*ljustified@setformatplain@setjustificationljustified
Information-theoretical analysis of statistical measures for multiscale dynamics
Abstract
Multiscale entropy (MSE) has been widely used to examine nonlinear systems involving multiple time scales, such as biological and economic systems. Conversely, Allan variance has been used to evaluate the stability of oscillators, such as clocks and lasers, ranging from short to long time scales. Although these two statistical measures were developed independently for different purposes in different fields in the literature, their interest is to examine multiscale temporal structures of physical phenomena under study. We show that, from an information-theoretical perspective, they share some foundations and exhibit similar tendencies. We experimentally confirmed that similar properties of the MSE and Allan variance can be observed in low-frequency fluctuations (LFF) in chaotic lasers and physiological heartbeat data. Furthermore, we calculated the condition under which this consistency between the MSE and Allan variance exists, which is related to certain conditional probabilities. Heuristically, physical systems in nature including the aforementioned LFF and heartbeat data mostly satisfy this condition, and hence the MSE and Allan variance demonstrate similar properties. As a counterexample, an artificially constructed random sequence is demonstrated, for which the MSE and Allan variance exhibit different trends.
I Introduction
Multiscale entropy (MSE) Costa, Goldberger, and Peng (2002) has been used widely to evaluate nonlinear systems that involve multiple time scales in biology,Catarino et al. (2011); Costa, Goldberger, and Peng (2005) economics,Martina et al. (2011) transportation,Wang et al. (2013) and other fields. Meanwhile, Allan variance Allan (1966) has been used to evaluate the stability of oscillators,Allan (1966); Filler (1988); Skrinsky, Skrinska, and Zelinger (2014) such as atomic clocks or lasers, over many time scales. Although these two statistical measures were developed independently in different domains, the MSE and its variantsHumeau-Heurtier (2015) and Allan variance have a similar objective: to characterize dynamical systems containing multiple time scales.
However, the relevance and differences between the MSE and Allan variance have yet to be examined in the literature. In this study, we discuss the similarities and differences between the MSE and Allan variance from an information-theoretical perspective and from the viewpoint of computational cost, and reveal the mechanisms behind them. We experimentally validated the similar tendencies of the MSE and Allan variance observed in low-frequency fluctuations (LFF) in chaotic lasers that are numerically simulated by the Lang–Kobayashi equations,Lang and Kobayashi (1980) and physiological heartbeat data available in the public domain.Goldberger et al. (e 13); Irurzun et al. (2021); Baim et al. (1986); Petrutiu, Sahakian, and Swiryn (2007) Furthermore, we present the underlying mechanism behind the consistency between the MSE and Allan variance based on conditional probabilities. We artificially constructed a random sequence that violated this condition, leading to a case exhibiting inconsistent results between the MSE and Allan variance.
As discussed in detail below, the LFF and heartbeat contain both slow and fast dynamics; they represent typical physical phenomena with multiple time scales. Furthermore, recent studies on physics-based computing and communications, such as reservoir computing,Larger et al. (2012) laser-chaos-based secure communication,Rogister et al. (2001); Mengue and Essimbi (2012) and laser networks for solving reinforcement learning problems,Mihana et al. (2020) work across multiple time scales; hence, understanding fundamental attributes in multiple time scales through statistical measures, such as the MSE and Allan variance, is essential for furthering our comprehension.
The remainder of this paper is organized as follows. We review the Allan variance and MSE in Sections II.1 and II.2, respectively. Section III examines the MSE and Allan variance for several time series, namely noise, RR interval,Wagner and Marriott (2008) and laser chaos. A similar tendency of the MSE and Allan variance is shown for each time series. Section IV discusses the mechanism behind the similarity between the two measures. Additionally, the cause of the differences in behavior is discussed. Section V concludes the paper.
II Theory
II.1 Allan variance
Coarse-graining of a time series with a scale factor refers to the operation that obtains another time series as follows:
| (1) |
Here, denotes floor function. The time series is called a coarse-grained time series. This operation obtains a new point by taking the average of every point. Using coarse-graining, the Allan varianceAllan (1966) of a time series with scale factor is defined as
| (2) |
where
| (3) |
The Allan variance considers the variance of the difference between successive points in the coarse-grained time series under study, with respect to the time scale given by the coarse-graining time .
Meanwhile, it is known that the Allan variance can be expressed using the power spectral density of the signal as follows, under the assumption that is stationary and ergodicBarnes et al. (1971):
| (4) |
Using Eq. (4), for example, the Allan variance of white noise is as follows:
| (5) |
Similarly, for noise, the Allan variance is
| (6) |
Here and represent the intensities of the white and components, respectively. We can then estimate and from the Allan variance with various . In this way, the Allan variance has been used to evaluate the variability characteristics of time-series data.
II.2 Multiscale entropy (MSE)
Before discussing multiscale entropy,Costa, Goldberger, and Peng (2002) it is necessary to introduce original sample entropy (SaEn). Richman and Moorman (2000) The theoretical background and examples of SaEn were described in detail by Richman and Moorman.Delgado-Bonal and Marshak (2019) We will use their definition of SaEn.
In short, SaEn quantifies the regularity of a time series. SaEn has several parameters: the embedding dimension , tolerance and length of the time series . The SaEn of a time series is defined with the correlation integral as follows:
| (7) |
Several steps must be taken to define and compute . First, the embedded vector series is constructed as follows:
| (8) |
Please note that the length of the vector series defined as Eq. (8) is because the -th component of is . Second, for each embedded vector, and are defined as follows:
| (9) | ||||
| (10) |
Here, denotes the unit step function, defined as
| (11) |
is the Chebyshev distance and is defined as follows:
| (12) |
Please note that the maximum is not but in Eq. (9) because we also calculate to compute SaEn and the total number of embedded vectors in the dimension is . Intuitively, the definition of is the probability of a randomly chosen satisfying
| (13) |
It is noteworthy that, by the definition of the Chebyshev distance, the following proposition holds:
| (14) | ||||
This proposition plays an important role in Sec. IV.1.
From the definition, can be regarded as the probability that a randomly chosen is a neighbor of the embedded vector . In other words, it is the likelihood of patterns which are considered repetitions of the pattern under the tolerance . With , the correlation integral is defined as
| (15) |
Intuitively, is the average of ; therefore, we can regard as the probability that randomly chosen vectors and are close. A large indicates that time series contains many repeating structures of length . SaEn then quantifies whether, when consecutive points in the time series are considered repeated, the -th point is also considered repeated.
In other words, it quantifies whether the -th point is predictable by looking at the preceding points. SaEn can be applied to real-world data without assuming any model governing the time series.
The MSE is defined as the SaEn of a coarse-grained time series and can be plotted as a function of , where the same is used for every . The MSE was proposed to quantify complexity at various time scales. noise has a long-time correlation; therefore, it is considered more complex than white noise. However, SaEn assigns the maximum value to white noise. In contrast, the MSE of white noise monotonically decreases with increasing , whereas the MSE of noise is constant,Costa, Goldberger, and Peng (2002) i.e., noise has more complexity than white noise over a longer time scale.
As introduced in Secs. II.1 and II.2, the definitions of the MSE and Allan variance are apparently completely different. In this study, we demonstrate that the MSE and Allan variance exhibit similar dependency, and reveal the underlying mechanism from an information-theoretical perspective. Note that for noise, it has already been shown theoretically that both the Allan variance and MSE are constants, independent of .
III Comparison of the MSE and Allan variance
To compare the behavior of the MSE and the correlation integral to that of the Allan variance, they were calculated for the three types of signals described later. was fixed to , and was fixed at ,Costa, Goldberger, and Peng (2002) where denotes the standard deviation of the signal .
III.1 Noise
Thirty temporal waveforms of white Gaussian noise (WGN) and noise containing points each were generated numerically, and the MSE and Allan variance were calculated up to points. We fixed the length of the coarse-grained time series to points for the MSE calculation owing to limitations of our computing environment, whereas the entire time series was used for the Allan variance calculation. The results are presented in Fig. 1.
The Allan variance and MSE or show similar trends with regard to , with appropriate scaling. Please note that the scales of the y-axes in plots and the Allan variance plots are identical (logarithmic), while the y-axes in the MSE plots are linear. Because the MSE is defined by the logarithm of , it is natural to plot it linearly when is plotted logarithmically.
Figures 1(a) and (c) show the MSE and Allan variance of WGN, respectively, where both decrease monotonically as a function of . This trend agrees well up to points. For points, the Allan variance still shows dependency, as indicated by Eq. (5), whereas the MSE saturates at 0. In this region, is almost 1, i.e., almost all of the embedded vectors are neighbors of each other. This saturation effect is one of the differences between the MSE and Allan variance.
Figures 1(b) and (d) show the MSE and Allan variance of noise, respectively. Theoretically, both are predicted to be independent of , whereas the simulation results show some dependency. This may be a result of the difficulty in properly generating noise on scales from = to , however it is noteworthy that the MSE, and Allan variance exhibit similar curves as a function of .

III.2 Physiological signal
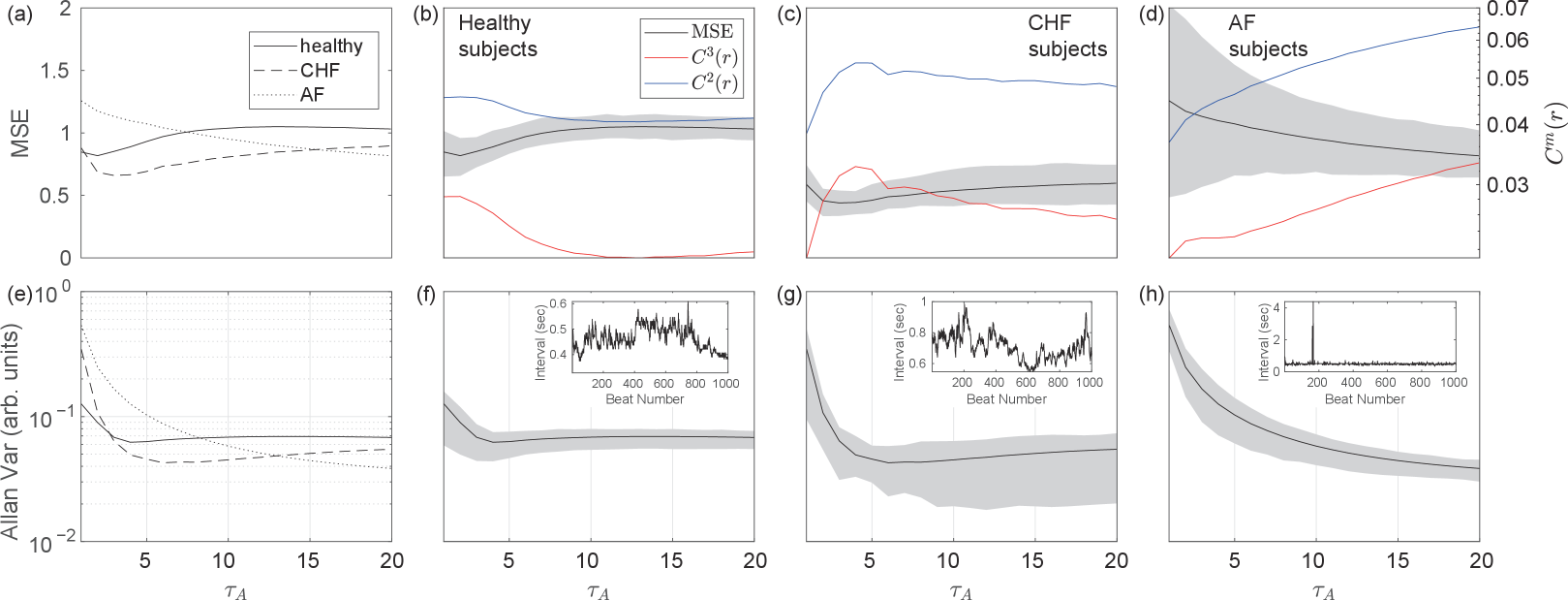
Costa et al.Costa, Goldberger, and Peng (2002) introduced the MSE to demonstrate that physiological signals observed in young, healthy individuals exhibit versatile signal levels across a variety of time scales, whereas unhealthy subjects do not. In this section, we compare the MSE and Allan variance of the RR intervalWagner and Marriott (2008) series, which are sequences of intervals between adjacent R waves in electro-cardiograms, for healthy subjects and those with congestive heart failure (CHF) or atrial fibrillation (AF), following Costa et al. Each dataset was obtained from PhysioNet.Goldberger et al. (e 13); Irurzun et al. (2021); Baim et al. (1986); Petrutiu, Sahakian, and Swiryn (2007)
The lengths of the time series varied, but the entirety of each time series was used in the calculations, because adjusting to the shorter ones would reduce the accuracy of the estimation. To compare the Allan variance, the standard deviation of each time series was normalized to 1. This normalization is consistent with the MSE calculation, because was fixed at . The MSE and Allan variance for each dataset is shown in Fig. 2. The Allan variance, MSE and show trends that are similar except for the location of the peaks.
Figures 2(a) and (e) respectively show the MSE and Allan variance overlaid for all three cases. Figure 2(a) shows that the RR interval for healthy subjects is the most complex on long time scales, which is consistent with the results of the previous study.Costa, Goldberger, and Peng (2002) As shown in Fig. 2(e), the ordering of the different classes of subjects for the Allan variance and MSE show a similar trend. However, the exact scale factor at which each curve intersects differs from that of the MSE. It seems plausible that the analysis of RR interval time series in general could be performed using Allan variance instead of the MSE.
III.3 Laser chaos
The MSE and Allan variance of the noise time series exhibit monotonic properties. However, the MSE and Allan variance of physiological signals show more complex properties, but the underlying dynamics are not completely known, which makes further analysis difficult.
As an example of a time series that includes multiple time scales and for which the underlying dynamics are known, we discuss a phenomenon called LFFUchida (2012) exhibited by a semiconductor laser with optical feedback. The Lang–Kobayashi equations,Lang and Kobayashi (1980) a set of model equations, was used to generate the time series. An example of a time series is shown in Fig. 3, where fast chaotic oscillations on the order of GHz coexist with irregular intensity dropouts and recovery on the order of MHz. The results are presented in Fig. 4. As the simulation step and time scale of the dynamics are important, was converted to time.
Figure 4 shows that the MSE, and Allan variance all capture the dynamics of fast oscillations on the order of GHz, corresponding to the fast peak in the MSE and Allan variance, and dropouts on the order of MHz, corresponding to the slow peak.


IV Information theoretical connections between the MSE and Allan variance
IV.1 and Allan variance
In Sec. III, we observe that exhibits behavior similar to that of the Allan variance. In this section, we discuss the underlying mechanisms.
IV.1.1 decomposition
First, we consider decomposing by the difference in the indices of the embedding vectors. Let be the length of the coarse-grained time series, and be . Considering the expectation and symmetry of and , and assuming or its first-order difference is strongly stationary,
| (16) | ||||
| (17) | ||||
| (18) | ||||
| (19) |
First we clarify the meaning of expectation. In the following, we regard the time series under study as a sequence of random variables following a specific probability distribution function (PDF). In this sense, and are also random variables, and thus each of the possible values of and has some probability of occurrence. The expectation is the weighted average of the likelihood of every potential value.
Here we explain the transformation of the equations from (16) to (19) line by line. The only change made from Eq. (16) to (17) is that the expectation term is changed to the probability term . We assume that a random variable sequence follows a PDF, and calculate . As previously mentioned, is also a random variable that is either 0 or 1 with the following probability:
| (20) |
Consequently,
| (21) |
holds.
From Eq. (17) to (18), the factor is added to the numerator, and the range of summation over is restricted to . Here, we use the fact that . From Eq. (18) to (19), we must assume that depends only on the difference in the indices . For example, is the same as . This assumption is satisfied when the original signal or its first-order difference is strongly stationary. This is a reasonable assumption when studying a time series from a dynamical system. The factor in Eq. (19) comes from the fact that, for each , the number of pairs satisfying is . For example, when , the pairs are , as the total number of embedded vectors is .
The probability in Eq. (19) can be decomposed further by considering conditional probabilities. Using the proposition (LABEL:iff:cheb),
| (22) |
holds. The probability of a product event, such as Eq. (22), can be represented as a product of conditional probabilities. For example, the probability that propositions , and hold simultaneously is
| (23) |
In the same way,
| (24) |
holds.
In the following, we show that the above conditional probability behaves oppositely to the Allan variance regardless of , while the unconditional probability does not. This point is the key to understanding why , the MSE and Allan variance show similar dependency.
Figure 6(a) shows a logarithmic-scale color map of , which is the first term on the right-hand side of Eq. (24), whereas Fig. 6(b) shows that of , corresponding to the conditional probability in the second term on the right-hand side of Eq. (24) for .
Each probability was calculated for the LFF time series. For , corresponding to the lowest row in Fig. 6(a) and the solid curve in Fig. 6(c), the unconditioned probability behaves opposite to the Allan variance (see Fig. 4(b)). However, for larger , the behavior differs from that of the case, as shown in the dashed plot in Fig. 6(c).
This can be understood as follows. First, the following equation holds:
| (25) |
For , whether is smaller than is closely related to the Allan variance. If the Allan variance for a certain is smaller than that of another , the distribution is biased toward the center, because the mean value of is zero by definition. Consequently, the probability is high for that . For larger , the distribution is affected by the time correlation of that the time series under study inherently has, and the Allan variance cannot predict the distribution well, so does not behave in a manner that is strongly correlated with the Allan variance.
Conversely, the conditional probability depicted in Fig. 6 (b) shows a similar trend to that of the Allan variance regardless of , which we can also observe in Fig. 6(d). That is, is the main connection that explains the similarity between the MSE and Allan variance. To examine this further, we discuss the variance of the corresponding quantity, rather than considering the probabilities in the following sections.
IV.1.2 Neighborhood-Likelihood-to-Variance-Relationship (NLVR)
In this section, we introduce an assumption called the Neighborhood-Likelihood-to-Variance-Relationship (NLVR) to connect the probability discussion to the variance discussion. First, define as the difference between for and . In the same way, is the difference between for and . Please note that the conditional probability is the same as that in Eq. (24), and the absolute value of , referred to in , is identical to in the definition of .
Then, to connect the probability with the variance, we assume the Neighborhood-Likelihood-to-Variance-Relationship (NLVR), as follows:
| (26) |
The inequality (26) states that the signs of and are always opposite.
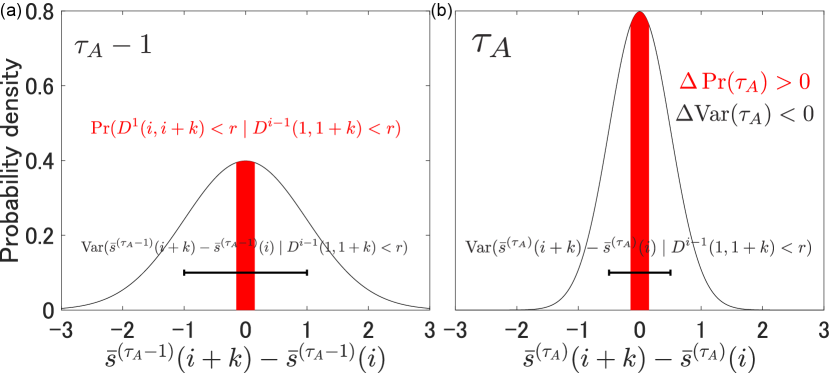
We will explain the NLVR in more detail. Both and are statistics of under the same condition of . Considering the PDF of , represents the area under the PDF in the range . In addition, when there is no condition, the mean of is zero by definition. Here we also assume that the mean value of is close to zero under the condition . When , the distribution of is more centrally biased. Accordingly, when , is likely to be negative.
Figure 5 schematically illustrates the concept of the NLVR. The black curves in Figs. 5 (a) and (b) represent the PDF of under the condition for and , respectively. The red-filled areas and black bars show and , respectively. and are the difference in the red-filled areas and black bars between Figs. 5(b) and (a), respectively. Please note that the plots shown here, based on Gaussian distributions, are for explanatory purposes only and are not obtained from a time series. The validity of the NLVR is discussed in Sec. IV.3.
IV.1.3 Variance decomposition
Here we further discuss the conditional variance , instead of the conditional probability following the NLVR assumption, as mentioned in Sec. IV.1.1. By decomposing as
| (27) |
the conditional variance, , can be decomposed as follows:
| (28) |
Here, the condition is abbreviated by the symbol on the right-hand side of Eq. (28).
[Overview of the variance decomposition]
There are six terms on the right-hand side of Eq. (28). The logarithmic scale color map of each term is shown in Figs. 7(a)–(f) to determine which term has the greatest influence on the conditional variance. Figure 7(g) represents the summation of each term, which is the original conditional variance. Meanwhile, Fig. 7(h) show cross-sectional profiles when regarding the first term (Fig. 7(a)), the third term (Fig. 7(c)) and the total conditional variance (Fig. 7(g)).
As discussed shortly below, the first through third terms in Eq. (28) are dominant, as shown in Figs. 7(a)–(c), whereas they show a similar dependency with the Allan variance regardless of , as indicated in Fig. 7(h).
Please note that we plotted the absolute values of the covariance terms, because the covariance can be negative. However, the dependency of , shown in Figs. 7(c) and (h), is still similar to that of the Allan variance. Conversely, the remaining panels (Figs. 7(d)–(f)) exhibit small values, regardless of and .
Therefore, we observe that the conditional variance , which is shown in Figs. 7(g) and (h), and the conditional probability , shown in Fig. 6(b) for the case of , exhibit the opposite dependency to the Allan variance from the NLVR.
[The first and the second terms]
The first and second terms are the conditional variances of and , namely the conditional Allan variances, respectively. Although the condition somewhat affects the and distribution, the size relationship of the variance of and concerning is almost the same as the Allan variance.
[The third term]
However, the third term is strongly influenced by the condition. In the absence of the condition, if is sufficiently large, there would be little correlation between and ; thus, the covariances are expected to be small. Fig. 8(a) shows the unconditional covariance of and , where the color scale is the same as in Fig. 7. Comparing to the conditional covariance plotted in Fig. 7(c), this covariance without the condition is smaller in most places.
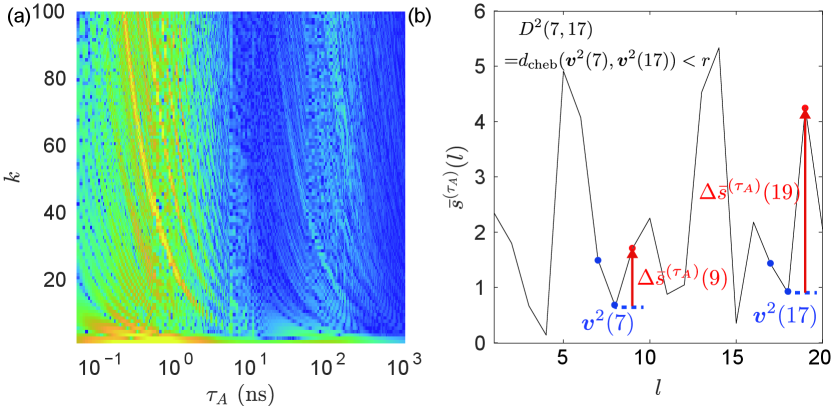
By contrast, when the condition is satisfied, consecutive points up to and are close values. In that case, and , i.e., the difference between these points and their consecutively following point, often have the same sign, and the distribution of their magnitudes follows the Allan variance.
Figure 8(b) shows an example of a pair of and satisfying the condition for . Because we can regard and , denoted by the blue dots, as identical under the tolerance , the red arrows, representing and are likely to be similar. By the definition of covariance, if and are similar, is close to , namely the Allan variance. From these considerations, the conditional covariance behaves similarly to the Allan variance.
Please note that the form of the condition in the Fig. 8(b), namely is slightly different from . However, as we assume stationary, it is allowed to shift the indices. For example, in this case, we examined and under the condition of , and this corresponds to the shifting of indices by six. To be more specific, we investigated and , under the condition of , where and .
[The fourth to the sixth terms]
The fourth to sixth terms do not contribute significantly to the conditional variance, as mentioned earlier. This is due to the fact that , which is involved in the variance or covariance in the fourth to sixth terms, is small when the condition is satisfied. Once again, the condition implies a sort of similarity on the time scale of points, and when these points are similar, the variance of these terms containing the difference will be small.
[Summary of the decomposition]
Adding the above six terms together, we see that the conditional variance eventually behaves similarly to the Allan variance, as shown in Figs. 7(g) and (h). Because the conditional variances and conditional probabilities are assumed by the NLVR to act in opposite directions for increasing scale factors, the conditional probabilities and , represented by the weighted average of the product of probability without conditions and the conditional probabilities , in turn, behave in the opposite direction for increasing scale factors for the Allan variance.
Although we observe the conditional variances and covariances from an LFF time series as an example, the discussion of behavior shown by the variances and covariances is valid for other time series to some extent. In the discussion, we assumed strong stationarity of the signal or its first-order difference to estimate probabilities and variances from the obtained time series. This is because in Eq. (17) cannot be estimated from a single time series. Conversely, the NLVR assumption between probability and variance can also be applied to and and could be valid to a certain extent. Thus, similar behavior exhibited by the MSE and Allan variance should hold for a more general class of signals.

-
(a)
and
-
(b)

-
(a)
,
-
(b)
,
-
(c)
,
-
(d)
,
-
(e)
and
-
(f)
.
-
(g)
The term before the above decomposition, which is .
-
(h)
Cross-sectional profiles when from (a) (red curve), (c) (blue curve), and (g) (black curve) indicated by the arrows.
IV.2 The MSE and Allan variance
In Sec. IV.1, the connection between and the Allan variance was discussed based on the connection between the conditional probability and variance. We can also apply this discussion to the connection between the MSE and Allan variance.
To simplify the discussion, we assume a sufficiently long (strongly stationary) time series, so that we can consider to be the same as the expectation . This is equivalent to assuming ergodicity.
Under this condition,
| (29) |
, in the numerator of Eq. (29) can be decomposed similarly, as shown in Sec. IV.1, as follows:
| (30) |
Let and . Considering the equality , Eq. (29) can be rewritten as follows:
| (31) |
Equation (31) states that the MSE is the negative logarithm of the weighted average of . Because is the conditional probability, the behavior of the MSE can be explained by the conditional probability as well as .
More precisely, we must care about the expectation. can be represented with probability when considering the expectation . The expectation of the MSE is
| (32) | ||||
| (33) |
From Eq. (32) to (33), we use the fact that the negative logarithm is convex, along with Jensen’s inequality. Eq. (33) in general is not the same as
| (34) |
However, it is noteworthy that Costa et al.Costa, Goldberger, and Peng (2005) showed that the MSE values calculated theoretically, using probability, agree well for the WGN and noise cases.
IV.3 Connection between the probability and variance
In Secs. IV.1 and IV.2, we discussed the connection between or the MSE and Allan variance based on the assumption of NLVR. In this section, we discuss the extent to which NLVR is valid, and what happens if it is violated.
[Considering independent identical distribution (i.i.d.)]
For simplicity, we consider the case of independent identical distributions (i.i.d.). In this case, the conditional probability distribution of is identical to the probability distribution of , which is independent of the condition . The distribution does not depend on (see Appendix A). Therefore, it is sufficient to consider the distribution of . In addition, the variances of and are and , respectively.
Therefore, the Allan variance for an i.i.d. system is inversely proportional to . For the WGN case, owing to the reproductive property, the PDF of and are also Gaussian, with variances and , respectively. In addition, because the mean value of is zero, the probability can be represented as follows:
| (35) |
where , and increases monotonically with increasing . Therefore, NLVR holds for all .
The variance of continuously decreases when increases in the i.i.d. case. That is, is negative for all . The cases in which NLVR does not hold are those in which the area under the PDF of in the range decreases with increasing , which means is also negative. This situation seems unlikely to occur when the i.i.d. process is unimodal. That is to say, the reduction of the variance means the shrinking of the distribution toward the center, which means an increase in the probabilities around the center.
[When NLVR is invalid]
However, situations that violate NLVR are likely to occur when, for example, the original system exhibits a multimodal distribution. It should be noted that of a multimodal distribution can have more peaks than the distribution of , owing to the effect of averaging. Thus, may also have many peaks.
The number of peaks increases as increases; however, beyond a certain point, the number of peaks eventually decreases because the peaks fuse with each other. According to the central limit theorem, the distribution of and finally assumes shapes close to a Gaussian distribution in the i.i.d. case. As the number of peaks increases, the area of the PDF of near the center is distributed to each peak, thus, is negative until the effects of this distribution and peaks merging become antagonistic.
[Violation of NLVR by bimodal distributions]
Figure 9 presents an example of this discussion. Figure 9(a) shows a histogram of the original bimodal i.i.d. system composed of two Gaussians centered around . Figures 9(c), (e), and (g) show the histograms of the coarse-grained time series for , respectively. Recall that coarse-graining means averaging over neighboring points. Because the process is i.i.d., two consecutive points have a probability of coming from opposite sides of the origin. Thus, for shown in Fig. 9(b), a third peak appears around the origin. More precisely, the leftmost peak shown in Fig. 9(c) corresponds to the case in which two consecutive points are negative, i.e., from the left peak in Fig. 9(a), which has a probability of . Similarly, the rightmost peak in Fig. 9(c) corresponds to two consecutive positive points, and the center peak corresponds to either positive and negative, or negative and positive points. The number of peaks increases up to a certain , until they start to merge with each other. For a sufficiently large , the distribution approaches a Gaussian distribution, as shown in Fig. 9(g).
Figures 9(b), (d), (f), and (h) show the histograms of the difference between adjacent coarse-grained points for , respectively. The red filled area represents the range and the black bar denotes the standard deviation of the distribution. In fact, the distributions can be regarded as convolutions of the corresponding distribution of . Similar to , the number of peaks increases until a certain and then decreases. In such cases, is negative until a certain , which can be observed from the reduction of the red area in Fig. 9(b)–(f), whereas is always negative. Thus, the NLVR is violated.

[Disagreement of MSE and Allan variance]
Plots of , the MSE, and Allan variance of this bimodal i.i.d. system are presented in Fig. 10. The dashed black line in Fig. 10(a) shows . In contrast to the continuously decreasing Allan variance, decreases until and then increases. (red and blue curves) shows the same trend, and the MSE (black curve) inherits the inverted trend. Actually and (see Appendix A). In contrast, the Allan variance curve plotted in Fig. 10(b) shows dependency (note that the plot is logarithmically scaled), as discussed above. Because the example under study here was an i.i.d. process, the Allan variance result may be considered the more reliable one, as it does not detect any specific time scales of relevance, whereas the MSE indicates a higher level of complexity for than at other scales.

From these discussions we can see that the NLVR is not always valid. For example, the condition may not hold when the original time series contains a multimodal distribution. If the NLVR is violated, meaning that for a large number of , , expressed as a weighted average of the probability, is expected to change in the same direction as the Allan variance. As a result, the Allan variance and MSE change with the opposite sign. In i.i.d. cases, and are independent of , so if NLVR does not hold for a specific and , it is violated for all .
Therefore, in the range of where NLVR holds, the MSE and the Allan variance show similar dependence; in the range where the NLVR is violated, they behave oppositely to . If the time series are time-correlated, as in dynamical systems, the NLVR may be violated by even more complex mechanisms.
IV.4 Empirical validation of the NLVR
Finally, we examine the extent to which the NLVR is satisfied based on empirical data. Specifically, the change in conditional probability () and conditional variance () are calculated for the time series studied in Sections III and IV.3 up to .
First, Fig. 11(a) shows a histogram of the intensity observed in the LFF time series. The intensity is normalized to that without optical feedback, i.e., the intensity in the single mode.Ohtsubo (2017) The histogram shown in Fig. 11(a) has a strong peak near the origin and a smaller peak near the normalized intensity of 3. That is, the probability distribution exhibits a somewhat multimodal distribution, which may cause a violation of the NLVR.
Figures 11(b), (c) and (d) show the scatter plot of () for LFF, WGN, and bimodal distribution, respectively, as explained below. If the NLVR holds, a positive means a negative and a negative means a positive . That is to say, the points in the scatter diagram should be in the second or fourth quadrants.
From Fig. 11(b), almost all the sampling points are concentrated in the second and fourth quadrants, i.e., in regions where the signs of and are opposite. That is to say, even though the probability distribution contains multimodality, this LFF system mostly does not violate the NLVR. From these observations, we speculate that the peaks of the distribution would need to be more separated to lead to a disagreement of the Allan variance and MSE.
Similarly, Fig. 11(c) shows and for the WGN time series. As discussed above, should always be positive, whereas is always negative, i.e., every point should be in the second quadrant. However, the distribution calculated from the time series is not precisely the Gaussian distribution, so some points are in the third quadrant.
Finally, Fig. 11(d) shows the same scatter plot for the bimodal case. In contrast to the LFF and WGN cases, many points are in the third quadrant in violation of the NLVR. This was expected, as we constructed this case specifically as a counter-example.

IV.5 Computation of the MSE and Allan variance
As introduced in Sec. II.2, the definition of MSE involves probabilities, whereas that of the Allan variance is based on the variability of the data under study. Section IV.3 reveals the common underlying mechanism from an information-theoretic viewpoint despite the seemingly different definitions of the statistical measures of multiscale dynamics. In this section, we discuss the difference from the viewpoint of computation between the MSE and Allan variance.
For the MSE, calculating is a computationally demanding task. Computing Eq. (9) for all requires calculations, as all pairs of embedded vectors are compared. Some implementations also require memory to store all the calculated Chebyshev distances. Thus, the MSE evaluates the details of the probability distribution at a high computational cost.
In contrast, the Allan variance calculation requires only computations and memory. The Allan variance does not consider the probability distribution; it depends only on the differences of successive coarse-grained points . As discussed in Sec. IV.3, the MSE for the i.i.d. process depends on the distribution, whereas the Allan variance does not.
Despite being computationally cheaper, it is not obvious that the Allan variance has any disadvantages when compared to the MSE for extracting multiscale features. The Allan variance is a statistical measure that is similar but not identical to the MSE, and that quantifies slightly different aspects of the time series.
In the literature, the range of applications of the MSE is versatile, such as bearing fault detectionWang, Yao, and Cai (2020) and sleep level qualification.Liang et al. (2012) However, the MSE suffers from severe computational difficulties as discussed above. Concerning the similar properties of the MSE and Allan variance, as well as the computationally lightweight nature of Allan variance, the extension of the Allan variance to real-time applications, such as bearing fault detection or prediction of epilepsy from electroencephalography (EEG), would be an interesting future topic.
V Conclusion
In this study, we examined the similarities shown by the multiscale statistics the MSE and Allan variance, and discussed the underlying mechanisms through an information-theoretic analysis. It is noteworthy that although the apparent definitions of the MSE and Allan variance are significantly different, they show a similar behavior for a wide range of time-series data. We experimentally confirmed the similar properties of the MSE and Allan variance observed in LFF in chaotic lasers and physiological heartbeat data, as well as white Gaussian and noise. The connection can be understood by decomposing the conditional probabilities in the MSE and extracting the dominant contributions. We derived a condition which must be satisfied for the MSE and Allan variance to exhibit similar tendencies via a discussion of conditional probabilities. Then, we artificially constructed a random sequence that violates the condition, leading to inconsistent MSE and Allan variance behavior. We also quantitatively demonstrated that the aforementioned LFF and heartbeat, which are physically plausible systems, mostly satisfy the condition.
Finally, we discussed future research topics. Using Allan variance instead of the MSE may lead to more computationally lightweight applications that are suitable for real-time tasks. In addition, there is a possibility of integrating further developments that have been devised for the MSE Humeau-Heurtier (2015) and Allan variance.Kroupa (2012)
Furthermore, more research on the theoretical foundations of coarse-graining and the MSE is needed. The MSE research to date has focused mainly on its application as a statistical tool, and there has been little research on its theoretical foundations. The relationship between the dynamics of a coarse-grained time series and those of the original time series is unclear. Coarse-graining can be regarded as a combination of a moving-average filter and downsampling; however, according to a previous study,Sauer, Yorke, and Casdagli (1991) a linear filter applied to the original time series during Takens’ embedding preserves its topological properties. From this theorem, it may be possible to discuss the theoretical basis of coarse-graining from the viewpoint of dynamical invariants, including entropies. Meanwhile, the theoretical foundations of the MSE should be more complicated, as the MSE shares the tolerance for all scales. As pointed out by Humeau-Heurtier,Humeau-Heurtier (2015) more and more embedded vectors may be regarded as neighbors of each other as the scale factor increases, owing to the reduction of the variance of the coarse-grained time series. Notably, Costa et al. Costa, Goldberger, and Peng (2005), the original proposers of the MSE, pointed out that the variance changes induced by coarse-graining are related to the temporal structures of the original time series. We may need a framework that allows us to connect the dynamical invariants at each time scale.
Acknowledgments
This work was supported in part by the CREST Project (JPMJCR17N2) funded by the Japan Science and Technology Agency and Grants-in-Aid for Scientific Research (JP20H00233), and Transformative Research Areas (A) (JP22H05197) funded by the Japan Society for the Promotion of Science (JSPS). AR is supported by JSPS as an International Research Fellow.
Appendix A Independent identical distributions case
In this section, we discuss the properties of conditional probability and conditional variance for i.i.d. systems.
Let be the i.i.d. time series under study. We can regard as a sequence of random variables. Obviously, the coarse-grained time series defined as
| (36) |
is also an i.i.d. sequence of random variables. To simplify the symbols, let the random variable be . We now define the PDF of as . Please note that the function itself is independent of .
The distribution of under the condition is then computed. For visibility, we define the random variable as follows:
| (37) |
Let be the PDF of under the condition of . can be represented by as follows:
| (38) |
where
| (39) | ||||
| (40) |
Here we used the fact that the joint PDF of i.i.d. random variables is equal to the product of PDFs of each random variable. Because the conditions in Eqs. (39) and (40) refer to different variables, the integral in the numerator of Eq. (38) can be separated into the integrals of variables and , and the other terms, as follows:
| (41) |
where
| (42) | |||
| (43) |
Here, different from Eqs. (39) and (40), there is no variable overlap between Eqs. (42) and (43). Similarly, the denominator can also be decomposed as follows:
| (44) |
Here we used the fact that
| (45) |
As a result, Eq. (38) can be reduced to
| (46) |
Equation (46) is the PDF of without any conditions. In conclusion, the condition does not matter in i.i.d. cases. In addition, the above calculation does not depend on and except for , as . Here appears in both and , so we cannot divide the integral in the same manner. However, the same conclusion can be derived for . Here we introduce a variable transformation, as follows:
| (47) |
Using , the integral of the numerator in Eq. (38) can be written as follows:
| (48) |
Similarly, the integral in the denominator in Eq. (38) is
| (49) |
Because the only difference between Eqs. (48) and (49) is the range of the integral for , we can cancel the integrals for , and the remaining integrals for the numerator and denominator are
| (50) |
and
| (51) |
respectively. Consequently, the resulting PDF is
| (52) |
This is equivalent to the PDF of without any conditions. Summarizing the results thus far, is the same as the PDF of without any conditions for all . In addition, the calculation does not depend on . Consequently, it is sufficient to discuss the distribution of in i.i.d. cases.
From the above results, can be expressed as follows:
| (53) | ||||
| (54) | ||||
| (55) | ||||
| (56) |
Here, we obtain Eq. (53) in the same manner as Eq. (24). From Eq. (53) to (54), we ignored the condition term, as discussed above. From Eq. (54) to(55) and (56), we used the fact that the distribution of is independent of and . Consequently, , and holds.
It is noteworthy that the variances of and are and respectively, with regard to the variance of , as
| (57) |
and
| (58) |
hold because and are i.i.d.
References
- Costa, Goldberger, and Peng (2002) M. Costa, A. L. Goldberger, and C.-K. Peng, “Multiscale entropy analysis of complex physiologic time series,” Phys. Rev. Lett. 89, 068102 (2002).
- Catarino et al. (2011) A. Catarino, O. Churches, S. Baron-Cohen, A. Andrade, and H. Ring, “Atypical eeg complexity in autism spectrum conditions: A multiscale entropy analysis,” Clinical Neurophysiology 122, 2375–2383 (2011).
- Costa, Goldberger, and Peng (2005) M. Costa, A. L. Goldberger, and C.-K. Peng, “Multiscale entropy analysis of biological signals,” Phys. Rev. E 71, 021906 (2005).
- Martina et al. (2011) E. Martina, E. Rodriguez, R. Escarela-Perez, and J. Alvarez-Ramirez, “Multiscale entropy analysis of crude oil price dynamics,” Energy Economics 33, 936–947 (2011).
- Wang et al. (2013) J. Wang, P. Shang, X. Zhao, and J. Xia, “Multiscale entropy analysis of traffic time series,” International Journal of Modern Physics C 24, 1350006 (2013), https://doi.org/10.1142/S012918311350006X .
- Allan (1966) D. Allan, “Statistics of atomic frequency standards,” Proceedings of the IEEE 54, 221–230 (1966).
- Filler (1988) R. Filler, “The acceleration sensitivity of quartz crystal oscillators: a review,” IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control 35, 297–305 (1988).
- Skrinsky, Skrinska, and Zelinger (2014) J. Skrinsky, M. Skrinska, and Z. Zelinger, “Allan variance - stability of diode-laser spectrometer for monitoring of gas concentrations,” in 2014 International Conference on Mathematics and Computers in Sciences and in Industry (2014) pp. 159–164.
- Humeau-Heurtier (2015) A. Humeau-Heurtier, “The multiscale entropy algorithm and its variants: A review,” Entropy 17, 3110–3123 (2015).
- Lang and Kobayashi (1980) R. Lang and K. Kobayashi, “External optical feedback effects on semiconductor injection laser properties,” IEEE Journal of Quantum Electronics 16, 347–355 (1980).
- Goldberger et al. (e 13) A. L. Goldberger, L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. C. Ivanov, R. G. Mark, J. E. Mietus, G. B. Moody, C.-K. Peng, and H. E. Stanley, “PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals,” Circulation 101, e215–e220 (2000 (June 13)), circulation Electronic Pages: http://circ.ahajournals.org/content/101/23/e215.full PMID:1085218; doi: 10.1161/01.CIR.101.23.e215.
- Irurzun et al. (2021) I. M. Irurzun, L. Garavaglia, M. M. Defeo, and J. T. Mailland, “Rr interval time series from healthy subjects (version 1.0.0),” PhysioNet (2021), https://doi.org/10.13026/51yd-d219.
- Baim et al. (1986) D. S. Baim, W. S. Colucci, E. S. Monrad, H. S. Smith, R. F. Wright, A. Lanoue, D. F. Gauthier, B. J. Ransil, W. Grossman, and E. Braunwald, “Survival of patients with severe congestive heart failure treated with oral milrinone,” Journal of the American College of Cardiology 7, 661–670 (1986).
- Petrutiu, Sahakian, and Swiryn (2007) S. Petrutiu, A. V. Sahakian, and S. Swiryn, “Abrupt changes in fibrillatory wave characteristics at the termination of paroxysmal atrial fibrillation in humans,” EP Europace 9, 466–470 (2007), https://academic.oup.com/europace/article-pdf/9/7/466/1470935/eum096.pdf .
- Larger et al. (2012) L. Larger, M. C. Soriano, D. Brunner, L. Appeltant, J. M. Gutierrez, L. Pesquera, C. R. Mirasso, and I. Fischer, “Photonic information processing beyond turing: an optoelectronic implementation of reservoir computing,” Opt. Express 20, 3241–3249 (2012).
- Rogister et al. (2001) F. Rogister, A. Locquet, D. Pieroux, M. Sciamanna, O. Deparis, P. Mégret, and M. Blondel, “Secure communication scheme using chaotic laser diodes subject to incoherent optical feedback and incoherent optical injection,” Opt. Lett. 26, 1486–1488 (2001).
- Mengue and Essimbi (2012) A. D. Mengue and B. Z. Essimbi, “Secure communication using chaotic synchronization in mutually coupled semiconductor lasers,” Nonlinear Dynamics 70, 1241–1253 (2012).
- Mihana et al. (2020) T. Mihana, K. Fujii, K. Kanno, M. Naruse, and A. Uchida, “Laser network decision making by lag synchronization of chaos in a ring configuration,” Opt. Express 28, 40112–40130 (2020).
- Wagner and Marriott (2008) G. S. Wagner and H. J. L. H. J. L. Marriott, Marriott’s practical electrocardiography, 11th ed. (Wolters Kluwer Health/Lippincott Williams & Wilkins, 2008).
- Barnes et al. (1971) J. A. Barnes, A. R. Chi, L. S. Cutler, D. J. Healey, D. B. Leeson, T. E. McGunigal, J. A. Mullen, W. L. Smith, R. L. Sydnor, R. F. C. Vessot, and G. M. R. Winkler, “Characterization of frequency stability,” IEEE Transactions on Instrumentation and Measurement IM-20, 105–120 (1971).
- Richman and Moorman (2000) J. S. Richman and J. R. Moorman, “Physiological time-series analysis using approximate entropy and sample entropy,” American Journal of Physiology-Heart and Circulatory Physiology 278, H2039–H2049 (2000), pMID: 10843903.
- Delgado-Bonal and Marshak (2019) A. Delgado-Bonal and A. Marshak, “Approximate entropy and sample entropy: A comprehensive tutorial,” Entropy 21 (2019), 10.3390/e21060541.
- Uchida (2012) A. Uchida, Optical Communication with Chaotic Lasers: Applications of Nonlinear Dynamics and Synchronization (Wiley-VCH, 2012).
- Ohtsubo (2017) J. Ohtsubo, Semiconductor Lasers: Stability, Instability and Chaos Fourth Edition (Springer, 2017).
- Wang, Yao, and Cai (2020) Z. Wang, L. Yao, and Y. Cai, “Rolling bearing fault diagnosis using generalized refined composite multiscale sample entropy and optimized support vector machine,” Measurement 156, 107574 (2020).
- Liang et al. (2012) S.-F. Liang, C.-E. Kuo, Y.-H. Hu, Y.-H. Pan, and Y.-H. Wang, “Automatic stage scoring of single-channel sleep eeg by using multiscale entropy and autoregressive models,” IEEE Transactions on Instrumentation and Measurement 61, 1649–1657 (2012).
- Kroupa (2012) V. Kroupa, Frequency stability (Wiley-IEEE PRESS, 2012).
- Sauer, Yorke, and Casdagli (1991) T. Sauer, J. A. Yorke, and M. Casdagli, “Embedology,” Journal of Statistical Physics 65, 579–616 (1991).