Interactive Knowledge Distillation for Image Classification
Abstract
Knowledge distillation (KD) is a standard teacher-student learning framework to train a light-weight student network under the guidance of a well-trained, large teacher network. As an effective teaching strategy, interactive teaching has been widely employed at school to motivate students, in which teachers not only provide knowledge, but also give constructive feedback to students upon their responses, to improving their learning performance. In this work, we propose Interactive Knowledge Distillation (IAKD) to leverage the interactive teaching strategy for efficient knowledge distillation. In the distillation process, the interaction between the teacher network and the student one is implemented by swapping-in operation: randomly replacing the blocks in the student network with the corresponding blocks in the teacher network. In this way, we directly involve the teacher’s powerful feature transformation ability for largely boosting the performance of the student network. Experiments with typical settings of teacher-student networks demonstrate that the student networks trained by our IAKD achieve better performance than those trained by conventional knowledge distillation methods on diverse image classification datasets.
Index Terms:
Interactive Mechanism, Knowledge Distillation, Model Compression.I Introduction
Over the past few years, deeper and deeper convolutional neural networks (CNNs) have demonstrated cutting edge performance on various computer vision tasks [1, 2, 3, 4, 5]. However, they usually undergo huge computational costs and memory consumption, and are difficult to be embedded into resource-constrained devices, e.g., mobiles and UAVs. To reduce the resource consumption while maintaining good performance, researchers leverage knowledge distillation techniques [6, 7, 8, 9, 10, 11] to transfer informative knowledge from a cumbersome but well-trained teacher network into a light-weight but unskilled student network.

Most of existing knowledge distillation methods [12, 13, 14, 15, 16, 17] encourage the student network to mimic the representation space of the teacher network for approaching its proficient performance. Those methods manually define various kinds of knowledge based on the teacher network responses, such as softened outputs [12], attention maps [13], flow of solution procedure [18], and relations [14]. These different kinds of knowledge facilitate the distillation process through additional distillation losses. If we regard the responses of the teacher network as the theorems in a textbook written by the teacher, manually defining those different kinds of knowledge just rephrases those theorems and further points out an easier way to make the student understand those theorems better. This kind of distillation process is viewed as non-interactive knowledge distillation, since the teacher network just sets a goal for the student network to mimic, ignoring the interaction with the student network.
The non-interactive knowledge distillation methods undergo one major problem: since the feature transformation ability of the student network is less powerful than that of the teacher network, the knowledge that the student has learned through mimicking is impossible to be identical with the knowledge provided by the teacher, which may impede the knowledge distillation performance. This problem becomes more tough when introducing multi-connection knowledge [13, 19]. Specifically, since the student can not perfectly mimic the teacher’s knowledge even if in the shallow blocks, the imperfectly-mimicked knowledge is reused in the following blocks to imitating the corresponding teacher’s knowledge. Therefore, the gap between the knowledge learned by the student and the one provided by the teacher becomes larger, restricting the performance of knowledge distillation.
Based on the discussion above, we try to make the distillation process interactive and the teacher network truly involved in guiding the student network. Specifically, the student first takes actions according to the problems he faces, then the teacher gives feedback based on the student’s actions, finally the student takes actions according to the teacher’s feedback. As shown in Fig. 1, instead of forcing the student network to mimic the teacher’s representation space, our interactive distillation directly involves the teacher’s powerful feature transformation ability into the student network. Consequently, the student can make the best use of the improved features to better exploit its potential on relevant tasks.
In this paper, we propose a simple yet effective knowledge distillation method named Interactive Knowledge Distillation (IAKD). In IAKD, we randomly swap in the blocks in the teacher network to replacing the blocks in the student network during the distillation phase. Each set of swapped-in teacher blocks responds to the output of previous student block, and provides better feature maps to motivate the next student block. In addition, randomly swapping in the teacher blocks makes it possible for the teacher to guide the student in many different manners. Compared with other conventional knowledge distillation methods, our proposed method does not deliberately force the student’s knowledge to be similar to the teacher’s knowledge. Therefore, we do not need the additional distillation losses to drive the knowledge distillation process, resulting in no need of hyper-parameters to balancing the task-specific loss and distillation losses. Besides, the distillation process of our IAKD method is highly efficient. The reason is that our IAKD discards the cumbersome knowledge transformation process and gets rid of the feature extraction of the teacher network, both of which commonly exist in conventional knowledge distillation methods. Experimental results demonstrate that our proposed method effectively boosts the performance of the student, which proves that the student can actually benefit from the interaction with the teacher.
II Related Work
Since Ba and Caruana [20] first introduced the view of teacher supervising student for model compression, many variant works have emerged based on their teacher-student learning framework. To achieve promising model compression results, these works focus on how to better capture the knowledge of the large teacher network to supervise the training process of the small student network. The most representative work about knowledge distillation (KD) comes from Hinton et al. [12]. They defined knowledge as the teacher’s softened logits and encouraged the student to mimic it instead of the raw activations before softmax [20], because they argued that the intra-class and inter-class relationships learned by the pre-trained teacher network can be described more accurately by the softened logits than by the raw activations. However, simply using logits as the learning goal for the student may limit the information that the teacher distills to the student. To introduce more knowledge of the teacher network, FitNets [21] added element-wise supervision on the feature maps at intermediate layers to assisting the training of the student. However, this approach only works well when one supervision loss is applied to one intermediate layer. It can not achieve satisfying results when more losses are added to supervising more intermediate layers [18]. This is because supervision on the feature maps at many different layers makes the constraints become too restrictive. There are many methods trying to soften the constraints while preserving meaningful information of feature maps. Zagoruyko and Komodakis [22] condensed feature maps to attention maps based on channel statistics of each spatial location. Instead of defining knowledge based on feature maps of a single layer, Yim et al. [18] employed Gramian matrix to measure the correlations between feature maps from different layers. Besides, Kim et al. [23] utilized convolutional auto-encoder, and Lee et al. [24] used Singular Value Decomposition (SVD) to perform dimension reduction on feature maps. Heo et al. [19, 15] demonstrated that simply using activation status of neurons could also assist the distillation process. Ahn et al. [25] proposed a method based on information theory which maximizes the mutual information between the teacher network and the student network. To enable the student to acquire more meaning information, a lot of studies defined knowledge based on relations rather than individual feature maps [14, 26, 27, 28].
On the other hand, our proposed IAKD is essentially different from aforementioned knowledge distillation methods. IAKD does not require distillation losses to drive the distillation process (see Eq. 1 and Eq. 5). In the learning process of the student, we directly involve the teacher’s powerful feature transformation ability to improve the relatively weak features extracted by the student, since better features are critical for getting a better prediction.
III Proposed Method
III-A Conventional Knowledge Distillation
In general, the conventional, feature-based knowledge distillation methods [19, 25, 13, 18, 15] decompose the student network and the teacher one into modules. The student network is trained to minimize the following loss function:
| (1) |
where is the task-specific loss. represents the ground truth. is the predicted result of the student network. and denote the transformed output of the student network and the one of the teacher network produced by the -th module. is a tunable balance factor to balancing the different losses. is the -th distillation loss to narrowing down the difference between and . varies from method to method because of different definitions of knowledge. As can be seen in Eq. 1, the conventional knowledge distillation methods essentially aim at forcing the student to mimic the teacher’s representation space.

III-B Interactive Knowledge Distillation
To achieve the interaction between the student network and the teacher network, our IAKD randomly swaps in the teacher blocks to replace the student blocks at each iteration. The swapped-in teacher blocks can respond to the output of the previous student block and then provide better features to motivate the next student block. To make all student blocks fully participate in the distillation process, after each training iteration, we put back the replaced student blocks to their original positions in the student network. Due to the return of replaced student blocks, the architecture of the student is kept consistent for the next swapping-in operation.
Hybrid block for swapping-in operation
As shown in Fig. 2, for effective implementation of such interactive strategy, we devise a two-path hybrid block, which is composed of one student block (the student path) and several teacher blocks to be swapped in (the teacher path). We use the hybrid block to replace the original student block in the student network to form a hybrid network. However, the blocks and layers that are shared by the teacher and the student are not replaced by the hybrid blocks111The fully-connected layer and the transition blocks in ResNet [29] are considered as the shared parts., since the shared parts have the same learning capacity. The number of hybrid blocks depends on the number of non-shared student blocks. Every non-shared student block will pair with one or several non-shared teacher blocks to form the hybrid block. All non-shared teacher blocks will be taken to form the hybrid blocks.
For the -th hybrid block in the hybrid network, let denotes a Bernoulli random variable, which indicates whether the student path is selected () or the teacher path is chosen (). Therefore, the output of the -th hybrid block can be formulated as
| (2) |
where and denote the input and the output of the -th hybrid block. is the function of the student block. is the nested functions of the teacher blocks.
If , the student path is chosen and Eq. 2 reduces to:
| (3) |
This means the hybrid block degrades to the original student block. If , the teacher path is chosen and Eq. 2 reduces to:
| (4) |
This implies the hybrid block degrades to the teacher blocks. Next, we denote the probability of selecting the student path in the -th hybrid block as . Therefore, each student block is randomly replaced by the teacher blocks with probability . The swapped-in teacher blocks can interact with the student blocks to inspire the potential of the student.
In addition, the student blocks are replaced by the teacher blocks in a random manner, which means the teacher can guide the student in many different situations through interaction. In contrast, swapping in the teacher blocks by manually-defined manners allows the teacher to guide the student only in limited situations. Therefore, to traverse as many different situations as possible, the student blocks are replaced by the teacher blocks in a random manner.
Distillation phase
When the image features go through each hybrid block, the path is randomly chosen during the distillation phase. Let us consider two extreme situations. The first is that for all hybrid blocks. The student path is chosen in every hybrid block and the hybrid network becomes the student network. The second is that for all hybrid blocks. Under such circumstances, all teacher paths are chosen, and the hybrid network becomes the teacher network. In other cases (), the input randomly goes through the student path or the teacher path in each hybrid block. The swapped-in teacher blocks interact with the student blocks, thus they can respond to the output of the previous student block and further provide better features to motivate the following student block. Before distillation phase, the parameters of the teacher blocks in each hybrid block are loaded from the corresponding teacher blocks in the pretrained teacher network. Next, during distillation process, those parameters are frozen, and the batch normalization layers still use the mini-batch statistics. The student block in each hybrid block, and other shared parts are randomly initialized. The optimized loss function of the hybrid network can be formulated as
| (5) |
where is the task-specific loss. denotes the ground truth. is the predicted result of the hybrid network. At each iteration, only the student parts which the feature maps go through are updated (the shared parts are considered as the student parts since they are trained from scratch).
Comparing Eq. 5 with Eq. 1, we can see our proposed method does not need the additional distillation losses to drive the knowledge distillation process. Therefore, laboriously searching the optimal hyper-parameters to balance the task-specific loss and different distillation losses can be avoided. Besides, the complicated knowledge transformation and extra forward computation of the teacher network are unnecessarily required by our proposed method, leading to an efficient distillation process (see Sec. IV-D for training time comparison).
Test phase
Since knowledge distillation aims at improving the performance of the student network, we just test the whole student network to check whether the student can achieve performance improvement or not. For convenient validation, we fix the probability to 1 in the test phase. Under this circumstances, the hybrid network becomes the student network during the test phase. Meanwhile, for practical deployment, it is not reasonable to directly use the cumbersome hybrid network. We can reduce the burden of resource consumption by separating the student network from the hybrid network for further inference.
III-C Probability Schedule
The interaction level between the teacher network and the student network is controlled by . The smaller value of indicates the student network has more interaction with the corresponding teacher blocks. For simplicity, we assume , which suggests that every hybrid block shares the same interaction rule. To properly utilize the interaction mechanism, we propose three kinds of probability schedules for the change of : 1) uniform schedule, 2) linear growth schedule and 3) review schedule. These schedules are discussed in detail as follows.

Uniform schedule
The simplest probability schedule is to fix for all epochs during the distillation phase. This means the interaction level does not change. See Fig. 3(a) for a schematic illustration.
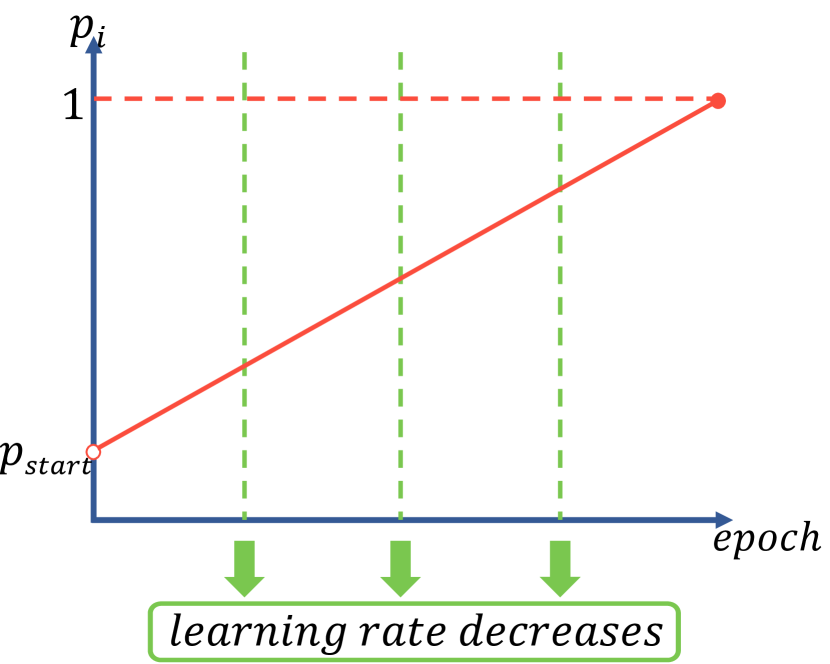
Linear growth schedule
With the epoch increasing, the teacher network could participate less in the distillation process as [21, 18, 19] do, because the student network gradually becomes more powerful to handle the task by itself. Thus, we set the value of according to a function of the number of epoch, and propose a simple linear growth schedule. The probability of choosing the student path in each hybrid block increases linearly from for the first epoch to for the last epoch (see Fig. 3(b)). The linear growth schedule indicates that as the knowledge distillation process proceeds, the interaction level between the student and the teacher gradually decreases. Vividly speaking, the teacher teaches the student through frequent interaction in early epochs, and the student attempts to solve the problem by himself in late epochs.
Review schedule
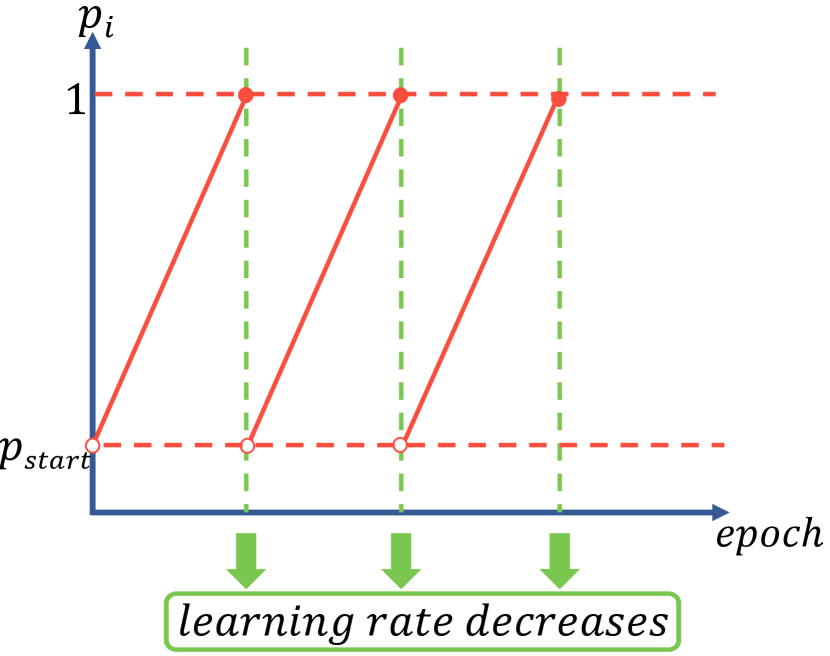
The proposed schedules above ignore the change of the learning rate during training. When the learning rate decreases, the optimization algorithm narrows the parameter search radius for more refined adjustments. Thus, we reset to when the learning rate decreases so that the teacher can re-interact with the student for better guidance. Within the interval where the learning rate remains unchanged, the probability increases linearly from to . Fig. 3(c) shows a schematic illustration. We call this kind of probability schedule as the review schedule because it is like the teacher gives review lessons after finishing a unit so that the student can grasp the knowledge more firmly.
The effectiveness of different probability schedules will be validated experimentally in Sec. IV-A.
IV Experiments
In this section, we first investigate the effectiveness of different probability schedules and then conduct a series of experiments to analyze the impact of the interactive mechanism on the distillation process. At last, we compare our proposed IAKD with conventional, non-interactive methods on several public classification datasets to demonstrate the superiority of our proposed method.
IV-A Different Probability Schedules
To investigate the effectiveness of different probability schedules, we conduct experiments on CIFAR-10 [22] and CIFAR-100 [22] datasets. The CIFAR-10 dataset consists of 60000 images of size in 10 classes. The CIFAR-100 dataset [22] has 60000 images of size from 100 classes. For all experiments in this subsection, we use SGD optimizer with momentum 0.9 to optimize the hybrid network. We set batchsize to 128 and set weight decay to . The hybrid network is trained for 200 epochs. The learning rate starts at 0.1 and is multiplied by 0.1 at 100, 150 epochs. Images of size are randomly cropped from zero-padded images. Each image is horizontally flipped with a probability of 0.5 for data augmentation.
IV-A1 Uniform Schedule
We first conduct experiments with the uniform schedule mentioned in Sec. III-C. We employ ResNet [29] as our base network architecture and denote ResNet-d as the ResNet with a specific depth d. ResNet-44 and ResNet-26 are used as the teacher/student (T/S) pair. Therefore, in each hybrid block, there is one student block in the student path, and two teacher blocks in the teacher path.
The experimental results are shown in Fig. 4. Note that and are not reasonable options. When , we train the teacher network with many frozen pretrained blocks. When , we just train the student network individually without interaction. As we can see from Fig. 4, IAKD with the uniform schedule (denoted as IAKD-U for short) can actually improve the performance of the student network when the value of is large (CIFAR-10: , CIFAR-100: ). However, we notice that the performance of the student drops dramatically when the value of is small (for example, for both CIFAR-10 and CIFAR-100). This is due to the small value of results in frequently choosing the teacher path in each hybrid block, which leads to the insufficient training of the student network.


IV-A2 Linear Growth Schedule
We still employ ResNet-44/ResNet-26 as the T/S pair when conducting experiments with the linear growth schedule. In this schedule, increases linearly from for the first epoch to 1 for the last epoch. During early epochs when the value of is relatively small, the selected student blocks and the shared parts frequently interact with the frozen teacher blocks, which means those blocks are supposed to have better initialization when the value of is relatively large in late epochs (when the hybrid network is more “student-like”). As gradually increases, the hybrid network transitions from “teacher-like” to “student-like”. Such distillation process is related to the two-stage knowledge distillation methods [21, 18, 19]. In these methods, the student network is better initialized based on the distillation losses in the first stage, and is trained for the main task based on the task-specific loss in the second stage. However, the two-stage knowledge distillation methods make the abrupt transition from the initialization stage to the task-specific training stage. As a result, the teacher’s knowledge may disappear as the training process proceeds, because the teacher is not involved in guiding the student in the second stage. On the contrary, as increases linearly, IAKD makes a smooth transition to the task-specific training.
The experimental results of IAKD with linear growth schedule (denoted as IAKD-L) are shown in Fig. 5. Comparing Fig. 5 with Fig. 4, we have two main observations. The first is IAKD-L improves the original student performance on almost every value of while IAKD-U only works for large . The second is the best distillation results of IAKD-L on both CIFAR-10 and CIFAR-100 datasets are better than the ones of IAKD-U. These two observations indicate that, as the student network becomes powerful, the interaction is more effective between the teacher network and student network when at a gradually reduced rate other than a fixed level.


IV-A3 Review Schedule
For fair comparison, we employ ResNet-44/ResNet-26 as the T/S pair to conduct experiments on IAKD with the review schedule (denoted as IAKD-R for short). The experimental results of IAKD-R are shown in Fig. 6. IAKD-R, which considers the change of learning rate, is actually an advanced version of IAKD-L. Comparing Fig. 6 with Fig. 5, IAKD-R could further improve the performance of the original student in contrast to IAKD-L. Even for very small value of , IAKD-R still provides improvement for the original student network.


| Method/Model | CIFAR-10 | CIFAR-100 |
| ResNet-44 (Teacher) | 92.91% | 71.07% |
| ResNet-26 (Student) | 92.01% | 68.94% |
| IAKD-U | 92.55%0.11% (0.9) | 69.54%0.32% (0.9) |
| IAKD-L | 92.71%0.24% (0.7) | 69.74%0.19% (0.3) |
| IAKD-R | 92.77%0.13% (0.9) | 70.18%0.31% (0.1) |
For more clearly comparison, we summarize the best results of different probability schedules in Tab. I. It can be seen that IAKD-R obtains the highest classification accuracy in comparison with IAKD-U and IAKD-L on both CIFAR-10 and CIFAR-100 datasets. From above discussions and comparisons, we can conclude that compared with uniform schedule and linear growth schedule, review schedule is the most effective interaction mechanism which makes the teacher network re-interact with the student network once the learning rate decreases. Thus, we take the review schedule as our final probability schedule setting when comparing with other state-of-the-art knowledge distillation methods. Besides, it is worth noticing that for IAKD-L and IAKD-R, we need to set to a small value when the number of classes is large, while we need to set to a large value when the number of classes is small. This reflects that the distillation process can be assisted well by adequate interaction based on the difficulty of a certain task.
Moreover, to ensure the generalization of the proposed review schedule, we conduct more experiments with different schedules, using different architecture combinations. The value of in each probability schedule on CIFAR-100 is the same as the one in Tab. I. Experimental results are shown in Tab. II. As we can see, review schedule (i.e.,IAKD-R) consistently outperforms other two schedules (IAKD-U and IAKD-L) and can achieve promising performance improvement over the student networks in different teacher/student settings, proving the generalization of the review schedule.
| Setup | (a) | (b) | (c) |
| Teacher | ResNet-18 [29] | VGG-19 [30] | ResNet-50x4 [29] |
| Student | VGG-8 [30] | VGG-11 [30] | ShuffleNet-v1 [31] |
| Teacher | 72.32% | 72.74% | 72.79% |
| Student | 68.91% | 68.84% | 67.11% |
| IAKD-U (=0.9) | 69.60%(0.12%) | 70.21%(0.27%) | 66.13%(0.41%) |
| IAKD-L (=0.3) | 68.98%(0.20%) | 69.96%(0.30%) | 66.47%(0.27%) |
| IAKD-R (=0.1) | 69.80%(0.23%) | 70.94%(0.15%) | 68.25%(0.10%) |
IV-B Study of Interaction Mechanism
In this subsection, the training settings are the same with those in Sec. IV-A. Each experiment is repeated 5 times, and we take the mean value as the final result.
IV-B1 Without Interaction
By randomly swapping in the teacher blocks at each iteration, we achieve the interaction between the teacher and the student. To investigate the effectiveness of the interaction mechanism, we turn off the interaction between the teacher network and the student one during the distillation process, i.e.,we do not replace the student block with the corresponding teacher blocks. Correspondingly, taking the whole pretrained teacher network and the student network, we force the output of each student block to be similar with the output of the corresponding teacher blocks. Given that IAKD randomly swaps in the teacher blocks to replace the student block, we can randomly measure the difference between the output of each student block and that of the corresponding teacher blocks. The student network is trained by the following loss function:
| (6) |
where is the ground truth. is the output of the student network. is the number of student blocks except the blocks shared by the teacher and the student. and are the outputs of the student block and the corresponding teacher blocks, respectively. NIA denotes No Interaction between the student and the teacher. is the cross-entropy loss. is the loss, penalizing the difference between and . denotes a Bernoulli random variable, and indicates whether the -th loss is added () or ignored (). We denote , which represents the probability of ignoring the -th loss. For simplicity and fair comparison, we set the probability schedule of to be the same as the probability schedule of in IAKD-U.
The experimental results are shown in Tab. III and Tab. IV. Comparing with IAKD-U when showing better performance improvement on CIFAR-10 () and CIFAR-100 (), the student networks trained without interaction (w/o IA) achieve slight performance improvement. This proves that interaction mechanism well assists the student to achieve much better performance.
IV-B2 Group-wise Interaction
Until now, we achieve IAKD by block-wise interaction (one student block pairs with several teacher blocks). To verify the effectiveness of block-wise interaction, we reduce the interaction level to group-wise [13] interaction (one student group pairs with one teacher group). For simplicity, we only choose IAKD-U to achieve group-wise interaction (denoted as IAKD-U-G). ResNet-44/ResNet-26 are employed as the T/S pair. As we can see from Tab. III and Tab. IV, IAKD-U outperforms IAKD-U-G on both datasets. Besides, IAKD-U-G fails to achieve performance improvement on CIFAR-100, because of the significant decrease in the interaction level caused by the group-wise interaction. The student blocks, except the first or the last one in each group, have no chance to interact with the teacher blocks.
| Model | w/o IA | IAKD-U-G | IAKD-U | |
|---|---|---|---|---|
| ResNet-44 (Teacher) | 92.91% | - | ||
| ResNet-26 (Student) | 92.01% | - | ||
| ResNet-26 | 92.10%(0.02%) | 92.05%(0.21%) | 92.11%(0.41%) | 0.7 |
| ResNet-26 | 92.18%(0.05%) | 92.28%(0.05%) | 92.31%(0.30%) | 0.8 |
| ResNet-26 | 92.18%(0.06%) | 92.37%(0.05%) | 92.55%(0.11%) | 0.9 |
| Model | w/o IA | IAKD-U-G | IAKD-U | |
| ResNet-44 (Teacher) | 71.07% | - | ||
| ResNet-26 (Student) | 68.94% | - | ||
| ResNet-26 | 69.20%(0.15%) | 68.68%(0.16%) | 69.54%(0.32%) | 0.9 |
IV-C Discussions about More Knowledge Distillation Points
From the view of the conventional, non-interactive knowledge distillation methods, the end of each set of swapped-in teacher blocks can be regarded as the knowledge distillation point where the knowledge of the teacher network is transferred to the student network. Randomly swapping in the teacher blocks to replace the student blocks implicitly increases the number of knowledge distillation points. To verify more knowledge distillation points do not necessarily lead to more performance improvement and may even harm the student performance, we introduce more connections between the teacher and the student to multi-connection knowledge based methods (i.e.,AT [13] and FSP [18]). Accordingly, we modify AT to transfer attention maps at the end of each student block rather than the end of each group, and name it as 9-point AT because there are totally 9 knowledge distillation points. Similarly, we modify FSP to calculate the Gramian matrix by the input and the output of each student block instead of each group, and name it as 9-point FSP. The experiments are conducted by ResNet-44/ResNet-26 pair on CIFAR-10 and CIFAR-100 datasets.
| Model/Method | CIFAR-10 | CIFAR-100 |
|---|---|---|
| ResNet-44 (Teacher) | 92.91% | 71.07% |
| ResNet-26 (Student) | 92.01% | 68.94% |
| 9-point AT | 92.01%(0.19%) | 69.56%(0.22%) |
| AT | 92.55%(0.12%) | 69.72%(0.17%) |
| 9-point FSP | 92.45%(0.27%) | 69.07%(0.43%) |
| FSP | 92.47%(0.06%) | 69.10%(0.34%) |
| IAKD-R (Ours) | 92.77%(0.13%) | 70.18%(0.31%) |
Experimental results are shown in Tab V. It turns out, for conventional, non-interactive knowledge distillation methods, more knowledge distillation points do not necessarily lead to more performance improvement. For AT, more distillation points even make the distillation performance worse than the performance of the original AT. This is because excessive supervision causes a hard constraint for the student network. However, as shown in Tab. I and Tab. II, introducing more possible distillation points even improves the distillation performance of our proposed IAKD.
IV-D Comparison with State-of-the-arts
We compare our proposed IAKD-R with other representative state-of-the-art knowledge distillation methods: HKD [12], AT [13], FSP [18], Feature distillation [15], AB [19], VID-I [25] and RKD-DA [14]. As the discussion above, all these comparison methods are non-interactive. We conduct experiments on three datasets: CIFAR-10 [22], CIFAR-100 [22], and TinyImageNet [32]. TinyImageNet contains images of size with 200 classes. Each experiment is repeated 5 times, and we take the mean value as the final report result. For other compared methods, we directly use the author-provided codes if publicly available, or implement those methods based on the original paper. The hyper-parameters of contrastive methods are listed as follows.
- 1.
- 2.
- 3.
-
4.
AB [19]: No balance factor for the task-specific loss and the distillation loss because the distillation is in the initialization stage where only the distillation loss applies. In the initialization stage, there are three hyper-parameters: , and to balance the different terms of the distillation loss. We set , and to , , and , respectively (See [19] for explanations of these hyper-parameters).
- 5.
- 6.
- 7.
For fair comparison, the optimization configurations are identical for all methods on one dataset.
| Method | Model | CIFAR-10 | CIFAR-100 | TinyImageNet | |||
|---|---|---|---|---|---|---|---|
| Size/FLOPs | Top-1 | Size/FLOPs | Top-1 | Size/FLOPs | Top-1 | ||
| Teacher | ResNet-44/80∗ | 0.66M/98.51M | 92.91% | 0.67M/98.52M | 71.07% | 1.26M/737.24M | 55.73% |
| Student | ResNet-26 | 0.37M/55.62M | 92.01% | 0.38M/55.62M | 68.94% | 0.38M/222.47M | 50.04% |
| HKD [12] | 92.90%(0.19%) | 69.59% (0.26%) | 50.25%(0.46%) | ||||
| AT [13] | 92.55%(0.12%) | 69.72%(0.17%) | 52.07%(0.21%) | ||||
| FSP [18] | 92.47%(0.06%) | 69.10%(0.34%) | 50.97%(0.50%) | ||||
| AB [19] | 92.59%(0.16%) | 69.40%(0.42%) | 48.48%(2.96%) | ||||
| VID-I [25] | 92.48%(0.10%) | 69.90%(0.23%) | 51.98%(0.15%) | ||||
| RKD-DA [14] | 92.70%(0.16%) | 69.46%(0.39%) | 51.69%(0.43%) | ||||
| Feature distillation [15] | 92.29%(0.10%) | 69.11%(0.17%) | 52.56%(0.22%) | ||||
| IAKD-R (Ours) | 92.77%(0.13%) | 70.18%(0.31%) | 53.28%(0.13%) | ||||
| IAKD-R+HKD (Ours) | 93.31%(0.08%) | 71.02%(0.16%) | 53.50%(0.31%) | ||||
-
•
∗ResNet-44 is used as the teacher on CIFAR-10 and CIFAR-100, while ResNet-80 is used as the teacher on TinyImageNet.
For CIFAR-10 and CIFAR-100, we use the same optimization configurations as described in Sec. IV-A. Specially, for two-stage methods like FSP and AB, 50 epochs are used for initialization and 150 epochs are used for classification training. The learning rate at the initialization stage is 0.1 and 0.001 for AB and FSP, respectively. For AB and FSP, the initial learning rate at the classification training stage is 0.1, and is multiplied by 0.1 at 75, 110 epochs. For TinyImageNet, we employ ResNet-80/ResNet-26 as the T/S pair. Horizontal flipping is applied for data augmentation. We optimize the network using SGD with batchsize 128, momentum 0.9 and weight decay . The number of total training epochs is 300. The initial learning rate is 0.1 and is multiplied by 0.2 at 60, 120, 160, 200, 250 epochs. Specially, for FSP and AB, 50 epochs are used for initialization and 250 epochs are used for classification training. The learning rate at the initialization stage is 0.1 and 0.001 for AB and FSP, respectively. For AB and FSP, the initial learning rate at the classification training is 0.1, and is multiplied by 0.2 at 60, 120, 160, 200 epochs.
For the proposed IAKD, we use the review schedule as the final probability schedule setting. is set to 0.9 for comparison on CIFAR-10, and is set to 0.1 for comparison on CIFAR-100 and TinyImageNet. The configurations are based on the experimental results and arguments in Sec. IV-A3.
In Tab. VI, we list the comparison results on CIFAR-10, CIFAR-100, and TinyImageNet by different methods. As we can see, the proposed IAKD improves the performance of the student network more effectively than most contrastive methods. Meanwhile, the distillation result of IAKD is competitive with HKD on CIFAR-10. We then combine HKD with our proposed IAKD through adding distillation loss to Eq. 5, and denote it as IAKD-R+HKD. Surprisingly, IAKD-R+HKD even outperforms the performance of the original teacher on CIFAR-10. On CIFAR-100 and TinyImageNet, IAKD-R+HKD outperforms all other contrastive methods. IAKD-R also shows highly competitive results on CIFAR-100 and TinyImageNet. In addition, our proposed method, robust as we can see, consistently achieves significant performance improvement on three datasets while most other contrastive methods do not.
Advantages on learning efficiency. Our proposed IAKD-R is also benefited from better learning efficiency. Conventional knowledge distillation methods update all student blocks along the whole training iterations. Our work reveals that this laborious distillation is not necessary for promising performance. In our IAKD-R, the student blocks replaced by the teacher ones will not be updated at that iteration. Thus, in each training iteration, a portion of the student network is updated. For the possible replaced student block, our training epochs number, the mathematical expectation, is 190, 110 and 165 on CIFAR-10, CIFAR-100 and TinyImageNet, respectively, which accounts for 95%, 55% and 55% of other contrastive methods on corresponding datasets. This demonstrates that our IAKD-R enjoys efficient learning capacity, and also validates that the student network indeed benefits well from the interaction with the teacher network.
As mentioned in Sec. I, our proposed IAKD discards the cumbersome knowledge transformation process and gets rid of the feature extraction of the entire teacher network, we compare the training time of different knowledge distillation methods, using ResNet-80/ResNet-26 teacher-student pair on TinyImageNet dataset. We conduct training time comparison on a single NVIDIA RTX 2080Ti GPU with Intel Core i7-8700 CPU and PyTorch framework. As shown in Tab. VII, our proposed method gives a highly competitive result in contrast to other methods. It only needs 4 hours and 40 minutes to complete the training process of the student network, which reflects that the high training efficiency of our proposed IAKD.
IV-E Different Architecture Combinations
To ensure the applicability of IAKD, we explore more architecture combinations on CIFAR-100, as shown in Tab. VIII. We replace the “Conv33-BN-ReLU” with “group Conv33-BN-ReLU-Conv11-BN-ReLU” to achieve the cheap ResNet, as suggested by [33]. The experimental settings are the same as those described in Sec. IV-D. As we can see from Tab. VIII, in all the architecture combinations, IAKD-R and IAKD-R+HKD can consistently achieve performance improvement over the student network. On the other hand, contrastive methods give different knowledge distillation performance in different settings. In the case of (a), only IAKD-R and IAKD-R+HKD can successfully achieve performance improvement over the student cheap ResNet-26. AT and RKD-DA fail to improve the student performance in the case of (b). RKD-DA and AB fail to achieve performance improvement in the case of (d). Therefore, the proposed IAKD, a novel knowledge distillation method without additional distillation losses, can also achieve promising performance improvement in different teacher/student settings.
| Setup | (a) | (b) | (c) | (d) |
| Teacher | ResNet-44 [29] | ResNet-18 [29] | VGG-19 [30] | ResNet-50x4 [29] |
| Student | cheap ResNet-26 | VGG-8 [30] | VGG-11 [30] | ShuffleNet-v1 [31] |
| Teacher | 71.07% | 72.32% | 72.74% | 72.79% |
| Student | 65.92% | 68.91% | 68.84% | 67.11% |
| HKD [12] | 65.55%(0.40%) | 70.63%(0.27%) | 71.09%(0.13%) | 68.58%(0.43%) |
| AT [13] | 65.90%(0.37%) | 68.54%(0.40%) | 70.93%(0.14%) | 68.13%(0.30%) |
| RKD-DA [14] | 65.66%(0.21%) | 68.69%(0.31%) | 70.84%(0.14%) | 66.69%(0.38%) |
| AB [19] | 65.64%(0.76%) | 69.86%(0.24%) | 71.21%(0.27%) | 66.89%(1.46%) |
| IAKD-R | 67.15%(0.33%) | 69.80%(0.23%) | 70.94%(0.15%) | 68.25%(0.10%) |
| IAKD-R+HKD | 66.11%(0.72%) | 70.51%(0.22%) | 71.76%(0.21%) | 68.65%(0.29%) |
V Conclusion
In this paper, we proposed a simple yet effective knowledge distillation method named Interactive Knowledge Distillation (IAKD). By randomly swapping in the teacher blocks to replace the student blocks in each iteration, we accomplish the interaction between the teacher network and the student one. To properly utilize the interaction mechanism during distillation process, we proposed three kinds of probability schedules. Our IAKD does not need additional distillation losses to drive the distillation process, and is complementary to conventional knowledge distillation methods. Extensive experiments demonstrated that the proposed IAKD could boost the performance of the student network on diverse image classification tasks. Instead of mimicking the teacher’s feature representation space, our proposed IAKD aims to directly leverage the teacher’s powerful feature transformation ability to motivate the student, providing a new perspective for knowledge distillation.
References
- [1] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in CVPR, 2017.
- [2] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in CVPR, 2019.
- [3] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in CVPR, 2019.
- [4] Z. Li, J. Yang, Z. Liu, X. Yang, G. Jeon, and W. Wu, “Feedback network for image super-resolution,” in CVPR, 2019.
- [5] S.-H. Gao, M.-M. Cheng, K. Zhao, X.-Y. Zhang, M.-H. Yang, and P. Torr, “Res2net: A new multi-scale backbone architecture,” IEEE TPAMI, 2020.
- [6] P. Luo, Z. Zhu, Z. Liu, X. Wang, and X. Tang, “Face model compression by distilling knowledge from neurons,” in AAAI, 2016.
- [7] G. Chen, W. Choi, X. Yu, T. Han, and M. Chandraker, “Learning efficient object detection models with knowledge distillation,” in NeurIPS, 2017.
- [8] Y. Chen, N. Wang, and Z. Zhang, “Darkrank: Accelerating deep metric learning via cross sample similarities transfer,” in AAAI, 2018.
- [9] T. Wang, L. Yuan, X. Zhang, and J. Feng, “Distilling object detectors with fine-grained feature imitation,” in CVPR, 2019.
- [10] Y. Liu, K. Chen, C. Liu, Z. Qin, Z. Luo, and J. Wang, “Structured knowledge distillation for semantic segmentation,” in CVPR, 2019.
- [11] Y. Hou, Z. Ma, C. Liu, and C. C. Loy, “Learning lightweight lane detection cnns by self attention distillation,” in ICCV, 2019.
- [12] G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” in NeurIPS Deep Learning and Representation Learning Workshop, 2015.
- [13] S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer,” in ICLR, 2017.
- [14] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in CVPR, 2019.
- [15] B. Heo, J. Kim, S. Yun, H. Park, N. Kwak, and J. Y. Choi, “A comprehensive overhaul of feature distillation,” in ICCV, 2019.
- [16] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” in ICLR, 2020.
- [17] S.-I. Mirzadeh, M. Farajtabar, A. Li, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assistant: Bridging the gap between student and teacher,” arXiv preprint arXiv:1902.03393, 2019.
- [18] J. Yim, D. Joo, J. Bae, and J. Kim, “A gift from knowledge distillation: Fast optimization, network minimization and transfer learning,” in CVPR, 2017.
- [19] S. Y. Byeongho Heo, Minsik Lee and J. Y. Choi, “Knowledge transfer via distillation of activation boundaries formed by hidden neurons,” in AAAI, 2019.
- [20] J. Ba and R. Caruana, “Do deep nets really need to be deep?” in NeurIPS, 2014.
- [21] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “Fitnets: Hints for thin deep nets,” in ICLR, 2015.
- [22] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Tech. Rep., 2009.
- [23] J. Kim, S. Park, and N. Kwak, “Paraphrasing complex network: Network compression via factor transfer,” in NeurIPS, 2018.
- [24] S. Hyun Lee, D. Ha Kim, and B. Cheol Song, “Self-supervised knowledge distillation using singular value decomposition,” in ECCV, 2018.
- [25] S. Ahn, S. X. Hu, A. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” in CVPR, 2019.
- [26] Y. Liu, J. Cao, B. Li, C. Yuan, W. Hu, Y. Li, and Y. Duan, “Knowledge distillation via instance relationship graph,” in CVPR, 2019.
- [27] S. Lee and B. C. Song, “Graph-based knowledge distillation by multi-head self-attention network,” in BMVC, 2019.
- [28] F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in ICCV, 2019.
- [29] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016.
- [30] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in ICLR, 2015.
- [31] X. Zhang, X. Zhou, M. Lin, and J. Sun, “Shufflenet: An extremely efficient convolutional neural network for mobile devices,” in CVPR, 2018.
- [32] L. Yao and J. Miller, “Tiny imagenet classification with convolutional neural networks,” CS 231N, 2015.
- [33] E. J. Crowley, G. Gray, and A. J. Storkey, “Moonshine: Distilling with cheap convolutions,” in NeurIPS, 2018.