JUMBO: Scalable Multi-task Bayesian Optimization using Offline Data
Abstract
The goal of Multi-task Bayesian Optimization (MBO) is to minimize the number of queries required to accurately optimize a target black-box function, given access to offline evaluations of other auxiliary functions. When offline datasets are large, the scalability of prior approaches comes at the expense of expressivity and inference quality. We propose JUMBO, an MBO algorithm that sidesteps these limitations by querying additional data based on a combination of acquisition signals derived from training two Gaussian Processes (GP): a cold-GP operating directly in the input domain and a warm-GP that operates in the feature space of a deep neural network pretrained using the offline data. Such a decomposition can dynamically control the reliability of information derived from the online and offline data and the use of pretrained neural networks permits scalability to large offline datasets. Theoretically, we derive regret bounds for JUMBO and show that it achieves no-regret under conditions analogous to GP-UCB (Srinivas et al. 2010). Empirically, we demonstrate significant performance improvements over existing approaches on two real-world optimization problems: hyper-parameter optimization and automated circuit design.
Introduction
Many domains in science and engineering involve the optimization of an unknown black-box function. Such functions can be expensive to evaluate, due to costs such as time and money. Bayesian optimization (BO) is a popular framework for such problems as it seeks to minimize the number of function evaluations required for optimizing a target black-box function (Shahriari et al. 2015; Frazier 2018). In real-world scenarios however, we often have access to offline evaluations of one or more auxiliary black-box functions related to the target function. For example, one might be interested in finding the optimal hyperparameters of a machine learning model for a given problem and may have access to an offline dataset from previous runs of training the same model on a different dataset for various configurations. Multi-task Bayesian optimization (MBO) is an optimization paradigm that extends BO to exploit such additional sources of information from related black-box functions for efficient optimization (Swersky, Snoek, and Adams 2013).
Early works in MBO employ multi-task Gaussian Processes (GP) with inter-task kernels to capture the correlations between the auxiliary and target function (Swersky, Snoek, and Adams 2013; Williams, Bonilla, and Chai 2007; Poloczek, Wang, and Frazier 2016). Multi-task GPs however fail to scale to large offline datasets. More recent works have proposed combining neural networks (NN) with probabilistic models to improve scalability. For example, MT-BOHAMIANN (Springenberg et al. 2016) uses Bayesian NNs (BNN) (Neal 2012) as surrogate models for MBO. The performance however, depends on the quality of the inference procedure. In contrast, MT-ABLR (Perrone et al. 2018) uses a deterministic NN followed by a Bayesian Linear Regression (BLR) layer at the output to achieve scalability while permitting exact inference. However, the use of a linear kernel can limit the expressiveness of the posterior.
We propose JUMBO, an MBO algorithm that sidesteps the limitations in expressivity and tractability of prior approaches. In JUMBO, we first train a NN on the auxiliary data to learn a feature space, akin to MT-ABLR but without the BLR restriction on the output layer. Thereafter, we train two GPs simultaneously for online data acquisition via BO: a warm-GP on the feature space learned by the NN and a cold-GP on the raw input space. The acquisition function in JUMBO combines the individual acquisition functions of both the GPs. It uses the warm-GP to reduce the search space by filtering out poor points. The remaining candidates are scored by the acquisition function for the cold-GP to account for imperfections in learning the feature space of the warm-GP. The use of GPs in the entire framework ensures tractability in posterior inference and updates.
Theoretically, we show that JUMBO is a no-regret algorithm under conditions analogous to those used for analyzing GP-UCB (Srinivas et al. 2010). In practice, we observe significant improvements over the closest baseline on two real-world applications: transferring prior knowledge in hyper-parameter optimization and automated circuit design.
Background
We are interested in maximizing a target black-box function defined over a discrete or compact set . We assume only query access to . For every query point , we receive a noisy observation . Here, we assume is standard Gaussian noise, i.e., where is the noise standard deviation. Our strategy for optimizing will be to learn a probabilistic model for regressing the inputs to using the available data and using that model to guide the acquisition of additional data for updating the model. In particular, we will be interested in using Gaussian Process regression models within a Bayesian Optimization framework, as described below.
Gaussian Process (GP) Regression
A Gaussian Process (GP) is defined as a set of random variables such that any finite subset of them follows a multivariate normal distribution. A GP can be used to define a prior distribution over the unknown function , which can be converted to a posterior distribution once we observe additional data. Formally, a GP prior is defined by a mean function and a valid kernel function . A kernel function is valid if it is symmetric and the Gram matrix is positive semi-definite. Intuitively, the entries of the kernel matrix measure the similarity between any two points and . Given points , the distribution of the function evaluations in a GP prior follows a normal distribution, such that where and is a covariance matrix. For simplicity, we will henceforth assume to be a zero mean function.
Given a training dataset , let and denote the inputs and their noisy observations. Since the observation model is also assumed to be Gaussian, the posterior over at a test set of points will follow a multivariate normal distribution with the following mean and covariance:
Due to the inverse operation during posterior computation, standard GPs can be computationally prohibitive for modeling large datasets. We direct the reader to (Rasmussen 2003) for an overview on GPs.
Bayesian Optimization (BO)
Bayesian Optimization (BO) is a class of sequential algorithms for sample-efficient optimization of expensive black-box functions (Frazier 2018; Shahriari et al. 2015). A BO algorithm typically runs for a fixed number of rounds. At every round , the algorithm selects a query point and observes a noisy function value . To select , the algorithm first infers the posterior distribution over functions via a probabilistic model (e.g., Gaussian Processes). Thereafter, is chosen to optimize an uncertainty-aware acquisition function that balances exploration and exploitation. For example, a popular acquisition function is the Upper Confidence Bound (UCB) which prefers points that have high expected value (exploitation) and high uncertainty (exploration). With the new point , the posterior distribution can be updated and the whole process is repeated in the next round.
At round , we define the instantaneous regret as where is the global optima and maximizes the acquisition function. Similarly, we can define the cumulative regret at round as the sum of instantaneous regrets . A desired property of any BO algorithms is to be no-regret where the cumulative regret is sub-linear in as , i.e., .
Multi-task Bayesian Optimization (MBO)
Our focus setting in this work is a variant of BO, called Multi-Task Bayesian Optimization (MBO). Here, we assume auxiliary real-valued black-box functions , each having the same domain as the target function (Swersky, Snoek, and Adams 2013; Springenberg et al. 2016). For each function , we have an offline dataset consisting of pairs of input points and the corresponding function evaluations . If these auxiliary functions are related to the target function, then we can transfer knowledge from the offline data to improve the sample-efficiency for optimizing . In certain applications, we might also have access to offline data from itself. However, in practice, is typically expensive to query and its offline dataset will be very small.
We discuss some prominent works in MBO that are most closely related to our proposed approach below. See Section Related Work for further discussion about other relevant work.
Multi-task BO (Swersky, Snoek, and Adams 2013) is an early approach that employs a custom kernel within a multi-task GP (Williams, Bonilla, and Chai 2007) to model the relationship between the auxiliary and target functions. Similar to standard GPs, multi-task GPs fail to scale for large offline datasets.
On the other hand, parametric models such as neural networks (NN), can effectively scale to larger datasets but do not defacto quantify uncertainty. Hybrid methods such as DNGO (Snoek et al. 2015) achieve scalability for (single task) BO through the use of a feed forward deep NN followed by Bayesian Linear Regression (BLR) (Bishop 2006). The NN is trained on the existing data via a simple regression loss (e.g, mean squared error). Once trained, the NN parameters are frozen and the output layer is replaced by BLR for the BO routine. For BLR, the computational complexity of posterior updates scales linearly with the size of the dataset. This step can be understood as applying a GP to the output features of the NN with a linear kernel (i.e. where is the NN function with parameters ). For BLR, the computational complexity of posterior inference is linear w.r.t. the number of data points and thus DNGO can scale to large offline datasets.
MT-ABLR (Perrone et al. 2018) extends DNGO to multi task settings by training a single NN to learn a shared representation followed by task-specific BLR layers (i.e. predicting , and based on inputs). The learning objective corresponds to the maximization of sum of the marginal log-likelihoods for each task: . The main task is included in the last index, is the Bayesian Linear layer weights for task with prior , and are the hyper-prior parameters, and is the observed data from task . Learning by directly maximizing the marginal likelihood improves the performance of DNGO while maintaining the computational scalability of its posterior inference in case of large offline data. However, both DNGO and ABLR have implicit assumptions on the existence of a feature space under which the target function can be expressed as a linear combination. This can be a restrictive assumption and furthermore, there is no guarantee that given finite data such feature space can be learned.
MT-BOHAMIANN (Springenberg et al. 2016) addresses the limited expressivity of prior approaches by employing Bayesian NNs to specify the posterior over and feed the NN with input and additional learned task-specific embeddings for task . While allowing for a principled treatment of uncertainties, fully Bayesian NNs are computationally expensive to train and their performance depends on the approximation quality of stochastic gradient HMC methods used for posterior inference.
Scalable MBO via JUMBO
In the previous section, we observed that prior MBO algorithms make trade-offs in either posterior expressivity or inference quality in order to scale to large offline datasets. Our goal is to show that these trade-offs can be significantly mitigated and consequently, the design of our proposed MBO framework, which we refer to as Joint Upper confidence Multi-task Bayesian Optimization (JUMBO), will be guided by the following desiderata: (1) Scalability to large offline datasets (e.g., via NNs) (2) Exact and computationally tractable posterior updates (e.g., via GPs) (3) Flexible and expressive posteriors (e.g., via non-linear kernels).
Regression Model

The regression model in JUMBO is composed of two GPs: a warm-GP and a cold-GP denoted by and , respectively. As shown in Figure 1, both GPs are trained to model the target function but operate in different input spaces, as we describe next.
(with hyperparameters ) operates on a feature representation of the input space derived from the offline dataset . To learn this feature space, we train a multi-headed feed-forward NN to minimize the mean squared error for each auxiliary task, akin to DNGO (Snoek et al. 2015). Thereafter, in contrast to both DNGO and ABLR, we do not train separate output BLR modules. Rather, we will directly train on the output of the NN using the data acquired from the target function . Note that for training , we can use any non-linear kernel, which results in an expressive posterior that allows for exact and tractable inference using closed-form expressions.
Additionally, we can encounter scenarios where some of the auxiliary functions are insufficient in reducing the uncertainty in inferring the target function. In such scenarios, relying solely on can significantly hurt performance. Therefore, we additionally initialize (with hyperparameters ) directly on the input space .
If we also have access to offline data from (i.e. ), the hyperparameters of the warm and cold GPs can also be pre-trained jointly along with the neural network parameters. The overall pre-training objective is then given by:
|
|
(1) |
where denotes the negative marginal log-likelihood for the corresponding GP on .
Acquisition Procedure
Post the offline pre-training of the JUMBO’s regression model, we can use it for online data acquisition in a standard BO loop. The key design choice here is the acquisition function, which we describe next. At round , let and be the single task acquisition function (e.g. UCB) of the warm and cold GPs, after observing data points, respectively.
Our guiding intuition for the acquisition function in JUMBO is that we are most interested in querying points which are scored highly by both acquisition functions. Ideally, we want to first sort points based on scores and then from the top choices select the ones with highest score. To realize this acquisition function on a continuous input domain, we define it as a convex combination of the individual acquisition functions by employing a dynamic interpolation coefficient . Formally,
| (2) |
In Eq. 2, By choosing to be close to for points with , we can ensure to acquire points that have high acquisition scores as per both and . Next, we will discuss some theoretical results that shed more light on the design of .
Theoretical Analysis
Here, we will formally derive the regret bound for JUMBO and provide insights on the conditions under which JUMBO outperforms GP-UCB (Srinivas et al. 2010). For this analysis, we will use Upper Confidence Bound (UCB) as our acquisition function for the warm and cold GPs. To do so, we utilize the notion of Maximum Information Gain (MIG).
Definition 1 (Maximum Information Gain (Srinivas et al. 2010)).
Let , . Consider any and let be a finite subset. Let be noisy observations such that , . Let denote the Shannon mutual information.
The MIG of set after evaluations is the maximum mutual information between the function values and observations among all choices of n points in . Formally,
This quantity depends on kernel parameters and the set , and also serves as an important tool for characterizing the difficulty of a GP-bandit. For a given kernel, it can be shown that where for discrete and for the continuous case (Srinivas et al. 2010). For example for Radial Basis kernel . For brevity, we focus on settings where is discrete. Further results and analysis for the continuous case are deferred to Appendix A.
For GP-UCB (Srinivas et al. 2010), it has been shown that for any , if (i.e., the GP assigns non-zero probability to the target function ), then the cumulative regret after rounds will be bounded with probability at least :
| (3) |
with and .
Recall that is a mapping from input space to the feature space . We will further make the following modeling assumptions to ensure that the target black-box function is a sample from both the cold and warm GPs.
Assumption 1.
.
Assumption 2.
Let denote the NN parameters obtained via pretraining (Eq. 1).Then, there exists a function such that .
Theorem 1.
Let and be some arbitrary partitioning of the input domain . Define the interpolation coefficient as an indicator . Then under Assumptions 1 and 2, JUMBO is no-regret.
Specifically, let be the number of rounds such that the JUMBO queries for points . Then, for any , running JUMBO for iterations results in a sequence of candidates for which the following holds with probability at least :
| (4) |
where , , and is the set of output features for .

Based on the regret bound in Eq. 4, we can conclude that if the partitioning is chosen such that and , then JUMBO has a tighter bound than GP-UCB. The first condition implies that the second term in Eq. 4 is negligible and intuitively means that will only need a few samples to infer the posterior of defined on , making BO more sample efficient. The second condition implies that the which in turn makes the regret bound of JUMBO tighter than GP-UCB. Note that cannot be made arbitrarily small, since (and therefore ) will get larger which conflicts with the first condition.
Figure 2 provides an illustrative example. If the learned feature space compresses set to a smaller set , then can infer the posterior of with only a few samples in (because MIG is lower). Such will likely emerge when tasks share high-level features with one another. In the appendix, we have included an empirical analysis to show that is indeed operating on a compressed space . Consequently, if is reflective of promising regions consisting of near-optimal points i.e. for some , BO will be able to quickly discard points from subset and acquire most of its points from .



Choice of interpolation coefficient
The above discussion suggests that the partitioning should ideally consist of near-optimal points. In practice, we do not know and hence, we rely on our surrogate model to define . Here, is the optimal value of and the acquisition threshold is a hyper-parameter used for defining near-optimal points w.r.t. . At one extreme, corresponds to the case where (i.e. the GP-UCB routine) and the other extreme corresponds to case with .
Figure 4 illustrates a synthetic 1D example on how JUMBO obtains the next query point. Figure 4(a) shows the main objective (red) and the auxiliary task (blue). They share a periodic structure but have different optimums. Figure 4(b) shows the correlation between the two.
Applying GP-UCB (Srinivas et al. 2010) will require a considerable amount of samples to learn the periodic structure and the optimal solution. However in JUMBO, as shown in Figure 4(c), the warm-GP, trained on () samples, can learn the periodic structure using only 6 samples, while the posterior of the cold-GP has not yet learned this structure.
It can also be noted from Figure 4(c) that JUMBO’s acquisition function is when the value of is close to . Therefore, the next query point (marked with a star) has a high score based on both acquisition functions. We summarize JUMBO in Algorithm 1.
Experiments
We are interested in investigating the following questions: (1) How does JUMBO perform on benchmark real-world black-box optimization problems relative to baselines? (2) How does the choice of threshold impact the performance of JUMBO? (3) Is it necessary to have a non-linear mapping on the features learned from the offline dataset or a BLR layer is sufficient?
Our codebase is based on BoTorch (Balandat et al. 2020) and is provided in the Supplementary Materials with additional details in Appendix C.
Application: Hyperparameter optimization
Datasets. We consider the task of optimizing hyperparameters for fully-connected NN architectures on 4 regression benchmarks from HPOBench (Klein and Hutter 2019): Protein Structure (Rana 2013), Parkinsons Telemonitoring (Tsanas et al. 2010), Naval Propulsion (Coraddu et al. 2016), and Slice Localization (Graf et al. 2011). HPOBench provides a look-up-table-based API for querying the validation error of all possible hyper-parameter configurations for a given regression task. These configurations are specified via 9 hyperparameters, that include continuous, categorical, and integer valued variables.
The objective we wish to minimize is the validation error of a regression task after 100 epochs of training. For this purpose, we consider an offline dataset that consists of validation errors for some randomly chosen configurations after 3 epochs on a given dataset. The target task is to optimize this error after 100 epochs. In (Klein and Hutter 2019), the authors show that this problem is non-trivial as there is small correlation between epochs 3 and 100 for top-1% configurations across all datasets of interest.

Evaluation protocol. We validate the performance of JUMBO against the following baselines with a UCB acquisition function (Srinivas et al. 2010):
- •
-
•
MT-BOHAMIANN (Springenberg et al. 2016) trains a BNN on all tasks jointly via SGHMC (Section Multi-task Bayesian Optimization (MBO)).
-
•
MT-ABLR (Perrone et al. 2018) trains a shared NN followed by task-specific BLR layers (Section Multi-task Bayesian Optimization (MBO)).
-
•
GCP (Salinas, Shen, and Perrone 2020) uses Gaussian Copula Processes to jointly model the offline and online data.
-
•
MF-GP-UCB (Kandasamy et al. 2019) extends the GP-UCB baseline to a multi-fidelity setting where the source task can be interpreted as a low-fidelity proxy for the target task.
-
•
Offline DKL (i.e. warm-GP only) is our proposed extension to Deep Kernel Learning, where we train a single GP online in the latent space of a NN pretrained on (See Section Related Work for details). Equivalently, it can be interpreted as JUMBO with in Eq. 2.
Results. We run JUMBO (with ) on all baselines for 50 rounds and 5 random seeds each and measure the simple regret per iteration. The regret curves are shown in Figure 5. We find that JUMBO achieves lower regret than the previous state-of-the-art algorithms for MBO in almost all cases. We believe the slightly worse performance on the slice dataset relative to other baselines is due to the extremely low top-1% correlation between epoch 3 and epoch 100 on this dataset as compared to others (See Figure 10 in (Klein and Hutter 2019)), which could result in a suboptimal search space partitioning obtained via the warm-GP. For all other datasets, we find JUMBO to be the best performing method. Notably, on the Protein dataset, JUMBO is always able to find the global optimum, unlike the other approaches.
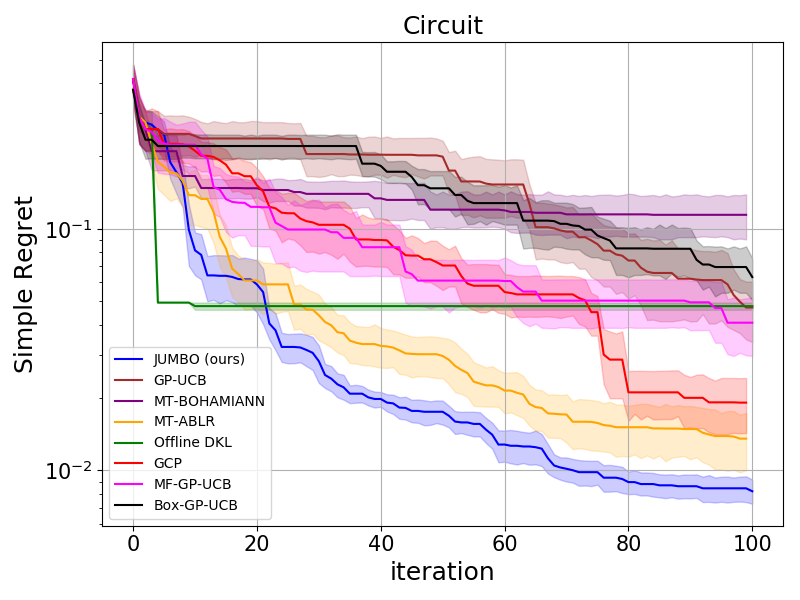


Application: Automated Circuit Design
Next, we consider a real-world use case in optimizing circuit design configurations for a suitable performance metric, e.g., power, noise, etc. In practice, designers are interested in performing layout simulations for measuring the performance metric on any design configuration. These simulations are however expensive to run; designers instead often turn to schematic simulations which return inexpensive proxy metrics correlated with the target metric.
In this problem, the circuit configurations are represented by an 8 dimensional vector, with elements taking continuous values between 0 and 1. The offline dataset consists of 1000 pairs of circuit configurations and 3 auxiliary signals including a scalar goodness score based on the schematic simulations. We consider the same baselines as before. We also consider BOX-GP-UCB (Perrone et al. 2019) which confines the search space to a hyper-cube over the promising region based on all auxiliary tasks in the offline data. Unlike the considered HPO problems, the offline circuit dataset contains data from more than just one auxiliary task, allowing us to consider BOX-GP-UCB as a viable baseline. MF-GP-UCB was ran with the schematic score as the lower fidelity approximation of the target function. We ran each algorithm with for 100 iterations and measured simple regret against iteration. As reflected in the regret curves in Figure 7(a), JUMBO outperforms other algorithms.
Ablations
Effect of auxiliary tasks. It is important to analyze how learning on other tasks affects the performance. To this end, we considered the circuit design problem with 1 and 3 auxiliary offline tasks. In Figure 7(b), task 1 (yellow) is the most correlated and task 3 (red) is the least correlated task with the objective function. The regret curves suggest that the performance would be poor if the correlation between tasks is low. Moreover, the features pre-trained on the combination of all three tasks provide more information to the warm-GP than those pre-trained only on one of the tasks.
BLR with JUMBO’s acquisition function. A key difference between JUMBO and ABLR (Perrone et al. 2018) is replacing the BLR layer with a GP. To show the merits of having a GP, we ran an experiment on Protein dataset and replaced the GP with a BLR in JUMBO’s procedure. Figure 7(c) shows that JUMBO with significantly outperforms JUMBO with a BLR layer.
Related Work
Transfer Learning in Bayesian Optimization: Utilizing prior information for applying transfer learning to improve Bayesian optimization has been explored in several prior papers. Early work of (Swersky, Snoek, and Adams 2013) focuses on the design of multi-task kernels for modeling task correlations (Poloczek, Wang, and Frazier 2016). These models tend to suffer from lack of scalability; (Wistuba, Schilling, and Schmidt-Thieme 2018; Feurer, Letham, and Bakshy 2018) show that this challenge can be partially mitigated by training an ensemble of task-specific GPs that scale linearly with the number of tasks but still suffer from cubic complexity in the number of observations for each task. To address scalability and robust treatment of uncertainty, several prior works have been suggested (Salinas, Shen, and Perrone 2020; Springenberg et al. 2016; Perrone et al. 2018). (Salinas, Shen, and Perrone 2020) employs a Gaussian Copula to learn a joint prior on hyper-parameters based on offline tasks, and then utilizes a GP on the online task for adapt to the target function. (Springenberg et al. 2016) uses a BNN as surrogates for MBO; however, since training BNNs is computationally intensive (Perrone et al. 2018) proposes to use a deterministic NN followed by a BLR layer at the output to achieve scalability.
Some other prior work exploit certain assumptions between the source and target data. For example (Shilton et al. 2017; Golovin et al. 2017) assume an ordering of the tasks and use this information to train GPs to model residuals between the target and auxiliary tasks. (Feurer, Springenberg, and Hutter 2015; Wistuba, Schilling, and Schmidt-Thieme 2015) assume existence of a similarity measure between prior and target data which may not be easy to define for problems other than hyper-parameter optimization. A simpler idea is to use prior data to confine the search space to promising regions (Perrone et al. 2019). However, this highly relies on whether the confined region includes the optimal solution to the target task. Another line of work studies utilizing prior optimization runs to meta-learn acquisition functions (Volpp et al. 2019). This idea can be utilized in addition to our method and is not a competing direction.
Multi-fidelity Black-box Optimization (MFBO): In multi-fidelity scenarios we can query for noisy approximations to the target function relatively cheaply. For example, in hyperparameter optimization, we can query for cheap proxies to the performance of a configuration on a smaller subset of the training data (Petrak 2000), early stopping (Li et al. 2017), or by predicting learning curves (Domhan, Springenberg, and Hutter 2015; Klein et al. 2017). We direct the reader to Section 1.4 in (Hutter, Kotthoff, and Vanschoren 2019) for a comprehensive survey on MBFO. Such methods, similar to MF-GP-UCB (Kandasamy et al. 2019) (section Application: Automated Circuit Design), are typically constrained to scenarios where such low fidelities are explicitly available and make strong continuity assumptions between the low fidelities and the target function.
Deep Kernel Learning (DKL): Commonly used GP kernels (e.g. RBF, Matern) can only capture simple correlations between points a priori. DKL (Huang et al. 2015; Calandra et al. 2016) addresses this issue by learning a latent representation via NN that can be fed to a standard kernel at the output. (Snoek et al. 2015) employs linear kernels at the output of a pre-trained NN while (Huang et al. 2015) extends it to use non-linear kernels. The warm-GP in JUMBO can be understood as a DKL surrogate model trained using offline data from auxiliary tasks.
Conclusion
We proposed JUMBO, a no-regret algorithm that employs a careful hybrid of neural networks and Gaussian Processes and a novel acquisition procedure for scalable and sample-efficient Multi-task Bayesian Optimization. We derived JUMBO’s theoretical regret bound and empirically showed it outperforms other competing approaches on set of real-world optimization problems.
References
- Balandat et al. (2020) Balandat, M.; Karrer, B.; Jiang, D.; Daulton, S.; Letham, B.; Wilson, A. G.; and Bakshy, E. 2020. BoTorch: A framework for efficient Monte-Carlo Bayesian optimization. Advances in Neural Information Processing Systems, 33.
- Bishop (2006) Bishop, C. M. 2006. Pattern recognition and machine learning. springer.
- Calandra et al. (2016) Calandra, R.; Peters, J.; Rasmussen, C. E.; and Deisenroth, M. P. 2016. Manifold Gaussian processes for regression. In 2016 International Joint Conference on Neural Networks (IJCNN), 3338–3345. IEEE.
- Coraddu et al. (2016) Coraddu, A.; Oneto, L.; Ghio, A.; Savio, S.; Anguita, D.; and Figari, M. 2016. Machine learning approaches for improving condition-based maintenance of naval propulsion plants. Proceedings of the Institution of Mechanical Engineers, Part M: Journal of Engineering for the Maritime Environment, 230(1): 136–153.
- Domhan, Springenberg, and Hutter (2015) Domhan, T.; Springenberg, J. T.; and Hutter, F. 2015. Speeding up automatic hyperparameter optimization of deep neural networks by extrapolation of learning curves. In Twenty-fourth international joint conference on artificial intelligence.
- Feurer, Letham, and Bakshy (2018) Feurer, M.; Letham, B.; and Bakshy, E. 2018. Scalable meta-learning for Bayesian optimization. arXiv preprint arXiv:1802.02219.
- Feurer, Springenberg, and Hutter (2015) Feurer, M.; Springenberg, J.; and Hutter, F. 2015. Initializing bayesian hyperparameter optimization via meta-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 29.
- Frazier (2018) Frazier, P. I. 2018. A tutorial on Bayesian optimization. arXiv preprint arXiv:1807.02811.
- Garrido-Merchán and Hernández-Lobato (2020) Garrido-Merchán, E. C.; and Hernández-Lobato, D. 2020. Dealing with categorical and integer-valued variables in bayesian optimization with gaussian processes. Neurocomputing, 380: 20–35.
- Golovin et al. (2017) Golovin, D.; Solnik, B.; Moitra, S.; Kochanski, G.; Karro, J.; and Sculley, D. 2017. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 1487–1495.
- Graf et al. (2011) Graf, F.; Kriegel, H.-P.; Schubert, M.; Pölsterl, S.; and Cavallaro, A. 2011. 2d image registration in ct images using radial image descriptors. In International Conference on Medical Image Computing and Computer-Assisted Intervention, 607–614. Springer.
- Hansen (2016) Hansen, N. 2016. The CMA evolution strategy: A tutorial. arXiv preprint arXiv:1604.00772.
- Huang et al. (2015) Huang, W.; Zhao, D.; Sun, F.; Liu, H.; and Chang, E. 2015. Scalable gaussian process regression using deep neural networks. In Twenty-fourth international joint conference on artificial intelligence. Citeseer.
- Hutter, Kotthoff, and Vanschoren (2019) Hutter, F.; Kotthoff, L.; and Vanschoren, J. 2019. Automated machine learning: methods, systems, challenges. Springer Nature.
- Kandasamy et al. (2019) Kandasamy, K.; Dasarathy, G.; Oliva, J.; Schneider, J.; and Poczos, B. 2019. Multi-fidelity gaussian process bandit optimisation. Journal of Artificial Intelligence Research, 66: 151–196.
- Klein et al. (2017) Klein, A.; Falkner, S.; Bartels, S.; Hennig, P.; and Hutter, F. 2017. Fast bayesian optimization of machine learning hyperparameters on large datasets. In Artificial Intelligence and Statistics, 528–536. PMLR.
- Klein and Hutter (2019) Klein, A.; and Hutter, F. 2019. Tabular benchmarks for joint architecture and hyperparameter optimization. arXiv preprint arXiv:1905.04970.
- Li et al. (2017) Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; and Talwalkar, A. 2017. Hyperband: A novel bandit-based approach to hyperparameter optimization. The Journal of Machine Learning Research, 18(1): 6765–6816.
- Neal (2012) Neal, R. M. 2012. Bayesian learning for neural networks, volume 118. Springer Science & Business Media.
- Perrone et al. (2018) Perrone, V.; Jenatton, R.; Seeger, M.; and Archambeau, C. 2018. Scalable hyperparameter transfer learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, 6846–6856.
- Perrone et al. (2019) Perrone, V.; Shen, H.; Seeger, M.; Archambeau, C.; and Jenatton, R. 2019. Learning search spaces for bayesian optimization: Another view of hyperparameter transfer learning. arXiv preprint arXiv:1909.12552.
- Petrak (2000) Petrak, J. 2000. Fast subsampling performance estimates for classification algorithm selection. In Proceedings of the ECML-00 Workshop on Meta-Learning: Building Automatic Advice Strategies for Model Selection and Method Combination, 3–14.
- Poloczek, Wang, and Frazier (2016) Poloczek, M.; Wang, J.; and Frazier, P. I. 2016. Warm starting Bayesian optimization. In 2016 Winter Simulation Conference (WSC), 770–781. IEEE.
- Rana (2013) Rana, P. 2013. Physicochemical properties of protein tertiary structure data set. UCI Machine Learning Repository.
- Rasmussen (2003) Rasmussen, C. E. 2003. Gaussian processes in machine learning. In Summer school on machine learning, 63–71. Springer.
- Salinas, Shen, and Perrone (2020) Salinas, D.; Shen, H.; and Perrone, V. 2020. A quantile-based approach for hyperparameter transfer learning. In International Conference on Machine Learning, 8438–8448. PMLR.
- Shahriari et al. (2015) Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R. P.; and De Freitas, N. 2015. Taking the human out of the loop: A review of Bayesian optimization. Proceedings of the IEEE, 104(1): 148–175.
- Shilton et al. (2017) Shilton, A.; Gupta, S.; Rana, S.; and Venkatesh, S. 2017. Regret bounds for transfer learning in Bayesian optimisation. In Artificial Intelligence and Statistics, 307–315. PMLR.
- Snoek et al. (2015) Snoek, J.; Rippel, O.; Swersky, K.; Kiros, R.; Satish, N.; Sundaram, N.; Patwary, M.; Prabhat, M.; and Adams, R. 2015. Scalable bayesian optimization using deep neural networks. In International conference on machine learning, 2171–2180. PMLR.
- Springenberg et al. (2016) Springenberg, J. T.; Klein, A.; Falkner, S.; and Hutter, F. 2016. Bayesian optimization with robust Bayesian neural networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, 4141–4149.
- Srinivas et al. (2010) Srinivas, N.; Krause, A.; Kakade, S.; and Seeger, M. 2010. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. In Proceedings of the 27th International Conference on Machine Learning. Omnipress.
- Swersky, Snoek, and Adams (2013) Swersky, K.; Snoek, J.; and Adams, R. P. 2013. Multi-Task Bayesian Optimization. Advances in Neural Information Processing Systems, 26: 2004–2012.
- Tsanas et al. (2010) Tsanas, A.; Little, M. A.; McSharry, P. E.; and Ramig, L. O. 2010. Enhanced classical dysphonia measures and sparse regression for telemonitoring of Parkinson’s disease progression. In 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, 594–597. IEEE.
- Volpp et al. (2019) Volpp, M.; Fröhlich, L. P.; Fischer, K.; Doerr, A.; Falkner, S.; Hutter, F.; and Daniel, C. 2019. Meta-learning acquisition functions for transfer learning in bayesian optimization. arXiv preprint arXiv:1904.02642.
- Williams, Bonilla, and Chai (2007) Williams, C.; Bonilla, E. V.; and Chai, K. M. 2007. Multi-task Gaussian process prediction. Advances in neural information processing systems, 153–160.
- Wistuba, Schilling, and Schmidt-Thieme (2015) Wistuba, M.; Schilling, N.; and Schmidt-Thieme, L. 2015. Learning hyperparameter optimization initializations. In 2015 IEEE international conference on data science and advanced analytics (DSAA), 1–10. IEEE.
- Wistuba, Schilling, and Schmidt-Thieme (2018) Wistuba, M.; Schilling, N.; and Schmidt-Thieme, L. 2018. Scalable gaussian process-based transfer surrogates for hyperparameter optimization. Machine Learning, 107(1): 43–78.
Appendix A Proofs of Theoretical Results
We will present proofs for Theorem 1 and an additional result in Theorem 5 that extends the no-regret guarantees of JUMBO to continuous domains. Our theoretical derivations will build on prior results from (Srinivas et al. 2010) and (Kandasamy et al. 2019).
Theorem 1
Let and denote the posterior mean and standard deviation of at the end of round after observing }. Similarly, we will use and to denote the posterior mean and standard deviation of at the end of round after observing .
Lemma 2.
Pick and set where , (e.g. ). Define and . Then,
Proof.
Fix and . Based on Assumption 1, conditioned on , . Similarly, Assumption 2 implies that conditioned on , . Let be the event that and the event that . From proof of Lemma 5.1 in (Srinivas et al. 2010) we know that given a normal distribution , . Using and , . Similarly, . Using union bound, we have:
By union bound, we have:
The event in this Lemma is just and the proof is concluded. ∎
Next, we state two lemmas from prior work.
Lemma 3.
If , then is bounded by .
Proof.
See Lemma 5.2 in (Srinivas et al. 2010). It employs the results of Lemma 2 to prove the statement. ∎
Lemma 4.
Let denote the posterior variance of a GP after observations, and let . Assume that we have queried at points of which points are in . Then .
Proof.
See Lemma 8 in (Kandasamy et al. 2019). ∎
Proof for Theorem 1
Extension to Continuous Domains
We will now derive regret bounds for the general case where is a d-dimensional compact and convex set with . This will critically require an additional Lipschitz continuity assumption on .
Theorem 5.
Suppose that kernels and are such that the derivatives of and sample paths are bounded with high probably. Precisely, for some constants ,
| (10) |
Pick , and set . Then, running JUMBO for iterations results in a sequence of candidates for which the following holds with probability at least :
where .
To start the proof, we first show that we have confidence on all the points visited by the algorithm.
Lemma 6.
Pick and set , where , . Define and . Then,
holds with probability of at least .
Proof.
Fix and . Similar to Lemma 3, . Since , using the union bound for concludes the statement. ∎
For the purpose of analysis, we define a discretization set , so that the results derived earlier can be re-applied to bound the regret in continuous case. To enable this approach we will use conditions on -Lipschitz continuity to obtain a valid confidence interval on the optimal solution . Similar to (Srinivas et al. 2010), let us choose discretization of size (i.e. uniformly spaced points per dimension in ) such that for all the closest point to in , , has a distance less than some threshold. Formally, .
Lemma 7.
Pick and set , where , . Then, for all , the regret is bounded as follows:
| (11) |
with probabilty of at least .
Proof of Theorem 5
Appendix B Implementation Details
Pre-training Details
Figure 8 illustrates the skeleton of the architecture that was used for all experiments. The input configuration is fed to a multi-layer perceptron of layers with hidden units. Then, optionally, a dropout layer is applied to the output and the result is fed to another non-linear layer with outputs. The latent features are then mapped to the output with a linear layer. All activations are .

For HPO experiments, we have used , and . For circuit experiments we used , and dropout rate of . These hyper-parameters were chosen based on random search by observing the prediction accuracy of the pre-training model on the auxiliary validation dataset which was 20% of the overall dataset.
Details of training the Gaussian Process hyper-parameters
For both warm and cold GP, we consider a Matern kernel (i.e. with where ). The length scale and observation noise are optimized in every iteration of BO by taking 100 gradient steps on the likelihood of observations via Adam optimizer with a learning rate of .
Acquisition Function Details
For all experiments, we used Upper Confidence Bound with the exploration-exploitation hyper-parameter at round set as where is the budget of total number of iterations. This way we favor exploration more initially and gradually drift to more exploitation as we approach the end of the budget. For optimization of acquisition function, we use the derivative free algorithm CMA-ES (Hansen 2016).
Dealing with Categorical Variables in HPO
We handle categorical and integer-valued variables in BO similar to (Garrido-Merchán and Hernández-Lobato 2020). In particular, we used as the kernel where is a deterministic transformation that maps the continuous optimization variable to a representation space that adheres to a meaningful distance measurement. For example, for categorical parameters, it converts a continuous input to a one-hot encoding corresponding to a choice for that parameter, and for integer-valued variables, it converts the continuous variable to the closest integer value. Similarly, for the pre-training phase, we also train using .
Appendix C Experimental Evidence
All the experiments were done on a quad-core desktop.
Space compression through the pretrained NN
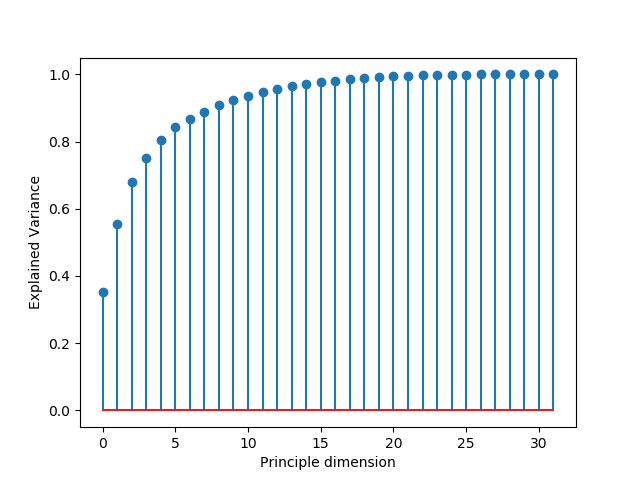
In this experiment we studied the latent space of a NN fed with uniformly sampled inputs for circuit design and see that 75% of data variance is preserved in only 4 dimensions (with ), suggesting that the warm-GP is operating in a compressed space.
Discussion: Choice of
The threshold is a key design hyperparameter for defining the acquisition function in JUMBO. JUMBO with reduces to GP-UCB (i.e. cold-GP only) and with , it reduces to offline DKL (i.e. warm-GP only).
Table 1 shows the effect of different choices for on the performance of the algorithm for both HPO and circuit design problems. As we can see, small values for (e.g. ) cause JUMBO to rely more on the accuracy of the warm-GP model and result in sub-optimal convergence in case of model discrepancy between warm-GP and the target task. On the other hand, bigger values of (e.g. ) cause JUMBO to give more weight to the cold-GP and rely less on prior data. We also note that there is a wide range of that JUMBO performs well relative to other baselines, suggesting a good degree of robustness and less tuning in practice. Even though the optimal choice of really depends on the exact problem setup (e.g. 0.05 for circuits problem, and for Slice localization), we have found that the choice of is a good initial choice for all the problems considered.
| GP-UCB | JUMBO-0.01 | JUMBO-0.05 | JUMBO-0.1 | JUMBO-0.2 | Offline DKL () | |
|---|---|---|---|---|---|---|
| Protein | 1.0 0.08 | 2.09 0.00 | 1.45 0.18 | 0.29 0.05 | 0.77 0.13 | |
| Parkinsons | 1.0 0.05 | 0.52 0.07 | 0.19 0.05 | 0.45 0.05 | 1.0 0.02 | |
| Naval | 1.0 0.07 | 0.97 0.07 | 0.49 0.04 | 0.78 0.07 | 1.78 0.06 | |
| Slice | 1.0 0.02 | 5.54 0.5 | 2.87 0.12 | 2.69 0.29 | 13.77 0.57 | |
| Circuit | 1.0 0.06 | 0.16 0.00 | 0.18 0.01 | 0.24 0.01 | 1.01 0.01 |
Ablation: Dynamic choice of
In this ablation we illustrate that the dynamic choice of is indeed better than choosing it to be a constant value. The intuition behind it is that by choosing a constant coefficient we essentially allow the acquisition function to choose points with very high but low scores. However, should not be trusted because of the warm-start problem in BO.
Figure 10 compares JUMBO with dynamic and constant on the four HPO problems. It can be seen that JUMBO with constant immaturely reaches a sub-optimal solution in all the experiments.

Tabular Experimental Results
In this section we present the quantitative comparison between JUMBO and the best outstanding prior work for each experimental case. In this table we have also included BOHB as another relevant multi-fidelity baseline.
BOHB combines the successive halving approach introduced in HyperBand (Li et al. 2017) with a probabilistic model that captures the density of good configurations in the input space. Unlike other methods BOHB employs a fixed budget and utilizes the information beyond epoch 3. It runs multiple hyperparameter configurations in parallel and terminates a subset of them after every few epochs based on their current validation error until the budget is exhausted.
| Protein () | Parkinsons () | Naval () | Slice () | |
|---|---|---|---|---|
| GP-UCB | 1.98 | 4.93 | 1.4 | 0.77 |
| MT-BOHAMIANN | 6.71 | 2.13 | 2 | 0.84 |
| MT-ABLR | 13.52 | 4.91 | 2.3 | 1.42 |
| OfflineDKL | 1.40 | 2.67 | 4.9 | 10.67 |
| BOHB | 6.38 | 3.16 | 2.1 | 0.23 |
| GCP | 7.50 | 3.15 | 3.3 | 0.46 |
| JUMBO (ours) | 0 | 0.23 | 0.7 | 0.73 |