Inverse-like Antagonistic Scene Text Spotting via Reading-Order Estimation and Dynamic Sampling
Abstract
Scene text spotting is a challenging task, especially for inverse-like scene text, which has complex layouts, e.g., mirrored, symmetrical, or retro-flexed. In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework dubbed IATS, which can effectively spot inverse-like scene texts without sacrificing general ones. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). To optimize and train REM, we propose a joint reading-order estimation loss () consisting of a classification loss, an orthogonality loss, and a distribution loss. With the help of IBM, we can divide the initial text boundary into two symmetric control points and iteratively refine the new text boundary using a lightweight boundary refinement module (BRM) for adapting to various shapes and scales. To alleviate the incompatibility between text detection and recognition, we propose a dynamic sampling module (DSM) with a thin-plate spline that can dynamically sample appropriate features for recognition in the detected text region. Without extra supervision, the DSM can proactively learn to sample appropriate features for text recognition through the gradient returned by the recognition module. Extensive experiments on both challenging scene text and inverse-like scene text datasets demonstrate that our method achieves superior performance both on irregular and inverse-like text spotting.
Index Terms:
Scene text spotting, inverse-like scene text, reading-order estimation, dynamic samplingI Introduction
Text spotting aims to localize and recognize text in images. It has received ever-increasing attention for its extensive real-world applications, such as vehicle intelligence and road sign recognition in autonomous driving. Although text spotting has made significant progress recently, existing methods still face challenges in recognizing text with complex layouts, such as arbitrary orientations or shapes [1, 2, 3, 4, 5]. To address these problems, existing text spotting frameworks propose the Masked RoI [1, 6, 7] and Thin Plate Spline (TPS) [8, 3, 9] strategies. Masked RoI based methods allow for the suppression of background information, as shown in Fig. 1 (a1-a2), but they still struggles with irregular texts. TPS based methods can transform irregular texts into horizontal texts by symmetrical boundary points, as seen in Fig. 1 (b1-b3), but they also suffers from the accuracy of detected boundaries.

In text spotting, two critical problems still require further improvement. Firstly, the crucial reading-order information is not fully explored for the recognizer to decode text characters in the correct sequence. Although many existing datasets follow the text reading direction, most ignore this issue, except Text Perceptron [8] and PGNet [10]. However, these two approaches only use information pointing to the head and tail of text, which in some cases (as shown in Fig. 1(a1)) cannot fully reflect the reading-order. Inverse-like texts are universal and appear mirrored, symmetrical, or retroflexed. Simply clipping the detection result of such exceptional text makes recognition difficult, as shown in Fig. 1 (a1-a3). Suppose the network can fully excavate and learn the reading-order information hidden in the training samples labeled with the reading direction. In that case, the reading-order information will suitably align the text for better recognition. The second issue is that text recognition accuracy is heavily dependent on the precision of detection, resulting in potential error propagation from detection to recognition, as pointed out in previous studies [11, 12]. Current methods [1, 8] generally adopt inflexible sampling strategies that rely on fixed sampling grids manually determined by detection boundaries or segmented masks. As a result, when detection accuracy is compromised or sampling features are inadequate, the recognizer may fail in decoding the correct sequence, as shown in Fig. 1 (c1-c3). Therefore, exploring an adaptive dynamic feature sampling approach that can improve recognition performance is nontrivial, especially in challenging scenarios where detection accuracy is limited.

In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework (dubbed IATS), which can effectively spot inverse-like scene texts without sacrificing general ones following human reading habits. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). As shown in Fig. 2 (a), the reading-order estimation module (REM) based on a circular convolution network can accurately estimate four key corner points on the coarse initial boundary. To ensure the reliability of REM, we propose a novel joint reading-order estimation loss () to optimize and train REM, which includes a classification loss, an orthogonality loss, and a distribution loss. According to the predicted reading-order, we divide the initial text boundary into two symmetric boundary control points and use a lightweight boundary refinement module (BRM) to iteratively refine them to adapt to the diversity of text shapes and scales. To further alleviate the incompatibility between detection and recognition, we propose a novel dynamic sampling module (DSM) with thin-plate spline, which is used to dynamically sample features in the detected text region for recognition. During training, DSM can actively learn how to dynamically sample optimal features through the gradient returned by the recognition module without extra supervision. Benefiting from the DSM, our method can recognize text instances accurately even if detected text boundaries are not perfect, as shown in Fig. 1 (d1-d3). Extensive experiments on challenging scene text (Total-Text, CTW-1500, and ICDAR2015) and inverse-like scene text datasets (Rot.Total-Text, and Inverse-Text) verify that our method achieves superior performance both on irregular and inverse-like text spotting tasks.
Overall, our main contributions are summarized as follows:
-
•
We propose a unified end-to-end trainable inverse-like antagonistic text spotting framework (dubbed IAST), which can effectively spot inverse-like scene texts without sacrificing general ones.
-
•
We propose an innovative reading-order estimation module (REM) with a joint reading-order estimation loss () to fully learn and excavate the key reading-order information in text boundaries.
-
•
We propose a dynamic sampling module (DSM), which can adaptively learn how to dynamically sample appropriate features in detected text regions through the gradient returned by the recognition module.
-
•
Extensive experiments verify that our method achieves competitive results in scene text spotting benchmarks and also significantly surpasses previous methods in spotting irregular and inverse-like scene text.

II Related Work
II-A Text Detection
Traditional deep learning-based text detection methods [13, 14, 15, 16, 17, 18, 19] mainly focus on multi-oriented texts. Anchor-based methods [13] adopt rotated anchors and RRoI pooling for detecting multi-oriented texts. Anchor-free methods [16] directly regress the offsets from boundaries or vertexes to the current point for detecting texts. Some methods [14, 20] try to design a hidden anchor mechanism to integrate the advantages of the anchor-based method into the anchor-free method. Recently, a series of text detection methods have been proposed for detecting irregular text. The Connected Component (CC) based methods [21, 22] usually detect individual text parts or characters first, followed by a link or group post-processing procedure for generating final texts. Segmentation-based methods [23, 17] use instance segmentation to detect arbitrary shape text and design different schemes to separate adjacent text instances. But, segmentation accuracy significantly determines the quality of detected boundaries. Contour-based methods [24, 25, 26, 27, 28] resort to modeling the text boundary for better representation of arbitrarily-shaped texts.
II-B Text Recognition
Scene text recognition involves recognizing texts in a cropped image. Traditional methods [29, 30] rely on character-level annotations for character detection, while methods [31, 32] extract features from line-level text using CNN and RNN, and use a CTC-based decoder for prediction alignment. However, these methods are designed for regular text recognition and struggle with irregular text. To address this problem, Shi et al. [33] propose a rectification network with STN for arbitrary shape text, while Litman et al. [34] use TPS and selective attention decoder for visual and contextual features. CharNet [35] uses a Character-Aware Neural Network to detect characters first and then separately transform them into a horizontal one. AON [36] extracts features with four directions and character position clues, while SAD [37] applies a 2D-attention mechanism to catch irregular text features, both achieving impressive results. To address the attention drift issue, RobustScanner [38] design a position enhancement branch in the recognition model. In addition, some methods use semantic segmentation to assist in text recognition.
II-C Text Spotting
Traditional text spotting methods [39, 40] perform text detection and recognition as two separate steps. Generally, a text detector extracts regions of interest (RoI), which are then fed into a recognition model. However, recent end-to-end text spotting approaches [41, 42, 43, 8] have confirmed that detection and recognition tasks are highly relevant and complementary to each other. By sharing features and jointly optimizing the modules [41, 44] in a unified end-to-end trainable network, they achieved improved detection and recognition performances simultaneously.
Recently, several methods [2, 45, 43, 6, 1, 46, 10, 27, 47, 48, 49, 50] have been proposed to address arbitrary shape text spotting. Mask TextSpotter [6] and PAN++ [1] use RoI Masking to focus on the arbitrarily shaped text region. MANGO [4] uses a Mask Attention module to retain global features for multiple instances but still requires centerline segmentation to guide the grouping of the predictions. Boundary TextSpotter [45] and TPSNet [9] localize the boundary points of text instances and rectify the features using Thin-Plate-Spline before feeding them into the recognition branch. CRAFTS [46] uses character region maps supervised by character-level annotations to help the attention-based recognizer attend to precise character center points. PGNet [10] transforms the polygonal text boundaries to the centerline, border offset, and direction offset and performs multi-task learning for these objectives. Inspired by Pix2Seq [51], some methods, such as TESTR [47], TTS [52], and SPTS [48], use a network combining CNN and Transformer that tackles text spotting as a sequence prediction task, similar to language modeling. However, these methods usually require extensive computing and data resources.
Although the text spotting methods (e.g., ABCNet [43, 53], TESTR [47] and SwinTextSpotter [54]) have achieved great improvement for arbitrarily shaped text spotting, they still suffer from inverse-like text because of the absence of key reading-order information. However, the reading of inverse-like scene text is important, even though it has just been noticed in DPText [27]. The other problem is that the reading performance of these methods also suffers from the accuracy of detected boundaries because of fixed feature sample. In this paper, we aim to effectively spot inverse-like scene texts without sacrificing general ones. Hence, we design a reading-order estimation module and a dynamic sampling module, which greatly improves the accuracy of inverse-like text spotting without losing generality.
III Proposed Method
III-A Overview
The framework of our method presented in Fig. 3 mainly consists of six components: feature extraction module, init boundary module (IBM), reading-order estimation module (REM), boundary deformation module, dynamic sampling module (DSM), and text recognition module. The feature extraction module extracts features from input images for the text detection and recognition tasks. To preserve spatial resolution and utilize multi-level information, we use a multi-level feature fusion strategy similar to [55]. As noted in [45], the two tasks have different requirements for feature maps. Specifically, the recognition task needs more detailed information for character sequence prediction, while the detection task focuses on the whole text instance. Therefore, we use lightweight convolutions to separate the detection and recognition features.
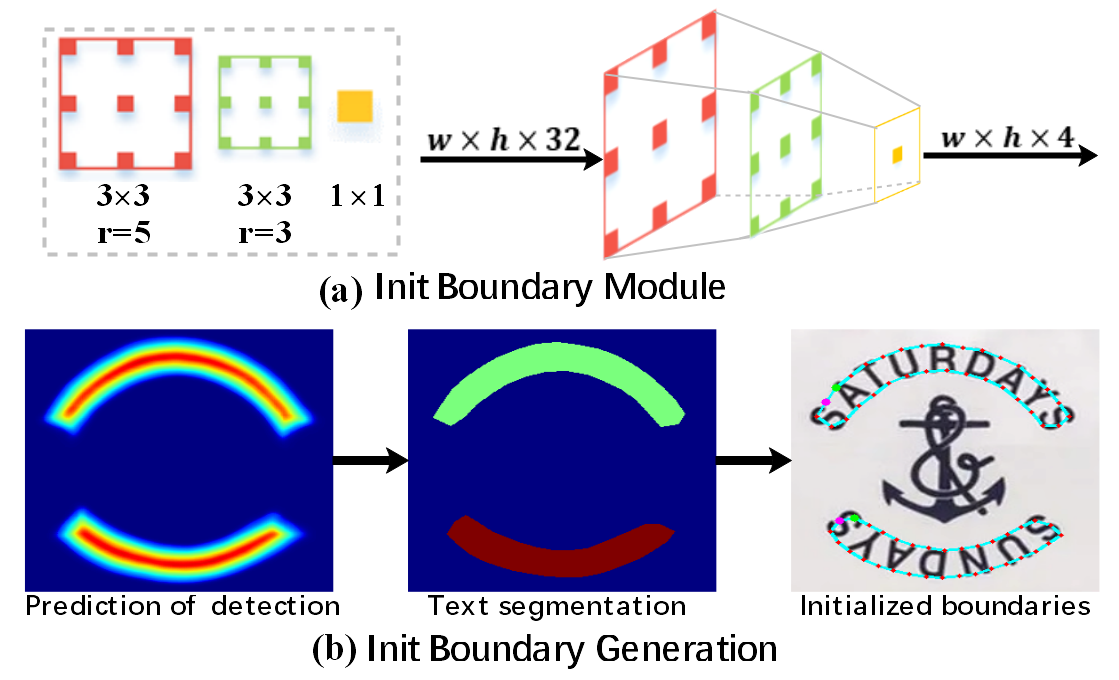
III-B Initial Text Boundary
The initial boundary module generates rough text boundaries to locate text instances. Similar to [25, 28], our module consists of multi-layer dilated convolutions, including two convolution layers with different dilation rates and one convolution layer, as illustrated in Fig. 4(a). It uses shared detection features to provide prior information for text location. The prior information can be in the form of field information such as classification, distance, and direction in[25, 28], probability maps in DB [56], or text kernels in PSENet [57] and PAN [58]. Using the prior information, we can obtain the text segmentation and generate a coarse text boundary, as shown in Fig. 4(b). The accuracy of these text boundaries is not deterministic, as they are only used as initial information and will be refined in our method.
III-C Reading-Order Estimation
The reading-order is crucial for accurate understanding and recognition of text sequences. In existing text detection datasets, the annotation of text detection follows the reading direction of human beings, as it aligns the text features suitably for better recognition. However, the implicit learning of reading-order can degrade the detector’s robustness, resulting in false positives and jagged edges, as shown in Fig. 5 (b). Even with extensive training with rotation augmentations, the detector still struggles to learn correct reading-orders, as shown in Fig. 5 (c).
Learning reading-order explicitly is rare in existing methods, except for Text Perceptron [8] and PGNet [10]. Text Perceptron uses order-aware segmentation to indicate the head and tail of text instance, while PGNet extracts the text reading-order using TDO maps, as shown in Fig. 5 (d) and (e). However, both methods only consider the order of information from the head to tail, neglecting the top and bottom. In some cases, this imperfect reading-order fails to reflect the actual case, such as inverse-like text, which may occur in natural images with more complex layouts like mirror, symmetry, or inversion, etc.. In these cases, simply clipping the detection results with an artificial or imperfect reading-order disturbs recognition, as shown in Fig. 1 (a1-a3) or Fig. 5 (b-e).



To fully explore the reading-order information of humans hidden in annotations [27], we design a reading-order estimation module (REM) to accurately learn the text reading-order information. In detection tasks, text instances are typically found in long strips, with two long edges in the text boundary, as noted in [59, 27]. Hence, we adopt four key corners at both ends of the text’s long side to indicate the reading-order, as depicted in Fig. 5 (f). In this work, we tackle the problem of reading-order estimation by treating it as a classification task. Our approach involves a reading-order estimation module (REM) that identifies whether each point on the initial boundary belongs to one of the four key corners. Specifically, we employ a “CirConv” block, a fusion block, and a prediction head (as depicted in Fig. 6 (a)) to construct REM. The “CirConv” block consists of four circular convolution layers with different dilation rates (e.g., [1, 1, 2, 4]) to enhance REM’s information aggregation capability. We use dense shortcut connections across all layers to improve the interaction between each layer [60]. The fusion block uses a 11 convolution layer and max pooling to merge information in the “CirConv” block. Then, the deeply fused features are distributed to each initial boundary point by concatenating their features. Finally, three 11 convolution layers with ReLU activation and sigmoid generate the classification information () for each initial boundary point.
To enable batch processing and avoid missing key corners due to a large sampling interval, we sample vertices () for each initial text boundary, forming a closed contour (as shown in Fig. 6 (b)-(1)). Circular convolution will encode the cyclicity of points along the closed contour effectively, building on the success of DeepSnake [61]. However, an excellent network structure is not sufficient to learn the correct reading-order, as the input information also plays a decisive role. To ensure REM obtains more reliable information to accurately estimate the reading-order, the input feature consists of geometric attributes () of vertex , visual features (), and order embedding features () of the initial boundary.
The geometric attributes () of vertex includes cosine () of angle, coordinates relative to the initial boundary centroid , and distance () relative to the . Thus, the geometric attributes () of vertex can be formulated as
| (1) |
The can be calculated as
| (2) |
where the angle () of vertex is defined as the angle between vector and , as shown in Fig. 6 (b)-(1). The is the centroid of the initial boundary, formulated as
| (3) |
After we get the , the coordinates and the distance () of vertex can be calculated as follows:
| (4) | |||
| (5) |
where and are the width and height of the bounding rectangle of the initial boundary (). Here, we have obtained three geometric attributes for vertex , providing important prior information for vertex classification.
We know that text instances in word-level and line-level typically have two long sides and two short sides in their boundaries, and the key points we need to identify are usually located at the intersection of the long and short sides. These points have distinct geometric attributes . As shown in Fig. 6 (b)-(1), the angle of these key points usually exhibits sudden changes and is significantly smaller than that of other non-key points. The distances from these key points to the centroid are typically greater than those of other points, although not always the smallest. To improve the fusion of visual () and geometric () features during module reasoning, we embed the geometric attributes of each vertex into a high-dimensional space as [21]. Specifically, we apply sine and cosine functions with varying wavelengths to . The geometric attribute embedding is calculated as follows:
| (6) | |||
| (7) |
where is the dimension of the embedding vector (emprirically set to 36). The geometric attribute of vertex is embedded into a vector of dimension . Because has four attribute values, the dimension of each attribute scalar is .
The includes a 32-D detection shared features obtained by CNN backbone and 4-D prior features , as
| (8) | |||
| (9) |
where “” denotes concatenation operation. has 36 dimensions. is the visual features of the centroid in .
As texts vary in scale, the sampled points may be too close to each other, resulting in very little difference between the visual and geometric features. This can cause confusion in the network output. To avoid this, we embed order information () of the point sequence into the input feature for vertex using an embedding operation in Pytorch. Therefore, the input feature of the reading-order estimation module is calculated as follows:
| (10) |
where denotes the -th sampling point in initial boundary. The classification results () of these sampling points will be obtained after the input features are encoded and reasoned by REM. is a probability distribution, and each element represents the probability that the vertex belongs to -th class of the key points.
Joint reading-order estimation loss. To optimize and train our REM, we propose a joint reading-order estimation loss (), consisting of a classification loss, an orthogonality loss, and a distribution loss. We use the balance binary cross entropy loss to supervise classification as
| (11) |
where represents the predicted labels for the classification of every control point. Thus, represents the label for -th control point , which is a one-dimensional vector with four elements in total (as ). When the control point belongs to -th key corner point, ; otherwise . Thus, is probability of control point belongs to the -th key corner point.
To ensure that the four key points found are independent and different from each other, we further designed an orthogonality loss and a distribution loss to constrain the optimization of REM. The orthogonality loss can be expressed as
| (12) |
where is the KL Divergence loss; is the similarity matrix of prediction of REM ( ); is an identity matrix of dimension .
As shown in Fig. 7 (a), the four key points not only have independent positions but also follow a specific spatial distribution. For word-level and line-level text detection, these key points are usually located at the intersection of the long and short sides in long strips of text. When these sampling points are flattened into a sequence from the short or long side (as ① ② ③ ④shown in Fig. 7 (a)), the distributions of the four key points are similar regardless of category, as shown in Fig. 7 (b) and (c). Typically, the sequence length of the long side () is greater than that of the short side (). To fully utilize this distribution information and better constrain the REM to learn and extract the hidden reading order information, we introduce a distribution constraint loss via KL-divergence as
| (13) |
where is a probability distribution predicted by REM. is the one hot representation of sample points () label belonging to -th category. Finally, the proposed reading-order estimation loss () is a combination of classification loss , orthogonality loss , and distribution loss , as follows
| (14) |
where is set to 0.1 because orthogonality loss , and distribution loss only serves as auxiliary constraints.
According to the four key points obtained, we divide the text boundary into top and bottom sides, as shown in Fig. 6 (b). At the same time, we re-sample control points according to the principle of equidistance on the top and bottom sides, respectively. As shown in Fig. 6 (b), the re-adjusted initial text boundary has control points (), which are symmetrically distributed on top and bottom sides.

Boundary Refinement Module. Due to the varying directions and shapes of text, it is challenging to directly predict accurate text boundary. Therefore, we first use the initial boundary to roughly locate text and separate the neighboring text. But, these coarse initial boundaries only partially cover the text instances, resulting in inaccurate recognition due to incomplete text regions. Similar to TextBPN++ [28], we employ a lightweight transformer network as our boundary refinement module (BRM). To simplify the model structure and reduce parameters, we adopt the strategy of sharing parameters and self-iterative refinement, as shown in Fig. 3. In each refinement iteration, the BRM takes the previously predicted boundary as input and generates a new boundary, enabling dynamic refinement of text boundaries to adapt to various text shapes and scales.
As illustrated in Fig. 3, the refined text boundaries become closer to the actual text boundaries as the number of iterations increases. Unlike TextBPN++[28], which uses point matching loss, we optimize this module by minimizing the Smooth L1 distance between each refined text boundary () and its corresponding target (). Specifically, the loss of this module is formulated as
| (15) |
where the is the number of iterations, is -th refined prediction of point .
III-D Dynamic Sampling
Thin-Plate Spline (TPS) has been widely used as a grid sampling approach in arbitrary shape scene text spotting [8, 45, 9]. However, TPS is an inflexible sampling strategy that only generates fixed sampling grids manually, as illustrated by the blue grid points in Fig. 9. These fixed sampling grids result in the sampled CNN features for recognition sequence being highly dependent on the detected text boundary. As a consequence, it becomes challenging for the recognizer to decode the correct sequences when the detection is inaccurate or the sampling features are inadequate, as shown in Fig. 1 (c1-c3). Therefore, the recognition performance highly relies on the text detection accuracy, leading to potential error propagation to recognition in these methods [8, 45, 9].

To solve this problem, we propose a novel dynamic sampling module with thin-plate spline, named DSM, which can dynamically sample the features in the detected text region for the recognition module. Our DSM can mitigate the incompatibility between text detection and recognition, especially when the detected text boundaries are imperfect for recognition. As shown in Fig. 9, the dynamic sampling module comprises two stacked convolutional layers with dilation [3,1] and one fully connected layer. Inspired by DCN[62], which learns offsets to produce deformable convolution kernels based on traditional convolution, we employ a lightweight convolution head to predict a set of position offsets for the basic grid points generated by the TPS algorithm. Specifically, we first use TPS to generate the fiducial grid points of size . Then, the lightweight convolution head produces a set of normalized position offsets for the fiducial grid points , as
| (16) |
where denotes convolutional layer, and denotes fully connected layer realized by convolution. is the input features of points extracted from recognition shared features (). and indicate that the dilation are set to 3 and 1, respectively. is the normalized offset of the point in gird . To make the learning of offset not affected by the size of the text instance, we normalize it by the sigmoid function. Therefore, the real offset can be calculated as
| (17) | |||
| (18) |
where and are the width and height of the bounding rectangle of the text instance. is the set of , and is the updated gird. is the scale coefficient and is set to 0.1, which can ensure a suitable offset space for the sampling points, as the detected text boundaries usually do not have significant errors.
In training, DSM adaptively adjusts the position of fiducial grid points by using the gradient returned from the recognition module without extra supervision. During inference, DSM can dynamically sample appropriate features in the detected text region for the recognition module to decode the text sequence accurately. Our DSM can decode text content more accurately, even in challenging scenes where the detected text boundaries may have flaws or are imperfect for recognition, as shown in Fig. 2 and Fig. 10. In Fig. 10, the detected text boundary does not cover the entire instance, making the recognition module decode the character ‘i’ as ‘l’ incorrectly. However, the sampling points of our DSM can exceed the detection boundary, enabling the recognition module to accurately decode the correct characters, even when the detected boundary does not completely cover the text instance.

| Method | Rotation | REM | DSM | Total-Text | Rot.Total-Text | Inverse-Text | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Detection | End-to-End | Detection | End-to-End | Detection | End-to-End | |||||||||||||
| P | R | F | None | Full | P | R | F | None | Full | P | R | F | None | Full | ||||
| 88.9 | 82.6 | 85.6 | 67.2 | 78.8 | 80.8 | 73.4 | 76.9 | 48.3 | 62.7 | 81.9 | 76.6 | 79.2 | 52.6 | 66.6 | ||||
| ✓ | 89.9 | 82.8 | 86.2 | 67.4 | 79.2 | 88.5 | 81.8 | 85.0 | 51.8 | 66.2 | 88.0 | 81.8 | 84.8 | 57.4 | 68.4 | |||
| ✓ | ✓ | 90.8 | 83.3 | 86.9 | 69.6 | 80.7 | 88.8 | 83.2 | 85.9 | 53.4 | 68.0 | 89.0 | 82.7 | 85.7 | 60.5 | 70.7 | ||
| ✓ | ✓ | 91.2 | 84.0 | 87.5 | 69.2 | 80.3 | 88.9 | 82.8 | 86.2 | 66.4 | 77.6 | 88.6 | 83.8 | 86.1 | 64.8 | 76.6 | ||
| ✓ | ✓ | ✓ | 92.7 | 84.8 | 88.6 | 70.5 | 81.6 | 89.4 | 84.6 | 86.9 | 68.8 | 80.2 | 90.3 | 83.6 | 86.8 | 67.1 | 78.3 | |
III-E Optimization
By dynamically sampling features by DSM, any recognition model can be applied for the recognition. For a fair comparison, we take the model in [53, 9] as our recognition module, which consists of 6 convolutional layers, one bidirectional LSTM layer, and an attention-based decoder.
For end-to-end training the network, the objective of the function is combined with the losses of modules mentioned above, which is formulated as
| (19) |
where is the loss of the initial boundary module as in TextBPN++ [28]; is the loss of reading-order estimation module as Eq. 14; is the loss of boundary refinement module as Eq. 15; is the Cross Entropy Loss for the recognition module as in [53, 9]. In pre-training, the is set to , the is set to . denotes the maximum epoch of training, and denote the -th epoch in training. In this way, our model can prioritise learning to find the interested text region at the beginning of training, ensuring that the training can converge normally. In fine-tuning, is set to 1.0, is set to . is empirically set to 0.2.
IV Experiments
IV-A Datasets
SynthText 150k is synthesized in [43] comes with 150k synthetic images containing mostly straight text and curved texts. It is different from SynthText 800k, which contains mostly straight texts in quadrilateral annotations.
Total-Text is a word-level dataset including the horizontal, oriented and curved text, which contains 1255 training images and 300 test images.
Rot.Total-Text [27] is a test set derived from Total-Text, which applies large rotation angles (0∘, 45∘, 135∘, 180∘, 225∘, 315∘) on images of the Total-Text test set to examine the model robustness, resulting in 1,800 test images.
CTW-1500 is a line-level dataset containing horizontal, multi-oriented and curved text instances, including 1000 training images and 500 test images.
ICDAR2015 is a word-level and multi-oriented text dataset, including 1000 training images and 500 test images. This dataset includes many incidental scene text, such as blur or small text, which challenges text spotting.
IV-B Implementation Details
We use ResNet-50 with DCN [62] as the backbone and pre-train our model for 100 epochs on a mixture of SynthText 150K, MLT-2017, Total-Text, and ICDAR2015 datasets. During pre-training, we apply the Adam optimizer with an initial learning rate of and weight decay of . The pre-trained model is then fine-tuned on the target dataset for 800 epochs with the initial learning rate set to and divided by ten at 400 epochs, using the Adam optimizer. We use 16 control points for text boundary and perform five iterations of BRM. The default number of sampling points is , and data augmentation techniques such as random scaling, cropping, and distortion (e.g., random blur, brightness adjustment, and color change) are applied. To enhance the model’s ability to recognize text in different reading-orders, we add random rotation with a wide-angle ()) and denser sampling around [].
During training, we randomly crop text regions without cutting any text and resize them to . We pre-train our model using two RTX-3090 GPUs with an image batch size of 24 and fine-tune using a single RTX-3090 GPU with an image batch size of 12. During inference, we maintain the aspect ratio of test images and resize and pad them to the same size. Our implementation is based on PyTorch 1.7 and Python 3, and testing is performed on a single RTX-3090 GPU with a single thread. Recall, Precision, and F-measure are represented by R”, P”, and “F”, respectively.
IV-C Ablation Studies
In exploration experiments, we only pre-train the model with ten epochs to reduce training time costs. Other training details are described in Sec. IV-B. Some special details are described in the corresponding section. In default, random rotation data augmentation is used.

| Sampling Method | REM | Detection | End-to-End | |||
|---|---|---|---|---|---|---|
| P | R | F | None | Full | ||
| Masking ROI | 88.4 | 80.4 | 84.2 | 55.8 | 66.4 | |
| BezierAlign | 89.3 | 81.2 | 85.1 | 58.3 | 69.2 | |
| TPS | 88.0 | 81.8 | 84.8 | 57.4 | 68.4 | |
| DSM | 89.0 | 82.7 | 85.7 | 60.5 | 70.7 | |
| Masking ROI | ✓ | 89.0 | 81.6 | 85.1 | 62.4 | 74.2 |
| BezierAlign | ✓ | 90.5 | 81.8 | 85.9 | 65.0 | 77.2 |
| TPS | ✓ | 88.6 | 83.8 | 86.1 | 64.8 | 76.6 |
| DSM | ✓ | 90.3 | 83.6 | 86.8 | 67.1 | 78.3 |

Reading-order estimation module (REM). Tab. I shows that using the reading-order estimation module (REM) improves both detection and recognition performance, especially on Rot.Total-Text and Inverse-Text datasets, compared to the baseline model without REM. REM also brings significant improvement in text spotting performance, with 14.6% and 11.4% improvement on ‘None’ and ‘Full’, respectively, on Rot.Total-Text, and 7.4% and 8.2% improvement on ‘None’ and ‘Full’ respectively on Inverse-Text. However, the gain brought by REM is less significant on Total-Text, with only 1.8% and 1.1% improvement on ‘None’ and ‘Full’, respectively. The experimental results suggest that the impact of REM on text spotting performance depends on the ratio of inverse-like text in the testing data, which is about 40% in Inverse-Text and relatively high in Rot.Total-Text due to small angle rotations that can turn some texts into inverse-like. The ratio of inverse-like instances is low in Total-Text, but REM is still important for accurately recognizing texts, as shown in Tab. II. Regardless of the sampling method, REM improves text recognition performance by about 6.5% on ‘None’ and 8% on ‘Full’ on Inverse-Text.
| Detection | End-to-End | |||||||
|---|---|---|---|---|---|---|---|---|
| P | R | F | None | Full | ||||
| + classification | ✓ | 89.2 | 82.1 | 85.5 | 64.5 | 76.3 | ||
| + orthogonal | ✓ | ✓ | 89.7 | 83.2 | 86.3 | 66.4 | 77.4 | |
| + distribution | ✓ | ✓ | ✓ | 90.3 | 83.6 | 86.8 | 67.1 | 78.3 |
Joint reading-order estimation loss (). In Tab. III, we examine the impact of the proposed joint reading-order estimation loss () on Inverse-Text, which comprises a classification loss , an orthogonality constraint , and a distribution constraint . By conducting incremental experiments, we evaluate the effectiveness of each component in . Our results reveal that when the orthogonality constraint is applied, there is a performance improvement of 0.8% in F-measure and 1.9% in ‘None’ for both detection and recognition tasks. Similarly, when we add the distribution constraint , we observe a 0.5% improvement in F-measure and 0.9% in ‘Full’ for both tasks. Combining and leads to significant performance improvement of 1.5% in Recall, 1.3% in F-measure, 2.6% in ‘None’, and 2.0% in ‘Full’. We also present intermediate visual comparison results to verify the impact of orthogonality and distribution constraints on the prediction of reading-order, as depicted in Fig. 12 (a-c). Specifically, ensures the independence of the four key points of reading-order and maintains their distinctness. In contrast, constrains the orderly distribution of these points at the corners of the text boundary. The combination of three losses (, , and ) significantly improves the detection and recognition performance, as shown in Fig. 12 (c).
Sampling methods. In Tab.II, we can see that our DSM sampling method outperforms other methods such as Masking ROI, BezierAlign, and TPS. Specifically, with REM, our DSM improves performance by 4.7% on ‘None’ and 3.1% on ‘Full’ compared to Masking ROI, by 2.1% on ‘None’ and 1.1% on ‘Full’ compared to BezierAlign, and by 2.3% on ‘None’ and 1.7% on ‘Full’ compared to TPS. When the detection results are slightly poor without REM, the advantages of our DSM become even more significant. This demonstrates that our DSM performs well when text detection results are imperfect and can improve text detection. Moreover, our DSM also brings slight performance improvements in detection compared to TPS. Fig. 13 shows visual comparisons between TPS and DSM sampling points.

| Method for initial Text Boundary | Detection Only | ||
|---|---|---|---|
| Precision | Recall | F-measure | |
| Text Kernel(PSENet) | 89.59 | 85.08 | 87.28 |
| Probability Map(DBNet) | 90.78 | 84.81 | 87.69 |
| Distance Field(TextBPN++) | 90.51 | 85.50 | 87.93 |
| Method | Data | Backbone | Published | Detection | End-to-end | FPS | ||||
| P | R | F | None | Full | ||||||
| Mask TextSpotter V1 [42] | Syn800k, IC13, IC15, TT | ResNet-50-FPN | ECCV’18 | 69.0 | 55.0 | 61.3 | 52.9 | 71.8 | 4.8 | |
| CharNet [35] | Syn800k, IC15, MLT, TT |
|
ICCV’19 | 87.3 | 85.0 | 86.1 | 66.2 | - | 1.2 | |
| TextDragon [2] | Syn800k, IC15, TT |
|
ICCV’19 | 85.6 | 75.7 | 80.3 | 48.8 | 74.8 | - | |
| TUTS [7] |
|
ResNet-50-MSF | ICCV’19 | 83.3 | 83.4 | 83.3 | 67.8 | - | 4.8 | |
| Mask TextSpotter V3 [6] | Syn800k, IC13, IC15, TT, AddF2k | ResNet-50-FPN | ECCV’20 | - | - | - | 65.3 | 77.4 | 2.0 | |
| Text Perceptron [8] | Syn800k, IC13, IC15, TT | ResNet-50-FPN | AAAI’20 | 88.8 | 81.8 | 85.2 | 69.7 | 78.3 | - | |
| ABCNet V1 [43] | Syn150k, COCO-Text, TT, MLT |
|
CVPR’20 | - | - | - | 48.8 | 74.8 | - | |
| CRAFTS [10] | Syn800k,TT IC13, IC15 |
|
ECCV’20 | 89.5 | 85.4 | 87.4 | 78.7 | - | - | |
| PGNet [10] | Syn150k, COCO-Text, TT, MLT |
|
AAAI’21 | 85.5 | 86.8 | 86.1 | 63.1 | - | 36 | |
| Boundary TextSpotter [45] | Syn150k, COCO-Text, TT, MLT |
|
TIP’22 | 89.6 | 81.2 | 85.2 | 66.2 | 78.4 | 13 | |
| Li et al. [63] | Syn800k, IC13, IC15, TT, MLT, AddF2k | ResNet-101-FPN | TPAMI’22 | - | - | - | 57.8 | - | 1.4 | |
| PAN++ [1] | Syn150k, COCO-Text, TT, MLT |
|
TPAMI’22 | 89.9 | 81.0 | 85.3 | 68.6 | 78.6 | 21 | |
| ABCNet V2 [53] | Syn150k, COCO-Text, TT, MLT LSVT |
|
TPAMI’22 | 90.2 | 84.1 | 87.0 | 70.4 | 78.1 | 10 | |
| SPTS [48] | Syn150k, COCO-Text, TT, MLT |
|
MM’22 | - | - | - | 74.2 | 82.4 | - | |
| TPSNet [9] | Syn150k, TT, MLT, ArT |
|
MM’22 | 90.2 | 86.8 | 88.5 | 76.1 | 82.3 | 9.3 | |
| TESTR [47] | Syn150k, TT, MLT, IC15, IC13 |
|
CVPR’22 | 93.4 | 81.4 | 86.9 | 73.3 | 83.9 | 5.3 | |
| IAST(Ours) | Syn150k, TT, MLT, IC15 | ResNet-50-FPN∗ | - | 94.7 | 85.2 | 89.7 | 71.9 | 83.5 | 7.8 | |
Initial boundary module (IBM). We conducted experiments on the Total-Text dataset to assess the robustness of our model with different initial boundary generation strategies (such as Text Kernel in PSENet [57], Probability map in DB [56], Distance Field in TextBPN++[28]). To ensure a fair comparison, we trained the detection branch with the same settings (600 epochs with AdamW optimizer and initial learning rate of ). Our results, as shown in Tab. IV, indicate that different initial boundary generation strategies do not have a significant impact on detection performance (87.28% F-measure for Text Kernel, 87.69% F-measure for Probability map, 87.93% F-measure for Distance Field). In our method, the initial boundaries are mainly used to locate the text instance roughly, and the subsequent boundary refinement module refines these coarse boundaries to accurate text boundaries. The detected text boundary of any text detection method can be used as our initial boundary, meaning that any text detection method (such as TextField, DB, PSENet, etc.) can serve as our IBM to quickly build an end-to-end text spotting method, even if its detection results are not as satisfactory.
| Iteration | Detection Only | |||
|---|---|---|---|---|
| Precision | Recall | F-measure | FPS | |
| Iter. 0 | 91.21 | 74.09 | 81.76 | 10.87 |
| Iter. 1 | 91.15 | 82.44 | 86.58 | 10.64 |
| Iter. 2 | 91.04 | 84.62 | 87.71 | 10.42 |
| Iter. 3 | 90.51 | 85.50 | 87.93 | 10.21 |
| Iter. 4 | 90.45 | 85.53 | 87.92 | 10.02 |
| Iter. 5 | 90.40 | 85.50 | 87.88 | 9.80 |
Refining iteration number. Our BRM model allows flexibility in choosing the number of iterations during testing, thanks to its shared parameters and self-iterative design. In Tab. VI, we demonstrate that as the number of iterations increases, the detection performance gradually improves and eventually stabilizes while the inference speed decreases. Notably, even a single iteration leads to a significant improvement in detection performance. With three iterations, the performance stabilizes around 87.9% on F-measure. The approximate time cost for each iteration is about 2ms, much less than the time cost of other parts (about 92 ms). Balancing efficiency and performance, we set the default number of iterations to 3 during testing.
IV-D Comparisons with State-of-the-art Methods
We evaluate our method on four publicly available benchmarks: Total-Text, CTW-1500, ICDAR2015, and Inverse-Text. Quantitative results against other state-of-the-arts are presented in Tab. V, VIII, VII, and IX. For inverse-like scene text detection and spotting, we show qualitative visual results in Fig. 11 and 14, respectively.
| Method | Detection | End-to-End | |||
|---|---|---|---|---|---|
| P | R | F | None | Full | |
| TextDragon[2] | 84.5 | 82.8 | 83.6 | 39.7 | 72.4 |
| Text Perceptron[8] | 87.5 | 81.9 | 84.6 | 57.0 | |
| ABCNet[43] | 45.2 | 74.1 | |||
| ABCNet v2[53] | 85.6 | 83.8 | 84.7 | 57.5 | 77.2 |
| MANGO[4] | 58.9 | 78.7 | |||
| TESTR-Bezier [47] | 89.7 | 83.1 | 86.3 | 53.3 | 79.9 |
| TESTR-Polygon [47] | 92.0 | 82.6 | 87.1 | 56.0 | 81.5 |
| SPTS-Bezier [48] | 52.6 | 73.9 | |||
| SPTS-Point [48] | 63.6 | 83.8 | |||
| TPSNet [9] | 87.7 | 85.1 | 86.4 | 59.7 | 79.2 |
| ABINet++ [64] | 60.2 | 80.3 | |||
| IAST(Ours) | 89.2 | 84.8 | 86.9 | 62.4 | 82.9 |
Total-Text. In testing, we scale the input image sides into (640, 1024) while maintaining the aspect ratio. As shown in Tab. V, our method outperforms all previous methods in detection, surpassing the best-reported result by 4.5% on Precision and 1.2% on F-measure. For the end-to-end case, our method achieves competitive results (83.5% on ‘Full’) compared to methods based on ”ResNet-50-Transformer” like TESTR [47] (83.9% on ‘Full’). Our method outperforms all previous methods based on ”ResNet-50-FPN” and surpasses the best-reported result [9] by 1.2% on ‘Full’.
| Method | Detection | End-to-End | |||||
| P | R | F | S | W | G | N | |
| TextNet[65] | 89.4 | 85.4 | 87.4 | 78.7 | 74.9 | 60.5 | |
| FOTS[41] | 91.0 | 85.2 | 88.0 | 81.1 | 75.9 | 60.8 | |
| CharNet R-50[35] | 91.2 | 88.3 | 89.7 | 80.1 | 74.5 | 62.2 | 60.7 |
| Boundary[3] | 89.8 | 87.5 | 88.6 | 79.7 | 75.2 | 64.1 | |
| TUTS[7] | 89.4 | 85.8 | 87.5 | 83.4 | 79.9 | 68.0 | |
| Text Perceptron[8] | 92.3 | 82.5 | 87.1 | 80.5 | 76.6 | 65.1 | |
| Mask TextSpotter v3[6] | 83.3 | 78.1 | 74.2 | ||||
| Boundary TextSpotter[45] | 88.7 | 84.6 | 86.6 | 82.5 | 77.4 | 71.7 | |
| ABCNet v2[53] | 90.4 | 86.0 | 88.1 | 82.7 | 78.5 | 73.0 | |
| MANGO[4] | 81.8 | 78.9 | 67.3 | ||||
| PGNet[10] | 91.8 | 84.8 | 88.2 | 83.3 | 78.3 | 63.5 | |
| PAN++ [1] | 91.4 | 83.9 | 87.5 | 82.7 | 78.2 | 69.2 | |
| TESTR [47] | 90.3 | 89.7 | 90.0 | 85.2 | 79.4 | 73.6 | 65.3 |
| SPTS [48] | 77.5 | 70.2 | 65.8 | ||||
| IAST(Ours) | 92.5 | 86.6 | 89.5 | 84.4 | 80.0 | 73.8 | 64.7 |

CTW-1500. For CTW-1500, we set the number of control points on the text boundary to 32, and the number of sampling points is set to due to the line-level curved text dataset. The input image sides are scaled into (640, 1024) while maintaining the aspect ratio. As shown in Tab. VII, our method outperforms all previous methods in both detection and end-to-end results, except for CNN-Transformer-based methods like TESTR [47] and SPTS [48]. Specifically, our method outperforms all previous CNN-based methods like ABINet++[64], TPSNet [9], ABCNet v2 [53], and surpasses the best-reported result [64] by 2.2% on ‘None’ and 2.6% on ‘Full’ in terms of F-measure. In detection, our method only slightly lags behind the best-reported CNN-Transformer-based method [47] by 0.2% on F-measure. Our method ranks second in most metrics, with only a slight gap to the first. Due to CTW-1500 is a line-level dataset, there are some overly long sentences inside. Our method based on CNN is limited by the receptive field, which may result in lower recognition accuracy than these transformer based method. Another problem is that CTW-1500 has some unreasonable or missing annotations, as mentioned in [17, 21], which also can bringing some performance losses.
ICDAR2015. We conducted evaluations on the ICDAR2015 benchmark, which includes many perspective texts, and the results are listed in Tab.VIII. During testing, we scaled the short side of the input image to 960 while maintaining its aspect ratio. Our method achieved comparable performance with text spotting methods like CharNet[35] and TESTR in the detection stage. In the Word Spotting tasks, our method also delivered a competitive performance with text spotting methods like Mask TextSpotter v3 [6] and TESTR, and it achieved remarkable performance (80.0%) on weak lexicon cases. Furthermore, our method significantly outperformed previous TPS-based methods like TUTS and ‘Boundary TextSpotter’, demonstrating the effectiveness of our method.
| Method | Rotation | P | R | F | End-to-End | |
|---|---|---|---|---|---|---|
| None | Full | |||||
| ABCNet v2 [53] | ✓ | 82.0 | 70.2 | 75.6 | 34.5 | 47.4 |
| TESTR [47] | ✓ | 83.1 | 67.4 | 74.4 | 34.2 | 41.6 |
| SwinTextSpotter [66] | ✓ | 94.5 | 85.8 | 89.9 | 55.4 | 67.9 |
| ABCNet-v2 (DPText repro.) | ✓ | 83.4 | 73.2 | 78.0 | 57.2 | 69.5 |
| ABCNet-v2 w/ Pos.Label (DPText repro.) | ✓ | 90.7 | 83.9 | 87.2 | 62.2 | 76.7 |
| TESTR (DPText repro.) | ✓ | 89.4 | 84.4 | 86.8 | 62.1 | 74.7 |
| TESTR w/ Pos.Label (DPText repro.) | ✓ | 88.8 | 85.7 | 87.2 | 61.9 | 74.1 |
| TESTR w/ Pos.Label (DPText detector) | ✓ | 90.7 | 84.2 | 87.3 | 63.1 | 75.4 |
| SwinTextSpotter (DPText repro.) | ✓ | 94.5 | 84.7 | 89.3 | 62.9 | 74.7 |
| SPTS [48] | ✓ | - | - | - | 38.3 | 46.2 |
| DeepSolo (Res-50,#2) [49] | ✓ | - | - | - | 64.6 | 71.2 |
| DeepSolo (ViTAEv2-S,#3) [49] | ✓ | - | - | - | 68.8 | 75.8 |
| IAST(Ours) | ✓ | 92.5 | 86.6 | 89.5 | 68.8 | 80.6 |

Inverse-Text. Although reading-order is important for scene text spotting, the ratios of inverse-like scene texts are relatively low in several datasets, such as 2.8% in Total-Text, 5.2% in CTW-1500, and 0.0% in ICDAR2015. Therefore, in these datasets, our reading-order estimation module (REM) does not fully demonstrate our DSM module achieves its advantages and more positive gains. To demonstrate the effectiveness of our REM, we conducted experiments on Inverse-Text, an arbitrary-shape scene text test set with approximately 40% inverse-like instances. As Inverse-Text does not have a training set, we fine-tuned our model on Total-Text with random rotation for 800 epochs and evaluated it on Inverse-Text, scaling the input image to (640, 1280) while maintaining its aspect ratio. Our method outperformed all previous methods and achieved the best performance on multiple evaluation metrics (e.g., Recall, F-measure, None, Full). In the text spotting task, our method surpassed the best result by 5.7% on ‘None’ and by 3.9% on ‘Full’, significantly outperforming CNN-Transformer based methods such as TESTR and SwinTextSpotter. Furthermore, our IAST accurately predicts the reading-order of scene text with very complex layouts and recognizes inverse-like scene text via the predicted reading-order, as shown in Fig. 11 and Fig. 14. Our results demonstrate the effectiveness of our methods in reading inverse-like scene text and highlight the importance of reading-order for scene text spotting, particularly in complex layout scenes.
Visual Comparison. We utilize some previous state-of-the-art spotters to get qualitative results on Inverse-text for giving a more intermediate visual comparison, as shown in Fig. 15. We select ABCNet-v2 [53] representing the CNN-based spotting methods which predict control points. We select SwinTextSpotter [66] representing the transformer-based spotting methods which predict text segmentation. Officially released model weights trained on Total-Text are adopted for producing visual results. We can find that the spotters (e.g., ABCNet-v2 and SwinTextSpotter) failed to correctly recognize inverse-like texts because of the unconventional reading-order, as shown in Fig. 15 (a) and (b). Benefiting from the ability to aware reading-order, our model can accurately recognize these inverse-like texts, as shown in Fig. 15 (c). These examples in Fig. 15 are enough to demonstrate the improvement of our method when reading the complex layout and inverse-like texts.

IV-E Weakness
The proposed method shows strong performance in spotting both normal and inverse-like scene text in most cases, although it may struggle with some special cases, such as mirror text, small blurry text, and occlusion text, as shown in Fig. 16. Some failure cases are also marked with yellow arrows in Fig. 11 and Fig. 14. As shown in Fig. 16 (a) and (d), mirror texts are especially challenging as their control points need to be pressed counterclockwise. Additionally, some small blurry texts are detected, but their recognition accuracy cannot be verified, as shown in Fig. 16 (b), as they were annotated as ‘Don’t Care’. In rare cases, overlapping key points in the reading-order may result in unsatisfactory predictions, as shown in Fig. 16 (c). Fortunately, these errors can be corrected through additional processing. It’s worth noting that these special cases are challenging for all text spotting methods and require further research.
V Conclusion
Inverse-like text is a common problem in scene text recognition, but it has not been attracted enough attention and effectively solved. To address this problem, we propose a unified end-to-end trainable framework called IAST, which accurately reads both normal and inverse-like scene text through reading-order estimation and dynamic sampling. Our REM module can learn and extract reading-order information from the initial text boundary, while the DSM can dynamically sample appropriate features for recognition in the detected text region. Extensive experiments demonstrate the effectiveness of our methods for reading inverse-like scene text and highlight the importance of reading-order information for scene text spotting, especially in complex layouts.
References
- [1] W. Wang, E. Xie, X. Li, X. Liu, D. Liang, Z. Yang, T. Lu, and C. Shen, “PAN++: towards efficient and accurate end-to-end spotting of arbitrarily-shaped text,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 9, pp. 5349–5367, 2022.
- [2] W. Feng, W. He, F. Yin, X.-Y. Zhang, and C.-L. Liu, “Textdragon: An end-to-end framework for arbitrary shaped text spotting,” in ICCV, 2019, pp. 9075–9084.
- [3] H. Wang, P. Lu, H. Zhang, M. Yang, X. Bai, Y. Xu, M. He, Y. Wang, and W. Liu, “All you need is boundary: Toward arbitrary-shaped text spotting,” in AAAI, 2020, pp. 12 160–12 167.
- [4] L. Qiao, Y. Chen, Z. Cheng, Y. Xu, Y. Niu, S. Pu, and F. Wu, “MANGO: A mask attention guided one-stage scene text spotter,” in AAAI, 2021, pp. 2467–2476.
- [5] R. Ronen, S. Tsiper, O. Anschel, I. Lavi, A. Markovitz, and R. Manmatha, “GLASS: global to local attention for scene-text spotting,” in ECCV, S. Avidan, G. J. Brostow, M. Cissé, G. M. Farinella, and T. Hassner, Eds., vol. 13688, 2022, pp. 249–266.
- [6] M. Liao, G. Pang, J. Huang, T. Hassner, and X. Bai, “Mask textspotter v3: Segmentation proposal network for robust scene text spotting,” in ECCV, vol. 12356, 2020, pp. 706–722.
- [7] S. Qin, A. Bissacco, M. Raptis, Y. Fujii, and Y. Xiao, “Towards unconstrained end-to-end text spotting,” in ICCV, 2019, pp. 4703–4713.
- [8] L. Qiao, S. Tang, Z. Cheng, Y. Xu, Y. Niu, S. Pu, and F. Wu, “Text perceptron: Towards end-to-end arbitrary-shaped text spotting,” in AAAI, 2020, pp. 11 899–11 907.
- [9] W. Wang, Y. Zhou, J. Lv, D. Wu, G. Zhao, N. Jiang, and W. Wang, “Tpsnet: Reverse thinking of thin plate splines for arbitrary shape scene text representation,” in ACM MM, 2022, pp. 5014–5025.
- [10] P. Wang, C. Zhang, F. Qi, S. Liu, X. Zhang, P. Lyu, J. Han, J. Liu, E. Ding, and G. Shi, “Pgnet: Real-time arbitrarily-shaped text spotting with point gathering network,” in AAAI, 2021, pp. 2782–2790.
- [11] S. Kim, S. Shin, Y. Kim, H. Cho, T. Kil, J. Surh, S. Park, B. Lee, and Y. Baek, “DEER: detection-agnostic end-to-end recognizer for scene text spotting,” CoRR, vol. abs/2203.05122, pp. 1–10, 2022.
- [12] J. Wu, P. Lyu, G. Lu, C. Zhang, K. Yao, and W. Pei, “Decoupling recognition from detection: Single shot self-reliant scene text spotter,” in ACM MM, 2022, pp. 1319–1328.
- [13] J. Ma, W. Shao, H. Ye, L. Wang, H. Wang, Y. Zheng, and X. Xue, “Arbitrary-oriented scene text detection via rotation proposals,” IEEE Trans. Multimedia, vol. 20, no. 11, pp. 3111–3122, 2018.
- [14] J. Hou, X. Zhu, C. Liu, K. Sheng, L. Wu, H. Wang, and X. Yin, “HAM: hidden anchor mechanism for scene text detection,” IEEE Trans. Image Process., vol. 29, pp. 7904–7916, 2020.
- [15] S. Zhang, X. Zhu, J. Hou, and X. Yin, “Graph fusion network for multi-oriented object detection,” Appl. Intell., vol. 53, no. 2, pp. 2280–2294, 2023.
- [16] M. He, M. Liao, Z. Yang, H. Zhong, J. Tang, W. Cheng, C. Yao, Y. Wang, and X. Bai, “MOST: A multi-oriented scene text detector with localization refinement,” in CVPR, 2021, pp. 8813–8822.
- [17] S.-X. Zhang, X. Zhu, L. Chen, J. Hou, and X. Yin, “Arbitrary shape text detection via segmentation with probability maps,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 3, pp. 2736–2750, 2023.
- [18] H. Bi, C. Xu, C. Shi, G. Liu, H. Zhang, Y. Li, and J. Dong, “Hgr-net: Hierarchical graph reasoning network for arbitrary shape scene text detection,” IEEE Trans. Image Process., vol. 32, pp. 4142–4155, 2023.
- [19] C. Yang, M. Chen, Z. Xiong, Y. Yuan, and Q. Wang, “Cm-net: Concentric mask based arbitrary-shaped text detection,” IEEE Trans. Image Process., vol. 31, pp. 2864–2877, 2022.
- [20] J. Hou, X. Zhu, C. Liu, C. Yang, L. Wu, H. Wang, and X. Yin, “Detecting text in scene and traffic guide panels with attention anchor mechanism,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 11, pp. 6890–6899, 2021.
- [21] S.-X. Zhang, X. Zhu, J.-B. Hou, C. Liu, C. Yang, H. Wang, and X.-C. Yin, “Deep relational reasoning graph network for arbitrary shape text detection,” in CVPR, 2020, pp. 9699–9708.
- [22] J. Tang, Z. Yang, Y. Wang, Q. Zheng, Y. Xu, and X. Bai, “Seglink++: Detecting dense and arbitrary-shaped scene text by instance-aware component grouping,” Pattern Recognition, vol. 96, 2019.
- [23] S.-X. Zhang, X. Zhu, J.-B. Hou, C. Yang, and X.-C. Yin, “Kernel proposal network for arbitrary shape text detection,” IEEE Trans. Neural Networks Learn. Syst., vol. 45, no. 3, pp. 2736–2750, 2023.
- [24] Y. Zhu, J. Chen, L. Liang, Z. Kuang, L. Jin, and W. Zhang, “Fourier contour embedding for arbitrary-shaped text detection,” in CVPR, 2021, pp. 3123–3131.
- [25] S.-X. Zhang, X. Zhu, C. Yang, H. Wang, and X.-C. Yin, “Adaptive boundary proposal network for arbitrary shape text detection,” in ICCV, 2021, pp. 1305–1314.
- [26] F. Wang, Y. Chen, F. Wu, and X. Li, “Textray: Contour-based geometric modeling for arbitrary-shaped scene text detection,” in ACM-MM, 2020, pp. 111–119.
- [27] M. Ye, J. Zhang, S. Zhao, J. Liu, B. Du, and D. Tao, “Dptext-detr: Towards better scene text detection with dynamic points in transformer,” in AAAI. AAAI, 2023, pp. 3241–3249.
- [28] S.-X. Zhang, C. Yang, X. Zhu, and X.-C. Yin, “Arbitrary shape text detection via boundary transformer,” IEEE Transactions on Multimedia, pp. 1–14, 2023.
- [29] A. Bissacco, M. Cummins, Y. Netzer, and H. Neven, “Photoocr: Reading text in uncontrolled conditions,” in ICCV. IEEE Computer Society, 2013, pp. 785–792.
- [30] K. Wang, B. Babenko, and S. J. Belongie, “End-to-end scene text recognition,” in ICCV, D. N. Metaxas, L. Quan, A. Sanfeliu, and L. V. Gool, Eds., 2011, pp. 1457–1464.
- [31] B. Shi, X. Bai, and C. Yao, “An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, no. 11, pp. 2298–2304, 2017.
- [32] P. He, W. Huang, Y. Qiao, C. C. Loy, and X. Tang, “Reading scene text in deep convolutional sequences,” in AAAI, 2016, pp. 3501–3508.
- [33] B. Shi, X. Wang, P. Lyu, C. Yao, and X. Bai, “Robust scene text recognition with automatic rectification,” in CVPR, 2016, pp. 4168–4176.
- [34] R. Litman, O. Anschel, S. Tsiper, R. Litman, S. Mazor, and R. Manmatha, “SCATTER: selective context attentional scene text recognizer,” in CVPR, 2020, pp. 11 959–11 969.
- [35] L. Xing, Z. Tian, W. Huang, and M. R. Scott, “Convolutional character networks,” in ICCV, 2019, pp. 9125–9135.
- [36] Z. Cheng, Y. Xu, F. Bai, Y. Niu, S. Pu, and S. Zhou, “AON: towards arbitrarily-oriented text recognition,” in CVPR, 2018, pp. 5571–5579.
- [37] H. Li, P. Wang, C. Shen, and G. Zhang, “Show, attend and read: A simple and strong baseline for irregular text recognition,” in AAAI, 2019, pp. 8610–8617.
- [38] X. Yue, Z. Kuang, C. Lin, H. Sun, and W. Zhang, “Robustscanner: Dynamically enhancing positional clues for robust text recognition,” in ECCV, vol. 12364, 2020, pp. 135–151.
- [39] M. Liao, B. Shi, X. Bai, X. Wang, and W. Liu, “Textboxes: A fast text detector with a single deep neural network,” in AAAI, 2017, pp. 4161–4167.
- [40] M. Liao, B. Shi, and X. Bai, “Textboxes++: A single-shot oriented scene text detector,” IEEE Trans. Image Processing, vol. 27, no. 8, pp. 3676–3690, 2018.
- [41] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao, and J. Yan, “FOTS: Fast oriented text spotting with a unified network,” in CVPR, 2018, pp. 5676–5685.
- [42] P. Lyu, M. Liao, C. Yao, W. Wu, and X. Bai, “Mask TextSpotter: An end-to-end trainable neural network for spotting text with arbitrary shapes,” in ECCV, 2018, pp. 71–88.
- [43] Y. Liu, H. Chen, C. Shen, T. He, L. Jin, and L. Wang, “Abcnet: Real-time scene text spotting with adaptive bezier-curve network,” in CVPR, 2020, pp. 9806–9815.
- [44] M. Busta, L. Neumann, and J. Matas, “Deep textspotter: An end-to-end trainable scene text localization and recognition framework,” in ICCV, 2017, pp. 2223–2231.
- [45] P. Lu, H. Wang, S. Zhu, J. Wang, X. Bai, and W. Liu, “Boundary textspotter: Toward arbitrary-shaped scene text spotting,” IEEE Trans. Image Process., vol. 31, pp. 6200–6212, 2022.
- [46] Y. Baek, S. Shin, J. Baek, S. Park, J. Lee, D. Nam, and H. Lee, “Character region attention for text spotting,” in ECCV, vol. 12374, 2020, pp. 504–521.
- [47] X. Zhang, Y. Su, S. Tripathi, and Z. Tu, “Text spotting transformers,” in CVPR, 2022, pp. 9509–9518.
- [48] D. Peng, X. Wang, Y. Liu, J. Zhang, M. Huang, S. Lai, J. Li, S. Zhu, D. Lin, C. Shen, X. Bai, and L. Jin, “SPTS: single-point text spotting,” in ACM MM, 2022, pp. 4272–4281.
- [49] M. Ye, J. Zhang, S. Zhao, J. Liu, T. Liu, B. Du, and D. Tao, “Deepsolo: Let transformer decoder with explicit points solo for text spotting,” in CVPR, 2023, pp. 19 348–19 357.
- [50] Y. Liu, J. Zhang, D. Peng, M. Huang, X. Wang, J. Tang, C. Huang, D. Lin, C. Shen, X. Bai, and L. Jin, “SPTS v2: Single-point scene text spotting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 12, pp. 15 665–15 679, 2023.
- [51] T. Chen, S. Saxena, L. Li, D. J. Fleet, and G. E. Hinton, “Pix2seq: A language modeling framework for object detection,” in ICLR, 2022.
- [52] Y. Kittenplon, I. Lavi, S. Fogel, Y. Bar, R. Manmatha, and P. Perona, “Towards weakly-supervised text spotting using a multi-task transformer,” in CVPR, 2022, pp. 4594–4603.
- [53] Y. Liu, C. Shen, L. Jin, T. He, P. Chen, C. Liu, and H. Chen, “Abcnet v2: Adaptive bezier-curve network for real-time end-to-end text spotting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 11, pp. 8048–8064, 2022.
- [54] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” in ICCV, 2021, pp. 9992–10 002.
- [55] T. Lin, P. Dollár, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie, “Feature pyramid networks for object detection,” in CVPR, 2017, pp. 936–944.
- [56] M. Liao, Z. Wan, C. Yao, K. Chen, and X. Bai, “Real-time scene text detection with differentiable binarization,” in AAAI, 2020, pp. 11 474–11 481.
- [57] W. Wang, E. Xie, X. Li, W. Hou, T. Lu, G. Yu, and S. Shao, “Shape robust text detection with progressive scale expansion network,” in CVPR, 2019, pp. 9336–9345.
- [58] W. Wang, E. Xie, X. Song, Y. Zang, W. Wang, T. Lu, G. Yu, and C. Shen, “Efficient and accurate arbitrary-shaped text detection with pixel aggregation network,” in ICCV, 2019, pp. 8439–8448.
- [59] S. Long, J. Ruan, W. Zhang, X. He, W. Wu, and C. Yao, “Textsnake: A flexible representation for detecting text of arbitrary shapes,” in ECCV, 2018, pp. 19–35.
- [60] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in CVPR, 2017, pp. 2261–2269.
- [61] S. Peng, W. Jiang, H. Pi, X. Li, H. Bao, and X. Zhou, “Deep snake for real-time instance segmentation,” in CVPR, 2020, pp. 8530–8539.
- [62] X. Zhu, H. Hu, S. Lin, and J. Dai, “Deformable convnets V2: more deformable, better results,” in CVPR, 2019, pp. 9308–9316.
- [63] P. Wang, H. Li, and C. Shen, “Towards end-to-end text spotting in natural scenes,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 10, pp. 7266–7281, 2022.
- [64] S. Fang, Z. Mao, H. Xie, Y. Wang, C. Yan, and Y. Zhang, “Abinet++: Autonomous, bidirectional and iterative language modeling for scene text spotting,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 6, pp. 7123–7141, 2023.
- [65] Y. Sun, C. Zhang, Z. Huang, J. Liu, J. Han, and E. Ding, “Textnet: Irregular text reading from images with an end-to-end trainable network,” in ACCV, vol. 11363, 2018, pp. 83–99.
- [66] M. Huang, Y. Liu, Z. Peng, C. Liu, D. Lin, S. Zhu, N. Yuan, K. Ding, and L. Jin, “Swintextspotter: Scene text spotting via better synergy between text detection and text recognition,” in CVPR, 2022, pp. 4583–4593.