Joint Spatio-Temporal Modeling for Semantic Change Detection in Remote Sensing Images
Abstract
Semantic Change Detection (SCD) refers to the task of simultaneously extracting the changed areas and the semantic categories (before and after the changes) in Remote Sensing Images (RSIs). This is more meaningful than Binary Change Detection (BCD) since it enables detailed change analysis in the observed areas. Previous works established triple-branch Convolutional Neural Network (CNN) architectures as the paradigm for SCD. However, it remains challenging to exploit semantic information with a limited amount of change samples. In this work, we investigate to jointly consider the spatio-temporal dependencies to improve the accuracy of SCD. First, we propose a Semantic Change Transformer (SCanFormer) to explicitly model the ’from-to’ semantic transitions between the bi-temporal RSIs. Then, we introduce a semantic learning scheme to leverage the spatio-temporal constraints, which are coherent to the SCD task, to guide the learning of semantic changes. The resulting network (SCanNet) significantly outperforms the baseline method in terms of both detection of critical semantic changes and semantic consistency in the obtained bi-temporal results. It achieves the SOTA accuracy on two benchmark datasets for the SCD.
Index Terms:
Semantic Change Detection, Change Detection, Convolutional Neural Network, Semantic Segmentation, Remote SensingI Introduction
In Earth observation applications, it is important to locate the areas on the ground affected by semantic changes and to identify what the changes are. Semantic Change Detection (SCD) [1, 2] is the task that addresses these issues by extracting the change areas and the ’from-to’ transition information in multi-temporal Remote Sensing (RS) data. This is valuable for a variety of real-world applications, such as Land Cover Land Use (LCLU) monitoring, resource management, disaster alarming, etc.
Differently from the binary change detection (BCD) task that generates only a change map, in SCD it is required to predict the semantic maps before and after the changes. For bi-temporal input images, the results are two semantic change maps associated with each observation time. An illustration of the SCD task is presented in Fig.1. With the results of SCD, it is possible to perform detailed change class analysis in the observed regions by detecting the LCLU transitions.

Previous research reveals that to learn the semantic changes, it is important to model the bi-temporal dependencies. The method in [3] first analyzes the change vectors to detect changes, after which classifies the LC classes in changed regions. In the pioneering studies in [4, 5], the Bayes rule is applied to iteratively estimate the LCLU transition, which takes into account the prior joint probabilities of pre-change and after-change semantic classes. In [6] the Bayes rule is also used to fuse the multi-temporal semantic maps with the change probability map to obtain the SCD results.
Recent works employ Convolutional Neural Networks (CNNs) to perform SCD in an end-to-end manner. This avoids the error accumulation problems which are common in the pre-Deep-Learning eras and allows the learned models to generate wider scenes. A widely accepted paradigm for bi-temporal SCD is a triple-branch CNN architecture [2, 7]. In this architecture, two CNN branches are designed to extract the temporal semantic information, while another CNN branch is deployed to embed the bi-temporal features into the change information. Therefore, the semantic information and change information are separately modeled (instead of being entangled), which fits in with the intrinsic mechanism in the SCD[8].
However, two severe challenges remain to be addressed. The first one is the discrimination of the semantic changes. Apart from salient changes (e.g., emergence of buildings), there are critical changes that are non-salient in local areas (e.g., degeneration of vegetation). Additionally, differences in appearance, illumination and occlusions can be easily confused with semantic changes. Due to these factors, missed alarms and false alarms are common in the results. The second challenge is the discrepancy between the bi-temporal results. In literature works, the bi-temporal semantic correlation is not well-considered, which often causes self-contradictory results (e.g., an area is segmented as change but the segmented semantic classes are the same).
In this work, we investigate the joint modeling of the spatial-temporal dependency to improve the learning of semantic changes. Our major contributions include:
-
1.
Proposing a SCanNet (Semantic Change Network) to learn the semantic transitions in SCD. The SCanNet first leverages triple ’encoder-decoder’ CNNs to learn semantic and change features, then introduces the SCanFormer to learn ’semantic-change’ dependencies. The SCanFormer is a variant of the CSWin Transformer, which enables deep and long-range modeling of temporal correlations in the semantic space. Compared to existing methods, the SCanNet shows advantages in discriminating the non-salient semantic changes.
-
2.
Proposing a semantic learning scheme that takes into account the task-specific prior information. The bi-temporal consistency (intrinsic to the SCD task) is utilized as extra supervision to guide the exploitation of semantic information and to reduce the discrepancy in bi-temporal results. We formulate and incorporate two SCD-specific constraints into a learning scheme considering the cases w./w.o. semantic labels in change/no-change areas, respectively.
The remainder of this paper is organized as follows. In Sec.II we review the literature works related to BCD, SCD and vision Transformers. In Sec.III we introduce the proposed method. Sec.IV and Sec.V report the experimental setups and the obtained results, respectively. Finally, we draw conclusions of this study in Sec.VI.
II Related Work
This section is organized following the development of CD methods. The pre-CNN and CNN-based methods are separately introduced. Recent methods for the SCD are also reviewed.
II-A Binary Change Detection
In the pre-Deep-Learning era, one possible way to classify change detection methods is to divide them into three categories based on the types of analyzed change features, including texture features, object-based features and angular features [9]. The CNNs can better capture the context in RSIs, thus they have been widely used for BCD in recent years. Early works on deep-CNN-based CD treats CD as a segmentation task, and employ UNet-like CNNs to directly segment the changes [10]. In [11] a paradigm for BCD is established, which uses two Siamese CNN encoders (i.e., weight-sharing CNNs) to extract temporal features, and transforms the features into change representations through a CNN decoder.
One of the objectives of CNN-based BCD methods is to discriminate the semantic changes from seasonal changes and spatial misalignment. To extract the change features, feature difference operations are commonly used in the CNNs methods [11, 12]. Since there is redundant spatial information in high-resolution (HR) RSIs, multi-scale features are often utilized to filter the spatial noise [13]. The attention mechanism is also effective to detect semantic changes. In [14] the channel attention is employed to refine the multi-scale features. In [15] and [16] hybrid spatial and channel attentions are used to embed discriminative change representations.
II-B Semantic Change Detection
Different from BCD which only detects ’where’ the changes are, SCD provides information on ’what’ the changes are, which is more valuable in many RS applications. In [17] the post-classification comparison method is introduced, which compares the multi-temporal results to classify the LCLU transitions. However, the temporal correlations are not considered in this method. In [4, 5] the compound classification method is proposed, which applies Bayes rules to iteratively maximize the posterior joint probabilities of multi-temporal LCLU classes. In [6] the posterior joint probabilities are considered to integrate the change probabilities, which are obtained through slow feature analysis.
The method in [18] is an early attempt to apply neural networks for SCD. It is a joint CNN-RNN network where the CNN extracts semantic features, while the RNN models temporal dependencies to classify multi-class changes. In [11] CNN architectures for SCD are elaborately analyzed and a triple-branch CNN architecture is suggested. Two of the branches are deployed to exploit temporal semantics, while another branch is deployed to model the binary change information. In [7] a well-annotated benchmark dataset for SCD is released and several evaluation metrics are proposed. In [8] a SSCDl (disentangled semantic segmentation and CD, late fusion) architecture is proposed, which has been demonstrated to be more effective for the SCD.
One of the challenges in the CNN-based methods is the learning of temporal dependencies. While the multi-temporal semantic features are separately embedded, it is important to bridge the connections between different temporal branches. In [8] a temporal spatial attention design is proposed to model the bi-temporal semantic correlations. In [19] the channel attention is used to embed change information into the temporal features. In [20] a learnable symmetric transform is proposed to align the temporal features and to learn the change maps.
Although these modules to some extent improve the feature representations, the modeling of spatio-temporal dependencies is still partial, one-sided, or shallow. We argue that to learn the intrinsic mechanism in SCD, it is important to jointly model the semantic-change correlations, which is the objective of this study.
II-C Vision Transformer
Vision transformer is a recent emerging research topic since its application in visual recognition tasks [21]. Differently from CNNs whose computations are limited to sliding kernels, vision transformers leverage self-attention to model global dependencies. The vision transformers have been first used in high-level recognition tasks such as image classification [22, 23] and object detection [24]. Then they have been applied to down-stream tasks such as semantic segmentation[25] and image synthesis [26]. Several literature works propose pure-CNN backbone networks for general vision tasks. They arrange hierarchical transformer blocks in CNN-like manner and limit the range of self-attention in local areas to reduce computation[27, 28, 29].
There are also investigations to apply transformers to better recognize the complex ground objects in RSIs. In [30] a context transformer is proposed to exploit wide-range context information through a context window. In [31] two siamese transformers are organized into a SegFormer-like [25] architecture for BCD in RSIs. Instead of using transformer as backbone networks feature extraction, the method in [32] employs transformer to model the bi-temporal context correlations. In a recent study, transformer is also used in the SCD task [33], which is also a variant of the SegFormer. However, the transformers are simply employed as feature extractors to replace the CNN counterparts. Differently, in this work, we investigate leveraging the transformers to deeply model the long-range spatio-temporal correlations that are coherent in the SCD task.
III Proposed SCanNet for SCD
This section introduces the proposed SCanNet (Semantic Change Network) for SCD in RSIs. Fig.3 provides an overview of the SCanNet architecture. This is a hybrid framework that consists of triple CNNs and a Transformer. First, temporal features and the change representations are extracted through a Triple Encoder-Decoder (TED) network. Then, we introduce the SCanFormer to learn jointly the spatio-temporal dependencies in the token space. Finally, a semantic learning scheme is proposed to guide the SCanNet toward modeling the intrinsic change-semantic correlations in SCD. Below we introduce the main components of the proposed method.
III-A CNN Architecture for SCD
Given a pair of input images , the task of SCD is to generate a pair of semantic change maps that present the changed areas and their semantic categories. An ideal SCD function can be formulated as:
| (1) |
where denotes a spatial position on and are the bi-temporal semantic classes at .
Recent works pointed out that compared to directly learning the semantic changes, separate embedding of the semantic features and change features obtains better accuracy [2, 7, 8]. In our previous work[8], an SCD framework named SSCDl has been introduced for SCD. As shown in Fig.2(a), the SSCDl includes two temporal encoders to exploit the semantic information and a CNN module to detect the changes. There are also optional network modules (presented as ’heads’) to enhance the feature representations and to segment the results. One of the remaining problems is that the obtained results are coarse-grained and lack a precise representation of spatial information. Here we improve the SSCDl by adding decoder modules. The resulting TED SCD framework has three feature representation branches organized in an encoder-decoder manner. Fig.2(b) presents the TED framework, where the ’Necks’ are decoding modules that are attached with lower layers in the encoders.
Let us consider images input into the TED. First, the encoder networks embed and reshape them into multi-scale features where . Then, the necks further enlarge and concatenate before forwarding them to the heads. Concurrently, there is also a change branch that detects changes by using bi-temporal features. Its inputs are semantic features obtained from the highest encoding layers in the temporal branches, while its output is the change feature . The neck in the change branch spatially aligns with temporal features . Finally, outputs of the triple embedding branches are . Compared with the SSCDl, the TED can better retain spatial details.


III-B SCanFormer: ’Semantic-Change’ dependency modeling with Transformer

In the TED framework, separate embedding of the temporal and change features disentangles the learning of semantic change into Semantic Exploitation (SE) and CD. Although this separate learning enables more dedicated exploitation of the semantic and change information, their correlation is not considered. Intuitively, the bi-temporal semantic differences/consistency helps to discriminate the changes/no-change classes, while the LCLU transition pattern allows to better recognize the semantic categories. To model this ’semantic-change’ dependency, we resort to the recently emerging transformers and introduce the SCanFormer.
As depicted in Fig.3, the SCanFormer can be plugged in the TED framework as the heads. The resulting network, i.e. the SCanNet, is a hybrid ’CNN-Transformer’ architecture. The CNN parts serve as feature extractors due to their efficiency and preservation of spatial information, which is the common practice in segmentation tasks [30]. Meanwhile, the SCanFormer is attentive to correlations in the embedded semantic space. This allows deep modeling of the ’semantic-change’ dependencies in the whole spatio-temporal domain, which differs from previous methods that only model the bi-temporal correlations [8] or one-way (change-to-temporal [19]) attention operations.
To jointly model the spatio-temporal correlations, we concatenate features and flatten them into a semantic token where is the depth of the token (equal to ). The SCanFormer consists of layers of attention blocks. Each of the blocks consists of a Self-Attention (SA) unit and an MLP unit. The units are organized in a residual manner and contain a normalization layer. Mathematically, the calculations inside each attention block are:
| (2) | ||||
where represents the output token of the -th block.
The original ViT [21] that uses full SA is calculation-intensive. Its computation complexity is quadratic to the image size, which is expensive for handling HR RSIs. Considering this, we adopt the Cross-Shaped Window (CSWin) SA [29] to model long-range context more efficiently. In the CSWin-SA unit, the input features are spatially partitioned into vertical and horizontal stripes (in two separate groups), each with the width . There are heads to perform SA, of the heads for the horizontal group and another ones for the vertical group. The calculations in the horizontal group are:
| (3) | ||||
where , represents the SA operation of the -th unit, are the projecting matrix for the query, key, value tokens, respectively. The calculations in the vertical group are similar, thus are omitted for simplicity. The CSWin-SA calculations for the -th stripe are:
| (4) |
where is the softmax operation, are linear projections of , is a learnable parameter matrix to encode the relative positions. Finally, the outputs of the heads are concatenated and projected:
| (5) |
where is a projection matrix to adjust the token dimension.
III-C Semantic Learning with Temporal Consistency Constraints

In the common settings of the SCD task, the changed areas are provided with semantic labels, whereas the unchanged areas are annotated as no-change. In other words, the number of semantic labels is very limited. This leads to the challenge of learning semantic information with limited samples. However, considering the intrinsic mechanism in the SCD, it is possible to utilize the bi-temporal consistency as prior information to guide the exploitation of semantic information. Considering the different cases in change and no-change areas, we propose a semantic learning scheme with two task-specific learning objectives. In the following, we separately discuss the two cases.
First, let us consider the changed areas that are provided with semantic labels. The semantic loss can be calculated with the commonly used cross-entropy loss, defined as:
| (6) |
where is the temporal index. To disentangle SE with CD, this loss is only calculated in the changed areas (i.e. ignoring the no-change class).
Meanwhile, the unchanged areas are annotated as no-change but usually are not provided with the specific semantic classes. However, it is possible to infer the semantic labels with bi-temporal predictions. Suppose that a place is known to be unchanged, if its bi-temporal semantic probabilities and are similar, we can assume with high confidence that its semantic class should be (or ). Therefore, we adopt the pseudo-labeling method to generate a pseudo semantic label for areas. Mathematically, the calculation is as follows:
| (7) |
where is a Cosine function calculated in the vector space to measure the semantic similarity, and is a threshold. We use annotation 0 to exclude the change areas from the loss calculation. A pseudo semantic objective can be calculated as:
| (8) |
The calculation of this objective function is illustrated in Fig.4(a).
Last but not least, according to the intrinsic logic in the SCD, there should be semantic consistency in the no-change areas on and , whereas there is a difference in the changed areas. Using this temporal constraint as prior information, a semantic consistency learning objective can be constructed to guide the network training. is calculated with the ground truth change label , which can be easily derived by binarizing or (setting the annotation of changed regions to ). The calculation of is as follow:
| (9) |
The calculation of this learning objective function is depicted in Fig.4(b). Note that this function is calculated in both no-change and change areas. It encourages the network to generate the same semantic predictions in change areas, whereas generating different predictions in no-change areas.
Incorporating these learning objective functions, the overall loss is given by:
| (10) |
By adding , the temporal semantic information contained in the two images is jointly considered, which improves the discrimination of critical areas.
III-D Implementation Details
In the following, we report the parameter settings and the training details in the implementation of SCanNet.
1) TED. The CNN encoders in TED are constructed following the practice in [8]. We adopt the ResNet blocks which are commonly used in segmentation tasks [34]. Since the pre and after-change input images are in the same domain, the temporal encoders are made Siamese (i.e., weight-sharing) to avoid over-fitting and to better align the extracted features. The convolutional layer to embed change features is a ResNet-like block with 6 residual layers. The necks are decoder blocks constructed as those in [35].
2) ScanFormer. The important parameters in the SCanFormer are , , and . determines the context modeling range, which is set to 2 considering the input feature size (). To avoid heavy computations, (the number of layers in the SA blocks) is set to 2. is set to 2 considering the feature dimensions.
3) Training Settings. The proposed methods are implemented with the PyTorch toolbox. The training is performed for 50 epochs. The batch size and initial learning rate are 8 and 0.1, respectively. The gradient descent optimization method is Stochastic Gradient Descent with Nesterov momentum. The learning rate is updated at each iteration as: . The augmentation operations consist of random flipping and rotation before loading the input images.
For more details, readers are encouraged to visit our codes released at: https://github.com/ggsDing/SCanNet.
IV Dataset Description and Experimental Settings
In this section, we describe the dataset, the evaluation metrics and the experimental settings.
IV-A Dataset
We conduct experiments on two openly-accessible benchmark datasets for the SCD: the SECOND and the Landsat-SCD datasets. The former is an HR dataset collected in city regions, whereas the latter is a mid-resolution dataset at the margin of a desert area. These differences in the spatial resolution and the observed scenes make it possible to assess the effectiveness of the tested methods in different scenarios.
1) SECOND[7]. The SEmantic Change detectiON Dataset (SECOND) is a large-scale and well-annotated benchmark dataset for the SCD in HR RSIs. This dataset includes 4662 pairs of RSIs acquired by different sensors and platforms. They are obtained in various cities including Hangzhou, Chengdu, and Shanghai in China. Each image has pixels. The ground sampling distance (GSD) in this dataset is in the range between 0.5 and 3m. Each pair of RSIs are spatially matched, recording the changes in the considered region. The manual annotations are the semantic change maps associated with each image. In the annotated labels, there are 1 no-change class and 5 LC classes, including non-vegetated ground surface, tree, low vegetation, water, buildings and playgrounds (only the changed areas are annotated). Comparing the pre-change and after-change classes, a total of 30 types of semantic changes can be derived. The change pixels account for 19.87% of the total image pixels. We further split 1/5 of the data (593 pairs of RSIs) as the test set and use the remaining ones for training (2375 pairs) following the practice in [8].
2) Landsat-SCD Dataset[33]. This dataset is constructed with Landsat images collected between 1990 and 2020. The observed region is in Tumushuke, Xinjiang, China, which is at the margin of the Taklimakan Desert. The ground sampling distance is 30m. Changed pixels account for 18.89% of the total pixels. The dataset is annotated into the no-change class and 4 LC classes, including farmland, desert, building and water (only the changed areas are annotated). These LC classes are associated with 10 types of semantic changes.
The Landsat-SCD dataset consists of 8468 pairs of images, each having the spatial resolution of . Excluding those samples obtained by spatial augmentation operations (including flipping, masking and resizing), there are 2425 pairs of original data. We further split them into training, validation and test sets with the numeric ratio of 3:1:1 (i.e., 1455, 485 and 485, respectively).
IV-B Evaluation Metrics
To evaluate the segmentation accuracy, we adopt 4 metrics commonly used in the SCD task, including overall accuracy (OA), mean Intersection over Union (mIoU), Separated Kappa (SeK) coefficient and SCD-targeted F1 Score (). OA is a common metric in segmentation tasks[36], which represents the numeric ratio between the correctly classified pixels and the total image pixels. Let be the confusion matrix, where represents the number of pixels that are classified into class while their GT index is ( ( represents no-change). OA is calculated as:
| (11) |
In the SCD task, since no-change class is the majority, OA cannot well-describe the discrimination of semantic classes. In [7] mIoU and SeK are introduced to evaluate the performance CD and SE, respectively. The mIoU in SCD is calculated based on the discrimination of change/no-change classes:
| (12) | |||
| (13) | |||
| (14) |
Meanwhile, SeK evaluates the segmentation of semantic classes especially in the changed areas. It is calculated based on the confusion matrix , where except that . This excludes the true positive non-changed pixels whose number is dominant. It is calculated as:
| (15) | |||
| (16) | |||
| (17) |
In [8] the is introduced to evaluate the segmentation accuracy in change areas. It is calculated deriving the () and () in the areas annotated as change:
| (18) | |||
| (19) | |||
| (20) |
V Experimental Results
In this section, we present the experimental results obtained on the benchmark datasets. First, ablation studies are conducted to demonstrate the effects of the different components of the proposed techniques. Then, we present the qualitative results obtained on sample test data. Finally, the proposed SCanNet is compared with SOTA methods in SCD.
| Methods | Proposed Techniques | Accuracy | |||||
| SCanFormer | OA(%) | mIoU(%) | Sek(%) | (%) | |||
| SSCDl [8] | 87.19 | 72.60 | 21.86 | 61.22 | |||
| TED | 87.39 | 72.79 | 22.17 | 61.56 | |||
| TED (w. ) | 87.67 | 73.10 | 22.83 | 62.29 | |||
| TED (w. ) | 87.75 | 73.45 | 23.46 | 62.76 | |||
| SCanNet (w/o. ) | 87.63 | 73.09 | 23.42 | 63.10 | |||
| SCanNet | 87.86 | 73.42 | 23.94 | 63.66 | |||
V-A Ablation Study
1) Quantitative Results. The techniques proposed in this work include i) the TED framework; ii) the semantic learning scheme and iii) the SCanNet (incorporating SCanFormer into the TED). Table.I reports the quantitative results after using the proposed techniques. The TED framework outperforms the SSCDl framework by around 0.3% in mIoU and , which demonstrates its advantages in both SE and CD. After applying the semantic learning scheme to the TED, there are significant improvements in all the metrics (around 0.7% in mIoU, SeK and ). Compared to the plain TED, the SCanNet (adding the SCanFormer) has significant improvements in SE (demonstrated by improvements of around 0.5% in Sek and 0.9% in ).
2) Effects of the Semantic Learning Scheme. The in the proposed semantic learning scheme is calculated with pseudo labels generated by bi-temporal semantic predictions. To visually assess the quality of generated pseudo labels, we present some examples in Fig.5. The pseudo labels cover the pixels with no semantic labels, thus their correctness can only be visually assessed together with the input images. One can observe that the generated labels are generally correct and multiple semantic categories are included. This supervision function improves the learning of semantic information in unchanged regions where the bi-temporal prediction confidence is high.
| (a1) |

|

|

|

|
| (a2) |

|

|

|
|
| (b1) |

|

|

|

|
| (b2) |

|

|

|
|
| Training | GT | |||
| images | (generated by the TED) | |||
| (a1) |

|

|

|

|

|
|---|---|---|---|---|---|
| (a2) |

|

|

|

|

|
| (b1) |

|

|

|

|

|
| (b2) |

|

|

|

|

|
| Test image | GT | TED | TED (w. ) | TED (w. ) |
Fig.6 presents qualitative comparisons of the results obtained w. and w./o using the semantic learning scheme. The comparisons are made on the plain TED framework where there is no other explicit spatio-temporal modeling design, so that all the differences can be attributed to the proposed learning scheme. After using the semantic learning scheme, some non-salient changes are captured (e.g., the emergence of a playground is detected in Fig.6(b)), while the discrimination of semantic classes is also improved (e.g., the error of segmenting ground as low vegetation in Fig.6(a)). These results indicate that the proposed learning scheme brings overall improvements to the SCD task.
| (a1) |

|

|

|

|
|---|---|---|---|---|
| (a2) |

|

|

|

|
| (b1) |

|

|

|

|
| (b2) |

|

|

|
|
| Test image | GT | TED (w. ) | SCanNet |
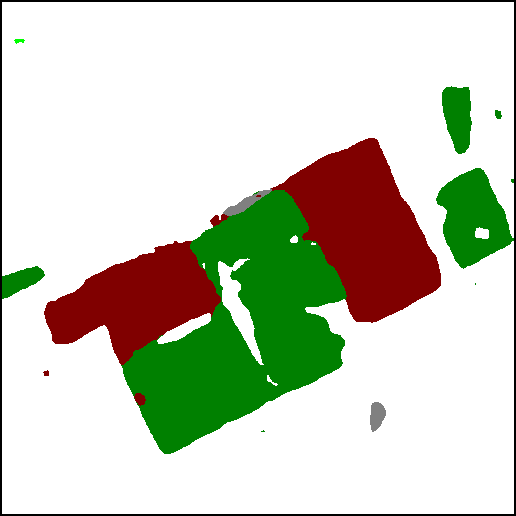
3) Effects of the SCanFormer. Fig.7 compares the results obtained w. and w/o. using the proposed SCanFormer. While the detected changes are mostly the same, the SCanNet, leveraging the joint spatio-temporal information, can better discriminate the semantic categories. Specifically, in the results of the SCanNet there are less errors in the discrimination of ground and building (see Fig.7(a)), as well as in the discrimination of low vegetation and ground (see Fig.7(b)).
To conclude, this ablation study demonstrates that: i) the proposed TED framework and the learning scheme bring improvements to the detection of changes and the extraction of their semantic information; ii) the SCanFormer significantly improves the learning of temporal semantic information.
V-B Comparative Experiments
To comprehensively evaluate the performance of the proposed method, we compare it with literature methods that are provided with accessible codes. The compared methods include i) the CD and SCD architectures proposed in [11, 2], ii) the hybrid CNN-RNN methods for SCD [18] and iii) other recent literature methods [19, 8].
| Method | SECOND | Landsat-SCD | ||||||
|---|---|---|---|---|---|---|---|---|
| OA(%) | mIoU(%) | Sek(%) | (%) | OA(%) | mIoU(%) | Sek(%) | (%) | |
| ResNet-GRU [18] | 85.09 | 60.64 | 8.99 | 45.89 | 90.55 | 74.16 | 26.51 | 71.87 |
| ResNet-LSTM [18] | 86.91 | 67.27 | 16.14 | 57.05 | 93.36 | 80.88 | 40.06 | 80.36 |
| FC-Siam-conv. [11] | 86.92 | 68.86 | 16.36 | 56.41 | 92.89 | 79.86 | 36.94 | 78.29 |
| FC-Siam-diff [11] | 86.86 | 68.96 | 16.25 | 56.20 | 91.95 | 76.44 | 30.23 | 73.97 |
| HRSCD-str.2 [2] | 85.49 | 64.43 | 10.69 | 49.22 | 86.06 | 74.92 | 2.89 | 36.52 |
| HRSCD-str.3 [2] | 84.62 | 66.33 | 11.97 | 51.62 | 91.10 | 78.33 | 31.43 | 73.17 |
| HRSCD-str.4 [2] | 86.62 | 71.15 | 18.80 | 58.21 | 91.27 | 79.10 | 32.29 | 73.34 |
| SCDNet[19] | 87.46 | 70.97 | 19.73 | 60.01 | 94.94 | 85.23 | 50.05 | 85.00 |
| SSCD-l[8] | 87.19 | 72.60 | 21.86 | 61.22 | 94.75 | 85.25 | 50.17 | 84.91 |
| Bi-SRNet[8] | 87.84 | 73.41 | 23.22 | 62.61 | 94.91 | 85.53 | 51.01 | 85.35 |
| TED (proposed) | 87.39 | 72.79 | 22.17 | 61.56 | 95.89 | 88.49 | 58.69 | 88.22 |
| SCanNet (proposed) | 87.86 | 73.42 | 23.94 | 63.66 | 96.26 | 88.96 | 60.53 | 89.27 |
1) Quantitative Results. We report the quantitative results obtained on the two benchmark datasets in Table.II. Among the compared methods, those SCD-targeted methods obtain higher accuracy metrics. Specifically, the ResNet-LSTM[18], which contains temporal-modeling recurrent modules, has a relatively high . The HRSCD-str.4, which integrates CD and LCLU mapping, obtains higher mIoU and on the SECOND. Among the literature methods, the SCDNet[19] that uses change-to-temporal attention operations obtains significantly higher accuracy. The Bi-SRNet[8] that enables interactions between the temporal semantic branches obtains the second-best and third-best accuracy on the SECOND and the Landsat-SCD dataset, respectively.
Without bells and whistles, plain TED outperforms most of the literature methods. Its advantages are more obvious in the Landsat-SCD dataset, which can be attributed to its spatial-preserving designs. The major difference between the TED and the HRSCD-str.4 is that the former reuses the large amount of semantic information presented in features from the temporal branches, therefore is more sensitive to the semantic changes. The proposed SCanNet enables deep and intrinsic modeling of the spatio-temporal dependencies in the SCD task. Thus it has significant advantages over the compared methods in all the metrics. Notably, its advantages over the second-best results in SeK are around 0.7% in and around 1% in . This demonstrates its superior capabilities in discriminating the semantic classes with a limited number of change samples.
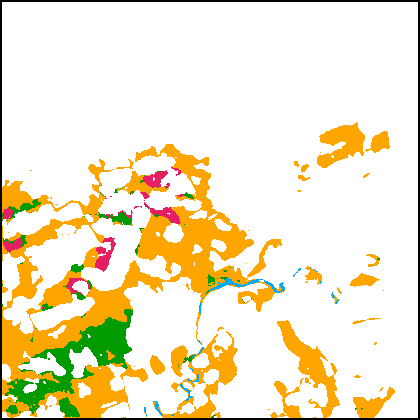
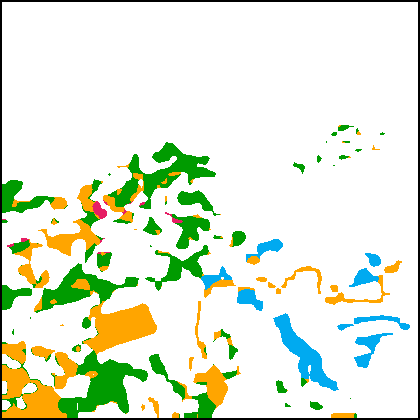
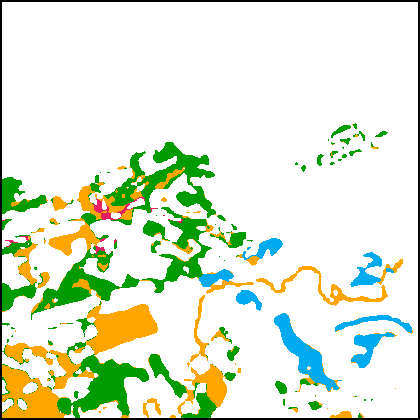
2) Qualitative Results. To visually compare the results, we present the segmentation maps obtained by different methods in Fig.8. The first 4 rows (Fig.8(a1)-(b2)) are results obtained on the SECOND. One can observe that the literature methods have difficulty in detecting the non-salient changes, e.g., the emergence of a playground in Fig.8(a) and the removal of small buildings in Fig.8(b). There are also discrepancies in the results. For example, in the SCD results of the HRSCD-str.4 and the SCDNet, there are areas that are segmented as building on both of the bi-temporal segmentation maps, which is contradictory with respect to the represented change information. These issues are mostly addressed in the results of the proposed methods. With the guidance of semantic learning objectives, the detection of non-salient changes is improved and there are much fewer discrepancies in the bi-temporal results. The SCanNet further outperforms the plain TED in recognizing the critical areas, e.g., discrimination between low vegetation and water in Fig.8(a).
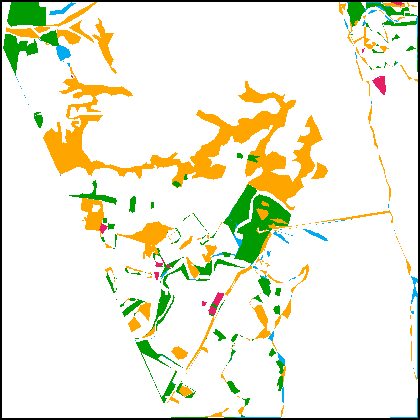
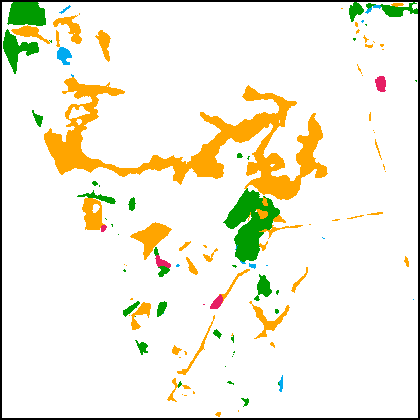
Fig.8(c1)-(d2) present SCD results obtained on the Landsat-SCD dataset. Since the GSD of this dataset is relatively low, it requires the SCD model to better preserve the spatial details. One can observe that the proposed methods based on the TED architecture can precisely capture fine-grained changes in LU types, such as the drying of a river in Fig.8(c), and the emergence of small farmlands in Fig.8(d). The SCanNet shows advantages in discriminating the semantic categories of the small objects.
| Method | SECOND | |||||
|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | 6th | |
| GT | groundbuilding | low vegetationground | groundlow vegetation | low vegetationbuilding | buildingground | groundtree |
| HRSCD-str.4 [2] | groundbuilding | low vegetationground | low vegetationbuilding | groundlow vegetation | buildingground | groundground |
| SCDNet[19] | groundbuilding | low vegetationbuilding | low vegetationground | buildingground | groundlow vegetation | groundtree |
| Bi-SRNet[8] | groundbuilding | low vegetationbuilding | low vegetationground | groundlow vegetation | buildingground | groundtree |
| SCanNet (proposed) | groundbuilding | low vegetationground | low vegetationbuilding | groundlow vegetation | buildingground | groundtree |
| Method | Landsat-SCD dataset | |||||
| 1st | 2nd | 3rd | 4th | 5th | 6th | |
| GT | desertfarmland | desertwater | farmlanddesert | waterdesert | farmlandbuilding | desertbuilding |
| HRSCD-str.4 [2] | desertfarmland | desertwater | desertdesert | farmlanddesert | farmlandfarmland | waterdesert |
| SCDNet[19] | desertfarmland | desertwater | farmlanddesert | waterdesert | farmlandbuilding | desertbuilding |
| Bi-SRNet[8] | desertfarmland | desertwater | farmlanddesert | waterdesert | farmlandbuilding | desertbuilding |
| SCanNet (proposed) | desertfarmland | desertwater | farmlanddesert | waterdesert | farmlandbuilding | desertbuilding |
| (a1) |

|

|

|

|

|

|

|
| (a2) |

|

|

|

|

|

|

|
| (b1) |

|

|

|

|

|

|

|
| (b2) |

|

|

|

|

|

|

|
| Test image | GT | HRSCD-str.4 | SCDNet | BiSRNet | TED (proposed) | SCanNet (proposed) | |
|
|
|||||||
| (c1) |

|

|
|

|

|

|

|
| (c2) |

|

|

|

|
|
|

|
| (d1) |

|

|

|

|

|

|

|
| (d2) |

|
|

|
|

|

|

|
| Test image | GT | HRSCD-str.4 | SCDNet | BiSRNet | TED (proposed) | SCanNet (proposed) |
3) Change Analysis. In Fig.9 we present the confusion matrices obtained on the bi-temporal SCD results, which intuitively present the ’from-to’ change types in the observed regions. The GT labels in the SECOND (see Fig.9(a)) indicate that the major semantic changes include groundbuilding, low vegetationground, groundlow vegetation and low vegetationbuilding, which account for 25.86%, 15.58%, 12.09% and 11.26% of the change proportions, respectively. This change pattern is generally consistent with the results of the SCanNet. To compare the semantic changes detected by the different methods, Table.III sorts the top-6 major changes derived from the change confusion matrices. One can observe that in the results of the SCanNet, there are fewer errors in terms of the sequence of the major semantic changes. Meanwhile, in the Landsat-SCD dataset, the major changes include desertfarmland, desertwater, farmlanddesert and waterdesert, accounting for 61.74%, 10.97%, 10.45% and 5.05% of the total changes, respectively. This dataset is less challenging, thus most of the methods successfully detected these changes.
It is worth noting that the results of the HRSCD.str4 (in the SECOND and in the Landsat) and the SCDNet (in the SECOND) show some discrepancies (i.e., false changes such as groundground and farmlandfarmland). Meanwhile, in the results of the SCDNet, the false changes are limited to only a small proportion. There are a total of 0.2% false changes in the SECOND (excluding the buildingbuilding changes which are affected by wrong annotations), and 0.26% in the Landsat-SCD dataset. In another word, most of the discrepancies in the results are eliminated.
VI Conclusions








SCD is a meaningful and challenging task in RS applications. It requires not only exploitation of the semantic and change features, but also comprehensive learning of the spatio-temporal dependencies, which are not fully considered in literature methods. We investigate to overcome this limitation in two-fold. First, we propose a hybrid CNN-transformer architecture for the SCD. The CNN branches effectively exploit the spatial context, while the SCanFormer is designed at the head of the network to jointly model the spatio-temporal dependencies. Second, we propose a semantic learning scheme that formulates the prior constraints contained in SCD. It contains a semantic consistency objective to boost the consistency in segmentation results, and a pseudo-learning objective to supervise the SE in no-change areas. Thus, in a word, the SCanFormer provides capabilities for joint spatio-temporal analysis, while the learning scheme drives the SCanNet to model the intrinsic change-semantic correlations in SCD.
Extensive experiments have been conducted to evaluate the performance of the proposed method. The results obtained on the SCD benchmark dataset indicate that the proposed SCanNet has achieved accuracy improvements over the SOTA methods (with a lead of over 1% in ). One of the remaining challenges is to discriminate the rare semantic changes with very few samples, which is left for future studies.
References
- [1] F. Bovolo and L. Bruzzone, “The time variable in data fusion: A change detection perspective,” IEEE Geoscience and Remote Sensing Magazine, vol. 3, no. 3, pp. 8–26, 2015.
- [2] R. C. Daudt, B. Le Saux, A. Boulch, and Y. Gousseau, “Multitask learning for large-scale semantic change detection,” Computer Vision and Image Understanding, vol. 187, p. 102783, 2019.
- [3] G. Xian, C. Homer, and J. Fry, “Updating the 2001 national land cover database land cover classification to 2006 by using landsat imagery change detection methods,” Remote Sensing of Environment, vol. 113, no. 6, pp. 1133–1147, 2009.
- [4] L. Bruzzone and S. B. Serpico, “An iterative technique for the detection of land-cover transitions in multitemporal remote-sensing images,” IEEE transactions on geoscience and remote sensing, vol. 35, no. 4, pp. 858–867, 1997.
- [5] L. Bruzzone, D. F. Prieto, and S. B. Serpico, “A neural-statistical approach to multitemporal and multisource remote-sensing image classification,” IEEE Transactions on Geoscience and remote Sensing, vol. 37, no. 3, pp. 1350–1359, 1999.
- [6] C. Wu, B. Du, X. Cui, and L. Zhang, “A post-classification change detection method based on iterative slow feature analysis and bayesian soft fusion,” Remote Sensing of Environment, vol. 199, pp. 241–255, 2017.
- [7] K. Yang, G.-S. Xia, Z. Liu, B. Du, W. Yang, and M. Pelillo, “Asymmetric siamese networks for semantic change detection,” arXiv preprint arXiv:2010.05687, 2020.
- [8] L. Ding, H. Guo, S. Liu, L. Mou, J. Zhang, and L. Bruzzone, “Bi-temporal semantic reasoning for the semantic change detection in hr remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022.
- [9] D. Wen, X. Huang, F. Bovolo, J. Li, X. Ke, A. Zhang, and J. A. Benediktsson, “Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions,” IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 4, pp. 68–101, 2021.
- [10] D. Peng, Y. Zhang, and H. Guan, “End-to-end change detection for high resolution satellite images using improved unet++,” Remote Sensing, vol. 11, no. 11, p. 1382, 2019.
- [11] R. C. Daudt, B. Le Saux, and A. Boulch, “Fully convolutional siamese networks for change detection,” in 2018 25th IEEE International Conference on Image Processing (ICIP). IEEE, 2018, pp. 4063–4067.
- [12] M. Zhang and W. Shi, “A feature difference convolutional neural network-based change detection method,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 10, pp. 7232–7246, 2020.
- [13] X. Hou, Y. Bai, Y. Li, C. Shang, and Q. Shen, “High-resolution triplet network with dynamic multiscale feature for change detection on satellite images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 177, pp. 103–115, 2021.
- [14] Z. Li, C. Tang, L. Wang, and A. Y. Zomaya, “Remote sensing change detection via temporal feature interaction and guided refinement,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [15] J. Chen, Z. Yuan, J. Peng, L. Chen, H. Huang, J. Zhu, Y. Liu, and H. Li, “Dasnet: Dual attentive fully convolutional siamese networks for change detection in high-resolution satellite images,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 1194–1206, 2020.
- [16] Q. Shi, M. Liu, S. Li, X. Liu, F. Wang, and L. Zhang, “A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection,” IEEE transactions on geoscience and remote sensing, vol. 60, pp. 1–16, 2021.
- [17] A. Singh, “Digital change detection techniques using remotely-sensed data,” Int. J. Remote Sensing, vol. 10, no. 6, pp. 989–1003, 1989.
- [18] L. Mou, L. Bruzzone, and X. X. Zhu, “Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 2, pp. 924–935, 2018.
- [19] D. Peng, L. Bruzzone, Y. Zhang, H. Guan, and P. He, “Scdnet: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery,” International Journal of Applied Earth Observation and Geoinformation, vol. 103, p. 102465, 2021.
- [20] Z. Zheng, Y. Zhong, S. Tian, A. Ma, and L. Zhang, “Changemask: Deep multi-task encoder-transformer-decoder architecture for semantic change detection,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 183, pp. 228–239, 2022.
- [21] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [22] K. Han, A. Xiao, E. Wu, J. Guo, C. Xu, and Y. Wang, “Transformer in transformer,” Advances in Neural Information Processing Systems, vol. 34, pp. 15 908–15 919, 2021.
- [23] X. Chu, Z. Tian, Y. Wang, B. Zhang, H. Ren, X. Wei, H. Xia, and C. Shen, “Twins: Revisiting the design of spatial attention in vision transformers,” Advances in Neural Information Processing Systems, vol. 34, pp. 9355–9366, 2021.
- [24] N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213–229.
- [25] E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,” Advances in Neural Information Processing Systems, vol. 34, pp. 12 077–12 090, 2021.
- [26] P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883.
- [27] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10 012–10 022.
- [28] W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, “Pyramid vision transformer: A versatile backbone for dense prediction without convolutions,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 568–578.
- [29] X. Dong, J. Bao, D. Chen, W. Zhang, N. Yu, L. Yuan, D. Chen, and B. Guo, “Cswin transformer: A general vision transformer backbone with cross-shaped windows,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 124–12 134.
- [30] L. Ding, D. Lin, S. Lin, J. Zhang, X. Cui, Y. Wang, H. Tang, and L. Bruzzone, “Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022.
- [31] W. G. C. Bandara and V. M. Patel, “A transformer-based siamese network for change detection,” arXiv preprint arXiv:2201.01293, 2022.
- [32] H. Chen, Z. Qi, and Z. Shi, “Remote sensing image change detection with transformers,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2021.
- [33] P. Yuan, Q. Zhao, X. Zhao, X. Wang, X. Long, and Y. Zheng, “A transformer-based siamese network and an open optical dataset for semantic change detection of remote sensing images,” International Journal of Digital Earth, vol. 15, no. 1, pp. 1506–1525, 2022.
- [34] L. Ding, H. Tang, and L. Bruzzone, “Lanet: Local attention embedding to improve the semantic segmentation of remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 1, pp. 426–435, 2020.
- [35] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” in ECCV, 2018.
- [36] L. Ding, H. Tang, Y. Liu, Y. Shi, X. X. Zhu, and L. Bruzzone, “Adversarial shape learning for building extraction in vhr remote sensing images,” IEEE Transactions on Image Processing, vol. 31, pp. 678–690, 2021.