Initialisation of Autonomous Aircraft Visual Inspection Systems via CNN-Based Camera Pose Estimation
Abstract
General Visual Inspection is a manual inspection process regularly used to detect and localise obvious damage on the exterior of commercial aircraft. There has been increasing demand to perform this process at the boarding gate to minimize the downtime of the aircraft and automating this process is desired to reduce the reliance on human labour. This automation typically requires the first step of estimating a camera’s pose with respect to the aircraft for initialisation. However, localisation methods often require infrastructure, which can be very challenging when performed in uncontrolled outdoor environments and within the limited turnover time (approximately 2 hours) on an airport tarmac. In addition, access to commercial aircraft can be very restricted, causing development and testing of solutions to be a challenge. Hence, this paper proposes an on-site infrastructure-less initialisation method, by using the same pan-tilt-zoom camera used for the inspection task to estimate its own pose. This is achieved using a Deep Convolutional Neural Network trained with only synthetic images to regress the camera’s pose. We apply domain randomisation when generating our dataset for training our network and improve prediction accuracy by introducing a new component to an existing loss function that leverages on known aircraft geometry to relate position and orientation. Experiments are conducted and we have successfully regressed camera poses with a median error of 0.22 m and 0.73°.
Index Terms:
LocalisationI Introduction
Aircraft must undergo regular inspection such as General Visual Inspection (GVI), which is a widely used technique. One of GVI’s processes involves visually examining the aircraft’s exterior for obvious damage or abnormalities and provides a means for early detection of typical airframe defects [1]. This is currently performed manually by well-trained personnel and is labour intensive as well as having high error rates [1, 2]. Several studies have explored using robotic systems such as drones and mobile robots [1, 2, 3], as well as deep learning using only visual images [4] to automate this labourious inspection task. However, these works focus on detecting or classifying defects within images, rather than localising defects with respect to a known reference point on the aircraft.
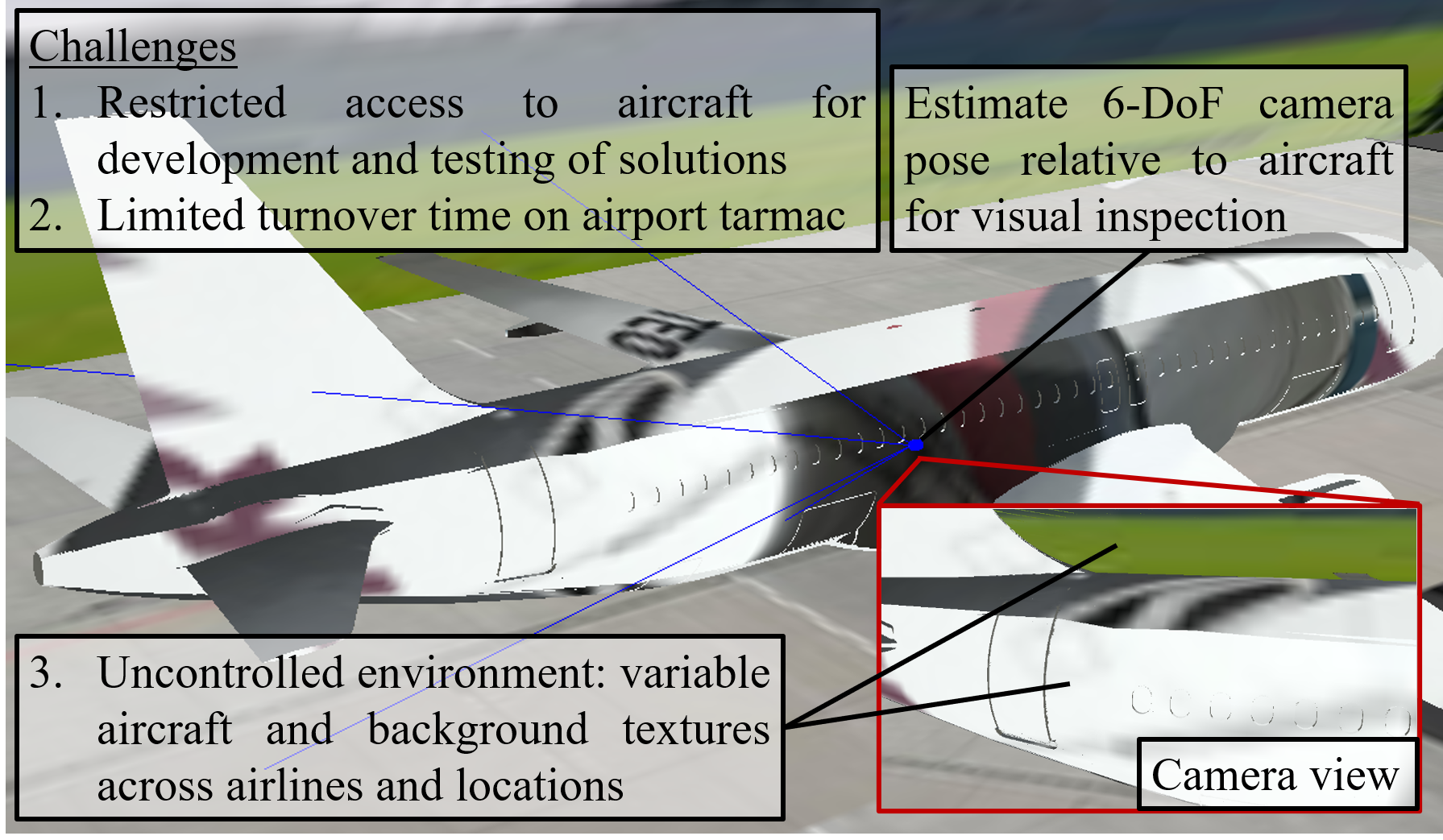
Pan-Tilt-Zoom (PTZ) cameras are commonly used in inspection systems and a study in 2015 has explored the use of processing images taken from a PTZ camera on a mobile robot moving autonomously to pre-defined locations for aircraft exterior inspection [5]. However, it is only designed to inspect specific items (such as an oxygen bay handle or an air-inlet vent) of an aircraft and does not achieve precise localisation. Such solutions are also usually designed to be implemented in a hangar during maintenance, which provides a controlled environment to set up infrastructure for establishing checkpoints around the aircraft. Hence, these solutions are not suitable to be performed outdoors on the airport tarmac and with limited turnover time (approximately 2 hours) between flights.
In order to localise a detected defect, location information for each image (such as the coordinates of where each image centre coincides with the aircraft) has to be known and it is required to first determine the camera’s pose relative to the aircraft. Visual localisation methods such as Simultaneous Localisation and Mapping (SLAM) [6] and visual odometry [7] are capable of outdoor localisation, but they also require an initial pose estimation [8] to work. In addition, SLAM typically requires the payload to move around the aircraft for mapping, which is not suitable for the airport tarmac. Moreover, the highly restricted access to aircraft makes the development of new solutions challenging.
The problem of estimating a camera’s initial pose can be referred to as Camera Pose Estimation (CPE) and the recent increase in the use of Deep Convolutional Neural Networks (DCNNs) for monocular CPE has shown its potential to out-perform classical 3D structure-based methods in several aspects. The benefits of using DCNNs include shorter inference times, smaller memory [9], and robustness to uncontrolled environments [10]. This shows the potential viability for the application of DCNNs for CPE as an infrastructure-less solution to outdoor aircraft inspection on airport tarmacs between flights, due to the time constraints and variations in lighting and background.
In this paper we propose an infrastructure-less method of estimating the pose of a PTZ camera with respect to an aircraft without the need for prior access to the real aircraft. This is achieved using a DCNN fine-tuned from pre-trained weights using only synthetic images obtained from a virtual camera capturing images of a 3D model of an aircraft. The PTZ camera is first roughly positioned and oriented within a reasonable boundary and faced perpendicular to the aircraft. The camera is then oriented to a fixed pan-tilt angle and an image is captured as input into a DCNN to regress a pose. We also leverage on known geometric information of the aircraft to modify an existing loss function and improve pose estimation accuracy. Our main contributions are as follows:
-
•
The proposed method does not require infrastructure or prior access to the real aircraft during development. This is achieved using a pose regressor network trained on only synthetic images of a 3D aircraft model and a background applied with domain randomisation.
-
•
We improved the network’s performance by introducing a new component to the network’s loss function. This additional loss component leverages on known geometry of an aircraft to provide a geometric relationship between the predicted position and orientation of the camera.
II Related Work
CPE can be described as taking an input image and output an estimate of the pose – position and orientation – of the camera [9]. In most cases, the pose is obtained with respect to a predefined global reference. PoseNet [11] and other similar deep architectures that predicts a camera pose [12, 13, 14, 15, 16, 17, 18] share a common process, where images from a database are pre-processed before being used as input into a DCNN architecture for training. This training is conducted with the aim of minimising the error between the predicted pose and ground truth pose labels, represented by a loss function.
PoseNet [11] is the pioneer to introduce the use of a DCNN – based on a modified GoogLeNet [19] – to directly regress a camera pose, and many improved methods based on deep learning architectures have since been proposed [9]. These deep pose estimation methods have been fine-tuned and tested on publicly available indoor and outdoor datasets such as 7Scenes [20] and Cambridge Landmarks [11]. These datasets contain thousands of images, generated via sampling of videos recorded using hand-held camera devices such as a KinectFusion system [20] or a mobile phone before using software to automate the retrieval of camera poses of corresponding images [11]. However, fine-tuning models with these datasets may not accurately represent their effectiveness in CPE for our application due to the difficulties in obtaining a real dataset to train with in the first place, as well as the need to accommodate scene changes such as different appearance of the same aircraft model and its background.
Several researchers [21, 22, 23, 24, 25, 26] have explored fine-tuning DCNNs without the need for real images by using synthetic scenes for camera and object pose estimation tasks. Among these, [24] proposed a learning method for a drone to autonomously navigate an indoor environment without collision, by training a network through reinforcement learning using only 3D CAD models. Only RGB images rendered from a manually designed 3D indoor environment are used to train the CNN which outputs velocity commands. The authors apply random textures, object positions and lighting to create diverse scenes for their model to generalise and have managed to achieve autonomous drone navigation and obstacle avoidance in some indoor scenarios. While this explores the ability of a network trained using synthetic images to generalise to the real world, their objective was to avoid collision as opposed to CPE.
Recently, Acharya et al. [26] have also proposed a solution for indoor CPE by fine-tuning PoseNet [11] using synthetic images rendered from a low-detail 3D indoor environment, modelled with reference to a Building Information Model (BIM). To avoid generating images for all possible positions and orientations within the 3D environment, the authors defined a boundary to the ground truths of the fine-tuning dataset. Images are captured by a virtual camera repositioned at 0.05m intervals along a pre-defined trajectory length of about 30m within the 3D building environment and kept within a height range of 1.5-1.8 m with a tilt of °. This work explores different methods of rendering, from cartoon-like to photo-realistic and textured to rendering only edges within each scene. They are able to estimate the camera’s position from real images with an accuracy of about 2 m. However, these existing methods have only been tested in known, controlled indoor environments with substantial changes in scenes and viewpoints as the camera relocates within the environment. This is as opposed to differentiating the camera pose between two images that are captured with slight changes in viewpoint in the context of aircraft GVI. Moreover, the reported accuracy in these works are insufficient for our application.
In a similar approach, Tobin et al. [25] have investigated the use of domain randomisation to bridge the gap between simulation and reality. They argue that models fine-tuned with only synthetic scenes can generalise to real scenes if the scenes are diverse enough. The authors generate their dataset by uniformly randomising many aspects of their domain, including size, shape, position and colour of objects in each scene, and successfully taught a robotic arm to pick objects within a real, crowded indoor environment using only “low-fidelity” rendered images. Following this, others [27, 28, 29] have also applied domain randomisation for deep pose estimation tasks without training with real data. Despite being robust to object distractors, these models only apply to object pose estimation and often have other unchanging major objects such as a table where objects are placed on or a robot gripper which provides useful information of each object’s pose relative to these major objects in the scene. In our work, we focus on CPE with respect to an aircraft without any other known objects in the scene.
In summary, it can be very challenging to develop deep solutions for CPE with respect to an aircraft on an airport tarmac due to the limited access to real aircraft and solutions need to be robust to large variations in environment and aircraft texture across airlines. We propose to address this challenge by removing the need to obtain real images for training and use only synthetic images of the aircraft’s 3D model in scenes varied using domain randomization. Interestingly, recent works [9, 30] also suggest that deep pose regressors are out-performed by structure-based methods due to the lack of information on the scene’s geometry. In this paper, we leverage on known geometry of an aircraft’s surface to explore a geometric relationship between the camera’s position and orientation within the network’s loss function and improve the pose estimation accuracy.

III METHODOLOGY
We propose a setup with realistic constraints and assumptions for how a PTZ camera of known specifications can be deployed next to an aircraft for the purpose of inspecting the upper surface of the aircraft’s fuselage. Based on this setup, we create a simple virtual 3D environment and capture images using a virtual camera while applying domain randomisation for our synthetic dataset. We use this synthetic dataset to train a deep network that can regress a camera’s pose from an input image. We base our network on an existing method, PoseNet with learnable weights [18] (we refer to as PoseNet+), in our approach and modify its loss function by introducing an additional loss component that provides a geometric relationship between the camera’s position and orientation. We summarise our deep learning approach in Fig. 2.
III-A Proposed Setup with PTZ Camera
We use only the back half of an Airbus A320 (A320 in short) for illustration purpose. The following requirements and deployment steps are proposed:


-
•
The PTZ camera’s specifications are known and the full Field of View (FOV) is used for initialisation.
-
•
The PTZ camera can be positioned within a reasonable area of 4 m by 4 m and raised to a height of 6.25 m to 7.25 m from the ground via equipment such as an electronic mast or a boom lift and easily approximated with the use of accessible equipment such as a range finder.
-
•
We assume that the PTZ camera’s base can be easily levelled (i.e. no roll and pitch relative to the ground) with the use of a gimbal or level gauge, and oriented about the z-axis to perpendicularly face the aircraft (within ° yaw error). This reduces the problem to 4 Degrees of Freedom (DoF) - position and yaw.
-
•
The camera is then panned 20° towards the aircraft’s tail and tilted 18° towards the ground with commands sent via software and an image is captured for initialisation.
Fig. 3 shows the proposed permissible space where the PTZ camera can be set up, while Fig. 4 shows the features (windows and pylons) of an A320 to use as visual guides for the boundaries of this space. The yaw error of ° due to manual orientation towards the aircraft suggests that the camera is oriented to between +10° to +30° about the z-axis.

III-B Virtual Environment and Synthetic Dataset
We have obtained the 3D model of an A320 from a GrabCAD contribution [31]. Using SolidWorks [32], minor modifications are made to match general features and overall dimensions of a real A320, based on details obtained from an A320’s Structural Repair Manual (SRM).
Our virtual setup is shown in Fig. 5. To create this 3D environment, we place our 3D model into a scene in robot simulator CoppeliaSim [33]. A large wall is added on one side of the aircraft model as background. A virtual camera is placed beside the aircraft and its FOV is set to match the real PTZ camera (61.6° horizontal FOV at 16:9 aspect ratio).
We apply domain randomisation [25] when generating our synthetic dataset as it has been demonstrated to be capable of generalising to real-world data, given sufficient simulated variability. We use a free stock image of a randomly scattered puzzle to apply as texture for the ground, aircraft model, and background. We randomise the following aspects when capturing each image for our dataset:
-
•
The PTZ camera’s position within the proposed 4 m x 4 m x 1 m boundary;
-
•
The PTZ camera’s pan between +10° to +30°, rotated about the z-axis;
-
•
The PTZ camera’s tilt between -17.5° to -18.5°. (slight tolerance of ° from the proposed 18° tilt;
-
•
Colour – RGB values of both ambient and specular components for the texture of every object; and
-
•
The position, orientation, as well as horizontal and vertical scaling factors of textures applied onto each surface.
A total of 4700 synthetic images are generated, of which 4000 are used for training and 700 for validation.
III-C Base Deep Learning Architecture
PoseNet [11] was introduced in 2015 and is first to use a DCNN to directly regress for CPE. Its model is based on modifying GoogLeNet’s (Inception v1) [19] architecture, which was then considered as the state-of-the-art DCNN for image classification. PoseNet made modifications to the model, including rescaling each input image and performing a centre crop to match GoogLeNet’s 224x224 pixel input and adding a fully connected layer while replacing all softmax layers (used for classification) with regression layers that output both position (x, y, z) and orientation vectors (quaternions – w, p, q, r). PoseNet also redefine its loss function as:
| (1) |
where and , with and representing the predicted position and orientation vectors respectively, while and represent ground truth pose. In practice, it is observed that is close enough to and the normalization of is removed from the loss function during implementation. is a hyperparameter that functions as a factor to scale the orientation error in attempt to keep the position and orientation errors similar.
However, substantial effort is required when tuning to obtain a reasonable balance between the orientation and position losses. To address this, PoseNet+ [18] proposes a loss function that learns a weighting between the position and orientation components. The loss function is formulated using the concept of homoscedastic uncertainty - a measure of uncertainty of the task and is independent of input data [34] - and is defined as:
| (2) |
where and represent the homoscedastic uncertainties and are optimised with respect to the loss function through back propagation. While the variance is learnt, the logarithmic regularisation term prevents the network from learning an infinite variance to achieve zero loss. During implementation, is learnt as it avoids a potential division by zero and the function becomes:
| (3) |
We base our method on loss function (3) as it has been proven to substantially outperform PoseNet’s original loss function (1). We apply this method onto a more recent deep architecture, Xception [35] (improved from Inception v3), as it results in substantially better performance than GoogLeNet (Inception v1). We made slight modifications to the Xception network in a similar fashion to PoseNet, by replacing the softmax layer with a regression layer with 7 pose outputs. We resize every input image to match the network’s 299 x 299 pixel input size without a centre crop as we found this to improve performance and attribute this to the increase in features and other spatial information that may be present in the whole image despite the distortion from resizing.
III-D Image Centre Scene Coordinate (ICSC) Loss
We propose to modify loss function (3) by introducing an additional component that uses the scene coordinate of each image’s centre pixel. This is obtained by finding the point of intersection between the equation describing the camera’s viewpoint (as a function of and ) and the aircraft’s surface. With our proposed setup, we find this point of intersection is always on the upper half of the fuselage and propose to model the aircraft’s surface as the equation of a cylinder. With as the cartesian coordinates of any point on the cylinder’s surface, the equation of the surface is given by:
| (4) |
Where , (any value along the cylinder’s length) and are the coordinates of a point on the cylinder’s surface, is the displacement of the cylinder’s cross-sectional centre from the scene’s origin, and is the aircraft’s fuselage radius. The line representing the camera’s viewpoint is formulated as:
| (5) |
Where represents the camera’s viewpoint, is the camera’s position, is obtained by rotating the camera’s default direction vector by quaternion , and is a variable that determines the position of any point along line .
For every pair of camera position and orientation, we use equations (4) and (5) to solve for where to determine the point of intersection between line and the surface of the cylinder. Since a line may intersect the surface of a cylinder at up to two points, only the point nearest to the camera’s position, , is kept. Fig. 6 illustrates how the aircraft fuselage’s surface is modelled as the surface of a cylinder, as well as how and can be related by . We combine our proposed loss component with (2) to result in:

| (6) |
Where , and represents the difference between the true and predicted point of intersection coordinates. The following function is then implemented:
| (7) |
Where , and are learnt and we arbitrarily initialise all of them to zero. We refer to our proposed additional loss component as the Image Centre Scene Coordinate (ICSC) loss and the network with loss function (7) as ICSC-PoseNet.
IV Experiments and Results
IV-A Obtaining Real Images with Ground Truths
To evaluate our approach, we have requested and obtained special access to an A320 in an outdoor area to obtain images and pose-related data for our real test dataset. We build a prototype consisting of a Panasonic AW-HE40H PTZ Camera and a Velodyne VLP-16 3D LiDAR secured onto a rig as shown in Fig. 7. The 3D LiDAR is used to obtain ground truth and is not used in the proposed methodology. While we can analyse the point cloud from the 3D LiDAR to obtain the camera pose, the process is very troublesome and time consuming. Multiple adjustments are required to ensure the desired features are present within the point cloud to obtain each acceptable pair of image and point cloud.

The prototype is powered by a portable power bank and programmatically accessed from a laptop. The prototype is brought within the proposed boundary atop a boom lift’s platform. Images for this setup are not shown due as they are deemed sensitive by the venue and airline. A total of 28 images with ground truths are obtained as our real dataset for testing. For comparison of the coverage, our training images are generated within +5 m to +9 m, -9.25 m to -5.25 m, +6.25 m to +7.25 m, and +10° to +30° in the x, y, z and pan respectively, while the ground truth of real test images spans +7 m to +8.5 m, -9.2 m to -6.3 m, +6.9 m to +7.2 m, and +11° to +26° in the x, y, z and pan respectively.



IV-B Implementation and Results
Our network is implemented using TensorFlow, supported by a NVIDA RTX Turbo 2080Ti GPU. For clarity, we refer to ‘training’ as fine-tuning our network pre-trained on ImageNet [36] to leverage on transfer learning. We also normalise all input images such that all pixel intensities range from -1 to 1. We optimise our network with ADAM [37] using default parameters at a learn rate of and a batch size of 25.
We train two networks with Xception [35] as their base architecture, one as PoseNet+ with the learnable weighting loss function (3) as the baseline and the other as ICSC-PoseNet with the modified loss function (7). The networks are evaluated by testing on the 28 real images with ground truths. We train each network for 200 epochs as we observe that overfitting tends to occur beyond that. Table I provides the best results as well as a comparison with PoseNet+. Four of the 28 real images that return the largest error when predicted by both networks are shown in Fig. 8, along with their prediction results overlaid in red on the real images.
V Discussion
V-A Deploying a PTZ Camera Within Proposed Boundaries
The spatial coverage of the real images obtained with their ground truths demonstrates that the proposed method of using aircraft features (windows and pylons) as landmarks to guide the positioning and orienting of the PTZ camera within our boundary is feasible. This is an important step since the use of DCNN for CPE performs best within a pre-defined range of predictions (for both position and orientation) that should be included in the training dataset. This limitation has been discussed in literature, where deep pose estimators still underperform in the task of generalising to unseen scenes [9] and perform more similar to image retrieval methods [30]. We show that we can manually position our PTZ camera within the same proposed boundary and pan range used to generate our synthetic training images.
| Loss | Error (lowest error in bold) | ||
|---|---|---|---|
| Function | Median | MAEa | RMSEb |
| PoseNet+[18] (Learnable Weighting) | 0.292m, 1.252° | 0.303m, 1.278° | 0.312m, 1.437° |
| ICSC-PoseNet (this work) | 0.217m, 0.731° | 0.226m, 0.815° | 0.237m, 0.882° |
| aMean Absolute Error, bRoot-Mean-Square Error. | |||
V-B Camera Pose Estimation Without Training on Real Images
Our results demonstrate the network’s ability to estimate a PTZ camera’s pose within a region next to an Airbus A320 without training on any real images. This is achieved without any knowledge of the scene other than the aircraft model, and without any infrastructure. Using single images as input into our network, we obtain a median prediction error of 0.217m and 0.731° (Table I) which is sufficient for initialisation given the scale of the aircraft. For comparison, the window-to-window distance of an A320 is about 0.53m. In Fig. 8, prediction results overlaid in red over four real images show the network’s ability to extract relevant aircraft features from the randomised textures in the synthetic training dataset and match their scale and position with the real images to regress a pose. We observe a high degree of overlap even in the four samples with the largest prediction error (up to 0.49m and 3.06°) across all predictions by both networks.
V-C Comparison of Loss Functions
We quantitatively compare results for pose prediction in Table I and find that training the network with our additional ICSC loss component in ICSC-PoseNet substantially improves pose prediction accuracy. Lower error is observed across Median Error, Mean Absolute Error (MAE) and Root-Mean-Square Error (RMSE), in both position and orientation predictions by ICSC-PoseNet as compared to PoseNet+. Qualitatively, we also observe in Fig. 8 a slight improvement in the region of overlap of the aircraft in the images from predictions by our network (ICSC-PoseNet) as compared to the predictions by PoseNet+. While the improvement seems minor visually, it can substantially impact the accuracy of defect localisation on the aircraft when the camera is zoomed in during inspection. We conclude that the addition of a component in the loss function that geometrically relates the position and orientation predictions during training can improve camera pose estimation accuracy in our application.
VI Conclusion
We have demonstrated that camera pose estimation with respect to an aircraft can be achieved without any infrastructure or prior access to a real aircraft. This is achieved through the proposed ICSC-PoseNet, which successfully reduced pose estimation error by leveraging on geometric information of an aircraft to introduce an additional component to the loss function of an existing network. In the future, we plan to adapt the method to perform sensor fusion with other sensor data such as from a LiDAR to improve performance.
Acknowledgment
This research is supported by ST Engineering Aerospace as part of a project with the Civil Aviation Authority of Singapore to develop a GVI system for detecting damage to the exterior of aircraft due to lightning strikes.
References
- [1] P. Umberto and P. Salvatore, “Preliminary design of an unmanned aircraft system for aircraft general visual inspection,” Electronics, vol. 7, no. 12, p. 435, 2018.
- [2] J. Gu, C. Wang, and X. Wu, “Self-adjusted adsorption strategy for an aircraft skin inspection robot,” Journal of Mechanical Science and Technology, vol. 32, no. 6, pp. 2867–2875, 2018.
- [3] J. Willsher Stephen, “Aircraft inspection - is there a role for robots?” Industrial Robot: An International Journal, vol. 25, no. 6, 1998.
- [4] T. Malekzadeh, M. Abdollahzadeh, H. Nejati, and N.-M. Cheung, “Aircraft fuselage defect detection using deep neural networks,” 2017 IEEE GlobalSIP, 2017.
- [5] I. Jovančević, S. Larnier, J.-J. Orteu, and T. Sentenac, “Automated exterior inspection of an aircraft with a pan-tilt-zoom camera mounted on a mobile robot,” Journal of Electronic Imaging, vol. 24, no. 6, p. 061110, 2015.
- [6] T. Takafumi, U. Hideaki, and I. Sei, “Visual slam algorithms: a survey from 2010 to 2016,” IPSJ Transactions on Computer Vision and Applications, vol. 9, no. 1, pp. 1–11, 2017.
- [7] G. Pascoe, W. Maddern, A. D. Stewart, and P. Newman, “Farlap: Fast robust localisation using appearance priors,” in 2015 IEEE International Conference on Robotics and Automation (ICRA), 2015, pp. 6366–6373.
- [8] N. Piasco, D. Sidibe, C. Demonceaux, and V. Gouet-Brunet, “A survey on visual-based localization: On the benefit of heterogeneous data,” Pattern Recognition, vol. 74, pp. 90–109, 2018.
- [9] Y. Shavit and R. Ferens, “Introduction to camera pose estimation with deep learning,” CVPR 2019, 2019.
- [10] Y. H. Ma, H. Guo, H. Chen, M. X. Tian, X. Huo, C. J. Long, S. Y. Tang, X. Y. Song, Q. Wang, and Ieee, A Method to Build Multi-Scene Datasets for CNN for Camera Pose Regression, ser. 2018 Ieee International Conference on Artificial Intelligence and Virtual Reality. New York: Ieee, 2018.
- [11] A. Kendall, M. Grimes, R. Cipolla, and Ieee, PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization, ser. IEEE International Conference on Computer Vision, 2015, pp. 2938–2946.
- [12] F. Walch, C. Hazirbas, L. Leal-Taixe, T. Sattler, S. Hilsenbeck, D. Cremers, and Ieee, Image-based localization using LSTMs for structured feature correlation, ser. IEEE International Conference on Computer Vision. New York: Ieee, 2017, pp. 627–637.
- [13] S. Brahmbhatt, J. Gu, K. Kim, J. Hays, and J. Kautz, “Geometry-aware learning of maps for camera localization,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [14] A. Valada, N. Radwan, and W. Burgard, “Deep auxiliary learning for visual localization and odometry,” ICRA 2018, 2018.
- [15] N. Radwan, A. Valada, and W. Burgard, “Vlocnet++: Deep multitask learning for semantic visual localization and odometry,” IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4407–4414, 2018.
- [16] E. Brachmann, A. Krull, S. Nowozin, J. Shotton, F. Michel, S. Gumhold, and C. Rother, “Dsac - differentiable ransac for camera localization,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [17] E. Brachmann and C. Rother, “Learning less is more - 6d camera localization via 3d surface regression,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [18] A. Kendall and R. Cipolla, “Geometric loss functions for camera pose regression with deep learning,” CVPR 2017, 2017.
- [19] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich, “Going deeper with convolutions,” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
- [20] B. Glocker, J. Shotton, A. Criminisi, and S. Izadi, “Real-time rgb-d camera relocalization via randomized ferns for keyframe encoding,” IEEE Transactions on Visualization and Computer Graphics, vol. 21, no. 5, pp. 571–583, 2015.
- [21] V. Dasagi, R. Lee, S. Mou, J. Bruce, N. Sünderhauf, and J. Leitner, “Sim-to-real transfer of robot learning with variable length inputs,” 2019 Australasian Conference on Robotics and Automation: ACRA 2019, 2018.
- [22] O.-M. Pedersen, “Sim-to-real transfer of robotic gripper pose estimation - using deep reinforcement learning, generative adversarial networks, and visual servoing,” Thesis, 2019.
- [23] A. A. Rusu, M. Vecerik, T. Rothörl, N. Heess, R. Pascanu, and R. Hadsell, “Sim-to-real robot learning from pixels with progressive nets,” CoRL 2017, 2016.
- [24] F. Sadeghi and S. Levine, “Cad2rl: Real single-image flight without a single real image,” Robotics: Science and Systems Conference (R:SS), 2017, 2016.
- [25] J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017.
- [26] D. Acharya, K. Khoshelham, and S. Winter, “Bim-posenet: Indoor camera localisation using a 3d indoor model and deep learning from synthetic images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 150, pp. 245–258, 2019.
- [27] X. Ren, J. Luo, E. Solowjow, J. A. Ojea, A. Gupta, A. Tamar, and P. Abbeel, “Domain randomization for active pose estimation,” 2019 International Conference on Robotics and Automation (ICRA), 2019.
- [28] J. Tobin, L. Biewald, R. Duan, M. Andrychowicz, A. Handa, V. Kumar, B. McGrew, J. Schneider, P. Welinder, W. Zaremba, and P. Abbeel, “Domain randomization and generative models for robotic grasping,” 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2017.
- [29] L. Pinto, M. Andrychowicz, P. Welinder, W. Zaremba, and P. Abbeel, “Asymmetric actor critic for image-based robot learning,” Robotics: Science and Systems (RSS), June 2018, 2017.
- [30] T. Sattler, Q. Zhou, M. Pollefeys, and L. Leal-Taixe, “Understanding the limitations of cnn-based absolute camera pose regression,” CVPR 2019, 2019.
- [31] S. Roy, “Airbus a320neo,” 2020. [Online]. Available: https://grabcad.com/library/airbus-a320neo-1/details?folder_id=7882341
- [32] D. Systèmes, “Solidworks,” 2017.
- [33] C. Robotics, “Coppeliasim,” 2019.
- [34] A. Kendall and Y. Gal, “What uncertainties do we need in bayesian deep learning for computer vision?” NIPS 2017, 2017.
- [35] F. Chollet, “Xception: Deep learning with depthwise separable convolutions,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [36] J. Deng, W. Dong, R. Socher, L. J. Li, K. Li, F. F. Li, and Ieee, ImageNet: A Large-Scale Hierarchical Image Database, ser. IEEE Conference on Computer Vision and Pattern Recognition. New York: Ieee, 2009, pp. 248–255.
- [37] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” ICLR 2015, 2014.