Integrating Large Language Models into Recommendation via Mutual Augmentation and Adaptive Aggregation
Abstract.
Conventional recommendation methods have achieved notable advancements by harnessing collaborative or sequential information from user behavior. Recently, large language models (LLMs) have gained prominence for their capabilities in understanding and reasoning over textual semantics, and have found utility in various domains, including recommendation. Conventional recommendation methods and LLMs each have their own strengths and weaknesses. While conventional methods excel at mining collaborative information and modeling sequential behavior, they struggle with data sparsity and the long-tail problem. LLMs, on the other hand, are proficient at utilizing rich textual contexts but face challenges in mining collaborative or sequential information. Despite their individual successes, there is a significant gap in leveraging their combined potential to enhance recommendation performance.
In this paper, we introduce a general and model-agnostic framework known as Large Language model with mutual augmentation and adaptive aggregation for Recommendation (Llama4Rec). Llama4Rec synergistically integrates conventional and LLM-based recommendation models. Llama4Rec proposes data augmentation and prompt augmentation strategies tailored to enhance the conventional model and the LLM respectively. An adaptive aggregation module is adopted to combine the predictions of both kinds of models to refine the final recommendation results. Empirical studies on three real-world datasets validate the superiority of Llama4Rec, demonstrating its consistent and significant improvements in recommendation performance over baseline methods.
1. Introduction
Recommender systems have emerged as crucial solutions for mitigating the challenge of information overload (He et al., 2023a, b; Luo et al., 2023a, 2022a). Recommender systems encompass a multitude of tasks, such as rating prediction (Steck, 2013; Khan et al., 2021) and top- recommendation (Le and Lauw, 2021; Luo et al., 2023b). The top- recommendation, which encompasses collaborative filtering-based direct recommendation (He et al., 2017, 2020), sequential recommendation (Kang and McAuley, 2018; Sun et al., 2019; Chen et al., 2023), and more, has found wide applications in various areas. However, recommender systems still suffer from the data sparsity and long-tail problem. Data sparsity arises from sparse user-item interactions, making the task of accurately capturing user preferences more challenging. The long-tail problem further intensifies data sparsity issue, as a substantial number of less popular items (i.e., long-tail items) are infrequently interacted with, leading to inadequate data for effective model training and compromised recommendation quality.
In recent years, Large Language Models (LLMs) have emerged, exhibiting exceptional capabilities in language understanding, text generation, and complex reasoning tasks (OpenAI, 2023; Touvron et al., 2023a, b; Wang et al., 2023; Zhou et al., 2023). Recent studies have started exploring their applicability in recommender systems (Liu et al., 2023; Bao et al., 2023; Zhang et al., 2023c). For example, Liu et al. employed ChatGPT with in-context learning (ICL) for various recommendation tasks (Liu et al., 2023). Further progress has been achieved by adopting the instruction tuning technique (Ouyang et al., 2022; Longpre et al., 2023) to align general-purpose LLMs with recommendation tasks for improved performance (Zhang et al., 2023c; Bao et al., 2023). For instance, TALLRec (Bao et al., 2023) reformulates the recommendation problem as a binary classification task and introduces an effective instruction fine-tuning framework for adapting the LLaMA model (Touvron et al., 2023b). However, these LLM-based recommendation methods may not perform optimally as they do not harness the collaborative or sequential information captured by conventional recommendation models.
Conventional recommendation models and LLM-based recommendation methods each have their respective strengths and weaknesses. Conventional methods excel in mining collaborative information and modeling sequential behaviors, while LLMs are proficient in leveraging rich textual contexts. As such, the integration of LLMs into recommender systems presents a significant opportunity to amalgamate the advantages of both methodologies while circumventing their respective shortcomings. There have been initial attempts to harness the strengths of both conventional and LLM-based recommenders (Geng et al., 2022; Zhang et al., 2023b; Zheng et al., 2023; Wei et al., 2023). Some efforts have sought to integrate collaborative/sequential information by enabling LLMs to comprehend user/item ID information (Geng et al., 2022; Zhang et al., 2023b; Zheng et al., 2023). For instance, a concurrent study by Zhang et al. encoded the semantic embedding into the prompt (Zhang et al., 2023b) and send it to LLM. On the other hand, some research works have aimed to augment conventional models using LLMs via data or knowledge augmentation (Wei et al., 2023; Xi et al., 2023). LLMRec (Wei et al., 2023) enhances recommender systems by deploying LLMs to augment the interaction graph, thereby addressing the challenges of data sparsity and low-quality side information.
However, existing methods have several limitations. Firstly, current methods lack generalizability. The strategy of integrating ID information proves challenging to generalize across different domains and necessitates additional training. The current data augmentation method is not universally applicable, as it only addresses a limited number of recommendation scenarios. Secondly, current research primarily focuses on the integration at the data-level (e.g., data augmentation) or model-level (e.g., make LLM understand ID semantics), leaving the result-level integration largely unexplored. Lastly, there is an absence of a comprehensive framework that combines and integrates these methods into a single construct. In light of these limitations, our objective is to explore the integration of conventional recommendation models and LLM-based recommendation methods in depth to address the above limitations and enhance recommendation performance.
In this paper, we introduce a general framework known as Large language model with mutual augmentation and adaptive aggregation for Recommendation, referred to as Llama4Rec, for brevity. The core idea of Llama4Rec is to allow conventional recommendation models and LLM-based recommendation models to mutually augment each other, followed by an adaptive aggregation of the augmented models to yield more optimized results. Specifically, Llama4Rec performs data augmentation for conventional recommendation models by leveraging instruction-tuned LLM to alleviate the data sparsity and long-tail problem. The data augmentation is tailored with different strategies depending on the recommendation scenarios. Furthermore, we use conventional recommendation models to perform prompt augmentation for LLMs. The prompt augmentation includes enriching collaborative information from similar users and providing prior knowledge from the conventional recommendation model within the prompt. We also propose an adaptive aggregation module that merges the predictions of the LLM and conventional models in an adaptive manner. This module is designed as a simple yet effective way to combine the strengths of both models and refine the final recommendation results. We conduct empirical studies on three real-world datasets, encompassing three different recommendation tasks, to validate the superiority of our proposed method. The results consistently demonstrate its superior performance over baseline methods, highlighting notable improvements in recommendation performance.
In a nutshell, the contributions of this work are threefold.
-
•
We introduce Llama4Rec, a general and model-agnostic framework to integrate LLM into conventional recommendation models. Llama4Rec performs the data augmentation for conventional models to alleviate the data sparsity problem and improve model performance. The prompt augmentation is applied to LLM for leveraging the information captured by the conventional models.
-
•
Llama4Rec employs an adaptive aggregation approach to combine the prediction from the conventional recommendation model and LLM for improved recommendation performance via leveraging and merging the information by both kinds of models.
-
•
To validate the effectiveness of Llama4Rec, we conduct extensive experiments on three real-world datasets across three diverse recommendation tasks. The empirical results demonstrate that Llama4Rec outperforms existing baselines, exhibiting notable improvements across multiple performance metrics.
2. Related Work
2.1. Conventional Recommendation Methods
Conventional recommendation methods serve as the cornerstone for the contemporary landscape of recommender systems (Zhang et al., 2019). Representative recommendation tasks include rating prediction, collaborative filtering-based direct recommendation, and sequential recommendation, where the latter two are usually formulated as top- recommendation problems. Specifically, one of the seminal techniques is the use of matrix factorization for rating prediction, popularized by methods such as Singular Value Decomposition (SVD) (Koren et al., 2009). Collaborative filtering (CF) is another commonly used technique for the recommender systems (Adomavicius and Tuzhilin, 2005). Recent advancements have evolved CF techniques into more complex neural network architectures and graph-based models (He et al., 2017; Wang et al., 2019) to enhance the model performance. Sequential recommendation models incorporate temporal patterns into the recommendation pipeline. Techniques such as recurrent neural networks have been adapted for this purpose (Hidasi et al., 2015). Recent research focuses on applying attention mechanisms to further refine these models, leading to a noteworthy boost in performance (Sun et al., 2019; Kang and McAuley, 2018).
Although conventional recommendation techniques are well-suited for capturing latent information associated with users and items, they often require a substantial amount of user-item interactions to provide accurate recommendations, which limits their effectiveness in data sparse and long-tail scenarios (Park and Tuzhilin, 2008).
2.2. Large Language Model for Recommendation
LLMs have brought a paradigm shift in numerous areas of machine learning, including recommendation methods (Fan et al., 2023). One of the most compelling advantages of LLM-based recommendation methods is their capacity for contextual understanding and in context learning (Dong et al., 2022). Inspired by this, reference (Liu et al., 2023) utilized ChatGPT across diverse recommendation tasks and found it to be effective in specific contexts, underpinned by robust experiments and human evaluations. Similarly, Wang et al. (Wang and Lim, 2023) introduced a novel zero-shot technique for next-item recommendations, further substantiating the utility of LLMs in this arena. However, it is noteworthy that these methods do not consistently demonstrate a marked improvement over conventional recommendation algorithms, which is largely attributable to the inherent misalignment between the general-purpose capabilities of LLMs and the specialized requirements of the recommendation task. To address this issue, recent studies further attempt to instruct tuning the specific LLM to align with human preference (Bao et al., 2023; Zhang et al., 2023c). Typically, these approaches involve creating an instruction tuning dataset in line with recommendation tasks, which is then used to tune the LLM for recommendation. Such methodologies have demonstrated improved performance in generating more aligned and accurate recommendations.
Nevertheless, while LLMs excel at capturing intricate textual patterns, they may encounter challenges in comprehensively encoding user and item collaborative or sequential information. Though some concurrent studies (Zhang et al., 2023b; Zheng et al., 2023) aim to address this gap, they often lack in terms of generalizability and comprehensibility. In response to this challenge, we propose a novel framework designed to mitigate this issue.
3. Preliminary
We consider a recommender system with a set of users, denoted , and a set of items, denoted . The rating prediction task aims to estimate the unknown values of in the user-item interaction matrix , where each entry is the rating assigned by user to item . Different from rating prediction, top- recommendation focuses on identifying a subset of items for each user . The subset is chosen to maximize a user-specific utility with the constraint , which can be formally expressed as:
| (1) |
In the context of LLM-based recommendation methods, let represent the original LLM. These kinds of methods first utilize prompt to interpret the recommendation task into natural language. The LLM-based recommendation for user with in-context learning is denoted by where is the recommendation prompt for user . The recommendation prompt could either ask LLM to predict a rating towards a target item, or rank candidate items derived by retrieval models in top-k recommendation. To instruction fine-tune LLM, a dedicated dataset consisting of various instructions is utilized. The resulting instruction-tuned LLM is denoted as . Therefore, the recommendation process in the fine-tuned model can be succinctly represented as .
4. Methodology
4.1. Overview
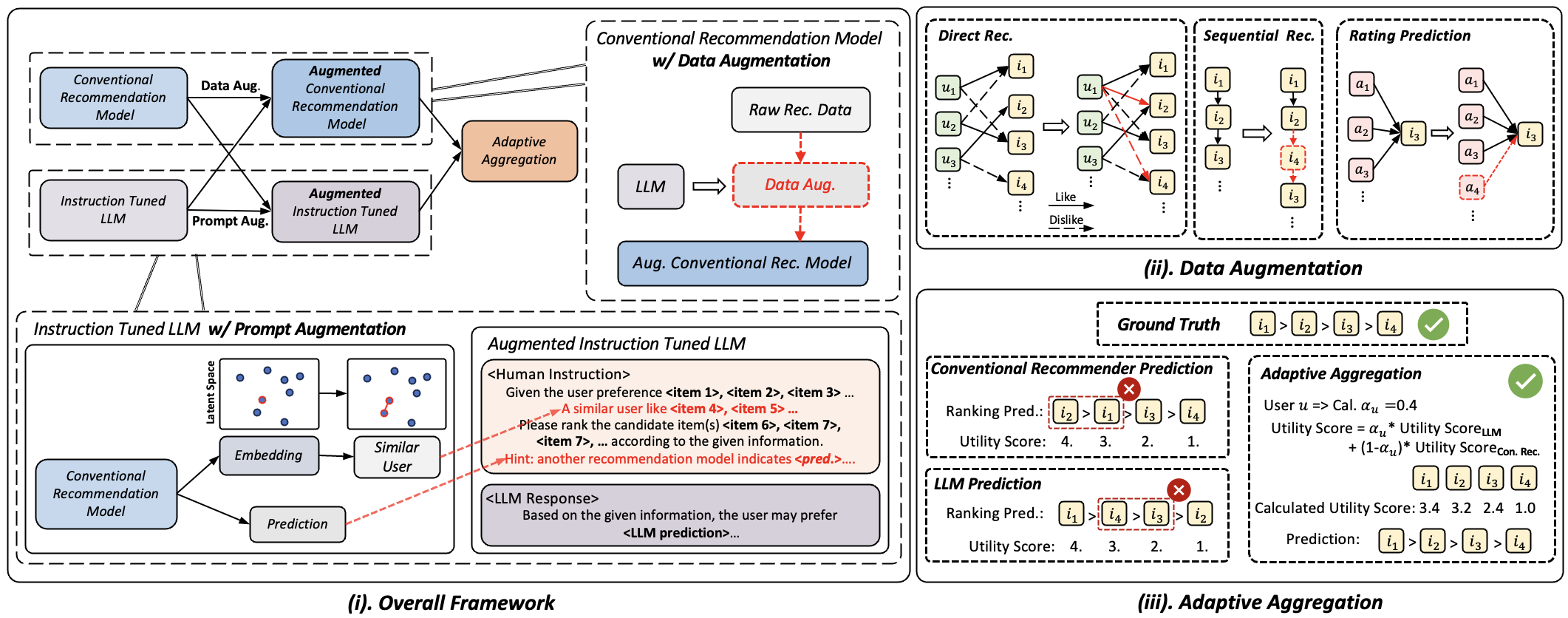
Figure 1 depicts the architecture of Llama4Rec, which consists of three components: data augmentation, prompt augmentation, and adaptive aggregation. More specifically, Llama4Rec leverages an instruction-tuned LLM to enhance conventional recommendation systems through data augmentation. The specific data augmentation strategies for different recommendation situations are detailed in Section 4.2. In addition, we employ conventional recommendation models to augment the LLM via prompt augmentation, with details in Section 4.3. To further refine the predictions of the conventional model and the LLM, we propose a simple yet effective adaptive aggregation module in Section 4.4. Lastly, we describe the training strategy for LLM in Section 4.5.
4.2. Data Augmentation for Conventional Recommendation Model
We design ad-hoc data augmentation strategies for different recommendation scenarios to mitigate prevalent issues of data sparsity and the long-tail problem. This design is motivated by the fact that data distribution and tasks significantly vary across different recommendation scenarios. In the context of direct recommendation, we capitalize on the power of the instruction-tuned LLM to predict items that a user may like or dislike. We form pairs of these items to calculate the Bayesian Personalized Ranking (BPR) (Rendle et al., 2012) loss. For sequential recommendation, we harness the capabilities of the instruction-tuned LLM to predict items that are highly preferred by the user. These predicted items are then randomly inserted into the sequence of items the user has interacted with. For rating prediction, we utilize the LLM to extract valuable side information (i.e., missing attributes), which is then seamlessly integrated as additional features within the training data.
4.2.1. Data Augmentation for Direct Recommendation
For direct recommendation, the Bayesian Personalized Ranking (BPR) loss is commonly used to optimize the model (Rendle et al., 2012). The objective of BPR is to maximize the score difference between correctly recommended items and incorrectly recommended items, thereby improving the accuracy of recommendations. The BPR loss is defined as:
| (2) |
where refers to a triple of user-item pairs, and the user has interacted with item (positive item) and item (negative item). represents the set of such user-item pairs in the training data. denotes the predicted score or preference of user for item .
Inspired by this, we propose a data augmentation strategy where we randomly select pairs of items for a user and prompt the LLM to rank each pair based on the user’s likely preference. The ranking prediction based on LLM is then combined with the original data and used to train a direct recommendation model. Formally, let denote a pair of items for a user . The LLM is prompted to rank these items, denoted as , where is the corresponding prompt and is the item preferred over . The training data is updated as . The BPR loss is then updated as:
| (3) |
This data augmentation strategy leverages the power of the instruction tuned LLM to enhance the performance of the direct recommendation model.
4.2.2. Data Augmentation for Sequential Recommendation
For sequential recommendation, the data augmentation strategy involves enriching the sequence of interacted items with additional items predicted by the LLM. Let’s consider a user with a corresponding sequence of interacted items . We randomly sample a list of un-interacted items , and adopt the prompt to ask the LLM to predict the item most likely to be preferred by the user, denoted as . This predicted item is then randomly inserted into the user’s sequence, resulting in an augmented sequence . This augmented data is then used to train a more powerful sequential recommendation model.
By including additional items predicted by the LLM, we can enrich the sequence of items for each user, providing a more comprehensive representation of the user’s preferences. This, in turn, can enhance the performance of the conventional recommendation model, leading to more accurate recommendations.
4.2.3. Data Augmentation for Rating Prediction
In rating prediction tasks, we introduce the use of in-context learning (ICL) in LLMs to provide side information. This is primarily due to the fact that recommendation datasets may contain incomplete information. For instance, the popular Movielens dataset (Harper and Konstan, 2015) lacks information about the director of the movies, which can hinder the performance of a conventional rating prediction model. To mitigate this issue, we leverage the extensive world knowledge contained in an LLM. We prompt the LLM to provide side information, acting as additional attributes for users/items.
Formally, we denote the rating prediction model as , and the attribute set as , where denotes a distinct attribute. The model predicts the rating as . We then prompt the LLM to provide additional attributes, where the prompt contains some corresponding examples followed by detailed instructions. The process is denoted as . The augmented attribute set is then formed as . The model then predicts the rating using the augmented attribute set, denoted as . This approach allows us to leverage the LLM’s world knowledge to enhance the performance of the rating prediction model.
Top-k Recommendation Prompt Example:
Instruction: Rank the candidate movies based on user historical interactions and make the top k recommendations.
Interaction History: Beyond Rangoon (1995); Alien (1979); Hollow Reed (1996); Primary Colors (1998); …; Birds, The (1963)
Candidate Items: Last Dance (1996); Remains of the Day, The (1993); Assassins (1995); …; Fatal Instinct (1993)
Similar User Interaction History: L.A. Confidential (1997); Apt Pupil (1998); Kolya (1996); …; Star Wars (1977)
Conventional Model Prediction: Remains of the Day, The (1993); Addiction, The (1995); …; Fugitive, The (1993)
Output: Fugitive, The (1993); Angel Baby (1995); …; Remains of the Day, The (1993)
Rating Prediction Prompt Example:
Instruction: Predict the rating of a target movie based on the user’s historical movie ratings.
Rating History: Independence Day (1996): 3; Grosse Fatigue (1994): 3; Face/Off (1997): 4; …; Shall We Dance? (1996): 3
Candidate Item: Pink Floyd - The Wall (1982)
Similar User Rating History: L.A. Confidential (1997): 3; Apt Pupil (1998): 4; …; English Patient, The (1996): 3
Conventional Model Prediction: 3.2
Output: 3
4.3. Prompt Augmentation for Large Language Model
Previous works (Bao et al., 2023; Zhang et al., 2023c) instruction tuning LLM for recommendation in a standard manner. However, these methods can be sub-optimal due to the challenges of distinguishing users based solely on text-based prompt descriptions. Although some concurrent studies (Zhang et al., 2023b; Zheng et al., 2023) incorporate unique identifiers to differentiate users, these approaches require complex semantic understanding of IDs and additional training, limiting their generalizability.
In this section, we introduce two text-based prompt augmentation strategies for LLM-based recommendations, i.e., we incorporate additional information within the prompt to enhance the model performance. First, we propose prompt augmentation with similar users, identifying users with analogous preferences to enrich the prompt, thereby enhancing the LLM’s ability to leverage collaborative information and generate personalized recommendations. Second, we propose prompt augmentation with conventional model prediction, providing prior knowledge to guide the LLM toward recommendations that align with user preferences. Collectively, these strategies harness the strengths of both LLMs and conventional recommendation models, ensuring generalizability across a wide range of recommendation scenarios. The illustration of prompt augmentation is underlined in Figure 2.
4.3.1. Prompt Augmentation with Collaborative Information from Similar User
To incorporate collaborative information within the prompt and facilitate LLM reasoning, we introduce a prompt augmentation strategy with similar user. Initially, we utilize a pre-trained conventional recommendation model to acquire embeddings for each user. These embeddings represent users in a latent space, which encapsulates their preferences and behaviors. Specifically, for a user , in conjunction with a conventional recommendation model , we use to obtain embeddings for each user, denoted as . These embeddings encapsulate the preferences and behaviors of the users, serving as a compact representation of the users in a latent space. We then calculate the similarity between these embeddings in the latent space. Various measurements, such as cosine similarity, Jaccard similarity, and Euclidean distance, could be employed in this context. In this paper, we calculate the cosine similarity to measure how closely two vectors align, denoted as:
| (4) |
where and are the embeddings of user and , respectively, and . The denotes the Euclidean norm and denotes the dot product. We identify the pair of users that have the highest similarity, indicating that they are the most similar in terms of their preferences and behaviors. We then use the items interacted with by the most similar user to enrich the prompt for the target user. This strategy leverages the collaborative information gleaned from similar users to generate more relevant and accurate prompts, thereby enhancing the recommendation performance of the LLM.
4.3.2. Prompt Augmentation with Prior Knowledge from Conventional Recommendation Model Prediction
To enable the LLM to leverage information captured by conventional models, we propose a prompt augmentation method that incorporates information from conventional recommendation models. More specifically, the augmented prompt is formed by concatenating the original prompt with the prediction from the conventional recommendation model in natural language form. It’s important to note that the prediction from the conventional model varies depending on the recommendation scenarios and base models. Through augmenting prompts with predictions from conventional recommendation models, our method integrates collaborative or sequential information captured by these models, thereby enhancing the LLM’s contextual understanding and reasoning capabilities and resulting in better recommendation performance.
Notably, unlike ID-based methods such as (Zhang et al., 2023b; Zheng et al., 2023), our approach relies entirely on text, enabling easy adaptation to new situations. Also, the prompt augmentation could be used as a plug-and-play component for recommendation with closed source LLM, such as the GPT-4 model (OpenAI, 2023).
4.4. Adaptive Aggregation
We endeavor to aggregate the outputs of LLM and conventional recommendation models at the result level for improved performance, considering the disparate model structures. However, indiscriminate aggregation of model predictions can potentially lead to suboptimal results. Conventional recommendation models, known for their susceptibility to the long tail issue, often struggle when dealing with the tail segment. In contrast, LLMs, by leveraging contextual information, are able to maintain a relatively uniform performance across all segments. Motivated by these observations, we first define the long-tail coefficient and subsequently adaptively aggregate the predictions from both model types.
We first define the long-tail coefficient for user to quantify where the user is located in the tail of the distribution. The long-tail coefficient is defined as follows:
| (5) |
where is the number of interaction for user . A lower long-tail coefficient value indicates that the user has fewer feedback.
While the overarching architecture remains consistent, the implementation details are different for the two tasks considered, namely rating prediction and top- recommendation.
4.4.1. Adaptive Aggregation for Rating Prediction
For the rating prediction task, we employ an instruction-tuned LLM to predict user-item utility scores directly. This approach incorporates the understanding of complex semantics and context by the LLM, which might be overlooked by traditional models. Similarly, conventional recommendation methods leverage collaborative information and user/item features for predicting the user rating. Specifically, the utility weight for user , denoted as , is directly set as its user rating. Subsequently, the LLM is engaged to predict the rating, symbolized as . There are various methods to derive a final result based on the utility scores, such as training a neural network to process the utility scores from LLM and conventional models, yielding a final output via learning the complex reflection. However, for the sake of simplicity in this paper, we adopt a simple yet effective linear interpolation approach. The final utility score for a user amalgamates the values from both models, represented as:
| (6) |
where is the adaptive parameter to control the weight for each model’s utility value for user . We define the as:
| (7) |
where and are the maximum and minimum long-tail coefficients of the users, respectively, is a hyper-parameter that controls the weight, and is a cut-off weight. From Equation (7), we can observe that for user , the further they are positioned in the long tail (i.e., the fewer items they have interacted with), the lower is the value of and the higher is the value of . As a result, in Equation (6), the weight of the utility score from the LLM model becomes more pronounced. This aligns with the motivation we previously discussed.
4.4.2. Adaptive Aggregation for Top- Recommendation
For the top- recommendation task, the LLM is employed to re-rank the item list generated by a conventional recommendation model. Specifically, from conventional recommendation methods, we curate a top-ranked list comprising items, denoted as . Each item in this list is assigned a utility weight, , where is a constant and represents the position of item , i.e., . A higher utility weight indicates a stronger inclination of the user’s preference. For listwise comparison conducted by the LLM, the process begins by using the LLM to directly output the predicted order of these candidate items. Then we assign utility scores for items at each position, denoted as , where . The final utility score for an item amalgamates the values from both the original rating and the LLM prediction, similar to the Equation (6).
4.5. Training Strategy for LLM
4.5.1. Instruction Tuning Dataset Construction
This section details the creation of an instruction-tuning dataset that encompasses two types of recommendation tasks catering to top- recommendation and rating prediction scenarios. A depiction of these two tasks, specifically referred to as listwise ranking and rating prediction, can be found in Figure 2. It is noteworthy that we also employ the LLM to execute pointwise ranking within top- recommendation scenarios, i.e., utilizing LLM to predict ratings for each item within the top-k recommendations and sorting the predicted ratings to derive the final result.
4.5.2. Optimization via Instruction Tuning
In this work, we perform full parameter instruction tuning to optimize LLMs using generated instruction data. Due to our need for customization, we chose LLaMA-2 (Touvron et al., 2023b), an open-source, high-performing LLM, which permits task-specific fine-tuning. During supervised fine-tuning, we apply a standard cross-entropy loss following Alpaca (Taori et al., 2023). The training set consists of instruction input-output pairs , which have been represented in natural language. The objective is to fine-tune the pre-trained LLM by minimizing the cross-entropy loss, formalized as:
| (8) |
where are the original parameters for LLM, is the conditional probability, is the number of tokens in , is the -th token in the target output , and represents tokens preceding in . By minimizing this loss function, the model fine-tunes its parameters to adapt to the specifics of the new instruction tuning dataset , while leveraging the general language understanding and reasoning that has been acquired during pre-training (Zhang et al., 2023a). In this manner, LLM can capture the user’s preferences for items expressed in natural language, facilitating diverse recommendation tasks, including top-k recommendation and rating prediction.
5. Experiment
In this section, we present a thorough empirical evaluation to validate the effectiveness of our proposed framework. Specifically, our objective is to investigate whether the incorporation of our proposed Llama4Rec could enhance existing recommendation models. The overarching goal is to answer the following research questions:
-
•
RQ1: Does our proposed Llama4Rec framework enhance the performance of existing recommendation models?
-
•
RQ2: How do the various modules in Llama4Rec affect the recommendation performance?
-
•
RQ3: How do different hyper-parameters impact the overall performance of the framework?
5.1. Experiment Setup
5.1.1. Dataset
Following (Bao et al., 2023), we rigorously evaluate the performance of our proposed framework by employing three heterogeneous, real-world datasets. MovieLens111https://grouplens.org/datasets/movielens/ (Harper and Konstan, 2015) serve as benchmark datasets in the realm of movie recommendation methods. We employ two variants of the dataset: MovieLens-100K (ML-100K) and MovieLens-1M (ML-1M). The former consists of approximately 100,000 user-item ratings, while the latter scales up to roughly 1,000,000 ratings. BookCrossing222Due to the absence of timestamp data, we synthesize historical interactions through random sampling. (Ziegler et al., 2005) includes user-generated book ratings on a scale of 1 to 10, alongside metadata such as ‘Book-Author’ and ‘Book-Title’. We employ LLM to augment the ‘director’ and ‘star’ features for ML-100K and ML-1M datasets, and augment the ‘genre’ and ‘page length’ features for the BookCrossing dataset. To ensure the data quality, we adopt the 5-core setting, i.e., we filter unpopular users and items with fewer than five interactions for the BookCrossing dataset. The key characteristics of these datasets are delineated in Table 1.
ML-100K ML-1M BookCrossing # of User 943 6,040 6,851 # of Item 1,682 3,706 9,085 # of Rating 100,000 1,000,209 115,219 Density 0.063046 0.044683 0.001851 User Features Gender, ZipCode, Gender, ZipCode, Location, Age Occupation, Age Occupation, Age Item Features Title, Genres Title, Genres Title, Author, Year Year, Publisher Augmented Movie Director, Movie Director, Book Genres, Features Movie Star Movie Star Page Length
5.1.2. Evaluation Metrics.
Aligning with (He et al., 2020; Sun et al., 2019), for the top- recommendation task, we turn to two well-established metrics: Hit Ratio (HR) and Normalized Discounted Cumulative Gain (NDCG), denoted by H and N, respectively. In our experiments, is configured to be either 3 or 5 for a comprehensive evaluation, similar to the experiment setting in (Zhang et al., 2023c). In accordance with (Fan et al., 2019), we employ Root Mean Squared Error (RMSE) and Mean Absolute Error (MAE) as evaluation metrics to ascertain the performance of the rating prediction task.
Backbone Method ML-100K ML-1M BookCrossing H@3 N@3 H@5 N@5 H@3 N@3 H@5 N@5 H@3 N@3 H@5 N@5 MF Base 0.0455 0.0325 0.0690 0.0420 0.0255 0.0187 0.0403 0.0248 0.0294 0.0227 0.0394 0.0269 IFT 0.0546 0.0388 0.0790 0.0488 0.0242 0.0175 0.0410 0.0244 0.0247 0.0177 0.0377 0.0230 Llama4Rec 0.0645* 0.0474* 0.0919* 0.0588* 0.0281* 0.0203* 0.0433* 0.0265* 0.0365* 0.0284* 0.0462* 0.0324* Impro. 18.13% 22.16% 16.33% 20.49% 10.20% 8.56% 5.61% 6.85% 24.15% 25.55% 17.26% 20.45% LightGCN Base 0.0492 0.0343 0.0744 0.0447 0.0283 0.0203 0.0432 0.0264 0.0358 0.0272 0.0480 0.0322 IFT 0.0537 0.0381 0.0846 0.0507 0.0268 0.0193 0.0441 0.0263 0.0287 0.0202 0.0448 0.0268 Llama4Rec 0.0647* 0.0476* 0.0967* 0.0608* 0.0304* 0.0222* 0.0461* 0.0286* 0.0434* 0.0338* 0.057* 0.0394* Impro. 20.48% 24.93% 14.30% 19.92% 7.42% 9.36% 4.54% 8.33% 21.23% 24.26% 18.75% 22.36% MixGCF Base 0.0526 0.0401 0.0757 0.0496 0.0159 0.0115 0.0238 0.0147 0.0426 0.0330 0.0556 0.0384 IFT 0.0617 0.0452 0.0906 0.0570 0.0162 0.0114 0.0259 0.0154 0.0337 0.0243 0.0506 0.0312 Llama4Rec 0.0690* 0.0515* 0.0949* 0.0621* 0.0174* 0.0128* 0.0259 0.0162* 0.0495* 0.0384* 0.0635* 0.0441* Impro. 11.83% 13.94% 4.75% 8.95% 7.41% 11.30% 0.00% 5.19% 16.20% 16.36% 14.21% 14.84% SGL Base 0.0505 0.0380 0.0729 0.0472 0.0284 0.0206 0.0434 0.0267 0.0419 0.0319 0.0566 0.0380 IFT 0.0520 0.0392 0.0792 0.0503 0.0275 0.0202 0.0438 0.0269 0.0326 0.0237 0.0499 0.0307 Llama4Rec 0.0632* 0.0479* 0.0917* 0.0596* 0.0308* 0.0224* 0.0480* 0.0294* 0.0501* 0.0393* 0.0634* 0.0448* Impro. 21.54% 22.19% 15.78% 18.49% 8.45% 8.74% 9.59% 9.29% 19.57% 23.20% 12.01% 17.89%
Backbone Method ML-100K ML-1M BookCrossing H@3 N@3 H@5 N@5 H@3 N@3 H@5 N@5 H@3 N@3 H@5 N@5 SASRec Base 0.0187 0.0125 0.0385 0.0205 0.0277 0.0165 0.0502 0.0257 0.0086 0.0049 0.0163 0.0081 IFT 0.0204 0.0136 0.0379 0.0207 0.0241 0.0159 0.0473 0.0254 0.0124 0.0086 0.0185 0.0111 Llama4Rec 0.0238* 0.0155* 0.0449* 0.0240* 0.0293* 0.0201* 0.0504 0.0287* 0.0142* 0.0098* 0.0227* 0.0131* Impro. 16.67% 13.97% 16.62% 15.94% 5.78% 21.82% 0.40% 11.67% 14.52% 13.95% 22.70% 18.02% BERT4Rec Base 0.0153 0.0104 0.0294 0.0161 0.0107 0.0069 0.0211 0.0112 0.0088 0.0058 0.0161 0.0088 IFT 0.0174 0.0119 0.0326 0.0100 0.0106 0.0071 0.0188 0.0104 0.0127 0.0092 0.0180 0.0113 Llama4Rec 0.0198* 0.0134* 0.0332 0.0189* 0.0115* 0.0078* 0.0206 0.0115* 0.0154* 0.0108* 0.023* 0.0139* Impro. 13.79% 12.61% 1.84% 17.39% 7.48% 9.86% -2.37% 2.68% 21.26% 17.39% 27.78% 23.01% CL4SRec Base 0.0243 0.0143 0.0436 0.0222 0.0259 0.0153 0.0492 0.0248 0.0083 0.0048 0.0165 0.0082 IFT 0.0230 0.0149 0.0428 0.0230 0.0234 0.0155 0.0447 0.0241 0.0102 0.0071 0.0177 0.0102 Llama4Rec 0.0255* 0.0182* 0.0440 0.0255* 0.0278* 0.0185* 0.0482 0.0268* 0.0138* 0.0093* 0.0220* 0.0127* Impro. 4.94% 22.15% 0.92% 10.87% 7.34% 19.35% -2.03% 8.06% 35.29% 30.99% 24.29% 24.51%
5.1.3. Data Preprocessing.
Following the methodology of prior works (Zhang et al., 2023c; Luo et al., 2022b), we adopt a leave-one-out evaluation strategy. More specifically, within each user’s interaction sequence, we choose the most recent item as the test instance. The item immediately preceding this serves as the validation instance, while all remaining interactions are used to constitute the training set. Moreover, regarding the instruction-tuning dataset construction, we randomly sampled 5K instructions for each recommendation task on the ML-100K, ML-1M, and BookCrossing datasets, respectively. We eliminated instructions that were repetitive or of low quality (identified by users with fewer than three interactions in their interaction history), leaving approximately 25K high-quality instructions. These instructions are mixed to create an instruction-tuning dataset to fine-tune the LLM.
5.1.4. Backbone Models
We incorporate our Llama4Rec with the following recommendation models that are often used for various recommendation tasks as the backbone models:
- •
- •
- •
We employ the LLaMA-2 7B version as the backbone LLM across all experiments, unless specifically mentioned otherwise. Our primary comparison is with the standard Instruction Fine-Tuning (IFT) method adopted in TALLRec (Bao et al., 2023) and InstructRec (Zhang et al., 2023c). For the rating prediction task, LLaMA-2 with IFT is used to directly predict the rating. For the top-k recommendation task, the tuned LLM is used to re-rank the list predicted by the backbone model, in accordance with (Hou et al., 2023), referred to as listwise ranking. Besides, we also adopt LLM for predicting the rating for each item and sort by the predicted scores, referred to as pointwise ranking.
5.1.5. Implementation Details.
During training for LLaMA 2 (7B) with full-parameter tuning, we use a uniform learning rate of and a context length of 2048, and we set the batch size as 16. Additionally, we use a cosine scheduler for three epochs in total with a 50-step warm-up period. To efficiently train the computationally intensive models, we simultaneously employ DeepSpeed training with ZeRO-3 stage (Rajbhandari et al., 2020) and flash attention (Dao et al., 2022). We trained the 7B model on 16 NVIDIA A800 80GB GPUs. For the inference stage, we employed the vLLM framework (Kwon et al., 2023) with greedy decoding, setting the temperature to 0. Only one GPU was utilized during the inference phase. We only evaluate the instruction-tuned LLaMA model for rating prediction task since it is not applicable for directly making top- recommendations.
We implement the models for rating prediction task using the DeepCTR-Torch333https://github.com/shenweichen/DeepCTR-Torch library. For the top- recommendation task, we utilize the SELFRec444https://github.com/Coder-Yu/SELFRec library (Yu et al., 2023) for implementation. As for the hyper-parameter settings, and are selected from 0.1, 0.3, 0.5, 0.7, 0.9 respectively for all experiments. is fixed to 1. We repeat the experiment five times and calculate the average. We report the best results obtained when the ranking method is selected from pointwise and listwise ranking. For all experiments, the best results are highlighted in boldfaces. * indicates the statistical significance for compared to the best baseline method based on the paired t-test. Improv. denotes the improvement of our method over the best baseline method.
Backbone Method ML-100K ML-1M BookCrossing RMSE MAE RMSE MAE RMSE MAE LLaMA IFT 1.2792 0.8940 1.2302 0.8770 2.0152 1.3782 DeepFM Base 1.0487 0.8082 0.9455 0.7409 1.7738 1.3554 Llama4Rec 1.0306* 0.7987* 0.9360* 0.7321* 1.6958* 1.2843* Impro. 1.73% 1.18% 1.00% 1.19% 4.40% 5.25% NFM Base 1.0284 0.8005 0.9438 0.7364 2.121 1.5984 Llama4Rec 1.0189* 0.7961 0.9369* 0.7303* 1.9253* 1.4473* Impro. 0.92% 0.55% 0.73% 0.83% 9.23% 9.45% DCN Base 1.0478 0.8063 0.9426 0.7342 2.0216 1.4622 Llama4Rec 1.0367* 0.8033 0.9345* 0.7272* 1.8518* 1.3566* Impro. 1.06% 0.37% 0.86% 0.95% 8.40% 7.22% AFM Base 1.0471 0.8035 0.9508 0.7464 1.6516 1.2614 Llama4Rec 1.0340* 0.7996 0.9426* 0.7394* 1.6244* 1.2259* Impro. 1.25% 0.49% 0.86% 0.94% 1.65% 2.81% xDeepFM Base 1.1472 0.8836 0.9519 0.7428 2.1756 1.6461 Llama4Rec 1.0947* 0.8483* 0.9401* 0.7336* 1.9610* 1.4833* Impro. 4.58% 4.00% 1.24% 1.24% 9.86% 9.89% AutoInt Base 1.0500 0.8120 0.9471 0.7404 1.9148 1.4501 Llama4Rec 1.0369* 0.8059* 0.9382* 0.7326* 1.7917* 1.3492* Impro. 1.25% 0.75% 0.94% 1.05% 6.43% 6.96%
5.2. Main Results (RQ1)
We conducted an extensive evaluation of our proposed Llama4Rec and the baseline methods on three datasets to assess the model’s performance under diverse recommendation scenarios. The experiment results for rating prediction, direct recommendation, and sequential recommendation are shown in Table 2, Table 3, and Table 4, respectively. We have the following key observations.
-
•
Llama4Rec consistently outperforms baseline methods in almost all scenarios, with particularly significant improvements observed in the direct recommendation task. Moreover, our findings reveal that direct instruction fine-tuning LLMs for recommendation tasks does not consistently yield promising performance. These results highlight the effectiveness of integrating LLMs into conventional recommendation models, underscoring the importance of incorporating the mechanism that utilizes instruction-tuned LLM to mutually augment and adaptively aggregate with conventional recommendation models.
-
•
In the scenario of the rating prediction task, while the instruction-tuned LLaMA model significantly underperforms when compared to conventional recommendation models, integrating the LLM yields a marked performance improvement. This suggests that the LLM and conventional recommendation models learn distinct aspects of information. Consequently, integrating the LLM with conventional recommendation models could enhance recommendation performance.
-
•
In the context of top- recommendations, Llama4Rec exhibits a more pronounced improvement for direct recommendations task. In addition, a more significant enhancement is observed on the Bookcrossing dataset, which can be attributed to the more fine-grained and distinguishable rating of the Bookcrossing dataset.
Models ML-1M BookCrossing H@3 N@3 H@3 N@3 LightGCN 0.0283 (-) 0.0203 (-) 0.0358 (-) 0.0272 (-) IFT 0.0268 (-5.30%) 0.0193 (-4.93%) 0.0287 (-19.84%) 0.0202 (-25.74%) Llama4Rec w/o DA 0.0294 (+3.89%) 0.0209 (+2.96%) 0.0408 (+13.97%) 0.0319 (+17.28%) Llama4Rec w/o PA 0.0277 (-2.12%) 0.0199 (-1.97%) 0.0372 (+3.92%) 0.0279 (+2.57%) Llama4Rec w/o AA 0.0298 (+5.30%) 0.0218 (+7.39%) 0.0429 (+19.83%) 0.0332 (+22.06%) Llama4Rec 0.0304 (+7.42%) 0.0222 (+9.36%) 0.0434 (+21.23%) 0.0338 (+24.26%)
5.3. Ablation Study (RQ2)
We conducted an ablation study to analyze the contributions of different components in our model. Table 5 summarizes the results of the ablation studies across three variants on the ML-1M dataset. It is evident that the full model performs considerably better than all its variants, indicating that all the main components contribute significantly to overall performance improvement. Moreover, compared to the conventional model, the instruction-tuned LLM does not achieve superior results, underscoring the importance of model aggregation. We further analyze the specific impact of each component, and our observations are as follows:
-
•
w/o Data Augmentation (w/o DA): In this variant, we remove the data augmentation module while maintaining other components the same. Experimental results reveal a obvious decline in performance when this module is excluded. This indicates the module’s capacity to mitigate data sparsity and long-tail problem, consequently enhancing model performance.
-
•
w/o Prompt Augmentation (w/o PA): In this variant, we remove the prompt augmentation component, a crucial element of the proposed framework. Experimental results demonstrate a significant degradation in model performance when this module is excluded, thereby validating its essential role. By employing the instruction-tuned LLM with prompt augmentation from prior knowledge by conventional recommendation models, we achieve an enhanced model performance, attributable to the capture of different aspects of information.
-
•
w/o Adaptive Aggregation (w/o AA): In this variant, we substitute adaptive aggregation with uniform aggregation and keep other modules unchanged. Experimental results demonstrate a drop in model performance, underscoring the significance of accounting for the user’s long-tail coefficient and employing adaptive aggregation.
5.4. Hyper-parameter Study (RQ3)
5.4.1. Analysis of Hyper-parameters and
We conducted an analysis of the effects of hyper-parameters and . These parameters play crucial roles in controlling the weight in adaptive aggregation, as illustrated in Equation (7). Figure 3 presents the results on the ML-1M dataset using LightGCN as the backbone model. As increases, we observe an initial surge in the model’s performance, followed by a decline. This trend suggests appropriate selection of would enhance the model performance. With respect to , we observe a similar trend but the decline is more pronounced. This observation is consistent with the principle of adaptive aggregation, which emphasizes the importance of assigning suitable weights to tail users.





5.4.2. Analysis of Model Scaling.
We further instruction-tuned the LLaMA-2 model with different model size.555Due to resource constraints, training the LLaMA-2 (70B) model with identical experimental settings was unfeasible, consistently leading to Out-Of-Memory (OOM) errors. A comparative analysis was conducted between the 7B and 13B variants of the instruction-tuned models, with performance differences specifically evaluated across various backbone models within the Bookcrossing dataset, as depicted in Figure 4. Our findings suggest that the LLaMA-2 (13B) model generally surpasses the 7B version in performance. This can be attributed to the superior language comprehension and reasoning abilities of the larger model, which contribute to improved recommendation results. However, it’s worth noting that the improvements are not substantial, indicating that while larger models may provide some performance benefits, the degree of improvement may not always justify the increased computational resources and training time required. It underscores the importance of considering the trade-off between model size, performance gain, and resource efficiency in the design and application of large language models.
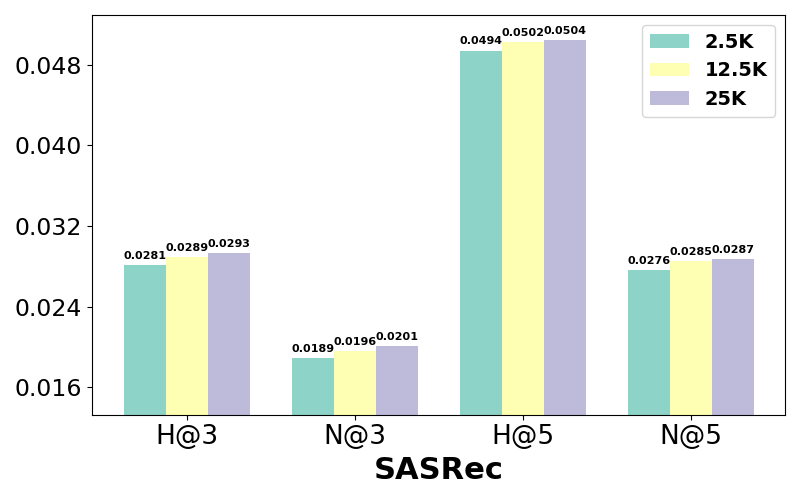
5.4.3. Analysis of Data Scaling.
We evaluated the effect of data size on LLM training by varying the number of instructions in the instruction-tuning dataset. Proportionality with our original configuration, the model with 2.5K instructions underwent 250 training steps, while the 12.5K instructions version was trained over 1250 steps. As depicted in Figure 5, a clear trend emerges: model performance improves with an increase in the number of instructions, particularly for direct recommendation models. This highlights the importance of utilizing larger and more diverse datasets for instruction tuning LLMs to optimize performance.
5.5. Further Discussion
In this part, we discuss about the computational efficiency and future improvements. In the Llama4Rec framework, additional training with augmented data is required, which may present a potential limitation. In the current experimental setup, we train a new model from scratch. However, this process could be optimized by continuing to train a previously tuned model, thereby reducing time costs. Additionally, in our experiment, we observed that training the LLaMA-2 7B model with around 25K instructions on 16 A800 GPUs with 2500 steps took approximately 1.94 hours. The inference time for each instruction averaged about 17 instructions per second, translating to a requirement of around 0.059 seconds per item for computation by a single A800 GPU.
This training and inference duration significantly exceeds that of conventional recommendation models, highlighting the limitations of current LLM-based recommender systems. The substantial demand for computational resources also represents a significant challenge. Consequently, employing instruction LLMs for large-scale industrial recommender systems, such as those with millions of users, is presently impractical. However, future advancements in accelerated and parallel computing algorithms for language model inference could potentially reduce inference times and computation resources. This improvement might make the integration of LLMs into large-scale recommender systems feasible, especially by leveraging many GPUs for parallel computation.
6. Conclusion and future work
In this study, we present Llama4Rec, a general and model-agnostic framework tailored to facilitate mutual augmentation between conventional recommendation models and LLMs through data augmentation and prompt augmentation. Data augmentation for conventional recommendation models could alleviate issues of data sparsity and the long-tail problem, thus improving conventional recommendation model performance. Prompt augmentation, on the other hand, allows the LLM to externalize additional collaborative or sequential information and further enhance the model capability. Furthermore, adaptive aggregation is employed to merge the predictions from both kinds of augmented models, resulting in more optimized recommendation performance. Comprehensive experimental results across three diverse recommendation tasks on three real-world datasets demonstrate the effectiveness of Llama4Rec. While our current approach focuses on mutual augmentation within a single step, our future work will explore expanding mutual augmentation in an iterative manner, potentially unlocking further improvements in model performance.
References
- (1)
- Adomavicius and Tuzhilin (2005) Gediminas Adomavicius and Alexander Tuzhilin. 2005. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE transactions on knowledge and data engineering 17, 6 (2005), 734–749.
- Bao et al. (2023) Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. arXiv preprint arXiv:2305.00447 (2023).
- Chen et al. (2023) Xiong-Hui Chen, Bowei He, Yang Yu, Qingyang Li, Zhiwei Qin, Wenjie Shang, Jieping Ye, and Chen Ma. 2023. Sim2Rec: A Simulator-based Decision-making Approach to Optimize Real-World Long-term User Engagement in Sequential Recommender Systems. arXiv preprint arXiv:2305.04832 (2023).
- Dao et al. (2022) Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems 35 (2022), 16344–16359.
- Dong et al. (2022) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey for in-context learning. arXiv preprint arXiv:2301.00234 (2022).
- Fan et al. (2019) Wenqi Fan, Yao Ma, Qing Li, Yuan He, Eric Zhao, Jiliang Tang, and Dawei Yin. 2019. Graph neural networks for social recommendation. In The world wide web conference. 417–426.
- Fan et al. (2023) Wenqi Fan, Zihuai Zhao, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Jiliang Tang, and Qing Li. 2023. Recommender systems in the era of large language models (llms). arXiv preprint arXiv:2307.02046 (2023).
- Geng et al. (2022) Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). In Proceedings of the 16th ACM Conference on Recommender Systems. 299–315.
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
- Harper and Konstan (2015) F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context. Acm transactions on interactive intelligent systems (tiis) 5, 4 (2015), 1–19.
- He et al. (2023b) Bowei He, Xu He, Renrui Zhang, Yingxue Zhang, Ruiming Tang, and Chen Ma. 2023b. Dynamic Embedding Size Search with Minimum Regret for Streaming Recommender System. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 741–750.
- He et al. (2023a) Bowei He, Xu He, Yingxue Zhang, Ruiming Tang, and Chen Ma. 2023a. Dynamically Expandable Graph Convolution for Streaming Recommendation. In Proceedings of the ACM Web Conference 2023. 1457–1467.
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648.
- He et al. (2017) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural collaborative filtering. In Proceedings of the 26th international conference on world wide web. 173–182.
- Hidasi et al. (2015) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks. arXiv preprint arXiv:1511.06939 (2015).
- Hou et al. (2023) Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2023. Large language models are zero-shot rankers for recommender systems. arXiv preprint arXiv:2305.08845 (2023).
- Huang et al. (2021) Tinglin Huang, Yuxiao Dong, Ming Ding, Zhen Yang, Wenzheng Feng, Xinyu Wang, and Jie Tang. 2021. Mixgcf: An improved training method for graph neural network-based recommender systems. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining. 665–674.
- Kang and McAuley (2018) Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In 2018 IEEE international conference on data mining (ICDM). IEEE, 197–206.
- Khan et al. (2021) Zahid Younas Khan, Zhendong Niu, Sulis Sandiwarno, and Rukundo Prince. 2021. Deep learning techniques for rating prediction: a survey of the state-of-the-art. Artificial Intelligence Review 54 (2021), 95–135.
- Koren et al. (2009) Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer 42, 8 (2009), 30–37.
- Kwon et al. (2023) Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. arXiv preprint arXiv:2309.06180 (2023).
- Le and Lauw (2021) Dung D Le and Hady Lauw. 2021. Efficient retrieval of matrix factorization-based top-k recommendations: A survey of recent approaches. Journal of Artificial Intelligence Research 70 (2021), 1441–1479.
- Lian et al. (2018) Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, and Guangzhong Sun. 2018. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 1754–1763.
- Liu et al. (2023) Junling Liu, Chao Liu, Renjie Lv, Kang Zhou, and Yan Zhang. 2023. Is chatgpt a good recommender? a preliminary study. arXiv preprint arXiv:2304.10149 (2023).
- Longpre et al. (2023) Shayne Longpre, Le Hou, Tu Vu, Albert Webson, Hyung Won Chung, Yi Tay, Denny Zhou, Quoc V Le, Barret Zoph, Jason Wei, et al. 2023. The flan collection: Designing data and methods for effective instruction tuning. arXiv preprint arXiv:2301.13688 (2023).
- Luo et al. (2023a) Sichun Luo, Chen Ma, Yuanzhang Xiao, and Linqi Song. 2023a. Improving Long-Tail Item Recommendation with Graph Augmentation. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management. 1707–1716.
- Luo et al. (2022a) Sichun Luo, Yuanzhang Xiao, and Linqi Song. 2022a. Personalized federated recommendation via joint representation learning, user clustering, and model adaptation. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 4289–4293.
- Luo et al. (2023b) Sichun Luo, Yuanzhang Xiao, Xinyi Zhang, Yang Liu, Wenbo Ding, and Linqi Song. 2023b. PerFedRec++: Enhancing Personalized Federated Recommendation with Self-Supervised Pre-Training. arXiv preprint arXiv:2305.06622 (2023).
- Luo et al. (2022b) Sichun Luo, Xinyi Zhang, Yuanzhang Xiao, and Linqi Song. 2022b. HySAGE: A hybrid static and adaptive graph embedding network for context-drifting recommendations. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 1389–1398.
- OpenAI (2023) OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Park and Tuzhilin (2008) Yoon-Joo Park and Alexander Tuzhilin. 2008. The long tail of recommender systems and how to leverage it. In Proceedings of the 2008 ACM conference on Recommender systems. 11–18.
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1–16.
- Rendle et al. (2012) Steffen Rendle, Christoph Freudenthaler, Zeno Gantner, and Lars Schmidt-Thieme. 2012. BPR: Bayesian personalized ranking from implicit feedback. arXiv preprint arXiv:1205.2618 (2012).
- Song et al. (2019) Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang, and Jian Tang. 2019. Autoint: Automatic feature interaction learning via self-attentive neural networks. In Proceedings of the 28th ACM international conference on information and knowledge management. 1161–1170.
- Steck (2013) Harald Steck. 2013. Evaluation of recommendations: rating-prediction and ranking. In Proceedings of the 7th ACM conference on Recommender systems. 213–220.
- Sun et al. (2019) Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. 2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM international conference on information and knowledge management. 1441–1450.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Wang et al. (2023) Ke Wang, Houxing Ren, Aojun Zhou, Zimu Lu, Sichun Luo, Weikang Shi, Renrui Zhang, Linqi Song, Mingjie Zhan, and Hongsheng Li. 2023. Mathcoder: Seamless code integration in llms for enhanced mathematical reasoning. arXiv preprint arXiv:2310.03731 (2023).
- Wang and Lim (2023) Lei Wang and Ee-Peng Lim. 2023. Zero-Shot Next-Item Recommendation using Large Pretrained Language Models. arXiv preprint arXiv:2304.03153 (2023).
- Wang et al. (2017) Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17. 1–7.
- Wang et al. (2019) Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR conference on Research and development in Information Retrieval. 165–174.
- Wei et al. (2023) Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2023. Llmrec: Large language models with graph augmentation for recommendation. arXiv preprint arXiv:2311.00423 (2023).
- Wu et al. (2021) Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised graph learning for recommendation. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 726–735.
- Xi et al. (2023) Yunjia Xi, Weiwen Liu, Jianghao Lin, Jieming Zhu, Bo Chen, Ruiming Tang, Weinan Zhang, Rui Zhang, and Yong Yu. 2023. Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models. arXiv preprint arXiv:2306.10933 (2023).
- Xiao et al. (2017) Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. 2017. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv preprint arXiv:1708.04617 (2017).
- Xie et al. (2022) Xu Xie, Fei Sun, Zhaoyang Liu, Shiwen Wu, Jinyang Gao, Jiandong Zhang, Bolin Ding, and Bin Cui. 2022. Contrastive learning for sequential recommendation. In 2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1259–1273.
- Yu et al. (2023) Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Jundong Li, and Zi Huang. 2023. Self-supervised learning for recommender systems: A survey. IEEE Transactions on Knowledge and Data Engineering (2023).
- Zhang et al. (2023c) Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2023c. Recommendation as instruction following: A large language model empowered recommendation approach. arXiv preprint arXiv:2305.07001 (2023).
- Zhang et al. (2023a) Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. 2023a. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792 (2023).
- Zhang et al. (2019) Shuai Zhang, Lina Yao, Aixin Sun, and Yi Tay. 2019. Deep learning based recommender system: A survey and new perspectives. ACM computing surveys (CSUR) 52, 1 (2019), 1–38.
- Zhang et al. (2023b) Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He. 2023b. Collm: Integrating collaborative embeddings into large language models for recommendation. arXiv preprint arXiv:2310.19488 (2023).
- Zheng et al. (2023) Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Adapting large language models by integrating collaborative semantics for recommendation. arXiv preprint arXiv:2311.09049 (2023).
- Zhou et al. (2023) Aojun Zhou, Ke Wang, Zimu Lu, Weikang Shi, Sichun Luo, Zipeng Qin, Shaoqing Lu, Anya Jia, Linqi Song, Mingjie Zhan, et al. 2023. Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification. arXiv preprint arXiv:2308.07921 (2023).
- Ziegler et al. (2005) Cai-Nicolas Ziegler, Sean M McNee, Joseph A Konstan, and Georg Lausen. 2005. Improving recommendation lists through topic diversification. In Proceedings of the 14th international conference on World Wide Web. 22–32.