20A Datun Road, Chaoyang District, Beijing 100012,People’s Republic of China 22institutetext: College of Astronomy and Space Sciences, University of Chinese Academy of Sciences, Beijing 100049, China 33institutetext: Department of Astronomy, Beijing Normal University, Beijing 100875, People’s Republic of China 44institutetext: Department of Physics, Lancaster University, Lancaster LA1 4YB, UK 55institutetext: PPGFis & Núcleo de Astrofísica e Cosmologia (Cosmo-ufes), Universidade Federal do Espírito Santo, 29075-910 Vitória, ES, Brazil 66institutetext: Departamento de Astrofísica, Universidad de La Laguna (ULL), E-38206 La Laguna, Tenerife, Spain 77institutetext: Consejo Superior de Investigaciones Científicas (CSIC), E-28006 Madrid, Spain 88institutetext: Consejo Superior de Investigaciones Científicas (CSIC), E-28006 Madrid, Spain Centro de Estudios de Física del Cosmos de Aragón (CEFCA), Unidad Asociada al CSIC, Plaza San Juan 1, 44001 Teruel, Spain 99institutetext: Instituto de Astronomia, Geofísica e Ciências Atmosféricas, Universidade de São Paulo, 05508-090 São Paulo, Brazil 1010institutetext: Observatório Nacional - MCTI (ON), Rua Gal. José Cristino 77, São Cristóvão, 20921-400 Rio de Janeiro, Brazil 1111institutetext: Donostia International Physics Centre (DIPC), Paseo Manuel de Lardizabal 4, 20018 Donostia-San Sebastián, Spain 1212institutetext: IKERBASQUE, Basque Foundation for Science, 48013, Bilbao, Spain 1313institutetext: University of Michigan, Department of Astronomy, 1085 South University Ave., Ann Arbor, MI 48109, USA 1414institutetext: University of Alabama, Department of Physics and Astronomy, Gallalee Hall, Tuscaloosa, AL 35401, USA 1515institutetext: Instituto de Astrofísica de Canarias, La Laguna, 38205, Tenerife, Spain
J-PLUS: Support vector machine applied to STAR-GALAXY-QSO classification
Abstract
Context. In modern astronomy, machine learning has proved to be efficient and effective in mining big data from the newest telescopes.
Aims. In this study, we construct a supervised machine-learning algorithm to classify the objects in the Javalambre Photometric Local Universe Survey first data release (J-PLUS DR1).
Methods. The sample set is featured with 12-waveband photometry and labeled with spectrum-based catalogs, including Sloan Digital Sky Survey (SDSS) spectroscopic data, the Large Sky Area Multi-Object Fiber Spectroscopic Telescope (LAMOST), and VERONCAT - the Veron Catalog of Quasars & AGN (VV13). The performance of the classifier is presented with the applications of blind test validations based on RAdial Velocity Extension (RAVE), the Kepler Input Catalog (KIC), the 2 MASS (the Two Micron All Sky Survey) Redshift Survey (2MRS), and the UV-bright Quasar Survey (UVQS). A new algorithm was applied to constrain the potential extrapolation that could decrease the performance of the machine-learning classifier.
Results. The accuracies of the classifier are 96.5% in the blind test and 97.0% in training cross-validation. The -scores for each class are presented to show the balance between the precision and the recall of the classifier. We also discuss different methods to constrain the potential extrapolation.
Key Words.:
methods: data analysis – techniques: spectroscopic - astronomical databases: miscellaneous1 Introduction
Developments in computer science and the technological applications have changed the ways of data processing and knowledge management. Especially, as a growing realm of technology, machine learning has gained worldwide popularity due to its powerful ability to manage large amounts of data. Machine-learning algorithms can reveal potential patterns and physical meanings that are otherwise indistinguishable by traditional methods. Furthermore, machine learning enables us to construct the structure of each observed quantity and to reveal its manner of working.
In modern astronomy, the newest telescopes now produce large amounts of unprocessed data. The Javalambre Photometric Local Universe Survey (J-PLUS, Cenarro et al. 2019) is designed to observe several thousand square degrees in the optical bands. It has been designed to observe more than 13 million objects with the Javalambre Auxiliary Survey Telescope (JAST80) at the Sierra de Javalambre in Spain, and to enhance knowledge from the Solar System to cosmology 111http://j-plus.es/survey/science, such as the Coma cluster (Jiménez-Teja et al. 2019), low-metallicity stars (Whitten et al. 2019), and galaxy formation (Nogueira-Cavalcante et al. 2019).
The current classification of sources detected by J-PLUS is morphological, this is to say it aims to distinguish between point-like and extended sources (Cenarro et al. 2019; López-Sanjuan et al. 2019). It is therefore not able to differentiate stars from quasi-stellar objects (QSOs), and it does not include valuable color information from the 12 optical J-PLUS bands. This paper presents the spectrum-based classification for the J-PLUS first data release (DR1) with machine-learning algorithms. The input catalog is a modified version of the J-PLUS data set which has been recalibrated by Yuan (2021). This version includes 13,265,168 objects with magnitudes obtained with 12 different filters (Sect. 2.1). From Sect. 2.2 to 2.4, we label the data set as STAR, GALAXY, and QSO based on the spectroscopy surveys, including the Sloan Digital Sky Survey (SDSS), the Large Sky Area Multi-Object Fiber Spectroscopy Telescope (LAMOST), and VERONCAT - the Veron Catalog of Quasars & AGN (VV13).
Several machine-learning algorithms have been applied for the classification (Sect. 3), including the Support Vector Machine (SVM,Cortes & Vapnik 1995), linear discrimination, the -nearest neighbor (NN,Cover & Hart 1967; Stone 1977), Bayesian, and decision trees (Quinlan 1986). In the pretraining, we adopted the algorithm with the highest accuracy (Sect. 3.1). In Sect. 3.2, we present the processes to test the parameters of the algorithms and to train the classifier. We also provide the blind test and a new method to constrain potential extrapolation (Sect. 3.3) in our prediction.
We present our result in Sect. 4, including our result catalogs (Sect. 4.1), considerations about ambiguous objects from the classification probabilities (Sect. 4.2), and a comparison between the J-PLUS parameter (Sect. 4.3). In Sect. 5, we discuss different methods to constrain the extrapolation. The classifier is compared with other published classifiers, and the difference is analyzed in detail (Sect. 5.2). Section 5.3 gives an outlook of the Javalambre Physics of the Accelerating Universe Astrophysical Survey (J-PAS, Benítez et al. 2014; Bonoli et al. 2021) and our future work.
2 Data
The rapid advance in telescopes and detectors has led to a significant data explosion in modern astronomy. New technologies help us accelerate information acquisition from the huge datasets. Several studies have focused on developing classifiers, and they have proved that spectral-based methods are more reliable than those only based on photometric data (Bai et al. 2018; Ball et al. 2006).
| Catalog | STAR | GALAXY | QSO | Total |
| SDSS DR16 | 45,350 | 68,381 | 44,745 | 158,476 |
| SDSS APOGEE | 13,749 | 0 | 0 | 13,749 |
| LAMOST DR7 | 299,907 | 16,004 | 4,758 | 345,975 |
| LAMOST A-, F-, G- and K- type stars | 212,114 | 0 | 0 | 212,114 |
| LAMOST A- stars | 5,145 | 0 | 0 | 5,145 |
| LAMOST M- stars | 25,604 | 0 | 0 | 25,604 |
| VV13 | 0 | 0 | 4,744 | 4,744 |
2.1 J-PLUS
J-PLUS333www.j-plus.es is being conducted from the Observatorio Astrofísico de Javalambre (OAJ, Teruel, Spain; Cenarro et al. 2014) using the 83 cm JAST80 and T80Cam, a panoramic camera of 9.2k 9.2k pixels that provides a field of view (FoV) with a pixel scale of 0.55 arcsec pix-1 (Marín-Franch et al. 2015). The J-PLUS filter system is composed of 12 passbands, including five broad and seven medium bands from 3000 to 9000 Å. The J-PLUS observational strategy, image reduction, and main scientific goals are presented in Cenarro et al. (2019). J-PLUS DR1 covers a sky area of 1,022 , and the limiting magnitudes are in the range . For different kinds of objects, the magnitudes of these bands exhibit different distributions 444http://j-plus.es/datareleases/data_release_dr1, and such a difference gives us a theoretical foundation for object classification.
Compared to other catalogs, the J-PLUS catalog is an ideal data set for classification owing to its characteristic of both large amounts and multiple wavebands. Multiple bands could provide more information for a single object. In machine learning, these 12-band magnitudes lead to a more expanding training instance space and a smoother training structure. We adopted the band magnitudes as training features, which are , , , , , , , , , , , and . We name them mag1 through to mag12.
Recently, Yuan (2021) recalibrated the J-PLUS catalog and increased the accuracy of photometric calibration by using the method of stellar color regression (SCR), similar to the method in Yuan et al. (2015). The catalog in Yuan (2021) contains 13,265,168 objects, including 4,126,928 objects with all 12 valid magnitudes.
2.2 SDSS
The observation of SDSS has covered one-third of the sky and yielded more than 3 million spectra. We explore the spectroscopy survey sets in data release 16 (DR16; Ahumada et al. 2020). With the help of SDSS Catalog Archive Server Jobs555http://skyserver.sdss.org/casjobs/, the objects with were chosen to label the J-PLUS data as “STAR”, “GALAXY”, and “QSO”.
The Apache Point Observatory Galactic Evolution Experiment (APOGEE) has observed more than 100,000 stars in the Milky Way, with reliable spectral information including stellar parameters and radial velocities (Zasowski et al. 2013). We adopted the APOGEE catalog to enlarge the training set.
We cross-matched the J-PLUS catalog with SDSS DR16 using Tool for OPerations on Catalogues And Tables (Topcat, Taylor 2005) 666http://www.star.bris.ac.uk/~mbt/topcat/ with a tolerance of one arcsec, and we obtained 45,350 stars, 68,381 galaxies, and 44,745 QSOs from the general catalog, as well as 13,749 stars from APOGEE. After cross-matching with other catalogs, APOGEE contributes 6,147 independent stars.
2.3 LAMOST
LAMOST (Cui et al. 2012; Luo et al. 2012; Zhao et al. 2012; guan Wang et al. 1996; Su & Cui 2004) is located at the Xinglong Observatory in China, which is able to observe 4,000 objects in simultaneously. LAMOST has many scientific projects, and two of them aim to understand the structure of the Milky Way (Deng et al. 2012) and external galaxies. The low-resolution spectra of LAMOST have a limiting magnitude of about mag in the band for a resolution R=500. Data release 7 (DR7) was adopted to label the sample. We also adopted information from stellar catalogs from DR7, including the A-, F-, G-, and K-type star catalog, as well as the A- and M-star catalogs.
The A-, F-, G-, and K-type star catalog has stars with a band signal-to-noise ratio higher than 6 in dark nights or 15 in bright nights. The A- and M-star catalogs contain all A and M stars from the pilot and general surveys. For overlapping stars, we followed the priority of the star catalogs and the general catalog.
In the LAMOST DR7 catalog, the cross-match yields 299,907 stars, 16,004 galaxies, and 4,758 QSOs. There are 212,114 matched stars in the A-, F-, G-, and K-type star catalog and 5,145 and 25,604 stars in the A- and M-star catalogs, respectively. Nearly all of the stars (except only one star) from the star catalogs are covered in the DR7 general catalog.

2.4 QSO catalog
Quasars in VV13 (VERONCAT - Veron Catalog of Quasars & AGN, the 13th edition) were also employed to enlarge our QSO samples. The catalog contains AGN objects with spectroscopic parameters (including redshift; Véron-Cetty & Véron 2010). The VV13 contains 4,744 QSOs after a one arcsec tolerance cross identification with J-PLUS, 4,593 QSOs are included in SDSS DR16, and 1,339 QSOs are in LAMOST DR7. The VV13 catalog provides 108 additional QSOs.
2.5 Sample construction
The machine-learning sample is made up of SDSS, LAMOST, and VV13 (Table 1, see more in Appendix C, and magnitude distributions are in Appendix B). There are 468,685 unique objects with 12 valid magnitudes, including 74,701 galaxies, 45,899 QSOs, and 348,085 stars. These 468,685 objects were all put in training with a 10-fold validation. The blind test set was carried out with 2,853 objects in other catalogs, see 3.3.2.
J-PLUS DR1 contains the stellar probability CLASS_STAR, estimated by SExtractor (Bertin & Arnouts 1996) with an artificial neural network (ANN). We present the comparison between the probability and the classification of the sample in Fig. 1. In our sample set, about 20% of the QSOs have a stellar probability of more than 95%, and more than 10% of the QSOs have a stellar probability of less than 5%. In the right panel, the CLASS_STAR roughly increases as the g-band magnitude becomes dimmer, because the stars in the sample set are brighter than galaxies (see Appendix B). The magnitude - CLASS_STAR relation is not significant for quasars.
3 Methodology
Machine learning has developed many algorithms that are able to deal with big data effectively. Three of them, that is to say decision trees, SVM, and -NN, are the most popular ones.
3.1 Pretraining
A pretraining process with 10-fold validation was adopted in order to determine which algorithm fits our problem best. The No-Free-Lunch theorem (Shalev-Shwartz & Ben-David 2014) tells us that a perfect learning algorithm that can fit every problem does not exist. In the pretraining, we considered the accuracy to be the most important factor of the training performance. The accuracies of the pretraining are shown in Table 2.
In the -NN algorithm, the label of each data point is defined by its neighborhood. By introducing a metric function, the algorithm can calculate the distance between every two objects. For each object, the nearest -objects are determined, and its label is defined. This process continues until the labels of all objects are stable. The -NN gives a reasonable result for a nonlinear or discrete training set, and it has good performance when extrapolating a prediction and separating for outliers. However, the -NN algorithm cannot present reliable results for unbalance data that are dominated by objects in one or two classes (Shalev-Shwartz & Ben-David 2014). This is one reason why we precluded the algorithm. In our test, we adopted a 10-NN algorithm with a Euclid norm, and no hyperparameters or weights were involved.
Decision tree is a nonparametric supervised learning method. The tree in the algorithm is built by the threshold calculated from the sample. For each node of a tree, a gain function defines the loss of the prediction (Quinlan 1986). If the loss function is low, the node is split. This procedure continues until all objects in the training set are labeled. The time cost of decision tree is low (Shalev-Shwartz & Ben-David 2014), but the gain function may lead to a bias or overfitting for the unbalanced data set. Random forest (RF, Breiman 2001) and bagging tree are enhanced decision tree algorithms that can decrease overfitting.
In our work, we tested three tree algorithms without hyperparameters. The decision tree algorithm is based on the Gini index (Quinlan 1986), and the maximum split is 100. The RF (Breiman 2001) algorithm also contains 30 learners and maximum splits to 468,684. The AdaBoost algorithm (Freund & Schapire 1995) contains 30 learners with a learning rate of 0.1, and it has a maximum split of 20.
For each model, we examined the accuracy and training time (Table 2), and the SVM algorithm provides the highest validation accuracy. Since the model accuracy is the primary factor in our consideration, we decided to adopt the SVM algorithm even if it needs a relatively long training time. The training time becomes significant in other situations, such as transient detection.
| Algorithm | Accuracy | Time Cost |
|---|---|---|
| Decision Tree | ||
| Linear Discrimination | ||
| Bayesian | ||
| SVM | ||
| NN | ||
| AdaBoost | ||
| Random Forest |
3.2 SVM
SVM is a binary classification method (see Cortes & Vapnik (1995) and Boser et al. (1992) for details). The theory of SVM is presented in Cristianini & Shawe-Taylor (2000) and Shalev-Shwartz & Ben-David (2014).
In brief, the SVM algorithm generates a super surface in the instance space by maximizing the margin. The margin is defined by the smallest distance between the object and the super surface. Given a super surface, the algorithm divides the instance space into two parts and labels the object in each part. The algorithm then compares each label with the sample and calculates the loss function. The margin is maximized when the loss function reaches its minimum. For our classification problem, there are 12 dimensions in the instance space.

SVM is a binary classification algorithm, while we are facing a multi-classification algorithm. The coding method can change a multi-classification problem into several binary classifications, such as one-versus-one coding and one-versus-all coding. For a -classification problem, one-versus-one coding finds all binary combinations of the labels. After making a democratic decision, the algorithm produces the predicted label. One-versus-one coding needs binary classifications to reach the aim. One-versus-all coding singly picks one label out and defines it as a positive class, and the rest of the labels are negative. After times binary classifications, the one-versuss-all coding presents the labels by democratic decision. One-versus-one coding has a higher accuracy in our classification.
The Gaussian kernel, also known as the radial basis function (RBF) kernel, is an important parameter in the SVM algorithm construction. It can accelerate the optimization of the margin in the SVM algorithm. In the Gaussian kernel, a kernel scale is an adjustable parameter that measures the distance to the half-space. A small kernel scale constrains the kernel function in low variation, and further parameterizes the margin exquisitely. The farther the data points are located from the margin, the less they weigh. In order to find the best kernel scale, we tested the scale from 0.5 to 1, with a step size of 0.05. For each kernel scale, we trained a classifier and calculated its accuracy. Finally, we conclude that 0.75 is the best kernel scale (Fig. 2).

The magnitude uncertainties in J-PLUS DR1 (Yuan 2021) depend on the observing condition and the photometric calibration. In our training process, we employed uncertainties as the training weight to describe the reliability of the data.
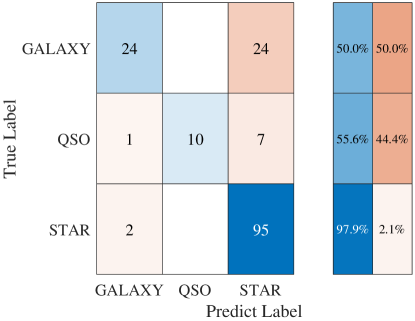
The confusion matrix is shown in Fig. 3. The total cross-validation accuracy is . The low accuracy of QSO may be due to its relatively small sample size.
3.3 Validation
Model validation has been designed to show the effectiveness and to avoid potential overfitting. Extrapolation is significant in model validation. It has been proved that the prediction accuracy might decrease when extrapolating outside the feature space region of training samples (Wang 2021). The other validating procedure is a blind test, which can reveal the potential overfitting of the classifier. Moreover, the appropriate training data size would be implied by comparing the training and blind test accuracy.
3.3.1 Extrapolation
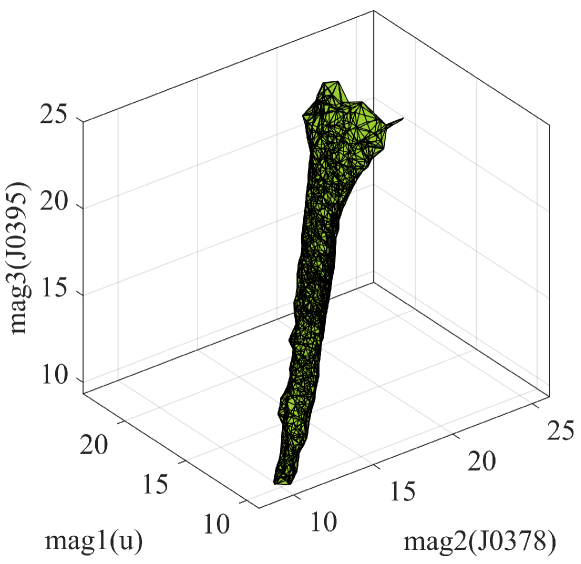
Applying any extrapolation may cause low accuracy due to the nonrepresentativeness between training data and predicting data (Wang 2021). Here, we use the density contour of the training sample to define the potential extrapolation. A dozen three-dimensional density contour surfaces were generated based on the distribution of training data. These surfaces were used as the boundary of the potential extrapolation. The magnitude combinations are (mag1, mag2, mag3), (mag2, mag3, mag4), … , and (mag12, mag1, mag2), and an example is shown in Fig. 4. We present all the contour surfaces in Appendix A. We then define the potential extrapolation with these 12 contour surfaces for the prediction. There are 3,496,867 () objects of J-PLUS DR1 located inside these contours.

3.3.2 Blind test
We applied a blind test to reveal the classifier’s validation and its potential overfitting of the training data. The blind test data set (Table 3) was built by stars from the RAdial Velocity Experiment (RAVE) and Kepler Input Catalog (KIC), galaxies from the 2 MASS (Two Micron All Sky Survey) Redshift Survey (2MRS) and QSOs from the UV-bright Quasar Survey (UVQS). The accuracy distribution and the confusion matrix of the blind test are shown in Fig. 5 and 6.
| Catalog | Interpolation | Extrapolation | Total |
|---|---|---|---|
| RAVE | 29 | 3 | 32 |
| KIC | 2,071 | 64 | 2,135 |
| 2MRS | 606 | 46 | 652 |
| UVQS | 16 | 18 | 34 |
| Total | 2,722 | 131 | 2,853 |
RAVE is a stellar survey that focuses on obtaining stellar radial velocities (Steinmetz et al. 2020). It provides precise spectroscopic parameters of stars. We obtained only 70 stars by cross-matching with J-PLUS with a one arcsec tolerance after removing the stars in the sample set. There are three stars suffering from potential extrapolating. The number of stars is too small to validate our algorithm, so the KIC catalog was adopted to enlarge the blind test set. The KIC catalog contains 2,135 stars of which 64 are extrapolations.
For galaxies in the blind test, we adopted the 2MRS catalog from Huchra et al. (2012). It is a redshift sky survey based on the 2 MASS database, including galaxies with high redshift. There are 652 galaxies and 46 extrapolating ones. These objects are independent of the sample set.
We used the UVQS catalog (Monroe et al. 2016) for QSO-blind testing and obtained 34 objects after cross-matching with J-PLUS. There are 18 objects that have fallen into the extrapolating region. UVQS contains UV bright QSOs, while the observation wavelength of VV13 is mainly in optical bands. This difference may cause a bias between training and testing, and further result in misclassifications.



The blind test set was constructed by the independent objects from the four catalogs. We then separated the testing data into the interpolation and extrapolation samples.
We also adopted some other parameters to describe the classifier: recall, precision, and -score. We first define true positives (TPs), false positives (FPs), and false negatives (FNs) to demonstrate these parameters. TP is the number that both the blind test labels and the predicted labels are positive. FP is the number that blind test labels are negative while the predicted labels are positive, FN is the number that blind test labels are positive, while the predicted labels are negative. Readers should recall that shows the fraction of right prediction for a label. Precision shows the fraction of right prediction, and shows the harmonic mean of the precision and the recall.
The total accuracy is for the interpolating sample (Fig. 5 and 6), and the parameters are shown in Table 4. We present the accuracy distribution corresponding to the magnitudes as well (Fig. 9). See more in Appendix B. The blind test indicates a high reliability of the classifier. For the rest of the sample, the total accuracy is 79.1% (Fig. 7 and 8), which is much lower than the interpolating sample, and the test parameters are shown in Table 5. This indicates that it is significant and effective to constrain extrapolation in prediction.
| Parameters | STAR | GALAXY | QSO |
|---|---|---|---|
| Recall | 99.4 | 88.5 | 76.9 |
| Precision | 96.1 | 97.7 | 1 |
| -score | 95.0 | 92.9 | 87.0 |
| Parameters | STAR | GALAXY | QSO |
|---|---|---|---|
| Recall | 99.0 | 61.0 | 68.3 |
| Precision | 83.3 | 90.4 | 1 |
| -score | 90.5 | 72.9 | 81.2 |


4 Results
4.1 Classification catalogs
The total number of objects in the J-PLUS data set is 13,265,168, and there are 4,126,928 objects with valid 12 magnitudes. We obtained a classifier using the 12-band magnitudes and their corresponding errors to classify objects into STAR, GALAXY, and QSO categories. The classifier was constructed with a SVM algorithm based on the data from J-PLUS, SDSS, LAMSOT, and VV13. We present a new classification catalog in Table 6. In order to avoid potential extrapolation, we set up 12 contours and there are 3,496,867 objects located inside.
| ID | R.A. | Dec | classstar | PredictClass | Probability |
|---|---|---|---|---|---|
| 26016-5 | 255.46835 | 22.76001 | 0.9990 | STAR | 92.96% |
| 26016-15 | 255.30506 | 22.76083 | 0.9990 | STAR | 99.91% |
| 26016-16 | 255.36753 | 22.76113 | 0.9990 | STAR | 99.20% |
| 26016-22 | 255.27928 | 22.76202 | 0.9536 | GALAXY | 79.71% |
| 26016-29 | 255.45243 | 22.76157 | 0.9814 | GALAXY | 76.31% |
| 26016-33 | 255.39194 | 22.76157 | 0.9780 | GALAXY | 93.95% |
| 26016-50 | 255.16394 | 22.76439 | 0.0460 | STAR | 64.35% |
| 26016-55 | 255.66306 | 22.76168 | 1.0000 | STAR | 99.49% |
| 26016-63 | 254.86508 | 22.76506 | 0.7656 | QSO | 86.82% |
| 26016-64 | 254.75625 | 22.76496 | 0.9663 | STAR | 84.58% |
We have 2,493,424 stars, 613,686 galaxies, and 389,757 QSOs. The average probability is for STAR, for GALAXY, and for QSO. We also present the color-color plot of these interpolating objects (Fig. 10, 11, and 12). In these plots, we chose mag6mag8 and mag8mag10 ( and ) to show the spread of interpolation objects. We also provide the magnitude distributions of each class in Appendix B. The objects suffering from potential extrapolation are shown in Table 7, including 223,924 stars, 239,616 galaxies, and 166,521 QSOs, which is a total of 630,061 objects.



| ID | RA | Dec | classstar | PredictClass | Probability |
|---|---|---|---|---|---|
| 26016-2 | 255.64129 | 22.75862 | 0.9213 | STAR | 58.49% |
| 26016-3 | 255.54013 | 22.75905 | 0.9345 | STAR | 60.68% |
| 26016-9 | 255.39760 | 22.76004 | 0.4218 | QSO | 64.53% |
| 26016-10 | 255.20027 | 22.76122 | 0.9497 | STAR | 64.68% |
| 26016-11 | 255.40765 | 22.76091 | 0.9711 | STAR | 54.15% |
| 26016-13 | 255.38474 | 22.76107 | 0.9604 | STAR | 96.74% |
| 26016-14 | 255.22779 | 22.76128 | 0.9975 | QSO | 89.82% |
| 26016-23 | 255.76778 | 22.76090 | 0.9379 | QSO | 95.45% |
| 26016-34 | 255.61690 | 22.76251 | 0.6918 | GALAXY | 46.79% |
| 26016-37 | 255.37846 | 22.76318 | 0.9785 | STAR | 95.16% |
4.2 Ambiguous objects
The classifier also presents the probabilities of three different classes, which enabled us to select ambiguous objects. The ambiguous objects show characteristics that are unlike any of the three classes. When one’s three-class probabilities are similar, it is selected as an ambiguous object. Table 8 shows different criteria and their corresponding object numbers. The criterion is the upper limit of the highest probability in three classes. We present 155 objects with three probabilities lower than 0.34 in Table 9.
In order to find the abnormal objects from the ambiguous samples, we calculated the Mahalanobis distance (De Maesschalck et al. 2000; Mahalanobis 1936). We then checked whether the objects were far from each label. The objects that have a higher distance to one label than the distance of this label to the other labels were treated as abnormal objects. These objects are not only located outside the region of three classes, but they are also far from all of them. The criteria of the Mahalanobis distance are as follows: 18.4 between STAR to GALAXY, 23.3 between GALAXY to QSO, and 50.3 between QSO to STAR. Table 10 presents 26 abnormal objects.
| ID | RA | Dec | classstar | PredictClass | GALAXY | QSO | STAR |
|---|---|---|---|---|---|---|---|
| 26016-20835 | 255.17392 | 23.50692 | 0.0008 | GALAXY | 33.50% | 32.81% | 33.68% |
| 26016-32840 | 255.67090 | 24.07627 | 0.5004 | STAR | 33.38% | 32.90% | 33.70% |
| 26015-6320 | 256.61032 | 23.07467 | 0.4304 | STAR | 32.54% | 33.51% | 33.94% |
| 26010-33609 | 257.27271 | 25.44612 | 0.0078 | GALAXY | 33.71% | 33.09% | 33.19% |
| 26012-8040 | 256.82760 | 25.80270 | 0.9121 | GALAXY | 33.95% | 32.38% | 33.65% |
| 26012-24063 | 256.34766 | 26.30697 | 0.4980 | GALAXY | 33.25% | 33.40% | 33.33% |
| 26028-3296 | 126.56224 | 29.97372 | 0.8632 | STAR | 32.39% | 33.63% | 33.97% |
| 26037-3692 | 139.61591 | 29.96809 | 0.0011 | GALAXY | 33.45% | 33.74% | 32.80% |
| 26038-17239 | 144.43648 | 30.72382 | 0.0027 | QSO | 33.22% | 33.51% | 33.25% |
| 26036-8820 | 146.18454 | 30.19118 | 0.0050 | GALAXY | 33.45% | 33.22% | 32.82% |
| ID | RA | Dec. | CLASS_STAR | PredictClass | GALAXY | Gdis | QSO | Qdis | STAR | Sdis |
|---|---|---|---|---|---|---|---|---|---|---|
| 26016-32840 | 255.67090 | 24.07627 | 0.5005 | STAR | 45.85 | 59.90 | 214.59 | |||
| 26047-19730 | 121.32316 | 31.91350 | 0.0001 | GALAXY | 78.09 | 51.34 | 204.47 | |||
| 26091-3622 | 128.45054 | 34.12899 | 0.4170 | GALAXY | 201.06 | 62.20 | 391.73 | |||
| 33209-2012 | 137.46224 | 39.60661 | 0.1433 | GALAXY | 55.05 | 61.91 | 224.79 | |||
| 26141-18524 | 169.58419 | 40.46721 | 0.0016 | STAR | 73.44 | 52.22 | 185.80 | |||
| 26145-15610 | 284.78880 | 39.72198 | 0.2306 | GALAXY | 133.31 | 50.71 | 278.23 | |||
| 33232-7122 | 126.08110 | 41.29631 | 0.1117 | GALAXY | 98.28 | 67.51 | 251.50 | |||
| 26151-29824 | 273.32033 | 41.61314 | 0.0013 | GALAXY | 229.37 | 56.60 | 255.62 | |||
| 26207-8959 | 137.26562 | 52.62772 | 0.0027 | GALAXY | 66.90 | 59.96 | 312.61 | |||
| 26241-25002 | 137.26562 | 52.62772 | 0.5029 | GALAXY | 129.51 | 70.59 | 278.00 |

4.3 Comparison with CLASS_STAR
In Fig. 13, we draw the difference between our results and the CLASS_STAR in J-PLUS catalog. The figure indicates that there are differences between the J-PLUS CLASS_STAR and our result. The difference may be caused by the different strategies of classifying the objects: binary classification for J-PLUS based on the point-source detection and our triple classification based on machine learning. The QSOs are probably not distinguished from stars or galaxies with the point-source detection, and such a detection could further result in the difference in Fig. 13. Therefore, the factor CLASS_STAR may not be suitable enough for multi-classifications.
5 Discussion
5.1 Different ways to constrain extrapolation
We constructed three methods to constrain extrapolation, including magnitude cuts and two density-dependence methods. The most straightforward thought is defining intervals based on magnitude distributions of our training sample. We can determine whether an object belongs to the intersection of these intervals or not.
We employed kernel distribution (Bowman & Azzalini 1997) to fit the distributions of each dimension in the instance space. The kernel distribution is a kind of probability measure. For each dimension, the objects situated in the middle part of the distribution are defined as interpolations. By cutting down 0.025 for each side of a magnitude distribution, the intervals were constructed, and the objects could be separated into interpolation or extrapolation. This method results in an accuracy of for the blind test. After the selection, 2,749,840 interpolating objects were left, and there was of the J-PLUS catalog (Fig. 14 and 15). This method is precluded due to its low accuracy and its unrepresentative of the interpolation boundary.


The ideal approach is to draw a 12-dimension density contour to select the interpolating sample. The adopted method (Sect. 3.3.1) is an approximation of such an ideal approach. The last method is four contours instead of 12 contours, which are (mag1, mag2, mag3), (mag4, mag5, mag6), (mag7, mag8, mag9), and (mag10, mag11, mag12). These rough contours result in an accuracy of , and they left 3,702,268 interpolating objects (Fig. 16 and 17). This method is also precluded due to its low accuracy.


5.2 Comparison of different classifiers
Bai et al. (2018) used a RF algorithm to gain a classifier with an accuracy of . We also tested RF, but its accuracy is lower than SVM. The different results of these two works are probably due to the different sample sizes and wavebands. The accuracy of the blind test is similar to the training accuracy, implying that there is no obvious overfitting in our training process (Shalev-Shwartz & Ben-David 2014).
The sample size may also influence the training accuracy. In our method, the sample size is 468,685, while in Bai et al. (2018), the number is 2,973,855. Both SVM or RF have a finite Vapnik-Chervonenkis dimension (VCdim; Shalev-Shwartz & Ben-David 2014). If a sample size goes to infinity, the training error and the validation error converge to the approximation error. This implies that there exists a limited accuracy of a classifier. In our work, the training error () is similar to the validation error (). Therefore, if we enlarge the sample size, the accuracy may not increase significantly.
Bai et al. (2018) applied nine-dimensional color spaces including infrared bands, while we used 12 optical magnitudes. More and broader bands involved in the training would lead to a higher total accuracy. The accuracy in our work is slightly lower. This is probably due to the strong correlation in the 12 bands. We calculated a correlation matrix (Fig. 18) for these 12 bands from their photometric results.

The minimum of the correlation coefficient stands at , mag4 (J0410), and mag5 (J0430) in Fig. 18. These high correlation values indicate that all of these wavebands are highly correlated. The correlation may be explained by not only the distance of the object that causes a similarity in all magnitudes, but also the overlapping of filter profiles. From the band plot in J-PLUS 151515The plot can be found both at http://www.j-plus.es/ancillarydata/dr1_lya_emitting_candidates and in Cenarro et al. (2019), the filter profile of , , , , have overlapped with other narrow bands, implying that they are not strongly independent. The wavebands adopted in Bai et al. (2018) cover a larger range, and the correlations are probably weaker.
The constitution of the data set may also influence the accuracy of a classifier. In Ball et al. (2006), a tree algorithm was developed to output the probability of a star, galaxy, and nsng (neither star nor galaxy object). In Bai’s and Ball’s training samples, there was a significant bias in the sample set. The sample construction of our SVM classifier and the two mentioned classifiers is shown in Table 11. Bai et al. (2018) and Ball et al. (2006) concluded that the biased sample can also present a training accuracy of better than 95%.
5.3 Future work
The advantages of J-PLUS are 12 optical filters and a large amount of data. The ongoing J-PAS has an all-time system of 56 optical narrowband filters, making it one of the most promising surveys in the world. The way we work on J-PLUS can be copy to J-PAS. The more bands applied, the more precise a classifier could be.
Baqui, P. O. et al. (2021) developed different classifiers to label the mini-JPAS (Bonoli et al. 2021), including RF and Extremely Randomized Trees (ERT). MiniJ-PAS is a previous project to test J-PAS. Their work has gained good performance with Area Under the Curve (AUC) greater than 0.95 in different classifiers. AUC is equal to the positive probability.
SVM is inferior when the instance space has too many dimensions, or when the data set is too large for calculation. More works are required to test the time cost of SVM when we apply larger data with more features. Although SVM is a good algorithm; its performance in J-PAS still needs to be tested considering the computational complexity and no-free-lunch theorem.
Acknowledgements.
This work was supported by the National Natural Science Foundation of China (NSFC) through grants NSFC-11988101/11973054/11933004 and the National Programs on Key Research and Development Project (grant No.2019YFA0405504 and 2019YFA0405000). Strategic Priority Program of the Chinese Academy of Sciences under grant number XDB41000000. H, B, Yuan, acknowledge funding from National Natural Science Foundation of China (NSFC) through grants NSFC-12173007. ELM acknowledges support from the Agencia Estatal de Investigación del Ministerio de Ciencia e Innovación (AEI-MCINN) under grant PID2019-109522GB-C53.Based on observations made with the JAST80 telescope at the Observatorio Astrofísico de Javalambre (OAJ), in Teruel, owned, managed, and operated by the Centro de Estudios de Física del Cosmos de Aragón (CEFCA). We acknowledge the OAJ Data Processing and Archiving Unit (UPAD) for reducing the OAJ data used in this work. Funding for the J-PLUS Project has been provided by the Governments of Spain and Aragón throughthe Fondo de Inversiones de Teruel; the Aragón Government through the Research Groups E96, E103, and E16_17R; the Spanish Ministry of Science, Innovation and Universities (MCIU/AEI/FEDER, UE) with grants PGC2018-097585-B-C21 and PGC2018-097585-B-C22; the Spanish Ministry of Economy and Competitiveness (MINECO) under AYA2015-66211-C2-1-P, AYA2015-66211-C2-2, AYA2012-30789, and ICTS-2009-14; and European FEDER funding (FCDD10-4E-867, FCDD13-4E-2685). The Brazilian agencies FINEP, FAPESP, and the National Observatory of Brazil have also contributed to this project. Guoshoujing Telescope (the Large Sky Area Multi-Object Fiber Spectroscopic Telescope LAMOST) is a National Major Scientific Project built by the Chinese Academy of Sciences. Funding for the project has been provided by the National Development and Reform Commission. LAMOST is operated and managed by the National Astronomical Observatories, Chinese Academy of Sciences. Funding for the Sloan Digital Sky Survey IV has been provided by the Alfred P. Sloan Foundation, the U.S. Department of Energy Office of Science, and the Participating Institutions. SDSS-IV acknowledges support and resources from the Center for High-Performance Computing at the University of Utah. The SDSS website is http://www.sdss.org/. SDSS-IV is managed by the Astrophysical Research Consortium for the Participating Institutions of the SDSS Collaboration including the Brazilian Participation Group, the Carnegie Institution for Science, Carnegie Mellon University, the Chilean Participation Group, the French Participation Group, Harvard-Smithsonian Center for Astrophysics, Instituto de Astrofísica de Canarias, The Johns Hopkins University, Kavli Institute for the Physics and Mathematics of the Universe (IPMU)/University of Tokyo, Lawrence Berkeley National Laboratory, Leibniz Institut für Astrophysik Potsdam (AIP), Max-Planck-Institut für Astronomie (MPIA Heidelberg), Max- Planck-Institut für Astrophysik (MPA Garching), Max-Planck-Institut für Extraterrestrische Physik (MPE), National Astronomical Observatories of China, New Mexico State University, New York University, University of Notre Dame, Observatário Nacional/MCTI, The Ohio State University, Pennsylvania State University, Shanghai Astronomical Observatory, United Kingdom Participation Group, Universidad Nacional Autónoma de México, University of Arizona, University of Colorado Boulder, University of Oxford, University of Portsmouth, University of Utah, University of Virginia, University of Washington, University of Wisconsin, Vanderbilt University, and Yale University. This work is supported by the CSST project on ”stellar activity and late evolutionary stage”.
References
- Ahumada et al. (2020) Ahumada, R., Allende Prieto, C., Almeida, A., et al. 2020, ApJS, 249, 3
- Bai et al. (2018) Bai, Y., Liu, J., Wang, S., & Yang, F. 2018, The Astronomical Journal, 157, 9
- Ball et al. (2006) Ball, N. M., Brunner, R. J., Myers, A. D., & Tcheng, D. 2006, The Astrophysical Journal, 650, 497–509
- Baqui, P. O. et al. (2021) Baqui, P. O., Marra, V., Casarini, L., et al. 2021, A&A, 645, A87
- Benítez et al. (2014) Benítez, N., Dupke, R., Moles, M., et al. 2014, [ArXiv:1403.5237] [arXiv:1403.5237]
- Bertin & Arnouts (1996) Bertin, E. & Arnouts, S. 1996, A&AS, 117, 393
- Bonoli et al. (2021) Bonoli, S., Marín-Franch, A., Varela, J., et al. 2021, A&A, 653, A31
- Boser et al. (1992) Boser, B. E., Guyon, I. M., & Vapnik, V. N. 1992, in Proceedings of the Fifth Annual Workshop on Computational Learning Theory, COLT ’92 (New York, NY, USA: Association for Computing Machinery), 144–152
- Bowman & Azzalini (1997) Bowman, A. W. & Azzalini, A. 1997, Applied smoothing techniques for data analysis: the kernel approach with S-Plus illustrations, Vol. 18 (OUP Oxford)
- Breiman (2001) Breiman, L. 2001, Statist. Sci., 16, 199
- Cenarro et al. (2019) Cenarro, A. J., Moles, M., Cristóbal-Hornillos, D., et al. 2019, Astronomy & Astrophysics, 622, A176
- Cenarro et al. (2014) Cenarro, A. J., Moles, M., Marín-Franch, A., et al. 2014, in Proc. SPIE, Vol. 9149, Observatory Operations: Strategies, Processes, and Systems V, 91491I
- Cortes & Vapnik (1995) Cortes, C. & Vapnik, V. 1995, Machine Learning, 20, 273
- Cover & Hart (1967) Cover, T. & Hart, P. 1967, IEEE Trans. Inf. Theory, 13, 21
- Cristianini & Shawe-Taylor (2000) Cristianini, N. & Shawe-Taylor, J. 2000, An Introduction to Support Vector Machines and Other Kernel-based Learning Methods (Cambridge University Press)
- Cui et al. (2012) Cui, X.-Q., Zhao, Y.-H., Chu, Y.-Q., et al. 2012, Research in Astronomy and Astrophysics, 12, 1197
- De Maesschalck et al. (2000) De Maesschalck, R., Jouan-Rimbaud, D., & Massart, D. 2000, Chemometrics and Intelligent Laboratory Systems, 50, 1
- Deng et al. (2012) Deng, L.-C., Newberg, H. J., Liu, C., et al. 2012, Research in Astronomy and Astrophysics, 12, 735
- FISHER (1936) FISHER, R. A. 1936, Annals of Eugenics, 7, 179
- Freund & Schapire (1995) Freund, Y. & Schapire, R. E. 1995, A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting
- guan Wang et al. (1996) guan Wang, S., qiang Su, D., quan Chu, Y., Cui, X., & nan Wang, Y. 1996, Appl. Opt., 35, 5155
- Huchra et al. (2012) Huchra, J. P., Macri, L. M., Masters, K. L., et al. 2012, The Astrophysical Journal Supplement Series, 199, 26
- Jiménez-Teja et al. (2019) Jiménez-Teja, Y., Dupke, R. A., Lopes de Oliveira, R., et al. 2019, Astronomy & Astrophysics, 622, A183
- López-Sanjuan et al. (2019) López-Sanjuan, C., Vázquez Ramió, H., Varela, J., et al. 2019, A&A, 622, A177
- Luo et al. (2012) Luo, A.-L., Zhang, H.-T., Zhao, Y.-H., et al. 2012, Research in Astronomy and Astrophysics, 12, 1243
- Mahalanobis (1936) Mahalanobis, P. C. 1936, Proceedings of the National Institute of Sciences (Calcutta), 2, 49
- Marín-Franch et al. (2015) Marín-Franch, A., Taylor, K., Cenarro, J., Cristobal-Hornillos, D., & Moles, M. 2015, in IAU General Assembly, Vol. 29, 2257381
- Monroe et al. (2016) Monroe, T. R., Prochaska, J. X., Tejos, N., et al. 2016, The Astronomical Journal, 152, 25
- Nogueira-Cavalcante et al. (2019) Nogueira-Cavalcante, J. P., Dupke, R., Coelho, P., et al. 2019, Astronomy & Astrophysics, 630, A88
- Quinlan (1986) Quinlan, J. R. 1986, Machine Learning, 1, 81
- Shalev-Shwartz & Ben-David (2014) Shalev-Shwartz, S. & Ben-David, S. 2014, Understanding Machine Learning: From Theory to Algorithms (Cambridge University Press)
- Steinmetz et al. (2020) Steinmetz, M., Matijevič, G., Enke, H., et al. 2020, The Astronomical Journal, 160, 82
- Stone (1977) Stone, C. J. 1977, The Annals of Statistics, 5, 595
- Su & Cui (2004) Su, D.-Q. & Cui, X.-Q. 2004, Chinese journal of Astronomy and Astrophysics, 4, 1
- Taylor (2005) Taylor, M. B. 2005, in Astronomical Society of the Pacific Conference Series, Vol. 347, Astronomical Data Analysis Software and Systems XIV, ed. P. Shopbell, M. Britton, & R. Ebert, 29
- Véron-Cetty & Véron (2010) Véron-Cetty, M. P. & Véron, P. 2010, A&A, 518, A10
- Wang (2021) Wang, S. 2021, Private communication
- Whitten et al. (2019) Whitten, D. D., Placco, V. M., Beers, T. C., et al. 2019, Astronomy & Astrophysics, 622, A182
- Yuan (2021) Yuan, H. 2021, In preparation and private communication
- Yuan et al. (2015) Yuan, H., Liu, X., Xiang, M., et al. 2015, The Astrophysical Journal, 799, 133
- Zasowski et al. (2013) Zasowski, G., Johnson, J. A., Frinchaboy, P. M., et al. 2013, The Astronomical Journal, 146, 81
- Zhao et al. (2012) Zhao, G., Zhao, Y.-H., Chu, Y.-Q., Jing, Y.-P., & Deng, L.-C. 2012, Research in Astronomy and Astrophysics, 12, 723
Appendix A Density contours of the sample set
We present all 12 three-dimensional contours of the predictions.











Appendix B Magnitude distributions
We present the magnitude distributions for each class, magnitude, and for both samples and interpolations. The red line indicates STAR, the green is for GALAXY, and the blue is for QSO.










Appendix C Sample of our training
We present the training sample in Table 12, and the subclasses of STARs are included. The overlap of the stars in the sample is presented in Table 13. The overlap of galaxies between SDSS DR16 and LAMOST DR7 is 9,871. The QSO overlaps between each catalog are 4,593 for VV13 and SDSS DR16, 1,339 for VV13 and LAMOST DR7, and 3,802 for SDSS DR16 and LAMOST DR7. Though the overlapping is so enormous for the LAMOST catalogs, there is still one independent object in the A-, F-, G-, and K-type star catalog. This catalog can provide more information. Also, there are 6,147 and 108 independent objects in APOGEE and VV13.
| ID | R.A. | Dec. | class | subclass | catalog |
|---|---|---|---|---|---|
| 25998-16 | 117.49152 | 39.45784 | STAR | G8 | LAMOST M |
| 25998-143 | 117.58813 | 39.46421 | STAR | M3 | LAMOST A- F- G- K- |
| 25998-309 | 116.08787 | 39.47680 | STAR | F7 | LAMOST |
| 25998-495 | 117.13277 | 39.48703 | QSO | SDSS | |
| 25998-942 | 116.99474 | 39.50345 | GALAXY | SDSS | |
| 25998-8981 | 116.47530 | 39.83560 | STAR | G2 | LAMOST M |
| 25998-9909 | 116.52973 | 39.82853 | STAR | APOGEE | |
| 26036-5884 | 145.42144 | 30.01548 | STAR | A2V | LAMOST A- F- G- K- |
| 26025-6501 | 125.43704 | 30.12984 | QSO | VV13 | |
| 26025-7265 | 124.35765 | 30.17180 | STAR | SDSS |
| Catalog | APOGEE | LAMOST | AFGK | LA | LM |
|---|---|---|---|---|---|
| SDSS | 91 | 7,266 | 3,993 | 960 | 333 |
| APOGEE | 7,564 | 6,419 | 69 | 294 | |
| LAMOST | 212,114 | 5,145 | 2,5604 | ||
| AFGK | 1,408 | 421 | |||
| LA | 6 |