Inherit with Distillation and Evolve with Contrast:
Exploring Class Incremental Semantic Segmentation without Exemplar Memory
Abstract
As a front-burner problem in incremental learning, class incremental semantic segmentation (CISS) is plagued by catastrophic forgetting and semantic drift. Although recent methods have utilized knowledge distillation to transfer knowledge from the old model, they are still unable to avoid pixel confusion, which results in severe misclassification after incremental steps due to the lack of annotations for past and future classes. Meanwhile data-replay-based approaches suffer from storage burdens and privacy concerns. In this paper, we propose to address CISS without exemplar memory and resolve catastrophic forgetting as well as semantic drift synchronously. We present Inherit with Distillation and Evolve with Contrast (IDEC), which consists of a Dense Knowledge Distillation on all Aspects (DADA) manner and an Asymmetric Region-wise Contrastive Learning (ARCL) module. Driven by the devised dynamic class-specific pseudo-labelling strategy, DADA distils intermediate-layer features and output-logits collaboratively with more emphasis on semantic-invariant knowledge inheritance. ARCL implements region-wise contrastive learning in the latent space to resolve semantic drift among known classes, current classes, and unknown classes. We demonstrate the effectiveness of our method on multiple CISS tasks by state-of-the-art performance, including Pascal VOC 2012, ADE20K and ISPRS datasets. Our method also shows superior anti-forgetting ability, particularly in multi-step CISS tasks.
Index Terms:
Class Incremental Learning, Semantic Segmentation, Knowledge Distillation, Contrastive Learning.1 Introduction
Incremental learning (IL), also known as continual learning, aims to learn a sequence of tasks and expects that it can achieve proper performance in both old and new tasks. Semantic segmentation assigns a label to every pixel in the image. Typically, the popular fully-supervised semantic segmentation methods require large-scale annotations to support model training. However, these models are typically designed for a closed set, meaning that they can only handle a fixed number of classes, and all the data must be fed to the model at once. In realistic scenes, data is usually accessed incrementally. Apparently, discarding the obtained models and re-training new ones on new data signifies a waste of time and computing resources. For example, ChatGPT costs $4.5 million for one-time training. And sometimes the old data can not be accessible due to privacy restrictions. On the other side, simply re-training the model will bring an Alzheimer-like problem, i.e., the model will lose the past ability due to the parameter update [1]. In this case, class incremental semantic segmentation (CISS) is a promising but challenging task that is relevant to practical vision computing fields such as remote-sensing observation and automatic driving, etc.
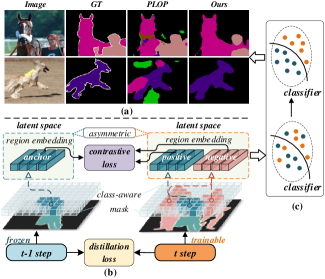
In recent years, IL in deep learning has been exploited in many visual tasks [3, 4]. The main obstacle of IL is catastrophic forgetting [5], i.e., models fail to update the parameters for learning new classes meanwhile preserving sufficient performance on the old ones. In terms of downstream performance, models often encounter classifier bias and pixel misclassification. As is well-known, a common strategy to alleviate catastrophic forgetting is knowledge distillation (KD) [6]. It normally follows a Teacher-Student architecture. KD has been proven to be effective in mitigating catastrophic forgetting in image classification [7, 8, 9, 10, 11, 12, 13, 14, 15] and object detection [16, 17, 18, 19, 20]. However, CISS is more challenging due to the dense prediction demand and complex context association.
Besides catastrophic forgetting, CISS encounters another challenge beyond the image classification task, which is the semantic drift. As illustrated in Fig. 1(a), due to the lack of old data, the models tend to confront class confusion and classifier bias. In addition, since only the current classes are labelled at each incremental step, the semantic of background pixels drifts because the connotation varies, i.e., known classes and future classes are mixed as one background class. As a consequence, it will lead to subsequent classification chaos. Some recent works [21, 22] try modelling the unknown background class by specifying classifier initialization or taking advantage of visual saliency. While existing exemplar-free approaches like [21, 2, 23] concentrate on the consistency of the endmost outputs between the old model and the current model. However, these pioneers fail to preserve the model structure consisting of internal feature distribution, causing the classifier bias on new classes, especially in multi-step IL tasks. In this paper, we present Inherit with Distillation and Evolve with Contrast (IDEC), addressing the CISS problem from two mutually reinforced manners performance in the latent space to maintain inner feature consistency and solid knowledge transfer.
As depicted in Fig. 1(b), at step t, the t-1 step model is frozen to generate the predictions as the pseudo label for t step training. Specifically, we propose to resolve CISS from two aspects. On the one hand, we utilize knowledge distillation to inherit from the old model and a customized distillation loss is introduced between the old and current models. Superior to the previous KD-based methods [2, 24], our distillation manner considers every intermediate layer and output logits synchronously with more emphasis on semantic-invariant knowledge inheritance. Motivated by human recognition patterns [25], we argue that the model tends to recognize and memorize things through semantic-invariant parts. For solid knowledge transfer, we believe the semantic-invariant term occupies a dominant position. Thus in our distillation strategy, we put more emphasis on the deep layers, which contain more semantic-invariant term. While for the low layers, the representation of detail features serves as the variance part to contribute to the intra-class variance. Considering different emphases on low- and high-level features in semantic interpretation, we design an attenuated layer-aware weight (ALW) to guide the distillation process. On the other hand, we pay attention to the adaptation on new classes in a specific contrastive learning manner. Obviously, the latent space of the old model and the current model is asymmetric since the cluster numbers are unequal since the additional classes at incremental steps, as the classifier varies (the number of prediction classes is changed). We run contrastive learning in this asymmetric latent space by selecting specific anchor from the old model, positive and negative embeddings from the current model, to alleviate the semantic drift and classifier bias.
Our contributions are summarized as follows.
-
We propose to address catastrophic forgetting and semantic drift synergistically for CISS in an end-to-end way. And we propose two mutually reinforced modules to enhance the anti-forgetting ability on old classes and compatibility with new classes synchronously.
-
We present an efficient dense distillation strategy and an asymmetric region-wise contrastive learning mechanism in the latent space without requiring exemplar memory.
-
We devise a class-specific pseudo-labelling strategy by launching a dynamic threshold to boost the continual updating with self-training.
-
The proposed approach achieves state-of-the-art performance in large-scale datasets including Pascal VOC 2012, ADE20K and ISPRS, and shows advantages in challenging multi-step CISS tasks.
2 Related Work
In this section, we review the previous researches on IL, CISS, KD and contrastive learning, respectively. By summarizing and analyzing the defects of the current cutting-edge, we propose to resolve catastrophic forgetting and semantic drift synergistically.
2.1 Class Incremental Learning
Incremental learning (IL) technique breaks through the typical one-off training process in deep learning. It enables a neural network to continually update its parameters to adjust incremental data. It has been explored in computer vision [26, 27, 28], natural language processing [29, 30] and remote sensing [31]. The most challenge of this technique is catastrophic forgetting due to the parameter updating. The problem of catastrophic forgetting has been discovered and discussed as early as the 1980s by McCloskey, et al. [32]. That is algorithms trained with backpropagation suffers from severe knowledge forgetting just like human suffers from gradual forgetting of previously learned tasks. To alleviate this problem, a range of researches [33, 34, 35, 36, 37] propose to retrospect known knowledge including sample selection as exemplar memory [38, 39, 40, 41, 42], prototypes guidance [43, 44, 10, 45], meta learning [46, 47, 48, 49], generative adversarial learning [50, 51, 52] and so on. These approaches can achieve effective continual learning performances but normally require extra memory to store old data. However, a more challenging but practical IL scene indicates no old data is available. In recent years, some researches concentrate on IL without data replay by using knowledge distillation [53, 54, 55, 56, 57, 58], conducting weight transfer [59, 60] and network architecture extension [61, 11, 62]. The present primary concern in IL is to balance the anti-forgetting and new knowledge assimilating, which is the priority in this paper.
2.2 Class Incremental Semantic Segmentation
Current class incremental learning (CIL) concentrates on image classification [1, 11, 63, 10, 15]. Some recent approaches [21, 2] extend it to more challenging dense prediction tasks. Class incremental semantic segmentation (CISS) faces two main challenges including catastrophic forgetting and semantic drift, which are because of the lacking of old data and parameter update [64, 65, 66]. According to whether to use exemplar memory, CISS approaches can be divided into two categories. For the first kind, [24, 67, 2, 68, 23] utilize knowledge distillation to inherit the capability of the old model. Cermelli et al. [21] propose to reduce semantic drift by modelling the background label. In remote sensing, researches focus on small objects enhancing [69] and multi-level distillation [70, 71]. The second kind stores a portion of past training data as exemplar memory. Rebuffi et al. [8] propose to conduct the incremental steps with the supervision of representative past training data. However, it will update the old model which may aggravate catastrophic forgetting. Cha et al. [22] proposes a class-imbalanced sampling strategy and uses a visual saliency detector to filter unknown classes. Maracani et al. [72] resort to relying on a generative adversarial network or web-crawled data to retrieve images. These data-replay-based methods bring extra memory consumption, which is critical especially under CISS circumstances. In recent years, few-shot/zero-shot approaches [73, 74] are also explored to reduce data and annotation dependency at incremental steps. Whereas these methods normally have low performance in complex visual tasks. Based on the analysis above, in this paper we propose to address CISS without exemplar memory, to meet with realistic applications.
2.3 Knowledge Distillation
In deep learning, knowledge distillation (KD) aims to transfer information learned from one model to another whilst training constructively. KD was firstly defined by [75] and generalized by [6]. The common characteristic of KD is symbolized by its Student-Teacher (S-T) framework [76]. In recent years, KD has been applied in model compression [77, 78], knowledge transfer [79, 80] and semantic segmentation [81]. And for dense prediction tasks, knowledge distillation has been demonstrated feasible and effective [76]. For example, pixel-wise similarity distillation [82] and channel-wise distillation [83] are proposed to improve the distillation efficiency. Wang et al. [84] propose to transfer the intra-class feature variation from teacher to student by constructing densely pairwise relations. In IL tasks, Zhou et al. [85] propose a multi-level knowledge distillation strategy by leveraging all previous model snapshots. In CISS, KD has been proven as an effective way to preserve the capability of classifying old classes without storing past data in incremental steps. A typical KD approach is to use the outputs from the old model to guide the new model by a distillation loss [21]. Further, Michieli et al. [24] explores distillation in intermediate feature space and indicates that L2-norm is superior to cross-entropy or L1-norm. Qiu et al. [86] use self-attention to capture both within-class and between-class knowledge.
2.4 Contrastive Learning
Contrastive learning has been widely used in learning representations without labels [87, 88, 89]. A typical contrastive learning way is to apply diversiform transforms on the source image to create positive pairs [90, 91]. For dense prediction tasks, Lee et al. [92] propose a supervised contrastive learning approach via highlighting semantic attention. Wang et al. [93] propose a pixel-wise contrastive algorithm for semantic segmentation in the fully-supervised setting. In recent years, similar to metric learning approaches, some contrastive methods attempt to learn the representations in the latent space by organizing positive embedding pairs against negative embedding pairs [94, 95]. Arnaudo et al. [96] explore a contrastive regularization between outputs of the old model and the new model but only rely on image transform. Recent state-of-the-art CISS methods SDR [94] and UCD [68] propose to compare feature vectors in the feature space. By contrast, the differences and advantages of the proposed method compared to [94, 68] are: 1) we perform contrastive learning in asymmetric latent space, enabling to enlarge divergence among the new classes, known classes the future/unknown classes; 2) we construct anchor embedding from the old model, which is more reliable by avoiding the impact of model performance degradation in IL steps; 3) our method supports region-wise embedding comparison, superior to the pixel-wise calculation in dense prediction task. By considering intact context association, the proposed model achieves more robust performance in multi-step CISS tasks.

3 Methodology
In this section, we present a CISS method named Inherit from Distillation and Evolve with Contrast (IDEC). Fig. 2 depicts the information flow at t step training. The main structure of the proposed network consists of the following subsections.
3.1 Preliminary
Let signifies the training dataset, where denotes the input image and denotes the corresponding ground truth. indicates the training dataset for t step. At step, indicates the previously learned classes and indicates the classes for learning. When training on , the training data of old classes, i.e., is inaccessible. And the ground truth in only covers . The complete training process consists of {Step-0, Step-1, , Step-T} steps. At step, we use and to represent the t-1 and t step model, respectively. indicates the -th layer feature map from generated by feature extractor F. is the layer number of the feature extractor network.
3.2 Dense Alignment Distillation on All Aspects

To address the catastrophic forgetting problem, we propose a novel knowledge distillation strategy. However, in contrast to the pioneers [24, 97, 2], we propose Dense Alignment Distillation on all Aspects (DADA) including intermediate layers as well as output logits synchronously but with different emphases on low- and high-level features. Dense feature distillation in multi-layer is necessary for CISS because semantic segmentation requires each pixel to be classified. We propose matching feature representation at different levels is beneficial for inheriting the feature representation of old models in a dense prediction task. To align with the pioneers, we take DeepLabv3 [98] as an example to present DADA. But the strategy can be embedded expediently into any other segmentation models as discussed in Sec. 4.4.4. As shown in Fig. 3, the input training batch is imported to both the and to extract multi-layer feature . Note that is frozen to avoid gradient backpropagation but is trainable. To take full advantage of context association, for each , we employ a typical atrous spatial pyramid pooling (ASPP) [98] to compute feature responses from different scales of the receptive field. After that, we obtain embeddings through , where , represents the feature channels. We calculate the similarity of the embeddings by measuring the Kullback-Leibler (K-L) divergence.
| (1) |
where and represent class probabilities of the i-th pixel in the softmax output when applying a 11 convolution on the embedding and , respectively.
For the output layer, we measure the embeddings similarity before the classification layer (e.g. softmax), which can be calculated by . In our implementation, the size of the deepest features is . and share the same semantic segmentation architecture [98]. In this case, can inherit the capacity of in feature space by distilling the immediate-layer and output-layer features synchronously.
In CISS tasks, it is necessary to balance old knowledge inheritance and new knowledge learning. Inspired by [99], the impact of distilling is not always positive, particularly it will inhibit from learning better in the latter training stage. Thus we give less concern to knowledge distillation with training iteration increases. On the other hand, compared to LocalPOD [2], we put different emphases on semantic-invariant features (mainly from deep layers) and sample-specific features (mainly from low layers). We believe the former matters more in IL steps because the old data is inaccessible in our CISS setting. Here we propose an Attenuated Layer-aware Weight (ALW) to guide the dense distillation process:
| (2) |
where is an initial weight of intermediate-layer distillation loss. and represent the -th epoch and total training epochs. indicates -th intermediate layer. And is a positive constant less than 1.The optimization goal for intermediate feature consistency is defined as:
| (3) |
In our implementation, we run above distillation across the middle three intermediate layers (by skipping the input layer). Therewith the distillation goal for the output layer is defined as:
| (4) |
Hence the proposed DADA is supervised by
| (5) |
where is a constant to balance the contribution of and in the training process. is calculated at every incremental step.
3.3 Asymmetric Region-wise Contrastive Learning
At each incremental step, since the lack of annotations, all the other classes are actually labelled as background (bg) except for current classes. Thus the connotation of background would contain known classes and future classes simultaneously, leading to semantic drift. To alleviate the classifier confusion caused by semantic drift, we propose an asymmetric region-wise contrast learning approach. Specifically, we select anchor embedding from the old model since the model faces catastrophic forgetting after IL steps. While the positive and negative embeddings are generated from the current model. Firstly, after obtaining the output logits from and on , we generate a class-aware mask under the guidance of model prediction. As depicted in Fig. 4, we use the output from to select anchor embeddings for a designated class. The corresponding positive and negative embeddings are from features generated by . To achieve this, we first construct the class-aware mask for class . In detail, is obtained by:
| (6) | ||||
We perform the embedding selection process in the deepest features , where . For a designated class , we obtain the anchor, positive and negative embeddings by:
| (7) | ||||
where is the mask for filtering -th class embedding in the latent space. indicates the Hadamard product between two matrices. represents the anchor embedding belonging to -th class in the latent space from . and indicate the corresponding positive and negative embeddings in the latent space from . After that, for computing the intra-class compactness and inter-class dispersion, we transform the , and to one-dimensional tensors {, , }.
| (8) |
where is the minimum length among the size of , and . We perform this embedding screening operation in each training batch to obtain cross-image semantic correlation. In this way, based on contrastive learning across and , DADA and ARCL tackle catastrophic forgetting and semantic drift with a mutually reinforced relationship.

Particularly, the asymmetry manifests itself in two ways. One is the inequality of class number at the current step and previous step, the other is the embedding pairing manner for contrastive learning. Specifically, we select anchor embedding from within old classes to reduce prediction error, while positive and negative embeddings from to optimize the current model. By filtering pixel embeddings belonging to the same class to a region, we achieve region-wise contrastive learning in those asymmetric latent spaces. Here we extend TripletMarginLoss [100] that considers intra-class compactness and inter-class dispersion with a margin between positive pairs and negative pairs. We construct positive pairs as and negative pairs as . The optimization goal is to minimize the distance within positive pairs meanwhile maximize the distance within negative pairs. Thus the optimization goal is defined as:
| (9) | ||||
where Nc is the class numbers of the dataset. is a distance measurement function and is a constant. We use L2-norm to construct in our implementation. The pseudocode of the proposed ARCL is shown in Algorithm 1.
3.4 Dynamic Class-specific Pseudo Labelling
We present a Dynamic Class-specific Pseudo Labelling (DCPL) strategy. The pioneer [2] proposes a class-specific threshold but ignores the influence of semantic drift, in which case the degraded performance may reduce the confidence of pseudo labels, even causing negative optimization. To avoid overfitting incorrect pseudo labels, a class-specific threshold of every pixel is designed to preserve high-confidence pseudo labels for supervision.
At step, the output segmentation map is . We calculate the prediction score range for each class in each training batch by and , where = indicates the probability for class on pixel . Specifically, at step, the proposed class-specific threshold is defined as:
| (10) | ||||
where indicates the score of at c-th class. measures the fluctuation of the model prediction on a class. Specifically, indicates high-confident predictions with small score fluctuation. indicates preserving the most reliable predictions while means the unstable score fluctuation on class . We simply set based on experience. is a fixed threshold to avoid being too small. is the minimum confidence threshold and we set following the traditional protocol. measures the score range of the prediction results from . is the pixel number being predicted as class . In this way, we try to balance preserving highly-confident pseudo labels with preserving as many pseudo labels as possible. Thus the pseudo-label for class can be generated from :
| (11) | ||||
where represents traversing pixels on . In this case, the high threshold ensures high-confident pseudo labels for easy classes. While the pseudo labels for hard classes have the least errors. Since only ground truth of is accessed at step training, we concatenate and to supervise :
| (12) |
where indicates the ground truth of , represents the label combination operation. Under the supervision of , the segmentation loss for image at step training can be calculated by cross-entropy (CE) loss:
| (13) |
where and represent the ground truth probability and the predicted probability of class on pixel , respectively. Aiming at addressing the CISS in an end-to-end way, we perform the above ARCL and DADA synchronously. The integrated objective is defined as:
| (14) |
Particularly, at the initial step, only is calculated, which is the same as the static training process. While at each incremental step, is calculated for the whole network training.
4 Experiments
4.1 Datasets and Protocols
Datasets. 1) PASCAL VOC 2012 [101] is a widely used benchmark for semantic segmentation. It consists of 10582 training images and 1449 images for validation with 20 semantic classes and an extra background class. We evaluate our model on 15-5 (2 steps), 15-1 (6 steps), 5-3 (6 steps) and 10-1 (11 steps) settings. For example, 15-1 means initially learning 15 classes and learning additional 5 classes at another step. 15-1 indicates initially learning 15 classes and then learning the additional one class at each step for a total of another 5 steps. 2) ADE20K [102] is a large-scale semantic segmentation dataset containing 150 classes that cover indoor and outdoor scenes. The dataset is split into 20210 training images and 2000 validation images. Compared to Pascal VOC 2012, ADE20K covers a wider variety of classes in natural scenes with more instances and categories. We evaluate our model on 100-50 (2 steps), 100-10 (6 steps), 50-50 (3 steps) and 100-5 (11 steps) settings. 3) ISPRS [103] consists of two airborne image datasets including Postdam and Vaihingen. We conduct our experiments on Postdam. It contains 38 images with the size of 60006000 pixels. The resolution of each image is 5 cm. As the source organizer suggested, we take 24 images for training and 14 images for validation. For training convenience, we partition each image into 600600 patches in sequential order. Semantic content in Postdam has been classified manually into six land cover classes, namely: imprevious surfaces, building, low vegetation, tree, car and clutter. Following previous works [69, 71], we choose to ignore class clutter in the training and validation process since it only accounts for very few pixel quantities and its unclear semantic scope. We evaluate our model on 4-1 (2 steps), 2-3 (2 steps), 2-2-1 (3 steps) and 2-1 (4 steps) settings.
Metrics. We compute Pascal VOC mean intersection-over-union (mIoU) [101] for evaluation:
| (15) |
where TP, FP and FN are the numbers of true positive, false positive and false negative pixels, respectively.
Specifically, we compute mIoU after the last step T for the initial classes , for the incremented classes , and for all classes (all).
Protocols. Following [21, 2], there are two different incremental settings: disjoint and overlapped. In both settings, only the current classes are labelled and an extra background (bg) class . In the former, images at step only contain . While the latter contains , which is more realistic and challenging. In this study, we focus on overlapped setting in our experiments. We report two baselines for reference, i.e., fine tuning on , and training on all classes offline. The former is the lower bound and the latter can be regarded as the upper bound in CISS tasks.
4.2 Implementation Details
We use DeepLabv3 [98] architecture with a ResNet-101 [104] backbone pretrained on ImageNet [105] as semantic segmentation baseline, as same as [2, 68]. For all experiments, the initial learning rate is 0.01 and decayed by a poly learning rate policy. The training batch size is set to 12 in all CISS settings. At each step, we use SGD [106] as the optimizer with a momentum of 0.9 and a weight decay of 510-4. We train the model with 30 (Pascal VOC 2012, ISPRS) and 50 (ADE20K) epochs for each incremental step, respectively. The input image is resized to 513513. Standard data augmentation methods are applied during training, such as random scaling from 0.5 to 2.0 and random flipping. For hyper-parameters, we set , and according to the analysis in Sec. 4.4.3. . Implementation of the proposed network is based on Pytorch 1.8 with CUDA 11.6 and all experiments are conducted on a workstation with 4 NVIDIA 3090 GPUs. The code will be available at our formal published version.
4.3 Quantitative Evaluation
Pascal VOC 2012. We compare our method with current state-of-the-art data-free approaches including [7, 1, 24, 97, 21, 2, 94, 68, 107, 23] and data-replay-based methods [72, 22]. Table I shows quantitative experiments on VOC 15-5, 15-1, 5-3 and 10-1 settings. In multi-step CISS tasks like 15-1, 5-3 and10-1, our method is superior to the closest contender [23]. For example, mIoU on all of the proposed IDEC is 67.32% in 15-1 case, of which the performance of achieves a large improvement than the competitors, proving the effectiveness of our distillation mechanism. And our performance of the incremental is superior to [2] by a significant margin, demonstrating the adaptive capacity on new classes. Since DADA and ARCL share a mutually reinforced relationship as introduced in Sec. 3.3, the experimental results also prove the cooperativity between the DADA and ARCL. It is worth mentioning that the proposed model achieves a performance close to the previous replay-based approaches like [72], validating the effectiveness of the proposed strategy.
In Fig. 5, we evaluate mIoU against the number of learned classes on VOC 15-1. For example, MiB [21] degenerates rapidly at the latter steps. Current state-of-the-art [23] is also confronted with severe performance degradation. The proposed IDEC maintains the highest mIoU among the contrast models after all incremental steps, indicating the strong ability against forgetting and adaptation to new classes. Fig. 6 shows the visualization comparison on VOC 15-1 task. The proposed method maintains the region integrity of different classes after all IL steps.
ADE20K. Table II shows quantitative experiments on ADE 100-50, 100-10, 50-50 and 100-5 tasks. Due to the large number of classes, it is more challenging thus the upper bound mIoU is only 38.9%, indicating that there is severe pixel misclassification. The representative PLOP [2] shows robustness in 100-50 and 50-50 with fewer IL steps. In contrast, the proposed IDEC shows robust learning ability in more challenging multi-step CISS tasks like 100-10 and 100-5. For example, in 100-5, IDEC shows strong ability against catastrophic forgetting as the mIoU of is the highest among all contenders and finally achieves 31.00% mIoU on all classes. In addition, compared with the first-tier replay-based method [22], the proposed method also shows competitive performance in anti-forgetting ability and new-class adaptation.
ISPRS. We extend our method to remote-sensing scenes. Space-based in-orbit remote sensing is a suitable field for model deployment with incremental learning. Compared to natural scenes, remote sensing image contains more terrain context including complex noise interference, occlusion issue and obscure region boundaries, etc. Table III displays the comparison of [7, 24, 21, 2] and our method. The proposed IDEC achieves the highest mIoU on ISPRS 4-1, 2-3, 2-2-1 and 2-1 tasks. For example, with respect to the most challenging task 2-1, our method is superior to MiB [21] with 7.06% mIoU. on 2-3, 2-2-1 and 2-1 tasks, IDEC remains a competitive anti-forgetting performance on the initial two classes imprevious surfaces and building, validating the anti-forgetting ability. Fig. 7 displays representative visualization results on multiple CISS tasks on all three datasets. During the IL steps, IDEC maintains the region integrity of different classes after all IL steps and also shows advantages in reducing pixel misclassification.

| Method | 15-5 (2 steps) | 15-1 (6 steps) | 5-3 (6 steps) | 10-1 (11 steps) | |||||||||
| 0-15 | 16-20 | all | 0-15 | 16-20 | all | 0-5 | 6-20 | all | 0-10 | 11-20 | all | ||
| Data-free | fine tuning | 2.10 | 33.10 | 9.80 | 0.20 | 1.80 | 0.60 | 0.50 | 10.40 | 7.60 | 6.30 | 2.80 | 4.70 |
| EWC* [7] | 24.30 | 35.50 | 27.10 | 0.30 | 4.30 | 1.30 | - | - | - | - | - | - | |
| LwF-MC* [1] | 58.10 | 35.00 | 52.30 | 6.40 | 8.40 | 6.90 | 20.91 | 36.67 | 24.66 | 4.65 | 5.90 | 4.95 | |
| ILT* [24] | 66.30 | 40.60 | 59.90 | 4.90 | 7.80 | 5.70 | 22.51 | 31.66 | 29.04 | 7.15 | 3.67 | 5.50 | |
| Umberto et al.‡ [97] | 67.20 | 38.42 | 60.35 | 8.75 | 7.99 | 8.56 | 26.15 | 37.84 | 34.50 | 6.52 | 5.16 | 5.87 | |
| MiB* [21] | 76.37 | 49.97 | 70.08 | 34.22 | 13.50 | 29.29 | 57.10 | 42.56 | 46.71 | 12.25 | 13.09 | 12.65 | |
| PLOP* [2] | 75.73 | 51.71 | 70.09 | 65.12 | 21.11 | 54.64 | 17.48 | 19.16 | 18.68 | 44.03 | 15.51 | 30.45 | |
| SDR [94] | 75.40 | 52.60 | 69.90 | 44.70 | 21.80 | 39.20 | - | - | - | 32.40 | 17.10 | 25.10 | |
| UCD‡ [68] | 77.50 | 53.10 | 71.30 | 49.00 | 19.50 | 41.90 | 31.35 | 23.43 | 25.69 | 38.73 | 22.52 | 31.01 | |
| UCD+PLOP [68] | 75.00 | 51.80 | 69.20 | 66.30 | 21.60 | 55.10 | - | - | - | 42.30 | 28.30 | 35.30 | |
| REMINDER [107] | 76.11 | 50.74 | 70.07 | 68.30 | 27.23 | 58.52 | - | - | - | - | - | - | |
| RCIL‡ [23] | 78.80 | 52.00 | 72.40 | 70.60 | 23.70 | 59.40 | 65.30 | 41.49 | 50.27 | 55.40 | 15.10 | 34.30 | |
| IDEC (Ours) | 78.01 | 51.84 | 71.78 | 76.96 | 36.48 | 67.32 | 67.05 | 48.98 | 54.14 | 70.74 | 46.30 | 59.10 | |
| Data-replay | RECALL-GAN [72] | 66.60 | 50.90 | 64.00 | 65.70 | 47.80 | 62.70 | - | - | - | 59.50 | 46.70 | 54.80 |
| RECALL-Web [72] | 67.70 | 54.30 | 65.60 | 67.80 | 50.90 | 64.80 | - | - | - | 65.00 | 53.70 | 60.70 | |
| SSUL-M [22] | 79.53 | 52.87 | 73.19 | 78.92 | 43.86 | 70.58 | 72.97 | 49.02 | 55.85 | 74.79 | 48.87 | 65.45 | |
| offline | 79.77 | 72.35 | 77.43 | 79.77 | 72.35 | 77.43 | 76.91 | 77.63 | 77.43 | 78.41 | 76.35 | 77.43 | |
| Method | 100-50 (2 steps) | 100-10 (6 steps) | 50-50 (3 steps) | 100-5 (11 steps) | |||||||||
| 1-100 | 101-150 | all | 1-100 | 101-150 | all | 1-50 | 51-150 | all | 1-100 | 101-150 | all | ||
| Data-free | fine tuning | 0.00 | 11.22 | 3.74 | 0.00 | 2.08 | 0.69 | 0.00 | 3.60 | 2.40 | 0.00 | 0.07 | 0.02 |
| ILT* [24] | 18.29 | 14.40 | 17.00 | 0.11 | 3.06 | 1.09 | 3.53 | 12.85 | 9.70 | 0.08 | 1.31 | 0.49 | |
| Umberto et al.‡ [97] | 22.79 | 13.81 | 19.80 | 3.28 | 5.44 | 4.00 | 8.89 | 14.40 | 12.56 | 1.02 | 1.25 | 1.10 | |
| MiB* [21] | 40.52 | 17.17 | 32.79 | 38.21 | 11.12 | 29.24 | 45.57 | 21.01 | 29.31 | 36.01 | 5.66 | 25.96 | |
| PLOP* [2] | 41.87 | 14.89 | 32.94 | 40.48 | 13.61 | 31.59 | 48.83 | 20.99 | 30.40 | 39.11 | 7.81 | 28.75 | |
| UCD+PLOP [68] | 42.12 | 15.84 | 33.31 | 40.80 | 15.23 | 32.29 | 47.12 | 24.12 | 31.79 | - | - | - | |
| REMINDER [107] | 41.55 | 19.16 | 34.14 | 38.96 | 21.28 | 33.11 | 47.11 | 20.35 | 29.39 | 36.06 | 16.38 | 29.54 | |
| RCIL [23] | 42.30 | 18.80 | 34.50 | 39.30 | 17.60 | 32.10 | 48.30 | 25.00 | 32.50 | 38.50 | 11.50 | 29.60 | |
| IDEC (Ours) | 42.01 | 18.22 | 34.08 | 40.25 | 17.62 | 32.71 | 47.42 | 25.96 | 33.11 | 39.23 | 14.55 | 31.00 | |
| Data-replay | SSUL-M [22] | 42.20 | 13.95 | 32.80 | 42.17 | 16.03 | 33.89 | 49.55 | 25.89 | 33.78 | 42.53 | 15.85 | 34.00 |
| offline | 44.30 | 28.20 | 38.90 | 44.30 | 28.20 | 38.90 | 50.90 | 32.90 | 38.90 | 44.30 | 28.20 | 38.90 | |
| Method | 4-1 (2 steps) | 2-3 (2 steps) | 2-2-1 (3 steps) | 2-1 (4 steps) | ||||||||
| 1-4 | 5 | all | 1-2 | 3-5 | all | 1-2 | 3-5 | all | 1-2 | 3-5 | all | |
| fine tuning | 2.75 | 30.28 | 8.26 | 5.60 | 19.22 | 13.77 | 0.53 | 7.90 | 4.95 | 0.02 | 1.05 | 0.64 |
| EWC‡ [7] | 27.01 | 31.25 | 27.86 | 39.59 | 25.94 | 31.40 | 17.88 | 10.46 | 13.43 | 8.97 | 2.35 | 5.00 |
| ILT‡ [24] | 42.37 | 30.92 | 40.08 | 41.29 | 25.83 | 32.01 | 35.28 | 19.77 | 25.97 | 20.92 | 8.44 | 13.43 |
| MiB‡ [21] | 67.11 | 38.90 | 61.47 | 76.49 | 44.45 | 57.27 | 67.83 | 39.07 | 50.57 | 65.28 | 41.46 | 50.99 |
| PLOP‡ [2] | 65.78 | 36.12 | 59.85 | 70.44 | 43.80 | 54.46 | 66.45 | 41.68 | 51.59 | 64.41 | 40.89 | 50.30 |
| IDEC (Ours) | 74.05 | 50.77 | 69.39 | 78.91 | 49.08 | 61.01 | 75.45 | 47.54 | 58.70 | 76.25 | 45.89 | 58.03 |
| offline | 75.23 | 63.97 | 72.98 | 83.31 | 66.09 | 72.98 | 83.31 | 66.09 | 72.98 | 83.31 | 66.09 | 72.98 |



4.4 Ablation Study
4.4.1 Module Contribution
Distillation Mechanism. As introduced in Sec. 3.2, we propose a distillation mechanism considering both intermediate layers and output logits. In Table IV we study the performance benefits of module contributions covering VOC 15-1, ADE 100-10 and ISPRS 2-1. For the distillation strategy, we present two settings, 1) OL-D after IL-D; 2) IL-D after OL-D, to reveal the contribution of KD in CISS tasks. Since the pseudo labels are generated by the old model to boost the latter-step learning, the IoU performance would reveal the impact of orders of IL-D and OL-D. In all three CISS tasks, firstly adopting IL-D then OL-D achieves higher IoU than the other setting. In our opinion, this validates the benefits of distilling low- and high-level features synchronously to CISS. Taking VOC 15-1 as an example, without distillation but only performing CE on , the performance is only 0.60% mIoU. With intermediate layer distillation (IL-D). and pseudo-labelling without DCPL (but with a fixed value ), the mIoU increases to 61.44%. It also proves that ALW can boost the layer-wise distillation with an extra 0.76% mIoU improvement. And with additional output logits distillation (OL-D), it gains another 3.60% improvement. Thus in the following experiments, we adopt the OL-D after IL-D setting with the ALW guidance.
| Method | VOC 15-1 | ADE 100-10 | ISPRS 2-1 | ||||||
| 0-15 | 16-20 | all | 1-100 | 101-150 | all | 1-2 | 3-5 | all | |
| fine tuning | 0.20 | 1.80 | 0.60 | 0.00 | 2.08 | 0.69 | 0.02 | 1.05 | 0.64 |
| +IL-D w/o ALW | 71.86 | 28.11 | 61.44 | 36.66 | 15.47 | 29.60 | 69.79 | 37.68 | 50.52 |
| +IL-D w/ ALW | 72.73 | 28.49 | 62.20 | 37.33 | 15.35 | 30.00 | 69.55 | 38.26 | 50.78 |
| +OL-D | 74.96 | 36.48 | 65.80 | 38.12 | 17.06 | 31.10 | 73.59 | 42.32 | 54.83 |
| +OL-D | 71.87 | 26.65 | 61.10 | 34.98 | 15.21 | 28.39 | 69.48 | 38.35 | 50.80 |
| +IL-D w/o ALW | 73.12 | 35.51 | 64.17 | 37.10 | 16.73 | 30.31 | 71.25 | 41.55 | 53.43 |
| +IL-D w/ ALW | 73.65 | 35.68 | 64.61 | 38.05 | 16.73 | 30.94 | 73.28 | 41.89 | 54.45 |
| +ARCL | 75.21 | 38.00 | 66.35 | 40.12 | 17.44 | 32.56 | 75.45 | 45.54 | 57.50 |
| +DCPL | 76.96 | 36.48 | 67.32 | 40.25 | 17.62 | 32.71 | 76.25 | 45.89 | 58.03 |
| Task | none | fixed | PLOP‡ | DCPL | mIoU |
| VOC 15-1 | ✓ | 61.87 | |||
| ✓ | 66.35 | ||||
| ✓ | 65.44 | ||||
| ✓ | 67.32 | ||||
| ADE 100-10 | ✓ | 29.17 | |||
| ✓ | 32.56 | ||||
| ✓ | 31.71 | ||||
| ✓ | 32.71 | ||||
| ISPRS 2-1 | ✓ | 54.68 | |||
| ✓ | 57.50 | ||||
| ✓ | 55.41 | ||||
| ✓ | 58.03 |
Contrastive Learning. Compared to the pioneers [94, 68], the proposed ARCL constructs contrastive learning through high-confidence embeddings to avoid the misleading caused by model degeneration. Based on the proposed KD strategies, we further evaluate the proposed contrastive learning efficiency in Table. IV. With respect to VOC 15-1 task, ARCL brings 0.55% mIoU improvement in all classes. In detail, it achieves 0.25% and 1.52% mIoU advancement on and the incremental classes , respectively. For ADE 100-10, ARCL achieves 1.46% mIoU improvement based on the KD strategy. As for ISPRS 2-1 task, the proposed ARCL also proves its robustness by bringing 2.07% mIoU advancement. From the analysis above, ARCL shows a robust ability on alleviating forgetting and classifier bias during IL steps.
Pseudo-labelling. Standing on the shoulders of the above two modules, we explore the contribution of the proposed DCPL. On the one hand, DCPL brings positive earnings in all classes on all three tasks. As seen in Table IV, compared to a fixed threshold, i.e., , DCPL brings 0.97%, 0.15% and 0.53% mIoU improvement on VOC 15-1, ADE 100-10 and ISPRS 2-1, respectively. However, there is an exception that in VOC 15-1, it brings 1.75% IoU improvement on but 1.52% negative earnings on . This reveals that in CISS, it is challenging to balance the anti-forgetting and new-class adaptation if the segmentation model achieves low performance, which is discussed in Sec. 4.4.2. On the other hand, Table V compares the efficiency of several pseudo-labelling strategies. In comparison with the uncertainty-based pseudo-labelling strategy in [2], the proposed approach also shows competitive efficiency. In line with our expectations, the proposed dynamic class-specific threshold benefits the IL performance because of the balance of pixel misclassification reduction and pseudo-label supplement.

4.4.2 Anti-forgetting and New-class Adaptation
As mentioned in Sec. 1, models after incremental steps face catastrophic forgetting. Thus the anti-forgetting ability in CISS is of great concern. We evaluate the mIoU for initially learned classes (those learned at Step-0) after each incremental step on VOC 15-1, ADE 100-10 and ISPRS 2-1, respectively. Taking VOC 15-1 as an example, we re-evaluated the mIoU of using the new model at each step in Table VI. It is observed that the mIoU of decreases step by step, which is in accordance with our expectations. While it also shows a strong anti-forgetting ability since there is only 2.81% mIoU decline after the final step. In terms of ADE 100-10, which is more challenging due to the large number of classes, the mIoU of drops 2.52% after the final step. IDEC also maintains the most capacity on the old classes. In ISPRS 2-1, the anti-forgetting is more challenging since the remote-sensing images normally contain more complex semantics and context association. At Step-0, the mIoU of achieves 91.88% and drops rapidly to 79.79% at Step-1, but finally maintains 76.07% at Step-3. We also compared the proposed method to the pioneer [2], and our method shows a more robust anti-forgetting performance on all three CISS tasks.
| task | VOC 15-1 mIoU | |||||
| Step-0 | Step-1 | Step-2 | Step-3 | Step-4 | Step-5 | |
| PLOP‡ [2] | 79.77 | 72.95 | 68.42 | 66.76 | 65.52 | 64.27 |
| IDEC | 79.77 | 79.32 | 78.21 | 77.60 | 77.05 | 76.96 |
| task | ADE 100-10 mIoU | |||||
| Step-0 | Step-1 | Step-2 | Step-3 | Step-4 | Step-5 | |
| PLOP‡ [2] | 42.77 | 41.38 | 40.71 | 40.52 | 40.41 | 40.13 |
| IDEC | 42.77 | 41.79 | 41.00 | 40.67 | 40.40 | 40.25 |
| task | ISPRS 2-1 mIoU | |||||
| Step-0 | Step-1 | Step-2 | Step-3 | - | - | |
| PLOP‡ [2] | 91.95 | 76.53 | 73.24 | 64.41 | - | - |
| IDEC | 91.95 | 79.36 | 77.89 | 76.25 | - | - |
Since we aim to stimulate the model to remember old classes and learn new classes concurrently, these two sides should boost each other. In dense prediction tasks, a pixel only can be assigned one label. It means with a favourable anti-forgetting ability, the model can achieve high-confident pseudo labels. Besides, since we tackle the catastrophic forgetting and semantic drift synergistically, a solid anti-forgetting ability is also conducive for the latter contrastive learning to improve the adaptation ability on new classes, which is validated in Sec. 4.4.1. To investigate the inner feature distribution after incremental steps, we use t-SNE [108] to map the high-dimensional features to 2D space. We evaluate our method on VOC 15-1 and 10-1 at the initial step and the final step. As seen in Fig. 9, the position is anchored for each class. We demonstrate the advantage of the proposed method compared with UCD+PLOP [68] in inner feature distribution. On VOC 15-1, UCD+PLOP is invaded by catastrophic forgetting resulting in class confusion at the final step. IDEC achieves consistent classification ability on the initial at Step-0 and Step-5. While new classes also can be distinguished from old classes and be classified into new clusters. It intuitively proves IDEC can effectively boost incremental learning efficiency, i.e., anti-forgetting performance on old classes and adequate compatibility with new classes.
4.4.3 Impact of Hyper-parameters
There are several hyper-parameters in our proposed network including and in Sec. 3.2 and in Sec. 3.4. We compare the final IL performance to reveal the impact of these hyper-parameters. Table VIII reveals the impact of , which can be concluded that an appropriate progressively decaying distillation intensity can boost the student network training. Table VIII shows the impact of . It proves the contribution of OL-D and the balance between IL-D and OL-D in the distillation process. Table IX shows the impact of on pseudo-labelling. The above hyper-parameters are settled based on the performance of the validation set. Please be noted that these hyper-parameters are not designed for a specific dataset, despite we only present the quantitative results on VOC 2012.
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 1.0 | |
| mIoU | 64.07 | 65.22 | 66.65 | 67.12 | 67.32 | 67.28 | 67.19 |
| 0.5 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | |
| mIoU | 66.33 | 67.24 | 67.32 | 67.28 | 67.13 | 67.15 |
| 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | |
| mIoU | 65.23 | 67.01 | 67.32 | 66.40 | 60.17 |
4.4.4 Impact of Segmentation Model
While most current CISS methods use DeepLabv3 [98] as the segmentation model. However, how the segmentation model affects the CISS performance is unexplored. By using various segmentation networks, we aim to reveal the relationship between CISS efficiency and segmentation model performance. We leverage three semantic segmentation models with two kinds of encoders, i.e., DeepLabv3 [98] with ResNet-101 [104], DeepLabv3+ [109] with ResNet-101 [104] and DeepLabv3 with Swin-Transformer [110]. The comparison among different segmentation encoders and models is conducted on VOC 15-1, ADE 100-10 and ISPRS 2-1 in Table X. On the one hand, the impact of the decoder is explored. Compared with DeepLabv3 [98], DeepLabv3+ [109] enhances the decoder by multi-scale feature concatenation, which has been proved to be more effective on segmentation tasks. Deeplabv3+ based model achieves 4.29% mIoU improvement on and 0.54% mIoU improvement on all classes than DeepLabv3 on VOC 15-1. With respect to more challenging ADE 100-10 and ISPRS 2-1, it also achieves a higher mIoU rate on the initial and the incremental . On the other hand, we explore the impact of the encoder on CISS performance by comparing CNN and the newfangled Transformer architecture. Specifically, we compare ResNet-101 [104] and Swin-Transformer [110] in our framework. Taking ISPRS 2-1 as an example, Transformer-based architectures can bring great benefits to the final performance since its stronger feature representation ability. Therefore, it can be proved that a more robust segmentation model could boost the IL performance in CISS tasks.
| Task | Seg.-Model | Backbone | mIoU (%) | ||
| all | |||||
| VOC 15-1 | DeepLabv3 [98] | ResNet-101 | 76.96 | 36.48 | 67.32 |
| DeepLabv3+ [109] | ResNet-101 | 76.32 | 40.77 | 67.86 | |
| Deeplabv3 [98] | Swin-T | 75.29 | 41.88 | 67.34 | |
| all | |||||
| ADE 100-10 | DeepLabv3 [98] | ResNet-101 | 40.25 | 17.62 | 32.71 |
| DeepLabv3+ [109] | ResNet-101 | 41.98 | 17.93 | 33.96 | |
| DeepLabv3[98] | Swin-T | 42.09 | 17.87 | 34.02 | |
| all | |||||
| ISPRS 2-1 | DeepLabv3 [98] | ResNet-101 | 76.25 | 45.89 | 58.03 |
| DeepLabv3+ [109] | ResNet-101 | 77.46 | 49.73 | 60.82 | |
| DeepLabv3 [98] | Swin-T | 76.42 | 48.35 | 59.58 | |
4.4.5 Computational Efficiency
Table XI reviews the training efficiency of the proposed model. In detail, we dissect module efficiency in terms of parameter, memory and floating point operations (FLOPs). We set a baseline to represent the model that only performs CE on new classes. It is observed that DADA and ARCL, i.e., the proposed distillation mechanism and contrastive learning strategy bring large memory consumption, and ARCL encumbers training efficiency due to its region embedding filter and iterated contrastive learning process. In Fig. 10, we present the impact of anchor class number in ARCL with mIoU evolution and time consumption in terms of VOC 15-1 task. Without ARCL, the mIoU is 65.78% in all classes. Taking two random classes belonging to (by skipping the background class) as anchor classes in every training batch, we achieve 0.95% mIoU improvement with the price of 12.17 training time consumption. While taking ten classes as anchor classes for contrastive learning, the model achieves the highest 67.32% mIoU but with a cost of 37.33 time consumption to complete the training process. For a large-scale dataset such as ADE20K, setting each learned class as anchor will bring tremendous time consumption. Thus we constrain the class number to ten to balance the performance and training efficiency.
| Module | VOC 15-1 | ||
| Param. (M) | Mem.(MB) | FLOPs (G) | |
| fine tuning | 59.34 | 1123.22 | 92.89 |
| +DADA | 74.11 | 1335.44 | 134.56 |
| +ARCL | 74.11 | 1351.42 | 137.78 |

4.4.6 Impact of Class Incremental Order
We review the impact of class incremental order to investigate the robustness of the proposed method. Taking VOC 15-1 as a representative, we set seven class orders including the ascending order and six random orders as follows:
Note that Table I results from the sequential order . Table XII shows the performance of IDEC on the above settings. We evaluate the mIoU on , and all . Through the standard deviation, we see that the final IL performance has slight fluctuations but is overall stable with different class orders, validating the robustness of the model. In addition, we display the detailed performance in VOC 15-5, 15-1, 5-3 and 10-1 for each class in Table XIII under the sequential class order a.
| order | 0-15 | 16-20 | all |
| a | 76.96 | 36.48 | 67.32 |
| b | 75.82 | 41.22 | 67.58 |
| c | 74.73 | 28.61 | 63.75 |
| d | 74.20 | 36.53 | 65.23 |
| e | 73.05 | 37.49 | 64.58 |
| f | 68.87 | 40.00 | 62.00 |
| g | 74.79 | 39.46 | 66.38 |
| avg.std. | - | - | 65.261.86 |
| class |
bg |
aeroplane |
bicycle |
bird |
boat |
bottle |
bus |
car |
cat |
chair |
cow |
diningtable |
dog |
horse |
motorbike |
person |
pottedplant |
sheep |
sofa |
train |
monitor |
| 15-5 | 91.29 | 87.63 | 39.83 | 90.89 | 68.89 | 77.01 | 90.25 | 88.55 | 93.67 | 35.28 | 85.50 | 57.01 | 88.49 | 82.46 | 85.85 | 85.46 | 32.70 | 68.81 | 29.15 | 72.07 | 56.47 |
| 15-1 | 89.45 | 86.73 | 40.24 | 88.58 | 66.43 | 75.62 | 87.56 | 88.43 | 92.84 | 36.00 | 75.63 | 59.33 | 89.13 | 83.48 | 86.55 | 85.43 | 29.28 | 48.64 | 23.55 | 47.31 | 33.61 |
| 5-3 | 88.09 | 66.06 | 33.01 | 84.29 | 57.14 | 73.70 | 64.68 | 67.91 | 75.34 | 13.41 | 42.45 | 37.73 | 65.36 | 41.89 | 63.29 | 76.09 | 27.78 | 40.47 | 18.85 | 49.25 | 50.14 |
| 10-1 | 87.62 | 78.21 | 36.88 | 86.32 | 60.18 | 72.12 | 83.68 | 83.83 | 88.92 | 32.71 | 67.70 | 30.47 | 74.56 | 46.57 | 65.51 | 78.33 | 22.00 | 39.27 | 24.39 | 39.31 | 42.54 |
4.4.7 Failure Example and Analysis
We demonstrate the effectiveness of the proposed method in both natural and remote-sensing scenes aforesaid. Taking a closer look at the prediction results, there are some flaws including 1) Complex scenes: as shown in line 1 in Fig 11, the segmentation model fails to recognize the complex semantic content, aggravating the catastrophic forgetting. 2) Hard examples: in Fig 11 line 2, class tree and low vegetation possess approximate colour and texture, causing pixel misclassification in multi-step tasks. We believe these obstacles can be alleviated by employing a stronger semantic segmentation model.

5 Conclusion
In this paper, we propose to addressing class incremental semantic segmentation without data replay. We reveal the associativity of catastrophic forgetting and semantic drift and review the progress in this field. To resolve these two problems, we make three main contributions: knowledge distillation to alleviate the former, and contrastive learning in asymmetric latent space to increase the discriminability between learned and incremental classes for the latter. Therewith a customized class-specific pseudo-labelling strategy is used to boost learning efficiency. They prove their effectiveness on various CISS tasks (VOC 2012, ADE20K, ISPRS) and settings (12 in total). And the most conspicuous point is we achieve robust CISS performance especially in multi-step tasks. We also demonstrate the anti-forgetting and model evolving can be non-antagonistic but concordant through enhancing the ability to differentiate old and new classes in the latent space. However, a crack in our contrastive learning strategy is that it requires vast time computation for training. If not comparing all classes at each incremental step may alleviate this problem. Our future work will focus on exploring human-like anti-forgetting mechanisms and adapting our method to more scenes like open-set situation, as well as few-shot/zero-shot CISS study.
Acknowledgments
This work was supported by the National Natural Science Foundation of China under Grant 62271018.
References
- [1] Z. Li and D. Hoiem, “Learning without forgetting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, pp. 2935–2947, 2018.
- [2] A. Douillard, Y. Chen, A. Dapogny, and M. Cord, “Plop: Learning without forgetting for continual semantic segmentation,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4039–4049, 2021.
- [3] J. Kirkpatrick, R. Pascanu, N. C. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,” Proceedings of the National Academy of Sciences, vol. 114, pp. 3521 – 3526, 2017.
- [4] M. D. Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks.” IEEE transactions on pattern analysis and machine intelligence, vol. PP, 2021.
- [5] V. V. Ramasesh, A. Lewkowycz, and E. Dyer, “Effect of scale on catastrophic forgetting in neural networks,” in International Conference on Learning Representations, 2022. [Online]. Available: https://openreview.net/forum?id=GhVS8_yPeEa
- [6] G. E. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” ArXiv, vol. abs/1503.02531, 2015.
- [7] J. Kirkpatrick, R. Pascanu, N. C. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,” Proceedings of the National Academy of Sciences, vol. 114, pp. 3521 – 3526, 2017.
- [8] S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lampert, “icarl: Incremental classifier and representation learning,” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5533–5542, 2017.
- [9] J. Smith, Y.-C. Hsu, J. C. Balloch, Y. Shen, H. Jin, and Z. Kira, “Always be dreaming: A new approach for data-free class-incremental learning,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9354–9364, 2021.
- [10] F. Zhu, X.-Y. Zhang, C. Wang, F. Yin, and C.-L. Liu, “Prototype augmentation and self-supervision for incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5867–5876, 2021.
- [11] Y. Liu, B. Schiele, and Q. Sun, “Adaptive aggregation networks for class-incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2544–2553, 2021.
- [12] C. Zhang, N. Song, G. Lin, Y. Zheng, P. Pan, and Y. Xu, “Few-shot incremental learning with continually evolved classifiers,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12 450–12 459, 2021.
- [13] M. Rostami, “Lifelong domain adaptation via consolidated internal distribution,” in NeurIPS, 2021.
- [14] Y. Tang, Y. Peng, and W. Zheng, “Learning to imagine: Diversify memory for incremental learning using unlabeled data,” ArXiv, vol. abs/2204.08932, 2022.
- [15] D.-W. Zhou, F. L. Wang, H.-J. Ye, L. Ma, S. Pu, and D.-C. Zhan, “Forward compatible few-shot class-incremental learning,” ArXiv, vol. abs/2203.06953, 2022.
- [16] K. Shmelkov, C. Schmid, and A. Karteek, “Incremental learning of object detectors without catastrophic forgetting,” 2017 IEEE International Conference on Computer Vision (ICCV), pp. 3420–3429, 2017.
- [17] K. J. Joseph, J. Rajasegaran, S. H. Khan, F. S. Khan, V. N. Balasubramanian, and L. Shao, “Incremental object detection via meta-learning,” IEEE transactions on pattern analysis and machine intelligence, vol. PP, 2021.
- [18] X. Liu, H. Yang, A. Ravichandran, R. Bhotika, and S. Soatto, “Multi-task incremental learning for object detection,” arXiv: Computer Vision and Pattern Recognition, 2020.
- [19] J. Wang, X. Wang, Y. Shang-Guan, and A. K. Gupta, “Wanderlust: Online continual object detection in the real world,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 10 809–10 818, 2021.
- [20] T. Feng, M. Wang, and H. Yuan, “Overcoming catastrophic forgetting in incremental object detection via elastic response distillation,” ArXiv, vol. abs/2204.02136, 2022.
- [21] F. Cermelli, M. Mancini, S. R. Bulò, E. Ricci, and B. Caputo, “Modeling the background for incremental learning in semantic segmentation,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9230–9239, 2020.
- [22] S. Cha, B. Kim, Y. Yoo, and T. Moon, “SSUL: Semantic segmentation with unknown label for exemplar-based class-incremental learning,” in Advances in Neural Information Processing Systems, A. Beygelzimer, Y. Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021. [Online]. Available: https://openreview.net/forum?id=8tgchc2XhD
- [23] C.-B. Zhang, J. Xiao, X. Liu, Y. Chen, and M.-M. Cheng, “Representation compensation networks for continual semantic segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition, 2022.
- [24] U. Michieli and P. Zanuttigh, “Incremental learning techniques for semantic segmentation,” 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pp. 3205–3212, 2019.
- [25] A. Treisman and G. A. Gelade, “A feature-integration theory of attention,” Cognitive Psychology, vol. 12, pp. 97–136, 1980.
- [26] V. Lomonaco, L. Pellegrini, P. R. López, M. Caccia, Q. She, Y. Chen, Q. Jodelet, R. Wang, Z. Mai, D. Vázquez, G. I. Parisi, N. Churamani, M. Pickett, I. H. Laradji, and D. Maltoni, “Cvpr 2020 continual learning in computer vision competition: Approaches, results, current challenges and future directions,” Artif. Intell., vol. 303, p. 103635, 2022.
- [27] H. Qu, H. Rahmani, L. Xu, B. M. Williams, and J. Liu, “Recent advances of continual learning in computer vision: An overview,” ArXiv, vol. abs/2109.11369, 2021.
- [28] E. Belouadah, A. D. Popescu, and I. Kanellos, “A comprehensive study of class incremental learning algorithms for visual tasks,” Neural networks : the official journal of the International Neural Network Society, vol. 135, pp. 38–54, 2021.
- [29] C. de Masson d’Autume, S. Ruder, L. Kong, and D. Yogatama, “Episodic memory in lifelong language learning,” ArXiv, vol. abs/1906.01076, 2019.
- [30] M. Biesialska, K. Biesialska, and M. R. Costa-jussà, “Continual lifelong learning in natural language processing: A survey,” ArXiv, vol. abs/2012.09823, 2020.
- [31] S. Bhat, B. Banerjee, S. Chaudhuri, and A. Bhattacharya, “Cilea-net: Curriculum-based incremental learning framework for remote sensing image classification,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 5879–5890, 2021.
- [32] M. McCloskey and N. J. Cohen, “Catastrophic interference in connectionist networks: The sequential learning problem,” Psychology of Learning and Motivation, vol. 24, pp. 109–165, 1989.
- [33] J. Bang, H. Kim, Y. J. Yoo, J.-W. Ha, and J. Choi, “Rainbow memory: Continual learning with a memory of diverse samples,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8214–8223, 2021.
- [34] E. Belouadah and A. D. Popescu, “Il2m: Class incremental learning with dual memory,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 583–592, 2019.
- [35] A. Chaudhry, A. Gordo, P. K. Dokania, P. H. S. Torr, and D. Lopez-Paz, “Using hindsight to anchor past knowledge in continual learning,” in AAAI, 2021.
- [36] C. D. Kim, J. Jeong, S. chul Moon, and G. Kim, “Continual learning on noisy data streams via self-purified replay,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 517–527, 2021.
- [37] R. Aljundi, L. Caccia, E. Belilovsky, M. Caccia, M. Lin, L. Charlin, and T. Tuytelaars, “Online continual learning with maximally interfered retrieval,” ArXiv, vol. abs/1908.04742, 2019.
- [38] R. Aljundi, M. Lin, B. Goujaud, and Y. Bengio, “Gradient based sample selection for online continual learning,” in NeurIPS, 2019.
- [39] B. Han, Q. Yao, X. Yu, G. Niu, M. Xu, W. Hu, I. W.-H. Tsang, and M. Sugiyama, “Co-teaching: Robust training of deep neural networks with extremely noisy labels,” in NeurIPS, 2018.
- [40] D. Rolnick, A. Ahuja, J. Schwarz, T. P. Lillicrap, and G. Wayne, “Experience replay for continual learning,” in NeurIPS, 2019.
- [41] E. Fini, S. Lathuilière, E. Sangineto, M. Nabi, and E. Ricci, “Online continual learning under extreme memory constraints,” ArXiv, vol. abs/2008.01510, 2020.
- [42] Y. Shi, L. Yuan, Y. Chen, and J. Feng, “Continual learning via bit-level information preserving,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16 669–16 678, 2021.
- [43] S. Ho, M. Liu, L. Du, L. Gao, and Y. Xiang, “Prototypes-guided memory replay for continual learning,” ArXiv, vol. abs/2108.12641, 2021.
- [44] H. Ahn, D. Lee, S. Cha, and T. Moon, “Uncertainty-based continual learning with adaptive regularization,” in NeurIPS, 2019.
- [45] K. Zhu, Y. Cao, W. Zhai, J. Cheng, and Z. Zha, “Self-promoted prototype refinement for few-shot class-incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6797–6806, 2021.
- [46] K. Javed and M. White, “Meta-learning representations for continual learning,” in NeurIPS, 2019.
- [47] Z. Wang, S. V. Mehta, B. Póczos, and J. G. Carbonell, “Efficient meta lifelong-learning with limited memory,” ArXiv, vol. abs/2010.02500, 2020.
- [48] M. Banayeeanzade, R. Mirzaiezadeh, H. Hasani, and M. Soleymani, “Generative vs. discriminative: Rethinking the meta-continual learning,” in NeurIPS, 2021.
- [49] J. Hurtado, A. Raymond-Saez, and A. Soto, “Optimizing reusable knowledge for continual learning via metalearning,” in NeurIPS, 2021.
- [50] S. Ebrahimi, F. Meier, R. Calandra, T. Darrell, and M. Rohrbach, “Adversarial continual learning,” ArXiv, vol. abs/2003.09553, 2020.
- [51] Y. Xiang, Y. Fu, P. Ji, and H. Huang, “Incremental learning using conditional adversarial networks,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 6618–6627, 2019.
- [52] V. K. Verma, K. J. Liang, N. Mehta, P. Rai, and L. Carin, “Efficient feature transformations for discriminative and generative continual learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13 860–13 870, 2021.
- [53] M. Kang, J. Park, and B. Han, “Class-incremental learning by knowledge distillation with adaptive feature consolidation,” ArXiv, vol. abs/2204.00895, 2022.
- [54] A. Douillard, M. Cord, C. Ollion, T. Robert, and E. Valle, “Podnet: Pooled outputs distillation for small-tasks incremental learning,” in ECCV, 2020.
- [55] H.-J. Ye, S. Lu, and D.-C. Zhan, “Distilling cross-task knowledge via relationship matching,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12 393–12 402, 2020.
- [56] J. Tian, X. Xu, Z. Wang, F. Shen, and X. Liu, “Relationship-preserving knowledge distillation for zero-shot sketch based image retrieval,” Proceedings of the 29th ACM International Conference on Multimedia, 2021.
- [57] T.-B. Xu and C.-L. Liu, “Deep neural network self-distillation exploiting data representation invariance,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, pp. 257–269, 2022.
- [58] Q. Zhao, Y. Ma, S. Lyu, and L. Chen, “Embedded self-distillation in compact multibranch ensemble network for remote sensing scene classification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15, 2022.
- [59] S. Ahn, S. X. Hu, A. C. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 9155–9163, 2019.
- [60] H. Slim, E. Belouadah, A.-S. Popescu, and D. M. Onchis, “Dataset knowledge transfer for class-incremental learning without memory,” 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 3311–3320, 2022.
- [61] M. Kanakis, D. Bruggemann, S. Saha, S. Georgoulis, A. Obukhov, and L. V. Gool, “Reparameterizing convolutions for incremental multi-task learning without task interference,” in ECCV, 2020.
- [62] S. Yan, J. Xie, and X. He, “Der: Dynamically expandable representation for class incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3013–3022, 2021.
- [63] J. Serra, D. Suris, M. Miron, and A. Karatzoglou, “Overcoming catastrophic forgetting with hard attention to the task,” in International Conference on Machine Learning. PMLR, 2018, pp. 4548–4557.
- [64] X. Hu, K. Tang, C. Miao, X. Hua, and H. Zhang, “Distilling causal effect of data in class-incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3956–3965, 2021.
- [65] P. Kaushik, A. Gain, A. Kortylewski, and A. L. Yuille, “Understanding catastrophic forgetting and remembering in continual learning with optimal relevance mapping,” ArXiv, vol. abs/2102.11343, 2021.
- [66] A. Chaudhry, P. K. Dokania, T. Ajanthan, and P. H. S. Torr, “Riemannian walk for incremental learning: Understanding forgetting and intransigence,” in Proceedings of the European Conference on Computer Vision (ECCV), September 2018.
- [67] M. Klingner, A. Bär, P. Donn, and T. Fingscheidt, “Class-incremental learning for semantic segmentation re-using neither old data nor old labels,” 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), pp. 1–8, 2020.
- [68] G. Yang, E. Fini, D. Xu, P. Rota, M. Ding, M. Nabi, X. Alameda-Pineda, and E. Ricci, “Uncertainty-aware contrastive distillation for incremental semantic segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. PP, 2022.
- [69] J. Li, X. Sun, W. Diao, P. Wang, Y. Feng, X. Lu, and G. Xu, “Class-incremental learning network for small objects enhancing of semantic segmentation in aerial imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–20, 2022.
- [70] O. Tasar, Y. Tarabalka, and P. Alliez, “Incremental learning for semantic segmentation of large-scale remote sensing data,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, pp. 3524–3537, 2019.
- [71] L. Shan, W. Wang, K. Lv, and B. Luo, “Class-incremental learning for semantic segmentation in aerial imagery via distillation in all aspects,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–12, 2022.
- [72] A. Maracani, U. Michieli, M. Toldo, and P. Zanuttigh, “Recall: Replay-based continual learning in semantic segmentation,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 7006–7015, 2021.
- [73] A. Cheraghian, S. Rahman, P. Fang, S. K. Roy, L. Petersson, and M. T. Harandi, “Semantic-aware knowledge distillation for few-shot class-incremental learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2534–2543, 2021.
- [74] X. Xu, C. Deng, M. Yang, and H. Wang, “Progressive domain-independent feature decomposition network for zero-shot sketch-based image retrieval,” ArXiv, vol. abs/2003.09869, 2020.
- [75] C. Bucila, R. Caruana, and A. Niculescu-Mizil, “Model compression,” in ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(KDD’06), 2006.
- [76] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, pp. 3048–3068, 2022.
- [77] T. Furlanello, Z. C. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, “Born again neural networks,” in ICML, 2018.
- [78] Z. Yang, L. Shou, M. Gong, W. Lin, and D. Jiang, “Model compression with two-stage multi-teacher knowledge distillation for web question answering system,” Proceedings of the 13th International Conference on Web Search and Data Mining, 2020.
- [79] C. Yang, L. Xie, C. Su, and A. L. Yuille, “Snapshot distillation: Teacher-student optimization in one generation,” 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2854–2863, 2019.
- [80] B. Heo, J. Kim, S. Yun, H. Park, N. Kwak, and J. Y. Choi, “A comprehensive overhaul of feature distillation,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1921–1930, 2019.
- [81] Y. Liu, C. Shu, J. Wang, and C. Shen, “Structured knowledge distillation for dense prediction,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. PP, no. 99, pp. 1–1, 2020.
- [82] Y. Feng, X. Sun, W. Diao, J. Li, and X. Gao, “Double similarity distillation for semantic image segmentation,” IEEE Transactions on Image Processing, vol. 30, pp. 5363–5376, 2021.
- [83] C. Shu, Y. Liu, J. Gao, Z. Yan, and C. Shen, “Channel-wise knowledge distillation for dense prediction,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 5291–5300, 2021.
- [84] Y. Wang, W. Zhou, T. Jiang, X. Bai, and Y. Xu, “Intra-class feature variation distillation for semantic segmentation,” in ECCV, 2020.
- [85] P. Zhou, L. Mai, J. Zhang, N. Xu, Z. Wu, and L. S. Davis, “M2kd: Multi-model and multi-level knowledge distillation for incremental learning,” ArXiv, vol. abs/1904.01769, 2019.
- [86] Y. Qiu, Y. Shen, Z. Sun, Y. Zheng, X. Chang, W. Zheng, and R. Wang, “Sats: Self-attention transfer for continual semantic segmentation,” ArXiv, vol. abs/2203.07667, 2022.
- [87] X. Chen, H. Fan, R. Girshick, and K. He, “Improved baselines with momentum contrastive learning,” arXiv preprint arXiv:2003.04297, 2020.
- [88] R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y. Bengio, “Learning deep representations by mutual information estimation and maximization,” in International Conference on Learning Representations, 2018.
- [89] Z. Wu, Y. Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3733–3742, 2018.
- [90] T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in International conference on machine learning. PMLR, 2020, pp. 1597–1607.
- [91] N. Komodakis and S. Gidaris, “Unsupervised representation learning by predicting image rotations,” in International Conference on Learning Representations (ICLR), 2018.
- [92] H. H. Lee, Y. Tang, Q. Yang, X. Yu, S. Bao, B. A. Landman, and Y. Huo, “Attention-guided supervised contrastive learning for semantic segmentation,” ArXiv, vol. abs/2106.01596, 2021.
- [93] W. Wang, T. Zhou, F. Yu, J. Dai, E. Konukoglu, and L. V. Gool, “Exploring cross-image pixel contrast for semantic segmentation,” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 7283–7293, 2021.
- [94] U. Michieli and P. Zanuttigh, “Continual semantic segmentation via repulsion-attraction of sparse and disentangled latent representations,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1114–1124, 2021.
- [95] S. Kan, Y. Cen, Y. Li, V. Mladenovic, and Z. He, “Relative order analysis and optimization for unsupervised deep metric learning,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13 994–14 003, 2021.
- [96] E. Arnaudo, F. Cermelli, A. Tavera, C. Rossi, and B. Caputo, “A contrastive distillation approach for incremental semantic segmentation in aerial images,” in ICIAP, 2022.
- [97] U. Michieli and P. Zanuttigh, “Knowledge distillation for incremental learning in semantic segmentation,” Computer Vision and Image Understanding, p. 103167, 2021.
- [98] L.-C. Chen, G. Papandreou, F. Schroff, and H. Adam, “Rethinking atrous convolution for semantic image segmentation,” ArXiv, vol. abs/1706.05587, 2017.
- [99] Z. Zhou, C. Zhuge, X. Guan, and W. Liu, “Channel distillation: Channel-wise attention for knowledge distillation,” 2020.
- [100] A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” ArXiv, vol. abs/1703.07737, 2017.
- [101] M. Everingham, S. M. A. Eslami, L. Van Gool, C. K. I. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes challenge: A retrospective,” International Journal of Computer Vision, vol. 111, no. 1, pp. 98–136, 2015.
- [102] B. Zhou, Z. Hang, F. X. P. Fernandez, S. Fidler, and A. Torralba, “Scene parsing through ade20k dataset,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [103] “Isprs test project on urban classification and 3d building reconstruction,” GIM international, 2013.
- [104] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778.
- [105] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009, pp. 248–255.
- [106] L. Bottou, “Large-scale machine learning with stochastic gradient descent,” in COMPSTAT, 2010.
- [107] M. H. Phan, T.-A. Ta, S. L. Phung, L. Tran-Thanh, and A. Bouzerdoum, “Class similarity weighted knowledge distillation for continual semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 16 866–16 875.
- [108] L. van der Maaten and G. Hinton, “Visualizing data using t-sne,” Journal of Machine Learning Research, vol. 9, no. 86, pp. 2579–2605, 2008. [Online]. Available: http://jmlr.org/papers/v9/vandermaaten08a.html
- [109] L.-C. Chen, Y. Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation.” in ECCV, 2018, pp. 833–851.
- [110] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” ArXiv, vol. abs/2103.14030, 2021.