Integer or Floating Point? New Outlooks for
Low-Bit Quantization on Large Language Models
Abstract
Efficient deployment of large language models (LLMs) necessitates low-bit quantization to minimize model size and inference cost. While low-bit integer formats (e.g., INT8/INT4) have been the conventional choice, emerging low-bit floating-point formats (e.g., FP8/FP4) offer a compelling alternative and are gaining support from cutting-edge hardware, such as NVIDIA’s H100 GPU. However, the superiority of low-bit INT versus FP formats for quantization on LLMs remains unclear. In this study, we conduct a comparative analysis of INT and FP quantization with the same bit-width, revealing that the optimal quantization format varies across different layers due to the complexity and diversity of tensor distribution. Consequently, we advocate the Mixture of Formats Quantization (MoFQ), which selects the optimal format on a layer-wise basis. This simple yet effective approach achieves state-of-the-art results in both weight-only (W-only) and weight-activation (WA) post-training quantization scenarios when tested on LLaMA across various tasks. In 4-bit W-only quantization, MoFQ surpasses GPTQ without complex hyperparameter tuning and with an order of magnitude faster quantization speed. While in 8-bit WA quantization, MoFQ significantly outperforms INT/FP-only methods, achieving performance close to the full precision model. Notably, MoFQ incurs no hardware overhead compared to INT/FP-only quantization, as the bit-width remains unchanged.
1 Introduction
Low-bit quantization plays a crucial role in the deployment of deep learning models due to its capacity to minimize the model size and inference cost [18; 10]. The recent advent of large language models (LLMs), which often contain tens or even hundreds of billions of parameters, has further intensified the need for effective quantization techniques [6; 20]. Conventional research in this domain has primarily focused on employing low-bit integer (INT) formats for quantization [21; 13; 11]. However, as the scale of LLMs expands, integer quantization faces challenges in maintaining the effectiveness observed in smaller models, thereby necessitating tailored optimizations or alternative approaches [7; 22; 8].
Recently, low-bit floating-point (FP) formats have emerged as promising alternatives for DNN quantization [12; 15; 19; 4]. FP8 has already garnered support from leading hardware vendors, such as NVIDIA, whose H100 GPU offers identical peak performance for FP8 and INT8 operations [2]. Additionally, other CPU and GPU vendors, such as Intel, AMD, and Qualcomm, are actively incorporating FP8 capabilities into their hardware. Compared to INT formats with the same bit width, FP formats offer a typically larger data range and higher precision for small values but have lower precision for large values and potentially higher hardware costs.
Given the notorious difficulty in quantizing LLMs, the relative effectiveness of INT and FP quantization remains ambiguous, motivating an interesting question: Considering that INT and FP formats with the same bit width can represent the same number of discrete values (e.g., both INT8 and FP8 can represent values) but differ in value distribution, what are the distinct impacts on model quantization and efficient inference?
To answer this question, we conduct a comparative analysis of INT and FP formats, focusing on hardware efficiency and quantization error. First, we compare hardware efficiency by benchmarking the cost of FP and INT multiply-accumulate (MAC) units. While FP MAC generally requires more hardware resources than INT MAC, the resource gap substantially narrows as the bit width decreases, with FP8 and INT8 costs being notably similar. Next, we examine the quantization error of INT and FP formats through the statistical analysis of real tensors and layers sampled from the LLaMA model. Our findings reveal no consistent superior format for all tensors or layers due to the complexity and diversity of tensor distribution. The optimal format is influenced by a combination of various factors, including the static/dynamic nature of tensors, outlier distribution, and quantization bit-width. For weight tensors with static distribution, INT quantization outperforms FP quantization at 8-bit but this advantage diminishes at 4-bit. For activation tensors with dynamic distribution and significant outliers, FP quantization surpasses INT quantization due to FP can represent large values with lower precision and small values with higher precision.
Inspired by the analysis finding of no consistent superior format, we propose the Mixture of Formats Quantization (MoFQ) approach, which selectively determines the optimal format from INT and FP with the same bit-width on a layer-wise basis. MoFQ effectively harnesses the complementary benefits of both formats, while ensuring that tensors within the same layer share the same data type and all quantized tensors have the same bit-width. A straightforward format selection method proves effective, choosing the format with the minimum quantization error based on metrics such as tensor MSE, layer output MSE, or model output MSE. MoFQ applies to W-only quantization for memory footprint compression and WA quantization for accelerated inference using lower-bit computation units. For W-only quantization, MoFQ ensures compatibility with a broad range of existing hardware and imposes no additional hardware overhead compared to integer-only quantization, as the bit-width remains unaltered. For WA quantization, MoFQ can be seamlessly integrated with hardware supporting both low-bit INT and FP operations, such as the off-the-shelf H100 GPU and upcoming Intel and AMD chips. In summary, this mixed-format approach demonstrates simplicity, effectiveness, and efficiency in quantization format selection and model performance.
When evaluated on large language models across various tasks, our MoFQ achieves state-of-the-art (SOTA) results on both W-only quantization and WA quantization. For W-only quantization with 4-bit, MoFQ achieves comparable or better accuracy than GPTQ with an order of magnitude faster quantization speed, because GPTQ is based on second-order information and our MoFQ adopts the naive linear quantization with round-to-nearest (RTN). For WA quantization with 8-bit, MoFQ significantly outperforms INT8-only and FP8-only quantization methods and achieves performance close to the full precision model.
Our contributions can be summarized as follows:
-
1.
We conduct an in-depth comparative analysis of INT and FP formats for quantizing LLMs, offering valuable insights to guide future quantization designs with low-bit FP formats.
-
2.
We propose the Mixture of Formats Quantization (MoFQ) approach, a simple yet effective layer-wise format selection scheme that seamlessly combines the benefits of both INT and FP formats. MoFQ is system and hardware-friendly.
-
3.
MoFQ achieves state-of-the-art (SOTA) results on both 4-bit W-only quantization and 8-bit WA quantization.
2 Preliminaries
Integer vs. Floating Point Formats
Integer and floating point formats are two primary ways to represent numbers in computing systems. The key distinction between them lies in the value distribution. Integer format has a uniform distribution across the representable range with a difference of 1 between two consecutive numbers. While the floating point format exhibits a non-uniform distribution due to the incorporation of the exponent and mantissa design, thus providing higher precision for smaller numbers and lower precision for larger ones. The emerging FP8 format features two widely-adopted options, E4M3 and E5M2, with fewer bits for both exponent and mantissa than FP32/16, as depicted in Figure 2. To highlight FP and INT distribution differences, Figure 2 visualizes a small portion of values around the zero point represented in INT8 and FP8-E5M2.
two figures:


Mainstream deep learning hardware typically supports high-bit FP and low-bit INT operations, while recently, H100 has introduced support for FP8-E5M2 and FP8-E4M3. As for hardware efficiency, FP operations generally incur higher costs and lower performance than INT operations. However, for low-bit quantization and inference where the bit-width drops to 8/4 bits, their hardware efficiency is not well-established. Therefore, this work also benchmarks the hardware cost of INT and FP operations at various bit widths, as will be shown in Section 3.1.
Model Quantization
Model quantization reduces the memory and computational cost of DNNs by using fewer bits to represent tensors. There are two primary methods of model quantization: weight-only (W-only) quantization and weight-and-activation (WA) quantization. W-only quantization compresses weight tensors only, still requiring higher bit-width operations during computation. Meanwhile, WA quantization further quantizes activation tensors, enabling lower bit-width computation and improved efficiency. Based on whether retraining is required, quantization can be divided into post-training quantization (PTQ) and quantization-aware training (QAT). PTQ converts pre-trained models into quantized versions without additional training, making it faster and more cost-effective, while QAT uses a lengthy training process to simulate quantitative effects. In this work, we focus on applying PTQ to LLMs due to the prohibitive training costs of QAT.
3 Comparative Analysis of Integer and Floating-Point Formats
In this section, we aim to shed light on the differences between INT and FP quantization formats by conducting a comprehensive comparison, specifically focusing on hardware efficiency and quantization error. We strive to understand their individual strengths and weaknesses, and how they impact model performance and efficiency. To ensure a fair comparison, we maintain the same bit-width for both formats throughout the analysis.
3.1 Hardware Cost
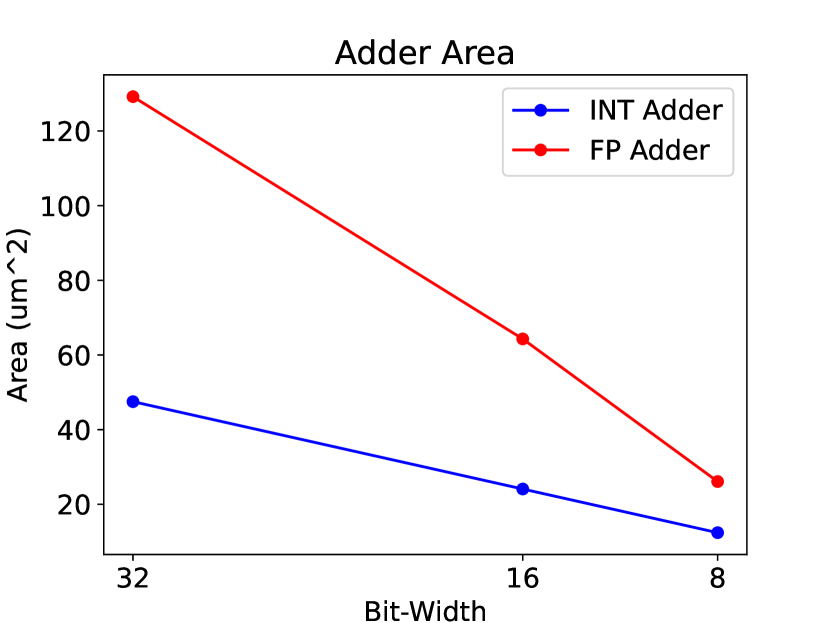
We first delve into hardware efficiency by comparing the hardware cost of INT and FP operators, including adders, multipliers, and multiply-accumulate (MAC) units, across various bit widths. Utilizing Synopsys Design Ware along with TSMC’s 7nm technology and the Synopsys Design Compiler, we are able to accurately determine the area requirements for each type of operator. In this experiment, we establish a target clock frequency of 0.5GHz for all operators. For 8-bit FP operators, we employ the E5M2 format, while E4M3 yields analogous outcomes. It is worth mentioning that, in 8-bit MAC, the multiplier is 8-bit, and the accumulator is 16-bit to prevent overflow, a standard configuration for low-bit MAC. As illustrated in Figure 3, FP multipliers require less area than their INT counterparts, whereas FP adders necessitate more area than INT adders. Concerning MAC units, which function as a fundamental building block for matrix multiplication in DNNs, FP operations typically demand more area than INT operations. However, this disparity narrows as the bit-width decreases. Intriguingly, at 8-bit, the area requirements for FP8 and INT8 MAC units are almost identical. This observation indicates that INT8 and FP8 demonstrate similar hardware costs and inference performance, aligning with the specifications of the H100 GPU.


3.2 Quantization Error
In this subsection, we compare quantization errors from different formats through statistical analysis of real tensors and layers in LLMs. Quantization primarily targets Linear layers (operators) as they dominate storage and computation. The linear layer is represented as , where is the weight tensor, is the input activation tensor, and is the output activation tensor. We analyze quantization errors on all three tensors for a comprehensive understanding. We perform static tensor analysis on , dynamic tensor analysis on , and layer analysis on , which is influenced by error accumulation from both inputs.
In our analysis, we use per-channel weight tensor quantization and per-tensor activation quantization, following widely-used approaches in previous quantization research [9]. The FP4 format adopts an E2M1 configuration, and the FP8 format follows an E4M3 configuration.
Static (Weight) Tensor Analysis
We quantize weight tensors using both FP and INT formats with 4-bit and 8-bit and calculate the mean squared error (MSE) between quantized and original tensors. The weight tensors used in this experiment are all sampled from the LLaMA-65B model [20].


Figure 4 presents the comparison between INT and FP quantization. For clarity, we sort the results by INT MSE. It should be noted that the Layer ID does not correspond directly to the actual number of layers in the model. When quantizing weight tensors with 8-bit, INT format exhibits a lower error than FP format, as shown in Figure 4-right. When the quantization bit-width decreases to 4-bit, there is no absolute winner between FP and INT formats as shown in Figure 4-left. In some layers, FP4 has lower errors, while in others, INT4 has lower errors.
This analysis result suggests that INT has an advantage in 8-bit weight quantization. However, when the bit-width decreases, the bits for exponent also decline, making the distribution of INT and FP more similar. The advantage of quantizing static tensors with uniformly distributed INT format fades away in 4-bit quantization, leading to no clear optimal solution for 4-bit quantization of weights.

Dynamic (Activation) Tensor Analysis
Unlike static weight tensors during inference, activation tensors are dynamic and change with each input. Therefore, calibration is an essential step in the quantization process for activation tensors to determine the appropriate scaling factors.
In this analysis, we select 32 layers from the LLaMA-65B model and quantize the input activation tensors of each layer with scales from calibration sets. Finally, we compare the MSE errors of FP8 and INT8 quantization as shown in Figure5. Our findings indicate that with scales obtained from calibration sets, the quantization error of FP8 is lower than that of INT8. This is because the calibration process always selects the largest value among multiple batches to determine the scaling factor in quantization. This process tends to derive a larger-than-suitable scaling factor for most of the batches. However, the FP format, with lower precision for large values and higher precision for small values, is inherently better suited for quantizing such dynamic tensors.
Layer (Operator) Analysis
Although quantization error analysis on input tensors can yield some insights, the relationship between the layer output quantization error and the input tensors’ quantization errors is not clear. Therefore, we investigate the quantization errors in the output tensors when the input tensors (,) are quantized using different formats. MSE errors in both W-only (W4A16) and WA (W8A8) quantization scenarios are presented, with and tensors from various layers in the LLaMa-65B model.



Figure 6 shows the results of W-only quantization with 4-bit. As different weight tensors favor different formats between INT4 and FP4, it is natural that different layers exhibit varying preferences between INT4 and FP4. Figure 7 shows the results of WA quantization with 8-bit, using the noise-signal power ratio to indicate quantization error (a lower value is preferable). The results suggest that when activation quantization is taken into account, FP8 leads to lower quantization error in most of the layers. However, there are still some cases where INT8 is favored as weight tensors prefer INT8 over FP8.

Based on the above observations, we can conclude that the suitability of FP or INT for LLaMA layers varies on a case-by-case basis when considering layer errors. Both INT4 and FP4 are useful for weights in different layers, as no optimal 4-bit format exists for static tensor quantization. Meanwhile, though we have drawn the conclusion that INT8 is better for weights and FP8 is better for activation, the accuracy of depends on the impact of and being multiplied, so there is also no consistent superior format for W8A8 quantization. In Section 5, we will demonstrate that an appropriate format choice for each layer can result in better model accuracy compared to using the same format for all layers.
4 Mixture of Formats Quantization
4.1 Exploiting the Complementary Advantages of Integer and Floating Point Formats
Given the analysis findings that no single quantization format consistently outperforms the others in all scenarios, we propose the Mixture-of-Formats Quantization (MoFQ) method. The key idea behind MoFQ is to leverage the complementary advantages of integer (INT) and floating-point (FP) formats in a unified framework, thereby maximizing the potential benefits of both formats.
Specifically, MoFQ allows for the selection of the most suitable format on a layer-by-layer basis. As illustrated in Algorithm 1, the algorithm considers the model to be quantized, a flag is_w_only, format candidates (e.g., INT and FP), bit width (e.g., 8 or 4), and error metric as inputs. If is_w_only is set to true, only the weight tensor in the layer will be quantized (i.e., W-only quantization); otherwise, both weights and activations will be quantized (i.e., WA quantization), resulting in a quantized operator that can leverage low-bit hardware matrix multiplication units. We concentrate on layer-wise format selection with the same format for each tensor/layer and the same bit-width across all quantized tensors/layers, as this approach adheres to the simplicity principle, offering a straightforward and efficient implementation with minimal adaptation to the existing system or hardware. Such a straightforward method can achieve satisfactory results, as will be demonstrated in Section 5. Utilizing a finer granularity than the layer level or increasing the bit-width can indeed improve the quantization effect, but it also comes at the cost of increased memory consumption and higher system or hardware complexity. We leave the exploration of this trade-off as future work, as it requires further investigation and analysis.
The selection of the error metric plays a crucial role in MoFQ, as it influences the balance between quantization accuracy and speed. Several metrics are available, including tensor error, layer output error, and model output error, from less precise to more precise. A more precise metric may lead to better quantization results but at the expense of increased computational time. Thus, choosing an appropriate error metric is essential for achieving the desired balance between accuracy and efficiency in the quantization process. It’s worth mentioning that the evaluation metric for determining the superiority of a format is empirical and doesn’t have an absolute standard. For example, a lower tensor error may indicate a higher likelihood of achieving better model accuracy, but it isn’t guaranteed. In MoFQ, we use various selection metrics to find the right balance between quantization accuracy and speed. Our empirical observations suggest that using tensor error or layer output error suffices to guide the format selection for W-only quantization. Meanwhile, for WA quantization, the model output error offers the best format selection choices.
4.2 Reallocating NaN and Inf for Enhanced Low-Bit Floating Point Quantization
In low-bit quantization, maximizing number representation efficiency is essential for achieving the best possible precision and expressiveness. One optimization opportunity lies in reallocating the special NaN (Not a Number) and Inf (Infinity) values in standard floating-point formats. In IEEE floating-point formats, an exponent field with all bits set to 1 denotes NaN and Inf values. However, during model quantization, these special values serve no practical purpose, resulting in wasted bit combinations that could otherwise be used to represent a broader range of numbers. By reallocating NaN and Inf representations to normalized numbers, we can enhance the precision and expressiveness of the low-bit FP format for improved model quantization.
In practical quantization scenarios, the impact of NaN and Inf redundancy varies depending on the number of bits used for representation. For instance, in an 8-bit floating-point format (FP8), the impact is relatively minor as it can represent 256 numbers, with NaN and Inf occupying only a small portion. On the other hand, FP8 is primarily used for WA quantization, which requires hardware support for matrix multiplication. Therefore, it may not be suitable to modify FP8 due to potential hardware compatibility issues. However, in a 4-bit format (FP4), the impact becomes more significant as it can only represent 16 numbers in total. As FP4 is primarily used for W-only quantization, format modification can be addressed at the software level. As illustrated in Table 1, 4 of these numbers are used to represent NaN and Inf when adhering to the IEEE 754 standard. By reallocating them, we can obtain additional represented numbers, specifically and . Tensor-wise analysis shows that our redesigned FP4 format can lead to about 35% lower quantization errors compared to the IEEE-aligned FP4 format. This improvement makes more layers prefer our re-designed FP4 than INT4 in W-only quantization.
| UINT4 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FP4 w/ NaN&Inf | 0 | 0.5 | 1 | 1.5 | 2 | 3 | Inf | NaN | -0 | -0.5 | -1 | -1.5 | -2 | -3 | Inf | NaN |
| FP4 w/o NaN&Inf | 0 | 0.5 | 1 | 1.5 | 2 | 3 | 4 | 6 | -0 | -0.5 | -1 | -1.5 | -2 | -3 | -4 | -6 |
5 Experiments
In the experiments, we present the validation results of our MoFQ approach for both W-only (W4A16) and WA (W8A8) quantization scenarios separately. We apply per-channel quantizations to weight tensors and per-tensor quantizations to activation tensors. The FP4 construction excludes NaN and Inf, using E2M1, while FP8 construction employs E4M3. For validation, we utilize LLaMA[20] and OPT[25] models. Validation datasets include: 1) WikiText-2[14]; 2) LAMBADA[16]; 3) PIQA[5]; 4) HellaSwag[24]. Our MoFQ implementation is based on the PPQ library[3] and GPTQ[1].
5.1 W-only 4bit quantization with SOTA quantization errors
Table 2 compares various quantization methods on LLaMA models, including INT4(GPTQ), FP4(ours), and MoFQ4. INT4(GPTQ) is the SOTA method from the GPTQ paper[8], FP4(ours) is our FP4 format, and MoFQ4 is mixture of FP4(ours) and INT4 formats. Evaluation results show that FP4(ours) and MoFQ4 generally outperform INT4(GPTQ), with MoFQ4 often yielding better results than FP4(ours). However, MoFQ doesn’t consistently surpass FP4, indicating room for further improvement in our MoFQ approach.
| WikiText-2 | LAMBADA | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FP16 |
|
|
|
FP16 |
|
|
|
|||||||||||||
| LLaMA-7B | 5.68 | 6.38 | 6.04 | 6.03(88.9%) | 0.884 | 0.862 | 0.878 | 0.878(88.9%) | ||||||||||||
| LLaMA-13B | 5.09 | 5.40 | 5.35 | 5.33(97.1%) | 0.883 | 0.877 | 0.879 | 0.874(97.1%) | ||||||||||||
| LLaMA-33B | 4.10 | 4.36 | 4.33 | 4.30(97.9%) | 0.862 | 0.853 | 0.858 | 0.845(97.9%) | ||||||||||||
| LLaMA-65B | 3.53 | 3.85 | 3.85 | 3.78(96.8%) | 0.909 | 0.907 | 0.911 | 0.916(96.8%) | ||||||||||||
| PIQA | HellaSwag | |||||||||||||||||||
| FP16 |
|
|
|
FP16 |
|
|
|
|||||||||||||
| LLaMA-7B | 0.780 | 0.764 | 0.781 | 0.776(88.9%) | 0.558 | 0.476 | 0.519 | 0.517(88.9%) | ||||||||||||
| LLaMA-13B | 0.783 | 0.792 | 0.806 | 0.808(97.1%) | 0.587 | 0.564 | 0.560 | 0.562(97.1%) | ||||||||||||
| LLaMA-33B | 0.787 | 0.788 | 0.781 | 0.784(97.9%) | 0.605 | 0.582 | 0.585 | 0.582(97.9%) | ||||||||||||
| LLaMA-65B | 0.769 | 0.761 | 0.761 | 0.764(96.8%) | 0.551 | 0.539 | 0.543 | 0.544(96.8%) | ||||||||||||
| LLaMA-7B | LLaMA-13B | LLaMA-33B | LLaMA-65B | |
|---|---|---|---|---|
| INT4(GPTQ) | 389 | 1088 | 2535 | 4684 |
| FP4(ours) | 5(77.8x) | 9(120.8x) | 19(133.4x) | 36(130.1x) |
| MoFQ4 | 42(9.3x) | 69(15.8x) | 162(15.6x) | 319(14.7x) |
In addition to comparing quantization accuracy, we also examine the runtime required for quantizing the models. As shown in Table 3, we observe that the quantization speed of FP4 is more than 77.8 times faster than INT4(GPTQ) (with calibration nsample = 128), while MoFQ4 is over 9.3 times faster compared to INT4(GPTQ). This can be attributed to the fact that GPTQ necessitates real-time updates of the original weight tensors during the quantization process, resulting in considerable computational overhead. In contrast, FP4(ours) and MoFQ4 adopt the naive linear quantization with round-to-nearest (RTN), leading to significantly faster speeds.
5.2 W8A8 quantization with accuracy close to full-precision models
In this subsection, we compare the performance of various quantization methods on LLaMA and OPT models. The methods evaluated include INT8, FP8, and MoFQ8, where MoFQ8 represents the mixture of FP8 and INT8 formats in the quantization method.
Table 4 compares various quantization methods on four datasets: WikiText-2, LAMBADA, PIQA, and HellaSwag. FP8 consistently outperforms INT8 across all cases. This can be attributed to the increased challenge of quantizing dynamic activation tensors compared to static weight tensors, as dynamic tensors exhibit more varied distributions and larger outlier values[22]. In Section 3, we determine that FP8 is better suited for quantizing dynamic tensors than INT8. Consequently, despite FP8’s potentially weaker performance on weight tensors compared to INT8, it still manages to achieve lower overall quantization errors for the models.
| WikiText-2 | LAMBADA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FP16 |
|
|
|
FP16 |
|
|
|
|||||||||
| LLaMA-7B | 5.68 | 368.21 | 6.59 | 6.49(87.2%) | 0.884 | 0.010 | 0.851 | 0.887(82.0%) | ||||||||
| LLaMA-13B | 5.09 | 637.95 | 5.64 | 5.41(86.1%) | 0.883 | 0.230 | 0.854 | 0.881(83.0%) | ||||||||
| LLaMA-33B | 4.10 | 10069.14 | 5.38 | 5.31(92.7%) | 0.862 | 0.000 | 0.822 | 0.859(90.0%) | ||||||||
| OPT-350M | 23.27 | 432.86 | 24.46 | 23.64(71.8%) | 0.674 | 0.290 | 0.658 | 0.669(69.2%) | ||||||||
| OPT-1.3B | 15.44 | 37.72 | 16.78 | 16.07(78.8%) | 0.758 | 0.716 | 0.735 | 0.746(80.0%) | ||||||||
| OPT-2.7B | 13.08 | 27.56 | 14.24 | 13.25(83.3%) | 0.778 | 0.693 | 0.764 | 0.777(80.0%) | ||||||||
| OPT-6.7B | 11.43 | 964.58 | 12.41 | 11.68(89.1%) | 0.806 | 0.164 | 0.762 | 0.800(89.4%) | ||||||||
| OPT-13B | 10.68 | 11858.78 | 12.52 | 10.79(87.2%) | 0.802 | 0.001 | 0.724 | 0.801(84.1%) | ||||||||
| OPT-30B | 10.09 | 13195.34 | 10.95 | 10.17(89.4%) | 0.813 | 0.007 | 0.744 | 0.812(86.0%) | ||||||||
| PIQA | HellaSwag | |||||||||||||||
| FP16 |
|
|
|
FP16 |
|
|
|
|||||||||
| LLaMA-7B | 0.780 | 0.539 | 0.706 | 0.779(85.8%) | 0.558 | 0.258 | 0.524 | 0.560(80.6%) | ||||||||
| LLaMA-13B | 0.783 | 0.532 | 0.768 | 0.788(82.3%) | 0.587 | 0.264 | 0.576 | 0.585(81.7%) | ||||||||
| LLaMA-33B | 0.787 | 0.530 | 0.767 | 0.789(81.3%) | 0.605 | 0.260 | 0.599 | 0.604(89.1%) | ||||||||
| OPT-350M | 0.619 | 0.554 | 0.615 | 0.621(71.9%) | 0.292 | 0.265 | 0.295 | 0.293(73.4%) | ||||||||
| OPT-1.3B | 0.693 | 0.667 | 0.690 | 0.691(75.2%) | 0.351 | 0.351 | 0.351 | 0.351(80.8%) | ||||||||
| OPT-2.7B | 0.708 | 0.687 | 0.712 | 0.714(75.1%) | 0.379 | 0.383 | 0.393 | 0.396(80.3%) | ||||||||
| OPT-6.7B | 0.721 | 0.609 | 0.718 | 0.720(87.0%) | 0.409 | 0.279 | 0.407 | 0.411(84.4%) | ||||||||
| OPT-13B | 0.716 | 0.516 | 0.688 | 0.715(82.9%) | 0.421 | 0.263 | 0.417 | 0.426(85.0%) | ||||||||
| OPT-30B | 0.725 | 0.524 | 0.713 | 0.727(80.5%) | 0.442 | 0.260 | 0.433 | 0.442(85.5%) | ||||||||
Crucially, we find that under our MoFQ8 quantization method, the accuracy of the quantized model remains remarkably close to that of the FP16 model, irrespective of the model size or dataset. This suggests that MoFQ8 effectively chooses the most appropriate format (INT8 or FP8) for each layer’s distribution, ultimately achieving W8A8 quantization results with minimal accuracy loss.
6 Related Work
Large Language Models (LLMs) have significantly transformed the field of natural language processing, introducing new challenges and opportunities in model quantization. ZeroQuant [23] and nuQmm [17] employ finer (group-wise) granularities to quantize tensors, which requires customized CUDA kernels. LLM.int8() [7] uses mixed precision (INT8+FP16) to quantize individual tensors or layers in LLMs. However, this approach results in substantial latency overhead. While MoFQ maintains the same data type and bit-width for each tensor/layer. SmoothQuant [22] improves quantization accuracy on LLMs by offline migrating the quantization difficulty from activations to weights. While previous research has primarily focused on low-bit integer quantization, MoFQ incorporates low-bit floating points (FP8 and FP4) for LLM quantization.
7 Conclusion
In this paper, we extensively investigate and compare low-bit integer (INT) and floating-point (FP) formats for quantizing LLMs. Our findings reveal that due to the complexity and diversity of tensor distribution, the optimal quantization format varies across different layers. Therefore, we propose the Mixture of Formats Quantization (MoFQ) approach, which selectively determines the optimal format from INT and FP with the same bit-width on a layer-wise basis. MoFQ is simple, effective, and efficient in format selection and model performance, achieving state-of-the-art results in both W-only and WA quantization.
Despite the promising results demonstrated by MoFQ, there are certain limitations and opportunities for future work: 1) The analysis presented in this paper is primarily empirical. Although this provides valuable insights into the practical performance of the proposed MoFQ, additional theoretical investigation is necessary to gain a deeper understanding of the principles and mechanisms involved in different quantization formats. 2) MoFQ can be extended to finer granularities, such as channel-wise or block-wise selection of optimal formats, to further enhance model accuracy.
References
- [1] GPTQ Library. https://github.com/IST-DASLab/gptq.
- [2] NVIDIA H100 Tensor Core GPU Architecture. https://resources.nvidia.com/en-us-tensor-core.
- [3] PPQ Library. https://github.com/openppl-public/ppq.
- [4] Ankur Agrawal, Sae Kyu Lee, Joel Silberman, Matthew Ziegler, Mingu Kang, Swagath Venkataramani, Nianzheng Cao, Bruce Fleischer, Michael Guillorn, Matthew Cohen, et al. 9.1 a 7nm 4-core ai chip with 25.6 tflops hybrid fp8 training, 102.4 tops int4 inference and workload-aware throttling. In 2021 IEEE International Solid-State Circuits Conference (ISSCC), volume 64, pages 144–146. IEEE, 2021.
- [5] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- [6] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [7] Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Llm. int8 (): 8-bit matrix multiplication for transformers at scale. arXiv preprint arXiv:2208.07339, 2022.
- [8] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [9] Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. arXiv preprint arXiv:2103.13630, 2021.
- [10] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- [11] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2704–2713, 2018.
- [12] Andrey Kuzmin, Mart Van Baalen, Yuwei Ren, Markus Nagel, Jorn Peters, and Tijmen Blankevoort. Fp8 quantization: The power of the exponent. arXiv preprint arXiv:2208.09225, 2022.
- [13] Darryl Lin, Sachin Talathi, and Sreekanth Annapureddy. Fixed point quantization of deep convolutional networks. In International conference on machine learning, pages 2849–2858. PMLR, 2016.
- [14] Stephen Merity. The wikitext long term dependency language modeling dataset. Salesforce Metamind, 9, 2016.
- [15] Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, et al. Fp8 formats for deep learning. arXiv preprint arXiv:2209.05433, 2022.
- [16] Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The lambada dataset: Word prediction requiring a broad discourse context. arXiv preprint arXiv:1606.06031, 2016.
- [17] Gunho Park, Baeseong Park, Se Jung Kwon, Byeongwook Kim, Youngjoo Lee, and Dongsoo Lee. nuqmm: Quantized matmul for efficient inference of large-scale generative language models. arXiv preprint arXiv:2206.09557, 2022.
- [18] Antonio Polino, Razvan Pascanu, and Dan Alistarh. Model compression via distillation and quantization. arXiv preprint arXiv:1802.05668, 2018.
- [19] Xiao Sun, Jungwook Choi, Chia-Yu Chen, Naigang Wang, Swagath Venkataramani, Vijayalakshmi Viji Srinivasan, Xiaodong Cui, Wei Zhang, and Kailash Gopalakrishnan. Hybrid 8-bit floating point (hfp8) training and inference for deep neural networks. Advances in neural information processing systems, 32, 2019.
- [20] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [21] Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev, and Paulius Micikevicius. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv preprint arXiv:2004.09602, 2020.
- [22] Guangxuan Xiao, Ji Lin, Mickael Seznec, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. arXiv preprint arXiv:2211.10438, 2022.
- [23] Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. Zeroquant: Efficient and affordable post-training quantization for large-scale transformers. Advances in Neural Information Processing Systems, 35:27168–27183, 2022.
- [24] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.
- [25] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.