Jointly Modeling Heterogeneous Student Behaviors and Interactions Among Multiple Prediction Tasks
Abstract.
Prediction tasks about students have practical significance for both student and college. Making multiple predictions about students is an important part of a smart campus. For instance, predicting whether a student will fail to graduate can alert the student affairs office to take predictive measures to help the student improve his/her academic performance. With the development of information technology in colleges, we can collect digital footprints which encode heterogeneous behaviors continuously. In this paper, we focus on modeling heterogeneous behaviors and making multiple predictions together, since some prediction tasks are related and learning the model for a specific task may have the data sparsity problem. To this end, we propose a variant of LSTM and a soft-attention mechanism. The proposed LSTM is able to learn the student profile-aware representation from heterogeneous behavior sequences. The proposed soft-attention mechanism can dynamically learn different importance degrees of different days for every student. In this way, heterogeneous behaviors can be well modeled. In order to model interactions among multiple prediction tasks, we propose a co-attention mechanism based unit. With the help of the stacked units, we can explicitly control the knowledge transfer among multiple tasks. We design three motivating behavior prediction tasks based on a real-world dataset collected from a college. Qualitative and quantitative experiments on the three prediction tasks have demonstrated the effectiveness of our model.
1. Introduction
Recently, more and more people are concerned about the educational field. By utilizing data mining techniques in this field, there arise various significant prediction tasks for better understanding students and the settings which students learn in, such as academic performance prediction (Yao et al., 2017; Xu et al., 2017), library circulation prediction (Tian, 2011; Wang et al., 2012), graduation failure prediction (Sukhbaatar et al., 2019). With the help of these tasks, educators could know grades of students, the library circulation, or whether students pass/fail for a specific given course ahead of time. Then educators could facilitate personalized education, do library strategic plan, or design in-time intervention.
Previous works about these prediction tasks mostly focus on the factors including values of historical observations (such as historical grades (Xu et al., 2017), historical library circulation (Tian, 2011; Wang et al., 2012)) and student demographic information (i.e., student profiles) (Shahiri et al., 2015; Nghe et al., 2007). These factors are relatively stable in the long run and are difficult to change via educational management. Besides, in online learning environments (e.g., massive open online courses), students’ digital records collected by online learning platforms such as logs about video-watching behavior, time spent on specific questions, and test/quiz grades have been leveraged (Brinton and Chiang, 2015; Calvo-Flores et al., 2006; Romero et al., 2013; Lopez et al., 2012; Minaei-Bidgoli et al., 2003). The digital records can directly reflect students’ efforts so they are important to prediction tasks. But these records are rarely digitized in traditional education.
Thanks to the development of information technology in colleges, there is a clear trend to augment physical facilities with sensing, computing, and communication capabilities (Zhang et al., 2010). These facilities unobtrusively record students’ digital footprints every day. The digital footprints of students encode heterogeneous behaviors that are helpful for prediction tasks. For example, academic efforts can be learned from entering the library records and entering the dormitory records. Academic efforts are key factors for predicting academic performance, the number of borrowed books, or the number of failed courses. In other words, students’ hard study (i.e., entering the library frequently, early; going back to the dormitory late) can pay off and may result in borrowing many books from libraries. Once the digital footprints are available, they can be used to improve prediction performances.


Besides, some prediction tasks are closely related. Figure 1 (a) shows the correlation between the academic performance and the number of borrowed books. The percentage of students who borrow more than books in one semester is low (around ) so we regard any number of borrowed books greater than as . We can see that the academic performance and the number of borrowed books have a positive correlation. In Figure 1 (b), the academic performance and the number of failed courses have a negative correlation. Hence, when predicting the number of books borrowed by student , the value is more likely to be large once knowing that the academic performance of student is good and the number of failed courses is small. In this paper, we collect digital footprints of students spanning one academic year from campus smart card usage for entering the library and the dormitory. One footprint record mainly contains the student identity number and the timestamp of the record.
Based on the above thoughts, we focus on jointly modeling heterogeneous student behaviors generated from digital footprints and interactions among multiple prediction tasks. We take Predicting Academic Performance (PAP), Predicting the Number of Borrowed Books (PNBB), and Predicting the Number of Failed Courses (PNFC) as three motivating examples of prediction tasks. However, we mainly confront the following challenges. First, the students’ profile information has a large impact on their behaviors. Similar behaviors of different kinds of students may mean differently. For instance, there are two students: student and student . Their records of entering the library are similar. Student is a freshman while student is a senior. Student would have less homework to do than student . In return, it means student works harder than student . Thus the academic performance of student should be better than student . Profile information has not been well considered in previous studies. So the challenge is how to consider profile information while modeling daily behaviors. Second, behaviors of different days have different degrees of impact. For instance, the academic efforts of students on different days will change due to many reasons such as study habits. So the challenge is how to dynamically find out informative days according to different students. Third, a simple way to capture correlations among multiple tasks is leveraging a simple multi-task learning framework. In this way, we can only capture latent interactions and we can not explicitly control the knowledge transfer, resulting in a lack of interpretability. So the challenge is how to explicitly model interactions among multiple tasks.
To address the first two challenges, we propose an attentional profile-aware multi-task model (APAMT) for modeling heterogeneous daily behaviors in our preliminary work (Liu et al., 2020). More specifically, for heterogeneous daily behaviors, each kind of behavior sequence is modeled by a variant of LSTM named Profile-aware LSTM. By adding profile information in the gates of LSTM, LSTM can consider profile information when modeling the behavior sequence, so as to improve the performances of prediction tasks. Besides, a novel soft-attention mechanism is designed over Profile-aware LSTM to dynamically learn the different importance degrees of different days for every student for improving the prediction performances. In APAMT model, we leverage a simple multi-task learning framework to implicitly model interactions among multiple tasks. Therefore, in this paper, we extend APAMT and propose a Dual Attention Profile-Aware Multi-Task model (DAPAMT) to explicitly model interactions among multiple tasks. Specifically, we design a unit called Multi-task Interaction Unit, the core of which is the co-attention mechanism. With the unit, we can explicitly control the process of knowledge transfer. Besides, we can stack more than one unit to model the high-level interactions. Moreover, we find that leveraging multi-task learning is necessary since there exists a data sparsity problem. For example, in our dataset, around of students do not borrow books in one semester. Thus, the input data of PNBB task can be sparse.
In summary, the main contributions of this paper are as follows:
-
•
We propose a Dual Attention Profile-Aware Multi-Task model (i.e., DAPAMT) to deal with multiple prediction tasks about students simultaneously. DAPAMT can jointly model heterogeneous student behaviors generated from digital footprints effectively and interactions among multiple prediction tasks explicitly.
-
•
We design a variant of LSTM called Profile-aware LSTM to capture profile information when modeling the daily behavior sequence. We design a soft-attention mechanism to dynamically find out informative days. We design a co-attention mechanism based unit called Multi-task Interaction Unit to explicitly control the knowledge transfer and alleviate the data sparsity problem.
-
•
We evaluate our proposed model on a large-scale real-world dataset. The experimental results demonstrate that our model outperforms competing baselines and every component of our model is well-designed, benefiting the prediction.
The rest of this paper is organized as follows. We first introduce the related work of our research in Section 2. Next, we introduce the problem statement in Section 3. Following that, we propose our model in Section 4. Then, Section 5 presents qualitative and quantitative results of different methods. Section 6 presents the ethical and social implications of this work. Finally, we conclude the paper in Section 7.
2. Related Work
In this section, we discuss existing studies that are related to the three prediction tasks or the methods we used in this paper.
2.1. RNNs for User Behavior Modeling
Recurrent Neural Networks (RNNs) have been widely adopted to model sequence data and have achieved good performance in various domains such as NLP (Sutskever et al., 2014). There are many well-known variants of RNN models, such as LSTM (Hochreiter and Schmidhuber, 1997), GRU (Chung et al., 2014), bidirectional LSTM (Graves and Schmidhuber, 2005). Hidasi et al. (Hidasi et al., 2016) firstly introduced GRU to recommender systems. They leveraged GRU to model click behaviors of users. Zhu et al. (Zhu et al., 2017) proposed a variant of LSTM called Time-LSTM. They proposed that it is important to exploit the time information when modeling users’ behaviors. To achieve this goal, they equipped LSTM with time gates to model time intervals.
2.2. Academic Performance Predictions
Academic performance prediction task is the most frequently studied among prediction tasks about students. In this paper, we choose Weighted Average Grade (WAG) which is on a 100-point scale to quantitatively describe the academic performance of a student in one semester. WAG can be seen as term GPA.
There are various factors that impact the academic performance in complex ways (Khan and Ghosh, 2021). Student demographic information and historical academic performance are widely explored by researchers (Shahiri et al., 2015; Khan and Ghosh, 2021). Some technologies such as online learning platforms are used in some courses nowadays. Students’ digital records collected by online learning platforms such as logs about video-watching behavior, time spent on specific questions, and test/quiz grades have been leveraged (Brinton and Chiang, 2015; Calvo-Flores et al., 2006; Romero et al., 2013; Lopez et al., 2012; Minaei-Bidgoli et al., 2003; Khan and Ghosh, 2021). A few studies find that effective teaching motivates the student to perform better (Khan and Ghosh, 2018, 2021). Besides, some studies explore other factors such as attitudes towards study (Osmanbegovic and Suljic, 2012). As for employing students’ behaviors on campus to predict academic performance, Wang et al. (Wang et al., 2015) found correlations between students’ cumulative GPAs and automatic sensing behavioral data obtained from smartphones. However, the passive sensing behavioral data they used is only collected from a small number of students and the collecting way is not universal enough. Yao et al. (Yao et al., 2017) studied the effect of social influence on predicting academic performance based on students’ multiple behaviors. The effect of students’ behaviors is very indirect. Zhang et al. (Zhang et al., 2018) extracted statistics features and relevance features from students’ multiple behaviors and used these features to predict academic performance.
Most methods used for academic performance prediction are based on traditional data mining techniques. Khan and Ghosh (Khan and Ghosh, 2018) regarded the student evaluation of teaching excellence and the number of student evaluations as input and used association rule mining to establish the relationship between teaching and academic performance. Feng et al. (Feng et al., 2009) did a stepwise linear regression to predict academic performance using the online measures as independent variables. Sweeney et al. (Sweeney et al., 2015) explored the factorization machine, a general-purpose matrix factorization algorithm based on (student, course) dyads. Xu et al. (Xu et al., 2017) leveraged an ensemble learning method to predict academic performance continuously in the program based on the evolving academic performances. Besides traditional methods, some researchers seek novel solutions with the help of deep learning. Wang and Liao (Wang and Liao, 2011) gathered information about gender, personality type, and anxiety level through questionnaires. Then they adopted a feed forward neural network to predict academic performance. LSTMs are also explored. Fei and Yeung (Fei and Yeung, 2015) leveraged an LSTM to model student weekly activities and predict academic performance in Massive Open Online Courses (MOOCs).
These studies will ignore the influence of profile information when modeling student daily behaviors and treat all days equally.
2.3. Book-Borrowing Predictions
Book-borrowing predictions are meaningful and have been studied by many researchers. Cano et al. (Cano et al., 2018) analysed student book-borrowing behavior during the semester through clustering and association rule algorithms. They proposed that librarians could take better decisions (such as decide the quantity to offer per topic and human resources needed to satisfy the demand) for their users after knowing the analysis results.
Besides, most existing studies on book-borrowing prediction focus on predicting library circulation. Tian (Tian, 2011) regarded the time series of library circulation flow as the chaotic time series and leveraged support vector regressions to predict library circulation of coming months. They mentioned that when the number of enrollments in a college increases sharply, the importance of book-borrowing predictions comes out conspicuously. Kumar and Raj (Kumar and Raj, 2016) found that the number of borrowed books one month and twelve months earlier could estimate the number of borrowed books in a month with an autoregressive integrated moving average model. Wang et al. (Wang et al., 2012) leveraged a feed forward neural network to predict library circulation of next five days based on data of previous twenty days. These works proposed that they were of positive significance for library capacity planning, management of library books and staff, and library acquisition budget supporting. These works ignore the impact of individuals.
2.4. Course-Failing Predictions
Existing studies on course-failing prediction mainly focus on classifying students into two categories: either pass or fail for a given course. Existing studies do not distinguish this task from academic performance prediction task (Yu et al., 2011). If there is only one course, these two tasks are the same. Once we knew one student’s mark, we know whether the student failed the course or not and vice-versa. If there is more than one course, these two tasks are different. For example, if student gets points in course ( credits) and gets points in course ( credits), the academic performance of student is which is above points. But, the number of failed courses of this student is (he/she fails course ).
Actually, both the two tasks could be equally important. According to college rules of student management, either a low Weighted Average Grade or a certain number of failed courses lead to the academic probation even the academic dismissal. Thus, to effectively predict those students who may violate college academic requirements, both the academic performance prediction and the course-failing prediction are needed. Besides, some students may be more concerned with their Weighted Average Grades, because they may apply for graduate studies. Knowing their Weighted Average Grades previously would help them to study harder. Nevertheless, some students may be more concerned with whether they fail or not, because if they failed a course, they would not be qualified for student loans. In this case, knowing whether they fail or not would help them to act accordingly.
Methods used in course-failing prediction include k-nearest neighbour methods (Tanner and Toivonen, 2010), ensemble methods (Yu et al., 2011), feed forward neural networks (Sukhbaatar et al., 2019) and so on. In detail, Tanner and Toivonen (Tanner and Toivonen, 2010) took student status features, student performance features, lesson requirement features, and customer demographic features as possible input of a k-nearest neighbor method to do course-failing prediction in an online course setting. Yu et al. (Yu et al., 2011) did feature engineering and used a random forest algorithm (i.e., an ensemble method) to predict whether the student will be correct on the first attempt for a step based on interaction logs generated in intelligent tutoring systems. Sukhbaatar et al. (Sukhbaatar et al., 2019) employed a feed forward neural network on the set of prediction factors extracted from the online learning activities of students to identify students at risk of failing in a course.
2.5. Multi-Task Learning
Multi-task learning (MTL) was first analyzed by Caruana (Caruana, 1997) in detail. Multi-task learning could improve learning efficiency and prediction accuracy for each task when compared to training a separate model for each task. One important reason is that multi-task learning allows sharing of statistical strength and transferring of knowledge between related tasks. Multi-task learning has been used successfully in many fields, such as computer vision (Dai et al., 2016; Ranjan et al., 2017), natural language processing (Collobert and Weston, 2008), urban computing (Lu et al., 2020).
3. Preliminaries
In this section, we introduce the problem statement.
Entering the Library Records. When students enter the library, they need to swipe their campus cards. Thus records are generated. One entering the library record can be represented as , where denotes student and denotes the timestamp of the record.
Entering the Dormitory Records. Similar to entering the library records, one entering the dormitory record is represented as , where denotes student and denotes the timestamp.
Student Profile Records. One record of this sub-dataset can be represented as , where is an attribute set about demographic information of student . In this paper, according to the dataset, the attributes include the place of birth, nationality, gender, grade, school, and department. If other demographic information was available, it could also be added.
Student Final Course Grade Records. Given course , one record can be represented as , where is the index of the whole semesters that student involves in; is the credit of course and is the final grade student achieves in course . .
Problem Statement. In this paper, we have three motivating tasks.
PAP task: Given digital footprints (i.e., and ) generated in the first days of the semester , profile information , and final course grade records generated in all previous semesters of student , our goal is to predict the future academic performance (i.e., WGA) of student in semester . .
PNBB task: Given digital footprints (i.e., and ) generated in the first days of the semester , profile information , and the number of borrowed books in each previous semester (the number of all previous semesters is ) of student , our goal is to predict the number of borrowed books of student in semester . .
PNFC task: Given digital footprints (i.e., and ) generated in the first days of the semester , profile information , and final course grade records generated in all previous semesters of student , our goal is to predict the number of failed courses of student in semester . .
4. Proposed DAPAMT Model
The main structure of our proposed Dual Attention Profile-Aware Multi-Task model (DAPAMT) is illustrated in Figure 2. The rest of this section is organized as follows. First, we introduce how to model the daily behavior sequence with Profile-aware LSTM and attention-based pooling. Then we introduce how to explicitly model the interaction among multiple prediction tasks with stacked Multi-task Interaction Units. Finally, we utilize task-specific output layers to get the final prediction results. Table 1 summarizes main notations and their meanings used throughout this paper.

| Notation | Description | ||
| Profile information of student . | |||
| Dense representation of the profile information. | |||
| Feature vector of the -th kind of behavior at the -th day. | |||
| , and | Input, forget and output gates. | ||
|
|||
| Hidden representation of all heterogeneous behaviors of the -th day. | |||
| terms | Soft-attention weights. | ||
| Advanced student behavior representation. | |||
| Student representation. | |||
| , and | WAG, # borrowed books and # failed courses in semester . | ||
| , and | Inputs (task-specific feature vectors) of the -th Multi-task Interaction Unit. | ||
| , and | More task-specific feature vectors. | ||
| terms | Co-attention weights. |
4.1. Inputs and Dense Embedding Layer
Student ’ profile information is represented in the form of one high-dimensional vector including many one-hot encoded vectors. To reduce the dimension and get a better representation, we use a dense embedding layer. The transformation is formalized as:
| (1) |
where is the mapping matrix.
Thinking that the combination of entering the library and going back to the dormitory behaviors can reveal students’ academic efforts, we extract the daily behavior sequence of entering the library and the daily behavior sequence of going back to the dormitory from and respectively.
More specifically, we divide one day into time slots by hour (i.e., ). According to , almost 100% of entering the library records are generated in 07:00-23:00. So we use elements to record entering the library frequency in 07:00-23:00 for each day. In this way, we get the daily behavior sequence of entering the library: ( is the index. since we make predictions after the first half of the semester (63 days).).
One going back to the dormitory record is defined as the last record of entering the dormitory of the day. Based on , around 84% of going back to the dormitory records are generated in 18:00-24:00. So we use a vector with a length of to record the situation of going back to the dormitory in 18:00-24:00 for each day. In this way, we get the behavior sequence of going back to the dormitory: .
4.2. Profile-aware LSTM
Similar behaviors of different kinds of students may mean differently. We propose a variant of LSTM called Profile-aware LSTM. We treat student profile information as a strong signal in the gates of Profile-aware LSTM (as Equation (2), (3) and (5) show). That is to say, what to extract, what to remember, and what to forward are affected by student profile information. The behavior sequence is the input of Profile-aware LSTM (as Equation (4) shows).
Profile-aware LSTM model is formulated as follows and the detailed structure is shown in Figure 3:

| (2) | |||
| (3) | |||
| (4) | |||
| (5) | |||
| (6) |
where and are one input element and the corresponding output of Profile-aware LSTM unit, i.e., hidden state at time , respectively. is calculated with Equation (1). . . terms denote weight matrices and terms are bias vectors. is the element-wise sigmoid function and is the element-wise product.
We use two Profile-aware LSTMs to model two kinds of behaviors respectively.
4.3. Attention-based Pooling Layer
The hidden representation of all heterogeneous behaviors of the -th day can be formalized as:
| (7) |
where is the concatenation operation.
Behaviors of different days to the task will have different degrees of impact. Inspired by the success of the attention mechanism in machine translation (Bahdanau et al., 2015), we apply a novel soft-attention mechanism over Profile-aware LSTM to draw information from the sequence by different weights. In detail, we consider each vector as heterogeneous behaviors representation of the -th day, and represent the sequence by a weighted sum of the vector representation of all days. The attention weight makes it possible to perform proper credit assignments to days according to their importance to the student. Mathematically, we compute soft-attention weight with the following equations:
| (8) | ||||
| (9) |
where is computed with Equation (1), is computed with Equation (7), terms denote weight matrices, and is the bias vector. Similar to Profile-aware LSTM, student profile information also contributes to the attention weights.
The advanced student behavior representation is generated using the following equation:
| (10) |
The student representation is the concatenation of and :
| (11) |
4.4. Stacked Multi-task Interaction Units

After obtaining the student representation, we concatenate it with task-related features. In detail, we have three tasks: PAP task, PNBB task, and PNFC task. For PAP task, the task-related information includes the historical WAG information and the involved course information; for PNBB task, the task-related information includes the historical number of borrowed books information; for PNFC task, the task-related information includes the historical number of failed courses and the involved course information as Figure 4 shows. Then we feed the concatenated features to stacked Multi-task Interaction Units. In what follows, we introduce how to handle the various kinds of task-related information and introduce the detailed structure of the Multi-task Interaction Unit.
PAP Task. As mentioned in Section 2, we use WAG to quantitatively describe the academic performance. Given , WAG is calculated with the following equation:
| (12) |
where is the number of courses chosen by student in semester . In this way, we get the historical WAG sequence of student : . The historical WAG sequence reveals students’ trends of academic performance. Note that the length of the historical WAG sequence may vary from student to student, so we adopt a dynamic LSTM to model the sequence:
| (13) |
where and are one input and the corresponding hidden state at time . We regard the last hidden state as the trend representation.
We find that students get higher grades easily in some courses such as CS362 as Figure 5 shows. This means different courses have different levels of difficulty. So for each course, we extract descriptive statistics (i.e., minimum, maximum, median, first quartile, third quartile, mean, standard deviation) as features. These features can describe the properties of distribution from multiple aspects. The feature vector of course is represented as . Next, we aggregate feature vectors of all courses by leveraging course credit information:
| (14) |

Then we concatenate , with :
| (15) |
PNBB Task. Similarly, the historical number of borrowed books sequence reveals students’ trends of the number of borrowed books. We utilize another dynamic LSTM to model the sequence:
| (16) |
where and are one input and the corresponding hidden state at time . is the trend representation.
Then we concatenate with :
| (17) |
PNFC Task. A LSTM is leveraged to model the historical number of failed courses sequence:
| (18) |
where and are one input and the corresponding hidden state at time .
We also extract some features such as course failure rate and descriptive statistics. The feature vector of course is represented as . We merger information of every course by:
| (19) |
Then we concatenate , with :
| (20) |
Multi-task Interaction Unit. We stack Multi-task Interaction Units. Formally, for the -th unit, the inputs are , , and . The outputs are , , and . .
Firstly, we utilize Fully Connected (FC) layers to make the inputs more task-specific and to let the inputs have the same dimensions, which can be written as:
| (21) | ||||
| (22) | ||||
| (23) |
where terms and terms are learnable parameters, and (He et al., 2015) is the nonlinear activation function. , , and are calculated with Equation (15), (17), and (20), respectively.
Then we utilize the co-attention mechanism to explicitly control the knowledge transfer. The co-attention mechanism was first proposed to jointly reasons about visual attention and question attention (Lu et al., 2016). The co-attention mechanism demonstrates the ability of capturing the complementary important information. With the co-attention mechanism, we can get the updated representation explicitly incorporating other tasks’ knowledge. Mathematically, we compute co-attention weights with the following equations:
| (24) | ||||
| (25) | ||||
| (26) |
where is the sigmoid function. That is to say, we leverage dot product and sigmoid function to calculate the co-attention weights.
The updated representations are generated using the following equations:
| (27) | ||||
| (28) | ||||
| (29) |
4.5. Output Layers
After Multi-task Interaction Units, we can get the outputs of the last unit: , , and . Then we adopt separate output layers to get the prediction results, which can be denoted as follows:
| (30) | ||||
| (31) | ||||
| (32) |
where terms and terms are parameters.
4.6. Optimization
We use the mean squared error (MSE) as the loss function for training the three tasks:
| (33) | ||||
| (34) | ||||
| (35) |
where denotes one training sample, is the number of training samples, and terms are all trainable parameters. , , and denote the labels of the -th sample.
The total loss is computed as the sum of the three individual losses:
| (37) |
where terms are balance weights. Here, balance weights of 1 are implicitly used among the three tasks.
The training process is outlined in Algorithm 1. We adopt the adaptive moment estimation (Adam) (Kingma and Ba, 2015) as the optimizer.
In order to improve the generalization capability of our models, we adopt dropout (Srivastava et al., 2014) to prevent the potential overfitting problem.
5. Experiments
In this section, we describe the detailed experimental settings and discuss the results.
5.1. Dataset
The data were collected in a college with an enrollment of undergraduate students. Dataset statistics are shown in Table 2.
5.2. Comparison Baselines
To demonstrate the effectiveness of our proposed model, we compared our proposed model, i.e., DAPAMT, with various baselines.
-
•
HA: We give the prediction result by the average value of historical observations.
-
•
LSTM (Fei and Yeung, 2015): LSTM is widely used to model sequence data. We leverage LSTMs to model historical observation sequences.
-
•
BRR (Wang et al., 2015): Bayesian Ridge Regression (BRR) is a generalized linear model which has regularization.
-
•
SVR (Tian, 2011): Support Vector Regression (SVR) is a variant of support vector machine (SVM) for supporting regression tasks. SVR is a minimum-margin regression which could model the non-linear relation between features.
-
•
RF (Chen et al., 2019): Random Forest (RF) is an ensemble method with decision trees as base learners. It is based on the “bagging” idea.
-
•
GBDT: Gradient Boosting Decision Tree (GBDT) is another kind of ensemble method using decision trees as base learners. GBDT is a generalization of boosting to arbitrary differentiable loss functions.
- •
-
•
APAMT (Liu et al., 2020): Attentional Profile-Aware Multi-Task model (APAMT) is proposed in our preliminary work. It leverages the Profile-aware LSTM and the soft-attention mechanism to model the daily behavior sequence. Besides, it adopts a simpler multi-task learning framework compared with DAPAMT. Specifically, it implicitly models the interactions among tasks by setting shared layers and task-specific layers.
| Item | Value | ||
| # Students | 10,000 | ||
| Student Behaviors Time Span |
|
||
|
|||
| # Library Entrance Records | 867,571 | ||
| # Dormitory Entrance Records | 1,783,595 | ||
| # Demographic Records | 10,000 | ||
| # Courses | 2,482 |
5.3. Evaluation Metric
We adopt Mean Square Error (MSE) to quantify the distance between the predicted scores and the actual ones. MSE penalizes large errors more heavily than the non-quadratic metrics, and thus takes higher numerical values. Given our tasks, if a method performs very well for half the students and poorly for the other half, we still think it is not a good method. Hence we select MSE as the metric to compare methods. The smaller the values are, the better results the method has. The metric is defined as:
| (38) |
where denotes one testing instance, is the number of testing samples, is the actual value, and is the predicted value. For better understanding the metric and actual data, we analyze our dataset. The minimum WAG is and the maximum WAG is in our dataset. Thus the MSE range could be between and on PAP task. The minimum number of borrowed books is and the maximum number is in our dataset. Thus the MSE range could be between and on PNBB task. The minimum number of failed courses is and the maximum number is in our dataset. Thus the MSE range could be between and on PNFC task. We can know one method is more likely to get a small MSE on PNFC task and get a big MSE on PNBB task.
5.4. Implementation Details
For baselines except APAMT, we extract features from heterogeneous student behaviors as Guan et al. (Guan et al., 2015) suggested. In addition, due to the uncertainty of the historical observation sequence, we extract some descriptive statistics (minimum, maximum and mean) as features. As for the data preprocessing, we represent the categorical features with one-hot encoding. We process numerical inputs with the Min-Max normalization to ensure they are within a suitable range. For WAG, the number of borrowed books and the number of failed courses, because we use as the activation function in the output layer, we scale them into . In the evaluation, we re-scale the predicted values back to the normal values, compared with the actual values. For the other numerical inputs, we scale them into . Around half of the data (Fall 2016) are used as the training set and the other half (Spring 2017) are used for testing.
The hyper-parameters of all models are tuned with a ten-fold cross-validation method on the training dataset. We only present the optimal settings of our model are as follows. The dense embedding layer has neurons. The dimensions of the hidden states in the Profile-aware LSTMs which handle entering the library and going back to the dormitory behaviors are set as and respectively. The dimension of the hidden state in the dynamic LSTM which handles the historical WAG/number of borrowed books/number of failed courses sequence is set as . The FC layer of the Multi-task Interaction Unit has neurons. The activation function used in the FC layer is . We adopt Multi-task Interaction Units in total. We apply dropout before the output layer with a dropout rate equal to .
5.5. Significance Test
The two-tailed unpaired -test is performed to detect significant differences between DAPAMT and the best baseline. There are two conditions that should be met: the two groups of samples should be normally distributed; the variances of the two groups are the same (this can be checked using Levene’s test).
5.6. Results and Discussion
To comprehensively evaluate our model, we conduct five experiments. First, we compare our proposed model with state-of-the-art methods to show the effectiveness of our model. Second, we do ablation studies to prove the effectiveness of the key components in DAPAMT such as the Profile-aware LSTM. Third, we provide the visualization of learned representations to show whether our model can learn general representations which could be transferred to some new tasks. Fourth, we randomly select some students to visualize soft-attention weights and co-attention weights. We do this experiment to see whether our model can provide interpretability and whether attention mechanisms are effective. Finally, we study how hyper-parameters in DAPAMT impact the performance.
| Compared Methods | PAP | PNBB | PNFC | |||
| MSE | RI | MSE | RI | MSE | RI | |
| HA | 31.85 | 61.82% | 63.50 | 65.95% | 0.344 | 54.94% |
| LSTM | 28.46 | 57.27% | 57.21 | 62.21% | 0.319 | 51.41% |
| BRR | 27.68 | 56.07% | 50.06 | 56.81% | 0.306 | 49.35% |
| SVR | 26.81 | 54.64% | 49.83 | 56.61% | 0.275 | 43.64% |
| RF | 18.24 | 33.33% | 30.17 | 28.34% | 0.197 | 21.32% |
| GBDT | 18.87 | 35.56% | 29.73 | 27.28% | 0.220 | 29.55% |
| MLP | 17.72 | 31.38% | 28.64 | 24.51% | 0.183 | 15.30% |
| APAMT | 14.52 | 16.25% | 24.77 | 12.72% | 0.167 | 7.19% |
| DAPAMT | - | - | - | |||
5.6.1. Exp-1: Comparison with Baselines.
We compare our model with baselines. Quantitative comparison between different models on the three prediction tasks is shown in Table 3. All baselines except APAMT are trained with single task. From the table, we can see that DAPAMT achieves the best performances with the lowest MSE on PAP task, the lowest MSE on PNBB task and the lowest MSE on PNFC task.
We can see that HA performs worst since the trend of the WAG/number of borrowed books/number of failed courses change is not so stable. This indicates that it is necessary to develop a method to predict the future trend. We can see that LSTM performs not well, as it only utilizes the historical WAG/number of borrowed books/number of failed courses values. Other baselines further consider more information, such as student profile information and heterogeneous student behaviors, and therefore achieve better performances. Although BRR performs better than LSTM, it still shows poor performance which indicates that capturing linear correlations is not sufficient. For SVR, we leverage RBF kernel thus it can model the non-linear relation between features. As a result, SVR performs better than BRR. Ensemble models (i.e., RF and GBDT) perform well. Ensemble methods usually outperform single models so they are popular. MLP performs best among baselines except for APAMT. Since it can model complex relations among features with the help of deep learning. APAMT performs best among baselines because it can not only extract features automatically from heterogeneous behaviors but also model the interactions among multiple tasks in an implicit way.
It is worth mentioning that DAPAMT achieves , , relative improvements on PAP, PNBB, PNFC tasks, compared with the best baseline, ie., APAMT. One important reason is that DAPAMT can explicitly model the interactions among multiple tasks. With the help of the co-attention mechanism, DAPAMT can control the knowledge transfer among multiple tasks.
| Methods | PAP | PNBB | PNFC |
| MSE | MSE | MSE | |
| APAMT Trained w. Single Task | 15.10 | 26.43 | 0.177 |
| DAPAMT w. Standard LSTM | 13.13 | 24.42 | 0.161 |
| DAPAMT w/o Soft-attention Mechanism | 13.15 | 24.89 | 0.167 |
| APAMT | 14.52 | 24.77 | 0.167 |
| DAPAMT | 12.16 | 21.62 | 0.155 |
5.6.2. Exp-2: Ablation Studies.
Table 4 provides the comparison results of variants of our proposed method.
First, we study the effectiveness of our proposed multi-task learning framework. We train DAPAMT with single task. In this way, DAPAMT becomes APAMT Trained w. Single Task. From the table we can see that DAPAMT achieves , , relative improvements on PAP, PNBB, PNFC tasks. It demonstrates the benefits of the multi-task learning framework. Multi-task learning allows transferring of useful knowledge among related tasks. Second, we prove the benefit of the Profile-aware LSTM. We replace the Profile-aware LSTM with the standard LSTM. The result is that DAPAMT achieves lower MSE values (a reduction of , , and , respectively) with the help of the Profile-aware LSTM. Profile-aware LSTM can capture profile information when modeling the daily behavior sequence. Third, we remove the soft-attention mechanism and the performances become much poorer. The improvements of DAPAMT are about , , on PAP, PNBB, PNFC tasks. This demonstrates the effectiveness of our soft-attention mechanism. Our soft-attention mechanism can dynamically learn the different importance degrees of different days for every student. Finally, compared with APAMT, we can conclude that our co-attention mechanism is effective. Our co-attention mechanism can explicitly control the knowledge transfer.
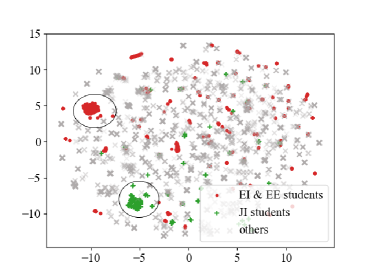



5.6.3. Exp-3: Learned Representations Visualization.
We remove course information (i.e., and ) from DAPAMT and retrain DAPAMT with the three tasks. Figure 6 (a) and (b) show visualizations of learned student representations based on the testing set. Figure 6 (c) and (d) show visualizations of learned PAP task-specific representations after the first two Multi-task Interaction Units based on the testing set. The technique we use is t-SNE algorithm (Maaten and Hinton, 2008). Specifically, with learned representations as input, t-SNE algorithm maps students to the 2-D space. One dot in the figure represents one student.
We randomly choose two groups of students (EI & EE (i.e., Electronic Information and Electrical Engineering) students and JI (i.e., Joint Institute) students) and mark these students. From Figure 6 (a), we can clearly find two clusters of EI & EE students and JI students. But we can not clearly find two clusters in Figure 6 (c). We can only distinguish these two groups.


Next, we mark the top students and the last students according to the mean of all WAGs. From Figure 6 (b), we can not distinguish these two groups of students. But there are clearly two clusters in Figure 6 (d).
This experiment indicates student representation is general and could be transferred to other tasks. Besides, after seeing the visualization of learned task-specific representations, we can know our model performs well and generates a meaningful layout of students (students with similar WAGs are distributed closer).


5.6.4. Exp-4: Attention mechanisms Visualization.
Exp-4.1: Soft-attention Visualization. We randomly select students in the testing set and visualize the soft-attention weights of days in Figure 7 to show whether DAPAMT can find out informative days for different students. The figure shows that soft-attention weights vary for days and students.
Next, we choose student to do the case study. For simplicity, we only show student ’s library entrance records. The fragment of the records is {(stu2,2017-02-22 15:21:54),(stu2,2017-02-25 15:58:29),(stu2,2017-04-15 12:07:32),(stu2,2017-04-16 08:52:53)}. In other words, during the first days, student enters the library on day , , , and . From the figure, we can see that the weights of these days are large.
This experiment visually indicates our designed soft-attention mechanism is effective (this conclusion can also be got in Section 5.6.2) and gives the informative day a large weight.
Exp-4.2: Co-attention Visualization. We still use the students and visualize the co-attention weights. In particular, we visualize the co-attention weights between PAP task and PNBB task (i.e., ), the weights between PAP task and PNFC task (i.e., ), and the weights between PNBB task and PNFC task (i.e., ) with the number of stacked units varying from to . We choose student and student to do the case studies. The WAG of student is , but the number of books borrowed by student is . So the weights of student are pretty small. The number of courses in which student failed is . Thus the weights of student are large. Next, we focus on student . The WAG of student is , and the number of books borrowed by student is . So the weights of student are large. The number of courses in which student failed is . Thus the weights of student become very small in unit 4.
This experiment visually indicates our designed co-attention mechanism is effective (this conclusion can also be got in Section 5.6.2) and explicitly controls the knowledge transfer among tasks by weights.
5.6.5. Exp-5: Effect of Hyper-parameters.
Exp-5.1: Effect of Activation Functions. We investigate the influence of the activation function which exists in FC layers. We choose PReLU, ReLU, and tanh to do the experiment. Figure 9 (a) shows the results. We observe that PReLU is more suitable.
Exp-5.2: Effect of the Number of Multi-task Interaction Units. A problem worth studying is that how many units are appropriate. Experimental results are shown in Figure 9 (b). As the number of units grows, the performances grow. When the number of units is , the performances except on PNFC drop. We think the reason might lie in the gradient vanishing or the overfitting problem as the whole network goes deeper. So we adopt stacked units.
6. Ethical Considerations
The ethical implication is our major concern. Nicholson and Glenn (Price and Cohen, 2019) proposed that the ethical analysis mainly depends on three aspects: the types of the data; the people who will be accessing the data; and the purpose of the work. So in what follows, we do the ethical analysis in three aspects.
For the types of data, the dataset used in our work has been processed and fully anonymized. Student names are removed. Sensitive information (i.e., student ID, place of birth, nationality, gender) is encrypted by being hashed to a vector space.
For the people who will be accessing the data, the data used in our work are not released for public access. In applications of our model, we stress that only college official management offices collect required data and prediction results should be constrained in a small group of official college staff.
For the purpose of this work, we would like to stress that the use of student data and prediction results should be constrained for the purpose of college student management only, not for general public access. Besides, the prediction results should not bias an instructor’s treatment of individual students. In the real world, machine learning algorithms will never achieve 100% accurate prediction results (Khan and Ghosh, 2021).
In addition, this work has been approved by the Institutional Review Board (IRB).
7. Conclusion
In this paper, we propose a Dual Attention Profile-Aware Multi-Task model (i.e., DAPAMT) to jointly modeling heterogeneous student behaviors generated from digital footprints and interactions among multiple prediction tasks. With DAPAMT, we can learn personalized and general student representations from student profiles and student heterogeneous behaviors. At the same time, we can explicitly control the knowledge transfer among prediction tasks. Qualitative and quantitative experiments on a real-world dataset have demonstrated the effectiveness of DAPAMT. We believe DAPAMT is an extensible framework. DAPAMT can be utilized to model heterogeneous behaviors of one person rather than one student and can be utilized to handle more tasks in actual scenarios.
Acknowledgements
We thank the anonymous reviewers for carefully reviewing and useful suggestions. This research is supported in part by the 2030 National Key AI Program of China 2018AAA0100503 (2018AAA0100500), National Science Foundation of China (No. 62072304, No. 61772341, No. 61472254, No. 61770238), Shanghai Municipal Science and Technology Commission (No. 18511103002, No. 19510760500, and No. 19511101500), the Program for Changjiang Young Scholars in University of China, the Program for China Top Young Talents, the Program for Shanghai Top Young Talents, SJTU Global Strategic Partnership Fund (2019 SJTU-HKUST), the Oceanic Interdisciplinary Program of Shanghai Jiao Tong University (No. SL2020MS032) and Scientific Research Fund of Second Institute of Oceanography (No. SL2020MS032).
References
- (1)
- Bahdanau et al. (2015) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2015. Neural machine translation by jointly learning to align and translate. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1409.0473
- Brinton and Chiang (2015) Christopher G Brinton and Mung Chiang. 2015. MOOC performance prediction via clickstream data and social learning networks. In 2015 IEEE Conference on Computer Communications, INFOCOM 2015, Kowloon, Hong Kong, April 26 - May 1, 2015. IEEE, 2299–2307. https://doi.org/10.1109/INFOCOM.2015.7218617
- Calvo-Flores et al. (2006) M Delgado Calvo-Flores, E Gibaja Galindo, MC Pegalajar Jiménez, and O Pérez Pineiro. 2006. Predicting students’ marks from Moodle logs using neural network models. Current Developments in Technology-Assisted Education 1, 2 (2006), 586–590.
- Cano et al. (2018) Luis Cano, Erick Hein, Mauricio Rada-Orellana, and Claudio Ortega. 2018. A case study of library data management: A new method to analyze borrowing behavior. In Information Management and Big Data, 5th International Conference, SIMBig 2018, Lima, Peru, September 3-5, 2018, Proceedings (Communications in Computer and Information Science), Vol. 898. Springer, 112–120. https://doi.org/10.1007/978-3-030-11680-4_12
- Caruana (1997) Rich Caruana. 1997. Multitask learning. Machine learning 28, 1 (1997), 41–75. https://doi.org/10.1023/A:1007379606734
- Chen et al. (2019) Weiyu Chen, Christopher G Brinton, Da Cao, Amanda Mason-Singh, Charlton Lu, and Mung Chiang. 2019. Early detection prediction of learning outcomes in online short-courses via learning behaviors. IEEE Transactions on Learning Technologies 12, 1 (2019), 44–58. https://doi.org/10.1109/TLT.2018.2793193
- Chung et al. (2014) Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014). https://arxiv.org/abs/1412.3555
- Collobert and Weston (2008) Ronan Collobert and Jason Weston. 2008. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Machine Learning, Proceedings of the Twenty-Fifth International Conference (ICML 2008), Helsinki, Finland, June 5-9, 2008, Vol. 307. ACM, 160–167. https://doi.org/10.1145/1390156.1390177
- Dai et al. (2016) Jifeng Dai, Kaiming He, and Jian Sun. 2016. Instance-aware semantic segmentation via multi-task network cascades. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE, 3150–3158. https://doi.org/10.1109/CVPR.2016.343
- Fei and Yeung (2015) Mi Fei and Dit-Yan Yeung. 2015. Temporal models for predicting student dropout in massive open online courses. In booktitle = IEEE International Conference on Data Mining Workshop, ICDMW 2015, Atlantic City, NJ, USA, November 14-17, 2015,. IEEE, 256–263. https://doi.org/10.1109/ICDMW.2015.174
- Feng et al. (2009) Mingyu Feng, Neil Heffernan, and Kenneth Koedinger. 2009. Addressing the assessment challenge with an online system that tutors as it assesses. User Modeling and User-Adapted Interaction 19, 3 (2009), 243–266. https://doi.org/10.1007/s11257-009-9063-7
- Graves and Schmidhuber (2005) Alex Graves and Jürgen Schmidhuber. 2005. Framewise phoneme classification with bidirectional LSTM networks. In 2005 IEEE International Joint Conference on Neural Networks. 2047–2052. https://doi.org/10.1109/IJCNN.2005.1556215
- Guan et al. (2015) Chu Guan, Xinjiang Lu, Xiaolin Li, Enhong Chen, Wenjun Zhou, and Hui Xiong. 2015. Discovery of college students in financial hardship. In 2015 IEEE International Conference on Data Mining, ICDM 2015, Atlantic City, NJ, USA, November 14-17, 2015. IEEE, 141–150. https://doi.org/10.1109/ICDM.2015.49
- He et al. (2015) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2015. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE, 1026–1034. https://doi.org/10.1109/ICCV.2015.123
- Hidasi et al. (2016) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2016. Session-based recommendations with recurrent neural networks. In 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings. http://arxiv.org/abs/1511.06939
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural Computation 9, 8 (1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
- Khan and Ghosh (2018) Anupam Khan and Soumya K Ghosh. 2018. Data mining based analysis to explore the effect of teaching on student performance. Education and Information Technologies 23, 4 (2018), 1677–1697. https://doi.org/10.1007/s10639-017-9685-z
- Khan and Ghosh (2021) Anupam Khan and Soumya K Ghosh. 2021. Student performance analysis and prediction in classroom learning: A review of educational data mining studies. Education and Information Technologies 26, 1 (2021), 205–240. https://doi.org/10.1007/s10639-020-10230-3
- Kingma and Ba (2015) Diederik P Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings. http://arxiv.org/abs/1412.6980
- Kumar and Raj (2016) K Kumar and MAM Raj. 2016. Improving efficacy of library services: ARIMA modelling for predicting book borrowing for optimizing resource utilization. Library Philosophy and Practice (e-journal), Paper 1395 (2016).
- Liu et al. (2020) Haobing Liu, Yanmin Zhu, and Yanan Xu. 2020. Learning from heterogeneous student behaviors for multiple prediction tasks. In Database Systems for Advanced Applications - 25th International Conference, DASFAA 2020, Jeju, South Korea, September 24-27, 2020, Proceedings, Part II (Lecture Notes in Computer Science), Vol. 12113. Springer, 297–313. https://doi.org/10.1007/978-3-030-59416-9_18
- Lopez et al. (2012) Manuel Ignacio Lopez, JM Luna, C Romero, and S Ventura. 2012. Classification via clustering for predicting final marks based on student participation in forums. In 5th International Conference on Educational Data Mining. EDM.
- Lu et al. (2016) Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. 2016. Hierarchical question-image co-attention for visual question answering. In Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain. 289–297. https://proceedings.neurips.cc/paper/2016/hash/9dcb88e0137649590b755372b040afad-Abstract.html
- Lu et al. (2020) Xinjiang Lu, Zhiwen Yu, Chuanren Liu, Yanchi Liu, Hui Xiong, and Bin Guo. 2020. Inferring lifetime status of point-of-interest: A multitask multiclass approach. ACM Transactions on Knowledge Discovery from Data 14, 1 (2020), 1–27. https://doi.org/10.1145/3369799
- Maaten and Hinton (2008) Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of Machine Learning Research 9, Nov (2008), 2579–2605.
- Minaei-Bidgoli et al. (2003) Behrouz Minaei-Bidgoli, Deborah A Kashy, Gerd Kortemeyer, and William F Punch. 2003. Predicting student performance: an application of data mining methods with an educational web-based system. In 33rd Annual Frontiers in Education, 2003. FIE 2003., Vol. 1. IEEE, T1A–13–T1A–18. https://doi.org/10.1109/FIE.2003.1263284
- Nghe et al. (2007) Nguyen Thai Nghe, Paul Janecek, and Peter Haddawy. 2007. A comparative analysis of techniques for predicting academic performance. In 2007 37th Annual Frontiers in Education Conference-Global Engineering: Knowledge Without Borders, Opportunities Without Passports. IEEE, T2G–7–T2G–12. https://doi.org/10.1109/FIE.2007.4417993
- Osmanbegovic and Suljic (2012) Edin Osmanbegovic and Mirza Suljic. 2012. Data mining approach for predicting student performance. Economic Review: Journal of Economics and Business 10, 1 (2012), 3–12. https://EconPapers.repec.org/RePEc:tuz:journl:v:10:y:2012:i:1:p:3-12
- Price and Cohen (2019) W Nicholson Price and I Glenn Cohen. 2019. Privacy in the age of medical big data. Nature Medicine 25, 1 (2019), 37–43. https://doi.org/10.1038/s41591-018-0272-7
- Ranjan et al. (2017) Rajeev Ranjan, Vishal M Patel, and Rama Chellappa. 2017. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence 41, 1 (2017), 121–135. https://doi.org/10.1109/TPAMI.2017.2781233
- Romero et al. (2013) Cristóbal Romero, Manuel-Ignacio López, Jose-María Luna, and Sebastián Ventura. 2013. Predicting students’ final performance from participation in on-line discussion forums. Computers & Education 68 (2013), 458–472. https://doi.org/10.1016/j.compedu.2013.06.009
- Shahiri et al. (2015) Amirah Mohamed Shahiri, Wahidah Husain, and Nur’aini Abdul Rashid. 2015. A review on predicting student’s performance using data mining techniques. Procedia Computer Science 72 (2015), 414–422. https://doi.org/10.1016/j.procs.2015.12.157
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research 15, 1 (2014), 1929–1958. http://dl.acm.org/citation.cfm?id=2670313
- Sukhbaatar et al. (2019) Otgontsetseg Sukhbaatar, Tsuyoshi Usagawa, and Lodoiravsal Choimaa. 2019. An artificial neural network based early prediction of failure-prone students in blended learning course. iJET 14, 19 (2019), 77–92. https://www.online-journals.org/index.php/i-jet/article/view/10366
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada. 3104–3112. https://proceedings.neurips.cc/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html
- Sweeney et al. (2015) Mack Sweeney, Jaime Lester, and Huzefa Rangwala. 2015. Next-term student grade prediction. In 2015 IEEE International Conference on Big Data, Big Data 2015, Santa Clara, CA, USA, October 29 - November 1, 2015. IEEE, 970–975. https://doi.org/10.1109/BigData.2015.7363847
- Tanner and Toivonen (2010) Tuomas Tanner and Hannu Toivonen. 2010. Predicting and preventing student failure-using the k-nearest neighbour method to predict student performance in an online course environment. International Journal of Learning Technology 5, 4 (2010), 356–377. https://doi.org/10.1504/IJLT.2010.038772
- Tian (2011) Mei Tian. 2011. Application of chaotic time series prediction in forecasting of library borrowing flow. In 2011 International Conference on Internet Computing and Information Services. IEEE, 557–559. https://doi.org/10.1109/ICICIS.2011.147
- Wang et al. (2015) Rui Wang, Gabriella Harari, Peilin Hao, Xia Zhou, and Andrew T Campbell. 2015. SmartGPA: How smartphones can assess and predict academic performance of college students. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp 2015, Osaka, Japan, September 7-11, 2015. ACM, 295–306. https://doi.org/10.1145/2750858.2804251
- Wang et al. (2012) Runhua Wang, Yi Tang, and Lei Li. 2012. Application of BP neural network to prediction of library circulation. In 11th IEEE International Conference on Cognitive Informatics and Cognitive Computing, ICCI*CC 2012, Kyoto, Japan, August 22-24, 2012. IEEE, 420–423. https://doi.org/10.1109/ICCI-CC.2012.6311183
- Wang and Liao (2011) Ya-huei Wang and Hung-Chang Liao. 2011. Data mining for adaptive learning in a TESL-based e-learning system. Expert Systems with Applications 38, 6 (2011), 6480–6485. https://doi.org/10.1016/j.eswa.2010.11.098
- Xu et al. (2017) Jie Xu, Yuli Han, Daniel Marcu, and Mihaela Van Der Schaar. 2017. Progressive prediction of student performance in college programs. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA. AAAI, 1604–1610. http://aaai.org/ocs/index.php/AAAI/AAAI17/paper/view/14234
- Yao et al. (2017) Huaxiu Yao, Min Nie, Han Su, Hu Xia, and Defu Lian. 2017. Predicting academic performance via semi-supervised learning with constructed campus social network. In Database Systems for Advanced Applications - 22nd International Conference, DASFAA 2017, Suzhou, China, March 27-30, 2017, Proceedings, Part II (Lecture Notes in Computer Science), Vol. 10178. Springer, 597–609. https://doi.org/10.1007/978-3-319-55699-4_37
- Yu et al. (2011) Hsiang-Fu Yu, Hung-Yi Lo, Hsun-Ping Hsieh, Jing-Kai Lou, Todd G McKenzie, Jung-Wei Chou, Po-Han Chung, Chia-Hua Ho, Chun-Fu Chang, Yin-Hsuan Wei, Jui-Yu Weng, En-Syu Yan, Che-Wei Chang, Tsung-Ting Kuo, Yi-Chen Lo, Po Tzu Chang, Chieh Po, Chien-Yuan Wang, Yi-Hung Huang, Chen-Wei Hung, Yu-Xun Ruan, Yu-Shi Lin, Shou-De Lin, Hsuan-Tien Lin, and Chih-Jen Lin. 2011. Feature engineering and classifier ensemble for KDD cup 2010. In JMLR Workshop and Conference Proceedings.
- Zhang et al. (2010) Daqing Zhang, Bin Guo, Bin Li, and Zhiwen Yu. 2010. Extracting social and community intelligence from digital footprints: An emerging research area. In Ubiquitous Intelligence and Computing - 7th International Conference, UIC 2010, Xi’an, China, October 26-29, 2010. Proceedings (Lecture Notes in Computer Science), Vol. 6406. Springer, 4–18. https://doi.org/10.1007/978-3-642-16355-5_4
- Zhang et al. (2018) Xi Zhang, Guangzhong Sun, Yigong Pan, Hao Sun, Yu He, and Jiali Tan. 2018. Students performance modeling based on behavior pattern. Journal of Ambient Intelligence and Humanized Computing 9, 5 (2018), 1659–1670. https://doi.org/10.1007/s12652-018-0864-6
- Zhu et al. (2017) Yu Zhu, Hao Li, Yikang Liao, Beidou Wang, Ziyu Guan, Haifeng Liu, and Deng Cai. 2017. What to do next: Modeling user behaviors by Time-LSTM. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017. IJCAI, 3602–3608. https://doi.org/10.24963/ijcai.2017/504