Intermittent Visual Servoing: Efficiently Learning Policies
Robust to Instrument Changes for High-precision Surgical Manipulation
Abstract
Automation of surgical tasks using cable-driven robots is challenging due to backlash, hysteresis, and cable tension, and these issues are exacerbated as surgical instruments must often be changed during an operation. In this work, we propose a framework for automation of high-precision surgical tasks by learning sample efficient, accurate, closed-loop policies that operate directly on visual feedback instead of robot encoder estimates. This framework, which we call intermittent visual servoing (IVS), intermittently switches to a learned visual servo policy for high-precision segments of repetitive surgical tasks while relying on a coarse open-loop policy for the segments where precision is not necessary. To compensate for cable-related effects, we apply imitation learning to rapidly train a policy that maps images of the workspace and instrument from a top-down RGB camera to small corrective motions. We train the policy using only 180 human demonstrations that are roughly 2 seconds each. Results on a da Vinci Research Kit suggest that combining the coarse policy with half a second of corrections from the learned policy during each high-precision segment improves the success rate on the Fundamentals of Laparoscopic Surgery peg transfer task from 72.9% to 99.2%, 31.3% to 99.2%, and 47.2% to 100.0% for 3 instruments with differing cable-related effects. In the contexts we studied, IVS attains the highest published success rates for automated surgical peg transfer and is significantly more reliable than previous techniques when instruments are changed. Supplementary material is available at https://tinyurl.com/ivs-icra.
I Introduction
Laparoscopic surgical robots such as the da Vinci Research Kit (dVRK) [15] are challenging to accurately control using open-loop techniques, because of the hysteresis, cable-stretch, and complex dynamics of their cable-driven joints [9, 31, 13]. Furthermore, encoders are typically located at the motors, far from the joints they control, making accurate state estimation challenging. Prior work addresses these issues by learning a model of the robot’s dynamics from data [13, 36, 52] for accurate open-loop control or by learning control policies that directly command the robot to perform tasks [51]. However, these approaches tend to require many training samples, which can take a long time to collect on a physical robot. Additionally, learning a model of the robot’s dynamics requires accurate state estimation, which may necessitate sophisticated motion capturing techniques using fiducials [13, 36]. Also, the learned dynamics models can overfit to the specific cabling properties of individual instruments (see Section V-C). Because instrument changes are commonplace within and across surgeries, control strategies must be robust to these shifts in cabling properties.
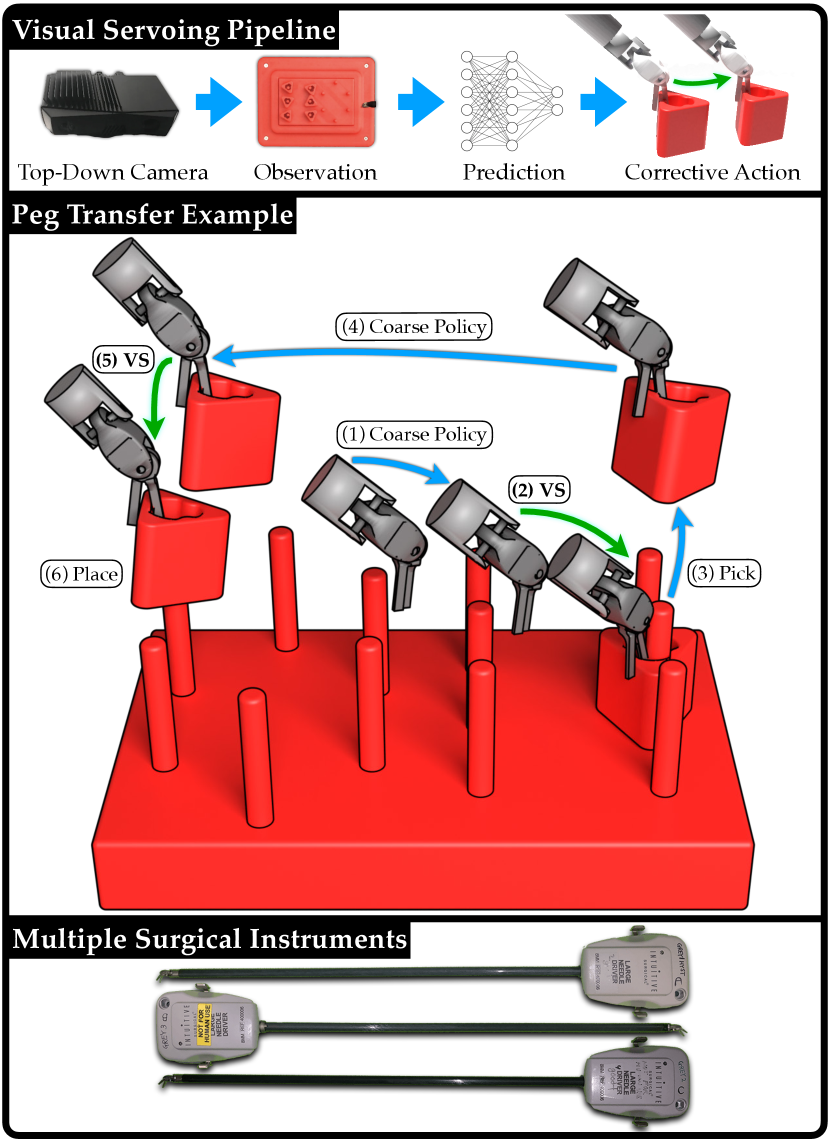
We propose a framework called intermittent visual servoing (IVS), which combines coarse planning over a robot model with learning-based, visual feedback control at segments of the task that require high precision. We use RGBD sensing to construct open-loop trajectories to track with a coarse policy, but during intermittent servoing, we only use RGB sensing, as it can capture images at a much higher frequency. Further, depth sensing requires a static environment, so using RGB allows for continuous visual servoing while the robot is still in motion. The higher capture rate of RGB imaging combined with not requiring the robot to fully stop to sense allows for 10.0 corrective updates per second during peg transfer experiments, compared with only 1.6 for RGBD servoing.
We use imitation learning (IL) to train a precise, visual feedback policy from expert demonstrations. Imitation learning is a popular approach for training control policies from demonstrations provided by a human or an algorithmic supervisor, but may require significant amounts of data [2, 33], which is expensive in the case of a human supervisor [41]. To mitigate this requirement, the learning-based visual feedback policy is only trained on segments where accuracy is necessary, while we rely on a coarse open-loop policy to navigate between these segments. As a result, training the policy requires fewer demonstrations than a policy trained to perform the entire task. Because this policy is trained to directly output controls from images, it does not require explicit state estimation techniques as in prior work. While dVRK surgical instruments can have errors up to 6 mm in positioning [13], this is sufficient for low-precision segments such as transferring a block between pegs.
We focus on the Fundamentals of Laparoscopic Surgery (FLS) peg-transfer surgeon training task, in which the surgeon must transfer 6 blocks from a set of pegs to another set of pegs, and then transfer them back (Fig. 2). As each block’s opening has a 4.5 mm radius, and each peg’s cylindrical is 2.25 mm wide, the task requires high precision, making it a popular benchmark task for evaluating human surgeons [1, 4, 39, 34, 26, 37]. Prior work in automating peg transfer suggests that servoing based on encoder readings cannot reliably perform this task, as positioning errors lead to failure [13, 12]. As a result, sophisticated calibration techniques are used to correct for cabling effects of the surgical instrument during execution [13, 12]. However, accuracy is only required directly before grasping or releasing the block, not during larger motions such moving with the block from one peg to another.
Switching surgical instruments during surgery is both necessary and common [29]. Depending on the type of procedure, up to four instruments may be exchanged on a single arm in rapid succession to perform a task, and this may occur multiple times over a given procedure [29]. These exchanges have been demonstrated to contribute to 10 to 30% of total operative time, increasing patient exposure to anesthesia [30]. Additionally, each instrument is only permitted to be used for 10 operations regardless of the operation length due to potential instrument degradation and even within this permitted-use window instruments frequently fail [49, 25]. Moreover, between patients, instruments must undergo high pressure, high heat sterilization that further degrades the instrument [49]. Instrument collisions during a procedure are common and can alter the cabling properties of the instrument, necessitating re-calibration in the case of automated surgery. Sophisticated, instrument-specific calibration techniques require many long trajectories of data [13], which further increases the wear on the instrument, reduces its lifespan, and can require time during or before a surgical procedure to collect data. Therefore, developing policies that are efficiently transferable across instruments is critical to automation of surgical tasks, since instruments are exchanged frequently and instrument properties change over time with increased usage.
This paper makes the following contributions: (1) IVS, a novel deep learning framework for automation of high-precision surgical tasks, (2) experiments on the FLS peg transfer task suggesting that IVS can match state-of-the-art calibration methods in terms of accuracy while requiring significantly less training data, (3) experiments suggesting that IVS is significantly more robust to instrument changes than prior methods, maintaining accuracy despite different robot instruments having different cabling-related properties.
II Related Work

Robot assisted surgery has been widely adopted based on pure teleoperation, as exemplified by the popularity of curricula such as the Fundamentals of Laparoscopic Surgery (FLS) [6, 8]. Automating robot surgery has proven to be difficult, and so far all standard surgical procedures using robot surgery techniques use a trained human surgeon to teleoperate the robot arms to compensate for various forces and inaccuracies in the robot system [54]. Automating surgical robotics using cable-driven Robotic Surgical Assistants (RSAs) such as the da Vinci [15] or the Raven II [10] is known to be a difficult problem due to backlash, hysteresis, and other errors and inaccuracies in robot execution [27, 45, 36].
II-A Surgical Robotics Tasks
Automation of surgical robotics tasks has a deep history in the robotics research literature. Key applications include cutting [53], debridement [16, 32, 45], suturing [46, 35, 42], and more broadly manipulating and extracting needles [48, 55, 7].
Several research groups have explored automating the FLS peg transfer task for robot surgery, most prominently Rosen and Ji [40] and Hwang et al. [12, 13]. These works, while producing effective and reliable results, require sophisticated visual servoing or calibration techniques, and the resulting systems are instrument-specific. In contrast, we focus on a system that does not require accurate calibration and transfers across a variety of surgical instruments.
II-B Visual Servoing for High Precision Tasks
Visual servoing has a rich history in robotics [11, 17]. Classical visual servoing mechanisms typically use domain-specific knowledge in the form of image features or system dynamics [5, 28]. In recent years, data-driven approaches to visual servoing have gained in popularity as a way to generalize from patterns in larger training datasets. For example, approaches such as Levine et al. [22] and Kalashnikov et al. [14] train visual servoing policies for grasping based on months of nonstop data collection across a suite of robot arms. Other approaches for learning visual servoing include Lee et al. [20], who use reinforcement learning and predictive dynamics for target following, Saxena et al. [44] for servoing of quadrotors, and Bateux et al. [3] for repositioning robots from target images.
In this work, to facilitate rapid instrument changes, it is infeasible to obtain massive datasets by running the da Vinci repeatedly for each new instrument, hence we prioritize obtaining high-quality demonstrations [2, 33] at the critical moments of when the robot inserts or removes blocks from pegs. This enables the system to rapidly learn a robust policy for the region of interest, while relying on a coarse, open-loop policy otherwise. Coarse-to-fine control architectures combining geometric planners with adaptive error correction strategies have a long history in robotics [24, 43, 38, 50, 23], with works such as Lozano-Pérez et al. [24] studying the combination of geometric task descriptions with sensing and error correction for compliant motions. We extend the work of Lee et al. [21], who use a model-based planner for moving a robot arm in free space, and reinforcement learning for learning an insertion policy when the gripper is near the region of interest.
III Problem Definition
We focus on the FLS peg transfer task, using the setup in Hwang et al. [13], which uses red 3D printed blocks and a red 3D printed pegboard (see Fig. 2). In real surgical environments, blood is common, so surgeons rely on minute differences in color, depth, and texture to complete high-precision tasks. We use a uniformly red pegboard setup, so the resulting difficulty in sensing the state in such an environment more accurately reflects the surgical setting. The task involves transferring blocks from the left pegs to the right pegs, and transferring them back from the right pegs to the left pegs (see Fig. 2). As in Hwang et al. [12, 13], we focus on the single-arm version of the task.
We define the peg transfer task as consisting of a series of smaller subtasks, with the following success criteria:
- Pick:
-
the robot grasps a block and lifts it off the pegboard.
- Place:
-
the robot securely places a block around a target peg.
We define a transfer as a successful pick followed by a successful place. A trajectory consists of a single instance of any of the two subtasks in action. A single trial of the peg transfer task initially consists of 6 blocks starting on one side of the peg board, each with random configurations. A successful trial without failures consists of 6 transfers to move all 6 blocks to the other side of the board, and then 6 more transfers to move the blocks back to the original side of the peg board. A trial can have fewer than 12 transfers if failures occur during the process.
IV IVS: Method
IV-A Subtask Segmentation and Policy Design
Due to cabling effects, tracking an open-loop trajectory to pick or place targets using the robot’s encoder estimates may result in positioning errors; we thus propose decomposing subtasks into 3 phases: (1) an open-loop approach phase, (2) a closed-loop visual-servoing correction phase, and (3) an open-loop completion phase. The open-loop phases are executed by a coarse policy that tracks predefined trajectories using the robot’s odometry. The closed-loop phases are executed by a learned, visual feedback policy that corrects the robot’s position for the subsequent completion motion. At time , the executed policy outputs an action vector , as well as a termination signal , which signals to the system to switch to the next segment.
Pick Subtask
The first segment uses an open-loop policy to execute a trajectory to a position above the target grasp (approach). After this motion, a visual feedback policy takes over to correct for positioning errors (correction). Once corrected, the robot again executes to perform a predefined grasping motion relative to its current pose (completion).
Place Subtask
Similar to block picking, an open-loop policy executes a trajectory to a position above the target placement (approach). After this motion, a visual feedback policy takes over to correct for positioning errors (correction). Once corrected, the robot opens its jaws, resulting in the block dropping onto the peg (completion).
IV-B Fine-Policy Data Collection
We collect demonstrations from a human teleoperator to generate a dataset to train a neural network for a fine policy. We collect 15 trajectories on each of the 12 pegs for both subtasks, resulting in 180 transfers, and 360 expert trajectories. Each trajectory consists of a small corrective motion, as the teleoperator navigates the end-effector from a starting position to the goal position. For picks, the goal position is directly above the optimal pick spot. For places, the goal position is such that the center of the block aligns with the center of the target peg. The starting position of each attempt is a random position within 5 mm of the goal position. Further, due to the size of the blocks, small segments of irrelevant blocks may be visible after data preprocessing (see Sec. IV-C1). To capture this data property, while collecting trajectories for a given target peg, we populate neighboring pegs with blocks. Then, prior to each attempt, we randomize the configurations of the neighboring blocks.
For each demonstration, we capture a top-down RGB image and end-effector position in the robot’s base frame estimated from encoder values at 5 Hz. We do not record the coordinate, because the correction phase for both subtasks will be performed in an plane with a fixed coordinate. While the recorded end-effector position has errors due to cabling properties [13, 36, 12], we demonstrate empirically that the high-frequency visual feedback policy trained from supervision extracted from these estimates is reliable (Sec. V). Each demonstration is a raw trajectory:
The pick dataset consists of 2400 datapoints, and the place dataset contains 1804 datapoints. The corrective pick trajectories are slighter longer than corrective place trajectories, resulting in 3.3 additional datapoints per demonstration.
IV-C Preprocessing of Visual Feedback Policy Training Data
IV-C1 Image Filtering
To train a single model on all 180 demonstrations, regardless of the target peg, we (1) crop images around the peg, and (2) color crop other blocks (see Fig. 3). For (1), we crop a 150150 image centered on the target peg. For (2), we color-crop out all red pixels outside of a block-sized radius from the center of the target peg. This removes the other blocks from the input image as much as possible while keeping the instrument, target block, and target peg visible. refers to the image after preprocessing (see Fig. 3).

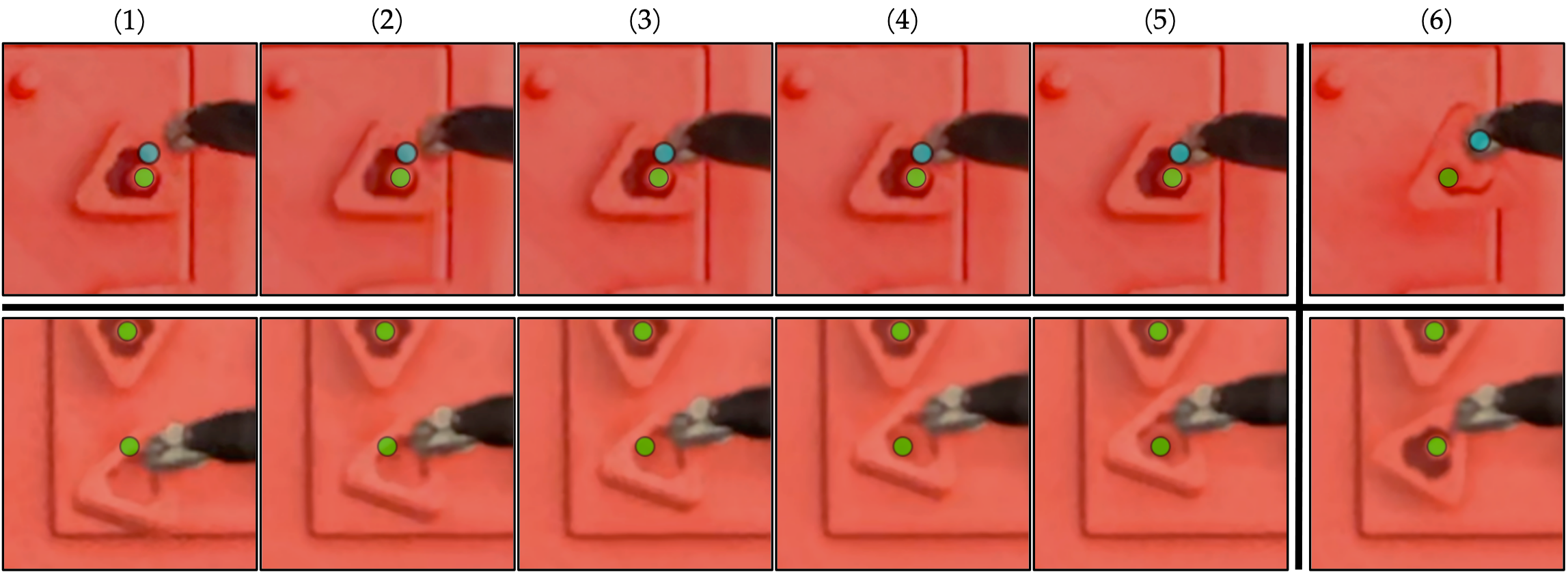
IV-C2 Supervision Extraction
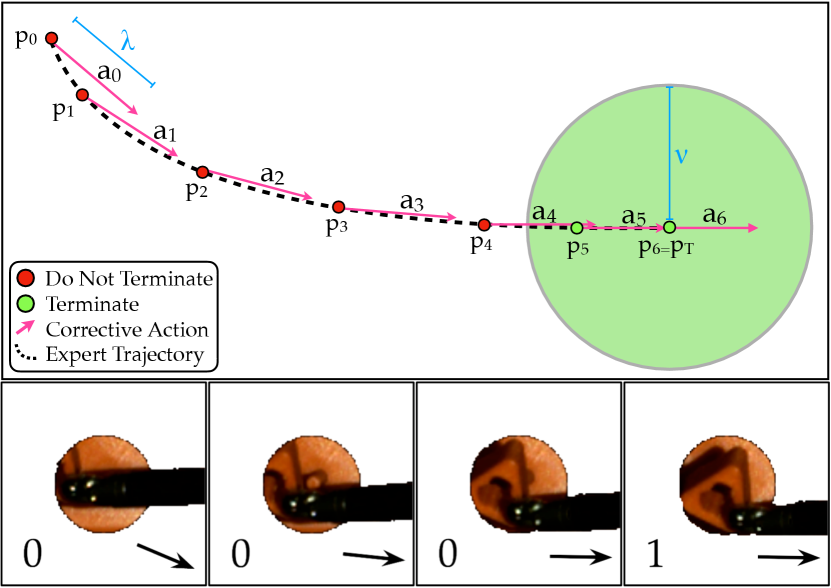
We additionally process the datasets to extract supervision for subsequent learning. For an input raw trajectory , we transform it via mappings and that extract the action executed and a terminal condition, respectively (see Fig. 4).
Corrective Action Extraction: We transform to get the action-labeled dataset , where
The action is a vector of length in the direction traveled by the demonstration trajectory, where is the next waypoint that is at least distance from . In the case the distance to the final position in the trajectory is less than , . In experiments, we set the hyperparameter to 1 mm, as 1 mm is an upper bound on the expected Cartesian distance traveled by the end-effector per corrective update.
Terminal Condition Extraction: We extract a binary completion label for each image. We transform to get the action-labeled dataset , where . The flag is if the distance to the final position is less than the hyperparameter . In experiments, we set to 2 mm, as 2 mm is strict enough to reliably confirm termination, and lenient enough to prevent label imbalance, as 30% of images are labeled positively.
IV-D Constructing the Visual Feedback Policy
We train the visual feedback policy for each subtask from demonstrations using supervised learning. The policy takes in a top-down RGB image as input and outputs , where is an action vector and is a termination condition.
IV-D1 Training the Visual Feedback Policy
The policy consists of an ensemble of 4 Convolutional Neural Networks [18, 19], denoted by . Each individual model consists of alternating convolution and max pooling layers, following by dense layers separated by Dropout [47]. We use an ensemble of models to make the policy more robust, and we evaluate for in Table I. We select to be . Each model uses a processed image as input and outputs estimates and of the supervisor action and terminal conditions respectively. Each model trains on 150 randomly sampled trajectories, with 30 for testing. We train each network by minimizing on sampled batches of its training data, where is a Mean Square Error loss on the action prediction, is a cross-entropy loss for the terminal condition prediction, and is a relative weighting hyperparameter. The weights in the convolutional layers are shared, as useful convolutional filters are likely similar across subtasks, while the weights in the dense layers are independent. Sharing convolutional layers provides two sources of supervision when training the filters.
| Num Models | Update Frequency | Transfer Success Rate |
|---|---|---|
| 1 | 15.6 | 97.2% |
| 2 | 12.8 | 98.6% |
| 4 | 10.0 | 100.0% |
| 8 | 7.1 | 100.0% |
| Pick Success Rate | Place Success Rate | Mean Transfer Time (s) | Success / Attempts | Transfer Success Rate | |
|---|---|---|---|---|---|
| Uncalibrated Baseline | 96.3% | 75.7% | 8.7 | 77 / 106 | 72.6% |
| Calibrated Baseline | 97.9% | 99.6% | 9.5 | 116 / 119 | 97.5% |
| IVS | 99.2% | 100% | 10.2 | 118 / 119 | 99.2% |
IV-D2 Querying the Visual Feedback Policy
Once trained, we evaluate the ensemble of models in parallel with a filtered RGB image (Sec. IV-C1). We let
where and are a hyperparameters set to 0.70 and 3 respectively. We hand-tune these hyperparameters to maximize speed and minimize false positives. The predicted action is the mean action across the ensemble, and the predicted termination condition checks if at least models predict termination with probability greater than .
V Experiments
The experimental setup has a top-down RGBD camera and uses the teleoperation interface [15] to collect demonstrations on the dVRK. Training data are collected on a single instrument, but the system is tested with different instruments that have unique dynamics due to differences in cabling properties. We use the position of the blocks and pegs estimated by an RGBD image to construct trajectories for picks and places, but only use RGB images for visual servoing.
We benchmark IVS against two baselines:
-
•
Uncalibrated Baseline (UNCAL): This is a coarse open-loop policy, implemented using the default unmodified dVRK controller. The trajectories are tracked in closed-loop with respect to the robot’s odometry, but open-loop with respect to vision.
-
•
Calibrated Baseline (CAL): This is a calibrated open-loop policy [13] that is the current state-of-the-art method for automating peg transfer. To correct for backlash, hysteresis, and cable tension, the authors train a recurrent dynamics model to estimate the true position of the robot based on prior commands. Similar to the uncalibrated baseline, the robot tracks reference trajectories in closed-loop with respect to the position estimated by the recurrent model, but open-loop with respect to visual inputs.
| Pick | |||
|---|---|---|---|
| Instrument | Corrective Updates | Time (sec) | Distance (mm) |
| A | 5.75 2.10 | 0.60 0.19 | 1.71 0.65 |
| B | 7.73 2.63 | 0.77 0.22 | 2.52 0.78 |
| C | 7.43 3.03 | 0.74 0.26 | 2.24 0.85 |
| Mean | 7.01 2.77 | 0.70 0.24 | 2.17 0.84 |
| Place | |||
| Instrument | Corrective Updates | Time (sec) | Distance (mm) |
| A | 4.90 4.82 | 0.52 0.43 | 2.04 1.77 |
| B | 5.63 4.20 | 0.58 0.37 | 2.12 1.57 |
| C | 4.68 4.21 | 0.49 0.37 | 1.78 1.43 |
| Mean | 4.97 4.47 | 0.52 0.39 | 1.93 1.58 |
V-A Accuracy Results
Overall, IVS achieves high success rates in the peg transfer task, with a pick and place success rate of 99.2% and 100.0% respectively. IVS succeeds on 118 of 119 transfers, resulting in a 99.2% transfer success rate, exceeding the uncalibrated baseline by over 25%. See Table II for details and we illustrate an example of IVS correcting positioning errors in Figure 5.
V-B Timing Results
The goal is to produce higher success rates, rather than to reduce the timing. However, we find that the proposed method is only marginally slower than the baselines (see Table II). Due to fast image capture and continuous servoing via RGB imaging, we are able to both update the robot’s velocity and check for termination 10 times per second, minimizing additions to the mean transfer time. As a result, the mean transfer time is only 1.5 seconds slower than the uncalibrated baseline, and 0.7 seconds slower than the calibrated baseline.
We report IVS timing results in Table III. On average, each pick requires 2.2 mm of correction, spanning 0.7 seconds and 7 corrective updates, and each place requires 1.9 mm of correction, spanning 0.5 seconds and 5 corrective updates.
V-C Transferability Results
To conduct instrument transfer evaluation, we experiment using multiple large needle drivers. Each instrument has inconsistent cabling characteristics resulting in various success rates. We have 3 different instruments: A, B, and C (Fig. 1 bottom). We trained with data from instrument A.
We investigate whether models learned from data using one instrument can transfer to another instrument without modification. This is challenging, because different surgical instruments, even of the same type, have different cabling properties due to differences in wear and tear. However, the visual servoing algorithm does not rely on the cabling characteristics of any specific instrument, but rather only requires that the robot is able to roughly correct in the desired direction. We hypothesize that errors in executing the corrective motion can be mitigated over time by executing additional corrective motions, as long as the cumulative error is decreasing. However, the calibrated baseline uses an observer model that explicitly predicts the motion of the robot based on prior commands, which requires learning the dynamics of the specific instrument used in training which may not be sufficiently accurate on a new instrument. We report transferability results in Table IV and observe that the IVS model trained on Instrument A does not decrease in performance on different instruments, while the calibrated baselines suffer significantly on different instruments.
| Instrument | UNCAL | CAL | CAL | CAL | IVS |
| A | 72.6% | 97.5% | 48.1% | 55.2% | 99.2% |
| B | 31.3% | 58.5% | 98.3% | 67.0% | 99.2% |
| C | 47.2% | 27.8% | 81.6% | 97.4% | 100.0% |
| Mean | 50.5% | 69.8% | 77.3% | 79.2% | 99.4% |
VI Discussion and Future Work
In this work, we propose intermittent visual servoing to attain the highest published success rates for automated surgical peg transfer. IVS maintains performance across different instruments surprisingly well (see Table IV), and this transferability is critical to implementing automated surgical techniques where instruments are being exchanged frequently and a instrument’s properties are expected to change over time. In future work, we will investigate how to further decrease timing, perform automated bilateral peg transfer with handovers between arms in each transfer, and apply IVS to surgical cutting [53], surgical suturing [46], and non-surgical applications such as assembly [23].
Acknowledgements
This research was performed at the AUTOLAB at UC Berkeley in affiliation with the Berkeley AI Research (BAIR) Lab, Berkeley Deep Drive (BDD), the Real-Time Intelligent Secure Execution (RISE) Lab, the CITRIS “People and Robots” (CPAR) Initiative, and with UC Berkeley’s Center for Automation and Learning for Medical Robotics (Cal-MR). This work is supported in part by the Technology & Advanced Telemedicine Research Center (TATRC) project W81XWH-18-C-0096 under a medical Telerobotic Operative Network (TRON) project led by SRI International. The authors were supported in part by donations from Intuitive Surgical, Siemens, Google, Toyota Research Institute, Honda, and Intel. The da Vinci Research Kit was supported by the National Science Foundation, via the National Robotics Initiative (NRI), as part of the collaborative research project “Software Framework for Research in Semi-Autonomous Teleoperation” between The Johns Hopkins University (IIS 1637789), Worcester Polytechnic Institute (IIS 1637759), and the University of Washington (IIS 1637444). Daniel Seita is supported by a Graduate Fellowships for STEM Diversity.
References
- [1] A. Abiri, J. Pensa, A. Tao, J. Ma, Y.-Y. Juo, S. J. Askari, J. Bisley, J. Rosen, E. P. Dutson, and W. S. Grundfest, “Multi-Modal Haptic Feedback for Grip Force Reduction in Robotic Surgery,” Scientific Reports, vol. 9, no. 1, p. 5016, 2019.
- [2] B. D. Argall, S. Chernova, M. Veloso, and B. Browning, “A Survey of Robot Learning From Demonstration,” Robotics and Autonomous Systems, vol. 57, 2009.
- [3] Q. Bateux, E. Marchand, J. Leitner, F. Chaumette, and P. Corke, “Training Deep Neural Networks for Visual Servoing,” in IEEE International Conference on Robotics and Automation (ICRA), 2018.
- [4] J. D. Brown, C. E. O’Brien, S. C. Leung, K. R. Dumon, D. I. Lee, and K. Kuchenbecker, “Using Contact Forces and Robot Arm Accelerations to Automatically Rate Surgeon Skill at Peg Transfer,” in IEEE Transactions on Biomedical Engineering, 2017.
- [5] F. Chaumette and S. Hutchinson, “Visual Servo Control I. Basic Approaches,” in IEEE Robotics and Automation Magazine, 2006.
- [6] A. M. Derossis, G. M. Fried, M. Abrahamowicz, H. H. Sigman, J. S. Barkun, and J. L. Meakins, “Development of a Model for Training and Evaluation of Laparoscopic Skills,” The American Journal of Surgery, vol. 175, no. 6, 1998.
- [7] C. D’Ettorre, G. Dwyer, X. Du, F. Chadebecq, F. Vasconcelos, E. De Momi, and D. Stoyanov, “Automated Pick-up of Suturing Needles for Robotic Surgical Assistance,” in IEEE International Conference on Robotics and Automation (ICRA), 2018.
- [8] G. M. Fried, L. S. Feldman, M. C. Vassiliou, S. A. Fraser, D. Stanbridge, G. Ghitulescu, and C. G. Andrew, “Proving the Value of Simulation in Laparoscopic Surgery,” Annals of Surgery, vol. 240, no. 3, 2004.
- [9] M. Haghighipanah, M. Miyasaka, Y. Li, and B. Hannaford, “Unscented Kalman Filter and 3D Vision to Improve Cable Driven Surgical Robot Joint Angle Estimation,” in IEEE International Conference on Robotics and Automation (ICRA), 2016.
- [10] B. Hannaford, J. Rosen, D. Friedman, H. King, P. Roan, L. Cheng, D. Glozman, J. Ma, S. Kosari, and L. White, “Raven-II: An Open Platform for Surgical Robotics Research,” in IEEE Transactions on Biomedical Engineering, 2013.
- [11] S. Hutchinson, G. Hager, and P. Corke, “A Tutorial on Visual Servo Control,” in IEEE Transactions on Robotics and Automation, 1996.
- [12] M. Hwang, D. Seita, B. Thananjeyan, J. Ichnowski, S. Paradis, D. Fer, T. Low, and K. Goldberg, “Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot,” in International Symposium on Medical Robotics (ISMR), 2020.
- [13] M. Hwang, B. Thananjeyan, S. Paradis, D. Seita, J. Ichnowski, D. Fer, T. Low, and K. Goldberg, “Efficiently Calibrating Cable-Driven Surgical Robots With RGBD Fiducial Sensing and Recurrent Neural Networks,” in IEEE Robotics and Automation Letters (RA-L), 2020.
- [14] D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke, and S. Levine, “QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation,” in Conference on Robot Learning (CoRL), 2018.
- [15] P. Kazanzides, Z. Chen, A. Deguet, G. Fischer, R. Taylor, and S. DiMaio, “An Open-Source Research Kit for the da Vinci Surgical System,” in IEEE International Conference on Robotics and Automation (ICRA), 2014.
- [16] B. Kehoe, G. Kahn, J. Mahler, J. Kim, A. Lee, A. Lee, K. Nakagawa, S. Patil, W. Boyd, P. Abbeel, and K. Goldberg, “Autonomous Multilateral Debridement with the Raven Surgical Robot,” in IEEE International Conference on Robotics and Automation (ICRA), 2014.
- [17] D. Kragic and H. I. Christensen, “Survey on Visual Servoing for Manipulation,” Computational Vision and Active Perception Laboratory, Tech. Rep., 2002.
- [18] A. Krizhevsky, I. Sutskever, and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Neural Information Processing Systems (NeurIPS), 2012.
- [19] Y. Lecun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based Learning Applied to Document Recognition,” in Proceedings of the IEEE, 1998, pp. 2278–2324.
- [20] A. X. Lee, S. Levine, and P. Abbeel, “Learning Visual Servoing with Deep Features and Fitted Q-Iteration,” in International Conference on Learning Representations (ICLR), 2017.
- [21] M. A. Lee, C. Florensa, J. Tremblay, N. Ratliff, A. Garg, F. Ramos, and D. Fox, “Guided Uncertainty-Aware Policy Optimization: Combining Learning and Model-Based Strategies for Sample-Efficient Policy Learning,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [22] S. Levine, P. Pastor, A. Krizhevsky, J. Ibarz, and D. Quillen, “Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection,” in International Journal of Robotics Research (IJRR), 2017.
- [23] T. Lozano-Perez, “The design of a mechanical assembly system,” 1976.
- [24] T. Lozano-Pérez, M. T. Mason, and R. H. Taylor, “Automatic Synthesis of Fine-Motion Strategies for Robots,” IJRR, 1984.
- [25] W. W. Ludwig, M. A. Gorin, M. W. Ball, E. M. Schaeffer, M. Han, and M. E. Allaf, “Instrument Life for Robot-assisted Laparoscopic Radical Prostatectomy and Partial Nephrectomy: Are Ten Lives for Most Instruments Justified?” Urology, vol. 86, no. 5, 2015.
- [26] N. Madapana, M. M. Rahman, N. Sanchez-Tamayo, M. V. Balakuntala, G. Gonzalez, J. P. Bindu, L. Venkatesh, X. Zhang, J. B. Noguera, T. Low et al., “DESK: A Robotic Activity Dataset for Dexterous Surgical Skills Transfer to Medical Robots,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2019.
- [27] J. Mahler, S. Krishnan, M. Laskey, S. Sen, A. Murali, B. Kehoe, S. Patil, J. Wang, M. Franklin, P. Abbeel, and K. Goldberg, “Learning Accurate Kinematic Control of Cable-Driven Surgical Robots Using Data Cleaning and Gaussian Process Regression.” in IEEE Conference on Automation Science and Engineering (CASE), 2014.
- [28] G. C. E. Marchand and E. M. Mouaddib, “Photometric Visual Servoing from Omnidirectional Cameras,” in Autonomous Robots, 2013.
- [29] N. Mehta, R. Haluck, M. Frecker, and A. Snyder, “Sequence and task analysis of instrument use in common laparoscopic procedures,” Surgical endoscopy, vol. 16, no. 2, 2002.
- [30] A. Melzer, “Endoscopic instruments: conventional and intelligent,” Tooli J, Gossot D, Hunter JG. eds. Endosurgery, 1996.
- [31] M. Miyasaka, J. Matheson, A. Lewis, and B. Hannaford, “Measurement of the Cable-Pulley Coulomb and Viscous Friction for a Cable-Driven Surgical Robotic System,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2015.
- [32] A. Murali, S. Sen, B. Kehoe, A. Garg, S. McFarland, S. Patil, W. D. Boyd, S. Lim, P. Abbeel, and K. Goldberg, “Learning by Observation for Surgical Subtasks: Multilateral Cutting of 3D Viscoelastic and 2D Orthotropic Tissue Phantoms,” in IEEE International Conference on Robotics and Automation (ICRA), 2015.
- [33] T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An Algorithmic Perspective on Imitation Learning,” Foundations and Trends in Robotics, vol. 7, 2018.
- [34] L. Panait, S. Shetty, P. Shewokits, and J. A. Sanchez, “Do Laparoscopic Skills Transfer to Robotic Surgery?” Journal of Surgical Research, 2014.
- [35] S. A. Pedram, P. Ferguson, J. Ma, and E. D. J. Rosen, “Autonomous Suturing Via Surgical Robot: An Algorithm for Optimal Selection of Needle Diameter, Shape, and Path,” in IEEE International Conference on Robotics and Automation (ICRA), 2017.
- [36] H. Peng, X. Yang, Y.-H. Su, and B. Hannaford, “Real-time Data Driven Precision Estimator for RAVEN-II Surgical Robot End Effector Position,” in IEEE International Conference on Robotics and Automation (ICRA), 2020.
- [37] M. M. Rahman, N. Sanchez-Tamayo, G. Gonzalez, M. Agarwal, V. Aggarwal, R. M. Voyles, Y. Xue, and J. Wachs, “Transferring Dexterous Surgical Skill Knowledge between Robots for Semi-autonomous Teleoperation,” in IEEE International Conference on Robot and Human Interactive Communication (Ro-Man), 2019.
- [38] C. Rauch, V. Ivan, T. Hospedales, J. Shotton, and M. Fallon, “Learning-driven coarse-to-fine articulated robot tracking,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 6604–6610.
- [39] I. Rivas-Blanco, C. J. P. del Pulgar, C. López-Casado, E. Bauzano, and V. F. Munoz, “Transferring Know-How for an Autonomous Camera Robotic Assistant,” Electronics: Cognitive Robotics and Control, 2019.
- [40] J. Rosen and J. Ma, “Autonomous Operation in Surgical Robotics,” Mechanical Engineering, vol. 137, no. 9, 2015.
- [41] S. Ross, G. J. Gordon, and J. A. Bagnell, “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning,” in International Conference on Artificial Intelligence and Statistics (AISTATS), 2011.
- [42] H. Saeidi, H. N. D. Le, J. D. Opfermann, S. Leonard, A. Kim, M. H. Hsieh, J. U. Kang, and A. Krieger, “Autonomous Laparoscopic Robotic Suturing with a Novel Actuated Suturing Tool and 3D Endoscope,” in IEEE International Conference on Robotics and Automation (ICRA), 2019.
- [43] S. Salcudean and C. An, “On the control of redundant coarse-fine manipulators,” in 1989 International Conference on Robotics and Automation (ICRA), pp. 1834–1840 vol.3.
- [44] A. Saxena, H. Pandya, G. Kumar, A. Gaud, and K. M. Krishna, “Exploring Convolutional Networks for End-to-End Visual Servoing,” in IEEE International Conference on Robotics and Automation (ICRA), 2017.
- [45] D. Seita, S. Krishnan, R. Fox, S. McKinley, J. Canny, and K. Goldberg, “Fast and Reliable Autonomous Surgical Debridement with Cable-Driven Robots Using a Two-Phase Calibration Procedure,” in IEEE International Conference on Robotics and Automation (ICRA), 2018.
- [46] S. Sen, A. Garg, D. V. Gealy, S. McKinley, Y. Jen, and K. Goldberg, “Automating Multiple-Throw Multilateral Surgical Suturing with a Mechanical Needle Guide and Sequential Convex Optimization,” in IEEE International Conference on Robotics and Automation (ICRA), 2016.
- [47] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A Simple Way to Prevent Neural Networks from Overfitting,” Journal of Machine Learning Research (JMLR), 2014.
- [48] P. Sundaresan, B. Thananjeyan, J. Chiu, D. Fer, and K. Goldberg, “Automated Extraction of Surgical Needles from Tissue Phantoms,” in IEEE Conference on Automation Science and Engineering (CASE), 2019.
- [49] D. V. S. System, “INC DVSSIS,” Endowrist Instrument and Accessory Catalog, 2013.
- [50] R. H. Taylor, “The synthesis of manipulator control programs from task-level specifications.” 1976.
- [51] B. Thananjeyan*, A. Balakrishna*, S. Nair, M. Luo, K. Srinivasan, M. Hwang, and J. E. Gonzalez, “Recovery rl: Safe reinforcement learning with learned recovery zones,” 2020.
- [52] B. Thananjeyan, A. Balakrishna, U. Rosolia, F. Li, R. McAllister, J. E. Gonzalez, S. Levine, F. Borrelli, and K. Goldberg, “Safety Augmented Value Estimation from Demonstrations (SAVED): Safe Deep Model-Based RL for Sparse Cost Robotic Tasks,” in IEEE Robotics and Automation Letters (RA-L), 2020.
- [53] B. Thananjeyan, A. Garg, S. Krishnan, C. Chen, L. Miller, and K. Goldberg, “Multilateral Surgical Pattern Cutting in 2D Orthotropic Gauze with Deep Reinforcement Learning Policies for Tensioning,” in IEEE International Conference on Robotics and Automation (ICRA), 2017.
- [54] M. Yip and N. Das, “Robot Autonomy for Surgery,” The Encyclopedia of Medical Robotics, 2017.
- [55] F. Zhong, Y. Wang, Z. Wang, and Y.-H. Liu, “Dual-Arm Robotic Needle Insertion With Active Tissue Deformation for Autonomous Suturing,” in IEEE Robotics and Automation Letters (RA-L), 2019.