INODE: Building an End-to-End Data Exploration System
in Practice [Extended Vision]
Abstract.
A full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process, by being reactive and anticipative both for data discovery and for data linking. Such systems are a real opportunity for our community to cater to users with different domain and data science expertise.
We introduce INODE - an end-to-end data exploration system - that leverages, on the one hand, Machine Learning and, on the other hand, semantics for the purpose of Data Management (DM). Our vision is to develop a classic unified, comprehensive platform that provides extensive access to open datasets, and we demonstrate it in three significant use cases in the fields of Cancer Biomarker Research, Research and Innovation Policy Making, and Astrophysics. INODE offers sustainable services in (a) data modeling and linking, (b) integrated query processing using natural language, (c) guidance, and (d) data exploration through visualization, thus facilitating the user in discovering new insights. We demonstrate that our system is uniquely accessible to a wide range of users from larger scientific communities to the public. Finally, we briefly illustrate how this work paves the way for new research opportunities in DM.
1. Introduction
The Data Management (DM) community has been actively catering to Machine Learning (ML) research by developing systems and algorithms that enable data preparation and flexible model learning. This has resulted in several major contributions in developing ML pipelines, and formalizing algebras and languages to facilitate and debug model learning, as well as designing and implementing algorithms and systems to speed up ML routines (Boehm et al., 2016; Sparks et al., 2017). Existing work that leverages ML for DM (Stoica, 2020) is nascent and covers the use of ML for query optimization (Kristo et al., 2020) or for database indexing (Kraska et al., 2018). This paper makes the case for democratizing Intelligent Data Exploration by leveraging ML for DM.
Traditionally, database systems assume the user has a specific query in mind, and can express it in the language the system understands (e.g., SQL). However, today, users with different technical backgrounds, roles, and tasks are accessing and leveraging voluminous and complex data sources. In many scenarios, they are only partially familiar with the data and its structure, and their needs are not well-formed. In such settings, expanding traditional query answering to data exploration is a natural consequence and requirement and with it comes the need to redesign systems accordingly. This need translates to several challenges at different levels.
(Interaction). Regarding interaction with the system, the biggest challenge is to enable the user to express her needs through a variety of access modalities, ranging from SQL and SPARQL to natural language (NL) and visual query interfaces, that can be used and intermingled depending on the user needs and expertise as well as the data exploration scenario. The second challenge is that of user guidance, i.e., users should be allowed to provide feedback to the system, and the system should leverage that feedback to improve subsequent exploration steps.

(Linking). Once a user need has been formulated and sent to the system, it is executed over a (fixed) data set. Users may be aware which additional data sets could be of interest. However, they do not always know how to correctly link, integrate, and query more than one data source to generate rich information. This introduces the challenges of data linking, so that new data sources can be added to the system, as well as knowledge generation, so that queries over unstructured data can be supported. Both of these aim at enabling the continuous expansion of the “pool” of available data sources, thus making more data available to users.
(Guidance). Traditionally, the system will return to the user a set of tuples that concludes the search. There is a lot of work on how to improve performance for query workloads (predict future queries, build indices adaptively, etc.), but still the system has a rather passive role: anticipating or at best trying to predict the next query and then optimize its performance accordingly. Hence, the challenge of system proactiveness arises. The output is not only the set of results but also recommendations for subsequent queries or exploration choices. In our vision, the system guides the user to find interesting, relevant or unexpected data and actively participates in shaping the query workload.
In a nutshell, a full-fledged data exploration system must combine different access modalities with a powerful concept of guiding the user in the exploration process. It must be reactive and anticipative co-shaping with the user the data exploration process. Finally, while data integration has been around for a while, the ability to tie together data discovery and linking is a central question in an intelligent data exploration system.
(Evaluation). An essential part of our proposal is the development of an evaluation framework to enable the end-to-end assessment of an intelligent data exploration system. This requires to formalize system and human metrics that are necessary for data linking and integration, multi-modal data access, guidance, and visualization.
Related Work. Several systems address components of our vision. A number of them enable NL-to-SQL (Blunschi et al., 2012), SQL-to-NL (Kokkalis et al., 2012) or both (John et al., 2017) (see a summary in (Affolter et al., 2019)). Recommendation strategies can be leveraged to guide users (Liu et al., 2019). Work on interactive data exploration aims at helping the user discover interesting data patterns based on an integration of classification algorithms and data management optimization techniques (Dimitriadou et al., 2016). Each of the above-mentioned systems tackles specific data management challenges as so-called insular solutions. However, these insular solutions have not been integrated to tackle the end-to-end aspect of intelligent data exploration targeted at a wide range of different end users.
Combining all the challenges above requires an elaborated system whose multi-aspect behavior and functionality is the result of a synergy between disjoint technologies, and integrates them into a new ensemble. This gives rise to multiple approaches that vary in computational complexity, and raises new challenges that can benefit from recent advances in ML.
In summary, this paper makes the following contributions. We advocate for using ML to solve DM problems that arise when building intelligent data exploration systems. We illustrate the need for intelligent data exploration with relevant use cases (Section 2). We describe the solution we have today, INODE111http://www.inode-project.eu/, that we are currently building as part of a European project (Section 3). To fully complete our vision, we provide open research challenges to be addressed at the intersection of DM and ML (Section 4).
2. Use Cases
In this section, we describe two use cases from cancer research and astrophysics and show how INODE can tackle them.
Use Case 1: Cancer Research (Natural Language and Visual Data Exploration). Fred is a biologist who studies cancer. His goal is to find which specific biomarkers are indicators for a certain type of lung cancer. He needs natural language exploration.
INODE offers support for NL queries, query recommendations, and interactive visualizations triggered by NL queries (see Figure 1). For instance, Fred starts with a request in NL for the topics related to lung cancer but is not sure how to continue after inspecting the results. INODE steps up and recommends different options: to expand the search using experimental drugs for treating lung cancer, or to focus on a subset of lung cancer types associated with a certain gene expression. Fred chooses to expand his search to one of the recommended topics, and receives a new list of lung cancers, drugs and genes. Additionally, INODE explains in NL how results are related. That helps him in selecting experimental drugs for certain gene expressions. After a few such queries, the system visually analyzes the results for Fred to study. Fred learns about the similarity between different types of cancer based on distance metrics that he can choose.
Use Case 2: Astrophysics (Exploration with SQL-Pipelines). In the era of big data, astronomers need to analyze dozens of databases at a time. With the ever increasing number of publically available astronomical databases from various astronomical surveys across the globe, it is becoming increasingly challenging for scientists to penetrate deep into the data structure and their metadata in order to generate new scientific knowledge. Sri, an astrophysicist, explores astronomical objects in SDSS, a large sky survey database222https://www.sdss.org/. Sri would like to examine Green Pea galaxies, first discovered in a citizen science project called ’Galaxy zoo’, that recently gained attention in astronomy as one of the potential sources that drove cosmic reionization.
Figure 2 shows a sequence of three consecutive processes of analyzing astrophysics data. Sri relies on selected examples at each step and requests to see comparable ones. In the first query, she asks to find galaxies with similar colors as Green Pea galaxies, she requests objects with similar spectral properties, like emission line measurements, star formation rates etc., as those returned in the first step. The last query finds similar galaxies in terms of their relative ratios and strength of emission lines. As a result, Sri discovers that green pea emission line ratios are similar to high redshift galaxies.
INODE guides any user in making such new discoveries in an intuitive simpler way, without having to write complicated SQL queries or manual analysis of thousands of galaxies. For instance, INODE helps a user choose among similarity dimensions rather than rely on her ability to provide them. Additionally, INODE shows to the user alternative queries to pay attention to, thus increasing the chances of making new discoveries.

3. Current INODE Architecture
The main novelty of INODE is bringing together different data management solutions to enable intelligent data exploration (see Figure 3). Although some of these solutions and research challenges have been tackled previously, they have not been combined into such an end-to-end intelligent data exploration system, which in turn opens up new research challenges.
INODE’s major components are as follows: (1) Data Modeling and Linking enables integration of both structured and unstructured data. (2) Integrated Query Processing enables efficient query processing across federated databases leveraging ontologies. (3) Data Access and Exploration enables guided data exploration in various modalities such as by natural language, by certain operators or visually.
3.1. Data Modeling and Linking
This component links loosely coupled collections of data sources such as relational databases, graph databases or text documents based on the well-established ontology-based data access (OBDA) paradigm (Xiao et al., 2018a). OBDA uses a global ontology (knowledge graph) to model the domain of interest and provides a conceptual representation of the information in the data sources. The sources are linked to elements in the global ontology through declarative mappings. It is well-known that designing OBDA mappings manually is a time-consuming and error-prone task. The Data Modeling and Linking component of INODE aims at automatizing this task by providing two mechanisms: data-driven and task-driven mapping generation.
Data-driven Mapping Generation. This mechanism deals with linking novel data sources to the system. The idea is to rely on mapping patterns that describe well-assessed and sound schema-transformation rules usually applied in the design process of relational databases. By analyzing (driven by the patterns) the data sources, it is possible to automatically derive a so-called putative ontology (Sequeda and Miranker, 2015) describing both the explicit entities and relationships constituting the schema and the implicit ones inferrable from the data. From the mapping patterns, one can also automatically derive mappings that link the data sources to the putative ontology.
Task-driven Mapping Generation. This mechanism is applied whenever a task or a query is formulated that uses specific target ontology elements that are not yet aligned with the putative ontology. In such scenario, the semantics of the query are used to automatically generate mappings to align the target ontology with the putative ontology.
Knowledge Graph (KG) Generation. This service transforms unstructured information hidden in large quantities of text (e.g. repositories of scientific papers) to an exploitable structured representation through an NLP pipeline. INODE follows an Open Information Extraction (OIE) approach to convert each sentence of the corpus into a set of relational triples, where each triple consists of a subject, an object, and a predicate (relationship) linking them. We leverage a number of preprocessing techniques, including co-reference resolution and extractive summarization to improve the quality of the extracted relational triples. We combine different OIE methods (rule-based, analytics-based and learning-based) to achieve both high precision and high recall (Papadopoulos et al., 2020). The relational triples are further linked with domain-specific ontology concepts before being integrated into the knowledge graph.

3.2. Integrated Query Processing
This component is responsible for the execution of queries using Ontop (Xiao et al., 2020), a the state-of-the-art OBDA system. Ontop allows the users to formulate queries in terms of concepts and properties of their domain of expertise (represented in knowledge graphs), rather than in terms of table and attribute names used in the actual data sources. Hence, users do not have to be aware of the specific storage details of the underlying data sources in order to satisfy their information needs.
Query Execution. This service provides on-the-fly reformulation of SPARQL queries over the domain ontology to SQL queries over the data sources. An approach based on reformulation has the advantage that the data available in the data sources does not need to be duplicated in the query processing system, but can be kept in the data sources as-is. This means that the Query Execution service is guaranteed even in the common scenario where the user does not own the data nor does have the right to copy them. To produce reformulations that can efficiently be executed over the data, in INODE we use optimization techniques such as self-join elimination for denormalized data (Xiao et al., 2020) and optimizations of left-joins arising from OPTIONAL and MINUS operators (Xiao et al., 2018b).
Source Federation. The Source Federation service deals with distributing the processing of queries over the available data sources. INODE provides different kinds of federation ranging from SQL federation to seamless SPARQL federation. With respect to SPARQL, we can distinguish between two forms of federation: seamless federation and SPARQL 1.1 SERVICE federation.
In seamless federation, users send queries against a unified view of the remote endpoints without the need to be aware of the actual vocabularies used in the federated endpoints. The challenge is to automatically detect to which sources which components of the query need to be dispatched, to collect the retrieved results, and to combine them into a coherent answer. We address this challenge by relying on the knowledge about the sources encoded in the OBDA mappings. Given that efficiency is a crucial requirement in this setting, our approach requires a dedicated cost-model able to minimize the number of distributed joins over the federation layer, in order to favor more efficient joins at the level of the sources.
Instead, SERVICE federation might be adopted in those cases where users want to directly refer to “external” SPARQL endpoints, not yet integrated with the ontology. In this setting, the user directly references the desired endpoints at query time using the SPARQL 1.1 SERVICE functionality. Observe that the user is required to be aware of the vocabulary used in the external endpoint. Hence, the Source Federation service can simply delegate the execution of the SPARQL query component referenced in the SERVICE call.
Data Analytics. The data analytics service exploits novel and efficient query reformulation and optimization techniques (Xiao et al., 2020) to compute complex analytical functions. Such techniques are based on algebraic transformations of the SPARQL algebra tree, rather than on Datalog transformations as traditionally done in the OBDA literature. This shift of paradigm allows for an efficient implementation of analytical functions such as SPARQL aggregates. It is worth noting that INODE, through Ontop, provides the first open-source reformulation-based system able to support SPARQL aggregates.
The Answer Justification service generates in an automatic way compact and easy to understand explanations for query results. In an OBDA setting, the explanations for a result must take into account, in addition to the query, the three components of the input, namely the ontology, the mappings, and the data sources (Calvanese et al., 2019). The ontology is taken care of by identifying the ontology axioms used for the rewriting of the input query. As for the mappings, those considered in the justification are the ones that were used for the unfolding of the rewritten query to produce the SQL reformulation. Finally, the data is taken care of by identifying the actual tables and tuples that contributed to build the considered result, using an approach based on provenance semirings (Senellart et al., 2018).
3.3. Data Access and Exploration
Exploration by Natural Language. For translating a natural language question into SQL or SPARQL, INODE uses pattern-based, graph-based and neural network-based approaches. For translating from NL to SQL, INODE extends the pattern-based system SODA (Blunschi et al., 2012) with NLP techniques such as lemmatization, stemming and POS tagging to allow both key word search queries as well as full natural language questions. In addition, we use Bio-SODA (Sima et al., 2019), a graph-based system to enable NL questions over RDF graph databases. In order to enable federated queries across both relational databases and RDF graph databases, INODE uses an ontology-based data access technology leveraging Ontop (Calvanese et al., 2017). The advantage of using pattern-based or graph-based approaches over neural network-based approaches is that they do not require training data, which is often very costly to gain.
Since neural network-based approaches typically require large amounts of training data, we also experimented with various training data generation approaches. INODE uses an inverse data annotation approach called OTTA (Deriu et al., 2020). Rather than writing NL questions and then the corresponding SQL or SPARQL statements, OTTA reverses the process. In particular, OTTA randomly generates so-called operator trees which are similar to logical query plans that can easily be understood by non-tech savvy users. Afterwards, given these operator trees, crowd workers write the corresponding NL questions. In INODE, we use both crowd workers and domain experts for generating training data.
Finally, INODE integrates the neural network-based approach ValueNet, which leverages transformer architectures to translate NL to SQL (Brunner and Stockinger, 2021). The ultimate goal of INODE is to combine all these techniques into an intelligent hybrid-approach that improves on the errors of each of the individual systems.
Exploration by Explanation. One of the biggest hurdles in today’s exploration systems is that the system provides no explanations of the results or system choices. Nor does the system trigger input from the user, for example, by asking the user to provide more information. In INODE, we enable a conversational setting, where the system can (a) ask clarifications and (b) explain results in natural language. This interaction assumes that the system is capable of analyzing and understanding user requests and generating its answers or questions in natural language.

One approach used in INODE builds on Template-based Synthesis (Kokkalis et al., 2012). This approach considers the database schema as a graph and a query as a subgraph. We use templates that tell us how to compose sentences as we traverse the graph and we use different traversal strategies that generate query descriptions as phrases in natural language. Furthermore, to generate NL descriptions that use the vocabulary of a particular database, INODE enriches its vocabulary by leveraging ontologies built by the Data Modeling and Linking components. To further improve INODE’s explanation capabilities, we are working on an approach to automatically learn templates, which is especially critical for databases with no descriptive metadata, such as SDSS. Essentially, we are using neural-based methods to translate from SQL or SPARQL to natural language.
For example, user questions in natural language inevitably hide ambiguity. Hence, the system can come up with several possible query interpretations that may lead to unexpected results or need the user’s help for query disambiguation.
Exploration by Example and by Analytics. By-example is a powerful operator that encapsulates multiple semantics. It takes a set of examples, such as galaxies or patients, and explores its different facets, filters them, finds similar/dissimilar sets, finds overlapping sets, joins them with other sets, finds a superset, etc. Additionally, by-example operators can be combined with by-analytics to find sets that are similar/dissimilar wrt some value distributions. Figures 4 shows an example data exploration pipeline (DEP) for exploring galaxies with different instances of by-example.
By-example and by-analytics operators can be represented in the Region Connection Calculus (RCC) (Li and Ying, 2003) and are, in their general form, computationally challenging. For instance, by-subset is akin to solving a set cover problem, which has been extensively studied (Cormode et al., 2010). Similarly, by-join requires to have appropriate indices. In INODE, we adopt two approaches. One is based on a relational backend in which individual operators are translated into SQL. The other one is an in-memory Python implementation that relies on pre-computing and indexing sets. For some operators such as by-facet, the SQL version is straightforward since it resolves into generating a GROUP BY-query. For others, such as by-overlap, the Python version is simpler as it relies on using an index that records pairwise overlaps between pre-computed sets.
Exploration by Recommendation. In a mixed-initiative setting, the system actively guides the user in what possible actions to perform or data to look at next. In INODE, we are interested in recommendations in both cold-start (where the user has not given any input) and warm-start settings (where the user has asked one or more queries but may not know what to do next). In the former case, the goal is to show a set of example or starter queries that the users could use to get some initial answers from the dataset (e.g. (Howe et al., 2011)). In the latter case, the system can leverage the user’s interactions (queries) to show possible next queries (e.g., (Guilly et al., 2018)).
A big differentiator is the availability of query logs. In case no query logs are available, the system should still provide recommendations. In INODE we are addressing the recommendation problem from different angles, i.e., generating recommendations: (a) based on data analysis (Glenis et al., 2020) (b) by NL-based processing and query augmentation techniques leveraging knowledge bases (c) by user log analysis.
Exploration by Visualization. In information retrieval, search queries result in a list of candidates ranked by their matching score (Manning et al., [n.d.]). This also holds true for INODE, as most exploration operators generate multiple potential answers. However, results are not individual items such as documents, but data sets (i.e. sets of items) and have to be communicated to the user differently to support their goals. Not only do users have to decide, which data set contains the answer they are looking for, but also to compare the results, to assess redundancies, discrepancies and other surprising or interesting differences to draw hints on how to continue the exploration.
The goals of the by-visualization data access and exploration interface are two-fold: (1) Enable ”explorers” to understand, compare and decide based on the provided results and (2) enable them to interact with the results by enabling indirect query manipulation, identifying and highlighting parts that are of interest for further analysis and guiding them towards interesting regions (Stahnke et al., [n.d.]; Steiger et al., [n.d.]; Ruotsalo et al., [n.d.]; May et al., 2012). Depending on the users information need, the optimal answer may take different forms. For example, some questions can be satisfied by a single data cell, while others require aggregated values or even multiple tables. Hence, making the results explorable with respect to the users’ needs is very challenging.
Our processes for user requirements elicitation confirms our goals stated above and is based on the User Centered Design standard (International Organization for Standardization, 2019). In addition to that, users emphasized the importance to compare differences as well as similarities of queries and results. As a base line, we enabled the visualization of multiple tables with direct manipulation capabilities and currently work on an overview visualization that spans the result data space.
A simple data exploration process with INODE for exploring EU-projects stored in the CORDIS333https://cordis.europa.eu/ database is shown in Figure 5.
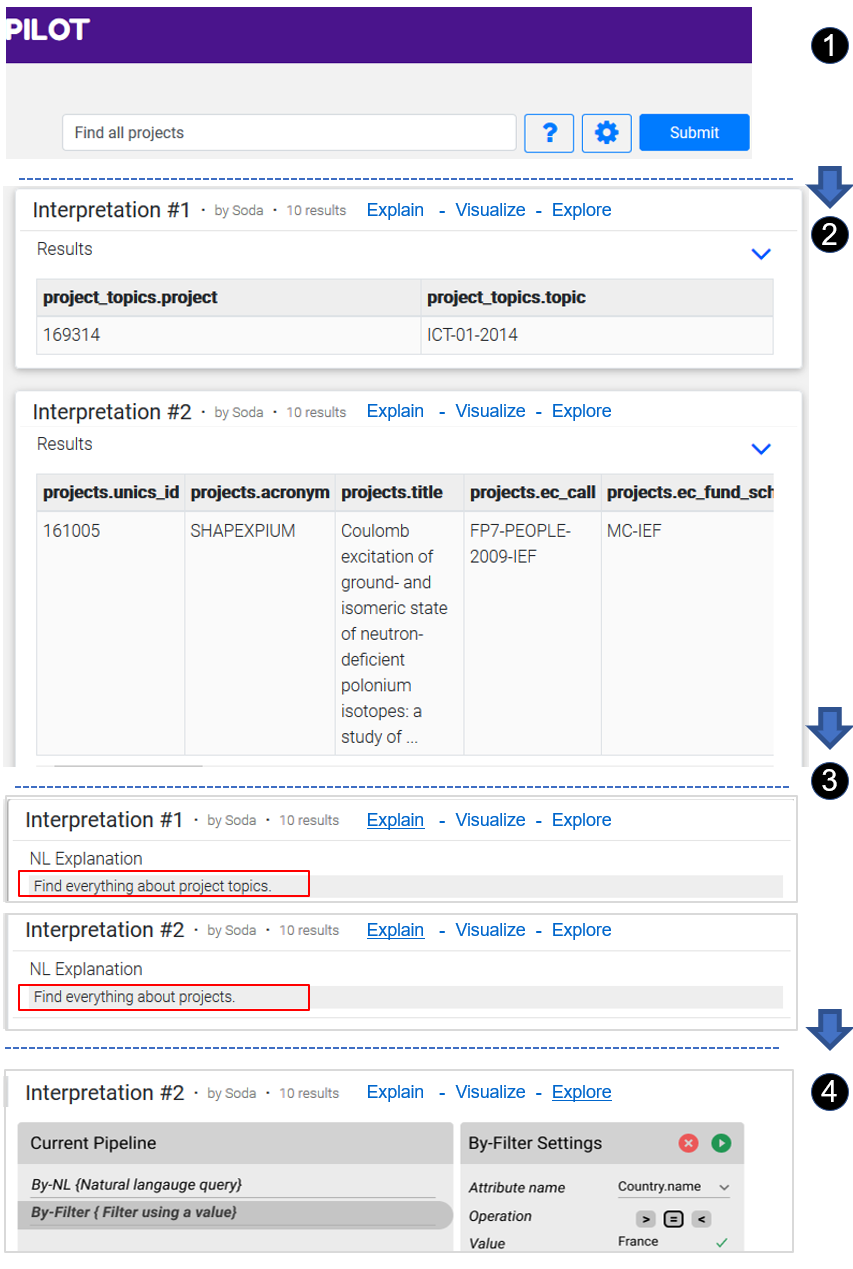
4. Open Research Challenges Beyond INODE
A full-fledged data exploration system should learn about data sources, learn about users and queries, and leverage this knowledge to facilitate and guide users. All these challenges constitute new opportunities for ML research to contribute to DM.
4.1. Learning about Data Sources
Traditionally SQL or SPARQL are used to query structured data stored in relational databases and graph databases, respectively. A manual time-consuming data integration process is usually required to integrate new data sources. Additionally, data integration techniques used for structured data are not directly applicable to unstructured data since they do not have a schema.
There are several data integration challenges that can be tackled with ML. The first one is to automate data integration (Golshan et al., 2017), in the spirit of existing work that improves entity matching using transformer architectures (Brunner and Stockinger, 2020). The second challenge is to automatically generate knowledge graphs, in the spirit of neural-network systems such as Snorkel (Ratner et al., 2017). Another powerful concept to automate knowledge graph construction is to combine user dialogs with graph construction (Nguyen et al., 2017). The idea is to augment the knowledge graphs by learning concepts that are commonly queried but do not exist in the graph. In summary, there has been a large amount of research on automatic knowledge base construction. However, the combination of knowledge base construction with natural language query processing has been largely untapped.
4.2. Understanding Users and Queries
Understanding user interests and expertise is a vital component for enabling intelligent data exploration. For instance, the general public interested in black holes has different expectations from an experienced astronomer with a vast knowledge of astrophysics. The challenge is to avoid overwhelming a novice user while providing interesting and relevant information to an expert user.
The system should constantly improve its behavior by learning and adapting to the user from task to task. Our operators are a great opportunity to learn and adapt to users, as they provide the ability to choose between utility and novelty, two dimensions that have not been explored together in the past. Additionally, they enable collecting user feedback at the level of individual operators and of a DEP. While ML methods for learning user profiles exist in the context of individual systems for web search or recommendations, they have not been studied before in the context of determining which operator caters for which user in the next step. A simple start is to use regression methods to determine the weight of utility and novelty when exploring data. Additionally, probabilistic language models (Cao et al., 2017) or matrix factorization-based approaches (Zhao et al., 2015) can be used to infer users’ topical interests, and latent factor models to mine user groups.
Traditional systems such as SODA, ATHENA, NALIR, or Logos (Blunschi et al., 2012; Saha et al., 2016; Li and Jagadish, 2014; Kokkalis et al., 2012) use pattern-based approach for NL to SQL or SQL to NL, or supervised ML (Kim et al., 2020; Brunner and Stockinger, 2021). A new opportunity here is to train a neural network for sequence-to-sequence prediction (Sutskever et al., 2014; Brunner and Stockinger, 2021) for translating from NL-to-SQL and vice versa. The key research challenge is how to use the feedback provided by users to disambiguate queries and feed the gained knowledge back into ML models to improve learning with semantic information for building ML models to tackle disambiguation and context modeling (Shekarpour et al., 2016).
This should allow to model and solve the two symmetrical translation problems at once. However, ML methods for query translation typically require large amounts of training data. Our vision is that a full-fledged exploration system should be able to leverage both pattern-based and ML-based approaches to provide the most relevant answers to the user.
4.3. Generating Data Exploration Pipelines
Understanding queries and users serves the ability to provide guidance in generating DEPs. This challenge can be approached in different ways depending on the user’s expertise and willingness to provide feedback. In a scenario where a DEP is given (see example in Section 2), the problem could be cast as finding the right parameters for each query in the DEP. In a scenario where the user is providing the next query, it could be seen as a query completion problem. In a scenario where the user does not write exploration queries and only provides feedback on results, it could be seen as the problem of learning the user’s DEP. All these cases result in partially-guided or fully-guided exploration.
Furthermore, since DEPs bring together several data access modalities, which may be initiated by the user (e.g. a user query) or by the system (recommendations or explanations), the system needs to learn how to use its options to help the user in meaningful and unobtrusive ways. While there has been work on each of these capabilities individually (e.g., recommendations or query explanations), these efforts only focus on small parts of the problem lacking a holistic understanding of the behavior and dynamics of a multi-aspect system. ML approaches and in particular, Reinforcement Learning (RL) and Active Learning (AL) can be leveraged.
Partial Guidance with AL. AL is claimed to be superior to faceted search when the goal is to help users formulate queries. Systems like AIDE (Dimitriadou et al., 2016) and REQUEST (Ge et al., 2016) assist users in constructing accurate exploratory queries, while at the same time minimizing the number of sample records presented to them for labeling. Both systems rely on training a decision tree classifier to build a model that classifies unlabeled records. A bigger challenge is to leverage AL in generating and refining queries that go beyond SQL predicates.
Full-Guidance with RL. RL and Deep RL are becoming (Milo and Somech, 2020) the methods of choice for creating exploration pipelines and for generating DEPs based on a simulated agent experience (El et al., 2020; Seleznova et al., 2020). In (El et al., 2020), a Deep RL architecture is used for generating notebooks that show diverse aspects of a data set in a coherent narrative. In (Seleznova et al., 2020), an end-to-end exploration policy is generated to find a set of users in a collection of groups. Both frameworks accept a wide class of exploration actions and do not need to gather exploration logs. An open question is the applicability of this framework to specific data sets and the transferability of learned policies across data sets.
4.4. Evaluating Data Exploration Pipelines
Evaluating data exploration requires a holistic approach that addresses performance, quality and user experience aspects (Eichmann et al., 2020). The iterative multi-step nature of DEPs makes evaluation particularly challenging since it is not simply a matter of summing up multiple local evaluations at each step. Regarding performance, the challenge lies in the design of logging mechanisms to export the performance of different steps in DEPs. Such logging must capture in fine details the time and memory usage each step takes so that they can be aggregated to assess a full DEP. The aggregation must be carefully designed to include user actions such as exploring multiple paths and backtracking. While some users prefer the shortest path to a goal, others may be more interested in exploring different paths.
Multiple evaluation questions arise: “How good are DEPs? How good are NL to SQL/SPARQL translations and vice versa? How good are the next-operator or next-data recommendations and explanations?” The novelty of our approach lies in the ability to jointly assess performance, quality and user experience for each use case.
We categorize INODE’s evaluation metrics into system metrics and human factors (Rahman et al., 2020). To answer above questions, certain key challenges need to be answered. The first challenge lies in extracting metrics from user interactions. We are addressing this by designing logging mechanisms to export various parameters. We use latency and memory usage for evaluating the system performance of a DEP. We also record the number of clicks, interaction time and user feedback. While some users prefer the shortest path to a goal, others may be more interested in exploring different paths.
Another challenge lies in the iterative multi-step nature of DEPs since it is not simply a matter of summing up multiple local evaluations at each step. An additional key challenge is human subject bias. To avoid such biases, our initial studies are designed in multiple stages such as pre-qualification of users, randomly assigning users to different treatment groups and finally feedback from users.
User acceptance of our system is strongly related to two key factors: accuracy - which reflects the closeness of exploration results to desired results, and controllability - which reflects the ability of our system to guide the user in the exploration (Eichmann et al., 2020). Accuracy is computed using standard methods such as precision and recall, and controllability is the inverse of the number of user-interactions. Our first endeavor is to deploy user studies that explore the relationship between accuracy and controllability. To do so, we will perform factorial design analysis and deploy questionnaires for exploration scenarios we are defining with our use case providers.
The key idea of using ML techniques here is to capture the dependence on users and data and learn different exploration profiles. A major challenge is to design pilot studies in a sound manner with direct observations via questionnaires and indirect ones (such as mouse tracking) to generate labeled datasets for learning. Using ML techniques, and in particular ensemble learning and multi-task learning, constitutes an unprecedented opportunity to adapt the evaluation to users and data.
5. Acknowledgements
This project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 863410.
References
- (1)
- Affolter et al. (2019) Katrin Affolter, Kurt Stockinger, and Abraham Bernstein. 2019. A comparative survey of recent natural language interfaces for databases. The VLDB Journal 28, 5 (2019), 793–819.
- Blunschi et al. (2012) Lukas Blunschi, Claudio Jossen, Donald Kossmann, Magdalini Mori, and Kurt Stockinger. 2012. Soda: Generating Sql for business users. Proceedings of the VLDB Endowment 5, 10 (2012), 932–943.
- Boehm et al. (2016) Matthias Boehm, Michael Dusenberry, Deron Eriksson, Alexandre V. Evfimievski, Faraz Makari Manshadi, Niketan Pansare, Berthold Reinwald, Frederick Reiss, Prithviraj Sen, Arvind Surve, and Shirish Tatikonda. 2016. SystemML: Declarative Machine Learning on Spark. Proc. VLDB Endow. 9, 13 (2016), 1425–1436.
- Brunner and Stockinger (2020) Ursin Brunner and Kurt Stockinger. 2020. Entity matching with transformer architectures-a step forward in data integration. In Int. Conference on Extending Database Technology, Copenhagen, 30 March-2 April 2020.
- Brunner and Stockinger (2021) Ursin Brunner and Kurt Stockinger. 2021. ValueNet: A Natural Language-to-SQL System that Learns from Database Information. International Conference on Data Engineering (ICDE) (2021).
- Calvanese et al. (2017) Diego Calvanese, Benjamin Cogrel, Sarah Komla-Ebri, Roman Kontchakov, Davide Lanti, Martin Rezk, Mariano Rodriguez-Muro, and Guohui Xiao. 2017. Ontop: Answering SPARQL Queries over Relational Databases. Semantic Web 8, 3 (2017), 471–487.
- Calvanese et al. (2019) Diego Calvanese, Davide Lanti, Ana Ozaki, Rafael Peñaloza, and Guohui Xiao. 2019. Enriching Ontology-based Data Access with Provenance. In Proc. of the 28th Int. Joint Conf. on Artificial Intelligence (IJCAI 2019). IJCAI Org., 1616–1623. https://doi.org/10.24963/ijcai.2019/224
- Cao et al. (2017) Cheng Cao, Hancheng Ge, Haokai Lu, Xia Hu, and James Caverlee. 2017. What Are You Known For?: Learning User Topical Profiles with Implicit and Explicit Footprints. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, August 7-11, 2017, Noriko Kando, Tetsuya Sakai, Hideo Joho, Hang Li, Arjen P. de Vries, and Ryen W. White (Eds.). ACM, 743–752.
- Cormode et al. (2010) Graham Cormode, Howard J. Karloff, and Anthony Wirth. 2010. Set cover algorithms for very large datasets. In Proceedings of the 19th ACM Conference on Information and Knowledge Management, CIKM 2010, Toronto, Ontario, Canada, October 26-30, 2010. 479–488.
- Deriu et al. (2020) Jan Deriu, Katsiaryna Mlynchyk, Philippe Schläpfer, Alvaro Rodrigo, Dirk Von Grünigen, Nicolas Kaiser, Kurt Stockinger, Eneko Agirre, and Mark Cieliebak. 2020. A Methodology for Creating Question Answering Corpora Using Inverse Data Annotation. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) (2020).
- Dimitriadou et al. (2016) Kyriaki Dimitriadou, Olga Papaemmanouil, and Yanlei Diao. 2016. AIDE: An Active Learning-Based Approach for Interactive Data Exploration. IEEE Trans. Knowl. Data Eng. 28, 11 (2016), 2842–2856.
- Eichmann et al. (2020) Philipp Eichmann, Emanuel Zgraggen, Carsten Binnig, and Tim Kraska. 2020. IDEBench: A Benchmark for Interactive Data Exploration. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020. 1555–1569.
- El et al. (2020) Ori Bar El, Tova Milo, and Amit Somech. 2020. Automatically Generating Data Exploration Sessions Using Deep Reinforcement Learning. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020. 1527–1537.
- Ge et al. (2016) Xiaoyu Ge, Yanbing Xue, Zhipeng Luo, Mohamed A. Sharaf, and Panos K. Chrysanthis. 2016. REQUEST: A scalable framework for interactive construction of exploratory queries. In 2016 IEEE International Conference on Big Data, BigData 2016, Washington DC, USA, December 5-8, 2016. 646–655.
- Glenis et al. (2020) Apostolis Glenis, Yannis Stavrakas, and Georgia Koutrika. 2020. PyExplore: Clustering-based SQL query recommendations. In under submission.
- Golshan et al. (2017) Behzad Golshan, Alon Halevy, George Mihaila, and Wang-Chiew Tan. 2017. Data integration: After the teenage years. In Proceedings of the 36th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. 101–106.
- Guilly et al. (2018) Marie Le Guilly, Jean-Marc Petit, and Vasile-Marian Scuturici. 2018. SQL Query Completion for Data Exploration. CoRR abs/1802.02872 (2018). arXiv:1802.02872 http://arxiv.org/abs/1802.02872
- Howe et al. (2011) Bill Howe, Garrett Cole, Nodira Khoussainova, and Leilani Battle. 2011. Automatic example queries for ad hoc databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2011, Athens, Greece, June 12-16, 2011, Timos K. Sellis, Renée J. Miller, Anastasios Kementsietsidis, and Yannis Velegrakis (Eds.). ACM, 1319–1322.
- International Organization for Standardization (2019) International Organization for Standardization. 2019. ISO 9241-210:2019 - Ergonomics of Human-System Interaction — Part 210: Human-Centred Design for Interactive Systems. , 33 pages. https://www.iso.org/standard/77520.html
- John et al. (2017) Rogers Jeffrey Leo John, Navneet Potti, and Jignesh M. Patel. 2017. Ava: From Data to Insights Through Conversations. In CIDR 2017, 8th Biennial Conference on Innovative Data Systems Research, Chaminade, CA, USA, January 8-11, 2017.
- Kim et al. (2020) Hyeonji Kim, Byeong-Hoon So, Wook-Shin Han, and Hongrae Lee. 2020. Natural language to SQL: Where are we today? Proc. VLDB Endowment 13, 10 (2020), 1737–1750. http://www.vldb.org/pvldb/vol13/p1737-kim.pdf
- Kokkalis et al. (2012) Andreas Kokkalis, Panagiotis Vagenas, Alexandros Zervakis, Alkis Simitsis, Georgia Koutrika, and Yannis E. Ioannidis. 2012. Logos: a system for translating queries into narratives. In Proceedings of the ACM SIGMOD International Conference on Management of Data, SIGMOD 2012, Scottsdale, AZ, USA, May 20-24, 2012. ACM, 673–676.
- Kraska et al. (2018) Tim Kraska, Alex Beutel, Ed H. Chi, Jeffrey Dean, and Neoklis Polyzotis. 2018. The Case for Learned Index Structures. In Proceedings of the 2018 International Conference on Management of Data, SIGMOD Conference 2018, Houston, TX, USA, June 10-15, 2018. 489–504.
- Kristo et al. (2020) Ani Kristo, Kapil Vaidya, Ugur Çetintemel, Sanchit Misra, and Tim Kraska. 2020. The Case for a Learned Sorting Algorithm. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference, June 14-19, 2020.
- Li and Jagadish (2014) Fei Li and H. V. Jagadish. 2014. Constructing an Interactive Natural Language Interface for Relational Databases. Proc. VLDB Endow. 8, 1 (Sept. 2014), 73–84.
- Li and Ying (2003) Sanjiang Li and Mingsheng Ying. 2003. Region Connection Calculus: Its models and composition table. Artificial Intelligence 145, 1 (2003), 121 – 146.
- Liu et al. (2019) Jianjun Liu, Zainab Zolaktaf, Rachel Pottinger, and Mostafa Milani. 2019. Improvement of SQL Recommendation on Scientific Database. In Proceedings of the 31st International Conference on Scientific and Statistical Database Management, SSDBM 2019, Santa Cruz, CA, USA, July 23-25, 2019, Carlos Maltzahn and Tanu Malik (Eds.). ACM, 206–209. https://doi.org/10.1145/3335783.3335800
- Manning et al. ([n.d.]) Christopher D Manning, Prabhakar Raghavan, and Hinrich Schütze. [n.d.]. Introduction to Information Retrieval. Cambridge University Press.
- May et al. (2012) Thorsten May, Martin Steiger, James Davey, and Jörn Kohlhammer. 2012. Using signposts for navigation in large graphs. In Computer Graphics Forum, Vol. 31. Wiley Online Library, 985–994.
- Milo and Somech (2020) Tova Milo and Amit Somech. 2020. Automating Exploratory Data Analysis via Machine Learning: An Overview. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020. 2617–2622.
- Nguyen et al. (2017) Dat Ba Nguyen, Abdalghani Abujabal, Khanh Tran, Martin Theobald, and Gerhard Weikum. 2017. Query-driven on-the-fly knowledge base construction. Proceedings of the VLDB Endowment 11, 1 (2017), 66–79.
- Papadopoulos et al. (2020) Dimitris Papadopoulos, Nikolaos Papadakis, and Antonis Litke. 2020. A Methodology for Open Information Extraction and Representation from Large Scientific Corpora: The CORD-19 Data Exploration Use Case. Applied Sciences 10, 16 (2020). https://www.mdpi.com/2076-3417/10/16/5630
- Rahman et al. (2020) Protiva Rahman, Lilong Jiang, and Arnab Nandi. 2020. Evaluating interactive data systems. VLDB J. 29, 1 (2020), 119–146.
- Ratner et al. (2017) Alexander J Ratner, Stephen H Bach, Henry R Ehrenberg, and Chris Ré. 2017. Snorkel: Fast training set generation for information extraction. In Proceedings of the 2017 ACM international conference on management of data. 1683–1686.
- Ruotsalo et al. ([n.d.]) Tuukka Ruotsalo, Kumaripaba Athukorala, Dorota G\ lowacka, Ksenia Konyushkova, Antti Oulasvirta, Samuli Kaipiainen, Samuel Kaski, and Giulio Jacucci. [n.d.]. Supporting Exploratory Search Tasks with Interactive User Modeling. In Proceedings of the 76th ASIS&T Annual Meeting: Beyond the Cloud: Rethinking Information Boundaries (Silver Springs, MD, USA, 2013) (ASIST ’13). American Society for Information Science, 39:1–39:10. http://dl.acm.org/citation.cfm?id=2655780.2655819
- Saha et al. (2016) Diptikalyan Saha, Avrilia Floratou, Karthik Sankaranarayanan, Umar Farooq Minhas, Ashish R Mittal, and Fatma Özcan. 2016. Athena: An ontology-driven system for natural language querying over relational data stores. Proceedings of the VLDB Endowment 9, 12 (2016), 1209–1220.
- Seleznova et al. (2020) Mariia Seleznova, Behrooz Omidvar-Tehrani, Sihem Amer-Yahia, and Eric Simon. 2020. Guided Exploration of User Groups. Proc. VLDB Endow. 13, 9 (2020), 1469–1482.
- Senellart et al. (2018) Pierre Senellart, Louis Jachiet, Silviu Maniu, and Yann Ramusat. 2018. ProvSQL: Provenance and Probability Management in PostgreSQL. Proc. of the VLDB Endowment 11, 12 (2018), 2034–2037.
- Sequeda and Miranker (2015) Juan F. Sequeda and Daniel P. Miranker. 2015. Ultrawrap Mapper: A Semi-Automatic Relational Database to RDF (RDB2RDF) Mapping Tool.. In Proc. of the 14th Int. Semantic Web Conf., Posters & Demonstrations Track (ISWC) (CEUR Workshop Proceedings, http://ceur-ws.org/), Vol. 1486.
- Shekarpour et al. (2016) Saeedeh Shekarpour, Kemele M Endris, Ashwini Jaya Kumar, Denis Lukovnikov, Kuldeep Singh, Harsh Thakkar, and Christoph Lange. 2016. Question answering on linked data: Challenges and future directions. In Proceedings of the 25th International Conference Companion on World Wide Web. 693–698.
- Sima et al. (2019) Ana Claudia Sima, Tarcisio Mendes de Farias, Erich Zbinden, Maria Anisimova, Manuel Gil, Heinz Stockinger, Kurt Stockinger, Marc Robinson-Rechavi, and Christophe Dessimoz. 2019. Enabling semantic queries across federated bioinformatics databases. Database 2019 (2019).
- Sparks et al. (2017) Evan R. Sparks, Shivaram Venkataraman, Tomer Kaftan, Michael J. Franklin, and Benjamin Recht. 2017. KeystoneML: Optimizing Pipelines for Large-Scale Advanced Analytics. In 33rd IEEE International Conference on Data Engineering, ICDE 2017, San Diego, CA, USA, April 19-22, 2017. 535–546.
- Stahnke et al. ([n.d.]) J. Stahnke, M. Dörk, B. Müller, and A. Thom. [n.d.]. Probing Projections: Interaction Techniques for Interpreting Arrangements and Errors of Dimensionality Reductions. 22, 1 ([n. d.]), 629–638. https://doi.org/10.1109/TVCG.2015.2467717
- Steiger et al. ([n.d.]) Martin Steiger, Jürgen Bernard, Sebastian Mittelstädt, Hendrik Lücke-Tieke, Daniel Keim, Thorsten May, and Jörn Kohlhammer. [n.d.]. Visual Analysis of Time-Series Similarities for Anomaly Detection in Sensor Networks. 33, 3 ([n. d.]), 401–410. https://doi.org/10.1111/cgf.12396
- Stoica (2020) Ion Stoica. 2020. Systems and ML: When the Sum is Greater than Its Parts. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference, June 14-19, 2020.
- Sutskever et al. (2014) Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014. Sequence to sequence learning with neural networks. In Advances in neural information processing systems. 3104–3112.
- Xiao et al. (2018a) Guohui Xiao, Diego Calvanese, Roman Kontchakov, Domenico Lembo, Antonella Poggi, Riccardo Rosati, and Michael Zakharyaschev. 2018a. Ontology-Based Data Access: A Survey. In Proc. of the 27th Int. Joint Conf. on Artificial Intelligence (IJCAI). IJCAI Org., 5511–5519. https://doi.org/10.24963/ijcai.2018/777
- Xiao et al. (2018b) Guohui Xiao, Roman Kontchakov, Benjamin Cogrel, Diego Calvanese, and Elena Botoeva. 2018b. Efficient Handling of SPARQL Optional for OBDA. In Proc. of the 17th Int. Semantic Web Conf. (ISWC) (Lecture Notes in Computer Science). Springer, 354–373.
- Xiao et al. (2020) Guohui Xiao, Davide Lanti, Roman Kontchakov, Sarah Komla-Ebri, Elem Güzel-Kalayci, Linfang Ding, Julien Corman, Benjamin Cogrel, Diego Calvanese, and Elena Botoeva. 2020. The Virtual Knowledge Graph System Ontop. In Proc. of the 19th Int. Semantic Web Conf. (ISWC 2020), Vol. 12507. 259–277.
- Zhao et al. (2015) Zhe Zhao, Zhiyuan Cheng, Lichan Hong, and Ed Huai-hsin Chi. 2015. Improving User Topic Interest Profiles by Behavior Factorization. In Proceedings of the 24th International Conference on World Wide Web, WWW 2015, Florence, Italy, May 18-22, 2015, Aldo Gangemi, Stefano Leonardi, and Alessandro Panconesi (Eds.). ACM, 1406–1416.