by-sa
”It Brought the Model to Life”: Exploring the Embodiment of Multimodal I3Ms for People who are Blind or have Low Vision
Abstract.
3D-printed models are increasingly used to provide people who are blind or have low vision (BLV) with access to maps, educational materials, and museum exhibits. Recent research has explored interactive 3D-printed models (I3Ms) that integrate touch gestures, conversational dialogue, and haptic vibratory feedback to create more engaging interfaces. Prior research with sighted people has found that imbuing machines with human-like behaviours, i.e., embodying them, can make them appear more lifelike, increasing social perception and presence. Such embodiment can increase engagement and trust. This work presents the first exploration into the design of embodied I3Ms and their impact on BLV engagement and trust. In a controlled study with 12 BLV participants, we found that I3Ms using specific embodiment design factors, such as haptic vibratory and embodied personified voices, led to an increased sense of liveliness and embodiment, as well as engagement, but had mixed impact on trust.

This figure includes two images showcasing one of the interactive 3D-printed models (I3Ms) we designed. Seen is the Egyptian Pyramid I3M operating in High Embodied Mode (HEM). It includes a base made of acrylic that is painted gold. It includes four 3D-printed objects – the Sphinx, and the Pyramids of Khufu, Menkaure, and Khafre. They are also painted gold. In A), the model introduces itself as a user picks up the Sphinx; In B), the user holds the Great Pyramid and Pyramid of Menkaure and asks which is larger, to which the Great Pyramid emits localised haptics and responds using an embodied personified voice and first-person narration.
1. Introduction
The lack of equitable access to graphical information, such as educational materials and navigation maps, can significantly reduce opportunities and overall quality of life for people who are blind or have low vision (BLV) (Butler et al., 2017; Sheffield, 2016). In recent years, 3D printing has been used to create accessible graphics (Stangl et al., 2015; Buehler et al., 2016; Holloway et al., 2018; Hu, 2015). Unlike traditional accessible graphics, 3D printing enables the fabrication of tangible models that directly represent three-dimensional objects and concepts. This allows a broader range of content to be effectively conveyed non-visually. 3D-printed models have demonstrated improved tactual understanding and mental model development compared to tactile graphics, as well as increased engagement (Holloway et al., 2018).
It is now becoming common to add button or touch-triggered audio labels to 3D-printed models (Ghodke et al., 2019; Holloway et al., 2018; Shi et al., 2016; Davis et al., 2020), creating interactive 3D-printed models (I3Ms). Audio labels support independent exploration and reduce the need for braille labels, which many blind people cannot read (of the Blind, 2009), may not fit on the model (Holloway et al., 2018), and can distort the model surface (Holloway et al., 2018; Shi et al., 2016). However, while useful, audio labels can only provide limited, predetermined information. With advances in intelligent agents, recent work has begun integrating conversational agents into I3Ms (Shi et al., 2017; Cavazos Quero et al., 2019; Reinders et al., 2020, 2023). These models afford greater agency and independence to BLV users, allowing them to generate their own queries and potentially access unlimited information about the model. One study involving the co-design of an I3M that combined touch gestures, conversational dialogue, and haptic vibratory feedback, found that participants desired an experience that felt more personal and ‘alive’ (Reinders et al., 2023).
Previous research has shown that imbuing machines with human-like behaviours and characteristics, that is – embodying them – can make them appear more lifelike and alive, increasing social perception and presence (Cassell, 2001; Lankton and Tripp, 2015; Lester et al., 1997; Nowak and Biocca, 2003; Shamekhi et al., 2018). Such embodiment has been found to increase subjective user engagement (Cassell, 2001; Shamekhi et al., 2018) and trust (Bickmore and Cassell, 2001; Bickmore et al., 2013; Minjin Rheu and Huh-Yoo, 2021; Shamekhi et al., 2018). A variety of conversational embodiment factors have been identified to increase embodiment, including speech that mimics human voices (Cassell, 2001), greeting users (Luria et al., 2019; Cassell, 2001; Shamekhi et al., 2018; Lester et al., 1997; Nowak and Biocca, 2003), conversational turn-taking (Cassell, 2001; Kontogiorgos et al., 2020), small talk (Liao et al., 2018; Pradhan et al., 2019; Shamekhi et al., 2018; Cassell, 2001; Bickmore and Cassell, 2001), and exhibiting personality (Lester et al., 1997). Visual embodiment attributes, such as giving the agent a face (Shamekhi et al., 2018; Bickmore and Cassell, 2001; Bickmore et al., 2013; Kontogiorgos et al., 2020), gestures (Cassell, 2001; Bickmore and Cassell, 2001), and employing gaze (Kontogiorgos et al., 2020; Shamekhi et al., 2018), have also been found to increase embodiment, as has physical embodiment (Luria et al., 2017; Kidd and Breazeal, 2004).
However, virtually all prior research has been conducted with sighted users and has not considered BLV users, who may not be able to fully discern or perceive visual characteristics or physical embodiment. Since the usefulness of an accessible graphic or interface depends on users’ willingness to engage with and accept the information it provides (Phillips and Zhao, 1993; Wu et al., 2017; Abdolrahmani et al., 2018), engagement and trust are critical for BLV users. We believe that embodiment, and its links with engagement and trust, may hold significant potential for I3Ms, which are designed to be spoken to, picked up, and touched. Embodied I3Ms could enable BLV students or self-learners to engage in deeper, more meaningful experiences with content, and therefore serve as a catalyst for their broader adoption. Here, we present the first exploration into the design of more embodied I3Ms and the impact of embodiment on the engagement and trust of BLV users. We believe our study is the first to explore embodiment in the context of both BLV users and I3Ms.
We selected five non-visual design factors and created two I3Ms – the Saturn V Rocket and Egyptian Pyramids – that could be configured in two states – High Embodied Mode (HEM) and Low Embodied Mode (LEM). These states differed based on the embodiment design factors. Those factors relating to conversational embodiment (introductions and small talk, embodied personified voices and embodied narration style) have previously been found to increase embodiment. Physical embodiment factors (embodied haptic vibratory feedback and location of speech output) were more novel and were motivated by feedback from BLV users interacting with I3Ms (Reinders et al., 2023). We conducted a within-subject user study with 12 BLV participants, using established questionnaires and subjective ratings to examine how lively, engaging and trustworthy participants perceived each model to be. The main findings of our study include:
-
•
Participants perceived the HEM I3Ms as having a greater sense of liveliness, appearing more embodied compared to LEM I3Ms;
-
•
HEM I3Ms appeared to be more engaging. This adds to research showing that more embodied conversational agents and social robots increase subjective user engagement, establishing that this relationship extends to I3Ms in the context of BLV users;
-
•
Differences in trust between LEM and HEM I3Ms were inconclusive, suggesting the impact of embodiment on trust may be more limited.
Our findings, which represent the first exploration into the embodiment and social perception of embodied I3Ms, provide initial design recommendations for creating I3Ms that BLV users find engaging. These recommendations will be of critical interest to the accessibility research community and to practitioners designing I3Ms for accessible exhibits in public spaces, such as museums and galleries, or as accessible materials for classroom use.
2. Related Work
This work builds on research on: accessible graphics and interactive 3D-printed models for BLV users; conversational agents; and embodied agents.
2.1. Accessible Graphics
BLV people face challenges accessing graphical information, which impacts education opportunities (Butler et al., 2017), makes independent travel difficult (Sheffield, 2016), and causes disengagement with culture and the creative arts (Bartlett et al., 2019). These barriers can lead to reductions in confidence and overall quality of life (Keeffe, 2005).
Graphical information can be made available in formats that improve non-visual access. Traditionally, accessible graphics – known as raised line drawings or tactile graphics – have been used to assist BLV people in accessing information. Tactile graphics are frequently used to facilitate classroom learning (Aldrich and Sheppard, 2001; Rosenblum and Herzberg, 2015) and orientation and mobility (O&M) training (Blades et al., 1999; Rowell and Ungar, 2005). Work has been conducted on the development of interactive tactile graphics, including the NOMAD (Parkes, 1994), IVEO (ViewPlus, [n. d.]), and Talking Tactile Tablet (Miele et al., 2006; Inc, [n. d.]). These devices combine printed tactile overlays with touch-sensitive surfaces, enabling BLV users to explore the graphics tactually and access audio labels by interacting with predefined touch areas. However, as these systems rely on printed tactile graphics, their scope is limited to two-dimensional content.
3D-printed models are an increasingly common alternative to tactile graphics. They enable a broader range of material to be produced, particularly for concepts that are inherently three-dimensional in nature. In recent years, the production cost and effort of 3D-printed models have fallen to levels comparable to tactile graphic production. 3D-printed models are increasingly being applied in various accessible graphic areas: mapping and navigation (Gual et al., 2012; Holloway et al., 2018, 2019b, 2022; Nagassa et al., 2023); special education (Buehler et al., 2016); art galleries (Karaduman et al., 2022; Butler et al., 2023); books (Kim and Yeh, 2015; Stangl et al., 2015); mathematics (Brown and Hurst, 2012; Hu, 2015); graphic design (McDonald et al., 2014); science (Wedler et al., 2012; Hasper et al., 2015); and programming (Kane and Bigham, 2014). Compared to tactile graphics, 3D-printed models have been shown to improve tactual understanding and mental model development among BLV people (Holloway et al., 2018). However, as with traditional tactile graphics, the provision of written descriptions or braille labelling presents challenges. The limited space on models and the low-fidelity of 3D-printed braille can significantly impact the utility and readability of labels (Brown and Hurst, 2012; Taylor et al., 2015; Shi et al., 2016).
2.2. Interactive 3D-Printed Models
To address labelling challenges, limitations on the type of content that can be produced, and to create more engaging and interactive experiences, there is growing interest in the development of interactive 3D-printed models (I3Ms). By combining 3D-printed models with low-cost electronics and/or smart devices, many I3Ms now include button or touch-triggered audio labels that provide verbal descriptions of the printed model (Landau, 2009; Shi et al., 2016; Reichinger et al., 2016; Giraud et al., 2017; Götzelmann et al., 2017; Holloway et al., 2018; Ghodke et al., 2019; Davis et al., 2020). Such I3Ms have been applied across various BLV-accessible graphic areas, including: art (Holloway et al., 2019a; Iranzo Bartolome et al., 2019; Butler et al., 2023); education (Ghodke et al., 2019; Shi et al., 2019; Reinders et al., 2020); and mapping and navigation (Götzelmann et al., 2017; Holloway et al., 2018; Shi et al., 2020). I3Ms with audio labels are especially useful for BLV users who are not fluent braille readers. Stored as text and synthesised in real-time, audio labels are easier to update compared to labels on non-interactive models. Many I3Ms also support multiple levels of audio labelling (Holloway et al., 2018; Shi et al., 2019; Reinders et al., 2020), extracted through unique button presses or touch gestures, enabling them to convey far more information than the written descriptions supplied alongside tactile graphics and non-interactive models.
I3Ms are inherently multimodal. Multimodality can improve the adaptability of a system (Reeves et al., 2004), and when modalities are combined, they can increase the resolution of information the system conveys (Edwards et al., 2015) and enable more natural interactions (Bolt, 1980). For BLV users, combining modalities has been shown to improve confidence and independence (Cavazos Quero et al., 2021). Modality adaptability allows BLV users to choose interaction methods based on context, ability, or effort. For example, a user may be uncomfortable engaging in speech interaction in public due to privacy concerns (Abdolrahmani et al., 2018), opting instead to use button or gesture-based inputs. Richer resolutions of information can be achieved when combining modalities, e.g., the tactile features of a 3D-printed model with haptic vibratory and auditory outputs. Combining modalities is critical to overcoming the ‘bandwidth problem’, in which BLV users’ non-visual senses cannot match the capacity of vision, necessitating their combined use (Edwards et al., 2015).
While early I3Ms primarily relied on button or gesture-based triggered audio labels, recent research has explored integrating speech interfaces and conversational agents. This shift is driven by research finding that BLV people find voice interaction convenient (Azenkot and Lee, 2013), along with widespread adoption (Pradhan et al., 2018) and high usage (Abdolrahmani et al., 2018) of conversational agents among BLV users. For instance, Quero et al. (Cavazos Quero et al., 2019) combined a tactile graphic of a floor plan with a conversational agent that focused on indoor navigation; however, voice interaction was performed through a connected smartphone rather than the graphic itself. Other works have developed voice-controlled agents to guide BLV users in exploring 3D-printed representations of gallery pieces (Iranzo Bartolome et al., 2019; Cavazos Quero et al., 2018). These systems, however, have primarily focused on basic command-driven interactions more analogous to voice menus rather than conversational dialogue. Shi et al. (Shi et al., 2017, 2019) proposed incorporating conversational agents into I3Ms to allow BLV users to expand their understanding of the modelled content.
Recent research into I3Ms has begun to explore modalities beyond audio and touch. Quero et al. (Cavazos Quero et al., 2018) designed an I3M representing an art piece that integrated localised audio, wind, and heat output. However, participants faced challenges in interpreting the semantic mapping of modalities, e.g., whether heat represented the morning sun or the shine of starlight. In our previous work, we found that BLV users desired I3Ms that combined touch, haptic vibratory feedback, and conversational dialogue (Reinders et al., 2020). Additionally, we co-designed an I3M with BLV co-designers to explore how these modalities could create natural interactions (Reinders et al., 2023), inspired by the ‘Put-That-There’ paradigm (Bolt, 1980). This work led to five I3M design recommendations, including: support interruption-free tactile exploration; leverage prior interaction experience with personal technology; support customisation and personalisation; support more natural dialogue; and tightly coupled haptic feedback. These studies motivated our current work, with participants finding the I3M engaging, and several beginning to embody it.
2.3. The Embodiment of Agents
Dourish (Dourish, 2001) presents a seminal view that embodiment “denotes a form of participative status”, where embodied interaction in natural forms of communication is influenced both by physical presence and context. They posit that this perspective applies to “spoken conversations just as much as to apples or bookshelves”. Within the design of agent-based systems, embodiment is largely understood as the use of different modalities – e.g., voice, visual output, gestures, gaze – to imbue machines with human-like behaviours and characteristics, making them appear more ‘alive’; with an enhanced perception of social presence that is capable of approximating human-human social interaction (Cassell, 2000; Lester et al., 1997; Lankton and Tripp, 2015; Biocca, 1999). Such agents are often described as being more ‘lifelike’ or possessing ‘lifelikeness’ (Lester et al., 1997; Cassell et al., 1999; Cassell and Vilhjálmsson, 1999; Cassell and Thorisson, 1999; Lester et al., 1999).
Research into embodiment has predominantly focused on sighted users. As systems become more embodied, users’ perceptions of social presence can increase, motivating users to treat them more favourably (Reeves et al., 2004). Lankton et al. (Lankton and Tripp, 2015) described how social presence can make systems appear more sociable, warm, and personal, while Cassell (Cassell, 2001) noted that embodying technology allows users to locate intelligence, illuminating what would otherwise be an ‘invisible computer’. Importantly, embodied agents exhibiting higher levels of social presence and perception have been shown to enhance user perception of engagement (Shamekhi et al., 2018; Luger and Sellen, 2016; Heuwinkel, 2013; Cassell, 2001) and trust (Bickmore and Cassell, 2001; Shamekhi et al., 2018; Bickmore et al., 2013; Minjin Rheu and Huh-Yoo, 2021).
In the HCI community, efforts to embody intelligent agents have focused on enhancing social perception through conversational, visual, and physical attributes. Conversational embodiment includes mimicking human voices (Cassell, 2001), small talk (Liao et al., 2018; Pradhan et al., 2019; Cassell, 2001; Shamekhi et al., 2018; Bickmore and Cassell, 2001), greetings (Cassell, 2001; Luria et al., 2019; Shamekhi et al., 2018; Lester et al., 1997), and conversational turn-taking (Cassell, 2001; Kontogiorgos et al., 2020). Lester et al. (Lester et al., 1997) described the persona effect, proposing that social presence can increase when agents exhibit personality, making them appear more lifelike. Many conversational agents, like Siri, incorporate attributes of conversational embodiment.
Visually embodied agents, which are often also conversationally embodied, associate systems with virtual avatars or characters, many of which have faces (Cassell, 2001; Kontogiorgos et al., 2020; Bickmore et al., 2013), and are capable of gesturing (Cassell, 2001; Bickmore and Cassell, 2001) and gaze (Kontogiorgos et al., 2020; Shamekhi et al., 2018; Bickmore and Cassell, 2001). Visual embodiment extends beyond the visual feedback that mainstream conversational agents emit, e.g., rings of light or animations used to indicate that agents are processing or ‘thinking’. Depending on the task, visually and conversationally embodied agents can improve social perceptions (Shamekhi et al., 2018; Luria et al., 2019; Cassell, 2001; Nowak and Biocca, 2003), trust (Bickmore and Cassell, 2001; Bickmore et al., 2013; Minjin Rheu and Huh-Yoo, 2021; Shamekhi et al., 2018), and engagement (Shamekhi et al., 2018; Cassell, 2001).
Embodied agents can extend beyond virtual embodiment and include physical bodies (Kontogiorgos et al., 2020; Luria et al., 2017). Lura et al. (Luria et al., 2017) found that users’ situational awareness was higher when using a physically embodied robot to perform smart-home tasks compared to an unembodied voice agent. Robots capable of emitting human-like warmth have been associated with increased perceptions of friendship and presence (Nie et al., 2012). Recent research has explored the use of haptic vibratory feedback to create lifelike cues, such as heartbeats (Borgstedt, 2023) and handshaking (Bevan and Stanton Fraser, 2015). Physically embodied agents can be perceived as having higher social presence than non-physically embodied agents (Kidd and Breazeal, 2004). Additionally, they have been found to be more forgivable during unsuccessful interactions; however, depending on their realism, thi can become distracting in high-stakes scenarios (Kontogiorgos et al., 2020).
2.4. The Embodiment of I3Ms
The design of embodied agents has traditionally focused on the perception of sighted users. However, in the last decade, work has begun exploring how human-human conversational cues can be converted into non-visual formats for BLV users. Many of these efforts utilise haptic belts/headsets (Rader et al., 2014; McDaniel et al., 2018) or AR glasses (Qiu et al., 2016, 2020) to convey body movements like head shaking, nodding, and gaze. Despite this, the impact of agent embodiment, and specifically embodied I3Ms, on BLV users’ perceptions remains unstudied.
In our previous work, we found that a number of participants desired I3Ms that felt more lively and human (Reinders et al., 2023). Participants suggested integrating a conversational agent with a personality, incorporating haptic vibratory feedback to make the I3M feel alive, and enabling speech to originate directly from the model itself. This desire for more human-like interactions aligns with findings with conversational agents. Choi et al. (Choi et al., 2020) reported that many BLV users valued human-like conversation with conversational agents as critical in relationship building, while Abdolrahmani et al. (Abdolrahmani et al., 2018) observed that BLV users preferred agents they could talk with as if they were other people rather than pieces of technology. Karim et al. (Karim et al., 2023) recommended that agents have customisable personalities, recognising that such features may not be relevant in all scenarios, such as group settings. Collins et al. (Collins et al., 2023), however, found hesitance among BLV users towards embodied AI agents in VR applications. Whether these perspectives and desires extend to I3Ms is unknown.
Further impetus for studying I3M embodiment comes from the links between embodiment, engagement, and trust with embodied agents that have been previously identified for sighted users. Trust and engagement are especially critical for BLV users, as the usefulness of accessible graphics, aids, or tools depends on users’ willingness to engage with and accept/rely on the information they provide. This directly determines the extent to which users rely on these tools (Phillips and Zhao, 1993; Wu et al., 2017; Abdolrahmani et al., 2018). Therefore, it is crucial to explore whether I3Ms can be effectively embodied and whether embodiment fosters greater trust and engagement between users and their I3Ms.
3. Embodied Design Factors
Our work was influenced by interpretations of embodiment and embodied interaction proposed by Dourish (Dourish, 2001) and Cassell (Cassell, 2001). Interfaces can be embodied using a range of design characteristics, including visual embodiment, conversational embodiment, and physical embodiment. However, as BLV users, particularly those who are totally blind, may not be able to fully discern visual characteristics, we approached I3M embodiment from a purely non-visual perspective. Traditional visual embodiment design factors, such as virtual avatars or gaze, were not considered. We drew from existing literature to identify a range of design factors shown to enhance perceived levels of social perception and embodiment. These were split between conversational and physical embodiment.
3.1. Model Selection & Design
To investigate conversational and physical embodiment, we created two I3Ms – (1) the Egyptian Pyramids and (2) the Saturn V Rocket [Figure 3]. These subjects were selected because they represent the types of materials commonly found in museums, galleries, or in science or history classes. Additionally, they facilitated the design of models with multiple components that could be individually picked up, detached, and manipulated, which has been shown to increase engagement (Reinders et al., 2020). Each I3M can be configured in two states – High Embodied Mode (HEM) or Low Embodied Mode (LEM) – based on five non-visual design factors (Sections 3.2 & 3.3).
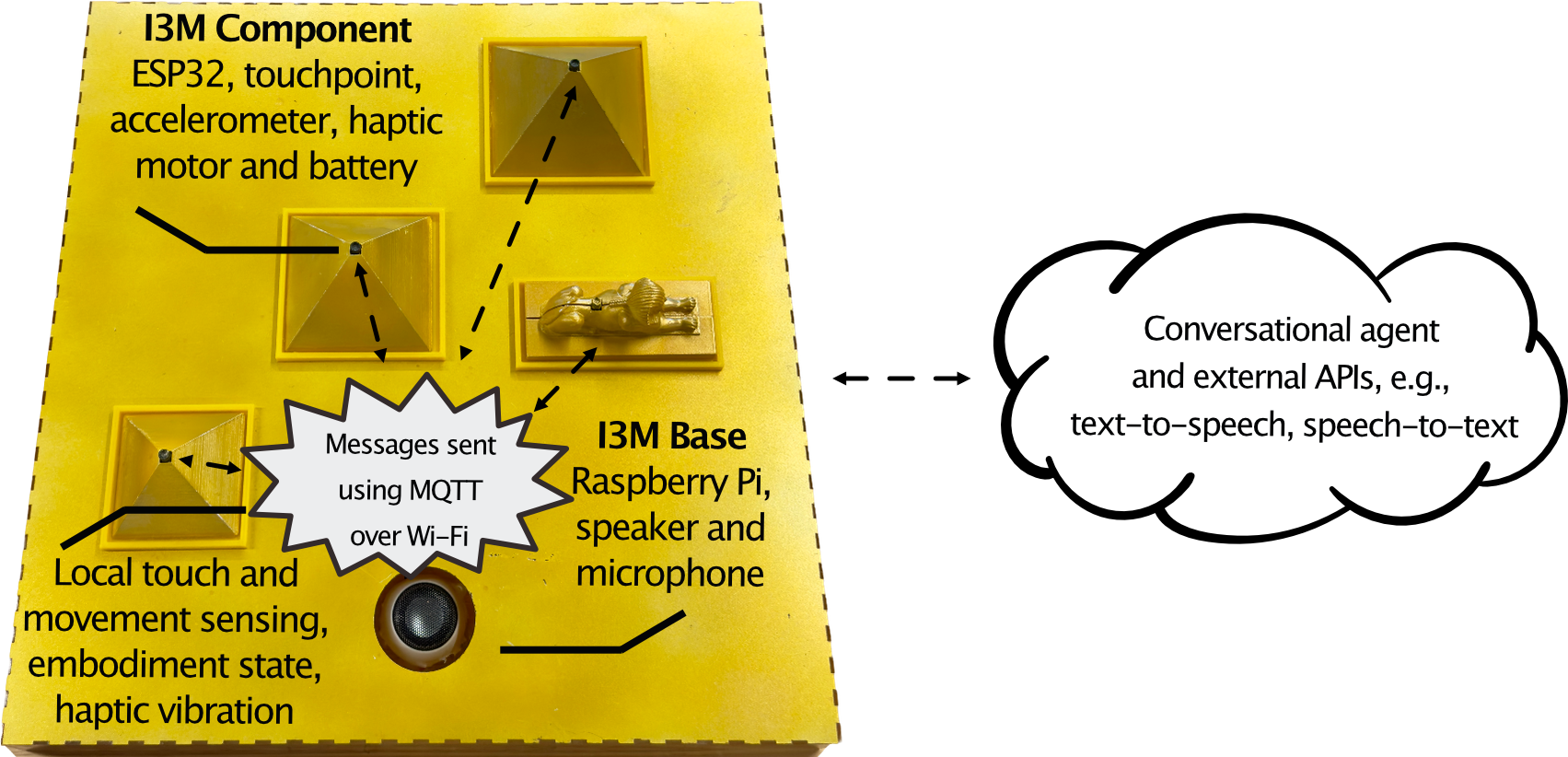
This figure includes an image outlining the architecture of the HEM I3Ms. Shown is a picture of the Egyptian Pyramid I3M, with annotations on top pointing to the various components and hardware it includes. The I3M Base includes a Raspberry Pi, speaker, and microphone. Four I3M Components are highlighted, each including an ESP32, touchpoint, accelerometer, haptic motor and battery. A bubble is depicted in between the Base and Components, highlighting the communication of messages using MQTT over Wi-Fi. These messages include local touch and movement sensing, embodiment state, and haptic vibrations. To the right is a bubble encompassing all the external APIs and libraries that the I3Ms use. This includes Dialogflow for the conversational agent, as well as text-to-speech and speech-to-text libraries.
The base of each I3M was constructed from laser-cut acrylic, serving as a stand to hold the constituent components of the I3M and to house a Raspberry Pi, speaker, and microphone (Figure 2). The Pi powered each I3M and handled the following responsibilities:
-
•
Maintaining a Wi-Fi connection with each I3M component and operating as a message broker (MQTT) to facilitate messaging between the Raspberry Pi and each component.
-
•
Managing the embodied state of the I3M by setting the design factors to operate in either HEM or LEM mode.
-
•
Controlling speech and auditory output through the connected speaker and microphone, using the Picovoice Porcupine wake word library and Google Cloud Speech-to-Text and Text-to-Speech for speech input and synthesis.
-
•
Connecting to the I3M’s conversational agent, built using Google Dialogflow, and integrating ChatGPT to perform external searches triggered by Dialogflow’s fallback intent.
Each I3M had four 3D-printed components. For the Saturn V Rocket, these were the Stage A, Stage B, and Stage C modules, and the Launch Tower. For the Egyptian Pyramid, these included the Sphinx, Great Pyramid, Pyramid of Menkaure, and Pyramid of Khafre. Each component had an ESP32 microcontroller embedded in the print, providing localised touch and movement sensing and haptic vibratory output. The microcontroller had integrated Wi-Fi, capacitive touch-sensing GPIO pins, and was connected to a touchpoint 3D-printed with conductive filament, a 3.7V 400mAh lithium polymer battery, an MPU6050 accelerometer and gyroscope, a DRV2605L haptic motor controller, and a vibrating haptic disc.
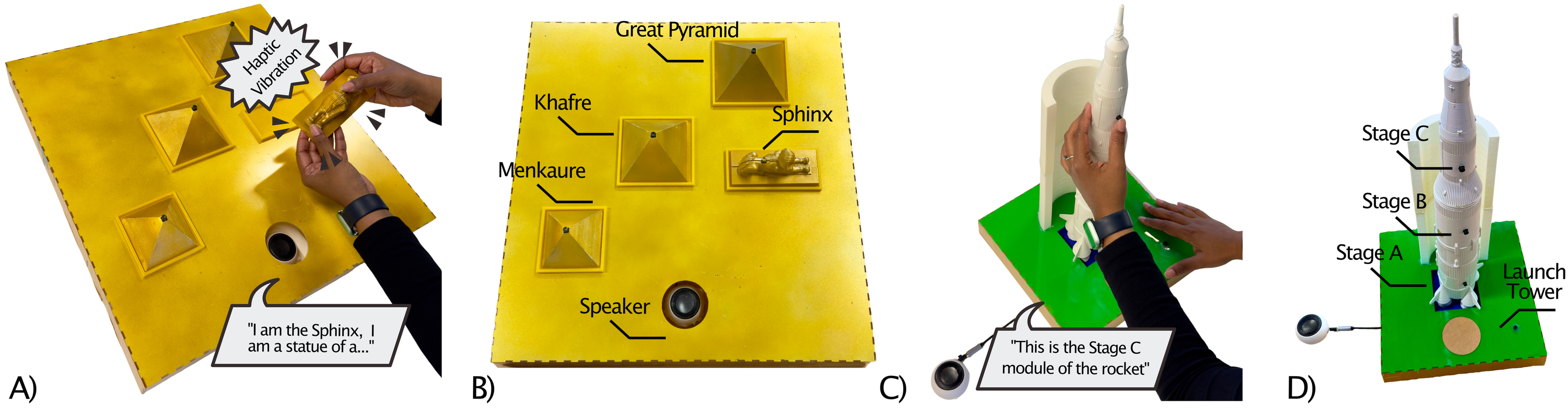
This figure includes four images showcasing our two I3Ms. In A), the Egyptian Pyramids I3M is configured in HEM. The user is pressing the touchpoint on the Sphinx, which emits localised haptics, and, using an embodied personified voice and first-person narration, responds through a speaker contained within the I3M’s enclosure. In B), the I3M consists of four 3D-printed components – the Great Pyramid, Sphinx, and Pyramids of Khafre/Menkaure – each of these is labelled, as is the speaker that is embedded inside the I3M enclosure/case in HEM. In C), the Saturn V Rocket I3M is configured in LEM. It includes a base made of acrylic that is painted green, representing the ground. Shown is a user pressing the Stage C module touchpoint. Speech output is played back through a speaker that is housed externally from the I3Ms enclosure — “This is the Stage C module of the rocket”; In D), the Saturn V Rocket I3M consists of four 3D-printed components, the Stage A, Stage B and Stage C rocket modules, which can be detached, and the rockets Launch Tower. The rocket components can be stacked on top of one another as they have magnets attached.
3.1.1. Touch Gestures.
Each I3M component, such as the Sphinx, had a touchpoint that protruded from its surface and was printed using a touch capacitive filament. Touch sensors underwent an automatic calibration process upon I3M startup. Touch gestures were implemented based on findings from our previous co-design work (Reinders et al., 2023). To enable independent tactile exploration, touchpoints needed to be activated before gestures could be used. Users could perform an Activate Press gesture by holding the touchpoint down for one second. This would activate the sub-component and play an audio label identifying it. Once activated, users could perform a Double Press gesture to cycle through 12 audio labels that provided different facts and information about the sub-component. For example, for the Sphinx, this included details about its location, the material it was made from, its construction date, purpose, size, and physical appearance. The final gesture supported was a Long Press, performed by holding down the touchpoint for two seconds. This gesture invoked the I3M’s conversational agent.
3.1.2. Conversational Agent.
Users could perform a Long Press or use the wake word – ‘Hey Model’ – to invoke the I3M’s conversational agent. The attached microphone recorded user queries, which were processed by the agent built using Google Dialogflow. The agent was trained to answer questions related to each component using a corpus containing all the information extractable via touch gestures. This dataset contained an average of 500 words of facts per component. For example, for the Sphinx, this included details about its missing nose, potential astronomical significance, historical restorations, and symbolic meaning. Like audio labels, speech responses were output through the I3M’s speaker, synthesised using the same high-quality voice. If the agent could not answer a query directly, it offered to perform an external search. Upon approval, the agent would send the query to ChatGPT, configured with a context to ensure consistency with the other agent outputs. For example, “You are an intelligent assistant that answers questions in 25 words or less about ancient Egypt and the Pyramids, including the Pyramid of Menkaure, Khafre, Khufu, and the Sphinx of Giza”.
3.1.3. Haptic Vibratory Feedback.
Each model component contained a haptic disc capable of delivering localised vibratory feedback, generated using the DRV2605 Waveform library. Haptic vibrations were emitted as system feedback when touch gestures were performed, following established recommendations (Reinders et al., 2023). These corresponded to the type of gesture executed: Activate (Strong Buzz, 150ms), Double (Strong Short Double Click), or Long Press (Strong Buzz, 500ms).
3.2. Conversational Embodiment Design Factors
In earlier work, we observed that I3M conversational agents should speak with high-quality, human-like voices (Reinders et al., 2023). When designing our I3Ms, the researchers made the decision that voice quality should be independent of embodiment state, to prevent preferences for high-quality voices from overpowering other design factors.
3.2.1. DF#1: Introductions and Small Talk.
Choi et al. (Choi et al., 2020) found that BLV people prefer agents that engage in human-like conversation, as this can help in relationship building. Embodied agents have been designed to introduce themselves to users (Shamekhi et al., 2018; Cassell, 2001; Luria et al., 2019; Lester et al., 1997) and engage in small talk (Liao et al., 2018; Pradhan et al., 2019; Cassell, 2001; Shamekhi et al., 2018). In our I3Ms, when configured in HEM, the conversational agent introduces itself to the user, and could detect and respond to small talk during interactions, using a version of Dialogflow’s small talk module. To avoid interrupting independent tactile exploration, HEM I3Ms only engage in user-initiated small talk, adhering to an established design recommendation (Reinders et al., 2023). This design factor can be configured as follows:
-
•
HEM: When turned on, the I3M is introduced, e.g., “Hello and welcome to the Pyramid model. Let’s learn about ancient Egyptian history together!”. Additionally, when a user initiates small talk, the I3M responds appropriately, e.g., when greeted with “Hello Sphinx”, it replies, “Hi, how are you?”.
-
•
LEM: When an I3M is turned on, a loading message is played, e.g., “Loading Pyramid model”. When a user engages in small talk, the I3M does not respond.
3.2.2. DF#2: Embodied Personified Voices.
Influenced by works where users personified and imbued characters into conversational agents (Purington et al., 2017; Pradhan et al., 2019; Lester et al., 1997), we designed HEM so that model components could ‘speak with their own unique voice’. This was achieved by assigning distinct synthesised voices with each model component, emulating aspects of a one-for-one social presence (Luria et al., 2019). HEM components cannot converse among themselves, in line with Luria et al. (Luria et al., 2019), who observed that users felt discomfort when two active social presences interacted with each other. In contrast, LEM I3Ms employ a singular voice, operating under a one-for-all social presence, where all model components are inhabited as a group.
-
•
HEM: Each I3M component speaks with its own unique synthesised voice, using a one-for-one social presence.
-
•
LEM: All I3M components speak with a unified synthesised voice, using a one-for-all social presence.
3.2.3. DF#3: Embodied Narration Style.
To further explore the personification of the models, we scripted speech output to be narrated from either a first or third-person perspective. This was influenced by work showing that some users anthropomorphise agents by using first and second-person pronouns (Liao et al., 2018; Coeckelbergh, 2011).
-
•
HEM: I3M components phrase verbal responses using first-person narration, e.g., “I am the Great Sphinx of Egypt. I am a statue of a reclining sphinx, a mythical creature. I have the head of a human and the body of a lion. Many suggest that my nose was lost to erosion, vandalism, or damage”. This also extended to external search responses fetched using ChatGPT, which had a modified context, e.g., “You are the Great Sphinx of Egypt and serve as an intelligent assistant, you answer questions in 25 words or less from a first-person perspective about yourself, ancient Egypt, and the Pyramids”.
-
•
LEM: Verbal responses are generated using objective third-person narration, e.g., “This is the Great Sphinx of Egypt. It is a statue of a reclining sphinx, a mythical creature with the head of a human and the body of a lion. Many suggest its nose was lost to erosion, vandalism, or damage”.
3.3. Physical Embodiment Design Factors
I3Ms are inherently designed to be perceived physically, i.e., picked up and tactually observed or manipulated. We sought to explore ways in which the tangible nature of I3Ms could be enhanced by physically embodying presence.
3.3.1. DF#4: Embodied Vibratory Feedback.
In our previous research, a BLV user described an I3M component as ‘lifeless’ except when it was emitting haptic vibrations (Reinders et al., 2023). This influenced our focus on richer haptic vibratory feedback, supported by other work exploring how haptics imbue lifelike cues (Nie et al., 2012; Bevan and Stanton Fraser, 2015; Borgstedt, 2023). We designed HEM I3Ms to emit localised haptic vibratory feedback, creating a sense of physical presence. In contrast, LEM I3Ms generate haptics, but only as system feedback confirming gesture inputs. This decision aligns with the recommendations in (Reinders et al., 2023), since model usability could be impacted if haptics were turned off entirely.
-
•
HEM: I3M components generate haptic vibratory feedback to embody a sense of physical presence. Components use haptics to highlight themselves during interactions, e.g., when a component identifies itself it emits a localised vibration (Transition Ramp Up - 0 to 100%), or when it is referenced during an auditory response (Strong Buzz, 1000ms).
-
•
LEM: Haptics are used only to confirm when a touch gesture has been correctly performed. Components do not use localised haptics to embody physical presence.
3.3.2. DF#5: Location of Speech Output.
Pradhan et al. (Pradhan et al., 2019) identified that an agent’s proximity can influence how human-like it is perceived. Agents closer to the user, or capable of operating across multiple devices to broadcast ubiquity, are often thought of as more present. Due to size constraints, we could not embed speakers directly into I3M components. However, the location of the auditory output can be configured to vary by the position of the speaker.
-
•
HEM: The speaker used by the I3M to output speech is housed within the enclosure.
-
•
LEM: The speaker used by the I3Ms to output speech is positioned externally from the enclosure, approximately 30cm to the left side of the model, reducing proximity.
4. User Study – Methodology
4.1. Hypotheses
We designed a controlled user study to explore and understand whether I3Ms configured with different embodied design factors influence BLV end-users’ perceptions of model embodiment, engagement, and trustworthiness. The study utilised both the Saturn V Rocket I3M and Egyptian Pyramids I3M, each configurable into two states – High Embodied Mode (HEM) and Low Embodied Mode (LEM) – as described in Section 3. We hypothesised that:
-
•
H#1: HEM I3Ms are perceived as more embodied than LEM I3Ms
-
•
H#2: HEM I3Ms are perceived as more engaging than LEM I3Ms
-
•
H#3: HEM I3Ms are perceived as more trustworthy than LEM I3Ms
4.2. Participants
Twelve BLV participants were recruited from our lab’s participant contact pool (Table 1). This sample size () falls within the range commonly seen in BLV accessibility studies, which often involve anywhere between 6-12 participants (Holloway et al., 2022; Nagassa et al., 2023; Shi et al., 2017, 2020) due to the low incidence of blindness in the general population and associated recruitment challenges (Butler et al., 2021).
Participants ranged in age from 27 to 78 years ( = 50, = 16.6). Nine participants self-reported as totally blind, while three reported being legally blind with low levels of light perception. Participants also varied in their prior experience with tactile graphics: Many reported substantial exposure and confidence (), some reported some use but lacked confidence (), and others reported limited or no exposure ( and , respectively).
Familiarity with 3D-printed models was slightly less common. All participants regularly used conversational agents, including Google Assistant (), Siri (), Alexa (), and ChatGPT (). These interfaces were accessed on various devices, such as smartphones (), smart speakers/displays (), smartwatches (), computers () and tablets ().
Participant demographic information, level of vision, accessible formats used, familiarity with tactile graphics and 3D models, and use of conversational agents. Participant #: 1 2 3 4 5 6 7 8 9 10 11 12 Level of Vision: Legally Blind ✓ - ✓ - - - - - - - ✓ - Totally Blind - ✓ - ✓ ✓ ✓ ✓ ✓ ✓ ✓ - ✓ Accessible Formats Used: Braille ✓ ✓ ✓ ✓ ✓ ✓ - ✓ ✓ ✓ ✓ ✓ Audio ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ Tactile Graphics ✓ ✓ ✓ ✓ ✓ ✓ - ✓ ✓ ✓ ✓ ✓ 3D Models - ✓ ✓ ✓ ✓ ✓ - - - - ✓ ✓ Familiarity (1: Not Familiar - 4: Very Familiar): Tactile Graphics 2 3 3 4 4 4 1 3 4 1 4 3 3D Models 1 2 3 4 4 4 1 2 3 1 4 3 Conversational Interfaces Used: Alexa - ✓ - - - ✓ - ✓ - ✓ - - ChatGPT ✓ ✓ - - ✓ - - ✓ - - - - Google Assistant ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ - ✓ ✓ Siri - ✓ ✓ ✓ ✓ ✓ ✓ ✓ ✓ - ✓ ✓
4.3. Study Measures
We used a series of questionnaires and asked participants to subjectively rate the I3Ms in order to investigate our hypotheses.
For Hypothesis H#1, to measure how embodied participants perceived the I3Ms, we utilised the Godspeed Questionnaire Series (GQS) (Bartneck et al., 2009). Originally devised to measure users’ social perceptions of robot and agent-based systems, GQS subscales such as anthropomorphism and intelligence have recently been applied to measure aspects of embodiment and liveliness in conversational agents (Shamekhi et al., 2018) and robots with human-like abilities (Kontogiorgos et al., 2020). We selected four subscales – anthropomorphism, animacy, likeability, and intelligence – as we felt each provides insight into components of embodied sociability. For example, anthropomorphism captures the attribution of human-like characteristics, animacy reflects perceptions of liveliness, likeability gauges formation of positive impressions, and intelligence focuses on perception of ability. Additionally, we also explored model embodiment by asking participants for their subjective perceptions by expressing the concept of ‘embodiment/embodied’ using the terms ‘lively/liveliness’ to ensure clarity. We felt this terminology would have more meaning to participants, and aligns with previous works that have used the similar terms ‘lifelike/lifelikeness’ to describe embodied agents (Lester et al., 1997; Cassell et al., 1999; Cassell and Vilhjálmsson, 1999; Cassell and Thorisson, 1999; Lester et al., 1999).
To explore Hypothesis H#2, we used two engagement measures – the User Engagement Scale [Short Form] (UES-SF) and the Playful Experiences Questionnaire (PLEXQ). The UES-SF measures user engagement as the depth of a user’s perceived investment with a system (O’Brien, 2016). It consists of 12 five-point Likert items across four subscales – focused attention, perceived usability, aesthetic appeal, and reward (O’Brien et al., 2018). The UES-SF has been widely applied across HCI to measure engagement in contexts such as interactive media (Carlton et al., 2019), video games (Wiebe et al., 2014), and 3D-printed building plans for BLV people (Nagassa et al., 2023). We used all four subscales. To complement the UES-SF, we also used PLEXQ, which measures playfulness, pleasurable experiences, and playful engagement (Boberg et al., 2015). PLEXQ is commonly used to assess how engaging games and game-like experiences are (Bischof et al., 2016; Cho et al., 2024). We used eight subscales that we felt were most relevant to I3Ms – captivation, challenge, control, discovery, exploration, humor, relaxation, and sensation.
To supplement these measures of perceived engagement, we also captured two behavioural metrics (time spent and interactions performed during tasks), as more time spent with the model and more interactions may indicate greater immersion and enjoyment (O’Brien and Lebow, [n. d.]; Doherty and Doherty, 2018). Note that comparing these between the LEM and HEM conditions was meaningful as the length of responses in both conditions was similar and every interaction type was available in both modes.
To investigate Hypothesis H#3 and measure trust, we utilised the Human-Computer Trust Model (HCTM). The HCTM conceptualises trust as a multifaceted construct, encompassing users’ perceptions of the perceived risk, benevolence, competence, and reciprocity during interactions. These perceptions can influence users’ reliance on a system and their likelihood of continued use (Siddharth Gulati and Lamas, 2019). Previous work has demonstrated the utility of HCTM in assessing trustworthiness in conversational agents like Siri (Gulati et al., 2018), machine learning systems (Guo et al., 2022), and other human-like technologies such as large language models (Salah et al., 2023) and chatbots (Degachi et al., 2023).
Based on pilot study feedback, we made minor adjustments to specific subscale items in the UES-SF and PLEXQ measures. For instance, the aesthetic appeal (UES-SF) and sensation (PLEXQ) subscales were adjusted, as concepts of “attractiveness”, “aesthetics”, and “visuals” held little meaning to our pilot user in BLV contexts. They recommended adding the phrase “to my senses” to these items. Per (O’Brien et al., 2018)’s guidance on modifying the UES-SF, we did not report an overall UES score, instead focusing on individual components of engagement. These adjustments also motivated our decision to add our own questions gathering participants’ subjective ratings of the I3Ms, supplementing the validated scales and providing additional nuance and insight. The modified UES-SF and PLEXQ, along with GSQ and HCTM, are provided in the Appendices.
4.4. Experiment Conditions
Our user study used a within-subject design. All participants were exposed to (one) LEM and (one) HEM-configured I3M. To control for bias related to model type (Rocket/Pyramids) and design factor state (LEM/HEM), the order in which the I3Ms were presented, along with their associated LEM/HEM configuration, was counterbalanced. The activities that participants completed with each I3M remained the same, regardless of its LEM/HEM state, and could be completed in either mode without significant difficulty.
4.5. Procedure
Each user study session lasted approximately two hours and included at least one researcher being present. Sessions began with the researcher providing an overview of the research project, and were divided into the following stages:
-
(1)
Training. Participants were guided through a 10-minute training exercise, which allowed them to familiarise themselves with how I3Ms operate. We designed and built an I3M that represented a non-descript sphere for training. Participants were first asked to explore the I3M tactually when it was turned off, before being taught how to extract basic information from the I3M using touch gestures, and asking questions through the conversational interface. The training I3M did not operate in either LEM or HEM mode and would, using a low-quality synthesised voice, only respond by confirming when interactions had been successfully performed (e.g., “Double Press”, “Recording query”). Operating outside of LEM/HEM states was a deliberate design decision to allow training of basic interaction functionality without biasing future LEM/HEM exposure.
-
(2)
Exposure to LEM/HEM I3Ms.
-
(a)
Activities. Participants were introduced to their first I3M, configured in one of the LEM/HEM states, and completed a walkthrough activity. The I3M identified and described each component it included, with participants given the opportunity to tactually explore the I3M throughout. These walkthroughs were carefully curated so that participants encountered the majority of system functionality specific to the HEM/LEM design factors111The only exception to this was the small talk component of the introductions and small talk design factor, which, unlike all other design factors that were explicit, required user initiation (see Section 3.2.1).. After the walkthrough, participants were given up to five minutes to explore the models, during which they could interact with the I3M in any way they wished. Participants were then asked to complete four researcher-directed information-gathering tasks (e.g., finding out how long it took to build the Great Pyramid, what happened to the nose of the Sphinx, or the significance of the Pyramids). Participants could access this information using their choice of either touch gesture interaction or using the model’s conversational agent. Before concluding, participants were given up to an additional five minutes for a free play task designed to mimic undirected, real-world use. They were instructed to discover something interesting about the modelled concept that they were not aware of prior.
-
(b)
Questionnaire Scales. Participants were taken through the questionnaire scales – GSQ, PLEXQ, UES-SF, and HCTM. In addition, participants were asked to rate how lively, engaging, and trustworthy the I3M was, using 5-point Likert scales. On average, these took 15 minutes to complete.
-
(c)
Remaining Model. Participants would then complete 2(a) and 2(b) again with the second I3M, configured in the remaining LEM/HEM state. Participants spent an average of 30 minutes with each I3M.
-
(a)
-
(3)
Semi-Structured Interview. At the end of the session, participants were asked questions about specific interactions with the LEM/HEM I3Ms and were asked to rank how lively, engaging and trustworthy each model was. We also asked about the role each design factor played, and whether they impacted perceptions of how lively, engaging, and trustworthy the I3Ms were. On average, it took 20 minutes to answer these questions.
4.6. Data Collection & Analysis
All sessions were video-recorded and subsequently transcribed. Collected data included responses to scale questions, semi-structured interview questions, and participant comments made during task completion. The time participants spent completing tasks, as well as the number of interactions they performed, were also recorded. Descriptive statistics were calculated on all subscale responses – GSQ, UES-SF, PLEXQ, and HCTM – as well as for interview questions that ranked the I3Ms and individual embodiment design factors.
For data that did not follow a normal distribution (e.g., our scale data), we conducted non-parametric statistical tests, specifically Wilcoxon signed-rank tests. Binomial tests were performed on the rankings of the I3Ms and the impact ratings of individual embodiment design factors. Paired t-tests were conducted on data that was normally distributed (e.g., time taken to complete tasks). We opted for one-tailed tests because our hypotheses were explicit in nature (described in Section 4.1). This approach was deliberate, allowing us to dedicate more power to detecting effects in one direction.
The analysis should be interpreted in light of both the exploratory nature of our user study and our small sample size ( 12). This influenced our approach in two ways. First, from the outset, due to our small sample size, we decided not to use 0.05 as the sole determinant of significance (Shamekhi et al., 2018; Cramer and Howitt, 2004), instead marking results 0.05 as significant (∗) and 0.05 0.1 as marginally significant (∧). Second, given the exploratory nature of our work, in order to reduce the risk of overlooking meaningful results (false negatives), we chose not to apply corrections for multiple comparisons (although this does increase the risk of false positives).
5. Results
Results are presented based on our hypotheses (Section 4.1) and separated across the embodiment of the I3Ms, engagement, and trust. Each section presents quantitative results, including questionnaire scales, rankings of the models and HEM/LEM-configured design factors, and qualitative results, in the form of participant responses from the semi-structured interview.
5.1. Embodiment of I3Ms
5.1.1. GSQ Scales.
HEM I3Ms elicited higher mean scores compared to I3Ms with LEM across all GSQ subscales – anthropomorphism ( +0.67), animacy ( +0.46), likeability ( +0.27), and intelligence ( +0.29). We conducted one-tailed Wilcoxon signed-rank tests for each GSQ subscale (Table 2), using design configuration (HEM, LEM) as the independent variable to assess significance. The positive effect of HEM was statistically significant across all GSQ subscales – anthropomorphism (), animacy (), likeability (), and intelligence ().
| Godspeed Questionnaire | |||||||||||
| Descriptive Statistics | Wilcoxon Test | ||||||||||
| HEM I3Ms | LEM I3Ms | ||||||||||
| Scale | M | SD | V | M | SD | V | z-score | p-value | |||
| Anthropomorphism | 4.00 | 3.75 | 1.36 | 1.85 | 3.00 | 3.08 | 1.35 | 1.83 | 2.288 | 0.011∗ | |
| Animacy | 5.00 | 4.17 | 1.14 | 1.31 | 4.00 | 3.71 | 1.37 | 1.87 | 1.895 | 0.029∗ | |
| Likeability | 5.00 | 4.58 | 0.68 | 0.47 | 4.50 | 4.31 | 0.78 | 0.60 | 2.428 | 0.008∗ | |
| Intelligence | 5.00 | 4.46 | 0.71 | 0.50 | 4.50 | 4.17 | 0.90 | 0.81 | 2.333 | 0.010∗ | |
| Did you find that the I3M felt lively? | |||||||||||
| Liveliness | 5.00 | 4.50 | 0.65 | 0.42 | 4.00 | 4.00 | 0.91 | 0.83 | 2.121 | 0.017∗ | |
| Did the design factors impact your perception of how lively the HEM I3M was? | |||||||
| Design Factor | Descriptive Statistics | Binomial Test | |||||
| M | SD | V | k, n | p-value | 95th CI | ||
| DF#1: Introductions & Small Talk | 4.00 | 4.17 | 0.55 | 0.31 | 11, 12 | ¡0.001∗ | 0.661, 1.000 |
| DF#2: Embodied Personified Voices | 4.00 | 4.25 | 0.72 | 0.52 | 10, 12 | 0.003∗ | 0.562, 1.000 |
| DF#3: Embodied Narration Style | 4.00 | 4.17 | 0.90 | 0.81 | 10, 12 | 0.003∗ | 0.562, 1.000 |
| DF#4: Embodied Vibratory Feedback | 4.50 | 4.33 | 0.85 | 0.72 | 11, 12 | ¡0.001∗ | 0.661, 1.000 |
| DF#5: Location of Speech Output | 4.00 | 4.00 | 0.82 | 0.67 | 8, 12 | 0.057∧ | 0.391, 1.000 |
5.1.2. How Lively Were The I3Ms?
Participants rated how lively each I3M was immediately after being exposed to it. HEM I3Ms were perceived as more lively ( +0.50) compared to the LEM configuration (Table 2). This was statistically significant (). In the post-activity interview, participants ranked the I3Ms based on perceived liveliness. Two-thirds of participants () indicated that the HEM I3Ms had higher liveliness compared to the LEM I3Ms, with the remainder split between no difference () and the LEM configuration (). A binomial test revealed the difference between the number of participants who ranked the HEM I3Ms higher and those who either selected the LEM I3M or could tell no difference was statistically significant (, , ).
Most participants were emphatic in their selection. P2 described how the HEM I3M’s design factors “brought it [the model] to life”, continuing, “it [the HEM I3M] created a relationship, [it is] like dealing with something that is alive, it *is* talking to you”. P8 referred to the HEM I3M as “more human-like and interactive, more natural”, while P11 noted that the HEM I3M “was more like an entity… less of a computer program”. Similarly, P4 mentioned that the HEM I3M “seemed to want to interact with me … [whereas] the other one could have been talking to the moon”. Six participants explicitly referred to the HEM I3M as being “more human-like” in their explanations (P3, P4, P8, P10, P11 and P12), with P3 also stating that the LEM I3M was “too machine-like”. However, P5 felt that the HEM and LEM configurations appeared just as lively as one another, stating that “they were both pretty active”. One participant (P1) selected the LEM Rocket I3M as the most lively, citing specific elements of that model’s design as the determining factor. P1 explained, “the rocket… [its] three sections made it more real” (P1).
5.1.3. Impact of Design Factors on Liveliness.
Participants rated how each HEM design factor influenced their perception of I3M liveliness using a 5-point Likert scale (Table 3). All factors appeared to influence perceptions of the liveliness of the HEM I3Ms. Embodied vibratory feedback elicited the highest mean score, while location of speech output scored the lowest. Binomial tests revealed that the difference between the number of participants who agreed or strongly agreed, and those who were neutral or below, was statistically significant for all factors, apart from location of speech output, which was marginally significant (, , ).
5.2. Engagement of I3Ms
5.2.1. UES & PLEXQ Scales.
HEM I3Ms elicited higher mean scores across three of the four UES-SF subscales (Table 4) – focused attention ( +0.17), perceived usability ( +0.45), and aesthetic appeal ( +0.14). Wilcoxon results for these subscales were significant for both perceived usability () and aesthetic appeal (), but marginally significant for focused attention (). The reward subscale, however, showed a higher mean score for LEM I3Ms ( +0.11), and was non-significant.
HEM I3Ms exhibited marginally higher mean scores across seven PLEXQ subscales. Significant results were found for control ( +0.22, ) and sensation ( +0.17, ), while humor ( +0.16) was marginally significant (). One subscale, exploration, showed a higher mean score for LEM I3Ms ( +0.08).
| User Engagement Scale | |||||||||||
| Descriptive Statistics | Wilcoxon Test | ||||||||||
| HEM I3Ms | LEM I3Ms | ||||||||||
| Scale | M | SD | V | M | SD | V | z-score | p-value | |||
| Focused Attention | 4.00 | 3.86 | 0.95 | 0.90 | 4.00 | 3.69 | 1.00 | 0.99 | 1.500 | 0.067∧ | |
| Perceived Usability | 5.00 | 4.56 | 0.55 | 0.30 | 4.00 | 4.11 | 0.84 | 0.71 | 3.025 | 0.001∗ | |
| Aesthetic Appeal | 5.00 | 4.53 | 0.60 | 0.36 | 4.00 | 4.39 | 0.64 | 0.40 | 1.889 | 0.029∗ | |
| Reward | 5.00 | 4.64 | 0.54 | 0.29 | 5.00 | 4.75 | 0.43 | 0.19 | -2.000 | 0.977 | |
| Playful Experiences Questionnaire | |||||||||||
| Captivation | 3.00 | 3.03 | 1.34 | 1.80 | 3.00 | 3.00 | 1.20 | 1.44 | 0.233 | 0.408 | |
| Challenge | 5.00 | 4.61 | 0.49 | 0.24 | 5.00 | 4.58 | 0.55 | 0.30 | 0.333 | 0.369 | |
| Control | 4.00 | 4.25 | 0.76 | 0.58 | 4.00 | 4.03 | 0.76 | 0.58 | 2.138 | 0.016∗ | |
| Discovery | 5.00 | 4.50 | 0.60 | 0.36 | 5.00 | 4.42 | 0.72 | 0.52 | 0.905 | 0.183 | |
| Exploration | 4.00 | 4.42 | 0.60 | 0.35 | 5.00 | 4.50 | 0.60 | 0.36 | -1.732 | 0.954 | |
| Humor | 4.00 | 4.22 | 0.85 | 0.73 | 4.00 | 4.06 | 0.97 | 0.94 | 1.328 | 0.092∧ | |
| Relaxation | 5.00 | 4.31 | 0.91 | 0.82 | 4.00 | 4.22 | 0.82 | 0.67 | 0.676 | 0.249 | |
| Sensation | 5.00 | 4.53 | 0.60 | 0.36 | 4.00 | 4.36 | 0.67 | 0.45 | 1.897 | 0.029∗ | |
| Did you find that the I3M felt engaging? | |||||||||||
| Engagement | 5.00 | 4.67 | 0.47 | 0.22 | 4.00 | 4.25 | 0.60 | 0.35 | 2.236 | 0.013∗ | |
5.2.2. How Engaging Were The I3Ms?
When asked to rate how engaging each I3M was, results indicated that HEM I3Ms were more engaging ( +0.42) than LEMs (Table 4). This difference was statistically significant (). In the post-activity interview, the majority of participants () ranked the HEM I3Ms as more engaging than the LEM condition, while the remaining participants () found no difference. A binomial test revealed that these rankings were statistically significant (, , ).
Participants clearly articulated their reasons, with seven directly referencing the HEM I3M as being either “more engaging” or “interactive” in their explanations (P2, P3, P5, P8, P9, P10, and P12). P2, who felt the HEM I3M was more engaging, described the difference as “one is more [like] reading an encyclopedia and the other [the HEM I3M] is an experience”, adding that they found the HEM I3M to be more ‘playful’. P7 expanded on this, “[I] wanted to ask [the HEM I3M] more questions, I wanted to get more information, whereas [I] just accepted [the LEM I3M] as fact”. P8 went a step further, stating that the LEM I3M was “boring” while the HEM I3M was “more enthusiastic”. P10 compared the HEM I3M to their screen reader, “Jaws is neutral, it is not interactive, it gets hypnotic. Using different voices is way more engaging!”. Despite being more interested in the subject matter of their LEM I3M, P8 ultimately found the HEM I3M more engaging, explaining, “I was interested in Egypt more than space … but the way the rocket acted made it more engaging”.
As a further indication of engagement, participants spent more time interacting with the HEMs ( 99.5 seconds) compared to the LEMs ( 68.8) during the free play exercise (Table 5). A one-tailed paired t-test revealed this to be statistically significant (, ). Participants also engaged in more interactions with the HEMs ( 3.3) compared to the LEMs ( 2.2). Wilcoxon results indicated this difference was marginally significant ().
Participants also chose to spend more time using the HEM I3Ms during both the model exploration ( +29.8 seconds) and researcher-directed ( +54.4) tasks. Paired t-tests revealed that the effect of the HEMs was statistically significant for time spent during model exploration (, ) and marginally significant for time spent completing the researcher-directed tasks (, ).
Regarding interactions, participants performed more interactions with the HEMs during these tasks. Paired t-tests indicated marginal significance for both model exploration ( +1.8, , ) and researcher-directed tasks ( +0.5, , ). Notably, during the researcher-directed tasks, participants occasionally chose to continue interacting beyond what was required to complete a task, performing additional interactions. These instances favoured the HEMs () over the LEMs ().
| Task Completion (Time Spent) | |||||||||
| Descriptive Statistics | Statistical Test | ||||||||
| HEM I3Ms | LEM I3Ms | ||||||||
| Task | M | SD | M | SD | test-statistic | p-value | |||
| Model Exploration | 240.0 | 228.9 | 63.2 | 180.0 | 199.1 | 40.8 | 2.025 | 0.035∗ | |
| Researcher-Directed | 592.5 | 592.3 | 120.5 | 557.5 | 537.9 | 150.7 | 1.595 | 0.070∧ | |
| Free Play | 92.5 | 99.5 | 39.9 | 60.0 | 68.8 | 17.0 | 2.899 | 0.007∗ | |
| Task Completion (Interactions Undertaken) | |||||||||
| Model Exploration | 13.0 | 11.9 | 2.6 | 10.0 | 10.1 | 3.0 | 1.583 | 0.071∧ | |
| Researcher-Directed | 4.5 | 4.8 | 0.9 | 4.0 | 4.3 | 0.5 | 1.732 | 0.056∧ | |
| Free Play | 2.0 | 3.3 | 2.1 | 2.0 | 2.2 | 0.7 | 1.483 | 0.069∧ | |
5.2.3. Impact of Design Factors on Engagement.
Participants rated how each design factor, presented in the HEM state, impacted their perception of I3M engagement (Table 6). All five design factors appeared to influence how engaging the HEM I3Ms were perceived and were statistically significant – introductions & small talk and location of speech output (both had , , ), and the remaining three factors (all , , ).
| Did the design factors impact your perception of how engaging the HEM I3M was? | |||||||
| Design Factor | Descriptive Statistics | Binomial Test | |||||
| M | SD | V | k, n | p-value | 95th CI | ||
| DF#1: Introductions & Small Talk | 4.00 | 4.08 | 0.76 | 0.58 | 11, 12 | ¡0.001∗ | 0.661, 1.000 |
| DF#2: Embodied Personified Voices | 4.00 | 4.25 | 0.72 | 0.52 | 10, 12 | 0.003∗ | 0.562, 1.000 |
| DF#3: Embodied Narration Style | 4.50 | 4.25 | 0.92 | 0.85 | 10, 12 | 0.003∗ | 0.562, 1.000 |
| DF#4: Embodied Vibratory Feedback | 4.00 | 4.25 | 0.72 | 0.52 | 10, 12 | 0.003∗ | 0.562, 1.000 |
| DF#5: Location of Speech Output | 4.00 | 4.25 | 0.60 | 0.35 | 11, 12 | ¡0.001∗ | 0.661, 1.000 |
5.3. Trustworthiness of I3Ms
5.3.1. HCTM Scales.
| Human Computer Trust Model | |||||||||||
| Descriptive Statistics | Wilcoxon Test | ||||||||||
| HEM I3Ms | LEM I3Ms | ||||||||||
| Scale | M | SD | V | M | SD | V | z-score | p-value | |||
| Perceived Risk | 1.00 | 1.58 | 0.72 | 0.52 | 2.00 | 1.86 | 0.98 | 0.95 | 2.428 | 0.008∗ | |
| Benevolence | 4.00 | 4.14 | 0.95 | 0.90 | 4.00 | 4.03 | 0.90 | 0.80 | 1.633 | 0.051∧ | |
| Competence | 5.00 | 4.50 | 0.55 | 0.31 | 4.00 | 4.31 | 0.66 | 0.43 | 2.646 | 0.004∗ | |
| Reciprocity | 4.00 | 4.31 | 0.70 | 0.49 | 4.00 | 4.08 | 0.80 | 0.63 | 1.929 | 0.027∗ | |
| Did you find that the I3M felt trustworthy? | |||||||||||
| Trustworthiness | 5.00 | 4.58 | 0.49 | 0.24 | 5.00 | 4.50 | 0.65 | 0.42 | 0.577 | 0.282 | |
HEM I3Ms outperformed LEM I3Ms across all four HCTM subscales (Table 7) – perceived risk222The perceived risk subscale relates to the willingness of a user to engage with a system despite possible risks. A lower perceived risk score is desired, signifying that the user is more willing to interact with the system. ( -0.28), benevolence ( +0.11), competence ( +0.19), and reciprocity ( +0.23). Wilcoxon results were significant for three HCTM subscales – perceived risk (), competence (), and reciprocity (). The remaining subscale, benevolence, was marginally significant ().
5.3.2. How Trustworthy Were The I3Ms?
When rating the trustworthiness of each I3M (Table 7), results were less clear. A minor increase in mean score for HEM I3Ms ( +0.08) over LEM I3Ms was observed; however, this difference was nonsignificant (). In the post-activity interview ranking, the majority of the participants () indicated that there was no major discernible difference in trust between the HEM and LEM models. The remaining participants () ranked the HEM I3Ms higher. A binomial test showed that this result was nonsignificant (, , ).
Participants described feeling indecisive, often basing their interpretation of trust on the believability of the information provided by the models. P2 noted that both models were “just giving [them] facts” and that their manner of acting or speaking did not matter. P4 explained that as both HEM and LEM I3Ms were “accessing information from the internet … that [they] trusted it to only access certain [appropriate] things”. Despite reporting no major differences in their ratings, P11 suggest that “incorrect facts, [when] talking in first person reduces trust”, while P5, who also rated no difference, focused on the salient physical design of the I3Ms, expressing concern about ‘the height of the rocket … knocking it over”.
5.3.3. Impact of Design Factors on Trust.
Participants were divided on how the individual HEM design factors influenced their perceptions of the trustworthiness of the I3Ms (Table 8). Embodied vibratory feedback elicited the highest mean score, while embodied narration style scored the lowest. Apart from embodied vibratory feedback, which was marginally significant (, , ), all other design factors were nonsignificant.
| Did the design factors impact your perception of how trustworthy the HEM I3M was? | |||||||
| Design Factor | Descriptive Statistics | Binomial Test | |||||
| M | SD | V | k, n | p-value | 95th CI | ||
| DF#1: Introductions & Small Talk | 4.00 | 3.67 | 0.62 | 0.39 | 7, 12 | 0.158 | 0.315, 1.000 |
| DF#2: Embodied Personified Voices | 3.50 | 3.67 | 0.75 | 0.56 | 6, 12 | 0.335 | 0.245, 1.000 |
| DF#3: Embodied Narration Style | 3.00 | 3.42 | 0.95 | 0.91 | 5, 12 | 0.562 | 0.181, 1.000 |
| DF#4: Embodied Vibratory Feedback | 4.00 | 3.83 | 0.69 | 0.47 | 8, 12 | 0.057∧ | 0.391, 1.000 |
| DF#5: Location of Speech Output | 3.50 | 3.67 | 0.75 | 0.56 | 6, 12 | 0.335 | 0.245, 1.000 |
6. Discussion
6.1. Hypothesis #1: HEM I3Ms are perceived as more embodied than LEM I3Ms
Participants felt that HEM I3Ms were more lively, with an increased perception of embodiment compared to the LEM I3Ms. When ranking the I3Ms on liveliness, 8/12 selected HEM I3Ms (Section 5.1.2). This was also statistically significant, with most participants providing emphatic explanations for their selections, supporting H#1.
Results from the Godspeed Questionnaire Series also supported H#1 and allowed us to explore different dimensions and key aspects of embodiment, adding nuance to our understanding of how the I3Ms appeared embodied (Table 2). All GQS subscales were statistically significant. It is particularly noteworthy that the anthropomorphism and animacy subscales were rated more positively for HEM I3Ms, as these subscales deal with the attribution of human-like behaviours and perception of life (Bartneck et al., 2009), which are key components of embodiment. The likeability and intelligence subscales were also perceived more favourably for HEM I3Ms.
Overall, our findings and participant comments help to support H#1 that BLV users do perceive I3Ms configured with HEM design factors as more embodied, ‘present’, and ‘lively’. These findings align with work on the embodiment of other interfaces in non-BLV contexts, including robots (Kontogiorgos et al., 2020) and conversational agents (Luria et al., 2017; Shamekhi et al., 2018; Luria et al., 2019), which has found that imbuing machines with human-like behaviours can enhance their perceived embodiment and sense of presence, creating a sense of ‘being there’ (Shamekhi et al., 2018).
6.2. Hypothesis #2: HEM I3Ms are perceived as more engaging than LEM I3Ms
Participants rated higher levels of engagement with HEM I3Ms compared to LEM I3Ms. When ranking which I3M was more engaging, the overwhelming majority (10/12) selected HEM (Section 5.2.2). These differences were statistically significant, supporting H#2.
We used the User Engagement Scale and Playful Experiences Questionnaire (Table 4) to explore different dimensions of engagement to add to and help contextualise our understanding of how engaging participants found the I3Ms. The UES-SF indicated that HEM I3Ms had higher average scores than LEM I3Ms across 3/4 subscales. Of these subscales, two were statistically significant, and one was marginally significant. These subscales focus on the extent to which users feel absorbed in an interaction (focused attention) and the usability/negative affect experienced during interactions (perceived usability), both of which are critical dimensions of engagement (O’Brien et al., 2018). The aesthetic appeal subscale, which the researchers adjusted to be more meaningful in BLV contexts – encompassing aesthetics beyond those purely visual – was also statistically significant. This is particularly noteworthy, with HEM-configured I3Ms providing more engaging sensory experiences. The reward subscale, centred on valued experiential outcomes, was not significant with respect to our hypothesis, and was the only subscale where LEM I3Ms received higher mean scores. This may indicate that the additional presence and feedback of HEM I3Ms could, in some circumstances, reduce initial curiosity.
It is our belief that several PLEXQ subscales may have had reduced meaning to participants, potentially as a result of the controlled nature and limited time exposure of the study. For example, subscales that focus on finding something hidden (discovery) or unwinding through playful experiences (relaxation) may have been less relevant. Interestingly, one subscale, exploration, elicited higher mean values for LEM I3Ms, possibly for similar reasons to the UES-SF reward subscale. Despite this, several PLEXQ results added support to H#2, with subscales related to excitement (sensation), enjoyment/amusement (humor), and power (control) being more favourably observed with HEM I3Ms.
Across all tasks, participants spent more time interacting with the HEM I3Ms and performed a greater number of interactions compared to the LEM I3Ms. We feel this was particularly noteworthy during the undirected free play task, which was designed to mimic real-world use. Time spent and the number of interactions were statistically significant and marginally significant, respectively. These metrics have previously been used as behavioural measures of engagement in HCI (O’Brien and Lebow, [n. d.]; Doherty and Doherty, 2018), and provide further evidence that participants were more engaged with the HEM I3Ms. They also complement the UES-SF, which ties engagement to the depth of a user’s investment with a system (O’Brien, 2016).
Based on emphatic participant discussions and clear preferences when directly asked, our study provides evidence supporting H#2 that HEM I3Ms are perceived as more engaging. Our scale data adds important nuance to this understanding, with key UES-SF and PLEXQ subscales showing that HEM I3Ms were more favourably perceived. Although ratings for both HEM and LEM I3Ms were generally high, which aligns with works showing that BLV users find 3D-printed models and I3Ms engaging (Nagassa et al., 2023; Reinders et al., 2020; Shi et al., 2019), our results suggest that HEM I3Ms are perceived as even more engaging. More broadly, our findings align with prior work demonstrating that interfaces imbued with more human-like behaviours can positively impact end-user perceptions of engagement (Lester et al., 1997; Cassell et al., 1999; Shamekhi et al., 2018).
6.3. Hypothesis #3: HEM I3Ms are perceived as more trustworthy than LEM I3Ms
Our participants were mixed on whether there were any discernible differences in the trustworthiness of HEM and LEM I3Ms. Hesitance was observed when participants were asked to rank which I3M was the more trustworthy model, with 9/12 indicating no major discernible difference between them (Section 5.3.2). Participants expressed indecisiveness, often basing their interpretation of trust solely on the believability of the information output from the models, rather than their interactions with the I3Ms.
On the other hand, results from the Human-Computer Trust Model (Table 7) suggest that HEM I3Ms may lead to greater trust, as all four HCTM subscales were either significant () or marginally significant (). Results did, however, reveal only very minor differences in mean scores between HEM I3Ms and LEM I3Ms. Despite this, these scales relate to the willingness of users to engage with a system despite the possible risks (perceived risk), whether a system possesses the functionalities needed to depend on it (competence), and a willingness to spend more time using it when support situations arise (reciprocity). The benevolence subscale, which was marginally significant, focuses on whether users believe that a system has the abilities required to help them achieve their goals.
Despite the statistical significance of the HCTM results, we believe that, overall, our results provide only mixed support for Hypothesis H#3. It is the researchers’ view that the HCTM questionnaire and subjective ratings may have been interpreted differently by participants. While the scale data appears to have successfully captured different dimensions of trust based on interactions with the HEM/LEM models, many participants, when asked about the concept of trust subjectively (Section 5.3.2), focused solely on the believability of the information provided by the models, independent of their HEM/LEM state. They tended to prioritise believability of information over considerations as to whether their interactions with the models and their behaviours influenced perceptions of reliance or competence. Our findings also suggest that the HEM design factors tested do not appear to play a strong role in influencing trust. As visually embodied conversational agents have been shown to be subjectively more trustworthy in non-BLV contexts (Heuwinkel, 2013; Bickmore et al., 2013; Sidner et al., 2018; Shamekhi et al., 2018; Gulati et al., 2018), it is clear that more research is needed in order to better understand the impact of embodiment on trustworthiness of I3Ms for BLV users, particularly in real-world situations.
6.4. How Did The Design Factors Impact Embodiment, Engagement and Trust?
Broadly speaking, our embodiment design factors and their implementations were well-received, contributing to how embodied and engaging the HEM I3Ms were perceived. However, connections to trust were mixed. These are discussed below in order of importance.
DF#4: Embodied Vibratory Feedback. Participants shared their enthusiasm regarding haptics. Referring to the liveliness of the HEM I3Ms, P3 described how the use of haptics made them feel “more three-dimensional… realistic”. Participants also discussed how haptics made the HEM I3Ms more engaging, including P5, “[haptics] added an extra sense of interaction”. These emphatic reactions align with other work, where haptics added life to I3Ms (Reinders et al., 2023), and support the growing body of research exploring how haptics can create physically embodied, lifelike cues (Nie et al., 2012; Bevan and Stanton Fraser, 2015; Borgstedt, 2023).
DF#2: Embodied Personified Voices. Participants highlighted how unique voices shaped their perception of embodiment. P9 was emphatic about how it made the HEM model feel more alive, “[it] made [the components] seem like they were their own things”. P6 detailed how the one-for-one social presence of the HEM model gave components their own ‘character’. Regarding engagement, several participants found the voices helpful for tracking which I3M component was active and talking. P2 explained, “different voices … broke the [HEM] model up into separate parts, it defined the objects better”. P8 reflected, “[a] single voice does not stack up”. This aligns with work by Choi et al. (Choi et al., 2020)’s finding that many BLV users value human-like conversation with agents.
DF#3: Embodied Narration Style. Participants frequently linked first-person narration to engagement and embodiment, creating a transformative experience. P2 described it as making interactions feel “like you were talking to someone, vs it talking to you”. Similarly, P4 remarked that it made conversations seem “more human-like … on a one-on-one basis”. While P9 noted that it enhanced HEM presence, they initially felt that “… it was a bit strange anthropomorphizing [a system]… like when Microsoft talks like a human”. The positive reception of first-person narration aligns with other research that has found that users anthropomorphise agents by using first and second-person pronouns (Liao et al., 2018; Coeckelbergh, 2011).
DF#5: Location of Speech Output. Participants noted that closer coupling with the I3M and its speaker impacted engagement. P4 found the HEM I3M’s audio output “easier to take in”, while P8 appreciated being able to “focus more directly on [the HEM I3M]”. P3 described HEM as “more intimate and engaging”. The researchers believe that embedding speakers inside each printed component could further enhance embodiment and engagement. P5 suggested this would make the I3Ms “feel more alive”, echoing feedback from previous work (Reinders et al., 2023). One possibility may be to use ultrasonics to project speech output (Iravantchi et al., 2020), acting as digital ventriloquism.
DF#1: Introductions & Small Talk. This factor had less impact on participants, who were less likely to reference it. The researchers believe this may be because it was not as explicit as other design factors. Many participants forgot that the HEM I3Ms introduced themselves, and small talk, being reliant on user initiation, was minimal. Only two participants (P2 and P4) engaged in small talk. Their responses revealed no meaningful deviation from the wider participant group regarding embodiment, engagement, and trust, suggesting that small talk played a minimal role. Despite this, P2 found it made the HEM I3M seem more playful, while P4 said introductions felt like an “invitation” to interact. Conversely, P6 felt HEM introductions diminished their independence, stating that “I did not like it [introducing itself]; I like finding out what things are by [looking at/touching] them”. These mixed reactions align with other works which have found that BLV users have varying perspectives on how proactive I3Ms should be (Reinders et al., 2020), suggesting that conversational strategies effective in embodied agents for sighted users (Liao et al., 2018; Pradhan et al., 2019; Cassell, 2001; Shamekhi et al., 2018) may hold less meaning in BLV contexts.
6.5. Can I3Ms Be Embodied & What Is Their Impact?
Our study supports the larger idea that I3Ms are able to be perceived as more embodied and are more engaging. This follows from H#1, where our findings support that BLV people perceive HEM I3Ms as more embodied and lively, and H#2, where HEM I3Ms were found to be more engaging. In the context of I3Ms, it appears that model embodiment increases end-user engagement, specifically with I3Ms using the set of embodied design factors we implemented. However, the impact of embodiment on trust (H#3) remains less clear, as BLV people generally appear to trust I3Ms regardless of embodiment.
Prior research has shown that the embodiment of an interface can increase both engagement (Shamekhi et al., 2018; Luger and Sellen, 2016; Heuwinkel, 2013; Cassell, 2001) and trust (Bickmore and Cassell, 2001; Shamekhi et al., 2018; Bickmore et al., 2013; Minjin Rheu and Huh-Yoo, 2021). Our findings support the relationship between embodiment and engagement, but stop short of any impacts on trust. With the bulk of this previous research focusing on conversational agents and robots, our work extends this relationship to include contexts relevant to both I3Ms and with people who are BLV.
The relationship between embodied I3Ms and their impact on engagement is particularly significant in learning contexts, allowing BLV students or self-learners to engage in deeper, more meaningful experiences where the I3M can assist in teaching and testing their knowledge. Embodied agents have been used in learning environments, and have been found to enrich the learning experiences of students (Schroeder et al., 2013). Pedagogic agents often rely on embodied designs, including combinations of visual and conversational embodiment (Lester et al., 1997; Moreno et al., 2001; Schroeder et al., 2013). While prior research on non-embodied I3Ms in learning contexts has highlighted positive feedback from both teachers and BLV students (Shi et al., 2019), we believe that understanding how I3Ms can be effectively embodied could further enhance engagement in educational settings, and facilitate broader adoption.
Based on the positive reception amongst participants of our embodied I3Ms, we propose extending our existing I3M design recommendations (Reinders et al., 2023) to include embodiment:
-
•
Support more embodied experiences: I3Ms that support human-like behaviours and characteristics in their design can make them appear more human, lively, and engaging to use. This may involve combining aspects of physical and conversational embodiment, e.g., introductions and small talk, embodied voices, embodied narration, embodied haptic vibratory feedback, and location of speech output.
7. Limitations & Future Work
There are a number of limitations regarding this study. While some are lenses through which the results should be interpreted, others present exciting avenues for future investigation.
Our investigation focused on five specific design factors, and our findings should be interpreted within that context. Future research should explore additional embodiment design factors. This could include models that are more autonomous, or incorporate visual embodiment elements, which may benefit low vision users with residual vision, e.g., virtual avatars or the emittance of light. Physical embodiment could also be extended with additional design dimensions not covered in this study. For example, haptic perception could extend beyond vibratory feedback to include model texturing, scale, orientation, or the impact of detachable components.
Furthermore, our design factors were implemented in specific ways, presenting an opportunity to further explore how the design space of embodied I3Ms can be expanded through alternative implementations. Often, our implementations were shaped by technical limitations or model choice. For instance, with the location of speech output design factor, embedding speakers within individual model components or using headphones could produce different results. Regarding model choice, while our models neatly segmented embodied personified voices based on individual components, a different type of model, e.g., a globe of Earth, could instead segment voices by country, continent, or hemisphere, depending on its purpose.
As our study looked at participants’ subjective ratings to assess the impact of the design factors, future research could formally isolate and test each factor to understand its individual effect on embodiment. The small talk component of DF#1 was also rarely used, likely because it required user initiation, unlike the other design factors. While this was an intentional design decision (see Section 3.2.1), future work should revisit small talk to determine if the design factor would be better utilised if it were agent-initiated.
We used validated scales to measure aspects of embodiment, engagement, and trust. Based on pilot feedback, we adjusted a small number of UES-SF and PLEXQ items to have more meaning in BLV contexts. We supplemented these scales with our own questions, providing additional nuance and insight. However, this raises a need for future work to explore how these instruments can be further modified and validated for BLV users, or whether entirely new tools should be developed to improve relevance and meaning.
Our study was conducted with 12 participants, consistent with similar studies involving BLV participants (Holloway et al., 2022; Nagassa et al., 2023; Shi et al., 2017, 2020). Nonetheless, we would like to run further sessions to confirm our findings. This presents multiple opportunities, such as using a broader selection of models, and conducting ‘in-the-wild’ and longitudinal studies to examine how the relationship between end-users and I3Ms evolves over time. Additionally, as our work represents the first investigation into embodied I3Ms, and its exploratory nature influenced the experimental design and analysis, future research should focus on targeted testing and conservative analysis.
Regarding trust, given the lack of discernible differences between the trustworthiness of HEM and LEM I3Ms, future work should focus on re-examining the concept of trust. Future research should explore real-world trust scenarios where confidence in HEM/LEM I3Ms may hold greater significance and contexts where model behaviours could influence perception.
In our previous research, we identified the importance of I3Ms supporting customisation (Reinders et al., 2023). In this study, participants had limited opportunities to personalise each model in order to better isolate the effects of each HEM design factor. Given the new insights into embodiment presented in this work, future work could seek to combine the HEMs described with greater user customisation.
This work utilised conversational agents specifically trained on information relevant to the modelled concepts. Rapid advancements in generative AI provide opportunities to expand the conversational capabilities of I3Ms. Future research should investigate how generative AI systems could be leveraged in place of bespoke conversational agents in order to enhance their flexibility.
Finally, future work should examine embodiment and engagement with sighted users. Given the potential for I3Ms, such as those presented in this work, to be used in contexts like museums and classrooms, it is important that they be highly engaging for all users, contributing to more inclusive social experiences.
8. Conclusion
Increasing the engagement and trust that exists between BLV users and their accessible materials is of critical importance, as the ultimate utility of these resources is diminished if users are unwilling to engage with or trust them. This is particularly relevant in educational and cultural contexts, such as classrooms, museums, and galleries, where I3Ms are beginning to be deployed.
Our work presents the first investigation into the relationship between embodiment, engagement, and trust in the context of I3Ms and BLV users. We created two I3Ms that supported a series of design factors aimed at making the models appear more embodied. Our findings revealed that our participants perceived many of the design factors as contributing to the embodiment of the I3Ms. Participants also believed that these design factors made the I3Ms more engaging. The impact on trust, however, was less clear.
While many of the subscales we used revealed statistical significance in favour of HEM I3Ms, ratings for both HEM and LEM I3Ms were generally high. In the case of embodiment and engagement, rankings and participant comments added important context to these results, revealing clearer preferences. For example, while participants found I3Ms engaging overall, HEM I3Ms were perceived as even more engaging. This was further supported by our behavioural metrics, which showed that participants spent more time and performed more interactions with the HEMs.
Based on the positive reception of the embodied I3Ms, we established a new I3M design recommendation to complement those previously proposed to the I3M community (Reinders et al., 2023) – support more embodied experiences. We advocate that, due to the connections between embodiment and engagement, I3Ms should incorporate human-like behaviours and characteristics into their design.
We hope that this initial exploration into embodiment represents the first step toward a growing interest in embodied I3Ms, helping to facilitate their widespread adoption. One day, we envision similar models being found in schools and public spaces, such as museums and galleries, with configurable embodiment that allows BLV people to engage with content in ways that are more meaningful to them.
We believe our work is relevant in the broader context of research into embodiment, and its relationship to engagement and trust. Virtually all prior research has involved sighted users; as such, our study is the first to explore this relationship in the context of blind users who cannot discern visual embodiment cues. We hope our findings will inspire further exploration in this space.
Acknowledgements.
This research was supported by an Australian Government Research Training Program (RTP) Scholarship. We want to thank our participants for their time and expertise.References
- (1)
- Abdolrahmani et al. (2018) Ali Abdolrahmani, Ravi Kuber, and Stacy M. Branham. 2018. ”Siri Talks at You”: An Empirical Investigation of Voice-Activated Personal Assistant (VAPA) Usage by Individuals Who Are Blind. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Galway, Ireland) (ASSETS ’18). ACM, New York, NY, USA, 249–258. doi:10.1145/3234695.3236344
- Aldrich and Sheppard (2001) Frances K. Aldrich and Linda Sheppard. 2001. Tactile graphics in school education: perspectives from pupils. British Journal of Visual Impairment 19, 2 (2001), 69–73. doi:10.1177/026461960101900204
- Azenkot and Lee (2013) Shiri Azenkot and Nicole B. Lee. 2013. Exploring the Use of Speech Input by Blind People on Mobile Devices. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Bellevue, Washington) (ASSETS ’13). ACM, New York, NY, USA, Article 11, 8 pages. doi:10.1145/2513383.2513440
- Bartlett et al. (2019) Rachel Bartlett, Yi Xuan Khoo, Juan Pablo Hourcade, and Kyle K. Rector. 2019. Exploring the Opportunities for Technologies to Enhance Quality of Life with People who have Experienced Vision Loss. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI ’19). ACM, New York, NY, USA, 1–8. doi:10.1145/3290605.3300421
- Bartneck et al. (2009) Christoph Bartneck, Dana Kulić, Elizabeth Croft, and Susana Zoghbi. 2009. Measurement Instruments for the Anthropomorphism, Animacy, Likeability, Perceived Intelligence, and Perceived Safety of Robots. International Journal of Social Robotics 1, 1 (01 Jan 2009), 71–81. doi:10.1007/s12369-008-0001-3
- Bevan and Stanton Fraser (2015) Chris Bevan and Danaë Stanton Fraser. 2015. Shaking Hands and Cooperation in Tele-present Human-Robot Negotiation. In Proc. of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction (Portland, Oregon, USA) (HRI ’15). ACM, New York, NY, USA, 247–254. doi:10.1145/2696454.2696490
- Bickmore and Cassell (2001) Timothy Bickmore and Justine Cassell. 2001. Relational agents: a model and implementation of building user trust. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Seattle, Washington, USA) (CHI ’01). ACM, New York, NY, USA, 396–403. doi:10.1145/365024.365304
- Bickmore et al. (2013) Timothy W. Bickmore, Daniel Schulman, and Candace Sidner. 2013. Automated interventions for multiple health behaviors using conversational agents. Patient Education and Counseling 92, 2 (2013), 142 – 148. doi:10.1016/j.pec.2013.05.011
- Biocca (1999) Frank Biocca. 1999. Chapter 6 The Cyborg’s dilemma. Progressive embodiment in virtual environments (c ed.). Number C in Human Factors in Information Technology. Elsevier, Netherlands, 113–144. doi:10.1016/S0923-8433(99)80011-2
- Bischof et al. (2016) Andreas Bischof, Kevin Lefeuvre, Albrecht Kurze, Michael Storz, Sören Totzauer, and Arne Berger. 2016. Exploring the Playfulness of Tools for Co-Designing Smart Connected Devices: A Case Study with Blind and Visually Impaired Students. In Proc. Computer-Human Interaction in Play Companion (Austin, Texas, USA) (CHI PLAY Companion ’16). ACM, New York, NY, USA, 93–99. doi:10.1145/2968120.2987728
- Blades et al. (1999) Mark Blades, Simon Ungar, and Christopher Spencer. 1999. Map Use by Adults with Visual Impairments. The Professional Geographer 51, 4 (1999), 539–553. doi:10.1111/0033-0124.00191
- Boberg et al. (2015) Marion Boberg, Evangelos Karapanos, Jussi Holopainen, and Andrés Lucero. 2015. PLEXQ: Towards a Playful Experiences Questionnaire. In Proc. of the 2015 Annual Symposium on Computer-Human Interaction in Play (London, United Kingdom) (CHI PLAY ’15). ACM, New York, NY, USA, 381–391. doi:10.1145/2793107.2793124
- Bolt (1980) Richard A. Bolt. 1980. “Put-That-There”: Voice and Gesture at the Graphics Interface. In Proc. of the 7th Annual Conference on Computer Graphics and Interactive Techniques (Seattle, Washington, USA) (SIGGRAPH ’80). ACM, New York, NY, USA, 262–270. doi:10.1145/800250.807503
- Borgstedt (2023) Jacqueline Borgstedt. 2023. Investigating the Potential of Life-like Haptic Cues for Socially Assistive Care Robots. In Companion of the 2023 ACM/IEEE International Conference on Human-Robot Interaction (Stockholm, Sweden) (HRI ’23). ACM, New York, NY, USA, 745–747. doi:10.1145/3568294.3579972
- Brown and Hurst (2012) Craig Brown and Amy Hurst. 2012. VizTouch: Automatically Generated Tactile Visualizations of Coordinate Spaces. In Proc. Tangible, Embedded, and Embodied Interaction (Kingston, Ontario, Canada) (TEI ’12). ACM, New York, NY, USA, 131–138. doi:10.1145/2148131.2148160
- Buehler et al. (2016) Erin Buehler, Niara Comrie, Megan Hofmann, Samantha McDonald, and Amy Hurst. 2016. Investigating the Implications of 3D Printing in Special Education. ACM Trans. Access. Comput. 8, 3, Article 11 (March 2016), 28 pages. doi:10.1145/2870640
- Butler et al. (2017) Matthew Butler, Leona Holloway, Kim Marriott, and Cagatay Goncu. 2017. Understanding the graphical challenges faced by vision-impaired students in Australian universities. Higher Education Research & Development 36, 1 (2017), 59–72. doi:10.1080/07294360.2016.1177001
- Butler et al. (2021) Matthew Butler, Leona M Holloway, Samuel Reinders, Cagatay Goncu, and Kim Marriott. 2021. Technology Developments in Touch-Based Accessible Graphics: A Systematic Review of Research 2010-2020. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Yokohama, Japan) (CHI ’21). ACM, New York, NY, USA, Article 278, 15 pages. doi:10.1145/3411764.3445207
- Butler et al. (2023) Matthew Butler, Erica J Tandori, Vince Dziekan, Kirsten Ellis, Jenna Hall, Leona M Holloway, Ruth G Nagassa, and Kim Marriott. 2023. A Gallery In My Hand: A Multi-Exhibition Investigation of Accessible and Inclusive Gallery Experiences for Blind and Low Vision Visitors. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (New York, NY, USA) (ASSETS ’23). ACM, New York, NY, USA, Article 9, 15 pages. doi:10.1145/3597638.3608391
- Carlton et al. (2019) Jonathan Carlton, Andy Brown, Caroline Jay, and John Keane. 2019. Inferring User Engagement from Interaction Data. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI EA ’19). ACM, New York, NY, USA, 1–6. doi:10.1145/3290607.3313009
- Cassell (2000) Justine Cassell. 2000. More than just another pretty face: Embodied conversational interface agents. Commun. ACM 43, 4 (2000), 70–78.
- Cassell (2001) Justine Cassell. 2001. Embodied Conversational Agents: Representation and Intelligence in User Interfaces. AI Magazine 22, 4 (Dec. 2001), 67. doi:10.1609/aimag.v22i4.1593
- Cassell et al. (1999) J. Cassell, T. Bickmore, M. Billinghurst, L. Campbell, K. Chang, H. Vilhjálmsson, and H. Yan. 1999. Embodiment in conversational interfaces: Rea. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Pittsburgh, Pennsylvania, USA) (CHI ’99). ACM, New York, NY, USA, 520–527. doi:10.1145/302979.303150
- Cassell and Thorisson (1999) Justine Cassell and Kristinn R. Thorisson. 1999. The power of a nod and a glance: Envelope vs. emotional feedback in animated conversational agents. Applied Artificial Intelligence 13, 4-5 (1999), 519–538. doi:10.1080/088395199117360
- Cassell and Vilhjálmsson (1999) J. Cassell and H. Vilhjálmsson. 1999. Fully Embodied Conversational Avatars: Making Communicative Behaviors Autonomous. Autonomous Agents and Multi-Agent Systems 2, 1 (01 Mar 1999), 45–64. doi:10.1023/A:1010027123541
- Cavazos Quero et al. (2019) Luis Cavazos Quero, Jorge Iranzo Bartolomé, Dongmyeong Lee, Yerin Lee, Sangwon Lee, and Jundong Cho. 2019. Jido: A Conversational Tactile Map for Blind People. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Pittsburgh, PA, USA) (ASSETS ’19). ACM, New York, NY, USA, 682–684. doi:10.1145/3308561.3354600
- Cavazos Quero et al. (2018) Luis Cavazos Quero, Jorge Iranzo Bartolomé, Seonggu Lee, En Han, Sunhee Kim, and Jundong Cho. 2018. An Interactive Multimodal Guide to Improve Art Accessibility for Blind People. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Galway, Ireland) (ASSETS ’18). ACM, New York, NY, USA, 346–348. doi:10.1145/3234695.3241033
- Cavazos Quero et al. (2021) Luis Cavazos Quero, Jorge Iranzo Bartolomé, and Jundong Cho. 2021. Accessible Visual Artworks for Blind and Visually Impaired People: Comparing a Multimodal Approach with Tactile Graphics. Electronics 10, 3 (2021). doi:10.3390/electronics10030297
- Cho et al. (2024) Haena Cho, Yoonji Lee, Woohun Lee, and Chang Hee Lee. 2024. Thermo-Play: Exploring the Playful Qualities of Thermochromic Materials. In Proc. Tangible, Embedded, and Embodied Interaction (Cork, Ireland) (TEI ’24). ACM, New York, NY, USA, Article 28, 16 pages. doi:10.1145/3623509.3633376
- Choi et al. (2020) Dasom Choi, Daehyun Kwak, Minji Cho, and Sangsu Lee. 2020. ”Nobody Speaks That Fast!” An Empirical Study of Speech Rate in Conversational Agents for People with Vision Impairments. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–13. doi:10.1145/3313831.3376569
- Coeckelbergh (2011) Mark Coeckelbergh. 2011. You, robot: on the linguistic construction of artificial others. AI & SOCIETY 26, 1 (01 Feb 2011), 61–69. doi:10.1007/s00146-010-0289-z
- Collins et al. (2023) Jazmin Collins, Crescentia Jung, Yeonju Jang, Danielle Montour, Andrea Stevenson Won, and Shiri Azenkot. 2023. “The Guide Has Your Back”: Exploring How Sighted Guides Can Enhance Accessibility in Social Virtual Reality for Blind and Low Vision People. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (New York, NY, USA) (ASSETS ’23). ACM, New York, NY, USA, Article 38, 14 pages. doi:10.1145/3597638.3608386
- Cramer and Howitt (2004) Duncan Cramer and Dennis. Howitt. 2004. The Sage dictionary of statistics: a practical resource for students in the social sciences. Sage Publications, London. Includes bibliographical references (p. [187]-188)..
- Davis et al. (2020) Josh Urban Davis, Te-Yen Wu, Bo Shi, Hanyi Lu, Athina Panotopoulou, Emily Whiting, and Xing-Dong Yang. 2020. TangibleCircuits: An Interactive 3D Printed Circuit Education Tool for People with Visual Impairments. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–13. doi:10.1145/3313831.3376513
- Degachi et al. (2023) Chadha Degachi, Myrthe Lotte Tielman, and Mohammed Al Owayyed. 2023. Trust and Perceived Control in Burnout Support Chatbots. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Hamburg, Germany) (CHI EA ’23). ACM, New York, NY, USA, Article 295, 10 pages. doi:10.1145/3544549.3585780
- Doherty and Doherty (2018) Kevin Doherty and Gavin Doherty. 2018. Engagement in HCI: Conception, Theory and Measurement. ACM Comput. Surv. 51, 5, Article 99 (nov 2018), 39 pages. doi:10.1145/3234149
- Dourish (2001) Paul Dourish. 2001. Where the Action Is: The Foundations of Embodied Interaction. The MIT Press. doi:10.7551/mitpress/7221.001.0001
- Edwards et al. (2015) Alistair D. N. Edwards, Nazatul Naquiah Abd Hamid, and Helen Petrie. 2015. Exploring Map Orientation with Interactive Audio-Tactile Maps. In Human-Computer Interaction – INTERACT 2015, Julio Abascal, Simone Barbosa, Mirko Fetter, Tom Gross, Philippe Palanque, and Marco Winckler (Eds.). Springer International Publishing, Cham, 72–79.
- Ghodke et al. (2019) Uttara Ghodke, Lena Yusim, Sowmya Somanath, and Peter Coppin. 2019. The Cross-Sensory Globe: Participatory Design of a 3D Audio-Tactile Globe Prototype for Blind and Low-Vision Users to Learn Geography. In Proc. ACM Designing Interactive Systems Conference (San Diego, CA, USA) (DIS ’19). ACM, New York, NY, USA, 399–412. doi:10.1145/3322276.3323686
- Giraud et al. (2017) Stéphanie Giraud, Anke M Brock, Marc J-M Macé, and Christophe Jouffrais. 2017. Map learning with a 3D printed interactive small-scale model: Improvement of space and text memorization in visually impaired students. Frontiers in Psychology 8, 930 (2017). doi:10.3389/fpsyg.2017.00930
- Götzelmann et al. (2017) Timo Götzelmann, Lisa Branz, Claudia Heidenreich, and Markus Otto. 2017. A Personal Computer-based Approach for 3D Printing Accessible to Blind People. In Proc. PErvasive Technologies Related to Assistive Environments (Island of Rhodes, Greece) (PETRA ’17). ACM, New York, NY, USA, 1–4. doi:10.1145/3056540.3064954
- Gual et al. (2012) Jaume Gual, Marina Puyuelo, Joaquim Lloverás, and Lola Merino. 2012. Visual Impairment and urban orientation. Pilot study with tactile maps produced through 3D Printing. Psyecology 3, 2 (2012), 239–250.
- Gulati et al. (2018) Siddharth Gulati, Sonia Sousa, and David Lamas. 2018. Modelling trust in human-like technologies. In Proc. Indian Conference on Human-Computer Interaction (Bangalore, India) (IndiaHCI ’18). ACM, New York, NY, USA, 1–10. doi:10.1145/3297121.3297124
- Guo et al. (2022) Lijie Guo, Elizabeth M. Daly, Oznur Alkan, Massimiliano Mattetti, Owen Cornec, and Bart Knijnenburg. 2022. Building Trust in Interactive Machine Learning via User Contributed Interpretable Rules. In Proc. International Conference on Intelligent User Interfaces (Helsinki, Finland) (IUI ’22). ACM, New York, NY, USA, 537–548. doi:10.1145/3490099.3511111
- Hasper et al. (2015) Eric Hasper, Rogier A. Windhorst, Terri Hedgpeth, Leanne Van Tuyl, Ashleigh Gonzales, Britta Martinez, Hongyu Yu, Zoltan Farkas, and Debra P. Baluch. 2015. Methods for Creating and Evaluating 3D Tactile Images to Teach STEM Courses to the Visually Impaired. Journal of College Science Teaching 44, 6 (2015), 92–99. http://www.jstor.org/stable/43632001
- Heuwinkel (2013) Kerstin Heuwinkel. 2013. Framing the Invisible – The Social Background of Trust. Springer Berlin Heidelberg, Berlin, Heidelberg, 16–26. doi:10.1007/978-3-642-37346-6_3
- Holloway et al. (2022) Leona Holloway, Swamy Ananthanarayan, Matthew Butler, Madhuka Thisuri De Silva, Kirsten Ellis, Cagatay Goncu, Kate Stephens, and Kim Marriott. 2022. Animations at Your Fingertips: Using a Refreshable Tactile Display to Convey Motion Graphics for People Who Are Blind or Have Low Vision. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Athens, Greece) (ASSETS ’22). ACM, New York, NY, USA, Article 32, 16 pages. doi:10.1145/3517428.3544797
- Holloway et al. (2018) Leona Holloway, Matthew Butler, and Kim Marriott. 2018. Accessible maps for the blind: Comparing 3D printed models with tactile graphics. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Montréal, QC, Canada) (CHI ’18). ACM. doi:10.1145/3173574.3173772
- Holloway et al. (2019a) Leona Holloway, Kim Marriott, Matthew Butler, and Alan Borning. 2019a. Making Sense of Art: Access for Gallery Visitors with Vision Impairments. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI ’19). ACM, New York, NY, USA, 1–12. doi:10.1145/3290605.3300250
- Holloway et al. (2019b) Leona Holloway, Kim Marriott, Matthew Butler, and Samuel Reinders. 2019b. 3D Printed Maps and Icons for Inclusion: Testing in the Wild by People Who Are Blind or Have Low Vision. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Pittsburgh, PA, USA) (ASSETS ’19). ACM, New York, NY, USA, 183–195. doi:10.1145/3308561.3353790
- Hu (2015) Michele Hu. 2015. Exploring New Paradigms for Accessible 3D Printed Graphs. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Lisbon, Portugal) (ASSETS ’15). ACM, New York, NY, USA, 365–366. doi:10.1145/2700648.2811330
- Inc ([n. d.]) Touch Graphics Inc. [n. d.]. T3 Tactile Tablet. ([n. d.]). Available from https://www.touchgraphics.com/education/t3.
- Iranzo Bartolome et al. (2019) Jorge Iranzo Bartolome, Luis Cavazos Quero, Sunhee Kim, Myung-Yong Um, and Jundong Cho. 2019. Exploring Art with a Voice Controlled Multimodal Guide for Blind People. In Proc. Tangible, Embedded, and Embodied Interaction (Tempe, Arizona, USA) (TEI ’19). ACM, New York, NY, USA, 383–390. doi:10.1145/3294109.3300994
- Iravantchi et al. (2020) Yasha Iravantchi, Mayank Goel, and Chris Harrison. 2020. Digital Ventriloquism: Giving Voice to Everyday Objects. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–10. doi:10.1145/3313831.3376503
- Kane and Bigham (2014) Shaun K. Kane and Jeffrey P. Bigham. 2014. Tracking@ stemxcomet: teaching programming to blind students via 3D printing, crisis management, and twitter. In Proc. ACM Computer Science Education. ACM, 247–252.
- Karaduman et al. (2022) Hıdır Karaduman, Ümran Alan, and E Özlem Yiğit. 2022. Beyond “do not touch”: the experience of a three-dimensional printed artifacts museum as an alternative to traditional museums for visitors who are blind and partially sighted. Universal Access in the Information Society (2022), 1–14.
- Karim et al. (2023) Saman Karim, Jin Kang, and Audrey Girouard. 2023. Exploring Rulebook Accessibility and Companionship in Board Games via Voiced-based Conversational Agent Alexa. In Proc. ACM Designing Interactive Systems Conference (Pittsburgh, PA, USA) (DIS ’23). ACM, New York, NY, USA, 2221–2232. doi:10.1145/3563657.3595970
- Keeffe (2005) Jill Keeffe. 2005. Psychosocial Impact of Vision Impairment. International Congress Series 1282 (2005), 167–173.
- Kidd and Breazeal (2004) C.D. Kidd and C. Breazeal. 2004. Effect of a robot on user perceptions. In Proc. IEEE/RSJ Intelligent Robots and Systems, Vol. 4. 3559–3564 vol.4. doi:10.1109/IROS.2004.1389967
- Kim and Yeh (2015) Jeeeun Kim and Tom Yeh. 2015. Toward 3D-printed movable tactile pictures for children with visual impairments. In Proc. ACM CHI Conference on Human Factors in Computing Systems. ACM, 2815–2824.
- Kontogiorgos et al. (2020) Dimosthenis Kontogiorgos, Sanne van Waveren, Olle Wallberg, Andre Pereira, Iolanda Leite, and Joakim Gustafson. 2020. Embodiment Effects in Interactions with Failing Robots. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–14. doi:10.1145/3313831.3376372
- Landau (2009) Steven Landau. 2009. An Interactive Talking Campus Model at Carroll Center for the Blind. (2009). http://www.touchgraphics.com/downloads/carrollcentertalkingcampusmodelfinalreportlow.pdf
- Lankton and Tripp (2015) D. Harrison; Lankton, Nancy K.; McKnight and John Tripp. 2015. Technology, Humanness, and Trust: Rethinking Trust in Technology. Journal of the Association for Information Systems 16, 10 (2015). doi:10.17705/1jais.00411
- Lester et al. (1997) James C. Lester, Sharolyn A. Converse, Susan E. Kahler, S. Todd Barlow, Brian A. Stone, and Ravinder S. Bhogal. 1997. The persona effect: affective impact of animated pedagogical agents. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Atlanta, Georgia, USA) (CHI ’97). ACM, New York, NY, USA, 359–366. doi:10.1145/258549.258797
- Lester et al. (1999) James C. Lester, Brian A. Stone, and Gary D. Stelling. 1999. Lifelike Pedagogical Agents for Mixed-initiative Problem Solving in Constructivist Learning Environments. User Modeling and User-Adapted Interaction 9, 1 (01 Apr 1999), 1–44. doi:10.1023/A:1008374607830
- Liao et al. (2018) Q. Vera Liao, Muhammed Mas-ud Hussain, Praveen Chandar, Matthew Davis, Yasaman Khazaeni, Marco Patricio Crasso, Dakuo Wang, Michael Muller, N. Sadat Shami, and Werner Geyer. 2018. All Work and No Play?. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Montreal QC, Canada) (CHI ’18). ACM, New York, NY, USA, 1–13. doi:10.1145/3173574.3173577
- Luger and Sellen (2016) Ewa Luger and Abigail Sellen. 2016. ”Like Having a Really Bad PA”: The Gulf between User Expectation and Experience of Conversational Agents. In Proc. ACM CHI Conference on Human Factors in Computing Systems (San Jose, California, USA) (CHI ’16). ACM, New York, NY, USA, 5286–5297. doi:10.1145/2858036.2858288
- Luria et al. (2017) Michal Luria, Guy Hoffman, and Oren Zuckerman. 2017. Comparing Social Robot, Screen and Voice Interfaces for Smart-Home Control. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Denver, Colorado, USA) (CHI ’17). ACM, New York, NY, USA, 580–628. doi:10.1145/3025453.3025786
- Luria et al. (2019) Michal Luria, Samantha Reig, Xiang Zhi Tan, Aaron Steinfeld, Jodi Forlizzi, and John Zimmerman. 2019. Re-Embodiment and Co-Embodiment: Exploration of Social Presence for Robots and Conversational Agents. In Proc. ACM Designing Interactive Systems Conference (San Diego, CA, USA) (DIS ’19). ACM, New York, NY, USA, 633–644. doi:10.1145/3322276.3322340
- McDaniel et al. (2018) Troy McDaniel, Samjhana Devkota, Ramin Tadayon, Bryan Duarte, Bijan Fakhri, and Sethuraman Panchanathan. 2018. Tactile Facial Action Units Toward Enriching Social Interactions for Individuals Who Are Blind. In Smart Multimedia, Anup Basu and Stefano Berretti (Eds.). Springer International Publishing, Cham, 3–14.
- McDonald et al. (2014) Samantha McDonald, Joshua Dutterer, Ali Abdolrahmani, Shaun K. Kane, and Amy Hurst. 2014. Tactile Aids for Visually Impaired Graphical Design Education. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Rochester, New York, USA) (ASSETS ’14). ACM, New York, NY, USA, 275–276. doi:10.1145/2661334.2661392
- Miele et al. (2006) Joshua A. Miele, Steven Landau, and Deborah Gilden. 2006. Talking TMAP: Automated generation of audio-tactile maps using Smith-Kettlewell’s TMAP software. British Journal of Visual Impairment 24, 2 (2006), 93–100. doi:10.1177/0264619606064436
- Minjin Rheu and Huh-Yoo (2021) Wei Peng Minjin Rheu, Ji Youn Shin and Jina Huh-Yoo. 2021. Systematic Review: Trust-Building Factors and Implications for Conversational Agent Design. International Journal of Human–Computer Interaction 37, 1 (2021), 81–96. doi:10.1080/10447318.2020.1807710
- Moreno et al. (2001) Roxana Moreno, Richard E. Mayer, Hiller A. Spires, and James C. Lester. 2001. The Case for Social Agency in Computer-Based Teaching: Do Students Learn More Deeply When They Interact With Animated Pedagogical Agents? Cognition and Instruction 19, 2 (2001), 177–213. doi:10.1207/S1532690XCI1902_02
- Nagassa et al. (2023) Ruth G Nagassa, Matthew Butler, Leona Holloway, Cagatay Goncu, and Kim Marriott. 2023. 3D Building Plans: Supporting Navigation by People who are Blind or have Low Vision in Multi-Storey Buildings. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Hamburg, Germany) (CHI ’23). ACM, New York, NY, USA, Article 539, 19 pages. doi:10.1145/3544548.3581389
- Nie et al. (2012) Jiaqi Nie, Michelle Pak, Angie Lorena Marin, and S. Shyam Sundar. 2012. Can you hold my hand? physical warmth in human-robot interaction. In Proc. ACM/IEEE Human-Robot Interaction (Boston, Massachusetts, USA) (HRI ’12). ACM, New York, NY, USA, 201–202. doi:10.1145/2157689.2157755
- Nowak and Biocca (2003) Kristine L. Nowak and Frank Biocca. 2003. The Effect of the Agency and Anthropomorphism on Users’ Sense of Telepresence, Copresence, and Social Presence in Virtual Environments. Presence 12, 5 (2003), 481–494. doi:10.1162/105474603322761289
- O’Brien (2016) Heather O’Brien. 2016. Theoretical Perspectives on User Engagement. Springer International Publishing, Cham, 1–26. doi:10.1007/978-3-319-27446-1_1
- O’Brien and Lebow ([n. d.]) Heather L. O’Brien and Mahria Lebow. [n. d.]. Mixed-methods approach to measuring user experience in online news interactions. Journal of the American Society for Information Science and Technology 64, 8 ([n. d.]), 1543–1556. doi:10.1002/asi.22871
- of the Blind (2009) National Federation of the Blind. 2009. The Braille Literacy Crisis in America: Facing the Truth, Reversing the Trend, Empowering the Blind. (2009). Available from https://nfb.org/images/nfb/documents/pdf/braille_literacy_report_web.pdf.
- O’Brien et al. (2018) Heather L. O’Brien, Paul Cairns, and Mark Hall. 2018. A practical approach to measuring user engagement with the refined user engagement scale (UES) and new UES short form. International Journal of Human-Computer Studies 112 (2018), 28–39. doi:10.1016/j.ijhcs.2018.01.004
- Parkes (1994) Don Parkes. 1994. Audio tactile systems for designing and learning complex environments as a vision impaired person: static and dynamic spatial information access. Learning Environment Technology: Selected Papers from LETA 94 (1994), 219–223.
- Phillips and Zhao (1993) Betsy Phillips and Hongxin Zhao. 1993. Predictors of Assistive Technology Abandonment. Assistive Technology 5, 1 (1993), 36–45. doi:10.1080/10400435.1993.10132205 PMID: 10171664.
- Pradhan et al. (2019) Alisha Pradhan, Leah Findlater, and Amanda Lazar. 2019. ”Phantom Friend” or ”Just a Box with Information”: Personification and Ontological Categorization of Smart Speaker-based Voice Assistants by Older Adults. Proc. ACM Hum.-Comput. Interact. 3, CSCW, Article 214 (nov 2019), 21 pages. doi:10.1145/3359316
- Pradhan et al. (2018) Alisha Pradhan, Kanika Mehta, and Leah Findlater. 2018. ”Accessibility Came by Accident”: Use of Voice-Controlled Intelligent Personal Assistants by People with Disabilities. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Montreal QC, Canada) (CHI ’18). ACM, New York, NY, USA, Article 459, 13 pages. doi:10.1145/3173574.3174033
- Purington et al. (2017) Amanda Purington, Jessie G. Taft, Shruti Sannon, Natalya N. Bazarova, and Samuel Hardman Taylor. 2017. ”Alexa is my new BFF”: Social Roles, User Satisfaction, and Personification of the Amazon Echo. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Denver, Colorado, USA) (CHI EA ’17). ACM, New York, NY, USA, 2853–2859. doi:10.1145/3027063.3053246
- Qiu et al. (2020) Shi Qiu, Pengcheng An, Jun Hu, Ting Han, and Matthias Rauterberg. 2020. Understanding visually impaired people’s experiences of social signal perception in face-to-face communication. Universal Access in the Information Society 19, 4 (01 Nov 2020), 873–890. doi:10.1007/s10209-019-00698-3
- Qiu et al. (2016) Shi Qiu, Siti Aisyah Anas, Hirotaka Osawa, Matthias Rauterberg, and Jun Hu. 2016. E-Gaze Glasses: Simulating Natural Gazes for Blind People. In Proc. Tangible, Embedded, and Embodied Interaction (Eindhoven, Netherlands) (TEI ’16). ACM, New York, NY, USA, 563–569. doi:10.1145/2839462.2856518
- Rader et al. (2014) Joshua Rader, Troy McDaniel, Artemio Ramirez, Shantanu Bala, and Sethuraman Panchanathan. 2014. A Wizard of Oz Study Exploring How Agreement/Disagreement Nonverbal Cues Enhance Social Interactions for Individuals Who Are Blind. In HCI International 2014 - Posters’ Extended Abstracts, Constantine Stephanidis (Ed.). Springer International Publishing, Cham, 243–248.
- Reeves et al. (2004) Leah M. Reeves, Jennifer Lai, James A. Larson, Sharon Oviatt, T. S. Balaji, Stéphanie Buisine, Penny Collings, Phil Cohen, Ben Kraal, Jean-Claude Martin, Michael McTear, TV Raman, Kay M. Stanney, Hui Su, and Qian Ying Wang. 2004. Guidelines for Multimodal User Interface Design. Commun. ACM 47, 1 (Jan. 2004), 57–59. doi:10.1145/962081.962106
- Reichinger et al. (2016) Andreas Reichinger, Anton Fuhrmann, Stefan Maierhofer, and Werner Purgathofer. 2016. Gesture-Based Interactive Audio Guide on Tactile Reliefs. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Reno, Nevada, USA) (ASSETS ’16). ACM, New York, NY, USA, 91–100. doi:10.1145/2982142.2982176
- Reinders et al. (2023) Samuel Reinders, Swamy Ananthanarayan, Matthew Butler, and Kim Marriott. 2023. Designing Conversational Multimodal 3D Printed Models with People who are Blind. In Proc. ACM Designing Interactive Systems Conference (Pittsburgh, PA, USA) (DIS ’23). ACM, New York, NY, USA, 2172–2188. doi:10.1145/3563657.3595989
- Reinders et al. (2020) Samuel Reinders, Matthew Butler, and Kim Marriott. 2020. ”Hey Model!” - Natural User Interactions and Agency in Accessible Interactive 3D Models. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–13. doi:10.1145/3313831.3376145
- Rosenblum and Herzberg (2015) L. Penny Rosenblum and Tina S. Herzberg. 2015. Braille and Tactile Graphics: Youths with Visual Impairments Share Their Experiences. Journal of Visual Impairment & Blindness 109, 3 (2015), 173–184. doi:10.1177/0145482X1510900302
- Rowell and Ungar (2005) Jonathan Rowell and Simon Ungar. 2005. Feeling our way: tactile map user requirements – a survey. In Proc. International Cartographic Conference.
- Salah et al. (2023) Mohammed Salah, Hussam Alhalbusi, Maria Mohd Ismail, and Fadi Abdelfattah. 2023. Chatting with ChatGPT: decoding the mind of Chatbot users and unveiling the intricate connections between user perception, trust and stereotype perception on self-esteem and psychological well-being. Current Psychology (20 Jul 2023). doi:10.1007/s12144-023-04989-0
- Schroeder et al. (2013) Noah L. Schroeder, Olusola O. Adesope, and Rachel Barouch Gilbert. 2013. How Effective are Pedagogical Agents for Learning? A Meta-Analytic Review. Journal of Educational Computing Research 49, 1 (2013), 1–39. doi:10.2190/EC.49.1.a
- Shamekhi et al. (2018) Ameneh Shamekhi, Q. Vera Liao, Dakuo Wang, Rachel K. E. Bellamy, and Thomas Erickson. 2018. Face Value? Exploring the Effects of Embodiment for a Group Facilitation Agent. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Montreal QC, Canada) (CHI ’18). ACM, New York, NY, USA, 1–13. doi:10.1145/3173574.3173965
- Sheffield (2016) Rebecca Sheffield. 2016. International Approaches to Rehabilitation Programs for Adults who are Blind or Visually Impaired: Delivery Models, Services, Challenges and Trends.
- Shi et al. (2019) Lei Shi, Holly Lawson, Zhuohao Zhang, and Shiri Azenkot. 2019. Designing Interactive 3D Printed Models with Teachers of the Visually Impaired. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Glasgow, Scotland Uk) (CHI ’19). ACM, New York, NY, USA, Article 197, 14 pages. doi:10.1145/3290605.3300427
- Shi et al. (2016) Lei Shi, Idan Zelzer, Catherine Feng, and Shiri Azenkot. 2016. Tickers and Talker: An accessible labeling toolkit for 3D printed models. In Proc. of the 34rd Annual ACM Conference on Human Factors in Computing Systems (CHI’16). doi:10.1145/2858036.2858507
- Shi et al. (2017) Lei Shi, Yuhang Zhao, and Shiri Azenkot. 2017. Designing Interactions for 3D Printed Models with Blind People. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Baltimore, Maryland, USA) (ASSETS ’17). ACM, New York, NY, USA, 200–209. doi:10.1145/3132525.3132549
- Shi et al. (2020) Lei Shi, Yuhang Zhao, Ricardo Gonzalez Penuela, Elizabeth Kupferstein, and Shiri Azenkot. 2020. Molder: An Accessible Design Tool for Tactile Maps. In Proc. ACM CHI Conference on Human Factors in Computing Systems (Honolulu, HI, USA) (CHI ’20). ACM, New York, NY, USA, 1–14. doi:10.1145/3313831.3376431
- Siddharth Gulati and Lamas (2019) Sonia Sousa Siddharth Gulati and David Lamas. 2019. Design, development and evaluation of a human-computer trust scale. Behaviour & Information Technology 38, 10 (2019), 1004–1015. doi:10.1080/0144929X.2019.1656779
- Sidner et al. (2018) Candace L. Sidner, Timothy Bickmore, Bahador Nooraie, Charles Rich, Lazlo Ring, Mahni Shayganfar, and Laura Vardoulakis. 2018. Creating New Technologies for Companionable Agents to Support Isolated Older Adults. ACM Trans. Interact. Intell. Syst. 8, 3, Article 17 (July 2018), 27 pages. doi:10.1145/3213050
- Stangl et al. (2015) Abigale Stangl, Chia-Lo Hsu, and Tom Yeh. 2015. Transcribing Across the Senses: Community Efforts to Create 3D Printable Accessible Tactile Pictures for Young Children with Visual Impairments. In Proc. ACM SIGACCESS Conference on Computers & Accessibility (Lisbon, Portugal) (ASSETS ’15). ACM, New York, NY, USA, 127–137. doi:10.1145/2700648.2809854
- Taylor et al. (2015) Brandon T. Taylor, Anind K. Dey, Dan P. Siewiorek, and Asim Smailagic. 2015. TactileMaps.net: A web interface for generating customized 3D-printable tactile maps. In Proc. ACM SIGACCESS Conference on Computers & Accessibility. ACM, 427–428. doi:10.1145/2700648.2811336
- ViewPlus ([n. d.]) ViewPlus. [n. d.]. IVEO 3 Hands-On Learning System. ([n. d.]). Available from https://viewplus.com/product/iveo-3-hands-on-learning-system/.
- Wedler et al. (2012) Henry B Wedler, Sarah R Cohen, Rebecca L Davis, Jason G Harrison, Matthew R Siebert, Dan Willenbring, Christian S Hamann, Jared T Shaw, and Dean J Tantillo. 2012. Applied computational chemistry for the blind and visually impaired. Journal of Chemical Education 89, 11 (2012), 1400–1404.
- Wiebe et al. (2014) Eric N. Wiebe, Allison Lamb, Megan Hardy, and David Sharek. 2014. Measuring engagement in video game-based environments: Investigation of the User Engagement Scale. Computers in Human Behavior 32 (2014), 123–132. doi:10.1016/j.chb.2013.12.001
- Wu et al. (2017) Shaomei Wu, Jeffrey Wieland, Omid Farivar, and Julie Schiller. 2017. Automatic Alt-Text: Computer-Generated Image Descriptions for Blind Users on a Social Network Service. In Proc. ACM Computer Supported Cooperative Work and Social Computing (Portland, Oregon, USA) (CSCW ’17). ACM, New York, NY, USA, 1180–1192. doi:10.1145/2998181.2998364
Appendix A Godspeed Questionnaire (GSQ)
GSQ items were mixed to mask intention and used a 5-point semantic scale.
Anthropomorphism
-
•
Machine-like Human-like
-
•
Unconscious Conscious
Animacy
-
•
Artificial Lifelike
-
•
Inert Interactive
Likeability
-
•
Dislike Like
-
•
Unfriendly Friendly
-
•
Unpleasant Pleasant
Perceived Intelligence
-
•
Ignorant Knowledgeable
-
•
Unintelligent Intelligent
Appendix B User Engagement Scale Short Form (UES-SF)
UES-SF items were mixed to mask intention and used a 5-point Likert scale.
Focused Attention
-
•
I lost myself in this experience.
-
•
The time spent using the model just slipped away.
-
•
I was absorbed in this experience.
Perceived Usability
-
•
I felt frustrated while using the model.
-
•
I found the model confusing to use.
-
•
Using the model was taxing.
Aesthetic Appeal
-
•
This model was attractive to my senses.
-
•
This model was aesthetically pleasing to my senses.
-
•
This model appealed to my senses.
Reward
-
•
Using the model was worthwhile.
-
•
This experience was rewarding.
-
•
I felt interested in this experience.
Appendix C Playful Experiences Questionnaire (PLEXQ)
PLEXQ items were mixed to mask intention and used a 5-point Likert scale.
Captivation
-
•
I forgot my surroundings.
-
•
I felt completely absorbed.
-
•
I lost track of space and time.
Challenge
-
•
It stimulated me to learn new things.
-
•
It was a true learning experience.
-
•
I enjoyed learning new things.
Control
-
•
I had the capability to influence what was happening.
-
•
I felt powerful.
-
•
I enjoyed being in control.
Discovery
-
•
I enjoyed discovering new things.
-
•
I enjoyed finding useful new ways of using it.
-
•
I enjoyed finding something unexpected.
Exploration
-
•
I felt curious.
-
•
I enjoyed experimenting.
-
•
I enjoyed trying out new things.
Humor
-
•
It made me laugh.
-
•
I had fun.
-
•
I experienced funny situations.
Relaxation
-
•
I felt relaxed.
-
•
I enjoyed passing time with it.
-
•
I felt relieved from stress.
Sensation
-
•
I felt pleased by its aesthetics to my senses.
-
•
I enjoyed the aesthetics to my senses.
-
•
I felt pleased by the quality of it.
Appendix D Human-Computer Trust Model (HCTM)
HCTM items were mixed to mask intention and used a 5-point Likert scale.
Perceived Risk
-
•
I believe that there could be negative consequences using the model.
-
•
I feel I must be cautious when using the model.
-
•
It is risky to interact with the model.
Benevolence
-
•
I believe that the model will act in my best interest.
-
•
I believe that the model will do its best to help me if I need help.
-
•
I believe that the model is interested in understanding my needs and preferences.
Competence
-
•
I think the model is competent and effective in facilitating my learning.
-
•
I think the model performs its role as a learning material very well.
-
•
I believe that the model has all the functionalities I would expect from a learning material.
Reciprocity
-
•
If I use the model, I think I would be able to depend on it completely.
-
•
I can always rely on the model for facilitating my learning.
-
•
I can trust the information presented to me by the model.