Interventional Causal Structure Discovery over Graphical Models with Convergence and Optimality Guarantees
Abstract
Learning causal structure from sampled data is a fundamental problem with applications in various fields, including healthcare, machine learning and artificial intelligence. Traditional methods predominantly rely on observational data, but there exist limits regarding the identifiability of causal structures with only observational data. Interventional data, on the other hand, helps establish a cause-and-effect relationship by breaking the influence of confounding variables. It remains to date under-explored to develop a mathematical framework that seamlessly integrates both observational and interventional data in causal structure learning. Furthermore, existing studies often focus on centralized approaches, necessitating the transfer of entire datasets to a single server, which lead to considerable communication overhead and heightened risks to privacy. To tackle these challenges, we develop a bilevel polynomial optimization (Bloom) framework. Bloom not only provides a powerful mathematical modeling framework, underpinned by theoretical support, for causal structure discovery from both interventional and observational data, but also aspires to an efficient causal discovery algorithm with convergence and optimality guarantees. We further extend Bloom to a distributed setting to reduce the communication overhead and mitigate data privacy risks. It is seen through experiments on both synthetic and real-world datasets that Bloom markedly surpasses other leading learning algorithms.
Index Terms:
Directed acyclic graph, Graphical model, Causal structure learning, Interventional data, Bilevel optimization, Polynomial optimization, Distributed setting.I Introduction
Causal structure learning aims to learn the directed acyclic graph (DAG) of causal graphical models from sampled data, which enables us to reveal and understand the potential causal relationships among different variables [1]. Recently, it has not only emerged in various artificial intelligence tasks, such as Natural Language Processing [2], Reinforcement Learning [3], and Anomaly Detection [4], but also played an essential role in other domains, such as healthcare [5], economics, and geosciences [6]. Learning DAGs from data, however, is regarded as an NP-hard problem [7], mainly owing to the acyclic constraints. Traditional methods, such as constraint-based [8, 9, 10], score-based methods [11] and functional causal models (FCMs) [12], typically search for causal graphs in a discrete manner based on some assumptions on the data and the underlying mechanisms. However, the large search space of DAGs makes these methods suffer from computational inefficiency. Zheng et al. [13] proposed Notears, which describes acyclic graphs with a smooth function over real matrices, and formulates the causal structure learning problem as a constrained optimization problem that can be successively optimized. And this work provides a foundation for subsequent research [14, 15].
However, these works [14, 16] often employ gradient descent-type algorithms such as SGD, which may lead to being stuck in locally optimal solutions and saddle points or experiencing gradient explosion or oscillations [17]. These issues often cause slow or unstable convergence, as discussed in [18]. Moreover, the gradient descent method is sensitive to data noise and outliers. In contrast, many global optimization methods, such as polynomial optimization (POP) methods, demonstrates superior convergence and robustness, and provide the potential for globally optimal solutions under mild assumptions [19]. Secondly, previous algorithms primarily rely on observational data, which poses theoretical limits in identifying true DAGs [20]. Interventions are now extensively applied in various real-world contexts, including genomics and microservice systems [4]. The introducing of interventional data can efficiently improve the identifiability of causal structures [21], and help establish causal relationships. Although some current research [22, 23] on causal structure learning has already incorporated interventional data, these studies either present high complexity issues [22, 24], or need a more generalized framework to integrate both types of data through a unified optimization strategy [25]. Also, many existing works typically lack sufficient theoretical foundations including guarantees of convergence and optimality. Consequently, developing a mathematical framework for causal structure learning that not only provides theoretic support but also integrates observational and interventional data remains a significant challenge. Lastly, many existing studies generally focus on centralized approaches, which may result in substantial communication overhead and higher privacy risks. When compared with some current federated-learning based works [26, 27], our approach can efficiently reduce the identification of spurious causalities by incorporating interventional data. [28] is also a distributed algorithm that uses interventional data, but it usually requires a sufficient amount of data to train a local neural network model on each client, and they lack convergence and optimality guarantees.
To this end, we propose an algorithm for causal structure learning with bilevel polynomial optimization (Bloom), which offers a robust mathematical modeling approach with theoretical support for learning causal structure from both interventional and observational data. And it can efficiently address the causal structure learning issue with convergence and optimality guarantees by solving a series of semidefinite (SDP) relaxation problems. We further expand Bloom to a distributed setting to reduce communication overhead and mitigate data privacy risks.
Our contributions can be summarized as follows:
-
1.
We propose a bilevel polynomial optimization modelling framework for causal structure discovery from both observational and interventional data. This framework allows us not only to seamlessly integrate the observational data with interventional data in the causal structure learning process, but also offers a fundamental yet unique perspective to the continuous optimization problem associated with the search of an optimal DAG of causal graph model. Given the fact that there exist a large body of efficient algorithms for bilevel and polynomial optimization problem, the proposed bilevel framework opens up new avenues for modelling and analyzing causal structure learning from both observational and interventional data.
-
2.
Existing continuous optimization-based algorithms often use gradient descent-type methods e.g., SGD to discover high-scoring causal structures. Such methods may get stuck at local optima or saddle points, which are notoriously difficult for SGD to escape. Instead, building upon the proposed bilevel polynomial optimization model, we delve into its unique structure and theoretically demonstrate its convertibility into a single-level optimization problem. Leveraging this reformulation, we introduce the Bloom algorithm, which can gradually approximate the global optimal solution for the causal structure learning problem and is capable of escaping local optima or saddle points in the searching process.
-
3.
Most works in the literature focus on centralized methods for causal structure learning, which can result in issues like high communication overhead, inadequate computation power, and potential data privacy breaches. Therefore, we further extend the proposed algorithm into distributed systems. The proposed algorithm does not require sharing the client’s local data, but only the learned model parameters. This ensures privacy protection requirements and has lower communication pressure.
II Background and Related works
II-A Causal Structure Learning
Causal structure learning is defined as learning a DAG, represented as , over the data sampled from a joint distribution . In graph , each node corresponds to a random variable , and edge denotes a direct causal relationship from the variable to , i.e., . The distribution of variable is , where denotes the parent set of node . Intervention on variable is defined as replacing the conditional distribution with a new distribution , including perfect and imperfect interventions. Perfect intervention refers to removing the effects of all parent variables, i.e., ; while imperfect intervention replaces the original conditional distribution with a new conditional distribution, i.e., .
There are many causal structure learning methods, which can be broadly categorized into FCMs, constraint-based and score-based methods. FCMs aim to learn and represent the causal relationship between cause and effect variables using a predefined function containing independent noise terms. Typical FCMs include LiNGAM [29], PNL [30] and ANM [31]. Constraint-based methods leverage conditional independence (CI) tests between the variables to identify causal relationships, such as PC and FCI[8]. COmbINE [32] and HEJ [33] support the introduction of interventional data, and they typically rely on Boolean satisfiability solvers. Mooij et al. [34] proposed the joint causal inference framework that can handle unknown interventions with by coupling with many constraint-based algorithms. Score-based methods aim to obtain a DAG by optimizing a score function. GES [11] searches for the highest scoring graphs from a discrete space by iteratively adding, removing and flipping edges. GIES [35] and GNIES [36] are the variants of GES that can be used for interventional data. IGSP is a hybrid method [24]. However, these methods typically search in discrete spaces.
Causal Structure Learning with Continuous Optimization
Zheng et al. [13] proposed Notears, which utilizes a smooth function over real matrices to encode the acyclic constraint, and transformed the aforementioned problem into the following continuous optimization problem:
| (1) |
The function holds if and only if graph corresponding to is a DAG. Let , where denotes the Hadamard product. And the acyclic constraint is equivalent to by performing a Taylor expansion of , with denoting weight coefficients. And counts the sum of length-k weighted closed walks in directed graphs. Notears uses linear SEM as the causal model and sets the scoring function to a least squares loss. Based on Notears, many subsequent studies and improvements have been developed, e.g., DAG-GNN [14], and Gran-DAG [37]. Deng et al. [38] proposed a bilevel optimization algorithm, in which it defines a constraint set based on KKT conditions to guide the search of topological order. But it can only iteratively search for local minimum and lacks the guarantee of optimality of the results. Wei et al. [39] generalized existing acyclic constraints Eq. (1) to a class of matrix polynomials and defined an explicit edge absence constraint set. It works by iteratively adding and removing elements to the constraint set until it reaches what they call ”irreducibility”. However, it can only guarantee local optimal solutions. Ng et al. [40] studied the optimality conditions and convergence property of the augmented Lagrangian method (ALM) and the quadratic penalty method (QPM) in structural learning problems, and Deng et al. [41] showed that a proper optimization method converges to the global minimum of the least squares objective in the bivariate case. Ng et al. [17] investigated the performance of continuous structure learning methods under different noise variances and analyzed the possible reasons.
Causal Structure Learning with Interventional Data
Interventional Greedy SP (IGSP) algorithm [22] is a hybrid approach that uses conditional independence tests in the score function and can be used with interventional data. Brouillard [42] introduced a novel differentiable causal structure learning method, named DCDI, leveraging neural networks, designed to harness the potential of interventional data. Meanwhile, ENCO [25] concentrated on both observational and interventional data, employing a methodology involving two alternating processes: fitting distributions and learning the causal structure. ENCO also uses two variables to parameterize the graph structure. While these methods prove effective, their reliance on gradient descent-based methods introduces the possibility of converging to local optima [42, 25]. This emphasizes the need for further exploration into causal structure learning methods with global search.
Causal Structure Learning with Distributed Learning
However, these methods usually require centralized data, which can easily cause privacy leakage and high communication consumption problems when these data come from different data sources. To this end, there are some works that study the problem of causal structure learning in distributed environments. Huang et al. [26] proposed a federated PC algorithm, which designed a layer-wise strategy to identify consistent separation sets among clients and identify accurate edge orientation without centralizing data from each client to the server. Li et al. [43] proposed a federated constraint-based method for heterogeneous data, which protects data privacy by aggregating statistics of the raw data on different clients. Abyaneh et al. [28] developed a federated framework (FedCDI) for inferring causal structures from distributed data containing interventional samples, which can uncover the underlying causal structure by exchanging belief updates of the clients without sharing local samples. Ng et al. [27] develop a distributed structure learning method based on continuous optimization, using the alternating direction method of multipliers (ADMM). FedDAG [44] is also a continuously optimized federated structure learning algorithm, which includes aggregation of graph structures and approximation of local mechanisms to accommodate the data heterogeneity of clients. But most of them only use observational data, which may lead to the spurious causal relationships.
| Symbol | Description | |
|---|---|---|
| Universal symbol | Variable | |
| Matirx | ||
| Vector | ||
| Function | ||
| Set, {1,…D} | ||
| Special symbol | Graph | |
| Nodes of the graph | ||
| Edges of the graph | ||
| Probability distribution | ||
| Symmetric matrix | ||
| Positive semidefinite matrix | ||
| DAG space | ||
| Monomial | ||
| Standard monomial basis | ||
II-B Bilevel Optimization
A bilevel optimization problem is an optimization problem with two levels, each of which has its own objective function and constraints. The general form can be denoted as:
| (2) |
where and are the upper- and lower-level objective function, and are decision variables, is the upper-level constraint, and denotes the lower-level constraint.
There are many approaches for bilevel optimization [45], here we focus on the method based on optimal conditions. This method aims to replace the lower-level optimization problem with the optimal conditions (e.g., Karush-Kuhn-Tucker (KKT) conditions) [46] and reformulates it as a Mathematical Problem with Complimentary Constraints, which can be expressed as follows.
| (3) |
Moreover, the problem is shown to be equivalent to the original bilevel optimization problem when Slater’s condition (Definition 1) is satisfied [47].
Definition 1 (Slater’s Condition)
Slater’s constraint qualification for the lower-level problem at any parameter : there exist such that , .
II-C Polynomial Optimization
The general form of the polynomial optimization problem (POP) denotes as follows:
| (4) |
The objective function and constraints are assumed to be polynomials in the variables , expressed as , where represents the coefficients, and . The monomial denotes , where is the order of each variable . The degree of monomial is . The support set of a polynomial function is defined as , and the degree of a polynomial function is . Let be the set of real -variate polynomials, and the set of polynomials of degree no more than is represented as . For , let (resp. ) denote the set of symmetric matrices (resp. positive semidefinite matrices).
Traditional approaches [19] achieve solutions by constructing a sum-of-squares (SOS) hierarchy for Eq. (4) and solving a sequence of corresponding SDP problems. The polynomial is expressed as , where is the Gram Matrix [48]. Here, represents the standard monomial basis of with a degree not exceeding , denoted as in the sequel. Let be the univariate vector corresponding to , then the monomial variable can be replaced by a real variable . Define as the linear function:
| (5) |
Let be the -order moment matrix associated with . The items in the matrix can be obtained as follows:
| (6) |
where denote indexes, and denotes the dimension of .
For the constraint function , the elements in the -order localizing matrix are presented as:
| (7) |
where . Let and .
By introducing Eq. (6) and (7), the problem Eq. (4) can be relaxed into a SDP problem (with relaxation order ):
| (8) |
However, it is more complicated to solve the above problem directly due to the scale of the issue [49].
II-C1 Correlative sparsity
H. Waki [50] proposed a sparse SOS hierarchy by utilizing the correlative sparsity among variables. The method defines the correlative sparsity pattern (CSP) graph associated with Eq. (4) as . If nodes , both appear in a constraint or a monomial, then .
According to definitions of chordal graph (Definition 2) and clique (Definition 3), the graph can be extended to a chordal graph by adding appropriate edges. Thus, the graph can be readily divided in cliques (Theorem 2.3 in [51]). Let represent the set of maximal cliques in , the variables in the clique are denoted as . And the constraint polynomials can be grouped into sets according to whether the variables in belong to clique . The sets are mutually exclusive, and .
Definition 2 (Chord and Chordal Graph)
A chord is defined as an edge between two nonconsecutive nodes in a cycle. A graph is said to be called a chordal graph if all cycles of length at least 4 have a chord.
Definition 3 (Clique and Maximal Clique)
A complete graph is a graph where every pair of nodes is connected by an edge. A clique in a graph is a group of nodes that form a complete subgraph. A maximal clique is a clique that is not a subset of any other clique.
Based on the cliques, the SDP matrices can be separated into blocks. And the relaxation problem based on correlative sparsity for the POP Eq. (4) is denoted as:
|
|
(9) |
II-C2 Term sparsity
Wang [52] proposed a sparse SOS with term sparsity by using correlations between monomials (terms). This method constructs a term sparsity pattern (TSP) graph, denoted as . The nodes in correspond to the terms in the monomial basis, and the set of edges is , where and .
The TSP subgraph for the constraint polynomial is represented as , where corresponds to the monomials in . The edges in the graph are constructed through the iterative process, involving two successive operations: support extension and chordal extension.
With , the relaxation problem based on term sparsity for the POP Eq. (4) is defined as:
|
|
(10) |
where represents the adjacency matrix of and denotes that the principal submatrices in the matrix are all positive semidefinite.

III Methodology
In this section, we first discuss the background of using Bloom for causal structure learning given both observational and interventional data. Then we present our method in detail, as illustrated in Fig. 1, and discuss the convergence guarantees. Finally, we introduce the distributed architecture of Bloom.
III-A Scope and Assumptions
We aim to learn a DAG of an causal graphical model given observational and intervention data. Here, we first make the causal faithful and causal sufficient assumptions for the causal model, i.e., the observed data is consistent with the real causal relationship, and all variables for inferring the causal relationship are included. However, in the following, we relax this assumption appropriately and experimentally discuss the causal structure discovery performance of the proposed method in scenarios with potentially confounding causal variables.
Furthermore, we assume that interventions are created by affecting only a single variable, and each intervention is independent of the other. The scope of this intervention closely follows Ke et al. [53]. Besides, we assume that all interventions are perfect, i.e., the distribution of the intervened variable is independent of the parent variables. And we assume interventions are conducted on each variable, and all samples, including the intervention target, are provided. In next section, we also try to relax this assumption and experimentally discuss the performance of the proposed method in the case of imperfect intervention.
III-B Bilevel Polynomial Optimization for Causal Structure Learning
Pearl’s Causal Hierarchy theory [1] posits that causal inference consists of three ascending levels: association, intervention, and counterfactual. Each level cannot provide higher-level information. In the first level, association problem is typically addressed by using passively observed data. On the second level, interventional data can offer more information of directed causality. However, learning causal structures relying solely on observational data is typically challenging. This is because, under the faithfulness assumption, the model may only be able to learn the Markov equivalence class of the true graph, whereas interventional data can effectively enhance identifiability.
Therefore, we can define two parameters to jointly determine the graph structure, respectively: denotes the existence of undirected edges, the direction of the edges. In particular, the diagonal entries of both and are , i.e., (or )=, , besides , . Then the weighted adjacency matrix of the DAG can be determined by . When , it means there is no directed causal relationship between variable and . By decomposing the adjacency matrix into these two parameters, we can model the causal structure learning with observational and interventional data as a bilevel optimization problem thereby improving the identifiability of the structure. However, this modelling may entail extensive matrix operations, particularly with acyclic constraints, resulting in heightened complexity and slow convergence. Let and be the concatenation of the non-diagonal elements from the upper triangular matrices of the matrices and , respectively, where .Thus, the elements in and can be easily expressed by and . And we can model the above problem with the following bilevel polynomial optimization formulation.
| (11) |
where is the observational data with representing the number of random variables. represents the interventional data, where interventions are performed on variable . And the interventional data under different variables is denoted as . and denote the polynomial objective function and polynomial constraints of the upper-level problem, respectively. The function is defined as the least squares loss, ( is an empirical parameter, relevant details are given in the Appendix B), and the function represents an acyclic constraint with different step lengths. Here, we use both observational and interventional data to learn variable in the upper-level function, which not only fully leverages the information from observational data, but also improves the accuracy of results by incorporating interventional data. When calculating the upper-level objective function, we masked the intervened variable because the parent set of it changes during perfect intervention. and represent the polynomial objective function and polynomial constraints of the lower-level problem respectively, with and . is the regularization function. Moreover, due to the sparsity of the causal structure, in most scenarios, we can simplify and by preprocessing or even introducing expert knowledge. For example, when there is obviously no causal relationship between two variables, the corresponding edge .
The proposed method can effectively utilize observational and interventional data, and improve the accuracy of causal structure learning. For some scenarios where there is no or limited intervention data, we can utilize data augmentation techniques to simulate the interventions to improve the usability of our method. M. Ilse [54] introduced Intervention-augmentation equivalence (IAE), demonstrating the feasibility of simulating interventional data through data augmentation using only observational data under IAE conditions. In an IAE causal process , every stochastic data augmentation transformation on is equivalent to a corresponding noise intervention on such that: . Hence, by verifying if the causal relationship between variables meets the IAE condition, an appropriate data augmentation model can be trained for each variable and simulate interventions through the addition of noise. More details can be found in the original publication.
Reformulation based on optimal conditions. Although Eq. (11) is a bilevel polynomial optimization problem with both upper and lower constraints, fortunately, the lower optimization problem can be proved convex because of the operations that preserve convexity [55]. According to Proposition 1, since the lower-level problem satisfies the Slater’s condition (Definition 1), Eq. (11) can be transformed into a single-level polynomial optimization problem.
| (12) |
We denote the inequality constraints and equality constraints as follows:
and
then the problem Eq. (12) can be expressed as
| (13) |
Proposition 1 (Equivalent single-level reformulation)
Consider Eq. (11) where the lower-level optimization problem is convex and satisfies the slater condition. Then is a global optimal solution of the bilevel polynomial optimization problem Eq. (11) when there exist Lagrange multipliers such that is the optimal solution to the single-level problem Eq. (12)
Proof. In order to prove the above proposition, we need to show that for any , there exists such that the feasible set of the lower optimization problem is equivalent to the following condition that
|
|
(14) |
According to the Theorem 2.1 [56], under the slater condition, a point is the global optimal point of the lower-level problem if and only if is the KKT point, i.e., there is such that
|
|
(15) |
Then we have and (), where .
III-C SDP Relaxations with Structured Sparsity
In this subsection, we investigate how to solve the above single-level polynomial optimization problem Eq. (13), which can be outlined into three steps. First, the variables are partitioned according to the correlative sparsity; then, the term sparsity graph is constructed according to the correlation between the monomials; finally, the SDP relaxation problem of the POP problem is provided and solved.
Generate Cliques
Let . First, we need to divide the variables involved in the POP problem into different cliques to reduce the scale of the final SDP problem. In Eq. (12), since and jointly define the causal structure, they have co-occurrence in the polynomial function and the acyclic constraint function . In addition, and also have co-occurrence in the constraint function . Therefore, we can quickly divide the variables by the following steps:
-
•
Construct the CSP graph for variable , denoted as , with nodes corresponding to variable . For variables and , the edge exists when one of the following two conditions is satisfied:
-
–
Let denote the support of the variable in the polynomial function . For , there are and ;
-
–
If both variables and are involved in the identical constraint function of Eq. (13).
-
–
-
•
The chordal extension of is denoted as and the variables in are partitioned and denoted as cliques, , with ;
-
•
Based on the co-occurrence relationship between the variables, the cliques are extended to , and .
Generate Term Sparsity
We first generate the standard monomial basis for each clique and obtain the term sparsity pattern by analyzing the correlations between monomials. Let denote supports in the problem, and be the supports w.r.t . For a relaxation order of and , denotes the TSP subgraph corresponding to the clique , with the nodes corresponding to the monomial basis . The edges in is obtained through two successive steps in Section 2, including support extension and chordal extension. We denote the adjacency matrix of the TSP graphs as , .
SDP Relaxation Problem of POP
Let denote the univariate vector corresponding to the standard monomial basis , and the linear function is defined as . The order of the functions is defined as , , . According to [50], we set the relaxation order as .
We can obtain the moment submatrix for each clique by the following equation:
| (16) |
where , are the indexes of the matrix, and is set as 1.
For , define as the localizing submatrix, where the entries in the matrix are derived from the following equation:
| (17) |
The POP problem can then be relaxed to an SDP problem by introducing moment submatrices and localizing submatrices, shown as follows.
| min | (18) | |||||
| s.t | ||||||
| var | ||||||
Proposition 2 (Monotonic convergence)
We give the proof of Proposition 2 in Appendix A.
It shows that by using different orders of semidefinite relaxation, the global optimal solution of the original problem can be gradually approximated. This provides sufficient theoretical guarantee for the global optimality of Bloom in solving the POP problems given in Eq. (11). In addition, there exist efficient interior point method [57] for SDP problems. It has been shown that theoretically the interior point method can provide a global optimal solution with a quadratic convergence rate [58, 59, 60]. In contrast, gradient descent algorithm often exhibit sublinear convergence rate for optimization problem with non-convex objective function [61, 62, 63]. Therefore, the proposed method is guaranteed to converge. In addition it exhibits faster convergence speed compared to gradient descent-type methods.
Proposition 3 (Optimality condition)
Proof. We denote the optimal solution of the problem Eq. (18) under the relaxation order as , since as the relaxation order increases, it gradually approaches the optimal solution of the original problem [50], that is:
Theoretically, the optimal solution will asymptotically converge to the global optimal solution of the original problem. But the most original optimization problem is a discrete problem, with and . Thus, and .By converting equality constraints into inequality constraints, we relax its domain to and so that it can be continuously optimized. Therefore, when the final solution satisfies the equality constraints, i.e., the obtained is exactly -1, 0, 1 vector and is 0, 1 vector, the current solution can be considered optimal.
In addition, according to [64], under sufficient rank conditions, we can also determine whether the optimal value under the current relaxation order is the optimal value of the original problem by checking whether finite convergence has occurred. The steps of Bloom are shown in Algorithm 1.
III-D Distributed Bloom
However, due to privacy concerns, local datasets are not allowed to be uploaded to a central server in some scenarios [65, 44, 43]. Therefore, we attempt to further extend the Bloom algorithm to distributed settings, enabling it to learn the graph structure from distributed data without sharing locally stored data.
Distributed Data. Let be the client set which includes different clients, and represent the central server. The dataset represent the local data owned by the client . The dataset is called distributed dataset. And we define as a homogeneous distributed dateset, which means they are sampled from an identical distribution.
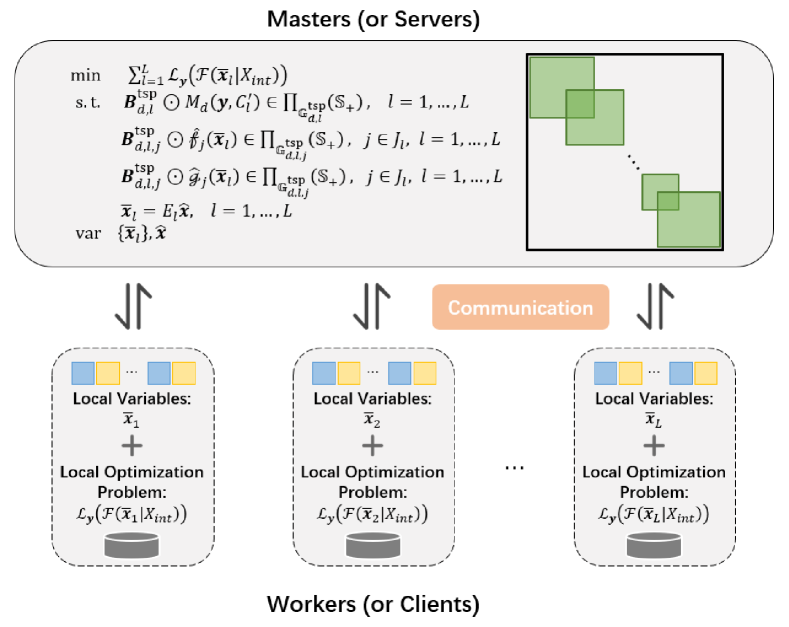
To learn causal structures from distributed data, the distributed Bloom solves each subproblem Eq. (19) by distributing it across all local clients. Since data is not shared between clients and the server, data privacy is significantly ensured. During training, the server and clients will exchange updated variables in each communication round to facilitate coordinated joint learning of the causal structure.
| min | (19) | |||||
| s.t | ||||||
| var | ||||||
Client Update. Essentially, solving the optimization problem on each client can be seen as an independent process. Therefore, each client will calculate sub-problems with local dataset, following the steps in Algorithm 1. After each communication round, the client will receive the updated variables, which will be used as the initial values for the next round of solving problem.
Server Update. After clients completed local updates, the server randomly selects clients and collects the learned variables to the set . By averaging the collected variables, we will get , which is then distributed to all clients.
The specific steps are shown in the Algorithm 2.
Privacy Protection. To avoid leakage of raw data in the client, distributed Bloom only exchanges the learned variables during the training process. Therefore, we consider the information leakage of local data to be relatively limited. For the graph structure information that may be contained in the transmission, we can address it by selecting a client as a proxy server [44]. It is worth mentioning that our work only provides a possible distributed extension of Bloom. Regarding further privacy protection efforts, we could introduce more advanced privacy protection techniques [66], which will be the focus of future research.
Communication Cost. Distributed Bloom only requires exchanging parameters between the server and clients during communication rounds. Despite introducing some communication costs, we consider this to be acceptable with relatively low communication overhead. In each communication round, servers only need to collect learned parameters from selected clients and distribute updated variables to each client. Furthermore, the trade-off between performance and communication costs can also be controlled by choosing the number of selected clients .
Additionally, for some large-scale structure learning problems, solving each subproblem still imposes significant demands on the computational resources of individual clients [42]. Fortunately, due to the sparsity of the constructed SDP problems Eq.(18), we can apply many existing distributed solving methods [67, 68, 69]. Although this is not the main focus of this article, we also present a feasible approach in Appendix B.
IV Experiments
IV-A Experimental Setup
We conduct experiments on synthetic and real data respectively to demonstrate its effectiveness by comparing the proposed method with some typical methods. All experiments are implemented on a server with Intel(R) Xeon(R) CPU E5-2690 v3 CPUs.
IV-A1 Datasets
We first randomly generated multiple datasets based on different structural causal models. These models vary in the size of the graph size, edge sparsity, and causal relationships. We use a scale-free (SF) graphical model to draw a random DAG and then generate data according to the causal order of . We mainly consider perfect interventions, where the conditional distribution of targeted nodes were replaced by a new distribution similarly to [35, 24, 42]. In experiments, we assume that the observational data is sampled from the Gaussian distributions, while the intervented variables obey the uniform distributions. Since some baseline methods assume linear relationships, we conducted two experiments in which the relationship between nodes was linear or polynomial, respectively. The linear datasets are generated following (), where the coefficients are sampled uniformly from . The nonlinear dataset are generated following a polynomial function , i.e., , where the degrees of the polynomial terms are randomly sampled from , similar to [42]. The sample length of each observational and interventional datasets are . Under the linear experimental setting, the number of nodes in the graph are , and the number of edges is . And in the polynomial experiments, the number of nodes are . In addition, we further tested the experimental results of the proposed algorithm under imperfect interventions in Section B.3. Finally, we also evaluated the scalability of our method on larger scales of nodes. In the scalability experiments, the number of nodes was set to , with edges proportional to . In all settings, we randomly sampled 5 graphs to compare the average performance of each algorithm.
We also tested the performance of different methods on a flow cytometry dataset from Sachs et al.[70]. This dataset measures the expression levels of phosphorylated proteins and phospholipids in human cells. Interventions were conducted by using reagents to activate or inhibit the measured proteins. In the experiment, we utilize a subset of this dataset, focusing on data where the measured proteins were directly perturbed. This subset comprises 5846 measurements, with 1755 being observational data, and the rest corresponding to measurements under interventions on five different single-node targets (target proteins: Akt, PKC, PIP2, Mek, PIP3). We employed Sachs’ consensus graph as the ground truth, consisting of 11 nodes and 17 edges. It is important to note that in this real-world dataset, the assumption of causal sufficiency may not hold, and the interventions may be considered imperfect.
IV-A2 Baselines
We compared our method with several methods based on observational or interventional data, including,
-
•
LINGAM: LINGAM (Linear Non-Gaussian Acyclic Model) is a method based on Functional Causal Model (FCM), which reveals causal relationships by testing whether there are linear and non-Gaussian functional relationships between variables.
-
•
PC: PC is an efficient constraint-based method that employs conditional independence tests to capture potential causal dependencies among variables. We employ the Fisher-z test (p-value = 0.05) for examination in linear experiments, and Kernel-based Conditional Independence (KCI) test (p-value = 0.05) [71] in polynomial experiments.
-
•
GES: GES is a score-based method, widely employed in various applications. Adopting a greedy approach, GES iteratively optimizes the estimated causal graph by computing the score function and adjusting potential edges. Here, we use Bayesian Information Criterion (BIC) score as the evaluation function in linear experiments, and apply generalized score function [72] for polynomial experiments.
-
•
Notears: Notears is a score-based method that characterizes acyclicity using an equality constraint, enabling its solution through continuous optimization techniques.
-
•
Sortnregress: Sortnregress [73] is a causal structure learning method for observational data. It utilizes ranking mechanisms and regression to effectively identify causal relationships between variables.
-
•
IGSP: IGSP is a hybrid method that optimizes a score based on conditional independence tests. We apply KCI test in nonlinear experiments.
-
•
GIES: GIES is a variant of GES designed for discovering causal relationships in observational and interventional data. GIES assumes the targets of the interventional data are known.
-
•
DCDI: DCDI is a method based on continuous optimization that uses observational and interventional data and can be used to discover nonlinear causal relationships.
-
•
ENCO: ENCO is also a nonlinear causal structure learning method with observational and interventional data.
Among the aforementioned methods, LINGAM, PC, GES, Notears and Sortnregress exclusively rely on observational data, whereas IGSP, GIES DCDI and ENCO are adept at handling both observational and intervention data. In experiments on synthetic data, we evaluate the best performance of each method across different experimental settings. But in real-world data, we only compared the best performance of those methods using both observational and intervention data.
IV-A3 Evaluation Metrics
We report True positive rate (TPR) and SHD (Structural Hamming Distance) to evaluate the quality of structure learning. SHD is the minimum number of edge additions, deletions, and inversions required to convert an estimated graph into a true DAG. It takes into account both false positives and false negatives, and a lower SHD indicates a better estimate.
IV-B Experimental Results
We tested the overall performance of all methods on two synthetic datasets and real datasets respectively.
IV-B1 Performance Comparison on Synthetic Dataset
We first conducted experiments under linear settings, and all results are displayed in Table II. Since some of the baseline methods could not employ interventional data, for the purpose of comparison, we experimented the proposed Bloom on observational data only by using a single-level polynomial optimization, and named it Bloom(obs). The experimental results consistently demonstrate Bloom’s superior performance over all baseline methods, highlighting the effectiveness of the proposed approach. And our method performs well when using only observational data, even outperforming methods that utilize interventional data in certain scenarios. Furthermore, Bloom excels in TPR and SHD across all scenarios. This indicates the superior ability of our method to estimate causal graphs, benefiting from the bilevel optimization framework that effectively captures causal information in various datasets. By formulating with POP, it allows our method to converge to an approximate global optimum through global search methods, ensuring a more accurate recovery of causal graphs. In contrast, GIES employs discrete greedy search methods, while most continuous optimization-based methods utilize gradient descent, which may be trapped in local optima. Additionally, the introduction of interventional data enhances the performance by supplying additional information about direct causal relationships between variables, enabling better learning of DAGs.
Table III shows the performance of the proposed method on polynomial datasets. In the experiments, our method demonstrated superior causal structure recovery capabilities. Because Bloom can effectively incorporate interventional data through bilevel optimization, which helps clearly identifying causal directions and reducing the identification of spurious relationships. Additionally, it utilizes polynomial optimization, which significantly avoids the problem of local optima and improves convergence, enabling our method to find better solutions in complex causal graph structures. On the other hand, although GIES showed suboptimal performance overall, its greedy strategy can sometimes cause it to get stuck in local optima, affecting the final outcome. Surprisingly, methods based on neural networks did not perform well. The main reason may be their high data requirement, which makes it difficult to fully optimize the model under limited conditions. In real-world scenarios, it is often challenging to obtain sufficient data.
| GES | LINGAM | PC | NOTEARS | Sortnregress | IGSP* | GIES* | Bloom(obs) | Bloom* | ||
|---|---|---|---|---|---|---|---|---|---|---|
| TPR | 5 Nodes | 0.5000±0.1250 | 0.4500±0.2739 | 0.6250±0.0884 | 0.6750±0.2271 | 0.8000±0.0685 | 0.3250±0.0612 | 0.8250±0.2437 | 0.8750±0.1250 | 0.9500±0.0685 |
| 7 Nodes | 0.4400±0.1517 | 0.3800±0.0834 | 0.4000±0.0353 | 0.7600±0.1140 | 0.8600±0.0894 | 0.4200±0.1720 | 0.8600±0.2191 | 0.9000±0.1000 | 0.9000±0.0000 | |
| 9 Nodes | 0.4833±0.1086 | 0.3167±0.1990 | 0.4667±0.1264 | 0.8167±0.2312 | 0.8667±0.0457 | 0.3833±0.1795 | 0.9000±0.0697 | 0.9167±0.0589 | 0.9334±0.0373 | |
| 11 Nodes | 0.5231±0.1480 | 0.2462±0.1141 | 0.6154±0.0769 | 0.8462±0.1216 | 0.8462±0.0769 | 0.4154±0.1427 | 0.8769±0.1771 | 0.8847±0.0444 | 0.8923±0.0421 | |
| 13 Nodes | 0.6133±0.1909 | 0.4133±0.1283 | 0.4533±0.1095 | 0.8933±0.1299 | 0.9333±0.0667 | 0.4933±0.0904 | 0.9467±0.1193 | 0.9333±0.0667 | 0.9600±0.0365 | |
| 15 Nodes | 0.4340±0.1839 | 0.4823±0.1044 | 0.5529±0.0670 | 0.8235±0.0832 | 0.8941±0.0873 | 0.6000±0.1596 | 0.9176±0.1289 | 0.9028±0.0688 | 0.9412±0.0588 | |
| SHD | 5 Nodes | 4.6±1.1 | 4.8±3.0 | 3.0±0.7 | 2.6±1.8 | 2.2±0.4 | 5.8±0.7 | 1.8±2.5 | 1.6±1.1 | 0.4±0.5 |
| 7 Nodes | 8.4±2.3 | 7.8±0.8 | 6.0±0.0 | 2.4±1.1 | 2.8±0.8 | 2.8±1.7 | 2.0±3.5 | 1.6±1.9 | 1.0±0.0 | |
| 9 Nodes | 8.8±1.9 | 10.2±3.0 | 6.4±1.5 | 2.2±2.8 | 3.0±1.9 | 8.0±2.4 | 1.8±1.1 | 1.8±1.3 | 1.6±1.1 | |
| 11 Nodes | 11.0±4.4 | 12.6±0.5 | 5.0±1.0 | 2.2±1.9 | 4.2±1.9 | 8.6±2.2 | 3.0±4.1 | 2.4±0.5 | 1.6±0.5 | |
| 13 Nodes | 11.6±3.8 | 10.8±2.2 | 8.2±1.6 | 1.8±1.9 | 2.4±0.9 | 9.6±1.6 | 1.6±3.6 | 2.4±1.8 | 2.0±1.4 | |
| 15 Nodes | 19.0±3.9 | 11.8±2.2 | 7.6±1.1 | 3.0±1.4 | 7.8±4.4 | 9.0±5.2 | 2.4±4.3 | 2.8±0.8 | 1.0±1.0 | |
-
•
The marker * indicates that the method uses both observational and interventional data.
-
•
The bold font in the table shows the best performance, while the underline font indicates the second best performance.
| PC | GES | GIES* | IGSP* | DCDI* | ENCO* | Bloom* | ||
|---|---|---|---|---|---|---|---|---|
| TPR | 5 Nodes | 0.4000±0.4214 | 0.6286±0.1278 | 0.6857±0.1195 | 0.0.4000±0.2555 | 0.4857±0.4802 | 0.5000±0.3595 | 0.7714±0.0782 |
| 10 Nodes | 0.4533±0.1282 | 0.5200±0.1095 | 0.6133±0.1592 | 0.4267±0.1115 | 0.3333±0.0667 | 0.3867±0.1726 | 0.7200±0.0558 | |
| 15 Nodes | 0.4235±0.1341 | 0.3882±0.0789 | 0.5294±0.0721 | 0.3999±0.1206 | 0.2510±0.0479 | 0.3294±0.1354 | 0.6823±0.1590 | |
| SHD | 5 Nodes | 4.8±2.8 | 3.0±1.2 | 2.6±1.1 | 4.6±2.3 | 5.0±1.9 | 4.8±1.5 | 2.0±0.7 |
| 10 Nodes | 14.4±4.0 | 10.4±2.7 | 12.6±5.6 | 10.6±2.6 | 14.8±1.3 | 12.4±1.5 | 6.8±1.3 | |
| 15 Nodes | 18.6±5.7 | 22.6±1.1 | 18.6±2.6 | 16.6±3.6 | 19.6±2.1 | 17.6±4.0 | 10.8±4.7 | |
-
•
The marker * indicates that the method uses both observational and interventional data.
-
•
The bold font in the table shows the best performance, while the underline font indicates the second best performance.
To validate the effectiveness of the distributed Bloom in large-scale causal structure learning problems, we conducted experiments under 50, 75 and 100 nodes, respectively. When the number of variables increases, learning causal structures becomes more complex and difficult. In this experiment, we only compared all methods that use both observational data and intervention data, and the experimental results are presented in Table IV. The results clearly indicate that our method maintains relatively good performance in large-scale problems and significantly outperforms the baseline methods. Additionally, Bloom can effectively improve the accuracy and reliability of problem solving by using polynomial optimization modeling, and make the obtained solution close to the global optimal. We further demonstrate the scalability of the proposed method on larger scale nodes in the Appendix E.
| IGSP | GIES | Bloom | ||
|---|---|---|---|---|
| TPR | 50 Nodes | 0.7000±0.1131 | 0.8520±0.0559 | 0.9560±0.0167 |
| 75 Nodes | 0.7042±0.0740 | 0.9093±0.0520 | 0.9173±0.0318 | |
| 100 Nodes | 0.7520±0.0286 | 0.8920±0.0228 | 0.9080±0.0465 | |
| SHD | 50 Nodes | 17.4±5.6 | 18.0±8.9 | 2.8±1.1 |
| 75 Nodes | 36.4±11.3 | 28.2±10.4 | 7.6±3.6 | |
| 100 Nodes | 46.0±10.6 | 40.6±7.3 | 15.2±2.8 | |
IV-B2 Performance Comparison on Real Dataset
We tested our approach on the flow cytometry data set from Sachs et al., a commonly used dataset for causal structure learning problems. In Table V, we report the SHD and TPR for all methods. Bloom performed exceptionally well, exhibiting the best overall performance with the lowest SHD and highest TPR. In contrast, other baseline methods often identify a considerable number of false or erroneous causal relationships. This is attributed to the increased complexity of causal relationships between variables in real-world scenarios, which might even be nonlinear, posing significant challenges for causal structure learning. However, experimental results demonstrate that our method exhibits robust causal inference performance in this real-world scenarios, and is capable of recovering causal structures more comprehensively.
| SHD | TPR | |
|---|---|---|
| IGSP | 18 | 0.4 |
| GIES | 13 | 0.2941 |
| DCDI | 33 | 0.3529 |
| ENCO | 25 | 0.4118 |
| Bloom | 5 | 0.7059 |
IV-B3 Experiment with Imperfect Interventions
In contrast to the previous experiments, we considered imperfect interventions in this study. As illustrated in the Fig. 2, the causal relationships between the intervened variable and its parents is not entirely removed; rather, we adjust the causal strength between them. Here we perform a simple verification experiment. Specifically, we sample observational data from the following linear SEM: , where the coefficients between variables are randomly sampled from the interval . Following [42], for imperfect interventions, we modify the initial weighted coefficients of the intervened variable by sampling from a new value range of . For nodes without parents, the distributions of intervened nodes are replaced by uniform distributions. We randomly generated a set of five different graphs, each containing six observed variables and ten directed edges. The experimental results are shown in the Table VI. It is evident that even in the case of imperfect interventions, our method remains relatively effective in recovering causal structures.

| SHD | TPR | |
|---|---|---|
| IGSP | 5.8±3.1 | 0.5600±0.2245 |
| GIES | 6.0±3.3 | 0.5800±0.2135 |
| DCDI | 6.4±0.9 | 0.4200±0.0837 |
| ENCO | 6.2±0.8 | 0.4200±0.1304 |
| Bloom | 2.4±0.5 | 0.7680±0.0271 |
IV-B4 Experiment with Latent Confounder
In the previous section, we assumed sufficiency of the causal structure learning, implying that all variables in the causal relationship can be observed. However, in real-world scenarios, the presence of latent confounders is often inevitable. As shown in Fig. 2, latent confounders are often unobserved common causal variables, which may introduce dependencies between two or more variables and lead to causal discovery methods identifying spurious causal relationships. Therefore, we intentionally relaxed this assumption and evaluated the performance of the proposed method in this subsection.
We randomly generated a set of five graphs, each containing one latent confounder and five observed variables. In the experiment, we assumed that this unobserved variable is not a descendant of any other observed variables, and the data generation process remained consistent with the previous. Our objective was to accurately learn the causal structure among the observed variables. The experimental results, as shown in the Table VII, indicate that our method is effective in learning causal relationships between other variables even in the presence of latent confounders. The inference performance of Bloom is closely associated with the introduction of intervention data and the modeling approach based on polynomial optimization.
| SHD | TPR | |
|---|---|---|
| IGSP | 3.6±1.4 | 0.4400±0.1497 |
| GIES | 2.0±0.0 | 0.9600±0.0800 |
| DCDI | 5.2±1.1 | 0.4000±0.1049 |
| ENCO | 4.6±0.9 | 0.5000±0.1250 |
| Bloom | 0.4±0.5 | 1.0000±0.0000 |
IV-B5 Ablation Experiment
To validate the benefits of incorporating interventional data into the modeling process, we further conducted experiments solely with observational data to assess the performance of model. The experiments were conducted on two distinct datasets comprising five and seven nodes, respectively. As represented in Table VIII, the outcomes reveal that the inclusion of interventional data significantly enhances the model’s capability to discover causalities and eliminate spurious relationships, thereby facilitating a more precise learning of the causal structure.
| SHD | TPR | |||||
| 5 Nodes | 7 nodes | 5 Nodes | 7 nodes | |||
|
0.8±0.4 | 2.2±0.8 | 0.8857±0.0639 | 0.8167±0.0697 | ||
| Bloom | 0.0±0.0 | 1.2±0.4 | 1.0000±0.0000 | 0.9000±0.0373 | ||
V Conclusion
This paper proposes Bloom for addressing the causal structure learning problem, which is based on bilevel polynomial optimization. This method efficiently integrates both observational and interventional data and can establish causal relationships with a higher level of confidence. Furthermore, we have extended it to a distributed setting for parallel processing across multiple distributed nodes. To our best knowledge, this study represents the inaugural exploration into employing bilevel polynomial optimization for causal structure discovery. Given the extensive literature on efficient algorithms as well as theoretical analyses of bilevel and polynomial optimization methods, we believe this novel perspective will pave new pathways for exploring the causal structure learning problem and contribute significantly to further research in this field.
References
- [1] J. Pearl et al., “Models, reasoning and inference,” Cambridge, UK: CambridgeUniversityPress, vol. 19, no. 2, p. 3, 2000.
- [2] Y. Niu, K. Tang, H. Zhang, Z. Lu, X.-S. Hua, and J.-R. Wen, “Counterfactual vqa: A cause-effect look at language bias,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 12 700–12 710.
- [3] D. Yang, G. Yu, J. Wang, Z. Wu, and M. Guo, “Reinforcement causal structure learning on order graph,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 9, 2023, pp. 10 737–10 744.
- [4] X. Lin, Y. Chen, G. Li, and Y. Yu, “A causal inference look at unsupervised video anomaly detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 2, 2022, pp. 1620–1629.
- [5] M. Peyrot, “Causal analysis: Theory and application,” Journal of Pediatric Psychology, vol. 21, no. 1, pp. 3–24, 1996.
- [6] R. J. Prill, D. Marbach, J. Saez-Rodriguez, P. K. Sorger, L. G. Alexopoulos, X. Xue, N. D. Clarke, G. Altan-Bonnet, and G. Stolovitzky, “Towards a rigorous assessment of systems biology models: the dream3 challenges,” PloS one, vol. 5, no. 2, p. e9202, 2010.
- [7] D. M. Chickering, “Learning bayesian networks is np-complete,” Learning from data: Artificial intelligence and statistics V, pp. 121–130, 1996.
- [8] P. Spirtes, C. N. Glymour, and R. Scheines, Causation, prediction, and search. MIT press, 2000.
- [9] J. Runge, P. Nowack, M. Kretschmer, S. Flaxman, and D. Sejdinovic, “Detecting and quantifying causal associations in large nonlinear time series datasets,” Science advances, vol. 5, no. 11, p. eaau4996, 2019.
- [10] J. Runge, “Conditional independence testing based on a nearest-neighbor estimator of conditional mutual information,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2018, pp. 938–947.
- [11] D. M. Chickering, “Optimal structure identification with greedy search,” Journal of machine learning research, vol. 3, no. Nov, pp. 507–554, 2002.
- [12] S. Shimizu, P. O. Hoyer, A. Hyvärinen, A. Kerminen, and M. Jordan, “A linear non-gaussian acyclic model for causal discovery.” Journal of Machine Learning Research, vol. 7, no. 10, 2006.
- [13] X. Zheng, B. Aragam, P. K. Ravikumar, and E. P. Xing, “Dags with no tears: Continuous optimization for structure learning,” Advances in neural information processing systems, vol. 31, 2018.
- [14] Y. Yu, J. Chen, T. Gao, and M. Yu, “Dag-gnn: Dag structure learning with graph neural networks,” in International Conference on Machine Learning. PMLR, 2019, pp. 7154–7163.
- [15] S. Zhu, I. Ng, and Z. Chen, “Causal discovery with reinforcement learning,” arXiv preprint arXiv:1906.04477, 2019.
- [16] I. Ng, S. Zhu, Z. Fang, H. Li, Z. Chen, and J. Wang, “Masked gradient-based causal structure learning,” in Proceedings of the 2022 SIAM International Conference on Data Mining (SDM). SIAM, 2022, pp. 424–432.
- [17] I. Ng, B. Huang, and K. Zhang, “Structure learning with continuous optimization: A sober look and beyond,” in Causal Learning and Reasoning. PMLR, 2024, pp. 71–105.
- [18] B. Hanin, “Which neural net architectures give rise to exploding and vanishing gradients?” Advances in neural information processing systems, vol. 31, 2018.
- [19] J. B. Lasserre, “Global optimization with polynomials and the problem of moments,” SIAM Journal on optimization, vol. 11, no. 3, pp. 796–817, 2001.
- [20] K. Yang, A. Katcoff, and C. Uhler, “Characterizing and learning equivalence classes of causal dags under interventions,” in International Conference on Machine Learning. PMLR, 2018, pp. 5541–5550.
- [21] F. Eberhardt, “Almost optimal intervention sets for causal discovery,” arXiv preprint arXiv:1206.3250, 2012.
- [22] Y. Wang, L. Solus, K. Yang, and C. Uhler, “Permutation-based causal inference algorithms with interventions,” Advances in Neural Information Processing Systems, vol. 30, 2017.
- [23] L. Lorch, S. Sussex, J. Rothfuss, A. Krause, and B. Schölkopf, “Amortized inference for causal structure learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 13 104–13 118, 2022.
- [24] C. Squires, Y. Wang, and C. Uhler, “Permutation-based causal structure learning with unknown intervention targets,” in Conference on Uncertainty in Artificial Intelligence. PMLR, 2020, pp. 1039–1048.
- [25] P. Lippe, T. Cohen, and E. Gavves, “Efficient neural causal discovery without acyclicity constraints,” in International Conference on Learning Representations, 2021.
- [26] J. Huang, X. Guo, K. Yu, F. Cao, and J. Liang, “Towards privacy-aware causal structure learning in federated setting,” IEEE Transactions on Big Data, 2023.
- [27] I. Ng and K. Zhang, “Towards federated bayesian network structure learning with continuous optimization,” in International Conference on Artificial Intelligence and Statistics. PMLR, 2022, pp. 8095–8111.
- [28] A. Abyaneh, N. Scherrer, P. Schwab, S. Bauer, B. Schölkopf, and A. Mehrjou, “Fed-cd: Federated causal discovery from interventional and observational data,” arXiv preprint arXiv:2211.03846, 2022.
- [29] S. Shimizu, P. O. Hoyer, A. Hyvärinen, A. Kerminen, and M. Jordan, “A linear non-gaussian acyclic model for causal discovery.” Journal of Machine Learning Research, vol. 7, no. 10, 2006.
- [30] K. Zhang and A. Hyvarinen, “On the identifiability of the post-nonlinear causal model,” arXiv preprint arXiv:1205.2599, 2012.
- [31] P. Hoyer, D. Janzing, J. M. Mooij, J. Peters, and B. Schölkopf, “Nonlinear causal discovery with additive noise models,” Advances in neural information processing systems, vol. 21, 2008.
- [32] S. Triantafillou and I. Tsamardinos, “Constraint-based causal discovery from multiple interventions over overlapping variable sets,” The Journal of Machine Learning Research, vol. 16, no. 1, pp. 2147–2205, 2015.
- [33] A. Hyttinen, F. Eberhardt, and M. Järvisalo, “Constraint-based causal discovery: Conflict resolution with answer set programming.” in UAI, 2014, pp. 340–349.
- [34] J. M. Mooij, S. Magliacane, and T. Claassen, “Joint causal inference from multiple contexts,” The Journal of Machine Learning Research, vol. 21, no. 1, pp. 3919–4026, 2020.
- [35] A. Hauser and P. Bühlmann, “Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs,” The Journal of Machine Learning Research, vol. 13, no. 1, pp. 2409–2464, 2012.
- [36] J. L. Gamella, A. Taeb, C. Heinze-Deml, and P. Bühlmann, “Characterization and greedy learning of gaussian structural causal models under unknown interventions,” arXiv preprint arXiv:2211.14897, 2022.
- [37] S. Lachapelle, P. Brouillard, T. Deleu, and S. Lacoste-Julien, “Gradient-based neural dag learning,” arXiv preprint arXiv:1906.02226, 2019.
- [38] C. Deng, K. Bello, B. Aragam, and P. K. Ravikumar, “Optimizing notears objectives via topological swaps,” in International Conference on Machine Learning. PMLR, 2023, pp. 7563–7595.
- [39] D. Wei, T. Gao, and Y. Yu, “Dags with no fears: A closer look at continuous optimization for learning bayesian networks,” Advances in Neural Information Processing Systems, vol. 33, pp. 3895–3906, 2020.
- [40] I. Ng, S. Lachapelle, N. R. Ke, S. Lacoste-Julien, and K. Zhang, “On the convergence of continuous constrained optimization for structure learning,” in International Conference on Artificial Intelligence and Statistics. Pmlr, 2022, pp. 8176–8198.
- [41] C. Deng, K. Bello, P. Ravikumar, and B. Aragam, “Global optimality in bivariate gradient-based dag learning,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [42] P. Brouillard, S. Lachapelle, A. Lacoste, S. Lacoste-Julien, and A. Drouin, “Differentiable causal discovery from interventional data,” Advances in Neural Information Processing Systems, vol. 33, pp. 21 865–21 877, 2020.
- [43] L. Li, I. Ng, G. Luo, B. Huang, G. Chen, T. Liu, B. Gu, and K. Zhang, “Federated causal discovery from heterogeneous data,” arXiv preprint arXiv:2402.13241, 2024.
- [44] E. Gao, J. Chen, L. Shen, T. Liu, M. Gong, and H. Bondell, “Feddag: Federated dag structure learning,” arXiv preprint arXiv:2112.03555, 2021.
- [45] S. Gould, B. Fernando, A. Cherian, P. Anderson, R. S. Cruz, and E. Guo, “On differentiating parameterized argmin and argmax problems with application to bi-level optimization,” arXiv preprint arXiv:1607.05447, 2016.
- [46] A. Biswas and C. Hoyle, “A literature review: solving constrained non-linear bi-level optimization problems with classical methods,” in International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, vol. 59193. American Society of Mechanical Engineers, 2019, p. V02BT03A025.
- [47] S. Dempe and J. Dutta, “Is bilevel programming a special case of a mathematical program with complementarity constraints?” Mathematical programming, vol. 131, pp. 37–48, 2012.
- [48] B. Reznick, “Extremal psd forms with few terms,” Duke Mathematical Journal, vol. 45, no. 2, p. 363, 1978.
- [49] R. Grone, C. R. Johnson, E. M. Sá, and H. Wolkowicz, “Positive definite completions of partial hermitian matrices,” Linear algebra and its applications, vol. 58, pp. 109–124, 1984.
- [50] H. Waki, S. Kim, M. Kojima, and M. Muramatsu, “Sums of squares and semidefinite program relaxations for polynomial optimization problems with structured sparsity,” SIAM Journal on Optimization, vol. 17, no. 1, pp. 218–242, 2006.
- [51] J. Agler, W. Helton, S. McCullough, and L. Rodman, “Positive semidefinite matrices with a given sparsity pattern,” Linear algebra and its applications, vol. 107, pp. 101–149, 1988.
- [52] J. Wang, V. Magron, and J.-B. Lasserre, “Tssos: A moment-sos hierarchy that exploits term sparsity,” SIAM Journal on optimization, vol. 31, no. 1, pp. 30–58, 2021.
- [53] N. R. Ke, O. Bilaniuk, A. Goyal, S. Bauer, H. Larochelle, B. Schölkopf, M. C. Mozer, C. Pal, and Y. Bengio, “Learning neural causal models from unknown interventions,” arXiv preprint arXiv:1910.01075, 2019.
- [54] M. Ilse, J. M. Tomczak, and P. Forré, “Selecting data augmentation for simulating interventions,” in International Conference on Machine Learning. PMLR, 2021, pp. 4555–4562.
- [55] S. P. Boyd and L. Vandenberghe, Convex optimization. Cambridge university press, 2004.
- [56] J. B. Lasserre, “On representations of the feasible set in convex optimization,” Optimization Letters, vol. 4, no. 1, pp. 1–5, 2010.
- [57] X. Bai, H. Wei, K. Fujisawa, and Y. Wang, “Semidefinite programming for optimal power flow problems,” International Journal of Electrical Power & Energy Systems, vol. 30, no. 6-7, pp. 383–392, 2008.
- [58] F. A. Potra and S. J. Wright, “Interior-point methods,” Journal of computational and applied mathematics, vol. 124, no. 1-2, pp. 281–302, 2000.
- [59] Y. Zhang, J. Wu, and L. Zhang, “The rate of convergence of proximal method of multipliers for nonlinear semidefinite programming,” Optimization, vol. 69, no. 4, pp. 875–900, 2020.
- [60] H. Yamashita and H. Yabe, “Quadratic convergence of a primal-dual interior point method for degenerate nonlinear optimization problems,” Computational Optimization and Applications, vol. 31, pp. 123–143, 2005.
- [61] X. Li, K.-Y. Lin, L. Li, Y. Hong, and J. Chen, “On faster convergence of scaled sign gradient descent,” IEEE Transactions on Industrial Informatics, 2023.
- [62] F. Zou, L. Shen, Z. Jie, W. Zhang, and W. Liu, “A sufficient condition for convergences of adam and rmsprop,” in Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition, 2019, pp. 11 127–11 135.
- [63] R. Johnson and T. Zhang, “Accelerating stochastic gradient descent using predictive variance reduction,” Advances in neural information processing systems, vol. 26, 2013.
- [64] J. B. Lasserre, “Moments, positive polynomials and their applications,” Series on Optimization and Its Applications, 2009.
- [65] O. Mian, D. Kaltenpoth, and M. Kamp, “Regret-based federated causal discovery,” in Proceedings of The KDD’22 Workshop on Causal Discovery, ser. Proceedings of Machine Learning Research, T. D. Le, L. Liu, E. Kıcıman, S. Triantafyllou, and H. Liu, Eds., vol. 185. PMLR, 15 Aug 2022, pp. 61–69. [Online]. Available: https://proceedings.mlr.press/v185/mian22a.html
- [66] C. Ma, J. Li, M. Ding, H. H. Yang, F. Shu, T. Q. S. Quek, and H. V. Poor, “On safeguarding privacy and security in the framework of federated learning,” IEEE Network, vol. 34, no. 4, pp. 242–248, 2020.
- [67] S. K. Pakazad, A. Hansson, M. S. Andersen, and A. Rantzer, “Distributed semidefinite programming with application to large-scale system analysis,” IEEE Transactions on Automatic Control, vol. 63, no. 4, pp. 1045–1058, 2018.
- [68] A. Kalbat and J. Lavaei, “A fast distributed algorithm for decomposable semidefinite programs,” in 2015 54th IEEE Conference on Decision and Control (CDC), 2015, pp. 1742–1749.
- [69] W. Li, X. Zeng, Y. Hong, and H. Ji, “Distributed consensus-based solver for semi-definite programming: An optimization viewpoint,” Automatica, vol. 131, p. 109737, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0005109821002570
- [70] K. Sachs, O. Perez, D. Pe’er, D. A. Lauffenburger, and G. P. Nolan, “Causal protein-signaling networks derived from multiparameter single-cell data,” Science, vol. 308, no. 5721, pp. 523–529, 2005.
- [71] K. Zhang, J. Peters, D. Janzing, and B. Schölkopf, “Kernel-based conditional independence test and application in causal discovery,” in 27th Conference on Uncertainty in Artificial Intelligence (UAI 2011). AUAI Press, 2011, pp. 804–813.
- [72] B. Huang, K. Zhang, Y. Lin, B. Schölkopf, and C. Glymour, “Generalized score functions for causal discovery,” in Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, 2018, pp. 1551–1560.
- [73] A. Reisach, C. Seiler, and S. Weichwald, “Beware of the simulated dag! causal discovery benchmarks may be easy to game,” Advances in Neural Information Processing Systems, vol. 34, pp. 27 772–27 784, 2021.
- [74] M. Putinar, “Positive polynomials on compact semi-algebraic sets,” Indiana University Mathematics Journal, vol. 41, pp. 49–95, 1993.
- [75] A. Yurtsever, J. A. Tropp, O. Fercoq, M. Udell, and V. Cevher, “Scalable semidefinite programming,” SIAM Journal on Mathematics of Data Science, vol. 3, no. 1, pp. 171–200, 2021.
Appendix A Proof
A-A The Proof of Proposition 2
Proposition 2 [Monotonic convergence]: For any relaxation order , the optimal value of the problem Eq.(20) monotonically converges to the optimal value of the original problem Eq.(11) as increases.
Before providing the proof of Proposition 2, we first give the following Lemma.
Lemma 1 (Putinar’s Positivstellensatz [74])
Let and be real polynomials of . Suppose that there exist and sum-of-squares polynomials such that for all . If over the set , then there exist such that .
According to [19], we have the sum-of-square relaxation problems for Eq. (13) when relaxation order is .
| (20) | ||||
| s.t. | ||||
| var. |
And it is known the above question that can be reformulated as SDP problem [64], i.e., Eq. (18) in our problem.
Proof. Let represent the optimal value of Eq.(20) with the relaxation order of . According to Lasserre hierarchical theorem [19], it can be easily verified that . Let and , we define . And over the feasible set. By applying Lemma 1, there exist such that
Then, we have . Since for all . Therefore, .
Appendix B Methodology
B-A Distributed Bloom for Large-Scale Structure Learning Problem
For causal structure learning problems, when the number of nodes is large, it will place high demands on the computing resources of a single client. Therefore, for each sub-problem on the client, we can further decouple it into multiple SDP sub-problems according to the sparsity of the SDP problem and solve them across distributed nodes.
Due to the sparsity of the problem, Eq. (19) can exhibit the following coupling form for sub-problem of each client (omit client superscript):
|
|
(21) |
This problem can be viewed as a coupling of sub-problems, each constituting an SDP problem with fewer variables. Then different sub-problems will be jointly learned by different clients to solve the problem of insufficient computing resources, similar to Algorithm 2.
To ensure solution consistency, we add consensus variables and constraints for each sub-problem, reformulating it into a consensus problem as follows:
|
|
(22) |
where are the local variables in worker, and are the consensus variables in the master node. By formulating the consensus problem, it enables the design of distributed algorithm based on architecture such as parameter server. As shown in Fig. 3, communication is centralized around the server. Clients retrieve the consensus variable from the server and transmit the local variable to it. By jointly solving all subproblems in Eq. (21), we will obtain a solution to the original problem.
Appendix C Experiments
C-A Experiments with Different
In the formulated bilevel optimization problem Eq. (11,12), we leverage both observational and interventional data to learn direction parameters of the causal structure, which aims to fully exploiting the causal information in datasets. Specifically, we introduce the weight coefficient to balance the influence of these two types of data. As mentioned earlier, interventions are the second level in the Pearl’s causal ladder theory, which can more effectively reveal the causal relationship between variables. The experimental results are shown in the Fig. 4. Analyzing the outcomes, it is evident that when is small, Bloom’s performance remains consistently robust, effectively discerning causal structures. Conversely, a larger may lead to the identification of spurious causal relationships, which is primarily resulted by the dominance of observational data. Therefore, in the upper-level objective function, we preferentially opt for smaller values to enhance the discernibility of the causal structure. Furthermore, the experimental results substantiate that the introduction of interventional data indeed contributes to an improved accuracy in identifying the causal structure.
C-B Experiments with Different Iteration Times
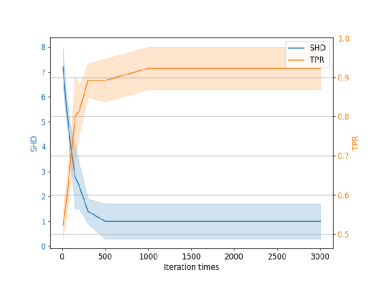
To analyze the sensitivity of the proposed method to the number of iterations, we tested the algorithm’s performance under different iteration settings. Fig. 6(a) shows the experiments with 5 nodes, and Fig. 6(b) with 10 nodes. When the iteration count is relatively low, especially below 100, the performance is suboptimal. This is because the algorithm may not have sufficiently explored the solution space with a low iterations, leading to suboptimal performance. However, as the number of iterations increases, the algorithm’s performance improves significantly. After reaching 300-500 iterations, the performance stabilizes. Specifically, the time required for the algorithm to run 500 iterations is around 29.3 seconds for 5 nodes and approximately 240.4 seconds for 10 nodes. Despite the increase in time required with more nodes, the overall convergence time remains acceptable. Based on the trade-off between algorithm performance and efficiency, the iteration number is generally set above 1000, the algorithm performance is relatively stable regarding this parameter setting. Hence, the algorithm is robust to the iteration parameter setting as long as it is set reasonably.
C-C Experiments on Large-scale Datasets
On large-scale datasets, we further compared the performance of the distributed Bloom algorithm and the federated learning-based Notears-ADMM algorithm [27]. The datasets are derived from a linear generative model, with a node-to-edge ratio of 1:1. Both algorithms were run for 1000 iterations, while the other parameters of Notears-ADMM are kept at their original settings. Fig. 5 show the SHD, TPR, and running time for both methods on all datasets. The experimental results indicate that as the number of nodes increases, the SHD for both methods also increases, but the SHD for distributed Bloom remains consistently lower than Notears-ADMM, demonstrating its superior performance for current problems. This is due to distributed Bloom’s use of interventional data, which effectively reduces spurious correlations. Additionally, the TPR for distributed Bloom remains consistently high, indicating its strong capability in identifying true causal relationships, partly attributed to the use of polynomial optimization. Regarding running time, although both methods are similar with fewer nodes (), distributed Bloom takes longer as the number of nodes increases. This is because Bloom needs converting the original POP problem into an SDP relaxation problem, causing the running time to grow exponentially with the number of nodes. Therefore, in practical applications, a trade-off between running efficiency and accuracy might be necessary. Overall, distributed Bloom still demonstrates good applicability and performance on larger-scale datasets. Future research will focus on optimizing the efficiency of the proposed method. Many existing studies [75] have explored how to accelerate scalable SDP problem, and we hope to apply these techniques to our algorithm.
C-D Experiments with Different Sampling Number
We tested the performance of the proposed method in data sets with different sampling lengths (15 Nodes) in this experiment, and the results are shown in the Fig. 7. The figures display the SHD and TPR of the algorithm under different settings. From the Fig. 7, we can observe that as the sampling number increases, the performance of our method improves rapidly. Moreover, the proposed method reaches relatively high performance and stabilizes when the sample length is 300.





C-E Experiments with Different Noise
In this study, we sampled data noise from Gaussian distributions with varying standard deviations (ranging from 0.1 to 10.0). The results of the experiment are depicted in Fig. 8, with the vertical axis indicating the standard deviation of the noise. We report the algorithm’s SHD and TPR. The figure shows that as the noise level increases, our algorithm maintains relatively high performance until the standard deviation reaches to 6.0. This partly illustrates the stability of the proposed algorithm in high-noise conditions.
C-F Convergence Experiment
Bloom initially relaxes the formulated bilevel polynomial problem and learn the causal structure by solving a sequence of SDP problems. Different from existing continuous optimization methods for causal discovery, we utilize Interior Point Method (IPM) and its variants as the solver for our problem. IPM is a powerful optimization algorithm that progresses towards the global optimum in each iteration, typically resulting in a faster global convergence rate. In contrast, existing continuous optimization methods often rely on gradient descent, updating parameters along the negative gradient direction of the objective function to gradually approach the optimal solution. In some cases, especially for non-convex problems, gradient descent may get trapped in local optima, leading to slower convergence rates. Additionally, IPM essentially employs Newton method for unconstrained convex subproblems. Compared to the gradient descent-based works, which shows a sub-linear or linear convergence rate, Newton method theoretically offers a quadratic convergence rate. Thus, our method achieves faster convergence
To verify this idea, we conducted additional experiments to analyze the convergence and speed of the algorithm. A comparison was made between the convergence of the SGD-based causal discovery method and the proposed algorithm on a data set (nodes = 5, edges = 8), as illustrated in the Fig. 9. The figure indicates that our method can achieve better experimental results in approximately 20 iterations, with the SHD of the learned causal graph being 1. In contrast, the SGD-based method requires more iterations to achieve convergence. This is due to the use of a global convergence approach (i.e., IPM) used to solve the SDP problems, which essentially utilizes the Newton method, known for its quadratic convergence, while the gradient descent method typically converges linearly. Furthermore, the experimental results presented in the Section 4 also demonstrate the superior performance of our proposed method.
