Joint Device Detection, Channel Estimation, and Data Decoding with Collision Resolution for MIMO Massive Unsourced Random Access
Abstract
In this paper, we investigate a joint device activity detection (DAD), channel estimation (CE), and data decoding (DD) algorithm for multiple-input multiple-output (MIMO) massive unsourced random access (URA). Different from the state-of-the-art slotted transmission scheme, the data in the proposed framework is split into only two parts. A portion of the data is coded by compressed sensing (CS) and the rest is low-density-parity-check (LDPC) coded. In addition to being part of the data, information bits in the CS phase also undertake the task of interleaving pattern design and channel estimation (CE). The principle of interleave-division multiple access (IDMA) is exploited to reduce the interference among devices in the LDPC phase. Based on the belief propagation (BP) algorithm, a low-complexity iterative message passing (MP) algorithm is utilized to decode the data embedded in these two phases separately. Moreover, combined with successive interference cancellation (SIC), the proposed joint DAD-CE-DD algorithm is performed to further improve performance by utilizing the belief of each other. Additionally, based on the energy detection (ED) and sliding window protocol (SWP), we develop a collision resolution protocol to handle the codeword collision, a common issue in the URA system. In addition to the complexity reduction, the proposed algorithm exhibits a substantial performance enhancement compared to the state-of-the-art in terms of efficiency and accuracy.
Index Terms:
belief propagation, compressed sensing, LDPC, MIMO, unsourced random accessI Introduction
I-A Background and Related Works
Next generation multiple access (NGMA) aims to support massive connectivity scenarios for many envisioned Internet of Things (IoT) applications, e.g. manufacturing, transportation, agriculture, and medicine, to be efficiently and flexibly connected [5, 2, 4, 6, 1, 3]. A generic scenario for IoT connectivity involves a massive number of machine-type connections [2], known as the massive machine-type communication (mMTC), which is one of the main use cases of the fifth-generation (5G) and beyond [3]. Compared to human-type communications (HTC), MTC has two distinct features: sporadic traffic and short packet communication. The sporadic access means that for any given time, for the sake of long battery life and energy saving, only a small fraction within a huge number of devices are active for data transmission [4]. While the small data payloads result in a fall of spectrum efficiency and an increase of latency when applied with traditional multiple access protocols. In this regard, a number of scalable random access schemes have been investigated in the content of massive connectivity. Conceptually, there are two lines of work for that end, namely, individual and common codebook-based approaches, respectively.
In the spirit of the individual codebook based approach, each device is equipped with a unique codebook for the identification conducted by the base station (BS) [4, 7]. Since the BS is interested in the IDs of devices, this framework can be referred to as sourced random access (SRA). A typical transmission process includes two phases in SRA, namely, training and data transmission, respectively. In the training phase, the BS conducts the task of device activity detection (DAD) and channel estimation (CE) based on the pre-allocated unique pilot sequences transmitted by active devices, while the data transmission is performed in the following phase. The task of DAD-CE can be modeled as the compressed sensing (CS) problem and there have been quantities of algorithmic solutions for this issue. Among these CS recovery techniques, the approximate message passing (AMP) algorithm, which is first proposed in [8] for the single measurement vector (SMV) based problem, exhibits great performance in terms of accuracy and complexity. Since the publication of [8], there have been vast variants based on the AMP algorithm, such as multiple measurement vector (MMV) AMP [4], generalized MMV (GMMV) AMP [9], orthogonal AMP (OAMP) [10], generalized AMP (GAMP) [11] and many other works. Another line of work is based on the belief propagation (BP) algorithm [12], which models the problem as a graph and iteratively calculates the messages among different nodes [13, 14, 15, 16]. Thanks to the consistency of the message updating rules, the messages can always be jointly updated within iterations to obtain improved performance. However, the premise of these algorithms is that each device should have a unique pilot sequence. As we jump out of these algorithmic solutions and go back to the essence of the individual codebook, we find this is inapplicable to assign each device a unique pilot in the mMTC scenario with a huge amount of potential devices. Meanwhile, it is a waste of resources especially with sporadic traffic. To mitigate this issue, the study on the framework of common codebooks is rapidly developed.
As opposed to the case of individual codebooks, active devices choose codewords from a common codebook for their messages. In this regard, the task of BS is only to produce the transmitted messages regardless of the corresponding IDs, thus leading to the so-called unsourced random access (URA). The main difference between URA with other grant-based and grant-free random access protocols is that the BS does not perform device identification but only decodes the list of active device messages up to permutations [3]. Conceptually, there are two distinct advantages for this novel framework: the BS is capable of accommodating massive devices, since all devices share the common codebook instead of being assigned unique preamble sequences as in traditional schemes. No device identification information is needed to be embedded in the transmitted sequence. As such, the overhead will be reduced, contributing to improved efficiency. The study on URA is first reported in [17], in which Polyanskiy considered the scenario of a massive number of infrequent and uncoordinated devices and discussed a random coding existence bound in the Gaussian multiple-access channel (GMAC). Since the publication of [17], there have been many works devoted to approaching that bound [18, 19, 20, 21, 23, 24, 25, 26]. A low complexity coding scheme is investigated in [18]. Based on the combination of compute-and-forward and coding for a binary adder channel, it exhibits an improved performance compared with the traditional schemes, such as slotted-ALOHA and treating interference as noise (TIN). However, the size of the codebook increases exponentially with the blocklength, resulting in difficulty in achieving that underlying bound. To mitigate this issue, a slotted transmission framework is proposed in [19], referred to as the coded compressed sensing (CCS) scheme. This cascaded system includes inner and outer codes. The outer tree encoder first splits the data into several slots with parity bits added. The CS coding is then employed within each slot to pick codewords from the codebook. The blocklength, as well as the size of the codebook in each slot, are greatly reduced, thus leading to a relaxation of the computational burden. On the receiver side, the inner CS-based decoder is first utilized to recover the slot-wise transmitted messages within each slot. The outer tree decoder then stitches the decoded messages across different slots according to the prearranged parity. This structure is inherited by the later works in [20, 21], where the authors exploit the concept of sparse regression code (SPARC) [22] to conduct the inner encoding and decode it with the AMP algorithm. Some other coding schemes for URA are also reported in [23, 24, 25, 26]. The polar coding schemes based on TIN and successive interference cancellation (SIC) are investigated in [23, 24]. In [25, 26], the author consider a hierarchical framework, where the device’s data is split into two parts. A portion of the data is encoded by a common CS codebook and recovered by the CS techniques, while the rest is encoded by the low-density parity check code (LDPC) [27] with the key parameters conveyed in the former part. Besides the above works considering the GMAC, there are also works in the fading channel [28, 29, 30].
Besides the above works considering a single receive antenna at the BS, the study of massive URA in multiple-input multiple-output (MIMO) systems has also drawn increasing attention. The BS equipped with multiple antennas provides extra dimensions for the received signal, thus offering more opportunity for signal detection and access of a massive number of devices. A coordinated-wise descend activity detection (AD) algorithm is proposed in [31, 32], which finds the large-scale fading coefficients (LSFCs) of all the devices (coordinates) iteratively. The authors adopt a concatenated coding scheme with the aforementioned tree code as the outer code, and a non-Bayesian method (i.e., maximum likelihood (ML) detection) is leveraged as the inner decoder based on the covariance of the received signal, referred to as the covariance-based ML (CB-ML) algorithm. However, the performance of the CB-ML algorithm degrades dramatically when the number of antennas is less than that of the active devices. There are also some improvements to this algorithm in terms of complexity or accuracy [33, 34]. The slotted transmission framework proposed in [33] eliminates the need for concatenated coding. That is, no parity bit is added within each slot and the slot-wise messages can be stitched together by clustering the estimated channels. However, the channels in [33] are assumed to be identically distributed over all the slots, which is difficult to hold in practice. Besides, the collision in codewords (more than one device chooses the same codeword) will lead to a superimposition of the estimated channels, resulting in a failure of the stitching process. Currently, the design of an efficient collision resolution scheme in URA remains missing. In [34], a more efficient coordinate selection policy is developed based on the multi-armed bandit approaches, leading to a faster convergence than the CB-ML algorithm. Nevertheless, these slotted transmission frameworks, such as CB-ML and its variants, all map a piece of data within each slot to a long transmitted codeword based on the CS coding, resulting in low efficiency. In this regard, the algorithmic design for the MIMO massive URA with high efficiency and accuracy remains missing.
I-B Challenges
In this paper, we investigate a two-phase transmission scheme for MIMO massive URA, where the device’s transmitted data is split into two phases with CS and LDPC coded, respectively. In this framework, no parity bits are needed to be embedded in the CS phase, and the data is encoded linearly in the LDPC phase instead of being mapped to a long codeword. As such, it exhibits higher efficiency and lower latency than the aforementioned slotted transmission scheme. The existing schemes considering this framework all focus on the single-antenna case. For instance, Polar coding [24] and LDPC coding schemes [25, 26] consider the GMAC with perfect channel state information (CSI) at the BS. In this regard, the above channel coding schemes can obtain satisfying performance. However, such an assumption cannot be established under the MIMO case. Besides, because of the massive connectivity and sporadic traffic of devices, the positions of active devices in the estimated equations are not determined. Consequently, conventional linear receivers, such as zero-forcing (ZF), are not applicable. Moreover, compared with the fading channel models [28, 29, 30] where the channel of each device is a scalar, in MIMO, the channel is a vector, and elements among antennas share the same activity. Therefore, elements in the channel vector should be estimated jointly rather than separately, of which the distribution is formulated as a multi-dimensional Bernoulli-Gaussian distribution in this paper. In this regard, the conventional estimators, such as the minimum mean square error (MMSE) estimation or the maximum a posteriori (MAP) estimation, are hard to carry out straightforwardly. Specifically, it is computationally intractable to obtain a precise posterior distribution, since it involves marginalizing a joint distribution of the activity and channel with high dimensions.
Another challenge for the proposed scheme in the MIMO case is activity detection. We note that whether in the GMAC [24, 25, 26] or fading channel [28, 29, 30] in the single-antenna case, the device activity can be directly detected. For instance, since the device’s channel is a scalar in the fading channel, it can be simply determined to be active when the estimated channel is non-zero or larger than a given threshold. However, it will be much involved in MIMO because there are multiple observations of the activity in the estimated channel vector. The existing works, such as [9], make a hard decision based on the energy of the channel and [33] considers the LLR at each antenna separately and sums them to obtain the final decision. However, the threshold for the decision is hard to obtain in practice and the distribution of the channel is not utilized in [9]. Although [33] considers the channel distribution and gives a closed-form expression for activity detection, the nature that channels at each antenna share the same activity is not considered.
Besides, the LDPC code is efficient but sensitive to the CE results. Therefore, the overall performance is limited by the accuracy of CE. Moreover, with the presence of collision in URA, if more than one device chooses the same codeword in the CS phase, the corresponding channels will be superimposed and thus the subsequent LDPC decoding process will fail.
I-C Contributions
To cope with the arising issues, based on the message passing (MP) algorithm, we propose the Joint DAD-CE algorithm to conduct the task of joint activity detection and channel estimate in the CS phase, and MIMO-LDPC-SIC Decoding algorithm for data decoding embedded in the LDPC phase. Moreover, to further improve the performance, we propose the Joint DAD-CE-DD algorithm to jointly update the messages in these two phases by utilizing the belief of each other. Finally, we propose a collision resolution protocol to address the collision in URA. The key and distinguishing features of the proposed algorithms are listed below.
-
•
Based on the principle of the BP algorithm, we develop a low-complexity iterative MP algorithm to decode the two parts of data. For the CS phase, we investigate the Joint DAD-CE algorithm to recover part of the data embedded in the device activities, the interleaving patterns, and channel coefficients, which are the key parameters for the remaining data. Specifically, we derive a close-form expression for DAD by utilizing the joint distribution of the channel among antennas. Combined with SIC and in the spirit of interleave-division multiple access (IDMA) [35], we elaborate on the MIMO-LDPC-SIC Decoding algorithm to decode the remaining data embedded in the LDPC phase. In addition to complexity reduction, the proposed algorithm exhibits a substantial performance enhancement in terms of accuracy and efficiency compared to the state-of-the-art CB-ML algorithm.
-
•
Thanks to the consistency of the MP algorithm, we propose the Joint DAD-CE-DD algorithm to further improve the performance. The proposed algorithm suggests a paradigm connecting the two parts. That is, messages in the decoding process of CS and LDPC parts can be jointly updated by utilizing the belief of each other, thus leading to improved performance. We employ the correctly decoded codewords as soft pilots to conduct CE jointly with the codewords in the CS phase, which contributes to improved accuracy of the estimated channel. Combined with the SIC method, the accuracy of the residual signal can be improved, leading to the enhanced decoding performance.
-
•
Under the current framework based on the common codebook, a collision happens if there are more than one device having the same preamble, which leads to a superimposition of the estimated channels. Accordingly, the superimposed channel will cause a failure in the LDPC decoding process. To this end, we propose a collision resolution protocol based on the energy detection (ED) and sliding window protocol (SWP). Succinctly, the ED is performed on the estimated channel of each device to find out the superimposition. Then, the BS broadcasts the indexes of the superimposed channels to all devices. Afterwards, the devices in collision slide the window in the data sequence and the CS coding is again performed for retransmission.
The rest of the paper is organized as follows. In Section II, we introduce the system model for MIMO massive URA . In Section III, we implement the two-phase encoding scheme and the collision resolution protocol is developed in Section IV. Then, we elaborate on the low-complexity iterative decoding algorithm based on BP and explain the joint update algorithm in Section V. After verifying the numerical results and analyzing the complexity in VI, we conclude the paper in Section VII.
I-D Notations
Unless otherwise noted, lower- and upper-case bold fonts, and , are used to denote vectors and matrices, respectively; the -th entry of is denoted as ; denotes the -th row of ; denotes the conjugate of a number; and denote transpose and conjugate transpose of a matrix, respectively; and denote the statistical expectation and variance, respectively; means that the random vector follows a complex Gaussian distribution with mean and auto-covariance matrix ; denotes the factorial; denotes the set of integers between and ; denotes the entries in set except ; and denote the real and imaginary parts of a complex number, respectively; denotes ceiling; is the imaginary unit (i.e., ).
II System Model
Consider the uplink of a single-cell cellular network consisting of single-antenna devices, which are being served by a base station (BS) equipped with antennas. This paper assumes sporadic device activity, i.e, a small number, of devices are active within a coherence time. Each device has bits of information to be coded and transmitted into a block-fading channel with channel uses. Let denote device ’s binary message and is some one-to-one encoding function. Typically, in URA scenario, the implementation of is to select the corresponding codeword from a shared codebook according to [31, 20, 32]. The corresponding received signal can be written as
| (1) |
where is the device activity indicator, which is modeled as a Bernoulli random variable and defined as follows:
| (2) |
is the channel vector of device and is the additive white Gaussian noise (AWGN) matrix distributed as . In line with the state-of-the-art setting [32], we assume for simplicity and fair comparison that are i.i.d., i.e., independent of each other and uncorrelated among antennas. Specifically, the Rayleigh fading model is considered in this paper, where and denotes the Rayleigh fading component, and denotes LSFC. We would like to mention that more realistic channel models in MIMO or massive MIMO have been discussed and well investigated, such as the spatially correlated fading channel [9, 36, 37, 38, 39]. Due to the limited angular spread, the channel in the virtual angular domain exhibits a sparsity among antennas. As such, the data of devices is not directly superimposed but staggered on different antennas, and the multi-user interference can be further reduced, contributing to improved performance. Nevertheless, for the sake of consistency with the benchmarks [4, 32] and isolating the fundamental aspects of the problem without additional model complication, we embark throughout this paper on the study of i.i.d. Rayleigh fading channel. The study on the spatially correlated channel is remarkable and left for future work.
The BS’s task is to produce a list of transmitted messages without identifying from whom they are sent, thereby leading to the so-called URA. The performance of a URA system is evaluated by the probability of missed detection and false alarm, denoted by and , respectively, which are given by:
| (3) | ||||
| (4) |
In this system, the code rate and the spectral efficiency . Let denote the power (per symbol) of each device, then the energy-per-bit is defined by
| (5) |
III Encoder
As aforementioned, the existing slotted transmission scheme exhibits low efficiency by the CS coding. To mitigate this issue, a two-phases coding scheme is proposed in [26, 25], which considers the -user Gaussian multiple access (GMAC) channel and also URA scenario. We extend this work to the MIMO system and refer to it as the CS-LDPC coding scheme. Similarly, the hierarchical form of the encoding process is considered in this paper. The bits of information are first divided into two parts, namely, and bits with . Typically, one would want . The former information bits are coded by a CS-based encoder to pick codeword from the common codebook. Based on the codebook, the BS is tasked to recover part of the messages, the number of active devices, channel coefficients as well as interleaving patterns for the latter part. The remaining bits are coded with LDPC codes. For clarity, we denote the former and latter encoding processes as CS and LDPC phases, respectively. Correspondingly, the total channel uses are split into two segments of lengths and , respectively, with . Since only a small fraction of data is CS coded and the rest is LDPC coded, the efficiency in our scheme is higher than those purely CS-coded schemes [33, 19, 20, 32]. The key features of this encoding process are summarized in Fig. 1. We elaborate on these two encoding phases below.

III-A CS Phase
The URA fashion is considered in this phase. Let denote the common codebook shared by all the devices. That is, the columns of form a set of codewords with power constraint , from which each active device chooses in order to encode its bits of information. With a slight abuse of notation, let denote the first bits of device ’s binary message, i.e., . To apply the encoding scheme, we convert into the -norm binary vector , in which a single one is placed at the location . The value of binary sequence is obtained by regarding it as an integer expressed in radix- (plus one), which we write as . Then, the coded sequence is obtained by taking the transpose of the -th column of , which we denote by . This facilitates the CS architecture, which maps the information to an elementary vector , according to which the corresponding codeword is selected from a fixed codebook. The corresponding received signal can be written as
| (6) |
where is the device activity indicator, as defined in (2). The matrix form of (6) is given by
| (7) |
where is the common codebook shared by all devices. denotes the binary selection matrix. For each active device , the corresponding column is all-zero but a single one in position , while for all the corresponding column is all zeros. corresponds to the MIMO channel coefficient matrix. We note that the number of total devices plays no role in URA. In order to get rid of this variable, with slight abuse of notation we define the modified activity indicator and selection matrix as and , respectively, where is the -th entry of . Correspondingly, the modified channel is with . Hence, (7) can be written as
| (8) |
Let . The goal for the BS in the CS phase is to detect the non-zero positions of the selection matrix and the corresponding channel vectors by recovering based on the noisy observation . Since is row sparse, i.e., many are zero, such reconstruction problem can be modeled as the CS problem [4]. Once is recovered, the message indicators of active devices are also recovered. Moreover, acts as the parameter of the LDPC code, since it determines the interleaving pattern of the data in the LDPC phase. Considering the fact that the bits of message carries key parameters for the latter phase, we name it the preamble. We note that it is different from the preamble in the traditional grant-free scenario, which is a pure pilot with no data embedded.
III-B LDPC Phase
Likewise, let denote the remaining information bits of device . is first encoded into an LDPC code , which is determined by the LDPC parity check matrix with size . We note that in the decoding process, if is a valid codeword, then . is then modulated to . We adopt a sparse spreading scheme introduced in [25]. That is, is zero-padded into a length vector
| (9) |
We then employ the index representation to permute the ordering of . This is implemented by a random interleaver with interleaving pattern . As mentioned in [26], the purpose for permuting the codewords is to decorrelate the random access interference from other devices. This is similar to the IDMA scheme since the interleaving patterns for most of the devices are different because of the distinctive indices . Hence, is finally encoded to . Appending it to the coded message in the CS phase yields the final codeword :
| (10) |
The received signal including both the CS and LDPC phases is given by
| (11) |
where is assumed to follow independent quasi-static flat fading within the above two phases in this paper. The goal for the BS is to recover based on the received signal and the channel estimated in the CS phase. We emphasize again that the BS only produces the transmitted messages without distinguishing the corresponding devices.
This hierarchical encoding process appears to be similar to the work of [26], where CS and channel coding techniques are utilized to encode the messages. However, unlike in [26] considering the GMAC system, our approach is in the MIMO channel. Hence, in addition to recovering the parameters of LDPC codes conveyed by the codebook as in [26], the BS is also tasked to estimate the channel coefficients. Besides, as we will see shortly in Section V-C, a belief propagation decoder draws a connection between the CS and LDPC phases. That is, messages in the CE as well as DD processes can be jointly updated by utilizing the belief of each other. Whereas the two phases in [26] are two independent modules and work sequentially.
IV Collision Resolution Protocol
It is possible that two or more devices have the same preamble message, , which, although, may occur in a small probability. In this case, the collided devices will have the same interleaving pattern in the LDPC phase, which goes against the principles of the IDMA scheme. Moreover, they will choose the same codeword as their coded messages in the CS phase, which results in the received signal in the CS phase being
| (12) |
where and denote the set of collided indexes and collided devices corresponding to the message index , respectively. In this regard, the BS can only recover the superimposed channels of these devices, instead of their own, which will lead to the failure of the LDPC decoding process. Although collision may occur in a small probability, it can occur. However, the design of an efficient collision resolution scheme in URA remains missing.


In this paper, we develop a collision resolution protocol based on the ED and SWP. We note that in real scenarios, the near-far effects can be well solved with the existing power control schemes [40, 41, 42]. In this regard, a flat fading channel is considered in this paper. That is, the LSFCs for all the devices are assumed to be identical, as also considered in [31, 32]. As mentioned above, if a collision happens, the recovered channels of the collided devices will be a superposition of their own, that is
| (13) |
where denotes the Gaussian noise. And is distributed as , which has a higher power than those without collision. Therefore, an effective way to detect collision is to perform ED on the estimated channel by the BS
| (14) |
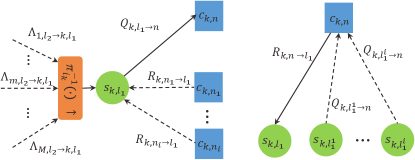
If is greater than a given threshold , then it is utilized as evidence that there are at least two devices that have the same preamble and thus they choose the same CS codeword . Since devices themselves do not know whether they have been in a collision, the BS needs to feed this information back. To this end, the BS will broadcast the collided index representations to all the devices to help them get the judgment. Fig. 2a showcases that device to realized that a conflict occurred after receiving the indexes broadcast by the BS. We note that in the above process, the additional information required at the BS is only the threshold and it can be easily preset in practice.
As illustrated in Fig. 2b, in order to get a new non-conflicting index representation, the collided devices will slide the window with length bits forward within the total bits to get new sequences, denoted by . We denote as the sliding length which satisfies . The reason behind is that there should be a common part, labeled in green in Fig. 2b, between the sequences before and after sliding the window, so as to splice back the sequences between different windows.
After obtaining , the CS-based encoder is again performed to encode to with . The encoding process is the same as that in III-A. Channels of the collided devices are expected to be recovered separately after the retransmission. The ED will be again performed on the recovered channels. If the collision still exists, the window sliding process will be executed again until the maximum number of retransmission is reached or no collision exists. The above collision resolution protocol is summarized in Algorithm 1. We give the analysis for this collision resolution protocol in Appendix -A, which illustrates that as the window sliding progresses, the number of collided devices will decrease and tend to zero.
V Decoder
The decoding process can be distilled into two key operations: the recovery of the preamble as well as the key parameters for the LDPC code, and the LDPC decoding process combined with SIC [43]. Both are carried out with the MP algorithm. We emphasize again that the beliefs of these two parts can be leveraged to jointly update the messages of the decoding process, which is not considered in [25, 26].
V-A Joint DAD-CE Algorithm
The recovery of the preamble as well as the channels in the CS phase is equivalent to the joint DAD-CE problem, which can be modeled as a CS problem. According to the formulation in (8), the recovery of the sparse matrix can be addressed by the CS-based methods, such as the AMP algorithm and its variants [8, 4, 9, 10, 11]. Besides, the MP-based approaches [13, 14] also work well on the above issues. The Bernoulli and Rician messages are jointly updated in [13], which considers the fading channel and grant-free scenario. This scenario is also considered in [14], which takes advantage of estimated data symbols as soft pilot sequences to perform joint channel and data estimation. In this subsection, we consider the MIMO system and derive the update rules of messages based on the BP algorithm.
We derive the update rules of the activity indicator and channel vector in (6), which are modeled as Bernoulli and Gaussian messages, respectively. The Gaussian messages can be characterized by the estimation of mean-value and auto-covariance matrix . That is, and are the estimation and estimating deviation of in (6), respectively. Besides, the Bernoulli messages for the activity indicator can be represented by , which is the probability of taking the value one. These messages are updated iteratively between the observation and variable nodes, which can be characterized by the factor graph in Fig. 3, where the received signal represents the observation node, denoted by SN, and channel and the activity pattern are the variable nodes, denoted by VN. The edges in the factor graph represent the connections among nodes. In the BP algorithm, messages are passed along these edges. We elaborate on the update rules of these messages below.

V-A1 Message Update at Observation Nodes
We denote as the Bernoulli message for the activity of device , which is passed from VN to SN in the -th iteration. Accordingly, and denote the Gaussian messages passed from VN to SN , which represent the estimation and the estimating deviation of the channel , respectively. The index denotes the -th antenna and also the -th value of . Since the update rules of the messages are the same with respect to different iterations, the index of iteration is omitted in the following derivation. For clarity, we assume there is no collision in the CS phase for the following derivation. As such, , the original subscript of is replaced by , since there is a one-to-one mapping between these two terms. We emphasize that the collision is considered in our implementation and addressed by the proposed resolution protocol in Algorithm 1.
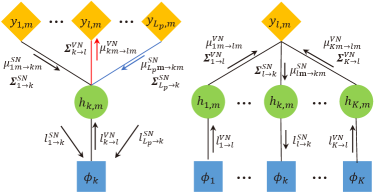
where is in and denotes the entries in set except . The term is modeled as an equivalent Gaussian noise with , where and is given by
| (16) |
For , the auto-covariance of , since is the same for antennas, resulting in the correlation among antennas, we should not consider the variance of at each antenna separately. Instead, the covariance of is considered in this paper. Rewrite (15) in a vector form:
| (17) | ||||
The -th entry for satisfies
| (18) | ||||
where denotes the probability that the Bernoulli variable equals to zero. If , we have
| (19) | ||||
Details about the derivation of are given in Appendix -B1. After obtaining the mean and covariance of , we can get the Gaussian messages and passed from SN to VN as below
| (20) | ||||
| (21) | ||||
where and denote the expectation and variance of conditioned on , respectively.
For the Bernoulli message passed for SN to VN , we have
| (22) | ||||
where
| (23) | ||||
| (24) |
which denote the mean-value and covariance of when , respectively. And denotes the probability density function (pdf) of the multi-dimensional complex Gaussian distribution , that is
| (25) |
Moreover, the Bernoulli message can be simplified by the use of log-likelihood ratio (LLR) to reduce the complexity as well as to avoid the computation overflow. Hence, the LLR of the message in (22) can be represented as
| (26) | ||||
V-A2 Message Update at Variable Nodes
Likewise, the Gaussian and Bernoulli messages at VNs are updated by collecting the incoming messages from SNs. To ensure convergence, messages from the VN’s own are not included in the calculation [12]. Typically, for the Gaussian messages, since follows the Gaussian distribution, the update rule at the VN is to multiply the pdfs observed at each SN to obtain a new one. We note that the prior Gaussian distribution of is also included in the multiplication. The new pdf still follows the Gaussian distribution, of which the mean and covariance are the updated messages at the VN. The pdf of passed from VN to SN is given by
| (27) | ||||
Accordingly, for the Gaussian pdf , the mean and covariance are give by
| (28) | ||||
| (29) | ||||
where and are the prior mean and covariance of , denotes the entries in set except . We give the derivations of (28) and (29) in Appendix -B2.
The derivation of the Bernoulli messages is the same as above, which is updated by collecting the messages observed at SNs. For passed for VN to SN , it is obtained by multiplying the probability of passed from all the SNs to VN and then normalizing. Likewise, for convergence, the message passed from SN to VN is not included. We emphasize that the prior activation probability of each device is also considered. As such, is given by
| (30) | ||||
Likewise, for complexity reduction, we also employ the LLR to represent this message in iterations, of which the relationship with the activation probability is
| (31) | ||||
where is the prior LLR of the probability for the device being active.
V-A3 DAD Decision and CE Output
Since the messages above are iteratively updated between SNs and VNs, after reaching the maximum number of iterations, the Bernoulli and Gaussian messages will have an output at VNs. For the Gaussian messages, similar to the above update rules, the output is obtained by combining all the incoming messages from SNs, i.e,
| (32) | ||||
| (33) | ||||
which denote the output estimation and estimating deviation of , respectively. For the Bernoulli messages, the LLR of the DAD decision is
| (34) |
Device ’s activity is detected as if and vice versa. The term in (34) is to improve the DAD accuracy by exploiting the CE result [13], which is derived as follows. The estimated channel can be modeled as , where is the complex Gaussian noise distributed as . Accordingly, the distribution of with respect to value of is
| (35) |
Therefore, this information can be leveraged to give an extra belief to the DAD decision. Similar to (22), is given by
| (36) | ||||
As aforementioned, we derive the LLR expression by utilizing the joint distribution of the channel among antennas. Finally, we obtain the estimated channel of device as
| (37) |

The above joint DAD-CE algorithm is summarized in Algorithm 2, where denotes the maximum number of iterations. We note that and both go to diagonal matrices over the iteration in our numerical verification. Hence, the corresponding matrix inverse operations can be simplified to the divisions to reduce the complexity with little performance loss. As shown in Fig. 5, Simplified denotes the approximation by treating and as diagonal matrices and Original means there is no approximation in Algorithm 2. We use normalized mean square error (NMSE) for the evaluation of the CE performance. Fig. 5 illustrates that this approximation introduces little performance loss, which, although, has greatly reduced the complexity as aforementioned.

V-B MIMO-LDPC-SIC Decoder
After obtaining the key parameters, such as interleaving patterns and channels by the joint DAD-CE algorithm, the LDPC decoding problem can be addressed by the standard BP algorithm [12, 44]. Likewise, the DD process is performed by updating messages iteratively at different nodes. Differently, since the LDPC is a forward error correction code, besides the observation and variable nodes, the check nodes (CNs) are considered in the factor graph to provide an extra belief, as shown in Fig. 6. We rewrite the received signal in the LDPC phase as
| (38) |
where is the last rows of . The LDPC decoder is tasked to recover the last bits of information based on the received signal , estimated interleaving patterns and channels using the low-complexity iterative BP algorithm. Owing to the two-phase encoding scheme, these key parameters can be recovered in the decoding of the CS phase. We emphasize that once the active indicators are recovered, the positions of in the selection matrix , i.e., , are determined. Thereby, the interleaving patterns of active devices are also recovered. As shown in (38), the zero-padded sequences are subject to different permutations, and each is determined by the interleaving pattern . Therefore, the effect of these permutations needs to be considered when the messages are being sent to and from the VNs, i.e., interleaving and de-interleaving in Fig. 6, respectively.
The connections among nodes in Fig. 6 appear to be more involved than those of Fig. 3. In the upper part of Fig. 6, the CNs (blue color) and VNs (green color) as well as the edges connecting them constitute the Tanner graph in LDPC. The subscript denotes the number of CNs in the LDPC code, which corresponds to the number of rows of the LDPC check matrix. denotes the number of active devices estimated in the CS phase. Other subscripts are consistent with the aforementioned. The edges between CNs and VNs are described by the LDPC check matrix, which cannot be marked explicitly in the graph. For example, in the check matrix of device , if the entry , there will be an edge between SN and VN .

The lower part of Fig. 6 refers to the graph for MIMO detection, of which the edges between VNs and SNs (yellow color) are simply determined by (38) though looking complicated. For example, the VN is connected to the -th SN from all antennas (i.e., ). We note that is not necessarily equal to in the presence of zero-padding and interleaving. Correspondingly, the VNs connected to SN depend on whose data is interleaved to the -th channel use. For instance, as illustrated in Fig. 7, the set of VNs connected to SN is . That is, after zero-padding and interleaving, the fifth, fourth, and second bits of devices , , and are mapped to the third channel use, respectively. Before conducting the MP algorithm, we define the types of messages as follows.
-
•
: Messages passed from CN to VN .
-
•
: Messages passed from VN to CN .
-
•
: Messages passed from VN to SN .
-
•
: Messages passed from SN to VN .
The massages and refer to the parity check constraints in the LDPC code, while and are related to the received signals in the MIMO system.
We first give the MP rules for the LDPC decoding with BPSK modulation, which is known as the sum-product algorithm. As illustrated in Fig. 8, the messages and are iteratively updated between CNs and VNs. Likewise, for the reduction of complexity, we give the updating rules in the LLR form.
| (39) | ||||
| (40) |
where denotes the set of CNs connected to except , i.e., in Fig. 8. Likewise, denotes the set of VNs connected to except , i.e., in Fig. 8.
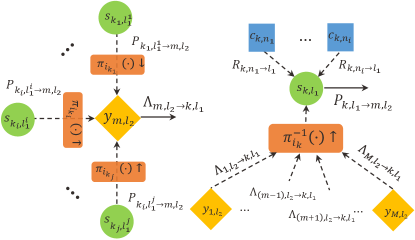
The message in (39) is the LLR with the probability of VN taking different values observed at SN . For BPSK modulated system, it is given by
| (41) | ||||
where is the channel matrix, which can be estimated in the CS phase. We note that similar to the joint DAD-CE algorithm, (41) is also obtained by treating the interference from other devices as noise. We rewrite (38) as
| (42) | ||||
where is the Gaussian noise with zero mean and variance , and denote the set of devices as well as the corresponding bits related with SN , respectively. Accordingly, the set of related VNs is and we note that the subscripts and are one-to-one mappings. For instance, Fig. 7 showcases the VNs related with SN . In this regard, and and the corresponding VNs are . The Gaussian noise and the interference from other devices are all treated as noise denoted by , which is a Gaussian variable with mean and variance given by
| (43) | ||||
| (44) |
And for BPSK modulation, the mean and variance of is given by
| (45) | ||||
| (46) |
where denotes the probability of VN , and is initialized to . We note that it needs to be interleaved before the calculation. As shown in Fig. 9, is updated by collecting the incoming messages from CNs related with VN and those from all SNs except . We give the update rule as below.
| (47) |
where
| (48) |
Similar to (39), the message needs to be de-interleaved in the update of . The LLR of VN at the end of an iteration is given by
| (49) |
The information bit is decoded as one if and zero otherwise. Since LDPC codes are described by the parity matrix , the iteratively decoding process is continued till or the maximum number of iterations is reached.
To further improve the spectrum efficiency, the QPSK modulation is also considered in this coding system, of which the constellation set is . Briefly, QPSK modulated signals can be split into two orthogonal BPSK ones. As such, we can implement the above MP algorithm on these two signals separately. Additionally, the real and imaginary parts of the messages and need to be considered separately, so does the parity of subscript in and . It is worth noting that the range of in and is half of that in and , i.e., , since there are both messages on the real and imaginary parts. In what follows we give the updated rules of these messages.
Similar to (41), is the LLR of the probability that takes different values in . However, it is no longer a real number. Instead, it is given by
| (50) |
where the mean and variance of are given in (43) and (44), respectively. And for QPSK modulation, the mean and variance of is given by
| (51) | ||||
| (52) |
where and are the real and imaginary parts of , respectively. Similar to (47) and (48), and are given by
| (53) | ||||
| (54) |
As such, the range of subscript in is half of that in as aforementioned. and are defined in (48). The update rule for message is the same as (40) and that for is given by
| (55) |
The LLR of VN at the end of an iteration is given by
| (56) |
The decision rule and termination condition are the same as those in the BPSK system mentioned earlier. Finally, we obtain the decoded messages.
Note that the estimated number of active devices is not guaranteed to be equal to . Therefore, not all the decoded messages satisfy the parity check. We denote and as the set of successfully decoded messages and the corresponding devices, respectively. And we have . To further improve the performance, we combine the MIMO-LDPC decoder with the SIC method and we denote it as the MIMO-LDPC-SIC algorithm, which works as follows.
Let and denote the channel matrix and the set of active devices estimated in the CS phase. Let and respectively denote the sets of correctly decoded messages (i.e., those that satisfy the check) and the corresponding devices obtained by the decoder, which are initialized to empty sets. With , interleaving patterns and , the decoder outputs the set of successfully decoded messages and the corresponding devices . Then we have , and for . The residual signal is updated by
| (57) |
where is the -th codeword in after modulation and zero-padding. The updated and as well as the interleaving patterns are sent to the MIMO-LDPC decoder for the next round of decoding. This iterative process ends when or . The overall decoding algorithm is summarized in Algorithm 3.
We note that the stitching of the messages in the CS and LDPC phases is easy. In URA, devices are not identified, as such, the IDs can not be employed to distinguish the messages. We have known that the interleaving patterns and channels obtained in the CS phase acting as key parameters participate in the decoding process in the LDPC phase. For each decoded message in , it is decoded with a specific interleaving pattern as well as the channel . As aforementioned, is uniquely determined by the message index representation , which directly corresponds to device ’ preamble. Therefore, and establish a connection of devices’ messages in the two phases. Briefly, if is successfully decoded with the participation of and , it is exactly the latter bits of message of device . As such, the stitching of the messages in two phases will not be a problem.
V-C Joint Update
The above CS and LDPC decoders can recover the bits of information with their work in tandem. Besides, thanks to the consistency of the above MP algorithm, the BP-based decoder can draw a connection of the decoding process in the CS and LDPC phases. That is, messages in the CE as well as the MIMO-LDPC decoding processes can be jointly updated by utilizing the belief of each other, thus leading to improved performance. This joint update algorithm is denoted as joint DAD-CE-DD algorithm and elaborated as follows.
For the successfully decoded devices , the corresponding messages can be leveraged as soft pilot sequences joint with their codewords in the CS phase to carry out a second CE. This longer pilot sequence will lead to a better CE performance, which has been confirmed in our simulation in Fig. 15. We note that the subsequent CE is conducted via the above joint DAD-CE algorithm with devices’ activity fixed. In this regard, the Gaussian messages in (20)-(21) and (28)-(29) are iteratively updated with a longer observation sequence . Besides, it is worth noting that in the CE output in (32)-(33), the prior mean and covariance are no longer zero and , respectively. Instead, they are the output estimation and estimating deviation of in the first CE, respectively.
Remark 1: We remark that messages in the MP algorithm exhibit the property of consistency and unity. As such, messages among different parts can always be jointly processed and updated. For instance, recalling the Joint DAD-CE algorithm, where the Bernoulli messages are updated by utilizing the Gaussian messages. Likewise, in the MIMO-LDPC-SIC Decoding algorithm, the MP algorithm can be applied to MIMO detection or LDPC decoding. In the proposed algorithm, we combine these two parts and update the underlying messages jointly, i.e., the LLR message of the symbol in MIMO detection can be involved in the LDPC decoding process, and vice versa. Moreover, the property is again exploited in the Joint DAD-CE-DD algorithm. By leveraging the belief of the estimated channel and the correctness of the LDPC codewords, the CE can be again performed aided with the correctly decoded codewords in the LDPC phase, thus connecting these two phases. Throughout the paper, we take into consideration the idea of the joint update for the messages in MP-based algorithms.
One might argue that for the correctly decoded messages, improving the accuracy of the corresponding channels will not bring substantial performance improvements. Nevertheless, according to the SIC method in (57), by improving the channel accuracy of those devices whose messages are successfully decoded, the residual signal of the incorrectly decoded messages can be obtained more accurately. We denote the residual signal with improved accuracy as . Consequently, will improve the performance for those messages that have not been successfully decoded yet. And this is the reason why the channel needs to be estimated twice or more times. We give a brief diagram for this algorithm in Fig. 10, where denotes the noisy signal reconstructed from the correctly decoded messages.

We note this data-aided CE algorithm appears to be similar to the work in [14], which employs the data as soft pilots to conduct CE jointly with the real pilot sequences. However, the convergence and correctness of the estimated data cannot be verified, which may result in the propagation of errors and failure of the joint data and channel estimation. Whereas the convergence of the proposed algorithm can be guaranteed. The proposed Joint DAD-CE-DD algorithm consists of two modules, namely, the Joint DAD-CE algorithm for activity detection and channel estimation, and the MIMO-LDPC-SIC Decoding algorithm for data decoding. Messages are passed between these two modules. For arbitrary channel estimation results as input, the decoding process will be executed by the MIMO-LDPC-SIC Decoding algorithm. Once a codeword is successfully decoded (i.e., satisfies the check), it will not be changed in subsequent iterations. Therefore, the number of correctly decoded codewords is monotonically non-decreasing at each iteration. Correspondingly, the error rate is monotonically non-increasing, and also, it is bounded below by zero. According to the well-known monotone convergence theorem [45], the proposed algorithm is guaranteed to converge. Besides, with the correctly decoded codewords aided to estimate the channel, an improved CE accuracy can be guaranteed and it contributes to a higher probability of successfully decoding for those who have not yet. This iterative algorithm ends when no more messages are correctly decoded or all the messages are decoded successfully, which is summarized in Algorithm 4.
V-D Complexity
In this section, we compare the complexity of the proposed algorithm with the existing alternative in terms of the real-number multiplication (or division), addition (or subtraction), and other operations (eg., exp, log, tan, ), as shown in Table I. As a divide-and-conquer strategy, there are inner and outer decoders in the CB-ML algorithm, referred to as ML and tree decoder, respectively. The complexity of our algorithm is mainly incurred by the Joint DAD-CE algorithm and MIMO-LDPC decoder. In Table I, the parameters and satisfy that , respectively. We note that the complexity of the tree decoder is defined by the total number of parity check constraints that need to be verified [19], and this is obtained in the regime that and tend to infinity. Nevertheless, in practice, it increases exponentially with the number of slots . Besides, the tree code in [32] verifies the estimated codewords in each segment successively, and the check and estimate are performed separately. While during the LDPC decoding process in our algorithm, the check and estimate of the codeword are performed jointly and simultaneously, both by calculating the soft messages. Once the codeword is estimated, the corresponding check is completed. As for the inner code, the complexity of the ML decoder is nearly the same order as that of our algorithm. However, as a consequence of the coordinate descent algorithm, there are cycles in the ML decoding per iteration, which can only be computed successively. On the contrary, as a remarkable property of the MP algorithm, all computations in our algorithm can be decomposed into many local ones, which can be performed in parallel over the factor graph. Hence, our algorithm has lower time complexity. In general, the proposed algorithm exhibits a complexity linear with , which is lower than the existing CB-ML algorithm.
| Algorithms | Real Multi. / Div. | Real Add. / Sub. | Others | ||
| CB-ML | ML decoder | ||||
| Tree decoder | |||||
| Joint DAD-CE-DD | Joint DAD-CE | exp / log: | |||
| MIMO-LDPC | exp: , tanh / : | ||||
|
|||||
VI Numerical Results
VI-A Parameter Settings
In this section, we assess the overall performance of the proposed framework with the metric defined in (3)-(4). The CB-ML proposed by Fengler et. al. in [32] serves as the baseline in this paper. For the sake of fair comparison to the benchmarks, and isolating the fundamental aspects of the problem without additional model complication, we consider the flat path loss model in the simulation, i.e., the channel is i.i.d. Rayleigh fading model and the LSFC is fixed to in all schemes. We note again that this can be achieved by the well-studied power control schemes [40, 41, 42] in practice. As such, the carrier frequency is not specified in the simulation, since it can be arbitrary and does not affect the performance of the proposed algorithm, when considering flat path loss model. The user distribution is considered to be uniformly distributed in the cell. The noise variance is set to and is known to all schemes. The maximum scheduling times for the collision resolution protocol is . For the joint DAD-CE algorithm, MIMO-LDPC-SIC decoder, and Joint DAD-CE-DD algorithm, the maximum number of iterations is set to , , and , respectively. We fix the message length to with and . The length of the CS codeword is in both schemes. In the channel coding part, we employ the -regular LDPC code [27] with the rate . In our scheme, the length of channel use varies with the number of zeros padded in the sequence. However, it is discretely valued in the CB-ML scheme and changes with the number of slots denoted as . Since the length of the information is fixed, we can change by adjusting the parity check allocation, which is given in Table II according to the principle in [19]. We note that the slot length aligns with .
| Parity Check Allocation | |
|---|---|
| 12 | (12,0), (3,9), (9,3), , (9,3), (0,12) |
| 13 | (12,0), (4,8), (8,4), , (0,12) |
| 14 | (12,0), (7,5), (7,5), , (7,5), (0,12) |
| 15 | (12,0), (7,5), (7,5), , (7,5), (0,12), (0,12) |
| 16 | (12,0), (6,6), (6,6), , (6,6), (0,12) |
| 17 | (12,0), (6,6), (6,6), , (6,6), (0,12), (0,12) |
VI-B Results


We first evaluate the error rate performance of the proposed schemes compared with the CB-ML scheme as a function of the code rate. The relationship between the code rate and channel use is . In Fig. 11, we fix the energy-per-bit dB, the number of antennas and active devices and , respectively. In our schemes, No-colli-avoid refers to the scheme that there is no collision avoidance or the joint update. That is, the CS and LDPC phases work sequentially and potential collision may exist in the CS phase. For the other three schemes, the collision resolution protocol has been implemented and No-SIC denotes that the SIC method is not utilized in the LDPC phase nor do the two phases work jointly. Joint-BPSK and Joint-QPSK refer to the joint update algorithm with the SIC method in BPSK and QPSK modulations, respectively. As illustrated in Fig. 11, there is a substantial performance enhancement compared to the CB-ML algorithm. The main reason is that the employed LDPC code has a higher code rate than the tree code proposed in [19]. As such, the proposed algorithm can work well in a relatively high rate region while the CB-ML algorithm can not. Once we set a high rate, there will be a substantial performance enhancement. However, this improvement decreases with the decrease of rate. For the target error rate , the required code rate of the proposed Joint-BPSK is increased by times that of CB-ML, while the Joint-QPSK increases even more. For instance, the proposed Joint-QPSK and Joint-BPSK outperform CB-ML with a nearly dB gap and a dB gap at , respectively. Additionally, we note that Joint-QPSK exhibits an overall dB performance gain compared with Joint-BPSK in terms of the error rate. This is because only half of the channel use is needed for the QPSK than BPSK modulation and thus more zeros can be padded into the sequence. Consequently, the interference of devices in the QPSK system is further reduced, resulting in improved performance. Altogether, the gain of the collision resolution protocol increases with the decrease of the code rate. However, there is no much gain for the work of joint update. This is because the gain mainly comes from the reduction of interference of devices, which has been reduced to a relatively low level by the zero-padding. As such, the joint update cannot provide more gains. Nevertheless, as we will see shortly, there is a certain gain by the joint update under a higher interference scenario.
For the sake of complexity reduction, we employ BPSK modulation instead of QPSK in the subsequent simulations since both of them have already outperformed CB-ML. In Fig. 12, we compare the error rate performance of the proposed algorithms with respect to , the number of antennas and active devices , respectively. The number of channel uses is fixed to . Correspondingly, the data is split into slots in the CB-ML algorithm, of which the parity check allocation is given in Table. II. The other parameters are set as dB, and . As illustrated in Fig. 12, the state-of-the-art method CB-ML suffers from high error floors, which stems from the poor parity check constraints. In contrast, with collision resolution, the proposed Joint and No-SIC schemes exhibit water-falling curves in terms of the error rate with respect to and , while they gradually stabilize with respect to . This is because the interference of devices cannot be reduced to infinitesimal by increasing . As such, error still exits even for a large .

Moreover, we evaluate the performance of the proposed Joint-DAD-CE-DD algorithm under a large-scale antenna with respect to different channel uses. As showcased in Fig. 13, the performance of the proposed algorithm is almost linear with the antennas, but with different slopes under different channel uses. We note that CB-ML cannot work at , while the Joint-DAD-CE-DD algorithm can achieve when . Besides, the proposed algorithm only needs half of the channel uses, i.e., to outperform CB-ML when . To sum up, the proposed algorithms outperform CB-ML in terms of error rate and spectral efficiency, with an explicit gain with respect to various variables.

In order to provide more insights about the performance gain of different methods, we compare the error rate and CE performance among the methods in terms of . In this regard, we fix the channel use to with BPSK modulation and no zero is padded, resulting in the increase of interference among devices. Besides, the code rate , which is relatively high and the CB-ML cannot work under this circumstance. In Fig. 14, No-Joint refers to the scheme with the SIC method but no joint update. Firstly, it is obvious that the collision resolution-based schemes all outperform the No-colli-avoid scheme with the increase of . Then, the performance gain of the SIC method in the LDPC phase is about dB or even more when increases according to the comparison of No-SIC and No-Joint. Finally, by the comparison of No-Joint and Joint, there is also about dB gain coming from the work of joint update and it decreases with the increase of . At a higher , such as dB, there is nearly no performance gain by the joint update. This demonstrates that under a higher interference level of devices, the joint update algorithm can provide a certain gain, which gradually decreases with the increase of .

The NMSE is employed to evaluate the CE performance. In Fig. 15, the AMP algorithm investigated in [4] is utilized as a baseline for comparison. When ranges from to dB, the performance of Joint and No-Joint is of slight difference and both are slightly worse than AMP. However, the Joint scheme outperforms AMP with an ultra-linear speed when exceeds dB. As aforementioned, this gain exactly comes from the Joint-DAD-CE-DD algorithm, where the real pilot sequences as well as correctly decoded messages jointly conduct the task of CE. Figs. 14 and 15 demonstrate that the joint update indeed contributes to the improved accuracy of both the DD and CE. In general, the proposed algorithms provide substantial performance enhancements compared with CB-ML in terms of efficiency and accuracy.
VII Conclusion
In this paper, we have investigated a joint DAD, CE, and DD algorithm for MIMO massive URA. Different from the state-of-the-art slotted transmission scheme, the data in the proposed framework has been split into only two parts. A portion of the data is coded by CS and the rest is LDPC coded. Based on the principle of the BP, the iterative MP algorithm has been utilized to decode these two parts of data. Moreover, by exploiting the concept of the belief within each part, a joint decoding framework has been proposed to further improve the performance. Additionally, based on the ED and SWP, a collision resolution protocol has been developed to resolve the codeword collision issue in the URA system. In addition to the complexity reduction, the proposed algorithm has exhibited a substantial performance enhancement compared to the state-of-the-art in terms of efficiency and accuracy. The possible avenues for future work are various. More realistic channel models can be taken into consideration for MIMO URA. By utilizing the sparsity in the virtual angular domain of the spatially correlated channel, the multi-user interference can be further reduced. In addition, the proposed algorithm can be extended to handle more practical scenarios in the presence of asynchronization and frequency offset. Moreover, although this paper only studies LDPC codes, other codes, such as Turbo codes and Polar codes, could be applied if iterative soft decodings with superior performance exist in a desired block length.
-A Analysis of the Collision Resolution Protocol
Let denote the vector composed of diagonal elements of and . is the modified selection matrix defined in (8). Then we have , which is drawn independently from the signal space
| (58) |
according to the multinomial probability mass function :
| (59) |
for . Then the probability of no collision among devices equals the probability that entries in are one and the others are zero, which is given by
| (60) | ||||
-A1 The first window sliding
The number of devices in collision is
| (61) |
Let and denote the numbers of collided messages in the first bits and collided devices with each message, respectively, which satisfies .

For the -th collided message, the probability of no collision in the sliding part is
| (62) |
where . Besides, the common part is for devices to splice back the messages among different windows. If the common parts of different collided messages are the same, the message of one device will be spliced to the other’s. As such, an error occurs. Therefore, this probability should also be taken into consideration. The probability that the common parts of different messages are different is
| (63) |
where . refers to the probability of no collision after sliding once, while represents the probability that messages of one device cross windows can be spliced back successfully after sliding and retransmission. However, there may still be collision after sliding once, which requires another round.
-A2 The second window sliding
For the -th collided message, the number of devices in collision after sliding once is
| (64) |
Without loss of generality, we consider the -th collided message in the first sliding. Likewise, let and denote the numbers of collided messages and the corresponding devices after the first sliding, respectively, which satisfies .

For the sliding part, the probability of no collision is
| (65) |
Note that in the common part, if there are identical sequences among messages, there will not be an error. What needs to be considered is whether the sequences among messages are the same or not. Thus, the probability of no collision in the common part is
| (66) |
Here we denote as the permutations, i.e., . It is obvious that since . However, the relationship between and is unknown. As such, the relationship between and is also unknown. Fortunately, since , we have , which demonstrates that as the window sliding progresses, the probability of devices in a collision will decrease.
-A3 The -th window sliding
In order to draw a general conclusion, we extend the above derivation to the -th () window sliding. Similarly, we denote and as the numbers collided messages and corresponding devices after the -th sliding, respectively, which satisfies . As such, the probability of no collision after the -th sliding is given by
| (67) |
where And the number of collided devices after the the -th sliding is
| (68) |
Obviously, we have
| (69) |
Consequently, the probability of no collision satisfies
| (70) |
In this regard, we further have
| (71) | ||||
which demonstrates that as the sliding times goes to infinity, the number of collided devices will eventually approach zero.
Although the collision probability of the common part does not show an obvious trend of decreasing, in practice, we can reduce the collision probability by controlling the length of the window. There is a compromise between the collision probability of common and sliding parts. A longer sliding length will result in a lower collision probability in the sliding part, but at the same time, it will also increase that of the common part. Since the collision probability of the sliding part will eventually approach zero, the sliding length can be shorter in practice to minimize the collision probability of the common part.
-B Derivation of the Gaussian and Bernoulli Messages in V-A
-B1 Derivation of at SNs
According to the formulation in (17), since the activity and channel among different devices are both independent from each other, the -th entry for is given by
| (72) | ||||
where
| (73) | ||||
Then we can rewrite (72) as
| (74) | ||||
where denotes the probability that the Bernoulli variable equals zero. Therefore, the covariance of is not diagonal. If , we have
| (75) | ||||
This completes the derivation.
-B2 Derivation of Gaussian Messages at VNs
We give the derivations of (28) and (29) here. Rewrite the multivariate complex Gaussian pdf in (25) to canonical notation as
| (76) |
where
| (77) | ||||
Therefore, the product of Gaussian pdfs is
| (78) | ||||
where
| (79) |
We make a simple substitution as below
| (80) | ||||
Then we can rewrite (78) as
| (81) | ||||
where is a constant for normalization. Since the Gaussian pdfs are independent, the product of which still follows the Gaussian distribution. Comparing with (77) and (78), the covariance and mean of the Gaussian distribution in (81) are
| (82) | ||||
Similarly, in (27), it is the product of Gaussian pdfs and . According to the rule in (82), we can obtain (28) and (29).
References
- [1] Y. Liu, S. Zhang, X. Mu, Z. Ding, R. Schober, N. Al-Dhahir, E. Hossain, and X. Shen, “Evolution of NOMA toward next generation multiple access (NGMA),” Aug. 2021. Online Available: arXiv:2108.04561.
- [2] L. Liu, E. G. Larsson, W. Yu, P. Popovski, C. Stefanovic, and E. de Carvalho, “Sparse signal processing for grant-free massive connectivity: A future paradigm for random access protocols in the internet of things,” IEEE Signal Process. Mag., vol. 35, no. 5, pp. 88-99, Sept. 2018.
- [3] X. Chen, D. W. K. Ng, W. Yu, E. G. Larsson, N. Al-Dhahir, and R. Schober, “Massive access for 5G and beyond,” IEEE J. Sel. Areas Commun., vol. 39, no. 3, pp. 615-637, March 2021.
- [4] L. Liu and W. Yu, “Massive connectivity with massive MIMO—Part I: Device activity detection and channel estimation,” IEEE Trans. Signal Process., vol. 66, no. 11, pp. 2933–2946, June 2018.
- [5] Y. Wu, X. Gao, S. Zhou, W. Yang, Y. Polyanskiy, and G. Caire, “Massive access for future wireless communication systems,” IEEE Wireless Commun., vol. 27, no. 4, pp. 148-156, Aug. 2020.
- [6] V. Shyianov, F. Bellili, A. Mezghani, and E. Hossain, “Massive unsourced random access based on uncoupled compressive sensing: Another blessing of massive MIMO,” IEEE J. Sel. Areas Commun., vol. 39, no. 3, pp. 820-834, Mar. 2021.
- [7] J. Gao, Y. Wu, Y. Wang, W. Zhang, and F. Wei, “Uplink transmission design for crowded correlated cell-free massive MIMO-OFDM systems,” Sci. China Inf. Sci., vol. 64, no. 8, pp. 182309:1–182309:16, Aug. 2021.
- [8] D. L. Donoho, A. Maleki, and A. Montanari, “Message-passing algorithms for compressed sensing,” Proc. Nat. Acad. Sci., vol. 106, no. 45, pp. 18 914–18 919, Nov. 2009.
- [9] M. Ke, Z. Gao, Y. Wu, X. Gao, and R. Schober, “Compressive sensing-based adaptive active user detection and channel estimation: Massive access meets massive MIMO,” IEEE Trans. Signal Process., vol. 68, pp. 764-779, Jan. 2020.
- [10] J. Ma and L. Ping, “Orthogonal AMP,” IEEE Access, vol. 5, pp. 2020-2033, Jan. 2017.
- [11] S. Rangan, “Generalized approximate message passing for estimation with random linear mixing,” in Proc. IEEE Int. Symp. Inform. Theory (ISIT), St. Petersburg, Russia, Aug. 2011, pp. 2168-2172.
- [12] J. S. Yedidia, W. T. Freeman, and Y. Weiss, “Understanding belief propagation and its generalizations,” Mitsubishi Tech. Rep. TR2001-022, Jan. 2002.
- [13] Z. Zhang, Y. Li, C. Huang, Q. Guo, L. Liu, C, Yuen, and Y. L. Guan, “User activity detection and channel estimation for grant-free random access in LEO satellite-enabled internet of things,” IEEE Internet Things J., vol. 7, no. 9, pp. 8811-8825, Sept. 2020.
- [14] H. Iimori, T. Takahashim, K. Ishibashi, G. T. F. de Abreu, and W. Yu, “Grant-free access via bilinear inference for cell-free MIMO with low-coherent pilots,” to appear in IEEE Trans. Wireless Commun.. Online Available: arXiv:2009.12863v1.
- [15] S. Jiang, X. Yuan, X. Wang, C. Xu, and W. Yu, “Joint user identification, channel estimation, and signal detection for grant-free NOMA,” IEEE Wireless Commun., vol. 19, no. 10, pp. 6960-6976, Oct. 2020.
- [16] C. Huang, L. Liu, C. Yuen, and S. Sun, “Iterative channel estimation using LSE and sparse message passing for mmWave MIMO systems,” IEEE Trans. Signal Process., vol. 67, no. 1, pp. 245-259, Jan. 2019.
- [17] Y. Polyanskiy, “A perspective on massive random-access,” in Proc. IEEE Int. Symp. Inform. Theory (ISIT), Aachen, Germany, June 2017, pp. 2523–2527.
- [18] O. Ordentlich and Y. Polyanskiy, “Low complexity schemes for the random access Gaussian channel,” in Proc. IEEE Int. Symp. Inf. Theory (ISIT), Aachen, Germany, June 2017, pp. 2528-2532.
- [19] V. K. Amalladinne, J. -F. Chamberland, and K. R. Narayanan, “A coded compressed sensing scheme for unsourced multiple access,” IEEE Trans. Inf. Theory, vol. 66, no. 10, pp. 6509-6533, Oct. 2020.
- [20] A. Fengler, P. Jung, and G. Caire, “SPARCs and AMP for unsourced random access,” in Proc. IEEE Int. Symp. Inf. Theory (ISIT), Paris, France, July 2019, pp. 2843-2847 .
- [21] A. Fengler, P. Jung, and G. Caire, “SPARCs for unsourced random access,” to appear in IEEE Trans. Inf. Theory. Online Available: https://arxiv.org/abs/1901.06234.
- [22] A. Joseph and A. R. Barron, “Least squares superposition codes of moderate dictionary size are reliable at rates up to capacity,” IEEE Trans. Inf. Theory, vol. 58, no. 5, pp. 2541–2557, Jan. 2012.
- [23] A. K. Pradhan, V. K. Amalladinne, K. R. Narayanan, and J. Chamberland, “Polar coding and random spreading for unsourced multiple access,” in Proc. IEEE Int. Conf. Commun. (ICC), Dublin, Ireland, June 2020, pp. 1-6.
- [24] M. Zheng, Y. Wu, and W. Zhang, “Polar coding and sparse spreading for massive unsourced random access,” in Proc. IEEE Veh. Technol. Conf. (VTC-Fall), Victoria, BC, Canada, Nov. 2020, pp. 1-5.
- [25] A. Pradhan, V. Amalladinne, A. Vem, K. R. Narayanan, and J. -F. Chamberland, “A joint graph based coding scheme for the unsourced random access Gaussian channel,” in Proc. IEEE Glob. Commun. Conf. (GLOBECOM), Waikoloa, HI, USA, Dec. 2019, pp. 1-6.
- [26] A. Vem, K. R. Narayanan, J. Chamberland, and J. Cheng, “A user-independent successive interference cancellation based coding scheme for the unsourced random access Gaussian channel,” IEEE Trans. Commun., vol. 67, no. 12, pp. 8258-8272, Dec. 2019.
- [27] R. Gallager, “Low-density parity-check codes,” IRE Trans. Inf. Theory, vol. 8, no. 1, pp. 21-28, Jan. 1962.
- [28] S. S. Kowshik, K. Andreev, A. Frolov, and Y. Polyanskiy, “Short-packet low-power coded access for massive MAC,” in Proc. Asilomar Conf. Signals Syst. Comput. (ACSSC), Pacific Grove, CA, USA, Nov. 2019, pp. 827-832.
- [29] S. S. Kowshik, K. Andreev, A. Frolov, and Y. Polyanskiy, “Energy efficient random access for the quasi-static fading MAC,” in Proc. IEEE Int. Symp. Inf. Theory (ISIT), Paris, France, 2019, July 2019, pp. 2768-2772.
- [30] S. S. Kowshik, K. Andreev, A. Frolov, and Y. Polyanskiy, “Energy efficient coded random access for the wireless uplink,” IEEE Trans. Commun., vol. 68, no. 8, pp. 4694-4708, Aug. 2020.
- [31] S. Haghighatshoar, P. Jung, and G. Caire, “Improved scaling law for activity detection in massive MIMO systems,” in Proc. IEEE Int. Symp. Inf. Theory (ISIT), Vail, CO, USA, Jun. 2018, pp. 381–385.
- [32] A. Fengler, S. Haghighatshoar, P. Jung, and G. Caire, “Non-Bayesian activity detection, large-scale fading coefficient estimation, and unsourced random access with a massive MIMO receiver,” IEEE Trans. Inf. Theory, vol. 67, no. 5, pp. 2925-2951, May 2021.
- [33] V. Shyianov, F. Bellili, A. Mezghani, and E. Hossain, “Massive unsourced random access based on uncoupled compressive sensing: Another blessing of massive MIMO,” IEEE J. Sel. Areas Commun., vol. 39, no. 3, pp. 820-834, Mar. 2021.
- [34] J. Dong, J. Zhang, Y. Shi, and J. H. Wang, “Faster activity and data detection in massive random access: A multi-armed bandit approach,” Jan. 2020. Online Available: arXiv:2001.10237v1.
- [35] L. Ping, L. Liu, K. Wu, and W. K. Leung, “Interleave division multiple access,” IEEE Trans. Wireless Commun., vol. 5, no. 4, pp. 938–947, Apr. 2006.
- [36] L. Sanguinetti, E. Björnson, and J. Hoydis, “Toward massive MIMO 2.0: Understanding spatial correlation, interference suppression, and pilot contamination,” IEEE Trans. Commun., vol. 68, no. 1, pp. 232-257, Jan. 2020.
- [37] Z. Gao, L. Dai, Z. Wang, and S. Chen, “Spatially common sparsity based adaptive channel estimation and feedback for FDD massive MIMO,” IEEE Trans. Signal Process., vol. 63, no. 23, pp. 6169-6183, Dec.1, 2015.
- [38] L. You, X. Gao, X.-G. Xia, N. Ma, and Y. Peng, “Pilot reuse for massive MIMO transmission over spatially correlated Rayleigh fading channels,” IEEE Trans. Wireless Commun., vol. 14, no. 6, pp. 3352-3366, June 2015.
- [39] X. Xie and Y. Wu, “Unsourced random access with a massive MIMO receiver: Exploiting angular domain sparsity,” in Proc. IEEE/CIC Int. Conf. Commun. China (ICCC), Xiamen, China, 2021, pp. 741-745.
- [40] V. Chandrasekhar, J. G. Andrews, T. Muharemovic, Z. Shen, and A. Gatherer, “Power control in two-tier femtocell networks,” IEEE Trans. Wireless Commun., vol. 8, no. 8, pp. 4316-4328, Aug. 2009.
- [41] P. Patel and J. Holtzman, “Analysis of a simple successive interference cancellation scheme in a DS/CDMA system,” IEEE J. Sel. Areas Commun., vol. 12, no. 5, pp. 796-807, June 1994.
- [42] G. Turin, “The effects of multipath and fading on the performance of direct-sequence CDMA systems,” IEEE J. Sel. Areas Commun., vol. 2, no. 4, pp. 597-603, July 1984.
- [43] T. Li, Y. Wu, M. Zheng, D. Wang, and W. Zhang, “SPARC-LDPC coding for MIMO massive unsourced random access,” in Proc. IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, Dec. 2020, pp. 1-6.
- [44] T. L. Narasimhan, A. Chockalingam, and B. S. Rajan, “Factor graph based joint detection/decoding for LDPC coded large-MIMO systems,” in Proc. IEEE Veh. Technol. Conf. (VTC-Spring), Yokohama, Japan, May 2012, pp. 1-5.
- [45] J. Bibby, “Axiomatisations of the average and a further generalisation of monotonic sequences”, Glas. Math. J., vol. 15, no. 1, pp. 63–65, 1974.