Integrated Decision Making and Trajectory Planning for Autonomous Driving Under Multimodal Uncertainties: A Bayesian Game Approach
Abstract
Modeling the interaction between traffic agents is a key issue in designing safe and non-conservative maneuvers in autonomous driving. This problem can be challenging when multi-modality and behavioral uncertainties are engaged. Existing methods either fail to plan interactively or consider unimodal behaviors that could lead to catastrophic results. In this paper, we introduce an integrated decision-making and trajectory planning framework based on Bayesian game (i.e., game of incomplete information). Human decisions inherently exhibit discrete characteristics and therefore are modeled as types of players in the game. A general solver based on no-regret learning is introduced to obtain a corresponding Bayesian Coarse Correlated Equilibrium, which captures the interaction between traffic agents in the multimodal context. With the attained equilibrium, decision-making and trajectory planning are performed simultaneously, and the resulting interactive strategy is shown to be optimal over the expectation of rivals’ driving intentions. Closed-loop simulations on different traffic scenarios are performed to illustrate the generalizability and the effectiveness of the proposed framework.
Index Terms:
Autonomous driving, game theory, multi-agent systems, decision-making, trajectory planning, game of incomplete information, Bayesian coarse correlated equilibrium, no-regret learning.I Introduction
Recent years have witnessed great advancements in the technology of autonomous vehicles, which aims to provide a new transportation style that improves traffic efficiency and safety. On the other hand, many technical difficulties remain unsolved in decision-making and trajectory planning for autonomous vehicles across highly complex traffic scenarios. Within this topic, one of the key issues is to effectively model the interaction between autonomous vehicles and other traffic participants, such as human drivers. This problem is particularly challenging, as the rationality of humans is often limited and the preferences of human drivers vary, leading to large uncertainties in decisions and actions. Many of the approaches in the literature adopt an architecture such that prediction and trajectory planning are essentially decoupled. In particular, a prediction module is utilized to forecast the future trajectories of human-driving vehicles. Afterward, the human-driving vehicles are fed into the planning module as immutable objects, and the planning process is grounded on this immutable hypothesis. These approaches are limited as they largely fail to capture the interactive nature of driving behaviors by ignoring the influence of the planned trajectories on other traffic participants. Also, they can lead to the “frozen robot” problem [1] and overly conservative behaviors when all possible trajectories are potentially unsafe according to the predictions.
In light of this, a branch of methods based on game theory is receiving increasing attention owing to its strength in modeling the interactions between agents. The game theory models the self-interested nature of all participants that drives them to a particular equilibrium, which is optimal in the sense that none of the participants can gain more profits by unilaterally altering its own strategy. By calculating the equilibrium of the game, the prediction and the planning are essentially coupled, resulting in an optimal trajectory with interaction properly considered. Efforts have been paid in this direction to model various traffic scenarios such as intersections [2, 3], ramp-merging [4, 5], lane-changing [6, 7], and roundabouts [8]. Among game-based methods, various types of games are intensively studied such as potential games [9, 10], congestion game [11], auction game [12], and Stackelberg games [13, 14]. Nevertheless, the majority of game-based methods focus on achieving a single equilibrium and largely neglect the multimodal nature of the solution. In reality, the decision space of human drivers is often discrete, and multiple distinct decisions can be reasonable with respect to a specific traffic scenario, while a single equilibrium can only reveal one of them. Catastrophic results are prone to occur when there is a discrepancy between the mode of the calculated equilibrium and the actual decisions made by other traffic participants. A few game-based methods aim to solve this problem by considering the multimodality in behaviors of the rival traffic participants [15, 16, 17], but the game settings are simple and scenario-specific, which prevent these methods from generalizing to complex game settings and a variety of traffic scenarios. Also, in these methods, the decision-making and the planning are separated, and therefore the results are prone to be suboptimal.
To address the aforementioned challenges, we present an innovative integrated decision-making and trajectory planning framework for autonomous vehicles, which properly considers the multimodal nature of driving behaviors utilizing game theory. In particular, interactions of traffic participants are modeled as a general Bayesian game (i.e., game of incomplete information) that can potentially be applied to various traffic scenarios. By computing the corresponding Bayesian Coarse Correlated Equilibrium (Bayes-CCE), the decision and the corresponding trajectory are obtained simultaneously, which are shown to be optimal over the expectations of the underlying intentions of other participants. An updating strategy based on Bayesian filtering is also introduced to update the estimation of the driving intentions. The main contribution of this paper is listed as follows:
-
The interactions between traffic participants are effectively modeled from the perspective of a Bayesian game, such that the multimodalities in driving behaviors are properly addressed. Unlike most of the existing methods, the game formulation is generic with multiple game stages and the information structures are potentially adaptive. Therefore, it exhibits the generalizability to various traffic scenarios.
-
A parallelizable Monte Carlo search algorithm is proposed to solve the introduced game with arbitrarily complex information structures. Meanwhile, rigorous proof is established to demonstrate the almost-sure convergence of the introduced algorithm to a Bayes-CCE.
-
With the attained Bayes-CCE, an integrated decision-making and trajectory planning strategy is presented to obtain the decision and the corresponding trajectory simultaneously, which bridges the gap between decision-making and trajectory planning to avoid suboptimality. Moreover, theoretic analysis is performed to demonstrate the optimality of the resulting strategy in terms of the expectation, given the up-to-date beliefs over the underlying driving intentions of other vehicles.
-
With a belief updating strategy based on Bayesian filtering to maintain the estimation of the participants’ driving intentions, a closed-loop autonomous driving framework is given. A series of simulations are performed to illustrate the superiority of the proposed method over traditional game methods.
II Related Works
II-A Non-Game-Theoretic Decision-Making and Trajectory Planning
In the past years, efforts have been made to tackle the decision-making and trajectory-planning problems for autonomous driving. State-machine-based methods [18, 19, 20], which utilize hand-crafted rules to generate decisions and trajectories based on the current state of the autonomous vehicle, are popular at the early stage due to their simplicity and interpretability. However, the innumerable nature of traffic scenarios prevents the wide application of these methods, as the difficulty in maintaining such a state machine increases dramatically with increasing scenario complexities. The research focus soon shifts to a more generic formulation of the problem. In light of this, various methods are proposed by actively employing the concept of searching [21, 22, 23], optimization [24, 25, 26], sampling [27, 28], and POMDP [29], etc. Recently, a branch of multi-policy planning methods, including MPDM [30], EUDM [31], EPSILON [32], and MARC [33], are gaining attention due to their ability in efficient behavior planning. These methods rely on dedicated forward simulators to evaluate the performance of each policy and perform the best one selectively. Nonetheless, the aforementioned approaches generally suffer from difficulties in modeling the interactions, particularly in the effect of the trajectory of the autonomous vehicle on the behaviors of the other vehicles. Meanwhile, a series of recent works address the decision-making and trajectory planning problem using a unified neural network trained through end-to-end imitation learning [34, 35, 36]. However, the lack of interpretability brings safety concerns, which prevents the wide application of these methods in real-world situations.
II-B Game-Theoretic Decision-Making and Trajectory Planning
To tackle the problem mentioned in the previous subsection, game-based methods are extensively researched. In this area, many of the existing methods calculate a single equilibrium and assume that all participants will follow the computed equilibrium [37, 4, 13, 38, 9]. These methods generally assume no uncertainty in agents’ behaviors. In [37, 4], efficient game-solving strategies are proposed to resolve differential games and reach typical Nash equilibriums. In [13], the interaction between traffic agents is formulated as a Stackelberg game, and a solving scheme based on dynamic programming is proposed to solve the game in real time. In [9], a general decision-making framework is introduced, which shows that typical traffic scenarios can be modeled as a potential game. In potential games, a pure-strategy Nash equilibrium is proven to exist and reachable, and therefore effective decision-making strategies can be derived. In [38], an efficient game-theoretic trajectory planning algorithm is introduced based on Monte Carlo Tree Search, together with an online estimation algorithm to identify the driving preferences of road participants. Although different types of games and various solving schemes are intensively studied in these researches, the uncertainties in human driving behaviors are not effectively revealed in the attained equilibria. Meanwhile, a few studies try to actively model different kinds of uncertainties involved in a game process. In [39], uncertainties in the observation model are actively addressed by formulating the interaction between agents as a stochastic dynamic game in belief space. However, the proposed method only considers observation uncertainties with Gaussian noise. In [40], the maximum entropy model is utilized to model the uncertainties in the equilibrium strategies for all agents. Nevertheless, the objectives and intentions of all agents are assumed to be known and fixed, which is unrealistic in complicated urban traffic scenarios.
To address the uncertainties residing in objectives and obtain the optimal strategy against the resulting multi-modal behaviors of rival agents, some of the researches study the game of incomplete information and the corresponding Bayesian equilibrium, where the equilibrium strategy is optimal over the distribution of rivals’ possible objectives and their equilibrium strategies. Representative works include [15, 17, 41, 42, 16, 43]. Nonetheless, these methods adopt overly simplified game settings of tiny scale and use hand-crafted solvers for obtaining the corresponding Bayesian equilibrium, which confines the application of these methods to simple scenarios like lane-switching. Besides, the decision-making and trajectory-planning processes are usually separated, and this discrepancy can lead to suboptimal decisions. A recent research [44] takes a game-theoretic perspective on contingency planning, and the resulting contingency game enables interaction with other agents by generating strategic motion plans conditioned on multiple possible intents for other actors. However, it is a motion planning framework lacking in the capacity to perform high-level decision-making. Also, the dedicated and unsymmetrical game settings make it hard to generalize to different types of games with multiple players, multiple policies, and multiple stages.
II-C No-Regret Learning
Another branch of methods closely related to this research is no-regret learning, which aims at providing general solutions to various extensive-form games (games with multiple stages). Despite their effectiveness in modeling sequential decision-making processes, solving for large extensive games has been a long-standing challenge. In [45], a counter-factual regret minimization (CFR) algorithm is introduced to iteratively solve this form of games, which is extended by MCCFR [46] with a Monte Carlo sampling process to avoid the difficulties traversing the entire game tree in each iteration. A follow-up work is proposed in [47], which further extends the MCCFR method to enable dynamic construction of the game tree. The convergence of these methods to a corresponding Nash equilibrium is only guaranteed on two-player zero-sum games. To extend these methods to multi-player general-sum games, CFR-S is introduced in [48], which performs sampling at each iteration and illustrates that the frequency distribution of the sampled strategies converges to a Coarse Correlated Equilibrium (CCE). For games of incomplete information with Bayes settings, the condition of convergence to a Bayes-CCE is provided in [49] without detailed solution schemes.
III Problem Statement
Consider a set of vehicles in a traffic scenario. For each vehicle , we denote the set of its potential intentions as . For each driving intention , the associated action space and utility function are denoted as and , respectively. Further, we use to denote the product space of , such that each is a vector of intentions of all vehicles, . It should be noted that the intention of vehicle , , is private and unknown to all other vehicles and vice versa. Instead, each vehicle is trying to maintain a probability distribution over the intentions of all other vehicles. We further assume that the historical trajectories of all vehicles, together with the surroundings, are fully observable by each vehicle. Since the predictions on driving intentions are determined by historical trajectories and surroundings, we can reasonably assume that all vehicles can arrive at the same belief on the intentions. Formally, the following assumption is introduced.
Assumption 1.
A common probability distribution over can be established and is known to all vehicles, such that , where is the common belief of all vehicles over the intention of vehicle .
Note that although vehicle has complete knowledge of its own intention, it also recognizes the fact that its intention is not known to others and that the belief of other vehicles over its own intention is .
With the aforementioned notations and assumptions, we formally introduce the following definition of games with incomplete information.
Definition 1.
(Harsanyi game of incomplete Information [50, Chapter 9.4]) A Harsanyi game of incomplete information is a vector , where is the state game for the type vector .
Note that the driving intentions of vehicles are modeled as types of players in one-to-one correspondence. Through playing a Harsanyi game of incomplete information, a desirable result is the corresponding Bayesian Nash equilibrium strategy. In particular, a behavior strategy of vehicle , is a map from each type to a probability distribution over the available actions: . Further, given the strategy vector of all vehicles as , we denote the expected payoff of vehicle with type as
| (1) |
The corresponding Bayesian Nash equilibrium is defined as follows.
Definition 2.
(Bayesian Nash Equilibrium [50, Chapter 9.4]) a strategy vector is a (mixed-strategy) Bayesian Nash Equilibrium if for all , for all , and for all , the following inequality holds:
| (2) |
When a Bayesian Nash equilibrium is reached, no player of any type can obtain a higher expected payoff by unilaterally modifying its own behavioral strategy. In the context of autonomous driving, it means that for an arbitrary vehicle , once its intention is determined, its strategy is optimal over the expectation of the intentions of all other vehicles, given that their strategies are fixed. Since this optimality condition holds for all vehicles, the bilateral signaling effects are modeled, such that the influence of own actions on the belief of other vehicles about the intention of ego vehicle, and further, their preferences on actions, can be properly considered. Thus, an interaction model that handles multimodality on both sides is established.
However, solving for such a mixed-strategy Bayesian Nash Equilibrium is not trivial, especially for a multi-player general-sum game, which is typically the case in common urban traffic scenarios. To leverage the merit of game of incomplete information, we consider instead the Bayes-CCE, which is a generalization of the Bayesian Nash equilibrium, and propose a general solver that is proven to converge to a Bayes-CCE with minimum assumptions required. To introduce the concept of Bayes-CCE, we first define the plan of player as a direct map from type to a specific action: , and further, is the concatenated vector of plans of all players. is the set of such that . The formal definition of a Bayes-CCE is as follows.
Definition 3.
(Bayes-CCE [49]) A strategy profile is a Bayes-CCE if for every player , for every type , and for every possible plan , the following inequality holds:
| (3) | ||||
In this paper, we formulate the driving game in urban traffic scenarios as a Harsanyi game of incomplete information. Specifically, the action spaces are represented as sets of sampled candidate trajectories, each associated with a particular driving intention (accelerating, lane switching, etc.) The utility functions include pertinent driving performance indices like smoothness and safety. Solving for the Bayes-CCE yields an open-loop equilibrium strategy, which is a joint probability distribution over candidate trajectories. We assume that all vehicles perform this equilibrium strategy. As time evolves and new information is gained, the prediction of vehicle intentions can be updated through Bayesian filtering, and the corresponding driving game can be resolved repeatedly, resulting in a closed-loop driving scheme.
IV Proposed Approach
IV-A Parallel Solver for Bayes-CCE
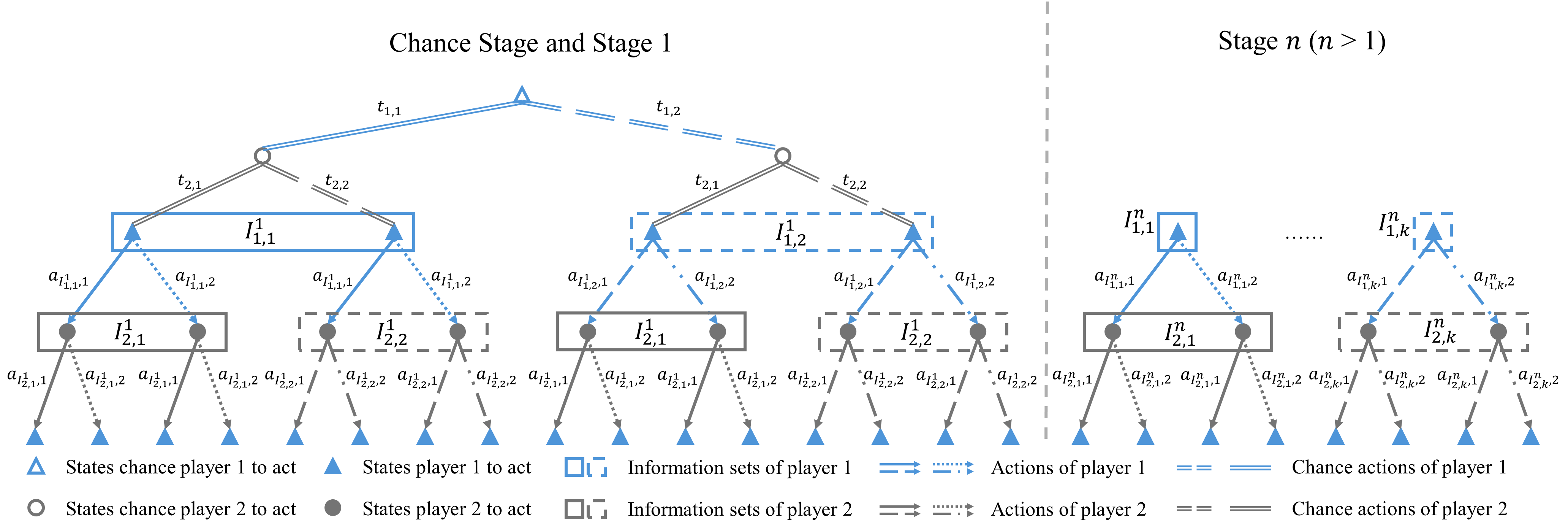
In this section, a parallel solver utilizing classic Monte Carlo counter-factual regret minimization (MCCFR) is introduced to resolve the game and enable a real-time solution for the open-loop Bayes-CCE in general traffic settings. In particular, the structure of a typical extensive-form game of incomplete information in traffic settings is shown as the game tree in Fig. 1. Each of the nodes on the game tree corresponds to a particular game state, and these game states are partitioned into information sets, such that players cannot distinguish between two states in the same information set. Therefore, the behavior strategy of each player is made with respect to information sets, , where is the information partition of player , or the set of information sets under which it is the turn of player to move. is a distribution over possible actions for player of type under Information set . At the beginning stage of the game, an extra chance player (also known as the nature) will take chance moves that will randomly select a type for each player subject to the common probability distribution . After the types of all players are determined, players will take moves in turns to proceed through the game tree until a leaf node is reached and the utilities of all players are thus determined.
Remark 1.
We assume that at each stage, the moves of all players are taken simultaneously, which means that each player cannot distinguish between the moves taken by others before it takes its own move. This setting is clearly revealed by the structure of the information sets in the game tree.
Remark 2.
Fig. 1 is an illustrative figure corresponding to a game with 2 players. A game with 3 or more players can be defined similarly. Meanwhile, the game tree description of a game is general enough such that other forms of games, such as a Stackelberg game, can also be well-represented by simply changing the configurations of the information sets. It will be shown that the proposed solving scheme does not rely on the particular structure of the game tree and therefore is also general.
Before we formally propose the solving scheme, we give a brief introduction to two relevant algorithms as preliminaries.
CFR [45] and MCCFR [46]: The vanilla CFR only considers a two-player zero-sum game without types of players. Therefore, , , and can be rewritten as , , and , respectively. Given the overall strategy as , the counterfactual value for information set is defined as
| (4) |
where is the set of all the paths on the game tree from root to leaf that pass through I, and is one of the paths in containing all historical actions of all players. is the prefix of from root to . is the cumulative product of the probabilities of moves taken by other agents along , and is the cumulative product of the probabilities of moves taken by all agents from to . In general, the counterfactual value describes the expected utility of Information set given strategy profile with the extra assumption that agent plays to reach .
The immediate counterfactual regrets of each action is , with define as the strategy profile identical to except that , namely that action is selected with probability . In the entire no-regret learning process, rounds of playing are conducted. In each round, the regret-matching strategy is conducted to improve the strategy. Particularly in round , the strategy is determined by , where . It is proven that when , the average strategy defined as converges to a Nash equilibrium for a two-player zero-sum game.
A drawback of the vanilla CFR method is that in each round of playing, traversing the entire game tree is required, which is time-consuming and even intractable when the size of the game is large. To cope with this problem, the method MCCFR is proposed, such that in each round of playing, only part of the game tree is explored. Particularly in outcome-sampling MCCFR, only one leaf node of the game tree is sampled according to some pre-defined distribution, , and all other leaves are dropped (equivalently, their utilities are zeroed out). The following sampled counterfactual value is introduced:
| (5) |
It is shown that . Replacing by yields the outcome-sampling MCCFR. It is obvious that in each round of playing, the only information sets that require updating are those passed through by the sampled path .
The previous restatement of CFR and MCCFR describes a solution to obtain the (mixed-strategy) Nash equilibrium in a two-player zero-sum extensive-form game. We integrate MCCFR, the no-regret learning method in game of incomplete information [49], and CFR-S [48] to introduce MCCFR-S for game of incomplete information, a parallelizable solving scheme that is proven to converge to a Bayes-CCE for a multi-player general-sum game of incomplete information settings. Details are shown in Algorithm 1. We give a brief explanation of each procedure used in this algorithm.
Bayes-CCE: this is the main procedure of Algorithm 1. is the game described in Fig.1. is the number of iterations and is the common distribution over intentions of vehicles. , , and are the array of cumulative counterfactual regrets, the array of behavioral strategies, and the frequency of plan , respectively. is the array of the cumulative sampled counterfactual values. All those arrays are zero-initialized. In each iteraction, a type vector representing vehicles’ intentions are sampled from distribution , and then the outcome-sampling MCCFR is performed once to update the regret array and the strategy array . A sampling process is then performed based on updated strategy such that a plan is sampled from and the frequency is updated.
MCCFR: this is a recursive implementation of MCCFR [46], where are defined as above. is the history of play or the past actions of all players concatenated together. For a particular , is the vector containing probabilities of all players play to reach according to current strategy , namely . is the probability of sampling , namely . The algorithm contains a forward pass and a backward pass. In the forward pass we randomly proceed through the game tree from the root to one of the leaf by sampling action from the -modulated strategy at each node (line 17 and 18) and calculate the and for current (line 19 and 20). Once a leaf is reached, we obtain the utility for all players (line 11 to 14). In the backward pass, we revisit all the information sets we visited in the forward pass in reverse order. For an information set , we obtain the probability playing from to the sampled leaf according to current strategy (line 23), and updates the cumulative counterfactual regret for (line 24 to 31). A standard regret matching is performed to update the behavioral strategy associated with (line 32).
RM: this is the standard regret matching algorithm for updating behavioral strategy associated with information set called by the MCCFR procedure.
Sample: this is the sampling procedure. given updated strategy , a plan is sampled for each . The concatenated plan is then obtained and record. measures the time when is sampled, such that is an empirical distribution over the space of plan .
Algorithm 1 is easily parallelizable and implemented with multiple processes, as each process samples the type vector , proceeds along the game tree, and samples the overall plan , independently. The only coupled part is the line 32, as each process needs to gather the computed by all other processes to perform the regret matching and update the strategy. For Algorithm 1, we have the following theorem.
Theorem 1.
The empirical distribution obtained with Algorithm 1 converges almost surely to a Bayes-CCE with common prior when .
Proof.
For a particular type of vehicle , , let denote the set of iteration number such that when . Define , which is the regret value that the player experience at iteration when its strategy is replaced by from the overall strategy . Furthermore, the cumulative regret value for player with type , supposed that player adopts strategy all the time, is defined as
| (6) |
Since each player of each type drawn from line 4 of Algorithm 1 maintains a separate MCCFR regret minimizer, it follows directly from [46, Theorem 5] that for all possible , we have with probability for any , where is a game constant and is the smallest probability of a leaf being sampled in the forward pass in the MCCFR process. It is obvious that when , it is also surely that if . In particular, a plan is also a strategy, and therefore this conclusion naturally holds for all , namely
| (7) |
holds for all with probability .
Next, at each iteration , we sample a plan from the strategy , and we define the sampled cumulative regret as
| (8) |
Since , the following equations hold naturally:
| (9) | ||||
Therefore, the following conclusion is directly obtained:
| (10) |
For simplicity we rewrite as , as , as , and we inspect the following expectation:
| (11) | ||||
The last two steps follow from the facts that and are independent with zero expectations, and that where is the range of utility of player with type .
Combining (10) and (LABEL:Var), and following [46, Lemma 1], we obtain that
| (12) |
with probability . Combining (7) and (12), we have
| (13) |
with probability . As a result, it is almost sure that for any , we have for all , all , and all . Following [49, Lemma 10], we conclude that the empirical distribution converges almost surely to a Bayes-CCE. ∎
Sampling an entire plan requires traversing the entire game tree and sampling action for each information set , which is computationally heavy for extensive-form games with multiple stages, as the number of information sets grows exponentially with respect to the number of stages. In the proposed framework, the receding horizon control is adopted, as each agent only performs the action computed in the first stage (details will be discussed in Section IV-D). Therefore, we only need to record the actions taken by players at the first stage, resulting in a partial plan. The resulting distribution can be viewed as a marginal distribution of the origin Bayes-CCE.
IV-B Integrated Decision Selection and Trajectory Planning
In a typical game of incomplete information, the type of each player is usually drawn by nature, a chance player, from the prior distribution. In the settings of autonomous driving, however, the types are self-determined by players, and therefore we can select the best type to perform. In the proposed framework, we view the selection of the best type from the type list as equivalent to the decision-making process. Formally given the computed Bayes-CCE , we denote the expected utility of a type as
| (14) |
Then the best type and equivalently the best decision, is determined by However, as we mentioned in Section IV-A, we only keep a partial record of the Bayes-CCE for computation efficiency, and therefore it is not feasible to directly calculate . Instead, we introduce an estimator of this expectation and use this estimator as a criterion of decision-making. We denote the root information set corresponding to as , and the estimator is given as . Immediately, we have the following theorem.
Theorem 2.
Suppose that the empirical distribution converges to a Bayes-CCE when , then when .
Proof.
For we have
| (15) | ||||
where is a binary function such that it equals to if the condition holds and otherwise. is the probability of . For , we examine its expectation
| (16) | ||||
which follows from [46, Lemma 1]. Plug in (9) and we have
| (17) | ||||
where is sampled from . The above equation follows from the law of large numbers. Obviously, when , we have
| (18) | |||
as can be viewed as samples from the Bayes-CCE , and are samples from . Again, the law of large numbers is applied. Therefore,
| (19) | ||||
Noted that each term , is independent and with bounded covariance, following the Kolmogorov’s strong law of large numbers [51, Theorem 2.3.10], we conclude that when . ∎
Theorem 2 indicates that is an unbiased and consistent estimator of . Moreover, it can be seen from Algorithm 1 that calculating , which corresponds to line 33 of the algorithm, adds only minimal computation load to the algorithm as no extra sampling is required. Therefore, we propose the decision-making strategy as
| (20) |
such that by selecting its type as , the player makes the decision that maximizes its overall expected utility corresponding to the given Bayes-CCE .
Remark 3.
The decision-making strategy presented does not distinguish between ego vehicle and surrounding vehicles. However, we should not assume that surrounding vehicles will adopt the same strategy since their decisions are subject to many factors (navigation, driving preference, bounded rationality, etc.) and are usually sub-optimal. Potential danger may occur if we assume that surrounding vehicles act optimally. Therefore, (20) is only used to make decisions for the ego vehicle but not to predict the driving purposes of surrounding vehicles.
Once the type is determined, we can select the optimal plan from the Bayes-CCE , such that the trajectory is given by . We introduce two different schemes to perform the Bayes-CCE and select the optimal plan.
Accurate implementation of Bayes-CCE : since a Bayes-CCE is correlated, the accurate performance of a Bayes-CCE will require either negotiation beforehand (which is unlikely in urban traffic scenarios) or a leader-follower assumption which is often adopted in the Stackelberg game formulation of traffic interactions [8, 13]. Without loss of generality, we assume that player 1 is the leader, and player is a direct follower of player for all and . The joint probability distribution can be decomposed into a series of marginal distributions and conditional distributions, such that the probability of a joint plan is given by
| (21) |
such that is the marginal distribution of the plan corresponding to player , and is the conditional distribution of the plans of player conditioned on the plan of all the players before . If plans are selected by maximum likelihood, the plans selected are
| (22) |
We consider this scheme to be overly idealistic due to the following reasons:
-
•
Although being widely adopted, the leader-follower assumption is not always valid, especially when more than two vehicles are involved.
-
•
Due to partial observation, vehicle cannot know for sure the plan adopted by vehicle . At best, it can only maintain a belief over .
Due to these reasons, we introduce the following marginal implementation of the Bayes-CCE.
Marginal implementation of Bayes-CCE : to avoid the problem mentioned before, we propose an approximation performance scheme of the Bayes-CCE . We define as the marginal distribution of the plan of player , and then the plan is determined as
| (23) |
The marginal implementation of Bayes-CCE is used in the simulation. Once the optimal plan is determined by one of the schemes introduced before, the planning process is conducted by taking with the optimal decision . As a result, an integrated decision-making and trajectory planning scheme is introduced based on the Bayes-CCE.
IV-C Bayesian Intention Update
Following a Bayes-CCE, the probabilities of actions taken by vehicles depend on their underlying driving intentions. Therefore, the actual actions performed by vehicles provide extra information gains over the belief of driving intentions. In this section, we introduce strategies to update the common belief over the driving intentions of all vehicles based on the observed actions. Corresponding to different implementations of the Bayes-CCE, different updating strategies are introduced.
Update strategy for the accurate implementation: suppose that at time stamp the common prior on intentions of vehicles is given as , the Bayes-CCE is given as , and the action performed by all vehicles is . The following equation gives the updated common prior
| (24) |
which follows the standard Bayes’ rule of posterior probability. is the observation model such that gives the probability that action is taken if all players follow the Bayes-CCE and their underlying types are defined by . To effectively model , we adopt the Mixture-of-Gaussians distributions, and is defined as
| (25) |
where is the probability density function of a Gaussian distribution . and are the end states of vehicles when action and are taken, respectively. is a predefined covariance matrix.
Update strategy for the marginal implementation: under this implementation, the update rule is similarly given as
| (26) |
where
| (27) |
This update strategy is performed individually for all .
Remark 4.
In the updating process, the belief of intentions is updated for both the surrounding vehicles and also the ego vehicle. Following Assumption 1, the updated belief is still common among all the vehicles involved in the game.
IV-D System Overview and Details of Implementation
Combining all aforementioned modules, we introduce Algorithm 2, which is an integrated decision-making and trajectory planning framework for autonomous driving. Detailed explanations are given as follow:
-
1.
A two-stage trajectory tree is constructed for each driving intention of each vehicle, which constitutes the action space (line 4 to 9). The methodology used to construct those trajectory trees is the same as the one used in [27].
-
2.
Given the sets of trajectory trees and the prior distribution, a game of incomplete information is established, and the solver introduced in Section IV-A is invoked to solve for the Bayes-CCE (line 10 to 12).
-
3.
Given the Bayes-CCE, the optimal decision is selected following the strategy described in equation (20) (line 13 to 16).
-
4.
One of the two implementation strategies of Bayes-CCE described in Section IV-B is applied to select the optimal plan. Together with the optimal decision selected in the previous step, the trajectory is determined and executed (line 17 to 18).
-
5.
Given the Bayes-CCE and the new trajectories, the corresponding update strategy is invoked to update the driving intentions of all vehicles. Thus, a new common belief over the driving intentions is established, and the algorithm goes back to Step for a new round of playing (line 19 to 22).
The prior belief over the driving intentions is initialized with uniform distribution. Note that data-driven prediction methods can also be applied to perform the initialization and obtain a better estimation of the driving intentions based on historical trajectories.
Considering important performance indices such as passenger comfort and safety, the utility is defined as
| (28) |
The trajectories of all vehicles are determined by the action history . To compute for the above performance indices, we sample along the trajectories of all vehicles with equal time spacing . The comfort indice is given by
| (29) | ||||
where , , , and are the lateral acceleration, the longitudinal acceleration, the lateral jerk, and the longitudinal jerk of vehicle at , respectively. , , , and are the corresponding weighting coefficients. The progress indice is given by
| (30) |
such that longitudinal velocity smaller than will be penalized. is the weighting coefficient. Indice is given by
| (31) |
which penalizes the deviations from the reference line by penalizing the lateral displacement . is the corresponding weighting coefficient. For collision avoidance, we represent each vehicle with two identical circles aligned along the longitudinal axis of the vehicle. For vehicle , the positions of the centers of circles are denoted as and , respectively. The safety indice is defined as
| (32) |
where defines the Euclidean distance, , and . is the weighting coefficient. As a result, a negative utility (namely a penalty) is added towards the overall utility when vehicle fails to maintain a safe distance with respect to other vehicles. Values of parameters are shown in Table I.
| Param. | Value | Param. | Value | Param. | Value | Param. | Value |
|---|---|---|---|---|---|---|---|
| 0.5 | 1.0 | 0.5 | 1.0 | ||||
| 20.0 | 10.0 | 2000.0 | 4.0 m |
V Simulation Results
To illustrate the effectiveness of the introduced method in handling multi-modal driving behaviors and to verify the generalizability, two case studies of different traffic scenarios and a quantitative analysis compared with a baseline are included in this section. In both case studies, each agent maintains its game solver and solves the game separately. The types of Human-driving vehicles are given and fixed while the autonomous vehicle determines its own type adopting the strategy described in (20). All algorithms are implemented in Python 3.8 running on a server with Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60GHz.
V-A Case I: Ramp Merging
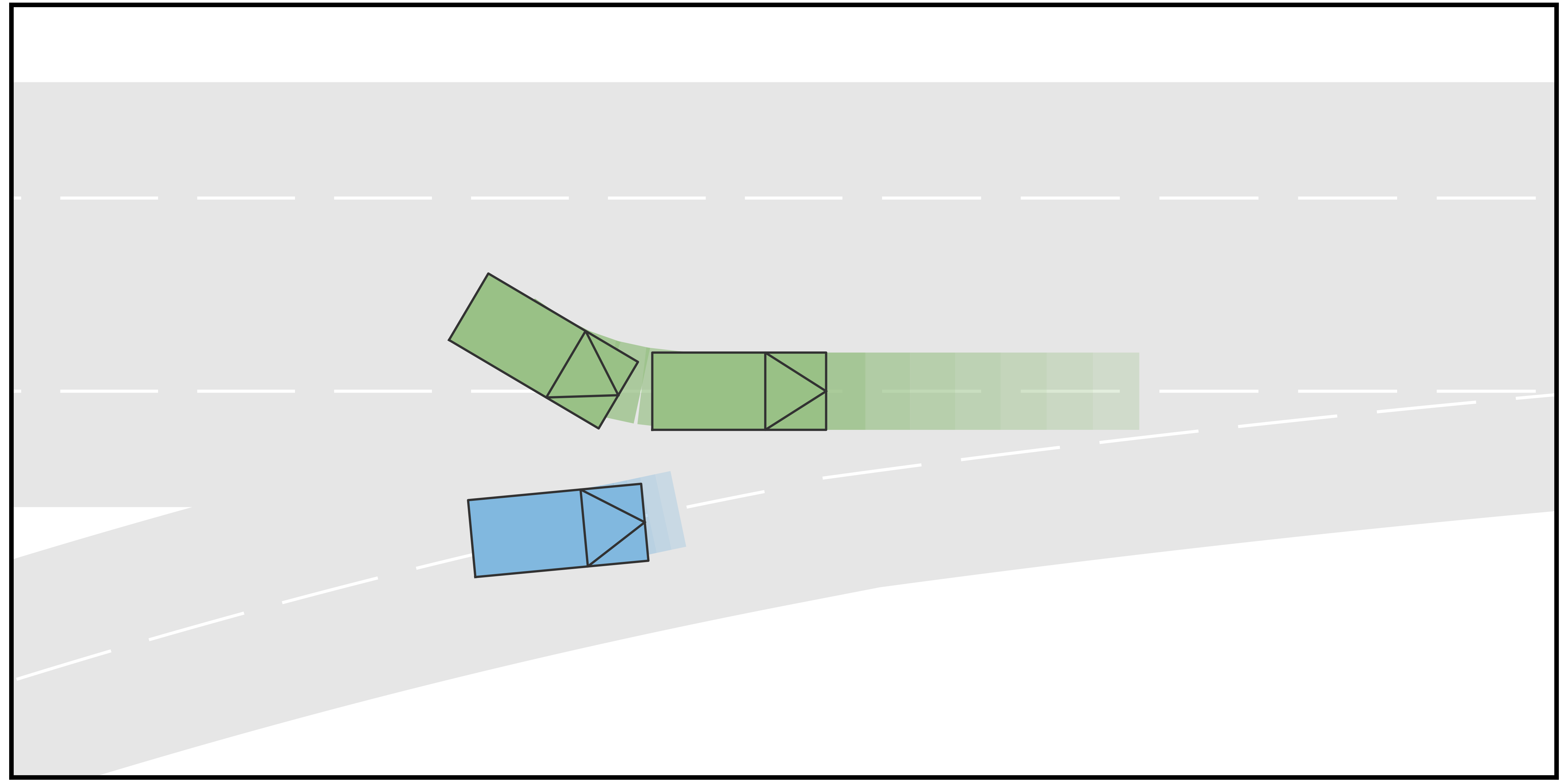
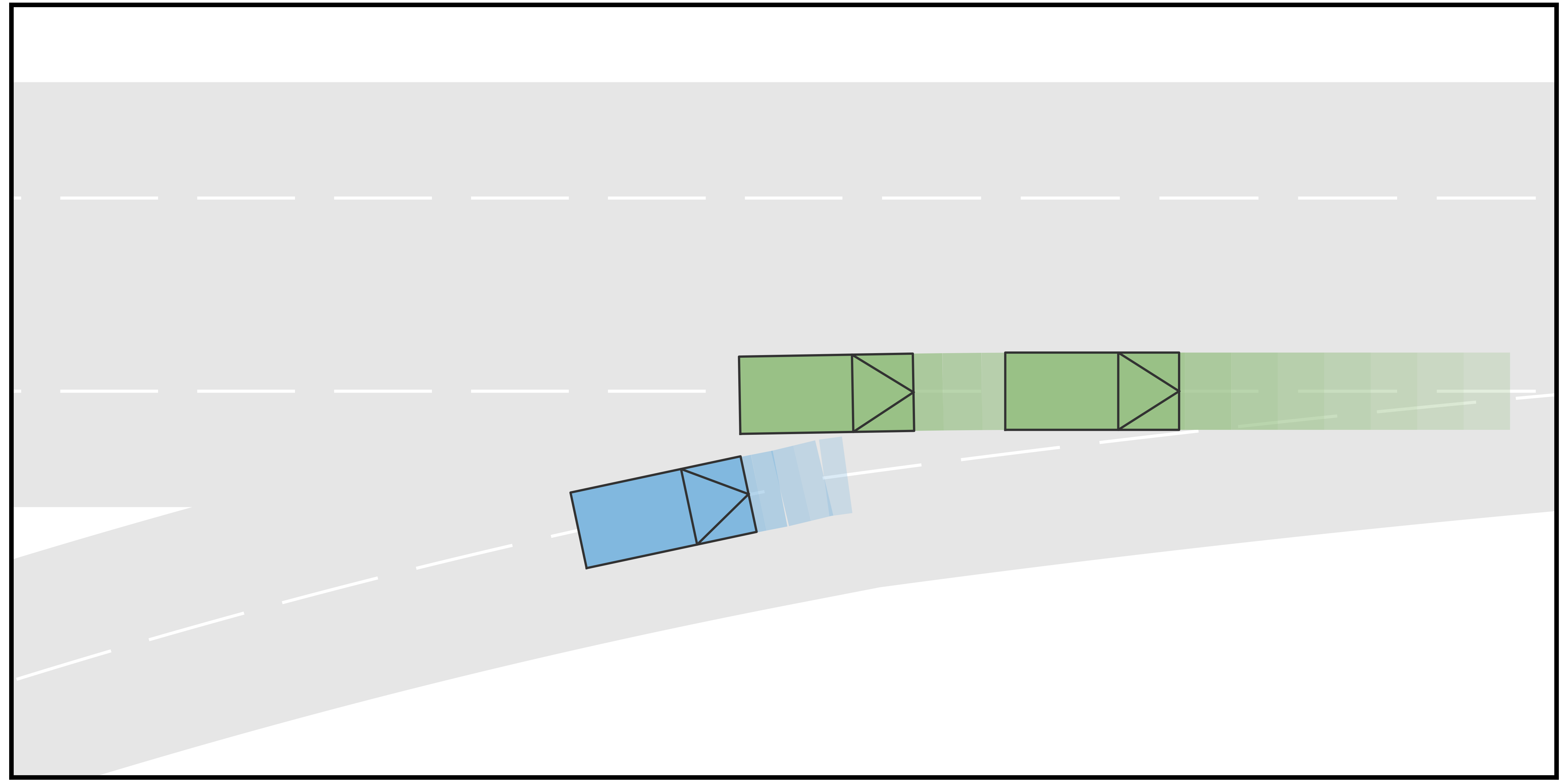
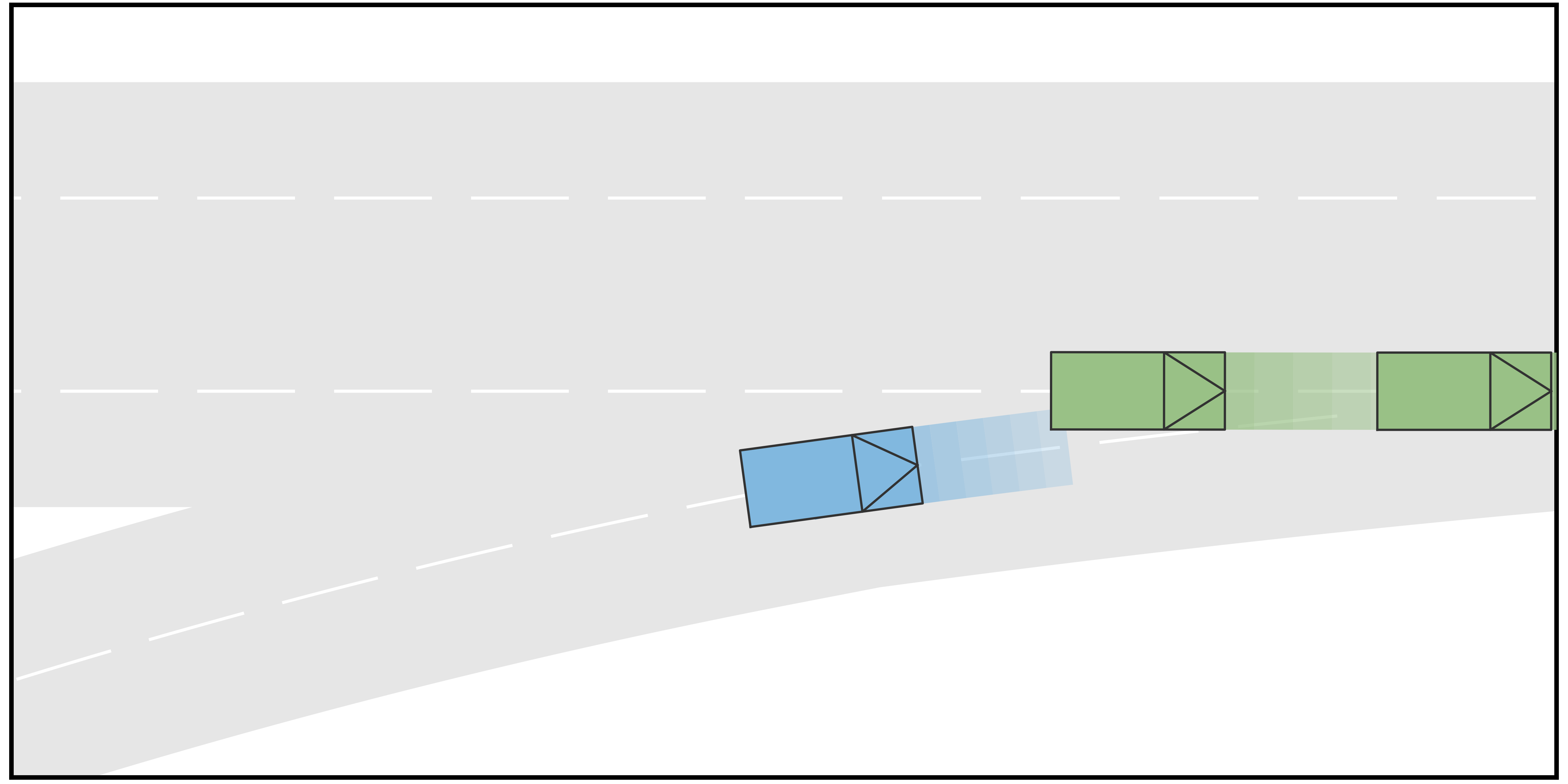
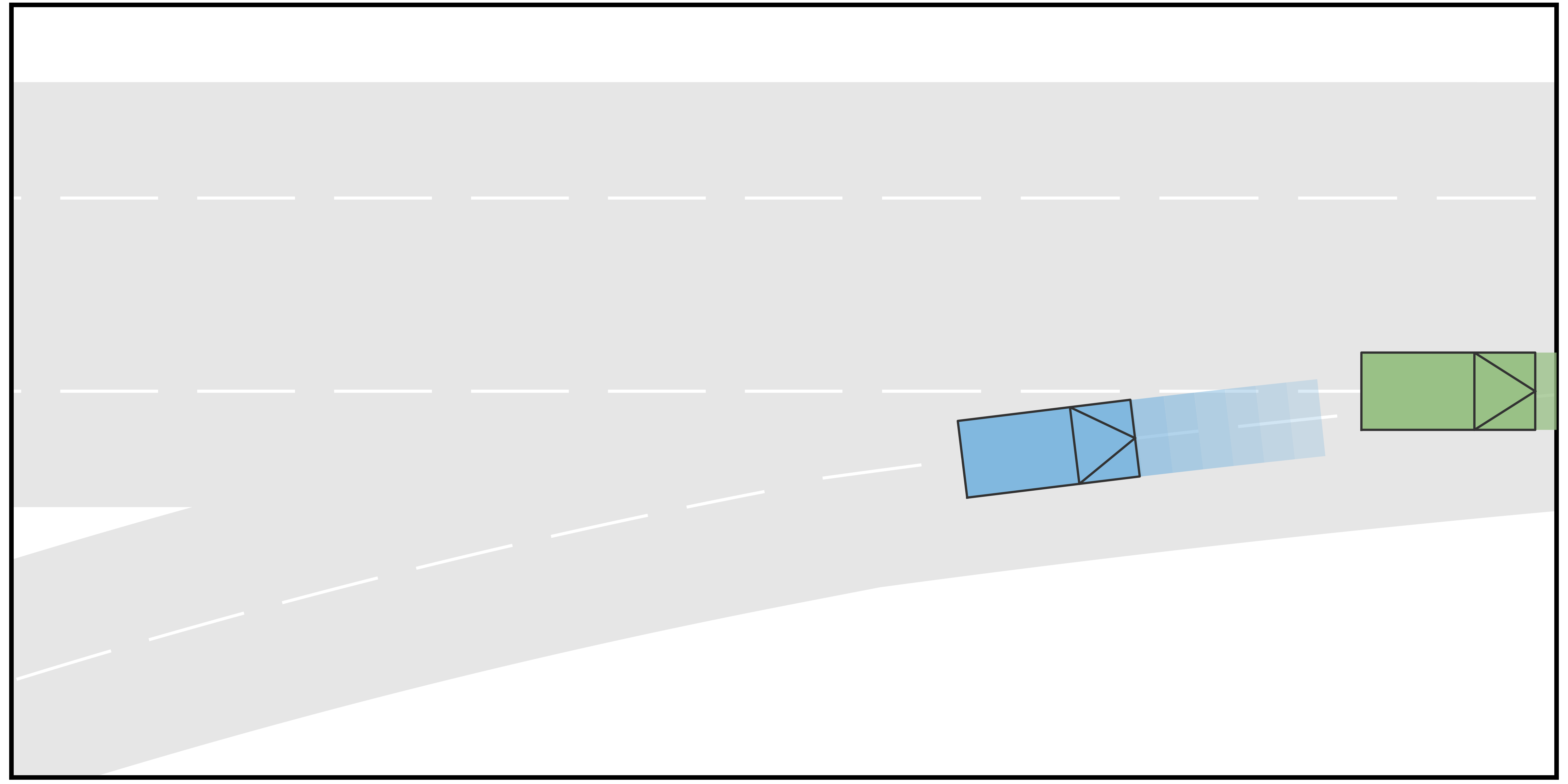
In this case, the goal of the autonomous driving vehicle (AV) is to merge into a two-lane road from the ramp. One human-driving vehicle (HV1) is currently driving in the target lane of AV, while another human-driving vehicle (HV2) is running in another lane of the main road but also tries to merge into the target lane of AV. The initial velocity of all three vehicles is . For the type settings, we consider each vehicle to be either a conservative-type vehicle or an aggressive-type vehicle. For each type, we sample the terminal longitudinal velocities that constitute the action space. In particular, for the aggressive type, the action space is determined to be , while for the conservative type, the action space is set to be . Furthermore, in this case, four different scenarios are considered. In Scenario A, the longitudinal initial positions of AV, HV1, and HV2 are , , and , respectively. HV1 and HV2 are conservative and aggressive, respectively. In Scenario B, the other settings are the same as in Scenario A but HV1 is also aggressive. In Scenario C, the longitudinal initial positions of AV, HV1, and HV2 are , , and , respectively. HV1 and HV2 are aggressive and conservative, respectively. In Scenario D, the other settings are the same as in Scenario C but the HV2 is also aggressive. The time span for both stages in the trajectory tree is .
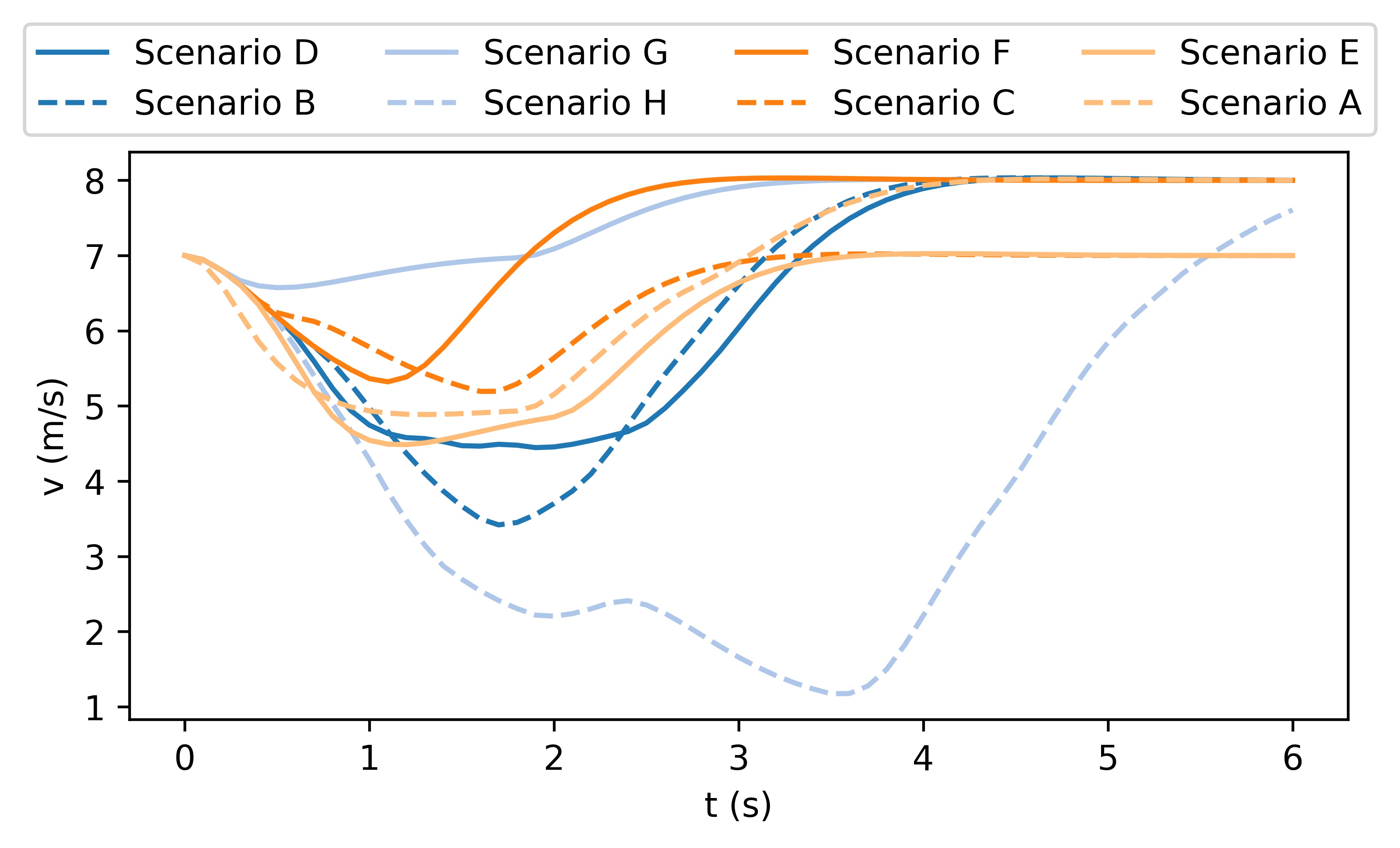
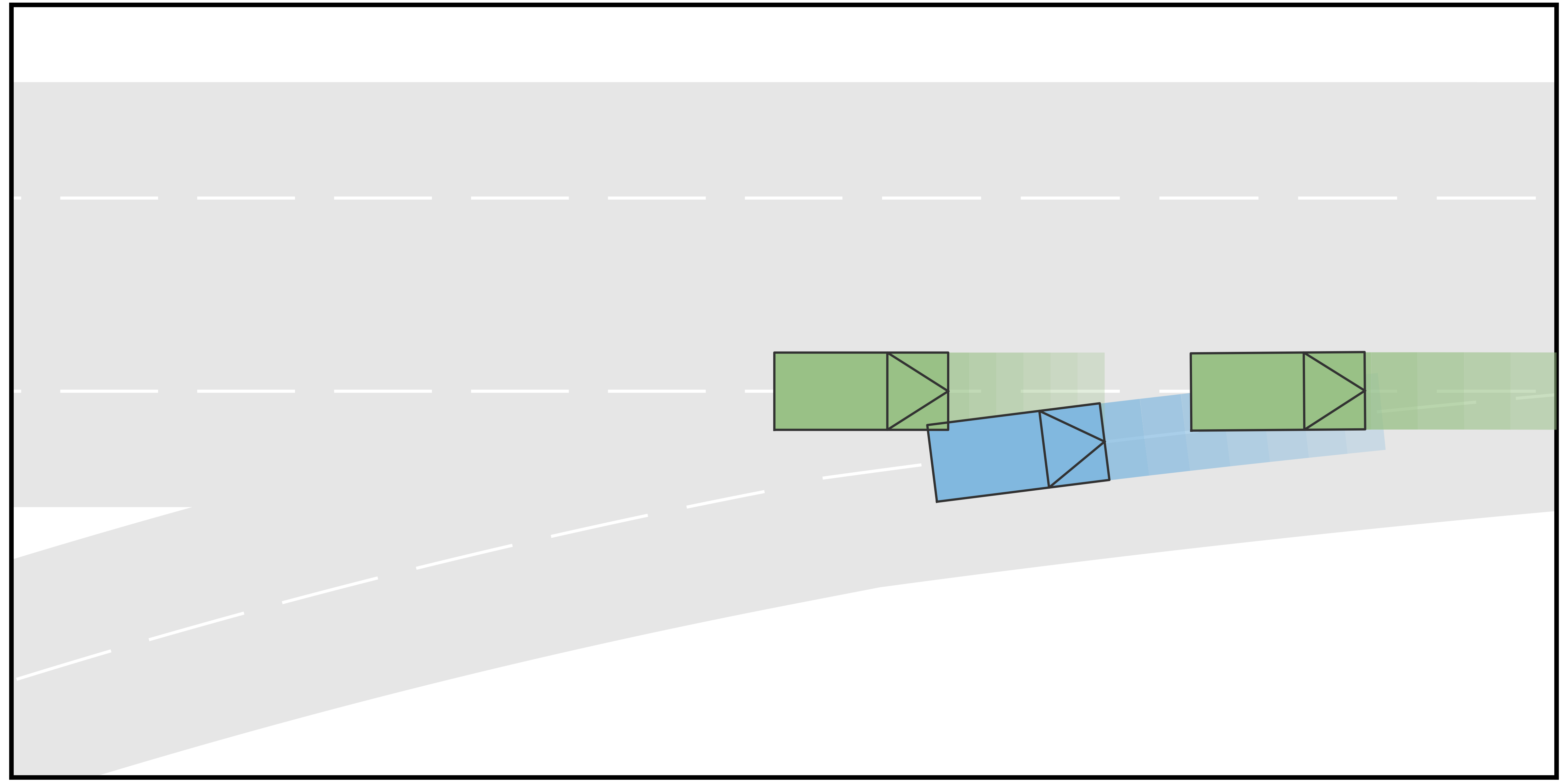
The simulation results are shown in Fig. 2. It can be seen from the results that when the rear HV decides to yield, the AV manages to identify the type of the HV and successfully merge into the gap between the two HVs, such that the driving efficiency is enhanced. On the contrary, when the rear HV decides not to yield, the AV also identifies and performs the merging after both HVs to avoid collisions. Fig. 3 shows the longitudinal velocities of AV for each scenario. It can be seen that for all 4 scenarios, the AV decelerates at the beginning because at the moment it is uncertain about the driving intentions of the HVs. With incoming observations, the AV keeps updating the belief on HVs’ intentions. When it is certain that the rear HV is going to yield (in Scenarios A and C), it accelerates to merge into the gap between the two HVs. On the contrary, when AV is certain that the rear HV is not going to yield (in Scenarios B and D), it takes further braking to avoid collisions and merges behind both HVs.
V-B Case II: Unprotected Left-Turn
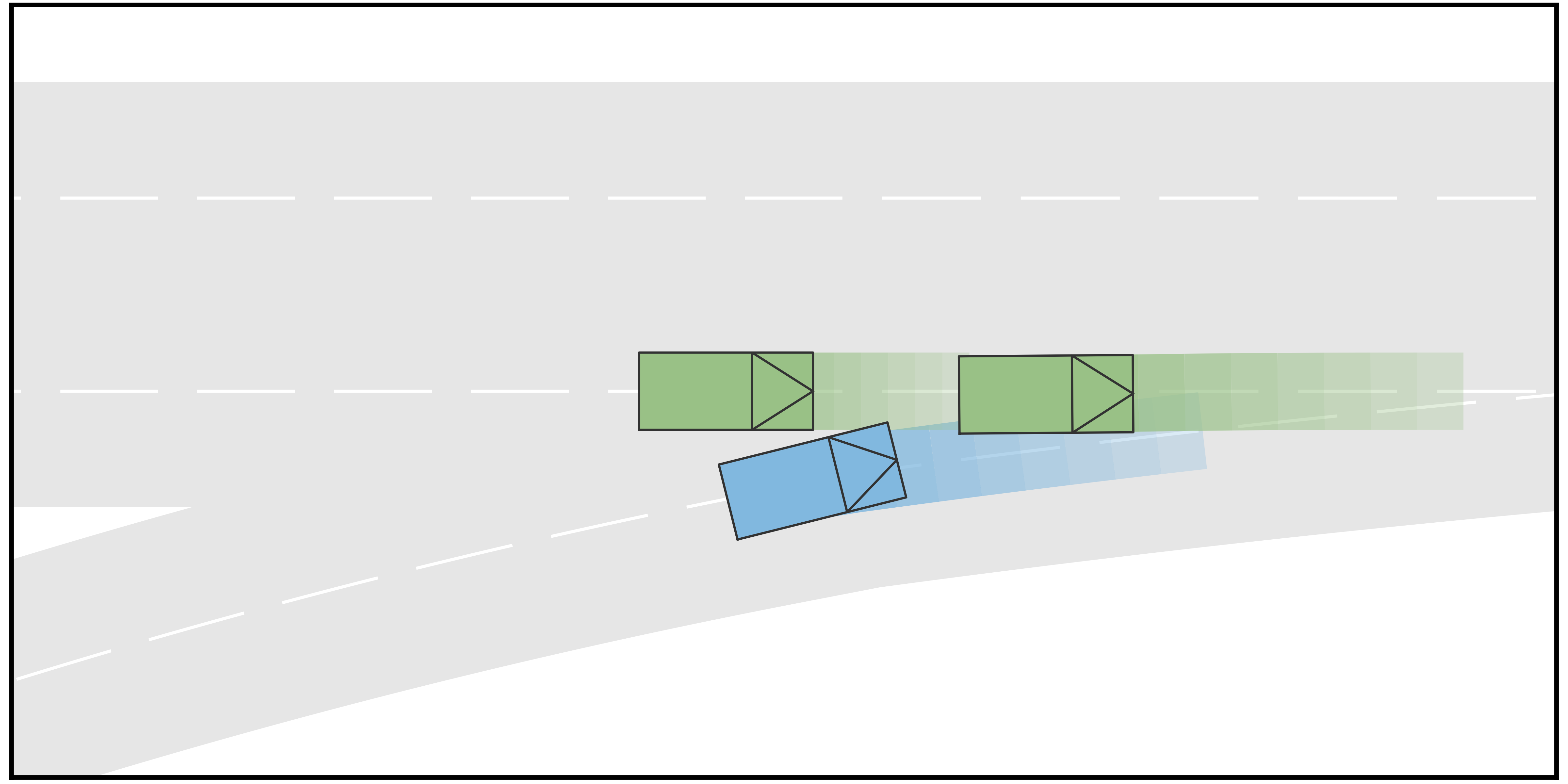
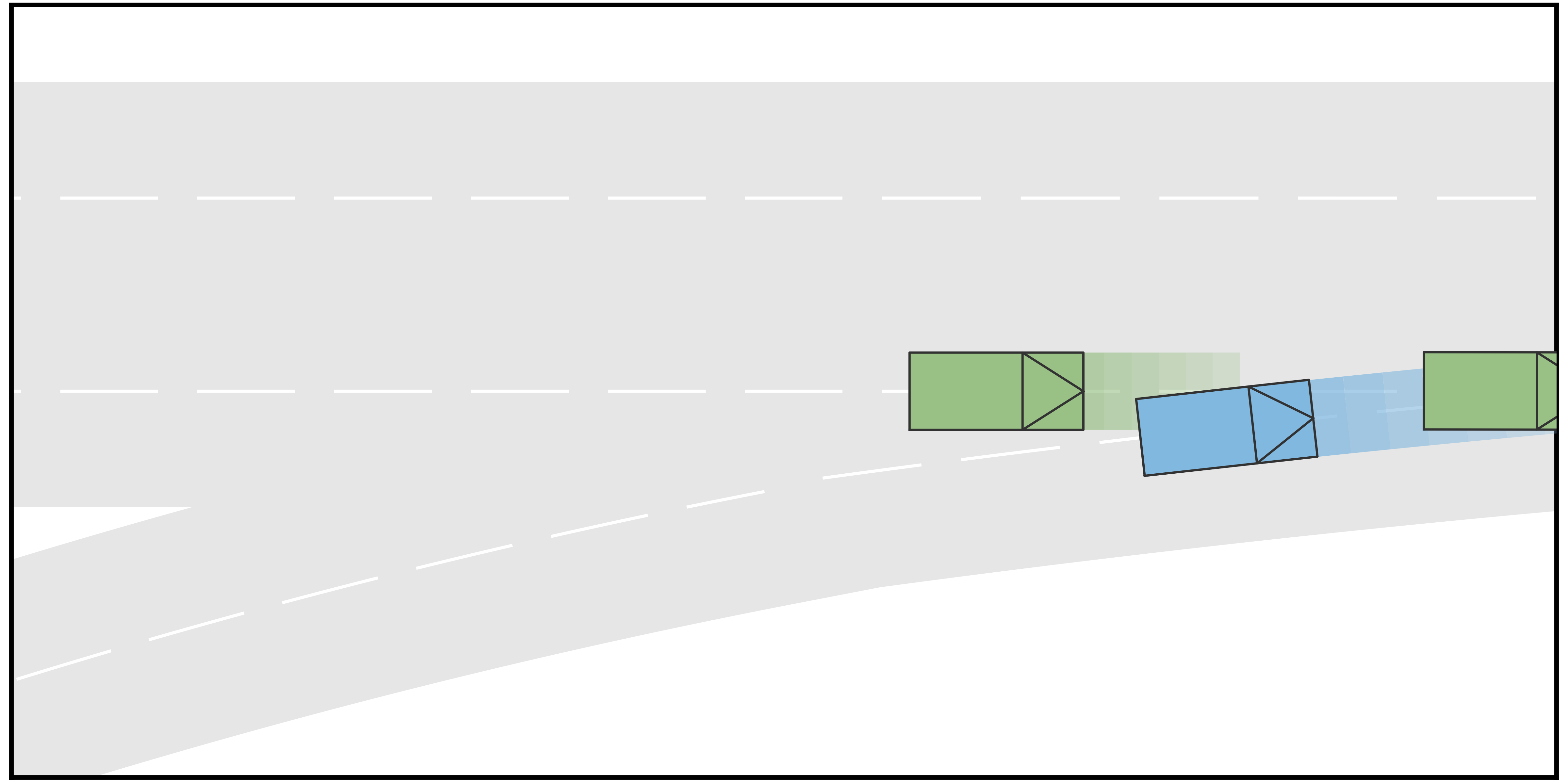
In this case, the goal of AV is to perform an unprotected left-turning in an unsignalized intersection. Two human-driving vehicles are considered in this scenario, including HV1 traveling from the left-hand side of AV and HV2 traveling in the opposite lane. The initial positions of AV, HV1, and HV2 are , , and , respectively, and the initial velocity is for all three vehicles. For each vehicle, four different types are considered. Specifically, those types are combinations of navigation types and longitudinal types. For AV, the types concerning navigation include straight-traveling and left-turning and the types concerning longitudinal strategies include aggressive and conservative, such that AV can be an aggressive straight-traveling agent or a conservative left-turning agent, etc. Although the driving intention of the AV is to perform left-turning, it is clearly not known by HVs, and therefore straight-traveling types of AV also need to be modeled (but not selected). The same types are considered for HV1. For HV2, the navigation types include straight-going and right-turning, while longitudinal types are the same. Since vehicles can swerve away from the reference line to avoid each other in an intersection, the action space should include lateral actions and longitudinal actions. The longitudinal actions are the same as in Case I, while the set of lateral action is the set of eligible longitudinal displacement with respect to the corresponding reference lines . In this case, 8 different scenarios are considered with respect to different types of HVs, and those scenarios are listed in Table II. The time span for the first stage in the trajectory tree is and that for the second stage is .
| Scenario | HV1 | HV2 |
|---|---|---|
| A | Straight-going, Aggressive | Straight-going, Aggressive |
| B | Straight-going, Aggressive | Straight-going, Conservative |
| C | Straight-going, Conservative | Straight-going, Aggressive |
| D | Straight-going, Conservative | Straight-going, Conservative |
| E | Left-turning, Aggressive | Straight-going, Aggressive |
| F | Left-turning, Aggressive | Straight-going, Conservative |
| G | Left-turning, Conservative | Straight-going, Aggressive |
| H | Left-turning, Conservative | Straight-going, Conservative |
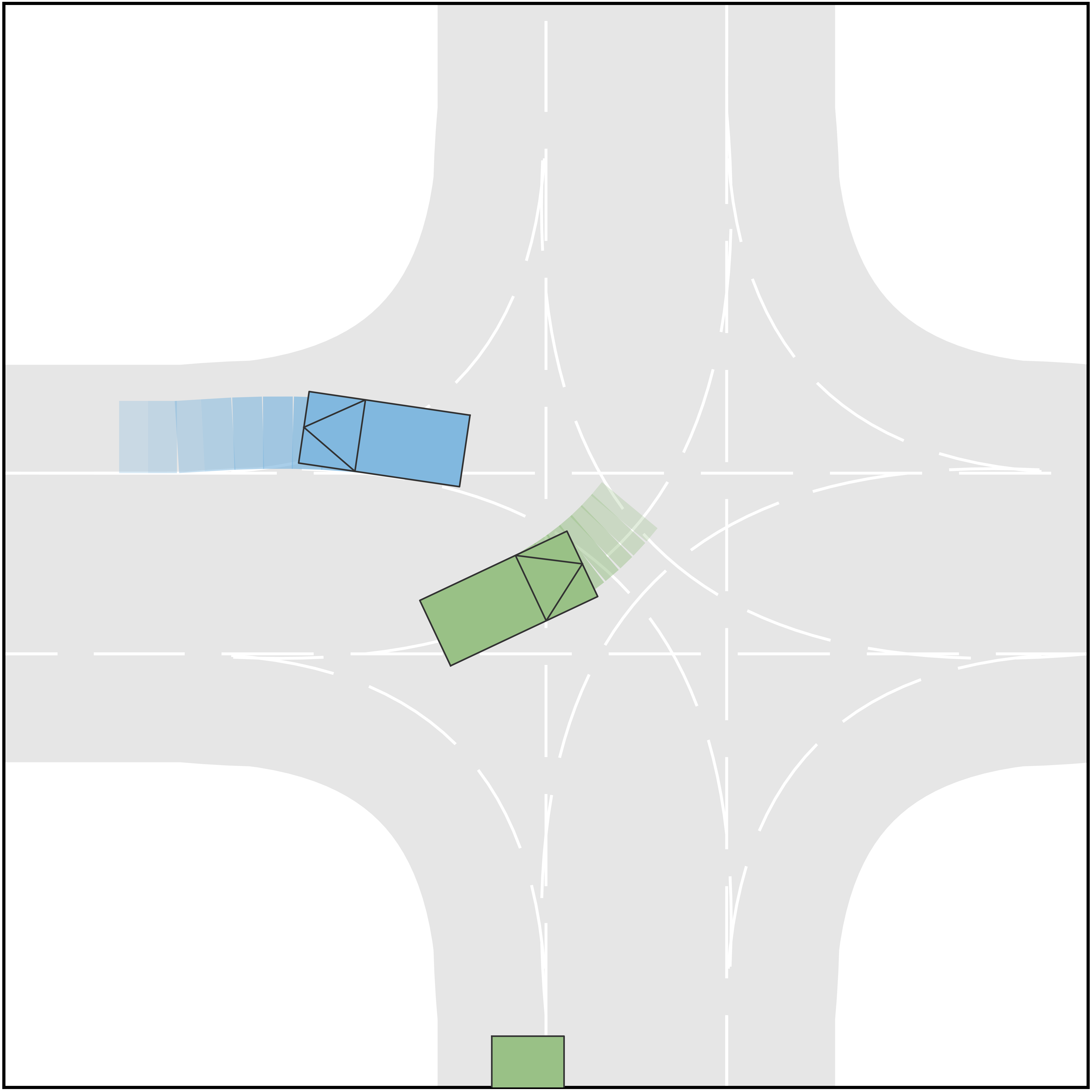
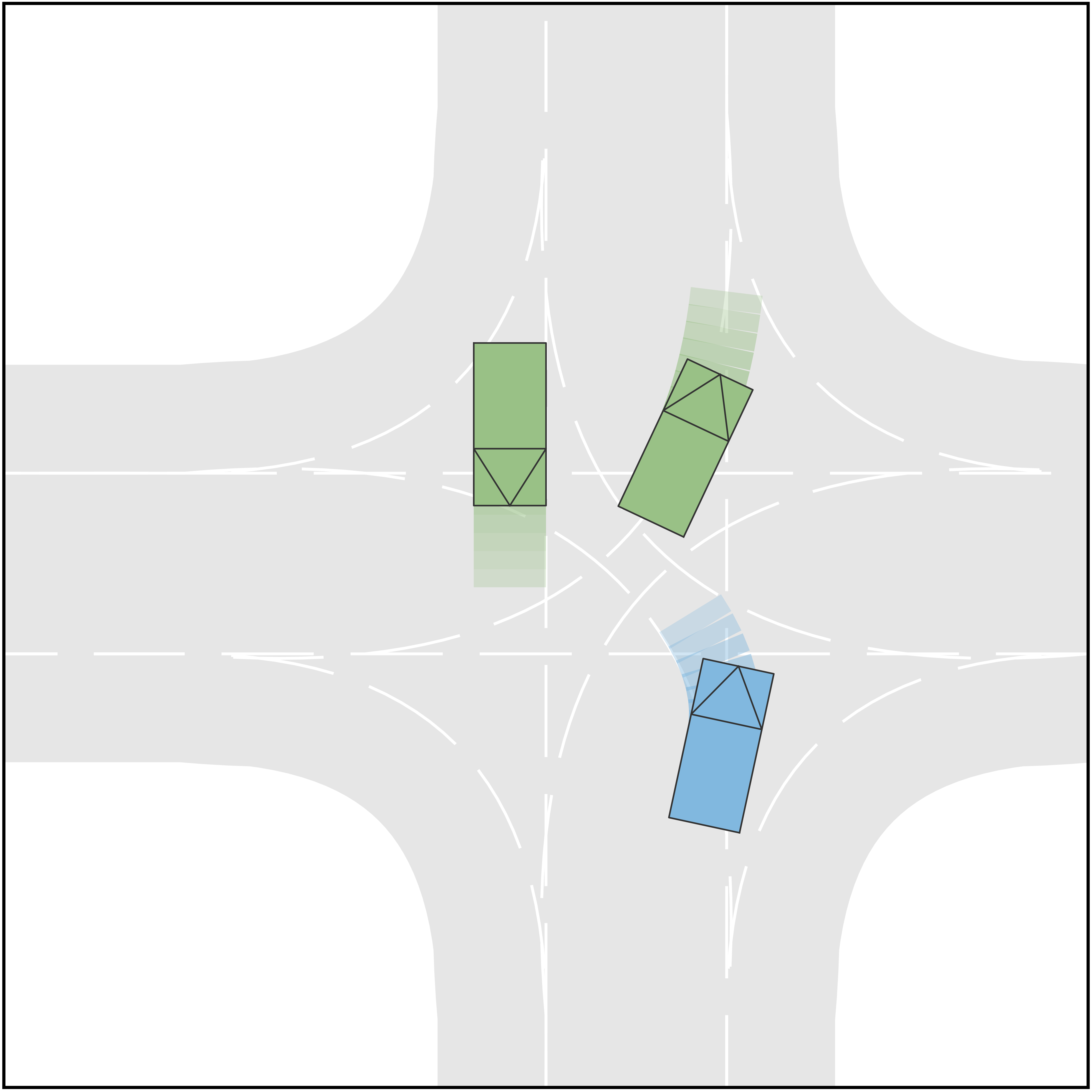
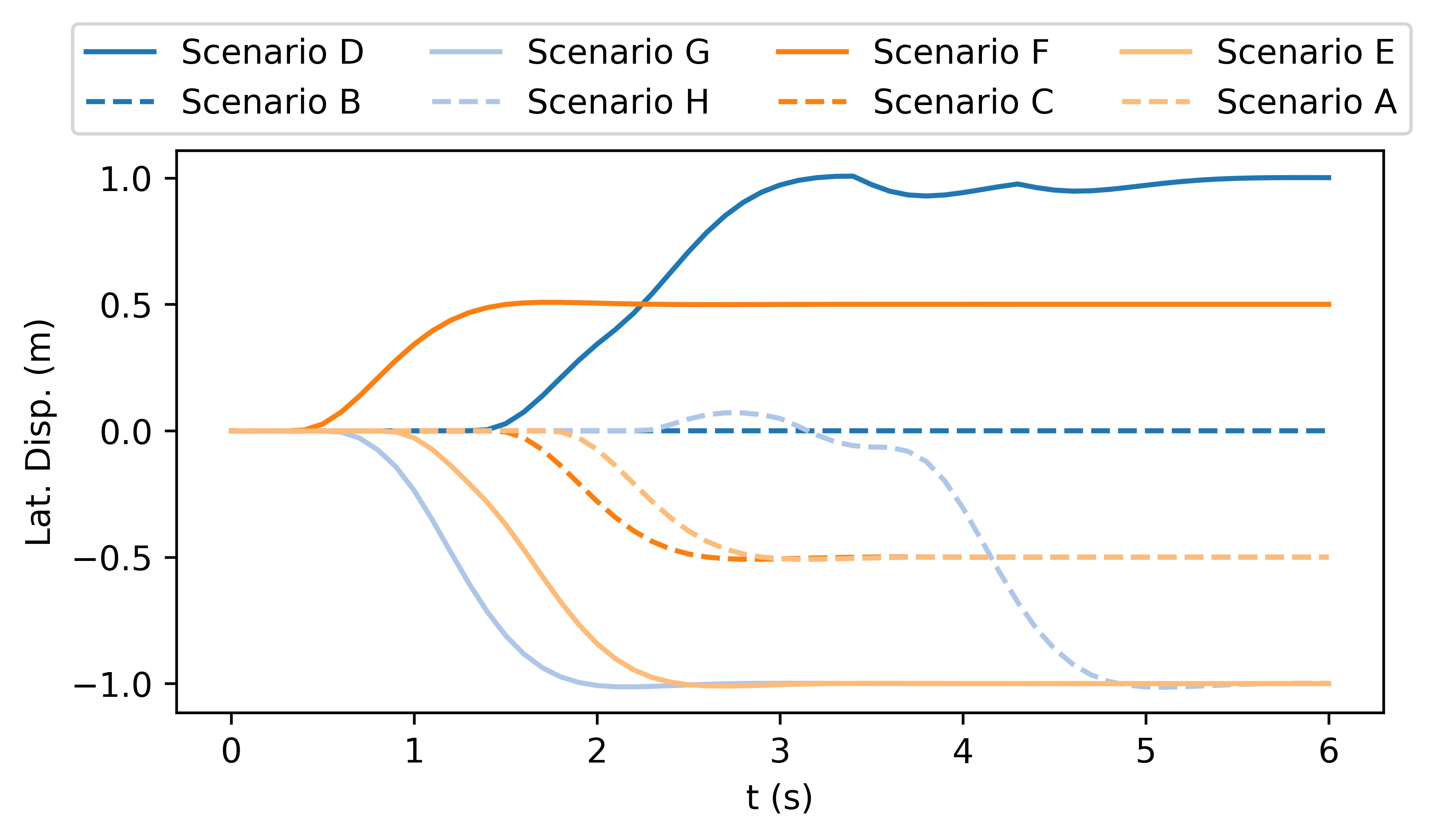
The qualitative simulation results are shown in Fig. 4. In general, AV successfully identifies the intentions and types of other vehicles and manages to pass the scenario in a smooth and secure manner. Diversified driving behaviors are exhibited with respect to different driving intentions of HVs. Specifically, in Scenario A where both HVs are aggressive and straight-going, AV slows down and passes through the intersection after both HVs. In Scenario B, AV slows down to yield to the HV1, which is straight-going and aggressive. Then it accelerates to pass in front of HV2, which is considered conservative. In Scenario C where HV1 is straight-going and conservative and HV2 is straight-going and aggressive, the AV swerve to the right to pass through the intersection from behind HV2. In Scenario D where both HVs are straight-going and conservative, AV accelerates and cuts across in front of both HVs. The behavior of AV in Scenario E, F, and G are similar to that in Scenario A, B, and C, respectively. In Scenario H, although both HVs are conservative, HV1 is performing a left-turning and therefore there is no room for AV to cut across. As a result, AV slows down to pass the intersection behind both HVs. In addition to the behaviors of AV, the proposed method also manages to simulate the interactive behaviors of the HVs. For example, in Scenario A, both HVs swerve to the left to keep safety distances from AV, and in Scenario B, HV2 steers to the right to pass through the intersection behind AV, etc. Fig. 3 shows the longitudinal velocities of AV in each scenario, and Fig. 6 shows the lateral displacements. In general, AV decelerates at the beginning to avoid collision when the intentions of HVs remain unclear and then takes responsive actions to different driving behaviors of HVs.
V-C Comparison
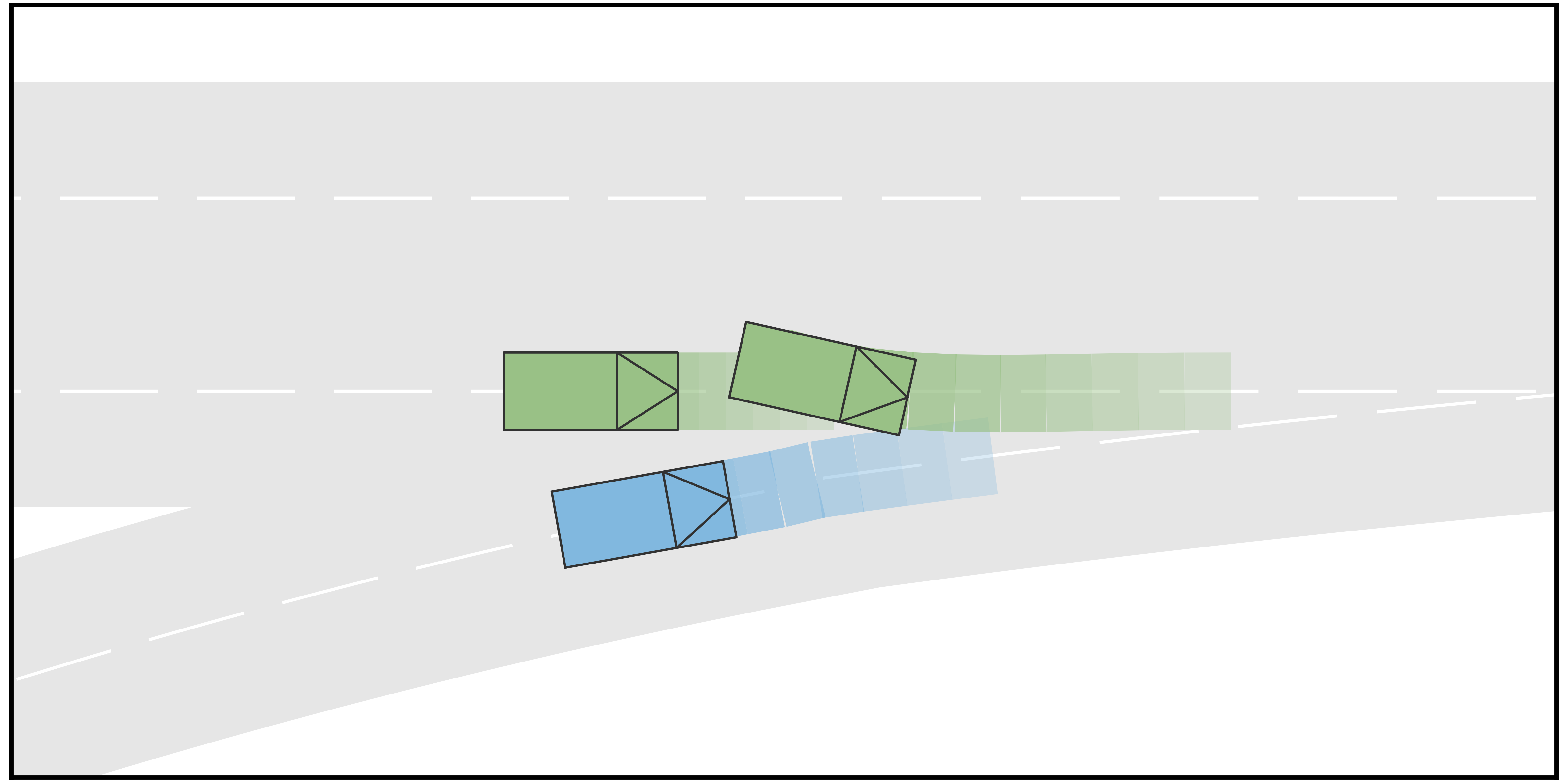
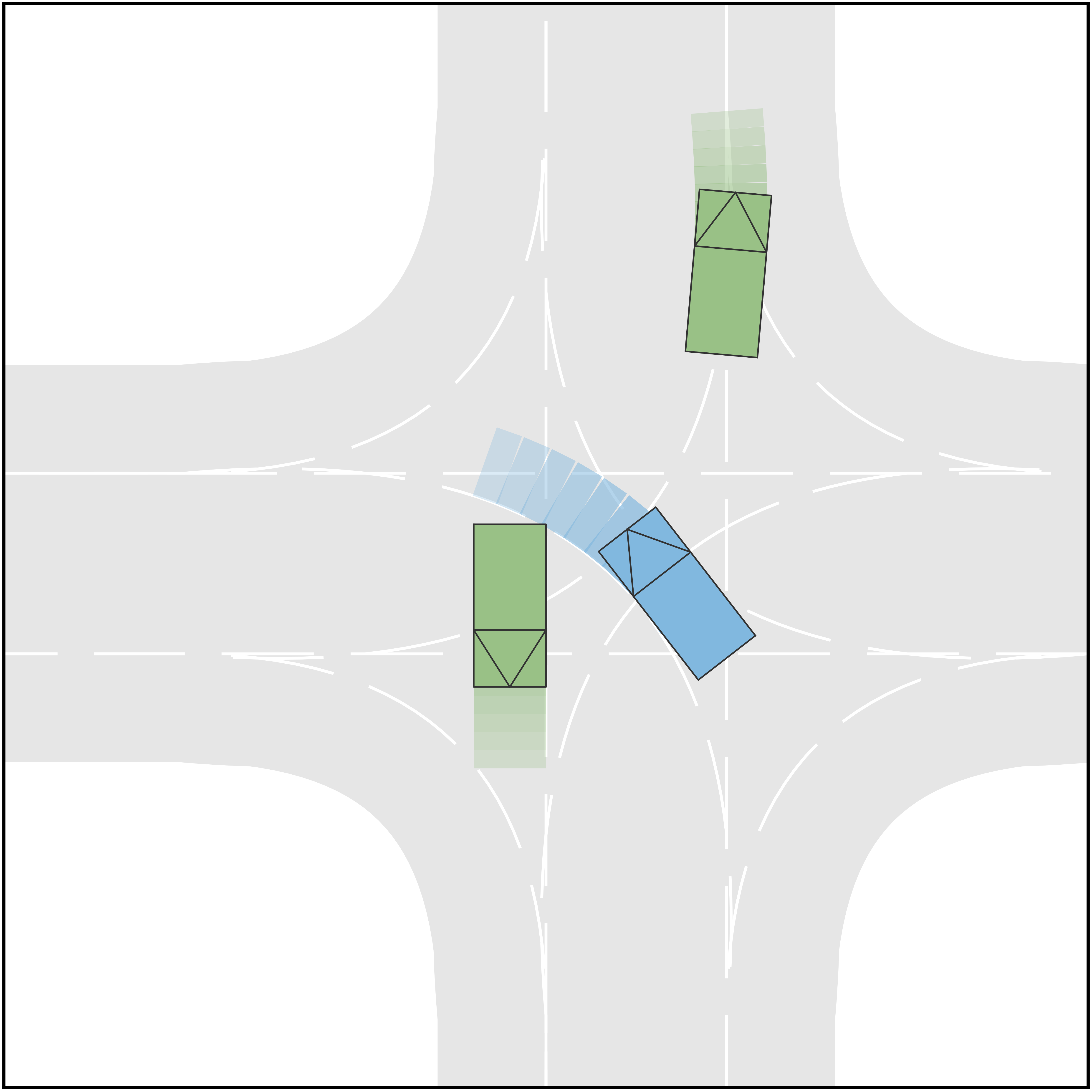
To further illustrate the advantage of the proposed method, we compared it with a planning scheme provided by a standard game of complete information. Specifically, the AV is trying to play a game of complete information, in which the action space of each agent is exactly the union of the action spaces of that agent under different types, and other settings are the same as in the game of incomplete information. Meanwhile, all other HVs are still playing the game of incomplete information with determined type. Simple qualitative results are shown in Fig. 7. In Scenario B of the ramp-merging case, since the longitudinal position of HV1 is behind AV and the initial velocities are the same for both vehicles, a typical Nash equilibrium is that AV will merge into the main road in front of the HV1. However, this equilibrium contradicts the actual driving intention of HV1, which is an aggressive agent and intends to accelerate. Due to this discrepancy, a catastrophic result occurs such that AV collides with HV1. This example illustrates the limitations of a traditional game of complete information and demonstrates the necessity of identifying the intentions of other vehicles.
We also present a quantitative analysis to compare the performance of the proposed method and the baseline of the traditional game. Since randomness exists in Monte-Carlo sampling, we perform repeated experiments for both cases with scenario settings described in Section V-A and Section V-B. For passenger comfort, we compare the following statistics of AV: 1) the root mean square of longitudinal acceleration, 2) the average maximum longitudinal acceleration, 3) the root mean square of lateral acceleration, and 4) the average maximum lateral acceleration. For driving safety, we compare 1) the average minimum distances between AV and All of the HVs and 2) the collision rates between AV and HV. Results are shown in Table III. It can be seen that in Case I, the collision rate of the baseline is unacceptable. Although the performance in terms of passenger comfort seems to be better, this is mainly because the baseline method chooses the theoretically optimal strategy disregarding the actual driving intentions of the HVs. In Case II, the proposed method is clearly better than the baseline method in terms of both passenger comfort and driving safety. Meanwhile, we also compare the computation time of both methods. It can be seen from Table IV that the computation efficiency of the proposed method is higher than the baseline, mainly due to the smaller action space.
| Case | Method | Avg. Max. Long. Acc. | RMS. Long. Acc. | Avg. Max. Lat. Acc. | RMS. Lat. Acc. | Min. Dis. | Collision Rate |
|---|---|---|---|---|---|---|---|
| I | Proposed | / | / | 0.716 m | |||
| Baseline | / | / | |||||
| II | Proposed | 1.069 m | |||||
| Baseline |
| Case | Method | 10000 Iter. | 20000 Iter. | 50000 Iter. |
|---|---|---|---|---|
| I | Proposed | 0.09 s | 0.14 s | 0.28 s |
| Baseline | ||||
| II | Proposed | 0.09 s | 0.18 s | 0.47 s |
| Baseline |
VI Conclusion
In this paper, we present an integrated decision-making and trajectory planning framework for autonomous vehicles. Based on the game of incomplete information, multimodal behaviors of human drivers are properly handled, the optimal decision is reached, and the planning is performed in a fully interactive manner. Simulation demonstrates the effectiveness of the proposed approach across multiple traffic scenarios and the improvements in terms of passengers’ comfort and security over traditional game method with smaller accelerations, larger safety distances, and lower collision rates. Possible future works include modeling the correlation between the driving intentions of vehicles and integrating data-driven methods to learn the cost functions online for accurate imitation of human driving behaviors.
References
- [1] P. Trautman and A. Krause, “Unfreezing the robot: Navigation in dense, interacting crowds,” in 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2010, pp. 797–803.
- [2] S. Jia, Y. Zhang, X. Li, X. Na, Y. Wang, B. Gao, B. Zhu, and R. Yu, “Interactive decision-making with switchable game modes for automated vehicles at intersections,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 11, pp. 11 785–11 799, 2023.
- [3] P. Hang, C. Huang, Z. Hu, and C. Lv, “Decision making for connected automated vehicles at urban intersections considering social and individual benefits,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 11, pp. 22 549–22 562, 2022.
- [4] S. L. Cleac’h, M. Schwager, and Z. Manchester, “ALGAMES: A fast solver for constrained dynamic games,” arXiv preprint arXiv:1910.09713, 2019.
- [5] P. Hang, C. Lv, C. Huang, Y. Xing, and Z. Hu, “Cooperative decision making of connected automated vehicles at multi-lane merging zone: A coalitional game approach,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 4, pp. 3829–3841, 2021.
- [6] F. Fabiani and S. Grammatico, “Multi-vehicle automated driving as a generalized mixed-integer potential game,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 3, pp. 1064–1073, 2019.
- [7] V. G. Lopez, F. L. Lewis, M. Liu, Y. Wan, S. Nageshrao, and D. Filev, “Game-theoretic lane-changing decision making and payoff learning for autonomous vehicles,” IEEE Transactions on Vehicular Technology, vol. 71, no. 4, pp. 3609–3620, 2022.
- [8] P. Hang, C. Huang, Z. Hu, Y. Xing, and C. Lv, “Decision making of connected automated vehicles at an unsignalized roundabout considering personalized driving behaviours,” IEEE Transactions on Vehicular Technology, vol. 70, no. 5, pp. 4051–4064, 2021.
- [9] M. Liu, I. Kolmanovsky, H. E. Tseng, S. Huang, D. Filev, and A. Girard, “Potential game-based decision-making for autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 8, pp. 8014–8027, 2023.
- [10] T. Kavuncu, A. Yaraneri, and N. Mehr, “Potential iLQR: A potential-minimizing controller for planning multi-agent interactive trajectories,” arXiv preprint arXiv:2107.04926, 2021.
- [11] A. Zanardi, P. G. Sessa, N. Käslin, S. Bolognani, A. Censi, and E. Frazzoli, “How bad is selfish driving? bounding the inefficiency of equilibria in urban driving games,” IEEE Robotics and Automation Letters, vol. 8, no. 4, pp. 2293–2300, 2023.
- [12] R. Chandra and D. Manocha, “GamePlan: Game-theoretic multi-agent planning with human drivers at intersections, roundabouts, and merging,” IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 2676–2683, 2022.
- [13] J. F. Fisac, E. Bronstein, E. Stefansson, D. Sadigh, S. S. Sastry, and A. D. Dragan, “Hierarchical game-theoretic planning for autonomous vehicles,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 9590–9596.
- [14] H. Yu, H. E. Tseng, and R. Langari, “A human-like game theory-based controller for automatic lane changing,” Transportation Research Part C: Emerging Technologies, vol. 88, pp. 140–158, 2018.
- [15] Z. Deng, W. Hu, Y. Yang, K. Cao, D. Cao, and A. Khajepour, “Lane change decision-making with active interactions in dense highway traffic: A bayesian game approach,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 3290–3297.
- [16] T. Zhao, W. ShangGuan, L. Chai, and Y. Cao, “A non-cooperative dynamic game-based approach for lane changing decision-making in mixed traffic diversion scenarios,” in 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2023, pp. 4776–4781.
- [17] Y. Zhang, P. Hang, C. Huang, and C. Lv, “Human-like interactive behavior generation for autonomous vehicles: a bayesian game-theoretic approach with turing test,” Advanced Intelligent Systems, vol. 4, no. 5, p. 2100211, 2022.
- [18] J. Ziegler, P. Bender, M. Schreiber, H. Lategahn, T. Strauss, C. Stiller, T. Dang, U. Franke, N. Appenrodt, C. G. Keller et al., “Making bertha drive—an autonomous journey on a historic route,” IEEE Intelligent Transportation Systems Magazine, vol. 6, no. 2, pp. 8–20, 2014.
- [19] C. Urmson, J. Anhalt, D. Bagnell, C. Baker, R. Bittner, M. Clark, J. Dolan, D. Duggins, T. Galatali, C. Geyer et al., “Autonomous driving in urban environments: Boss and the urban challenge,” Journal of Field Robotics, vol. 25, no. 8, pp. 425–466, 2008.
- [20] M. Montemerlo, J. Becker, S. Bhat, H. Dahlkamp, D. Dolgov, S. Ettinger, D. Haehnel, T. Hilden, G. Hoffmann, B. Huhnke et al., “Junior: The stanford entry in the urban challenge,” Journal of Field Robotics, vol. 25, no. 9, pp. 569–597, 2008.
- [21] J. Wei, J. M. Snider, T. Gu, J. M. Dolan, and B. Litkouhi, “A behavioral planning framework for autonomous driving,” in 2014 IEEE Intelligent Vehicles Symposium Proceedings. IEEE, 2014, pp. 458–464.
- [22] W. Zhan, J. Chen, C.-Y. Chan, C. Liu, and M. Tomizuka, “Spatially-partitioned environmental representation and planning architecture for on-road autonomous driving,” in 2017 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2017, pp. 632–639.
- [23] Z. Ajanovic, B. Lacevic, B. Shyrokau, M. Stolz, and M. Horn, “Search-based optimal motion planning for automated driving. in 2018 IEEE,” in RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 4523–4530.
- [24] T. Kessler and A. Knoll, “Cooperative multi-vehicle behavior coordination for autonomous driving,” in 2019 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2019, pp. 1953–1960.
- [25] J. Ma, Z. Cheng, X. Zhang, M. Tomizuka, and T. H. Lee, “Alternating direction method of multipliers for constrained iterative LQR in autonomous driving,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 12, pp. 23 031–23 042, 2022.
- [26] Z. Huang, S. Shen, and J. Ma, “Decentralized iLQR for cooperative trajectory planning of connected autonomous vehicles via dual consensus ADMM,” IEEE Transactions on Intelligent Transportation Systems, vol. 24, no. 11, pp. 12 754–12 766, 2023.
- [27] K. A. Mustafa, D. J. Ornia, J. Kober, and J. Alonso-Mora, “RACP: Risk-aware contingency planning with multi-modal predictions,” IEEE Transactions on Intelligent Vehicles, 2024.
- [28] M. Werling, S. Kammel, J. Ziegler, and L. Gröll, “Optimal trajectories for time-critical street scenarios using discretized terminal manifolds,” The International Journal of Robotics Research, vol. 31, no. 3, pp. 346–359, 2012.
- [29] W. Liu, S.-W. Kim, S. Pendleton, and M. H. Ang, “Situation-aware decision making for autonomous driving on urban road using online pomdp,” in 2015 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2015, pp. 1126–1133.
- [30] A. G. Cunningham, E. Galceran, R. M. Eustice, and E. Olson, “MPDM: Multipolicy decision-making in dynamic, uncertain environments for autonomous driving,” in 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2015, pp. 1670–1677.
- [31] L. Zhang, W. Ding, J. Chen, and S. Shen, “Efficient uncertainty-aware decision-making for automated driving using guided branching,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 3291–3297.
- [32] W. Ding, L. Zhang, J. Chen, and S. Shen, “EPSILON: An efficient planning system for automated vehicles in highly interactive environments,” IEEE Transactions on Robotics, vol. 38, no. 2, pp. 1118–1138, 2022.
- [33] T. Li, L. Zhang, S. Liu, and S. Shen, “MARC: Multipolicy and risk-aware contingency planning for autonomous driving,” IEEE Robotics and Automation Letters, 2023.
- [34] Y. Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang et al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 17 853–17 862.
- [35] Z. Huang, H. Liu, J. Wu, and C. Lv, “Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving,” IEEE transactions on neural networks and learning systems, 2023.
- [36] Z. Huang, H. Liu, and C. Lv, “Gameformer: Game-theoretic modeling and learning of transformer-based interactive prediction and planning for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3903–3913.
- [37] D. Fridovich-Keil, E. Ratner, L. Peters, A. D. Dragan, and C. J. Tomlin, “Efficient iterative linear-quadratic approximations for nonlinear multi-player general-sum differential games,” in 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 1475–1481.
- [38] C. Li, T. Trinh, L. Wang, C. Liu, M. Tomizuka, and W. Zhan, “Efficient game-theoretic planning with prediction heuristic for socially-compliant autonomous driving,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 248–10 255, 2022.
- [39] W. Schwarting, A. Pierson, S. Karaman, and D. Rus, “Stochastic dynamic games in belief space,” IEEE Transactions on Robotics, vol. 37, no. 6, pp. 2157–2172, 2021.
- [40] N. Mehr, M. Wang, M. Bhatt, and M. Schwager, “Maximum-entropy multi-agent dynamic games: Forward and inverse solutions,” IEEE Transactions on Robotics, vol. 39, no. 3, pp. 1801–1815, 2023.
- [41] H. Shao, M. Zhang, T. Feng, and Y. Dong, “A discretionary lane-changing decision-making mechanism incorporating drivers’ heterogeneity: A signalling game-based approach,” Journal of Advanced Transportation, vol. 2020, no. 1, p. 8892693, 2020.
- [42] R. Yao and X. Du, “Modelling lane changing behaviors for bus exiting at bus bay stops considering driving styles: A game theoretical approach,” Travel Behaviour and Society, vol. 29, pp. 319–329, 2022.
- [43] L. Li, W. Zhao, and C. Wang, “Cooperative merging strategy considering stochastic driving style at on-ramps: A bayesian game approach,” Automotive Innovation, vol. 7, no. 2, pp. 312–334, 2024.
- [44] L. Peters, A. Bajcsy, C.-Y. Chiu, D. Fridovich-Keil, F. Laine, L. Ferranti, and J. Alonso-Mora, “Contingency games for multi-agent interaction,” IEEE Robotics and Automation Letters, 2024.
- [45] M. Zinkevich, M. Johanson, M. Bowling, and C. Piccione, “Regret minimization in games with incomplete information,” Advances in Neural Information Processing Systems, vol. 20, 2007.
- [46] M. Lanctot, K. Waugh, M. Zinkevich, and M. Bowling, “Monte carlo sampling for regret minimization in extensive games,” Advances in Neural Information Processing Systems, vol. 22, 2009.
- [47] V. Lisỳ, M. Lanctot, and M. H. Bowling, “Online monte carlo counterfactual regret minimization for search in imperfect information games.” in AAMAS, 2015, pp. 27–36.
- [48] A. Celli, A. Marchesi, T. Bianchi, and N. Gatti, “Learning to correlate in multi-player general-sum sequential games,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [49] J. Hartline, V. Syrgkanis, and E. Tardos, “No-regret learning in bayesian games,” Advances in Neural Information Processing Systems, vol. 28, 2015.
- [50] M. Maschler, S. Zamir, and E. Solan, Game Theory. Cambridge, U.K.: Cambridge University Press, 2013.
- [51] P. K. Sen and J. M. Singer, Large sample methods in statistics: An introduction with applications. Boca Raton, FL: Chapman & Hall CRC, 2000.