KE-RCNN: Unifying Knowledge based Reasoning into Part-level Attribute Parsing
Abstract
Part-level attribute parsing is a fundamental but challenging task, which requires the region-level visual understanding to provide explainable details of body parts. Most existing approaches address this problem by adding a regional convolutional neural network (RCNN) with an attribute prediction head to a two-stage detector, in which attributes of body parts are identified from local-wise part boxes. However, local-wise part boxes with limit visual clues (i.e., part appearance only) lead to unsatisfying parsing results, since attributes of body parts are highly dependent on comprehensive relations among them. In this article, we propose a Knowledge Embedded RCNN (KE-RCNN) to identify attributes by leveraging rich knowledges, including implicit knowledge (e.g., the attribute “above-the-hip” for a shirt requires visual/geometry relations of shirt-hip) and explicit knowledge (e.g., the part of “shorts” cannot have the attribute of “hoodie” or “lining”). Specifically, the KE-RCNN consists of two novel components, i.e., Implicit Knowledge based Encoder (IK-En) and Explicit Knowledge based Decoder (EK-De). The former is designed to enhance part-level representation by encoding part-part relational contexts into part boxes, and the latter one is proposed to decode attributes with a guidance of prior knowledge about part-attribute relations. In this way, the KE-RCNN is plug-and-play, which can be integrated into any two-stage detectors, e.g., Attribute-RCNN, Cascade-RCNN, HRNet based RCNN and SwinTransformer based RCNN. Extensive experiments conducted on two challenging benchmarks, e.g., Fashionpedia and Kinetics-TPS, demonstrate the effectiveness and generalizability of the KE-RCNN. In particular, it achieves higher improvements over all existing methods, reaching around 3% of on Fashionpedia and around 4% of on Kinetics-TPS. Code and models are publicly available at: https://github.com/sota-joson/KE-RCNN.
Index Terms:
Attribute Parsing; Object Detection; Knowledge Modeling.I Introduction
Part-level attribute parsing refers to localize human body parts and identify their attributes within an image, in which multiple persons and countable body parts with their attributes are expected to be resolved in a unified pipeline. It is a fundamental task in computer vision, as it provides fine-grained human understanding an explainable structure of a person. Optimally addressing this task would greatly support a wide range of human-centric applications, such as human fashion analysis [1, 2, 3, 4] and human behavior analysis [5, 6, 7].
Over the past decade, we have witnessed tremendous success in instance-level recognition tasks due to the advances in regional convolution neural networks (RCNNs). Numerous RCNN based frameworks such as FPN[8], Mask-RCNN[9], Cascade-RCNN[10] and Transformer based RCNN[11] have been developed, which have substantially pushed forward the state-of-the-art methods in object detection [8, 12, 13, 10, 14, 15, 16], instance segmentation [9, 17] and human parsing [18, 19, 20, 21, 22]. Inspired by this, recent attempts [4, 6, 5, 7] directly adopt RCNN based frameworks to support part-level attribute parsing, where successful approaches are derived from object detection models by applying a new branch with attribute prediction head on part-level region features. A well-known example is the Attribute-RCNN [4] extended from Mask-RCNN [9], in which part-level attributes are identified from local-wise part boxes. However, local-wise part boxes with limit visual clues (i.e., part appearance only) will lead to unsatisfied parsing results, since many part-level attributes are not only decided by part-self but also relevant to others.

To handle above issue, we argue that not only visual information derived from local-wise part boxes but also relational knowledges representing rich clues of a part are needed. There are two reasons behind this: First, jointly considering part visual information with its implicit knowledge, i.e., parts’ visual/geometry context, is crucial for making a correct attribute recognition. For instance, in Fig. 1 when identifying an attribute of a “Sweatshirt” (e.g., “above-the-hip”), its visual information is not sufficient enough and we also need its visual contextual information (e.g., ), which is a geometry relationship to another part “Pants”. Other attributes, such as “Short” or “Wrist-length” of a sleeve, rely on visual relationships between “sleeve” with other parts. Secondly, explicit knowledge is essential for understanding parts and their attributes, as it is a piece of wisdom summarized from human practice. Humans are able to identify attributes from complex situations with the help of explicit knowledge. For instance, when identifying attributes for “Skirt” in Fig. 1, instead of visually observing for an answer, a human tends to intuitively recall an explicit knowledge to infer a set of candidate attributes for “Skirt”, such as “Symmetrical”, “Mini” and “High-waist”. As a result, related candidate attributes are provided, and meanwhile numerous irrelevant attributes that are associated with other parts are filtered out. In essential, imitating a human decision process is capable of providing more accurate results but not involving extra computation cost for other unrelated parts’ attributes.
Motivated by above analysis, in this paper we aim to answer one question: how to utilize implicit/explicit knowledge to enhance part-level attribute parsing. To tackle this, we propose a Knowledge Embedded regional convolution neural network (KE-RCNN), which is a simple yet effective RCNN based framework for part-level attribute parsing. It follows an encoder-decoder design pattern that involves two novel components: (1) Implicit Knowledge based Encoder (IK-En) and (2) Explicit Knowledge based Decoder (EK-De). Specifically, the IK-En is designed to enhance part-level representation by encoding implicit knowledge about - relational contexts into part boxes, where it smartly decides which - relations are needed and what contexts to add. After that, the EK-De is proposed to identify attributes from the part-level representation with a guidance of prior knowledge about part-attribute relations, which is derived from statistical priors. With the help of proposed knowledge modeling, the KE-RCNN outperforms state-of-the-art part-level attribute parsing methods. In particular, our KE-RCNN achieves a significant improvement by around 3% of on Fashionpedia and around 4% of on Kinetics-TPS.
To summarize, our main contributions are three-folds:
-
(1)
We propose an effective part-level attribute parsing method named Knowledge Embedded RCNN (KE-RCNN), which identifies part-level attributes by jointly considering visual clues of a part as well as relational knowledge modeling, including implicit knowledge modeling and explicit knowledge modeling.
-
(2)
The KE-RCNN is designed in a play-and-plug fashion and it can be integrated into any two-stage detectors, such as Attribute-RCNN, Cascade-RCNN, HRNet based RCNN and SwinTransformer based RCNN.
-
(3)
Extensive experiments conducted on two challenging benchmarks (i.e., Fashionpedia and Kinetics-TPS) demonstrate the superiority and generalizability of our approach.

II Related Work
Part-level human parsing: Traditionally, human parsing aims to segment human bodies into semantic parts. Inspired by the success of RCNN based methods [10, 12, 9, 17], numerous frameworks for part-level human parsing have been developed, which can be categorized into bottom-up, one-stage top-down and two-stage top-down approaches. In general, bottom-up approaches [20, 23, 24, 25] interpret part-level human parsing as a parsing-then-grouping pipeline, where it firstly predicts instance-agnostic body parts and then groups them into corresponding human instances. Different from them, top-down approaches [19, 26, 18, 27, 28] firstly detect human instances and then parse each human parts independently, which becomes the mainstream solution in part-level human parsing. Furthermore, the major difference between one-stage and two-stage is whether the human detection branch is combined together with part-level RCNN in a unified manner. In a different line of part-level human parsing, recent works [4, 6, 5, 7] make one more step forward to part-level attribute parsing. In these works, they follow the traditional pipeline and adopt local-wise reasoning by propagating regional visual content only, which may fail since surrounding context of a part is usually required. Instead, our method infers attribute with the help of knowledge modeling, thus improving overall performance of part-level attribute parsing as demonstrated in Section IV.
Knowledge modeling: Many works try to enhance deep neural networks by incorporating external knowledges. According to the formation of knowledges, these works can be classified into implicit knowledge based methods and explicit knowledge based methods. Note that implicit knowledge is usually stored in learned models and explicit knowledge is often summarized by human beings. In recent years, knowledge distillation technique and self-attention mechanism are widely used in implicit knowledge based methods [29, 30, 31, 11]. For example, some works [30, 31] build an implicit knowledge for object detection by training a high-capacity model. Then, they set this trained model as a “teacher” and enhance other object detectors with small capacity by distilling implicit knowledge from the “teacher”. In [11, 32], implicit knowledge about visual context of an object is modeled by an attention mechanism, where only relevant contexts of the object are utilized to facilitate accurate object recognition. On the other hand, explicit knowledge based methods adopt statistical priors as the explicit knowledge. In general, the statistical priors are often constructed from large-scale data sources (e.g., Wikipedia or Visual Genome), which record general relations among categories. Therefore, previous works cast those priors as the feature representations and encode them into deep neural networks for addressing the issue of class-imbalance, which facilitates many visual tasks such as scene graph generation [33, 34, 35], object detection [36] and human parsing [19]. Though impressive, how to explore knowledge to part-level attribute parsing, still remains an open question. As a supplement to them, our method can be viewed as an early attempt to jointly explore implicit and explicit knowledge in the area of part-level attribute parsing.
III Methodology
In this section, we firstly revisit standard part-level attribute parsing based on Regional Convolution Networks (RCNNs). Then, we give a technical description of our proposed method.
III-A RCNN-based Part-level Attribute Parsing
Given an input image , the goal of part-level attribute parsing is to localize body parts and identify attributes for each localized part. Traditionally, a standard pipeline utilizes a backbone network (e.g., ResNet) to project an image to a feature with a size of , where indicates the number of channes and denotes spatial size. Then, numerous region proposals are provided by applying a region proposal network [37]. Finally, a detection branch, which is a standard RCNN architecture [4] with a box classifier , a location regressor as well as an attribute classifier , is adopted to simultaneously locate body parts and identify attributes from the region proposals. It is worth noting that attribute parsing depends on the region proposals within the standard pipeline. However, region proposals are low-qualified bounding boxes as they are needed to further refined in RCNN. Therefore, parsing attributes conditioning on region proposals lead to numerous false predictions.
III-B Knowledge Embedded RCNN
In this section, we introduce our proposed method for part-level attribute parsing. An overview of our proposed framework is presented in Fig. 2. Different from standard pipeline that unifies part detection and attribute parsing into one RCNN branch, our method decouples attribute parsing from the standard pipeline and establishes an independent branch, named as KE-RCNN, for attribute parsing. In this setting, we first utilize a standard RCNN to refine region proposals, obtaining final detected boxes of body parts. Then, we apply RoIAlign method [9] to extract part features from final detected boxes instead of low-qualified region proposals. To identify attributes for each detected part, our KE-RCNN first utilizes an Implicit Knowledge based Encoder (IK-En) to enhance the part feature by incorporating part-part relational contexts. Then, under a guidance of explicit knowledge about part-attribute relations, candidate attribute queries that are relevant to the part are provided. Next, conditioning on candidate attribute queries, the enhanced part feature is further projected to attribute embeddings by applying an Explicit Knowledge based Decoder (EK-De). Finally, a calculated similarity between generated attribute embeddings and attribute queries, is used to identify attributes of the part.
Notations. Before presenting details of our KE-RCNN, we give some notations for clarity. Firstly, we denote as a detected person and as one of associative body parts that belong to . Their features extracted by RoIAlign are denoted as and , respectively. In addition, and are spatial sizes of features. We denote as a predicted categorical distribution about the part , where is the number of part classes.
III-B1 Implicit Knowledge Encoder
One of our goal is to fully explore implicit knowledge for enhancing part-level attribute parsing. In the following, we discuss the two major components (i.e., visual and geometry context encoding) of our Implicit Knowledge based Encoder (IK-En).
Visual context encoding: Note that each pixel-level person feature represents a set of parts covering the whole person . Thus, a part feature can be enhanced by incorporating its visual context relations with other parts by considering relations between and . Following [38], we start from evenly splitting part representation into two subsets, respectively denoted as and , which enables our encoder with strong multi-scale feature extraction ability, while maintaining a similar computation cost. Furthermore, each subset has different spatial size and number of channels compared with the person representation . In our encoder the is used to represent part visual information, while the is further utilized to encode visual contexts by interacting with . Specifically, we first compute an affinity matrix by comparing with across all spatial size. Then, each pixel feature in person representation is fused into part representation w.r.t the affinity matrix. Formally, we cast this process as Eq. 1:
| (1) |
where , and are linear matrices that project and into a common embedding space. is the standard function. is an affinity matrix, which decides what visual context in is needed to propagate to the part. is an updated part feature that involves relevant visual contexts. is a learnable matrix, which linearly fuses the part’s visual information and visual contexts to attain a visually enhanced part representation .
Geometry context encoding: In addition to visual contextual relations, recognizing attributes also benefits from geometry contexts of a part. Specifically, a geometry relation between part and person is encoded in their relative locations. Therefore, we represent geometry context of the part through Eq. 2:
| (2) |
where are coordinates and scales extracted from part region and are counterpart from person region. is a linear matrix that maps the relative geometry context into a high dimensional vector . After that, a part representation with implicit knowledge (i.e., visual relation and geometry relation) is obtained by simply fusing and , which is formalized in Eq. 3.
| (3) |
where is a concatenate operation.
III-B2 Explicit Knowledge based Decoder
In this section, we introduce how to identify attributes of the part by our Explicit Knowledge Embedded Decoder (EK-De). In particular, our key idea is to decode attributes relying on human prior knowledge, which differs from former approaches [4, 6] that directly apply an attribute classifier on part representations. Compared with directly applying attribute classifier, decoding with human prior knowledge helps to make a correct attribute recognition, as it alleviates adverse effect from decoding irrelevant attributes. Therefore, we embody the EK-De as a conditional projection , which maps input variable to output variable conditioning on , as well as . For clarity, we denote as a part representation and as decoded attributes. , and respectively represent explicit knowledge, part identifier and attribute queries. Next, we present details of each element.
Explicit knowledge : Statistical relations between part-attribute pairs provide strong priors to infer an attribute, and it is beneficial to identifying attributes of a part. Therefore, we define explicit knowledge as an undirected relation graph , where denotes part categorical nodes and denotes attribute nodes, is a set of edges which encode all pairwise relationships between parts and attributes. Furthermore, we build this graph by calculating a frequent statistics matrix from the occurrence among all part-attribute pairs, where is the number of attribute categories. Specifically, we use all relationship annotations and count frequent statistics of each part-attribute relation. After counting, each element in is further rescaled into (0, 1) by a row normalization.
Part identifier : Categorical distribution indicates probability of each part classes, which is predicted from part detection branch. For simplicity, we directly use it as the part identifier.
Attribute queries : Parameters that come from attribute classifier contain global semantic information about attribute categories since it needs to adapt to all attribute embeddings trained from all part samples. Therefore, we use as initial attribute queries. Given and , attribute queries are further filtered, reminding candidate attribute queries of the part . Formally, we cast this process as Eq. 4:
| (4) |
where denotes a weighting vector that decides which attribute is the candidate. denotes the Hadamard product (element-wise broadcast multiplication) and is the weighted attribute queries. denotes a filtering function that outputs candidate attribute queries conditioning on , where each attribute query is selected as a candidate if its’ corresponding score in is higher than a predefined threshold value (e.g., 0).
Part representation : With all conditions, we now build part representation. Except for enhanced part feature yielded from IK-En, parameters that come from box classifier , are utilized to represent semantics of parts. Next, we project the categorical part representation to categorical attribute representation w.r.t a part identifier , which is formalized by Eq. 5:
| (5) |
where is ReLU nonlinear function and is a linear transformation matrix. is the categorical attribute representation, which is dynamically generated from specific part with part-attribute priors . is the final part representation that embeds implicit knowledge from as well as explicit knowledge from .
Conditional projection : In this work, we define projection function as a composition of two independent functions: , where is a projection function that maps part representation to attribute representation and is a decoding function that identifies attributes of a part. Following[39] , we implement based on standard Transformer, as formalized in Eq. 6:
| (6) |
where is the decoded attribute embeddings. denotes standard multi-head self-attention function that decodes depending on and . is the LayerNorm function for normalizing input feature and is the Multilayer Perceptron that applies nonlinear transformation on input features. It is worth noting that in original Transformer both and are derived from same inputs. However, in our model they are derived from two different representations (i.e., and ), where the former one is dynamically produced according to the particular part . Compared with original version, our model is more flexible and reliable to produce accurate attributes since numerous irrelevant attribute embeddings are removed by Eq. 4.
Next, we define as a similarity measurement based on Euclidean distance. Therefore, attributes of the part are identified through a similarity matrix calculated between and , as formalized in Eq 7.
| (7) |
where is the Sigmoid nonlinear function. is the attribute categorical distribution, where each element indicates predicted probability of attribute category.
IV Experiment
In this section, we perform extensive experiments on two challenging benchmarks, one part-level fashion parsing dataset (i.e., Fashionpedia) and one part-level action parsing dataset (i.e., Kinetics-TPS). In the following, we first introduce implementation details. Then, we compare the proposed KE-RCNN with the previous state-of-the-arts on the two tasks. Next, we perform extensive ablation studies to explore the importance design of KE-RCNN.
IV-A Implementation Details
The KE-RCNN is implemented based on OpenMMLab111https://github.com/open-mmlab on an Ubuntu server with eight Tesla V100 graphic cards. We adopt the FPN, which is pretrained on ImageNet, as backbone model unless otherwise stated. We separately train models on the two aforementioned datasets with their respective annotations. Following common practice used in previous works [8, 9, 11], we use SGD solver for optimizing convolution based model and Adam solver for Transformer based model. When training model on Fashionpedia dataset, learning rate is 1e-4 and it is decreased by 10 at the 28-th and 30-th epoch. Besides, the training is stopped at 32-th epoch. For Kinetics-TPS, we train for 12 epochs, starting from a learning rate of 0.02 and decreasing it by 10 at the 8-th and 11-th epoch. A batch size of 16 is used. To provide full details of our approach, our code is made publicly available.
IV-B Part-level Fashion Parsing on Fashionpedia
| Without Attribute Parsing Branch | |||||||
| Settings | Backbone | Attribute Parsing branch | |||||
| Attribute-RCNN [4] | ResNet50 | - | 26.6 | - | - | - | - |
| Attribute-RCNN [4] | ResNet101 | - | 28.6 | - | - | - | - |
| Attribute-RCNN [4] | SpineNet-49 | - | 32.4 | - | - | - | - |
| Attribute-RCNN [4] | SpineNet-96 | - | 34.0 | - | - | - | - |
| Attribute-RCNN [4] | SpineNet-143 | - | 35.7 | - | - | - | - |
| Attribute-RCNN∗ [4] | ResNet50 | - | 27.3 | 34.2 | 8.0 | 36.9 | 30.4 |
| Attribute-RCNN∗ [4] | ResNet101 | - | 27.9 | 35.0 | 8.0 | 38.1 | 31.4 |
| Cascade-RCNN∗ [10] | ResNet50 | - | 29.3 | 37.1 | 8.2 | 39.0 | 32.1 |
| Cascade-RCNN∗ [10] | ResNet101 | - | 29.2 | 36.7 | 8.6 | 39.2 | 31.8 |
| HRNet∗ [18] | HRNet-W18 | - | 25.7 | 31.9 | 8.0 | 35.1 | 29.1 |
| HRNet∗ [18] | HRNet-W32 | - | 27.6 | 34.2 | 8.6 | 37.8 | 31.1 |
| SwinTransformer∗ [11] | Swin-T | - | 36.2 | 43.0 | 18.6 | 42.2 | 38.0 |
| SwinTransformer∗ [11] | Swin-S | - | 37.3 | 44.2 | 18.9 | 45.2 | 39.3 |
| With Attribute Parsing Branch | |||||||
| Settings | Backbone | Attribute Parsing branch | |||||
| Attribute-RCNN∗ [4] | ResNet50 | Standard RCNN | 35.1 | 40.5 | 20.5 | 39.8 | 36.6 |
| KE-RCNN (Ours) | 39.1 | 44.2 | 26.0 | 40.4 | 38.8 | ||
| Attribute-RCNN∗ [4] | ResNet101 | Standard RCNN | 35.8 | 41.6 | 20.5 | 40.7 | 37.5 |
| KE-RCNN (Ours) | 39.9 | 44.8 | 26.6 | 42.3 | 40.4 | ||
| Cascade-RCNN∗ [10] | ResNet50 | Standard RCNN | 36.9 | 42.2 | 22.1 | 41.9 | 38.5 |
| KE-RCNN (Ours) | 41.2 | 47.0 | 26.2 | 42.5 | 40.7 | ||
| Cascade-RCNN∗ [10] | ResNet101 | Standard RCNN | 39.0 | 45.7 | 22.2 | 43.1 | 40.1 |
| KE-RCNN (Ours) | 42.7 | 48.8 | 26.7 | 44.4 | 42.7 | ||
| HRNet∗ [18] | HRNet-18 | Standard RCNN | 32.7 | 37.0 | 20.1 | 36.7 | 33.2 |
| KE-RCNN (Ours) | 36.4 | 40.4 | 25.7 | 38.1 | 36.3 | ||
| HRNet∗ [18] | HRNet-32 | Standard RCNN | 35.2 | 39.5 | 22.8 | 39.9 | 36.3 |
| KE-RCNN (Ours) | 39.0 | 43.1 | 27.0 | 41.7 | 39.7 | ||
| SwinTransformer∗ [11] | Swin-T | Standard RCNN | 41.0 | 47.1 | 25.8 | 42.6 | 40.5 |
| KE-RCNN (Ours) | 42.1 | 48.2 | 27.3 | 42.8 | 41.2 | ||
| SwinTransformer∗ [11] | Swin-S | Standard RCNN | 43.5 | 49.9 | 27.6 | 46.3 | 43.5 |
| KE-RCNN (Ours) | 44.3 | 51.1 | 28.1 | 45.6 | 43.7 | ||
Dataset and metrics. Fashionpedia dataset [4] is used for evaluating part-level fashion parsing models. It contains 48k images in total, which are collected from Flickr and free license photo websites. It is divided into two subsets: 45623 images for training, 1158 images for validation, respectively. The part-level annotations cover 46 apparel categories, e.g., dress, shorts, leg warmer, and involve 294 attributes, e.g., fit, above-the-knee, regular. Following official settings [4], we adopt to evaluate the performance. It is an extended version of standard detection metric defined in COCO [40], which considers both IoU score for detected part and macro F1 score for predicted attributes of detected part. Based on this, we report standard mean average precision over the validation set: 1) (the mean of box AP scores across all IoU thresholds (ranging from 0.5 to 0.95), all macro F1 scores, and all apparel categories); 2) for outerwear categories; 3) for garment parts categories; 4) (the mean of box AP scores across all IoU thresholds and all apparel categories with a threshold equal to 0.5) and 5) (the mean of box AP scores across all IoU thresholds and all apparel categories with a threshold equal to 0.75).
Main Results. We compare our approach with the state-of-the-art attribute parsing approaches on the Fashionpedia validation set. Specifically, we choose four representative RCNN based models as baselines, including Attribute-RCNN [4], Cascade-RCNN [10], HRNet based RCNN [18] and SwinTransformer based RCNN [11]. In particular, we implement two versions for each baseline model. In the first version, we unify part detection and attribute parsing into one RCNN branch, which is the same as traditional methods [1]. In the second version, we build an independent RCNN branch for attribute parsing, where it identifies attributes from refined detected boxes rather than region proposals. Following common practices [9, 4], we adopt a standard RCNN as the attribute parsing branch in baseline model, where it consists of four consecutive convolutions followed by two fully-connected layers. Tab. I lists several standard evaluation metrics for different method/backbone pairs. For fair comparisons with baseline models, we report our re-implementation results of them, which are comparable to or higher than those were reported in papers.
From the results, we find that all traditional approaches based on standard parsing pipeline are significantly improved after decoupling attribute parsing from standard pipeline, where overall improvements achieve at least 6% . For example, the Attribute-RCNN with proposed KE-RCNN outperforms first version of baselines by 11.8%12.0% when applying different backbones (i.e., ResNet-50 and ResNet-101). On two higher baselines of 29.3% using Cascade-RCNN and 36.2% using Swin-T framework, the gains by KE-RCNN are also high, achieving +11.9% and +5.9% , respectively. It indicates that the performance of attribute parsing increases as identifying attributes from refined boxes, rather than from low-qualified region proposals. The comparison results between two versions of baseline models also support this fact. This is reasonable since attribute parsing depends on part detection. When comparing the KE-RCNN with baseline models based on second version, experimental results in Tab. I also show consistent improvements (e.g., around 3% ) by KE-RCNN at various evaluation metrics, indicating the effectiveness and generalizability of the proposed method. Furthermore, it also demonstrates that implicit and explicit knowledge modeling is a promising direction for attribute parsing.
IV-C Part-level Action Parsing on Kinetics-TPS
Dataset and metrics. For part-level action parsing, we use the Kinetics-TPS dataset222https://deeperaction.github.io/kineticstps/ for model evaluation. It contains 3,809 videos in total, which are collected from a subset of Kinetics dataset [41]. We randomly pick 30% of training set as the validation set, resulting in 2,686 videos for training and 1,123 videos for validation. Following official setting, we report several metrics on the validation set: 1) (the mean of video classification accuracy conditioned on frame-level Part State Correctness (PSC)); 2) (the mean of part-level action classification accuracy); 3) (the mean of box AP scores across all body part categories).
Main Results. Similar to experiments conducted on Fashionpedia, we adopt Attribute-RCNN, Cascade-RCNN, HRNet based RCNN and SwinTransformer based RCNN as the baseline models. Corresponding results are shown in Tab. II. In line with findings from Tab. I, proposed KE-RCNN outperforms baselines by a margin (+2.24.4 ). Based on this, one can conclude that our method performs general improvement on part-level action parsing problem.
| Settings | Attribute Parsing branch | |||
|---|---|---|---|---|
| Attribute-RCNN [4] | Standard RCNN | 49.1 | 64.0 | 84.9 |
| (ResNet50) | KE-RCNN (Ours) | 53.5 | 69.8 | 84.8 |
| Cascade-RCNN [10] | Standard RCNN | 49.0 | 63.5 | 85.0 |
| (ResNet50) | KE-RCNN (Ours) | 53.2 | 69.2 | 84.2 |
| HRNet [18] | Standard RCNN | 52.3 | 66.9 | 86.6 |
| (HRNet-W32) | KE-RCNN (Ours) | 54.5 | 70.4 | 86.2 |
| SwinTransformer [11] | Standard RCNN | 52.2 | 67.2 | 86.2 |
| (Swin-T) | KE-RCNN (Ours) | 56.2 | 72.2 | 86.8 |
| SwinTransformer [11] | Standard RCNN | 54.1 | 68.9 | 87.1 |
| (Swin-S) | KE-RCNN (Ours) | 57.0 | 72.6 | 87.6 |
IV-D Ablation Study
To deeply analyze the proposed method and its components, we conduct extensive ablation studies on Fashionpedia dataset. We choose the decoupling version of Attribute-RCNN with ResNet50 backbone as the baseline model. In the following, we first conduct ablation study to investigate effects of each proposed component. Then, we would like to attain a further insight into implicit knowledge modeling as well as explicit knowledge. After that, we provide a deep analysis of learned models from a visualization aspect.
Ablation studies of each component. The KE-RCNN consists of implicit knowledge based encoder (IK-En) and explicit knowledge based decoder (EK-De). In this section, we would like to investigate the effect of each component for attribute parsing. Based on this, we build two additional variants of KE-RCNN, where each consists of either IK-En or EK-De.
The experimental results are reported in Tab. III, where all models are tested on two benchmarks (i.e., Fashionpedia and Kinetics-TPS). From the results, we have following findings: 1) Both KE-RCNN with IK-En and KE-RCNN with EK-De outperforms standard RCNN on both Fashionpedia validation set (35.1% vs 37.2%, 35.1% vs 38.4%) and Kinetics-TPS validation set (49.1% vs 52.2%, 49.1% vs 51.7%), suggesting that incorporating implicit or explicit knowledge facilitates attribute parsing. 2) The KE-RCNN with EK-De shows better performance (i.e., 37.2% vs 38.4%) than that of KE-RCNN with IK-En for fashion attribute parsing . However, the results are reversed (i.e., 52.2% vs 51.7%) when applying them for action attribute parsing. This suggests that identifying dynamic attributes (e.g., action state) benefits more from implicit knowledges than that from explicit knowledges, while identifying static attributes (e.g., fashion tags) prefers explicit knowledges. 3) Jointly applying IK-En and EK-De brings the best results on both two tasks, suggesting that each component is complementary to each other for attribute parsing.
| Part-level Fashion Attribute Parsing (Fashionpedia) | |||||
| Parsing Branch | IK-En | EK-De | |||
| Standard RCNN | - | - | 35.1 | 40.5 | 20.5 |
| KE-RCNN | ✓ | 37.2 | 41.4 | 24.9 | |
| KE-RCNN | ✓ | 38.4 | 42.9 | 26.0 | |
| KE-RCNN | ✓ | ✓ | 39.1 | 44.2 | 26.0 |
| Part-level Action Attribute Parsing (Kinetics-TPS) | |||||
| Parsing Branch | IK-En | EK-De | |||
| Standard RCNN | - | - | 49.1 | 64.0 | 84.9 |
| KE-RCNN | ✓ | 52.2 | 67.7 | 85.1 | |
| KE-RCNN | ✓ | 51.7 | 67.7 | 84.5 | |
| KE-RCNN | ✓ | ✓ | 53.5 | 69.8 | 84.8 |
| RCNN variants | RoI Size | # Params | |||
|---|---|---|---|---|---|
| Standard RCNN | 61.1M | 35.1 | 40.5 | 20.5 | |
| ASPP RCNN | 256.0M | 35.8 | 41.0 | 22.2 | |
| IK-En | 58.9M | 37.2 | 41.4 | 24.9 |
Ablation studies of part extraction. The global context of a part is the key to attribute parsing. Hence, we investigate various options of part context modeling and compare three different RCNN variants, including: 1) “Standard RCNN”, where the attribute parsing branch consists of four consecutive convolution layers for generating the part representation; 2) “ASPP RCNN”, which refers to inserting multiple dilated convolutions into “Standard RCNN” for enlarging receptive fields of bounding boxes; 3) IK-En, which denotes the KE-RCNN is composed of proposed IK-En only. In particular, we choose “ASPP RCNN” as one of the options due to its effectiveness of contextual modeling on bounding boxes, as demonstrated in [42]. For fair comparison, all models adopt one fully connected layer to predict attributes for a part.
From experimental results summarized in Tab. IV, we observe that replacing “standard RCNN” with “ASPP RCNN” brings minor gains but requires large model size. It suggests that contextual modeling by enlarging visual receptive field has a little effect to attribute parsing, and simply enlarging model capacity has reached performance bottleneck as well. Secondly, the proposed IK-En outperforms “Standard RCNN” by 2.1 and requires less parameters. Similar improvements (i.e., 37.2% vs 35.8%) are also observed when comparing IK-En with ASPP RCNN. It is worth noting that the standard RCNN applies convolution operations on a part bounding box only, which cannot model global contexts of a part. Instead, the ASPP RCNN can incorporate global contexts outside a part bounding box into the part representation via dilated convolutions, but lacks modeling on relevant contexts of a part. Different from them, the IK-En further filters out irrelevant global visual contexts and encodes geometry contexts into the part representation, thus outperforming both Standard RCNN and ASPP RCNN. Consistent improvements demonstrates the importance of implicit knowledge modeling.
| Part representation | |||
|---|---|---|---|
| 39.1 | 44.2 | 26.0 | |
| 38.5 | 43.0 | 26.3 | |
| 38.2 | 42.4 | 26.5 |
Ablation studies of part representation . In KE-RCNN, the part representation is derived from three sources, i.e., visual contexts , geometry contexts and attribute representation conditioning on predicted part . In this section, we investigate the effect of each representation and corresponding experimental results are summarized in Tab. V. Specifically, we choose the the KE-RCNN with a score of 39.1% as the baseline, and gradually remove the and . From the results, we observe that the score of is decreased from 39.1% to 38.5% when removing the conditional attribute representation . It further drops to 38.2% after removing the geometry contexts . Hence, one can conclude that all representations benefit attribute parsing and visual contexts of a part lead to major contribution among them. We conjecture the possible reason is that most attributes rely on visual appearance while only small part of attributes (e.g., above) depends on the geometry relations. Besides, conditional attribute representation provides possible attributes of a part, which are needed to be further refined in EK-De.
| Modifications | |||
|---|---|---|---|
| Averaging | 37.9 | 42.5 | 25.1 |
| Statistics (Fashionpedia) | 39.1 | 44.2 | 26.0 |
| Statistics (Wikipedia) | 39.6 | 44.3 | 27.0 |
Ablation studies of explicit knowledge . In this section, we investigate the important design of explicit knowledge. In particular, the key component of explicit knowledge is the frequent statistics matrix , where it decides whether an attribute is relevant to a part or not. Hence, we compare three different settings based on modifications of : 1) Averaging, where the frequent statistics matrix is defined as an averaging matrix that propagates all attribute queries without filtering. 2) Statistics (Fashionpedia), where the data source used for calculating the frequent statistics matrix is based on annotations in Fashionpedia training set. 3) Statistics (Wikipedia), where the data source used for calculating the frequent statistics matrix comes from all phrases in Wikipedia Corpus333https://dumps.wikimedia.org/. Tab. VI lists corresponding results. From the results, we can find that the explicit knowledge is critical, as the performance decreases by 1.2% (37.9% vs 39.1%) if the explicit knowledge is removed (see 1st and 2nd setting). Furthermore, using explicit knowledge stored in Wikipedia improves the performance from 39.1 to 39.6. This suggests that explicit knowledge is particularly effective for accurate attribute parsing.


| method | Top-5 Hard Classes | Ave. | ||||
|---|---|---|---|---|---|---|
| Collar | Lapel | Sleeve | Neckline | |||
| Attribute-RCNN∗ | 16.0% | 16.9% | 43.7% | 20.8% | 14.2% | 22.3% |
| w KE-RCNN | 19.8% | 36.8% | 46.4% | 24.1% | 21.0% | 29.6% |
| Cascade-RCNN∗ | 17.5% | 17.8% | 46.4% | 23.0% | 16.0% | 24.5% |
| w KE-RCNN | 19.8% | 34.6% | 47.3% | 25.2% | 20.5% | 29.5% |
Analysis of learned model. As demonstrated in [4], current attribute parsing datasets present the characteristic of long-tail, which seriously hinders model’s performance. In particular, parsing models trained on imbalanced datasets are likely dominated by major classes. As shown in Fig. 3, the number of labeled samples for outerwear in Fashionpedia are much larger than that of garment part, resulting in large performance gap (e.g., 26% AP) between them as shown in Fig. 4. To investigate whether proposed KE-RCNN suffers from this or not, we evaluate them on “hard” cases. In particular, these “hard” cases are selected from samples of tail classes. We report evaluation results in Tab. VII. From the results, we observe that our method significantly improves two baselines (+7.3 and +5.0) for parsing those “hard” classes, indicating that the adverse effect caused by imbalanced issue can be alleviated with the proposed method. It is worth noting that the proposed KE-RCNN identifies attributes of a part with the help of general explicit knowledge, thus improving performance for “hard” examples.

To further attain insight into the learned model, we visualize the implicit knowledge that the KE-RCNN utilizes to parse attributes of a part. In particular, the affinity matrix for each part is visualized, since it decides which part of a person feature is used to identify attributes. The visualization results in Fig. 5 shows that the KE-RCNN can well focus on relevant contexts for parsing attributes of a part. For example, when identifying “above-the-hip” for the Jacket, the KE-RCNN focuses on both torso and hip. In terms of action attributes, relevant body parts that perform actions are also captured by the KE-RCNN as well.

Qualitative comparison. In Fig. 6 we show some examples of qualitative part-level attribute parsing results randomly selected from the Fashionpedia dataset. It is clear that our method performs the best while the Attribute-RCNN performs the worst. In addition, given six parts examples, our method provides four parts with completely correct attribute predictions, while the most competitive method Swin-T provides three parts with completely right attributes. To summary, this qualitative results are consistent with the quantitative results shown in Tab. I, which demonstrates the superiority of our proposed method and proves the important role of implicit and explicit knowledge in part-level attribute parsing.
The bottleneck of KE-RCNN. The part-level attribute parsing depends on the precise predictions of sub-tasks, i.e., the body detection, the body part detection and the prediction of attributes. In this section, we perform an experiment to gauge the relative difficulty of sub-tasks, that is, which part is the main bottleneck of part-level attribute parsing so far. We evaluate KE-RCNN on the Fashionpedia dataset as well as Kinetics-TPS dataset, hoping to inspire future research. Specifically, we replace predictions with corresponding ground-truth labels. The results in Tab. VIII suggest that there is still a large room for improvement in part detection and attribute parsing.
In addition, Fig. 7 shows visualization results obtained from predictions for “hard” examples. From Fig. 7, one can conclude that “hard” examples share a common characteristic of “small”. Intuitively, parsing those hard examples requires rich visual contexts. The proposed KE-RCNN jointly encodes such contexts by implicit knowledge modeling as well as explicit knowledge modeling, thus improving overall performance for those “hard” examples. For more details, we refer the reader to supplementary materials.
| Part-leve Fashion Attribute Parsing on Fashionpedia Dataset | |||||
|---|---|---|---|---|---|
| Methods | GT- | ||||
| Attribute-RCNN | 41.9 | 39.1% | 44.2% | 26.0% | |
| ✓ | 99.9% (+58.0%) | 61.4% (+22.3%) | 66.7% (+22.5%) | 42.1% (+16.1%) | |
| Part-level Action Attribute Parsing on Kinetics-TPS Dataset | |||||
| Methods | GT- | GT- | |||
| Attribute-RCNN | 72.8% | 84.8% | 53.5% | ||
| ✓ | 99.9% (+27.1%) | 86.3%(+1.8%) | 54.6% (+1.1%) | ||
| ✓ | ✓ | 99.9% (+27.1%) | 99.9% (+15.1%) | 62.0% (+8.5%) | |

V Conclusion and Discussion
In this paper, we propose an effective method named Knowledge Embedded RCNN (KE-RCNN), aiming at identifying part-level attributes by utilizing implicit and explicit knowledge. By building Implicit Knowledge based Encoder (IK-En), we enhance part representations by incorporating visual contexts as well as geometry contexts. Then Explicit Knowledge based Decoder (EK-De) is proposed to identify attributes of a part by human prior knowledge. Extensive experiments on two benchmarks prove the effectiveness and generalizability of our approach.
References
- [1] N. Inoue, E. Simo-Serra, T. Yamasaki, and H. Ishikawa, “Multi-label fashion image classification with minimal human supervision,” in ICCV, 2017.
- [2] U. Mall, K. Matzen, B. Hariharan, N. Snavely, and K. Bala, “Geostyle: Discovering fashion trends and events,” in ICCV, 2019, pp. 411–420.
- [3] Y. Ge, R. Zhang, X. Wang, X. Tang, and P. Luo, “Deepfashion2: A versatile benchmark for detection, pose estimation, segmentation and re-identification of clothing images.” in CVPR, 2019, pp. 5337–5345.
- [4] M. Jia, M. Shi, M. Sirotenko, Y. Cui, C. Cardie, B. Hariharan, H. Adam, and S. Belongie, “Fashionpedia: Ontology, segmentation, and an attribute localization dataset,” in ECCV, 2020.
- [5] X. Chen, X. Liu, K. Liu, W. Liu, and T. Mei, “A baseline framework for part-level action parsing and action recognition,” arXiv preprint arXiv:2110.03368, 2021.
- [6] Y.-L. Li, L. Xu, X. Liu, X. Huang, Y. Xu, S. Wang, H.-S. Fang, Z. Ma, M. Chen, and C. Lu, “Pastanet: Toward human activity knowledge engine,” in CVPR, 2020.
- [7] X. Wang, X. Chen, L. Gao, L. Chen, and J. Song, “Technical report: Disentangled action parsing networks for accurate part-level action parsing,” arXiv preprint arXiv:2111.03225, 2021.
- [8] T. Lin, P. Dollár, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie, “Feature pyramid networks for object detection,” in CVPR, 2017.
- [9] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick, “Mask R-CNN,” in ICCV, 2017.
- [10] Z. Cai and N. Vasconcelos, “Cascade r-cnn: Delving into high quality object detection,” in CVPR, 2018.
- [11] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in ICCV, 2021.
- [12] Y. Li, Y. Chen, N. Wang, and Z. Zhang, “Scale-aware trident networks for object detection,” in ICCV, 2019.
- [13] J. Pang, K. Chen, J. Shi, H. Feng, W. Ouyang, and D. Lin, “Libra r-cnn: Towards balanced learning for object detection,” in CVPR, 2019.
- [14] X. Zhang, Y. Wei, Y. Yang, and T. S. Huang, “Sg-one: Similarity guidance network for one-shot semantic segmentation,” IEEE Transactions on Cybernetics, 2020.
- [15] G. Chen, H. Wang, K. Chen, Z. Li, Z. Song, Y. Liu, W. Chen, and A. C. Knoll, “A survey of the four pillars for small object detection: Multiscale representation, contextual information, super-resolution, and region proposal,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 52, no. 2, pp. 936–953, 2022.
- [16] J. Li, Z. Pan, Q. Liu, Y. Cui, and Y. Sun, “Complementarity-aware attention network for salient object detection,” IEEE Transactions on Cybernetics, vol. 52, no. 2, pp. 873–886, 2022.
- [17] K. Chen, J. Pang, J. Wang, Y. Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Shi, W. Ouyang, C. C. Loy, and D. Lin, “Hybrid task cascade for instance segmentation,” in CVPR, 2019.
- [18] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in CVPR, 2019, pp. 5693–5703.
- [19] X. Wang, L. Gao, J. Song, and H. T. Shen, “KTN: knowledge transfer network for multi-person densepose estimation,” in ACMMM, 2020, pp. 3780–3788.
- [20] W. Wang, H. Zhu, J. Dai, Y. Pang, J. Shen, and L. Shao, “Hierarchical human parsing with typed part-relation reasoning,” in CVPR, 2020.
- [21] T. Wang, Y. Chen, Z. Lin, A. Zhu, Y. Li, H. Snoussi, and H. Wang, “Recapnet: Action proposal generation mimicking human cognitive process,” IEEE Transactions on Cybernetics, vol. 51, no. 12, pp. 6017–6028, 2021.
- [22] J. Gao, Y. Yuan, and Q. Wang, “Feature-aware adaptation and density alignment for crowd counting in video surveillance,” IEEE Transactions on Cybernetics, vol. 51, no. 10, pp. 4822–4833, 2021.
- [23] K. Gong, X. Liang, Y. Li, Y. Chen, M. Yang, and L. Lin, “Instance-level human parsing via part grouping network,” in ECCV, 2018, pp. 805–822.
- [24] A. Newell, Z. Huang, and J. Deng, “Associative embedding: End-to-end learning for joint detection and grouping,” in NIPS, 2017.
- [25] Z. Cao, G. Hidalgo, T. Simon, S. Wei, and Y. Sheikh, “Openpose: Realtime multi-person 2d pose estimation using part affinity fields,” CoRR, vol. abs/1812.08008, 2018.
- [26] L. Yang, Q. Song, Z. Wang, and M. Jiang, “Parsing R-CNN for instance-level human analysis,” in CVPR, 2019.
- [27] Y. Dai, X. Wang, L. Gao, J. Song, and H. T. Shen, “RSGNet: relation based skeleton graph network for crowded scenes pose estimation,” in AAAI, 2021, pp. 1193–1200.
- [28] X. Wang, L. Gao, Y. Dai, Y. Zhou, and J. Song, “Semantic-aware transfer with instance-adaptive parsing for crowded scenes pose estimation,” in ACMMM, 2021, pp. 686–694.
- [29] M. Hao, Y. Liu, X. Zhang, e. A. Sun, Jian”, H. Bischof, T. Brox, and J.-M. Frahm, “Labelenc: A new intermediate supervision method for object detection,” in ECCV, 2020, pp. 529–545.
- [30] T. Wang, L. Yuan, X. Zhang, and J. Feng, “Distilling object detectors with fine-grained feature imitation,” in CVPR, 2019, pp. 4933–4942.
- [31] Q. Li, S. Jin, and J. Yan, “Mimicking very efficient network for object detection,” in CVPR, 2017, pp. 7341–7349.
- [32] G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?” in ICML, 2021.
- [33] Y. Guo, L. Gao, X. Wang, Y. Hu, X. Xu, X. Lu, H. T. Shen, and J. Song, “From general to specific: Informative scene graph generation via balance adjustment,” in ICCV, 2021.
- [34] R. Zellers, M. Yatskar, S. Thomson, and Y. Choi, “Neural motifs: Scene graph parsing with global context,” in CVPR, 2018, pp. 5831–5840.
- [35] Y. Guo, L. Gao, J. Song, P. Wang, N. Sebe, H. T. Shen, and X. Li, “Relation regularized scene graph generation,” IEEE Transactions on Cybernetics, 2021.
- [36] H. Xu, C. Jiang, X. Liang, L. Lin, and Z. Li, “Reasoning-rcnn: Unifying adaptive global reasoning into large-scale object detection,” in CVPR, 2019, pp. 6419–6428.
- [37] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in CVPR, 2014.
- [38] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE Trans. Pattern Anal. Mach. Intell., pp. 652–662, 2021.
- [39] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” in ICLR, 2021.
- [40] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft COCO: common objects in context,” in ECCV, 2014.
- [41] J. Carreira and A. Zisserman, “Quo vadis, action recognition? A new model and the kinetics dataset,” 2017, pp. 4724–4733.
- [42] N. Neverova, D. Novotny, V. Khalidov, M. Szafraniec, P. Labatut, and A. Vedaldi, “Continuous surface embeddings,” in NIPS, 2020.
A1. Detailed Architecture
In terms of part-level attribute parsing branch, Fig. 8 presents major differences between standard RCNN and proposed KE-RCNN. For each model, Tab. IX further lists the model size, FLOPs and . From the results, we can see that the parameter size of the standard RCNN is around 61.1M, 256.0M for ASPP RCNN and 48.9M for the KE-RCNN with ResNet-50 backbone. Thus, the size of KE-RCNN has 12.2M and 207.1M smaller respectively than that of standard RCNN and ASPP RCNN, but the performance of KE-RCNN has +4.0% and +3.3% larger than that of standard RCNN and ASPP RCNN. Furthermore, in terms of speed comparison, all KE-RCNN based models process around 10 frames per second (fps), which are comparable to baseline models. This implies that knowledge modeling is more important than increasing model size for improving ability of attribute parsing.

| Settings | Bacbone | # Params | FLOPs | Speed (img/s) | |
|---|---|---|---|---|---|
| Standard RCNN | ResNet-50 | 61.1M | 391.3G | 15.3 | 35.1 |
| ASPP RCNN | ResNet-50 | 256.0M | 754.0G | 14.5 | 35.8 |
| KE-RCNN | ResNet-50 | 48.9M | 445.3G | 12.8 | 39.1 |
| KE-RCNN | HRNet-18 | 32.2M | 373.4G | 11.1 | 36.4 |
| KE-RCNN | Swin-T | 52.2M | 449.8G | 9.5 | 42.1 |
| KE-RCNN | Swin-S | 75.5M | 542.5G | 7.9 | 44.3 |

A2. A Deep Analysis of Knowledge Modeling in KE-RCNN
A2.1. Implicit Knowledge Modeling in IK-En.
The core idea of implicit knowledge modeling in IK-En lies in two global context encodings, where the IK-En jointly incorporates relevant visual contexts and geometry contexts into a part representation. Hence, one question is posed: how much each context contributes to identifying attributes. To answer this, Fig. 9 lists class-wise accuracy scores and compares three different models: 1) standard RCNN without implicit knowledge modeling; 2) the IK-En in KE-RCNN is only with visual context encoding; and 3) the IK-En in KE-RCNN is only with geometry context encoding. In particular, we use ground-truth bounding boxes as inputs, eliminating adverse effects caused by false part detection. From the results, we find KE-RCNN with visual context encoding improves standard RCNN on fix attributes, which are related to cloth patterns or cloth styles, such as “dirndl” and “culottes”. As for those location-sensitive attributes, such as “above-the-hip” and “three quarter length”, the KE-RCNN with geometry context encoding improves standard RCNN most. Therefore, one can conclude that both visual contexts and geometry contexts are indispensable for accurate attribute parsing. For more evaluation results, we refer readers to Fig. 12.

A2.2. Explicit Knowledge Modeling in EK-De.
Explicit knowledge can be summarized from different data sources, i.e., either from annotations of a dataset or from task-irrelevant information source. Hence, annotations of Fashionpedia and large scale language corpus in Wikipedia are used to construct explicit knowledges about part-attribute relations. Tab. X compares Fashionpedia and Wikipedia on part-level fashion parsing, where they are applied to KE-RCNN with different backbones. While the Fashionpedia is used as a default data source for explicit knowledge generation, we generally observe comparable accuracy by replacing it with the Wikipedia. It indicates that the difference between the two kinds of knowledge is slightly minor. We thus use annotations of Fashionpedia to construct explicit knowledge about part-attribute relations.
| Settings | Knowledge Source | |
|---|---|---|
| KE-RCNN (ResNet-50) | Fashionpedia | 39.1 |
| Wikipedia | 39.6 | |
| KE-RCNN (ResNet-101) | Fashionpedia | 39.9 |
| Wikipedia | 40.7 | |
| KE-RCNN (Cascade-R50) | Fashionpedia | 41.2 |
| Wikipedia | 41.6 | |
| KE-RCNN (Cascade-R101) | Fashionpedia | 42.7 |
| Wikipedia | 42.3 | |
| KE-RCNN (HRNet-18) | Fashionpedia | 36.4 |
| Wikipedia | 37.7 | |
| KE-RCNN (HRNet-32) | Fashionpedia | 39.0 |
| Wikipedia | 39.2 | |
| KE-RCNN (Swin-T) | Fashionpedia | 42.1 |
| Wikipedia | 41.7 | |
| KE-RCNN (Swin-S) | Fashionpedia | 44.3 |
| Wikipedia | 45.0 |
A2.3. Implicit Knowledge or Explicit Knowledge ?
In this section, we would like to investigate what attributes can benefit from knowledge modeling and which knowledge they prefer. To answer this, we compare three different models: 1) a standard RCNN without knowledge modeling; 2) KE-RCNN with IK-En only; and 3) KE-RCNN with EK-De only. For each model, we conduct class-wise evaluation and calculate the attribute classification accuracy. The corresponding accuracy scores are summarized in Fig. 10, where only partial representative categories are presented due to the space limitation. From the results, we generally observe improved accuracy for most attributes after applying proposed IK-En or EK-De, indicating general effectiveness of proposed method.
In terms of static attributes (i.e., fashion), as shown in Fig. 10 (a), most attributes prefer EK-De as it generally outperforms other two approaches by a large margin. We conjecture the possible reason behind this is that EK-De significantly narrows down the recognition space via statistical priors since fashion attributes are strongly correlated to corresponding clothes. In this way, the attribute parsing model only focus on few attributes, thus benefiting final parsing performance. As for dynamic attributes (i.e., action states), as shown in Fig. 10 (b), most attributes with diverse poses or large motion changes, such as “jump” and “upturn”, generally benefit more from IK-En than EK-De. However, those attributes with a fixed pose or slight motion variations, such as “clutch” and “hold”, prefer EK-De. Thus, one can conclude that EK-De is particularly helpful for those attributes with a strong correlation to the body part or those with slight changes, while IK-En is generally beneficial to those complex attributes with large changes or location sensitive ones. For more details, we refer readers to Fig. 13 and Fig. 14.
| Initialization | Epoch | |||
|---|---|---|---|---|
| ImageNet | 24 | 50.6 | 65.7 | 84.9 |
| COCO | 12 | 51.2 | 66.7 | 84.9 |
| COCO | 24 | 52.7 | 68.5 | 84.7 |
| 2021 Leaderboard | ||
|---|---|---|
| Ranks | Participants | |
| (1) | yuzheming | 0.630532 |
| (2) | Sheldong | 0.613722 |
| (3) | JosonChan | 0.605059 |
| (4) | fangwudi | 0.590167 |
| (5) | uestc.wxh | 0.536067 |
| (6) | hubincsu | 0.490984 |
| (6) | scc1997 | 0.490984 |
| (7) | KGH | 0.486483 |
| (8) | zhao_THU | 0.434311 |
| (9) | TerminusBazinga | 0.396735 |
| (10) | cjx_AILab | 0.370753 |
| (11) | xubocheng | 0.358834 |
| (12) | haifwu | 0.247614 |
| (13) | Aicity | 0.189669 |
| (14) | fog | 0.188455 |
| - | KE-RCNN (Ours) | 0.653541 |
A3. Detailed Training Practices on Kinetics-TPS
This section provides training details of part-level action parsing models. In particular, we consider two training factors, including initialization method and learning schedule. In general, a good initialization will lead to better results. In line with this finding, we observe that action parsing models pre-trained on COCO dataset outperforms the counterpart that is pre-trained on ImageNet dataset, as shown in Tab.XI. Besides, Tab. XI also compares training schedule and training schedule, where it indicates longer training schedule will be likely to obtain a better parsing model.
DeeperAction 2022 Challenge: After exploring good practices of training action parsing models, we participated in the DeeperAction 2022 Kinetics-TPS track. Our proposed method outperforms all entries from the leaderboard of DeeperAction 2021 Kinetics-TPS, as shown in Tab. XII. Our entry only uses a single model of KE-RCNN with Swin-B backbone, and attains a score of 65% on the test server, which surpasses the 1st place in 2021 leaderboard by 2.3 points.
A4. The Limitation of KE-RCNN
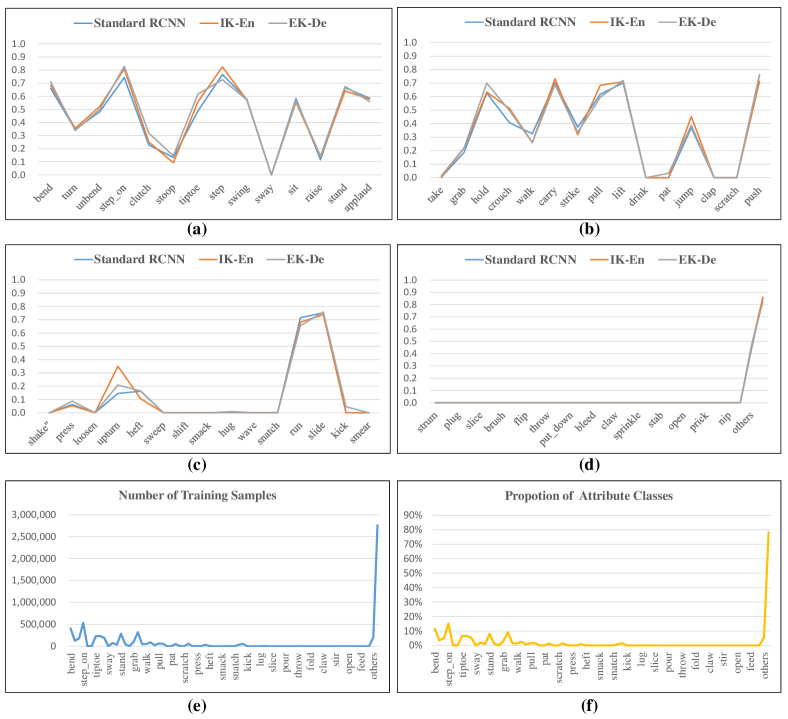
In this section, we discuss the limitation of the KE-RCNN. One major limitation is that the KE-RCNN highly depends on the part detection results. In this way, the performance of attribute parsing will drop significantly if the detection performance decreases dramatically. Fig. 11 shows some failure cases performed by KE-RCNN. Most failure cases suffer from misclassifying complex attributes conditioning on false predicted bounding boxes. The second limitation is that the number of labeled data is not sufficient. Both Fashionpedia and Kinetics-TPS present a characteristic of imbalance and sparse, as shown in Fig.13 and Fig.14. In particular, numerous action attribute classes in Kinetics-TPS dataset involve few training samples and most samples (around 78%) are annotated as unknown state (i.e., labeled as “none”). Therefore, the KE-RCNN directly trained on Kinetics-TPS performs worst on those minor classes, as shown in Fig. 11 and Fig.14.
To remedy for it, one possible solution is that parsing attributes conditioning on bounding box as well as mask for a part. The box decides rough location of a part and the mask decides which area the model should attend. Another possible solution is to design a standalone pipeline, where the model directly parsing instance-level attribute parsing results without extra part detection. In particular, the second one is the promising future research direction as single-stage recognition pipelines have been explored on many related research works, e.g., general object detection. As for the second limitation, one-shot or few-shot learning paradigm should be a good way for enhancing generalizability, which can be studied in the future works. For more details, we refer the reader to our project page444https://github.com/sota-joson/KE-RCNN.