Inter-BIN: Interaction-based Cross-architecture IoT Binary Similarity Comparison
Abstract
The big wave of Internet of Things (IoT) malware reflects the fragility of the current IoT ecosystem. Research has found that IoT malware can spread quickly on devices of different processer architectures, which leads our attention to cross-architecture binary similarity comparison technology. The goal of binary similarity comparison is to determine whether the semantics of two binary snippets is similar. Existing learning-based approaches usually learn the representations of binary code snippets individually and perform similarity matching based on the distance metric, without considering inter-binary semantic interactions. Moreover, they often rely on the large-scale external code corpus for instruction embeddings pre-training, which is heavyweight and easy to suffer the out-of-vocabulary (OOV) problem. In this paper, we propose an interaction-based cross-architecture IoT binary similarity comparison system, Inter-BIN. Our key insight is to introduce interaction between instruction sequences by co-attention mechanism, which can flexibly perform soft alignment of semantically related instructions from different architectures. And we design a lightweight multi-feature fusion-based instruction embedding method, which can avoid the heavy workload and the OOV problem of previous approaches. Extensive experiments show that Inter-BIN can significantly outperform state-of-the-art approaches on cross-architecture binary similarity comparison tasks of different input granularities. Furthermore, we present an IoT malware function matching dataset from real network environments, CrossMal, containing 1,878,437 cross-architecture reuse function pairs. Experimental results on CrossMal prove that Inter-BIN is practical and scalable on real-world binary similarity comparison collections.
Index Terms:
IoT malware, binary analysis, code similarity comparison, cross-architecture interaction, deep neural network.I Introduction
I-A Background and Motivation
Binary code similarity comparison (or matching) aims to detect whether the semantics of two given pieces of binary code are similar or not. It is a significant issue in software security analysis and has a wide range of application scenarios, such as vulnerability detection, malware analysis, software plagiarism detection, and code authorship verification. Recently, security issues in new application scenarios have led us to pay attention to cross-architecture binary similarity analysis, including the big wave of Internet of Things (IoT) malware [1] [2]. As the extension and development of the Internet, IoT technology has been widely used in various industries, such as intelligent transportation, smart medical care, and industrial control systems, which greatly facilitate our lives. The fast-developing IoT system introduces a wide variety of devices, and the platforms and functions of the devices are highly heterogeneous. It is estimated that by 2025, there will be more than 30 billion IoT connections worldwide, with nearly four IoT devices per person 111https://iot-analytics.com/iot-2020-in-review/. Due to the rapid increase in demand for IoT devices and applications, developers are focused on quickly implementing the core functions of their products and launching them on the market, while the security issues of the IoT environment have not received sufficient attention. Many IoT devices and software have not yet reached the current security standards and suffer vulnerabilities and weaknesses, making them a new hot target of malware developers. In 2016, the malware family Mirai infected hundreds of thousands of IoT devices and operated them to launch large-scale DDoS attacks, causing massive damage and reflecting the fragility of the current IoT ecosystem[3].
Compared with the malware families of desktops and the Android platform that have been extensively studied, the analysis for the IoT malware is currently not comprehensive and systematic enough. Previous research deploys IoT honeypots to simulate fragile IoT devices and capture malware instances for in-depth analysis. The designers of IoTPOT [4] and IoTCMal [5] found that some malware families evolved rapidly in a short period and quickly reused and disseminated on a large number of devices of diverse CPU architectures. Based on this characteristic, a practical cross-architecture binary code matching solution can help efficiently discover malware targeting the IoT devices of different architectures.
Cross-architecture binary similarity comparison is non-trivial because different architectures have separate instruction sets with different mnemonics, CPU registers, calling conventions, and memory access strategies [6] [7]. Figure1 shows the assembly code compiled from the same code snippet separately on x86 and ARM architectures, and the generated instruction sequences look completely different. We compile several popular Linux packages on x86 and ARM for quantitative statistical analysis. Figure2 is the cumulative distribution function (CDF) of assembly code difference rate complied from the same source code. Under the same compiler and optimization level, the cross-architecture function pairs have an average of 58.34% code differences. Therefore, it is difficult to determine whether a pair of cross-architecture binaries are similar or not by matching the lexical and syntax characteristics of their instruction sequence.

Moreover, we consider that a binary comparison approach should be able to support different input granularities flexibly. Malware developers may reuse malicious modules and functions of existing instances, or deconstruct the benign program’s functions and only add small code pieces to inject malicious behavior. Code copyists may splice and rearrange the original procedures or functions to hide their plagiarism intentions. In these cases, coarse-grained binary semantic similarity comparison like whole program level is difficult to discover suspicious behavior or detect software plagiarism accurately.
Motivated by the practical value of the cross-architecture binary similarity comparison problem, our goal is to implement a multi-granularity universal binary matching framework, which can match semantically similar binaries from different architectures, and provide efficient and scalable defense solutions for cross-architecture reuse IoT malware threats.
I-B Limitation of Prior Art
Traditional binary similarity analysis approaches compare the functions of the code by monitoring their runtime behavior [8] [9] or extracting syntax features of binary sequences [10] [11]. Recently, researchers propose learning-based approaches to improve the binary comparison accuracy and scalability in cross-architecture scenarios. A binary file, after disassembled, is represented as an assembly instruction sequence, and each instruction is composed of an opcode and zero to several operands. INNEREYE [12] is a state-of-the-art approach modeling binary fragments by RNN layers and using cosine similarity as the semantic comparison metric. The disadvantage of INNEREYE is that the encoding process of the two input instruction sequences is trained individually, without considering the correlation of semantically similar instructions from different architectures. Redmond et al. [13] associate cross-architecture instruction pairs through linear mapping of their position indexes within the sequences. However, this hard alignment way is not accurate because the number and order of instructions in a pair of similar binary snippets from separate platforms may be very different, as shown in figure 1. Faced with the above challenges, we introduce an inter-sequence interaction scheme that can realize the precise soft alignment of cross-architecture semantically related instruction pairs.
Another limitation of previous learning-based binary comparison work is that they often rely on the large-scale external code corpus to pre-train instruction embeddings (i.e., numerical vectors) [12] [13] [14] [15]. The collection and processing of the code corpus are labor-intensive, and this method easily suffers the out-of-vocabulary (OOV) problem. Specifically, the OOV problem occurs because the external binary corpus collected for pre-training cannot comprehensively include disassembly instructions in various compilation environments. Therefore, there are instructions of the input binary pieces that are not appeared in the pre-trained instruction vocabulary, and we cannot obtain their corresponding embeddings for the subsequent binary semantic comparison process. OOV is a well-known problem in the natural languages processing field. With IoT binary similarity comparison as the target domain, this problem will be severe since the binaries are likely to be compiled from various platforms and compile settings, so it is unrealistic to train a comprehensive vocabulary covering all possible dissambly instructions.
To solve this problem, we consider modeling instructions based on the fusion of multiple lightweight features. We build a character (char) dictionary table for cross-architecture instructions. The character-level (char-level) processing way can effectively reduce the vocabulary scale. INNEREYE’s vocabulary size reached 49,760 under one compiler setting and two architectures, while the size of our char table can be controlled to dozens, and we almost ensure that OOV will not occur. Then we perform opcode embedding and operands attributes extraction to learn more precise instruction semantic information. We fuse the char-level spatial instruction features and the semantic features to generate meaningful instruction representations without pre-training.

I-C Proposed Approach
In this paper, we propose an interaction-based cross-architecture IoT binary similarity comparison approach, Inter-BIN. Given assembly instruction sequences from different architectures, we devise a multi-feature fusion method to fully extract the semantic information of instructions without relying on the context information provided by the external code collections. Specifically, we first extract instructions’ spatial features by a character (char) embedding layer and a 1-D convolutional layer, which can generate meaningful char-level n-gram patterns. Then we extract statistical attributes of the preprocessed instruction and conduct an opcode embedding layer and operands feature mapping layer to further characterize the instructions. The captured semantic features of different views are concatenated as the final instruction embedding vectors. We use Bi-directional Long Short-Term Memory (Bi-LSTM) encoders to model the context information and generate representations of the two instruction sequences. To realize the information interaction between the instruction sequences, we perform automatic soft alignment of cross-architecture instructions by a co-attention mechanism. It will assign high weights to the instruction pair with high semantic correlation. Finally, we concatenate the sequence representations enhanced by interaction and use a fully-connected layer to determine their similarity comparison result.
The key insight of our method is to introduce inter-sequence interaction scheme into the cross-architecture IoT binary similarity matching problem for finding similar functional instruction pairs with different lexical and syntax expressions. To the best of our knowledge, this is the first work that uses a deep neural network with an interaction mechanism for cross-architecture binary comparison. Moreover, the instruction representation module of Inter-BIN fuses multiple lightweight instruction features without relying on the large-scale external code corpus for instruction pre-training. It can significantly reduce the workload, and can adaptively replace the instruction embedding module of the existing binary similarity comparison approaches, alleviating their performance loss when suffering serious OOV problems on the evaluation dataset.

I-D Key Contributions
We summarize our major contributions as follows:
-
•
We propose an IoT binary similarity comparison approach introducing semantic interaction between different architectures’ instruction sequences. It performs automatic flexible soft alignment of instruction pairs and models their functional correlations, which significantly improves the cross-architecture binary matching accuracy. And we devise a multi-feature fusion-based instruction embedding method, which can avoid the heavy workload and the OOV problem of commonly used instruction pre-training approaches.
-
•
We implement our solution as an interaction-based cross-architecture IoT binary similarity comparison system, Inter-BIN. Inter-BIN can receive binary snippets of different granularities, perform end-to-end binary representation and inter-binary interaction process, and accurately matching input pairs with similar semantics.
-
•
We conduct extensive evaluations and results show that Inter-BIN achieves high accuracy on both basic block level (AUC = 0.99) and function level (precision@1 = 0.85 to 0.96) inputs, significantly outperforms state-of-the-art cross-architecture binary comparison approaches.
-
•
We present CrossMal, a large-scale IoT malware dataset collected from wild network environments containing 1,878,437 cross-architecture reuse function pairs, involving seven malware families such as Mirai, Gafgyt, and Hajime. Evaluation and case analysis on CrossMal prove that Inter-BIN is practical and scalable in real-world IoT scenarios.
II Problem Defination
In this section, we formalize the cross-architecture binary similarity comparison problem as follows:
Given two binary code pieces and compiled on different architectures with separate instruction sets, our goal is to compute their semantic similarity score ranging from 0 to 1. 0 represents their semantics are completely different, and 1 denotes they are semantically equivalent. Semantic similarity score can measure the functional similarity of code pieces. If and are semantically equivalent, they will produce exactly the same output when given the same input.
We determine the semantic similarity of and based on their corresponding disassembly instruction sequences and . and indicate the length of the two instruction sequences. denotes the position assembly instruction of . As demonstrated in section I.A, the lexical and syntax expressions of similar functional instruction pairs compiled on different architectures may be completely different, indicating cross-architecture binary similarity comparison is a nontrivial task.
III System Overview
Inter-BIN is an end-to-end interaction-based cross-architecture binary code similarity comparison system. Figure3 shows the overall workflow of Inter-BIN, including four modules to implement its functionality:
-
•
Multi-feature fusion-based instruction representation module: We disassemble IoT binaries and preprocess the instructions, extract their character sequences and statistics attributes. Then we extract the instruction’s spatial features by char-level embedding and a 1-D convolutional layer, and use an opcode embedding layer and an operand feature linear mapping layer to learn deeper semantic information of the instruction. We fuse the learned vectors as the final representation of the instruction.
-
•
Instruction Sequence Encoding module: This module uses Bi-LSTM to encode instruction sequence streams, generating sequence representations with bidirectional context information. The parameters of instruction representation layers and the sequence encoding layer are shared among binaries of different architectures.
-
•
Cross-architecture interaction module: This module performs automatic soft alignment of cross-architecture instruction pairs as an inter-sequence interaction schema, which can associate instructions with relevant functional semantics but different lexical and syntax expressions.
-
•
Binary similarity matching module: We concatenate cross-architecture instruction sequence representations enhanced by the interaction module, and use a fully connected layer to generate binary matching result.
We will elaborate on the specific technical implementation of each module in section IV, section V, section VI, and section VII.
IV Multi-feature Fusion-based Instruction Representation
To avoid the laborious workload and the out-of-vocabulary (OOV) problem of instruction pre-training methods, we design an instruction vectorization approach based on fusing multiple lightweight features, including char-level features, opcode features and operands features.
The iput of the multi-feature fusion-based instruction representation module is a pair of disassembled cross-architecture binary snippets and , which can be formalized as and . An assembly instruction is composed of an opcode and zero to more operands. The opcode specifies the operation to be conducted, and the operands specify literals, registers, or memory locations of the opcode. For each instruction, we first preprocess it to reduce the lexical gap among instructions of different architectures. We replace string literals, numeric literals, function names, and other symbolic constants with unified identifiers. Then we treat the preprocessed instruction as a whole target for vectorization.

Char-level features. We create a char dictionary table for the character sequences of the preprocessed assembly instructions. Unlike the large instruction vocabulary used by previous work [12] [15], the char dictionary table can be maintained at a small scale. The size of our char table is 58, containing 26 English letters, ten digits, and 22 special characters that may appear in the instruction, such as $, +, -, [, and ].
For the assembly instruction, we look up the position index of each character of the instruction in the char dictionary and express it as a one-hot encoding vector. The characters not appeared in the table are represented as all-zero vectors, while this phenomenon didn’t happen in our evaluation. Then we use a char embedding layer to map the one-hot vectors into discrete dense vectors. The char sequence of an instruction will be translated to a char embedding vector sequence.
We truncate the character vector sequence of the instruction to a fixed length and then use a 1-D convolutional layer to extract its char-level spatial features. The 1-D convolutional layer uses multiple convolution filters to slide on the instruction’s character sequence, capturing feature patterns from different perspectives. It is worth mentioning that a convolution kernel of size can generate a feature map containing char-level n-gram information as Equation 1:
| (1) |
is the feature generated by the convolution operation on the characters window . is the 1-D convolution filter and is a bias. is a non-linear activation function.
Char-level n-gram features are beneficial for the semantic characterization of disassembly instructions. For example, on the x86 architecture, opcodes “” have similar semantics. When setting to , their generated char 3-gram features will all contain the “” term, which implies that the instructions will execute operations related to data copies. Furthermore, although different CPU architectures have separate instruction sets, some opcodes with similar operations may have similar char-level lexical features. Such as ”” of the x86 architectures, and ”” of the ARM architecture will perform similar operations. Their char 3-grams will all contain ””. Our instruction representation layers are shared among different architectures. Similar char n-gram features extracted from disassembly instructions of different architectures will imply their semantic similarity information. It is beneficial for the cross-architecture instruction alignment of the subsequent module.
Completing the convolution operation on each character sliding window of size , the overall character sequence within an instruction of length will generate a feature map .
After the feature pattern extraction by the 1-D convolutional layer, we use a 1-D max-pooling layer to extract the most important char-level feature information in the temporal dimension of the feature map :
| (2) |
Opcode features. To further learn the semantic information of the assembly instructions, we set up the opcode feature extraction layer and the operands feature extraction layer to learn the corresponding representation.
For opcode, we construct an opcode lookup table for each architecture and generate a one-hot representation of the input instruction’s opcode type. Then we fed the one-hot vector into an embedding layer to generate the distributed opcode-based feature vector .
Operands features. For operands, we build a register dictionary table for each architecture, and extract the following statistical attributes: (1) The number of string literals. (2) The number of integer literals. (3) The number of functions names. (4) The number of other symbolic constants. (5) The one-hot vectors of the registers sequence. We concatenate the statistical information of operands and send it to a fully connected layer to generate the operands-based feature vector .
The overall multi-feature fusion-based instruction vectorization process is shown in Figure4. The char-based feature vector , opcode-based feature vector , and the operands-based feature vector of instruction are concatenated together as Equation 3 to generate the final output of the instruction representation module. The vectorized instruction representations will be used as input to the subsequent instruction sequence modeling module.
| (3) |
The output of the multi-feature fusion-based instruction representation module is the instruction representation sequences and .
V Instruction Sequence Encoding
After the multi-feature fusion-based instruction representation module, the binary pieces pair and are converted into and as the input of the instruction sequence encoding module. denotes the representation of the position instruction of . We use Bi-LSTM to encode the two instruction sequences. The LSTM network can alleviate the gradient disappearance and gradient explosion problems of the basic RNN recursive architecture and model long-distance dependence with better performance [16]. To better model the context-dependent information in the instruction sequence, we consider Bi-LSTM, which simultaneously maintains a forward hidden state and a backward hidden state at time step . The two hidden layer states are used to model the preceding and following information of current instruction, respectively. The overall -th step update process of Bi-LSTM hidden layer representation can be formalized as Equation 4:
| (4) |
represents the vector of the -th instruction in the sequence, and represents the Bi-LSTM hidden state of the -th step, which is formed by concatenating the forward and backward hidden states. We concatenate the bidirectional representations of each Bi-LSTM hidden state as the encoded instruction sequence embeddings of binary snippets and , represented as and . and are the output of the instruction sequence encoding module.
VI Cross-architecture Interaction

In this section, we introduce the semantic interaction between cross-architecture instruction sequence representations. The input of our cross-architecture interaction module is the instruction vector sequences and generated by the instruction sequence encoding module. Our goal is to flexibly and accurately associate instruction pairs with similar functions but different syntax expressions. We use the co-attention mechanism to achieve inter-sequence interactions, which can realize automatic soft alignment between instruction pairs by modeling their semantic correlation.
Figure5 shows the calculation of our co-attention based instruction sequence interaction process. For the instruction sequences pair and from different architectures, we first calculate the instruction semantical similarity matrix by a bilinear layer as Equation 5:
| (5) |
Then we get the attentive representation of under the guidance of , and vice versa:
| (6) |
| (7) |
and indicate the vectors of the instruction and in and generated by the sequence encoding module. represents their semantic similarity. is the parameter matrix of the bilinear layer. For the instruction representation in , we use the semantic similarity between it and each instruction vector of to calculate the attention coefficient through softmax. Then we perform a weighted summation to obtain the attentive representation . The instruction representation of is updated in the same way. The cross-architecture sequence interaction process is performed symmetrically in parallel.
To further enhance the effect of the interaction module, we follow [17] to perform multiple combination ways of the original instruction representation and the attentive representation , including concatenation, element-wise difference, and element-wise product. We concatenate the three enhanced results as and , then generate the final instruction representations and by a one-layer feed-forward neural network as Equations 8-11:
| (8) |
| (9) |
| (10) |
| (11) |
The enhanced instruction vector sequences and act as the output of the cross-architecture interaction module.
VII Binary Similarity Matching
The input of the binary similarity matching module is the instruction vector sequences and generated by the cross-architecture interaction module. We use the summation function to aggregate the instruction vectors of each sequence enhanced by the cross-architecture interaction module, as shown in Equations 12–13. and represent the final representation of binary snippets and . We also tried other instruction sequence aggregation methods but observed no further improvement. The ultimate vectors contain bidirectional context information and the semantic interaction information of cross-architecture instructions.
| (12) |
| (13) |
We concatenate the final sequence representations and feed them into fully connected layers. Then we deploy a softmax output layer to generate the binary similarity comparison result. We employ the cross-entropy function to calculate loss as Equation 14. denotes the total number of binary pairs, and denotes the category of the matching result, 1 for similar and 0 for dissimilar. is the model’s prediction of the probability that the similarity comparison result of the binary pair is , and denotes the ground-truth.
| (14) |
VIII Experimental Evaluation
We implement our solution as a universal cross-architecture binary similarity comparison prototype, Inter-BIN. In this section, we evaluate Inter-BIN on two input granularities: basic block level and function level. First, we describe the datasets and evaluation metrics used in our experiments (section VIII.A). Next, we compare our multi-feature fusion-based instruction representation module with the instruction pre-training approach (section VIII.B). Then we perform ablation studies to evaluate how the designed core components contribute to Inter-BIN’s performance improvements (section VIII.C), and we adjust the hyper-parameters to achieve the optimal performance (section VIII.D). We evaluate Inter-BIN’s multi-granularity performance and make comparisons with state-of-the-art binary similarity comparison approaches, and carry out specific studies on the improved cases (section VIII.E and section VIII.F). Furthermore, we evaluate the scalability and efficiency of Inter-BIN on our collected real-world cross-architecture IoT malware reuse function matching dataset CrossMal (section VIII.G).
We implement our prototype using the PyTorch-matchzoo framework [18].
VIII-A Dataset and Metrics
We collect three datasets in our experiments: Dataset1 is a collection of basic blocks for evaluating Inter-BIN’s characterization and comparison ability of small and common binary code pieces. Dataset2 is function level for evaluating Inter-BIN on binary snippets with richer semantics and more complex structure. Dataset3 is used to evaluate the feasibility of Inter-BIN in real-world IoT scenarios.
-
•
Dataset1: We use the dataset provided by the state-of-the-art approach INNEREYE 222https://nmt4binaries.github.io/ to evaluate Inter-BIN at the basic block level. The dataset compiles OpenSSL and four popular Linux packages, including coreutils, findutils, diffutils, and binutils, on x86 and ARM platforms. It contains 56,082 similar basic block pairs and 55,937 dissimilar pairs.
-
•
Dataset2: We expand Dataset1 into a function level binary similarity comparison dataset, using two compilers, clang and GCC, and four optimization levels from O0 to O3. Dataset2 contains a total of 485,025 function pairs.
-
•
Dataset3: We collect malware targeting IoT devices (routers and video surveillance devices) by the IoTCMal honeypot [5] to evaluate Inter-BIN in real-world scenarios. The captured instances involve seven malware families, including Mirai, Hajime, Gafgyt, XXorDDoS, Dofloo, Ddostf, Mining, and spread on different CPU architectures. We select malware from x86, ARM, and MIPS and annotate the malware pairs compiled from the same source code based on their code structure and external information, including binary names and the captured IP address. We disassemble binaries by radare2 333https://www.radare.org/ and extract function level instruction sequences to construct a cross-architecture binary comparison dataset containing 1,878,437 function pairs, and we name it as CrossMal.
Ground truth. The ground truth of Dataset1 is labelled by INNEREYE. They modified the LLVM-backend to annotate the boundaries of basic blocks and assign a unique ID for each assembly block. The same ID indicates that the assembly blocks are compiled from the same piece of source code.
For Dataset2 and Dataset3, the function level binary comparison datasets, we use the binary name and function name as the unique ID to identify functions compiled from the same source code. For each query function, we randomly sample the function with the same ID from the target architectures as the positive candidate function, and then sample functions with different IDs as the negative candidates.
Evaluation metrics. We use the following metrics in evaluation: For basic block pairs, we set up a classification task evaluated by accuracy and Area Under the Curve (AUC) metrics, which is commonly used in previous basic block comparison works [12] [13]. For function granularity evaluation, we set up a ranking task to meet the needs of real-world scenarios such as malware reuse modules detection and vulnerability function discovery. We treat each assembly function as a query, perform a one-to-many comparison with the target functions, and rank the similarity comparison results. We set one positive pair for each query and use precision@1 and mean reciprocal rank (MRR) metrics for evaluation. precision@1 calculates the correct rate of function matching result ranked at position 1. MRR is defined as Equation 15:
| (15) |
is the number of query functions, is the position of the first correctly matched function of query .
VIII-B Comparison with Instruction Pre-training Approach
In this section, we compare Inter-BIN’s multi-feature fusion-based instruction representation module with the instruction pre-training approach and char feature-based instruction encoding methods.
we use the released instruction embedding files of dimensions (dims) 50, 100, and 150 provided by INNEREYE 444https://nmt4binaries.github.io/, which were trained on a large-scale external code corpus by the skip-gram model. For char feature-based instruction encoding, we test the appearance frequencies of the chars and the combination of their frequency and position information, including the position of the char’s first and last appearance. We also evaluate char-level 2-gram and 3-gram features. Table I shows the comparison results on Dataset1.
| Approaches | Accuracy |
| Pre-trained embedding-50 dims | 0.9585 |
| Pre-trained embedding-100 dims | 0.9633 |
| Pre-trained embedding-150 dims | 0.9628 |
| Char frequency | 0.9370 |
| Char frequency with position | 0.9515 |
| Char 2-gram | 0.9260 |
| Char 3-gram | 0.9103 |
| Inter-BIN | 0.9757 |
From the table, Inter-BIN’s instruction representation module significantly outperforms the hard-encoded char features. Compared with INNEREYE’s heavyweight instruction pre-training, the char spatial features and instruction semantic features extracted by Inter-BIN can achieve better results, and the implementation way is very efficient.
VIII-C Ablation Studies
In this section, we design ablation studies to evaluate the effects of Inter-BIN’s core components.
| Setting | Dataset1 Accuracy | Dataset2 Precision@1 |
| (- Char-based features) | 0.9662 | 0.9050 |
| (- Opcode-based features) | 0.9669 | 0.9054 |
| (- Operands-based features) | 0.9706 | 0.9672 |
| (- Backward LSTM layer) | 0.9605 | 0.9575 |
| (- Co-attention mechanism) | 0.9428 | 0.8951 |
| Inter-BIN | 0.9757 | 0.9691 |
We first study the effectiveness of different instruction features in the multi-feature fusion-based instruction representation module. Table II shows the performance of Inter-BIN when removing the char-based features, opcode features, and operands features, respectively. It can be seen that Dataset1 is not very sensitive to the instruction feature ablation, and we can achieve acceptable basic block comparison accuracy on each setting. On the Dataset2 O0 subset, removing char-based spatial features or the opcode embedding features significantly impacts the function matching result. The precision@1 value reduces 6.48 and 6.37 points, respectively, and removing the operands features results in a slight performance decrease.
Next, in our instruction sequence encoding module, we use a Bi-LSTM encoder to extract the forward and backward context information of the embedded instruction sequence. When removing the backward LSTM layer, the binary similarity comparison performance on Dataset1 and Dataset2 O0 subset decreased by 1.52 and 1.16 points in accuracy and precision@1, respectively. It shows that adding backward sequential information positively impacts the semantic modeling of disassembly code snippets.
Finally, we evaluate the influence of the co-attention based instruction alignment in the cross-architecture interaction module. As shown in table II, when the instruction sequence interaction process is removed, the performance of Inter-BIN on Dataset1 and Dataset2 O0 subset has a significant drop, the accuracy and precision@1 value are reduced by 3.29 and 7.40 points, respectively. This proves that the cross-architecture instruction alignment mechanism is necessary for the performance improvement of binary similarity comparison.
VIII-D Parameter Selection
We adjust the following vital hyper-parameters of Inter-BIN to achieve the optimal performance: a) The RNN architecture of the instruction sequence encoding module. b) The hidden dimensions of RNN layers. c) The attention function of the cross-architecture interaction module. d) The enhancement mode of the interaction module. We discuss how to choose appropriate values for these hyper-parameters.
a) The RNN architecture of the instruction sequence encoding module: We evaluate different RNN variants for instruction sequence encoding, including LSTM, Bi-LSTM, Bi-GRU, and multi-layer Bi-LSTM.
b) The hidden dimensions of RNN layers: defines the hidden state dimension generated by each RNN layer. We vary in the range of .
c) The attention function of the cross-architecture interaction module: We evaluate dot-product attention, scaled dot-product attention, cosine attention, and bilinear attention.
d) The enhancement mode of the interaction module: defines the enhancement way of the inter-sequence interaction results to the original sequence representations. We test concatenation, element-wise product, element-wise difference, and their combinations.





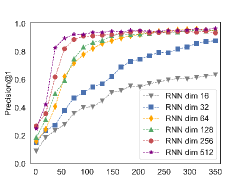


Figure6 and Figure7 show Inter-BIN’s validation accuracy on Dataset1 and precision@1 on Dataset2 O0 validation subset under different hyper-parameters settings. The abscissa indicates the number of training epochs. Figure6. (a) and Figure7. (a) show that Bi-LSTM performs slightly better than other RNN variants, and more Bi-LSTM layers doesn’t show performance improvement. From Figure6. (b) and Figure7. (b), a larger Bi-LSTM hidden dimension has a stronger expressive ability. For the trade-off of accuracy and efficiency, we finally set to 256. From Figure6. (c) and Figure7. (c), Bilinear attention has a slight advantage in network fitting speed and similarity matching results. From Figure6. (d) and Figure7. (d), the combinations of three enhancement way can achieve better results.
Other implementation details of Inter-BIN are as follows: The parameters of our neural network are optimized by Adam with a learning rate of 1e-4. The kernel size of the 1-D convolutional layer is set to 3, and the number of filters is set to 64. The hidden dimension of the opcode embedding layer is set to 8 for the basic block level and 64 for the function level, and the dimension of the operands mapping layer is set to 8. The MLP classifier of the binary matching module contains two fully connected layers. Their hidden dimensions are set to 512 and 256, respectively. On our validation sets, the performance of Inter-BIN is not sensitive to these hyper-parameters, and the above settings can achieve the best results.
VIII-E Basic block level Evaluation
In this section, we evaluate Inter-BIN at the basic block level and compare it with state-of-the-art approaches. Then we perform visualization analysis of our cross-architecture interaction module to show the performance of the automatic instruction soft alignment mechanism. Finally, we analyze the false-positive and false-negative cases generated by the previous approaches but can be avoided by Inter-BIN.
VIII-E1 Comparison with State-of-the-Arts
We evaluate Inter-BIN on Dataset1 and compare it with state-of-the-art cross-architecture binary matching approaches Gemini [19], INNEREYE [12], and the work of Redmon et al. [13]. These methods are all related to cross-architecture basic block characterization and comparison. Their implementations are as follows:
- •
-
•
INNEREYE [12] separately trains two LSTMs to encode instruction streams and then uses distance metric to measure the similarity of cross-architecture binary snippets.
-
•
Redmon et al. [13] perform hard alignment of cross-architecture instructions based on their position indexes, then use a joint learning approach with mono-architecture and cross-architecture objectives to learn instruction embeddings.
We use the instruction embedding files of INNEREYE 4 and the work of Redmond et al. 555https://github.com/nlp-code-analysis/cross-arch-instr-model for replication. The RNN hidden states of Inter-BIN and INNEREYE are all set to 256 dimensions, the training epochs is 50, and the batch size is 32. We also compare Inter-BIN with string edit distance and char n-gram based similarity comparison methods, respectively. We use the python-Levenshtein package 666https://pypi.org/project/python-Levenshtein/ to calculate the edit distance of assembly basic block pairs. For char n-gram features, we use 4-gram and Jaccard similarity, which performs best in our evaluation. The AUC comparison results on Dataset1 are shown in Figure8.
From the figure we can see that, the neural network-based approach INNEREYE and Inter-BIN achieve good performance on basic block level comparison, significantly outperform Gemini’s statistical features, string edit distance, and char n-gram based methods. But INNEREYE does not introduce the inter-sequence interaction between different architectures. Redmond et al. use the linear mapping of position indexes to perform hard alignment of instruction pairs and construct cross-architecture contexts. However, this alignment way is not flexible and accurate. On basic blocks with similar semantics but significantly differ in instruction sequence length and order, it will generate a large number of incorrect instruction pair associations. Moreover, simply summing the instruction vectors will lose the internal sequence context information of the basic blocks, so the performance of their method is not ideal. Inter-BIN’s performance is superior to these approaches, proving that our automatic soft alignment of cross-architecture instruction pairs can effectively improve the binary comparison accuracy, and the bidirectional context encoder is suitable for instruction sequence representation.

VIII-E2 Visualization
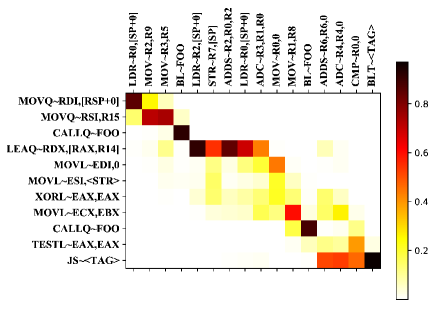
To present the automatic instructions soft alignment of Inter-BIN’s interaction module on instruction pairs across different architectures, we visualize the attention similarity matrices of the cross-architecture instruction sequences, as shown in Figure9. Darker colors indicate stronger semantic correlations between instruction pairs.
From the figure, we can directly observe that the function call instruction of the x86 architecture and of the ARM architecture show high attention weight because they specific the same operation. Similarly, the jump if sign instruction of x86 and of ARM, the greater than or equal branch transfer instructions and , and the instructions related to memory access, including , , of x86 and , , of ARM have also been effectively linked.
We perform in-depth analysis of the behavior achieved by the combination of multiple instructions. In the left subfigure, the first two instructions of x86 basic block use opcode , general-purpose registers and and stack pointer register to realize function parameter transfer behavior. Meanwhile, the first three instructions of ARM basic block use opcode and , general-purpose registers , , , and stack pointer register to perform similar behavior. These cross-architecture instructions involved in the function parameter transfer behavior show higher similarity correlations in Figure9, and the subsequent function call instructions and instructions are also associated with a high weight.
The visualization results show that Inter-BIN can achieve flexible and accurate soft alignment between semantically related instruction pairs of different architectures, which is significant for detecting cross-architecture binary code with similar functional semantics but different lexical expressions.

VIII-E3 Case study of Dataset1
Reduce false-positive cases. INNEREYE uses single directional LSTM to encode basic block level instruction sequences. The final basic block representations generated by this serialized modeling method are more affected by the last several instructions. Therefore, we observe that although the lengths of some dissimilar basic block pairs are very different, INNEREYE may incorrectly determine that they are similar. Inter-BIN can accurately determine these dissimilar pairs by the pairwise cross-architecture instructions alignment mechanism.
Table III shows two of INNEREYE’s false-positive cases. For the first dissimilar pair, although the instruction length difference of the two basic blocks is 19, the instructions including , opcodes at the end of the x86 basic block and the instructions including , at the end of the ARM basic block have high semantic similarities, so INNEREYE misjudges it as a similar pair. For the second dissimilar pair, the x86 basic block contains only a instruction, but INNEREYE determines it as a similar pair since the ARM basic block ending with the instruction. For these two examples, Inter-BIN can correctly determine that they are dissimilar basic block pairs. On the overall test set of Dataset1, Inter-BIN reduces the number of false-positive cases by 176 compared to INNEREYE.
Reduce false-negative cases. At basic block level, some small pieces of binary code contain only a few instructions and provide a small amount of information. It is difficult for RNN-type models trained separately on different instruction sequences to identify these similar binary pairs accurately. Table IV lists two similar basic block pairs that INNEREYE cannot correctly identify, while Inter-BIN with inter-sequence instruction interaction module can realize information transfer between the sequences and correctly identify them as similar.
| Dissimilar pair 1 | Dissimilar pair 2 | ||||||||||||||||||||||||||||
| x86 | ARM | x86 | ARM | ||||||||||||||||||||||||||
|
|
JMP<TAG> |
|
||||||||||||||||||||||||||
| Similar pair 1 | Similar pair 2 | |||||||||||||||||||||
| x86 | ARM | x86 | ARM | |||||||||||||||||||
|
|
|
|
|||||||||||||||||||
VIII-F Function level Evaluation
In this section, we first show the specific information of the function level Dataset2, which is established by four different optimization levels. Then we evaluate Inter-BIN on Dataset2 and compare it with state-of-the-art approaches. Finally, we conduct a case analysis to explain why Inter-BIN can significantly improve the performance of the function level binary similarity comparison task.
VIII-F1 Comparison with State-of-the-Arts
| Opt-level | # Training pairs | # Validation pairs | # Testing pairs | Total |
| O0 | 88,050 | 10,877 | 9,784 | 108,711 |
| O1 | 69,080 | 8,545 | 7,676 | 85,301 |
| O2 | 60,611 | 7,495 | 6,735 | 74,841 |
| O3 | 57,966 | 7,161 | 6,441 | 71,568 |
| Cross-opts | 117,123 | 14,467 | 13,014 | 144,604 |
| Total | 392,830 | 48,545 | 43,650 | 485,025 |
We divide Dataset2 into multiple subsets according to optimization levels to evaluate Inter-BIN on the function level binary matching task. Table V shows the statistics of Dataset2, containing a total of 485,025 function pairs.
We compare Inter-BIN with INNEREYE, the best performing state-of-the-art approach in our basic block level experiments. Since we additionally use a new compiler GCC, the out-of-vocabulary (OOV) rate of INNEREYE’s pre-trained instruction embeddings on subsets of Dataset2 is in the range of 42.12% to 53.11%. So we replaced INNEREYE’s pre-training module with our multi-feature fusion-based instruction representation method as an improver variant.
We also make comparisons with a function level binary similarity comparison approach, SAFE [15]. Similar to INNEREYE, SAFE deploys an assembly instruction pre-training module and uses bi-directional RNN to encode function instruction sequences of different architectures separately. Then it performs self-attention on each sequence individually to enhance the role of instructions that are more important for the similarity matching result. Since SAFE’s instruction pre-training is generated under different compile settings and packages with our Dataset2, we cannot directly use the provided instruction embeddings. So we also replace its instruction embedding module with our own instruction representation module.
| Opt-level | Precision@1 | MRR | ||||||
| Pre-trained INNEREYE | Improved INNEREYE | Improved SAFE | Inter-BIN | Pre-trained INNEREYE | Improved INNEREYE | Improved SAFE | Inter-BIN | |
| O0 | 0.6486 | 0.7838 | 0.9266 | 0.9691 | 0.7791 | 0.8742 | 0.9557 | 0.9833 |
| O1 | 0.6502 | 0.7199 | 0.8034 | 0.9214 | 0.7614 | 0.8291 | 0.8810 | 0.9572 |
| O2 | 0.5014 | 0.6555 | 0.7255 | 0.9048 | 0.6619 | 0.7819 | 0.8285 | 0.9433 |
| O3 | 0.6308 | 0.7419 | 0.7918 | 0.9179 | 0.7647 | 0.8302 | 0.8723 | 0.9524 |
| Cross-opts | 0.5951 | 0.6459 | 0.6967 | 0.8520 | 0.7165 | 0.7695 | 0.8105 | 0.9108 |
We set up a ranking task on Dataset2, the number of negative samples per query function () is set to 20, and the number of training epochs is 300. The evaluation results are shown in Table VI. Benefit from the cross-architecture interaction module, Inter-BIN outperforms INNEREYE and SAFE by large margins at the function granularity. On the O0 optimization level subset, Inter-BIN’s precision@1 outperforms the improved INNEREYE variant by 18.53 points, and the MRR is increased by 0.2042. On the multiple optimization levels setting, Inter-BIN’s precision@1 outperform the improved variants of INNEREYE and SAFE by 20.61 points and 15.53 points. Moreover, our multi-feature fusion-based instruction representation module can effectively help INNEREYE avoid the performance loss caused by OOV. The precision@1 of INNEREYE is increased by 13.52 points on the O0 optimization level subset by extracting instruction char level spatial features and attributes of opcode and operands.
VIII-F2 Case study of Dataset2

In the function level binary similarity comparison scenario, we observe that the performance improvement of Inter-BIN’s for long function matching is more prominent. A long function usually contains multiple basic blocks and can be represented as a control-flow-graph (CFG) structure. Each node is a basic block, and the edges represent the transfer relationships between the blocks. Figure10 shows the CFG structure of the disassembled function from the coreutils 8.29 package. We omit the specific instruction sequences within the basic blocks. When the source code of this function is compiled on the x86 and ARM architectures, Block 1 and Block 2 are divided into two blocks, respectively, resulting in different CFG patterns.
INNEREYE and SAFE cannot match this function pair correctly, while Inter-BIN can rank the similarity of the correct cross-architecture candidate function at the top position. Although Inter-BIN models assembly instruction sequences by Bi-LSTM without directly using the structural information, the pairwise cross-architecture instruction alignment mechanism can handle changes of CFG patterns. Meanwhile, it can avoid the expensive CFG extraction and matching process.
INNEREYE also designs an INNEREYE-CC sub-system, which achieves the code component similarity matching by performing the longest common subsequence (LCS) algorithm on basic block sequences extracted from the CFG. However, INNEREYE-CC needs to train a large number of basic block embeddings to fully cover the fragments of target code components, which is not practical in real scenarios.
VIII-G Evaluation on Real-world IoT Malware Dataset
In this section, we use Dataset3, the cross-architecture IoT malware dataset CrossMal collected in real network environments to evaluate Inter-BIN’s practicality and scalability. We first show the statistics information of CrossMal. Then evaluate Inter-BIN and compare it with state-of-the-art approaches. We analyze specific malware cases to demonstrate the ability of Inter-BIN on cross-architecture reuse function detection. Finally, we evaluate the runtime overheads of Inter-BIN on the CrossMal dataset.
VIII-G1 Cross-architecture Effectiveness Evaluation
We construct CrossMal as a function pairs collection to detect reused malware functions between IoT devices of different architectures, characterizing malicious behavior patterns from a finer granularity. Table VII shows the overall information of CrossMal, containing a total of 1,878,437 function pairs compiled from x86, ARM, and MIPS architectures 777The CrossMal dataset can be downloaded by the link https://drive.google.com/file/d/1kluoLPojJ-gwyGHgu2uJ5kt_NDDVeITi/view?usp=sharing.. Through our statistics, most function’s instruction sequence length in Dataset3 is in the range of 20 to 100. We use 50 as the threshold to divide Dataset3 into large-function subsets and small-function subsets to comprehensively evaluate Inter-BIN’s performance and runtime efficiency.
| Settings | # Training pairs | # Validation pairs | # Testing pairs | Total |
| x86-ARM | 409,588 | 45,510 | 42,754 | 497,852 |
| x86-MIPS | 364,154 | 40,462 | 47,292 | 451,908 |
| ARM-MIPS | 372,617 | 41,402 | 45,044 | 4590,63 |
| Cross 3-arcs | 376,141 | 41,794 | 51,679 | 469,614 |
| Total | 1,522,500 | 169,168 | 186,769 | 1,878,437 |
We evaluate Inter-BIN’s function level similarity comparison performance on different settings of CrossMal and make comparisons with state-of-the-art approaches. Since CrossMal involves more architectures than the instruction pre-training code corpus used by INNEREYE and SAFE, we only compare Inter-BIN with the their variants improved by our multi-feature fusion-based instruction representation module to avoid the severe OOV problem. We set training epochs to 100, and other hyper-parameters settings are the same as section VIII.D.
| Settings | All-functions | Large-functions | Small-functions | |||||||
| INNEREYE | SAFE | Inter-BIN | INNEREYE | SAFE | Inter-BIN | INNEREYE | SAFE | Inter-BIN | ||
| x86-ARM | Precision@1 | 0.8922 | 0.8994 | 0.9025 | 0.9386 | 0.9176 | 0.9582 | 0.8315 | 0.8525 | 0.8734 |
| MRR | 0.9398 | 0.9440 | 0.9468 | 0.9674 | 0.9563 | 0.9789 | 0.9036 | 0.9170 | 0.9299 | |
| x86-MIPS | Precision@1 | 0.9067 | 0.9143 | 0.9172 | 0.8760 | 0.9058 | 0.9428 | 0.8656 | 0.8920 | 0.8992 |
| MRR | 0.9502 | 0.9547 | 0.9571 | 0.9309 | 0.9514 | 0.9708 | 0.9283 | 0.9419 | 0.9467 | |
| ARM-MIPS | Precision@1 | 0.8826 | 0.8155 | 0.9044 | 0.9129 | 0.8946 | 0.9382 | 0.8376 | 0.8014 | 0.8679 |
| MRR | 0.9375 | 0.9001 | 0.9495 | 0.9539 | 0.9458 | 0.9683 | 0.9118 | 0.8915 | 0.9285 | |
| Cross 3-arcs | Precision@1 | 0.8674 | 0.8781 | 0.9010 | 0.8135 | 0.8261 | 0.9260 | 0.8594 | 0.8454 | 0.8895 |
| MRR | 0.9277 | 0.9339 | 0.9464 | 0.8942 | 0.9066 | 0.9624 | 0.9208 | 0.9110 | 0.9381 | |
-
*
INNEREYE and SAFE refer to the variants improved by our multi-feature fusion-based instruction representation module.
Table VIII shows that on different settings and the subsets of different function scales, Inter-BIN all outperforms the state-of-the-art approaches without the cross-architecture interaction module. On the test set containing 42,285 function pairs from three CPU architectures, Inter-BIN’s precision@1 reaches 0.9010, and MRR is up to 0.9464. Through further analysis, we found that the larger function contains more semantic information for fully interacting with another instruction sequence, so the improvement of Inter-BIN’s cross-architecture interaction module is significant. On the large-function subset of three mixture architectures, the precision@1 Inter-BIN are 11.25 points and 9.99 points higher than the multi-feature fusion-based INNEREYE and SAFE.
VIII-G2 Case study of CrossMal
CrossMal contains malware targeting IoT devices of different architectures captured by the IoTCMal honeypot [5]. We manually analyze two binary files named cc9x86 and cc9arm6 of the IoT malware family Gafgyt 888The sha256 values of these two binaries are af47b7f0b887d8ce09a3a260945b658dc9b5323c5f0efa2e66c67905d0c0dbe3 and 7c0e22da32c8ce46927e3f7671535d6f75d6bcdcf70a1919afe1695dcd1c2c33.. They were complied on x86 and ARM architectures and caught by us on August 2, 2020. Their code structures are highly similar and share a large number of reuse functions. In all the cross-architecture function pairs implemented by malicious developers, INNEREYE cannot correctly match the sendSTD, sendVSE, makeIPPacket, makeVSEPacket, and connectTimeout functions compiled on the x86 and ARM platforms, while Inter-BIN can match these cross-architecture function pairs correctly. We regard ranking the candidate function compiled from the same source code at the top as a successful match. Due to the cross-architecture interaction module, the overall successful matching rate of the reuse function pairs of these two binary files increased from 79% to 85%. Among the 60 industrial anti-virus scanners on VirusTotal, six can only detect one of the binary files, but not the other, and 29 can detect neither of them.
When using only the user-defined main function developed by malicious developers for cross-architecture binary comparison, Inter-BIN can achieve a matching accuracy of 95.16% on the dataset of of ARM and MIPS architectures which are widely used in IoT devices. As a reference, the accuracy of INNEREYE and SAFE are 86.29% and 91.94%, respectively. In conclusion, the cross-architecture interaction module introduced by Inter-BIN enhances the reuse function detection accuracy, which is meaningful for preventing the rapid spread of IoT malware on devices of different architectures.
VIII-G3 Runtime Overhead on CrossMal
Figure11. (a) to Figure11. (c) respectively show the runtime overheads of Inter-BIN on four cross-architecture settings and three function scales for binary preprocessing, off-line training, and on-line prediction. And we compare the training and prediction time of INNEREYE and SAFE variants improved by our multi-feature fusion-based instruction representation module. Our evaluations are performed on a server with four 8-core Intel Xeon Silver-4110 CPUs running at 2.10GHz and 128GB of physical memory. The deep neural network of Inter-BIN runs on a GeForce RTX 2080 graphic card.
Preprocessing time. We utilize multi-core CPUs to run 20 pre-processing procedures in parallel and skip binaries that take more than 120 seconds to be successfully processed. For most instances, the function-level instruction sequence extraction performed by radare2 999https://www.radare.org/ can complete within 5 seconds.
Off-line training time. Inter-BIN’s model training time is positively correlated with the size of the train sets and the number of epochs. As shown in Figure11. (b), each bar represents the runtime for all samples in the train set completing one epoch of training. On the dataset across three architectures, Inter-BIN takes 123.95 seconds to complete an epoch of training on 380,564 function pairs, and can complete 100 training epochs within 3.5 hours.
On-line prediction time. Inter-BIN can achieve efficient on-line similarity predictions of unknown cross-architecture binary snippets pairs. For the dataset across three architectures, Inter-BIN can return the semantic similarity matching result for a large query function within 1.63 milliseconds. Under all settings, Inter-BIN can predict the comparison result of the query and candidate function pair within two milliseconds.
The cross-architecture semantic interactions makes the model training time of Inter-BIN slightly longer than INNEREYE, but we avoid the laborious instruction pre-training on the large-scale external code corpus. INNEREYE processed over 6,115K basic blocks only for the x86 platform, and SAFE uses 1,299K unique functions containing 190 million assembly code lines for two architectures instruction pre-training, which is undoubtedly a heavyweight work. The overall off-line training speed of Inter-BIN and INNEREYE is significantly faster than SAFE, and the on-line prediction time of the three approaches is in similar ranges. In conclusion, Inter-BIN can achieve efficient cross-architecture function similarity comparison on large-scale real-world IoT malware collection.



IX Related Work
IX-A Binary Similarity Comparison
Binary similarity comparison has a wide range of applications in software security areas, such as patch analysis, bug search, and code clone detection. Previous binary similarity comparison approaches can be systematically divided into traditional methods and learning-based methods.
Traditional methods. Traditional binary matching approaches are usually implemented by program static analysis [7] [11] [20] [21] [22] [23] and dynamic analysis [8] [24] [25] [26] techniques. Esh [20] used a theorem prover to measure the semantic similarity of decomposed small code fragments. ImOpt [26] adopted the SSA (static single-assignment) transforming algorithm for code re-optimizing, improving the binary matching accuracy across different optimization levels. Most of these approaches only support binary similarity comparison under a single architecture. Multi-MH [7] is the first cross-architecture binary matching method. It converted the binaries of different CPU architectures to intermediate representation (IR) code and then performed function indexing according to the input and output semantics of basic blocks. However, It is computationally expensive and unscalable on large-scale binary collections.
Learning-based methods. To improve the code analysis accuracy and efficiency, researchers have recently commenced using learning-based binary similarity matching approaches [12] [13] [14] [15] [19] [27] [28] [29] [30]. Asm2Vec [27] used the PV-DM model on instruction execution traces to train function embeddings. DEEPBINDIFF [14] generated structural basic block embeddings by TADW algorithm, and combined them with context-based embeddings. These methods are designed for binary matching across versions or optimization levels, without supporting different architectures. For cross-architecture scenarios, Gemini used [19] a Structure2vec network and the cosine similarity to achieve control-flow-graphs (CFG) comparison. VulSeeker [28] extended Gemini’s graph structure by adding data flow edges. However, extracting accurate CFG is a non-trivial job relying on complex program control flow analysis techniques. INNEREYE [12] deployed skip-gram model for instruction pre-training and used LSTM to model instruction sequences separately. Redmond et al. [13] designed a rough position-based hard alignment method to perform association of cross-architecture instructions. In addition, many precious methods rely on the large-scale external code corpus to pre-train instructions [12] [13] [14] [29], which is labor-intensive and prone to suffer the out-of-vocabulary (OOV) problem. The Inter-BIN system we propose deploys a multi-feature fusion-based instruction representation module to avoid OOV, and we design an inter-sequence interaction mechanism to perform automatic soft alignment of cross-architecture instructions.
IX-B IoT Malware Detection
Costin et al. [1] manually collected unique resources of over 60 IoT malware families and pointed out that the current security community is still inadequate in vulnerability management and malware defense solutions. Alasmary et al. [2] extracted the graph-theoretic features of CFG and established a deep learning-based IoT malware detection model. MSimDroid [31] proposed a multi-dimensional similarity-based method to detect fake IoTs app in the markets. IoTPOT [4] and IoTCMal [5] can simulate fragile IoT devices in the public network and capture attacks targeting them. The analysis of captured samples showed that some IoT malware families evolved rapidly in a short period and disseminated malware on a large number of devices of different CPU architectures. Lee et al. [32] extracted statistical features of printable strings to characterize IoT malware of different architectures. However, string-based features are not robust enough and can easily be modified or obfuscated by malicious developers. We design an interaction-based semantic similarity comparison method for binary assembly instruction sequences, which can detect reuse IoT malware spread on devices of different architectures.
IX-C Deep Sequence Matching Models
The design of Inter-BIN is inspired by the text sequence matching technique in natural language processing (NLP). Existing text sequence matching models can be divided into two categories: sequence encoding models [17] [33] and sequence pair interaction models [34] [35] [36] [37]. Infersent [17] trained universal sentence representations and perform evaluations on 12 transfer tasks. MatchPyramid [34] generated a corresponding matching matrix based on different word-level similarity metrics. MatchLSTM [35] designed a hypothesis to premise attention to realize semantic interaction on textual entailment task. ESIM [36] designed an enhanced natural language inference model considering recursive architectures in both local inference modeling and inference composition. Inspired by interaction-based text matching methods, we design an automatic soft alignment mechanism of inter-sequence instruction pairs to improve the cross-architecture binary matching accuracy.
X Conclusion and Future Work
This paper proposes the first use of a deep neural network with an interaction mechanism for cross-architecture IoT binary similarity comparison, and provides effective security solutions against IoT malware threats. To avoid the heavy workload and the OOV problem of commonly used instruction pre-training approaches, we design a multi-feature fusion-based instruction representation method to extract the spatial and semantic features of assembly instructions. To overcome the lexical and syntax variations of similar binaries from different architectures, we perform inter-binary semantic interaction by co-attention, which can realize automatic soft alignment of assembly instruction pairs.
We implement our solution as an end-to-end multi-granularity cross-architecture binary similarity comparison system, Inter-BIN. Experimental results show that Inter-BIN outperforms state-of-the-art approaches on both basic block level and function level inputs. We establish CrossMal, a large-scale IoT malware dataset containing 1,878,437 cross-architecture function pairs. Experiments and case analysis on CrossMal prove that Inter-BIN is practical and scalable in real-world reuse function detection scenarios, which is significant for defending the IoT devices against malware that disseminates rapidly across different architectures.
In the future, we will further study the performance of our designed cross-architecture instructions alignment mechanism on the code containment problem, which determines whether a query piece of code is contained in another code snippet of a different architecture. It can help discover small malicious payloads injected into benign code modules. In addition, Inter-BIN’s function level instruction sequence encoding module follows the state-of-the-art approach SAFE [15], which directly treated the function level assembly instructions as a sequence. In the future, we consider sampling the possible execution paths of functions within the control-flow-graph to explore whether it can perform semantic modeling better.
References
- [1] A. Costin and J. Zaddach, “Iot malware: Comprehensive survey, analysis framework and case studies,” in BlackHat USA, 2018.
- [2] H. Alasmary, A. Khormali, A. Anwar, J. Park, J. Choi, A. Abusnaina, A. Awad, D. Nyang, and A. Mohaisen, “Analyzing and detecting emerging internet of things malware: A graph-based approach,” IEEE Internet Things J., vol. 6, no. 5, pp. 8977–8988, 2019.
- [3] M. Antonakakis, T. April, M. Bailey, M. Bernhard, E. Bursztein, J. Cochran, Z. Durumeric, J. A. Halderman, L. Invernizzi, M. Kallitsis et al., “Understanding the mirai botnet,” in Proc. 26th USENIX Security Symp., 2017, pp. 1093–1110.
- [4] Y. M. P. Pa, S. Suzuki, K. Yoshioka, T. Matsumoto, T. Kasama, and C. Rossow, “Iotpot: A novel honeypot for revealing current iot threats,” J. Information Processing, vol. 24, no. 3, pp. 522–533, 2016.
- [5] B. Wang, Y. Dou, Y. Sang, Y. Zhang, and J. Huang, “Iotcmal: Towards a hybrid iot honeypot for capturing and analyzing malware,” in Proc. IEEE Int. Conf. Commun. (ICC), 2020, pp. 1–7.
- [6] I. U. Haq and J. Caballero, “A survey of binary code similarity,” CoRR, vol. abs/1909.11424, 2019.
- [7] J. Pewny, B. Garmany, R. Gawlik, C. Rossow, and T. Holz, “Cross-architecture bug search in binary executables,” in Proc. 35th IEEE Symp. Secur. Privacy (SP), 2015, pp. 709–724.
- [8] M. Egele, M. Woo, P. Chapman, and D. Brumley, “Blanket execution: Dynamic similarity testing for program binaries and components,” in Proc. 23rd USENIX Security Symp.), 2014, pp. 303–317.
- [9] J. Ming, D. Xu, Y. Jiang, and D. Wu, “Binsim: Trace-based semantic binary diffing via system call sliced segment equivalence checking,” in Proc. 26th USENIX Security Symp.), 2017, pp. 253–270.
- [10] I. Santos, F. Brezo, J. Nieves, Y. K. Penya, B. Sanz, C. Laorden, and P. G. Bringas, “Idea: Opcode-sequence-based malware detection,” in Proc. 2nd Int. Symp. Eng. Secure Software and Syst. (ESSoS), 2010, pp. 35–43.
- [11] Z. Xu, B. Chen, M. Chandramohan, Y. Liu, and F. Song, “Spain: security patch analysis for binaries towards understanding the pain and pills,” in Proc. 39th Int. Conf. Software Eng. (ICSE), 2017, pp. 462–472.
- [12] F. Zuo, X. Li, P. Young, L. Luo, Q. Zeng, and Z. Zhang, “Neural machine translation inspired binary code similarity comparison beyond function pairs,” in Proc. 25th Annu. Netw. Distrib. Syst. Security Symp. (NDSS), 2018.
- [13] K. Redmond, L. Luo, and Q. Zeng, “A cross-architecture instruction embedding model for natural language processing-inspired binary code analysis,” in Proc. 18th Annu. Netw. Distrib. Syst. Security Symp. Workshop (NDSS), 2019.
- [14] Y. Duan, X. Li, J. Wang, and H. Yin, “Deepbindiff: Learning program-wide code representations for binary diffing,” in Proc. 27th Annu. Netw. Distrib. Syst. Security Symp. (NDSS), 2020.
- [15] L. Massarelli, G. A. Di Luna, F. Petroni, R. Baldoni, and L. Querzoni, “Safe: Self-attentive function embeddings for binary similarity,” in Proc. 16th Detection Intrusions Malware Vulnerability Assessment (DIMVA), 2019, pp. 309–329.
- [16] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comp., vol. 9, no. 8, pp. 1735–1780, 1997.
- [17] A. Conneau, D. Kiela, H. Schwenk, L. Barrault, and A. Bordes, “Supervised learning of universal sentence representations from natural language inference data,” in Proc. Conf. Empirical Methods Natural Lang. Process (EMNLP), 2017.
- [18] J. Guo, Y. Fan, X. Ji, and X. Cheng, “Matchzoo: A learning, practicing, and developing system for neural text matching,” in Proc. 42nd Int. ACM SIGIR Conf. Res. Dev. Inf. Retr., 2019, pp. 1297–1300.
- [19] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural network-based graph embedding for cross-platform binary code similarity detection,” in Proc. ACM Conf. Computer. Commun. Secur. (CCS), 2017, pp. 363–376.
- [20] Y. David, N. Partush, and E. Yahav, “Statistical similarity of binaries,” in Proc. 37th ACM SIGPLAN Conf. Program Lang. Des. Implementation (PLDI), 2016, pp. 266–280.
- [21] M. Chandramohan, Y. Xue, Z. Xu, Y. Liu, C. Y. Cho, and H. B. K. Tan, “Bingo: Cross-architecture cross-os binary search,” in Proc. 24th Joint Meeting Eur. Softw. Eng. Conf. ACM SIGSOFT Symp. Found. Softw. Eng. (FSE), 2016, pp. 678–689.
- [22] D. Gao, M. K. Reiter, and D. Song, “Binhunt: Automatically finding semantic differences in binary programs,” in Proc. 10th Int. Conf. Inf. Commun. Secur. (ICICS), 2008, pp. 238–255.
- [23] S. Eschweiler, K. Yakdan, and E. Gerhards-Padilla, “discovre: Efficient cross-architecture identification of bugs in binary code,” in Proc. 23rd Annu. Netw. Distrib. Syst. Security Symp. (NDSS), 2016.
- [24] J. Ming, M. Pan, and D. Gao, “ibinhunt: Binary hunting with inter-procedural control flow,” in Proc. 15th Annu. Int. Conf. Inf. Secur. Cryptology, 2012, pp. 92–109.
- [25] Z. Tian, Q. Zheng, T. Liu, and M. Fan, “Dkisb: Dynamic key instruction sequence birthmark for software plagiarism detection,” in Proc. 10th IEEE Int. Conf. High Perform. Comput. Commun., HPCC IEEE Int. Conf. Embedded Ubiquitous Comput., EUC, 2013, pp. 619–627.
- [26] J. Jiang, G. Li, M. Yu, G. Li, C. Liu, Z. Lv, B. Lv, and W. Huang, “Similarity of binaries across optimization levels and obfuscation,” in Proc. 25th ESORICS, 2020, pp. 295–315.
- [27] S. H. Ding, B. C. Fung, and P. Charland, “Asm2vec: Boosting static representation robustness for binary clone search against code obfuscation and compiler optimization,” in Proc. IEEE Symp. Security Privacy, (SP), 2019, pp. 472–489.
- [28] J. Gao, X. Yang, Y. Fu, Y. Jiang, and J. Sun, “Vulseeker: a semantic learning based vulnerability seeker for cross-platform binary,” in Proc. 33rd ACM/IEEE Int. Conf. Autom. Soft. Eng. (ASE). IEEE, 2018, pp. 896–899.
- [29] Z. Yu, R. Cao, Q. Tang, S. Nie, J. Huang, and S. Wu, “Order matters: Semantic-aware neural networks for binary code similarity detection,” in Proc. 34th AAAI Conf. Artif. Intell., vol. 34, no. 01, 2020, pp. 1145–1152.
- [30] B. Liu, W. Huo, C. Zhang, W. Li, F. Li, A. Piao, and W. Zou, “diff: cross-version binary code similarity detection with dnn,” in Proc. 33rd ACM/IEEE Int. Conf. Autom. Soft. Eng. (ASE), 2018, pp. 667–678.
- [31] P. Wu, D. Liu, J. Wang, B. Yuan, and W. Kuang, “Detection of fake iot app based on multidimensional similarity,” IEEE Internet Things J., vol. 7, no. 8, pp. 7021–7031, 2020.
- [32] Y.-T. Lee, T. Ban, T.-L. Wan, S.-M. Cheng, R. Isawa, T. Takahashi, and D. Inoue, “Cross platform iot-malware family classification based on printable strings,” in Proc. 19th IEEE Int. Conf. Trust, Secur. Priv. Comput. Commun. (TrustCom), 2020, pp. 775–784.
- [33] Y. Nie and M. Bansal, “Shortcut-stacked sentence encoders for multi-domain inference,” in Proc. Conf. Empirical Methods Natural Lang. Process. Workshop (EMNLP), 2017.
- [34] L. Pang, Y. Lan, J. Guo, J. Xu, S. Wan, and X. Cheng, “Text matching as image recognition,” in Proc. 30th AAAI Conf. Artif. Intell., 2016.
- [35] S. Wang and J. Jiang, “Machine comprehension using match-lstm and answer pointer,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017.
- [36] Q. Chen, X. Zhu, Z. Ling, S. Wei, H. Jiang, and D. Inkpen, “Enhanced lstm for natural language inference,” in Proc. 55th Annu. Meeting Assoc. Comput. Linguistics (ACL), 2017.
- [37] W. Lan and W. Xu, “Neural network models for paraphrase identification, semantic textual similarity, natural language inference, and question answering,” in Proc. 27th Int. Conf. on Comput. Linguist. (COLING), 2018, pp. 3890–3902.