A., N. Shazeer, N. Parmar, et al. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, R. Garnett, eds., Advances in Neural Information Processing Systems, vol. 30. Curran Associates, Inc., 2017.
- [17] Dosovitskiy, A., L. Beyer, A. Kolesnikov, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. 2021.
- [18] Deng, J., R. Socher, L. Fei-Fei, et al. Imagenet: A large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), vol. 00, pages 248–255. 2009.
- [19] Liu, Z., Y. Lin, Y. Cao, et al. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9992–10002. IEEE, 2021.
- [20] Liu, S., H. Yu, C. Liao, et al. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. In International Conference on Learning Representations. 2022.
- [21] Çiçek, Ö., A. Abdulkadir, S. S. Lienkamp, et al. 3d u-net: Learning dense volumetric segmentation from sparse annotation. In International Conference on Medical Image Computing and Computer-Assisted Intervention. 2016.
- [22] Perslev, M., M. Jensen, S. Darkner, et al. U-time: A fully convolutional network for time series segmentation applied to sleep staging. In Advances in Neural Information Processing Systems, vol. 32. Curran Associates, Inc., 2019.
- [23] Han, N., L. Zhou, Z. Xie, et al. Multi-level u-net network for image super-resolution reconstruction. Displays, 73:102192, 2022.
- [24] Zhang, K., Y. Li, J. Liang, et al. Practical blind image denoising via swin-conv-UNet and data synthesis. Mach. Intell. Res., 2023.
- [25] Azar, J., G. B. Tayeh, A. Makhoul, et al. Efficient lossy compression for iot using sz and reconstruction with 1d u-net. Mob. Netw. Appl., 27(3):984–996, 2022.
- [26] Cao, H., Y. Wang, J. Chen, et al. Swin-unet: Unet-like pure transformer for medical image segmentation. In L. Karlinsky, T. Michaeli, K. Nishino, eds., Computer Vision – ECCV 2022 Workshops, pages 205–218. Springer Nature Switzerland, 2023.
- [27] Du, Y., W. Wang, L. Wang. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1110–1118. 2015.
- [28] Xiao, M., C. Liu. Semantic relation classification via hierarchical recurrent neural network with attention. In Y. Matsumoto, R. Prasad, eds., Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 1254–1263. The COLING 2016 Organizing Committee, 2016.
- [29] Kowsari, K., D. E. Brown, M. Heidarysafa, et al. HDLTex: Hierarchical deep learning for text classification. In 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pages 364–371. 2017.
- [30] Hong, J., J. Yoon. Multivariate time-series classification of sleep patterns using a hybrid deep learning architecture. In 2017 IEEE 19th International Conference on e-Health Networking, Applications and Services (Healthcom), pages 1–6. 2017.
- [31] Hochreiter, S., J. Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, 1997.
- [32] Ulyanov, D., A. Vedaldi, V. Lempitsky. Instance normalization: The missing ingredient for fast stylization, 2017.