Interpretable Rule Discovery Through Bilevel Optimization of Split-Rules of Nonlinear Decision Trees for Classification Problems
Abstract
For supervised classification problems involving design, control, other practical purposes, users are not only interested in finding a highly accurate classifier, but they also demand that the obtained classifier be easily interpretable. While the definition of interpretability of a classifier can vary from case to case, here, by a humanly interpretable classifier we restrict it to be expressed in simplistic mathematical terms. As a novel approach, we represent a classifier as an assembly of simple mathematical rules using a non-linear decision tree (NLDT). Each conditional (non-terminal) node of the tree represents a non-linear mathematical rule (split-rule) involving features in order to partition the dataset in the given conditional node into two non-overlapping subsets. This partitioning is intended to minimize the impurity of the resulting child nodes. By restricting the structure of split-rule at each conditional node and depth of the decision tree, the interpretability of the classifier is assured. The non-linear split-rule at a given conditional node is obtained using an evolutionary bilevel optimization algorithm, in which while the upper-level focuses on arriving at an interpretable structure of the split-rule, the lower-level achieves the most appropriate weights (coefficients) of individual constituents of the rule to minimize the net impurity of two resulting child nodes. The performance of the proposed algorithm is demonstrated on a number of controlled test problems, existing benchmark problems, and industrial problems. Results on two to 500-feature problems are encouraging and open up further scopes of applying the proposed approach to more challenging and complex classification tasks.
Index Terms:
Classification, Decision trees, Machine learning, Bi-level optimization, Evolutionary algorithms.I Introduction
In a classification task, usually a set of labelled data involving a set of features and its belonging to a specific class are provided. The task in a classification task is to design an algorithm which works on the given dataset and arrives at one or more classification rules (expressed as a function of problem features) which are able to make predictions with maximum classification accuracy. A classifier can be expressed in many different ways suitable for the purpose of the application. In a quest to make the classifier interpretable, classifier representation through a decision-list or a decision-tree (DT) had been a popular choice. In decision trees, the classification rule-set is represented in an inverted tree based structure where non-terminal conditional nodes comprise of conditional statements, mostly involving a single feature, and the terminal leaf-nodes have a class label associated with them. A datapoint traverses through the DT by following the rules at conditional nodes and lands at a particular leaf-node, marking its class. In the artificial neural network (ANN) approach, an implicit relationship among features is captured through a multi-layered network, while in the support-vector-machine (SVM) approach, a complex mathematical relationship of associated support vectors is derived. One common aspect of these methods is that they use an optimization method of arriving at a suitable DT, ANN or SVM based on maximizing the classification accuracy.
Due to their importance in many practical problems involving design, control, identification, and other machine learning related tasks, researchers have spent a lot of efforts to develop efficient optimization-based classification algorithms [1, 2, 3]. While most algorithms are developed for classifying two-class data sets, the developed methods can be extended to multi-class classification problems as hierarchical two-class classification problems or by extending them to constitute a simultaneous multi-class classification algorithm. In this paper, we do not extend our approach to multi-class classification problems, except showing a proof-of-principle study.
In most classification problem solving tasks, maximizing classification accuracy (or minimizing classification error) on the labelled dataset is usually used as the sole objective. However, besides the classification accuracy, in many applications, users are also interested in finding an easily interpretable classifier for various practical reasons: (i) it helps to identify the most important rules which are responsible for the classification task, (ii) it also helps to provide a more direct relationship of features to have a better insight for the underlying classification task for knowledge enhancement and future developmental purposes. The definition of an easily interpretable classifier largely depends on the context, but the existing literature represents them as a linear, polynomial, or posynomial function involving only a few features.
In this paper, we propose a number of novel ideas towards evolving a highly accurate and easily interpretable classifier. First, instead of a DT, we propose a nonlinear decision tree (NLDT) as a classifier, in which every non-terminal conditional node will represent a nonlinear function of features to express a split-rule. Each split-rule will split the data into two non-overlapping subsets. Successive hierarchical splits of these sub-sets are carried out and the tree is allowed to grow until one of the termination criteria is met. We argue that flexibility of allowing nonlinear split-rule at conditional nodes (instead of a single-variable based rule which is found in tradition ID3 based DTs [4]) will result in a more compact DT (having a fewer nodes). Second, to derive the split-rule at a given conditional-node, a dedicated bilevel-optimization algorithm is applied, so that learning of the structure of the rule and associated coefficients are treated as two hierarchical and inter-related optimization tasks. Third, our proposed methodology is customized for classification problem solving, so that our overall bilevel optimization algorithm is computationally efficient. Fourth, we emphasize evolving simplistic rule structures through our customized bilevel optimization method so that obtained rules are also interpretable.
In the remainder of the paper, we provide a brief survey of the existing approaches of inducing DTs in Section II. A detailed description about the problem of inducing interpretable DTs from optimization perspective and a high-level view on proposed approach is provided in Section III. Next, we provide an in-depth discussion of the proposed bilevel-optimization algorithm which is adopted to derive interpretable split-rules at each conditional node of NLDT in Section IV. Section V provides a brief overview on the post-processing method which is used to prune the tree to simplify its topology. Compilation of results on standard classification and engineering problems are given in section VI. The paper ends with concluding remarks and some highlights on future work in Section VII.
II Past Studies
There exist many studies involving machine learning and data analytics methods for discovering rules from data. Here, we provide a brief mention of some studies which are close to our proposed study.
Traditional induction of DTs is done in axis-parallel fashion [4], wherein each split rule is of type or . Algorithms such as ID3, CART and C4.5 are among the popular ones in this category. The work done in the past to generate non-axis-parallel trees can be found in [5, 6, 7], where the researchers rely on randomized algorithms to search for multi-variate hyperplanes. Work done in [8, 9] use evolutionary algorithms to induce oblique DTs. The idea of OCI [7] is extended in [10] to generate nonlinear quadratic split-rules in a DT. Bennett Et al. [11] uses SVM to generate linear/nonlinear split rules. However, these works do not address certain key practical considerations, such as the complexity of the combined split-rules and handling of biased data.
Next, we discuss some studies which take the aspect of complexity of rule into consideration. In [12], ellipsoidal and interval based rules are determined using the set of support-vectors and prototype points/vertex points. The authors there primarily focus at coming up with compact set of if-then-else rules which are comprehensible. Despite its intuitiveness, the approach proposed in [12] doesn’t result into comprehensible set of rules on high-dimensional datasets. Another approach suggested in [13] uses the decompositional based technique of deriving rules using the output of a linear-SVM classifier. The rules here are expressed as hypercubes. The method proposed is computationally fast, but it lacks in its scope to address nonlinear decision boundaries and its performance is limited by the performance of a regular linear-SVM. On the other hand, this approach has a tendency to generate more rules if the data is distributed parallel to the decision boundary. The study conducted in [14] uses a trained neural-network as an oracle to develop a DT of at least m-of-n type rule-sets (similar to the one described in ID2-of-3 [15]). The strength of this approach lies in its potential to scale up. However, its accuracy on unseen dataset usually falls by about from the corresponding oracle neural-network counterpart. Authors in [16] use a pedagogical technique to evolve comprehensible rules using genetic-programming. The proposed algorithm G-REX considers the fidelity (i.e. how closely can the evolved AI agent mimic the behaviour of the oracle NN) as the primary objective and the compactness of the rule expression is penalized using a parameter to evolve interpretable set of fuzzy rules for a classification problem. The approach is good enough to produce comprehensible rule-set, but it needs tweaking and fine tuning of the penalty parameter. A nice summary of the above-mentioned methods is provided in [17]. Ishibuchi et al. in [18] implemented a three-objective strategy to evolve fuzzy set of rules using a multi-objective genetic algorithm. The objectives considered in that research were the classification accuracy, number of rules in the evolved rule-set and the total number of antecedent conditions. In [19], an ANN is used as a final classifier and a multi-objective optimization approach is employed to find simple and accurate classifier. The simplicity is expressed by the number of nodes. Hand calculations are then used to analytically express the ANN with a mathematical function. This procedure however becomes intractable when the evolved ANN has a large number of nodes.
Genetic programming (GP) based methods have been found efficient in deriving relevant features from the set of original features which are then used to generate the classifier or interpretable rule sets [20, 21, 22, 23, 24, 25]. In some studies, the entire classifier is encoded with a genetic-representation and the genome is then evolved using GP. Some works conducted in this regard also simultaneously consider complexity of the classifier [26, 27, 28, 29], but those have been limited to axis-parallel or oblique splits. Application of GP to induce nonlinear multivariate decision tree can be found in [30, 31]. Our approach of inducing nonlinear decision tree is conceptually similar to the idea discussed in [30], where the DT is induced in the top-down way and at each internal conditional node, the nonlinear split-rule is derived using a GP. Here, the fitness of a GP solution is expressed as a weighted-sum of misclassification-rates and generalizability term. However, the interpretability aspect of the final split-rule does not get captured anywhere in the fitness assignment and authors do not report the complexity of the finally obtained classifiers. Authors in [32] use a three-phase evolutionary algorithm to create a composite rule set of axis parallel rules for each class. Their algorithm is able to generate interpretable rules but struggles to achieve respectable classification accuracy on datasets which are not separable by axis-parallel boundaries. In [33], GP is used to evolve DTs with linear split-rules, however the work does not focus on improving the interpretability of the evolved DT classifier. Eggermont et al. [34] induce the DT using GP by allowing multiple splits through their clustering and refined atomic (internal nodes) representations and conduct a global evolutionary search to estimate the values of attribute thresholds. A multi-layered fitness approach is adopted with first priority given to the overall classification accuracy followed by the complexity of DT. Here too, splits occur based on the box conditions and hence it becomes difficult to address classification datasets involving non-linear (or non axis-parallel) decision boundaries. In [35], a decision list is generated using a GP by incorporating concept-mapping and covering techniques. Similar to [32], a dedicated rule-set for each class is generated and this method too is limited to work well on datasets which can be partitioned through boxed boundaries. An interesting application of GP to derive interpretable classification rules is reported in [36]. Here, a dedicated rule of type IF-ANTECEDENT-THEN-DECISION is generated for each class in the dataset using a GP and a procedure is suggested to handle intermediate cases. The suggested algorithm shows promising results for classification accuracy but the study does not report statistics regarding the complexity of the evolved ruleset.
In our proposed approach, we attempt to evolve nonlinear DTs which are robust to different biases in the dataset and simultaneously target in evolving nonlinear yet simpler polynomial split-rules at each conditional node of NLDT with a dedicated bilevel genetic algorithm (shown pictorially in Figure 1). In oppose to the method discussed in [30], where the fitness of GP individual doesn’t capture the notion of complexity of rule expression, the bilevel-optimization proposed in our work deals with the aspects of interpretability and performance of split-rule in a logically hierarchical manner (conceptually illustrated in Figure 2). The results indicate that the proposed bilevel algorithm for evolving nonlinear split-rules eventually generates simple and comprehensible classifiers with high or comparable accuracy on all the problems used in this study.
III Proposed Approach
III-A Classifier Representation Using Nonlinear Decision Tree
An interpretable classifier for our proposed method is represented in the form of a nonlinear decision tree (NLDT), as depicted in Figure 1.

The decision tree (DT) comprises of conditional (or non-terminal) nodes and terminal leaf-nodes. Each conditional-node of the DT has a rule () associated to it, where represents the feature vector. To make the DT more interpretable, two aspects are considered:
-
1.
Simplicity of split-rule at each conditional nodes (see Figure 2) and
-
2.
Simplicity of the topology of overall DT, which is computed by counting total number of conditional-nodes in the DT.
Under an ideal scenario, the simplest split-rule will involve just one attribute (or feature) and can be expressed as , for -th rule. Here, the split occurs solely based on the feature (). In most complex problems, such a simple split rule involving a single feature may not lead to a small-depth DT, thereby making the overall classifier un-interpretable. DTs induced using algorithms such as ID.3 and C4.5 fall under this category. In the present work, we refer to these trees with classification and regression trees (CART) [4].
On the other extreme, a topologically-simplest tree will correspond to the DT involving only one conditional node, but the associated rule may be too complex to interpret. SVM based classifiers fall in this category, wherein decision-boundary is expressed in form of a complicated mathematical equation. Another way to represent a classifier is through an ANN, which when attempted to express analytically, will resort into a complicated nonlinear function without any easy interpretability.
In this work, we propose a novel and compromise approach to above two extreme cases so that the resulting DT is not too deep and associated split-rule function at each conditional node assume a nonlinear form with controlled complexity and is easily interpretable. The development of a nonlinear DT is similar in principle to the search of a linear DT in CART, but this task requires the use of an efficient nonlinear optimization method for evolving nonlinear rules (), for which we exploit recent advances in bilevel optimization. The proposed bilevel approach is discussed in Section IV and a high-level perspective of the optimization process is provided in Figure 1. During the training phase, NLDT is induced using a recursive algorithm as shown in Algorithm 1. Brief description about subroutines used in Algorithm 1 is provided below and relevant pseudo codes for ObtainSplitRule subroutine and an evaluator for upper-level GA are provided in Algorithm 2 and 3 respectively. For brevity, details of the termination criteria is provided in the Supplementary Section.
-
•
ObtainSplitRule(Data)
-
–
Input: -matrix representing the dataset, where the last column indicates the class-label.
-
–
Output: Non linear-split rule .
-
–
Method: Bilevel optimization is used to determine . Details regarding this are discussed in Sec IV.
-
–
-
•
SplitNode(Data, SplitRule)
-
–
Input: Data, Split Rule .
-
–
Output: LeftNode and RightNode which are node-data-structures, where LeftNode.Data are the datapoints in input Data satisfying while the RightNode.Data are the datapoints in the input Data violating the split rule.
-
–
III-B Split-Rule Representation
In this paper, we restrict the expression of split-rule at a conditional node of the decision tree operating on the feature vector to assume the following structure:
| (1) |
where can be expressed in two different forms depending on whether a modulus operator is sought or not:
| (2) |
Here, ’s are coefficients or weights of several power-laws (’s), ’s are biases, is the modulus-flag which indicates the presence or absence of the modulus operator, is a user-specified parameter to indicate the maximum number of power-laws () which can exist in the expression of , and represents a power-law rule of type:
| (3) |
is a block-matrix of exponents , given as follows:
| (4) |
Exponents ’s are allowed to assume values from a specified discrete set . In this work, we set and to make the rules interpretable, however they can be changed by the user. The parameters and are real-valued variables in . The feature vector is a data-point in a -dimensional space. Another user-defined parameter controls the maximum number of variables that can be present in each power-law . The default is (i.e. dimension of the feature space).
IV Bilevel Approach for Split-Rule Identification
IV-A The Hierarchical Objectives to derive split-rule
Here, we illustrate the need of formulating the problem of split-rule identification as a bilevel-problem using Figure 2.

The geometry and shape of split-rules is defined by exponent terms appearing in its expression (Eq. 2 and 3) while the orientation and location of the split-rule in the feature-space is dictated by the values of coefficients and biases (Eq. 2). Thus, the above optimization task of estimating split-rule involves two types of variables:
-
1.
-matrix representing exponents of -terms (i.e. as shown in Eq. 4) and the modulus flag indicating the presence or absence of a modulus operator in the expression of , and
-
2.
weights and biases in each rule function .
Identification of a good structure for terms and value of is a more difficult task, compared to the weight and bias identification. We argue that if both types of variables (, , , ) are concatenated in a single-level solution, a good combination may be associated with a not-so-good , combination (like split-rule in Fig. 2), thereby making the whole solution vulnerable to deletion during optimization. It may be better to separate the search of a good structure of combination from the weight-bias search at the same level, and search for the best weight-bias combination for every pair as a detailed task. This hierarchical structure of the variables motivates us to employ a bilevel optimization approach [37] to handle the two types of variables. The upper level optimization algorithm searches the space of and . Then, for each pair, the lower level optimization algorithm is invoked to determine the optimal values of and . Referring to Fig. 2, the upper-level will search for the structure of which might have a nonlinearity (like in rule ) or might be linear (like rule ). Then, for each upper-level solution (for instance a solution corresponding to a linear rule structure), the lower-level will adjust its weights and biases to determine its optimal location .
The bi-level optimization problem can be then formulated as shown below:
| (5) |
where the upper level objective is the quantification of the simplicity of the split-rule, and, the lower-level objective quantifies quality of split resulting due to split-rule . An upper-level solution is considered feasible only if it is able to partition the data within some acceptable limit which is set by a parameter . A more detailed explanation regarding the upper level objective and the lower-level objective is provided in next sections. A pseudo code of the bilevel algorithm to obtain split-rule is provided in Alogrithm 2 and the pseudo code provided in Algorithm 3 gives on overview on the evaluation of population-pool in upper level GA.
IV-A1 Computation of
The impurity of a node in a decision tree is defined by the distribution of data present in the node. Entropy and Gini-score are popularly used to quantify the impurity of data distribution. In this work, we use gini-score to gauge the impurity of a node, however, entropy measure could also be used. For a binary classification task, gini-score ranges from 0-0.5, while entropy ranges from 0-1. Hence, the value of (Eq. 5) needs to be changed if we use entropy instead of gini while everything else stays same. For a given parent node in a decision tree and two child nodes and resulting from it, the net-impurity of child nodes () can be computed as follows:
| (6) |
where is the total number of datapoints present in the parent node , and and indicate the total number of points present in left () and right () child nodes, respectively. Datapoints in which satisfy the split rule (Eq 1) go to left child node, while the rest go to the right child node. The objective of minimizing the net-impurity of child nodes favors the creation of purer child nodes (i.e. nodes with a low gini-score).
IV-A2 Computation of
The objective is subjective in its form since it targets at dealing with a subjective notion of generating visually simple equations of split rule. Usually, equations with more variables and terms seem visually complicated. Taking this aspect into consideration, is set as the total number of non-zero exponent terms present in the overall equation of the split rule (Eq. 1). Mathematically, this can be represented with the following equation:
| (7) |
where , if ; zero, otherwise. Here, we use only to define , but another more comprehensive simplicity term involving presence or absence of modulus operators and relative optimal weight/bias values of the rule can also be used.
IV-B Upper Level Optimization (ULGA)
A genetic algorithm (GA) is implemented to explore the search space of power rules ’s and modulus flag in the upper level. The genome is represented as a tuple wherein is a matrix as shown in Equation 4 and assumes a Boolean value of 0 or 1.
The upper level GA focuses at estimating a simple equation of the split-rule within a desired value of net impurity () of child nodes. Thus, the optimization problem for upper level is formulated as a single objective constrained optimization problem as shown in Eq. 5. The constraint function is evaluated at the lower level of our bilevel optimization framework. The threshold value indicates the desired value of net-impurity of the resultant child nodes (Eq. 6). In our experiments, we set to be 0.05. As mentioned before, a solution satisfying this constraint implies creation of purer child nodes. Minimization of objective function should result in a simplistic structure of the rule and the optimization will also reveal the key variables needed in the overall expression.
IV-B1 Custom Initialization for Upper Level GA
Minimization of objective (given in Eq 7) requires to have less number of active (or non-zero) exponents in the expression of split-rule (Eq 1). To facilitate this, the population is initialized with a restriction of having only one active (or non-zero) exponent in the expression of split-rule, i.e., any-one of the ’s in the block matrix is set to a non-zero value from a user-specified set and the rest of the elements of matrix are set to zero. Note here that only number of unique individuals ( individuals with and individuals with ) can exist which satisfy the above mentioned restriction. If the population size for upper level GA exceeds , then remaining individuals are initialized with two non-zero active-terms.As the upper level GA progresses, incremental enhancement in rule complexity is realized through crossover and mutation operations, which are described next.
IV-B2 Ranking of Upper Level Solutions
The binary-tournament selection operation and survival selection strategies are implemented for the upper level GA. Selection operators use the following hierarchical ranking criteria to perform selection:
Definition IV.1.
For two individuals and in the upper level, is better than , when any of the following is true:
-
•
and are both infeasible AND ,
-
•
is feasible (i.e. ) AND is infeasible (i.e. ),
-
•
and both are feasible AND ,
-
•
and both are feasible AND
AND , -
•
and both are feasible AND
AND AND .
IV-B3 Custom Crossover Operator for Upper Level GA
Before crossover operation, population members are clustered according to their -value – all individuals with belong to one cluster and all individuals with belong to another cluster. The crossover operation is then restricted on individuals belonging to the same cluster. The crossover operation in the upper level takes two block matrices from the parent population ( and ) to create two child block matrices ( and ). First, rows of block matrices of participating parents are rearranged in descending order of the magnitude of their corresponding coefficient values (i.e. weights of Eq. 2). Let the parent block matrices be represented as and after this rearrangement. The crossover operation is then conducted element wise on each row of and . For better understanding of the cross-over operation, a psuedo code is provided in Algorithm 4.
IV-B4 Custom Mutation Operator for Upper Level GA
For a given upper level solution with block matrix and modulus flag , the probability with which ’s and gets mutated is controlled by parameter . From the experiments, value of is found to work well. The mutation operation then changes the value of exponents and the modulus flag . Let the domain of be given by , which is a sorted set of finite values. Since is sorted, these ordinal values can be accessed using an integer-id , with id-value of representing the smallest value and representing the largest value in set . In our case, (making ). The mechanism with which the mutation operator mutates the value of for any arbitrary sorted array is illustrated in Fig. 3.

Here, the red tile indicates the id-value () of in array . The orange shaded vertical bars indicate the probability distribution for mutated-values. The can be mutated to either of , or id-values with a probability of , , , and respectively. The parameter is preferred to be greater than one and is supplied by the user. The parameter can then be computed as by equating the sum of probabilities to . In our experiments, we have set . The value of the modulus flag is mutated randomly to either 0 or 1 with probability.
In order to bias the search to create simpler rules (i.e. split-rules with a small number of non-zero s), we introduce a parameter . The value of parameter indicates the probability with which a variable participating in mutation is set to zero. In our case, we use , making with a net probability of .
Duplicates from the the child-population are then detected and changed so that the entire child-population comprises of unique individuals. This is done to ensure creation of novel rules and preservation of diversity. Details about this procedure can be found in the supplementary document.
() survival selection operation is then applied on the combined child and parent population. The selected elites then go to the next generation as parents and the process repeats. Parameter setting for upper-level-GA is provided in the supplementary document.
IV-C Lower Level Optimization (LLGA)
For a given population member of the upper level GA (with block matrix and modulus flag as variables), the lower level optimization determines the coefficients (Eq. 2) and biases such that (Eq. 6) is minimized. The lower level optimization problem can be stated as below:
| Minimize: | ||||
IV-C1 Custom Initialization for Lower Level GA
In a bilevel optimization, the lower level problem must be solved for every upper level variable vector, thereby requiring a computationally fast algorithm for the lower level problem. Instead of creating every population member randomly, we use the mixed dipole concept [38, 9, 39] to facilitate faster convergence towards optimal (or near-optimal) values of and . Let and be the data-points belonging to Class-1 and Class-2, respectively. Then, weights and bias corresponding to the hyperplane which separates and , and is orthogonal to vector , can be given by the following equation:
| (9) | ||||
| (10) |
where is a random number between 0 and 1. This is pictorially represented in Fig. 4.

The dipole pairs (, ) for all individuals in the initial population pool are chosen randomly from the provided training dataset. The variables and for an individual are then initialized as mentioned below:
| (11) | ||||
| (12) | ||||
| (13) |
This method of initialization is found to be more efficient than randomly initializing and . This is because, for the regions beyond the convex-hull bounding the training dataset, the landscape of is flat which makes any optimization algorithm to stagnate.
IV-C2 Selection, Crossover, and Mutation for Lower Level GA
IV-C3 Termination Criteria for Lower level GA
The lower level GA is terminated after a maximum of 50 generations were reached or when the change in the lower level objective value () is less than in the past consecutive generations.
Other parameter values for lower-level GA can be found in the supplementary document. Results from the ablation-studies on LLGA and the overall bilevel-GA are provided in supplementary document for conceptually understanding the efficacy of the proposed approach.
V Overall Tree Induction and Pruning
Once the split-rule for a conditional node is determined using the above bilevel optimization procedure, the resulting child nodes are checked with respect to the following termination criteria:
-
•
Depth of the Node Maximum allowable depth,
-
•
Number of datapoints in node , and
-
•
Node Impurity .
If any of the above criteria is satisfied, then that node is declared as a terminal leaf node. Otherwise, the node is flagged as an additional conditional node. It then undergoes another split (using a split-rule which is derived by running the proposed bilevel-GA on the data present in the node) and the process is repeated. This process is illustrated in Algorithm 1. This eventually produces the main nonlinear decision tree . The fully grown decision tree then undergoes pruning to produce the pruned decision tree .
During the pruning phase, splits after the root-node are systematically removed until the training accuracy of the pruned tree does not fall below a pre-specified threshold value of (set here after trial-and-error runs). This makes the resultant tree topologically less complex and provides a better generalizability. In subsequent sections, we provide results on final NLDT obtained after pruning (i.e. ), unless otherwise specified.
VI Results
This section summarizes results obtained on four customized test problems, two real-world classification problems, three real-world optimization problems, eight multi-objective problems involving 30-500 features and one multi-class problem. For each experiment, 50 runs are performed with random training and testing sets. The dataset is split into training and testing sets with a ratio of 7:3, respectively. Mean and standard deviation of training and testing accuracy-scores across all 50 runs are evaluated to gauge the performance of the classifier. Statistics about the number of conditional nodes (given by #Rules) in NLDT, average number of active terms in the split-rules of decision tree (i.e. /Rule) and rule length (which gives total number of active-terms appearing in the entire NLDT) is provided to quantify the simplicity and interpretability of classifier (lesser this number, simpler is the classifier). The comparison is made against classical CART tree solution [4] and SVM [42] results. For SVM, the Gaussian kernel is used and along with overall accuracy-scores; statistics about the number of support vectors (which is also equal to the rule-length) is also reported. It is to note that the decision boundary computed by SVM can be expressed with a single equation, however the length of the equation usually increases with the number of support vectors [43].
For each set of experiments, best scores are highlighted in bold and Wilcoxon signed-rank test is performed on overall testing accuracy scores to check the statistical similarity with other classifiers in terms of classification accuracy. Statistically similar classifiers (which will have their -value greater than ) are italicized.
VI-A Customized Datasets: DS1 to DS4
The compilation of results of 50 runs on datasets DS1-DS4 (see supplementary for details regarding customized datasets) is presented in Table I. The results clearly indicate the superiority of the proposed nonlinear, bilevel based decision tree approach over classical CART and SVM based classification methods.
| Dataset | Method | Training Accuracy | Testing Accuracy | p-value | #Rules | /Rule | Rule Length | ||
| DS1 | NLDT | – | 1.0 0.0 | ||||||
| CART | 7.34e-10 | 1.0 0.0 | |||||||
| SVM | 1.29e-05 | 1.0 0.0 | |||||||
| DS2 | NLDT | – | 1.0 0.0 | ||||||
| CART | 5.90e-10 | 1.0 0.0 | |||||||
| SVM | 2.43e-10 | 1.0 0.0 | |||||||
| DS3 | NLDT | – | 1.0 0.0 | ||||||
| CART | 7.00e-10 | 1.0 0.0 | |||||||
| SVM | 7.16e-09 | 1.0 0.0 | |||||||
| DS4 | NLDT | – | |||||||
| CART | 7.31e-10 | 1.0 0.0 | |||||||
| SVM | 1.31e-05 | 1.0 0.0 |
Bilevel approach finds a single rule with two to three appearances of variables in the rule, whereas CART requires 11 to 31 rules involving a single variable per rule, and SVM requires only one rule but involving 44 to 90 appearances of variables in the rule. Moreover, the bilevel approach achieves this with the best accuracy. Thus, the classifiers obtained by bilevel approach are more simplistic and simultaneously more accurate.
VI-B Breast Cancer Wisconsin Dataset
This problem was originally proposed in 1991. It has two classes: benign and malignant, with 458 (or 65.5) data-points belonging to benign class and 241 (or 34.5) belonging to malignant class. Each data-point is represented with 10 attributes. Results are tabulated in Table II. The bilevel method and SVM had similar performance (p-value), but SVM requires about 90 variable appearances in its rule, compared to only about 6 variable appearances in the single rule obtained by the bilevel approach. The proposed approach outperformed the classifiers generated using techniques proposed in [12, 17, 16, 13, 14] in terms of both: accuracy and comprehensibility/compactness. The NLDT classifier obtained by a specific run of the bilevel approach has five variable appearances and is presented in Fig. 5.
| Method | Training Accuracy | Testing Accuracy | p-value | #Rules | /Rule | Rule Length | ||
| NLDT | ||||||||
| CART | 8.51e-09 | 1.00 0.00 | ||||||
| SVM | – | 1.00 0.00 |

Figure 6 provides B-Space visualization of decision-boundary obtained by the bilevel approach, which is able to identify two nonlinear -terms involving variables to split the data linearly to obtain a high accuracy.

VI-C Wisconsin Diagnostic Breast Cancer Dataset (WDBC)
This dataset is an extension to the dataset of the previous section. It has 30 features with total 356 datapoints belonging to benign class and 212 to malign class. Results shown in Table III indicate that the bilevel-based NLDT is able to outperform standard CART and SVM algorithms. The NLDT generated by a run of the bilevel approach requires seven out of 30 variables (or features) and is shown in Fig. 7. It is almost as accurate as that obtained by SVM and is more interpretable (seven versus about 107 variable appearances).
| Method | Training Accuracy | Testing Accuracy | p-value | #Rules | /Rule | Rule Length | ||
| NLDT | 4.65e-05 | |||||||
| CART | 1.09e-09 | 1.00 0.00 | ||||||
| SVM | – | 1.00 0.00 |

The -space plot (Fig. 8) shows an efficient discovery of -functions to linearly classify the supplied data with a high accuracy.

VI-D Real-World Auto-Industry Problem (RW-problem)
This real-world engineering design optimization problem has 36 variables, eight constraints, and one objective function. The dataset created was highly biased, with 188 points belonging to the good-class and 996 belonging to the bad-class. Results obtained using the bilevel GA are shown in Table IV. The proposed algorithm is able to achieve near accuracy scores requiring only two split rules. The best performing NLDT has the testing-accuracy of and is shown in Fig. 9.
SVM performed the best in terms of accuracy, but the resulting classifier is complicated with about 241 variable appearances in the rule. However, bilevel GA requires only about two rules, each having about only 10 variable appearances per rule to achieve slightly less-accurate classification. CART requires about 30 rules with a deep DT, making the classifier difficult to interpret easily.
| Method | Training Accuracy | Testing Accuracy | p-value | #Rules | /Rule | Rule Length | ||
| NLDT | 4.35e-09 | |||||||
| CART | 9.80e-08 | 1.00 0.00 | ||||||
| SVM | – | 1.00 0.00 |

VI-E Results on Multi-Objective Optimization Problems
Here we evaluate performance of NLDT on two real-world multi-objective problems: welded-beam design and 2D truss design, and modified versions of ZDT [44] and DTLZ [45] problems – m-ZDT and m-DTLZ. The data generation process of multi-objective datasets is provided in the supplementary document. Complexity of these datasets in controlled by two parameters and , explanation to which is provided in supplementary document. Results for multi-objective problems are compiled in Table V. Due to space limitations, we report scores of only testing accuracy, total number of rules and .
VI-E1 Truss 2D
Truss 2D problem [46] is a three-variable problem. Clearly, the bilevel NLDT has the best accuracy and fewer variable appearances (meaning easier intrepretability) compared to CART and SVM generated classifiers as shown in Table V. Fig. 10(a) shows a 100% correct classifier with a single rule obtained by our bilevel NLDT, whereas Fig. 10(b) shows a typical CART classifier with 19 rules, making it difficult to interpret easily.


VI-E2 Welded Beam Design Problem
This bi-objective optimization problem has four variables and four constraints [46]. The NLDT (having a single rule) obtained with is shown in Fig. 11. Interestingly, the bilevel NLDTs have similar accuracy to that of CART and SVM with a very low complexity as shown in Table V.

VI-E3 m-ZDT and m-DTLZ Problems
Experiments conducted on datasets involving 500 features (see Table V) and for two and three-objective optimization problems confirm the scalability aspect of the proposed approach. In all these problems, traditional methods like CART and SVM find themselves difficult to conduct a proper classification task. The provision of allowing controlled non-linearity at each conditional-node provides the proposed NLDT approach with necessary flexibility to make an appropriate overall classification. Additional results and visualization of some of the obtained NLDT classifiers are provided in the supplementary document.
| Method | Testing Acc. | # Rules | /Rule | |||
| Welded Beam design with and . | ||||||
| NLDT | ||||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-ZDT1-2-30 | ||||||
| NLDT | 98.96 0.59 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-ZDT2-2-30 | ||||||
| NLDT | 98.96 0.57 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-DTLZ1-3-30 | ||||||
| NLDT | 96.65 2.86 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-DTLZ2-3-30 | ||||||
| NLDT | 97.22 2.25 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| Method | Testing Acc. | # Rules | /Rule | |||
| Truss 2D with and . | ||||||
| NLDT | ||||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-ZDT1-2-500 | ||||||
| NLDT | ||||||
| CART | 1.00 0.00 | |||||
| SVM | ||||||
| m-ZDT2-2-500 | ||||||
| NLDT | ||||||
| CART | 1.00 0.00 | |||||
| SVM | 100.00 0.00 | 1.00 0.00 | ||||
| m-DTLZ1-3-500 | ||||||
| NLDT | 93.77 4.24 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
| m-DTLZ2-3-500 | ||||||
| NLDT | 95.33 4.46 | |||||
| CART | 1.00 0.00 | |||||
| SVM | 1.00 0.00 | |||||
VI-F Multi-class Iris Dataset
Though the purpose of the current study was to develop an efficient algorithm for two-class problems, its extension to multi-class problem is possible. The iris dataset is a popular multi-class dataset involving total three classes and four features, and is used here as a benchmark problem to check the feasibility of extending our method. The NLDT classifier, producing 94.8% classification accuracy on test data and 98.6% accuracy on training data, is presented in Figure 12 (see supplementary document for more details). Notice that of the four features, feature 1 () is not required for the classification task. Statistics on results obtained across 50 runs is provided in the supplementary document. We are currently investigating further on a more efficient extension of our approach to multi-class problems.

VII Conclusions and Future work
In this paper, we have addressed the problem of generating interpretable and accurate nonlinear decision trees for classification. Split-rules at the conditional nodes of a decision tree have been represented as a weighted sum of power-laws of feature variables. A provision of integrating modulus operation in the split-rule has also been formulated, particularly to handle sandwiched classes of datapoints. The proposed algorithm of deriving split-rule at a given conditional-node in a decision tree has two levels of hierarchy, wherein the upper-level is focused at evolving the power-law structures and operates on a discrete variable space, while the lower-level is focused at deriving values of optimal weights and biases by searching a continuous variable space to minimize the net impurity of child nodes after the split. Efficacy of upper-level and lower-level evolutionary algorithm have been tested on customized datasets. The lower-level GA is able to robustly and efficiently determine weights and biases to minimize the net-impurity. A test conducted on imbalanced dataset has also revealed the superiority of the proposed lower-level GA to achieve a high classification accuracy without relying on any synthetic data. Ablation studies conducted on the upper-level GA (see supplementary document) also demonstrate the efficacy of the algorithm to obtain simpler split-rules without using any prior knowledge. Results obtained on standard classification benchmark problems and a real-world single-objective problem has amply demonstrated the efficacy and usability of the proposed algorithm.
The classification problem has been extended to discriminate Pareto-data from non-Pareto data in a multi-objective problem. Experiments conducted on multi-objective engineering problems have resulted in determining simple polynomial rules which can assist in determining if the given solution is Pareto-optimal or not. These rules can then be used as design-principles for generating future optimal designs. As further future studies, we plan to integrate non-polynomial and generic terms in the expression of the split-rules. The proposed bilevel framework can also be tested for regression and reinforcement-learning related tasks. The upper-level problem can be converted to a bi-objective problem for optimizing both and simultaneously, so that a set of trade-off solutions can be obtained in a single run. Nevertheless, this proof-of-principle study on the use of a customized bilevel optimization method for classification tasks is encouraging for us to launch such future studies.
Acknowledgment
An initial study of this work was supported by General Motors Corporation, USA.
References
- [1] S. B. Kotsiantis, I. Zaharakis, and P. Pintelas, “Supervised machine learning: A review of classification techniques,” Emerging artificial intelligence applications in computer engineering, vol. 160, pp. 3–24, 2007.
- [2] J. S. Bergstra, R. Bardenet, Y. Bengio, and B. Kégl, “Algorithms for hyper-parameter optimization,” in Advances in neural information processing systems, 2011, pp. 2546–2554.
- [3] C. Thornton, F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Auto-weka: Combined selection and hyperparameter optimization of classification algorithms,” in Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2013, pp. 847–855.
- [4] L. Breiman, Classification and regression trees. Routledge, 2017.
- [5] D. Heath, S. Kasif, and S. Salzberg, “Induction of oblique decision trees,” in IJCAI, vol. 1993, 1993, pp. 1002–1007.
- [6] S. K. Murthy, S. Kasif, and S. Salzberg, “A system for induction of oblique decision trees,” Journal of artificial intelligence research, vol. 2, pp. 1–32, 1994.
- [7] S. K. Murthy, S. Kasif, S. Salzberg, and R. Beigel, “Oc1: A randomized algorithm for building oblique decision trees,” in Proceedings of AAAI, vol. 93. Citeseer, 1993, pp. 322–327.
- [8] E. Cantú-Paz and C. Kamath, “Using evolutionary algorithms to induce oblique decision trees,” in Proceedings of the 2nd Annual Conference on Genetic and Evolutionary Computation. Morgan Kaufmann Publishers Inc., 2000, pp. 1053–1060.
- [9] M. Kretowski, “An evolutionary algorithm for oblique decision tree induction,” in International Conference on Artificial Intelligence and Soft Computing. Springer, 2004, pp. 432–437.
- [10] A. Ittner and M. Schlosser, “Non-linear decision trees-ndt,” in ICML. Citeseer, 1996, pp. 252–257.
- [11] K. P. Bennett and J. A. Blue, “A support vector machine approach to decision trees,” in Neural Networks Proceedings, 1998. IEEE World Congress on Computational Intelligence. The 1998 IEEE International Joint Conference on, vol. 3. IEEE, 1998, pp. 2396–2401.
- [12] H. Núñez, C. Angulo, and A. Català, “Rule extraction from support vector machines.” in Esann, 2002, pp. 107–112.
- [13] G. Fung, S. Sandilya, and R. B. Rao, “Rule extraction from linear support vector machines,” in Proceedings of the eleventh ACM SIGKDD international conference on Knowledge discovery in data mining. ACM, 2005, pp. 32–40.
- [14] M. Craven and J. W. Shavlik, “Extracting tree-structured representations of trained networks,” in Advances in neural information processing systems, 1996, pp. 24–30.
- [15] P. M. Murphy and M. J. Pazzani, “Id2-of-3: Constructive induction of m-of-n concepts for discriminators in decision trees,” in Machine Learning Proceedings 1991. Elsevier, 1991, pp. 183–187.
- [16] U. Johansson, R. König, and L. Niklasson, “The truth is in there-rule extraction from opaque models using genetic programming.” in FLAIRS Conference. Miami Beach, FL, 2004, pp. 658–663.
- [17] D. Martens, B. Baesens, T. Van Gestel, and J. Vanthienen, “Comprehensible credit scoring models using rule extraction from support vector machines,” European journal of operational research, vol. 183, no. 3, pp. 1466–1476, 2007.
- [18] H. Ishibuchi, T. Nakashima, and T. Murata, “Three-objective genetics-based machine learning for linguistic rule extraction,” Information Sciences, vol. 136, no. 1-4, pp. 109–133, 2001.
- [19] Y. Jin and B. Sendhoff, “Pareto-based multiobjective machine learning: An overview and case studies,” IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 3, pp. 397–415, 2008.
- [20] S. Nguyen, M. Zhang, and K. C. Tan, “Surrogate-assisted genetic programming with simplified models for automated design of dispatching rules,” IEEE transactions on cybernetics, vol. 47, no. 9, pp. 2951–2965, 2016.
- [21] K. Nag and N. R. Pal, “A multiobjective genetic programming-based ensemble for simultaneous feature selection and classification,” IEEE transactions on cybernetics, vol. 46, no. 2, pp. 499–510, 2015.
- [22] J. M. Luna, J. R. Romero, C. Romero, and S. Ventura, “On the use of genetic programming for mining comprehensible rules in subgroup discovery,” IEEE transactions on cybernetics, vol. 44, no. 12, pp. 2329–2341, 2014.
- [23] A. Lensen, B. Xue, and M. Zhang, “Genetic programming for evolving a front of interpretable models for data visualization,” IEEE Transactions on Cybernetics, 2020.
- [24] H. Guo and A. K. Nandi, “Breast cancer diagnosis using genetic programming generated feature,” Pattern Recognition, vol. 39, no. 5, pp. 980–987, 2006.
- [25] M. Muharram and G. D. Smith, “Evolutionary constructive induction,” IEEE transactions on knowledge and data engineering, vol. 17, no. 11, pp. 1518–1528, 2005.
- [26] M. Shirasaka, Q. Zhao, O. Hammami, K. Kuroda, and K. Saito, “Automatic design of binary decision trees based on genetic programming,” in Proc. The Second Asia-Pacific Conference on Simulated Evolution and Learning (SEAL’98. Citeseer, 1998.
- [27] S. Haruyama and Q. Zhao, “Designing smaller decision trees using multiple objective optimization based gps,” in IEEE International Conference on Systems, Man and Cybernetics, vol. 6. IEEE, 2002, pp. 5–pp.
- [28] C.-S. Kuo, T.-P. Hong, and C.-L. Chen, “Applying genetic programming technique in classification trees,” Soft Computing, vol. 11, no. 12, pp. 1165–1172, 2007.
- [29] M. C. Bot, “Improving induction of linear classification trees with genetic programming,” in Proceedings of the 2nd Annual Conference on Genetic and Evolutionary Computation, 2000, pp. 403–410.
- [30] R. E. Marmelstein and G. B. Lamont, “Pattern classification using a hybrid genetic program-decision tree approach,” Genetic Programming, pp. 223–231, 1998.
- [31] E. M. Mugambi, A. Hunter, G. Oatley, and L. Kennedy, “Polynomial-fuzzy decision tree structures for classifying medical data,” in International Conference on Innovative Techniques and Applications of Artificial Intelligence. Springer, 2003, pp. 155–167.
- [32] A. Cano, A. Zafra, and S. Ventura, “An interpretable classification rule mining algorithm,” Information Sciences, vol. 240, pp. 1–20, 2013.
- [33] M. C. Bot and W. B. Langdon, “Application of genetic programming to induction of linear classification trees,” in European Conference on Genetic Programming. Springer, 2000, pp. 247–258.
- [34] J. Eggermont, J. N. Kok, and W. A. Kosters, “Genetic programming for data classification: Partitioning the search space,” in Proceedings of the 2004 ACM symposium on Applied computing, 2004, pp. 1001–1005.
- [35] K. C. Tan, A. Tay, T. H. Lee, and C. Heng, “Mining multiple comprehensible classification rules using genetic programming,” in Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), vol. 2. IEEE, 2002, pp. 1302–1307.
- [36] I. De Falco, A. Della Cioppa, and E. Tarantino, “Discovering interesting classification rules with genetic programming,” Applied Soft Computing, vol. 1, no. 4, pp. 257–269, 2002.
- [37] A. Sinha, P. Malo, and K. Deb, “A review on bilevel optimization: From classical to evolutionary approaches and applications,” IEEE Transactions on Evolutionary Computation, vol. 22, no. 2, pp. 276–295, 2017.
- [38] L. Bobrowski and M. Kretowski, “Induction of multivariate decision trees by using dipolar criteria,” in European Conference on Principles of Data Mining and Knowledge Discovery. Springer, 2000, pp. 331–336.
- [39] M. Kretowski and M. Grześ, “Global induction of oblique decision trees: an evolutionary approach,” in Intelligent Information Processing and Web Mining. Springer, 2005, pp. 309–318.
- [40] K. Deb and R. B. Agrawal, “Simulated binary crossover for continuous search space,” Complex systems, vol. 9, no. 2, pp. 115–148, 1995.
- [41] K. Deb, Multi-objective optimization using evolutionary algorithms. John Wiley & Sons, 2001, vol. 16.
- [42] V. Vapnik, The nature of statistical learning theory. Springer science & business media, 2013.
- [43] J.-P. Vert, K. Tsuda, and B. Schölkopf, “A primer on kernel methods,” Kernel methods in computational biology, vol. 47, pp. 35–70, 2004.
- [44] K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: Nsga-ii,” IEEE transactions on evolutionary computation, vol. 6, no. 2, pp. 182–197, 2002.
- [45] K. Deb, L. Thiele, M. Laumanns, and E. Zitzler, “Scalable multi-objective optimization test problems,” in Proceedings of the 2002 Congress on Evolutionary Computation. CEC’02 (Cat. No. 02TH8600), vol. 1. IEEE, 2002, pp. 825–830.
- [46] K. Deb and A. Srinivasan, “Innovization: Innovating design principles through optimization,” in Proceedings of the 8th annual conference on Genetic and evolutionary computation. ACM, 2006, pp. 1629–1636.
- [47] J. Blank and K. Deb, “pymoo - Multi-objective Optimization in Python,” https://pymoo.org.
- [48] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “Smote: synthetic minority over-sampling technique,” Journal of artificial intelligence research, vol. 16, pp. 321–357, 2002.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fea99158-5e0e-4a34-8ff9-e570542e76f2/yashesh.jpg) |
Yasheh Dhebar is a PhD student in the Department of Mechanical Engineering at Michigan State University. He did his bachelors and masters in Mechanical Engineering from the Indian Institute of Technology Kanpur and graduated in 2015 with his thesis on modular robotics and their operation in cluttered environments. Currently he is actively pursuing his research in the field of explainable and interpretable artificial intelligence, machine learning and knowledge discovery. He has worked on applied optimization and machine learning projects with industry collaborators. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/fea99158-5e0e-4a34-8ff9-e570542e76f2/kdeb.jpg) |
Kalyanmoy Deb is Fellow, IEEE and the Koenig Endowed Chair Professor with the Department of Electrical and Computer Engineering, Michigan State University, East Lansing, Michigan, USA. He received his Bachelor’s degree in Mechanical Engineering from IIT Kharagpur in India, and his Master’s and Ph.D. degrees from the University of Alabama, Tuscaloosa, USA, in 1989 and 1991. He is largely known for his seminal research in evolutionary multi-criterion optimization. He has published over 535 international journal and conference research papers to date. His current research interests include evolutionary optimization and its application in design, modeling, AI, and machine learning. He is one of the top cited EC researchers with more than 144,000 Google Scholar citations. |
Supplementary Document
Supplementary Document
In this supplementary document, we provide additional information related to our original paper.
S1 Summary of Supplementary Document
In this document, we first provide details of parameter settings used for all our proposed algorithms, followed by explanation on the procedure to create customized datasets for benchmarking lower-level and upper-level GAs. Details of the duplicate update operator used in the upper level GA of our proposed bilevel optimization approach is mentioned next. Thereafter, we present additional results to support the algorithms and discussions of the original paper.
S2 Parameter Setting
S2-A Parameter Setting for NSGA-II and NSGA-III
We used the implementation of NSGA-II and NSGA-III Algorithm as provided in pymoo [47]. pymoo is an official python package for multiobjective optimization algorithms and is developed under supervision of the original developer of NSGA-II and NSGA-III algorithm. Following parameter setting was adopted to create Pareto and non-Pareto datasets for two objective Truss and Welded beam problems:
-
•
Population Size = 500
-
•
Maximum Generations = 1000
-
•
Cross Over = SBX
-
•
SBX = 15
-
•
SBX probabililty = 0.9
-
•
Mutation type = Polynomial Mutation
-
•
Mutation = 20
-
•
Mutation probability = (where is total number of variables)
S2-B Parameter Setting for Upper Level GA
This section provides the general parameter setting used for the upper level of our bilevel GA.
-
•
Population size = , where is the dimension of the feature space of the original problem.
-
•
Selection = Binary tournament selection.
-
•
Crossover probability () = 0.9
-
•
Mutation parameters:
-
–
Mutation probability () = .
-
–
Distribution parameter = 3 (any value will be good).
-
–
-
•
= 0.75
-
•
Maximum number of generations = 100
S2-C Parameter Setting for Lower Level GA
Following parameter setting is used for lower level GA:
-
•
Population size = 50,
-
•
Maximum generations = 50,
-
•
Variable range = ,
-
•
Crossover type = Simulated Binary Crossover (SBX)
-
•
Mutation type = Polynomial Mutation
-
•
Selection type = Binary Tournament Selection
-
•
Crossover probability = 0.9,
-
•
Mutation probability = ,
-
•
Number of variables , if or if , where is the total number of power-laws allowed and is the modulus flag,
-
•
SBX and polynomial mutation parameters: .
S2-D Parameter Setting for Inducing a Non-linear Decision Tree
-
•
Number of power-laws per split-rule: ,
-
•
Allowable set of exponents: ,
-
•
Impurity Metric: Gini Score.
-
•
Minimum Impurity to conduct a split:
-
•
Minimum number of points required in a node conduct a split:
-
•
Maximum allowable Depth = 5
-
•
Pruning threshold:
S3 Creation of Customized 2D Datasets
Datasets presented in this section were synthetically generated. Datapoints in space were created using a reference curve and were assigned to either the Class-1 or Class-2. Two additional parameters and controlled the location of a datapoint relative to the reference curve . Datapoints () for a given dataset were generated using following steps:
-
•
First points falling on curve were initialized for reference. Lets denote these reference points on the curve with (where ). Thus,
-
•
points () for a dataset were then generated using the following equation
(14) where is a random number between and , represents the offset and indicates the amount of spread.
Four datasets generated for conducting ablation studies are graphically represented in Fig. S1.
Parameter setting which was used to generate these datasets is provided Table S1. and indicate the number of datapoints belonging to Class-1 and Class-2, respectively.
| Dataset | Class-1 | Class-2 | ||
| DS1 | 100 | 100 | ||
| DS2 | 10 | 200 | ||
| DS3 | 100 | 100 | ||
| DS4 | 100 | 50 | ||
| 50 | ||||




S4 Multi-objective Datasets
S4-A ZDT, Truss and Welded Beam Datasets
For each problem, NSGA-II [44] algorithm is first applied to evolve the population of individuals for generations. Population for each generation is stored. Naturally, population from later generations are closer to Pareto-front than the population of initial generations. We artificially separate the entire dataset into two classes – good and bad – using two parameters (indicating an intermediate generation for data collection) and (indicating the minimum non-dominated rank for defining the bad cluster). First, population members from and generations are merged. Next, non-dominated sorting is executed on the merged population to determine their non-domination rank. Points belonging to same non-domination rank are further sorted based on their crowding-distance (from highest to lowest) [44]. For the good-class, top points from rank-1 front are chosen and for the bad-class, top points from front onward are chosen. Increasing the increases the separation between good and bad classes, while the parameter has the inverse effect.
Visualization of this is provided in Fig. S2 and Fig. S3 for truss and welded-beam problems respectively.






The parameter setting used to create datasets for ZDT1, ZDT2, ZDT3, Truss and Welded-beam problems are shown in Table S2.
| Problem | Pop-Size () | |||||
| ZDT-1 | 100 | 200 | 200 | 10 | 100 | 5000 |
| ZDT-2 | 100 | 200 | 200 | 5 | 100 | 5000 |
| ZDT-3 | 100 | 200 | 200 | 10 | 100 | 5000 |
| Truss-2D | 200 | 1000 | 1 | – | 200 | 200 |
| WB | 200 | 1000 | – | 3 | 200 | 200 |
S4-B m-ZDT, m-DTLZ Problems
These are the modified versions of ZDT and DLTZ problems [44, 45]. For m-ZDT problems, the g-function is modified to the following:
| (15) |
Many two-variable relationships () must be set to be on the Pareto set.
For m-DTLZ problems, the g-function for variables is
| (16) |
Pareto points for m-ZDT and m-DTLZ problems are generated by using the exact analytical expression of Pareto-set (locations where ). The non-Pareto set is generated by using two parameters and . To compute the location of a point belonging to non-Pareto set from the location of the point on the Pareto set, following equation is used:
| (17) | ||||
| where | (18) |
Here, and are randomly generated for each . For m-ZDT problems, , while for m-DTLZ problems . Parameter setting for generating m-ZDT and m-DTLZ datasets is provided in Table S3. For 30 variable problems, all are changed according to Eq. 18 for generate non-pareto points. However, for 500 vars problems, only first 28 of variables in are modified according to Eq. 18 to generate non-pareto data-points.
| Prob. | |||
| m-ZDT1 | 30 | 0.3 | 0.1 |
| m-ZDT1 | 500 | 0.3 | 0.1 |
| m-ZDT2 | 30 | 0.3 | 0.1 |
| m-ZDT2 | 500 | 0.3 | 0.1 |
| m-DTLZ1 | 30 | 0.05 | 0 |
| m-DTLZ1 | 500 | 0.05 | 0 |
| m-DTLZ2 | 30 | 0.05 | 0 |
| m-DTLZ2 | 500 | 0.05 | 0 |








S5 Duplicate Update Operator for Upper Level GA
After creating the offspring population, we attempt to eliminate duplicate population members. For each duplicate found in the child population, the block-matrix of that individual is randomly mutated using the following equation
| (19) |
where and are randomly chosen integers within specified limits. This process is repeated for all members of child population, until each member is unique within the child population. This operation allows to maintain diversity and encourages the search to generate multiple novel and optimized equations of the split-rule.
S6 Ablation Studies and Comparison
In this section, we test the efficacy of lower-level and upper-level optimization algorithm by applying them on four customized problems (DS1-DS4) which are shown pictorially in Fig. S1. Their performances are compared against two standard classifiers: CART and support-vector-machines (SVM)111Here, the support vector machine is applied without any kernal-trick..
S6-A Ablation Studies on Lower Level GA
Since the lower level GA (LLGA) focuses at determining coefficients and bias of linear split-rule in B-space, DS1 and DS2 data-sets are used to guage its efficacy. The block matrix is fixed to identity matrix and the modulus-flag is set to 0. Hence, the split-rule (classifier) to be evolved is
where and are to be determined by the LLGA.
The classifier generated by our LLGA is compared with that obtained using the standard SVM algorithm (without any kernel-trick) on DS1 data-set. Since DS2 dataset is unbalanced, SMOTE algorithm [48] is first applied to over-sample data-points of the minority class before generating the classifier using SVM. For the sake of completeness, classifier generated by SVM on DS2 dataset, without any oversampling, is also compared against the ones obtained using LLGA and SMOTE+SVM. The results are shown in Fig. S6 and Fig. S7, respectively, for DS1 and DS2 data-sets. Type-1 and Type-2 errors are reported for each experiment222Type-1 error indicates the percentage of data-points belonging to Class-1 getting classified as Class-2. Type-2 error indicates the percentage of points belonging to Class-2 getting classified as Class-1)..


It is clearly evident from the results shown in Fig. S6 that the proposed customized LLGA is more efficient than SVM in arriving at the desired split-rule as a classifier. The LLGA is able to find the decision boundary with prediction accuracy on training and testing data-sets. However, the classifier generated by SVM has an overlap with the cloud of data-points belonging to the scattered class and there-by resulting into the accuracy of on the testing data-set.



On the DS2 dataset, the SVM is needed to rely on SMOTE to synthetically generate data-points in order to achieve respectable performance as can be seen from Fig. 7(b) and 7(c). However, LLGA performs better without SMOTE, as shown in Fig. 7(a).
Ablation study conducted above on LLGA clearly indicates that the customized optimization algorithm developed for estimating weights and bias in the expression of a split-rule is reliable and efficient and could easily outperform the classical SVM algorithm.
S6-B Ablation Studies on Proposed Bilevel GA
As mentioned before, the upper level of our bilevel algorithm aims at determining optimal power-law structures (i.e. s) and the value of modulus flag . Experiments are performed on DS3 and DS4 datasets to guage the efficacy of upper level (and thus the overall bilevel) GA. No prior information about the optimal values of block matrix and modulus flag is supplied. Thus, the structure of the equation of the split-rule is unknown to the algorithm. Results of these experiments are shown in Figs. 8(a) and 8(b).


As can be seen from Fig. 8(a) that the proposed bilevel algorithm is able to find classifiers which are able to classify the data-sets with no Type-I or Type-II error. Results on DS4 data-set validated the importance of involving modulus-flag as a search variable for upper level GA in addition to the block-matrix . The algorithm is able to converge at the optimal tree topology (Fig. 8(b)) with classification accuracy. It is to note here that the algorithm had no prior knowledge about optimal block matrix of exponents . This observation suggests that the upper level GA is successfully able to navigate through the search space of block-matrices and modulus-flag (which is a binary variable) to arrive at the optimal power-laws and split-rule.
S6-C Visualization of Split Rule: X-Space and B-Space
A comprehensible visualization of the decision boundary is possible if the dimension of the feature space is up to three. However, if the dimension of the original feature space (or, X-space) is larger than three, the decision-boundary can be visualized on the transformed-feature-space (or B-space). In our experiments, the maximum number of allowable power-law-rules () is fixed to three (i.e. ). Thus, any data-point in a -dimensional X-space can be mapped to a three-dimensional B-space. A conceptual illustration of this mapping is provided in Fig. S9,

where, for the sake of simplicity, a three-dimensional X-space ( to ) is mapped to a two-dimensional B-space using two power-law-rules ( and ).
It is to note here that the power-law rules ’s are not known a priori. The proposed bilevel optimization method determines them so that the data becomes linearly separable in B-space.
S7 Additional Results
Here we provide some additional results. Fig. S10 and Fig. S11 shows plots of one of the decision boundary (classifier) obtained using our bilevel-algorithm and its comparison against decision-tree generated using traditional CART algorithm on DS3 and DS4 datasets.




S7-A 2D Truss Problem
In table S4, comparison of accuracy-scores and complexity obtained for datasets generated using and for bi-objective truss design problem are provided.
| Training Accuracy | Testing Accuracy | #Rules | n-vars | /Rule | |
| 6 | |||||
| 9 |
Since the dataset generated with is relatively difficult, we conduct further analysis on it and compare the result obtained using our NLDT approach with that of CART and SVM. Compilation of these results is shown in Table S5.
¿ Method Training Accuracy Testing Accuracy p-value #Rules /Rule Rule Length NLDT – CART 6.04e-08 SVM 0.135
S7-B Welded Beam Design Resutls
Additional results for Welded beam design problem are shown in Table S6. Here, two sets of experiments are conducted for two different values of , keeping the value of fixed to three. A higher value of results in good and bad data-points too close to each other, thereby making it difficult for the classification algorithm to determine a suitable classifier. This can be validated from the results presented in Table S6. However, bilevel NLDTs have produced one rule with about 2 to 4 variable appearances compared to 39.5 to 126 (on average) for SVM classifiers. CART does well in this problem with, on average, 2.94 to 8.42 rules.
¿ Method Training Accuracy Testing Accuracy p-value #Rules /Rule Rule Length 1 NLDT 0.158 CART – SVM 0.331 10 NLDT 3.42e-02 CART 4.63e-08 SVM –
S7-C ZDT Problems
ZDT problems are two-objective optimization problems and their formulations can be found in [44]. The dataset created was highly biased with -datapoints in Pareto-class and -datapoints in non-Pareto-class. Visualization of these datasets is provided in Figure S12. As can be seen from the figure S12, the classification task was deliberately made more difficult by tightening the gap between Pareto and non-Pareto class.



Due to highly biased distribution, a naive classifier predicting all points as non-Pareto would have the classification accuracy of (). Hence, the pruning implementation with will prune the entire tree, resulting into a tree with only one split-rule. Thus, we investigate the performance of the unpruned-NLDT and the prune-NLDT with . The compilation of results on ZDT problems is provided in Table S7.
| Problem | Method | Training Accuracy | Testing Accuracy | p-value | #Rules | /Rule | Rule Length | ||
| ZDT1 | NLDT | 5.65e-01 | |||||||
| NLDT-pruned | 9.36e-02 | ||||||||
| CART | 1.10e-05 | ||||||||
| SVM | – | ||||||||
| ZDT2 | NLDT | 9.41e-01 | |||||||
| NLDT-pruned | 1.40e-02 | ||||||||
| CART | 2.58e-04 | ||||||||
| SVM | – | ||||||||
| ZDT3 | NLDT | 9.71e-06 | |||||||
| NLDT-pruned | – | ||||||||
| CART | 2.30e-03 | ||||||||
| SVM | 7.28e-10 |
Clearly, the pruned NLDT requires one or two rules with fewer variables (or features) per rule than CART (on an average 3.6 versus 9.0 on ZDT1 and 9.7 versus 286.7 on ZDT3), but achieves a similar classification accuracy. The difficulty with CART solutions is that they are too deep to be easily interpretable. Although theoretical Pareto-optimal points for ZDT problems can be identified by checking for , NSGA-II, being a stochastic optimization algorithm, is not expected to find the exact Pareto-optimal solutions, thereby making classification methods to find a classifier with more than one participating variables.
Visualization of NLDT obtained using our bilevel algorithm on ZDT problems is provided in Figures S13, S14 and S15.



S7-D m-ZDT and m-DTLZ problems
Visualization of some NLDTs obtained for m-ZDT and m-DTLZ problems are shown in Figure S16 and S17, respectively. For m-ZDT problems, a relationship with two consecutive variables would constitute a relationship present in the Pareto set, but our approach finds a different two-variable interaction which has been found to be present in the dataset and was enough to classify Pareto versus non-Pareto data. For m-DTLZ problems, the relationships are a little more complex. Interestingly, for 500-var problem, only seven variables are needed in a nonlinear fashion to classify two classes of data.


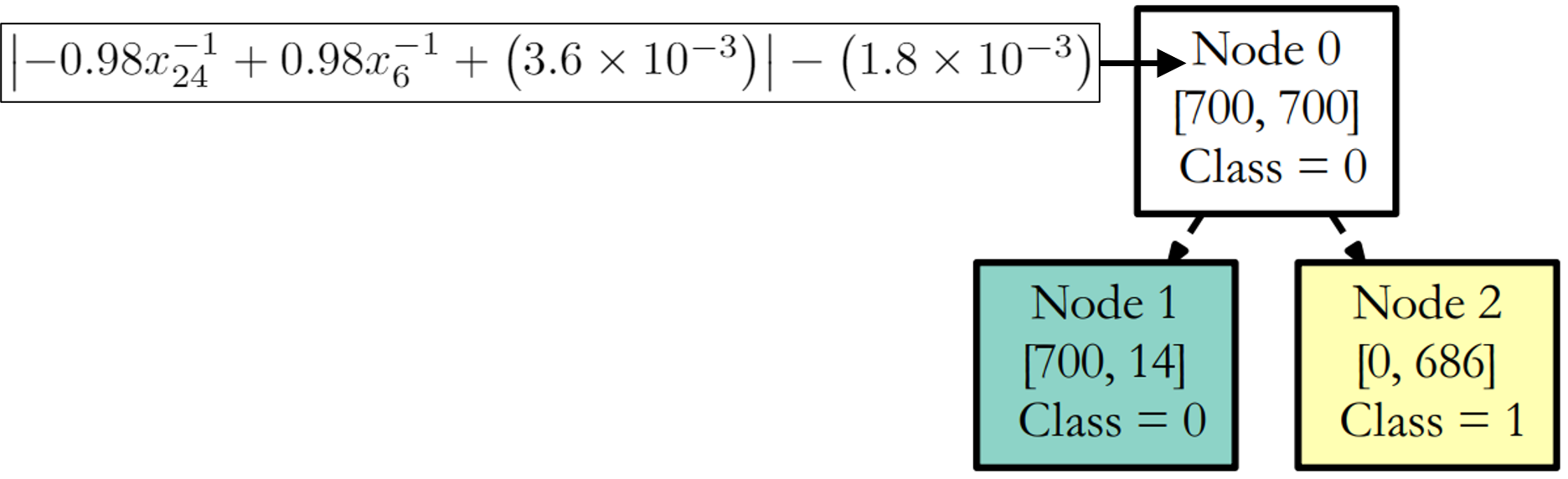





S8 Influence of Parameter
In this section, we study the influence of parameter on the complexity of the split-rule and the accuracy of overall decision tree. As can be seen from Figure S18, value of seemed to be reasonable enough for a two-class classification dataset.

S9 Multi-Class Iris Dataset Results
Results obtained on three class iris dataset using NLDT, CART and SVM are shown in Table S8. From the results it is clear that the proposed approach can be extended to multi-class problems as well. In our future study, we will extend our work to multi-class problems with more complicated decision boundaries than the standard iris dataset.
| Method | Training Acc | Testing Acc. | # Rules | /Rule | Rule Length | |
| NLDT | 98.59 0.69 | |||||
| CART | 1.00 0.00 | 3.80 0.49 | ||||
| SVM | 96.13 2.51 | 1.00 0.00 |
S10 Summary
Results of the main paper and additional results presented in this document amply indicate that the proposed bilevel-based NLDT approach is a viable strategy for classification tasks with fewer rules than a standard decision tree (CART, for example) produces and is more simplistic than a single complex rule that a SVM procedure produces. Hence, our nonlinear rules with restricted complexity are more humanly interpretable and useful not only for a mere classification task, but also for a better understanding of the classifier.