Joint State and Noise Covariance Estimation
Abstract
This paper tackles the problem of jointly estimating the noise covariance matrix alongside primary parameters (such as poses and points) from measurements corrupted by Gaussian noise. In such settings, the noise covariance matrix determines the weights assigned to individual measurements in the least squares problem. We show that the joint problem exhibits a convex structure and provide a full characterization of the optimal noise covariance estimate (with analytical solutions) within joint maximum a posteriori and likelihood frameworks and several variants. Leveraging this theoretical result, we propose two novel algorithms that jointly estimate the primary parameters and the noise covariance matrix. To validate our approach, we conduct extensive experiments across diverse scenarios and offer practical insights into their application in robotics and computer vision estimation problems with a particular focus on SLAM.
I Introduction
Maximum likelihood (ML) and maximum a posteriori (MAP) are the two most common point-estimation criteria in robotics and computer vision applications such as all variants of simultaneous localization and mapping (SLAM) and bundle adjustment. Under the standard assumption of zero-mean Gaussian measurement noise—and, for MAP, Gaussian priors—these estimation problems reduce to least squares; i.e., finding estimates that minimize the weighted sum of squared errors between observed and expected measurements (and, when priors are available, the weighted squared errors between parameter values and their expected priors).
Each measurement error in the least squares objective is weighted by its corresponding noise information matrix (i.e., the inverse of the covariance matrix). Intuitively, more precise sensors receive “larger” weights, thus exerting greater influence on the final estimate. Moreover, the weight matrices enable the estimator to account for correlations between different components of measurements, preventing “double counting” of information. Therefore, obtaining an accurate estimate of the noise covariance matrix is critical for achieving high estimation accuracy. In addition, the (estimated) noise covariance matrix also determines the (estimated) covariance of the estimated parameter values often used for control and decision making in robotics. Consequently, an inaccurate noise covariance estimate can cause overconfidence or underconfidence in state estimates, potentially leading to poor or even catastrophic decisions.
In principle, the noise covariance matrix can be estimated a priori (offline) using a calibration dataset where the true values of the primary parameters (e.g., robot poses) are known (see Remark 6). This can be done either by the sensor manufacturer or the end user. However, in practice, several challenges arise:
-
1.
Calibration is a labor-intensive process and may not always be feasible, particularly when obtaining ground truth for primary parameters requires additional instrumentation.
-
2.
In many cases, raw measurements are preprocessed by intermediate algorithms before being used in the estimation problem (e.g., in a SLAM front-end), making it difficult to model their noise characteristics.
-
3.
The noise characteristics may evolve over time (e.g., due to dynamic environmental factors such as temperature), making the pre-calibrated noise model obsolete.
Due to these challenges, many applications rely on ad hoc noise covariances, such as arbitrary isotropic (or diagonal) covariances, which are either manually set by experts or determined through trial-and-error tuning. Despite being recognized as one of the most critical and widely acknowledged challenges in SLAM [12, Sections III.B, III.G, and V], the problem of noise covariance estimation remains unsolved and understudied in robotics and computer vision literature.
This paper addresses the problem of jointly estimating the (primary) parameters and noise covariance matrices from noisy measurements in a general setting that covers a wide range of estimation problems in robotics and computer vision. For the first time, our algorithms enable automatic estimation of the noise covariance matrix online (i.e., during deployment) without the need for a separate calibration stage with ground truth information. Furthermore, our MAP framework allows the users to incorporate prior information about the noise covariance, such as manufacturer-provided noise calibration.
Our main contributions are as follows:
-
1.
Formulate the joint MAP and ML estimation problems along with several variants that incorporate different structural assumptions on the true noise covariance matrix. To the best of our knowledge, this is the first time such an approach has been proposed in the SLAM literature.
-
2.
Provide analytical expressions for (conditionally) optimal noise covariances (under MAP and ML criteria, and their constrained variants) in Theorem 1.
-
3.
Building on our theoretical results, we propose two (local) types of optimization methods to solve the joint estimation problem and present a rigorous convergence analysis (Theorems 2 and 3). Our algorithms can be easily incorporated into popular (sparse) nonlinear least squares solvers such as [2, 10, 17] as we demonstrate in our experimental results.
-
4.
Offer practical insights for noise covariance estimation in sparse graph-structured problems such as SLAM, and present extensive experimental and ablation studies for linear(ized)-Gaussian problems and pose-graph optimization (PGO).
Notation
We use to denote the set of integers from to . The abbreviated notation is used to denote . The zero matrix (and vector) is denote by where the size should be clear from the context. and denote the sets of symmetric positive semidefinite and positive definite real matrices, respectively. For two symmetric real matrices and , (resp., ) means is positive semidefinite (resp., positive definite). denotes the element of matrix , and denotes the diagonal matrix obtained by zeroing out the off-diagonal elements of . The standard (Frobenius) inner product between real matrices and is denoted by . The Frobenius norm of is denoted by . The weighted Euclidean norm of given a weight matrix is denoted by . The probability density function of the multivariate normal distribution of random variable with mean vector and covariance matrix is denoted by .
II Related Works
We refer the reader to [6, 11, 12, 24] for comprehensive reviews of state-of-the-art estimation frameworks in robotics and computer vision. Sparse nonlinear least squares solvers for solving these estimation problems can be found in [2, 10, 17]. However, all of these works assume that the noise covariance is known beforehand. In contrast, our approach simultaneously estimates both the primary parameters (e.g., robot’s trajectory) and the noise covariance matrix directly from noisy measurements. The importance of automatic hyperparameter tuning has recently gained recognition in the SLAM literature; see, e.g., [12, Section V] and [13, 14]. We share this perspective and present, to the best of our knowledge, the first principled approach for optimal noise covariance estimation in SLAM and related problems.
II-A Optimal Covariance Estimation via Convex Optimization
ML estimation of the mean and covariance from independent and identically distributed (i.i.d.) Gaussian samples using the sample mean and sample covariance is a classic example found in textbooks. Boyd and Vandenberghe [5, Chapter 7.1.1] show that covariance estimation in this standard setting and several of its variants can be formulated as convex optimization problems. However, many estimation problems that arise in robotics and other engineering disciplines extend beyond the standard setting. While noise samples are assumed to be i.i.d. for each measurement type (Section IV-C1), the measurements themselves are not identically distributed. Each measurement follows a Gaussian distribution with the corresponding noise covariance matrix and a unique mean that depends on an unknown parameter belonging to a manifold. Furthermore, the measurement function varies across different measurements and is often nonlinear. We demonstrate that the noise covariance estimation problem in this more general setting can also be formulated as a convex optimization problem. Similar to [5], we explore several problem variants that incorporate prior information and additional structural constraints on the noise covariance matrix. These variants differ from those studied in [5, Chapter 7.1.1] and admit analytical (closed-form) solutions.
II-B Iterated Generalized Least Squares
Zhan et al. [26] propose a joint pose and noise covariance estimation method for the perspective--point (PP) problem in computer vision. Their approach is based on the iterated (or iterative) generalized least squares (IGLS) method (see [22, Chapter 12.5] and references therein), alternating between pose and noise covariance estimation. They report improvements in estimation accuracy ranging from to compared to baseline methods that assume a fixed isotropic noise covariance. To the best of our knowledge, before [26], IGLS had not been applied in robotics or computer vision.111We were unable to find the original reference for IGLS. However, the concept was already known and analyzed in the econometrics literature in 1970s [18]. IGLS is closely related to the feasible generalized least squares (FGLS) method which also has a long history in econometrics and regression. Our work (developed concurrently with [26]) generalizes and extends both IGLS and [26] in several keys ways. First, we prove that the joint ML estimation problem is ill-posed when the sample covariance matrix is singular. This critical problem arises frequently in real-world applications, where the sample covariance matrix can be singular or poorly conditioned (Remark 5). We address this critical issue by (i) constraining the minimum eigenvalue of the noise covariance matrix, and, in our MAP formulation, (ii) imposing a Wishart prior on the noise information matrix. We derive analytical optimal solutions for the noise covariance matrix, conditioned on fixed values of the primary parameters, for MAP and ML joint estimation problems and several of their constrained variants (Theorem 1). These enable the end user to leverage prior information about the noise covariance matrix (from, e.g., manufacturer’s calibration) in addition to noisy measurements to solve the joint estimation problem. We propose several algorithms for solving these joint estimation problems and present a rigorous theoretical analysis of their convergence properties. Our formulation is more general than IGLS and we show how our framework can be extended to heteroscedastic measurements, nonlinear (with respect to) noise models, and manifold-valued parameters. Finally, we provide insights into the application of our approach to “graph-structured” estimation problems [16], such as PGO and other SLAM variants. These problems present additional challenges compared to the PP problem due to the increasing number of primary parameters (thousands of poses in PGO vs. a single pose in PP) and the sparsity of measurements, which reduce the effective signal-to-noise ratio.
II-C Noise Covariance Estimation in Kalman Filtering
The problem of identifying process and measurement noise models in Kalman filtering has been extensively studied since 1970s; see, e.g., [27, 9, 15] and references therein. The Kalman filter (KF) is equivalent to the recursive MAP estimator in linear-Gaussian models. Similarly, nonlinear variants of the KF, such as the extended Kalman filter (EKF), can be viewed as approximate MAP estimators. Despite conceptual similarities between problems and proposed solutions, Kalman filtering methods are specifically tailored for linear(ized) models in filtering estimation problems within a recursive framework. Consequently, they are not directly applicable to the smoothing problems (or batch settings) addressed in this paper, which represent the state-of-the-art approach in SLAM and related computer vision problems; see, e.g., [11].

III Problem Statement
Consider the standard problem of estimating an unknown vector given noisy -dimensional measurements corrupted by i.i.d. zero-mean Gaussian noise:
| (1) |
where is the unknown noise covariance. For Euclidean-valued measurements (such as relative position of a landmark with respect to a robot pose), reduces to addition in . For matrix Lie group-valued measurements (such as relative pose or orientation between two poses), is equivalent to multiplication by where denotes the matrix exponential composed with the so-called hat operator. We denote the residual of measurement evaluated at with . As above, is subtraction in for Euclidean measurements, and in the case of matrix Lie-group-valued measurements is the matrix logarithm composed with the so-called vee operator (in this case, refers to the dimension of Lie algebra).
In this paper, we refer to as the primary “parameters” to distinguish them from . To simplify the discussion, we first consider the case where all measurements share the same noise distribution, meaning there is a single noise covariance matrix in (1). See Section IV-C1 for extensions to more general cases. In robotics and computer vision applications, is typically a (smooth) product manifold comprised of and components () and other real components (e.g., time offsets, IMU biases). We assume the measurement functions are smooth. This standard model (along with extensions in Section IV) is quite general, capturing many estimation problems such such as SLAM (with various sensing modalities and variants), PGO, point cloud registration (with known correspondences), perspective--point, and bundle adjustment.
In this paper, we are interested in the setting where the noise covariance matrix is unknown and must be estimated jointly with based on the collected measurements . For convenience, we formulate the problem in the information form and estimate the noise information (or precision) matrix . Without loss of generality, we assume a non-informative prior on which is almost always the case in real-world applications (effectively treating it as an unknown “parameter”). We assume a Wishart prior on the noise information matrix and denote its probability density function with where is the scale matrix and the integer is the number of degrees of freedom; Figure 1 illustrates random samples drawn from . The Wishart distribution is the standard choice for prior in Bayesian statistics for estimating the information matrix from multivariate Gaussian data (in part due to conjugacy); see, e.g., [3, Eq. (2.155)]. In Algorithm 1, we propose a procedure for setting the parameters of the prior, and , when the user has access to a prior estimate for the noise covariance matrix (e.g., from prior calibration by the manufacturer of the sensor); see Appendix A for a justification.
The joint MAP estimator for and are the maximizers of the posterior. Invoking the Bayes’ Theorem (and omitting the normalizing constant) results in the following problem:
| (2) |
For any , define the sample covariance at as follows:
| (3) |
Then, computing the negative log-posterior, omitting normalizing constants, dividing the objective by , and using the cyclic property of yields the following equivalent problem.
Problem 1 (Joint MAP).
| (4) |
where
| (5) |
We also introduce and study three new variants of Problem 1 by imposing additional (hard) constraints on the noise covariance matrix . These constraints enable the user to enforce prior structural information about the covariance.
In the first variant, (and thus ) is forced to be diagonal. This allows the user to enforce independence between noise components.
Problem 2 (Diagonal Joint MAP).
| (6) |
In the second variant, we constrain the eigenvalues of to where . These eigenvalues specify the minimum and maximum variance along all directions in (i.e., variance of all normalized linear combinations of noise components), Therefore, this constraint allows the user to incorporate prior knowledge about the sensor’s noise limits. We will also show that in many real-world instances (especially with a weak or no prior ), constraining the smallest eigenvalue of (or largest eigenvalue of ) is essential for preventing from collapsing to zero.
Problem 3 (Eigenvalue-constrained Joint MAP).
| (7) |
The last variant imposes both constraints simultaneously.
Problem 4 (Diagonal Eigenvalue-constrained Joint MAP).
| (8) |
Remark 1.
It is easy to verify that by fixing to a predetermined value, Problem 1 reduces to the standard (weighted) nonlinear least squares over and can be (locally) solved using existing solvers [2, 10, 17].222Note that . Similarly, algebraically the problem reduces to joint ML estimation when where is the prior weight in Algorithm 1.333The prior cannot be exactly zero due to matrix inversion in line 6 of Algorithm 1. To be more precise, refers to the case where is set to zero in (5) and . This abuse of language allows us to save space by treating ML estimation as a special of the MAP problems introduced in Problems 1-4. In that case, the linear term in the objective becomes . See also [26] for the unconstrained ML formulation.
Remark 2.
Singularity of may lead to an ill-conditioned problems when the prior is weak (i.e., is small) as the corresponding objective function becomes very sensitive in certain directions that correspond to the smallest eigenvalues of . In the unconstrained joint ML estimation case (i.e., and without ), the minimization problem is ill-posed (unbounded from below) when is singular.444This can be shown by inspecting the objective value along where is in the nullspace of and is an arbitrarily large positive scalar. See Remark 5 for more information regarding scenarios where may become singular.
IV Optimal Information Matrix Estimation
Problems 1-4 are in general non-convex in because of the residuals ’s and, when estimating rotations (e.g., in SLAM), the constraints imposed on rotational components of . In this section, we reveal a convexity structure in these problems and provide analytical (globally) optimal solutions for estimating the covariance matrix for a given .
IV-A Inner Subproblem: Covariance Estimation
Problems 1-4 can be separated into two nested subproblems: an inner subproblem and an outer subproblem, i.e.,
| (9) |
where the constraints for each problem are given in Problems 1-4. The inner subproblem focuses on minimizing the objective function over the information matrix and as a function of . The outer subproblem minimizes the overall objective function by optimizing over when the objective is evaluated at the optimal information matrix obtained from the inner subproblem.
Remark 3.
For (9) to be well defined, we require the constraint set to be closed and the cost function to be bounded from below. As is positive definite by construction, the cost is bounded from below. The positive semidefinite constraint guarantees the closedness of the constraint set. However, due to the presence of the term in the cost function, if a solution exists, the cone constraints are not active at this solution. Thus, a singular can never be a solution to this problem.
IV-B Analytical Solution to the Inner Subproblem
The inner subproblem for a fixed can be written as
| (10) |
Proposition 1.
For any , the inner subproblem (10) is a convex optimization problem and has at most one optimal solution.
Proof.
See Appendix B. ∎
Theorem 1 (Analytical Solution to the Inner Problem).
Consider the inner problem (10) for a given . The following statements hold:
-
1.
Inner Subproblem in Problem 1: The optimal solution is given by
(11) -
2.
Inner Subproblem in Problem 2: The optimal solution is given by
(12) -
3.
Inner Subproblem in Problem 3: Let
(13) be an eigendecomposition of where and are orthogonal and diagonal, respectively. The optimal solution is given by
(14) where is a diagonal matrix with the following elements:
(15) -
4.
Inner Subproblem in Problem 4: The optimal solution is a diagonal matrix with the following elements:
(16)
Proof.
See Appendix C. ∎
Remark 4 (ML Estimation).
As we mentioned earlier, the objective function in the ML formulation for estimating the noise covariance can be written as which is similar to (10). However, unlike , the sample covariance can become singular. Therefore, Theorem 1 readilly applies to the ML case (and its constrained variants) with an important exception: without the constraint , if becomes singular, the problem becomes unbounded from below and thus ML estimation becomes ill-posed.
Remark 5 (Singularities of ).
According to Theorem 1, when is singular, the spectrum of and consequently solution to the inner subproblems associated with Problems 1 and 2 become more influenced by the Wishart prior than the observed data. The sample covariance matrix could be singular in many different situations, but two particular cases that can lead to singularity are as follows:
-
1.
When (i.e., there are not enough measurements to estimate ), will be singular at any .
-
2.
Specific values of can lead to singularity in some problems. For example, consider the problem of estimating odometry noise covariance matrix in PGO. Let be the odometry estimate obtained from composing odometry measurements. At , the residuals (and thus ) will be zero.
Theorem 1 has a clear geometric interpretation. For instance, the optimal covariance matrix for Problem 3 (14) has the following properties: (i) it preserves the eigenvectors of , which define the principal axes of the associated confidence ellipsoid; (ii) it matches along directions corresponding to eigenvalues within the range ; and (iii) it only adjusts the radii of the ellipsoid along the remaining principal axes to satisfy the constraint. This is visualized in Figure 2. Similarly, the confidence ellipsoid associated to (12) is obtained by projecting the confidence ellipsoid of onto the standard basis. In the case of (16), the radii of the projected ellipsoid are adjusted to satisfy the eigenvalue constraint.

Remark 6 (Calibration).
The inner subproblem (10) also arises in offline calibration. In this context, a calibration dataset is provided with ground truth (or a close approximation). The objective is to estimate the noise covariance matrix based on the calibration dataset, which can then be used for future datasets collected with the same sensors. Note that this approach differs from the joint problems (Problems 1-4), where and must be estimated simultaneously without the aid of a calibration dataset containing ground truth information. Applying Theorem 1 at directly provides the optimal noise covariance matrix for this scenario. If calibration is performed using an approximate ground truth , the estimated noise covariance matrix will be biased.
IV-C Two Important Extensions
IV-C1 Heteroscedastic Measurements
For simplicity, we have so far assumed that measurement noises are identically distributed (i.e., homoscedastic). However, in general, there may be distinct types of measurements (e.g., obtained using different sensors in sensor fusion problems, odometry vs. loop closure in PGO, etc), where the noises corrupting each type are identically distributed. In such cases, the inner problem (10) decomposes into independent problems (with different ), solving each yields one of the noise information matrices. Theorem 1 can then be applied independently to each of these problems to find the analytical optimal solution for each noise information matrix as a function of .
IV-C2 Preprocessed Measurements and Non-Additive Noise
In SLAM, raw measurements are often preprocessed and transformed nonlinearly into standard models supported by popular solvers. For instance, raw range-bearing measurements (corrupted by additive noise with covariance ) are often expressed in Cartesian coordinates. As a result, although the raw measurements generated by the sensor have identically distributed noise, the transformed measurements that appear in the least squares problem may have different covariances because of the nonlinear transformation. Let be the covariance of raw measurements, and be the covariance of the th transformed measurement. In practice, is approximated by linearization, i.e., in which is the (known) Jacobian of the transformation. It is easy to verify that Theorem 1 readilly extends to this case when ’s are full-rank square matrices by replacing the sample covariance as defined in (3) with
| (17) |
A similar technique can be used when measurements are affected by zero-mean Gaussian noise in a nonlinear manner, i.e., (in that case, the Jacobians of ’s with respect to noise will in general depend on ).
V Algorithms for Joint Estimation
In principle, one can employ existing constrained optimization methods to directly solve (locally) Problems 1-4. However, this requires substantial modification of existing highly optimized solvers such as [2, 10, 17] and thus may not be ideal. In this section, present two types of algorithms that leverage Theorem 1 for solving the joint estimation problems.
V-A Variable Elimination
We can eliminate from the joint problems (9) by plugging in the optimal information matrix (as a function of ) for the inner subproblem (10) provided in Theorem 1. This leads to the following reduced optimization problem in :
| (18) |
Therefore, if is an optimal solution for the above problem, then and are MAP estimates for and , respectively. This suggests the simple procedure outlined in Algorithm 2. Note that the reduced problem (18) (like Problems 1-4) is a non-convex optimization problem, and thus the first step in Algorithm 2 is subject to local minima.
Remark 7 (Reduced Problem for Problems 1 and 2).
The objective function of the reduced problem (18) further simplifies in the case of Problems 1 and 2. Specifically, for any , the linear term in the objective (i.e., ) is constant for the values of given in (11) and (12);
| (19) | ||||
| (20) |
Therefore, in these cases the reduced problem further simplifies to the following:
| (21) | ||||
| (22) |
These simplified problems have an intuitive geometric interpretation (as noted in [26] for the unconstrained ML estimation case): the MAP estimate of is the value of that minimizes the volume of confidence ellipsoid (in Problem 1) and the volume of the projected (onto the standard basis) ellipsoid (in Problem 2) characterised by .
The variable elimination algorithm has the following practical drawbacks:
-
1.
In many real-world estimation problems, the residuals are typically sparse, meaning each measurement depends on only a small subset of elements in . Exploiting this sparsity is essential for solving large-scale problems efficiently. However, this sparse structure is generally lost after eliminating in the reduced problem (18).
- 2.
V-B Block-Coordinate Descent
In this section we show how block-coordinate descent (BCD) methods can be used to solve the problem of interest. A BCD-type algorithm alternates between the following two steps until a stopping condition (e.g., convergence) is satisfied:
- 1.
- 2.
We explore two variants of this procedure shown in Algorithms 3 and 4. The BCD algorithms of the type considered here address the limitations of Algorithm 2. Specifically, the problem in the first step can be readily solved using standard solvers widely used in robotics and computer vision, which are also capable of exploiting sparsity in residuals. The second step is highly efficient, as it only requires computing the matrix as defined in (5), which can be done in time. In the case of Problem 3, one must also compute the eigendecomposition of . In practice, (the dimension of the residuals) is typically a small constant (i.e., ; e.g., in 3D PGO, ), and therefore the overall time complexity of the second step of BCD is , i.e., linear in the number of measurements.
Before studying the convergence properties of these algorithms we introduce the necessary assumption below. See Appendix E for background information. For simplifying the presentation we define .
Assumption 1.
Let denote the constraint set for the noise information matrix . The sets and are closed and nonempty and the function is differentiable and its level set is bounded for every scalar .
Assumption 2 (Lipschitz Smoothness in ).
Function is continuously differentiable and Lipschitz smooth in , i.e., there exists a positive constant such that for all and all :
| (23) |
Theorem 2.
Proof.
See Appendix D. ∎
As can be seen in Algorithm 4, one might be able to solve the optimization problems associated with each of the coordinates uniquely and exactly. For example, for the case where the residuals are affine functions of and is convex, the optimization problem associated with has a unique solution (assuming a non-singular Hessian) can be solved exactly. This case satisfies the following assumption.
Assumption 3.
For all and all , the following problems have unique solutions:
| (25) |
Theorem 3.
Proof.
The proof of the theorem follows directly from [20, Theorem 1]. ∎
VI Experiments
VI-A Linear Measurement Model



We first evaluate the algorithms on a simple linear measurement model. Although the joint problem is still non-convex in this scenario, the problem is (strictly) convex in and separately, enabling exact minimization in both steps of BCD (Algorithm 4) with analytical solutions (i.e., linear least squares and (10)).
Setup: In these experiments, and is set to the all-ones vector. We generated measurements, where the dimension of each measurement is . Measurement is generated according to
| (26) |
Each measurement function is a random matrix drawn from the standard normal distribution. The Measurement noise where
| (27) |
in which is a fixed random covariance matrix, and is a variable that controls the noise level in our experiments. We did not impose a prior on (i.e., prior weight ; see (31) in Appendix A), leading to unconstrained joint ML estimation of and .
We conducted 50 Monte Carlo simulations per noise level, each with a different noise realization. In each trial, we generated measurement noise according to the model described above and applied Elimination and BCD (Algorithms 2 and 4) to estimate and under the Problem 1 formulation. Both algorithms were initialized with and executed for up to iterations. The Elimination algorithm uses the Limited-memory BFGS solver from SciPy [25].
Metrics: We use the root mean square error (RMSE) to evaluate the accuracy of estimating . For covariance estimation accuracy, we use the 2-Wasserstein distance between the true noise distribution and the estimated noise distribution :
| (28) |
Results: The results are shown in Figure 3.
Figure 3(a) illustrates the value of the objective function in Problem 1 during one of the Monte Carlo simulations (). The objective value for BCD is recorded after updating (Step 1 of Algorithm 4). This figure demonstrates that both methods eventually converge to the same objective value, although BCD exhibits faster convergence.
Figure 3(b) presents the average RMSE for the solution , obtained by Elimination and BCD (at their final iteration), across the Monte Carlo simulations for various noise levels. The figure also includes average RMSEs for estimates obtained using fixed covariance matrices: (i.e., the true noise covariance) and (i.e., an arbitrary identity matrix often used in practice when is unknown). The results show that Elimination and BCD achieve identical RMSEs across all noise levels, with RMSE increasing as the noise level rises. Notably, under low noise, the accuracy of the solutions produced by these algorithms matches that achieved when the true covariance matrix is known. This indicates that the algorithms can accurately estimate without prior knowledge of . The gap between the RMSEs widens as the noise level increases, which is expected because the algorithms must jointly estimate and under a low signal-to-noise ratio. Nonetheless, the RMSE trends consistently across noise levels.
Furthermore, the results highlight that using a naïve approximation of the noise covariance matrix (i.e., fixing ) leads to a poor estimate . However, as the noise level increases, the RMSE for this approximation eventually approaches that of the case where is perfectly known. This behavior is partly due to the setup in (27): as grows, the diagonal components of the covariance matrix dominate, making the true covariance approximately isotropic. Since the estimation of (given a fixed noise covariance matrix) is invariant to the scaling of the covariance matrix, the performance of aligns with that of despite the scaling discrepancy.
Finally, Figure 3(c) shows the 2-Wasserstein distance averaged over the Monte Carlo simulations. Similar to the previous figure, the covariance estimates obtained by Elimination and BCD are consistently close to those derived using . As the noise level increases, covariance estimation error also rises, widening the gap, as expected.
VI-B Pose-Graph Optimization Ablations
Dataset: We used a popular synthetic PGO benchmark, the Manhattan dataset [19], and generated new measurement realizations with varying values of the actual noise covariance matrix. The dataset consists of poses and relative-pose measurements. This dataset is notoriously poorly connected [16]. Therefore, to analyze the effect of connectivity on covariance estimation, we also performed experiments on modified versions of this dataset, where additional loop closures were introduced by connecting pose to poses and . This modification increased the total number of measurements to .
We generated zero-mean Gaussian noise in the Lie algebra for the following models:
-
1.
Homoscedastic Measurements: In these experiments, all measurements share the same information matrix, given by , where is a scaling factor that controls the noise level (hereafter referred to as the “information level”).
-
2.
Heteroscedastic Measurements: We introduce two distinct noise models for odometry and loop-closure edges. The true information matrix for odometry noise is fixed at , while the loop-closure noise information matrix is varied as .
For each value of the information level , we conducted Monte Carlo simulations with different noise realizations.
Algorithms: We implemented a variant of Algorithm 3 in C++, based on g2o [17], for PGO problems. Instead of using Riemannian gradient descent, we used g2o’s implementation of Powell’s Dog-Leg method [21] on to optimize . In each outer iteration, our implementation retrieves the residuals for each measurement, computes as defined in (5), and updates the noise covariance estimate using Theorem 1. To handle cases where (i.e., ML estimation) and is poorly conditioned, we set and in all experiments. We then perform a single iteration of Powell’s Dog-Leg method [21] to update the primary parameters , initializing the solver at the latest estimate of . To ensure convergence across all Monte Carlo trials, we ran 13 outer iterations.
We report the results for the following methods:
- 1.
- 2.
- 3.
- 4.
For BCD (Wishart) and BCD (diag+Wishart) where a Wishart prior was used, we applied our Algorithm 1 to set the prior parameters (i.e., and ), for a prior weight of and a prior estimate of for both odometry and loop-closure edges. Note that this prior estimate is far from the true noise covariance value.
Additionally, we report results for estimating using Powell’s Dog-Leg solver in g2o under two fixed noise covariance settings: (i) the true covariance matrix (as a reference) and (ii) the identity matrix (a common ad hoc approximation used in practice). To ensure convergence across all trials, we performed eight iterations for these methods. All algorithms were initialized using a spanning tree to compute [17].
Metrics: We use RMSE to measure error in the estimated robot trajectory (positions). In all cases, the first pose is fixed to the origin and therefore aligning the estimates with the ground truth is not needed. We also use the 2-Wasserstein distance (28) to measure the covariance estimation error.


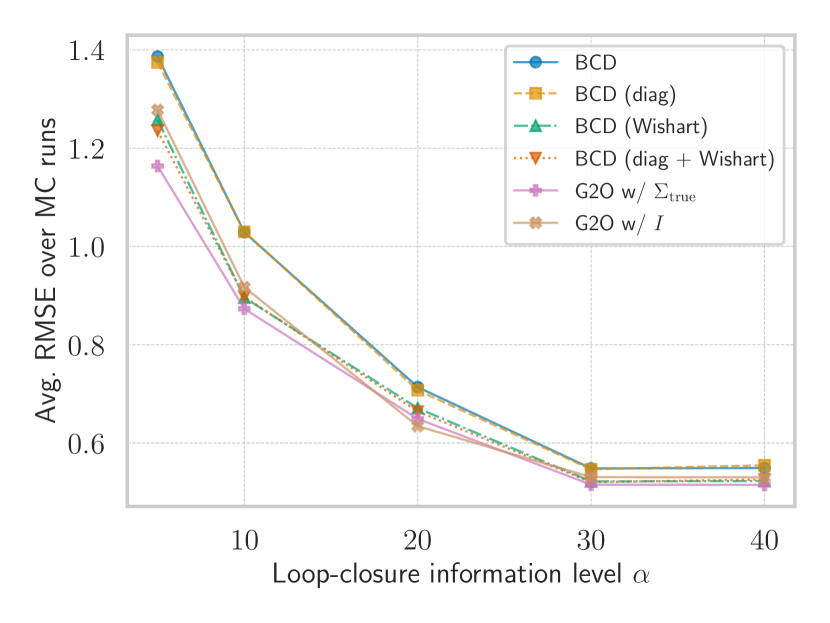


Figure 4 shows the average RMSE over Monte Carlo trials for different values of the information level . Figure 4(a) presents the results for the homoscedastic case, while Figures 4(b) and 4(c) show the results for the heteroscedastic case before and after additional loop closures, respectively. The results show that our framework, across all variants, succesfully produced solutions with an RMSE close to the reference setting where the true noise covariance matrix was available (g2o with ). For almost all values of and all experiments, BCD (Wishart) and BCD (diag+Wishart) achieved a lower average RMSE compared to the other variants, highlighting the importance of incorporating a prior. Notably, this is despite the prior being assigned a small weight and the fact that the prior estimate is not close to . Incorporating a prior is particularly crucial in PGO, as we observed that the eigenvalues of can become severely small in practice. In such cases, without a prior and without enforcing a minimum eigenvalue constraint , the ML estimate for the noise covariance can collapse to zero, leading to invalid results and excessive overconfidence. The average RMSE achieved by those variants with diagonal and without constraints are generally similar. Interestingly, the RMSE achieved by the diagonal variants appears to be close to that of their counterparts without this constraint, despite the true noise covariance being diagonal.
For some values of in Figure 4(b), the BCD variants with the Wishart prior achieved a lower MSE than the reference solution. However, we expect that, on average, the reference solution will perform better with a larger number of Monte Carlo simulations. The RMSE trends look similar in all experiments, with the exception of a slight increase for for BCD and BCD (diag) in Figure 4(b). In terms of RMSE, BCD variants with a Wishart prior outperform or perform comparably to the baseline with a fixed identity covariance in most cases. That said, especially under larger information levels (i.e., lower noise), this naïve baseline estimates quite accurately.
Figure 5 presents the average 2-Wasserstein distance (28) between the noise covariance matrices estimated by various BCD variants and the true covariance in both homoscedastic and heteroscedastic scenarios. In all cases, BCD variants achieved a small 2-Wasserstein error. For reference, the 2-Wasserstein error between and the baseline exceeds 1, which is more than 20 times the errors attained by our algorithms. As noted in Section I, an incorrect noise covariance leads to severe overconfidence or underconfidence in the estimated state (e.g., the estimated trajectory in SLAM), potentially resulting in poor or catastrophic decisions.
The results indicate that, in most cases, diagonal BCD variants yield lower errors. This is expected, as the true noise covariance matrices are diagonal, and enforcing this prior information enhances estimation accuracy. Additionally, the MAP estimates obtained by BCD (Wishart) and BCD (diag+Wishart) outperform their ML-based counterparts. This is due to the fact that the eigenvalues of the sample covariance matrix can be very small, indicating insufficient information for accurate noise covariance estimation. In such cases, the eigenvalue constraint effectively prevents a complete collapse of the estimated covariance. Interestingly, this issue was not encountered in [26] for ML estimation of the noise covariance matrix in PP. This discrepancy may suggest additional challenges in estimating noise covariance in SLAM (and related) problems, which typically involve a larger number of variables and sparse, graph-structured relative measurements. In such cases, incorporating a prior estimate may be necessary for accurate identification of noise covariance matrices. Finally, Figure 5(b) illustrates that the MAP estimation error is lower for the noise covariance of loop closures compared to odometry edges. This difference is partly because the prior value based on is closer to the true noise covariance matrix for loop closures.
VI-C RIM Dataset



In this section, we present qualitative results on RIM, a large real-world 3D PGO dataset collected at Georgia Tech [8]. This dataset consists of poses and measurements. The g2o dataset includes a default noise covariance matrix, but with these default values, g2o struggles to solve the problem. Specifically, the Gauss-Newton and Dog-Leg solvers terminate after a single iteration, while the Levenberg-Marquardt solver completes 10 iterations but produces the trajectory estimate shown in Figure 6(a).
We ran BCD without and with the Wishart prior (i.e., ML and MAP estimation) for 10 outer iterations, using a single Dog-Leg iteration to optimize in each round. We set the prior parameter based on and . The results are displayed in Figures 6(b) and 6(c), respectively. It is evident that the trajectory estimates obtained by BCD are significantly more accurate than those obtained using the original noise covariance values.
A closer visual inspection reveals that the trajectory estimated using the Wishart prior (right) appears more precise than the ML estimate (middle). This is expected, as without imposing a prior, some eigenvalues of collapsed until they reached the eigenvalue constraint . In contrast, in the MAP case, the estimated covariance did not reach this lower bound.
Interestingly, despite being isotropic, the estimate obtained by BCD with the Wishart prior was not. In particular, the information matrix component associated with the coordinate was almost twice as large as those of and . This likely reflects the fact that the trajectory in this dataset is relatively flat. This finding highlights that in this case, in addition to the prior, the measurements also contributed information to the estimation of the noise covariance matrix.
VII Limitations
This paper did not explore the issue of outliers. Our BCD-type methods can be viewed as (unconventional) instances of iteratively reweighted least squares (IRLS) techniques, where we estimate the entire weight matrix instead of a scalar weight. Consequently, we believe that our joint MAP estimation framework can be easily adapted to integrate with M-estimation IRLS techniques commonly used for outlier-robust estimation, to accurately estimate both the primary parameters and the noise covariance matrix (for inlier measurements) when the dataset contains outliers. We are currently exploring this direction and also aim to implement our method in real-time visual and LiDAR-based SLAM and odometry systems such as [7, 23].
Moreover, our Theorem 2 requires to be compact. This result therefore does not immediately apply to problems where contains translational components. However, we believe we can address this issue in SLAM by confining translational components to potentially large but bounded subsets of (where is the problem dimension).
Finally, we acknowledge the extensive research on IGLS and Feasible GLS (FGLS) conducted as early as 1970s in econometrics and statistics, which remain largely unknown in engineering; see relevant references in [22, Chapter 12.5] and [26]. Exploring this rich literature may result in new insights and methods that can further improve noise covariance estimation in SLAM and computer vision applications.
VIII Conclusion
This work presented a novel and rigorous framework for joint estimation of primary parameters and noise covariance matrices in SLAM and related computer vision estimation problems. We derived analytical expressions for (conditionally) optimal noise covariance matrix (under ML and MAP criteria) under various structural constraints on the true covariance matrix. Building on these solutions, we proposed two types of algorithms for finding the optimal estimates and theoretically analyzed their convergence properties. Our results and algorithms are quite general and can be readily applied to a broad range of estimation problems across various engineering disciplines. Our algorithms were validated through extensive experiments using linear measurement models and PGO problems.
References
- Absil et al. [2009] P-A Absil, Robert Mahony, and Rodolphe Sepulchre. Optimization algorithms on matrix manifolds. Princeton University Press, 2009.
- Agarwal et al. [2023] Sameer Agarwal, Keir Mierle, and The Ceres Solver Team. Ceres Solver, 10 2023. URL https://github.com/ceres-solver/ceres-solver.
- Bishop and Nasrabadi [2006] Christopher M Bishop and Nasser M Nasrabadi. Pattern recognition and machine learning, volume 4. Springer, 2006.
- Boumal [2020] Nicolas Boumal. An introduction to optimization on smooth manifolds. Available online, Aug 2020. URL http://www.nicolasboumal.net/book.
- Boyd and Vandenberghe [2004] S. Boyd and L. Vandenberghe. Convex optimization. Cambridge university press, 2004.
- Cadena et al. [2016] Cesar Cadena, Luca Carlone, Henry Carrillo, Yasir Latif, Davide Scaramuzza, Jose Neira, Ian D Reid, and John J Leonard. Simultaneous localization and mapping: Present, future, and the robust-perception age. arXiv preprint arXiv:1606.05830, 2016.
- Campos et al. [2021] Carlos Campos, Richard Elvira, Juan J. Gómez, José M. M. Montiel, and Juan D. Tardós. ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. IEEE Transactions on Robotics, 37(6):1874–1890, 2021.
- Carlone et al. [2015] Luca Carlone, Roberto Tron, Kostas Daniilidis, and Frank Dellaert. Initialization techniques for 3d slam: A survey on rotation estimation and its use in pose graph optimization. In 2015 IEEE international conference on robotics and automation (ICRA), pages 4597–4604. IEEE, 2015.
- Chen et al. [2023] Zhaozhong Chen, Harel Biggie, Nisar Ahmed, Simon Julier, and Christoffer Heckman. Kalman filter auto-tuning through enforcing chi-squared normalized error distributions with bayesian optimization. arXiv preprint arXiv:2306.07225, 2023.
- Dellaert and Contributors [2022] Frank Dellaert and GTSAM Contributors. borglab/gtsam, May 2022. URL https://github.com/borglab/gtsam).
- Dellaert et al. [2017] Frank Dellaert, Michael Kaess, et al. Factor graphs for robot perception. Foundations and Trends® in Robotics, 6(1-2):1–139, 2017.
- Ebadi et al. [2023] Kamak Ebadi, Lukas Bernreiter, Harel Biggie, Gavin Catt, Yun Chang, Arghya Chatterjee, Christopher E Denniston, Simon-Pierre Deschênes, Kyle Harlow, Shehryar Khattak, et al. Present and future of SLAM in extreme environments: The DARPA SubT challenge. IEEE Transactions on Robotics, 2023.
- Fontan et al. [2024a] Alejandro Fontan, Javier Civera, Tobias Fischer, and Michael Milford. Look ma, no ground truth! ground-truth-free tuning of structure from motion and visual SLAM. arXiv preprint arXiv:2412.01116, 2024a.
- Fontan et al. [2024b] Alejandro Fontan, Javier Civera, and Michael Milford. Anyfeature-vslam: Automating the usage of any chosen feature into visual SLAM. In Robotics: Science and Systems, volume 2, 2024b.
- Forsling et al. [2024] Robin Forsling, Simon J Julier, and Gustaf Hendeby. Matrix-valued measures and wishart statistics for target tracking applications. arXiv preprint arXiv:2406.00861, 2024.
- Khosoussi et al. [2019] Kasra Khosoussi, Matthew Giamou, Gaurav S Sukhatme, Shoudong Huang, Gamini Dissanayake, and Jonathan P How. Reliable graphs for SLAM. The International Journal of Robotics Research, 38(2-3):260–298, 2019.
- Kuemmerle et al. [2011] Rainer Kuemmerle, Giorgio Grisetti, Hauke Strasdat, Kurt Konolige, and Wolfram Burgard. g2o: A general framework for graph optimization. In Proc. of the IEEE Int. Conf. on Robotics and Automation (ICRA), 2011.
- Malinvaud [1980] Edmond Malinvaud. Statistical methods of econometrics. 1980.
- Olson et al. [2006] E. Olson, J. Leonard, and S. Teller. Fast iterative alignment of pose graphs with poor initial estimates. In Robotics and Automation, 2006. ICRA 2006. Proceedings 2006 IEEE International Conference on, pages 2262–2269. Ieee, 2006.
- Peng and Vidal [2023] Liangzu Peng and René Vidal. Block coordinate descent on smooth manifolds: Convergence theory and twenty-one examples. arXiv preprint arXiv:2305.14744, 2023.
- Powell [1970] MJD Powell. A new algorithm for unconstrained optimization. UKAEA, 1970.
- Seber and Wild [1989] George A. F. Seber and C. J. Wild. Nonlinear Regression. Wiley-Interscience, 1989.
- Shan et al. [2020] Tixiao Shan, Brendan Englot, Drew Meyers, Wei Wang, Carlo Ratti, and Rus Daniela. Lio-sam: Tightly-coupled lidar inertial odometry via smoothing and mapping. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5135–5142. IEEE, 2020.
- Triggs et al. [1999] Bill Triggs, Philip F McLauchlan, Richard I Hartley, and Andrew W Fitzgibbon. Bundle adjustment—a modern synthesis. In International workshop on vision algorithms, pages 298–372. Springer, 1999.
- Virtanen et al. [2020] Pauli Virtanen, Ralf Gommers, Travis E. Oliphant, Matt Haberland, Tyler Reddy, David Cournapeau, Evgeni Burovski, Pearu Peterson, Warren Weckesser, Jonathan Bright, Stéfan J. van der Walt, and et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods, 17:261–272, 2020. doi: 10.1038/s41592-019-0686-2.
- Zhan et al. [2025] Tian Zhan, Chunfeng Xu, Cheng Zhang, and Ke Zhu. Generalized maximum likelihood estimation for perspective-n-point problem. IEEE Robotics and Automation Letters, 2025.
- Zhang et al. [2020] Lingyi Zhang, David Sidoti, Adam Bienkowski, Krishna R Pattipati, Yaakov Bar-Shalom, and David L Kleinman. On the identification of noise covariances and adaptive kalman filtering: A new look at a 50 year-old problem. IEEE Access, 8:59362–59388, 2020.
Appendix A Wishart Prior
Consider as a prior for the information matrix. Here we assume where is the dimension of covariance matrix and . The mode of this distribution is given by
| (29) |
Let be our prior guess for the covariance matrix. We set the value of the scale matrix by matching the mode with our prior estimate :
| (30) |
Let be the following:
| (31) |
Then we can rewrite as
| (32) |
In the unconstrained case (11), the optimal (MAP) estimate (conditioned on a fixed value of ) is given by:
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) |
This shows that the (conditional) MAP estimator simply blends the sample covariance matrix and prior based on the prior weight . We directly set (e.g., by default) based on our confidence in the prior relative to the likelihood. Large values of will result in stronger priors. For the chosen value of ,
| (37) | ||||
| (38) |
This procedure is summarized in Algorithm 1.
Appendix B Proof of Proposition 1
The objective function is strictly convex because log-determinant is strictly concave over and the second term is linear in . The equality (diagonal) and “inequality” (eigenvalue) constraints are also linear and convex, respectively. Since the objective is strictly convex, there is at most one optimal solution (i.e., if a minimizer exists, it is unique).
Appendix C Proof of Theorem 1
1)
For a given , the Lagrangian of the inner subproblem in Problem 1 is given by
| (39) |
where is the Lagrange multiplier corresponding to the semidefinite cone constraints. Observe that for . Since, in this case is primal feasible then optimal dual variable would . Thus, is the optimal solution to the problem.
2)
For the case of the inner subproblem in Problem 2, the problem can be rewritten as
| subject to | (40) |
The Lagrangian of this problem is given by
| (41) |
where are the Lagrange multipliers corresponding to the constraints. The KKT conditions for this problem are
| (42) | |||
| (43) |
It can be observed that since is positive by the virtue of being a positive definite matrix, and , , is the solution to the above KKT system.
3)
The Lagrangian of the inner subproblem of Problem 3 is given by
| (44) | ||||
| (45) |
The KKT conditions corresponding to this problem read
| (46) | |||
| (47) | |||
| (48) | |||
| (49) | |||
| (50) |
Let and where the elements of diagonal matrices and are
| (51) |
and
| (52) |
It can be observed that the choice of as in (14) along with and defined above satisfy the KKT conditions and are the primal-dual optimal solutions to the porblem. This completes the proof.
4)
The solution to the inner subproblem of Problem 4 can be obtained by a reformulation similar to case 2) above and checking the conditions similar to case 3).
Appendix D Proof of Theorem 2
The proof follows from specializing the proof of [20, Theorem 4] to the problem considered in this paper. Specifically, the compactness of manifolds along with Assumptions 1 and 2 lead to the existence of of as described in Lemma 1. Then following the steps of the proof of [20, Theorem 4] and setting completes the proof.
Appendix E Background Information for Section V-B
Let be a smooth submanifold in Euclidean space. Each is associated with a linear subspace, called the tangent space, denoted by . Informally, the tangent space contains all directions in which one can tangentially pass through . For a formal definition see [1, Definition 3.5.1, p. 34]. A smooth function is associated with the gradient of , as well as the orthogonal projection of onto the tangent space , known as the Riemannian gradient of at , denoted by . See [1, p. 46] for more detail. The manifold is also associated with a map , called a retraction that enables moving from along the direction while remaining on the manifold – see [4, Definition 3.47] and [1, Definition 4.1.1] for formal definitions.
A sufficient condition for Assumption 2 to hold is for the manifolds to be compact subsets of the Euclidean space. Under this assumption we have the following lemma from [20].
Lemma 1.
Let be a compact submanifold of the Euclidean space. Then we have,
for some constant . Moreover, if satisfies Assumption (2) and is compact, then there exists a positive such that for all and all , we have
| (53) |