ItôWave: Itô Stochastic Differential Equation Is All You Need For Wave Generation
Abstract
In this paper, we propose a vocoder based on a pair of forward and reverse-time linear stochastic differential equations (SDE). The solutions of this SDE pair are two stochastic processes, one of which turns the distribution of wave, that we want to generate, into a simple and tractable distribution. The other is the generation procedure that turns this tractable simple signal into the target wave. The model is called ItôWave. ItôWave use the Wiener process as a driver to gradually subtract the excess signal from the noise signal to generate realistic corresponding meaningful audio respectively, under the conditional inputs of original mel spectrogram. The results of the experiment show that the mean opinion scores (MOS) of ItôWave can exceed the current state-of-the-art (SOTA) methods, and reached 4.350.115. The generated audio samples are available online111https://wushoule.github.io/ItoAudio/..
Index Terms— Vocoder, diffusion model, stochastic differential equations, generative model
1 Introduction
The vocoder model is roughly categorized as autoregressive (AR) or non-autoregressive (non-AR), where the AR model generates the signal frame by frame, and the generation of the current signal frame depends on the previously generated signal. Non-AR models generate the signal in parallel, and the current signal frame does not depend on the previous signal. Generally speaking, the voice quality generated by the AR model is higher than the non-AR model, but the amount of computation is also larger, and the generation speed is slow. While for the non-AR generation model, the generation speed is faster, but the generated voice quality is slightly worse. To name a few, for example, WaveNet [1] is the earliest AR model, using sampling points as the unit and achieves a sound quality that matches the naturalness of human speech. In addition, other recent AR models, including sampleRNN [2] and LPCNet [3] have further improved the sound quality. However, due to the large amount of computation and the slow generation speed, researchers currently mainly focus on developing non-AR wave generation models, such as Parallel WaveNet [4], GanSynth [5], MelGan [6], WaveGlow [7], Parallel WaveGan [8], and so on.
In this paper, vocoder is modeled with a new framework based on linear Itô stochastic differential equations (SDE) and score matching modeling. We call it ItôWave. The linear Itô SDE, driven by the Wiener process, can slowly turn the wave data distributions into data distributions that are easy to manipulate, such as white noise. This transformation process is the stochastic process solution of the linear Itô SDE. Therefore, the corresponding reverse-time linear Itô SDE can generate the wave data distribution required by vocoder, from this easy data distribution, such as white noise. It can be seen that the reverse-time linear Itô SDE is crucial for the generation, and Anderson [9] shows the explicit form of this reverse-time linear SDE, and the formula shows that it depends on the gradient of the log value of the probability density function of the stochastic process solution of the forward-time equation. This gradient value is also called the stein score [10]. ItôWave predict the stein score corresponding to the wave by trained neural networks. After obtaining this score, ItôWave can achieve the goal of generating wave through reverse-time linear Itô SDE or Langevin dynamic sampling.
Our contribution is as follows, 1) We are the first to proposed a vocoder model based on linear Itô SDE, and reached state-of-the-art performance; 2) We explicitly put vocoder under a more flexible framework, which can construct different vocoder models by selecting different drift and diffusion coefficients of the linear SDE; 3) For ItôWave, we propose a network structure, which is suitable for estimating the gradient of log value of the density function of the wave data distributions.
2 The ItôWave
2.1 Audio data distribution transformation based on Itô SDE
Itô SDE is a very natural model that can realize the transformation between different data distributions. The general Itô SDE is as follows
| (3) |
for , where is the drift coefficient, is the diffusion coefficient, is the standard Wiener process. Let be the density of the random variable . This SDE (3) changes the initial distribution into another distribution by gradually adding the noise from the Wiener process . In this work, , and is to denote the data distribution of wave in ItôWave. is an easy tractable distribution (e.g. Gaussian) of the latent representation of the wave signal corresponding to the conditional mel spectrogram. If this stochastic process can be reversed in time, then the corresponding target waveform of the conditional mel spectrogram can be generated from a simple latent distribution.
Actually the reverse-time diffusion process is the solution of the following corresponding reverse-time Itô SDE [9]
| (7) |
for , where is the distribution of , is the standard Wiener process in reverse-time. The solution of this reverse-time Itô SDE (7) can be used to generate wave data from a tractable latent distribution . Therefore, it can be seen from (7) that the key to generating wave with SDE lies in the calculations of , which is always called score function [10, 11] of the data.
2.2 Score estimation of audio data distribution
In this work, a neural network is used to approximate the score function, where denotes the parameters of the network. The input of the network includes time , , and conditional input mel spectrograms input in ItôWave. The expected output is . The objective of score matching is [10]
| (8) |
Generally speaking, in the low-density data manifold area, the score estimation will be inaccurate, which will further lead to the low quality of the sampled data [11]. If the wave signal is contaminated with a very small scale noise, then the contaminated wave signal will spread to the entire space instead of being limited to a small low-dimensional manifold. When using perturbed wave signal as input, the following denoising score matching (DSM) loss [12, 11]
| (9) |
is equal to the loss (8) of a non-parametric (e.g. Parzen windows densiy) estimator [12]. This DSM loss is used in this paper to train the score prediction network. If we can accurately estimate the score of the distribution, then we can generate wave sample data from the original distribution.
It should be noted that in the experiment we found that the choice of training loss is very critical. For ItôWave, the loss is more appropriate than loss.
Generally the transition densities and the score in the DSM loss are difficult to calculate, but for linear SDE, these values have close formulas [13].
2.3 Linear SDE and transition densities
Empirically it is found that different types of linear SDE for different audio generation tasks, e.g. the variance exploding (VE) SDE [14] is much suitable for wave generation. VE SDE is of the following form
| (12) |
where .
Then the differential equation satisfied by the mean and variance of the transition densities is as follows
| (15) |
Solving the above equation, and choose makes , we get the transition density of this as
| (16) |
The score of the VE linear SDE is
| (17) |
The prior distribution is a Gaussian
| (18) |
thus .
2.4 Training and wave sampling algorithms
Based on subsections 2.1 and 2.2, we can get the training procedure of the score networks based on general SDEs, as shown in Algorithm 1.
Input and initialization: The wave and the corresponding mel spectrogram condition , the diffusion time .
1: for
2: Uniformly sample from .
3: Randomly sample batch of and , let . Sample from the distribution , compute the target score as . Average the following
4: Do the back-propagation and the parameter updating of .
5: .
6: Until stopping conditions are satisfied and converges, e.g. to .
Output: .
After we get the optimal score network through loss minimization, thus we can get the gradient of log value of the distribution probability density of the wave with . Then we can use Langevin dynamics or the reverse-time Itô SDE (7) to generate the wave corresponding to the specific mel spectrogram . The reverse-time SDE (7) can be solved and used to generate target audio data. Assuming that the time schedule is fixed, the discretization of the diffusion process (3) is as follows
| (23) |
since is a wide sense stationary white noise process [15], which is denoted as in this paper.
The corresponding discretization of the reverse-time diffusion process (7) is
| (30) |
In this paper, we use the strategy of [14], which means that at each time step, Langevin dynamics is used to predict first, and then reverse-time Itô SDE (30) is used to revises the first predicted result.
The generation algorithm of wave based on VE linear SDE is as follows
Input and initialization: the score network , input mel-spectrogram , and .
1: for
2:
3:
4: .
Output: The generated wave .
2.5 Architectures of .
It was found that although the score network model does not have as strict restrictions on the network structure as the flow model [16, 7, 17], not all network structures are suitable for score prediction.
The structure of ItôWave’s score prediction network is shown in Figure 1. The input is the wave to be generated, and the conditional input has mel spectrogram and time . The output is the score at time . All three types of input require preprocessing processes. The preprocessing of the wave is through a convolution layer; the preprocessing of mel spectrogram is based on the upsampling by two transposed convolution layers. After all inputs are preprocessed, they will be sent to the most critical module of , which is of several serially connected dilated residual blocks. The main input of the dilated residual block is the wave, and the step time condition and mel spectrogram condition will be input into these dilated residual blocks one after another, and added to the feature map after the transformation of the wave signal. Similarly, there are two outputs of each dilated residual block, one is the state, which is used for input to the next residual block, and the other is the final output. The advantage of this is the ability to synthesize information of different granularities. Finally, the outputs of all residual blocks are summed and then pass through two convolution layers as the final output score.

3 Experiments
3.1 Dataset and setup
The data set we use is LJSpeech [18], a single female speech database, with a total of 24 hours, 13100 sentences, randomly divided into 13000/50/50 for training/verification/testing. The sampling rate is 22050. In the experiment, for mel spectrogram, the window length is 1024, hop length is 256, the number of mel channels is 80. We use the same Adam [19] training algorithm for ItôWave. We have done quantitative evaluations based on mean opinion score (MOS) with other state-of-the-art methods on ItôWave. We compared with WaveNet [1], WaveGlow [7], Diffwave [20], and WaveGrad [21]. All experiments were performed on a GeForce RTX 3090 GPU with 24G memory.
3.2 Results and discussion
In order to verify the naturalness and fidelity of the synthesized voice, we randomly select 40 from 50 test data for each subject, and then let the subject give the synthesized sound a MOS score of 0-5.
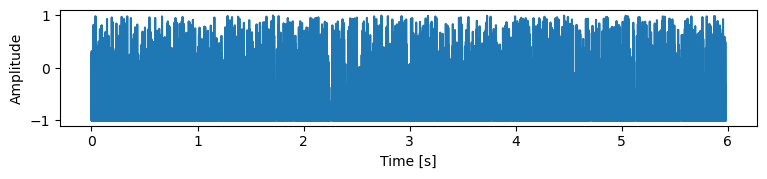








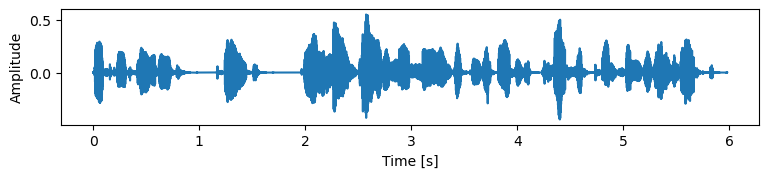
For ItôWave, the original mel spectrogram of the test set was used as the condition input to the score estimation network. ItôWave uses 30 residual layers. For the comparison methods,
The results are shown in Table 1, and you can see that ItôWave scores the best. It has approached the true value of ground truth. As shown in Figure 2, we can see how ItôWave gradually turns white noise into meaningful wave.
| Methods | MOS |
|---|---|
| Ground truth | 4.45 0.07 |
| WaveNet | 4.3 0.130 |
| WaveGlow | 3.95 0.161 |
| DiffWave | 4.325 0.123 |
| WaveGrad | 4.1 0.158 |
| ItôWave | 4.35 0.115 |
4 Conclusion
This paper proposes a new vocoder ItôWave based on linear Itô SDE. Under conditional input, ItôWave can continuously transform simple distributions into corresponding wave data through reverse-time linear SDE and Langevin dynamic. ItôWave use neural networks to predict the required score for reverse-time linear SDE and Langevin dynamic sampling, which is the gradient of the log probability density at a specific time. For ItôWave, we designed the corresponding effective score prediction networks. Experiments show that the MOS of ItôWave can achieved the state-of-the-art respectively.
References
- [1] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu, “Wavenet: A generative model for raw audio,” arXiv preprint arXiv:1609.03499, 2016.
- [2] Soroush Mehri, Kundan Kumar, Ishaan Gulrajani, Rithesh Kumar, Shubham Jain, Jose Sotelo, Aaron Courville, and Yoshua Bengio, “Samplernn: An unconditional end-to-end neural audio generation model,” arXiv preprint arXiv:1612.07837, 2016.
- [3] Jean-Marc Valin and Jan Skoglund, “Lpcnet: Improving neural speech synthesis through linear prediction,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 5891–5895.
- [4] Aaron Oord, Yazhe Li, Igor Babuschkin, Karen Simonyan, Oriol Vinyals, Koray Kavukcuoglu, George Driessche, Edward Lockhart, Luis Cobo, Florian Stimberg, et al., “Parallel wavenet: Fast high-fidelity speech synthesis,” in International conference on machine learning. PMLR, 2018, pp. 3918–3926.
- [5] Jesse Engel, Kumar Krishna Agrawal, Shuo Chen, Ishaan Gulrajani, Chris Donahue, and Adam Roberts, “Gansynth: Adversarial neural audio synthesis,” arXiv preprint arXiv:1902.08710, 2019.
- [6] Kundan Kumar, Rithesh Kumar, Thibault de Boissiere, Lucas Gestin, Wei Zhen Teoh, Jose Sotelo, Alexandre de Brébisson, Yoshua Bengio, and Aaron Courville, “Melgan: Generative adversarial networks for conditional waveform synthesis,” arXiv preprint arXiv:1910.06711, 2019.
- [7] Ryan Prenger, Rafael Valle, and Bryan Catanzaro, “Waveglow: A flow-based generative network for speech synthesis,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 3617–3621.
- [8] Ryuichi Yamamoto, Eunwoo Song, and Jae-Min Kim, “Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6199–6203.
- [9] Brian DO Anderson, “Reverse-time diffusion equation models,” Stochastic Processes and their Applications, vol. 12, no. 3, pp. 313–326, 1982.
- [10] Aapo Hyvärinen and Peter Dayan, “Estimation of non-normalized statistical models by score matching.,” Journal of Machine Learning Research, vol. 6, no. 4, 2005.
- [11] Yang Song and Stefano Ermon, “Generative modeling by estimating gradients of the data distribution,” arXiv preprint arXiv:1907.05600, 2019.
- [12] Pascal Vincent, “A connection between score matching and denoising autoencoders,” Neural computation, vol. 23, no. 7, pp. 1661–1674, 2011.
- [13] Simo Särkkä and Arno Solin, Applied stochastic differential equations, vol. 10, Cambridge University Press, 2019.
- [14] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole, “Score-based generative modeling through stochastic differential equations,” arXiv preprint arXiv:2011.13456, 2020.
- [15] Lawrence C Evans, An introduction to stochastic differential equations, vol. 82, American Mathematical Soc., 2012.
- [16] Chenfeng Miao, Shuang Liang, Minchuan Chen, Jun Ma, Shaojun Wang, and Jing Xiao, “Flow-tts: A non-autoregressive network for text to speech based on flow,” in ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7209–7213.
- [17] Rafael Valle, Kevin Shih, Ryan Prenger, and Bryan Catanzaro, “Flowtron: an autoregressive flow-based generative network for text-to-speech synthesis,” arXiv preprint arXiv:2005.05957, 2020.
- [18] Keith Ito and Linda Johnson, “The lj speech dataset,” Online: https://keithito. com/LJ-Speech-Dataset, 2017.
- [19] Diederik P Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [20] Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro, “Diffwave: A versatile diffusion model for audio synthesis,” arXiv preprint arXiv:2009.09761, 2020.
- [21] Nanxin Chen, Yu Zhang, Heiga Zen, Ron J Weiss, Mohammad Norouzi, and William Chan, “Wavegrad: Estimating gradients for waveform generation,” arXiv preprint arXiv:2009.00713, 2020.