Information Elicitation Meets Clustering
Abstract
In the setting where we want to aggregate people’s subjective evaluations, plurality vote may be meaningless when a large amount of low-effort people always report “good” regardless of the true quality. “Surprisingly popular” method, picking the most surprising answer compared to the prior, handle this issue to some extent. However, it is still not fully robust to people’s strategies. Here in the setting where a large number of people are asked to answer a small number of multi-choice questions (multi-task, large group), we propose an information aggregation method which is robust to people’s strategies. Interestingly, this method can be seen as a rotated “surprisingly popular”. It is based on a new clustering method, Determinant MaxImization (DMI)-clustering, and a key conceptual idea that information elicitation without ground-truth can be seen as a clustering problem. Of independent interest, DMI-clustering is a general clustering method that aims to maximize the volume of the simplex consisting of each cluster’s mean multiplying the product of the cluster sizes. We show that DMI-clustering is invariant to any non-degenerate affine transformation for all data points. When the data point’s dimension is a constant, DMI-clustering can be solved in polynomial time. In general, we present a simple heuristic for DMI-clustering which is very similar to Lloyd’s algorithm for k-means. Additionally, we also apply the clustering idea in the single-task setting and use spectral method to propose a new aggregation method that utilizes the second-moment information elicited from the crowds.
1 Introduction
When we want to forecast an event, make a decision, evaluate a product, or test a policy, we need to elicit information from the crowds and then aggregate the information. In many scenarios, we may not have ground-truth answer to verify the elicited information. For example, when we poll people’s voting intentions or elicit people’s subjective evaluations, there is no ground-truth for people’s feedback. Recently, a line of work [17, 18, 20, 14, 15, 13] explore how to incentivize people to be honest without ground-truth. Some work [19, 15] also study how to aggregate the information without ground-truth.
A natural way to aggregate information without ground-truth is “plurality vote”, i.e., output the most popular option. For example, in product evaluation, when the feedback of is 56% “good”, 40% “so so”, 4% “bad”, the plurality answer is “good”. However, if there are a large amount of people who always choose “good” regardless of the quality, plurality vote will always output “good” thus becomes meaningless. A more robust method is “surprisingly popular”, proposed by Prelec et al. [19]. In the above example, if the prior is 70% “good”, 26% “so so”, 4% “bad”, “surprisingly popular” will aggregate the feedback to “so so” which is the most surprisingly popular answer (). This will handle the above issue to a certain degree. However, “surprisingly popular” may not work in some scenarios.
Example 1.1.
When the ground truth state is “good”, the distribution over people’s feedback is (56% “good”, 40% “so so”, 4% “bad”); when the ground truth state is “so so”, the distribution is (56% “good”, 34% B, 10% “bad”); ground truth state “bad” corresponds to (46% “good”, 44% “so so”, 10% “bad”). Each state shows up with equal probability. Thus, the prior is approximately (52.7% “good”,39.3% “so so”,8% “bad”)
In the above example, for both (56% “good”, 34% “so so”, 10% “bad”) and (46% “good”, 44% “so so”, 10% “bad”), the “surprisingly popular” answer is “bad”, while they correspond to different ground truth.
Therefore, “surprisingly popular” requires an additional prior assumption about the relationship between the ground truth state and people’s answers [19]. However, even if people’s honest answers satisfy the assumption, people can perform a strategy to their answers to break the assumption. Here is an example.
Example 1.2.
When the ground truth state is “good”, the distribution over people’s feedback is (100%,0%,0%); when the ground truth state is “so so”, the distribution is (0%,100%,0%); ground truth state “bad” corresponds to (0%,0%,100%). All people perform a strategy: given my private answer is “good”, I will report “good” with probability .56, “so so” with probability .4, “bad” with probability .04, given my answer is “so so”, I will … The strategy is represented by a row-stochastic matrix where each row represents the reporting distribution for each private answer. In this case, people’s strategic behaviors change the report distribution to the previous example and "surprisingly popular" will not work here.
Thus, a fundamental problem of the “surprisingly popular” method is that though it is more robust than plurality vote method, it is not fully robust to people’s strategies.
To this end, we can naturally ask for an information aggregation method that is robust to people’s strategies, that is, regardless of people’s strategies, the aggregation result will not change.
However, it may ask too much since people can permute their answers and no method is robust to this permutation strategy. Thus we change the requirement to the aggregation result will not change up to a permutation and use side information (e.g. ground truth of a small set of questions) to determine the permutation.

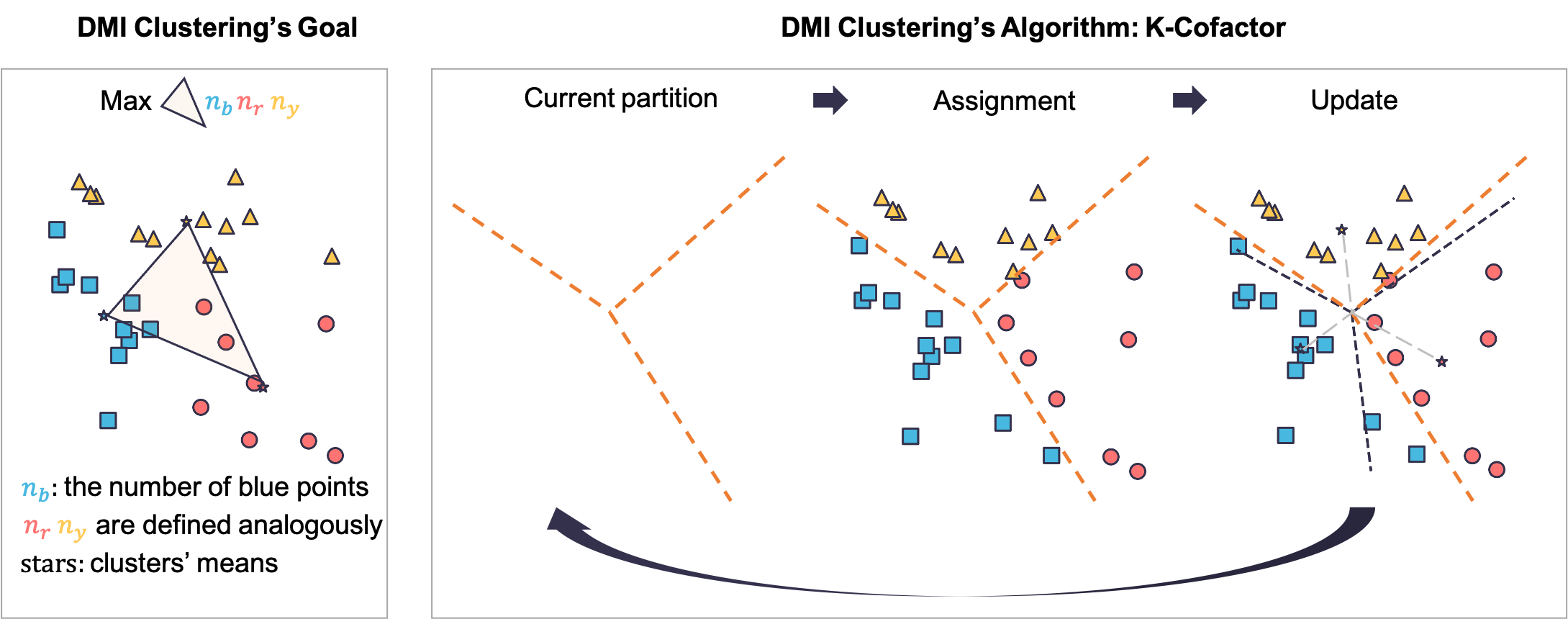
It turns out that when we have a large number of people, and a small set of a priori similar tasks (each task is a multi-choice question), the answer is yes. A key conceptual idea is to reduce information aggregation without ground truth to a clustering/unsupervised learning problem. That is, we can use a datapoint to represents a task’s feedback. Assigning answers to the tasks can be understood as clustering the data points (Figure 1). Recall the previous example, when people perform a strategy to their reports, all feedback are transformed by an affine transformation 111It holds even if people adopt different strategies as long as each task is performed by a large number random people.. Therefore, designing a robust information aggregation method is equivalent to design an affine-invariant clustering method. We then propose an affine-invariant clustering method, Determinant MaxImization (DMI) clustering, and apply it into the information elicitation without verification.
DMI-clustering is the technical highlight in this paper. Previous affine-invariant clustering work [2, 10] either has a different definition for affine-invariance222They require that items that are same up to affine transformations (e.g. images of the same chair observed in different angles) should be clustered into the same cluster. In our setting, we require the clustering result remains the same when all items are transformed by the same affine transformation. from this work or has an underlying probabilistic model assumption and requires sufficiently number of data points [5, 12]. In contrast, DMI-clustering is a non-parametric affine-invariant method that applies to any finite number of data points and does not require any probabilistic model assumption. DMI-clustering provides a relatively affine-invariant evaluation to each clustering, the volume of the simplex consisting of each cluster mean multiplying the product of the cluster sizes, and aims to find the clustering with the highest evaluation.
When we apply DMI-clustering into information elicitation, the dimension of the data points is the number of options, which can be seen as a constant. In this case, we show that there exists a polynomial time algorithm for DMI-clustering. In general, we present a simple local-maximal searching heuristic for DMI-clustering, k-cofactors, which is similar to Lloyd’s algorithm [16] for k-means. We illustrate the geometric interpretation of DMI-clustering and k-cofactors for 2d points in Figure 2.
To apply DMI-clustering to multi-task information elicitation, we can normalize each question’s feedback as a data point (e.g. (46% A, 44% B, 10% C)). Given multiple questions’ feedback, we can apply DMI-clustering to obtain the final answer333To determine the cluster’s label, we can use side information like ground-truth of a small set of questions..
We also compare DMI-clustering with the surprisingly popular method. Interestingly, we find that they are equivalent for binary-question and in general, DMI-clustering can be understood as a “rotated” surprisingly popular method.
In addition to the multi-task setting, it’s also very useful to think from a clustering view in the single-task setting where we only have a single multi-choice question to people. The “surprisingly popular” method can be seen as a clustering method which only employs the first moment. To obtain the first moment, we can ask people’s second moment information (e.g. what’s your prediction for other people’s answer) and reconstruct the first moment using the second moment [19]. From a clustering view, it’s very natural to apply spectral method, which uses the second moment information, to design a new information aggregation method in the single-task case. If we can use a hypothetical question to elicit a higher-order-moment information, we can apply higher-order-moment clustering method for single-task setting.
Our results
We connect information elicitation without ground truth with clustering, and
- Multi-task & Affine-invariance
-
we propose an affine-invariant clustering method and apply it to propose a multi-task information elicitation mechanism that 1) aggregates information in a way that is robust to people’s strategies when the number of agents is infinite, 2) reduces the payment variance in some scenarios while still preserves previous multi-task mechanisms’ incentive properties;
- Single-task & Methods of moments
-
we apply method of moments clustering method in the single-task setting. With only the second-moment information, we apply spectral method to propose a new aggregation mechanism which is better than the “surprisingly popular” method in some scenarios.
The main conceptual contribution of this work is the connection between clustering and information elicitation without ground truth. This connection not only brings clustering techniques to information elicitation without verification, but also brings attention to the clustering setting where the input data point, and the property of the data (e.g. moment information) can be elicited from the crowds. We hope this connection can generate more results in the future for information elicitation/aggregation without ground truth in the future.
1.1 Related Work
Information elicitation without ground truth (peer prediction) is proposed by Miller et al. [17]. The core problem is how to incentivize people to report high-quality answer even if the answer cannot be verified. The key idea is to reward each agent based on her report and her peer’s reports. A series of work [18, 8, 20, 14, 15, 13] have focused on this problem and develop reward schemes in varies of settings. However, in many scenarios, we want to not only incentivize high-quality answer but also make an aggregation of the answers. Thus, Some of information elicitation work also explore how to aggregate information without ground truth and there are two approaches here.
One approach is to use the plurality of high-payment agents’ answer. Liu et al. [15] employ this way to aggregate people’s reports based on various of payment schemes. However, incentive-compatible payment schemes only guarantees high-quality answer receives high payment in expectation. If the payment has a high variance, which happens especially when the number of tasks is small, high-payment agent may not provide high quality answers. Thus, here each agent needs to perform a sufficiently number of tasks to reduce the payment variance. A large literature of extracting wisdom from crowd also uses the idea that first estimate the crowd’s quality and then use the estimated quality to aggregate their opinions (e.g. (e.g. [6, 22])). The quality can either be estimated from previous performance the crowds or from a EM framework proposed by Dawid and Skene [9]. Though the EM framework based estimation does not requires historical data, it still requires each person to answer a sufficient amount questions to get a good estimation. Moreover, it usually requires an underlying probabilistic model: there exists a ground truth and conditioning on the ground truth, people’s reports are independent.
Another approach is to directly evaluate the answer itself. A popular method is the “surprisingly popular” method. Prelec et al. [19] uses this method in the single-task setting by eliciting people’s predictions for other people’s answer and reconstructing the prior using the predictions. In the setting we have already known the prior, this method can be directly implemented. However, like we mentioned in introduction this method requires an additional assumption for the prior.
More importantly, none of these aggregation approaches is robust to people’s strategies. Though for Determinant based Mutual Information (DMI)-Mechanism [13], the expected payment is relatively robust to other people’s strategies, we still need each agent to perform a sufficiently number of tasks to reduce the payment variance. However, the setting when we have a large number of agents and each agent performs a small number of tasks may be more practical. The multi-task setting in this work focuses on this more practical setting and proposes an aggregation method, DMI-clustering, which is robust to people’s strategies. DMI-clustering is inspired by DMI-Mechanism [13]. Unlike DMI-Mechanism based aggregation approach uses the plurality of high-payment agents’ answer, DMI-clustering learns the answers which has the highest determinant mutual information with the collection of people’s answers. When we have a large number of participants, the learning process is independent of their strategies, even if each participant only performs a small number of tasks. Xu et al. [24] also employ the property of Determinant based Mutual Information to design a robust loss function. Unlike this work, Xu et al. [24] focus on the noisy labels setting rather than the unsupervised clustering setting.
DMI-clustering is a new general clustering method. The most important property of DMI-clustering is affine-invariance. Affine-invariant clustering is well studied in image classification [23, 10, 2]. However, they have a different definition for affine-invariance from this work. In their definition, images that are about the same item observed in different angles should be classified into the same cluster.
Unlike the above work about affine-invariance, we focus on the setting where all data points are transformed by the same affine transformation and we want the clustering for these data points remains invariant to the transformation. Brubaker and Vempala [5], Huang and Yang [12] also use this definition and propose an affine-invariant clustering method. However, Brubaker and Vempala [5] focus on the application in mixture model and require the knowledge of the number of components and sufficient amount of sample data points. Huang and Yang [12] have an underlying probabilistic model and develop a maximum likelihood estimator based algorithm. In contrast, DMI-clustering is a non-parametric affine-invariant method that applies to any finite number of data points and does not require any probabilistic model assumption. Moreover, DMI-clustering provides a relatively affine-invariant evaluation to each clustering. Thus, when we have side information that gives a constraint for the set of clustering (e.g. we need to pick one from clustering I or clustering II), DMI-clustering method is still affine-invariant.
DMI-clustering is more similar to k-means clustering. Like k-means, it has a natural geometric interpretation and a simple local-maxima searching heuristic that uses each cluster’s mean. One difference from k-means is that DMI-clustering can not pick any it wants since it needs to satisfy the affine-invariance444If we have linearly independent -dimensional data points, k-means method can pick any . However, DMI-clustering must pick and make each individual data point a cluster by itself since these data points can be any other linearly independent -dimensional data points by a proper affine-transformation. .
The definition of DMI-clustering uses determinant. Log-determinant divergence [7]’s definition also uses determinant and is affine-invariant in its definition. However, still, the affine-invariance of log-determinant divergence is different from this work. It refers to the property that the divergence between two positive definite matrices is invariant to affine transformations. The geometric interpretation of DMI-clustering is maximizing the volume of simplex constituted by cluster’s means, multiplying the product of cluster sizes. Thurau et al. [21] also connect simplex volume maximization with clustering. However, their problem is very different from ours and irrelevant to affine-invariance. They aim to design an efficient algorithm for matrix factorization by greedily picking the basis vectors such that the simplex formed by these basis vectors has the maximal volume.
2 Determinant MaxImization (DMI) Clustering
In this section, we will introduce a new clustering method, DMI-clustering, that is based on determinant maximization. We will show that this method is invariant to any affine transformation which is performed on all data points due to the multiplicative property of determinant. We will also show that this clustering method will generate a clustering which has a natural geometric interpretation: there will be a representative vector for each cluster and each data point is mapped to the cluster whose representative vector has the highest inner-product with the data point.
Moreover, we will introduce a heuristic algorithm, k-cofactors, which is similar to Lloyd’s algorithm for k-means. When the data points are in 2-dimension, we visualize the algorithm and introduce an interesting geometric way to perform the algorithm. All synthetic data used for demonstration is attached in appendix. We will also show that there exists a polynomial time algorithm for DMI-clustering when is a constant. We first introduce the clustering method.
The core of DMI-clustering is an evaluation metric for each clustering, DMI-score. We will show that intuitively, DMI-score is the volume of the simplex formed by clusters’ means, multiplying the product of cluster sizes. DMI-clustering aims to find the clustering that has the highest DMI-score. A naive attempt to solve the optimization problem in DMI-clustering is to enumerate all possible . However, it needs an exponential running time in , even when is a constant. To have a better algorithm, in addition to show that DMI-clustering is affine-invariant, we also analyze the clustering result of DMI-clustering and find that it is linearly-partitioned. This linearly-partitioned property will directly induce a polynomial time algorithm when is a constant and a simple local maximal-searching heuristics in general. We will use the following notation to describe the clustering result of DMI-clustering.
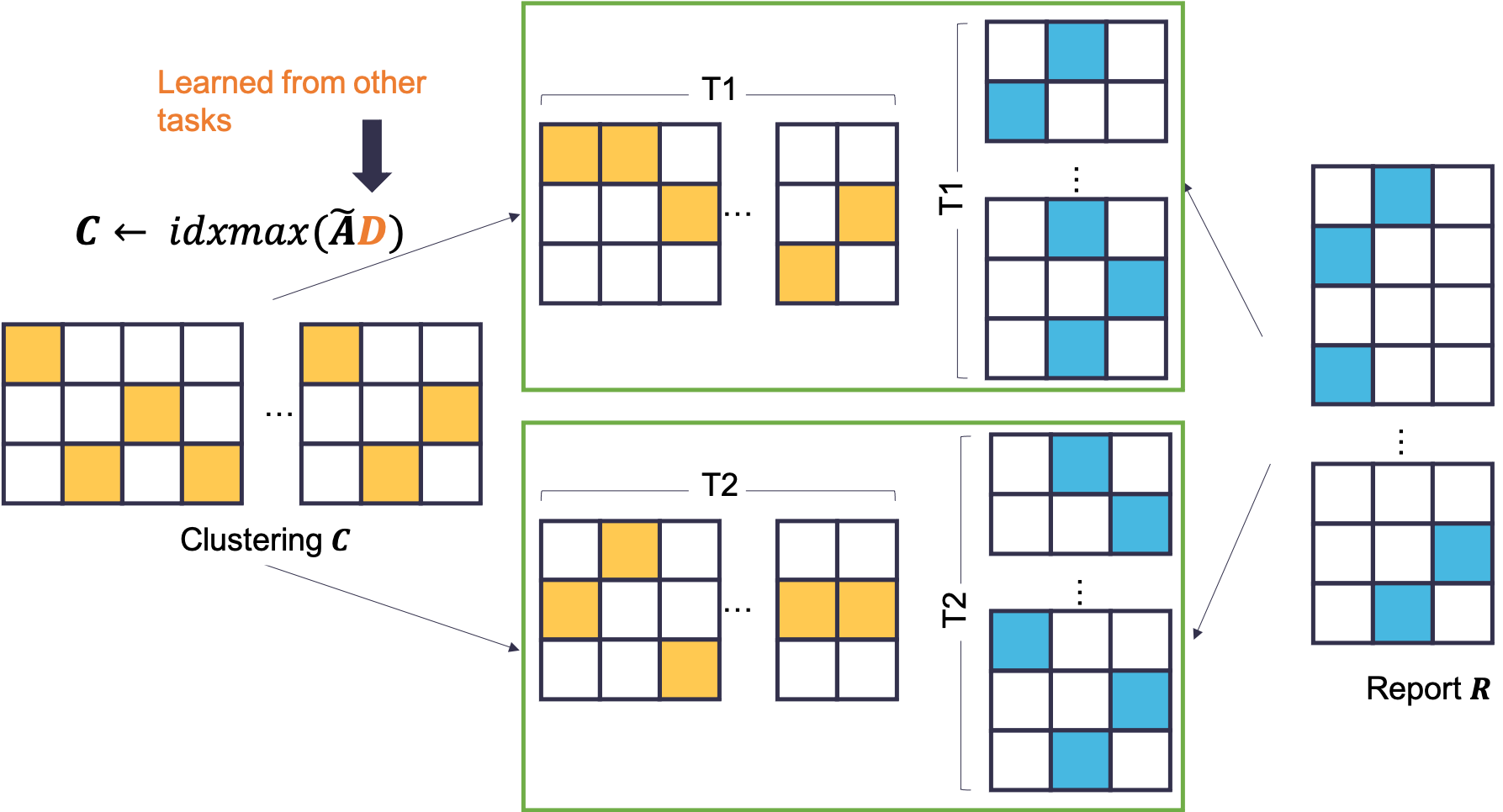
Definition 2.1 (Index of row’s max).
For matrix , we define as a matrix such that for all , ’s row is a one-hot vector that indicates the index of the largest entry of ’s row. When there is a tie, we define as a set of all matrices whose rows indicate the index of the largest entry of ’s rows. For example,
We start to introduce the theoretic properties of DMI-clustering and visualize them in Figure 3.

Theorem 2.2.
DMI-clustering is
- Legal
-
when there exists full rank such that where is invertible, for both hard constraint and soft constraint , equals (up to column permutation).
- Affine-invariant
-
the DMI-score of is relatively invariant to any invertible affine transformation of the data points, i.e., for all invertible and , for all which have non-zero DMI-score regarding ,
thus, for any constraint set , is equivalent to in the sense that any solution of is also a solution of , vice versa;
- Linearly-partitioned
-
when we maximize over , is a local maximal of if and only if where .
Geometrically, the average of ’s row vectors is the intersection of all partitions, i.e., and if ’s rank is d, the optimization goal is equivalent with maximizing the volume of the simplex consist of each cluster’s mean, multiplying the product of the cluster sizes.
For simple one-dimensional case, we show that DMI-clustering will partition the numbers based on the mean (Corollary 2.3). For other dimensions, the linearly-partitioned property directly induce an algorithm (Algorithm 2) to find the local optimum. This algorithm is very similar to Lloyd’s algorithm for k-means: 1. assignment: assign the points according to the current partition; 2. update: update the partition using the current clusters. We call this algorithm k-cofactors since the update step employs the cofactors of the matrix which consists of the current cluster means. In the 2d case, we will translate the operations in k-cofactors into natural geometric operations (Algorithm 3, Figure 4). In the end of this section, we will also show that the linearly-partitioned property induces a polynomial algorithm when the dimension is a constant, based on properties of shatter functions.
Corollary 2.3 (1d points).
For n real numbers where there exists such that , DMI-clustering will partition the numbers into two clusters: above the average and below the average.
Proof of Corollary 2.3.
Since DMI-clustering is affine-invariant, we subtract the average from each number and define vector .
| (add first row the second row) | ||||
| (the sum of is 0) | ||||
To maximize , the 0-1 vector will pick all positive entries of . Thus, DMI-clustering will partition the numbers into two clusters: above the average and below the average. ∎


Corollary 2.4 (2d points).
For any , if ’s rank is two888Otherwise it will reduce to the 1d case., then running (Algorithm 1) with k-cofactors algorithm (Algorithm 2) is equivalent to Algorithm 3. Geometrically, the optimization goal is equivalent with maximizing the area of the triangles multiplying the where is the number of points in cluster .
Proof of Corollary 2.4.
If ’s rank is two, then is rank three. Therefore, we will pick .
where is the number of points in cluster . Thus maximizing is equivalent to maximizing the area of the triangles multiplying the .
For , we have
We also have that
and by similar analysis,
For point ,
and
when , should be mapped to cluster 1 and when , can be mapped to either cluster 2 or cluster 3. Thus, we can obtain the partition line for cluster 2 and 3, call it line 2-3, by extending line segment . By analogous analysis for , we obtain three partition lines like Figure 4.
For each point between line 1-2 and 2-3, we can represent it as where . Then , and . Thus, belongs to cluster 2. By analogous analysis for other points, we finish the proof.
∎
Proof of Theorem 2.2.
We first prove the affine-invariance. Note that
Thus, for invertible , both and have the same rank .
Since are linearly independent columns of , there exists such that . Therefore, we have .
Thus, for any that consists of linearly independent columns in , we pick corresponded column vectors of to construct matrix . We have and is invertible (otherwise ’s rank will be less than which is a contradiction).
Therefore,
due to the multiplicative property of determinant. The relative-invariance of DMI-score and affine-invariance of DMI-clustering directly follows from the above formula.
We then show that DMI-clustering is legal. Note that since it is affine-invariant, we only need to analyze . Since the sum of the column vectors of is all one vector and the rank of is , we can pick itself as the matrix that consists of linearly independent columns of .
We normalize by dividing each column vector by its sum to obtain . Note that this normalization is equivalent to multiplying a diagonal matrix on the right. Thus, maximizing over is equivalent to .
Moreover, is an identity matrix whose determinant is one. Since both and are column-stochastic matrices999Each entry is in [0,1] and each column sums to 1., their product is still a column-stochastic matrix. When does not equal to even up to column permutation, i.e., there does not exist a permutation matrix such that , the product of and will be a non-permutation column-stochastic matrix whose determinant is strictly less than 1. Therefore, when there exists full rank such that where is invertible, equals (up to column permutation).
Finally, we prove that the clustering result is linearly-partitioned. ’s row vectors are . ’s row vectors are denoted by .
For all , we denote the cluster it is mapped to by , i.e., . For all , when is a local maximum, the current assignment is better than moving to cluster , that is,
Due to the multilinear property of determinant,
Thus, we have
for all .
Since , is the cofactors of matrix . We denote ’s column vectors by .
Due to Laplace expansion, we have
Since is the maximum that must be positive, we have for all , for all ,
Thus, . Moreover,
which shows that , i.e., the mean of all data points is in the intersection of all partitions. We also have
whose determinant is proportional to the volume of the simplex formed by , multiplying the product of cluster sizes . We finish the proof.
∎
The linearly-partitioned part in the above theorem shows that instead of trying all possible , we can try all possible and check whether its corresponding is optimal to obtain the result of DMI-clustering. In particular, when dimension is a constant, there exists the number of distinct linear-partitions are polynomial in the number of data points due to theory of VC dimension [4]. This implies the following corollary.
Corollary 2.5.
When dimension is a constant, when we maximize over the default constraint , there exists a polynomial algorithm for DMI-clustering.
Proof.
When is a constant, the number of clusters is a constant as well. Given data points, for any linear-partition , the points that belong to cluster 1 is the set of all points thus is intersections of half-spaces. Since half-space’s VC dimension is a constant here, there will be at most polynomial distinct cluster 1. Moreover, the number of clusters is a constant here. Thus there will be most distinct linear-partitions. Thus, we can enumerate these linear-partitions in polynomial time and check which one gives the best cluster that maximizes the determinant.
∎
In the next section, we will apply DMI-clustering to extract knowledge from elicited information without ground truth. We will show that this method will be robust to people’s strategies and expertise.
3 Multi-task & Invariant Clustering
This section will introduce a multi-task information elicitation mechanism which is not only dominantly-truthful but also extracts knowledge from the collected answers. The extraction is robust when each task is answered by a large number of randomly selected people.
3.1 Knowledge-Extracted DMI (K-DMI)-Mechanism
Setting
There are a priori similar tasks and agents. Each task is a multi-choice question with options. Each agent is assigned a random set of tasks (size ) in random order independently. Agents finish tasks without communication. Each agent ’s reports are represented as a 0-1 report matrix where the entry of is 1 if and only if agent reports option for task . The all zero rows in are the tasks that agent does not perform.
Model
Tasks have states which are drawn i.i.d. from an unknown distribution. Each task ’s state is a vector where each agent will receive signal with probability . Each agent is associated with a strategy where is the probability that she receives and reports . We assume that each agent performs the same strategy for all tasks. This assumption is reasonable since the tasks are a priori similar and agents receive tasks in a random order independently. A payment scheme is dominantly truthful if for each agent, regardless of other people’s strategies, telling the truth pays her higher101010not strictly higher than any other strategy in expectation.

K-DMI-Mechanism is a modification of DMI-Mechanism which pays each agent the determinant mutual information between her report and her peer’s report in expectation.
Definition 3.1 (Determinant based Mutual Information (DMI) [13]).
For two random variables whose joint distribution is denoted as a matrix ,
Since DMI satisfies data processing inequality and its square has a polynomial format, we can use tasks to implement it. Compared to DMI, K-DMI-Mechanism adds a clustering process, which can be interpreted as finding a clustering which has the highest determinant mutual information with the collection of all agents’ answers. For the payment calculation, K-DMI-Mechanism pays each agent the determinant mutual information between her report and the clustering result to reduce variance. The original DMI-Mechanism’s payments may not be fair to the hard-working agents when there exists a lot of low-efforts agents. The current payment calculation method may be more robust to other people’s strategies. For example, in the simple case where the answer distributions only have distinct formats, we can use other tasks to learn the correct partition and each agent is rewarded between her report and the underlying ground-truth in K-DMI.
Theorem 3.2.
K-DMI-Mechanism is dominantly-truthful. If the number of agents goes to infinite and exists and is invertible, the clustering result is invariant to people’s strategies. When ’s rank is , is equivalent to and also indicates the quality of answers: decreases when agents perform strategies.
Proof of Theorem 3.2.
From agent ’s view, each task’s elicited answers are drawn i.i.d. from a distribution. Thus, the partition learned from the set of tasks is independent of the set of tasks she performs. Therefore, after operating on ’s answers (excluding agent ’s own answer) to obtain a clustering result, the i.i.d. assumption is still satisfied for the pair of agent ’s answer and the clustering result . We can think the clustering result is answer from a virtual peer agent. The payment calculation reduced to DMI-Mechanism. Since DMI-Mechanism is dominantly-truthful, k-DMI-Mechanism is also dominantly truthful.
For each task , in expectation, the honest answer distributions will be . Note that each agent is assigned a random set of tasks independently. We denote the probability each agent is assigned task as . In expectation, there will be agents who assign task . Moreover, after agents perform strategies, before normalization, the expected answer feedback will be . Thus, when goes to infinite, the expected answer distribution will be . Since DMI-clustering is affine-invariant, then clustering result is invariant to people’s strategies.
When ’s rank is , we can pick (all one column is the sum of ’s columns thus cannot be added here). Thus, is equivalent to .
For , when agents perform strategies, it becomes
since the absolute value of any transition matrix’s determinant is less than one.
Thus, we finish the proof.
∎
Discussion for the practical implementation of K-DMI
In DMI-clustering, we cannot distinguish two clustering if they are equivalent up to a permutation for the options. However, if we have a small set of labeled questions, given an agreement measure, we can pick an option-permutation that has the highest agreement with the labeled questions. In addition to the default constraint, we can also pick other constraint set without losing the strategy-invariant property. For example, we can use other aggregation methods’ results as candidates and determine the best candidate using DMI-clustering. In the payment calculation part, if we have some assumption about each agent’s honest answer and the obtained clustering like the determinant of their multiplication is positive in expectation, we do not need to divide the tasks into two parts. We can just pay the agent the determinant of the product of her report matrix and clustering result. In running DMI-clustering, we can employ some easy heuristics to obtain an initialization. For example, we can run the surprisingly popular method or use plurality vote of high-payment agents to get an initialization.
3.2 DMI-clustering vs. Surprisingly Popular
Surprisingly popular method picks the option which is the most surprisingly popular compare to the prior. In the multi-task setting, we can use the average to estimate the prior.
Definition 3.3 (Surprisingly popular).
For task whose answer distribution is , we map it to cluster .
The surprisingly popular method shows a certain amount of robustness to people’s strategies compared to plurality vote. For example, if a large set of people always report one option with 100% probability, the plurality vote method will be distorted but the surprising popular method will decrease this distortion. In fact, in the binary question case, we will show that the surprisingly popular method is equivalent to DMI-clustering thus is robust to people’s strategies. However, in general, without any prior assumption, the surprisingly popular method does not satisfy the legal nor affine-invariant property, thus is not robust to people’s strategies even if the number of agents goes to infinite. We will show a visual comparison between DMI-clustering and the surprisingly popular method for three-options case in Figure 8.
Corollary 3.4 (Binary question: DMI-clustering = Surprisingly popular).
In the binary case, DMI-clustering will map to cluster if for .
Proof.
In this case, is a row-stochastic matrix. Since DMI-clustering is affine-invariant, we subtract the row average from each row . Note that is rank 2, we pick as the first and third columns and use as a shorthand for . Note that the sum of is 0. Then by the same analysis in Corollary 2.3, the optimal 0-1 vector will pick all positive entries of . Thus, DMI-clustering will map to cluster if for . ∎

Both surprisingly popular and DMI-clustering method set the mean of all points as the intersection of the partitions. We normalize each column of by dividing it by its sum and will see that DMI-clustering can be seen as a “rotated” version of surprisingly popular.
Corollary 3.5 (DMI-clustering = “rotated” surprisingly popular).
With column-normalized , , the surprisingly popular method is represented as . If is rank , there exists such that DMI-clustering’s result is represented as .
Proof.
The first statement follows directly from the definition of surprisingly popular method. It’s left to prove the second statement. Since DMI-clustering is invariant right affine transformation to , we can use column-normalized as input. For , the last column is a linear combination of ’s columns since ’s columns sum to . If is rank , then we can pick . Thus, there exists such that DMI-clustering’s result is represented as .
∎
4 Single-task & Method of Moments
The biggest advantage of surprisingly popular is that it only uses the first moment information. Thus, it is originally proposed for the single-task setting. In this section, we will introduce the single-task setting and show that from a clustering view, we can utilize the second moment information to propose a spectral clustering based mechanism which can be better than surprising popular in some settings.
Setting
Agents are assigned a single task (e.g. Have you ever text while driving before?). Agents finish the task without any communication. Each agent is asked to report her signal (e.g. No) and her prediction for other people’s signals (e.g. I think 10% people say yes and 90% people say no).

Lemma 4.1.
[3] The first eigenvector of the covariance matrix of mixture of two spherical gaussians passes through the means.
The above lemma shows that if the two Gaussian are sufficiently separated, we can project all points into and set the overall mean as the separator. This leads to spectral truth serum. Thus, in the scenarios that the ground-truth clustering is more like a well-separated mixture of two spherical Gaussian, spectral truth serum is better than surprisingly popular. Intuitively, spectral truth serum is applicable to the setting where there is only two underlying ground-truth states (e.g. fake news or not) and we elicit many signals from the crowds. The eigenvector of the covariance matrix tells us which signal is important and which signal is not. We then project people’s feedback into the eigenvector, the important direction, and compare it to the average.
Hsu and Kakade [11] show that with a third-order moment, a mixture of gaussians can be detected. A future direction will be using a hypothetical question (e.g. will you update your prediction for other people’s answers if you have seen some one answers A?) to elicit a third-order moment and obtain a better information aggregation results.
5 Conclusion and Discussion
We provide a new clustering perspective for information elicitation. With this perspective, we propose a new information elicitation mechanism which is not only dominantly truthful but also aggregates information robustly when there are a large number of people in the multi-task setting. We also propose a spectral method based information aggregation mechanism in the single-task setting. Of independent interest, we propose a novel affine-invariant clustering method, DMI-clustering method.
The geometric interpretation of DMI-clustering can be extended to any other easily. For example, in a three-dimensional space, when we pick , the clustering goal is to find two clusters such that the distance between their mean, multiplying the product of cluster sizes is maximized. We know that picking other will lose the affine-invariant property but we can still explore the properties of other in the future.
Another interesting future direction is to apply other clustering techniques like non-linear clustering techniques (e.g. kernel method) to information elicitation. This work focuses on discrete setting and we can also consider continuous setting or study new information elicitation scenarios to provide new settings for clustering. Empirical validation is also an important future direction.
References
- [1]
- Begelfor and Werman [2006] Evgeni Begelfor and Michael Werman. 2006. Affine invariance revisited. In 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), Vol. 2. IEEE, 2087–2094.
- Blum et al. [2016] Avrim Blum, John Hopcroft, and Ravindran Kannan. 2016. Foundations of data science. Vorabversion eines Lehrbuchs 5 (2016), 5.
- Blumer et al. [1989] Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K Warmuth. 1989. Learnability and the Vapnik-Chervonenkis dimension. Journal of the ACM (JACM) 36, 4 (1989), 929–965.
- Brubaker and Vempala [2008] S Charles Brubaker and Santosh S Vempala. 2008. Isotropic PCA and affine-invariant clustering. In Building Bridges. Springer, 241–281.
- Budescu and Chen [2015] David V Budescu and Eva Chen. 2015. Identifying expertise to extract the wisdom of crowds. Management Science 61, 2 (2015), 267–280.
- Cichocki et al. [2015] Andrzej Cichocki, Sergio Cruces, and Shun-ichi Amari. 2015. Log-determinant divergences revisited: Alpha-beta and gamma log-det divergences. Entropy 17, 5 (2015), 2988–3034.
- Dasgupta and Ghosh [2013] Anirban Dasgupta and Arpita Ghosh. 2013. Crowdsourced judgement elicitation with endogenous proficiency. In Proceedings of the 22nd international conference on World Wide Web. International World Wide Web Conferences Steering Committee, 319–330.
- Dawid and Skene [1979] Alexander Philip Dawid and Allan M Skene. 1979. Maximum likelihood estimation of observer error-rates using the EM algorithm. Journal of the Royal Statistical Society: Series C (Applied Statistics) 28, 1 (1979), 20–28.
- Fitzgibbon and Zisserman [2002] Andrew Fitzgibbon and Andrew Zisserman. 2002. On affine invariant clustering and automatic cast listing in movies. In European Conference on Computer Vision. Springer, 304–320.
- Hsu and Kakade [2013] Daniel Hsu and Sham M Kakade. 2013. Learning mixtures of spherical gaussians: moment methods and spectral decompositions. In Proceedings of the 4th conference on Innovations in Theoretical Computer Science. 11–20.
- Huang and Yang [2020] Hsin-Hsiung Huang and Jie Yang. 2020. Affine-transformation invariant clustering models. Journal of Statistical Distributions and Applications 7, 1 (2020), 1–24.
- Kong [2020] Yuqing Kong. 2020. Dominantly Truthful Multi-task Peer Prediction with a Constant Number of Tasks. In Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2398–2411.
- Kong and Schoenebeck [2019] Yuqing Kong and Grant Schoenebeck. 2019. An Information Theoretic Framework For Designing Information Elicitation Mechanisms That Reward Truth-telling. ACM Trans. Econ. Comput. 7, 1, Article 2 (Jan. 2019), 33 pages. https://doi.org/10.1145/3296670
- Liu et al. [2020] Y. Liu, J. Wang, and Y. Chen. 2020. Surrogate Scoring Rules. In EC ’20: The 21st ACM Conference on Economics and Computation.
- Lloyd [1982] Stuart Lloyd. 1982. Least squares quantization in PCM. IEEE transactions on information theory 28, 2 (1982), 129–137.
- Miller et al. [2005] N. Miller, P. Resnick, and R. Zeckhauser. 2005. Eliciting informative feedback: The peer-prediction method. Management Science (2005), 1359–1373.
- Prelec [2004] D. Prelec. 2004. A Bayesian Truth Serum for subjective data. Science 306, 5695 (2004), 462–466.
- Prelec et al. [2017] Dražen Prelec, H Sebastian Seung, and John McCoy. 2017. A solution to the single-question crowd wisdom problem. Nature 541, 7638 (2017), 532–535.
- Shnayder et al. [2016] Victor Shnayder, Arpit Agarwal, Rafael Frongillo, and David C Parkes. 2016. Informed truthfulness in multi-task peer prediction. In Proceedings of the 2016 ACM Conference on Economics and Computation. ACM, 179–196.
- Thurau et al. [2010] Christian Thurau, Kristian Kersting, and Christian Bauckhage. 2010. Yes we can: simplex volume maximization for descriptive web-scale matrix factorization. In Proceedings of the 19th ACM international conference on information and knowledge management. 1785–1788.
- Weller [2007] Susan C Weller. 2007. Cultural consensus theory: Applications and frequently asked questions. Field methods 19, 4 (2007), 339–368.
- Werman and Weinshall [1995] Michael Werman and Daphna Weinshall. 1995. Similarity and affine invariant distances between 2D point sets. IEEE Transactions on Pattern Analysis and Machine Intelligence 17, 8 (1995), 810–814.
- Xu et al. [2019] Yilun Xu, Peng Cao, Yuqing Kong, and Yizhou Wang. 2019. L_DMI: A Novel Information-theoretic Loss Function for Training Deep Nets Robust to Label Noise. In Advances in Neural Information Processing Systems. 6222–6233.